https://swivid.github.io/F5-TTS/
F5-TTS
-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching Abstract This paper introduces F5-TTS, a fully non-autoregressive text-to-speech system based on flow matching with Diffusion Transformer (DiT). Without requiring complex designs s
swivid.github.io
초록
이 논문은 Diffusion Transformer(DiT)를 이용한 흐름 매칭 기반의 완전 비자기회귀 방식 텍스트-음성 변환 시스템인 F5-TTS를 소개합니다. 복잡한 설계 요소들, 예를 들어 지속 시간 모델, 텍스트 인코더, 음소 정렬 등을 필요로 하지 않고, 텍스트 입력을 음성 입력과 같은 길이로 패딩한 후 디노이징을 통해 음성을 생성하는 방식입니다. 이러한 접근은 원래 E2 TTS에 의해 실현 가능함이 입증되었습니다. 그러나 E2 TTS의 초기 설계는 수렴 속도가 느리고 강건성이 낮아 따라하기 어렵다는 단점이 있습니다. 이를 해결하기 위해, 우리는 먼저 ConvNeXt를 이용해 입력을 모델링하여 텍스트 표현을 정제함으로써 음성과의 정렬을 용이하게 만듭니다. 또한, 우리는 추론 단계에서 Sway Sampling이라는 샘플링 전략을 제안하여, 모델의 성능과 효율성을 크게 향상시켰습니다. 이 샘플링 전략은 흐름 단계에 쉽게 적용될 수 있으며, 기존 흐름 매칭 기반 모델에도 재학습 없이 적용 가능합니다. 우리의 설계는 학습 속도를 높일 뿐만 아니라 추론 실시간 계수(RTF)를 0.15로 달성하여, 최첨단 확산 기반 TTS 모델과 비교했을 때 크게 개선된 결과를 보입니다. 10만 시간의 공공 다국어 데이터셋으로 학습된 Fairytaler Fakes Fluent and Faithful speech with Flow matching(F5-TTS)은 매우 자연스럽고 표현력 있는 제로샷 능력, 매끄러운 코드 전환 능력, 그리고 속도 제어 효율성을 보여줍니다. 데모 샘플은 https://SWivid.github.io/F5-TTS 에서 확인할 수 있습니다. 우리는 커뮤니티 발전을 위해 모든 코드와 체크포인트를 공개합니다.
[코드 및 체크포인트 링크: https://github.com/SWivid/F5-TTS]
1. 서론
최근 텍스트-음성 변환(TTS) 연구는 큰 발전을 이루었습니다 [1, 2, 3, 4, 5, 6, 7, 8]. 몇 초간의 오디오 프롬프트만으로도 현재의 TTS 모델은 주어진 텍스트에 대해 음성을 합성하고, 오디오 프롬프트의 화자를 모방할 수 있습니다 [9, 10]. 합성된 음성은 높은 충실도와 자연스러움을 달성하여 사람의 음성과 거의 구별할 수 없을 정도입니다 [11, 12, 13, 14].
자기회귀(AR) 기반의 TTS 모델은 직관적으로 다음 토큰을 연속적으로 예측하는 방식으로, 유망한 제로샷 TTS 능력을 보여주고 있습니다. 그러나 AR 모델링의 고유한 한계로 인해 추론 지연 및 노출 편향과 같은 문제를 해결하기 위해 추가적인 노력이 필요합니다 [15, 16, 17, 18, 19]. 또한, AR 모델이 고충실도의 합성을 달성하기 위해서는 음성 토크나이저의 품질이 중요합니다 [20, 21, 22, 23, 24, 25, 26]. 이러한 이유로 최근 합성된 음성의 품질을 향상시키기 위해 연속적인 공간에서의 직접 모델링을 탐구하는 연구들이 진행되고 있습니다 [27, 28, 29].
비록 AR 모델이 암시적인 지속 시간 모델링을 수행하고 다양한 샘플링 전략을 활용하여 인상적인 제로샷 성능을 보여주지만, 비자기회귀(NAR) 모델은 병렬 처리를 통해 빠른 추론이 가능하며 합성 품질과 지연 시간의 균형을 효과적으로 유지합니다. 특히, 확산 모델은 [30, 31] 현재 NAR 음성 모델의 성공에 큰 기여를 하고 있습니다 [11, 12]. 특히, 최적 수송 경로를 이용한 흐름 매칭(FM-OT)은 [32] 최근 연구 분야에서 텍스트-음성 변환뿐만 아니라 [14, 33, 34, 35, 36] 이미지 생성 [37], 음악 생성 [38] 등에도 널리 사용되고 있습니다.

그림 1: F5-TTS의 학습(왼쪽) 및 추론(오른쪽)의 개요
모델은 텍스트 기반 음성 채우기 작업과 조건 흐름 매칭 손실로 학습됩니다. 입력 텍스트는 문자 시퀀스로 변환되고, 음성 입력과 동일한 길이로 필러 토큰으로 패딩된 후, 음성 입력과의 병합 전에 ConvNeXt 블록을 통해 정제됩니다. 추론 과정에서는 Sway Sampling을 활용하여 흐름 단계에서 모델과 ODE 솔버를 이용해 샘플링된 노이즈로부터 음성을 생성합니다.
AR 기반 모델과는 달리, 입력 텍스트와 합성된 음성 간의 정렬 모델링은 NAR 기반 모델에서는 매우 중요하고 도전적인 과제입니다. NaturalSpeech 3 [12]와 Voicebox [14]는 프레임 단위 음소 정렬을 사용하는 반면, Matcha-TTS [34]는 단조 정렬 검색을 채택하고 음소 수준 지속 시간 모델에 의존합니다. 최근 연구들은 텍스트와 음성 간의 이러한 강직하고 비유연한 정렬이 모델이 더욱 자연스러운 결과를 생성하는 데 방해가 된다는 것을 발견했습니다 [36, 39].
