https://arxiv.org/abs/2410.05954
Pyramidal Flow Matching for Efficient Video Generative Modeling
Video generation requires modeling a vast spatiotemporal space, which demands significant computational resources and data usage. To reduce the complexity, the prevailing approaches employ a cascaded architecture to avoid direct training with full resoluti
arxiv.org
초록
비디오 생성은 광범위한 시공간 공간을 모델링해야 하며, 이는 상당한 계산 자원과 데이터 사용을 요구합니다. 복잡성을 줄이기 위해, 기존 접근법은 전체 해상도로 직접 학습하는 것을 피하기 위해 계단식 아키텍처를 사용합니다. 이러한 방식은 계산 부담을 줄이지만, 각 하위 단계의 별도 최적화로 인해 지식 공유가 제한되고 유연성이 감소됩니다. 본 연구는 통합된 피라미드 흐름 매칭 알고리즘을 제안합니다. 이 알고리즘은 원래의 노이즈 제거 경로를 피라미드 단계의 시리즈로 재해석하며, 최종 단계만 전체 해상도로 동작하여 더욱 효율적인 비디오 생성 모델링을 가능하게 합니다. 우리의 정교한 설계를 통해 피라미드 각 단계의 흐름이 서로 연결되어 연속성을 유지할 수 있습니다. 더 나아가, 우리는 전체 해상도 기록을 압축하기 위해 시간 피라미드를 이용한 자기회귀 비디오 생성을 설계했습니다. 전체 프레임워크는 단일 통합된 디퓨전 트랜스포머(DiT)를 사용하여 종단 간 최적화가 가능합니다. 광범위한 실험 결과, 우리의 방법은 768p 해상도와 24 FPS로 5초(최대 10초) 길이의 고품질 비디오를 생성할 수 있으며, 20.7k A100 GPU 학습 시간을 필요로 한다는 것을 보여줍니다. 모든 코드와 모델은 https://pyramid-flow.github.io에서 오픈소스화될 예정입니다.
1. 서론
비디오는 물리적 세계의 변화를 기록하는 미디어 형태입니다. AI 시스템이 다양한 비디오 콘텐츠를 생성하도록 가르치는 것은 현실 세계의 동역학을 시뮬레이션하고(예: Hu et al., 2023; Brooks et al., 2024) 인간과 상호작용하는 데 중요한 역할을 합니다(예: Bruce et al., 2024; Valevski et al., 2024). 현재 최첨단 디퓨전 모델(예: Ho et al., 2022c; Blattmann et al., 2023a; OpenAI, 2024)과 자기회귀 모델(예: Yan et al., 2021; Hong et al., 2023; Kondratyuk et al., 2024)은 데이터와 계산 자원의 확장을 통해 현실적이고 장시간의 비디오를 생성하는 데 큰 성과를 거두었습니다. 하지만 이러한 비디오 생성 모델의 훈련은 상당히 넓은 시공간 공간을 모델링해야 하므로 계산과 데이터 집약적입니다.
고차원 비디오 데이터를 생성하는 데 있어서 계산 부담을 덜기 위해 중요한 요소는 원래의 비디오 픽셀을 VAE(예: Kingma & Welling, 2014; Esser et al., 2021; Rombach et al., 2022)를 사용해 저차원 잠재 공간으로 압축하는 것입니다. 그러나 일반적인 압축률(보통 8배)은 특히 고해상도 샘플의 경우 여전히 과도한 토큰을 초래합니다. 이에 따라 널리 사용되는 접근법은 계단식 아키텍처(예: Ho et al., 2022b; Pernias et al., 2024; Teng et al., 2024)를 활용하여 고해상도 생성 과정을 여러 단계로 나누며, 샘플을 먼저 고도로 압축된 잠재 공간에서 생성한 후 추가적인 초해상도 모델을 사용하여 점진적으로 업샘플링합니다. 이러한 계단식 파이프라인은 높은 해상도에서 직접 학습하는 것을 피하고 계산 요구를 줄이는 장점이 있지만, 서로 다른 해상도에서 각기 다른 모델을 사용해야 하는 요구로 인해 유연성과 확장성이 희생됩니다. 또한 여러 서브 모델의 개별 최적화는 획득한 지식을 공유하는 데 장애가 됩니다.
본 연구는 이전의 계단식 접근법의 한계를 초월하는 효율적인 비디오 생성 모델링 프레임워크를 제안합니다. 우리의 동기는 Fig. 1(a)에서 보이는 바와 같이, 디퓨전 모델의 초기 단계가 상당히 노이즈가 많고 정보가 적다는 관찰에서 비롯됩니다. 이는 전체 생성 경로에서 항상 풀 해상도로 동작할 필요가 없음을 시사합니다. 이를 위해, 우리는 원래의 생성 경로를 서로 다른 규모의 압축된 표현에서 동작하는 피라미드 단계의 시리즈로 재해석합니다. 특히 이미지 피라미드(Adelson et al., 1984)의 효용성은 판별 신경망(Lin et al., 2017; Wang et al., 2020)뿐만 아니라 최근의 디퓨전 모델(Ho et al., 2022b; Pernias et al., 2024; Teng et al., 2024) 및 멀티모달 LLM(Yu et al., 2023; Tian et al., 2024)에서도 널리 검증되었습니다. 여기서 우리는 프레임 내의 공간 피라미드와 연속 프레임 간의 시간 피라미드 두 가지 유형을 탐구합니다(Fig. 1(b) 참조). 이러한 피라미드형 생성 경로에서는 최종 단계만 풀 해상도로 동작하며, 이는 초기 단계에서 불필요한 계산을 크게 줄여줍니다. 주요 이점은 두 가지입니다: (1) 피라미드 각 단계의 생성 경로가 서로 연결되어 이후 단계가 이전 단계에서 계속 생성할 수 있습니다. 이를 통해 일부 계단식 모델에서 각 단계가 순수 노이즈에서부터 다시 생성할 필요가 없어집니다. (2) 각 이미지 피라미드에 대해 개별 모델을 사용하는 대신 이를 단일 통합 모델로 통합하여 종단 간 최적화를 가능하게 하며, 실험을 통해 확인된 바와 같이 더욱 우아한 구현과 크게 가속된 학습이 가능합니다.

