https://arxiv.org/abs/2101.00027
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Recent work has demonstrated that increased training dataset diversity improves general cross-domain knowledge and downstream generalization capability for large-scale language models. With this in mind, we present \textit{the Pile}: an 825 GiB English tex
arxiv.org
요약
최근 연구에 따르면, 훈련 데이터셋의 다양성이 증가할수록 대규모 언어 모델의 일반적인 교차 도메인 지식과 다운스트림 일반화 능력이 향상되는 것으로 나타났습니다. 이를 염두에 두고, 우리는 대규모 언어 모델 훈련을 목표로 한 825 GiB 크기의 영어 텍스트 코퍼스인 The Pile을 소개합니다. The Pile은 기존과 새로 구성된 22개의 다양한 고품질 하위 집합으로 구성되어 있으며, 많은 부분이 학문적 또는 전문적인 출처에서 파생되었습니다. 우리는 GPT-2와 GPT-3의 The Pile에 대한 미조정 성능 평가를 통해 이 모델들이 학문적 글쓰기와 같은 여러 구성 요소에서 어려움을 겪는다는 것을 보여줍니다. 반면, The Pile에서 훈련된 모델들은 Raw CC와 CC-100 모두에서 The Pile의 모든 구성 요소에서 성능이 크게 향상되었으며, 다운스트림 평가에서도 성능이 향상되었습니다. 심층 탐색 분석을 통해 잠재적인 사용자에게 데이터의 잠재적으로 우려되는 측면을 문서화합니다. 우리는 그 구성에 사용된 코드를 공개적으로 제공합니다.
서론
최근 일반 목적 언어 모델링의 획기적인 발전은 대규모 텍스트 코퍼스를 사용한 대규모 모델 훈련이 다운스트림 애플리케이션에 효과적임을 입증했습니다 (Radford et al., 2019; Shoeybi et al., 2019; Raffel et al., 2019; Rosset, 2019; Brown et al., 2020; Lepikhin et al., 2020). 언어 모델 훈련의 규모가 계속 확대됨에 따라, 고품질 대규모 텍스트 데이터에 대한 수요는 계속 증가할 것입니다 (Kaplan et al., 2020).
언어 모델링에서 데이터의 필요성이 증가함에 따라, 대부분의 기존 대규모 언어 모델들은 대부분 또는 전부의 데이터를 Common Crawl에서 가져가고 있습니다 (Brown et al., 2020; Raffel et al., 2019). Common Crawl에서의 훈련이 효과적이긴 했지만, 최근 연구에서는 데이터셋의 다양성이 다운스트림 일반화 능력을 향상시킨다는 것을 보여주었습니다 (Rosset, 2019). 또한, 대규모 언어 모델은 해당 도메인에서 비교적 적은 양의 훈련 데이터만으로도 새로운 도메인에서 지식을 효과적으로 습득할 수 있다는 것이 입증되었습니다 (Rosset, 2019; Brown et al., 2020; Carlini et al., 2020). 이러한 결과는 다수의 소규모, 고품질, 다양한 데이터셋을 혼합함으로써, 소수의 데이터 출처에서만 훈련된 모델에 비해 모델의 일반적인 교차 도메인 지식과 다운스트림 일반화 능력을 향상시킬 수 있음을 시사합니다.
이러한 필요를 해결하기 위해, 우리는 대규모 언어 모델 훈련을 위해 설계된 825.18 GiB의 영어 텍스트 데이터셋인 The Pile을 소개합니다. The Pile은 22개의 다양한 고품질 데이터셋으로 구성되어 있으며, 기존 자연어 처리 데이터셋과 새로 도입된 몇 가지 데이터셋을 포함합니다.
대규모 언어 모델 훈련에 유용할 뿐만 아니라, The Pile은 언어 모델의 교차 도메인 지식과 일반화 능력을 평가하는 광범위한 벤치마크로도 사용될 수 있습니다.
우리는 PubMed Central, ArXiv, GitHub, FreeLaw Project, Stack Exchange, US Patent and Trademark Office, PubMed, Ubuntu IRC, HackerNews, YouTube, PhilPapers, NIH ExPorter와 같은 출처에서 새로운 데이터셋을 도입했습니다. 또한 원래의 OpenWebText (Gokaslan and Cohen, 2019)와 BookCorpus (Zhu et al., 2015; Kobayashi, 2018) 데이터셋을 확장한 OpenWebText2와 BookCorpus2도 도입했습니다.
이 외에도, 기존의 고품질 데이터셋 몇 가지를 통합했습니다: Books3 (Presser, 2020), Project Gutenberg (PG-19) (Rae et al., 2019), OpenSubtitles (Tiedemann, 2016), 영어 위키피디아, DM Mathematics (Saxton et al., 2019), EuroParl (Koehn, 2005), Enron Emails corpus (Klimt and Yang, 2004). 이를 보완하기 위해, 개선된 추출 품질의 새로운 Common Crawl 필터링 하위 집합인 Pile-CC도 도입했습니다.
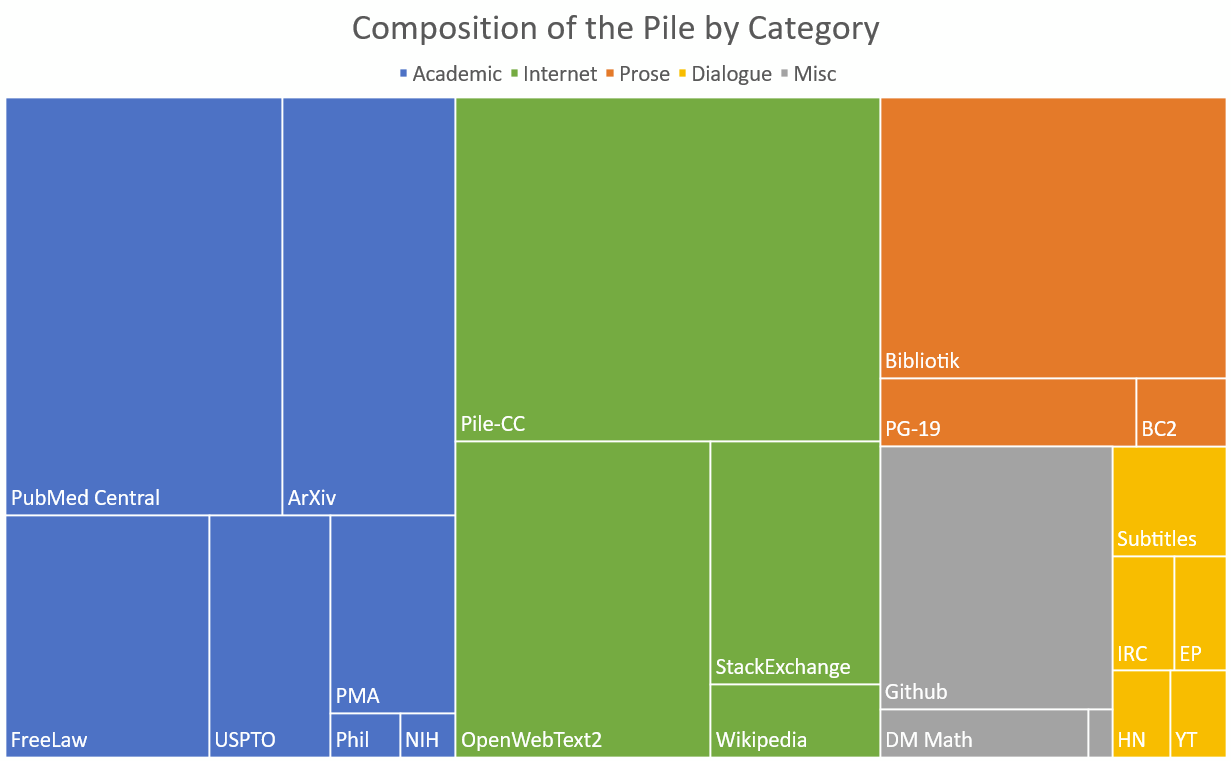
그림 1: 효과적인 크기에 따른 Pile 구성 요소의 트리맵.
우리의 분석을 통해 The Pile이 순수한 Common Crawl 데이터와는 상당히 다르다는 것을 확인했습니다. 또한, 기존의 GPT-2와 GPT-3 모델이 The Pile의 여러 구성 요소에서 성능이 저조하며, The Pile에서 훈련된 모델이 원본 및 필터링된 Common Crawl 모델보다 성능이 훨씬 뛰어나다는 것을 평가 결과로 확인했습니다. 성능 평가를 보완하기 위해, The Pile 내의 텍스트에 대한 탐색적 분석을 수행하여 데이터에 대한 자세한 그림을 제공합니다. 우리는 The Pile의 구성과 특성에 대한 우리의 광범위한 문서화가 연구자들이 잠재적인 다운스트림 애플리케이션에 대해 정보에 입각한 결정을 내리는 데 도움이 되기를 바랍니다.
마지막으로, The Pile의 구성 데이터셋 전처리 코드와 대체 버전 구성 코드를 공개합니다. 재현성을 위해, 각 데이터셋(및 The Pile 전체)에 수행된 모든 처리를 가능한 한 자세히 문서화했습니다. 각 데이터셋의 처리에 대한 자세한 내용은 섹션 2 및 부록 C를 참조하십시오.
1.1 기여
이 논문의 핵심 기여는 다음과 같습니다:
- 22개의 다양한 소스를 결합한 825.18 GiB 크기의 영어 데이터셋을 언어 모델링을 위해 도입했습니다.
- 연구자들에게 독립적인 관심을 끌 것으로 예상되는 14개의 새로운 언어 모델링 데이터셋을 도입했습니다.
- GPT-2 크기의 모델이 이 새로운 데이터셋으로 훈련될 경우, CC-100과 원본 Common Crawl로 훈련된 모델보다 여러 도메인에서 성능이 크게 향상된다는 평가를 보여줍니다.
- 이 데이터셋에 대한 조사 및 문서화를 통해 연구자들이 이를 사용하는 방법에 대해 더 잘 이해하고, 자신들의 데이터에 대한 유사한 조사를 수행하도록 유도하기를 바랍니다.
