https://arxiv.org/abs/2106.04560
Scaling Vision Transformers
Attention-based neural networks such as the Vision Transformer (ViT) have recently attained state-of-the-art results on many computer vision benchmarks. Scale is a primary ingredient in attaining excellent results, therefore, understanding a model's scalin
arxiv.org
초록
Vision Transformer(ViT)와 같은 어텐션 기반 신경망은 최근 여러 컴퓨터 비전 벤치마크에서 최첨단 결과를 달성했습니다. 우수한 결과를 얻기 위해서는 규모가 핵심 요소이므로, 모델의 스케일링 특성을 이해하는 것이 미래 세대의 효과적인 설계에 중요합니다. Transformer 언어 모델의 스케일링 법칙은 연구되었지만, Vision Transformer가 어떻게 스케일되는지는 알려져 있지 않습니다. 이를 해결하기 위해, 우리는 ViT 모델과 데이터를 상하로 스케일링하여 오류율, 데이터 및 계산 간의 관계를 특성화했습니다. 그 과정에서 ViT의 아키텍처와 학습 방식을 개선하여 메모리 소비를 줄이고 모델의 정확도를 높였습니다. 그 결과, 우리는 20억 개의 파라미터를 가진 ViT 모델을 성공적으로 학습시켰으며, 이는 ImageNet에서 새로운 최고 성능인 90.45%의 top-1 정확도를 달성했습니다. 이 모델은 few-shot 전이 학습에서도 우수한 성능을 보이며, 예를 들어 클래스당 10개의 예시만으로 ImageNet에서 84.86%의 top-1 정확도를 달성했습니다.
1 서론

그림 1: Few-shot 전이 학습 결과. 우리의 ViT-G 모델은 10-shot 선형 평가로 ImageNet에서 84.86%의 top-1 정확도를 달성했습니다.
어텐션 기반의 Transformer 아키텍처 [45]는 컴퓨터 비전 분야를 강타하며 [16, 8], 연구와 실무에서 점점 더 인기 있는 선택이 되고 있습니다. 이전에는 Transformer가 자연어 처리(NLP) 분야에서 널리 채택되었습니다 [15, 7]. NLP에서 Transformer의 최적 스케일링은 [22]에서 신중하게 연구되었으며, 주요 결론은 큰 모델이 더 나은 성능을 보일 뿐만 아니라 큰 계산 자원을 더 효율적으로 사용한다는 것이었습니다. 그러나 이러한 발견이 몇 가지 중요한 차이점이 있는 비전 분야에 어느 정도까지 적용되는지는 여전히 명확하지 않습니다. 예를 들어, 비전에서 가장 성공적인 사전 학습 방식은 NLP 분야의 비지도 사전 학습과는 대조적으로 지도 학습입니다.
이 논문에서 우리는 이미지 분류 작업에서 사전 학습된 ViT 모델의 전이 성능에 대한 스케일링 법칙에 집중합니다. 특히, 우리는 500만에서 20억 개의 파라미터를 가진 모델, 100만에서 30억 개의 훈련 이미지를 가진 데이터셋, 그리고 1 TPUv3 코어-일 이하에서 10,000 코어-일을 넘는 계산 자원에 이르는 실험을 수행합니다. 우리의 주요 기여는 두 개의 데이터셋에서 ViT 모델의 성능-계산 자원 프론티어를 특성화한 것입니다.


그림 2:
왼쪽/중앙: 총 학습 계산량의 함수로서 ImageNet 파인튜닝과 선형 10-shot 오류율로 측정된 표현 품질. 포화되는 멱법칙이 파레토 프론티어를 상당히 정확하게 근사합니다. 더 작은 모델(파란색 음영)이나 더 적은 이미지로 학습된 모델(더 작은 마커)은 더 오래 학습하면 포화되어 프론티어에서 벗어납니다.
오른쪽 상단: 모델 크기에 의해 병목이 생길 때의 표현 품질. 각 모델 크기마다 큰 데이터셋과 많은 계산량을 사용하므로, 모델 용량이 주요 병목입니다. 연한 음영의 마커는 각 모델의 최적이 아닌 실행을 나타냅니다.
오른쪽 하단: 데이터셋 크기에 따른 표현 품질. 각 데이터셋 크기마다 최적의 모델 크기와 계산량을 가진 모델이 강조되어 있으므로, 데이터셋 크기가 주요 병목입니다.
그 과정에서 우리는 개선된 대규모 학습 레시피를 만들었습니다. 우리는 학습 하이퍼파라미터를 조사하고, few-shot 전이 성능에 극적인 향상을 가져오는 미묘한 선택들을 발견했습니다. few-shot 전이 평가 프로토콜은 이전의 NLP 도메인에서의 대규모 사전 학습 노력에서도 채택되었습니다 [6]. 특히, 우리는 매우 강한 L2 정규화를 최종 선형 예측 층에만 적용하면, 매우 강력한 few-shot 전이 능력을 가진 시각적 표현을 학습하게 된다는 것을 발견했습니다. 예를 들어, 클래스당 단 하나의 예시만으로도(1,000개의 클래스를 가진 ImageNet 데이터셋에서) 우리의 최고 모델은 69.52%의 정확도를 달성하며, 클래스당 10개의 예시로는 84.86%의 정확도를 달성합니다. 추가로, 우리는 [16]에서 제안된 원래의 ViT 모델의 메모리 사용량을 상당히 줄였습니다. 이는 하드웨어에 특화된 아키텍처 변경과 다른 옵티마이저를 통해 달성했습니다. 그 결과, 우리는 20억 개의 파라미터를 가진 모델을 학습하여 ImageNet에서 새로운 최고 성능인 90.45%의 정확도를 달성했습니다.
