https://arxiv.org/abs/2203.00555
DeepNet: Scaling Transformers to 1,000 Layers
In this paper, we propose a simple yet effective method to stabilize extremely deep Transformers. Specifically, we introduce a new normalization function (DeepNorm) to modify the residual connection in Transformer, accompanying with theoretically derived i
arxiv.org
이 논문에서는 매우 깊은 트랜스포머(Transformers)를 안정화시키는 간단하면서도 효과적인 방법을 제안합니다. 구체적으로, 우리는 트랜스포머의 잔차 연결(residual connection)을 수정하기 위해 새로운 정규화 함수인 "DeepNorm"을 도입하고, 이와 함께 이론적으로 유도된 초기화를 제시합니다. 심층 이론 분석을 통해 모델 업데이트가 안정적으로 제한될 수 있음을 보여줍니다. 제안된 방법은 Post-LN의 우수한 성능과 Pre-LN의 안정적인 훈련을 결합하여 DeepNorm이 더 나은 대안임을 입증합니다. 우리는 트랜스포머를 최대 1,000개의 레이어(즉, 2,500개의 어텐션 및 피드포워드 네트워크 하위 레이어)까지 확장하는 데 성공했으며, 이는 이전의 깊은 트랜스포머보다 10배 더 깊은 수준입니다. 특히, 7,482개의 번역 방향이 포함된 다국어 벤치마크에서 3.2B 파라미터를 가진 200개 레이어 모델이 12B 파라미터를 가진 48개 레이어의 최신 모델을 BLEU 점수 5점 차이로 크게 능가하며, 이는 트랜스포머 모델의 확장 가능성에 대한 유망한 방향성을 제시합니다.

Figure 1: 최첨단 NLP 모델의 트랜스포머 깊이에 따른 시간적 추세를 보여줌.
1. 서론
최근 몇 년 동안 대규모 트랜스포머(Transformer) 모델로의 전환이 이루어졌습니다. 모델의 용량은 수백만 개의 파라미터(Devlin et al., 2019; Conneau et al., 2020)에서 수십억 개(Radford et al., 2019; Brown et al., 2020; Huang et al., 2019; Raffel et al., 2020; Lepikhin et al., 2021; Rae et al., 2021; Lin et al., 2021; Smith et al., 2022), 그리고 심지어 수조 개(Du et al., 2021)까지 크게 증가했습니다. 대규모 모델은 다양한 작업에서 최첨단 성능을 제공하며, few-shot 및 zero-shot 학습에서 인상적인 능력을 보여줍니다. 그러나 수많은 파라미터에도 불구하고 트랜스포머의 깊이는 학습 불안정성 때문에 제한됩니다(Figure 1에서 보여준 것처럼).
Nguyen과 Salazar(2019)는 사후 정규화(Post-LN) 기반 트랜스포머에 비해 사전 정규화(Pre-LN) 잔차 연결이 트랜스포머의 안정성을 향상시킨다는 사실을 발견했습니다. 하지만 Pre-LN의 하위 레이어에서의 기울기(gradient)는 상위 레이어보다 커지는 경향이 있으며(Shleifer et al., 2021), 이로 인해 Post-LN에 비해 성능이 저하되는 문제가 발생합니다. 이 문제를 해결하기 위해 더 나은 초기화 방법(Zhang et al., 2019a, b; Huang et al., 2020) 또는 더 나은 아키텍처(Wang et al., 2019; Liu et al., 2020; Bachlechner et al., 2020; Shleifer et al., 2021)를 통해 깊은 트랜스포머의 최적화를 개선하려는 시도가 있었습니다. 이러한 접근 방식은 수백 개의 레이어를 가진 트랜스포머 모델의 안정화를 가능하게 했지만, 이전 방법 중 어느 것도 1,000개 레이어로 확장하는 데 성공하지 못했습니다.