(a) Sora와 같은 비디오 디퓨전 모델 (OpenAI, 2024) (b) 우리가 제안한 피라미드 흐름 매칭
그림 1: 피라미드 흐름 매칭의 동기를 제공하는 예시: (a) 기존의 디퓨전 모델은 풀 해상도에서 동작하여 매우 노이즈가 많은 잠재 공간에 많은 계산을 소비합니다. (b) 우리의 방법은 흐름 매칭의 유연성을 활용하여 서로 다른 해상도의 잠재 변수 사이를 보간합니다. 이를 통해 시각적 콘텐츠의 생성과 압축 해제를 동시에 수행하면서 더 나은 계산 효율성을 달성할 수 있습니다. 검은색 화살표는 노이즈 제거 경로를 나타내며, 파란색 화살표는 시간적 조건을 나타냅니다.
앞서 언급한 피라미드 표현을 바탕으로, 우리는 최근 유행하는 흐름 매칭 프레임워크(Lipman et al., 2023; Liu et al., 2023; Albergo & Vanden-Eijnden, 2023)를 기반으로 하는 새로운 피라미드 흐름 매칭 알고리즘을 소개합니다. 구체적으로, 우리는 각 피라미드 해상도에 대해 구간별 흐름(piecewise flow)을 설계하였으며, 이 흐름들이 결합되어 노이즈에서 데이터로 가는 생성 과정을 형성합니다. 각 피라미드 단계 내의 흐름은 유사한 형식을 가지며, 픽셀화(압축된)되고 더 많은 노이즈가 있는 잠재 변수와 픽셀화가 제거되고(압축 해제된) 더 깨끗한 잠재 변수 사이를 보간합니다. 우리의 정교한 설계 덕분에, 이들은 통합된 흐름 매칭 목표에 의해 단일 디퓨전 트랜스포머(DiT) (Peebles & Xie, 2023)에서 함께 최적화될 수 있으며, 이를 통해 여러 개의 별도 모델 없이 시각적 콘텐츠의 생성과 압축 해제를 동시에 수행할 수 있습니다. 추론 중에는 각 단계의 출력이 교정용 가우시안 노이즈로 재노이즈화되며, 이는 연속적인 피라미드 단계들 간의 확률 경로의 연속성을 유지하는 데 기여합니다. 더욱이, 우리는 이전에 생성된 기록을 조건으로 다음 비디오 잠재 변수를 반복적으로 예측하는 자기회귀 방식으로 비디오 생성을 정식화했습니다. 전체 해상도 기록에 높은 중복성이 존재하므로, 우리는 점진적으로 압축된 저해상도 기록을 조건으로 사용하여 시간 피라미드 시퀀스를 구성함으로써 토큰 수를 줄이고 훈련 효율을 개선했습니다.
공간 피라미드와 시간 피라미드의 협력은 비디오 생성에서 놀라운 훈련 효율을 가져옵니다. 일반적으로 사용되는 전체 시퀀스 디퓨전과 비교했을 때, 우리의 방법은 훈련 중 비디오 토큰의 수를 크게 줄입니다(예: 10초, 241프레임 비디오의 경우 ≤ 15,360 토큰 대 119,040 토큰), 따라서 요구되는 계산 자원과 훈련 시간을 줄입니다. 오픈소스 데이터셋만으로 훈련하여, 우리의 모델은 768p 해상도와 24 fps로 고품질의 10초 비디오를 생성할 수 있습니다. 이 논문의 핵심 기여는 다음과 같이 요약됩니다:
- 우리는 공간 및 시간 피라미드 표현을 통합한 새로운 비디오 생성 모델링 알고리즘인 피라미드 흐름 매칭을 제안합니다. 이 프레임워크를 활용하면 훈련 효율성을 크게 향상시키면서도 비디오 생성 품질을 유지할 수 있습니다.
- 제안된 통합 흐름 매칭 목표는 피라미드 단계를 단일 디퓨전 트랜스포머(DiT)에서 공동으로 훈련하도록 하여 여러 모델의 개별 최적화를 피할 수 있습니다. 종단 간 훈련에 대한 지원은 그 단순성과 확장성을 더욱 강화합니다.
- 우리는 VBench (Huang et al., 2024) 및 EvalCrafter (Liu et al., 2024)에서 이를 평가했으며, 공공 데이터셋으로 훈련된 비디오 생성 모델들 중에서도 매우 경쟁력 있는 성능을 보여줍니다.
3 방법
본 연구에서는 효율적인 비디오 생성 모델링 방식인 피라미드 흐름 매칭을 제안합니다. 다음의 텍스트에서는 먼저 흐름 매칭 알고리즘을 (3.1절) 효율적인 공간 피라미드 표현으로 확장합니다 (3.2절). 이후 3.3절에서는 훈련 효율성을 더욱 향상시키기 위한 시간 피라미드 설계를 제안합니다. 마지막으로 3.4절에서는 실용적인 구현에 대해 논의합니다.


3.2 피라미드 흐름 매칭
비디오 생성 모델링에서 주요 도전 과제는 시공간적 복잡성입니다. 우리는 먼저 공간적 복잡성에 대해 다루고자 합니다. 그림 1에서 이전에 언급된 주요 관찰에 따르면, 초기 생성 단계는 보통 매우 노이즈가 많고 정보가 적기 때문에 풀 해상도로 동작할 필요가 없습니다. 이는 우리에게 공간적으로 압축된 피라미드 흐름을 연구하게 하는 동기가 되었으며, 이는 그림 2에 설명되어 있습니다.

여기서 Up(⋅)은 업샘플링 함수입니다. 이렇게 함으로써, 마지막 단계만 풀 해상도로 수행되며, 대부분의 단계는 저해상도로 수행되어 적은 계산을 사용합니다. 균일한 단계 분할 하에서는 공간 피라미드의 아이디어가 계산 비용을 거의 1/K로 줄입니다. 아래에서는 훈련과 추론에서 각각 피라미드 흐름의 구현 방식을 설명합니다.
3.2.1 통합된 훈련
피라미드 흐름의 구축에서 우리의 주요 관심사는 각 단계의 통합된 모델링입니다. 이전 연구들(Ho et al., 2022b; Pernias et al., 2024; Teng et al., 2024)은 모두 개별 생성 및 초해상도를 위해 여러 모델을 훈련해야 했으며, 이는 지식 공유를 방해합니다.

