https://arxiv.org/abs/2404.07965
Rho-1: Not All Tokens Are What You Need
Previous language model pre-training methods have uniformly applied a next-token prediction loss to all training tokens. Challenging this norm, we posit that "9l training". Our initial analysis examines token-level training dynamics of language model, reve
arxiv.org
초록
기존의 언어 모델 사전 학습 기법은 모든 학습 토큰에 동일하게 다음 토큰 예측 손실을 적용해 왔습니다. 이러한 관행에 의문을 제기하며, 우리는 “코퍼스 내의 모든 토큰이 언어 모델 학습에 똑같이 중요하지는 않다”고 주장합니다. 이를 위해 토큰 단위에서의 언어 모델 학습 동태를 살펴본 결과, 서로 다른 토큰은 서로 다른 손실 패턴을 보인다는 사실을 확인했습니다. 이러한 통찰을 바탕으로, 우리는 새로운 언어 모델인 Rho-1을 소개합니다. 기존의 언어 모델이 코퍼스 내 모든 차기 토큰을 예측하도록 학습하는 것과 달리, Rho-1은 Selective Language Modeling(SLM)을 도입하여 원하는 분포에 부합하는 유용한 토큰만 선별적으로 학습합니다. 이 방법은 우선 참고 모델을 통해 토큰에 점수를 매긴 뒤, 점수가 높은 토큰에 집중적으로 손실을 부여하여 언어 모델을 학습하는 과정으로 이루어집니다.
15억 개 규모의 OpenWebMath 코퍼스로 지속적 사전 학습을 수행한 결과, Rho-1은 9가지 수학 과제에서 최대 30%에 달하는 few-shot 정확도 절대 향상을 달성했습니다. 이어진 파인튜닝 과정에서, Rho-1-1B와 Rho-1-7B 모델은 MATH 데이터셋에서 각각 40.6%와 51.8%의 최고 성능을 기록했으며, 이는 사전 학습 토큰의 3%만 사용하고도 DeepSeekMath 수준에 도달한 결과입니다. 또한 800억 개에 달하는 일반 토큰으로 지속적 사전 학습을 추가로 수행했을 때, Rho-1은 15개의 다양한 과제에서 평균 6.8%의 성능 향상을 보이며 데이터 효율성과 언어 모델 사전 학습 성능을 모두 끌어올렸습니다.

Figure 1: 우리는 파라미터 규모가 10억(1B)과 70억(7B)인 모델을 대상으로 150억 개의 OpenWebMath 토큰을 활용해 지속적 사전 학습을 진행했습니다. Rho-1은 제안된 Selective Language Modeling(SLM) 기법으로 학습했으며, 비교 모델들은 전통적인 인과적 언어 모델링(CLM)을 사용했습니다. 그 결과, SLM은 GSM8k와 MATH 과제에서 평균 few-shot 정확도를 16% 이상 끌어올렸으며, 동일한 정확도에 도달하기까지 필요한 학습 단계도 기존 대비 5~10배 절감했습니다.
전통적인 인과적 언어 모델링(Causal Language Modeling, CLM)은 언어 모델이 텍스트를 순차적으로 생성하도록 훈련하는 표준적인 방법을 가리킵니다. 쉽게 말해, 모델이 “지금까지 본 단어(토큰)를 바탕으로 다음 단어를 예측”하도록 학습하는 것입니다.
예를 들어, 문장을 왼쪽에서 오른쪽으로 읽어나가면서, 모델은 ‘이미 주어진 단어들만’ 보고 그다음 단어를 맞추는 방식으로 훈련됩니다. 이를 통해 모델이 텍스트 생성을 점진적으로 익히도록 유도하죠. GPT 시리즈처럼 널리 알려진 대규모 언어 모델들이 모두 이 CLM 방식을 사용합니다

Figure 2: (상단) 철저히 필터링된 사전 학습 코퍼스라 할지라도, 토큰 단위 수준의 노이즈는 여전히 존재할 수 있습니다. (왼쪽) 기존 인과적 언어 모델링(CLM)은 모든 토큰에 대해 학습을 진행합니다. (오른쪽) 우리가 제안하는 Selective Language Modeling(SLM)은 유용하고 깨끗한 토큰만 선별적으로 학습 손실을 적용합니다.