2. The Pile 데이터셋
The Pile은 표 1에 나열된 22개의 구성 하위 데이터셋으로 구성되어 있습니다. Brown et al. (2020)을 따르며, 더 높은 품질의 구성 요소의 가중치를 증가시켰고, 예를 들어 위키피디아와 같은 일부 고품질 데이터셋은 The Pile의 전체 에포크 동안 최대 3회 반복되었습니다. 각 데이터셋의 구성에 대한 자세한 정보는 부록 C에 나와 있습니다.
| 구성 요소 | 원본 크기 | 가중치 | 에포크 수 | 효과적인 크기 | 문서 평균 크기 |
| Pile-CC | 227.12 GiB | 18.11% | 1.0 | 227.12 GiB | 4.33 KiB |
| PubMed Central | 90.27 GiB | 14.40% | 2.0 | 180.55 GiB | 30.55 KiB |
| Books3† | 100.96 GiB | 12.07% | 1.5 | 151.44 GiB | 538.36 KiB |
| OpenWebText2 | 62.77 GiB | 10.01% | 2.0 | 125.54 GiB | 3.85 KiB |
| ArXiv | 56.21 GiB | 8.96% | 2.0 | 112.42 GiB | 46.61 KiB |
| GitHub | 95.16 GiB | 7.59% | 1.0 | 95.16 GiB | 5.25 KiB |
| FreeLaw | 51.15 GiB | 6.12% | 1.5 | 76.73 GiB | 15.06 KiB |
| Stack Exchange | 32.20 GiB | 5.13% | 2.0 | 64.39 GiB | 2.16 KiB |
| USPTO Backgrounds | 22.90 GiB | 3.65% | 2.0 | 45.81 GiB | 4.08 KiB |
| PubMed Abstracts | 19.26 GiB | 3.07% | 2.0 | 38.53 GiB | 1.30 KiB |
| Gutenberg (PG-19)† | 10.88 GiB | 2.17% | 2.5 | 27.19 GiB | 398.73 KiB |
| OpenSubtitles† | 12.98 GiB | 1.55% | 1.5 | 19.47 GiB | 30.48 KiB |
| Wikipedia (en)† | 6.38 GiB | 1.53% | 3.0 | 19.13 GiB | 1.11 KiB |
| DM Mathematics† | 7.75 GiB | 1.24% | 2.0 | 15.49 GiB | 8.00 KiB |
| Ubuntu IRC | 5.52 GiB | 0.88% | 2.0 | 11.03 GiB | 545.48 KiB |
| BookCorpus2 | 6.30 GiB | 0.75% | 1.5 | 9.45 GiB | 369.87 KiB |
| EuroParl† | 4.59 GiB | 0.73% | 2.0 | 9.17 GiB | 68.87 KiB |
| HackerNews | 3.90 GiB | 0.62% | 2.0 | 7.80 GiB | 4.92 KiB |
| YouTubeSubtitles | 3.73 GiB | 0.60% | 2.0 | 7.47 GiB | 22.55 KiB |
| PhilPapers | 2.38 GiB | 0.38% | 2.0 | 4.76 GiB | 73.37 KiB |
| NIH ExPorter | 1.89 GiB | 0.30% | 2.0 | 3.79 GiB | 2.11 KiB |
| Enron Emails† | 0.88 GiB | 0.14% | 2.0 | 1.76 GiB | 1.78 KiB |
| The Pile | 825.18 GiB | 1254.20 GiB | 5.91 KiB |
표 1: The Pile의 데이터셋 개요 (held-out 세트 생성 전). 원본 크기는 업샘플링 또는 다운샘플링 전의 크기입니다. 가중치는 최종 데이터셋에서 각 데이터셋이 차지하는 바이트의 비율입니다. 에포크 수는 The Pile의 전체 에포크 동안 각 구성 데이터셋에 대한 반복 횟수입니다. 효과적인 크기는 The Pile에서 각 데이터셋이 차지하는 대략적인 바이트 수입니다. † 표시가 있는 데이터셋은 이전 작업에서 최소한의 전처리로 사용되었습니다.
2.1 Pile-CC
Common Crawl은 2008년부터 시작된 웹사이트 크롤링 모음으로, 원시 웹 페이지, 메타데이터, 텍스트 추출을 포함합니다. 데이터셋의 원시 특성으로 인해 Common Crawl은 다양한 도메인의 텍스트를 포함하는 장점이 있지만, 데이터 품질이 일정하지 않은 단점도 있습니다. 따라서 Common Crawl을 사용할 때는 잘 설계된 추출 및 필터링이 필요합니다. 우리 데이터셋인 Pile-CC는 Web Archive 파일(raw HTTP 응답 포함 페이지 HTML)에서 jusText (Endrédy and Novák, 2013)를 사용하여 추출하며, 이는 WET 파일(추출된 평문)을 직접 사용하는 것보다 더 높은 품질의 출력을 제공합니다.
2.2 PubMed Central
PubMed Central(PMC)은 미국 국립 생명공학 정보 센터(NCBI)가 운영하는 생물 의학 기사 온라인 저장소인 PubMed의 하위 집합으로, 약 500만 건의 출판물에 대한 개방형 전체 텍스트 접근을 제공합니다. PMC에 색인된 대부분의 출판물은 최근의 것이며, NIH 공공 접근 정책에 따라 2008년부터 NIH가 자금을 지원한 모든 연구에 대해 포함이 의무화되었습니다. 우리는 PMC가 의료 도메인에 대한 잠재적 다운스트림 애플리케이션에 도움이 될 것이라고 기대하며 포함했습니다.
2.3 Books3
Books3는 Shawn Presser (Presser, 2020)가 제공한 Bibliotik 개인 트래커의 내용을 기반으로 한 책 데이터셋입니다. Bibliotik은 픽션과 논픽션 책이 혼합된 것이며, 우리의 다음으로 큰 책 데이터셋(BookCorpus2)보다 거의 한 자릿수 더 큽니다. 책은 장거리 문맥 모델링 연구와 일관된 스토리텔링에 매우 귀중하기 때문에 Bibliotik을 포함했습니다.
2.4 OpenWebText2
OpenWebText2(OWT2)는 WebText (Radford et al., 2019)와 OpenWebTextCorpus (Gokaslan and Cohen, 2019)에 영감을 받은 일반화된 웹 크롤 데이터셋입니다. 원래 WebText와 유사하게, 우리는 Reddit 제출물에 대한 순 추천수를 외부 링크 품질의 대용치로 사용합니다. OpenWebText2는 2020년까지의 최신 Reddit 제출물, 다국어 콘텐츠, 문서 메타데이터, 여러 데이터셋 버전 및 오픈 소스 복제 코드를 포함합니다. OWT2는 고품질의 일반 목적 데이터셋으로 포함되었습니다.
2.5 ArXiv
ArXiv는 1991년부터 운영되고 있는 연구 논문 프리프린트 서버입니다. 그림 10에서 볼 수 있듯이, arXiv 논문은 주로 수학, 컴퓨터 과학, 물리학 분야에 속합니다. 우리는 arXiv가 고품질의 텍스트와 수학 지식의 원천이 되고, 이 분야의 연구에 대한 잠재적 다운스트림 애플리케이션에 도움이 될 것이라는 기대에서 포함했습니다. ArXiv 논문은 수학, 컴퓨터 과학, 물리학 및 일부 인접 분야에서 일반적으로 사용되는 조판 언어인 LaTeX로 작성됩니다. LaTeX로 작성된 논문을 생성할 수 있는 언어 모델을 훈련시키는 것은 연구 커뮤니티에 큰 도움이 될 수 있습니다.
2.6 GitHub
GitHub는 오픈 소스 코드 저장소의 큰 모음입니다. GPT-3(Brown et al., 2020)가 명시적으로 수집된 코드 데이터셋을 포함하지 않은 훈련 데이터에도 불구하고 그럴듯한 코드 완성을 생성할 수 있는 능력에 동기 부여되어, 우리는 GitHub을 포함하여 코드 관련 작업에서 더 나은 다운스트림 성능을 가능하게 하기를 기대했습니다.
2.7 FreeLaw
Free Law Project는 법학 분야의 학문적 연구를 위한 접근 및 분석 도구를 제공하는 미국 등록 비영리 단체입니다. Free Law Project의 일부인 CourtListener는 연방 및 주 법원에서 수백만 건의 법적 의견에 대한 일괄 다운로드를 제공합니다. 전체 데이터셋은 법적 절차의 여러 양식을 제공하지만, 우리는 풍부한 전체 텍스트 항목이 많아 법원 의견에 집중했습니다. 이 데이터는 전적으로 공공 도메인에 속합니다.
2.8 Stack Exchange
Stack Exchange Data Dump는 Stack Exchange 네트워크에서 사용자가 기여한 모든 콘텐츠의 익명화된 집합을 포함하며, 사용자 기여 질문과 답변을 중심으로 하는 인기 있는 웹사이트 모음입니다. 이는 공개적으로 사용 가능한 질문-답변 쌍의 가장 큰 저장소 중 하나로, 프로그래밍부터 정원 가꾸기, 불교까지 다양한 주제를 다룹니다. 우리는 Stack Exchange를 포함하여 다운스트림 모델이 다양한 도메인에서 질문 답변 능력을 향상시키기를 기대했습니다.
2.9 USPTO Backgrounds
USPTO Backgrounds는 미국 특허청이 부여한 특허의 배경 섹션을 포함한 데이터셋으로, 공개된 대량 아카이브에서 파생되었습니다. 일반적인 특허 배경은 발명의 일반적인 맥락을 설명하고, 기술 분야 개요를 제공하며, 문제 영역을 설정합니다. 우리는 USPTO Backgrounds를 포함하여 기술적인 주제에 대한 대량의 기술 문서를 제공하고, 비전문가를 대상으로 한 내용을 포함하기를 기대했습니다.
2.10 Wikipedia (English)
Wikipedia는 언어 모델링을 위한 고품질 텍스트의 표준 소스입니다. 고품질의 깨끗한 영어 텍스트 소스일 뿐만 아니라, 설명적인 산문으로 작성되었고 많은 도메인을 아우르기 때문에 가치가 있습니다.
2.11 PubMed Abstracts
PubMed Abstracts는 국립 의학 도서관이 운영하는 생물 의학 기사 온라인 저장소인 PubMed의 3천만 개 출판물의 초록으로 구성되어 있습니다. PMC(섹션 2.2 참조)가 전체 텍스트 접근을 제공하는 반면, 커버리지는 상당히 제한적이며 최근 출판물에 편중되어 있습니다. PubMed는 또한 1946년부터 현재까지 생물 의학 초록의 커버리지를 확장하는 MEDLINE을 포함합니다.
2.12 Project Gutenberg
Project Gutenberg는 고전 서양 문학의 데이터셋입니다. 우리가 사용한 특정 Project Gutenberg 파생 데이터셋인 PG-19는 1919년 이전의 Project Gutenberg 책으로 구성되어 있으며, 이는 현대적인 Books3와 BookCorpus와는 다른 스타일을 나타냅니다. 또한 PG-19 데이터셋은 이미 장거리 문맥 모델링에 사용되고 있습니다.
2.13 OpenSubtitles
OpenSubtitles 데이터셋은 영화와 TV 프로그램에서 수집된 영어 자막 데이터셋으로, Tiedemann(2016)이 수집했습니다. 자막은 자연스러운 대화의 중요한 소스이며, 스크린라이팅, 연설 작성 및 인터랙티브 스토리텔링과 같은 창의적 글쓰기 생성 작업에 유용할 수 있는 산문 외의 허구 형식을 이해하는 데 도움이 됩니다.