E3 TTS [40]는 음소 수준 지속 시간을 포기하고 입력 시퀀스에 교차 주의를 적용했으나, 제한된 오디오 품질을 보였습니다. DiTTo-TTS [35]는 사전 학습된 언어 모델에서 인코딩된 텍스트에 조건부된 교차 주의를 사용하는 Diffusion Transformer(DiT) [41]를 사용합니다. 정렬을 더욱 향상시키기 위해, 이 모델은 사전 학습된 언어 모델을 이용해 신경 오디오 코덱을 미세 조정하여 생성된 표현에 의미 정보를 주입합니다. 반면, E2 TTS [36]는 Voicebox [14]를 기반으로 필러 토큰으로 패딩된 문자들을 멜 스펙트로그램의 길이만큼 입력으로 사용하는 더 간단한 방식을 채택합니다. 이 단순한 접근법 또한 매우 자연스럽고 현실적인 합성 결과를 달성했습니다. 그러나 E2 TTS는 텍스트와 음성 정렬에서 강건성 문제를 가진다는 것을 발견했습니다. Seed-TTS [39]는 유사한 전략을 채택하여 우수한 결과를 달성했으나, 모델 세부사항에 대한 설명은 부족했습니다. 이러한 음소 수준의 지속 시간을 명시적으로 모델링하지 않는 방식에서는, 모델이 주어진 총 시퀀스 길이에 따라 각 단어 또는 음소의 길이를 할당하는 방법을 배우게 되어 운율과 리듬이 개선됩니다.
본 논문에서는 F5-TTS를 제안합니다. 이 모델은 흐름 매칭을 통해 유창하고 충실한 음성을 생성하는 'Fairytaler'입니다. F5-TTS는 음소 정렬, 지속 시간 예측기, 텍스트 인코더, 의미적으로 주입된 코덱 모델 없이도 간단한 파이프라인을 유지하면서, ConvNeXt V2 [42]와 함께 Diffusion Transformer를 활용하여 맥락 내 학습 중 텍스트-음성 정렬을 더욱 효과적으로 다룹니다. 우리는 E2 TTS 모델 설계에서 의미적 및 음향적 특성의 깊은 얽힘이 고유한 문제를 가지며, 단순히 재랭킹으로 해결할 수 없는 정렬 실패 문제를 일으킬 수 있음을 강조합니다. 심층적인 절제 연구를 통해, 제안한 F5-TTS는 텍스트 프롬프트에 보다 충실한 음성을 생성하는 데 있어 더 강력한 강건성을 보이면서도 화자 유사성을 유지함을 입증합니다. 또한, 흐름 단계에서 자연스러움, 명료성, 그리고 화자 유사성을 크게 개선하는 추론 단계 샘플링 전략을 소개합니다. 이 접근법은 기존의 흐름 매칭 기반 모델에 재학습 없이도 원활하게 통합될 수 있습니다.
2. 기초 개념
2.1 흐름 매칭
2.2 분류기-없는 안내(Classifier-Free Guidance)
분류기 안내(Classifier Guidance, CG)는 [46]에 의해 제안되었으며, 추가적인 분류기의 그라디언트를 추가하여 작동합니다. 그러나 이러한 명시적인 방식으로 생성 과정을 조건화하는 데는 여러 문제가 있을 수 있습니다. 분류기를 추가로 학습해야 하며, 생성 결과는 분류기의 품질에 직접적인 영향을 받습니다. 또한 그라디언트를 업데이트하는 방식으로 안내가 도입됨에 따라 적대적 공격도 발생할 수 있습니다. 이러한 문제로 인해 인간의 눈으로는 알아차리기 힘든, 조건을 따르지 않는 기만적인 이미지가 생성될 수 있습니다.
-----
-----
3. 방법
이 연구는 고수준의 텍스트-음성 변환 시스템을 구축하는 것을 목표로 합니다. 우리는 텍스트 기반 음성 채우기 작업 [48, 14]에서 모델을 학습시켰습니다. 최근 연구 [35, 36, 49]에 따르면, 음소 수준의 지속 시간 예측기를 사용하지 않고 학습하는 것이 유망하며, 명시적인 음소 수준 정렬을 사용하지 않음으로써 제로샷 생성에서 더 높은 자연스러움을 달성할 수 있습니다. 우리는 E2 TTS [36]와 유사한 파이프라인을 채택하고, F5-TTS라는 고급 아키텍처를 제안하여 E2 TTS의 느린 수렴(초기 단계에서 음색은 잘 학습되었으나 정렬 학습에 어려움을 겪음)과 강건성 문제(어려운 케이스 생성 실패)를 해결합니다. 또한, 우리는 추론 시 흐름 단계에서 Sway Sampling 전략을 제안하여 참조 텍스트에 대한 충실도와 화자 유사성에서 모델의 성능을 크게 향상시켰습니다.
3.1 파이프라인
학습

-----
-----
추론


-----
-----
3.2 F5-TTS
E2 TTS는 패딩된 문자 시퀀스를 입력 음성과 직접 연결하여 의미적 특징과 음향적 특징을 깊이 얽히게 하며, 효과적인 정보의 길이 차이가 크기 때문에 학습이 어려워지고 제로샷 시나리오에서 여러 문제를 야기합니다(Sec. 5.1). 이러한 느린 수렴과 낮은 강건성 문제를 완화하기 위해, 우리는 F5-TTS를 제안합니다. 이 모델은 학습과 추론을 가속화하며 생성 시 높은 강건성을 보여줍니다. 또한, 추론 시 Sway Sampling을 도입하여 성능을 유지하면서도 더 빠른 추론(적은 NFE 사용)을 가능하게 합니다. 이러한 흐름 단계 샘플링 방식은 다른 CFM 모델에도 직접 적용될 수 있습니다.
모델
그림 1에 보이는 것처럼, 우리는 잠재 확산 변환기(latent Diffusion Transformer, DiT) [41]를 백본으로 사용합니다. 구체적으로는 제로로 초기화된 적응형 Layer Norm (adaLN-zero)을 가진 DiT 블록을 사용합니다. 모델의 정렬 능력을 향상시키기 위해 ConvNeXt V2 블록 [42]도 활용합니다. ConvNeXt V1 [50]은 여러 작업에 사용되었으며, 음성 도메인 작업에서 강력한 시간적 모델링 능력을 보여주었습니다 [51, 52].
Sec. 3.1에서 설명한 바와 같이, 모델 입력은 문자 시퀀스, 노이즈가 있는 음성, 그리고 마스크된 음성입니다. 특징 차원에서 연결하기 전에, 문자 시퀀스는 먼저 ConvNeXt 블록을 거칩니다. 실험 결과, 개별적인 모델링 공간을 제공하는 이러한 방식이 텍스트 입력이 이후 맥락 내 학습을 준비하는 데 더 유리하다는 것을 보여주었습니다. Voicebox에서의 음소 수준 강제 정렬과 달리, 텍스트에 대한 강직한 경계는 명시적으로 도입되지 않았습니다. 의미적 특징과 음향적 특징은 전체 모델과 함께 공동으로 학습됩니다. 또한, E2 TTS처럼 정보의 효과적인 길이가 큰 차이가 나는 입력을 모델에 제공하는 방식과는 다르게, 우리의 설계는 이러한 격차를 완화합니다.