Figure 2를 보면 “노이즈(undesired tokens)”를 출력하지 않는다기보다는, “학습에 사용하지 않는다”에 가깝습니다. 즉, SLM(Selective Language Modeling)은 ‘노이즈 토큰’을 입력에서는 그대로 보지만(텍스트 시퀀스에 존재하기는 함), 그 토큰에 대해서는 학습 손실을 계산하지 않는 방식입니다.
- 기존 CLM은 코퍼스에 있는 모든 토큰(파란색+빨간색)에 대해 다음 토큰을 예측하도록 손실(loss)을 계산합니다.
- SLM은 동일한 입력 시퀀스를 보고, “파란색(유용한 토큰)에만 손실을 계산”하고, “빨간색(노이즈 또는 덜 유용한 토큰)에는 손실을 주지 않는다”는 차이가 있습니다.
다시 말해, 노이즈 토큰이 모델의 ‘출력 시퀀스’에서 아예 사라지는 것은 아니지만, 학습할 때 “노이즈 토큰을 정확히 예측해야 한다”는 압박(손실)은 없으므로, 모델이 노이즈 쪽으로 과도하게 맞추려 하지 않게 됩니다. 이 때문에 최종적으로 유용한 토큰(정보가치가 높은 부분)을 중심으로 모델이 최적화되어, 노이즈로 인해 모델이 잘못 학습되는 것을 줄이는 효과가 있습니다.
즉,
- SLM은 노이즈 토큰을 아예 제거하는 것이 아니라 ‘손실을 안 주거나, 극히 일부만 준다’는 식으로 조정하여, 모델이 유의미한 정보(=유용한 토큰)에 더 많은 학습 용량을 투자하도록 하는 것이 핵심 목적입니다.
- 실제로 논문에서, 이렇게 노이즈 토큰을 “선택적으로” 다뤘을 때 수학 등 특정 도메인 과제에서 상당한 성능 향상을 보고하고 있으므로, 모든 토큰에 손실을 부여했을 때보다 전반적인 효과가 더 좋다고 결론을 내릴 수 있는 것입니다.
1 서론
모델 파라미터와 데이터셋 규모를 확장함으로써 대형 언어 모델의 다음 토큰 예측 정확도가 꾸준히 향상되었고, 이는 인공지능 분야에서 큰 진전을 이끌어 왔습니다 (Kaplan et al., 2020; Brown et al., 2020; OpenAI, 2023; Team et al., 2023). 그러나 이용 가능한 모든 데이터를 전부 학습에 사용하는 것이 언제나 최적이거나 실현 가능한 것은 아닙니다. 이 때문에 다양한 휴리스틱과 분류기(Brown et al., 2020; Wenzek et al., 2019)를 사용해 학습에 필요한 문서를 선별하는 데이터 필터링 기법이 점차 중요해지고 있습니다. 이러한 방식은 데이터 품질을 높여 모델 성능을 크게 향상시킵니다.
하지만 문서 단위에서 치밀하게 필터링을 수행하더라도, 그림 2 (위쪽)에서 보이듯이 높은 품질의 데이터셋 안에도 여전히 많은 ‘노이즈 토큰’이 포함되어 있어 학습에 부정적 영향을 줄 수 있습니다. 단순히 해당 토큰들을 제거하면 문장의 의미가 훼손될 수 있고, 너무 엄격하게 필터링하면 오히려 유용한 데이터를 놓쳐버릴 위험이 있습니다 (Welbl et al., 2021; Muennighoff et al., 2024). 또한 이로 인해 편향이 생길 수도 있습니다 (Dodge et al., 2021; Longpre et al., 2023). 더 나아가 웹 데이터를 그대로 사용할 경우, 이는 실제 응용 분야와는 거리가 있는 분포를 학습하게 될 수도 있음이 지적된 바 있습니다 (Tay et al., 2022; Wettig et al., 2023). 예컨대, 토큰 레벨에서 보면 흔히 등장하는 코퍼스 안에도 환각(hallucination)성 정보나 예측하기 매우 모호한 토큰 등이 포함될 수 있습니다. 모든 토큰에 동일한 손실을 부여하는 것은, 중요하지 않은 토큰까지 모델이 학습하려 애쓰게 만들어 계산 효율을 떨어뜨리고, 결국 대형 언어 모델(LLM)이 더욱 높은 수준의 지능을 달성하지 못하게 막을 수 있습니다.
