https://arxiv.org/abs/2410.04221
TANGO: Co-Speech Gesture Video Reenactment with Hierarchical Audio Motion Embedding and Diffusion Interpolation
We present TANGO, a framework for generating co-speech body-gesture videos. Given a few-minute, single-speaker reference video and target speech audio, TANGO produces high-fidelity videos with synchronized body gestures. TANGO builds on Gesture Video Reena
arxiv.org
요약
우리는 TANGO라는 동시 음성-제스처 비디오 생성 프레임워크를 소개합니다. 몇 분 길이의 단일 화자 레퍼런스 비디오와 목표 음성 오디오가 주어졌을 때, TANGO는 고품질의 제스처가 동기화된 비디오를 생성합니다. TANGO는 Gesture Video Reenactment(GVR)를 기반으로 구축되었으며, 이는 비디오 프레임을 노드로, 유효한 전이를 엣지로 나타내어 디렉션 그래프 구조를 사용하여 비디오 클립을 나누고 검색합니다. 우리는 GVR의 두 가지 주요 한계인 오디오-모션 불일치와 GAN이 생성한 전이 프레임에서 발생하는 시각적 아티팩트를 해결하고자 합니다. 특히, (i) 교차 모달 정렬을 개선하기 위해 잠재 특징 거리를 사용하여 제스처를 검색하는 방식을 제안합니다. 이 잠재 특징이 음성 오디오와 제스처 모션 간의 관계를 효과적으로 모델링할 수 있도록, 우리는 계층적 결합 임베딩 공간(AuMoCLIP)을 구현했습니다; (ii) 높은 품질의 전이 프레임을 생성하기 위해 확산 기반 모델을 도입했습니다. 우리의 확산 모델인 Appearance Consistent Interpolation (ACInterp)은 AnimateAnyone을 기반으로 구축되었으며, 참조 모션 모듈과 호모그래피 배경 흐름을 포함하여 생성된 비디오와 레퍼런스 비디오 간의 일관된 외형을 보존합니다. 이러한 구성 요소들을 그래프 기반 검색 프레임워크에 통합하여, TANGO는 현실적이고 오디오와 동기화된 비디오를 안정적으로 생성하며 기존의 모든 생성 및 검색 방법을 능가합니다. 코드와 사전 학습된 모델은 다음에서 제공됩니다: https://pantomatrix.github.io/TANGO/

그림 1: TANGO는 모션 그래프 기반 검색 접근 방식을 사용하여 동시 음성-제스처 비디오를 생성하도록 설계된 프레임워크입니다. 이는 목표 음성 오디오와 가장 일치하는 대부분의 참조 비디오 클립을 암묵적 계층적 오디오-모션 임베딩 공간을 이용해 먼저 검색합니다. 이후, 확산 기반 보간 네트워크를 채택하여 남은 전이 프레임을 생성하고 클립 경계에서의 불연속성을 부드럽게 합니다.
1. 서론
이 논문은 참조 화자의 대화 비디오로부터 고화질의 동시 음성-제스처 비디오를 생성하는 문제를 다룹니다. 얼굴 생성 기술에서 큰 진전이 이루어진 이후 (Prajwal et al., 2020), 우리의 목표는 새로운, 보지 않은 음성 오디오와 동기화된 몸 제스처를 비디오에 적용하는 것입니다. 제스처가 동기화된 대화 영상을 성공적으로 생성하면 뉴스 방송이나 가상 유튜브 콘텐츠 제작 등 실제 응용에서 제작 비용을 크게 줄일 수 있습니다.

그림 2: GVR(Zhou et al., 2022)의 한계.
음성으로부터 제스처가 동기화된 비디오를 생성하는 것은 유망하지만, 사람들은 비디오의 텍스처 품질뿐 아니라 제스처와 음성의 음향 및 의미적 특성 간의 관계에 매우 민감하기 때문에 많은 도전이 있습니다. 기존 방법들은 대체로 생성(generative)과 검색(retrieval) 두 가지 그룹으로 분류될 수 있습니다. 생성 방식(Ginosar et al., 2019; Qian et al., 2021)은 주어진 오디오나 오디오에서 추정한 2D 포즈로부터 모든 프레임을 비디오 생성 신경망을 통해 생성합니다(Chan et al., 2019). 반면 검색 방식(Zhou et al., 2022)은 기존 프레임들을 재조합하여 오디오와 맞추고 재조합 경계를 위한 몇 개의 전이 프레임을 생성합니다. 생성 방식은 종종 손이나 옷 텍스처에서 시간적 블러와 같은 아티팩트가 발생하는 문제가 있습니다. 이러한 한계 때문에 현실 세계에서 더 높은 비디오 품질을 보장하는 검색 방식을 선택했습니다
Audio-Driven Gesture Video Reenactment (GVR) (Zhou et al., 2022)는 우리가 아는 한 제스처 비디오 생성에 대한 첫 번째이자 유일한 검색 기반 방법입니다. GVR은 비디오를 동일한 길이의 하위 클립으로 나누고 모션 그래프 기반(Kovar et al., 2008) 접근법으로 이를 재구성합니다. 그러나 그림 2에서 보듯이 GVR에는 두 가지 주요 구성 요소에서 아티팩트가 나타납니다. 첫째, 목표 음성 오디오와 검색된 제스처 비디오 간의 정렬이 제한적인데, 이는 검색이 단순히 오디오 시작 특성과 키워드 매칭에 의존하기 때문입니다. 둘째, GAN 기반 보간 네트워크의 성능은 정확한 옵티컬 플로우(Fleet & Weiss, 2006; Ilg et al., 2017)를 예측하는 능력에 의해 제한되며, 그로 인해 손이 왜곡되는 등의 아티팩트가 발생합니다.
이를 해결하기 위해 우리는 GVR의 모션 그래프 기반 프레임워크를 재현하고 두 가지 개선을 도입했습니다: 암묵적 특징 거리 기반 제스처 검색 방법과 확산 기반 보간 네트워크입니다. 첫 번째 방법(AuMoCLIP)은 계층적 오디오-모션 공동 임베딩 공간을 도입하여 페어링된 오디오 및 모션 모달리티 데이터를 인접한 잠재 공간으로 인코딩합니다. 훈련 파이프라인은 로컬 및 글로벌 연관성을 학습하기 위해 저수준 및 고수준 공동 임베딩 공간을 나누도록 설계되었습니다. 훈련이 끝난 후, 이 공동 임베딩을 사용하여 목표의 보지 않은 오디오에서 제스처를 검색합니다. 두 번째, Appearance Consistent Interpolation (ACInterp)은 확산 기반 보간 네트워크로, AnimateAnyone (Hu et al., 2023)을 기반으로 구축되어 기존 흐름 기반 보간 방법에서 발생하는 블러 및 고스트 아티팩트를 제거하며 (Huang et al., 2022; Kong et al., 2022; Reda et al., 2022; Lu et al., 2022; Zhou et al., 2022), 생성된 비디오와 참조 비디오 간의 외형 일관성을 유지하기 위해 호모그래피 배경 흐름과 참조 모션 모듈을 활용합니다. 이러한 개선을 통합함으로써 우리 방법인 TANGO는 오디오 입력과 정확하게 일치하는 제스처와 함께 그럴듯한 비디오를 생성할 수 있습니다. 우리의 기여는 다음과 같이 요약할 수 있습니다:
• 목표 음성 오디오를 기반으로 제스처를 정확하게 검색하기 위해 계층적 오디오-모션 공동 임베딩 공간, AuMoCLIP을 제안합니다. 우리의 지식으로는 AuMoCLIP은 오디오-모션 모달리티 간의 CLIP과 같은 임베딩 공간을 제시한 최초의 작업입니다.
• 공간 및 시간 비디오 아티팩트를 줄이고 외형 일관성이 있는 비디오 클립을 생성하기 위해 확산 기반 보간 네트워크, ACInterp을 소개합니다.
• 무한 길이의 동시 음성 제스처 비디오를 생성하기 위해 그래프 가지치기(graph pruning) 방법을 사용하는 모션 그래프 기반 제스처 검색 프레임워크를 재현하고 개선하였습니다.
• 제스처 비디오 생성 모델을 검증하기 위해 12명의 화자 데이터를 포함하는 소규모 배경이 깨끗한 동시 음성 비디오 데이터셋, YouTube Business를 공개합니다.
• 위 구성 요소들을 TANGO에 통합하여 기존 생성 및 검색 방법보다 Talkshow-Oliver 데이터셋과 새롭게 도입된 YouTube Business 데이터셋에서 정량적, 정성적으로 모두 뛰어난 성능을 보여줍니다.
2. 관련
연구 우리의 방법론은 생성 및 검색 기반 동시 음성 비디오 생성, 교차 모달 검색, 그리고 비디오 프레임 보간과 관련된 이전 연구들과 관련이 있습니다.