우리의 목표는 트랜스포머의 학습 안정성을 개선하고 모델 깊이를 여러 배로 확장하는 것입니다. 이를 위해 우리는 학습 불안정성의 원인을 연구했고, 폭발적인 모델 업데이트가 불안정성의 주된 원인임을 발견했습니다. 이러한 관찰을 바탕으로, 우리는 잔차 연결에서 모델 업데이트를 일정 상수로 제한할 수 있는 이론적 근거를 갖춘 새로운 정규화 함수 "DeepNorm"을 도입했습니다(He et al., 2016). 제안된 방법은 코드 몇 줄만으로 간단하게 구현할 수 있지만 매우 효과적입니다. 이 접근 방식은 트랜스포머의 안정성을 개선하여 모델 깊이를 1,000개 이상의 레이어로 확장할 수 있도록 합니다. 실험 결과에 따르면, DeepNorm은 Post-LN의 좋은 성능과 Pre-LN의 안정적인 학습의 장점을 결합하여 트랜스포머의 더 나은 대안이 될 수 있습니다. 이는 1,000개 이상의 레이어를 가진 극히 깊은 모델뿐만 아니라 기존의 대형 모델에도 적용될 수 있습니다. 특히, 우리 200개 레이어, 32억 개 파라미터의 모델은 48개 레이어와 120억 개 파라미터를 가진 최신 모델(Fan et al., 2021)보다 BLEU 점수 5점을 향상시키며, 대규모 다국어 기계 번역 벤치마크에서 크게 성능을 개선했습니다.
2. 실무자를 위한 TL;DR
def deepnorm(x):
return LayerNorm(x * α + f(x))
def deepnorm_init(w):
if w is ['ffn', 'v_proj', 'out_proj']:
nn.init.xavier_normal_(w, gain=β)
elif w is ['q_proj', 'k_proj']:
nn.init.xavier_normal_(w, gain=1)

Figure 2: (a) DeepNorm의 의사 코드. 여기서 우리는 Xavier 초기화(Glorot와 Bengio, 2010)를 예시로 사용했으며, 다른 표준 초기화 방법으로 대체할 수 있습니다. 여기서 α는 상수입니다. (b) 다양한 아키텍처(예: N-레이어 인코더, M-레이어 디코더)에 대한 DeepNorm의 파라미터.
Figure 2에 보여진 것처럼, Post-LN을 사용하는 트랜스포머를 기반으로 우리의 방법을 구현하는 것은 간단합니다. Post-LN과 비교했을 때, DeepNorm은 층 정규화를 수행하기 전에 잔차 연결을 업스케일합니다. 또한 초기화 시 파라미터를 다운스케일합니다. 특히, 우리는 피드포워드 네트워크의 가중치와 어텐션 레이어의 값 프로젝션(value projection) 및 출력 프로젝션(output projection)의 가중치만 스케일합니다. 잔차 연결과 초기화의 스케일은 아키텍처에 따라 다릅니다(Figure 2 참조). 더 자세한 내용은 4.3절에서 제공합니다.
3. 깊은 트랜스포머의 불안정성

이 내용은 트랜스포머의 깊이가 깊어질수록 발생할 수 있는 학습 불안정성 문제를 해결하기 위해 적절한 초기화 전략이 얼마나 중요한지를 설명하는 과정입니다. Xavier 초기화를 기반으로 레이어별 가중치를 스케일 조정함으로써 깊은 네트워크에서 안정적인 학습이 가능해집니다.

여기서 d'는 입력과 출력 차원의 평균을 나타냅니다. 우리는 이 모델을 Post-LN-init이라고 명명합니다. 이전 연구(Zhang et al., 2019a)와는 달리, 우리는 상위 레이어 대신 하위 레이어의 스케일을 줄였습니다. 이는 기울기 스케일과 모델 업데이트의 영향을 분리하는 데 도움이 된다고 믿습니다. 또한, Post-LN-init은 Post-LN과 동일한 아키텍처를 사용하기 때문에 아키텍처로 인한 영향을 제거할 수 있습니다.