CFM을 위한 흐름 단계 t는 Voicebox에서처럼 연결된 입력 시퀀스에 추가하는 대신, adaLN-zero의 조건으로 제공됩니다. 우리는 TTS 작업에서 adaLN 조건을 위해 텍스트 시퀀스의 추가적인 평균 풀링된 토큰이 필수적이지 않다는 것을 발견했으며, 이는 아마도 TTS 작업이 더 엄격하게 안내된 결과를 필요로 하고, 평균 풀링된 텍스트 토큰이 더 거칠기 때문일 것입니다.
우리는 Voicebox의 몇 가지 위치 임베딩 설정을 채택했습니다. 흐름 단계는 사인 함수 위치에 임베딩됩니다. 연결된 입력 시퀀스에는 컨볼루션 위치 임베딩이 추가됩니다. 대칭적인 양방향 ALiBi 편향 [54] 대신, 자기 주의(attention)에 대해 회전 위치 임베딩(RoPE) [53]을 적용했습니다. 또한 확장된 문자 시퀀스 y^에는 ConvNeXt 블록에 입력하기 전에 절대 사인 함수 위치 임베딩을 추가했습니다.
Voicebox와 E2 TTS와 비교했을 때, 우리는 U-Net [55] 스타일의 스킵 연결 구조를 버리고 DiT와 adaLN-zero를 사용하도록 변경했습니다. 음소 수준 지속 시간 예측기나 명시적 정렬 과정 없이, 그리고 DiTTo-TTS에서의 추가 텍스트 인코더와 의미가 주입된 신경 코덱 모델도 없이, 우리는 텍스트 입력에 약간의 자유(개별적인 모델링 공간)를 부여하여 음성 입력과의 연결 및 맥락 내 학습 전에 스스로 준비할 수 있도록 했습니다.
샘플링


-----
-----
Sway Sampling 수식:
fsway(u;s) = u + s * (cos(πu/2) - 1 + u)
주요 요소:
- u: 0~1 사이의 균등 분포 샘플
- s: 분포 기울기 조절 (-1 ~ 2/π-2)
- cos(πu/2): 비선형 변환 항
효과:
- s < 0: 초기 단계 중점 (기본 형태 생성)
- s = 0: 균등 분포 유지
- s > 0: 후기 단계 중점 (세부 정교화)
4. 실험 설정
데이터셋
우리는 멀티링구얼 음성 데이터셋 Emilia [57]을 사용하여 기본 모델을 학습시켰습니다. 단순히 전사 실패와 잘못 분류된 언어 음성을 필터링한 후, 약 95,000시간의 영어와 중국어 데이터를 보유했습니다. 또한, WenetSpeech4TTS [58] 프리미엄 하위 집합(945시간 분량의 중국어 코퍼스)에서 소형 모델을 학습하여 절제 연구와 아키텍처 탐색을 수행했습니다. 기본 모델 구성은 아래에 소개되며, 소형 모델 구성은 부록 B.1에 있습니다. 평가를 위해 세 개의 테스트 세트를 채택했으며, 이는 LibriSpeech-PC 테스트 클린 [59], Seed-TTS 테스트-영어 [39] (Common Voice [60]에서 추출한 1088개의 샘플), Seed-TTS 테스트-중국어 (DiDiSpeech [61]에서 추출한 2020개의 샘플)입니다. 대부분의 이전 영어 전용 모델들은 LibriSpeech 테스트 클린의 서로 다른 하위 집합에서 평가되었으며, 사용된 프롬프트 목록은 공개되지 않아 공정한 비교가 어려웠습니다. 따라서 우리는 커뮤니티 비교를 용이하게 하기 위해 1127개의 샘플로 이루어진 4~10초 길이의 LibriSpeech-PC 하위 집합을 구축하고 공개했습니다.
학습
우리의 기본 모델은 배치 크기 307,200 오디오 프레임(0.91시간)으로 120만 번의 업데이트 동안 학습되었으며, 8개의 NVIDIA A100 80G GPU에서 일주일 이상 학습되었습니다. AdamW 옵티마이저 [62]를 사용하였으며, 학습률은 최대 7.5e-5까지 증가하고, 20,000번의 업데이트 동안 선형으로 워밍업한 후 나머지 학습 기간 동안 선형으로 감소합니다. 최대 그라디언트 노름 클립은 1로 설정했습니다. F5-TTS 기본 모델은 22개 층, 16개의 어텐션 헤드, 1024/2048의 임베딩/피드포워드 네트워크(FFN) 차원을 가지는 DiT로 구성됩니다. ConvNeXt V2의 경우 4개 층, 512/1024 임베딩/FFN 차원으로, 총 3억 3,580만 개의 파라미터를 갖습니다. 재현된 E2 TTS 모델은 3억 3,320만 개의 파라미터를 가지며, 평면 U-Net을 장착한 트랜스포머로, 24개 층, 16개의 어텐션 헤드, 1024/4096의 임베딩/FFN 차원을 가집니다. 두 모델 모두 Sec. 3.2에서 언급된 대로 RoPE를 사용하고, 어텐션 및 FFN에는 드롭아웃 비율 0.1을 적용하며, Voicebox[14]에서 사용한 동일한 컨볼루션 위치 임베딩을 사용합니다.
우리는 영어에 대해 알파벳과 기호를 직접 사용하고, 중국어의 경우 원본 문자를 전 처리하기 위해 jieba4(https://github.com/fxsjy/jieba)와 pypinyin5(https://github.com/mozillazg/python-pinyin)를 사용합니다. 문자 임베딩 어휘 크기는 2,546이며, 특별 필러 토큰과 Emilia 데이터셋에 존재하는 모든 언어 문자를 포함합니다. 이는 많은 코드 스위칭 문장이 있기 때문입니다. 오디오 샘플에는 24kHz 샘플링 속도와 홉 길이 256을 가진 100차원의 로그 멜-필터뱅크 특징을 사용합니다. 인필링 작업 학습을 위해 멜 프레임의 70%에서 100%가 무작위로 마스킹됩니다. CFG 학습(Sec. 2.2)을 위해, 먼저 마스킹된 음성 입력을 30% 비율로 제거하고, 이후 마스킹된 음성에 텍스트 입력을 함께 사용하여 20% 비율로 다시 제거합니다. 우리는 이러한 2단계 CFG 학습 통제를 통해 모델이 텍스트 정렬과 관련해 더 많이 학습할 수 있을 것이라고 가정합니다.