(a) 피라미드 흐름의 통합 모델링 (b) 리노이징을 통한 점프 포인트 처리
그림 2: 공간 피라미드의 설명
(a) 피라미드 흐름은 여러 단계로 나뉘며, 각 단계는 픽셀화되고 노이즈가 많은 시작점에서 시작해 픽셀화가 제거되고 더 깨끗한 결과로 도달합니다. (b) 추론 중에는 각 단계 간의 점프 포인트에서 경로의 연속성을 보장하기 위해 교정용 노이즈를 추가합니다.
생성과 압축/초해상도의 목표를 통합하기 위해, 우리는 서로 다른 노이즈 수준과 해상도 간의 보간을 통해 확률 경로를 구성합니다. 이 과정은 저해상도에서 업샘플링된 더 많은 노이즈와 픽셀화된 잠재 변수로 시작하여, 고해상도에서 더 깨끗하고 세밀한 결과로 도달합니다(그림 2(a) 참고). 형식적으로, 조건부 확률 경로는 다음과 같이 정의됩니다:


3.2.2 리노이징을 통한 추론
추론 과정에서는 각 피라미드 단계 내에서 표준 샘플링 알고리즘을 적용할 수 있습니다. 하지만 서로 다른 해상도의 연속 피라미드 단계 사이의 점프 포인트(Campbell et al., 2023)를 신중하게 처리해야 확률 경로의 연속성을 보장할 수 있습니다.

알고리즘 1: 피라미드 흐름 매칭을 이용한 샘플링

보정 노이즈와 그 공분산을 도출하기 위해, 우리는 가장 단순한 경우인 최근접 이웃 업샘플링을 고려합니다. 이 경우, Σ는 대각선 상의 4×4 블록에만 비영의 요소를 가지는 블록 구조를 가집니다(같은 픽셀에서 업샘플링된 요소에 해당). 이로부터 보정 노이즈의 공분산 행렬 Σ′ 역시 블록 구조를 가짐을 추론할 수 있습니다:

3.3 피라미드 시간 조건
앞선 섹션에서 다룬 공간적 복잡성을 넘어서, 비디오는 그 시간적 길이 때문에 또 다른 큰 도전을 제시합니다. 현재의 전체 시퀀스 디퓨전 방법은 모든 비디오 프레임을 동시에 생성하여, 고정된 길이의 생성만을 가능하게 하며 이는 훈련과 일치합니다. 반면에, 자기회귀 비디오 생성 패러다임은 추론 중 유연한 길이의 생성을 지원합니다. 최근의 발전(Chen et al., 2024a; Valevski et al., 2024)도 긴 시간의 비디오 콘텐츠 생성에 있어서 그 효과를 입증했습니다. 그러나 이들의 훈련은 여전히 전체 해상도의 긴 기록 조건으로 인한 계산 복잡성 때문에 심각하게 제한됩니다.

(a) 시간 피라미드는 행으로 재배열됨 (b) 공간 및 시간 피라미드에서의 위치 인코딩
그림 3: 시간 피라미드의 설명
(a) 각 피라미드 단계에서 생성은 자기회귀 모델의 훈련 효율성을 향상시키기 위해 압축된 저해상도 기록 조건에 따라 이루어지며, 이는 행으로 표시되어 있습니다. (b) 조건의 공간적 정렬을 허용하기 위해, 공간 피라미드에서는 외삽하고 시간 피라미드에서는 보간하는 호환 가능한 위치 인코딩 방식을 고안했습니다.

3.4 실용적인 구현
이 섹션에서는 위의 피라미드 설계를 표준 트랜스포머 아키텍처(Vaswani et al., 2017)와 파이프라인을 사용해 쉽게 구현할 수 있음을 보여줍니다. 이는 기존의 가속 프레임워크를 기반으로 효율적이고 확장 가능한 비디오 생성 사전 훈련을 위해 매우 중요합니다.
이전 방법들(Ma et al., 2024)이 계산 복잡성을 줄이기 위해 공간 및 시간 주의를 분리하여 사용한 것과 달리, 우리는 피라미드 표현 덕분에 필요한 토큰의 수가 훨씬 적기 때문에 전체 시퀀스 주의를 직접 사용합니다. 또한 각 트랜스포머 레이어에서는 블록 단위의 인과적(causal) 주의를 채택하여, 각 토큰이 이후 프레임에 주의를 기울일 수 없도록 합니다. C.2절의 소거 실험 결과는 이러한 인과적 주의 설계가 자기회귀 비디오 생성에 매우 중요하다는 것을 보여줍니다. 또 다른 중요한 설계 선택은 위치 인코딩인데, 피라미드 설계가 여러 공간 해상도를 도입하기 때문입니다. 그림 3(b)에 나타난 바와 같이, 공간 피라미드에서는 더 정교한 세부 사항을 위해 위치 인코딩을 외삽하고(Yang et al., 2024), 시간 피라미드 입력에서는 기록 조건을 공간적으로 정렬하기 위해 보간합니다.
훈련 중에는 각 피라미드 단계가 매 업데이트 반복마다 균등하게 샘플링됩니다. 우리의 방법의 자기회귀 특성은 비디오의 첫 번째 프레임이 이미지로 동작하기 때문에 이미지와 비디오의 공동 훈련을 본질적으로 지원합니다. 우리는 다양한 토큰 수를 가진 훈련 샘플을 함께 묶어 Patch n’ Pack(Dehghani et al., 2023)을 따라 길이 균형 훈련 배치를 구성합니다. 훈련 후, 우리의 방법은 본래 텍스트-비디오 및 텍스트 조건 이미지-비디오 생성 능력을 갖추게 됩니다. 추론 샘플링 중에는 분류기 없는 가이던스(classifier-free guidance) 전략을 사용하여 생성된 비디오의 시간적 일관성과 움직임의 부드러움을 향상시킬 수 있습니다.
4 실험
4.1 실험 설정
훈련 데이터셋.
우리 모델은 오픈소스 이미지와 비디오 데이터셋의 혼합된 코퍼스를 사용해 훈련되었습니다. 이미지의 경우, 우리는 LAION-5B(Schuhmann et al., 2022)의 고미학적(high-aesthetic) 하위 집합, CC-12M(Changpinyo et al., 2021)에서 1,100만 개, SA-1B(Kirillov et al., 2023)의 비블러(blur) 하위 집합 690만 개, JourneyDB(Sun et al., 2023)에서 440만 개, 그리고 1,400만 개의 공개적으로 사용 가능한 합성 데이터를 사용했습니다. 비디오 데이터의 경우, WebVid-10M(Bain et al., 2021), OpenVid-1M(Nan et al., 2024), 그리고 Open-Sora Plan(PKU-Yuan Lab et al., 2024)에서 주로 수집된 고해상도 비디오 100만 개를 추가했습니다. 후처리 후 약 1,000만 개의 싱글샷 비디오가 훈련에 사용되었습니다.
평가 지표.
우리는 정량적 성능 평가를 위해 VBench(Huang et al., 2024)와 EvalCrafter(Liu et al., 2024)를 사용했습니다. VBench는 비디오 생성 모델의 모션 품질과 의미적 정렬을 체계적으로 측정하기 위해 16개의 세분화된 차원을 포함하는 종합적인 벤치마크입니다. EvalCrafter는 비디오 생성 능력을 평가하기 위해 약 17개의 객관적인 지표를 포함하는 또 다른 대규모 평가 벤치마크입니다. 자동화된 평가 지표 외에도, 생성된 비디오에 대한 사람들의 선호도를 측정하기 위해 인간 참여자와 함께 연구를 진행했습니다. 비교한 기준 모델들은 부록 B에 요약되어 있습니다.
구현 세부사항.
우리는 SD3 Medium(Esser et al., 2024)의 기존 MM-DiT 아키텍처를 기본 모델로 사용하였으며, 총 20억 개의 파라미터를 가지고 있습니다. 이 모델은 공간 차원에서 사인 위치 인코딩(Vaswani et al., 2017)을 사용합니다. 시간 차원의 경우, 다양한 비디오 길이에서 유연한 훈련을 지원하기 위해 1D 회전 위치 임베딩(RoPE)(Su et al., 2024)을 추가하였습니다. 또한, 우리는 비디오를 공간적, 시간적으로 압축하기 위해 다운샘플링 비율이 8×8×8인 3D 변분 오토인코더(VAE)를 사용했습니다. 이는 MAGVIT-v2(Yu et al., 2024)와 유사한 구조를 가지고 있으며, WebVid-10M 데이터셋(Bain et al., 2021)에서 처음부터 훈련되었습니다. 모든 실험에서 피라미드 단계의 수는 3으로 설정되었습니다. Valevski et al. (2024)를 따르며, 우리는 자기회귀 생성의 저하를 완화하는 데 중요한 기록 피라미드 조건에 균일하게 샘플링된 강도 [0,1/3]의 부정적 노이즈를 추가했습니다.
4.2 효율성