이러한 문제의식을 바탕으로, 우리는 먼저 2.1절에서 언어 모델이 토큰 단위로 학습하는 과정, 특히 일반적인 사전 학습(pretraining) 중에 토큰별 손실이 어떻게 변화하는지를 조사했습니다. 다양한 체크포인트에서 모델의 토큰 퍼플렉시를 확인하고, 이를 기준으로 토큰들을 여러 유형으로 분류했습니다. 그 결과, 실제로 모델이 손실을 크게 줄인 토큰들은 특정 그룹에 국한된다는 사실을 발견했습니다. 상당수 토큰은 이미 “쉽게 학습된(easy tokens)” 상태이고, 또 일부는 “어려운(hard)” 토큰으로 분류되어 손실이 들쭉날쭉하여 학습이 잘 수렴되지 않았습니다. 이런 토큰들로 인해 많은 비효율적인 그래디언트 업데이트가 일어날 수 있습니다.
이러한 분석을 기반으로, 우리는 Selective Language Modeling (SLM)이라는 새로운 목적함수를 사용하여 학습한 Rho-1 모델을 제안합니다.
“Rho”라는 명칭은 정보량(ρ)이 높은 토큰을 선택적으로 모델링한다는 의미를 담고 있습니다.
그림 2 (오른쪽)에서 보이듯, 이 기법은 모델에 전체 시퀀스를 입력하되, 원치 않는(노이즈) 토큰들의 손실은 선택적으로 제거합니다. 구체적인 파이프라인은 그림 4에 나와 있습니다. 먼저, SLM은 참조 언어 모델(reference model)을 고품질 코퍼스에 대해 학습해, 원하는 분포에 부합하는 지표(utility metrics)를 설정합니다. 이를 통해 자연스럽게 불필요하거나 부정확한(unclean/irrelevant) 토큰을 거른 뒤, 2.2절에서 설명하듯 각 토큰의 손실 값을 활용해 점수를 매깁니다. 마지막으로, 학습 대상 모델은 참조 모델과의 손실 차이가 큰(즉, 추가 학습의 가치가 높은) 토큰만 골라 집중적으로 학습함으로써(2.2절), 실제 응용 분야에 최적화된 분포를 효과적으로 학습하게 됩니다.
다양한 실험 결과, SLM은 학습 과정에서 토큰 효율성을 크게 향상시킬 뿐 아니라, 다운스트림 과제에서도 성능을 높인다는 사실을 확인했습니다. 더불어, SLM이 실제로 목표 분포와 밀접한 토큰을 선별해준 덕분에, 모델이 이 토큰들만 학습했을 때도 벤치마크에서 좋은 퍼플렉시를 달성한다는 점이 드러났습니다. 3.2절에서는 수학 도메인에 관한 지속적 사전 학습(continual pretraining)을 수행해 본 결과를 제시합니다. 여기서 1B 및 7B 파라미터를 지닌 Rho-1 모델은 GSM8k와 MATH 데이터셋에서 기존 인과적 언어 모델링(CLM)을 사용한 베이스라인 대비 16% 이상 성능을 뛰어넘습니다. 그림 1에서 확인할 수 있듯, 동일 정확도에 도달하는 데 필요한 학습 단계 역시 최대 10배가량 단축되었습니다. 놀랍게도 Rho-1-7B는 DeepSeekMath-7B가 5천억(500B) 개의 토큰으로 달성한 성능을 단 150억(15B) 토큰 학습만으로 구현했습니다. 파인튜닝 후에는, Rho-1-1B와 Rho-1-7B가 각각 MATH에서 40.6%, 51.8%의 정확도를 달성했습니다. 특히 Rho-1-1B는 10억(1B) 규모의 모델로는 사상 최초로 40% 정확도를 넘겼으며, 이는 초기 GPT-4가 사슬 추론(CoT) 방식으로 달성한 42.5%에 근접하는 수준입니다. 이어서 3.3절에서는 일반적인 텍스트에 대한 지속적 사전 학습 사례를 보여줍니다. Tinyllama-1B 모델에 대해 800억(80B) 개 토큰을 SLM으로 학습했을 때, 15개 벤치마크에서 평균 6.8%의 성능 향상이 있었고, 특히 코드와 수학 과제에서는 10% 이상의 향상이 확인되었습니다. 3.4절에서는 고품질 참조 데이터가 없는 상황에서도, SLM을 자기 자신에게 참조(self-referencing) 방식으로 적용하여 다운스트림 과제에서 최대 3.3%의 평균 성능 향상을 얻을 수 있음을 시연합니다.