추론
추론 과정은 주로 Sec. 3.1에서 자세히 설명되었습니다. 우리는 추론을 위해 지수 이동 평균(EMA) [63] 가중치를 사용하고, F5-TTS에는 오일러 ODE 솔버를 사용하며, E2 TTS에는 중간점(midpoint) 방법을 사용합니다([36]에서 설명한 대로). 생성된 로그 멜 스펙트로그램을 오디오 신호로 변환하기 위해 사전 학습된 보코더 Vocos [51]를 사용합니다.
비교 모델(Baselines)
우리는 주요한 TTS 시스템과 우리의 모델을 비교했습니다. 여기에는 (주로) 자기회귀 모델들이 포함되며, VALL-E 2 [13], MELLE [29], FireRedTTS [64], 그리고 CosyVoice [65] 등이 있습니다. 비자기회귀 모델로는 Voicebox [14], NaturalSpeech 3 [12], DiTTo-TTS [35], MaskGCT [66], Seed-TTSDiT [39], 그리고 우리가 재현한 E2 TTS [36]이 포함됩니다. 비교된 모델의 세부 사항은 부록 A를 참고하십시오.
평가지표
우리는 문장 간 작업에서 성능을 측정합니다. 모델은 참조 텍스트, 짧은 음성 프롬프트, 그리고 해당 전사를 입력받아 참조 텍스트를 읽으면서 음성 프롬프트의 화자를 모방하여 음성을 합성합니다. 구체적으로는, 생성된 음성과 원래 목표 음성 간의 워드 오류율(WER)과 화자 유사도(SIM-o)를 보고합니다. WER 측정을 위해 Whisper-large-v3 [67]을 사용해 영어를 전사하고, 중국어는 Paraformer-zh [68]을 사용합니다([39]에 따름). SIM-o 측정을 위해 WavLM-large 기반 [69] 화자 검증 모델을 사용해 화자 임베딩을 추출하고, 생성된 음성과 실제 음성 간의 코사인 유사도를 계산합니다.
주관적인 평가를 위해 비교 평균 의견 점수(CMOS)와 유사도 평균 의견 점수(SMOS)를 사용합니다. CMOS 평가에서는 평가자들이 무작위로 정렬된 합성 음성과 실제 음성을 듣고, 프롬프트 음성에 대해 더 나은 자연스러움이 상대를 얼마나 뛰어넘는지를 결정해야 합니다. SMOS 평가에서는 평가자들이 합성 음성과 프롬프트 간의 유사도를 평가해야 합니다.
5. 실험 결과
표 5와 표 6은 객관적 및 주관적 평가의 주요 결과를 보여줍니다. 우리는 모델과 공개된 기준 모델들을 사용해 3개의 랜덤 시드로 생성한 결과의 평균 점수를 보고합니다. 기본적으로 F5-TTS에서는 CFG 강도를 2로, Sway 샘플링 계수를 −1로 설정했습니다.
표 1: LibriSpeech 테스트 클린과 LibriSpeech-PC 테스트 클린에서의 결과
굵은 글씨는 최상의 결과를 나타내며, *는 다른 하위 집합을 사용한 평가에서 기준 논문에 보고된 점수를 의미합니다. 실시간 계수(RTF)는 10초 음성의 추론 시간을 기준으로 계산됩니다. #Param.은 학습 가능한 파라미터 수를 나타내며, #Data는 사용된 학습 데이터셋의 시간(시간 단위)을 나타냅니다.
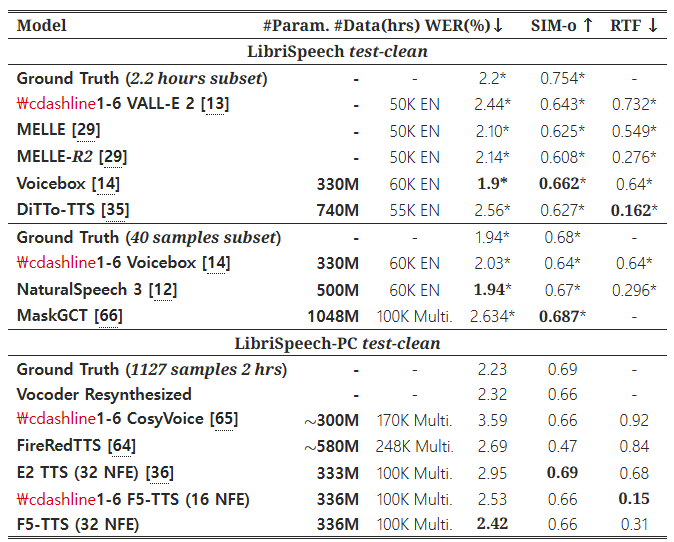
영어 제로샷 평가의 경우, 이전 연구들은 서로 다른 LibriSpeech 테스트 클린 [70]의 하위 집합을 사용하기 때문에 직접 비교하기 어렵습니다. 대부분은 410초 길이의 발화를 생성 대상으로 필터링했다고 주장하지만, 사용된 프롬프트 오디오는 공개되지 않았습니다. 따라서 우리는 추가적인 구두점 및 대소문자 정보를 포함한 LibriSpeech 확장판인 LibriSpeech-PC [59]를 기반으로 410초 샘플 테스트 세트를 구축했습니다. 향후 비교를 용이하게 하기 위해 39명의 화자(하나의 화자가 누락됨)로부터 1,127개의 샘플을 포함한 2시간 분량의 테스트 세트를 공개합니다.