Figure 3: (a) 18L-18L 모델의 상위 레이어에서의 기울기 노름(gradient norm). (b) 깊이가 6L-6L에서 24L-24L까지 다양한 모델의 마지막 레이어에서의 기울기 노름. (c) 18L-18L 모델의 검증 손실 곡선.

(a) 누적된 모델 업데이트

(b) 피드포워드 네트워크(FFN)에서 층 정규화(LN)로 전달되는 입력
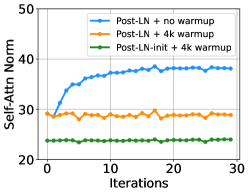
(c) 어텐션에서 층 정규화(LN)로 전달되는 입력
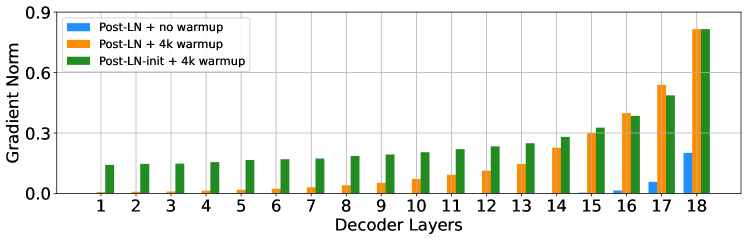
(d) 모든 디코더 레이어에서의 기울기 노름(gradient norm)
Figure 4: 18L-18L 모델의 학습 초기에 모델 업데이트, 층 정규화에 대한 평균 입력, 그리고 기울기의 시각화를 보여줍니다.
우리는 IWSLT-14 독일어-영어 기계 번역 데이터셋에서 18L-18L Post-LN과 18L-18L Post-LN-init 모델을 훈련했습니다. Figure 3은 두 모델의 기울기와 검증 손실 곡선을 시각화한 것입니다. Figure 3(c)에 따르면, Post-LN-init은 수렴했으나 Post-LN은 그렇지 않았습니다. Post-LN-init은 가중치가 축소되었음에도 불구하고 마지막 몇 개의 레이어에서 더 큰 기울기 노름을 보였습니다. 또한, 모델 깊이가 6L-6L에서 24L-24L로 변화하는 동안 마지막 디코더 레이어의 기울기 노름을 시각화했습니다. Figure 3에서 볼 수 있듯이, Post-LN-init의 마지막 레이어에서의 기울기 노름은 모델 깊이에 관계없이 Post-LN보다 훨씬 큽니다. 이를 통해, 깊은 레이어에서의 폭발적인 기울기가 Post-LN의 불안정성의 근본 원인이 아니며, 모델 업데이트의 규모가 불안정성의 주요 원인임을 알 수 있습니다.
다음으로, Post-LN의 불안정성은 기울기 소실과 과도한 모델 업데이트를 포함한 여러 문제의 연쇄에서 비롯된다는 점을 설명합니다. Figure 4(a)에서 보여주듯이, 우리는 먼저 학습 초기에 모델 업데이트의 노름 ‖ΔF‖ 을 시각화했습니다:
여기서 x는 입력을, θ_i는 번째 업데이트 후의 모델 파라미터를 나타냅니다. Post-LN은 학습 초기에 폭발적인 업데이트를 겪고, 그 후에는 거의 업데이트가 이루어지지 않습니다. 이는 모델이 잘못된 지역 최적점에 갇혔다는 것을 의미합니다. 워밍업(warm-up)과 더 나은 초기화는 이 문제를 완화하여 모델이 원활하게 업데이트될 수 있도록 돕습니다. 업데이트가 폭발하면 LN에 대한 입력이 커지게 됩니다(Figure 4(b) 및 Figure 4(c) 참조). Xiong et al. (2020)의 이론적 분석에 따르면, LN을 통과하는 기울기의 크기는 입력 크기에 반비례합니다:
‖∂LN(x)/∂x‖=𝒪(d/‖x‖)
Figure 4(b)와 Figure 4(c)는 워밍업이나 적절한 초기화 없이 ‖x‖ 가 d(d=512)보다 훨씬 크다는 것을 보여줍니다. 이는 Post-LN 학습 중 발생한 기울기 소실 문제를 설명합니다(Figure 4(d) 참조).