표 1: VBench(Huang et al., 2024)에서의 실험 결과
총 점수와 품질 점수 측면에서, 우리 모델은 모델 크기가 두 배인 CogVideoX-5B(Yang et al., 2024)보다도 더 뛰어난 성능을 보여줍니다. 이후 표에서는 공개 데이터로 훈련된 모델들 중 가장 높은 점수를 파란색으로 표시하였습니다.

표 2: EvalCrafter(Liu et al., 2024)에서의 실험 결과. 원시 지표는 C.1절을 참조하세요.

4.3 주요 결과
텍스트-비디오 생성.
우리는 먼저 제안된 방법의 텍스트-비디오 생성 능력을 평가했습니다. 각 텍스트 프롬프트에 대해, 5초 길이의 121 프레임 비디오를 생성하여 평가하였습니다. VBench(Huang et al., 2024)와 EvalCrafter(Liu et al., 2024)에서의 자세한 정량적 결과는 각각 표 1과 표 2에 요약되어 있습니다. 전체적으로, 우리의 방법은 이 두 벤치마크에서 비교된 모든 오픈소스 비디오 생성 기준을 능가합니다. 공개적으로 접근 가능한 비디오 데이터만으로 훈련했음에도 불구하고, Kling(Kuaishou, 2024)과 Gen-3 Alpha(Runway, 2024)와 같은 훨씬 더 큰 독점 데이터를 사용해 훈련된 상업적 경쟁자와 비슷한 성능을 달성합니다. 특히, 우리는 품질 점수(84.74 vs. Gen-3의 84.11)와 VBench에서의 모션 부드러움 측면에서 뛰어난 성능을 보였으며, 이는 생성된 비디오의 시각적 품질을 반영하는 데 중요한 기준입니다. EvalCrafter에서 평가했을 때, 우리의 방법은 대부분의 비교된 방법들보다 더 나은 시각적 및 모션 품질 점수를 달성했습니다. 의미적 점수는 상대적으로 낮았는데, 이는 주로 우리가 사용한 합성 캡션이 대략적이기 때문이며, 더 정확한 비디오 캡셔닝으로 개선할 수 있습니다.

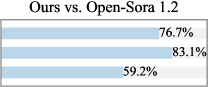
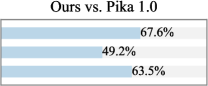
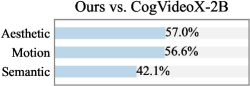


그림 4: 샘플된 VBench 프롬프트에 대한 사용자 선호도.
우리의 비디오는 5초 길이, 768p 해상도, 24fps로 생성되었습니다.
더 정확한 비디오 캡션이 제공된다면 성능이 더욱 향상될 수 있으며, 일부 생성된 5–10초 비디오는 그림 5에 제시되어 있습니다. 이 비디오는 영화적인 시각적 품질을 보여주며 피라미드 흐름 매칭의 효능을 검증합니다. 추가적인 시각화 결과는 C.3절에 제공되어 있습니다.
사용자 연구
정량적 평가 점수가 비디오 생성 능력을 어느 정도 반영하긴 하지만, 시각적 품질에 대한 인간의 선호도와 반드시 일치하지는 않습니다. 따라서, 우리는 추가적인 사용자 연구를 통해 CogVideoX(Yang et al., 2024)와 Kling(Kuaishou, 2024)을 포함한 여섯 개의 기준 모델과 우리의 성능을 비교했습니다. 우리는 VBench에서 샘플링된 50개의 프롬프트를 사용하였으며, 20명 이상의 참여자에게 생성된 비디오의 미적 품질, 모션 부드러움, 의미적 정렬을 기준으로 각 모델을 평가하도록 요청했습니다. 그림 4에서 볼 수 있듯이, 우리의 방법은 특히 모션 부드러움 측면에서 Open-Sora와 CogVideoX-2B와 같은 오픈소스 모델보다 더 선호되었습니다. 이는 피라미드 흐름 매칭을 통해 달성된 상당한 토큰 절약 덕분에, 5초(최대 10초) 768p 비디오를 24 fps로 생성할 수 있기 때문이며, 기준 모델들은 비슷한 길이의 비디오 합성을 대개 8 fps로만 지원합니다. 사용자 연구의 자세한 설정은 부록 B에 제시되어 있습니다.
이미지-비디오 생성
우리 모델의 자기회귀 속성과 인과적 주의 설계 덕분에, 각 비디오의 첫 번째 프레임은 훈련 중 이미지 조건과 유사하게 동작합니다. 따라서 우리 모델은 텍스트-비디오 생성을 위해 최적화되었음에도 불구하고, 추론 중 텍스트 조건의 이미지-비디오 생성을 자연스럽게 처리할 수 있습니다. 이미지와 텍스트 프롬프트가 주어지면, 추가적인 미세 조정 없이 정적 입력 이미지를 자기회귀적으로 예측하여 이후 프레임들을 애니메이션화할 수 있습니다. 그림 6에서는 이미지-비디오 생성 성능의 정성적 예시를 보여주고 있으며, 각 예시는 5초 동안 120개의 새로 합성된 프레임으로 구성되어 있습니다. 보시다시피, 우리 모델은 합리적인 이후의 모션을 성공적으로 예측하며, 이미지에 풍부한 시간적 동적 정보를 부여합니다. 더 많은 생성된 비디오 예시는 우리의 프로젝트 페이지 https://pyramid-flow.github.io에서 가장 잘 볼 수 있습니다.