F5-TTS는 32 NFE와 Sway 샘플링을 사용하여 LibriSpeech-PC 테스트 클린에서 2.42의 WER을 달성하며, 제로샷 생성에서 높은 강건성을 입증합니다. 16 NFE로 추론 시, F5-TTS는 0.15의 RTF를 얻으며, 여전히 2.53의 WER로 고품질 생성을 지원합니다. 이는 Sway 샘플링 전략이 성능을 크게 향상시킨다는 것을 명확히 보여줍니다. 재현된 E2 TTS는 제로샷 시나리오에서 우수한 화자 유사도(SIM)를 보여주었지만, WER는 훨씬 더 나쁜 결과를 보였으며, 이는 정렬 강건성의 본질적인 결함을 나타냅니다.
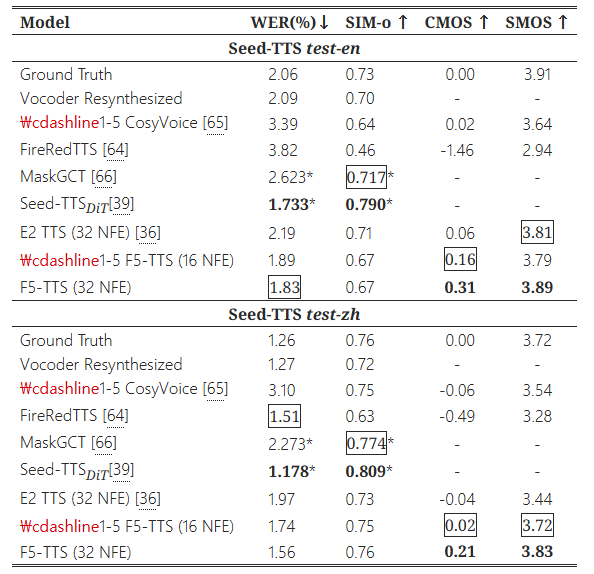
Seed-TTS 테스트 세트에 대한 평가 결과에서, F5-TTS는 실제 데이터와 유사한 WER 및 유사한 SIM 점수를 보여주며 비슷한 성능을 보였습니다. 제로샷 생성에서 매끄럽고 유창한 음성을 생성하며, Seed-TTS 테스트-영어(test-en)에서는 0.31, 테스트-중국어(test-zh)에서는 0.21의 CMOS, 각각 3.89와 3.83의 SMOS를 달성하여 일부 더 큰 규모로 학습된 기준 모델들을 능가했습니다. 주목할 점은 최상의 결과를 보인 Seed-TTS 모델이 우리 모델보다 훨씬 더 큰 모델 크기와 데이터셋(수백만 시간 규모)으로 학습되었다는 것입니다. Sec. 3.1에서 언급한 것처럼, 우리는 단순히 오디오 프롬프트의 전사 길이와 텍스트 프롬프트 길이의 비율을 기준으로 지속 시간을 추정합니다. 만약 실제 지속 시간을 제공한다면, 32 NFE와 Sway 샘플링을 사용한 F5-TTS는 테스트-영어(test-en)에서 1.74, 테스트-중국어(test-zh)에서 1.53의 WER을 달성하면서도 동일한 SIM을 유지할 수 있으며, 이는 높은 상한값을 나타냅니다. ELLA-V [15]의 어려운 문장들에 대한 강건성 테스트는 부록 B.5에 추가로 포함되어 있습니다.
표 2: 두 개의 테스트 세트, Seed-TTS test-en과 test-zh에서의 결과
굵은 글씨는 최상의 결과를 나타내며, 밑줄은 두 번째로 좋은 결과를 나타내며, *는 기준 논문에 보고된 점수를 의미합니다.
5.1 모델 아키텍처의 절제 연구
우리 F5-TTS의 효율성을 명확히 하고 E2 TTS의 한계를 강조하기 위해 심층적인 절제 연구를 수행했습니다. 우리는 소형 모델을 학습시키기 위해, 각각 8개의 NVIDIA RTX 3090 GPU로 일주일 동안 80만 번의 업데이트를 수행했으며, 모든 모델은 약 1억 5,500만 개의 파라미터로 스케일링되었습니다. 사용된 데이터셋은 WenetSpeech4TTS 프리미엄 945시간 분량의 중국어 데이터셋이며, 배치 크기는 기본 모델의 절반으로 설정하고 동일한 옵티마이저와 스케줄러를 사용했습니다. 소형 모델 구성의 세부 사항은 부록 B.1을 참조하십시오.

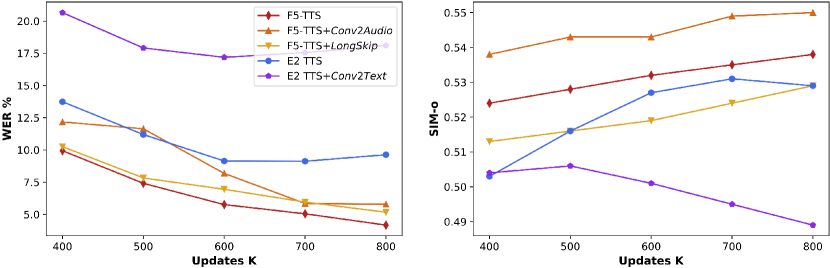
그림 2: 모델 아키텍처에 대한 절제 연구
Seed-TTS test-zh에서 평가된 1억 5,500만 개의 소형 모델들에 대한 WenetSpeech4TTS 프리미엄 945시간 중국어 코퍼스로 학습된 결과입니다.

우리는 F5-TTS의 장점을 더 명확히 설명하고 E2 TTS의 결함의 가능성 있는 이유를 밝히기 위해, 모델들의 다른 입력 조건에서의 행동을 조사했습니다. 부록 B.2의 표 4에서 볼 수 있듯이, 실제 지속 시간을 제공하면 F5-TTS가 E2 TTS보다 WER에서 더 많은 이득을 얻으며, 이는 F5-TTS의 정렬 강건성을 보여줍니다. 오디오 프롬프트를 제거하고 텍스트 프롬프트만으로 음성을 합성한 경우, E2 TTS는 실패가 발생하지 않았습니다. 이 현상은 E2 TTS의 모델 설계에서 의미적 특징과 음향적 특징이 깊이 얽혀 있음을 시사합니다. 부록 B.3의 표 3의 GFLOPs 통계에서, F5-TTS는 E2 TTS보다 더 빠른 학습과 추론을 수행함을 확인할 수 있습니다.