그림 3: 사전 학습 과정에서 네 가지 유형의 토큰이 보이는 손실(Loss)을 나타낸 그래프. (a)는 H→H, L→H, H→L, L→L 토큰 각각에 대한 손실 변화를 보여주며, (b)와 (c)는 사전 학습 중 손실이 변동하는 L→L, H→H 토큰에 대한 세부 사례를 보여준다.
논문에서 언급하는 “다운스트림 과제에서도 성능을 높였다”는 말은,
- 언어 모델이 사전 학습(Pretraining) 단계에서 SLM 방식을 도입하여 학습한 뒤,
- 이후 특정 응용 분야(예: 수학 문제 해결, 코드 생성, 질의응답, 분류 등)로 “파인튜닝(Fine-tuning)”을 하거나 “few-shot/in-context 학습”을 적용했을 때,
- 기존 방식으로 학습된 모델에 비해 결과(정확도, F1 스코어 등)가 더 좋게 나왔다는 의미입니다.
즉, “다운스트림(Downstream) 과제”는 언어 모델을 단순 텍스트 예측 이상의 특정 작업(수학 문제, 요약, 번역, 분류 등)에 활용할 때를 가리키며, 이 단계에서 SLM 기법으로 학습된 모델이 더 좋은 성능을 보였다고 요약할 수 있습니다.
논문에서 H와 L은 각각 “High”와 “Low” 정도로 이해하시면 됩니다. 즉, H는 손실(loss) 값이 높은 토큰을, L은 손실 값이 낮은 토큰을 가리키죠. 그리고 화살표(→)는 사전 학습 과정에서 해당 토큰이 어떻게 변했는지를 나타냅니다. 예를 들어:
- H→H: 학습 전에도 손실이 높았고(High), 학습 후에도 여전히 손실이 높은 토큰
- L→H: 학습 전에는 손실이 낮았는데(Low), 학습을 진행하니 손실이 높아진 토큰
- H→L: 학습 전에는 손실이 높았으나(High), 학습 후에는 손실이 낮아진 토큰
- L→L: 학습 전에도 손실이 낮았고(Low), 학습 후에도 계속 낮은 토큰
이렇게 구분하면 “어떤 토큰들은 학습을 통해 손실이 많이 줄어들고(H→L), 어떤 토큰들은 쉽게 이미 학습된 상태였다(L→L)” 같은 식으로 토큰별 학습 동태를 더 구체적으로 파악할 수 있게 됩니다.
2 Selective Language Modeling
2.1 모든 토큰이 똑같지 않다: 토큰 손실의 학습 동태
우리의 연구는 표준 사전 학습 과정에서 각각의 토큰 손실이 어떻게 변화하는지에 대한 면밀한 관찰에서 시작됩니다. 우리는 OpenWebMath에서 추출한 150억(15B) 개의 토큰을 사용해 Tinyllama-1B 모델을 사전 학습하되, 10억(1B) 개 토큰씩 학습할 때마다 체크포인트를 저장했습니다. 이후 약 32만(320,000) 개 토큰으로 구성된 검증 세트를 이용해 각 체크포인트에서 토큰 단위 손실을 평가했습니다.
그 결과, 그림 3(a)에서는 손실 궤적(loss trajectory)에 따라 토큰이 다음 네 가지 부류로 구분됨을 확인할 수 있었습니다.
