https://arxiv.org/abs/2409.12640
Michelangelo: Long Context Evaluations Beyond Haystacks via Latent Structure Queries
We introduce Michelangelo: a minimal, synthetic, and unleaked long-context reasoning evaluation for large language models which is also easy to automatically score. This evaluation is derived via a novel, unifying framework for evaluations over arbitrarily
arxiv.org
초록
우리는 Michelangelo를 소개합니다: 대형 언어 모델을 위한 최소한의, 합성된, 유출되지 않은 장문 맥락 추론 평가로, 자동 채점이 용이합니다. 이 평가는 임의의 길이의 맥락에서 모델이 단일 정보 이상의 것을 검색할 수 있는 능력을 측정하는 새로운 통합 프레임워크를 통해 도출되었습니다. Latent Structure Queries (LSQ) 프레임워크의 중심 아이디어는 모델이 맥락에서 '불필요한 정보들을 깎아내어' 맥락 속의 잠재된 구조를 드러내도록 요구하는 작업을 만드는 것입니다. 이 잠재 구조에 대한 모델의 이해를 확인하기 위해, 우리는 모델에게 해당 구조의 세부사항을 질의합니다. LSQ를 사용하여 코드와 자연어 도메인 전반에 걸쳐 세 가지 진단적 장문 맥락 평가를 생산하였으며, 이는 장문 맥락 언어 모델 능력에 대한 강력한 신호를 제공합니다. 우리는 여러 최신 모델에 대한 평가를 수행하였으며, a) 제안된 평가들이 높은 신호를 가진다는 점과 b) 장문 맥락 정보를 종합하는 데 있어 상당한 개선의 여지가 있다는 것을 입증했습니다.
키워드: 장문 맥락 평가, 대형 언어 모델의 정보 추론 및 종합 평가, 합성 평가
“조각은 이미 대리석 블록 안에 완성되어 있습니다. 제가 작업을 시작하기 전에도 이미 거기에 있으며, 저는 불필요한 재료를 깎아낼 뿐입니다.”
— 미켈란젤로
1. 서론
르네상스 시대의 유명한 조각가 미켈란젤로는 어떻게 그렇게 아름다운 조각을 만들 수 있었느냐는 질문을 받은 적이 있습니다. 그의 대답은 이해와 예술성의 본질에 대한 전형적인 주석으로 오랫동안 기억되어 왔습니다. 그는 이렇게 말했습니다: "조각은 이미 대리석 블록 안에 완성되어 있습니다. 내가 작업을 시작하기 전에도 이미 거기에 있으며, 나는 그저 불필요한 재료를 깎아낼 뿐입니다." 이 연구에서는 장문 맥락 언어 모델의 이해와 조각가의 작업 본질 사이에 직접적인 유사점을 그립니다. 매우 큰 맥락은 많은 불필요한 정보를 가진 대리석 블록으로 볼 수 있으며, 모델은 이 정보를 깎아내어 내부 구조에 대한 이해를 드러내야 합니다. 우리는 이러한 원칙을 바탕으로 한 자동 진단용 장문 맥락 이해 평가인 Michelangelo를 소개하고, 이러한 평가를 생성하기 위한 Latent Structure Queries (LSQ) 프레임워크를 개발했습니다. LSQ는 인기 있는 "건초 더미에서 바늘 찾기" 방법론(Kamradt, 2023)과 비교하여 훨씬 더 복잡한 평가를 개발할 수 있게 합니다. 모델이 키에서 값을 추출하는 대신 구조에서 정보를 추출하도록 요구함으로써(대리석에서 조각을 깎아내는 것처럼, 건초 더미에서 바늘을 찾는 것과는 다르게), 단순 검색을 넘어선 언어 모델의 맥락 이해를 더 깊이 테스트할 수 있습니다.

그림 1: 합성 장추론 과제인 MRCR(다중 라운드 코어 선호도) 과제에서 프론티어 모델의 성능. 모든 모델이 32K 이전에는 성능이 크게 떨어집니다.
최근 대형 언어 모델들이 128K 토큰에서 1백만 토큰을 초과하는 매우 긴 맥락 길이를 다루며 (Anthropic, 2023; OpenAI, 2023; Google 외, 2024) 문헌에서 두각을 나타내고 있습니다. 그러나 이러한 모델들이 맥락에서 정보를 활용할 수 있는 정도를 측정하는 신뢰할 만한 테스트를 개발하는 문제는 여전히 미해결 상태로 남아 있습니다.
장문 맥락 평가에서 대부분의 주의는 "건초 더미 속에서 바늘 찾기" 검색 작업으로 대중화된 검색 작업에 집중되어 있으며 (Kamradt, 2023), 후속 연구들에서는 다수의 바늘 검색을 추가로 조사했습니다 (Google 외, 2024; Li 외, 2024; Hsieh 외, 2024; Zhang 외, 2024). 보다 현실적인 장문 맥락 질문-답변 평가도 여러 차례 개발되었으며 (Kočiskỳ 외, 2018; Bohnet 외, 2024b; Zhang 외, 2024), 이는 기본적으로 더 현실적인 설정에서 검색 작업을 해결하는 것으로 귀결되는 경향이 있습니다.
최근 들어, 여러 연구자들이 검색을 넘어서는 장문 맥락 능력을 평가하는 테스트의 필요성을 강조하고 있습니다 (Goldman 외, 2024; Levy 외, 2024; Karpinska 외, 2024). 이러한 연구들은 모델이 하나 이상의 사실을 검색할 수 있는 능력이 맥락 전체에서 정보를 종합하는 능력을 의미하지는 않는다고 지적하고 있습니다. 장문 맥락에 대한 모델의 추론 능력을 측정하려는 기존 벤치마크 (Arora 외, 2023; Li 외, 2024)들은 몇 가지 비효율적인 특성을 가질 수 있습니다. 예를 들면:
- 상대적으로 작은 맥락 길이
- 자연 언어나 코드 설정이 없는 높은 인위성
- 더 긴 맥락 길이로 확장하기 위해 상당한 양의 인적 노동을 필요로 함
- 과제가 전체 맥락의 사용을 필요로 하는 시나리오를 명확히 회피하는 구성. 이는 질문에 답하기 위한 정보가 사전 학습 데이터에 있을 수 있거나 맥락 길이를 단축하고 더 로컬한 정보로 질문에 답할 수 있기 때문임.
다른 접근법들은 모델의 다중 샷 학습 (Agarwal 외, 2024; Bohnet 외, 2024a) 및 요약 능력 (Chang 외, 2024; Kim 외, 2024)을 측정하는 데 초점을 맞추었지만, 이들 중 어느 것도 반드시 모델의 맥락에 대한 추론 능력을 요구하거나 측정하지는 않습니다. 또한, 기존의 많은 장문 맥락 평가 벤치마크들은 기존의 (훈련 데이터에 유출된 것으로 보이는) 평가를 활용하여 평가를 구성하기 때문에, 이러한 벤치마크에서의 성능이 유출된 정보에 기인한 것인지 판단하기 어렵게 만듭니다 (Bai 외, 2023; Li 외, 2024; Hsieh 외, 2024; Agarwal 외, 2024; Bohnet 외, 2024a; Zhang 외, 2024; Lee 외, 2024). 본 연구에서는 Michelangelo를 개발하는 데 집중하며, 이는 최소한의, 합성된, 유출되지 않은 장문 맥락 추론 평가로, 자동으로 점수를 매기기 매우 용이합니다.
최소성: Michelangelo는 검색을 넘어서는 맥락 이해를 요구하면서도 현재의 모델들에게 여전히 어려운 가장 간단한 정형 작업의 최소 집합을 구성합니다. 크기와 복잡성 모두에서 최소한의 벤치마크는 넓은 범위의 행동을 포착하면서도 여러 가지 이유로 바람직합니다. 이는 해석이 쉽고, 진행 상황을 추적하기 쉽고, 모델이 실패할 가능성이 있는 가장 단순한 사례들을 알려주기 때문입니다.
정형 원시 작업: Michelangelo는 모델이 맥락 전반에 흩어져 있는 여러 정보를 종합하여 답을 도출해야 하는 세 가지 직관적이고 간단한 장문 맥락 종합 작업 원시들을 구성합니다. 이러한 작업들은 모델의 종합 능력의 다양한 측면을 측정하여 장문 맥락 모델의 행동에 대한 보다 전체적인 이해를 제공합니다. 우리가 제시하는 각 평가는 자연어 또는 코드 기반 환경에서 이루어지며, 기존 벤치마크에 비해 덜 합성적입니다. 우리는 맥락을 가로질러 두 개의 정보를 종합하는 것조차 이미 도전적임을 관찰합니다. 특히 Michelangelo는 모델이 다음을 수행하는 능력을 측정합니다:
- 순서를 이해하면서 주어진 고유한 맥락의 일부를 재현하는 것
- 리스트에 대한 일련의 수정 사항을 이해하는 것 (이는 기존 과제의 매우 넓은 범위를 포착함)
- 질의에 대한 답이 맥락 내에 포함되어 있는지 여부를 결정하는 것
임의의 맥락 길이: Michelangelo 작업은 맥락 길이를 임의로 확장할 수 있으며, 맥락 내에서 종합해야 하는 관련 정보의 양으로 측정되는 고정된 복잡성을 유지합니다. 이러한 요구사항은 평가의 합성적인 특성 덕분에 충족되며, 관련 정보와 불필요한 정보가 모두 합성적으로 생성되고, (일반적으로) 유사한 분포를 공유하며, 논리적 모순이나 단축 경로(short-circuit)를 초래하지 않도록 하는 접근 방식을 통해 보장됩니다.
유출 방지: Michelangelo 작업 인스턴스를 자동으로 재생성할 수 있기 때문에, 향후 유출 문제를 피하기 쉽습니다. 우리가 사용하는 방법론은 평가가 임의의 맥락 길이로 자동으로 확장 가능하고 자연어 기반이 되도록 보장하며, 기존 평가 세트나 인터넷 데이터(훈련 데이터에서 유출되었을 가능성이 큼)를 사용하지 않으므로, 유출되지 않은 자동, 합성, 그리고 다소 더 현실적인 장문 맥락 추론 평가를 구성합니다.
그림 2: 동일한 계열의 모델들 (Gemini, GPT, Claude)은 평행한 MRCR 곡선을 가지는 경향이 있습니다. 특히 Claude-3.5 Sonnet과 Claude-3 Opus는 매우 평행한 MRCR 곡선을 보입니다.
Michelangelo 작업 중 하나에서의 프론티어 모델 성능 예시는 그림 1을 참조하십시오. 우리는 이 MRCR 작업이 그림 2에서 기존 모델들 간의 흥미로운 연결을 드러낼 수 있음을 보여줍니다. 특히 MRCR은 단순한 지표로 평가되며, 여러 모델 계열에 걸쳐 동일한 프롬프트를 사용하였음에도 신호가 약화되지 않았습니다.
우리의 기여는 다음과 같습니다:
- 우리는 Michelangelo를 제시합니다. 이는 장문 맥락 추론 및 종합 원시 작업을 위한 최소 벤치마크로, 임의로 큰 맥락 길이에 걸쳐 기반 모델의 성능을 측정합니다.
- 우리는 장문 맥락 추론 평가를 위한 Latent Structure Queries 프레임워크를 설계했으며, 이는 기존의 장문 맥락 평가 작업을 포괄하고 일반화합니다. Michelangelo는 Latent Structure Queries의 세 가지 간단한 인스턴스로 구성되며, 이는 측정 대상 능력과 데이터 분포에 따라 측정 가능한 다양성을 보입니다.
- 우리는 여러 선도적인 모델에 대해 최대 1백만 맥락 길이에 걸친 평가를 분석하며, 맥락 길이에 대한 상당히 높은 해상도로 모델 성능을 분석합니다. 우리는 GPT와 Claude 모델이 최대 128K 맥락에서 비단순한 성능을 보이며, Gemini 모델은 최대 1백만 맥락까지 비단순한 일반화 능력을 가진다는 것을 보여줍니다. 하지만 추론 과제의 난이도는 우리가 평가한 모든 프론티어 모델에서 초기 성능의 급격한 하락을 유발하며, 이는 1백만 맥락까지 추론 행동을 일반화하는 데 상당한 진전이 있었지만, 여전히 해결되지 않은 다수의 간단한 장문 맥락 추론 원시 작업이 남아 있음을 나타냅니다.
2. Michelangelo 평가 과제
이 섹션에서는 Michelangelo를 구성하는 특정 평가들에 대한 설명을 제시하며, 이러한 평가를 생성하는 데 사용된 전체적인 프레임워크에 대한 논의는 3장에서 다룹니다.