E2 TTS의 이러한 제한 사항은 실제 응용에서 큰 걸림돌이 되며, 실패한 생성은 재랭킹으로 해결될 수 없습니다. 도메인 밖의 데이터를 처리하기 위해서는 감독된 미세 조정이나 대규모의 사전 학습이 E2 TTS에서는 필수적이며, 이는 산업적 배포에 불편함을 초래합니다. 반면, 우리의 F5-TTS는 제로샷 생성을 더 잘 처리하며, 더 강력한 강건성을 보여줍니다.
5.2 Sway Sampling에 대한 절제 연구
그림 3에서 알 수 있듯이, 음수 s를 가진 Sway Sampling은 생성 결과를 개선합니다. 더욱 음수의 s 값을 사용할수록 모델은 더 낮은 WER과 더 높은 SIM 점수를 달성합니다. 추가로, 부록 B.4에서는 Sway Sampling이 있는 경우와 없는 경우의 기본 모델에 대한 결과 비교를 포함하고 있습니다.

이 실험 결과는 초기 흐름 단계가 주어진 프롬프트를 기반으로 목표 음성의 실루엣을 충실하게 스케치하는 데 중요한 역할을 하며, 이후 단계는 형성된 중간 노이즈 출력을 더 집중적으로 다룬다는 강력한 증거를 제공합니다. 우리 방식의 왼쪽으로 기울어진 샘플링 (s<0)은 이러한 유리한 틈새를 찾아 이를 활용합니다. 우리는 우리의 추론 시 Sway Sampling이 기존의 CFM 기반 모델에 재학습 없이도 쉽게 적용될 수 있음을 강조합니다. 앞으로 우리는 이를 학습 시 노이즈 스케줄러와 증류 기술과 결합하여 효율성을 더욱 높이는 작업을 진행할 계획입니다.
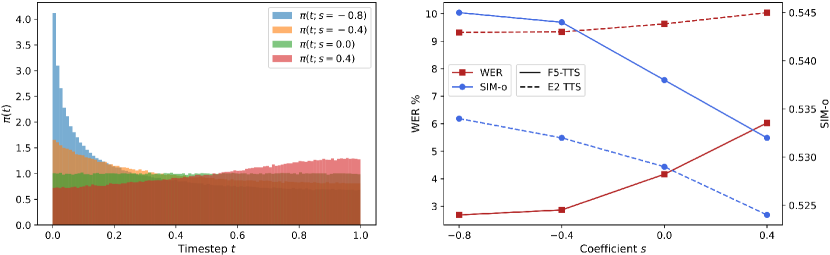
그림 3: Sway Sampling의 흐름 단계 tt에 대한 서로 다른 계수 s의 확률 밀도 함수(왼쪽)와 Seed-TTS test-zh에서 Sway Sampling을 적용한 소형 모델들의 성능(오른쪽)
6. 결론
이 연구는 F5-TTS, 즉 확산 변환기(DiT)를 사용한 흐름 매칭 기반의 완전 비자기회귀 텍스트-음성 변환 시스템을 소개합니다. 텍스트를 입력하면 음성이 출력되는 깔끔한 파이프라인을 통해, F5-TTS는 산업 규모의 데이터로 학습된 기존 연구와 비교해 최첨단 제로샷 성능을 달성합니다. 우리는 텍스트 모델링에 ConvNeXt를 채택하고, 테스트 시 Sway Sampling 전략을 제안하여 음성 생성의 강건성과 추론 효율성을 더욱 향상시켰습니다. 우리 설계는 0.15의 테스트 시 실시간 계수(RTF)를 달성함으로써, 유사한 성능을 가진 다른 고도로 최적화된 TTS 모델들과 경쟁할 수 있도록 더 빠른 학습과 추론을 가능하게 합니다. 우리는 이 연구의 코드와 모델을 오픈소스로 공개하여, 이 분야의 투명성과 재현 가능한 연구를 촉진하고자 합니다.
감사의 말
저자들은 Tianrui Wang, Xiaofei Wang, Yakun Song, Yifan Yang, Yiwei Guo, Yunchong Xiao에게 귀중한 논의에 대한 감사를 표하고자 합니다.
윤리적 성명
이 연구는 순수히 연구 프로젝트입니다. F5-TTS는 대규모 공개 다국어 음성 데이터로 학습되었으며, 높은 자연스러움과 화자 유사성을 가진 음성을 합성할 수 있습니다. 모델의 오남용, 예를 들어 음성 식별을 속이는 행위와 같은 잠재적 위험을 고려할 때, 오디오 출력물에 대한 워터마크를 구현하고 탐지 모델을 개발하는 것이 필수적입니다.
부록 A: 기준 모델 세부사항
VALL-E 2 [13]
대규모 TTS 모델로 VALL-E [9]와 동일한 아키텍처를 공유하지만, 반복 인지 샘플링 전략을 사용하여 더 신중한 샘플링 선택을 촉진합니다. Libriheavy [71] 50,000시간 분량의 영어 데이터셋으로 학습되었습니다. 우리는 [29]에 보고된 결과와 비교했습니다.
MELLE [29]
자기회귀 대규모 모델로, 텍스트-음성 변환을 위해 연속 값 토큰을 변동적 추론으로 활용합니다. 그 변형 모델들은 각 시간 단계에서 여러 멜-스펙트로그램 프레임을 예측할 수 있으며, MELLE-Rx로 불리며 여기서 x는 감소 계수를 나타냅니다. 모델은 Libriheavy [71] 50,000시간 분량의 영어 데이터셋으로 학습되었습니다. 우리는 [29]에 보고된 결과와 비교했습니다.
Voicebox [14]
인필링 작업으로 학습된 흐름 매칭 기반의 비자기회귀 대규모 모델입니다. 우리는 60,000시간 영어 데이터셋으로 학습된 3억 3천만 개의 파라미터 모델의 결과를 [14]와 [12]에 보고된 결과와 비교했습니다.
NaturalSpeech 3 [12]
비자기회귀 대규모 TTS 시스템으로, 인자화된 신경 코덱을 활용하여 음성 표현을 분리하고 인자화된 확산 모델을 사용하여 분리된 속성을 기반으로 음성을 생성합니다. 5억 개의 기본 모델은 Librilight [72] 60,000시간 영어 데이터셋으로 학습되었습니다. 우리는 [12]에 보고된 점수와 비교했습니다.