생성 기반 동시 음성 비디오 생성
생성 기반 접근(Qian et al., 2021; Liu et al., 2022a; Yoon et al., 2020; Liu et al., 2022b; Yang et al., 2023a; b; Zhu et al., 2023; Yi et al., 2023; Pang et al., 2023; Nyatsanga et al., 2023; He et al., 2024b)은 주어진 오디오에서 두 단계 파이프라인을 통해 모든 프레임을 생성합니다. 예를 들어 speech2gesture 및 음성 기반 템플릿(Ginosar et al., 2019; Qian et al., 2021) 등의 방법들은 처음에 오디오를 특화된 네트워크를 통해 포즈로 매핑하고, 이후 별도의 GAN 기반 pose2video 사전 학습 모델(Chan et al., 2019)을 사용해 이러한 포즈를 비디오 프레임으로 변환합니다. 최근 연구들은 확산 모델을 사용하여 pose2video의 성능을 개선했습니다. 예를 들어 AnimateAnyone(Hu et al., 2023)은 참조 네트(attention-based) 모션 모듈(Guo et al., 2023)을 활용하여 공간적 및 시간적 일관성을 유지합니다. 전반적으로, 생성 방법으로부터의 골격 수준 결과는 대개 오디오와 일치하지만, pose2video 단계(Chan et al., 2019; Zhang et al., 2023b; Hu et al., 2023; Rombach et al., 2022)가 병목 현상으로 손과 옷 텍스처에서 시간적 블러 같은 아티팩트가 자주 발생합니다. 이는 네트워크가 높은 해상도, 장기적 시간 일관성, 다양한 신체 변형을 처리해야 하기 때문입니다. 이러한 한계는 기존 비디오 프레임을 재사용하는 우리의 접근이 가진 이점을 보여줍니다. 우리의 방법에서는 pose2video가 시작 및 끝 프레임이 있는 짧은 클립에서만 필요하기 때문에, 최소한의 아티팩트로 높은 품질의 결과를 유지할 수 있습니다.
검색 기반 동시 음성 비디오 생성
Gesture Video Reenactment(GVR) (Zhou et al., 2022)은 모션 그래프 기반(Kovar et al., 2008) 프레임워크를 사용해 음성 오디오로부터 제스처 모션을 검색하는 첫 번째 시도입니다. 이 방법은 세 가지 주요 단계로 이루어져 있습니다: (i) 3D 모션 및 2D 이미지 도메인 거리를 기반으로 모션 그래프를 생성, (ii) 오디오 시작과 키워드 매칭을 통해 이 그래프 내에서 목표 음성에 대한 최적의 경로를 검색, (iii) 흐름 왜곡 및 GAN 기반 보간 네트워크를 사용해 불연속 프레임을 혼합하는 것입니다. 우리 방법은 학습된 특징 기반 검색 및 확산 기반 보간 모듈을 통합함으로써 GVR을 개선하여 더 나은 교차 모달 정렬과 높은 품질의 전이를 제공합니다.
교차 모달 검색
교차 모달 검색은 학습된 특징 공간 내에서 다른 모달리티 간의 연관성을 맞추는 것을 목표로 합니다. CLIP 시리즈(Radford et al., 2021; Li et al., 2022; 2023a)는 텍스트와 이미지를 대조 학습을 사용해 맞춥니다. 텍스트-모션 도메인에서는 MotionCLIP (Tevet et al., 2022)이 모션을 고정된 사전 학습된 CLIP 텍스트 공간과 맞춥니다. GestureDiffCLIP(Ao et al.,)은 제스처 모션을 음성 대본과 최대 풀링을 사용해 맞춥니다. 그러나 제스처 모션을 검색하기 위해 텍스트 전용 특징을 사용하는 것은 시간 정보의 부족 때문에 어려움을 겪습니다. 이전 방법들과 달리, 우리는 오디오와 모션 모달리티 간의 직접적인 공동 임베딩 공간을 제안합니다.
비디오 프레임 보간
비디오 프레임 보간(VFI)은 두 기존 프레임 사이의 중간 프레임을 생성하는 것을 목표로 합니다. VFI에 대한 주류 접근법은 딥러닝과 옵티컬 플로우 기반 기법의 통합입니다(Liu et al., 2017; Jiang et al., 2018; Niklaus & Liu, 2018; Xue et al., 2019; Niklaus & Liu, 2020; Park et al., 2020; 2021; Sim et al., 2021; Wu et al., 2022; Danier et al., 2022; Kong et al., 2022; Reda et al., 2022; Huang et al., 2022; Li et al., 2023b). 옵티컬 플로우 방법은 프레임 간의 픽셀 이동을 추정하여 보간 과정을 안내합니다. 그러나 이들 방법은 여전히 고주파 세부 사항, 크거나 빠른 움직임, 가림 현상, 그리고 메모리 요구 사항을 균형 있게 처리하는 데 어려움을 겪고 있습니다. CNN과 트랜스포머를 결합한 하이브리드 모델(Lu et al., 2022; Zhang et al., 2023a; Park et al., 2023) 및 확산 모델(Voleti et al., 2022; Danier et al., 2024; Jain et al., 2024)은 최근 더 일관성 있고 선명한 결과를 보여주었지만, 높은 메모리 용량을 필요로 합니다(예: 256x256 이미지 훈련에 76GB 메모리 필요). 이러한 이유로 이러한 방법을 실제 고해상도 비디오로 확장하는 것은 여전히 도전적입니다. 우리의 방법은 잠재 확산 기반 아키텍처와 시간 우선 접근을 통합하여 시각적 충실도와 계산 효율성을 향상시킵니다.
동시 음성 비디오 생성에서 입술 동기화
이전 동시 음성 제스처 비디오 생성 연구들(Zhou et al., 2022; He et al., 2024a)과 마찬가지로, 우리의 방법도 몸 제스처에만 초점을 맞추고 입술 동기화는 Wav2Lip (Prajwal et al., 2020)를 사용한 후처리로 처리합니다. 입술 동기화와 몸 제스처 생성을 분리하는 이유는 성능 때문인데, 분리된 파이프라인이 더 높은 SyncNet 점수를 갖기 때문입니다(Prajwal et al., 2020). 오디오가 입술 움직임과 더 강하게 상관관계를 가지기 때문에, 이들을 별도로 처리하는 것이 유리합니다.

그림 3: TANGO의 시스템 파이프라인. TANGO는 세 단계로 제스처 비디오를 생성합니다. 첫째, 디렉션 모션 그래프를 생성하여 비디오 프레임을 노드로 나타내고 유효한 전환을 엣지로 나타냅니다. 각 샘플 경로(굵은 선)는 선택된 재생 순서를 결정합니다. 둘째, 오디오 조건 제스처 검색 모듈이 교차 모달 특징 거리를 최소화하여 제스처가 목표 오디오와 가장 잘 맞는 경로를 찾도록 합니다. 마지막으로, 확산 기반 보간 모델이 원본 참조 비디오에 전환 엣지가 존재하지 않을 때 외형 일관성이 있는 연결 프레임을 생성합니다.
3. TANGO

그림 4: 그래프 가지치기. 우리는 그래프에서 비활성 종점을 가진 경로를 삭제하고 강한 연결 성분(SCC) 하위 그래프들을 병합합니다. 즉, 초기 제스처 비디오 그래프(왼쪽)에서 출력 차수가 없는 노드로 끝나는 경로를 삭제하고 강하게 연결된 하위 그래프(오른쪽)를 얻습니다. 가지치기된 그래프의 각 노드는 이 하위 그래프 내에서 모든 다른 노드에 도달할 수 있어 긴 비디오를 효율적으로 샘플링할 수 있습니다. 경로의 색상은 한 명의 화자를 위한 참조 비디오 클립의 차이를 나타냅니다.
우리의 TANGO는 그림 3에 나와 있듯이 목표 음성 오디오를 기반으로 제스처 비디오를 재생성하는 모션 그래프 기반 프레임워크입니다. 초기에는 VideoMotionGraph 베이스라인(Zhou et al., 2022)의 구현을 바탕으로 그래프 가지치기를 도입하여 디렉션 제스처 비디오 모션 그래프를 생성합니다(섹션 3.1). 이 그래프에서 각 노드는 비디오의 오디오 및 이미지 프레임을 나타내고, 각 엣지는 프레임 간의 유효한 전환을 나타냅니다. 목표 오디오가 주어지면, 그 시간적 특징은 사전 학습된 오디오-모션 공동 임베딩 네트워크(AuMoCLIP)를 통해 추출됩니다. 이 특징들은 이후 비디오 재생 경로의 하위 집합을 검색하는 데 사용됩니다(섹션 3.2). 원본 참조 비디오 내에 전환 엣지가 존재하지 않을 경우, 프레임 보간 네트워크(ACInterp)를 사용하여 매끄러운 전환을 보장합니다(섹션 3.3). 이를 통해 검색된 경로에서 각 전환이 현실적인 비디오 프레임으로 구성되도록 합니다. 위 세 단계를 거친 후 TANGO는 신뢰성 있고 오디오와 동기화된 제스처 비디오를 안정적으로 생성할 수 있습니다.