2.14 DeepMind Mathematics
DeepMind Mathematics 데이터셋은 대수학, 산수, 미적분학, 수론, 확률 등과 같은 주제의 수학 문제를 자연어 프롬프트로 형식화한 모음입니다(Saxton et al., 2019). 대형 언어 모델의 주요 약점 중 하나는 수학 문제에서의 성능이었으며(Brown et al., 2020), 이는 부분적으로 훈련 세트에 수학 문제가 부족했기 때문일 수 있습니다. 수학 문제 데이터셋을 명시적으로 포함하여, The Pile에서 훈련된 언어 모델의 수학적 능력을 향상시키기를 기대합니다.
2.15 BookCorpus2
BookCorpus2는 "아직 출판되지 않은 저자"가 쓴 책으로 구성된 원래 BookCorpus(Zhu et al., 2015)의 확장판입니다. 따라서 BookCorpus는 출판된 책으로 구성된 Project Gutenberg와 Books3와 상당한 중복이 없을 가능성이 큽니다. BookCorpus는 또한 언어 모델 훈련 데이터셋으로 일반적으로 사용됩니다(Radford et al., 2018; Devlin et al., 2019; Liu et al., 2019).
2.16 Ubuntu IRC
Ubuntu IRC 데이터셋은 Freenode IRC 채팅 서버의 모든 Ubuntu 관련 채널의 공개된 채팅 기록에서 파생되었습니다. 채팅 로그 데이터는 다른 소셜 미디어 모드에서는 일반적으로 발견되지 않는 자발성을 특징으로 하는 실시간 인간 상호 작용을 모델링할 기회를 제공합니다.
2.17 EuroParl
EuroParl(Koehn, 2005)은 원래 기계 번역을 위해 도입된 다국어 병렬 코퍼스로, NLP의 여러 다른 분야에서도 사용되었습니다(Groves and Way, 2006; Van Halteren, 2008; Ciobanu et al., 2017). 우리가 사용한 가장 최신 버전은 1996년부터 2012년까지의 21개 유럽 언어로 된 유럽 의회의 회의록으로 구성되어 있습니다.
2.18 YouTube Subtitles
YouTube Subtitles 데이터셋은 YouTube에서 사람이 생성한 폐쇄 자막에서 수집된 텍스트의 병렬 코퍼스입니다. 다국어 데이터를 제공할 뿐만 아니라, YouTube Subtitles는 교육 콘텐츠, 대중 문화 및 자연스러운 대화의 출처이기도 합니다.
2.19 PhilPapers
PhilPapers 데이터셋은 웨스턴 온타리오 대학교의 디지털 철학 센터에서 관리하는 국제 데이터베이스에서 가져온 공개 접근 철학 출판물로 구성되어 있습니다. PhilPapers는 광범위한 추상적이고 개념적인 담론을 포함하며, 그 기사들은 고품질의 학문적 글쓰기를 포함하고 있기 때문에 포함되었습니다.
2.20 NIH Grant Abstracts: ExPORTER
NIH Grant 초록은 1985 회계연도부터 현재까지 ExPORTER 서비스를 통해 수상된 신청서에 대한 대량 데이터 저장소를 제공합니다. 이 데이터셋에는 고품질 과학 글쓰기의 예제가 포함되어 있기 때문에 포함되었습니다.
2.21 Hacker News
Hacker News는 스타트업 인큐베이터 및 투자 펀드인 Y Combinator가 운영하는 링크 집합체입니다. 사용자는 "지적 호기심을 만족시키는 모든 것"으로 정의된 기사를 제출하지만, 제출된 기사는 주로 컴퓨터 과학과 기업가 정신에 초점을 맞춥니다. 사용자는 제출된 이야기에 댓글을 달 수 있으며, 제출된 이야기에 대해 토론하고 비판하는 댓글 트리가 형성됩니다. 우리는 이러한 댓글 트리를 스크랩하고 분석하여 포함했으며, 이는 고품질의 대화와 토론을 제공한다고 믿기 때문입니다.
2.22 Enron Emails
Enron Emails 데이터셋(Klimt and Yang, 2004)은 이메일 사용 패턴에 대한 연구에 일반적으로 사용되는 귀중한 코퍼스입니다. Enron Emails는 다른 데이터셋에서는 일반적으로 발견되지 않는 이메일 통신의 양식을 이해하는 데 도움을 주기 위해 포함되었습니다.
3. The Pile을 사용한 언어 모델 벤치마킹
The Pile은 대규모 언어 모델 훈련용 데이터셋으로 구상되었지만, 여러 다른 도메인을 포괄하고 있어 평가 데이터셋으로도 적합합니다. 이 섹션에서는 The Pile을 언어 모델 벤치마킹을 위한 광범위한 커버리지 데이터셋으로 사용하는 방법에 대해 설명합니다.
3.1 벤치마킹 지침
The Pile은 훈련, 검증 및 테스트 분할로 제공됩니다. 검증 및 테스트 구성 요소는 각각 데이터의 0.1%를 포함하며, 무작위로 균일하게 샘플링됩니다. 대부분의 데이터셋보다 훨씬 작은 비율이지만, 데이터셋의 거대한 크기로 인해 각각 1 GiB 이상의 검증 및 테스트 데이터를 포함합니다. The Pile 내의 문서를 중복 제거하기 위해 노력했지만(섹션 D.2 참조), 여전히 훈련/검증/테스트 분할 간에 일부 문서가 중복될 가능성이 있습니다.
우리가 선호하는 메트릭은 UTF-8로 인코딩된 바이트당 비트(BPB)입니다. Pile을 메트릭으로 사용할 때 비트/바이트는 다양한 토크나이제이션 방식에 대한 불변성과 유니코드에서 문자를 측정하는 모호성 때문에 비트/문자나 당혹도(perplexity)보다 선호됩니다. 주어진 음의 로그 우도 손실 에서 바이트당 비트를 계산하려면 다음과 같이 계산합니다:

여기서 L_T는 토큰 단위로 된 데이터셋의 길이이고 L_B는 UTF-8로 인코딩된 바이트 단위로 된 데이터셋의 길이입니다. 우리는 The Pile 전체에서 L_T / L_B 값이 0.29335 GPT-2-토큰/바이트임을 발견했습니다; 데이터셋별 L_T / L_B 값은 표 7에서 확인할 수 있습니다.
3.2 GPT-2 및 GPT-3로 테스트 당혹도(perplexity) 측정
우리는 GPT-2 (Radford et al., 2019)와 GPT-3 (Brown et al., 2020)를 사용하여 The Pile의 구성 데이터셋에 대한 테스트 당혹도를 계산했습니다. 결과는 그림 2에 나타나 있습니다. 우리는 GPT-2의 모든 사용 가능한 버전과 OpenAI API를 통해 사용할 수 있는 GPT-3의 네 가지 버전을 사용했습니다. OpenAI API 사용과 관련된 비용 때문에, 대부분의 구성 데이터셋에 대해 해당 테스트 세트의 10분의 1에 대해서만 평가를 수행했습니다. 우리는 당혹도를 UTF-8로 인코딩된 바이트(BPB)당 비트로 변환하여 보고합니다. 중요한 점은, 우리는 각 데이터셋 내에서 모든 문서를 연결하는 대신 각 문서를 독립적으로 평가하여 당혹도를 계산했습니다. 당혹도 계산의 전체 세부 사항은 부록 E.2에서 확인할 수 있습니다.
예상대로, 더 큰 언어 모델은 일반적으로 더 작은 모델에 비해 낮은 당혹도를 달성합니다. 최근 연구에서는 언어 모델의 경험적 스케일링 법칙에 대한 관심이 증가했습니다 (Kaplan et al., 2020; Henighan et al., 2020). 따라서 우리는 The Pile에서 GPT-2 및 GPT-3 모델 패밀리의 당혹도 평가에 대한 스케일링 법칙을 조사합니다. GPT-3 모델 패밀리의 스케일링 법칙 관계는 그림 2에 나타나 있습니다. 그림에 표시된 최적의 적합선은 계수 -0.1674와 절편 2.5516을 가집니다.
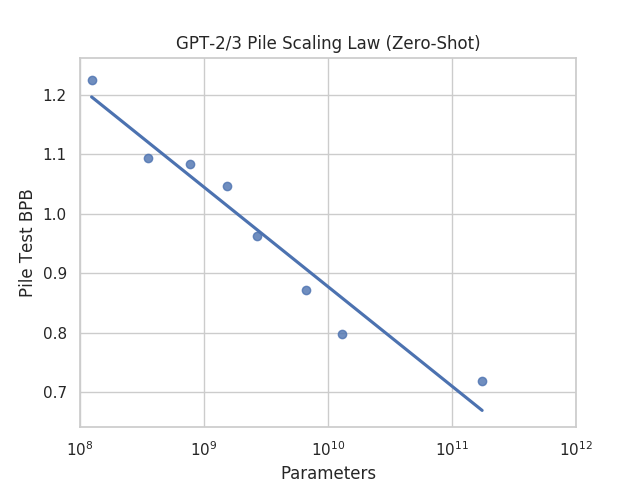
그림 2: GPT-2/3 모델의 성능에 대한 스케일링 법칙. '제로샷'은 모델들이 The Pile의 데이터로 미세 조정되지 않았음을 나타냅니다.
흥미롭게도, GPT-2와 GPT-3이 The Pile에서 훈련되지 않았음에도 불구하고, 여전히 명확한 스케일링 법칙이 존재하며, 수익 감소 현상이 나타나지 않습니다. 이는 이러한 모델들의 내재된 일반화 능력 때문이라고 가정할 수 있습니다. 제로샷 스케일링 법칙에 대한 더 엄격한 분석은 추후 연구로 남겨둡니다.
3.3 구성 요소별 GPT-3의 상대적 Pile 성능
GPT-3이 어떤 구성 요소에서 성능이 저조한지 결정하는 것은 GPT-3이 훈련된 텍스트(웹 페이지와 책)의 분포와 가장 다른 Pile 구성 요소를 식별하는 데 유용합니다. 이러한 구성 요소는 GPT-3 훈련 데이터를 보완하는 데 특히 좋은 후보가 됩니다. 이 결과는 향후 The Pile의 반복에서 어떤 유형의 데이터셋을 강조해야 할지를 결정하는 데도 가치가 있습니다.