2 핵심 결과
우리는 먼저 3장에서 자세한 아키텍처와 학습 프로토콜 개선 사항을 제시하기 전에, 스케일링 트렌드에 대한 주요 결과를 소개합니다. 다음 실험에서, 우리는 공개된 ImageNet-21k [14] 데이터셋과 사적으로 수집한 최대 30억 개의 약하게 라벨된 이미지에 대해 여러 ViT 모델을 학습합니다. 우리는 아키텍처 크기, 학습 이미지의 수, 학습 기간을 다양하게 조절합니다. 모든 모델은 TPUv3에서 학습되며, 따라서 총 계산량은 TPUv3 코어-일로 측정됩니다. 모델이 학습한 표현의 품질을 평가하기 위해, 우리는 (i) 고정된 가중치에서 선형 분류기를 학습하는 few-shot 전이를 통해, (ii) 전체 모델을 모든 데이터에 대해 파인튜닝하는 전이를 통해 여러 벤치마크 작업에서 성능을 측정합니다.
2.1 계산량, 모델, 데이터의 동시 스케일업
그림 2는 ImageNet [14]에서의 10-shot 선형 평가와 파인튜닝 평가를 보여줍니다. 다른 데이터셋인 Oxford IIIT Pets [28], CIFAR-100 [24], Caltech-UCSD Birds [47]에서의 유사한 경향은 부록의 그림 9에 제시되어 있습니다. 모델 크기와 데이터 크기의 각 조합에 대해 우리는 다양한 스텝 수로 사전 학습합니다. 그림 2에서, 연결된 점들은 동일한 모델을 다른 학습 스텝 수로 학습한 것을 나타냅니다. 우리는 다음과 같은 관찰을 합니다.
첫째, 계산량, 모델, 데이터를 함께 스케일업하면 표현 품질이 향상됩니다. 왼쪽 그래프와 중앙 그래프에서, 오른쪽 하단의 점은 가장 큰 모델 크기, 데이터셋 크기, 계산량으로 최저 오류율을 달성한 모델을 보여줍니다. 그러나 가장 큰 크기에서 모델들이 포화되기 시작하고, 멱법칙 프론티어(로그-로그 플롯에서의 선형 관계, 그림 2 참조)보다 뒤처지기 시작하는 것으로 보입니다.
둘째, 표현 품질은 모델 크기에 의해 병목될 수 있습니다. 오른쪽 상단 그래프는 각 모델 크기에 대해 달성된 최상의 성능을 보여줍니다. 용량의 제한으로 인해, 작은 모델들은 가장 큰 데이터셋이나 계산 자원으로부터 이점을 얻을 수 없습니다. 그림 2의 왼쪽과 중앙은 많은 이미지로 학습하더라도 Ti/16 모델이 높은 오류율로 향하는 경향을 보여줍니다.
셋째, 큰 모델은 10억 개 이상의 추가 데이터로부터 이점을 얻습니다. 모델 크기를 스케일업할 때, 표현 품질은 더 작은 데이터셋에 의해 제한될 수 있습니다; 심지어 3천만~3억 개의 이미지도 가장 큰 모델들을 포화시키기에 충분하지 않습니다. 그림 2의 중앙에서, 30M 데이터셋에서의 L/16 모델의 오류율은 27% 이하로 개선되지 않습니다. 더 큰 데이터셋에서는 이 모델이 19%를 달성합니다. 더욱이, 데이터셋 크기를 늘릴 때, 우리는 큰 모델에서 성능 향상을 관찰하지만 작은 모델에서는 그렇지 않습니다. 가장 큰 모델들은 학습 세트 크기가 10억에서 30억 이미지로 증가할 때도 성능 향상을 얻습니다(그림 2, 오른쪽 하단). 그러나 Ti/16 또는 B/32와 같은 작은 모델에서는 데이터셋 크기를 늘려도 도움이 되지 않습니다. 예를 들어, 그림 2의 왼쪽과 중앙에서, Ti/16의 모든 곡선이 겹쳐져 있으며, 이는 이 모델이 데이터셋 크기에 관계없이 동일한 성능을 달성함을 보여줍니다.

그림 3: 사전 학습 중에 본 이미지 수에 따른 ImageNet에서의 오류율. 큰 모델은 다양한 설정에서 일관되게 샘플 효율성이 더 높습니다: 고정된 표현에서의 few-shot 전이, ImageNet에서의 네트워크 파인튜닝, 그리고 파인튜닝된 모델을 v2 테스트 세트에서 평가합니다.
