https://arxiv.org/abs/2405.12130
MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning
Low-rank adaptation is a popular parameter-efficient fine-tuning method for large language models. In this paper, we analyze the impact of low-rank updating, as implemented in LoRA. Our findings suggest that the low-rank updating mechanism may limit the ab
arxiv.org
초록
Low-rank adaptation (LoRA)는 대형 언어 모델(LLM)에 대한 인기 있는 파라미터 효율적 미세 조정(PEFT) 방법입니다. 본 논문에서는 LoRA에서 구현된 저차원(rank) 업데이트의 영향을 분석합니다. 우리의 분석 결과, 저차원 업데이트 메커니즘이 LLM이 새로운 지식을 효과적으로 학습하고 기억하는 능력을 제한할 수 있다는 것을 시사합니다. 이러한 관찰에 영감을 받아 우리는 MoRA라는 새로운 방법을 제안합니다. MoRA는 같은 수의 학습 가능한 파라미터를 유지하면서 고차원(rank) 업데이트를 달성하기 위해 정사각 행렬을 사용합니다. 이를 위해 우리는 정사각 행렬에 대해 입력 차원을 줄이고 출력 차원을 늘리는 비파라미터 연산자를 도입합니다. 또한, 이러한 연산자는 가중치를 LLM에 다시 병합할 수 있도록 하여 MoRA도 LoRA처럼 배포될 수 있게 합니다. 우리는 다섯 가지 작업(지시 튜닝, 수학적 추론, 연속 사전 훈련, 기억 및 사전 훈련)에 걸쳐 우리 방법을 종합적으로 평가했습니다. 우리의 방법은 기억 집약적 작업에서 LoRA를 능가하며, 다른 작업에서도 유사한 성능을 달성했습니다. 우리의 코드는 https://github.com/kongds/MoRA 에서 제공될 예정입니다.
1 서론
언어 모델의 크기가 커짐에 따라, 파라미터 효율적 미세 조정(PEFT) (Houlsby et al., 2019)이 이러한 모델을 특정 다운스트림 작업에 적응시키기 위한 인기 있는 기술로 부상했습니다. 전체 미세 조정(Full Fine-Tuning, FFT)이 모든 모델 파라미터를 업데이트하는 것과 달리, PEFT는 파라미터의 일부만을 수정합니다. 예를 들어, 일부 작업에서 전체 파라미터의 1% 미만을 업데이트하면서도 FFT와 유사한 성능을 달성할 수 있습니다 (Hu et al., 2021). 이는 옵티마이저의 메모리 요구량을 크게 줄여주며, 미세 조정된 모델의 저장 및 배포를 용이하게 만듭니다.