다양한 데이터셋의 엔트로피 차이 때문에, GPT-3이 다양한 Pile 구성 요소에서 보이는 당혹도를 직접 비교하는 것은 상대적 성능을 정확하게 나타내지 않습니다. 이상적으로는 The Pile에서 처음부터 GPT-3 모델을 훈련시키고, 원래의 GPT-3과 각 데이터셋에서 손실의 차이를 비교해야 합니다. 자원 제한 때문에, 대신 The Pile에서 처음부터 훈련된 GPT-2 모델을 사용하여 대체 측정을 구성합니다(섹션 4 참조). 대체 측정을 구성하기 위해, 먼저 각 구성 요소에서 GPT-2-Pile 모델에서 GPT-3으로의 성능 향상을 측정합니다. 그런 다음, OpenWebText2에서의 변화를 0으로 설정하여 결과를 정규화합니다. 이 계산은 아래의 식에 나타나 있습니다:
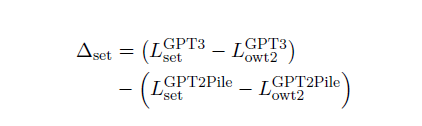
GPT2-Pile 모델이 OWT2와 우리가 평가하는 데이터셋에서 모두 훈련되었기 때문에, 우리는 두 번째 항이 두 데이터셋의 본질적인 난이도 차이를 반영할 것으로 기대합니다. 따라서 전체 값은 우리가 평가하는 데이터셋이 GPT-3에게 OWT2보다 얼마나 더 어려운지를 나타냅니다. 이 값은 두 작업의 상대적 난이도를 뺀 것입니다. GPT-3이 OWT2와 매우 유사한 데이터로 훈련되었기 때문에, 이는 GPT-3이 The Pile로 훈련되었을 경우 얼마나 더 잘 수행할지를 보여줍니다.
결과는 그림 3에 나와 있습니다. 논리적으로, GPT-3의 훈련 세트에 포함되거나 매우 유사한 데이터셋(예: Books3, Wikipedia (en), Pile-CC, Project Gutenberg)은 우리의 지표에서 거의 0에 가까운 점수를 기록합니다. 이는 GPT-3이 이러한 데이터셋에서 잘 수행함을 의미합니다. 반면, GPT-3은 연구 또는 학문적 글쓰기와 관련된 데이터셋(PubMed Central, PubMed Abstracts, ArXiv), 도메인 특화 데이터셋(FreeLaw, HackerNews, USPTO Backgrounds), 그리고 주로 자연어가 아닌 텍스트를 포함하는 데이터셋(GitHub, DM Mathematics)에서 성능이 저조합니다.
대부분의 데이터셋은 OpenWebText2보다 성능 향상이 적습니다. 따라서 우리는 The Pile로 훈련된 GPT-3 모델이 연구 관련 작업, 소프트웨어 작업, 기호 조작 작업에서 기본 모델보다 훨씬 더 잘 수행할 것으로 기대합니다. 또한, 이 실험은 The Pile의 대부분의 구성 요소가 주로 웹 기반인 GPT-3 훈련 데이터와 중복되지 않음을 보여줍니다.
이 지표는 단순히 유사성에 대한 대략적인 척도일 뿐이며, 데이터셋 특유의 확장 효과로 인해 혼란스러울 수 있습니다. 우리의 결과가 대체로 기대와 일치하지만, GPT-3이 GPT-2 Pile보다 더 잘 수행한 데이터셋과 같은 일부 예상치 못한 결과도 있습니다. 우리는 GPT-3이 이러한 데이터셋에서 매우 잘 학습하여 명시적으로 훈련하는 것이 모델 성능에 큰 이점을 주지 않는다고 가정합니다. 이러한 효과에 대한 더 철저한 분석은 추후 연구로 남겨둡니다.
4. 평가
The Pile이 언어 모델링 품질을 개선하는 데 얼마나 효과적인지 확인하기 위해, 우리는 Brown et al. (2020)의 모델을 기반으로 한 동일한 구조의 13억 개 매개변수 모델을 다양한 데이터셋에서 훈련시키고, WikiText와 LAMBADA 작업을 언어 모델링 능력의 벤치마크로 평가합니다. 또한 The Pile에서의 결과를 교차 도메인 일반화의 척도로 보고합니다.
4.1 방법론
다른 크기의 데이터셋 간의 공정한 비교를 보장하기 위해, 우리는 Brown et al. (2020)에서 사용된 것과 동일한 13-그램 중복 필터링을 사용하여 평가 세트의 모든 인스턴스를 정제하고, 데이터셋 크기를 제어하기 위해 40GB로 다운샘플링합니다. 데이터셋 크기를 제어하기 때문에, 우리의 평가는 실제로 The Pile 크기의 약 1/3인 CC-100 (en)에 대해 관대하다고 강조합니다.
우리는 다음 데이터셋을 비교합니다: The Pile, CC-100 데이터셋의 영어 구성 요소 (Wenzek et al., 2019; Conneau et al., 2020), 그리고 영어로만 필터링된 원본 CC WET 파일 샘플.
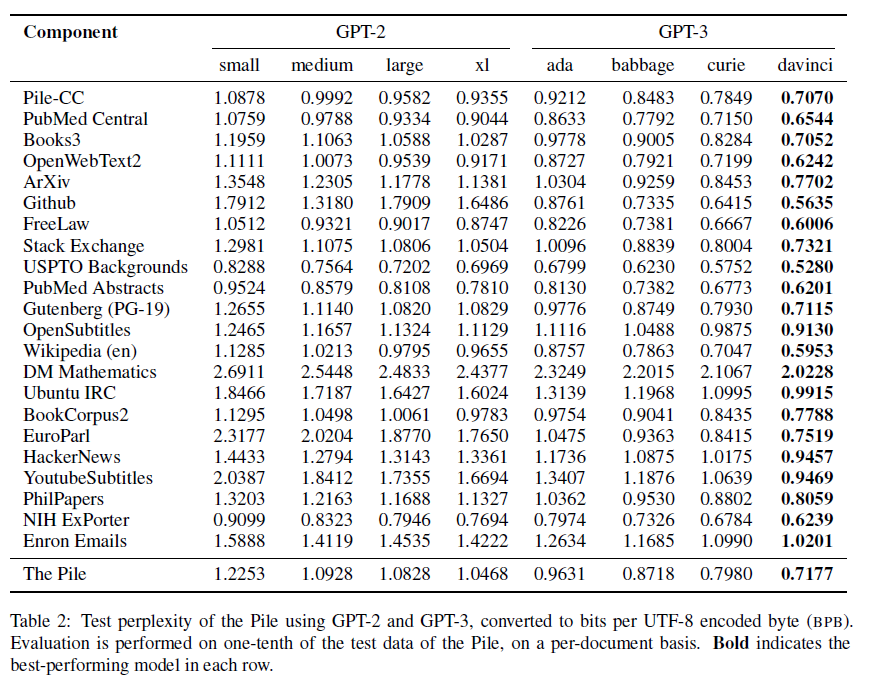
표 2: GPT-2와 GPT-3을 사용하여 The Pile의 테스트 당혹도를 UTF-8로 인코딩된 바이트당 비트(BPB)로 변환하여 나타낸 것. 평가는 The Pile 테스트 데이터의 10분의 1을 문서 단위로 수행. 각 행에서 가장 성능이 좋은 모델은 굵게 표시.
4.2 결과
전통적인 언어 모델링 벤치마크에서 The Pile은 WikiText에서 크게 개선되었고 LAMBADA에서는 거의 변화가 없었습니다. 그러나 The Pile에서 훈련된 모델은 Raw CC와 CC-100 모두에서 The Pile의 모든 구성 요소에 대해 크게 개선되었습니다(표 4 참조). 이는 The Pile에서 훈련된 모델이 전통적인 벤치마크에서의 성능을 저하시키지 않으면서도 교차 도메인 일반화 능력이 뛰어남을 나타냅니다.
세트별로 CC-100에 대한 개선 정도는 그림 4에 나와 있습니다. 예상대로 Pile-CC에서는 거의 개선이 없었습니다. 그러나 The Pile에서 훈련된 모델은 ArXiv, PubMed Central, FreeLaw, PhilPapers와 같은 학문적 데이터셋에서 다른 모델보다 훨씬 더 뛰어난 성능을 보였습니다. 또한 GitHub 및 StackExchange와 같은 프로그래밍 관련 데이터셋, 다국어 텍스트가 다른 데이터셋에는 없는 EuroParl, 그리고 수학적 능력이 크게 향상된 DM Mathematics에서 크게 개선되었습니다.
놀랍게도, 원시 Common Crawl은 LAMBADA와 WikiText에서는 크게 뒤처지지만, The Pile BPB에서는 CC-100보다 더 나은 성능을 보였습니다. 우리는 이것이 CC-100에서 사용된 당혹도 기반 필터링 때문이라고 가정합니다. 여기서 언어 모델은 위키백과에서 훈련되고 당혹도가 너무 높거나 낮은 모든 데이터가 버려집니다. 이는 실질적으로 위키백과와 너무 유사하거나 너무 다른 모든 데이터를 버리게 되어 수집된 데이터의 다양성을 심각하게 제한합니다. 이 결과는 Common Crawl을 사용하는 미래 연구에서 필터링을 신중하게 하여 다양성을 유지해야 함을 시사합니다.
5. 구조적 통계
이 섹션에서는 The Pile의 데이터셋에 대한 구조적 통계 정보를 다룹니다. 이는 더 거친 수준의 통계 정보와 The Pile에 대한 일반적인 정보를 제공합니다. 섹션 6에서는 The Pile 데이터셋 내 텍스트 콘텐츠에 대한 더 자세한 조사와 문서를 제공합니다.
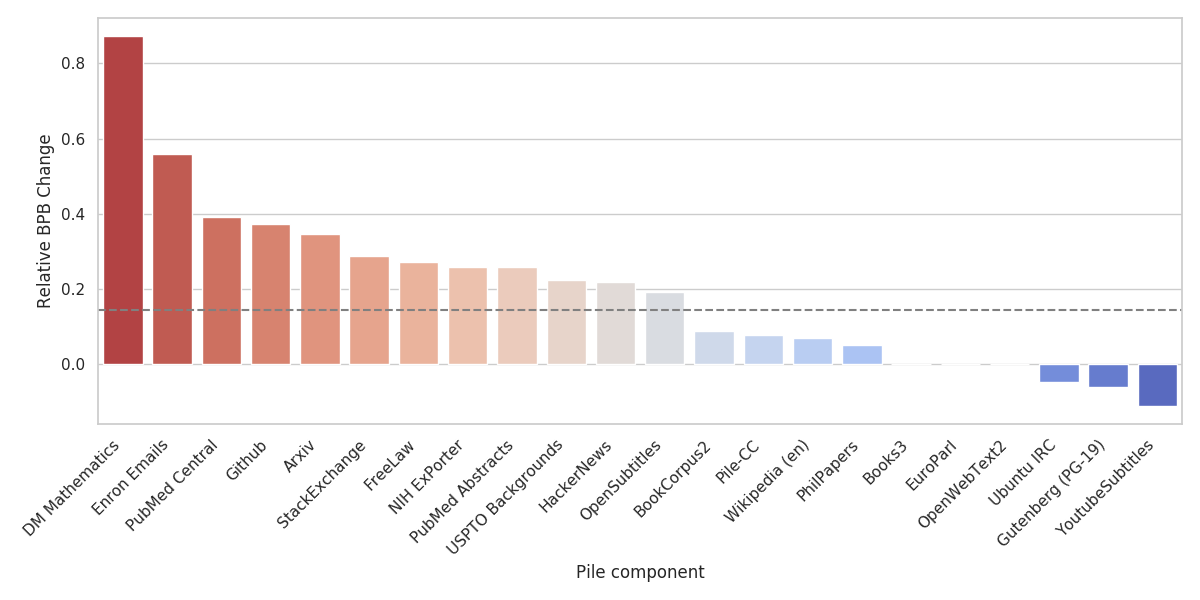
그림 3: Pile에서 훈련된 GPT-2와 OpenWebText2 BPB 변화를 기준으로 한 GPT-3 제로샷의 BPB 변화. 점선은 전체 Pile 변화를 나타냅니다. 값이 낮을수록 GPT-3의 상대적 성능이 더 좋음을 의미합니다.