- 지속적으로 높은 손실(H→H)
- 손실이 증가하는(L→H)
- 손실이 감소하는(H→L)
- 계속해서 낮은 손실(L→L)
이들 유형에 대한 더 자세한 내용은 §D.1을 참고하십시오. 분석 결과, 오직 26%의 토큰만이 눈에 띄는 손실 감소(H→L)를 보인 반면, 대다수인 51%의 토큰은 이미 학습된 상태를 의미하는 L→L에 머무는 것으로 나타났습니다. 흥미롭게도 11%의 토큰은 지속적으로 높은 손실(H→H)을 유지했으며, 이는 고(高) 불확정성(aleatoric uncertainty)(Hüllermeier and Waegeman, 2021)에 기인한 것으로 보입니다. 추가로 12%의 토큰은 학습 도중 예상치 못하게 손실이 증가(L→H)하는 현상을 보였습니다.
두 번째로 주목할 점은, 많은 토큰 손실이 지속적으로 큰 변동폭을 보이면서 수렴을 거부한다는 사실입니다. 그림 3(b)와 (c)에서 볼 수 있듯, L→L 및 H→H 유형에 해당하는 토큰 상당수가 학습 과정에서 높은 분산(variance)을 나타냅니다. §D.2에서는 이러한 토큰들의 실제 내용을 시각화하여 분석했는데, 이들 중 상당수가 ‘노이즈’ 토큰임을 확인했으며, 이는 우리의 가설과 일치합니다.
결국, 개별 토큰에 대한 손실은 전체 평균 손실처럼 부드럽게 감소하지 않으며, 토큰마다 서로 다른 복잡한 학습 동태가 존재함을 알 수 있습니다. 학습 과정에서 모델이 집중해야 할 토큰을 적절히 선택할 수 있다면, 모델 학습 궤적을 한층 안정화하고, 데이터 효율성 또한 높일 수 있을 것으로 기대됩니다.
2.2 Selective Language Modeling
개요
문서 단위 필터링에서 “참조 모델(reference model)” 기법을 쓰는 아이디어에 착안하여, 우리는 토큰 단위에서 데이터를 선별하는 단순한 파이프라인인 Selective Language Modeling (SLM)을 제안합니다. 이 방법은 그림 4에서 보이듯 세 단계로 진행됩니다. 먼저 고품질로 선별된(curation) 데이터셋을 통해 참조 모델을 학습하고, 이를 이용해 사전 학습에 쓰일 코퍼스의 각 토큰 손실을 측정합니다. 마지막으로 학습 대상 모델은 참조 모델과의 손실 격차가 큰(즉, 학습 가치가 높은) 토큰들에 집중하여 선택적으로 학습합니다. 이러한 설계 의도는 “참조 모델 대비 손실이 많이 남아 있는 토큰일수록 학습 효과가 크고, 우리가 원하는 분포에 더 부합한다”는 판단에 근거합니다. 자연스럽게 의미가 없거나 품질이 낮은 토큰들은 배제되는 효과가 있습니다. 아래에서는 각 단계를 구체적으로 살펴봅니다.
참조 모델링 (Reference Modeling)
먼저 우리가 원하는 목표 분포를 반영할 수 있는 고품질 데이터셋을 마련합니다. 이 데이터로 참조 모델(RM)을 표준적인 교차 엔트로피 손실(cross-entropy loss) 기반으로 학습합니다. 이렇게 학습된 RM은 이후 대규모 사전 학습 코퍼스 안의 각 토큰 손실을 측정하는 데 사용됩니다.


그림 4: Selective Language Modeling (SLM)의 전체 파이프라인.
SLM은 사전 학습(pre-training) 과정에서 가치 있고 깨끗한 토큰에 집중함으로써 언어 모델의 성능을 높입니다. 1단계: 우선 고품질 데이터로 참조 모델을 학습합니다. 2단계: 이 참조 모델을 사용해 코퍼스 내 각 토큰의 손실값을 측정합니다. 3단계: 측정된 손실 점수가 높은(학습 가치가 높은) 토큰만을 선택적으로 학습 대상 모델에 반영합니다.
Selective Pretraining
주목할 점은, 전통적인 인과적 언어 모델링(Causal Language Modeling, CLM)이 교차 엔트로피 손실을 사용한다는 사실입니다:


왜 모든 토큰에 대해 손실을 더하는가?
- 언어 모델은 시퀀스 내 모든 위치에서 “다음 토큰”을 잘 맞히는 능력을 길러야 합니다.