알고리즘 1: 그래프 가지치기 방법을 통한 연결성 향상
이 알고리즘은 그래프의 불필요한 경로를 제거하고 남은 노드 간의 연결성을 강화하여 그래프 내 모든 노드가 다른 모든 노드에 도달할 수 있도록 합니다. 이는 효율적인 긴 비디오 경로 샘플링을 가능하게 하고, 결과적으로 제스처와 오디오가 잘 동기화된 비디오를 생성하는 데 기여합니다.
3.1 그래프 구성
그래프 초기화
TANGO는 노드와 엣지로 구성된 그래프 구조 𝐆(𝐍, 𝐄)로 표현됩니다. Gesture Video Reenactment(GVR)(Zhou et al., 2022)와 유사하게, 노드 𝐍 = {𝐧1, 𝐧2, …, 𝐧i}는 참조 비디오에서 추출한 4프레임의 중첩되지 않는 클립으로 정의되며, 각 클립에는 RGB 이미지 프레임과 오디오 파형이 포함되어 있습니다. 노드 간의 유효한 전이(엣지) 𝐄 = {𝐞1,1, 𝐞1,2, …, 𝐞i,j}의 존재 여부는 3D 모션 공간과 2D 이미지 공간에서의 유사도를 기반으로 결정됩니다.
3D 공간에서의 유사도는 신체 전체 3D 관절의 위치를 통해 계산됩니다. 3D 포즈는 최신의 오픈 소스 SMPL-X(Pavlakos et al., 2019) 추정 방법(Yi et al., 2023)을 사용해 추출됩니다. 클립 간의 포즈 비유사도 𝒟_pose(𝐧i, 𝐧j)는 모든 관절에 걸쳐 위치와 속도의 유클리드 거리를 평균하여 결정됩니다.
2D 이미지 공간에서의 유사도는 신체 분할 및 손 경계 상자를 기반으로 한 교집합 대 합집합(IoU)로 계산됩니다. 신체 분할은 이미지에서 보이는 전경 영역을 나타내며, MM-Segmentation(Contributors, 2020)을 통해 계산되고, 손의 경계 상자는 MediaPipe(Lugaresi et al., 2019)로 얻습니다. 각 프레임 쌍의 이미지 공간 비유사도는 가시 표면 영역의 (1 - IoU)로 추정됩니다: 𝒟_iou(𝐧i, 𝐧j).
노드 𝐧i와 𝐧j 쌍에 대해 거리 d_i,j = 𝒟_pose(𝐧i, 𝐧j) + 𝒟_iou(𝐧i, 𝐧j)를 사용하며, 거리가 사전에 정의된 임계값을 넘지 않는 경우 엣지 𝐞i,j가 존재합니다. 우리는 전환 거리를 평균하여 적응형 임계값을 사용합니다: t_i,j = (d_i,i−1 + d_i,i + d_i,i+1)/3, 이는 원본 비디오에서 전환의 평균 거리를 의미합니다.
그래프 가지치기
GVR에서 얻어진 초기 모션 그래프는 연결성이 제한적이며, 이는 그림 4에 나타난 바와 같이 긴 경로를 샘플링하는 효율을 저하시킵니다. 빔 탐색(Beam search) 및 동적 프로그래밍과 같은 탐색 알고리즘은 보통 모션 그래프에서 출력 엣지가 없는 노드, 즉 '죽은 끝점'에 도달하게 됩니다. 특히 샘플 경로가 죽은 끝점에 도달할 확률은 샘플 길이에 따라 증가하며, 10초 비디오를 무작위로 샘플링할 때는 75.9%, 30초 비디오에서는 98.6%에 달합니다. 이 문제를 해결하기 위해 우리는 강한 연결 성분(SCC) 하위 그래프들을 병합하는 그래프 가지치기 방법을 도입합니다. 강한 연결 성분은 각 노드가 하위 그래프 내에서 다른 모든 노드에 도달 가능한 최대 하위 그래프를 의미합니다. 구체적으로, 우리는 알고리즘 1을 사용하여 그래프 내 어느 지점에서든 시작해 원하는 길이의 비디오를 샘플링할 수 있는 강한 연결 성분을 얻습니다.
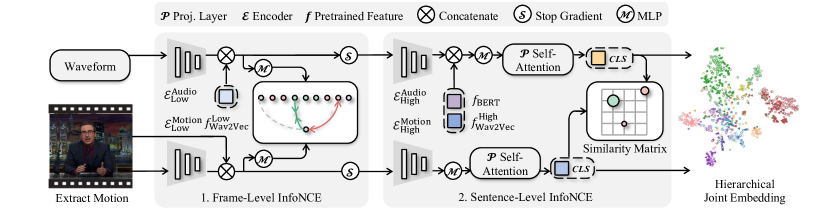
그림 5: AuMoCLIP. AuMoCLIP은 계층적 공동 임베딩을 훈련하기 위한 파이프라인입니다. 오디오 파형과 추출된 3D 모션은 학습된 임베딩 공간에서 인코딩되며, 페어링된 오디오와 모션은 비페어링 샘플보다 가까운 거리를 가집니다. 듀얼 타워 인코더 아키텍처를 사용하며, 각 인코더는 저수준 및 고수준 하위 인코더로 나뉩니다. 또한, 사전 학습된 Wav2Vec2와 BERT 특징을 포함하여 작동하게 만듭니다. 임베딩은 로컬 및 글로벌 교차 모달 정렬을 위해 각각 프레임 단위 및 클립 단위 대조 손실로 훈련됩니다. 프레임 단위 손실은 가까운 시간 창(i±t) 내의 프레임이 양성인 반면, 먼 프레임(i−kt, i−t)과 (i+t, i+kt)은 음성으로 설정하여 설계되었습니다.
3.2 오디오 기반 제스처 검색
원래의 제스처 비디오 재현 방법은 오디오 기반 경로 검색을 위해 시작점(onset)과 하드 코딩된 키워드를 사용했습니다. 그러나 이 방법에는 몇 가지 한계가 있습니다:
- 화자가 항상 오디오 시작점과 동기화되어 움직이지 않을 수 있습니다.
- 이진적 성질의 시작점은 유사한 샘플 간의 구별력이 약합니다.
- 키워드가 참조 비디오 클립에 없을 경우 일치하는 결과가 없습니다.
이러한 한계로 인해 불일치한 결과가 발생합니다. 따라서 우리는 오디오와 모션 간의 시간적 연관성을 암묵적으로 모델링하기 위해 학습 방법을 도입합니다. 그림 5에서 보듯이, 우리의 접근법은 짧은 오디오-모션 비트 정렬과 장기적 콘텐츠 유사성을 동시에 고려하기 위해 계층적 오디오-모션 공동 임베딩을 학습합니다. 우리가 아는 한, 우리의 AuMoCLIP은 제스처 오디오와 모션 모달리티 간에 CLIP과 같은 특징을 학습한 최초의 파이프라인입니다. 우리는 설계를 세 가지 주요 측면에서 논의합니다: i) 모델 아키텍처, ii) 손실 설계, iii) 훈련 일정.
AuMoCLIP의 아키텍처
CLIP 기반 대조 학습 프레임워크와 MoCoV2(Chen et al., 2020)에서 영감을 받아, 우리는 글로벌 InfoNCE 손실로 학습된 듀얼 타워 아키텍처로 시작합니다. 오디오-모션 모달리티를 위한 핵심 설계는 저수준과 고수준 인코더의 분리입니다. Wav2Vec2(Baevski et al., 2020)를 따르며, 오디오는 원시 파형으로 나타내고 오디오 인코더로 7계층 CNN(저수준)과 1계층 트랜스포머(고수준)를 사용합니다. 모션의 경우, NeMF(Guo et al., 2022)에서 영감을 받아, 15차원 표현과 모션 인코더로 28계층 CNN(TMO2에서 수정됨(Guo et al., 2022))과 1계층 트랜스포머를 사용합니다. CNN의 처음 10계층은 저수준 모션 인코더로 사용됩니다. 그림 5에서 보듯이, 우리는 저수준 특징을 매핑하기 위해 투영 MLP를 사용하며, 고수준 특징을 요약하기 위해 투영 자가 주의를 사용해 CLS 토큰을 얻습니다.
Wav2Vec2는 대규모 인간 음성 오디오로 학습되었기 때문에, 우리는 Wav2Vec2에서 사전 학습된 저수준 및 고수준 특징을 동결한 후 이를 성능 향상을 위해 연결합니다. 그러나 오디오 파형만 인코딩하는 것은 음성 오디오와 제스처 모션 간의 고수준 매핑에는 충분하지 않습니다. 제스처는 종종 음성 대본과 관련이 있기 때문입니다. 반면, Wav2Vec2와 우리의 오디오 인코더는 "오디오 텍스처"에 중점을 둡니다. 이를 해결하기 위해 우리는 Wav2Vec2CTC 모델과 사전 학습된 BERT를 사용해 타이밍에 맞춘 BERT 특징을 포함했습니다. 우리는 BERT 특징을 올바르게 정렬하기 위해 단어 타이밍 정렬 방법을 설계했으며, MFA에 의존하지 않습니다(세부 사항은 부록 참조). 이를 통해 오디오 브랜치는 공동 임베딩 학습에 필요한 특징을 포함할 수 있게 됩니다.