표 3: 크기 조절 평가 결과 각 데이터셋은 모든 평가 메트릭에 대해 중복 제거되고 약 40GB로 하위 샘플링되어 데이터셋 크기의 영향을 제어합니다. LAMBADA의 경우, Radford et al. (2019)에서 소개된 데이터 변형을 사용하며 마지막 단어가 아닌 마지막 토큰에 대한 당혹도만 평가합니다. WikiText의 경우, GPT-2 토큰당 당혹도를 보고합니다. †는 크기가 추정치임을 나타냅니다.
5.1 문서 길이와 토크나이제이션
각 데이터셋은 다수의 문서로 구성됩니다. 우리는 문서 길이 분포와 GPT-2 토크나이저를 사용한 토큰당 바이트 수를 분석하여 우리의 실험 맥락을 이해하려고 합니다.
대부분의 문서는 짧지만, 매우 긴 문서들도 소수 존재합니다(그림 5).
GPT-2 BPE 토크나이저는 WebText에서 훈련되었기 때문에, 토큰당 평균 바이트 수는 각 Pile 구성 요소가 WebText와 얼마나 구문적으로 다른지에 대한 대략적인 지표입니다. 예를 들어, NIH ExPorter, OpenWebText2, Books3와 같은 데이터셋은 주로 일반 텍스트로 구성되어 있으며, 이는 더 많은 토큰당 바이트 수에 반영됩니다. 반면, 토큰당 바이트 수가 가장 적은 많은 데이터셋은 비문자 텍스트로 구성된 데이터셋(Github, ArXiv, Stack Exchange, DM Mathematics)이나 영어 외의 언어로 된 데이터셋(EuroParl)입니다.
5.2 언어와 방언
세계 인구의 13%만이 영어를 구사하지만, 대부분의 NLP 연구는 영어로 이루어집니다. The Pile의 경우, Brown et al. (2020)에서 사용된 데이터셋과 유사한 접근 방식을 취하여 주로 영어에 중점을 두었지만, 데이터를 수집할 때 다른 언어를 명시적으로 필터링하지는 않았습니다. 다국어 데이터셋을 평가할 때, 포함 여부를 결정하는 주요 기준은 데이터셋의 영어 구성 요소가 단독으로 포함할 가치가 있는지 여부였습니다. 우리는 향후 작업으로 The Pile의 완전한 다국어 확장을 계획하고 있습니다.
fasttext (Suárez et al., 2019a)를 사용하여 The Pile이 97.4% 영어로 구성되었음을 확인했습니다. 언어 식별 문제, 특히 드문 언어의 경우(Caswell et al., 2020), 이 방법론은 영어 콘텐츠에 대한 대략적인 추정치만 제공하며, 저자원 언어에 대한 신뢰할 수 있는 결론을 도출할 수 없습니다.
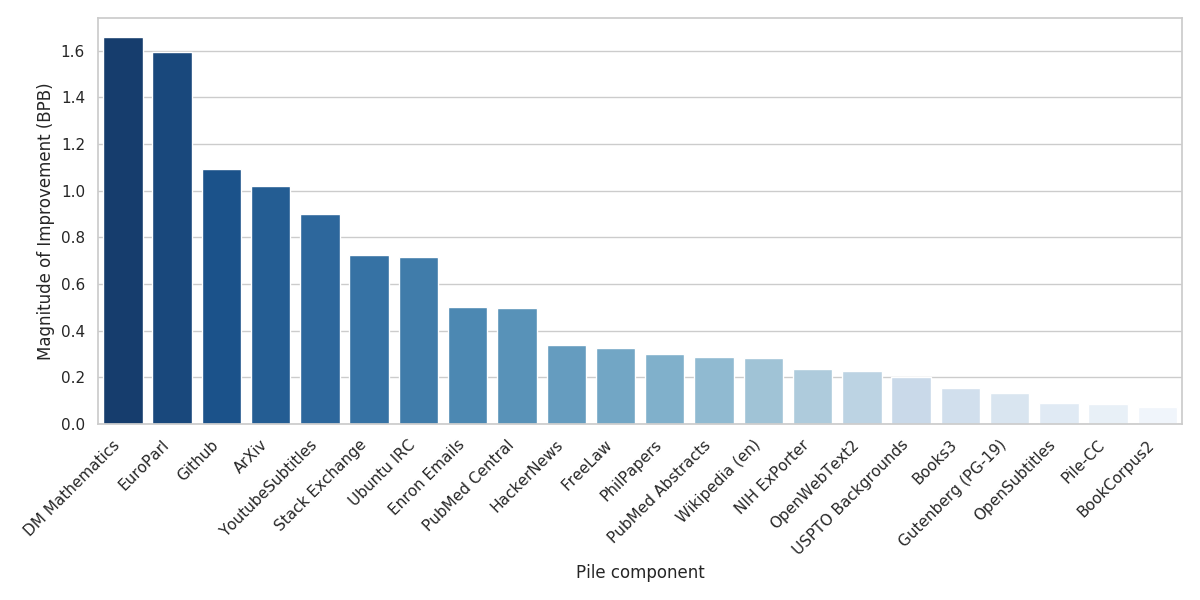
그림 4: 각 테스트 세트에서 CC-100 모델 대비 Pile 모델의 BPB 개선 정도.
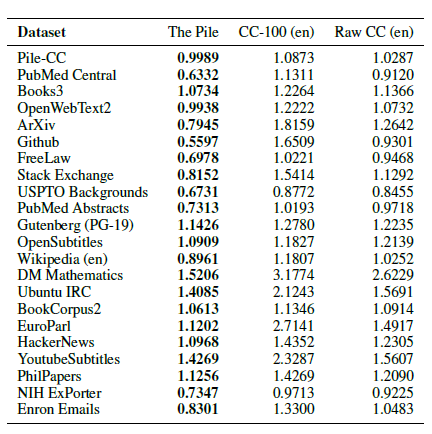
표 4: Pile의 홀드아웃 테스트 세트에 대한 BPB 분석. 열은 각 모델이 훈련된 데이터셋을 나타내며, 행은 평가된 데이터셋을 나타냅니다. 각 행에서 가장 성능이 좋은 모델은 굵게 표시되어 있습니다.
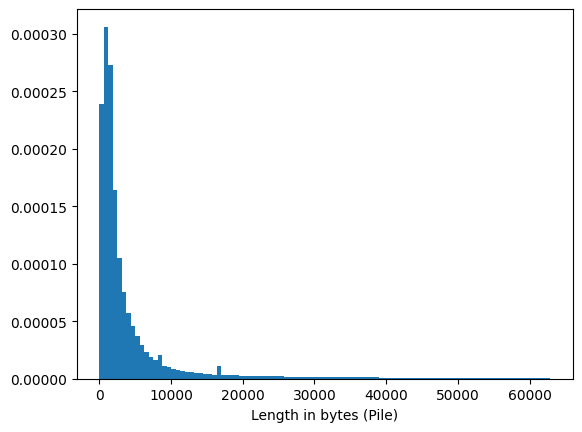
그림 5: Pile에서 문서 길이 분포. 문서 길이 상위 1 백분위는 이상치로 간주되어 이 그림에서 제외되었습니다.
6. 데이터셋 조사 및 문서화
기계 학습 연구의 규모가 커짐에 따라, 모델이 훈련되는 대규모 데이터셋에 대한 검토가 이루어지고 있습니다(Prabhu와 Birhane, 2020; Biderman과 Scheirer, 2020).
이 문제는 AI 윤리 및 편향 연구 내에서 제기되었지만(Hovy와 Spruit, 2016; Hutchinson et al., 2020; Blodgett et al., 2020), 언어 모델링 커뮤니티에서는 주된 관심사가 아니었습니다. 데이터셋의 문제를 탐구하고 문서화하는 작업이 늘어나고 있음에도 불구하고(Gebru et al., 2018; Bender와 Friedman, 2018; Jo와 Gebru, 2020), 대규모 언어 모델 훈련을 위한 데이터셋이 그 창작자들에 의해 진지하게 문서화된 사례는 없었습니다. 따라서 우리의 분석은 두 가지 목표를 가지고 있습니다: The Pile에 대한 윤리적 우려를 해결하고, AI 윤리 문헌과의 교류를 촉진하고 이를 정상화하는 것입니다.