- 만약 한 위치의 예측이 틀렸다고 해서 시퀀스 전체를 “하나의 잘못된 예측”으로 보는 것이 아니라, 토큰 한 개당 예측 결과를 따로 계산하고, 그 모든 위치의 예측 오류를 합산하여 평균을 냅니다.
- 이는 “한 위치에서만 틀렸다 해서 전체 예측이 실패”라고 간주하는 것이 아니라, 각 토큰 예측을 독립적·누적적으로 평가한다는 점이 핵심입니다.
정리
- (2) 식에서 손실을 전부 더한다고 해서 “시퀀스 전체가 틀렸다”는 뜻이 아니라,
- 시퀀스 각 토큰을 제대로 예측했는지 여부를 각각 평가한 뒤 모아(합산)서 모델이 얼마나 잘 예측하고 있는지를 정량화하는 방식입니다.
- 이것이 “다음 토큰 예측(next-token prediction)”을 하는 전통적인 오토리그레시브 언어 모델의 표준 손실 계산 방법입니다.

(3), (4), (5)는 그렇게 보니 명확하네. 높은 loss를 유발하는 애들을 바탕으로 정답확률을 누적해서, 선별하겠다는거니
SLM(Selective Language Modeling)에서는 “참조 모델 대비 초과 손실(excess loss)이 큰 토큰”일수록 추가 학습의 여지가 많은 토큰이라고 보고, 그 토큰들에 대해 집중적으로 학습합니다. 즉,
- 현재 모델이 그 토큰을 잘못 맞출 때(=높은 손실)
- 참조 모델은 상대적으로 그 토큰을 훨씬 더 쉽게 맞추는 경우(=낮은 손실)
이런 경우일수록, “학습할 가치가 큰 토큰”으로 간주해 모델이 주어진 분포(또는 목표 도메인)에 더 빠르게 적응하도록 선별하는 것이죠.
결국 (3), (4), (5)에서 정의한 초과 손실 계산과 지표 함수(Indicator Function)는 “어떤 토큰에 대해 학습 손실을 적용해야 하는가?”를 판별하는 과정으로, 높은 초과 손실을 유발하는 토큰들에 대해 집중 학습하는 전략을 구체화하고 있습니다.
3 실험(Experiments)
우리는 수학 분야와 일반 분야 두 영역에서 모델을 지속적 사전 학습(continual pretraining)하며, SLM의 효용을 검증하기 위한 다양한 에블레이션(부분 소거) 및 분석 실험을 설계했습니다.
3.1 실험 설정(Experimental Setup)
참조 모델(Reference Model) 학습
수학 분야 참조 모델을 학습하기 위해, 약 5억(0.5B) 개 규모의 고품질 수학 관련 토큰으로 구성된 데이터셋을 준비했습니다. 이 데이터셋은 GPT 기반의 합성 데이터(Yu et al., 2024; Huang et al., 2024)와 사람이 직접 선별한 데이터(Yue et al., 2024; Ni et al., 2024)를 혼합한 것입니다. 한편, 일반 분야 참조 모델을 위해서는 Tulu-v2(Ivison et al., 2023)나 OpenHermes-2.5(Teknium, 2023)와 같은 오픈소스 데이터셋에서 추출한 19억(1.9B) 개의 토큰으로 이루어진 코퍼스를 구축했습니다.
참조 모델들은 총 3에폭(epoch) 동안 학습되었습니다. 1B 파라미터 모델에는 최대 학습률을 5e-5로, 7B 파라미터 모델에는 1e-5로 설정한 뒤, 코사인 감쇠(cosine decay) 스케줄을 적용했습니다. 시퀀스 길이는 1B 모델에는 최대 2048, 7B 모델에는 최대 4096으로 설정해, 여러 샘플을 하나의 시퀀스에 합쳐서 입력에 활용했습니다. 모든 주요 실험에서, 지속적 사전 학습을 수행하는 모델과 참조 모델은 동일한 베이스 모델로 초기화했습니다.
논문에서 간단히 “코사인 감쇠 스케줄을 적용했다”고만 적어뒀다면, 대개는 전체 훈련 스텝(3에폭 전체)에 걸쳐 부드럽게 학습률을 내리는 표준 방식을 사용했을 가능성이 큽니다.