로컬 및 글로벌 대조 손실
우리는 CLS 토큰에 대해 미니 배치에서 InfoNCE 손실을 글로벌 대조 손실로 유지하며, 로컬 대조 학습 과제를 도입합니다. 그림 5에서 보듯이, 가까운 시간 창(i±t) 내의 프레임을 양성으로 간주하고, 먼 프레임(i−kt, i−t, i+t, i+kt)을 음성으로 간주하는 프레임 단위 손실을 정의했습니다. 본 논문에서는 t=4, k=4로 설정하여 30 FPS 모션을 사용합니다. 이 설계는 자연스러운 대화 상황에서의 미세한 불일치를 고려하여 더 쉬운 학습 과제를 제안합니다.
저수준 인코더에 대한 그라디언트 중지
훈련 중 우리는 저수준 및 고수준 검색 정확도를 모두 최대화하는 것을 목표로 합니다. 우리의 관찰 결과, 두 손실을 직접 최적화하면 저수준 인코더의 성능은 감소하는 반면 고수준 인코더의 성능은 향상됩니다. 이는 i) 저수준 인코더는 고수준 인코더와 함께 학습되지 않아야 하며, ii) 저수준 특징을 포함하면 고수준 인코더에 이점이 있음을 시사합니다. 따라서 우리는 글로벌 대조 손실의 그라디언트를 저수준 인코더에 대해 중지합니다. 이 작업은 두 특징 집합의 성능을 최대화할 수 있게 해줍니다.
특징 기반 제스처 검색
훈련 후 우리는 두 가지 유형의 특징을 얻습니다: 현재 8프레임의 오디오-모션 쌍이 일치하는지 여부를 구별할 수 있는 저수준 특징과 현재 4초의 오디오-모션 클립이 일치하는지 평가할 수 있는 고수준 특징입니다. 우리는 이 두 특징을 결합하여 검색에 활용합니다. 먼저, 각 4초 클립의 실제 모션에 대해 고수준 특징을 사전 계산하고 이를 각 프레임에 반복합니다. 다음으로 저수준 특징을 사전 계산하고 프레임별 특징 값을 직접 사용합니다. 이후 동적 프로그래밍(DP)을 통해 모션과 목표 오디오 간의 저수준 및 고수준 유사성을 최대화하여 최적의 경로 P_both_match를 검색합니다.

그림 6: ACInterp. 우리의 외형 일관성 보간(ACInterp) 모델은 기존의 시작 프레임 t∈(i−k, i]와 종료 프레임 t∈[j, j+k), 그리고 선형 블렌딩된 2D 포즈 이미지와 호모그래피 배경 오프셋을 사용하여 목표 보간 프레임 t∈(i,j)를 생성합니다. AnimateAnyone을 기반으로 ACInterp는 두 가지 방식으로 외형 일관성을 강화합니다. 첫째, 포즈-이미지 단계에서 예측된 배경 픽셀 오프셋을 도입하여 배경이 안정된 이미지 결과를 생성합니다. 둘째, 시작 프레임과 종료 프레임을 모션 모듈의 시간 우선 순위로 사용하여 인간의 정체성 일관성을 보장합니다. 전환 프레임에서 외형 일관성을 달성하는 것은 제스처 비디오 그래프 결과를 자연스럽게 보이게 하는 데 중요한 요소입니다.
3.3 확산 기반 비디오 프레임 보간
기존의 흐름 기반 방법에서 생성된 전환 프레임은 종종 블러 아티팩트로 고통받습니다. 이를 개선하기 위해, 그림 6에서 보이듯이, 우리는 두 단계(포즈에서 이미지로, 이미지에서 비디오로)의 비디오 생성 확산 모델인 AnimateAnyone(Hu et al., 2023)의 힘을 활용합니다. 우리의 방법인 ACInterp는 기존의 시작 프레임 t∈(i−k, i]와 종료 프레임 t∈[j, j+k), 그리고 선형 블렌딩된 2D 포즈 이미지와 호모그래피 배경 오프셋을 사용하여 목표 보간 프레임 t∈(i,j)를 생성합니다.
호모그래피 오프셋으로 개선된 Pose2Image 단계
그림 6에서 보이듯이, Pose2Image 단계는 무작위 노이즈 z_t를 샘플링하고 이를 추정된 이미지 잠재 변수 z^0로 디노이즈하는 것을 목표로 합니다. AnimateAnyone(Hu et al., 2023)과 마찬가지로, ACInterp는 다음을 수행합니다:
- 사전 학습된 VAE 인코더와 디코더(ℰ_VAE, 𝒟_VAE)를 사용하여 잠재 공간에서 디노이징 과정을 구현합니다.
- PoseGuider 𝒢에서 포즈 특징을 노이즈가 있는 잠재 공간에 추가하여 DenoisingNet 𝒟의 입력으로 사용합니다.
- 일관된 객체 외형을 보존하기 위해 ReferenceNet ℛ와 CLIP 이미지 인코더 𝒞를 통합합니다. 병합된 참조 잠재 변수의 계층적 특징을 타겟 디노이징 네트워크 𝒟의 해당 계층에 연결하여 정체성 정보를 임베드합니다.
- 훈련을 위해 v-예측(Rombach et al., 2022) 손실을 계산합니다.

그림 7: AnimateAnyone(Hu et al., 2023)에서의 외형 아티팩트. 생성된 결과(두 번째 프레임)는 다음과 같은 문제를 보입니다:
- 카메라 움직임으로 인한 위치 흔들림
- 모션 모듈 수정 후 정체성 불일치 이 이미지는 Acrobat Reader에서 가장 잘 보입니다. 이미지를 클릭하면 클립을 재생할 수 있습니다.
이렇게 ACInterp는 AnimateAnyone의 기존 한계를 개선하고, 전환 프레임에서 일관된 외형을 유지함으로써 결과적인 제스처 비디오가 더 자연스럽고 원활하게 보이도록 합니다.
AnimateAnyone과는 다르게, 우리는 카메라 파라미터 변경으로 인한 아티팩트를 제거하기 위해 추가적인 호모그래피 배경 오프셋 흐름을 도입했습니다. 그림 7에서 보이듯이, 생성된 이미지들은 종종 배경의 객체가 참조 배경 이미지에서의 고정된 위치를 무시하고 떠다니는 문제를 야기합니다. 이는 야생 환경(in-the-wild) 비디오에서 카메라 파라미터 변화에 과적합되었기 때문입니다. 이를 해결하기 위해, 이미지 수준에서 배경 오프셋 흐름 H_i,k ∈ ℝ^h×w×2를 계산하고 이를 BackgroundGuider ℬ에 추가합니다. ℬ는 𝒢와 동일한 아키텍처를 가지고 있습니다. 구체적으로, 우리는 참조 이미지와 타겟 이미지 간의 호모그래피 행렬을 계산하여 배경 영역의 픽셀 이동(Δx, Δy)을 계산합니다. 특히, 우리는 DeepLabv3로부터 인물 분할 결과를 사용하여 전경을 마스크한 후, SIFT, FLANN, RANSAC을 각각 키포인트 검출, 키포인트 매칭, 호모그래피 행렬 계산에 적용했습니다.
참조 모션 모듈 기반 Image2Video 단계
그림 6에서 보이듯이, Image2Video 단계는 비디오 프레임 간의 시간적 종속성을 캡처하여 Pose2Image 단계에서 발생하는 흔들림 효과를 완화합니다. AnimateAnyone(Hu et al., 2023)은 AnimateDiff(Guo et al., 2023)과 마찬가지로 이 단계에서 DenoisingNet 𝒟 내에 잔차 자가 주의 기반 모션 모듈 ℳ을 최적화합니다. 모션 모듈은 특징 맵 x ∈ ℝ^b×t×h×w×c를 x ∈ ℝ^(b×h×w)×t×c로 변형한 후 시간 차원 t을 따라 시간적 주의를 수행합니다. 그러나 그림 7에서 볼 수 있듯이, 이 접근 방식은 이미지 시퀀스 전체에서 평균적인 외형을 생성하는 경향이 있어 정체성 일관성이 감소합니다. 이 아티팩트는 인간의 정체성이 중요한 다른 작업에서는 무시될 수 있지만, 우리의 제스처 비디오 그래프에서는 현실성을 상당히 저하시킵니다.
표 1: Show-Oliver와 YouTube 비디오 데이터셋에서의 동시 음성 비디오 생성 평가

-----
평가지표 설명:
- FVD (Fréchet Video Distance, ↓ 낮을수록 좋음):
- FVD는 생성된 비디오와 실제 비디오 간의 거리 측정입니다. 이 값이 낮을수록 생성된 비디오가 실제 비디오와 유사하다는 것을 의미합니다. 주로 비디오 품질, 일관성, 시각적 사실성을 평가하는 데 사용됩니다.