2.2 이중 포화 멱법칙
그림 2의 왼쪽과 중앙은 표현 품질 대 학습 계산량의 파레토 프론티어를 보여줍니다. 이 프론티어에는 계산량을 모델 형태와 학습 기간에 가장 잘 할당한 모델들이 포함되어 있습니다.


2.3 큰 모델은 더 샘플 효율적입니다
그림 3은 사전 학습 중에 "본" 총 이미지 수(배치 크기 × 스텝 수)에 따른 표현 품질을 보여줍니다. 공개 검증 세트에서의 ImageNet 파인튜닝 및 선형 10-shot 결과에 추가로, 우리는 강건한 일반화의 지표로서 ImageNet-v2 테스트 세트 [33]에서의 ImageNet 파인튜닝된 모델의 결과도 보고합니다. 30억 개의 이미지로 사전 학습된 세 개의 ViT 모델이 이 플롯에 제시되어 있습니다.
우리는 더 큰 모델이 더 샘플 효율적이며, 더 적은 본 이미지로 동일한 수준의 오류율에 도달한다는 것을 관찰합니다. 10-shot의 경우, Ti/16 모델은 L/16 모델의 표현 품질과 일치하기 위해 거의 100배 더 많은 이미지를 봐야 합니다. 파인튜닝할 때, 이 계수는 100에서 약 20으로 감소합니다. 우리의 결과는 충분한 데이터가 있을 때, 더 큰 모델을 더 적은 스텝으로 학습하는 것이 바람직하다는 것을 시사합니다. 이 관찰은 언어 모델링 및 기계 번역에서의 결과와 일치합니다 [22, 26].

그림 4: ImageNet-21k 데이터셋에서의 결과. 왼쪽: 총 학습 계산량의 함수로 측정한 ImageNet 선형 10-shot 오류율로 나타낸 표현 품질. 이중 포화 멱법칙이 여전히 적용됩니다. 오른쪽: 모델 크기와 데이터셋 크기에 따른 표현 품질.
표 1: 이전 최첨단 모델과 비교한 ViT-G/14의 결과.

2.4 스케일링 법칙은 적은 이미지에서도 여전히 적용되는가?
우리는 공개된 ImageNet-21k 데이터셋에서 100만에서 1,300만 개의 훨씬 적은 이미지로 연구를 확장했습니다. 그림 4의 왼쪽에서, 우리는 모델 크기, 데이터셋 크기 및 계산 자원을 변화시킬 때도 이중 포화 멱법칙이 여전히 적용된다는 것을 발견했습니다. 이는 연구의 결론이 잘 일반화되며, 비전 트랜스포머 아키텍처의 미래 설계 선택에 지침을 제공할 수 있음을 나타냅니다. 그림 4의 오른쪽에서, 우리는 모델 성능이 데이터셋 크기에 의해 병목되는 유사한 현상을 관찰합니다. 계산량, 모델, 데이터를 함께 스케일업할 때 최고의 표현 품질을 얻을 수 있습니다.
2.5 ViT-G/14 결과
우리는 약 20억 개의 파라미터를 가진 대형 비전 트랜스포머인 ViT-G/14를 학습했습니다. 아키텍처의 형태에 대한 자세한 내용은 3.6절에서 다룹니다. 우리는 ViT-G/14 모델을 다양한 다운스트림 작업에서 평가하고, 최근의 최첨단 결과와 비교했습니다. 우리는 ImageNet에서 파인튜닝하고, ImageNet [34], ImageNet-v2 [33], ReaL [4], ObjectNet [2]의 정확도를 보고합니다. 추가로, 19개의 작업으로 구성된 VTAB-1k 벤치마크 [53]에서의 전이 학습 결과를 제공합니다.
그림 1은 ImageNet에서의 few-shot 전이 결과를 보여줍니다. ViT-G/14는 이전 최고 모델인 ViT-H/14 [16]보다 큰 차이(5% 이상)로 앞서며, 클래스당 10개의 예시로 84.86%의 정확도를 달성했습니다. 클래스당 10개의 이미지는 자기지도 및 반지도 학습에서 일반적으로 사용되는 ImageNet 데이터(클래스당 13개의 예시)의 1% 미만입니다 [52]. 참고로, 그림 1은 1%의 ImageNet 데이터를 사용하는 세 가지 최첨단 자기지도 학습 모델인 SimCLR v2 [10], BYOL [17], 그리고 클래스당 20개의 예시를 사용하는 DINO [9]를 보여줍니다. 그러나 이러한 접근 방식은 상당히 다르다는 점에 유의해야 합니다. ViT-G/14는 약하게 지도된 데이터의 큰 소스를 사용하며, 한 번만 사전 학습하고 다양한 작업에 전이됩니다. 반면에, 자기지도 학습 모델은 레이블이 없는 그러나 도메인 내 데이터를 사전 학습에 사용하며, 단일 작업을 목표로 합니다.