코사인 감쇠 스케줄(cosine decay)은 에폭 수가 적더라도, 혹은 많더라도, 학습 초반-중반-후반에 걸쳐 모델이 일정하게 또는 부드럽게 학습률이 변화할 수 있도록 해 주는 방법 중 하나입니다.
- 에폭 수가 적다면: 짧은 학습 기간 안에도 “초반에 상대적으로 높은 학습률로 빠르게 적응 → 후반에 학습률을 낮춰 미세 조정” 과정을 유연하게 수행할 수 있습니다.
- 에폭 수가 많다면: 점진적인 학습률 감소로 오버슈팅(overshooting)을 줄이고, 후반에 안정적으로 수렴하게 만들어 줍니다.
즉, 3에폭이라고 해서 꼭 ‘단순 일정한 학습률(예: 고정된 학습률)로 끝까지 달리면 된다’고 볼 수만은 없습니다.
- 데이터셋 크기나 모델 구조에 따라,
- 혹은 에폭 중간에 batch size 조정 등이 이뤄질 수도 있고,
- 원하는 목표에 더 부드럽게 수렴시키고자 할 수도 있기 때문이죠.
다시 말해, 에폭이 많든 적든, 코사인 감쇠 같은 동적인 학습률 스케줄을 적용하면, 학습 과정에서 모델이 보다 효과적으로 손실 지형(loss landscape)에 적응할 가능성을 높이는 장점이 있습니다.
표 1: 수학 분야 사전 학습의 few-shot CoT(reasoning) 결과.
모든 모델은 few-shot 프롬프트로 시험했으며, 이전 최고 성능은 파란색, 본 논문에서 달성한 최고 성능은 보라색으로 표시했습니다.
- ∗ 고유한 수학 관련 토큰만 계산합니다. Rho-1 모델의 경우, 실제 학습에 사용된 ‘선택된 토큰’만 집계합니다.
- † 공개된 학습 세트(예: PRM800k)에서 사용된 일부 원본 테스트 샘플 때문에, 평가에는 OpenAI의 MATH 서브셋(Lightman et al., 2023)을 사용했습니다.
- ‡ SAT 데이터는 총 32개의 사지선다 문제만 포함하므로, 가능하다면 마지막 세 개 체크포인트의 결과를 평균해 표에 반영했습니다.
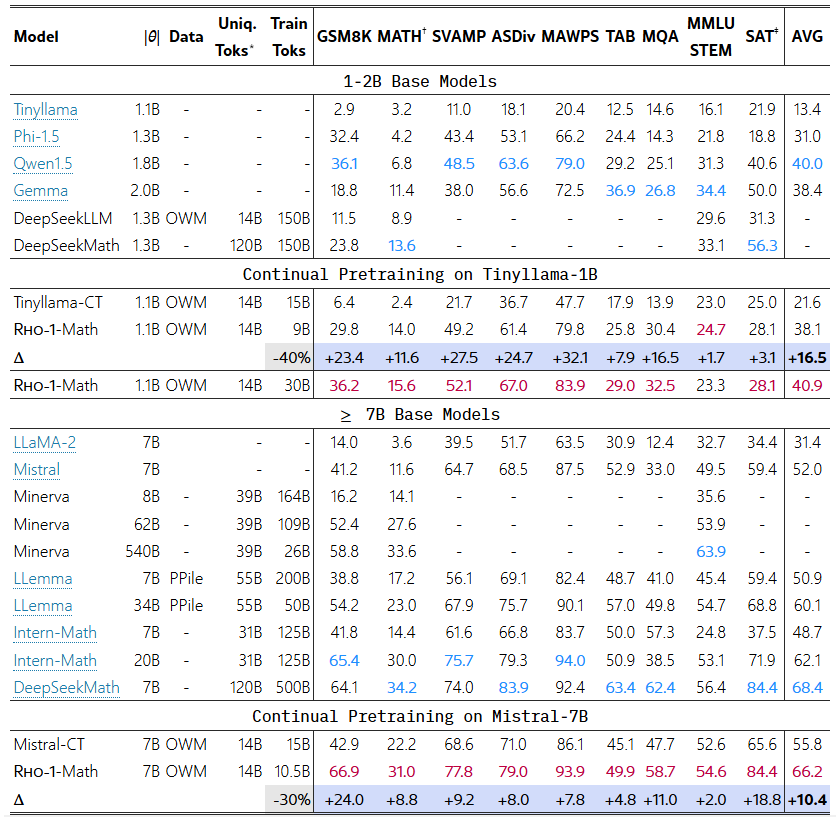
프리트레이닝 코퍼스(Pretraining Corpus)
수학적 추론을 위해, 우리는 OpenWebMath (OWM) 데이터셋 (Paster et al., 2023)을 사용합니다. 이는 Common Crawl에서 수집된 수학 관련 웹페이지 약 140억(14B) 토큰으로 구성됩니다. 일반 도메인 학습을 위해서는, SlimPajama (Daria et al., 2023)와 StarCoderData (Li et al., 2023a)(이 둘은 모두 Tinyllama 코퍼스에 포함)를 OpenWebMath와 섞어 총 800억(80B) 토큰을 학습하며, 이때 혼합 비율은 6:3:1입니다.