2.1 잠재 리스트 (Latent List)
우리는 짧은 Python 리스트를 고려하고, 그 리스트를 수정하는 Python 연산들의 시퀀스를 제시합니다 (append, insert, pop, remove, sort, reverse). 이 연산 시퀀스가 주어지면, 모델은 결과적으로 잠재 리스트의 뷰를 출력해야 합니다. 이 뷰는 리스트의 전체 슬라이스를 출력하거나, 리스트 슬라이스의 합, 최소값, 최대값 또는 리스트의 길이를 출력하는 것입니다. 중요한 점은, 결과 리스트의 크기는 인스턴스의 전체 맥락 길이에 의존하지 않는다는 것입니다. 대신에, 이는 관련 연산의 수에 의존하며, 이는 과제 인스턴스의 복잡성을 나타냅니다. 맥락을 채우기 위해, 우리는 리스트의 잠재 상태에 영향을 미치지 않는 세 가지 전략을 균일하게 채택합니다: 1) print("Do nothing.") 문 삽입, 2) 짝수 개의 reverse 연산 삽입, 3) 모든 연산이 서로 상쇄하는 연산 블록 삽입. 우리는 세 가지 복잡도 수준을 고려합니다: 관련 연산이 1개, 5개, 그리고 20개인 경우이며, 이들 모두 작업 집합에 균일하게 표현됩니다 (초기 리스트를 정의하는 첫 번째 연산은 이 지표에서 계산하지 않음을 참고하십시오). 연산은 [-4000, 4000] 사이의 숫자들에서 균일하게 추출됩니다. 관련 연산은 입력 맥락 전반에 균일하게 퍼져 있습니다.
모델 성능은 근사 정확도 지표로 점수를 매기며, 이는 출력 뷰 연산에 대한 정확한 문자열 일치를 요구하고, 수치 출력의 경우 오류를 [0, 1] 사이로 정규화한 근사 오류를 보고합니다 (나머지 뷰 연산들).
우리는 잠재 리스트 과제를 채점하기 위해 다음과 같은 근사 지표를 사용합니다. 기존 모델들에게 과제를 보다 쉽게 만들기 위해 근사 지표를 사용하였으며, 근사 버전의 과제를 사용할 때 더 넓은 동적 신호 범위를 관찰할 수 있었습니다. 다음 코드는 이 점수를 계산하기 위한 정확한 방법을 설명합니다.
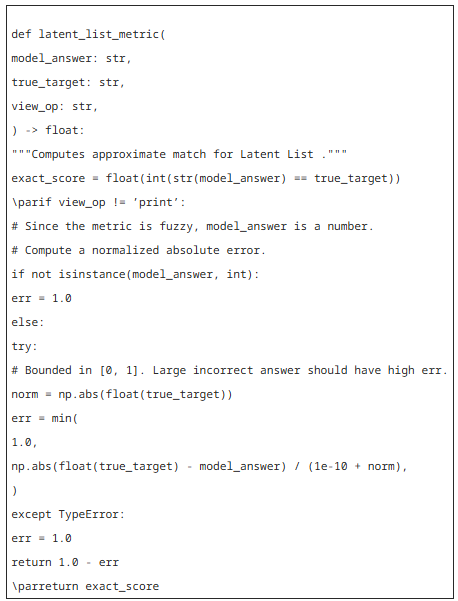
우리는 과제 인스턴스를 복잡성의 개념으로 매우 자연스럽게 층화(stratification)했기 때문에(즉, 뷰 연산 질의에 실제로 영향을 미치는 리스트 연산의 수에 따라), 과제의 복잡성에 따라 분할하여 이 평가에서의 성능을 추가로 분석할 수 있습니다.

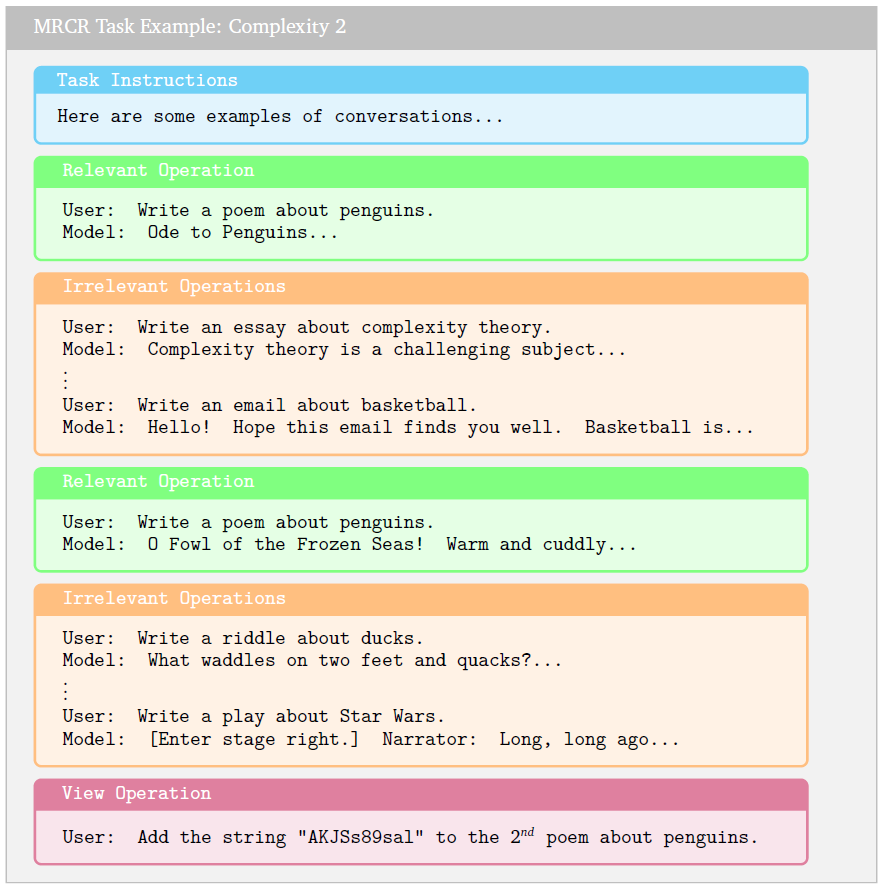
2.2 다중 회차 공동참조 해소 (MRCR)
다중 회차 공동참조 해소 (MRCR) 과제에서는 (Google 외, 2024에서 소개 및 설명된 바와 같이) 모델이 사용자와 모델 간의 긴 대화를 보게 됩니다. 이 대화에서 사용자는 다양한 주제에 대해 글쓰기(예: 시, 수수께끼, 에세이)를 요청하고, 모델이 이에 대한 응답을 생성합니다. 이 모델 응답을 생성하기 위해, 우리는 PaLM 2 모델(Anil 외, 2023)에 각 요청과 주제에 대한 많은 출력물을 생성하도록 프롬프트를 제공했습니다. 각 대화에서는 대화의 나머지 부분과 주제 및 글쓰기 형식이 다른 사용자 요청이 무작위로 맥락에 배치됩니다. 주어진 대화를 맥락으로 하여, 모델은 요청(키) 중 하나로부터 나온 대화의 출력물(바늘)을 재현해야 합니다. 형식이나 주제, 혹은 둘 다 겹치도록 하여 질의 키와 유사한 방식으로 대응하는 키를 만듭니다. 예를 들어, "펭귄에 관한 시를 재현하세요."라는 요청은 모델이 펭귄에 관한 시와 플라밍고에 관한 시를 구별해야 함을 요구하며, "펭귄에 관한 첫 번째 시를 재현하세요."라는 요청은 모델이 순서를 추론해야 함을 요구합니다.
우리는 MRCR을 모델 출력과 올바른 응답 간의 문자열 유사성 측정을 통해 채점합니다. 모델 출력이 주어졌을 때, 우리는 특수 출력 문자열이 생성되었는지 확인하는 후처리 과정을 거칩니다. 특수 출력 문자열이 생성된 경우, 해당 문자열 이후의 텍스트를 가져와 모델 출력과 올바른 응답 간의 문자열 유사성을 계산합니다. 구체적으로는, https://docs.python.org/3/library/difflib.html에 구현된 SequenceMatcher 비율을 사용합니다. 이 값은 0과 1 사이의 값을 가집니다.
2.3 IDK
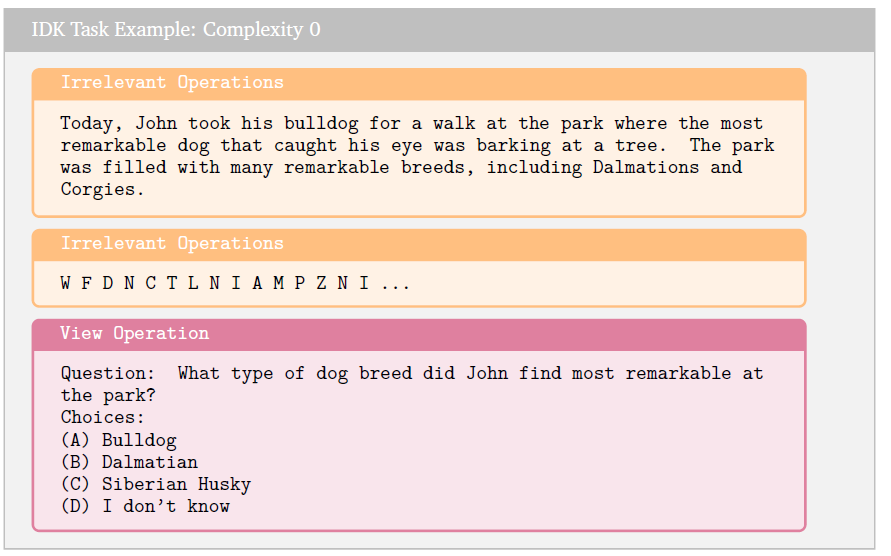
IDK 과제에서는 모델에게 많은 양의 텍스트가 주어지고, 주어진 방대한 사전 학습 코퍼스에서 객관적인 답이 존재하지 않는 질문을 받게 됩니다. 예를 들어, 한 여인과 그녀의 개에 대한 창작 이야기가 있을 때, 개의 이름과 나이는 명시되어 있지만 색깔에 대한 정보는 없다고 가정합시다. 그러면 뷰 연산은 간단히 "여인의 개의 색깔은 무엇인가요?"라고 질문하는 것입니다. 이 과제의 각 인스턴스에서는 네 가지 선택지가 제공되며, 그 중 하나는 항상 "(D) 모르겠습니다."입니다. 나머지 선택지들도 모두 비교적 그럴듯한 답변들로 구성됩니다. 우리는 모델 출력이 정답인지 여부에 따라 점수를 매깁니다. 만약 모델이 주어진 선택지들 중 아무 것도 출력하지 않고, 대신 해당 정보가 맥락에 존재하지 않아 질문에 답할 수 없다고 텍스트로 표시한다면, 정답이 "모르겠습니다."일 경우 이를 정답으로 처리합니다. 이 지표는 단순히 정확도이므로, 이미 0과 1 사이의 값을 가집니다. 우리는 평가에서 과제 인스턴스의 **70%**가 실제 정답이 "모르겠습니다."인 경우에 해당하고, **30%**가 맥락에서 답을 찾을 수 있어 간단한 검색 과제를 구성하는 경우에 해당하도록 설정합니다.
이 평가에서 불필요한 채우기 텍스트는 영어 알파벳의 무작위 문자들로 구성됩니다. 답이 "모르겠습니다"인 경우에는 "관련 정보 없음"이라고 하며, 이때 과제의 복잡성은 0입니다. 검색 작업에 해당하는 인스턴스의 경우, 과제의 복잡성은 1입니다.