(a)LoRA (r=8)
(b)MoRA (r=256)
그림 1: 동일한 수의 학습 가능한 파라미터 하에서 우리의 방법과 LoRA의 개요 비교 W는 모델에서 고정된 가중치입니다. A와 B는 LoRA에서 사용되는 학습 가능한 저차원(rank) 행렬입니다. M은 우리의 방법에서 사용하는 학습 가능한 행렬입니다. 회색 부분은 입력 차원을 줄이고 출력 차원을 증가시키기 위한 비파라미터 연산자를 나타냅니다. r은 두 방법에서의 rank를 나타냅니다.
기존의 PEFT 방법들 중, Low-Rank Adaptation (LoRA) (Hu et al., 2021)은 LLM에서 특히 널리 사용되고 있습니다. LoRA는 저차원 행렬을 통해 파라미터를 업데이트하여 프롬프트 튜닝 (Lester et al., 2021)이나 어댑터 (Houlsby et al., 2019)와 같은 다른 PEFT 방법보다 성능을 향상시킵니다. 이러한 행렬은 원래 모델의 파라미터에 병합될 수 있어 추론 시 추가적인 계산 비용을 피할 수 있습니다. LLM을 개선하기 위해 LoRA를 개선하는 다양한 방법이 존재하지만, 대부분의 방법은 GLUE (Wang et al., 2018) 기반으로 효율성을 평가하거나 더 적은 수의 학습 가능한 파라미터로 더 나은 성능을 달성하는 데 중점을 둡니다. 최근 방법들 (Liu et al., 2024; Meng et al., 2024; Zhu et al., 2024)은 Alpaca (Wang et al., 2024)와 같은 지시 튜닝 작업이나 GSM8K (Cobbe et al., 2021)와 같은 추론 작업을 이용해 LLM의 성능을 더 잘 평가하고자 합니다. 하지만 평가에 사용되는 다양한 설정과 데이터셋은 이들의 발전을 이해하는 데 복잡함을 더합니다.
본 논문에서는 동일한 설정 하에서 지시 튜닝, 수학적 추론, 연속 사전 학습을 포함한 다양한 작업에서 LoRA를 종합적으로 평가했습니다. 우리는 LoRA와 유사한 방법들이 이러한 작업에서 유사한 성능을 보이며, 지시 튜닝에서는 FFT와 비교 가능한 성능을 보이지만 수학적 추론과 연속 사전 학습에서는 부족한 성능을 보이는 것을 발견했습니다. 이들 작업 중, 지시 튜닝은 주로 포맷과의 상호 작용에 초점을 맞추며, 이는 거의 전적으로 사전 학습 동안 학습된 지식과 능력에 의존합니다 (Zhou et al., 2024). 우리는 LoRA가 지시 튜닝에서 응답 포맷을 쉽게 따르도록 적응하지만, 미세 조정을 통해 지식과 능력을 강화해야 하는 다른 작업에서는 어려움을 겪는 것을 관찰했습니다.
LoRA에서 관찰된 이러한 제한의 한 가지 가능한 설명은 저차원(rank) 업데이트에 대한 의존성 (Lialin et al., 2023)일 수 있습니다. 저차원 업데이트 행렬 ΔW는 FFT에서의 전체 rank 업데이트를 추정하는 데 어려움을 겪으며, 특히 도메인 특정 지식을 기억해야 하는 연속 사전 학습과 같은 메모리 집약적 작업에서 그러합니다. ΔW의 rank가 전체 rank에 비해 현저히 작기 때문에, 이 제한은 미세 조정을 통해 새로운 정보를 저장하는 능력을 제한합니다. 또한, 현재의 LoRA 변형들은 저차원 업데이트의 본질적인 특성을 변경할 수 없습니다. 이를 검증하기 위해, 우리는 LoRA의 새로운 지식 기억 성능을 평가하기 위한 가상 데이터(pseudo-data)를 사용한 기억화 작업을 수행했습니다. 우리는 큰 rank(예: 256)에서도 LoRA가 FFT보다 현저히 낮은 성능을 보인다는 것을 발견했습니다.
우리의 기여는 다음과 같습니다:
- 우리는 LoRA의 저차원 행렬 대신 정사각 행렬을 사용하여 고차원 업데이트를 달성하는 MoRA라는 새로운 방법을 소개하며, 학습 가능한 파라미터 수를 동일하게 유지합니다.
- 정사각 행렬의 입력 차원을 줄이고 출력 차원을 증가시키기 위한 네 가지 비파라미터 연산자를 논의하며, 가중치가 LLM에 병합될 수 있도록 합니다.
- 우리는 MoRA를 메모리, 지시 튜닝, 수학적 추론, 연속 사전 학습 및 사전 학습 등 다섯 가지 작업에 대해 평가했습니다. 우리의 방법은 메모리 집약적 작업에서 LoRA를 능가하며, 다른 작업에서도 유사한 성능을 달성하여 고차원 업데이트의 효과를 입증했습니다.
2 관련 연구
2.1 LoRA
LoRA는 다른 방법들과 비교했을 때 그 광범위한 적용성과 강력한 성능 덕분에 LLM을 미세 조정하기 위한 가장 인기 있는 PEFT 방법 중 하나입니다. FFT에서 업데이트된 가중치 ΔW를 근사하기 위해 LoRA는 두 개의 저차원 행렬을 사용하여 분해합니다. 이 두 행렬의 rank를 조정함으로써, LoRA는 학습 가능한 파라미터를 수정할 수 있습니다. 이를 통해 LoRA는 미세 조정 후 이 행렬들을 병합할 수 있으며, FFT와 비교했을 때 추론 지연을 발생시키지 않습니다. LLM에서의 적용을 위해 LoRA를 더욱 개선하는 다양한 방법들이 존재합니다. 예를 들어, DoRA (Liu et al., 2024)는 원래 가중치를 크기와 방향 성분으로 추가 분해하고, 방향 성분을 업데이트하기 위해 LoRA를 사용합니다. LoRA+ (Hayou et al., 2024)는 두 저차원 행렬에 대해 서로 다른 학습 속도를 적용하여 학습 효율을 개선합니다. ReLoRA (Lialin et al., 2023)는 최종 ΔW의 rank를 증가시키기 위해 LoRA를 LLM의 훈련 과정에 통합합니다.