(a) 글렌피난 고가교는 역사적인 철도 다리입니다... 증기 기차가 다리를 떠나 아치형 고가교를 지나가는 모습은 멋진 광경입니다. 풍경은 푸릇푸릇한 초목과 바위산으로 점점이 덮여 있습니다...

(b) 아름다운 눈 덮인 도쿄 도시는 활기차게 움직입니다. 카메라는 번잡한 도시 거리를 지나가며 눈이 내리는 아름다운 날씨를 즐기며 근처 가판대에서 쇼핑을 하는 몇몇 사람들을 따라갑니다. 아름다운 벚꽃 잎...

(c) 불꽃놀이가 먼 거리에서 터지는 배경으로 여성의 옆모습을 찍은 장면.
그림 5: 텍스트-비디오 생성 결과의 시각화. 상위 두 비디오는 5초, 768p, 24fps로 생성되었고, 하위 비디오는 10초, 768p, 24fps로 생성되었습니다. 더 많은 생성된 비디오는 우리의 프로젝트 페이지에서 확인하세요.

(a) 하늘에서 달이 떠오르고 땅 위의 불빛이 밝게 빛납니다.

(b) 몬스터 일러스트, 평면 디자인 스타일의 다양한 몬스터 가족. 이 그룹에는 털복숭이 갈색 몬스터, 안테나가 달린 매끈한 검은색 몬스터, 얼룩진 녹색 몬스터, 그리고 작은 물방울무늬 몬스터 등이 포함되어 있습니다...
그림 6: 텍스트 조건 이미지-비디오 생성 결과의 시각화 (5초, 768p, 24fps).

그림 7: 50k 이미지 훈련 단계에서 공간 피라미드의 소거 연구. 오른쪽에는 FID 결과의 정량적 비교가 있으며, 우리 방법이 거의 세 배의 수렴 속도를 달성한 것을 보여줍니다.

그림 8: 100k 저해상도 비디오 훈련 단계에서 시간 피라미드의 소거 연구.
4.4 소거 연구(Ablation Study)
이 섹션에서는 제안한 방법의 중요한 구성 요소들을 검증하기 위해 소거 연구를 진행합니다. 여기에는 노이즈 제거 경로의 공간 피라미드와 기록 조건의 시간 피라미드가 포함됩니다. 공간의 제한으로 인해, 다른 설계 선택에 대한 소거 연구는 C.2절에 제공됩니다.
공간 피라미드의 효과
제안된 공간 피라미드의 생성 경로에서, 최종 단계만이 풀 해상도로 동작하며, 이는 대부분의 노이즈 제거 단계에서 토큰 수를 크게 줄여줍니다. 동일한 계산 자원으로 더 많은 샘플을 한 훈련 배치에서 처리할 수 있어 수렴 속도를 크게 향상시킵니다. 그 효율성을 검증하기 위해, 초기 실험에서 텍스트-이미지 생성을 훈련하기 위해 표준 흐름 매칭 목표를 사용하는 기준 모델을 설계했습니다. 이 기준 모델은 동일한 훈련 데이터, 배치당 토큰 수, 하이퍼파라미터 설정, 모델 아키텍처를 사용하여 공정성을 보장했습니다. 성능 비교는 그림 7에 설명되어 있습니다. 피라미드 흐름을 사용하는 변형이 시각적 품질과 프롬프트 따르기 능력에서 우수함을 확인할 수 있습니다. 우리는 또한 MS-COCO 벤치마크(Lin et al., 2014)에서 3천 개의 프롬프트를 무작위로 샘플링하여 이러한 방법의 FID 지표를 정량적으로 평가했습니다. 훈련 단계에 따른 FID 성능 곡선은 그림 7의 오른쪽에 제시되어 있습니다. 표준 흐름 매칭과 비교할 때, 우리의 방법의 수렴 속도가 크게 향상된 것을 알 수 있습니다.
시간 피라미드의 효과
4.2절에서 언급한 바와 같이, 시간 피라미드 설계는 전통적인 전체 시퀀스 디퓨전과 비교하여 계산 요구를 크게 줄일 수 있습니다. 공간 피라미드와 마찬가지로, 우리는 동일한 실험 설정에서 전체 시퀀스 디퓨전 기준 모델을 설정하여 훈련 효율성 개선을 조사했습니다. 기준 모델과의 정성적 비교는 그림 8에 제시되어 있으며, 같은 훈련 단계에서 피라미드 변형이 훨씬 더 나은 시각적 품질과 시간적 일관성을 보여줍니다. 반면, 전체 시퀀스 디퓨전 기준 모델은 수렴에 도달하지 못했으며, 일관된 모션을 생성하지 못해 생성된 비디오에서 분절된 시각적 디테일과 심각한 아티팩트를 초래했습니다. 이러한 성능 차이는 비디오 생성 모델링에서 우리의 방법이 달성한 훈련 가속을 명확히 보여줍니다.
5 결론
본 연구는 피라미드 시각 표현에 기반한 효율적인 비디오 생성 모델링 프레임워크를 제시합니다. 서로 다른 이미지 피라미드를 개선하기 위해 개별 모델을 사용하는 계단식 디퓨전 모델과 달리, 우리는 피라미드 단계를 통해 시각적 콘텐츠를 동시에 생성하고 압축 해제하는 통합된 피라미드 흐름 매칭 목표를 제안하여 지식 공유를 효과적으로 촉진합니다. 또한, 비디오의 풀 해상도 기록에서 계산 중복을 줄이기 위해 시간 피라미드 설계를 도입했습니다. 제안된 방법은 VBench와 EvalCrafter에서 광범위하게 평가되어 그 우수한 성능을 입증했습니다. 모든 코드와 모델 가중치는 https://pyramid-flow.github.io에서 오픈 소스로 제공될 예정입니다.
감사의 말씀
사용자 연구에 도움을 준 Jinghan Li에게 감사드립니다.
부록 A: 유도 과정
이 섹션에서는 공간 피라미드의 점프 포인트를 처리하기 위한 식 (15)의 상세 유도 과정을 제공합니다.