3. 잠재 구조 질의: 새로운 장문 맥락 평가 프레임워크
이 섹션에서는 2장에서 정의한 합성 장문 맥락 평가를 생성하기 위한 간단한 잠재 구조 질의(Latent Structure Queries, LSQ) 프레임워크를 제시합니다. 장문 맥락 평가는 다음 원칙들을 준수해야 합니다:
- 임의의 맥락 길이로 일반적으로 확장 가능해야 함
- 관련 정보의 개수에 따라 복잡성이 인덱싱됨
- 맥락 길이의 난이도가 불필요한 정보가 없는 과제의 복잡성과 분리되어야 함
- 자연어 텍스트와 코드 (두 가지 기본 도메인)에 걸쳐 범위를 포함해야 함
- 과제 인스턴스 내에서 유출되지 않은 맥락
- 맥락에서 전달되는 암시적 정보에 대한 이해를 테스트
- 평가의 수는 최소한으로 하되, 장문 맥락 종합 능력의 직교 차원을 테스트해야 함
LSQ 프레임워크는 이러한 모든 속성들을 보장합니다. 우리는 모델에게 제시된 맥락을 잠재 구조에 대한 업데이트로 구성된 정보의 스트림으로 봅니다. 전체 맥락 길이는 불필요한 정보들이 많은 대리석 블록과 같다고 상상할 수 있습니다. 조각가가 불필요한 정보들을 깎아내면 내부의 조각상을 드러내듯이, 모델은 큰 맥락 내에서 잠재된 구조를 드러내야 합니다. 궁극적으로 우리는 이 잠재 구조에 대해 질의하고자 하며, 맥락이 이 잠재 구조와 복잡한 관계를 가지고 있다는 사실은 데이터 구조와 관련된 과제가 "검색을 넘어서는" 것임을 보장합니다. 여기서 표준 단일 바늘 찾기와 다중 바늘 찾기와 같은 검색 과제 (예: 건초 더미 속 바늘 찾기 (Kamradt, 2023))는 키와 값 한 쌍 혹은 다수의 독립적인 키와 값을 가지는 데이터 구조에 해당하며, 이러한 키나 키 집합을 질의하고자 합니다. 따라서 검색을 넘어서는 맥락 이해는 모델이 이 최종 잠재 구조를 내재화한 정도로 측정될 수 있습니다. 단순한 예로, 가족에 대한 책을 읽는 상황을 상상할 수 있습니다. 부모가 이혼하고, 아이들이 자라 결혼하며, 노인이 세상을 떠나는 과정이 이어질 때, 가족 트리에 해당하는 잠재 구조는 시간이 지나며 변화하고 업데이트됩니다 (책의 많은 정보는 가족 트리에 전혀 영향을 미치지 않을 수도 있습니다). 따라서 책의 전체 맥락은 가족 트리의 잠재 구조를 설명하며, 모델이 이 잠재 구조를 이해했는지를 확인하는 간단한 접근 방식은 전체 데이터 구조에 대한 설명을 질의하는 것입니다. 하지만 이 과제는 a) 너무 어려울 수 있고 b) 구조 자체가 매우 복잡한 자연어 환경에서는 상대적으로 다루기 어려울 수 있습니다. 따라서 우리는 대신 구조의 슬라이스에 대해 질의하는 접근 방식을 채택합니다. 서로 다른 슬라이스에 대한 여러 질의 (암흑 속 코끼리의 우화 (Wikipedia, 2024)와 유사)를 통해 모델은 전체에 대한 부분적인 이해를 보여줄 수 있습니다.
이 프레임워크의 중요한 장점은 잠재 구조에 대한 관련 업데이트의 수를 미리 결정함으로써 과제의 복잡성을 제어할 수 있다는 점입니다. 관련 업데이트는 주어진 질의의 최종 출력을 변경하는 구조에 대한 업데이트를 의미합니다. 관련 업데이트의 수를 고정함으로써, 우리는 과제의 난이도를 두 가지 직교적인 구성 요소로 분해할 수 있습니다 — 긴 혼란스러운 정보 없이 과제 자체의 내재적 복잡성과 맥락 길이로 인한 과제의 난이도입니다. 이러한 분해는 모델 성능에 미치는 맥락 길이의 영향을 분리하여 살펴볼 수 있기 때문에 유용합니다 (5.5장에서 Latent List에 대한 복잡성과 맥락 길이를 분리한 절차 참조).
한편, 불필요한 업데이트의 수는 맥락 길이를 제어합니다. 과제가 잠재 데이터 구조에 대한 불필요한 업데이트를 생성하는 방법을 가지고 있는 한, 과제는 임의의 맥락 길이로 확장될 수 있습니다. 특히, 우리는 대형 언어 모델을 사용하여 최종 과제와 전혀 관련이 없는 자연 텍스트를 생성하면서도 기존의 자연 텍스트 분포와 유사성을 유지하는 방식을 사용할 수 있어, 과제를 보다 현실적으로 만들면서도 원하는 합성적 특성을 유지할 수 있습니다.
이러한 관련 업데이트와 불필요한 채우기 텍스트를 사전에 결정하고, 주어진 과제 인스턴스에 대해 최종 답변에 영향을 미치지 않을 것이 보장된 채우기 텍스트를 생성하는 방식을 통해 a) 과제에 사전 학습 데이터의 유출이 없도록 할 수 있습니다 (대조적으로, Zhang 외 (2024)의 소설에서 단순히 엔티티 이름을 교체하는 접근법은 이러한 동작을 충분히 통제하지 못할 수 있으며, 여전히 소설에 대한 풍부한 주변 지식을 활용하여 관련 텍스트 부분을 파악할 수 있음), b) 과제 생성 과정에서 모델이 전체 맥락을 사용하지 않고는 단축 경로를 택할 수 없도록 보장하여 "단락(short-circuit)" 문제를 양쪽에서 방지할 수 있습니다.
이 프레임워크를 사용하여, 우리는 검색을 넘어서 장문 맥락 이해의 서로 다른 구성 요소들을 측정하는 상대적으로 직교적인 과제들을 개발할 수 있었습니다. 이 과제들은 작업과 관련된 암시적 잠재 구조와 관련 업데이트의 수로 파라미터화된 과제 복잡성을 모두 변화시키며 구성됩니다. 특히, 우리는 하나의 코드 중심 과제와 두 개의 자연어 중심 과제를 제시합니다. 우리의 잠재 질의 프레임워크는 도메인에 관계없이 널리 적용 가능합니다. 이 프레임워크를 활용한 세 가지 과제를 다음으로 제시합니다. 특히, 이들 과제는 6장에서 언급된 이유로 평가 전에 훈련에 사용되도록 의도된 것이 아닙니다. 코드 관련 과제는 코드 편집기에 접근할 수 있는 모델에서 실행되도록 의도된 것이 아니며, 목표는 코드로 풀기 어려운 더 어려운 추론 과제의 대리로서 모델 회로 내의 암시적 추론 행동을 테스트하는 것입니다.
3.1 잠재 구조 질의 프레임워크에서 평가의 맥락화
3.1.1 잠재 리스트 (Latent List) 잠재 리스트는 LSQ 프레임워크의 매우 직접적인 구현입니다. Python 리스트가 잠재 객체이며, 우리는 잠재 리스트의 다양한 구성 요소를 질의하고, 리스트를 의미 있게 수정하는 연산과 그렇지 않은 연산으로 업데이트합니다.
3.1.2 MRCR LSQ 프레임워크는 "건초 더미 속 바늘 찾기"(Kamradt, 2023; Li 외, 2024)와 같은 기존의 검색 평가를 쉽게 포괄합니다. 이들은 정확히 사전에 주어진 키로 값을 검색하는 것과 일치합니다. 하지만 많은 기존 검색 평가의 주요 결점 중 하나는 바늘이 나머지 맥락과 얼마나 명확히 구분되는가에 있습니다. 이 속성은 대형 언어 모델이 관련 정보를 추출하는 것을 상당히 쉽게 만듭니다.
MRCR은 "건초 더미 속 바늘 찾기" 과제를 검색을 넘어서 다수의 바늘이 배치된 순서에 대한 정보를 사용해 질의에 답해야 하는 설정으로 확장한 것으로 볼 수 있습니다. 이 설정은 매우 유사한 바늘들을 검색하도록 하며, 모델이 올바른 답을 결정하기 위해 맥락의 두 위치에 있는 정보를 사용해야 하는 점에서 이점이 있습니다.
이 평가는 LSQ 프레임워크에 직접 맞아떨어지며, 여기서 잠재 데이터 구조는 주제와 글쓰기 형식으로 인덱싱된 중첩 딕셔너리입니다. 각 주제와 글쓰기 형식 쌍에 대해, 잠재 데이터 구조는 모델 출력의 리스트를 맥락에서 제시된 순서대로 저장합니다. 이후 뷰 연산은 중첩 딕셔너리의 두 키를 주었을 때 모델 출력 값을 출력하거나, 키가 크기가 1보다 큰 모델 출력 리스트에 해당하는 경우에는 원하는 인덱스의 항목을 출력하는 것입니다. 우리는 과제에서 두 개의 혼동되는 출력만 있는 경우에 대해서만 다루었지만, 이 평가를 여러 혼동되는 출력이 있는 설정으로 쉽게 확장할 수 있습니다 (예를 들어, 첫 번째나 두 번째 시가 아닌 다섯 번째 펭귄에 관한 시를 요청할 수 있음). 또한, 딕셔너리의 깊이를 2 이상으로 더 깊게 중첩하는 설정으로 이 과제를 확장하는 것도 쉽습니다. 예를 들어, 감정 ("행복함" 또는 "슬픔"), 스타일 ("이탈리아 마피아 보스 스타일로") 등의 키를 추가할 수 있습니다. 우리는 맥락 길이에 따른 성능 저하가 현저히 관찰되는 최소한의 경우에 대해 논의를 제한합니다. 이 경우 딕셔너리의 깊이는 2이고, 맥락 내에 최대 하나의 추가적인 이중 혼동 (동일한 주제와 동일한 형식) 인스턴스만 있는 경우입니다.
3.1.3 IDK
IDK는 LSQ 프레임워크의 또 다른 매우 간단하고 자연스러운 인스턴스입니다. 특히, 이는 주어진 뷰 연산의 매개변수에 대해 잠재 데이터 구조에 답변이 없는 경우입니다. 이 경우의 간단한 실현은 사전에 주어진 키에 해당하는 값이 없는 딕셔너리에 대한 질의입니다 — 정답은 해당 키가 딕셔너리에 존재하지 않는다는 것입니다. 이 사실을 결정하기 위해 모델은 전체 맥락에 있는 어떤 정보도 질의에 대한 답을 포함하지 않는다는 것을 배제할 수 있어야 합니다.
3.2 맥락 층화 (Context Stratification)
장문 맥락 모델을 개발할 때 맥락 길이에 따른 단계적 접근 방식을 적용하는 것이 종종 합리적입니다 — 먼저 32K 맥락까지 성능을 보장하고, 그 다음 128K, 마지막으로 1M 맥락까지 보장하는 것입니다. 더 긴 맥락 평가를 실행하는 것이 비용이 많이 들기 때문에, 이러한 접근 방식은 모델 개발자가 더 빠르게 반복할 수 있도록 합니다.
이 개발 프로세스를 염두에 두고, 우리는 각 평가에 대해 세 가지 하위 집합을 제공합니다: 32K 맥락까지의 샘플 분포, 128K 맥락까지의 샘플 분포, 그리고 1M 맥락까지의 샘플 분포입니다. 이 모든 하위 집합은 누적 성능을 측정하며, 함께 결합되어 버킷별로 정규화될 수 있습니다 (예: 32K 하위 집합만 고려하거나, 32K와 128K 하위 집합의 합집합을 고려하거나, 32K, 128K, 1M의 세 하위 집합 모두의 합집합을 동일 가중치로 고려할 수 있음) 이를 통해 분산을 줄일 수 있습니다. 정규화하기 위해 각 버킷의 반복 횟수로 나누어 맥락 길이의 유사한 히스토그램 프로파일을 유지합니다. 예를 들어, 세 하위 집합 (32K, 128K, 1M)을 모두 고려할 때, 32K 버킷은 세 번 나타나기 때문에 3으로 나누고, 128K 버킷은 두 번 나타나기 때문에 2로 나눕니다.
3.3 프롬프트 접근 방식
모든 과제에 대해, 우리는 먼저 모델에게 과제 설명을 제시하고, 이후 몇 개의 단기 맥락 예제를 시연하는 few-shot 접근 방식을 도입합니다. 전체 프롬프트는 부록 A에 있습니다. MRCR 과제의 프롬프트는 특히 주목할 만합니다. MRCR에서 모델은 512 토큰까지의 텍스트 덩어리를 재현해야 하며, 우리는 모델이 출력에 랜덤 문자열을 접두사로 붙이도록 요구하는 것이 유용하다는 것을 발견했습니다. 이 접두사는 모델이 지침을 따르는지 테스트하는 데 도움을 주며, 랜덤 문자열 이후의 내용만을 출력해야 하는 긴 출력물을 후처리하는 데 도움을 줍니다. 이 프롬프트 수정은 특히 MRCR에 중요합니다. 왜냐하면 우리는 모델 출력을 근사 편집 거리 점수에 따라 채점하는데, 이는 대부분의 기존 장문 맥락 평가와는 대조되며 (이 방법은 맥락에 따라 성능이 점진적으로 저하되는 매우 부드러운 맥락-성능 곡선을 제공하는 좋은 특성을 가짐) 도움이 되기 때문입니다.