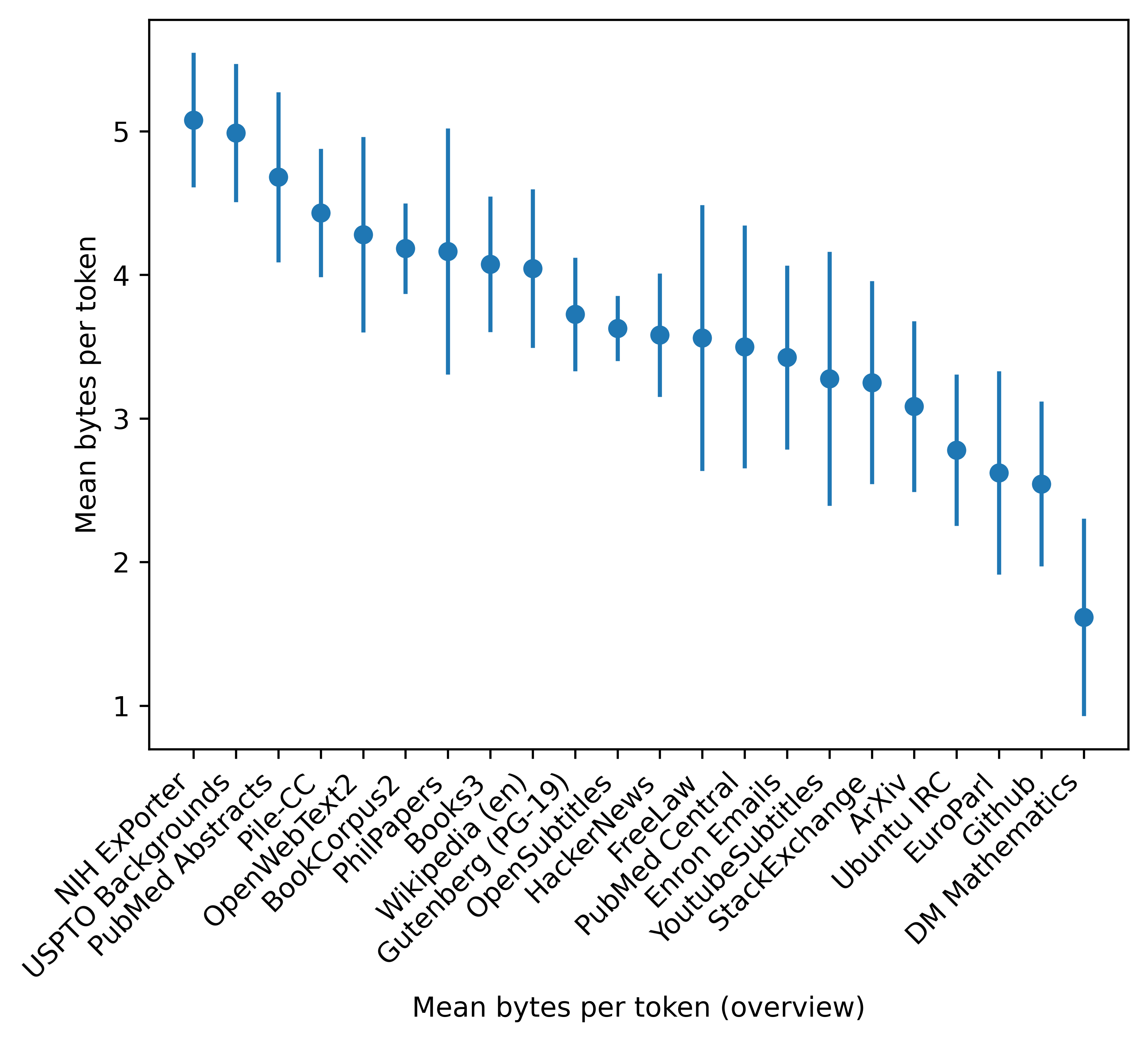
그림 6: Pile에 포함된 각 데이터셋의 GPT-2 토큰당 평균 바이트. 오차 막대는 표준 편차를 나타냅니다.
자연어 처리 기술은 매우 다양한 맥락에서 적용될 수 있습니다. 따라서 어떤 데이터가 훈련에 적절한지 여부는 응용 맥락에 따라 크게 달라질 수 있습니다. 우리의 견해로는, 데이터셋의 잠재적으로 우려되는 측면을 제거하기보다는 문서화하는 것이 더 나은 접근 방식입니다. 특히 The Pile의 목적이 범용 언어 모델을 훈련하는 것이기 때문에 그렇습니다. 따라서 우리의 문서화의 주요 목표는 NLP 연구자들이 정보에 입각한 결정을 내릴 수 있도록 돕는 것입니다.
6.1 문서화 방법
The Pile을 문서화하기 위해 우리는 방법론자들과 윤리 연구자들이 제안한 두 가지 프레임워크를 구현하기로 했습니다. 첫 번째는 데이터시트 방법론(Gebru et al., 2018)으로, 여러 방법론자들이 추천하며(Raji와 Yang, 2019; Biderman과 Scheirer, 2020), 실무자들이 다른 대안보다 더 자주 사용하는 것으로 보입니다(Seck et al., 2018; Costa-jussà et al., 2020; Thieme et al., 2020). 두 번째는 데이터 명세서 방법론(Bender와 Friedman, 2018)으로, 자연어 처리에 특별히 제안되었으며 NLP 커뮤니티에서 잘 받아들여졌습니다. 우리의 데이터시트와 데이터 명세서는 The Pile의 코드가 저장된 GitHub 저장소에 게시되며, arXiv에서도 별도의 문서로 제공될 것입니다(Biderman et al., 2021; Biderman, 2021).
데이터시트와 데이터 명세서 외에도 이 문서들이 다루지 않는 언어 모델 훈련자들에게 유용할 추가 정보가 있을 수 있습니다. 이 섹션의 나머지 부분에서는 이러한 추가 맥락 정보를 더 자세히 조사하고 문서화합니다.
6.2 주제 분포
The Pile이 다루는 특정 주제를 더 잘 이해하기 위해, 우리는 그 구성 요소에 대한 주제 모델링 분석을 수행했습니다. Gensim(Rehurek et al., 2011)을 사용하여 각 구성 요소의 검증 세트에 대해 16개 주제의 잠재 디리클레 할당(Blei et al., 2003) 모델을 동시에 온라인 방식으로 훈련했습니다(Hoffman et al., 2010). 이 분석을 위해 The Pile을 영어로만 필터링했습니다. 이후, Common Crawl에서 파생된(Pile-CC) 주제 모델의 당혹도를 다른 구성 요소의 문서 세트에서 계산했습니다. 이를 통해 The Pile의 일부가 Common Crawl 내에서 잘 다루어지지 않는 주제를 포함하는 정도를 대략적으로 측정할 수 있습니다.
그림 7에서는 이러한 구성 요소 간의 당혹도를 보여주며, OpenWebText2 문서에서 평가된 Pile-CC 주제 모델의 당혹도를 나타내는 수직선을 포함합니다. 이 구성 요소는 이전 평가와 유사한 이유로 비교 기준으로 선택되었습니다. 이는 Common Crawl과 유사한 방식(오픈 웹의 필터링된 크롤)으로 파생되었기 때문에 유사한 주제 분포를 포함할 것으로 예상됩니다. Pile-CC의 내용은 어느 정도 다양하지만, Pile의 다른 구성 요소 중 몇몇은 주제적 초점에서 크게 벗어나 있음을 확인할 수 있습니다. 예를 들어, Github, PhilPapers, EuroParl에서는 당혹도가 더 높게 나타납니다.
각 구성 요소에 대한 LDA 모델에서 추론된 주제 클러스터도 문서화했으며, 이는 부록 C에 제공됩니다. 예상대로, 더 큰 CC 파생 구성 요소는 정치, 교육, 스포츠 및 엔터테인먼트를 포함한 다양한 콘텐츠를 나타내지만, 다른 Pile 구성 요소와 질적으로 비교할 때 놓친 콘텐츠 클러스터가 분명해집니다. 특히 프로그래밍, 논리, 물리학, 법률 지식을 다루는 데이터 모드는 거의 없습니다.
6.3 경멸적 내용
다양한 출처로 인해 The Pile에는 경멸적, 성적으로 노골적이거나 기타 불쾌한 내용이 포함될 수 있습니다. 이러한 내용은 일부 사용 사례에서는 바람직하지 않을 수 있으므로, 데이터셋별로 불경스러운 내용을 분류합니다.
우리는 profanity-checker Python 패키지(Zhou, 2019)를 사용했습니다. 이 패키지는 여러 욕설 목록과 Wikidetox 독성 댓글 데이터셋(Wulczyn et al., 2016)을 사용해 훈련된 "독성 모델"을 포함하며, 주어진 문자열을 불경스럽거나 불경스럽지 않은 것으로 분류합니다.
각 데이터셋의 영어 문장만 고려했습니다. 이는 profanity-checker가 영어에 맞추어 설계되었고 다른 언어는 결과에 부정적인 영향을 미칠 수 있기 때문입니다. 예를 들어, 독일어 여성형/복수형 명사 "die"는 맥락에 관계없이 불경스럽다고 표시됩니다. 각 문장을 단어로 나누고 각 Pile 구성 요소에서 불경스럽다고 표시된 단어의 비율을 계산했습니다. 주어진 단어 또는 구가 맥락에서 불경스러운지 여부를 결정하는 것은 복잡하므로 이 방법론은 불경스러움을 측정하는 대략적인 척도일 뿐임을 강조합니다.
그림 8에 나타난 바와 같이, The Pile 전체는 Pile-CC보다 덜 불경스럽습니다. 또한, 대부분의 Pile 구성 요소는 Pile-CC보다 덜 불경스럽습니다.
우리는 각 데이터셋을 문장 수준으로 분할하여 profanity-checker가 전체 문장을 검사할 수 있도록 했습니다. 문장 단위로 데이터셋을 분할하면 내용이 경멸적인지 여부를 결정할 때 추가적인 맥락을 고려할 수 있습니다. 결과는 그림 12에 나와 있습니다.
6.4 편향 및 감정 공존
언어 모델은 훈련 데이터에서 예상치 못한 편향을 얻을 수 있기 때문에, 우리는 The Pile을 구성하는 다양한 요소에 대한 예비 분석을 수행했습니다. The Pile에서 다른 특성을 가진 모델이 훈련될 수 있으므로, 특정 모델이 아닌 데이터의 편향을 문서화하는 것이 목표입니다. 주로 공존 테스트에 중점을 두어 특정 단어와 같은 문장에 등장하는 단어를 분석했습니다. 이를 통해 특정 단어에 대해 강하게 편향된 단어를 추정하고, 주변 단어의 일반적인 감정을 계산할 수 있습니다.
우리는 성별, 종교, 인종에 중점을 두어 분석했습니다. 이 데이터셋의 사용자에게 다양한 구성 요소가 어떻게 편향되어 있는지에 대한 예비 지침을 제공하여 훈련할 구성 요소를 결정할 수 있도록 돕는 것이 목표입니다.
이 섹션의 모든 표와 그림은 부록에 있습니다.
6.4.1 성별
우리는 이진 대명사의 공존을 계산하여 성별 연관성을 분석했습니다. 각 단어에 대해 "he"와 "she"와 공존하는 비율의 차이를 계산하고, 빈도의 제곱근으로 가중치를 두었습니다. 각 성별에 대해 가장 편향된 상위 15개의 형용사 또는 부사를 표 10에 보고합니다. "군사적", "범죄적", "공격적"과 같은 단어는 남성에게 강하게 편향된 반면, "작은", "기혼", "성적인", "행복한"과 같은 단어는 여성에게 편향되어 있습니다.
또한, 그림 13에서 각 데이터셋에 걸쳐 성별 대명사와 공존하는 단어의 평균 감정을 계산했습니다(Baccianella et al., 2010). 일반적으로 남성이나 여성에 대한 중요한 감정 편향은 발견되지 않았습니다. 이는 물론, 데이터셋이 성별 편향이 없다는 것을 의미하지 않습니다(우리의 공존 테스트가 보여주는 바와 같이).