부록 B: 실험 설정
모델 구현 세부사항
우리는 SD3 Medium(Esser et al., 2024)을 기반으로 한 MM-DiT 아키텍처를 채택했으며, 이는 총 24개의 트랜스포머 레이어와 20억 개의 파라미터로 구성되어 있습니다. MM-DiT의 가중치는 SD3 Medium에서 초기화됩니다. 최근의 FLUX.1(Black Forest Labs, 2024)을 따라, T5(Raffel et al., 2020)와 CLIP(Radford et al., 2021) 인코더를 프롬프트 임베딩에 사용했습니다. 비디오 데이터의 중복 문제를 해결하기 위해, 우리는 비디오를 공간적, 시간적으로 잠재 공간으로 압축하는 3D VAE를 설계했습니다. 이 VAE의 아키텍처는 MAGVIT-v2(Yu et al., 2024)와 유사하며, 각 프레임이 이전 프레임에만 의존하도록 3D 인과적(convolution)을 사용합니다. 이 모델은 잠재 변수에 대해 Kullback-Leibler(KL) 정규화를 적용한 비대칭 인코더-디코더를 특징으로 합니다. 전체적으로, 3D VAE는 픽셀을 잠재 변수로 압축하는 압축률이 8×8×8입니다. 이 모델은 WebVid-10M 및 690만 개의 SAM 이미지를 사용해 처음부터 훈련되었습니다. 매우 긴 비디오의 토크나이징을 지원하기 위해, CogVideoX(Yang et al., 2024)와 유사하게 여러 GPU에 비디오를 분산하여 계산을 나누어 처리합니다.
훈련 절차
우리 모델은 128개의 NVIDIA A100 GPU를 사용하여 세 단계의 훈련 절차를 거칩니다.
(1) 이미지 훈련. 첫 번째 단계에서는 LAION-5B(Schuhmann et al., 2022)에서 1억 8천만 개의 이미지, CC-12M(Changpinyo et al., 2021)에서 1,100만 개, SA-1B(Kirillov et al., 2023)에서 비블러 이미지 690만 개, JourneyDB(Sun et al., 2023)에서 440만 개의 이미지를 포함하는 순수 이미지 데이터셋을 사용합니다. 우리는 이미지의 원래 종횡비를 유지하며 이를 다양한 버킷으로 재배열했습니다. 총 50,000단계 동안 훈련되며, 약 1536 A100 GPU 시간이 소요됩니다. 이 단계 이후, 모델은 시각적 픽셀 간의 의존성을 학습하여 이후 비디오 훈련의 수렴을 촉진합니다.
(2) 저해상도 비디오 훈련. 이 단계에서는 WebVid-10M(Bain et al., 2021), OpenVid-1M(Nan et al., 2024), 그리고 Open-Sora Plan(PKU-Yuan Lab et al., 2024)에서 100만 개의 비워터마크 비디오를 사용합니다. 또한, 최신 비디오 이해 모델인 Video-LLaMA2(Cheng et al., 2024)를 활용하여 각 비디오 샘플에 대해 재캡션을 생성합니다. 1단계의 이미지 데이터도 각 배치에서 12.5% 비율로 사용됩니다. 우리는 모델을 먼저 2초 비디오 생성을 위해 80,000단계 동안 훈련한 후, 추가로 5초 비디오에 대해 120,000단계 동안 훈련합니다. 이 단계에서 총 약 11,520 A100 GPU 시간이 소요됩니다.
(3) 고해상도 비디오 훈련. 마지막 단계에서는 앞서 언급한 다양한 길이의 고해상도 비디오 데이터셋(5-10초)으로 모델을 계속 미세 조정하기 위해 같은 전략을 사용합니다. 최종 단계에서 50,000단계 동안 약 7,680 A100 GPU 시간이 소요됩니다.
하이퍼파라미터 설정
각 최적화 단계에 대한 상세한 훈련 하이퍼파라미터 설정은 표 3에 보고되어 있습니다.
표 3: 우리 방법의 상세한 훈련 하이퍼파라미터

기준 방법(Baseline Methods)
VBench(Huang et al., 2024)에서 우리는 여덟 개의 기준 방법과 비교합니다. 여기에는 Open-Sora Plan V1.1(PKU-Yuan Lab et al., 2024), Open-Sora 1.2(Zheng et al., 2024), VideoCrafter2(Chen et al., 2024b), Gen-2(Runway, 2023), Pika 1.0(Pika, 2023), T2V-Turbo(Li et al., 2024), CogVideoX(Yang et al., 2024), Kling(Kuaishou, 2024), 그리고 Gen-3 Alpha(Runway, 2024)가 포함됩니다. 이 중에서 Open-Sora Plan, Open-Sora, CogVideoX, Kling, 그리고 Gen-3 Alpha는 긴 비디오를 생성할 수 있습니다. EvalCrafter(Liu et al., 2024)에서는 여섯 개의 기준 모델과 비교하며, ModelScope(Wang et al., 2023a), Show-1(Zhang et al., 2024), LaVie(Wang et al., 2023b), VideoCrafter2(Chen et al., 2024b), Pika 1.0(Pika, 2023), 그리고 Gen-2(Runway, 2023)가 포함됩니다. 위의 모델들은 모두 전체 시퀀스 디퓨전을 기반으로 하며, 우리의 방법은 자기회귀 생성과 흐름 생성 모델의 장점을 결합하여 비디오 생성의 훈련 효율성을 높였습니다.