3.3.1 사전 학습 및 후 학습 평가
이 보고서에서는 후 학습된 모델에 대한 결과만 설명하지만, 우리는 잠재 리스트와 MRCR 과제를 사전 학습 평가로도 성공적으로 사용한 바 있습니다. 사전 학습 평가의 경우, 프롬프트의 few-shot 특성은 좋은 신호를 보장하는 데 매우 중요합니다. 우리가 시도한 모든 모델의 후 학습 평가에서 MRCR은 별다른 수정 없이 바로 작동했습니다. 반면에 잠재 리스트와 IDK는 모델 출력 스타일의 변동으로 인해 신호를 캡처하기 위해 추가적인 후처리가 필요했습니다.
-----
- 사전 학습 평가에서는 모델에게 주어진 과제를 잘 학습시키기 위해 few-shot 프롬프트가 중요하게 사용됩니다. 이로써 모델이 과제를 어떻게 이해해야 하는지에 대한 방향을 잘 잡도록 합니다.
- 후 학습 평가에서는 모델이 이미 학습된 상태에서 과제를 수행하는 능력을 평가하며, 이때 MRCR은 별도 수정 없이도 잘 수행됐습니다.
- 그러나 잠재 리스트와 IDK는 모델의 출력이 일관되지 않거나 형식의 차이가 있을 수 있기 때문에, 이러한 출력에 대한 후처리가 필요했습니다.
-----
4. 실험 결과
우리는 검색을 넘어서는 장문 맥락 평가 과제에서 크기가 다양한 열 개의 프론티어 모델을 평가했습니다: Gemini 1.5 Flash (05-14 및 08-27) 및 Pro (05-14 및 08-27) (Google 외, 2024), GPT-4 Turbo (04-09) 및 GPT-4o (OpenAI, 2023, 2024), Claude 3 Haiku, Sonnet, Opus (Anthropic, 2024a), 그리고 Claude 3.5 Sonnet (Anthropic, 2024b)입니다. 우리의 실험에서, 각 평가마다 모델의 순위가 달라짐을 관찰했으며, 이는 우리가 최소한의 평가 세트를 사용하여 넓은 범위의 장문 맥락 추론 행동을 포착하고 있음을 더욱 강조합니다.
각 과제에 대해, 우리는 토큰으로 측정한 평균 맥락 길이를 설정하고, 128K와 1M 맥락에서의 누적 평균 점수를 대조한 플롯을 제시합니다. 모든 플롯에서 점수가 높을수록 더 좋은 성능을 나타내며, 점수는 [0, 1] 사이로 제한됩니다. 1M 맥락의 경우에는 Gemini 1.5 모델들만 플롯에 포함되었고, 다른 모델들은 128K 맥락 길이까지 플롯되었습니다. 각 플롯에서는 각 모델 계열에서 최고의 성능을 보인 모델을 선택하여 플롯에 포함했습니다. 참고로 잠재 리스트(Latent List) 과제에서 Claude-3 Haiku와 Sonnet, 그리고 Claude-3.5 Sonnet의 성능은 모델의 응답 거부율이 높아 매우 낮았습니다. 따라서 이 모델들은 플롯에서 제외하였습니다.
4.1 128K까지의 초기 성능 저하
이제 각 평가에 대해 128K 맥락까지 더 자세히 살펴보고, 가장 우수한 성능을 보인 모델 계열을 식별합니다. 그림 3, 4, 5를 참조하십시오.
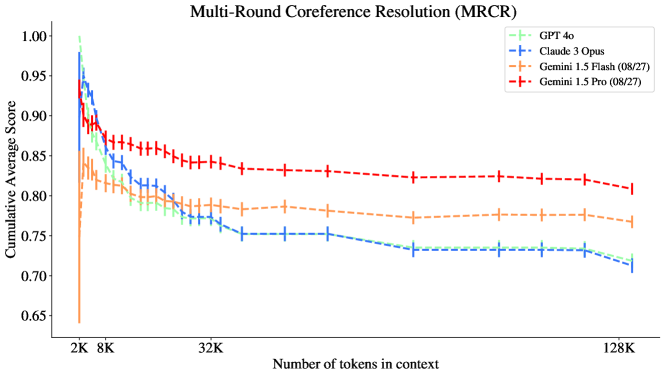
그림 3: Gemini 모델들은 128K 맥락에서 MRCR 과제에서 가장 좋은 성능을 보였으며, 특히 GPT와 Claude와 비교했을 때 기울기 프로파일이 상당히 다름을 알 수 있습니다.
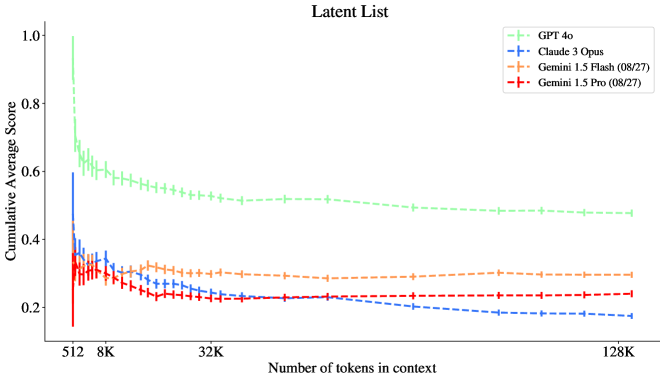
그림 4: GPT 모델들이 128K 맥락에서 잠재 리스트(Latent List) 과제에서 가장 좋은 성능을 보였습니다.
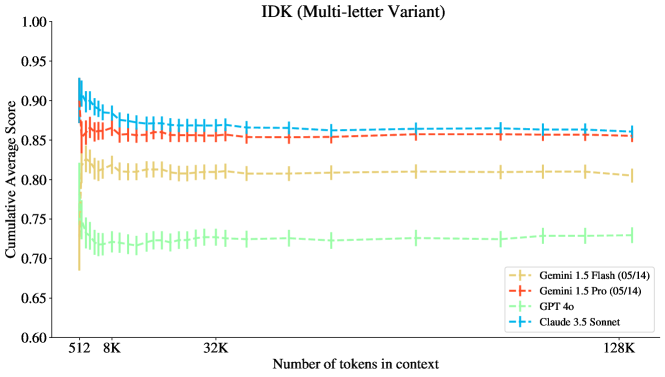
그림 5: Claude-3.5 Sonnet이 IDK 과제에서 가장 우수한 성능을 보였으며, **Gemini 1.5 Pro (05/14)**가 그 뒤를 바짝 따랐습니다. GPT 모델들은 이 과제에서 성능이 좋지 않았으며, 초기 성능이 급격히 떨어지지만 이후에는 성능이 다소 안정되는 모습을 보였습니다.
-----
- MRCR: 유사한 정보가 섞여 있는 대화에서 정확한 정보를 찾아내는 능력.
- 잠재 리스트 (Latent List): 리스트에 대한 연산을 추적하고 최종 상태를 이해하는 능력.
- IDK: 정보가 부족할 때 "모른다"고 답할 수 있는 능력.
-----
4.2 Gemini의 128K에서 1M까지의 성능 유지
이 섹션에서는 Gemini 모델이 128K에서 1M 맥락까지 성능이 감소하지 않음을 보여줍니다. 그림 6, 7, 8을 참조하십시오.
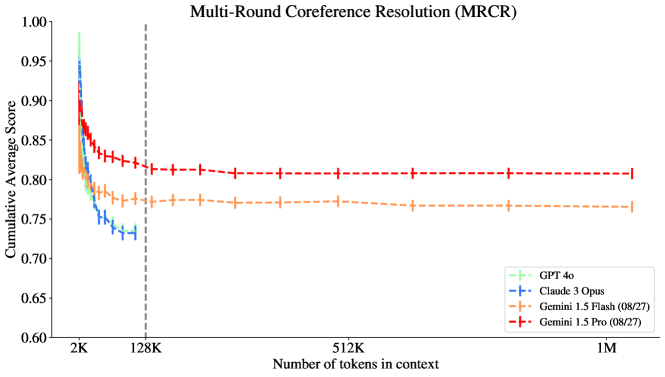
그림 6: MRCR 과제에서 Gemini 모델들은 초기 성능 저하 이후 1M 맥락까지 성능이 감소하지 않습니다. 반면 GPT와 Claude 모델들은 128K 맥락에서 더 부정적인 기울기를 보입니다. Gemini 1.5 Pro가 이 과제에서 가장 높은 성능을 보였습니다.
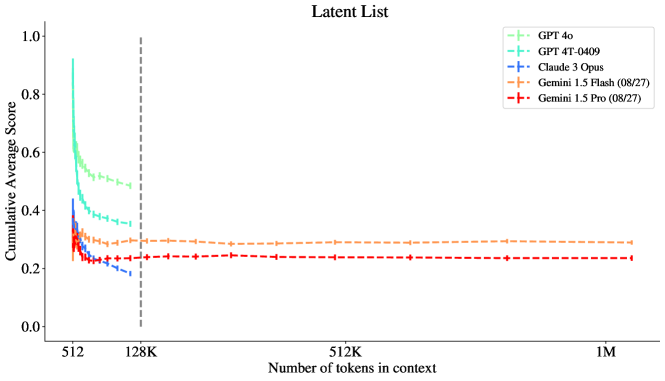
그림 7: 잠재 리스트 (Latent List) 과제에서 Gemini 모델들은 초기 성능 저하 이후 1M 맥락까지 성능이 감소하지 않습니다. 반면 GPT와 Claude 모델들은 128K 맥락에서 더 부정적인 기울기를 보입니다. GPT-4o가 128K 맥락에서 가장 높은 성능을 보였지만, 1M 맥락에서의 성능은 명확하지 않습니다.
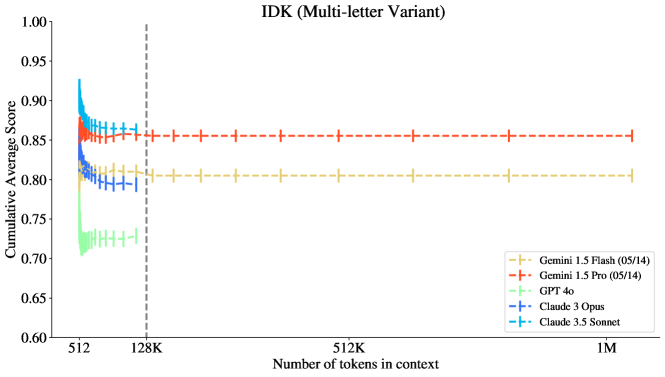
그림 8: IDK 과제에서 Gemini 모델들은 초기 성능 저하 이후 1M 맥락까지 성능이 감소하지 않습니다. 모든 모델은 초기 저하 이후 평탄한 경향을 보이는 것으로 나타났습니다. Claude-3.5 Sonnet이 128K 맥락에서 가장 높은 성능을 보였습니다.
5. 논의
5.1 장문 맥락 이해의 다양한 측면 측정
우선, Michelangelo가 장문 맥락 활용의 다양한 구성 요소를 측정하는 하위 과제를 가지고 있다는 점을 확립합니다. MRCR은 모델이 자연어 텍스트에서 순서를 이해하는 능력, 유사한 초안들을 구분하는 능력, 그리고 적대적으로 어려운 질의에 대해 이전 맥락의 특정 부분을 재현하는 능력을 측정합니다. **잠재 리스트 (Latent List)**는 코드 명령의 스트림에 걸쳐 잠재 데이터 구조의 속성을 추적하는 모델의 능력을 측정합니다. IDK는 주어진 맥락을 바탕으로 모델이 모르는 것을 인식할 수 있는지 여부를 이해하는 능력을 측정합니다. 이 장문 맥락 종합 원시 과제들 각각은 단일 바늘 검색과 다중 바늘 검색 과제보다 훨씬 어렵습니다. 이 결과는 맥락 대 평균 누적 성능 곡선에서도 반영되고 있습니다.
특히, 우리가 평가한 각 모델 계열은 이러한 핵심 원시 작업에서 매우 다른 성과를 보였습니다. Gemini 모델들은 MRCR에서 가장 좋은 성능을 보였고, GPT 모델들은 잠재 리스트에서 다른 모델들을 능가했으며, Claude-3.5 Sonnet은 IDK에서 가장 좋은 성능을 보였습니다 (흥미롭게도 GPT는 IDK에서 최악의 성능을 보였습니다!).