6.4.2 종교
종교에 대해서도 유사한 공존 분석을 수행했으며, 이는 표 11에 나와 있습니다. 성별과 마찬가지로, 이러한 공존은 온라인 담론의 일부에서 이러한 용어가 어떻게 사용되는지를 반영합니다. 예를 들어, "radical"은 "muslim"과 높은 비율로 공존하며, "rational"은 종종 "atheist"와 공존합니다. 이 분석은 순수한 공존 기반 분석의 한계도 보여줍니다. 예를 들어, "religious"는 종종 "atheist"와 공존하는데, 이는 "atheist"라는 단어가 발생할 가능성이 높은 대화 유형을 반영하며, "atheist"의 설명어로서가 아닙니다.
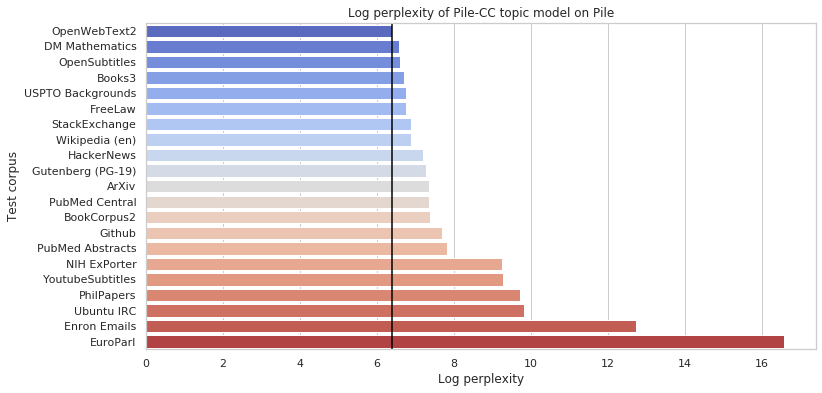
그림 7: Pile-CC에서 훈련된 16개 주제 LDA의 다른 Pile 구성 요소에 대한 로그 당혹도. 점선은 OpenWebText2에 대한 주제 모델의 로그 당혹도를 나타냅니다. 값이 높을수록 Pile-CC와 주제적으로 더 큰 차이가 있음을 의미합니다.
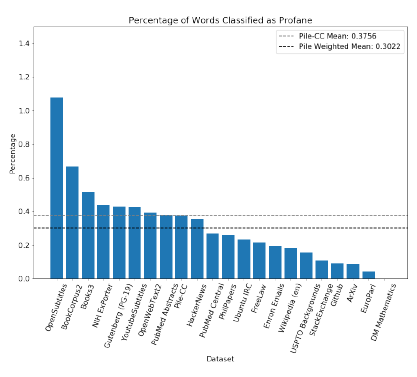
그림 8: The Pile에서 불경스럽다고 분류된 단어의 비율. CC 구성 요소와 전체 Pile의 가중 평균 비율이 수평선으로 표시됩니다.
또한, 우리는 각 구성 데이터셋에서 공존하는 단어들의 평균 감정을 그림 14에서 계산했습니다. 전체 데이터셋에서 "불교도"가 가장 높은 감정을 가지고 있으며, 그 다음으로 "힌두교도", "기독교도", "무신론자", "이슬람교도" 순입니다. 특히, "유대인"이 가장 낮은 감정을 보이는데, 이는 역사적으로 경멸적인 용어로 사용된 것을 반영할 수 있습니다.
6.4.3 인종
마지막으로, 우리는 인종 그룹에 대해 동일한 분석을 수행했습니다. 여기서 "black"이나 "white"와 같은 식별자는 종종 인종을 나타내지 않기 때문에, 대신 "black man"이나 "white woman"과 같은 구문과의 공존을 계산했습니다.
각 인구 집단에 대해 가장 편향된 상위 15개의 단어를 표 12에 보여줍니다. 다시 한 번, 우리는 공존이 이러한 용어가 사용되는 맥락을 반영한다는 것을 발견했습니다. 예를 들어, "black"에 대해 가장 편향된 네 가지 단어는 "unarmed", "civil", "criminal", "scary"입니다.
위와 마찬가지로, 공존하는 단어들의 평균 감정을 계산했습니다. 평균 감정 수치는 표 13에 나와 있습니다. "히스패닉/라틴계"가 가장 높은 감정을 나타내며, 그 다음으로 "아시아계"가 뒤따르고, 그 다음이 "백인"입니다. 반면에, "black"은 -0.15로 가장 낮은 감정을 나타냈습니다.
모든 인구 집단에서 평균 감정이 부정적임을 알 수 있습니다. 우리는 이것이 우리가 공존을 계산하는 데 사용한 구문이 나타나는 특정 맥락 때문이라고 가정합니다. 예를 들어, 뉴스 기사에서 용의자를 "asian man"이라고 묘사하는 경우가 매우 흔합니다.
6.5 저자 동의와 공개 데이터
자연어 처리 연구에서 텍스트 사용과 관련된 또 다른 문제는 동의입니다. 일반적으로 저자의 작품을 NLP 알고리즘 훈련에 사용하는 데 있어 저자의 허락을 받을 법적 의무는 없지만(Obar, 2020; Prabhu와 Birhane, 2020), 많은 사람들은 이를 도덕적 의무나 오용을 방지하는 좋은 방법으로 간주합니다. 반면, 서비스 약관으로 보호된 데이터를 연구 목적으로 재사용하는 윤리에 대해 상당한 의견 차이가 있습니다(Vitak et al., 2016; Fiesler et al., 2020). 특히 디지털 플랫폼의 고유한 권력 불균형을 고려할 때, 이는 독립 연구자가 공개 데이터를 조사하는 것을 방해하면서 동시에 사용자가 개인적인 용도에 동의하도록 강요하는 경우가 많습니다(Halavais, 2019).
The Pile의 데이터 대부분은 연구 목적으로 널리 배포 및 사용에 명시적으로 동의한 출처에서 제공되었지만, 연구자들은 종종 그들의 데이터 출처와 사용 동의 조건을 명확히 문서화하지 못합니다. 이에 비추어 우리는 The Pile을 데이터 저자들이 해당 데이터를 어떻게 사용할 수 있다고 명시했는지에 대한 투명성을 가지고 공개하는 것이 적절하다고 생각했습니다.
동의에 대한 논의를 보다 세분화하기 위해 우리는 공개 사용 가능성의 세 가지 수준을 식별했습니다. 공개 데이터는 인터넷에서 자유롭게 이용할 수 있는 데이터입니다. 여기에는 페이월이 있는 데이터(페이월을 우회하기 쉬운지 여부와 상관없이)와 쉽게 얻을 수 없지만 얻을 수 있는 데이터(예: 토렌트나 다크 웹을 통해)를 제외합니다. 서비스 약관(ToS) 준수 데이터는 데이터 호스트의 서비스 약관과 일치하는 방식으로 얻고 사용하는 데이터입니다. 저자 동의 데이터는 원작자가 자신의 데이터 사용에 동의한 데이터이거나, 합리적인 사람이 해당 데이터가 연구와 같은 목적으로 사용되지 않을 것이라고 가정할 수 없는 데이터입니다. ToS 준수 데이터와 저자 동의 데이터는 두 가지 주요 측면에서 다릅니다: 사람들이 일반적으로 서비스 약관을 읽지 않는다는 점과 ToS 준수가 저자의 동의를 의미하지 않는다는 점입니다. 우리는 모호하거나 알려지지 않은 동의를 비동의로 간주하는 엄격한 동의 모델을 채택했습니다.
표 5는 The Pile 내 각 데이터셋의 상태에 대한 우리의 이해를 요약한 것입니다. 관련 측면에서 준수하는 데이터셋에는 3 표시가 되어 있으며, 몇 가지 데이터셋에 대해 특히 언급할 가치가 있습니다. Book3와 OpenSubtitles는 데이터 호스트의 서비스 약관과 일치하는 방식으로 사용되고 있습니다. 그러나 이는 데이터 호스트가 해당 데이터를 온라인에 게시하도록 권한을 부여받지 않은 당사자들에 의해 게시되었기 때문에 다소 오해의 소지가 있습니다. Enron Emails 데이터셋은 저자의 허락 없이 수집되었지만, 미국 정부가 형사 조사 과정에서 수집한 것입니다. Enron 데이터셋에 있는 이메일의 사람들은 이 사실을 알고 있지만, 그 포함에 동의할 수 있는 기회는 없었습니다.
The Pile에 포함된 다섯 개의 데이터셋은 ToS 준수 방식으로 수집 및 배포되지 않았으며, 저자가 자신의 데이터 사용에 동의할 수 없었던 데이터입니다. 이러한 데이터셋은 NLP 문헌 및 전 세계적으로 널리 사용되고 있습니다. YouTube Subtitles 데이터셋을 제외하고, 이러한 데이터셋 각각은 연구자들에 의해 공개되었으며 인터넷에서 자유롭게 공유되고 있습니다. YouTube Subtitles 데이터셋은 이 프로젝트를 위해 우리가 만든 것이며, 널리 사용되고 쉽게 구할 수 있는 비공식 API를 사용하여 만들어졌습니다. 이러한 데이터셋에 적용된 처리 및 The Pile에서 특정 파일을 식별하는 어려움을 고려할 때, 우리는 이러한 데이터셋의 사용이 이미 널리 공개된 데이터셋에 의해 초래된 해를 크게 증가시키지 않는다고 생각합니다.
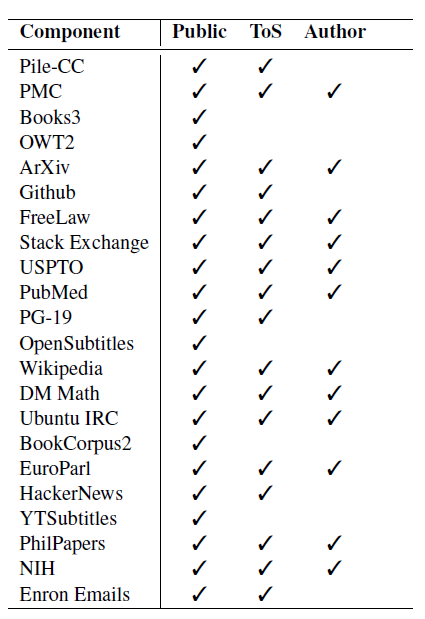
표 5: 각 데이터셋의 동의 유형
데이터셋, 공공 데이터, 서비스 약관(ToS) 준수, 저자 동의
7. 의미와 광범위한 영향
The Pile은 모델과 데이터셋을 점점 더 큰 규모와 능력으로 확장하는 과정에서 또 하나의 중요한 단계입니다. 더 강력한 AI 시스템의 등장으로 인해 전 세계에 미칠 영향에 대한 많은 심각한 우려가 있으며(Brundage et al., 2018; Amodei et al., 2016; Bostrom and Yudkowsky, 2014; Bostrom, 2014; Critch and Krueger, 2020), 우리는 이러한 우려가 심도 있는 고려를 필요로 한다고 믿습니다. 이 섹션에서는 The Pile의 법적 의미와 AI 정렬에 대한 The Pile의 영향을 두 가지 관점에서 논의합니다: AI 일정 가속화와 정렬되지 않은 언어 모델이 초래하는 위험.