표 1은 나머지 벤치마크에서의 결과를 보여줍니다. ViT-G/14는 ImageNet에서 90.45%의 top-1 정확도를 달성하여 새로운 최첨단을 설정했습니다. ImageNet-v2에서 ViT-G/14는 EfficientNet-L2를 기반으로 한 Noisy Student 모델 [49]보다 3% 향상되었습니다. ReaL에서는 ViT-G/14가 ViT-H [16]와 BiT-L [23]보다 약간 앞서는데, 이는 ImageNet 분류 작업이 포화점에 도달하고 있음을 다시 한번 나타냅니다. ObjectNet에서 ViT-G/14는 BiT-L [23]보다 큰 폭으로 앞서며, Noisy Student보다 2% 더 좋지만 CLIP [31]보다는 약 2% 뒤처집니다. 다른 방법들과 달리, CLIP은 ImageNet에서 파인튜닝하지 않고 직접 ObjectNet에서 평가한다는 점에 유의하십시오. 이는 그 견고성을 향상시킬 가능성이 있습니다. 마지막으로, ViT-G/14 모델을 VTAB에 전이할 때, 모든 작업에서 단 하나의 하이퍼파라미터로도 일관되게 더 나은 결과를 얻습니다. 작업별로 무거운 하이퍼파라미터 스윕을 사용하는 VTAB의 최첨단은 79.99 [21]이며, 우리는 ViT-G/14로 무거운 스윕을 수행하는 것을 향후 작업으로 남겨둡니다.
3 방법 상세
우리는 ViT 모델과 학습에 대한 여러 가지 개선 사항을 제시합니다. 이러한 개선 사항은 대부분 구현이 간단하며, 메모리 활용도와 모델 품질을 크게 향상시킬 수 있습니다. 이를 통해 전체 모델을 단일 TPUv3 코어에 맞추어 데이터 병렬 처리만으로 ViT-G/14를 학습할 수 있습니다.
3.1 "헤드"에 대한 분리된 가중치 감쇠(Weight Decay)


그림 5: 왼쪽과 중앙: 5-shot ImageNet 정확도와 업스트림 성능은 가중치 감쇠 강도에 따라 달라집니다. 일반적으로 단일 가중치 감쇠 값이 모든 가중치에 적용되며(히트맵의 대각선에 해당), 우리는 '헤드'와 나머지 가중치에 대해 가중치 감쇠 값을 분리하면 few-shot 전이 성능을 크게 향상시킬 수 있음을 보여줍니다. 오른쪽: 다양한 종류의 헤드에 대한 ImageNet에서의 few-shot 성능. 헤드에 높은 가중치 감쇠를 적용하면 모든 경우에서 동일하게 잘 작동합니다.
가중치 감쇠는 데이터가 적은 환경에서 모델 적응에 큰 영향을 미칩니다. 우리는 중간 규모에서 이 현상을 연구했습니다.
우리는 모델에서 최종 선형 층('헤드')과 나머지 가중치('바디')에 대해 가중치 감쇠 강도를 분리하면 이점을 얻을 수 있음을 발견했습니다. 그림 5는 이 효과를 보여줍니다. 우리는 JFT-300M에서 ViT-B/32 모델의 모음을 학습했으며, 각 셀은 헤드/바디 가중치 감쇠 값이 다른 경우의 성능에 해당합니다. 대각선은 두 감쇠에 동일한 값을 사용하는 경우를 나타냅니다. 최고의 성능은 대각선 밖에서 나타남을 알 수 있습니다(즉, 헤드와 바디에 대한 가중치 감쇠를 분리한 경우). 흥미롭게도, 헤드에서의 높은 가중치 감쇠는 전이 성능을 향상시키지만 사전 학습(업스트림) 작업의 성능은 감소시킵니다(표시되지 않음).
우리는 이 현상에 대한 완전한 설명을 가지고 있지는 않습니다. 그러나 우리는 헤드에서의 더 강한 가중치 감쇠가 클래스 간의 더 큰 마진을 가진 표현을 만들어, 더 나은 few-shot 적응을 가져온다고 가정합니다. 이는 SVM의 주요 아이디어와 유사합니다 [12]. 이 큰 감쇠는 업스트림 사전 학습 동안 높은 정확도를 얻기 어렵게 만들지만, 우리의 주요 목표는 높은 품질의 전이입니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
우리는 이 현상에 대한 완전한 설명을 가지고 있지는 않습니다. 그러나 우리가 제안하는 가설은 다음과 같습니다:
- 헤드에 더 강한 가중치 감쇠(Weight Decay)를 적용하면, 모델이 학습하는 표현에서 **클래스 간의 마진(margin)**이 더 커집니다.
- 클래스 간의 마진이 크다는 것은 서로 다른 클래스에 속한 데이터 포인트들이 더 잘 구분된다는 것을 의미합니다.
- 마진이 큰 표현을 가진 모델은 적은 데이터로 새로운 작업에 적응하는 few-shot 학습에서 더 나은 성능을 보입니다.
이러한 아이디어는 **서포트 벡터 머신(SVM)**의 주요 개념과 유사합니다. SVM에서는 데이터 포인트 사이의 마진을 최대화하여 일반화 성능을 높입니다.