결론적으로, 불안정성은 학습 초기에 발생하는 과도한 모델 업데이트에서 시작됩니다. 이는 모델이 나쁜 지역 최적점에 갇히게 만들고, 그 결과 LN에 대한 입력의 크기가 증가합니다. 학습이 계속됨에 따라 LN을 통과하는 기울기는 점점 작아지며, 이는 심각한 기울기 소실로 이어집니다. 기울기 소실은 지역 최적점에서 벗어나기 어렵게 만들고, 최적화를 더욱 불안정하게 만듭니다. 반면, Post-LN-init은 상대적으로 작은 업데이트와 안정적인 LN 입력을 가지고 있어 기울기 소실 문제를 완화하고 최적화를 더 안정적으로 만듭니다.
4. DeepNet: 극도로 깊은 트랜스포머
이 섹션에서는 우리가 제안한 DeepNet이라는 매우 깊은 트랜스포머 모델을 소개합니다. DeepNet은 폭발적인 모델 업데이트 문제를 완화하여 최적화를 안정화할 수 있습니다. 먼저 DeepNet의 모델 업데이트 예상 크기를 추정한 후, 제안한 DeepNorm을 통해 모델 업데이트가 상수로 제한될 수 있음을 이론적으로 분석합니다.
4.1 아키텍처
DeepNet은 트랜스포머 아키텍처를 기반으로 합니다. 기존의 트랜스포머와 비교했을 때, DeepNet은 각 서브 레이어에 Post-LN 대신 새로운 DeepNorm을 사용합니다. DeepNorm의 수식은 다음과 같이 작성할 수 있습니다:

DeepNet의 주요 차별점은 DeepNorm을 사용하여 기존 트랜스포머에서 발생하는 학습 불안정성 문제를 해결하면서, 훨씬 더 깊은 네트워크로 확장할 수 있다는 점입니다.
4.2 모델 업데이트 크기의 예상값





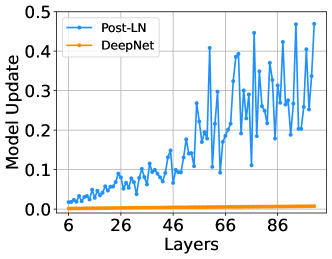
Figure 5: Post-LN과 DeepNet의 초기 학습 단계에서의 모델 업데이트를 비교한 시각화. 64-128-2 Tiny 트랜스포머 모델을 사용하여 깊이가 6L-6L에서 100L-100L까지 다양한 경우를 시각화한 결과, DeepNet이 Post-LN보다 훨씬 작고 더 안정적인 업데이트를 보였습니다.
4.3 DeepNorm 및 초기화에 대한 유도
우리는 DeepNet의 모델 업데이트가 적절한 파라미터 α와 β를 사용하면 상수로 제한될 수 있음을 보입니다. 우리의 분석은 확률적 경사 하강법(SGD) 업데이트를 기반으로 하며, 경험적으로 Adam 옵티마이저(Kingma와 Ba, 2015)에서도 잘 작동함을 확인했습니다. 우리는 인코더-디코더 아키텍처에 대한 분석을 제공하며, 이는 동일한 방식으로 인코더 전용 또는 디코더 전용 모델에도 자연스럽게 확장될 수 있습니다. Zhang et al. (2019b)와 유사하게, 우리는 모델 업데이트의 목표를 다음과 같이 설정합니다.