7.1 콘텐츠의 합법성
기계 학습 커뮤니티는 저작권 데이터로 모델을 훈련하는 것의 합법성 문제를 논의하기 시작했지만, 타인의 데이터 처리 및 배포가 저작권 법을 위반할 수 있다는 사실은 거의 인식하지 못합니다. 그 방향으로 나아가는 한 걸음으로, 우리는 저작권 데이터를 사용하는 것이 미국 저작권법을 준수한다고 믿는 이유를 논의합니다.
1984년 이전의 판례와 그 이후의 판결(예: 2013년 판결; 2015년 구글 판결)에 따르면, 비상업적이고 비영리적 목적으로 저작권 미디어를 사용하는 것은 선제적으로 공정 사용에 해당합니다. 또한, 우리의 사용은 원본 데이터의 형태가 우리의 목적에 효과적이지 않고 우리의 데이터 형태가 원본 문서의 목적에 효과적이지 않다는 점에서 변형적입니다. 비록 저작권 작품의 전체 텍스트를 사용하지만, 전체 작업이 필요할 때 이는 반드시 실격 요인이 되지는 않습니다(2003년 판결). 우리의 경우, 자연어의 장기적 종속성을 고려할 때 최상의 결과를 얻기 위해 전체 텍스트를 사용하는 것이 필요합니다(Dai et al., 2019; Rae et al., 2019; Henighan et al., 2020; Liu et al., 2018).
저작권법은 국가마다 다르며, 특정 관할 구역에서는 일부 작품에 추가 제한이 있을 수 있습니다. 지역 법률을 보다 쉽게 준수할 수 있도록 The Pile 재생산 코드는 공개되어 있으며, 사용자가 부적절하다고 생각하는 특정 구성 요소를 제외하는 데 사용할 수 있습니다. 불행히도, 어떤 텍스트가 저작권이 있는지 정확히 결정하는 데 필요한 메타데이터가 없으므로 이는 구성 요소 수준에서만 수행할 수 있습니다. 따라서 이는 정밀한 결정이라기보다는 휴리스틱한 접근으로 간주되어야 합니다.
7.2 AI 타임라인의 가속화
AI 시스템이 곧 모든 관련 경제적 과제에서 인간보다 의미 있게 더 능력 있을 수 있다는 심각한 우려가 있습니다(Grace et al., 2018; Yudkowsky, 2013). 이와 관련하여, 이러한 강력한 AI 시스템을 인간의 이익에 맞게 제대로 정렬하는 방법에 대한 해결되지 않은 중요한 질문들이 있습니다(Bostrom and Yudkowsky, 2014; Russell, 2019; Bostrom, 2014; Amodei et al., 2016). 일반적으로 도덕적으로 재앙적인 결과를 피하는 방법에 대한 질문도 있습니다(Sotala and Gloor, 2017; Shulman and Bostrom, 2020). 따라서 이러한 우려가 충분히 해결되기 전에 강력한 AI 시스템 개발을 가속화하는 것은 바람직하지 않을 수 있다는 주장이 제기되었습니다(Bostrom, 2014).
이 견해에 대한 몇 가지 실용적인 대응이 있습니다:
- 인간의 경쟁, 호기심, 문화적 다양성 때문에 기술 개발을 중단하는 것은 매우 어렵거나 불가능할 수 있습니다(Russell, 2019; Critch and Krueger, 2020).
- AI 개발은 본질적으로 실험적입니다: 정렬 문제는 개발, 테스트 및 (희망적으로는 존재론적이지 않은) 실패를 통해서만 해결될 수 있습니다.
- 고성능 언어 모델과 그보다 더 일반적인 후속 모델은 도덕적으로 문제가 있는 콘텐츠를 자신의 출력에 반영하지 않고도 볼 수 있어야 합니다. 다음 섹션에서 이에 대해 더 자세히 설명합니다.
이 점을 염두에 두고, 우리는 The Pile이 AI 타임라인을 가속화할 가능성이 있음을 인정합니다. 그러나 우리는 데이터의 내용을 철저히 문서화하는 등의 모범 사례를 확립하려는 노력이 정렬 문제에 대한 후속 연구자들의 주의를 환기시키는 데 도움이 되기를 바랍니다.
7.3 부정적인 언어 모델 출력
강력한 언어 모델이 세상에 미칠 수 있는 부정적인 효과에 대한 논의가 많았습니다(Brown et al., 2020; Brundage et al., 2018). 이러한 문제 중 일부는 검색 엔진 최적화(SEO)를 위해 저품질 콘텐츠를 대량 생산할 수 있는 능력과 같은 본질적인 문제로, 온라인 콘텐츠가 배포되는 방식과 관련이 있으며 언어 모델 개발자들만으로는 해결할 수 없습니다. 이러한 문제를 직접적으로 해결하려면 공공 키 기반 구조(PKI) 및 분산된 신원 인증과 같은 인터넷 아키텍처의 대대적인 변화가 필요합니다(Ferguson and Schneier, 2003).
또 다른 우려는 이러한 모델을 대규모 데이터셋에서 훈련할 때, 혐오적인 고정관념을 조장하는 등의 바람직하지 않은 콘텐츠가 훈련 세트에 포함될 가능성이 거의 필연적이라는 점입니다(Christian, 2020). 모델이 바람직하지 않은 콘텐츠를 출력하는 것은 정의상 바람직하지 않지만, 우리는 이 문제를 훈련 세트 측에서 해결하는 것은 비생산적이며 궁극적으로 최적의 해결책에서 멀어지게 한다고 믿습니다. 사람이 인종차별적인 콘텐츠를 읽더라도 즉시 그 인종차별적인 견해를 채택하지 않는 것처럼, 이를 이해하고 무시할 수 있는 능력은 중요한 미래 연구 방향입니다. 이는 모델이 "더러운" 데이터를 더 적은 우려로 사용할 수 있게 할 뿐만 아니라, 얻은 지식을 통해 무엇을 하지 말아야 하는지 더 잘 이해할 수 있게 합니다. 최근 인간이 지도하는 학습(Stiennon et al., 2020)에서의 진전에도 불구하고, 기술은 아직 이 단계에 이르지 않았으며, 따라서 우리는 이 논문에서 설명한 여러 편집 결정을 내렸습니다. 그러나 이 접근 방식은 이러한 모델과 더 넓은 AI의 미래에 필수적이며, 더 많은 연구가 필요합니다.
8. 관련 연구
대규모 비표지 텍스트 코퍼스에서 자연어 처리 모델을 자체 지도 학습하는 방식은 널리 채택되었습니다. GloVe (Pennington et al., 2014)와 word2vec (Mikolov et al., 2013) 같은 단어 표현 모델은 Wikipedia, Gigaword (Graff et al., 2003), 또는 비공개 Google 뉴스 코퍼스와 같은 데이터셋에서 훈련되었습니다. 최근에는 언어 모델(Radford et al., 2018, 2019; Brown et al., 2020; Rosset, 2019; Shoeybi et al., 2019)과 마스킹 언어 모델(Devlin et al., 2019; Liu et al., 2019; Raffel et al., 2019)이 Wikipedia, BookCorpus (Zhu et al., 2015), RealNews (Zellers et al., 2019), CC-Stories (Trinh and Le, 2018) 및 아래에 논의된 다른 인터넷 스크래핑 데이터셋에서 훈련되었습니다. WikiText (Stephen et al., 2016)와 같은 다른 데이터셋도 유사한 자체 지도 학습에 사용되었습니다.
언어 모델링에 대한 데이터 요구사항이 증가함에 따라, 이 분야는 대규모 데이터셋을 위해 인터넷 스크래핑으로 전환되었습니다(Gokaslan and Cohen, 2019). 특히 Common Crawl이 널리 사용되고 있습니다. Brown et al. (2020); Wenzek et al. (2019); Suárez et al. (2019b); Raffel et al. (2019)과 같은 작업은 대규모 모델의 훈련 데이터셋을 구축하기 위해 Common Crawl을 사용했습니다. 그러나 이러한 작업은 종종 Common Crawl 데이터를 정리하고 필터링하는 어려움을 강조하며, 결과 데이터 품질이 모델 성능을 결정하는 중요한 요소임을 강조합니다.
언어 모델을 훈련할 때 여러 데이터셋을 결합하는 것도 점점 일반적인 관행이 되었습니다. 예를 들어, GPT (Radford et al., 2018)는 Wikipedia와 BookCorpus에서 훈련되었으며, GPT-3 (Brown et al., 2020)는 Wikipedia, 두 개의 소설 데이터셋 및 두 개의 웹 스크래핑 데이터셋에서 훈련되었습니다. The Pile은 대규모 웹 스크래핑을 더 작고 높은 품질의 데이터셋과 결합하여 언어 모델 훈련에 가장 유익할 지식을 포착하는 추세를 이어갑니다.
The Pile과 가장 비교할 만한 공개 데이터셋은 CC-100 (Wenzek et al., 2019)과 C4/mC4 (Raffel et al., 2019)입니다. C4는 The Pile과 비교할 만한 크기이며, mC4와 CC-100은 더 큰 다국어 데이터셋입니다. 그러나 C4/mC4는 데이터를 전처리하는 데 막대한 계산 자원이 필요하며, 유지 관리자는 분산 클라우드 서비스를 사용할 것을 권장합니다. CC-100은 직접 다운로드 가능하고 사전 정리되어 있지만, 영어 부분은 The Pile보다 훨씬 작습니다. 중요한 것은, 이 세 가지 데이터셋 모두 Common Crawl에서 파생되었습니다. 앞서 논의한 바와 같이, 대규모 언어 모델을 훈련하는 현재의 모범 사례는 대규모 웹 스크래핑과 더 목표지향적이고 높은 품질의 데이터셋을 모두 사용하는 것을 포함하며, The Pile은 이를 직접적으로 다룹니다.
9. 감사의 말
저자들은 평가를 위한 계산 자원을 제공한 TensorFlow Research Cloud와 GPT-3 평가를 위한 OpenAI API에 접근 및 크레딧을 제공한 OpenAI에 감사를 표합니다. 또한 원고를 검토한 Farrukh Raman, JR Smith, Michelle Schmitz에게도 감사를 표합니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
이래놓고는 2024년 5월 쯤부터 배포 중단함
-----------------------------------------------------------------------------------------------------------------------------------------------------------------