하지만 헤드에 높은 가중치 감쇠를 적용하면, 모델이 원래의 사전 학습(업스트림) 작업에서 높은 정확도를 얻기 어렵게 만듭니다. 이는 가중치 감쇠가 모델의 파라미터 값을 작게 만들어 과적합(overfitting)을 방지하지만, 동시에 모델이 훈련 데이터에 완벽하게 맞추는 것을 어렵게 만들기 때문입니다.
요약하자면:
- 헤드 부분에 강한 가중치 감쇠를 적용하면, 모델은 클래스 간의 구분을 더 명확히 하는 표현을 학습합니다.
- 이는 적은 양의 데이터로도 새로운 작업에 효과적으로 적응할 수 있게 해주며, few-shot 학습 성능을 향상시킵니다.
- 그러나 사전 학습 단계에서의 성능은 일부 희생될 수 있습니다. 하지만 우리의 주요 목표는 다양한 작업으로의 전이 성능을 높이는 것이기 때문에, 이러한 트레이드오프가 가치 있다고 판단합니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
3.2 [class] 토큰 제거로 메모리 절약하기
[16]의 가장 큰 ViT 모델은 224×224 이미지에서 14×14 패치를 사용합니다. 이는 각각 이미지 패치에 해당하는 256개의 시각적 "토큰"을 생성합니다. 이 외에도, ViT 모델은 최종 표현을 생성하는 데 사용되는 추가적인 [class] 토큰을 가지고 있어, 총 토큰 수는 257개가 됩니다.
ViT 모델의 경우, 현재 TPU 하드웨어는 토큰 차원을 128의 배수로 패딩하므로 최대 50%의 메모리 오버헤드가 발생할 수 있습니다. 이 문제를 해결하기 위해 우리는 추가적인 [class] 토큰을 사용하는 대신 다른 대안을 조사했습니다. 특히, 모든 패치 토큰으로부터의 표현을 집계하기 위해 글로벌 평균 풀링(GAP)과 멀티헤드 어텐션 풀링(MAP) [25]을 평가했습니다. MAP에서의 헤드 수는 모델의 나머지 부분에서의 어텐션 헤드 수와 동일하게 설정했습니다. 헤드 설계를 더욱 간소화하기 위해, 원래 ViT 논문에 있었던 최종 예측 층 이전의 비선형 투영을 제거했습니다.
최상의 헤드를 선택하기 위해, 우리는 [class] 토큰과 GAP/MAP 헤드를 나란히 비교했습니다. 결과는 그림 5(오른쪽)에 요약되어 있습니다. 우리는 모든 헤드가 유사한 성능을 보이며, GAP와 MAP는 앞서 언급한 패딩 고려 사항으로 인해 메모리 효율성이 훨씬 높다는 것을 발견했습니다. 또한, 비선형 투영을 안전하게 제거할 수 있음을 관찰했습니다. 따라서 우리는 가장 표현력이 높고 가장 균일한 아키텍처를 제공하는 MAP 헤드를 선택했습니다. MAP 헤드는 메모리를 절약하기보다 더 나은 품질을 위해 다른 문맥에서 [42]에서도 탐구되었습니다.

그림 6: 추가적인 스케일링 없이 JFT-300M에서 JFT-3B로 전환한 효과. 작은 모델과 큰 모델 모두 이 변화를 통해 선형 few-shot 평가(왼쪽)와 전체 데이터셋을 사용하는 전이(오른쪽)에서 약간의 일정한 비율로 이점을 얻습니다.
3.3 데이터 스케일업
이 연구에서는 이전의 대규모 컴퓨터 비전 모델 연구들 [37, 23, 16]에서 사용된 JFT-300M 데이터셋의 더 큰 버전인 독점적인 JFT-3B 데이터셋을 사용합니다. 이 데이터셋은 약 30억 개의 이미지로 구성되어 있으며, 반자동 파이프라인을 통해 약 3만 개의 레이블로 이루어진 클래스 계층 구조로 주석이 달려 있습니다. 따라서 데이터와 관련된 레이블은 노이즈가 있습니다. 우리는 레이블의 계층적 측면을 무시하고, [23, 16]을 따라 시그모이드 크로스 엔트로피 손실을 통한 다중 레이블 분류의 타겟으로 할당된 레이블만을 사용합니다.
우리는 [1]에서 설명된 대로 민감한 카테고리 연관성 분석을 수행했습니다. 우리는 원시 데이터, 정제된 데이터, 이 데이터로 학습된 모델, 그리고 인간 평가자가 검증한 레이블 전반에 걸쳐 민감한 카테고리의 분포를 (레이블별로) 측정했습니다. 인간 평가자는 추가로 데이터셋에서 공격적인 콘텐츠를 제거하는 데 도움을 주었습니다.