Post-LN과 비교하여, 우리는 IWSLT-14 독일어-영어 번역 데이터셋에서 DeepNet의 학습 초기 단계에서의 모델 업데이트를 시각화했습니다. Figure 5는 DeepNet의 모델 업데이트가 거의 일정한 반면, Post-LN의 모델 업데이트는 폭발적인 경향을 보인다는 것을 보여줍니다.
요약하면, 우리의 접근 방식은 다음과 같이 적용됩니다:

5. 신경 기계 번역 (Neural Machine Translation)
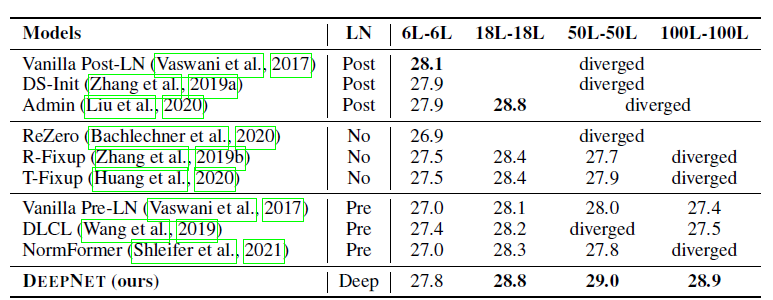
Table 1: WMT-17 En-De 테스트 셋에서 다양한 깊이를 가진 모델들의 BLEU 점수.
A-레이어 인코더와 B-레이어 디코더를 나타내는 A-BL 모델들을 비교.
우리는 IWSLT-14 독일어-영어(De-En) 데이터셋과 WMT-17 영어-독일어(En-De) 데이터셋을 포함한 인기 있는 기계 번역 벤치마크에서 DeepNet의 효과를 검증했습니다. 우리의 방법을 여러 최신 깊은 트랜스포머 모델들과 비교했습니다. 비교 대상은 DLCL(Wang et al., 2019), NormFormer(Shleifer et al., 2021), ReZero(Bachlechner et al., 2020), R-Fixup(Zhang et al., 2019b), T-Fixup(Huang et al., 2020), DS-init(Zhang et al., 2019a), Admin(Liu et al., 2020)입니다. 모든 베이스라인은 오픈 소스 코드를 사용하여 재현했으며, 공정한 비교를 위해 하이퍼파라미터를 동일하게 설정했습니다.
모든 실험에서 평가 지표로 BLEU 점수를 사용했습니다. Table 1은 WMT-17 En-De 번역 데이터셋에서 베이스라인과 DeepNet의 결과를 보고합니다. 베이스라인 모델들은 그들의 층 정규화(LN) 방법에 따라 Pre-LN, Post-LN, No-LN의 세 가지 카테고리로 그룹화되었습니다. 비교된 모든 모델은 기본 크기(base-size)이며 깊이만 다릅니다.
Post-LN을 사용하는 모델들과 비교했을 때, DeepNet은 더 안정적이며, 100L-100L 모델로 확장할 수 있고, 테스트 셋에서 28.9 BLEU 점수를 기록했습니다. 반면 Post-LN 베이스라인은 깊이가 50L-50L에 도달하면 최적화가 불안정해집니다. 또한, 얕은 모델에서 DeepNet은 베이스라인들과 유사한 성능을 보였습니다.
LN 없이 학습하는 방법들과도 DeepNet을 비교했습니다. R-Fixup과 T-Fixup 모두 더 나은 초기화 방법을 도입하여 LN이 없는 트랜스포머의 50-50 레이어 학습을 안정화했지만, Post-LN을 사용하는 모델들보다는 성능이 좋지 않았습니다. 또한, 반 정밀도(half-precision)는 ReZero의 학습을 불안정하게 만들어 18-18 레이어 모델에서 발산(divergence)이 발생했습니다. 이는 Liu et al. (2020)에서도 언급된 바 있습니다. 게다가 더 깊은 모델들(50L-50L)은 얕은 모델들(18L-18L)보다 성능이 더 나아지지 않았습니다. 반면, DeepNet은 이러한 방법들보다 더 나은 번역 정확도를 달성했으며, 더 깊은 모델로 확장해도 성능에 해를 끼치지 않았습니다.