2.2 LLM과 함께하는 미세 조정
LLM의 컨텍스트 학습에서 인상적인 성능을 보였음에도 불구하고, 특정 상황에서는 여전히 미세 조정이 필요하며, 이는 크게 세 가지 유형으로 나눌 수 있습니다. 첫 번째 유형은 지시 튜닝으로, LLM을 최종 작업과 사용자 선호에 더 잘 맞추기 위함이며, LLM의 지식과 능력을 크게 향상시키지 않습니다 (Zhou et al., 2024). 이 접근 방식은 다양한 작업을 다루고 복잡한 지시를 이해하는 과정을 단순화합니다. 두 번째 유형은 수학적 문제 해결 (Collins et al., 2023; Imani et al., 2023; Yu et al., 2023)과 같은 복잡한 추론 작업을 포함하며, 일반적인 지시 튜닝으로는 복잡하고 상징적이며 다단계인 추론 작업을 처리하기 어려운 경우입니다. LLM의 추론 능력을 개선하기 위해, 연구의 대부분은 GPT-4와 같은 더 큰 교사 모델을 활용하거나 (Fu et al., 2023), 질문을 추론 경로에 따라 재구성하는 방식으로 대응하는 훈련 데이터셋을 생성하는 데 집중합니다 (Yu et al., 2023). 세 번째 유형은 연속 사전 학습 (Cheng et al., 2023; Chen et al., 2023; Han et al., 2023; Liu et al., 2023)으로, LLM의 도메인 특정 능력을 향상시키기 위함입니다. 이는 지시 튜닝과 달리, 해당 도메인 특정 지식과 능력을 강화하기 위한 미세 조정이 필요합니다.
그러나 대부분의 LoRA 변형 (Kopiczko et al., 2023; Lialin et al., 2023; Dettmers et al., 2024; Zhu et al., 2024)은 주로 지시 튜닝이나 GLUE (Wang et al., 2018)에서의 텍스트 분류 작업을 사용하여 LLM에서의 효율성을 검증합니다. 지시 튜닝이 다른 유형에 비해 미세 조정을 위한 요구 용량이 가장 적기 때문에, LoRA 변형의 효과를 정확히 반영하지 못할 수 있습니다. 이러한 방법들을 더 잘 평가하기 위해 최근의 연구들 (Meng et al., 2024; Liu et al., 2024; Shi et al., 2024; Renduchintala et al., 2023)은 추론 작업을 사용하여 방법을 테스트했습니다. 그러나 사용된 훈련 데이터셋이 LLM이 효과적으로 추론을 학습하기에는 너무 작은 경우가 많습니다. 예를 들어, 일부 방법들 (Meng et al., 2024; Renduchintala et al., 2023)은 7,500개의 훈련 샘플만 있는 GSM8K (Cobbe et al., 2021)을 사용합니다. SOTA 방법이 395,000개의 훈련 샘플을 사용하는 것과 비교했을 때 (Yu et al., 2023), 이 작은 훈련 세트는 추론에서 더 낮은 성능을 보이며, 이러한 방법들의 효과를 평가하기 어렵게 만듭니다.
3 저차원 업데이트의 영향 분석
LoRA (Hu et al., 2021)의 핵심 아이디어는 저차원 업데이트를 사용하여 FFT에서의 전체 rank 업데이트를 근사하는 것입니다.
이러한 관찰에 기반하여, 우리는 저차원 업데이트가 LLM의 기존 지식과 능력을 활용하여 작업을 해결하기에는 용이하지만, LLM의 지식과 능력을 강화해야 하는 작업을 처리하는 데에는 어려움이 있다는 가설을 제안합니다.
그림 2: FFT와 LoRA를 통한 미세 조정에서 UUID 쌍을 기억하는 성능
이 가설을 입증하기 위해, 우리는 미세 조정을 통해 새로운 지식을 기억하는 측면에서 LoRA와 FFT의 차이를 조사합니다. LLM의 기존 지식을 활용하는 것을 피하기 위해, 우리는 무작위로 10,000개의 범용 고유 식별자(UUID) 쌍을 생성했으며, 각 쌍은 32개의 16진수 값을 가진 두 개의 UUID로 구성됩니다. 이 작업은 LLM이 입력 UUID를 기반으로 대응하는 UUID를 생성하는 것을 요구합니다. 예를 들어, "205f3777-52b6-4270-9f67-c5125867d358"과 같은 UUID가 주어졌을 때, 모델은 10,000개의 학습 쌍을 기반으로 대응하는 UUID를 생성해야 합니다. 이 작업은 질문-응답 작업으로 볼 수도 있으며, 이를 수행하는 데 필요한 지식은 LLM 자체가 아닌 오로지 학습 데이터셋에서 제공됩니다.