그림 6은 스케일을 증가시키지 않았음에도 불구하고 JFT-300M에서 JFT-3B로 변경했을 때 모델 성능에 미치는 영향을 보여줍니다. 그림 6의 왼쪽은 전체에 걸쳐 평가된 선형 10-shot ImageNet 성능을 보여줍니다. 우리는 JFT-3B가 JFT-300M의 한 에포크를 완전히 완료하기도 전에 더 나은 모델을 생성한다는 것을 관찰합니다. 따라서 JFT-300M의 과적합이 개선의 유일한 원인은 아닙니다. 이 차이는 작은 B/32 모델뿐만 아니라 더 큰 L/16 모델에서도 볼 수 있습니다. 우리는 모델을 전체 ImageNet 데이터셋에 파인튜닝하고(오른쪽), 이러한 개선이 전체 파인튜닝 설정으로 전이됨을 확인합니다. 전반적으로, 데이터셋의 변경은 작은 모델과 큰 모델 모두에서 ImageNet으로의 전이를 약 1% 향상시킵니다. 성능 향상 외에는, JFT-300M과 JFT-3B에서의 학습 동작은 유사합니다. 가장 중요한 것은, JFT-3B를 통해 과적합과 정규화에 대한 우려를 덜면서 더 큰 규모로 확장할 수 있다는 것입니다.
중복 제거: 우리는 평가하는 데이터셋의 학습 세트와 테스트 세트의 이미지와 거의 중복된 JFT-3B 데이터셋의 모든 이미지를 제거했습니다. 전체적으로 우리는 JFT-3B에서 92만7천 개의 중복 이미지를 식별하고 제거했습니다.
3.4 메모리 효율적인 옵티마이저
대형 모델을 학습할 때, 모델 파라미터에 필요한 저장 공간이 병목 현상이 됩니다. 우리의 가장 큰 모델인 ViT-G는 약 20억 개의 파라미터를 가지며, 이는 장치 메모리에서 8 GiB를 차지합니다. 상황을 더욱 악화시키는 것은, Transformer를 학습하는 데 일반적으로 사용되는 Adam 옵티마이저가 각 파라미터마다 두 개의 추가 부동 소수점 스칼라를 저장한다는 점으로, 이는 추가로 두 배의 오버헤드(추가로 16 GiB)를 초래합니다. Adam 옵티마이저에 의해 발생하는 오버헤드를 해결하기 위해 우리는 두 가지 수정 사항을 탐구합니다.
반정밀도 모멘텀을 사용하는 Adam. 우리는 경험적으로 모멘텀을 반정밀도(bfloat16 타입)로 저장해도 학습 동적에 영향을 미치지 않으며 결과에 영향이 없음을 관찰했습니다. 이는 옵티마이저 오버헤드를 2배에서 1.5배로 줄일 수 있게 해줍니다. 주목할 만한 것은, 두 번째 모멘텀을 반정밀도로 저장하면 성능이 크게 저하된다는 것입니다.
Adafactor 옵티마이저. 위의 옵티마이저도 여전히 큰 메모리 오버헤드를 유발합니다. 따라서 우리는 Adafactor 옵티마이저 [35]에 주목하게 되었으며, 이는 랭크 1 분해를 사용하여 두 번째 모멘텀을 저장합니다. 실용적인 관점에서, 이는 무시할 만한 메모리 오버헤드를 초래합니다. 그러나 Adafactor 옵티마이저는 바로 작동하지 않았기 때문에, 우리는 다음과 같은 수정을 가했습니다:
- 첫 번째 모멘텀을 반정밀도로 다시 도입했습니다, 권장 설정에서는 첫 번째 모멘텀을 전혀 사용하지 않습니다.
- 가중치 노름에 따른 학습률 스케일링을 비활성화했습니다, 이는 Adafactor의 일부 기능입니다.
- Adafactor는 학습 과정에서 두 번째 모멘텀을 0.0에서 1.0으로 점진적으로 증가시킵니다. 우리의 예비 실험에서, 두 번째 모멘텀을 0.999(Adam의 기본값)로 클리핑하는 것이 더 나은 수렴을 가져온다는 것을 발견하여, 이를 채택했습니다.
결과적으로, 이 옵티마이저는 모델 파라미터를 저장하는 데 필요한 공간에 추가로 50%의 메모리 오버헤드만을 도입합니다.
우리는 제안한 두 옵티마이저 모두 원래의 Adam 옵티마이저와 동등하거나 약간 더 나은 성능을 보인다는 것을 관찰했습니다. 다른 메모리 효율적인 옵티마이저들 [32, 40]이 있다는 것을 알고 있으며, 이들에 대한 탐구는 미래의 작업으로 남겨둡니다.

그림 7: 다양한 "무한" 학습률 스케줄과 참조용으로 유한한 선형 스케줄.
3.6 모델 차원 선택하기

그림 8: 원래 ViT의 "Shapefinder" 시뮬레이션 결과를 주황색으로, 우리의 개선 사항과 반정밀도 Adam(예: ViT-g)을 결합한 것은 녹색으로, 마지막으로 수정된 AdaFactor를 사용한 것은 파란색으로 나타냈습니다. 흰색 영역은 메모리가 부족한 경우입니다. 점의 밝기는 상대적인 학습 속도를 나타냅니다.