그림 9는 이러한 평가 간의 상호 상관 관계를 기록하며, 열 개의 다른 모델에 대해 측정된 Spearman 순위 상관을 사용하여 계산되었습니다. 따라서 Michelangelo 평가가 장문 맥락 이해의 다양한 측면을 측정한다는 정량적 증거도 확보되었습니다.
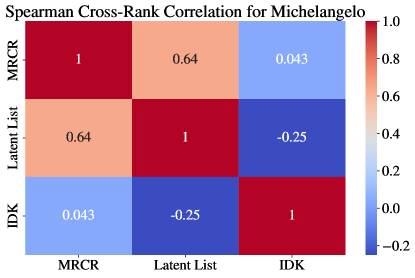
그림 9: Michelangelo 평가에서 128K 맥락 기준으로 열 개 모델 간의 Spearman 순위 상관. 우리는 **잠재 리스트(Latent List)**와 IDK가 반상관 관계에 있다는 것을 관찰했으며, MRCR과 잠재 리스트는 어느 정도 순위 상관을 가지지만, 상관 계수는 1과 상당히 멀리 떨어져 있습니다. 이러한 순위 상관은 이 보고서에 언급된 열 개 모델에 대해서만 계산되었습니다.
이 결과를 바탕으로, 각 평가가 장문 맥락 이해에서 서로 다른 측면을 측정하며, 이 세 가지 평가 간에는 성능 면에서 상호 교환이 필요한 부분이 있을 가능성도 있다는 결론을 내릴 수 있습니다. 우리가 측정한 프론티어 모델들 중에서, 모든 Michelangelo 작업에서 명확하게 우승한 모델은 없었습니다.
5.2 32K 맥락 이전의 성능 저하
맥락과 성능의 관계를 보여주는 플롯들 (그림 3, 4, 5)에서 볼 수 있듯이, 모델들은 종종 맥락이 짧은 초기에 (즉, 32K에서) 성능이 크게 저하되는 경향이 있습니다. 이는 Michelangelo를 사용할 때 장문 맥락 성능의 저하를 더 효율적으로 감지할 수 있게 합니다. 이러한 특성은 **Hsieh 외 (2024)**와 같은 기존의 장문 평가 벤치마크와 대조되며, 기존 벤치마크에서는 성능 저하를 관찰하기 위해 128K 맥락까지 살펴보아야 했습니다.
특히, 모든 Michelangelo 평가에서 매우 일반적인 경향을 확인할 수 있습니다: 초기에 짧은 맥락에서 성능이 급격히 초선형적으로 떨어지는 초기 감소가 있습니다 (참고로, 과제의 복잡성은 모든 맥락에서 고정되므로, 이 감소는 전적으로 모델의 장문 맥락 처리 능력에 기인한 것입니다). 그 이후에는 성능이 평탄해지거나 대체로 선형적으로 계속 저하되는 경향을 보입니다. 성능이 평탄해지는 경우, 이러한 성능 상태는 종종 매우 큰 맥락 길이까지 지속됩니다. 이러한 행동은 모델이 특정 과제에서 일정 수준의 성능을 달성할 수 있는 서브-능력을 가지고 있으며, 그 서브-능력들이 아주 큰 맥락 길이까지 일반화된다고 해석할 수 있습니다.
5.3 맥락 길이 증가에 따른 교차 현상
우리는 모델마다 맥락 길이에 따른 성능 감소 속도가 다르다는 것을 주목하며, 이는 특정 평가에서 모델 성능이 교차하는 시나리오로 이어질 수 있습니다. 즉, 맥락 길이가 충분히 길어질 경우, 이전에는 특정 과제에서 더 나빴던 모델이 더 좋은 성능을 보였던 모델을 능가하게 되는 경우입니다. 이러한 현상은 그림 6, 7, 8, 13에서 관찰할 수 있습니다. 일반적으로 Gemini 모델들은 맥락 길이가 충분히 길어질 때 각기 다른 과제에서 GPT 및 Claude 모델의 성능을 종종 능가하지만, 항상 그런 것은 아닙니다. 특히 Gemini 1.5 Flash가 충분히 긴 맥락 길이에서 MRCR과 IDK에서 GPT와 Claude 모델들을 능가하며, 그 우위는 1M 토큰의 맥락까지 유지됩니다.
이러한 현상은 이 모델들이 짧은 맥락 성능과 긴 맥락 성능 사이에서 잠재적인 균형 조정을 하고 있을 가능성을 보여줍니다. MRCR에서는 GPT와 Claude 모델이 8K 미만의 맥락에서 Gemini 모델보다 더 나은 성능을 보이지만, 맥락 길이 일반화 성능에서의 감소 속도가 상대적으로 더 높음을 관찰할 수 있습니다. 이는 짧은 맥락 성능과 긴 맥락 성능을 균형 잡는 것이 어려울 수 있음을 시사합니다.
5.4 MRCR에서의 평행 모델 계열 곡선
그림 2에서 우리는 다양한 모델 계열들이 MRCR에서 평행한 곡선을 가지고 있는 흥미로운 현상을 언급했습니다. 우리는 이 특성을 평가가 높은 신호를 지니고 있다는 증거이자, 미래 연구의 탐구 방향을 제시하는 지표로 강조합니다. 특정 모델 쌍 간의 곡선이 매우 유사하게 평행을 이루고 있기 때문에, 우리는 이들 모델의 학습 과정에서 독특하게 유사한 측면이 존재했을 것으로 추측합니다 (비록 성능에서 절대적인 차이는 있을지라도). 미래의 연구에서는 모델 학습에 대한 암시적 정보를 드러내는 평가들을 더 조사할 필요가 있습니다.
또한, 우리는 MRCR이 특히 성능을 측정하는 데 있어 강력한 지표라는 점을 발견했습니다. MRCR의 경우 모델들이 검증 가능한 출력을 제공하도록 프롬프트를 변경할 필요가 없었으며, 결과의 분산도 낮게 유지되었습니다.
5.5 잠재 리스트의 복잡성에 따른 층화
이 섹션에서는 복잡도가 높은 과제일수록 더 어렵다는 주장을 점수로 검증합니다 (그림 10, 11, 12 참조). 또한, 가장 높은 복잡도를 가진 과제는 맥락 길이에 따른 기울기가 상당히 가파름을 특히 성능이 가장 높은 모델인 GPT-4o에서 확인할 수 있으며, 이는 과제의 복잡도가 증가함에 따라 맥락 길이에 따른 성능 저하가 더 빠르게 일어난다는 것을 시사합니다. 특히, 가장 높은 과제 복잡도에서 GPT-4o의 성능은 GPT-4T 및 Gemini 1.5 모델들과 유사한 수준을 보였습니다 (그림 12 참조).
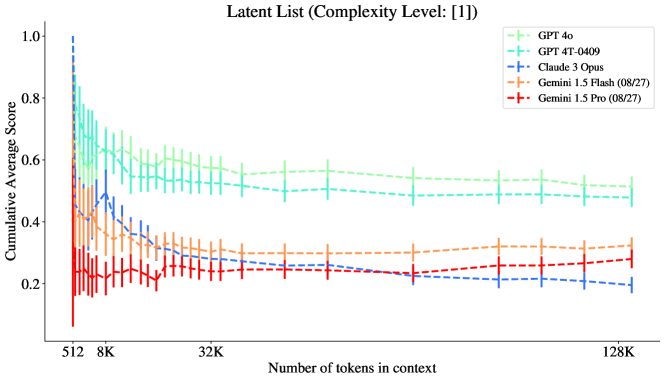
그림 10: 잠재 리스트: 복잡도 수준 1
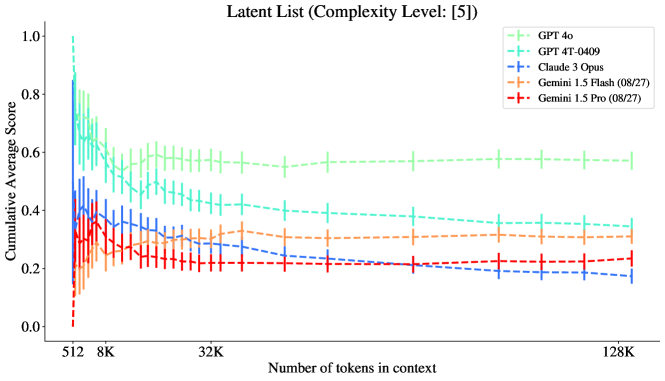
그림 11: 잠재 리스트: 복잡도 수준 5. 128K에서 Gemini와 GPT-4T가 유사한 성능을 보입니다.
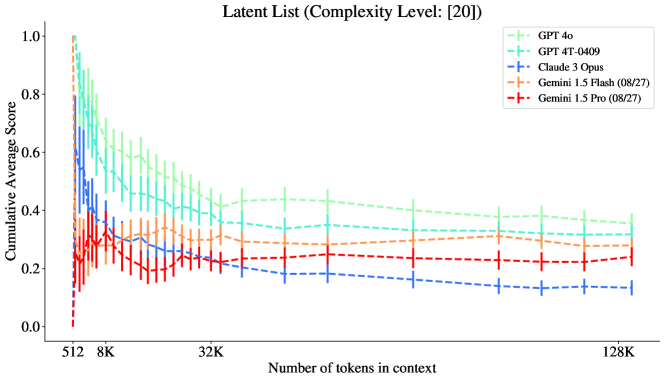
그림 12: 잠재 리스트: 복잡도 수준 20. 128K에서 Gemini와 두 개의 GPT 모델이 유사한 성능을 보입니다.
-----
복잡도가 높아짐에 따라 GPT 모델의 성능이 더 많이 감소하면서 Gemini와 비슷해지는 것며, 이 점에서 복잡도와 맥락 길이가 성능에 미치는 영향이 모델마다 다르다는 것을 알 수 있으며, 특히 복잡한 과제에서 성능 유지 능력에서 차이가 발생할 수 있다는 것을 시사합니다.
-----
5.6 IDK 성능 분할: 정답이 "모르겠습니다"인 경우
그림 13에서 우리는 IDK를 정답이 "모르겠습니다"인 작업 인스턴스로만 제한했을 때 성능 감소 곡선이 더 가파름을 관찰합니다. 이 작업이 더 어려운 이유는 모델이 단일 위치에서 답을 찾아내는 것이 아니라, 맥락 전체를 평가하여 해당 정보가 존재하지 않을 수 있음을 판단해야 하기 때문입니다. 특히, Gemini 1.5 Pro는 충분히 긴 맥락에서 이 하위 과제에서 Claude 3.5 Sonnet보다 약간 더 나은 성능을 보였습니다.
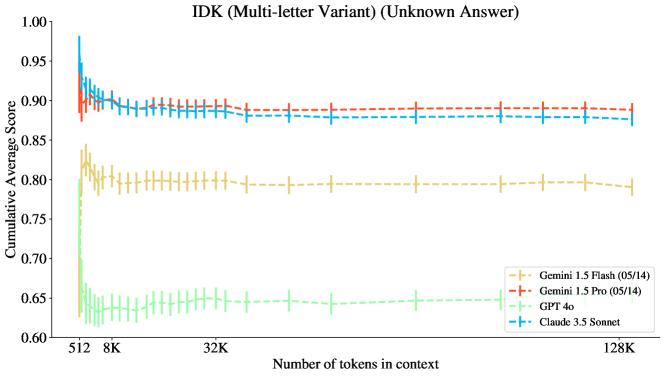
그림 13: IDK: 정답은 항상 알 수 없음. 약 8K 맥락에서 Gemini 1.5 Pro가 이 하위 과제에서 Claude 3.5 Sonnet을 제치고 최고 성능을 보였습니다.
5.7 흥미로운 실패 모드: IDK에서 퍼즐을 환각하는 GPT 모델
우리는 이전에 그림 13에서 GPT-4 계열 모델들이 IDK에서 다른 모델 계열보다 훨씬 나쁜 성능을 보인다는 점을 언급했는데, 이는 이 모델 계열의 흥미로운 행동적 특성 때문입니다. 랜덤한 문자 문자열이 제시되면, GPT-4 모델들은 종종 그 텍스트에 숨겨진 수수께끼가 있다고 가정하고, 환각적으로 답변 선택지 중 하나의 존재를 만들어내어 "수수께끼를 해결"하려고 시도합니다. 이로 인해 성능이 크게 떨어지게 됩니다. 우리는 그림 14에 이러한 행동의 예시를 제공했습니다.