그림 9: 비디오 생성 성능에 대한 사용자 연구 인터페이스.
사용자 연구
주 논문에서의 정량적 평가를 보완하기 위해, 우리는 이러한 생성 모델에 대한 인간의 선호도를 수집하기 위한 엄격한 사용자 연구를 진행했습니다. 이를 위해 VBench 프롬프트 리스트에서 50개의 프롬프트를 샘플링하고, 기준 모델에서 각 프롬프트에 대해 하나의 생성된 비디오를 무작위로 샘플링했습니다. 총 여섯 개의 기준 모델이 고려되었으며, Open-Sora Plan V1.1(PKU-Yuan Lab et al., 2024), Open-Sora 1.2(Zheng et al., 2024), Pika 1.0(Pika, 2023), CogVideoX-2B 및 5B(Yang et al., 2024), Kling(Kuaishou, 2024)가 포함됩니다. 그런 다음 이 결과들을 우리가 생성한 비디오와 짝지어, 참가자들에게 미적 품질, 모션 부드러움, 의미적 정렬이라는 세 가지 측면에서 선호도를 평가하도록 요청했습니다. 각각의 측면은 비디오 품질의 중요한 요소를 나타냅니다. 사용자 연구를 위한 인터페이스는 그림 9에 예시되어 있으며, 사용자들은 프롬프트와 두 개의 생성된 비디오(모델의 출처를 나타내는 워터마크 등 불필요한 정보를 제거한 상태)를 받아, 세 가지 차원에서 어떤 모델이 더 나은지 선택합니다. 우리는 이 사용자 연구를 20명 이상의 참가자에게 배포하여 총 1411개의 유효한 선호도 선택을 수집하였고, 이를 통해 연구의 효과성을 보장했습니다. 이 사용자 연구의 결과는 그림 4에 제시되어 있으며, 우리 모델이 비교된 기준 모델들 사이에서 매우 경쟁력 있는 성능을 보였음을 확인할 수 있습니다.
부록 C: 추가 결과
C.1 정량적 결과
표 4: VBench (Huang et al., 2024)의 상세 결과. 요약된 결과는 표 1을 참조하세요. 공개 데이터셋으로 훈련된 모델들 중에서 가장 높은 점수를 파란색으로 표시하였습니다.

표 5: EvalCrafter (Liu et al., 2024)의 원시 지표. 기준 결과는 해당 웹사이트에서 찾을 수 있지만, LaVie(Wang et al., 2023b)에 대한 결과는 없었습니다. 요약된 결과는 표 2를 참조하세요.

이 섹션은 주 논문의 실험 섹션에서 성능 비교를 보완하기 위해 VBench(Huang et al., 2024)와 EvalCrafter(Liu et al., 2024)의 전체 결과를 제공합니다. 우리 모델의 평가는 24 fps로 생성된 5초 길이의 768p 비디오를 사용하여 수행되었습니다.
VBench (Huang et al., 2024)
VBench의 전체 실험 결과는 표 4에 나와 있습니다. 볼 수 있듯이, 우리 모델은 오픈소스와 상업적 경쟁자들 사이에서 선두 또는 매우 경쟁력 있는 결과를 달성하였으며, 특히 모션 품질과 관련된 지표에서 뛰어났습니다. 예를 들어, 우리 모델의 동적 정도(dynamic degree) 지표는 모든 모델 중 64.63으로 2위를 차지하여, 시간적 역학을 학습하는 생성 모델의 효과를 입증하였습니다. 나머지 지표에서도 우리 결과는 오픈소스 Open-Sora Plan v1.1(PKU-Yuan Lab et al., 2024) 및 Open-Sora 1.2(Zheng et al., 2024)보다 일반적으로 우수하며, 앞서 언급한 바와 같이 훨씬 낮은 훈련 계산 비용을 가지고 있습니다. 또한 우리의 결과 중 절반은 최근의 CogVideoX-5B(Yang et al., 2024)를 능가했으며, 이는 더 큰 DiT 모델을 기반으로 한 것임에도 불구하고 우리 모델의 성능을 보여줍니다. 반면에, 우리 모델은 색상 및 외형 스타일과 같은 지표에서 비교적 낮은 성능을 보였으며, 이는 이미지 생성 능력 및 세밀한 프롬프트 따르기와 관련이 있습니다. 이는 비디오 LLM을 기반으로 한 비디오 캡셔닝 절차가 대략적인 캡션을 생성하는 경향이 있기 때문에 이러한 능력을 저해한 부분이 큽니다. 그럼에도 불구하고, 비디오 생성을 첫 프레임 생성과 이후 프레임 생성으로 나누는 자기회귀 생성 프레임워크 덕분에, 향후 훈련 단계에서 추가적으로 잘 캡션된 이미지 데이터를 사용하여 이러한 이미지 품질 문제를 별도로 해결할 수 있습니다. 마찬가지로, 인체 구조로 악명이 높은 SD3-Medium 가중치 초기화로 인해 인간 행동 지표에서 낮은 점수를 기록하였으며, 이는 다른 기본 모델로 전환하거나 처음부터 훈련하여 해결할 수 있을 것입니다.
EvalCrafter (Liu et al., 2024)
EvalCrafter의 원시 지표는 표 5에 제공되어 있습니다. 전체적으로 우리 모델은 대부분의 지표에서 매우 경쟁력 있는 성능을 발휘하며, 이전의 많은 오픈소스 및 폐쇄형 모델을 능가합니다. 특히, 시간적 모션 품질과 관련된 모션 AC 점수에서 우리 방법은 모든 방법 중 2위를 기록하여, 피라미드 설계가 비디오에서 복잡한 시공간 패턴을 학습할 수 있는 능력을 입증했습니다. 또한 의미적 정렬과 관련된 BLIP-BLUE 및 CLIP 점수와 같은 여러 다른 지표에서도 우위를 보여주었습니다. 비교된 모델들, 포함하여 폐쇄형 모델인 Gen-2(Runway, 2023)를 대상으로 두 지표 모두에서 상위 두 개에 위치한 것은 우리 모델이 텍스트-비디오 의미적 정렬에서 가지는 장점을 확인해줍니다. 우리 모델이 성능이 떨어지는 유일한 지표는 얼굴 일관성(face consistency)으로, 이는 기록 조건을 압축하기 위해 채택한 시간 피라미드 설계 때문입니다. 우리는 이를 더 정교한 시간적 압축 방식으로 해결할 수 있는 문제로 보고 있습니다.
C.2 소거 연구(Ablation Study)