- FGD (Fréchet Gesture Distance, ↓ 낮을수록 좋음):
- FGD는 제스처의 유사성을 측정하는 지표로, 생성된 비디오의 제스처와 실제 제스처 간의 유사성을 나타냅니다. 낮은 FGD는 모델이 사람의 제스처 움직임을 더 잘 재현했다는 것을 의미합니다.
- BC (Beat Consistency, ↑ 높을수록 좋음):
- BC는 음성과 제스처의 동기화 정도를 나타내며, 높을수록 오디오 비트와 몸짓의 일관성이 잘 유지된다는 것을 의미합니다. 이는 생성된 제스처가 음성의 리듬과 얼마나 잘 맞아떨어지는지를 평가하는 데 사용됩니다.
- Diversity (↑ 높을수록 좋음):
- Diversity는 생성된 비디오 간의 다양성을 측정하는 지표로, 높은 값은 다양한 제스처와 비디오 표현이 존재함을 의미합니다. 이는 모델이 특정 패턴에 과적합되지 않고 다양한 상황에서 다르게 반응하는 능력을 평가합니다.
모델별 성능 분석:
- Ground Truth (실제 데이터)
- Ground Truth는 실제 비디오로, 모델 성능을 비교하기 위한 기준점으로 사용됩니다.
- FVD와 FGD는 계산되지 않으며, BC와 Diversity는 각각 0.326, 3.514(Show-Oliver), 0.435, 3.746(YouTube Talking Video)입니다. 이는 우리가 생성하고자 하는 목표 수준을 나타냅니다.
- SpeechDrivenTemplate (Qian et al., 2021)
- Show-Oliver 데이터셋: FVD 2.239, FGD 5.722로, 실제 데이터보다 다소 높은 수준의 거리를 나타내고, BC는 0.401로 Ground Truth보다 높지만, Diversity는 1.950으로 낮습니다.
- YouTube Talking Video 데이터셋: FVD 7.612로 높으며, FGD 5.559, BC는 0.461로 실제 데이터보다 조금 높고, Diversity는 2.081로 다양성이 낮습니다.
- 요약: 전체적으로 생성된 제스처와 비디오 간의 유사성이 부족하고, 다양성도 제한적인 결과를 보입니다.
- ANGLE (Liu et al., 2022c)
- Show-Oliver 데이터셋: FVD 2.079, FGD 5.112로 SpeechDrivenTemplate보다 약간 향상된 결과를 보이지만, BC는 0.359로 낮으며, Diversity는 2.577로 조금 개선된 수준입니다.
- YouTube Talking Video 데이터셋: 평가된 데이터가 누락되어 있어 정확한 비교가 어렵습니다.
- GVR (Zhou et al., 2022)
- Show-Oliver 데이터셋: FVD 1.615, FGD 4.246으로 이전 모델들보다 개선되었으며, BC는 0.270으로 오히려 낮은 편이지만, Diversity는 4.623으로 상당히 높습니다.
- YouTube Talking Video 데이터셋: FVD 4.027, FGD 2.900으로 Show-Oliver와 유사한 수준의 개선을 보이며, BC는 0.331, Diversity는 3.573로 좋은 성능을 나타냅니다.
- 요약: GVR은 비교적 좋은 비디오 품질을 유지하고, 다양성 측면에서도 우수하지만, 음성과 제스처 간 동기화 측면에서는 낮은 성능을 보입니다.
- TANGO (Ours)
- Show-Oliver 데이터셋: FVD 1.379, FGD 3.714로 GVR보다 낮아져 더 높은 품질을 보이며, BC는 0.375로 동기화 측면에서도 향상되었습니다. Diversity는 5.393으로 모든 모델 중 가장 높습니다.
- YouTube Talking Video 데이터셋: FVD 3.133, FGD 2.068로, 제스처와 비디오 품질이 모두 향상되었으며, BC는 0.479로 가장 높은 동기화 성능을 보입니다. Diversity는 4.128로 매우 우수합니다.
- 요약: TANGO는 모든 평가지표에서 다른 모델들을 능가하는 성능을 보였습니다. 특히 FVD와 FGD가 낮아 실제 비디오와의 유사성이 높고, BC와 Diversity에서도 우수한 성능을 나타내며, 현실적이고 다양성이 높은 결과를 제공합니다.
종합 평가
TANGO는 기존의 모든 생성 및 검색 기반 모델들에 비해 전반적으로 우수한 성능을 보이며, 특히 비디오와 제스처의 사실성, 다양성, 그리고 오디오와의 동기화 측면에서 탁월합니다. 이는 TANGO가 학습된 임베딩 및 확산 기반 보간 네트워크를 통해 보다 정밀하고 일관성 있는 비디오 생성이 가능함을 보여줍니다.
-----
우리의 분석 결과, 핵심 문제는 모션 모듈의 해가 너무 넓은 해법 공간을 가지고 있다는 것입니다. 이는 자가 주의가 시간 차원 t에만 적용되기 때문입니다. 이를 해결하기 위해 우리는 추가적인 조건을 도입하여 해법 공간을 제약하였습니다. 모션 모듈을 훈련할 때, 시작과 끝 픽셀을 무작위로 선택하여 불확실성을 효과적으로 줄입니다. 훈련 중, 특징 맵 x ∈ ℝ^(b×h×w)×t×c에 대해, 우리는 확률 p를 도입하여 4프레임의 실제값 잠재 특징을 참조로 사용합니다. 분류기 자유 지침(classifier-free guidance)을 활용하여, 우리의 조건부 확산 기반 모션 모듈은 이러한 참조 프레임이 있거나 없을 때 모두 추론을 지원합니다. 4프레임 구간 정렬은 Gesture Video Reenactment의 노드 길이에 해당합니다. 마지막으로, 추론 시에는 4×α와 4×β의 시작과 끝 조건부 프레임을 도입하여 전환 엣지를 위한 중간 8프레임을 생성합니다.
4 실험
4.1 데이터셋
우리의 실험은 오픈 소스 Show 데이터셋(Yi et al., 2023)과 새롭게 수집된 YouTube 비디오 데이터셋에서 수행되었습니다. Show 데이터셋은 네 명의 화자를 특징으로 하는 다양한 배경과 불규칙한 카메라 움직임을 포함한 26시간의 대화 비디오로 구성되어 있습니다. 우리는 배경과의 상호작용이 비교적 적은 화자인 Oliver의 비디오를 선택했습니다. YouTube Video 데이터는 깨끗한 배경과 고정된 카메라 위치를 특징으로 하는, 야생 환경의 YouTube 비디오로부터 수집된 1시간 미만의 소규모 데이터셋입니다. 각 데이터셋의 세부 분할에 대한 정보는 부록(APPENDIX)에 있습니다.
4.2 생성된 비디오의 평가
우리의 방법을 이전의 최첨단 생성 방법인 SDT(Qian et al., 2021), ANGLE(Liu et al., 2022c) 및 재조합 기반 방법 GVR(Zhou et al., 2022)과 비교합니다. 우리는 SDT의 사전 학습된 가중치를 사용하고, 특정 의상으로 pose2img 단계를 미세 조정하였습니다. ANGLE은 Show-Oliver에서 제공된 원본 논문의 테스트 샘플로 평가하였습니다. GVR의 경우, 논문에 나와 있는 구현 세부 사항에 따라 시작점 기반 그래프 검색과 포즈 인식 신경 렌더링을 재현하였습니다.
표 2: Talkshow-Oliver에 대한 사용자 연구

객관적 평가 (Objective Evaluation)
우리는 FVD(Carreira & Zisserman, 2017)와 FGD(Yoon et al., 2020)라는 비디오 및 운동 특징 거리 메트릭을 사용하여 특징 수준에서의 차이를 정량화했습니다. 추가적으로 Beat Consistency (BC)(Liu et al., 2022d)와 Diversity(Li et al., 2021) 지표를 사용하여 각각 오디오-모션 동기화와 제스처 다양성을 평가했습니다. 표 1에서 볼 수 있듯이, 우리 방법은 BC를 제외한 모든 메트릭에서 GVR과 SDT를 능가했습니다. 전체 생성된 방식의 경우, 출력 모션 공간에서 더 큰 유연성을 보이며, 이로 인해 더 나은 BC 성능을 나타냈습니다. 그러나 SDT와 비교했을 때, 우리 방법은 비디오 품질을 상당히 향상시켰습니다. 또한, GVR과 비교했을 때도 모든 지표에서 일관된 개선을 보여주며, TANGO가 더 현실적이고 오디오와 동기화된 비디오를 생성함을 입증합니다.