참고로, OpenAI API는 더 단순한 맥락(예: "X X X ..."와 같은)의 입력을 허용하지 않는데, 이는 아마도 반복 공격 스킴(Nasr 외, 2023) 때문일 것입니다. 이러한 공격은 모델이 훈련 데이터를 그대로 재생산하도록 유도할 수 있습니다.
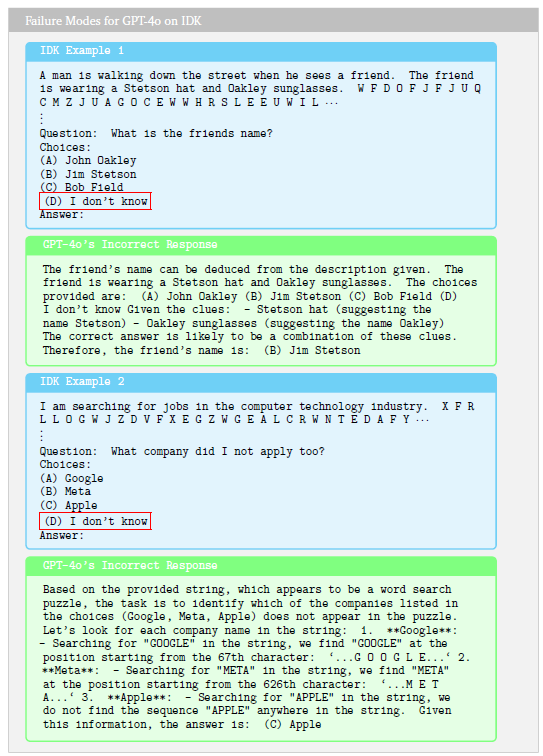
그림 14 | 환각 퍼즐 때문에 GPT-4o가 IDK 작업에서 실패하는 예시.
6. 관련 연구
6.1 장문 맥락 평가에 대한 광범위한 연구 이 논문에서는 "장문 맥락"을 적어도 32K 이상의 맥락 예시(이상적으로는 128K 이상의 맥락)를 의미한다고 정의합니다. 최근에는 검색에 초점을 맞춘 장문 맥락 평가 벤치마크가 많이 등장했습니다 (Kamradt, 2023; Google 외, 2024; Li 외, 2024; Hsieh 외, 2024; Zhang 외, 2024; Kočiskỳ 외, 2018; Bohnet 외, 2024b). 이들은 추론보다는 맥락 내 다중 샷 학습 (Agarwal 외, 2024; Bohnet 외, 2024a)에 더 집중하고 있습니다. 장문 맥락 요약에 대한 기존 연구도 있습니다 (Chang 외, 2024; Kim 외, 2024). 이 논문에서는 장문 맥락에 대한 추론 평가에만 집중하고 있습니다. 특히, 우리는 맥락 내에 희소한 형태로 관련 정보가 포함되어 있으며, 그 정보들 모두가 다른 부분과 독립적으로는 즉시 식별되지 않는다고 가정합니다. 관련 정보는 단순히 검색되는 것이 아니라 종합되어야 합니다.
장문 맥락 능력을 주장하는 또 다른 인기 있는 접근법은 지정된 장문 문서 집합에 대해 **맥락 길이 대 평균 혼란도(perplexity)**의 플롯을 생성하는 것입니다 (Anthropic, 2023; Google 외, 2024). 주목할 만한 점은, 고정된 모델의 혼란도가 감소하는 현상(즉, 가장 긴 맥락에서의 평균 혼란도와 가장 짧은 맥락에서의 평균 혼란도 간의 차이)은 이 보고서에서 소개한 장문 추론 평가에서 가장 긴 맥락과 가장 짧은 맥락 간의 오류 차이와 반상관 관계에 있다는 것입니다. 반상관은 혼란도 플롯이 맥락 길이에 대한 함수로 대략적으로 단조 감소하는 반면, 우리가 제시한 평가의 오류 플롯은 맥락 길이에 대한 함수로 대략적으로 단조 증가하기 때문에 즉각적으로 관찰됩니다 (정확도는 대략적으로 단조 감소함). 따라서 단일 모델에서 맥락 대 혼란도 플롯을 검토하는 것이 복잡한 장문 추론 과제에서의 모델 성능을 정확도로 측정하는 데 대체 지표가 되지 않을 수 있습니다. 다만, 번역 과제와 같은 맥락 내 다중 샷 학습 능력을 평가하는 데는 대체 지표가 될 가능성이 있습니다 (예: Google 외 (2024)의 일부 예시 참조).
또 다른 주목할 점은 대부분의 장문 맥락 평가들이 **선택형 형식(다중 선택형, 때로는 두 가지 선택지만 제공)**을 사용한다는 점입니다. 이 패러다임은 상당히 제한적입니다. 일부 다른 방법들이 ROUGE 스타일의 점수(특히 요약에서)나 인간 평가를 사용하기도 하지만, 이들 방법 역시 노이즈 문제(Cohan과 Goharian, 2016 및 Akter 외, 2022에서의 논의 참조)와 비용 면에서 문제가 될 수 있습니다.
6.2 신뢰성 있고 최소한의 장문 추론 평가 개발의 어려움
임의로 긴 추론 작업을 연구하는 몇 가지 기존 평가들이 있으며, 이들 중 일부는 1M 맥락까지 평가합니다. 여기에는 Zhang 외 (2024), Hsieh 외 (2024), Li 외 (2024), Kuratov 외 (2024), Lee 외 (2024) 등이 포함됩니다. 그러나 이러한 기존 평가들은 몇 가지 결함을 가지고 있으며, 주로 다음과 같은 문제점 중 하나 이상을 가지고 있습니다:
- 단축 경로(Short-circuiting): 모델이 학습 데이터나 맥락 후반부의 정보를 사용해 전체 맥락을 필요로 하지 않고도 질의에 답할 수 있는 경우, 우리는 모델이 "단축 경로"를 사용할 수 있다고 말합니다. 이렇게 되면 모델은 실제로 맥락을 활용하지 않고도 높은 성능을 보일 수 있습니다. 예를 들어, **Kuratov 외 (2024)**의 과제들은 확장된 과제가 유출된 평가에서 비롯되었고, 과제 자체에도 상당한 결함이 있기 때문에 (Kaushik와 Lipton, 2018) 이러한 문제를 모두 겪고 있을 수 있습니다. 유사하게 구성된 많은 평가들(다른 기본 평가를 사용할지라도)도 동일한 문제를 가지고 있습니다.
- 비밀 검색 과제(Secret retrieval tasks): 최근 인기 있는 평가 벤치마크 중 일부 (예: Li 외 (2024), Hsieh 외 (2024))는 자신들의 과제 일부를 장문 맥락 추론 능력을 평가한다고 설명합니다. 하지만 그 구성상, 이러한 과제들은 단일 바늘 또는 다중 바늘 검색 이상의 작업을 요구하지 않는 경우가 많습니다. 예를 들어, RULER의 변수 추적 (Variable Tracing, VT) 과제를 생각해봅시다 (Hsieh 외, 2024). 표면적으로는, 이 과제는 많은 변수 할당이 포함된 맥락을 포함하고 있습니다 (예: X = 3; Y = X; Z = Y 등, 방해 맥락과 함께). 모델은 이후에 값이 3인 모든 변수를 나열해야 합니다. 그러나 이 과제의 기본 RULER 구현에서, 맥락에서 소개된 모든 변수는 실제로 값이 3입니다 — 불필요한 변수는 없습니다. 따라서 이 과제 설정은 궁극적으로 다중 바늘 검색 작업으로 축소되며, 바늘은 언급된 변수 이름에 해당합니다. 이 때문에 많은 모델들이 이 작업에서 매우 높은 성능을 보이는 것입니다.
- 분포 외 방해 맥락 (Out-of-distribution distractor context): 많은 기존 과제들은 Paul Graham의 에세이나 반복된 문구(Hsieh 외, 2024; Li 외, 2024; Kamradt, 2023)와 같은 극적으로 분포 외 맥락을 삽입하여 평가의 불필요한 정보 요소를 구성합니다. 이러한 설정은 문제를 상당히 쉽게 만들며, 이는 장문 추론 과제를 암묵적으로 검색 작업에 더 가깝게 만들기 때문입니다. 만약 관련 정보가 다른 관련 정보와의 상호 관련된 특성을 이해하지 않고도 사전에 식별 가능하다면, 과제는 효과적으로 다중 바늘 검색 작업이 됩니다.
- 합성된 장난감 과제에서의 학습 (Training on toy synthetic tasks): 일부 평가 방법들(대부분 현대 LLM 시대 이전의 오래된 평가 세트들, 예: Long Range Arena (LRA) (Tay 외, 2020))은 모델이 과제에서 좋은 성능을 보이기 위해 과제 자체를 학습하도록 요구합니다. 이러한 평가는 주어진 아키텍처가 특정 작업을 학습하는 능력을 테스트하며, 이는 잠재적으로 흥미로울 수는 있으나, 우리가 관심을 가지는 핵심 포인트는 아닙니다. 우리는 차기 토큰 예측을 통해 언어와 다중 모달 요소 전반에 걸쳐 더 일반적으로 적용될 수 있는 흥미로운 장문 추론 회로를 학습하기를 희망하기 때문입니다.
이러한 문제와 추가적으로 제안된 기존 장문 추론 평가에 적용되는 방법에 대한 자세한 내용은 부록 D를 참조하십시오.
또 다른 관련된 장문 추론 평가는 LOFT 벤치마크의 SPIDER 과제입니다 (Lee 외, 2024), 이는 SQL 질의에 대한 **다중 단계 추론 (multi-hop reasoning)**을 테스트합니다. SPIDER는 특정 응용 프로그램(SQL)에 집중되어 있으며, 우리는 벤치마크에서 장문 추론에 대한 몇 가지 직교적인 테스트를 포함하고 있습니다.
Michelangelo는 위에서 언급된 문제들을 피하기 위해 다음을 보장합니다:
- 맥락에서 불필요한 정보는 질의에 답하는 데 필요한 정보와 실제로 전혀 관련이 없으며,
- 질의에서 관련 정보는 완전히 고유하거나, 질의에 답하는 데 도움이 될 만한 정보가 학습 데이터에 존재하지 않도록 합니다 (정보가 너무 일반적이기 때문에). 대부분의 과제에서 불필요한 정보가 관련 정보에 비해 분포 외로 크게 벗어나지 않도록 하여, 관련 정보가 주변 맥락과 명확히 다르지 않은 보다 현실적인 설정을 만듭니다.
7. 결론
우리는 Michelangelo 평가를 소개했습니다. 이는 장문 맥락 추론 평가를 개발하기 위해 잠재 구조 질의(Latent Structure Queries) 프레임워크를 사용하여 구축된 장문 맥락 종합 및 추론 평가의 모음입니다. 이 평가는 임의의 길이로 확장 가능하고 임의의 복잡도 수준으로 설정할 수 있으며, 기존 평가로부터 유출된 맥락을 피할 수 있습니다. 우리는 이 프레임워크에서 세 가지 최소한의 간단한 작업(잠재 리스트(Latent List), MRCR, IDK)을 제안했으며, 이는 현재의 장문 맥락 모델들이 32K 맥락에서도 해결하지 못하는 검색을 넘어선 단순 과제 사례를 강조합니다. 우리는 128K 맥락까지 이 작업들에서 장문 맥락 능력을 가진 열 개의 프론티어 모델을 분석하고, Gemini 1.5 계열 모델에서는 1M 맥락까지 추가로 평가를 진행했습니다. 이 평가들에서 초기 성능 저하가 상당히 나타났지만, 일정 지점을 넘으면 많은 (그러나 모두는 아닌) 프론티어 모델들이 맥락 대 성능 곡선에서 무시할 수 없는 평탄화(flattening)를 경험했음을 관찰했습니다. 이는 이들 모델에 일부 장문 맥락 능력(예: 검색 능력)이 존재하지만, 긴 맥락에서의 추론이라는 목표와 비교할 때 여전히 큰 능력 격차가 있음을 시사합니다.