4 방법 위의 분석을 바탕으로, 우리는 저차원 업데이트의 부정적인 영향을 완화하기 위한 새로운 방법을 제안합니다.




-----
즉 입력을 줄였다가 다시 늘리는 것을 하나의 함수로 진행하기때문에
-----



-----
위와 같이 되기 때문
-----


-----
-----

5 실험
우리는 다양한 작업에서 우리의 방법을 평가하여 고차원 업데이트의 영향을 이해하고자 합니다. 섹션 5.1에서는 UUID 쌍을 기억하는 작업에서 LoRA와 우리의 방법을 평가하여, 고차원 업데이트가 기억 성능에 미치는 이점을 보여줍니다. 섹션 5.2에서는 지시 튜닝, 수학적 추론, 연속 사전 학습의 세 가지 미세 조정 작업에서 LoRA, LoRA 변형, 그리고 FFT를 재현합니다. 섹션 5.3에서는 트랜스포머를 처음부터 학습하여, 우리의 방법과 LoRA 및 ReLoRA를 사전 학습 측면에서 비교합니다.

그림 3: Rank 8과 256에서 LoRA와 우리의 방법을 사용하여 UUID 쌍을 기억하는 성능 비교

표 1: 지시 튜닝, 수학적 추론, 연속 사전 학습 작업에서 FFT, LoRA, LoRA 변형 및 우리의 방법의 성능


표 2: 300, 500, 700, 900 훈련 단계에서 해당 키의 값을 생성하여 UUID 쌍을 기억하는 문자 수준 정확도
5.2 미세 조정 작업
5.2.1 설정
우리는 대형 언어 모델(LLM)에 대한 세 가지 미세 조정 작업에서 우리의 방법을 평가합니다: 지시 튜닝, 수학적 추론, 연속 사전 학습입니다. 이러한 작업에 대해, 우리는 LoRA와 우리의 방법을 테스트하기 위해 고품질의 해당 데이터셋을 선택했습니다. 지시 튜닝에서는, 고품질 지시 데이터셋을 혼합하여 326,000개의 필터링된 샘플을 포함한 Tülu v2 (Ivison et al., 2023)을 사용합니다. 우리는 MMLU (Hendrycks et al., 2020)을 사용하여 제로샷 및 5샷 설정 모두에서 지시 성능을 평가합니다. 수학적 추론에서는 MetaMath (Yu et al., 2023) 데이터셋의 395,000개의 샘플을 사용하여 수학적 추론 능력을 강화하며, 추가 평가를 위해 GSM8K (Cobbe et al., 2021)와 MATH (Hendrycks et al., 2021)도 사용합니다. 연속 사전 학습에서는 PubMed 초록 (Pile 데이터셋에서 가져옴, Gao et al., 2020)과 금융 뉴스를 사용하여 생물의학 및 금융 도메인에 LLM을 적응시키며, AdaptLLM (Cheng et al., 2023)의 데이터 전처리 방법을 보완하여 성능을 향상시킵니다. 우리는 연속 사전 학습에 대해 해당 작업의 평균 성능을 보고합니다. 자세한 내용은 부록 C에서 확인할 수 있습니다.

(a) 2억 5천만 모델에서의 사전 학습 손실.