Post-LN 베이스라인과 비교했을 때, Pre-LN을 사용하는 모델들은 더 안정적이었습니다. 기본 Pre-LN과 DLCL 모두 100L-100L로 확장할 수 있었으며, 50L-50L NormFormer도 성공적으로 학습되었습니다. 그럼에도 불구하고, Pre-LN 모델은 수렴된 Post-LN 모델에 비해 BLEU 점수가 0.5~1.0점 하락했습니다. 이는 Pre-LN의 하위 레이어에서의 기울기가 상위 레이어보다 더 커지는 문제 때문이라고 추정됩니다(Shleifer et al., 2021). 이 문제는 미래의 연구로 남겨두었습니다. 반면, DeepNet은 Post-LN을 사용하여 이 문제를 완화하며, 모든 Pre-LN 베이스라인보다 더 나은 성능을 보였습니다.
모델 깊이에 따른 수렴
우리는 모델의 깊이를 10L-10L에서 100L-100L까지 10 레이어 간격으로 변화시켰습니다. 모든 실험은 혼합 정밀도(mixed precision) 학습으로 수행되었으며, ReZero는 예외입니다.
1 ReZero는 모델이 얕을 때조차도 반 정밀도(half precision)에서 불안정하다는 것을 실험에서 확인했습니다.
Figure 6은 IWSLT-14 데이터셋에서의 결과를 보여줍니다. 우리는 모델을 8,000 스텝 동안 학습했으며, 대부분의 발산(divergence)은 최적화 초기에 발생하는 것을 발견했습니다. 전반적으로, DeepNet은 얕은 모델에서 깊은 모델까지 안정적입니다. DeepNet은 빠르게 수렴하며, 8,000 스텝 안에 30 BLEU 이상의 성능을 달성했고, 대부분의 베이스라인 모델들은 그렇지 못했습니다. 또한, 모델이 깊어질수록 성능이 계속해서 향상되었습니다.
대형 학습률, 배치 크기, 히든 차원
우리는 DeepNet을 더 큰 학습률, 배치 크기, 히든 차원으로 각각 확장했습니다. 각 실험에서 다른 하이퍼파라미터는 고정한 채 하나의 하이퍼파라미터만 변경했습니다. Figure 7은 WMT-17 검증 세트에서의 손실 곡선을 보여줍니다. 이 결과는 DeepNet이 가장 큰 설정에서도 문제없이 학습될 수 있음을 보여줍니다. 히든 크기 1024를 가진 DeepNet은 10,000 스텝 이후 과적합으로 인해 손실이 증가했습니다. 또한, 더 큰 설정에서 DeepNet은 더 빠른 수렴과 더 낮은 검증 손실을 보이며 이점을 얻을 수 있음을 보여줍니다.

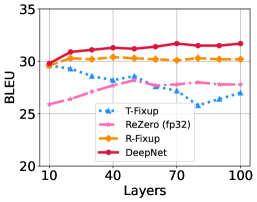
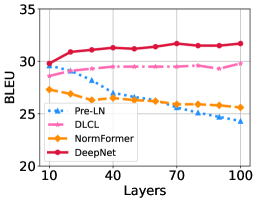
Figure 6: IWSLT-14 독일어-영어(De-En) 테스트 셋에서 다양한 깊이(10L-10L부터 100L-100L까지)를 가진 깊은 모델들의 BLEU 점수를 보여줍니다.