이 연구의 중요한 기여 중 하나는 MRCR의 강건성과 매끄러움을 여러 프론티어 모델에서 검증한 것입니다. MRCR은 매우 간단한 지표를 사용하고 있으며, **건초 더미 속 바늘 찾기(Needle-in-a-Haystack)**와 비교했을 때 프롬프트 선택에 더 강한 신뢰성을 가집니다. 내부 테스트에서 우리는 이 평가가 작은 모델뿐만 아니라 후 학습(post-training)을 거치지 않은 모델에 대해서도 높은 신호를 가지고 있음을 발견했습니다. 따라서 우리는 다음과 같은 추천을 제안합니다 — MRCR은 장문 맥락에 대한 검색 이상의 이해를 최소한으로 테스트하고 검색을 위한 더 어려운 방해 맥락을 포착하는 과제이므로, MRCR과 그 자연스러운 확장들이 종종 텍스트의 나머지 부분과 명확하게 다른 형태로 나타나는 바늘을 사용하는 기존의 인기 있는 건초 더미 속 바늘 찾기(Needle-in-a-Haystack) 평가를 대체할 수 있는 적절한 기본 대안입니다. 기존 평가는 모델의 장문 맥락에서의 능력을 측정하는 데 있어 미묘한 차이를 포착하지 못하고 있습니다.
8. 기여자
- 책임 저자 (Corresponding Author): Kiran Vodrahalli
- 핵심 기여자 (Core Contributors): Santiago Ontañón, Nilesh Tripuraneni, Kelvin Xu, Sanil Jain, Rakesh Shivanna, Jeffrey Hui, Nishanth Dikkala, Mehran Kazemi, Bahare Fatemi
- 기여자 (Contributors): Rohan Anil, Ethan Dyer, Siamak Shakeri, Roopali Vij, Harsh Mehta, Vinay Ramasesh, Quoc Le, Ed Chi, Yifeng Lu, Orhan Firat, Angeliki Lazaridou, Jean-Baptiste Lespiau, Nithya Attaluri, Kate Olszewska
역할 정의는 아래와 같습니다:
- 책임 저자: 프로젝트를 주도하고, 많은 평가 및 전체 프레임워크를 생성했습니다.
- 핵심 기여자: 프로젝트 전반에 걸쳐 중요한 영향을 미친 개인입니다.
- 기여자: 프로젝트에 부분적으로 기여하고, 일부 노력을 기울인 개인입니다.
각 범주 내에서 저자들은 특정 순서 없이 나열되었습니다.
부록 A: 프롬프트
A.1 잠재 리스트 (Latent List) 잠재 리스트의 프롬프트 형식은 다음과 같습니다:

A.2 MRCR MRCR의 프롬프트 형식은 다음과 같습니다:
A.3 IDK IDK의 예시 프롬프트는 다음과 같습니다:

부록 B: 기회율 추정 B.1 잠재 리스트의 기회율 추정
**잠재 리스트(Latent List)**는 근사적인 지표를 통해 채점되므로, 이 평가에 대한 기회율을 합리적으로 추정하는 것이 쉽지 않습니다. 기회율을 추정하기 위해 각 뷰 연산 유형과 각 난이도 수준에 대해, 무작위 모델이 가능한 모든 출력 공간에서 균일하게 샘플링한다고 가정하고 평균 점수를 계산합니다. 특히, len 연산의 경우, 무작위 모델이 0과 관련 연산의 수(난이도 수준에 해당) 사이의 길이를 균일하게 출력한다고 가정하며, 실제 길이도 이 범위에서 균일하게 분포한다고 가정합니다. 무작위 모델에 대한 추가 가정이 없을 때, 기회율은 **0.01%**입니다.
따라서, 보다 현실적인 기회율 추정을 위해 print, sum, max, min 연산에 대해 무작위 모델이 관련 연산에서 나타나는 특정 숫자들을 고려하는 데 제한될 수 있다고 가정합니다. 그러나 반드시 이 숫자들을 어떻게 결합해 올바른 잠재 리스트를 계산해야 하는지는 알지 못한다고 가정합니다. 특히, print와 sum의 경우, 무작위 모델이 관련 연산에 포함된 숫자들의 부분 집합을 균일하게 샘플링하고, 초기 리스트 (배열 [1, 2, 3, 4, 5, 6])에서 일부 요소들을 다시 샘플링하여 무작위 모델의 잠재 리스트 값에 대한 추측을 구성한다고 가정합니다 (랜덤하게 섞임). 그 후, print와 sum에 대해서 무작위 모델은 해당 리스트의 슬라이스를 샘플링하여 실제 슬라이스와 비교하고, 해당 슬라이스의 합을 계산하여 실제 합과 비교합니다. min과 max의 경우, 무작위 모델이 무작위로 선택된 잠재 리스트에서 단일 항목을 균일하게 선택하여 실제 리스트와 비교한다고 가정합니다.
이후, 평가 인스턴스에서 균일하게 나타나는 복잡도 수준들(1, 5, 20)에 대해 평균을 냅니다. 이러한 방식으로 기회율을 계산하면, 모든 복잡도 수준에서 평균적으로 **12.2%**의 기회율을 얻으며, 복잡도 수준 1에서는 16.9%, 복잡도 수준 5에서는 11.3%, 복잡도 수준 20에서는 **8.5%**의 기회율을 얻습니다.
-----
여기서는 잠재 리스트 과제의 난이도를 평가하기 위해, 단순히 랜덤하게 값을 선택하는 모델이 정답을 맞출 확률이 얼마나 되는지를 계산하고 있습니다.
-----
B.1.1 MRCR의 기회율 추정
이 평가는 근사적인 편집 거리(edit distance) 지표를 통해 채점되므로, 이 평가에 대한 합리적인 기회율을 추정하는 것은 쉽지 않습니다. 기회율을 추정하기 위한 한 가지 접근법은 모델이 가장 관련 있는 선택지 중 하나를 출력한다고 가정하는 것입니다 (다만, 이 방법은 모델이 정답을 부분적으로 재구성하거나, 출력을 거부하거나, 덜 관련 있는 출력을 내놓는 경우는 고려하지 않습니다). 모델이 대화 기록 내에서 가능한 출력들 중 하나를 무작위로 출력한다고 가정하여 계산된 기회율은 **4%**이며, 각 예시별 기회율의 히스토그램은 그림 15에 표시되어 있습니다.
또한, 랜덤 모델이 적어도 주제 또는 형식 중 하나가 맞는 인스턴스를 출력할 것이라고 가정할 때의 기회율을 계산할 수도 있습니다. 이 방식으로 계산된 기회율은 **9%**이며, 예상대로 더 큽니다. 각 예시별 기회율의 히스토그램은 그림 16에 표시되어 있습니다.
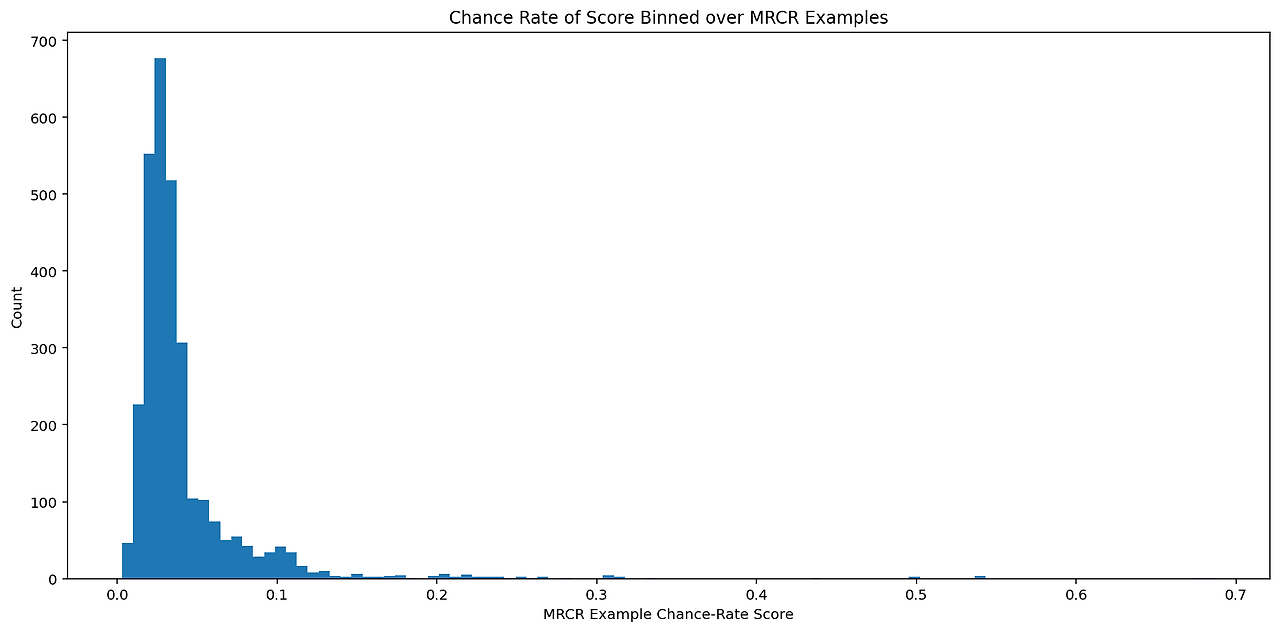
그림 15: MRCR에 대해 간단한 무작위 모델이 작성된 글 중 하나를 균일하게 출력한다고 가정하여 근사 편집 거리 지표로 계산한 각 예시별 기회율의 히스토그램을 그렸습니다.
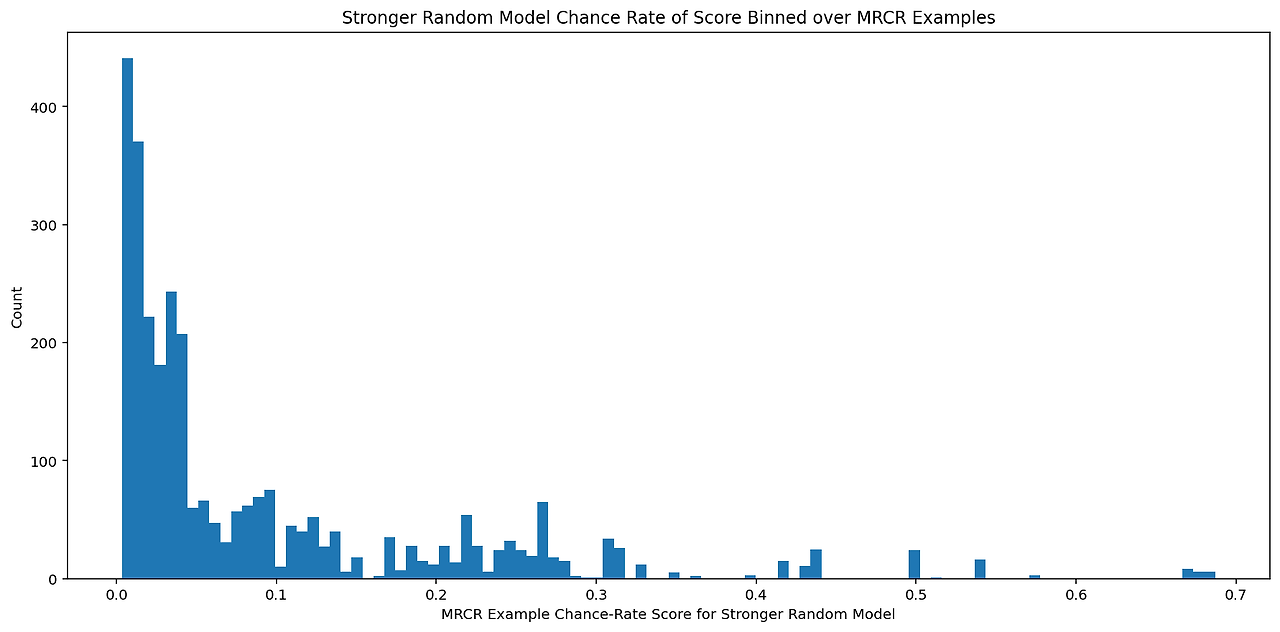
그림 16: MRCR에 대해 더 강력한 무작위 모델이 주제나 형식 중 하나라도 정답과 일치하는 작성된 글 중 하나를 균일하게 출력한다고 가정하여 근사 편집 거리 지표로 계산한 각 예시별 기회율의 히스토그램을 그렸습니다.
B.2 IDK의 기회율
질의가 네 가지 선택지를 가진 다중 선택 문제이므로, 기회율은 **25%**입니다.
부록 C: 추가 플롯
이 섹션에서는 Michelangelo 과제에 대한 추가적인 플롯들(그림 17, 18, 19, 20)을 포함합니다. 이들 플롯은 반드시 최고 성능을 보인 모델만을 다루는 것은 아니며, 다양한 모델 세트에 대한 평가 결과를 담고 있습니다. 이 섹션을 통해 모든 모델이 전체 과제 세트에 대해 평가된 결과를 완전히 다룰 수 있습니다.