그림 10: 추론 단계에서 보정 리노이징에 대한 소거 연구

그림 11: 100k 훈련 단계에서 블록 단위 인과적 주의에 대한 소거 연구
이 섹션에서는 제안한 피라미드 흐름 매칭에서 중요한 두 가지 설계 세부 사항에 대한 추가 소거 연구를 수행합니다. 여기에는 공간 피라미드 추론 중 추가된 보정 노이즈와 자기회귀 비디오 생성을 위해 사용된 블록 단위 인과적 주의가 포함됩니다.
보정 노이즈의 역할
공간 피라미드에서 그 효용성을 연구하기 위해, 우리는 이 보정 가우시안 노이즈를 추가하지 않고 추론하는 기준 방법을 설계했습니다. 우리 방법과 이 변형 방법의 상세 비교 결과는 그림 10에 나와 있습니다. 기준 방법은 전반적인 구조는 정확하나, 세밀하고 고해상도의 풍부한 디테일을 가진 이미지를 생성하지 못하고, 대신 블록 같은 아티팩트가 있는 흐릿한 이미지를 생성합니다(확대할 때 더 잘 보임). 이는 서로 다른 해상도의 피라미드 단계 간의 점프 포인트에서 업샘플링 함수를 적용하는 것이 공간적으로 인접한 잠재 값들 사이의 과도한 상관성을 초래하기 때문입니다. 이에 비해, 우리가 생성한 이미지는 풍부한 디테일과 생동감 있는 색상을 가지며, 채택된 보정 리노이징 방식이 공간 피라미드에서 발생하는 아티팩트 문제를 효과적으로 해결했음을 확인시켜줍니다.
인과적 주의의 효과
그림 11에서 우리는 블록 단위 인과적 주의와 전체 시퀀스 디퓨전에서 사용된 양방향 주의를 비교하여 그 효과를 연구합니다. 직관적으로 양방향 주의는 정보 교환을 촉진하고 모델의 수용 능력을 증가시킨다고 생각될 수 있지만, 이는 자기회귀 비디오 생성에 대해 충분히 연구되지 않았습니다. 초기 실험에서는, 서로 다른 잠재 프레임 사이에 양방향 주의를 사용하는 기준 모델을 훈련하였으며, 그 결과는 그림 11에 시각화되어 있습니다. 1초 비디오의 샘플링된 키프레임에서 볼 수 있듯이, 이 모델은 생성된 비디오의 대상이 계속해서 모양과 색상이 변하여 시간적 일관성이 부족합니다. 반면, 우리 모델은 합리적인 모션과 함께 좋은 시간적 일관성을 보여줍니다. 이는 양방향 주의의 기록 조건이 진행 중인 생성에 의해 영향을 받아 일탈하는 반면, 인과적 주의의 기록 조건은 고정되어 있어 자기회귀 생성 과정을 안정화시키기 때문이라고 추론됩니다.
C.3 시각화

그림 12: Gen-3 Alpha(Runway, 2024)와 Kling(Kuaishou, 2024)과 같은 최첨단 폐쇄형 모델과 생성된 비디오 시각화 비교.
우리 모델은 텍스트 프롬프트를 충실히 따르면서도 영화적인 시각적 품질을 제공함.

그림 13: CogVideoX(Yang et al., 2024)와의 생성된 비디오 시각화 비교.
우리 모델은 동일한 모델 크기인 CogVideoX-2B를 능가하며, 5B 버전과도 유사한 성능을 보임.
이 섹션에서는 Gen-3 Alpha(Runway, 2024), Kling(Kuaishou, 2024), CogVideoX(Yang et al., 2024)와 같은 최근 주요 모델과 비교하여 텍스트-비디오 생성의 추가 정성적 결과를 제공합니다. 생성된 비디오에서 균등하게 샘플링된 프레임은 그림 13과 12에 나와 있으며, 우리 비디오는 5초, 768p, 24fps로 생성되었습니다. 전반적으로, 우리 모델은 공개 데이터만으로 훈련되고 적은 계산 비용을 사용했음에도 불구하고, 기준 모델들 사이에서 매우 경쟁력 있는 시각적 미학과 모션 품질을 제공합니다.
구체적으로, 결과는 우리 모델의 다음과 같은 특성을 강조합니다: (1) 생성 사전 훈련을 통해, 우리 모델은 영화 품질과 합리적인 콘텐츠의 비디오를 생성할 수 있습니다. 예를 들어, 그림 12(a)에서 우리의 생성 비디오는 "지구 표면에서 일어나는 대규모 폭발"로 인한 버섯 구름을 보여주며, 이는 SF 영화 분위기를 자아냅니다. 하지만 현재 모델은 그림 12(b)의 "소금 사막"과 같은 일부 프롬프트에 완전히 충실하지 않으며, 이는 더 정교한 캡션 데이터를 만들어 해결할 수 있을 것입니다. (2) SD3-Medium(Esser et al., 2024)에서 초기화된 20억 개의 파라미터만으로도 우리 모델은 추가 훈련 데이터를 갖춘 동일한 모델 크기의 CogVideoX-2B를 분명히 능가하며, 일부 측면에서는 5B 전체 버전과도 유사한 성능을 보입니다. 예를 들어, 그림 13(a)와 (b)에서는 우리 모델과 그 5B 버전만이 입력 프롬프트에 따라 합리적인 바다 물결을 생성할 수 있었으며, 2B 변형 모델은 거의 정적인 바다 표면만을 묘사했습니다. 이는 주로 훈련 효율성을 높이기 위한 피라미드 흐름 매칭 덕분입니다. 전반적으로, 이러한 결과는 공간 및 시간 피라미드 설계를 통해 복잡한 시공간 패턴을 모델링하는 데 있어 우리 접근 방식의 효과를 입증합니다. 생성된 비디오는 https://pyramid-flow.github.io에서 가장 잘 볼 수 있습니다.
부록 D: 한계점
우리 방법은 자기회귀 생성만을 지원하며, 키프레임 보간이나 비디오 보간으로 확장할 수 없습니다. 또한, 훈련 효율성을 향상시키기 위한 시간 피라미드 설계가 때때로 주제 일관성의 미묘한 문제를 초래할 수 있으며, 특히 장기적으로 그럴 수 있습니다. 이는 일반적인 문제가 아니지만, 보다 정교한 시간 압축 방법을 개발하는 것이 우리 비디오 생성 모델의 광범위한 적용 가능성에 있어 중요하다고 생각합니다.
훈련 데이터와 관련된 몇 가지 문제도 있습니다. 데이터 큐레이션에서 프롬프트 재작성 절차를 포함하지 않았기 때문에, 실험 결과는 비교적 짧은 프롬프트에 초점이 맞추어져 있습니다. 또한, 데이터 필터링 절차로 인해, 우리 모델은 훈련 중 장면 전환을 학습하지 못했습니다. 이는 추가적인 모델을 장면 디렉터로 도입하여 극복할 수 있을 것입니다(Lin et al., 2024).