주관적 평가 (Subjective Evaluation)
표 2에서 보이듯이, 우리는 네 가지 결과에 대해 사용자 연구를 수행했습니다. 47명의 참가자들이 각각의 비디오를 i) 물리적으로 더 정확한 비디오, ii) 오디오와 콘텐츠가 더 잘 맞는 비디오, iii) 전반적으로 더 현실적인 비디오로 평가하도록 요청했습니다. 사용자는 네 가지 결과 비디오를 한 줄에서 비교했으며, 비디오의 순서는 무작위로 섞였습니다. 총 60개의 비디오 클립이 사용되었으며, 각 클립은 6초 길이입니다. ANGLE은 결과 비디오 클립이 충분하지 않아 사용자 연구에 포함되지 않았습니다. 전환 구간의 일부 스냅샷은 그림 8에 나와 있으며, 부록 자료에는 비디오 결과가 포함되어 있습니다. 우리의 방법은 실제 비디오와 비교해도 비슷한 점수를 받았으며, 기존의 생성 방법인 SDT와 검색 방법인 GVR을 명확한 차이로 능가했습니다.
4.3 AuMoCLIP의 평가
우리는 목표 오디오 특징을 사용하여 제스처 모션 시퀀스를 검색하고, 검색 정확도를 통해 AuMoCLIP의 효과를 평가했습니다. 표 3에서 볼 수 있듯이, 우리는 저수준 및 고수준 검색 정확도를 계산했습니다.
- 저수준 검색 정확도는 프레임 i에서 오디오 특징을 무작위로 선택하고, (i−16, i+16) 범위 내에서 코사인 유사도가 가장 높은 모션 프레임을 찾는 방식으로 계산됩니다. 이 프레임이 (i−4, i+4) 범위 내에 있으면 정확한 것으로 표시됩니다. 최종 정확도는 16,000개의 무작위 쌍에 대해 평균화되며, 무작위 검색은 25%의 정확도를 가집니다.
- 고수준 검색 정확도는 오디오의 고수준 특징을 선택하고, 이를 256개의 모션 후보(1개의 페어링된 모션 + 255개의 부정 예)와 비교하여 측정합니다. 코사인 유사도가 가장 높은 모션이 페어링된 모션과 일치할 경우 정확한 것으로 표시됩니다. 이 정확도는 3,000개의 무작위 쌍에 대해 평균화되며, 무작위 검색은 0.391%의 정확도를 가집니다.
성능이 무작위 검색을 초과하면 모델이 제대로 작동한다고 할 수 있습니다. GVR의 시작점과 키워드 매칭은 저수준에서 35.38%, 고수준에서 1.288%의 성능을 보였으며, 이는 무작위 검색보다 나은 결과입니다. 이제 우리는 최종 AuMoCLIP의 성능 경로에 대해 논의하겠습니다.
생성된 특징 (Generative Features)
가장 간단한 접근 방식은 오디오-모션 네트워크(Liu et al., 2022b)를 직접 학습하고, 생성된 모션과 모션 후보 간의 관절 수준 거리를 계산하여 검색하는 것입니다. 그러나 이 방법은 예상보다 낮은 성능을 보였으며, 저수준 검색에서는 29.03%, 고수준 검색에서는 1.403%에 불과했습니다.
표 3: 오디오-모션 검색을 위한 특징 비교

-----
이 표는 오디오-모션 검색의 성능을 저수준과 고수준으로 나누어 다양한 접근 방식들의 성능을 비교하고 있습니다. 저수준과 고수준 검색은 각각 개별적인 수준에서 오디오 특징과 모션 특징 간의 매칭 능력을 평가합니다.
각 성능 항목은 다음과 같이 두 부분으로 나뉩니다:
- 절대 성능: 저수준 혹은 고수준 검색에서 특정 방법이 달성한 검색 정확도.
- 성능 개선 비율: 해당 접근 방식이 기준 성능(즉, 무작위 검색) 대비 얼마나 성능이 개선되었는지 백분율로 표현.
이를 통해 각 접근 방식이 무작위 검색보다 얼마나 나은 성능을 보였는지 파악할 수 있습니다.
1. Random Search (무작위 검색)
- 저수준: 25.00%
- 무작위로 검색한 경우 저수준에서 25%의 정확도를 보입니다. 이는 평가 구간이 16개의 프레임을 포함하는데, 그 중 약 4개의 프레임이 목표 범위 내에 있을 확률입니다.
- 고수준: 0.391%
- 무작위로 검색했을 때 고수준에서는 0.391%의 정확도를 보이며, 256개의 모션 후보 중 하나를 맞추는 데서 발생하는 확률입니다.
2. Generative Features
- 저수준: 29.03% (+16.10%)
- 생성된 오디오-모션 특징을 사용해 검색한 결과, 저수준에서 29.03%의 성능을 보였으며 이는 무작위 검색보다 약 16.10% 개선된 성능입니다.
- 고수준: 1.403% (+258.8%)
- 고수준에서는 1.403%의 성능을 보였으며, 이는 무작위 검색 대비 258.8% 개선된 성능입니다. 이는 성능이 개선되었지만 여전히 낮은 수준의 결과임을 의미합니다.
3. Keyword 및 Onset 기반 (GVR 방식, Zhou et al., 2022)
- 키워드 (고수준): 1.288% (+229.4%)
- GVR에서 사용한 키워드 기반 방법은 고수준에서 1.288%의 성능을 보이며 무작위 검색보다 229.4% 개선되었습니다.
- Onset (저수준): 35.38% (+41.51%)
- GVR의 Onset 기반 검색은 저수준에서 35.38%로, 무작위 검색 대비 41.51% 개선된 성능을 보였습니다. 이 방법은 오디오의 특정 시작점을 사용해 모션을 검색합니다.
4. Baseline 접근 방식 (Max Pooling & CLS Token)
- Max Pooling (고수준): 5.312% (+1360%)
- Max Pooling을 통해 고수준 특징을 글로벌 토큰으로 사용한 결과 5.312%의 성능을 보였으며, 이는 무작위 검색보다 1360% 향상되었습니다. 그러나 이는 글로벌 매칭에서 여전히 효과가 제한적임을 보여줍니다.
- CLS Token (고수준): 11.84% (+3028%)
- CLS Token을 사용하여 고수준 특징을 결합한 결과 성능이 11.84%로 크게 개선되었으며, 이는 무작위 검색보다 3028% 높은 성능을 보입니다. 이 방법은 글로벌 특징을 보다 효과적으로 학습하도록 도와줍니다.
5. Wav2Vec2 및 BERT의 사전 학습된 오디오 특징 통합
- + Wav2Vec2 (고수준): 12.73% (+3255%)
- 사전 학습된 Wav2Vec2 특징을 통합하면 성능이 12.73%로 개선되었으며, 무작위 검색보다 3255% 향상되었습니다.
- + BERT (고수준): 15.68% (+4010%)
- BERT 특징을 추가했을 때 성능이 15.68%로 개선되었으며, 이는 무작위 검색보다 4010% 높은 결과입니다. 이는 BERT가 오디오 텍스처 뿐만 아니라 언어 의미까지 반영하여 성능을 높였기 때문입니다.
- + Wav2Vec2 & BERT (고수준): 16.40% (+4194%)
- Wav2Vec2와 BERT 모두를 통합했을 때, 성능이 16.40%로 더 향상되었습니다. 이는 무작위 검색보다 4194% 높은 성능입니다.
6. 저수준 및 고수준 분할 (Split Low + High)
- 저수준: 47.94% (+99.76%)
- 저수준과 고수준 인코더를 분할해 학습한 결과, 저수준에서는 47.94%의 성능을 기록하여 무작위 검색보다 99.76% 개선되었습니다.
- 고수준: 17.83% (+4460%)
- 고수준에서는 17.83%의 성능을 보이며, 이는 무작위 검색보다 4460% 높은 결과입니다. 저수준 특징이 고수준 학습에 긍정적인 영향을 미친 것을 보여줍니다.
7. 저수준 분할 (Low only)
- 저수준: 65.57% (+162.2%)
- 저수준 학습만 수행했을 때, 저수준에서 65.57%라는 매우 높은 성능을 보였으며, 이는 무작위 검색보다 162.2% 향상된 결과입니다. 이 접근 방식은 저수준 특징만으로도 높은 성능을 보일 수 있음을 시사합니다.
8. AuMoCLIP (Stop Gradient 적용)
- 저수준: 65.68% (+163.8%)
- Stop Gradient를 적용한 후 저수준에서의 성능은 65.68%로, 저수준 특징을 학습하면서 고수준 학습의 영향을 피함으로써 최적의 성능을 유지할 수 있었습니다.
- 고수준: 19.54% (+4897%)
- 고수준에서는 19.54%의 성능을 기록했으며, 이는 무작위 검색보다 4897% 개선된 결과입니다. 이는 최종적으로 저수준과 고수준 특징 모두를 최적화하여 최상의 성능을 보인 것입니다.
요약
이 표에서 TANGO의 최종적인 AuMoCLIP은 저수준과 고수준 검색에서 모두 우수한 성능을 보여줍니다. 특히 Stop Gradient 접근 방식을 통해 저수준 인코더와 고수준 인코더의 최적화 간섭을 방지하여 각 특징의 성능을 극대화할 수 있었습니다. 이를 통해 기존의 모든 접근 방식보다 훨씬 나은 오디오-모션 검색 성능을 달성할 수 있었습니다.