(b) 13억 모델에서의 사전 학습 손실.
그림 4: 2억 5천만 및 10억 모델에서 LoRA와 MoRA를 처음부터 학습한 사전 학습 손실 비교. LoRA와 MoRA는 모두 동일한 수의 학습 가능한 파라미터를 사용하며, r=128입니다. ReMoRA와 ReLoRA는 학습 중에 MoRA 또는 LoRA를 모델에 병합하여 ΔW의 rank를 증가시키는 방법을 나타냅니다.
5.2.2 기준선 및 구현
LoRA와 유사한 방법들과 MoRA의 경우, 우리는 r=8과 r=256에서 실험을 수행하고, 세 가지 작업에 대해 다음과 같은 방법들을 재현했습니다: FFT, LoRA, LoRA+ (Hayou et al., 2024), AsyLoRA (Zhu et al., 2024), ReLoRA (Lialin et al., 2023), DoRA (Liu et al., 2024). LoRA+는 이론적 분석을 바탕으로 LoRA의 행렬 B의 학습률을 향상시켜 효율적인 특징 학습을 촉진합니다. 우리는 해당 하이퍼파라미터 λ를 {2, 4}에서 탐색했습니다. AsyLoRA는 행렬 A와 B의 비대칭성을 분석하며, 우리는 그들의 초기화 전략을 채택했습니다. ReLoRA는 학습 중에 저차원 행렬을 모델에 병합하여 ΔW의 rank를 증가시키는 방법을 제안합니다. 우리는 병합 단계에 대해 {1k, 2k}에서 탐색하고 50단계 재시작 예열(warmup)을 사용했습니다. DoRA는 성능을 향상시키기 위해 가중치 분해를 활용하여 견고한 기준선을 제공합니다. FFT의 경우, 해당 데이터셋에서 제안된 설정을 따랐습니다. MoRA의 경우, 회전 연산자를 사용하여 r=8에 대해 식 (9)에 명시된 대로 압축 및 복원을 구현하였고, r=256에서는 식 (6)에서 명시된 대로 행과 열을 공유하며 인접한 r′개의 행이나 열을 함께 그룹화하였습니다. 미세 조정에 관한 자세한 하이퍼파라미터는 부록 A에서 확인할 수 있습니다.
5.2.3 결과 및 분석 미세 조정 작업의 결과를 표 1에 제시합니다. 지시 튜닝에 대해서는 MMLU의 제로샷 및 5샷 설정 결과를 보고하고, 수학적 추론에서는 GSM8K와 MATH, 그리고 연속 사전 학습에서는 생물의학 작업과 금융 작업에서의 평균 성능을 보고합니다.
MoRA는 지시 튜닝과 수학적 추론에서 LoRA와 유사한 성능을 보였습니다. 새로운 지식을 기억하기 위한 고차원 업데이트의 이점 덕분에, MoRA는 연속 사전 학습에서 생물의학 및 금융 도메인 모두에서 LoRA보다 우수한 성능을 보였습니다.
또한, LoRA 변형들이 이 미세 조정 작업들에서 LoRA와 유사한 성능을 보인다는 것도 발견했습니다. AsyLoRA는 지시 튜닝에서 최고의 성능을 달성했지만, 수학적 추론에서는 저조한 성능을 보였습니다. ReLoRA의 경우, 학습 중에 저차원 행렬을 병합하는 것이 특히 높은 rank (예: 256)에서 성능에 해를 끼칠 수 있었습니다.
세 가지 작업 간의 차이를 고려했을 때, 이들은 각기 다른 미세 조정 능력에 대한 요구사항을 보여줍니다. 지시 튜닝의 경우, 미세 조정에서 새로운 지식을 학습하지 않기 때문에 rank 8로도 FFT와 유사한 성능을 달성할 수 있습니다. 수학적 추론의 경우, rank 8로는 FFT 성능을 따라잡을 수 없습니다. 그러나 rank를 8에서 256으로 증가시키면 성능 격차를 해소할 수 있습니다. 연속 사전 학습의 경우, rank 256을 사용한 LoRA도 여전히 FFT에 비해 성능이 낮았습니다.
5.3 사전 학습
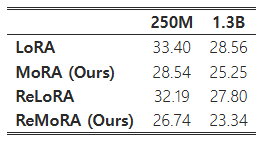
표 3: C4 검증 데이터셋에서의 Perplexity
고차원 업데이트의 영향을 이해하기 위해, 우리는 C4 데이터셋 (Raffel et al., 2020)에서 트랜스포머를 처음부터 학습합니다. 모델 아키텍처로는 LLaMA 기반 모델을 RMSNorm (Zhang and Sennrich, 2019), SwiGLU (Shazeer, 2020), 그리고 RoPE (Su et al., 2024)를 사용하여 2억 5천만 및 13억 크기에서 학습합니다. 하이퍼파라미터로는 10,000단계, 배치 크기 1024, 시퀀스 길이 512를 사용하며, Lialin 등의 설정을 따릅니다. LoRA와 우리의 방법에서는 rank r=128을 사용하고, LoRA와 유사한 레이어 정규화(layernorm)나 임베딩을 적용하지 않고 모듈을 유지한 채로 학습합니다. 우리는 우리의 방법을 LoRA 및 ReLoRA와 비교합니다. 고차원과 저차원 업데이트 간의 차이를 더 잘 보여주기 위해, ReLoRA 및 다른 방법들을 전체 rank 학습 예열(warmup) 없이 재현합니다. MoRA의 경우, 열과 행을 공유하여 식 (6)에서의 압축 및 복원 함수를 사용합니다.