DiTTo-TTS [35]
크로스 어텐션 Diffusion Transformer를 사용하며, 사전 학습된 언어 모델을 활용하여 정렬을 향상시키는 비자기회귀 대규모 TTS 모델입니다. 우리는 55,000시간 분량의 영어 데이터셋으로 학습된 7억 4천만 개의 파라미터를 가진 DiTTo-en-XL 모델과 [35]에 보고된 점수와 비교했습니다.
FireRedTTS [64]
산업 수준 생성 음성 응용을 위한 기본 TTS 프레임워크입니다. 자기회귀 텍스트-의미 토큰 모델은 4억 개의 파라미터를 가지고 있으며, 토큰-파형 생성 모델은 절반 정도의 파라미터를 가지고 있습니다. 이 시스템은 248,000시간의 라벨링된 음성 데이터로 학습되었습니다. 공식 코드와 사전 학습된 체크포인트를 사용하여 평가를 진행했습니다.
https://github.com/FireRedTeam/FireRedTTS
MaskGCT [66]
마스크 및 예측 학습 패러다임을 따르며 텍스트와 음성 간의 정확한 정렬 정보 없이 학습된 비자기회귀 대규모 TTS 모델입니다. 모델은 여러 단계로 구성되며, 6억 9천5백만 개의 텍스트-의미 모델(T2S)과 3억 5천3백만 개의 의미-음향(S2A) 모델로 이루어져 있습니다. 모델은 Emilia [57] 데이터셋의 약 100,000시간의 중국어 및 영어 실전 음성 데이터를 사용해 학습되었습니다. 우리는 [66]에 보고된 결과와 비교했습니다.
Seed-TTS [39]
이전의 가장 큰 TTS 시스템보다 몇 배 더 큰 규모의 데이터로 학습된 고품질 다용도 음성 생성 모델들입니다. Seed-TTSDiT는 완전 비자기회귀 대규모 모델입니다. 우리는 [39]에 보고된 결과와 비교했습니다.
E2 TTS [36]
완전 비자기회귀 TTS 시스템으로, Voicebox에서 음소 수준 정렬 없이 모델링할 것을 제안했습니다. 원래는 Libriheavy [71] 50,000시간 영어 데이터셋으로 학습되었습니다. 우리는 중국어 및 영어 실전 음성 데이터 약 100,000시간을 포함한 Emilia [57] 데이터셋으로 학습된 3억 3천 3백만 개의 다국어 E2 TTS와 비교했습니다.
CosyVoice [65]
두 단계로 이루어진 대규모 TTS 시스템으로, 첫 번째는 자기회귀 텍스트-토큰, 그 다음은 흐름 매칭 확산 모델입니다. 이 모델은 약 3억 개의 파라미터를 가지고 있으며, 170,000시간의 다국어 음성 데이터로 학습되었습니다. 우리는 공식 코드와 사전 학습된 체크포인트를 사용하여 평가를 진행했습니다. https://huggingface.co/model-scope/CosyVoice-300M
model-scope/CosyVoice-300M · Hugging Face
CosyVoice [CosyVoice Paper][CosyVoice Studio][CosyVoice Code] For SenseVoice, visit SenseVoice repo and SenseVoice space. Install Clone and install git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git cd CosyVoice git submodule update --init
huggingface.co
B.1 소형 모델 구성
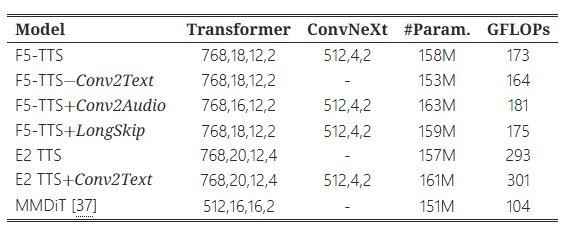
소형 모델들의 자세한 구성은 표 3에 나와 있습니다. 트랜스포머 열에서는 모델 차원, 층 수, 헤드 수, 히든 사이즈의 배수를 나타냅니다. ConvNeXt 열에서는 모델 차원, 층 수, 히든 사이즈의 배수를 나타냅니다. GFLOPs는 Python 패키지 'thop'을 사용하여 평가되었습니다.

표 3: 소형 모델 구성의 세부 사항
B.2 입력 조건에 대한 절제 연구
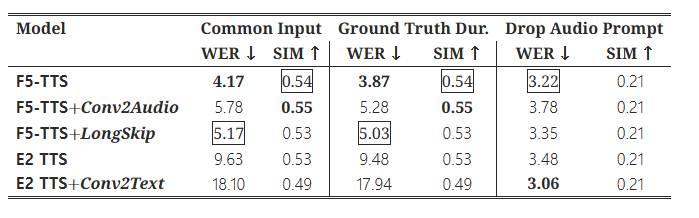
입력 조건에 대한 절제 연구는 세 가지 설정으로 수행되었습니다: 일반적인 텍스트 및 오디오 프롬프트 입력, 추정값 대신 실제 지속 시간 정보를 제공하는 경우, 그리고 오디오 프롬프트를 제거하고 텍스트 입력만을 유지하는 경우입니다. 표 4에서, 모든 평가는 WenetSpeech4TTS 프리미엄에서 학습된 80만 업데이트의 1억 5천 5백만 개의 소형 모델 체크포인트를 사용해 수행되었습니다.
표 4: 서로 다른 입력 조건에 대한 절제 연구
굵은 글씨는 최상의 결과를 나타내며, 밑줄은 두 번째로 좋은 결과를 나타냅니다. 모든 점수는 3개의 랜덤 시드 결과의 평균입니다.
B.3 ODE 솔버 비교
F5-TTS 추론 중 Euler 또는 중간점 ODE 솔버를 사용하는 경우에 대한 비교 결과는 표 B.3에 나와 있습니다. Euler는 본질적으로 더 빠르며(1차 방식) Sway Sampling을 사용한 경우 더 큰 NFE 추론에서 약간 더 나은 성능을 보입니다 (그렇지 않으면 Euler 솔버는 성능 저하를 초래할 수 있습니다).
표 5:
F5-TTS(F5)의 LibriSpeech-PC 테스트 클린, Seed-TTS 테스트-영어(test-en), Seed-TTS 테스트-중국어(test-zh)에 대한 평가 결과로, Euler 또는 중간점 ODE 솔버를 사용하고, 서로 다른 Sway Sampling ss 값을 적용한 결과를 나타냅니다. 실시간 계수(RTF)는 10초 음성의 추론 시간을 기준으로 계산되었습니다.