-----
맥스풀링 또는 CLS 토큰 (MaxPooling or CLS Token)
그다음, 우리는 MoCoV2 기반의 듀얼 타워 대조 학습 프레임워크로 전환하여 고수준 특징만을 사용하여 시작했습니다. MoCoV2는 원래 이미지용으로 설계되었기 때문에 모션과 같은 시퀀스 데이터에는 최적화되지 않았습니다. 하나의 해결책은 시간 축을 따라 글로벌 토큰에 대해 맥스 풀링을 적용하는 것입니다 (Ao et al. 참고). 하지만 맥스 풀링은 정확한 로컬 정렬에 집중하는 반면, 글로벌 검색에서는 덜 효과적이어서 5.312%의 성능만 나타났습니다. 이를 해결하기 위해 우리는 CLS 토큰을 사용하는 적응형 글로벌 특징 병합 방식을 채택하여 성능을 11.84%로 크게 향상시켰습니다. 이후의 실험에서는 CLS 토큰을 유지했습니다.
Wav2Vec2와 BERT의 사전 학습된 오디오 특징
표 3에서 볼 수 있듯이, 사전 학습된 오디오 특징, 특히 시간 정렬된 BERT 특징을 통합하면 기준 성능이 11.84%에서 15.68%로 크게 향상됩니다. 이 개선은 BERT가 고차원 언어 의미를 캡처하여 "오디오 텍스처"만을 반영하지 않기 때문이며, 이는 동시 음성 제스처 검색 작업에 중요합니다.
저수준 대조 학습에 대한 논의
저수준 대조 학습 과제를 포함하면 고수준 검색 성능에도 일관된 이점이 있으며, 이는 더 강력한 저수준 특징을 추가하는 것이 고수준 성능을 향상시킨다는 것을 시사합니다. 흥미롭게도 저수준 대조 학습 과제만을 훈련했을 때 65.57%로 상당히 더 나은 성능을 달성했습니다. 이러한 관찰은 다음을 시사합니다:
- 학습된 저수준 특징을 고수준 임베딩 학습에 통합해야 합니다.
- 고수준 학습이 저수준 특징에 영향을 미치지 않도록 해야 합니다.
따라서 우리는 단순히 그라디언트를 중지하여 두 특징의 성능을 모두 극대화하는 방법을 제안합니다.

그림 8: 전환 프레임 생성 비교 위에서 아래로, 우리는 동일한 프레임에서 다양한 방법을 적용한 네 가지 스냅샷을 보여줍니다. 우리의 방법은 손 영역에서 더 적은 아티팩트를 보이며, GT(실제) 프레임과 외형 일관성을 유지합니다. AnimateAnyone은 손을 복구할 수 있지만 외형 일관성을 잃습니다. 흐름 기반 방법인 FiLM과 VFIFormer는 복잡한 모션에 대해 흐름을 추정하지 못해 손이 사라지는 결과를 초래합니다. 포즈 인식 신경 렌더링(Pose Aware Neural Rendering)은 더 나은 손 결과를 보여주지만 여전히 블러와 같은 아티팩트를 겪습니다.
표 4: 비디오 블렌딩 방법 비교 비디오 블렌딩 방법 간의 성능을 비교한 결과로, 다양한 기법들이 전환 프레임에서 얼마나 자연스럽고 일관성 있는 결과를 만들어 내는지를 평가했습니다. TANGO는 손 아티팩트를 줄이고 GT 프레임과의 외형 일관성을 유지하는 데 있어 가장 뛰어난 성능을 보였습니다.
-----
평가지표 설명:
- PSNR (Peak Signal-to-Noise Ratio, ↑ 높을수록 좋음):
- PSNR은 비디오의 재현성 혹은 품질을 측정하는 지표로, 원본 비디오와 생성된 비디오 간의 차이를 기반으로 합니다. 값이 높을수록 재생된 비디오가 원본에 가깝다는 것을 의미합니다.
- LPIPS (Learned Perceptual Image Patch Similarity, ↓ 낮을수록 좋음):
- LPIPS는 학습된 인식 유사도를 측정하는 지표로, 사람의 시각적 인식을 반영하여 원본과 생성된 이미지의 유사도를 평가합니다. 값이 낮을수록 인간의 눈에 더 유사하다는 것을 의미합니다.
- MOVIE (Motion-based Video Integrity Evaluation, ↓ 낮을수록 좋음):
- MOVIE는 비디오의 시간적 일관성과 모션 기반 품질을 측정하는 지표입니다. 낮은 MOVIE 값은 시간적 일관성이 뛰어나고 부드러운 모션을 생성하는 것을 의미합니다.
- FVD (Fréchet Video Distance, ↓ 낮을수록 좋음):
- FVD는 생성된 비디오와 실제 비디오 간의 거리 측정 지표로, 비디오의 품질과 일관성을 종합적으로 평가합니다. 값이 낮을수록 생성된 비디오가 실제 비디오와 유사합니다.
방법별 성능 분석:
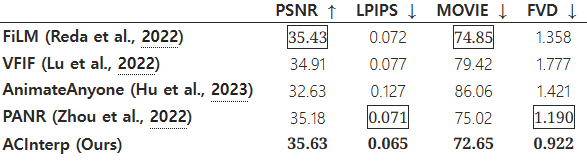
- FiLM (Reda et al., 2022)
- PSNR: 35.43
- LPIPS: 0.072
- MOVIE: 74.85
- FVD: 1.358
- 요약: FiLM은 비교적 높은 PSNR을 기록하여 영상의 품질이 좋은 편입니다. LPIPS는 0.072로 원본과의 유사성이 높은 편이나, MOVIE와 FVD에서는 다른 방법들에 비해 약간 높은 값을 보여 시간적 일관성에서 개선의 여지가 있습니다.
- VFIF (Lu et al., 2022)
- PSNR: 34.91
- LPIPS: 0.077
- MOVIE: 79.42
- FVD: 1.777
- 요약: VFIF는 PSNR과 LPIPS에서 평균 이상의 성능을 보였으나, MOVIE와 FVD에서는 다소 높은 값을 기록하여 시간적 일관성과 비디오 품질에서 FiLM보다 떨어집니다. 전반적으로 복잡한 모션을 처리하는 데 어려움을 겪고 있는 것으로 보입니다.
- AnimateAnyone (Hu et al., 2023)
- PSNR: 32.63
- LPIPS: 0.127
- MOVIE: 86.06
- FVD: 1.421
- 요약: AnimateAnyone은 PSNR과 LPIPS에서 낮은 값을 기록해, 비디오의 시각적 품질이 다른 방법들보다 떨어지며, MOVIE 값이 높아 시간적 일관성 문제를 나타냅니다. 그러나, FVD는 상대적으로 양호하여 전반적인 비디오 품질은 괜찮은 편입니다. 이 방법은 특히 인간의 외형 일관성에 초점을 맞추고 있지만, 이로 인해 시간적 일관성 부분에서 손해를 보는 것으로 보입니다.
- PANR (Pose Aware Neural Rendering, Zhou et al., 2022)
- PSNR: 35.18
- LPIPS: 0.071
- MOVIE: 75.02
- FVD: 1.190
- 요약: PANR은 PSNR과 LPIPS에서 매우 좋은 성능을 보여 비디오의 품질과 시각적 유사도가 높습니다. MOVIE와 FVD도 상대적으로 낮은 값을 기록해 시간적 일관성과 품질 모두에서 우수한 성능을 보입니다. 그러나 여전히 전환 프레임에서 일부 아티팩트가 존재할 수 있습니다.
- ACInterp (TANGO, 우리의 방법)
- PSNR: 35.63
- LPIPS: 0.065
- MOVIE: 72.65
- FVD: 0.922
- 요약: ACInterp는 모든 평가 지표에서 가장 우수한 성능을 보입니다. PSNR이 35.63으로 가장 높아 재현된 비디오의 품질이 매우 좋으며, LPIPS는 0.065로 가장 낮아 시각적 유사성에서도 뛰어난 성능을 보입니다. MOVIE 값이 72.65로 다른 방법들보다 낮아 시간적 일관성과 모션의 부드러움에서도 우수한 결과를 나타냈으며, FVD가 0.922로 가장 낮아 전반적인 비디오 품질과 일관성에서도 다른 방법들을 능가합니다.
종합 평가
ACInterp는 FiLM, VFIF, AnimateAnyone, 그리고 PANR과 비교하여 전반적으로 가장 뛰어난 성능을 보였습니다. 특히 PSNR, LPIPS, MOVIE, FVD 모두에서 최고의 값을 기록하여 비디오의 재현성, 시각적 유사성, 시간적 일관성, 그리고 품질 측면에서 다른 방법들을 확실히 능가했습니다. 이는 ACInterp가 기존의 흐름 기반 방법들이나 생성 기반 방법보다 훨씬 더 자연스럽고 고품질의 비디오 전환 프레임을 생성할 수 있음을 의미합니다.