사전 학습 손실은 그림 4에, C4 검증 데이터셋에서의 해당 perplexity는 표 3에 제시되어 있습니다. 우리의 방법은 동일한 학습 가능한 파라미터 수를 사용했을 때 LoRA 및 ReLoRA보다 사전 학습에서 더 나은 성능을 보였습니다. 고차원 업데이트의 이점을 통해 ReMoRA 또한 MoRA보다 더 많은 개선을 이루었으며, 이는 ReMoRA에서의 병합 및 재통합 전략의 효과를 입증합니다.
6 분석

그림 5: 2억 5천만 모델에서 사전 학습된 모델에서 ΔW의 특이값 >0.1인 개수
6.1 고차원 업데이트

-----




-----
6.2 복원 및 압축의 영향
MoRA에서 복원 및 압축 함수의 영향을 탐구하기 위해, 우리는 다양한 방법(잘라내기, 공유, 분리, 회전)을 사용하여 GSM8K에서의 성능을 표 4에 보고합니다. 이러한 방법 중 잘라내기(truncation)는 압축 중의 중요한 정보 손실로 인해 가장 저조한 성능을 보였습니다. 공유(sharing)는 입력 정보를 보존하기 위해 행 또는 열을 공유함으로써 잘라내기보다 더 나은 성능을 달성할 수 있었습니다. 그러나 r=8인 경우에는 공유되는 행이나 열의 수가 많기 때문에, 4장에서 논의한 것처럼 공유 방식은 분리(decouple) 및 회전(rotation) 방식보다 낮은 성능을 보였습니다. 회전은 사각 행렬이 입력 정보를 구별하는 데 도움을 줄 수 있는 회전 정보를 활용하여 분리 방식보다 효율적이었습니다.

표 4: GSM8K에서 r=8과 r=256에 대한 복원 및 압축 함수의 영향
7 결론
이 논문에서는 LoRA를 통한 저차원 업데이트의 영향을 분석하였으며, 이러한 업데이트가 메모리 집약적인 작업에서는 한계를 가지며 현재의 LoRA 변형에도 제약을 가한다는 것을 관찰했습니다. 이러한 제한을 극복하기 위해, 우리는 비파라미터 연산자를 이용한 고차원 업데이트 방법인 MoRA를 소개했습니다. MoRA 프레임워크 내에서 우리는 복원 및 압축 함수를 구현하기 위한 다양한 방법을 탐구했습니다. 성능 비교 결과, MoRA는 지시 튜닝과 수학적 추론에서 LoRA와 비슷한 성능을 나타내며, 연속 사전 학습과 메모리 작업에서 우수한 성능을 보였습니다. 또한, 사전 학습 실험을 통해 고차원 업데이트의 효과를 더욱 입증하고 ReLoRA와 비교해 우수한 결과를 보였습니다.
부록 A 하이퍼파라미터
우리는 표 5에서 하이퍼파라미터를 제안합니다.

표 5: 세 가지 데이터셋에 대한 미세 조정 하이퍼파라미터


부록 C 연속 사전 학습의 다운스트림 작업
생물의학 분야에서는 PubMedQA (Jin et al., 2019), RCT (Dernoncourt and Lee, 2017), USMLE (Jin et al., 2021), 그리고 MMLU에서 생물의학 관련 주제를 선택하여 성능을 평가합니다. 금융 분야에서는 BloombergGPT (Wu et al., 2023)를 따르며 ConvFinQA (Chen et al., 2022), NER (Salinas Alvarado et al., 2015), Headline (Sinha and Khandait, 2021), FiQA SA (Maia et al., 2018), 그리고 FPB (Malo et al., 2014)를 사용합니다. 이러한 작업들의 세부 성능은 아래에 보고합니다:

표 6: 생물의학 작업에서의 성능

표 7: 금융 작업에서의 성능