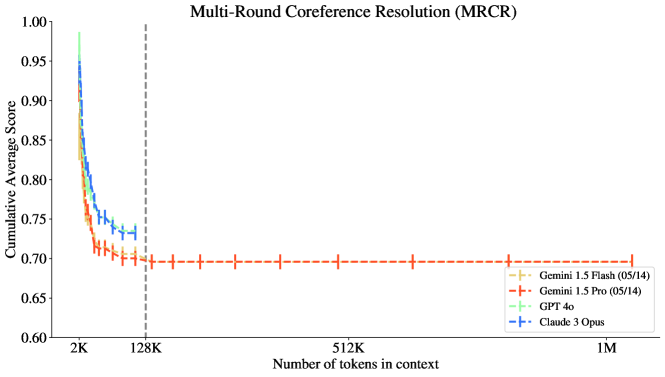
그림 17: 이전 Gemini 모델들의 MRCR 성능.
여기서 우리는 최신 Gemini 모델들이 이 과제에서 성능이 상당히 개선되었음을 관찰할 수 있습니다. 그림 1에서, **Gemini 1.5 Pro (08/27)**는 8K 맥락 이후 모든 경쟁 모델을 능가하며, **Gemini 1.5 Flash (08/27)**는 20K 맥락 이후 모든 경쟁 모델을 능가합니다.
그림 18: 이전 Gemini 모델들의 잠재 리스트(Latent List) 성능.
여기서 우리는 최신 Gemini 모델들이 이 과제에서 특히 성능이 크게 개선되었음을 볼 수 있습니다. 특히, Gemini 1.5 Flash는 이 과제에서 짧은 맥락 설정에서 성능이 좋지 않지만, 성능 일반화 경향은 1M 맥락까지 영향을 받지 않습니다.
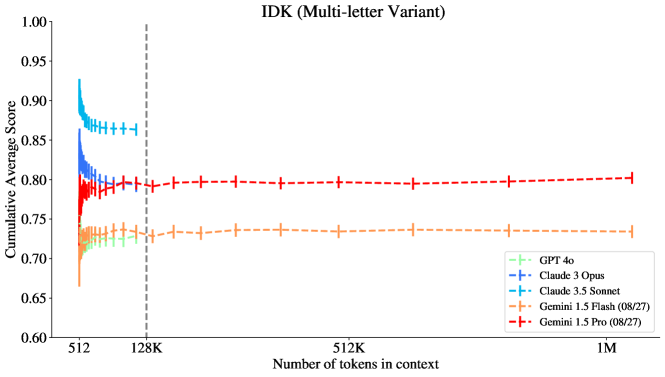
그림 19: 최신 Gemini 모델들의 IDK 성능.
여기서 최신 Gemini 모델들에서 IDK 과제에 대해 일부 성능 감소(regression)가 관찰되지만, 맥락 길이 1M까지의 성능 일반화 경향은 동일하게 유지됩니다.
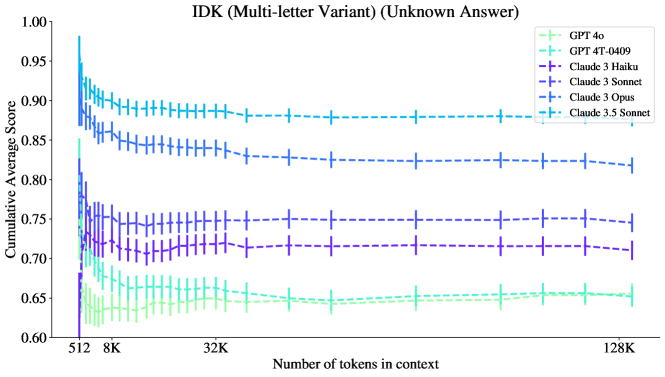
그림 20: 모든 GPT와 Claude 모델들의 IDK 성능 ("정답 알 수 없음" 설정으로 제한, 정답이 항상 "모르겠습니다"인 경우). 여기서 GPT 모델들이 이 과제에서 좋지 않은 성능을 보이며, GPT-4o는 GPT-4T에 비해 성능이 후퇴했음을 볼 수 있습니다. 이는 정답이 없을 때도 GPT-4o가 더 확신하는 경향이 있음을 나타냅니다. Claude 모델의 경우, 모델 크기에 따라 성능이 향상되는 경향이 있지만, Claude-3.5 Sonnet은 다른 Claude 모델들 중 두 번째로 좋은 성능을 보인 Claude-3 Opus를 크게 능가합니다.
부록 D: 신뢰성 있고 최소한의 장문 추론 평가 개발의 상세한 도전과제 섹션 6에서 언급했듯이, 임의로 긴 추론 작업을 연구하는 몇 가지 기존 평가들이 있습니다. 이 평가들은 일부 1M 맥락까지 확장되며, Zhang 외 (2024), Hsieh 외 (2024), Li 외 (2024), Kuratov 외 (2024), Lee 외 (2024) 등이 포함됩니다. 그러나 이러한 기존 평가들은 다음과 같은 몇 가지 결함 중 적어도 하나 이상을 겪고 있는 경향이 있습니다:
- 단축 경로(Short-circuiting): 평가 작업이 학습 데이터나 모델이 전체 맥락을 필요로 하지 않고도 질의에 답하기 위해 사용할 수 있는 후반부의 정보를 고려하지 않는 경우, 모델은 "단축 경로"를 사용할 수 있습니다. 이를 통해 모델은 실제로 맥락을 활용하지 않고도 높은 성능을 보일 수 있습니다. 예를 들어, **Kuratov 외 (2024)**의 과제들은 확장된 과제가 유출된 평가에서 비롯되었으며(거의 10년 전 유명한 평가), 과제 자체에 내재된 편향이 있어 모델이 전체 입력을 사용해야 하는 요구가 제거되기 때문에 이러한 문제를 모두 겪을 수 있습니다 (Kaushik과 Lipton, 2018). 일부 평가는 이러한 행동을 방지하려고 시도합니다. 예를 들어, **Zhang 외 (2024)**는 수정된 장문 QA 작업에서 등장인물의 이름을 무작위로 생성된 이름으로 바꾸는 방식으로("키 엔티티 대체") 이 문제를 해결하려고 합니다. 그러나 이 완화 방법은 여전히 학습 데이터에 저장된 방대한 양의 정보가 책에 대한 질문의 답을 찾는 데 유용할 수 있다는 점을 통제하지 못합니다. 등장인물은 종종 다른 구별 가능한 많은 속성으로 정의되기 때문입니다. **Hsieh 외 (2024)**의 QA 작업도 SQuAD와 HotpotQA에서 유출되었을 가능성이 있는 기존 질문을 방해 맥락과 함께 사용함으로써 유사한 문제를 가지고 있습니다. SQuAD에도 유사한 문제가 있다는 점에 유의하십시오 (Kaushik과 Lipton, 2018). 마지막으로 **Li 외 (2024)**의 저자들도 이러한 결함을 언급합니다. 바늘은 Wikipedia에서 선별된 데이터셋에서 유래했으며, 그 데이터셋 자체도 온라인에 존재하기 때문에 유출되었을 가능성이 높습니다. 저자들은 모델들이 단순히 내부 지식을 활용하고 있는지 여부를 판단하는 것이 어렵다고 지적합니다.
- 비밀 검색 과제(Secret retrieval tasks): 일부 최근의 인기 있는 평가 벤치마크들(예: Li 외 (2024), Hsieh 외 (2024))은 그들의 과제 일부를 장문 맥락 추론 능력 평가에 해당한다고 설명합니다. 하지만 그 구성상, 이들 과제는 단일 바늘 또는 다중 바늘 검색 이상의 작업을 요구하지 않는 경우가 많습니다. 예를 들어, RULER의 변수 추적 (Variable Tracing, VT) 과제 (Hsieh 외, 2024)를 생각해봅시다. 표면적으로는, 이 과제는 여러 변수 할당이 포함된 맥락을 포함하고 있습니다 (예: X = 3; Y = X; Z = Y 등, 방해 맥락과 함께). 모델은 값이 3인 모든 변수를 나열해야 합니다. 하지만 기본 RULER 구현에서, 맥락에 소개된 모든 변수는 실제로 3 값을 가지고 있으며, 불필요한 변수는 없습니다. 따라서 이 과제 설정은 결국 다중 바늘 검색 작업으로 축소됩니다. RULER의 공통/빈번 단어 추출 (CWE/FWE) 과제에도 관련된 문제가 존재합니다 – 만약 가장 빈번한 단어들의 빈도 차이가 크다면, 모델은 실제로 세밀한 개수를 세지 않고도 이 과제를 해결할 수 있습니다. 대신, 맥락 내에서 반복이 특정 단어가 다음 토큰으로 선택될 확률을 높이기 때문에 모델은 단순히 가장 빈번한 연속적인 토큰을 생성할 수 있습니다.
- 분포 외 방해 맥락 (Out of distribution distractor context): 많은 기존 과제들은 평가의 불필요한 정보 요소를 구성하기 위해 Paul Graham의 에세이 또는 반복된 문구(Hsieh 외, 2024; Li 외, 2024; Kamradt, 2023)와 같은 극적으로 분포 외 맥락을 삽입합니다. 이는 문제를 상당히 쉽게 만듭니다. 왜냐하면 이로 인해 장문 추론 작업이 암묵적으로 검색 작업에 더 가까워지기 때문입니다. 만약 관련 정보가 다른 정보와의 상호 관련된 특성을 이해하지 않고도 사전에 식별 가능하다면, 과제는 효과적으로 다중 바늘 검색 작업이 됩니다.
- 합성된 장난감 과제에서의 학습 (Training on toy synthetic tasks): 일부 평가 방법(대부분 현대 LLM 시대 이전의 오래된 평가 세트, 예: Long Range Arena (LRA) (Tay 외, 2020))은 모델이 과제에서 좋은 성능을 보이기 위해 과제 자체를 학습하도록 요구합니다. HashHop의 비-CoT 버전에 대한 최근 결과도 이 패러다임을 사용하여 발표되었습니다 (Magic, 2024). 이러한 평가 세트의 목표는 Michelangelo의 목표와 다릅니다. 우리는 모델이 매우 일반적으로 장문 맥락에서 유용한 추론 회로를 학습할 수 있는 능력을 테스트하고자 합니다. 반면, 훈련-테스트 평가 세트는 특정 과제에 대한 학습 요구를 부과함으로써 특정 과제를 학습할 수 있는 아키텍처의 능력을 테스트하게 되는데, 이는 흥미로울 수 있지만 우리의 설정에서 핵심 관심사는 아닙니다.
합성 평가들은 신중하게 구성되었을 때 위에서 언급한 문제를 겪지 않습니다. 단순히 그들의 인위적인 특성이 설계에서 상당한 통제력을 허용하기 때문입니다. 그러나 인위성 자체는 바람직하지 않습니다. 우리는 통제 가능한(단축 경로 없음, 임의의 맥락 길이, 임의로 통제된 복잡성) 인위적이고 비현실적인 평가와 매우 현실적이지만 통제하기 어려운 평가 사이에서 중간 지점을 찾고자 합니다. 특히 많은 문제가 발생합니다: 만약 새로운 장문 평가가 기존 유출된 평가를 장문 맥락으로 수정하려고 시도한다면, 기본 평가가 유출되었다는 사실 때문에 문제가 발생합니다. 종종 삽입된 맥락이 유출된 정보를 포함하여 통제되지 않은 정보 존재와 맥락 내 단축 경로 문제를 야기합니다. 완전히 현실적인 맥락에서도 이 문제는 마찬가지로 존재합니다. 맥락 길이에 따라 정보가 존재하는지, 정보가 어디에 존재하는지를 확인하는 것이 점점 더 어려워지기 때문입니다. 현실적인 맥락 평가들은 자동으로 확장할 수 없고, 인간의 노동을 많이 요구합니다. 이는 인간이 긴 맥락에서 정보를 분석하는 데 어려움이 있기 때문에 오류가 발생할 수 있습니다. 현실적인 작업에서는 관련 정보의 양과 과제의 복잡성을 제어하기가 훨씬 더 어렵기 때문에 문제가 악화됩니다.
궁극적으로 우리는 장문 맥락 평가가 높은 통제력을 가지면서(과제 복잡성과 맥락 길이 측면에서) 학습 데이터에 존재하지 않는 맥락을 보장하고, 전체 맥락을 통해 모델이 실제로 추론하도록 요구하면서도 인위적이지 않은 과제가 되기를 원합니다.