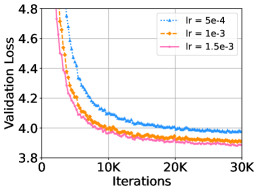
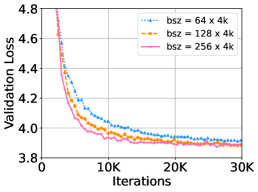
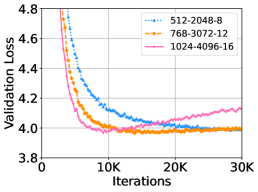
Figure 7: WMT-17 영어-독일어(En-De) 검증 세트에서 18L-18L DeepNet의 학습률, 배치 크기, 히든 차원을 변화시킨 경우의 검증 손실 곡선을 보여줍니다.
6. 대규모 다국어 신경 기계 번역 (Massively Multilingual Neural Machine Translation)
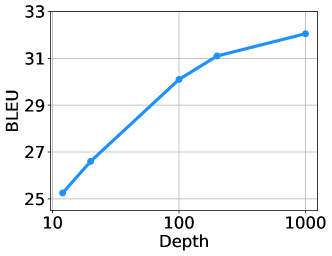
Figure 8: OPUS-100 영어-기타 언어(En-X) 및 기타 언어-영어(X-En) 테스트 셋에서 DeepNet의 다양한 깊이에 따른 평균 BLEU 점수를 보여줍니다.
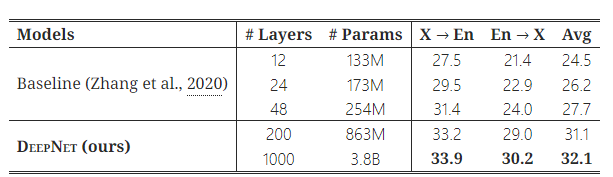
Table 2: OPUS-100 테스트 셋에서 DeepNet과 베이스라인의 평균 BLEU 점수를 비교한 표.

Table 3: 여러 평가 셋에서 DeepNet과 M2M-100의 BLEU 점수를 비교한 표.
우리는 대규모 다국어 기계 번역 실험을 수행했으며, 이는 대형 모델을 평가하기에 적합한 테스트베드입니다. 먼저 OPUS-100 코퍼스(Zhang et al., 2020)를 사용하여 모델을 평가했습니다. OPUS-100은 영어를 중심으로 한 다국어 코퍼스로, OPUS 컬렉션에서 무작위로 샘플링된 100개 언어를 포함합니다. 우리는 DeepNet을 1,000개의 레이어까지 확장했습니다. 이 모델은 500개의 인코더 레이어, 500개의 디코더 레이어, 512의 히든 크기, 8개의 어텐션 헤드, 2,048 차원의 피드포워드 레이어로 구성되어 있습니다. 자세한 내용은 부록에서 확인할 수 있습니다.
Table 2는 DeepNet과 베이스라인의 결과를 요약한 표입니다. 모델 깊이를 증가시키면 NMT의 번역 품질이 크게 향상된다는 것을 보여줍니다. 48개 레이어의 베이스라인은 12개 레이어 모델에 비해 평균적으로 3.2점 향상을 달성했습니다. DeepNet은 깊이를 1,000 레이어까지 성공적으로 확장했으며, 베이스라인보다 4.4 BLEU 점수만큼 더 우수한 성능을 보였습니다. DeepNet은 단 4 에포크 동안만 훈련되었으며, 더 많은 계산 자원을 할당하면 성능이 더욱 향상될 수 있습니다.
깊이에 따른 확장 법칙 (Scaling Law in Terms of Depth)
우리는 OPUS-100 데이터셋에서 DeepNet을 {12, 20, 100, 200, 1000} 레이어로 학습시켰습니다. Figure 8은 확장 곡선을 보여줍니다. 이중 언어 NMT와 비교했을 때, 다국어 NMT는 모델 용량에 대한 요구가 크기 때문에 깊이 확장에서 더 많은 이점을 얻습니다. 우리는 다국어 NMT의 BLEU 점수가 로그 함수적으로 증가하는 것을 관찰했으며, 그 확장 법칙은 다음과 같이 쓸 수 있습니다:
L(d)=Alog(d)+B
여기서 d는 깊이를 의미하고, A와 B는 다른 하이퍼파라미터와 관련된 상수입니다.