ViT 모델은 모델의 형태를 제어하는 많은 파라미터를 가지고 있으며, 자세한 내용은 원래의 출판물을 참조하십시오. 간단히 말하면, 여기에는 패치 크기, 인코더 블록 수(깊이), 패치 임베딩과 자기 어텐션의 차원(너비), 어텐션 헤드 수, MLP 블록의 히든 차원(MLP-너비)이 포함됩니다. 이 외에도, 우리는 모델의 실행 시간 속도와 메모리 사용량을 최적화하기 위해 XLA 컴파일러에 의존합니다. 내부적으로 XLA는 메모리와 속도를 최적으로 절충하기 위해 모델을 특정 하드웨어에 대한 코드로 컴파일하는 복잡한 휴리스틱을 사용합니다. 결과적으로, 단일 장치의 메모리에 어떤 모델 구성들이 들어맞을지 예측하기 어렵습니다.
따라서 우리는 다양한 형태의 많은 ViT를 인스턴스화하고, 품질을 고려하지 않고 몇 단계 동안 학습을 시도하는 광범위한 시뮬레이션을 실행했습니다. 우리는 깊이, 너비, 헤드 수, MLP-너비를 다양하게 조절하였으며, 패치 크기는 14 px로 유지했습니다. 이렇게 하여, 주어진 모델이 장치 메모리에 들어맞는지와 그들의 속도를 측정했습니다. 그림 8은 이 시뮬레이션의 결과를 요약한 것입니다. 각 블록은 하나의 모델 구성을 나타내며, 블록의 명암은 학습 속도를 나타냅니다(밝을수록 빠름). 주황색 블록은 우리의 수정 없이 원래의 ViT 모델이 들어맞는 경우를 보여줍니다. 녹색 블록은 3.2절에서 설명한 메모리 절약과 3.4절에서 설명한 반정밀도 Adam을 결합한 경우를 추가로 포함합니다. 마지막으로, 파란색 블록은 수정된 AdaFactor 옵티마이저를 사용한 경우입니다. 흰색 영역의 형태들은 어떤 설정에서도 메모리에 들어맞지 않았습니다. 공간상의 이유로, 우리는 여기에서 제시된 실험과 관련된 모델만을 보여주지만, 우리의 수정으로 최대 100개의 인코더 블록 깊이를 가진 얇은 ViT 모델을 메모리에 맞출 수 있었음을 주목하십시오.
표 2: 모델 아키텍처 세부 정보.
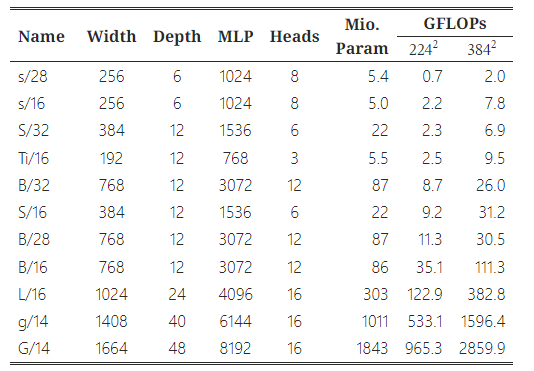
원래의 Vision Transformer 출판물은 부록 D2에서 다양한 구성 요소를 스케일링할 때의 트레이드오프에 대한 연구를 포함하고 있으며, 깊이, 너비, MLP-너비, 패치 크기 등 모든 측면을 동시에 유사한 양으로 스케일링하는 것이 가장 효과적이라고 결론지었습니다. 우리는 이 권고를 따랐으며, 그림 8에 표시되고 표 2에 요약된 대로 ViT-g와 ViT-G에 맞는 형태를 선택했습니다.
4 관련 연구
작은 비전 트랜스포머 초기 비전용 Transformer 연구는 CIFAR-10 [11]을 위한 작은 네트워크에 초점을 맞췄습니다. 그러나 Vision Transformer [16]는 최첨단 중간 및 대규모 이미지 인식의 맥락에서 제안되었으며, 가장 작은 모델(ViT-B)은 8600만 개의 파라미터를 포함합니다. [41]은 ViT-Ti(500만 개의 파라미터)까지 축소된, 처음부터 학습할 수 있는 더 작은 ViT 크기를 제시합니다. 새로운 ViT 변형들은 더 작고 저렴한 아키텍처를 도입합니다. 예를 들어, T2T-ViT [51]는 새로운 토크나이제이션과 더 좁은 네트워크를 사용하여 파라미터 수와 계산량을 줄입니다. 밀도 예측 작업을 위해 설계된 피라미드 형태의 ViT [46]는 CNN과 유사한 피라미드 구조를 따르며, 이는 모델의 크기도 줄여줍니다. CNN과 Transformer의 하이브리드는 일반적으로 작은 모델이 잘 작동하도록 하며, [16]의 ViT-CNN 하이브리드, BoTNet [36], HaloNet [44] 등이 있습니다. 그러나 ViT의 규모를 키우는 방향은 덜 탐구되었습니다. 언어용 Transformer는 여전히 Vision Transformer보다 훨씬 크지만, 이 논문에서 소개된 스케일링 특성과 개선 사항을 이해하는 것은 이 방향으로의 한 걸음을 나타냅니다.