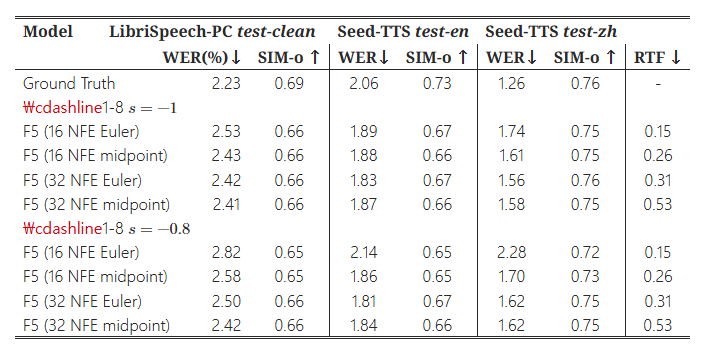
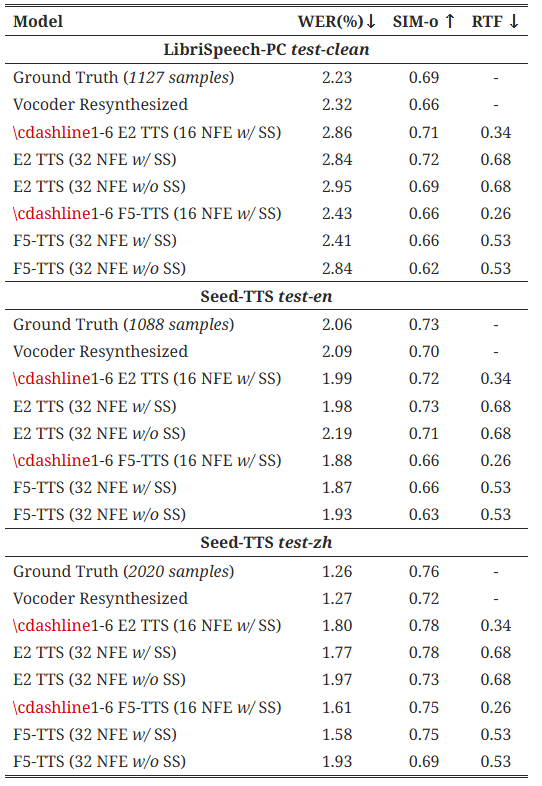
표 6:
LibriSpeech-PC 테스트 클린, Seed-TTS 테스트-영어(test-en), 테스트-중국어(test-zh)에 대한 기본 모델 평가 결과로, 제안된 테스트 시 Sway Sampling (SS, 계수 s=−1) 전략을 사용한 경우와 사용하지 않은 경우를 비교한 결과입니다. 모든 생성 과정에서는 절제 연구의 용이성을 위해 중간점 ODE 솔버를 사용했습니다.
B.4 기본 모델에서 Sway Sampling의 효과성
표 B.3에서 알 수 있듯이, 우리의 Sway Sampling 전략은 테스트 시 흐름 단계에서 프롬프트 텍스트에 대한 충실도(WER)와 화자 유사도(SIM) 측면에서 제로샷 생성 성능을 꾸준히 향상시킵니다. E2 TTS [36]에 Sway Sampling을 적용했을 때의 성능 향상은, 우리의 Sway Sampling 전략이 기존의 흐름 매칭 기반 TTS 모델에 보편적으로 적용 가능함을 입증합니다.
B.5 ELLA-V 어려운 문장 평가
ELLA-V [15]는 TTS 모델의 강건성을 평가하기 위해 100개의 어려운 텍스트 패턴을 포함한 도전적인 세트를 제안했습니다. 이전 연구 [13, 29, 36]를 따라, 우리는 생성된 샘플들을 데모 페이지8 https://SWivid.github.io/F5-TTS에 포함시켰습니다. 추가적으로, 우리는 E1 TTS [49]에서 보고된 객관적 평가 결과와 우리의 모델을 비교했습니다.
StyleTTS 2는 스타일 확산과 대립적 학습을 활용한 TTS 모델로, 대규모 음성 언어 모델을 사용합니다. CosyVoice는 텍스트-토큰 자기회귀 모델과 토큰-음성 흐름 매칭 모델로 구성된 두 단계의 대규모 TTS 시스템입니다. 우리 연구와 동시에 진행된 E1 TTSDMD는 확산 기반의 비자기회귀 모델로, 분포 매칭 증류 기술을 사용하여 단일 단계 TTS 생성을 달성합니다. E1 TTSDMD에서 사용된 프롬프트는 공개되지 않았으므로, 우리는 LibriSpeech-PC 테스트 클린 세트에서 임의로 3초 길이의 음성을 샘플링하여 오디오 프롬프트로 사용했습니다. 평가 결과는 표 7에 나와 있습니다. 우리는 재현된 E2 TTS와 우리의 F5-TTS를 32 NFE와 Sway Sampling으로 평가하고, 세 개의 랜덤 시드 결과의 평균 점수를 보고했습니다.
표 7: ELLA-V 어려운 문장에 대한 제로샷 TTS WER 결과
별표(*)는 E1 TTS에서 보고된 점수를 의미합니다. Sub.는 대체(substitution), Del.은 삭제(deletion), Ins.는 삽입(insertion)을 나타냅니다.
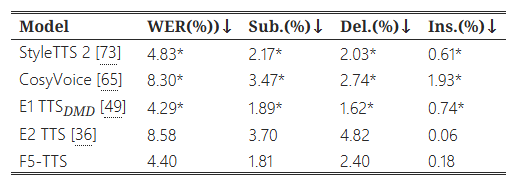
일반적으로 사용되는 테스트 세트에서의 결과와 비교했을 때 더 높은 WER이 나타난 것은 부분적으로 잘못된 발음 때문입니다(예: yogis를 yojus로, cavorts를 caverts로). 높은 삭제율은 모델이 반복적인 단어 뭉치를 만났을 때 단어를 건너뛰는 현상을 나타냅니다. 낮은 삽입률은 우리의 모델이 무한 반복 없이 정확하게 동작함을 보여줍니다. 우리는 또한 다른 화자들의 프롬프트가 매우 다른 발화를 초래할 수 있으며, 이에 대해 ASR 모델이 한쪽에서는 정확히 전사하고 다른 쪽에서는 실패할 수 있다는 점을 강조하고 싶습니다(예: quokkas를 Cocos로).