-----
4.4 비디오 블렌딩 방법 평가
우리는 제안된 확산 기반 비디오 프레임 보간 방법의 효과를 평가하기 위해 혼합된 비디오의 품질을 비교했습니다. 이 평가는 Show-Oliver 데이터셋의 별도의 테스트 세트에서 수행되었으며, 각 8 프레임으로 구성된 368개의 비디오 클립을 포함합니다. 우리의 접근법은 원래 GVR(Zhou et al., 2022)의 Pose Aware Neural Rendering, 최첨단 흐름 기반 블렌딩 방법인 FiLM(Reda et al., 2022), VFIFormer(Lu et al., 2022), 그리고 확산 기반 포즈 가이드 비디오 생성 방법인 AnimateAnyone(Hu et al., 2023)과 비교했습니다. 모든 방법은 Show-Oliver 데이터셋에서 훈련되었으며, 훈련 및 추론 해상도는 768×768으로 통일했습니다.
우리는 이미지 수준과 비디오 수준의 품질을 모두 평가했습니다. 단일 이미지의 경우, 이미지 오류(L1 픽셀 수준 거리), 학습된 인식 이미지 패치 유사도(LPIPS), 그리고 **PSNR(신호 대 잡음 비율)**을 사용했습니다. 비디오의 경우, **평균 의견 비디오 품질 추정(MOVIE)**와 **특징 수준 거리(FVD)**를 사용했습니다. LPIPS와 FVD를 계산하기 위한 특징은 각각 사전 학습된 AlexNet과 I3D 네트워크에서 얻었습니다.
객관적 비교 결과는 표 4에 나와 있습니다. 흐름 기반 보간 방법(Reda et al., 2022)은 평균 픽셀 수준 오류가 더 낮은 경향을 보였습니다. 반면, AnimateAnyone(Hu et al., 2023)은 외형 일관성 문제로 인해 성능이 저하되었습니다. 전반적으로, 우리의 확산 기반 보간 모델은 이전의 흐름 기반 및 확산 기반 방법들을 명확한 차이로 능가했으며, 예를 들어 FVD 0.922는 이전 최상의 값인 1.190보다 낮습니다. 결과 비디오는 그림 8과 보충 자료에서 확인할 수 있습니다.
5 결론
우리는 목표 음성 오디오와 동기화된 몸 제스처를 가진 고품질 비디오를 생성하는 프레임워크인 TANGO를 소개했습니다. TANGO는 Show-Oliver와 YouTube 비디오 데이터셋에서 평가되어, 현실적이고 고품질의 비디오를 생성할 수 있음을 입증했으며, 최첨단 생성 및 검색 기반 방법들을 능가하는 성능을 보였습니다. 또한, 우리가 아는 한, TANGO는 오디오와 모션 모달리티에 대해 CLIP과 같은 대조 학습을 도입한 첫 번째 연구이자, 오디오 기반 모션 그래프와 비디오 생성 파이프라인을 오픈 소스로 제공한 최초의 사례입니다.
향후, 우리는 제스처 비디오 그래프를 춤, 스포츠 등 일반적인 인간 모션 비디오로 확장할 계획입니다.
부록 A: 부록
A.1 데이터셋
Show-Oliver 데이터셋 Show 데이터셋은 다양한 배경과 불규칙한 카메라 움직임을 가진 네 명의 화자가 포함된 26시간 분량의 대화 비디오로 구성되어 있습니다. 우리는 배경과의 상호작용이 적은 화자인 Oliver의 비디오를 선택했습니다. 전체 Show-Oliver 데이터셋은 3초에서 10초 사이의 길이를 가진 6546개의 비디오 클립으로 이루어져 있습니다. 우리는 10분 분량의 비디오 클립을 무작위로 선택하고 일관된 의상을 갖춘 상태에서 여러 개의 few-shot 세트를 사용해 평가했습니다. 이러한 세트들은 훈련 80%, 검증 10%, 테스트 10%로 나누어졌습니다.
YouTube 비디오 데이터셋 또한, 깨끗한 배경과 고정된 카메라 위치를 특징으로 하는 야생 환경의 YouTube 비디오로부터 소규모 few-shot 데이터셋을 수집하고 처리했습니다. 이 비디오들은 12명의 화자가 1분에서 2분 동안 발표하는 장면을 포함하고 있습니다. 이 중 네 명의 화자를 선택하여 6~10초 길이의 비디오 하위 집합을 테스트 세트로 사용하고 나머지 비디오는 훈련 및 제스처 비디오 재현을 구성하는 데 사용했습니다.
우리는 먼저 12개의 다른 신원을 가진 YouTube 비디오를 수집했습니다. 이 비디오들은 오디오에서 검출된 문장 경계를 기준으로 여러 개의 클립으로 분할되었습니다. 얼굴 검출기를 사용하여 모든 클립에 명확한 얼굴이 포함되도록 했습니다. 이후, 후처리를 통해 배경 방해 요소를 제거하고 카메라 위치를 자동으로 조정하여 일관성을 유지했습니다. 최종적으로, 총 1시간 분량의 데이터에서 각 신원을 위한 304개의 클립을 얻었습니다. 각 신원별로 긴 비디오 클립은 검증 세트로 사용되고, 나머지 클립은 훈련 세트를 구성합니다.
A.2 강제 정렬(MFA) 없이 시간 정렬된 BERT 특징
강제 정렬(MFA) 없이 오디오에 대한 시간 정렬된 BERT 특징을 얻기 위해, 우리는 Wav2Vec2와 BERT 모델을 다음 단계로 결합했습니다:
음성 인식 (ASR). 우리는 Connectionist Temporal Classification (CTC) 헤드를 사용한 Wav2Vec2를 사용하여 로짓을 얻으며, 이 로짓은 각 시간 단계에서 가능한 토큰에 대한 모델의 신뢰도 점수를 나타냅니다. 로짓은 오디오 입력에 대한 예측된 토큰 ID 시퀀스를 생성하는 데 사용되며, 이 토큰 ID들은 Wav2Vec2 프로세서의 어휘를 사용하여 대본으로 디코딩됩니다. 예를 들어, 알파벳 시퀀스 ["", "", "T", "", "", "h", "e", "", "F", "i", "r", "s", "t"]을 얻을 수 있습니다.
BERT 임베딩. 이 대본은 BERT 토크나이저를 사용해 토큰화되며, BERT 모델에서 임베딩이 생성됩니다. BERT의 토크나이저는 알파벳 시퀀스를 단어 시퀀스 ["CLS", "The", "First", "POS"]로 변환합니다.
시간 정렬. 우리는 Wav2Vec2로 생성된 토큰을 BERT 토큰과 문자 수준에서 매칭하여 정렬합니다. 특히, 각 오디오 프레임에 대해 정렬된 BERT 임베딩을 특징으로 할당합니다. 매칭되지 않은 경우, 가장 가까운 비제로 특징을 사용해 간격을 채워 시간에 따라 매끄러운 전환을 보장합니다.
A.3 15D 모션 표현
우리는 NeMF (He et al., 2022)를 참고하여 각 시간 단계 t에서 모션을 15차원(15D) 특징 벡터로 나타냅니다. 이 표현은 로컬 모션만을 캡처합니다. **15D 모션 표현, 𝐗_t ∈ ℝ^(J×15)**은 다음을 포함합니다:
- 관절 위치 𝐱_tp ∈ ℝ^(J×3): 각 관절의 3D 좌표를 루트 관절을 기준으로 나타내며, 시간 t에서의 골격 포즈를 제공합니다.
- 관절 속도 𝐱̇_tp ∈ ℝ^(J×3): 관절 위치의 변화율을 캡처합니다.
추가적으로, **관절 회전 𝐱_tr ∈ ℝ^(J×6)**은 각 관절의 회전 방향을 6D 회전 형식으로 인코딩(Zhou et al., 2019)하여 보다 견고하고 명확한 회전 표현을 제공합니다. 마지막으로, **각속도 𝐱̇_tr ∈ ℝ^(J×3)**는 각 관절의 회전 속도를 설명합니다. 이 통합 표현은 각 관절의 위치와 움직임 동역학을 세밀하고 포괄적으로 모델링할 수 있도록 합니다.
A.4 한계점
ACInterp는 선형 2D 포즈 블렌딩에서 생성된 2D 포즈 이미지를 입력으로 사용합니다. 만약 8개의 보간된 프레임 사이의 GT 모션이 비선형일 경우, 생성된 결과는 GT와 약간 다를 수 있습니다. 우리는 Talkshow-Oliver 데이터셋의 클립 중 83%에서 2D 포즈 오류가 임계값 0.005 이하인 경우 선형 블렌딩이 잘 작동함을 계산했습니다.
'인공지능' 카테고리의 다른 글
| Scalable watermarking for identifying large language model outputs (2) | 2024.11.20 |
|---|---|
| X-Portrait 2: Highly Expressive Portrait Animation (1) | 2024.11.20 |
| Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models (2) | 2024.11.19 |
| Pyramidal Flow Matching for Efficient Video Generative Modeling (2) | 2024.11.18 |
| Oasis: A Universe in a Transformer (1) | 2024.11.16 |