스케일링 법칙 [22]는 신경 언어 모델의 경험적 스케일링 법칙에 대한 철저한 연구를 제시합니다. 저자들은 계산량, 데이터 크기, 모델 크기, 성능 간의 관계를 설명하는 멱법칙을 맞춥니다. 이러한 법칙을 따라 1750억 개의 파라미터를 가진 언어 모델 GPT-3가 성공적으로 학습되었습니다 [7]. [19]는 이미지 생성 등 다른 모달리티에서의 자기회귀 생성 모델링에 대한 법칙을 제시합니다. 우리 논문은 이미지의 판별 모델링에 대한 스케일링 법칙에 대한 첫 번째 연구를 포함합니다.
비전 모델의 스케일업 많은 논문들이 CNN을 스케일업하여 성능을 향상시킵니다. EfficientNets [38, 39]는 깊이, 너비, 해상도 간의 계산 균형을 맞추는 스케일링 전략을 제시하고 이를 MobileNet에 적용합니다. 이 전략은 [3, 48]에서 재검토되어 ResNet [18]의 성능을 더욱 향상시킵니다. 대형 CNN은 AmoebaNet-B(18, 512) (5억5700만 개의 파라미터, GPipe 파이프라인 병렬 처리를 사용하여 학습됨) [20], 약하게 라벨링된 인스타그램 이미지로 사전 학습된 ResNeXt-101 32×48d (8억2900만 개의 파라미터) [27], JFT-300M에서 ImageNet 의사 라벨로 학습된 EfficientNet-L2 (4억8000만 개의 파라미터) [50], JFT-300M에서 사전 학습된 BiT-L-ResNet152x4 (9억2800만 개의 파라미터) [23] 등과 같이 시각 인식에서 우수한 성능을 달성했습니다. 최근에는 [54, 42]에서 ViT의 깊이를 스케일업하는 전략을 탐구하고 있습니다. 우리는 Vision Transformer를 더욱 큰 규모로 스케일업하고 이를 통해 새로운 최첨단 결과를 달성한 첫 번째 연구입니다. 동시에 진행된 연구인 [13]은 CNN과 ViT 하이브리드 아키텍처에 초점을 맞추고 있습니다.
5 토론
제한 사항. 이 연구는 스케일링 법칙 연구를 위해 독점적인 JFT-3B 데이터셋을 사용합니다. 우리의 통찰력을 보다 신뢰할 수 있고 일반화 가능하게 만들기 위해, 우리는 스케일링 법칙이 공개된 ImageNet-21k 데이터셋에도 적용됨을 확인했습니다.
사회적 영향. 이 연구의 잠재적인 더 큰 비용은 특히 가장 큰 ViT-G 모델을 학습할 때 스케일링 연구에서 실험을 수행하는 데 필요한 에너지입니다. 그러나 이 비용은 두 가지 방식으로 분산될 수 있습니다. 첫째, 이러한 스케일링 법칙 연구는 한 번만 수행하면 됩니다; 우리는 ViT 모델의 미래 개발자들이 우리의 결과를 사용하여 더 적은 계산 자원으로 학습할 수 있는 모델을 설계할 수 있기를 바랍니다. 둘째, 학습된 모델은 주로 전이 학습을 위해 설계되었습니다. 사전 학습된 가중치의 전이는 다운스트림 작업에서 처음부터 학습하는 것보다 훨씬 저렴하며, 일반적으로 더 높은 정확도에 도달합니다. 따라서 우리의 모델을 많은 작업에 전이함으로써, 사전 학습 계산량은 더욱 분산됩니다.
6 결론
우리는 충분한 학습 데이터가 있는 ViT 모델에 대한 성능-계산량 프론티어가 대략적으로 (포화되는) 멱법칙을 따름을 보여줍니다. 결정적으로, 이 프론티어에 머무르기 위해서는 계산량과 모델 크기를 동시에 스케일업해야 합니다; 즉, 추가적인 계산 자원이 주어질 때 모델의 크기를 늘리지 않는 것은 최적이 아닙니다. 우리는 또한 더 큰 모델이 훨씬 더 샘플 효율적이며 훌륭한 few-shot 학습자임을 보여줍니다. 마지막으로, 우리는 대형의 성능이 우수한 ViT 모델을 효율적으로 학습할 수 있는 새로운 학습 레시피를 제시합니다. 우리의 결론이 우리가 연구한 규모를 넘어 일반화되지 않을 수도 있으며, ViT 모델 계열을 넘어 일반화되지 않을 수도 있음을 주의해야 합니다.
감사의 말
우리는 대규모 인프라 사용에 도움을 준 James Bradbury와 Vivek Sharma에게 감사드립니다; 통찰력 있는 토론을 제공해 준 Alexey Dosovitskiy, Joan Puigcerver, Basil Mustafa, Carlos Riquelme에게 감사드립니다; JFT에 대한 토론을 함께한 Tom Duerig, Austin Tarango, Daniel Keysers, Howard Zhou, Wenlei Zhou, Yanan Bao에게 감사드립니다; 지원적인 연구 환경을 제공해 준 구글 브레인 팀 전체에게 감사드립니다.