더 많은 데이터와 언어 방향
DeepNet의 다국어 NMT 한계를 탐구하기 위해, 우리는 CCMatrix(Schwenk et al., 2021) 데이터를 사용하여 학습 데이터를 확장했습니다. 또한 CCAligned(El-Kishky et al., 2020), OPUS(Zhang et al., 2020), Tatoeba 데이터에서 더 많은 데이터를 추가하여 Flores101 평가 세트의 모든 언어를 다루도록 했습니다. 최종 데이터는 102개 언어, 1,932개의 번역 방향, 120억 개의 문장 쌍으로 구성되었습니다. 이 데이터로 우리는 100 레이어 인코더, 100 레이어 디코더, 1,024 히든 차원, 16개의 어텐션 헤드, 4,096 차원의 피드포워드 레이어를 가진 DeepNet을 학습시켰습니다. 자세한 내용은 부록에서 확인할 수 있습니다.
우리는 DeepNet을 최신 다국어 NMT 모델인 M2M-100(Fan et al., 2021)과 비교했습니다. M2M-100은 24 레이어 인코더, 24 레이어 디코더, 4,096 히든 크기를 가지고 있으며, 총 120억 개의 파라미터를 포함하고 있습니다. 이에 비해 DeepNet은 32억 개의 파라미터만으로 더 깊고 좁은 구조입니다. 공정한 비교를 위해, 우리는 빔 크기 5와 길이 패널티 1을 사용하여 모델을 생성했습니다.
M2M-100(Fan et al., 2021)을 따라 우리는 여러 다국어 번역 평가 데이터셋(WMT, OPUS, TED, Flores)에서 모델을 평가했습니다. WMT 데이터셋의 언어 쌍은 영어 중심이며, 10개의 언어가 포함되어 있습니다. OPUS 데이터셋에서는 30개의 평가 쌍을 가진 비영어 방향을 선택했습니다. TED 평가 세트는 28개 언어와 756개의 번역 방향을 포함하며, 데이터는 구어체 언어 도메인에서 가져왔습니다. Flores 데이터셋은 102개 언어 간의 모든 번역 쌍을 포함하며, 우리는 M2M-100과 DeepNet이 지원하는 87개 언어와 7,482개의 번역 방향을 사용했습니다.
Table 3에서 결과를 보고합니다. 공정한 비교를 위해, 우리는 베이스라인과 동일한 평가 방법을 사용했습니다. 자세한 내용은 부록에 나와 있습니다. 결과는 DeepNet이 모든 평가 데이터셋에서 M2M-100보다 훨씬 더 나은 성능을 보여주며, 모델을 더 깊게 만드는 것이 NMT 모델의 품질을 개선하는 매우 유망한 방향임을 나타냅니다.
7. 결론 및 향후 작업
우리는 트랜스포머의 안정성을 개선하고 1,000개 레이어까지 확장하는 데 성공했습니다. 이는 DeepNorm이라는 새로운 정규화 함수를 사용하는 DeepNet을 통해 달성되었으며, 모델 업데이트에 대해 상수 상한을 갖는 이론적 근거가 있습니다. 실험 결과는 여러 벤치마크에서 우리의 방법이 효과적임을 검증했습니다. 현재 실험에서는 기계 번역을 테스트베드로 사용했지만, 향후에는 DeepNet을 언어 모델 사전 학습, 단백질 구조 예측, BEiT 비전 사전 학습 등 더 다양한 작업에 확장할 계획입니다.
감사의 말
CCMatrix 코퍼스를 제공한 Saksham Singhal에게 감사를 표합니다.