프리트레이닝 설정(Pretraining Setting)
- 수학 분야 사전 학습(Math Pretraining):
- Tinyllama-1.1B 모델(Zhang et al., 2024)과 Mistral-7B 모델(Jiang et al., 2023)을 대상으로 지속적 사전 학습을 수행합니다.
- Tinyllama-1.1B 모델에는 학습률 8e-5를, Mistral-7B 모델에는 2e-5를 적용했습니다.
- 1.1B 모델의 경우, 32대의 H100 80G GPU 환경에서 약 150억(15B) 토큰을 3.5시간, 500억(50B) 토큰을 12시간 정도에 학습할 수 있었습니다.
- 7B 모델의 경우, 동일한 하드웨어 환경에서 150억(15B) 토큰을 학습하는 데 약 18시간이 걸렸습니다.
- 일반 도메인 학습(General Domain):
- Tinyllama-1.1B 모델에 대해 학습률 1e-4로 설정, 동일한 하드웨어 조건에서 800억(80B) 토큰을 학습하며, 약 19시간이 소요되었습니다.
- 배치 사이즈는 두 도메인 모두 1M 토큰으로 동일하게 유지했습니다.
- 토큰 선택 비율(Token Selection Ratio)은 Tinyllama-1.1B 모델에 60%, Mistral-7B 모델에 70%를 적용했습니다.
베이스라인 설정(Baseline Setting)
- Tinyllama-CT와 Mistral-CT처럼 인과적 언어 모델링(CLM) 방식으로 지속적 사전 학습을 마친 모델들을 베이스라인으로 사용합니다.
- 또한 Rho-1 모델을, Gemma(Team et al., 2024), Qwen1.5(Bai et al., 2023), Phi-1.5(Li et al., 2023b), DeepSeekLLM(DeepSeek-AI, 2024), DeepSeekMath(Shao et al., 2024), CodeLlama(Roziere et al., 2023), Mistral(Jiang et al., 2023), Minerva(Lewkowycz et al., 2022), Tinyllama(Zhang et al., 2024), LLemma(Azerbayev et al., 2023), InternLM2-Math(Ying et al., 2024) 등 유명하고 성능이 뛰어난 여러 모델과 비교 평가했습니다.
- 파인튜닝 결과에 대해서는, 기존 최고 모델인 MAmmoTH(Yue et al., 2024) 및 ToRA(Gou et al., 2024)와도 비교를 수행했습니다.
평가 설정(Evaluation Setup)
- 사전 학습된 모델들의 역량을 폭넓게 평가하기 위해, 다양한 과제에서 few-shot 성능과 파인튜닝 성능을 모두 비교했습니다.
- 일반 과제 평가에는 lm-eval-harness<sup>2</sup>(Gao et al., 2023)를 사용하였으며<sup>2</sup>( 링크 ), 수학 과제 평가를 위해서는 math evaluation suite<sup>3</sup>( 링크 )를 개발해 활용했습니다.
- 추론 속도 향상을 위해 vllm (v0.3.2)(Kwon et al., 2023)을 사용했습니다. 추가적인 평가 세부 정보는 부록 E(Appendix E)에 수록되어 있습니다.
표 2: 수학 분야 사전 학습에서 툴 통합 추론(tool-integrated reasoning) 결과.
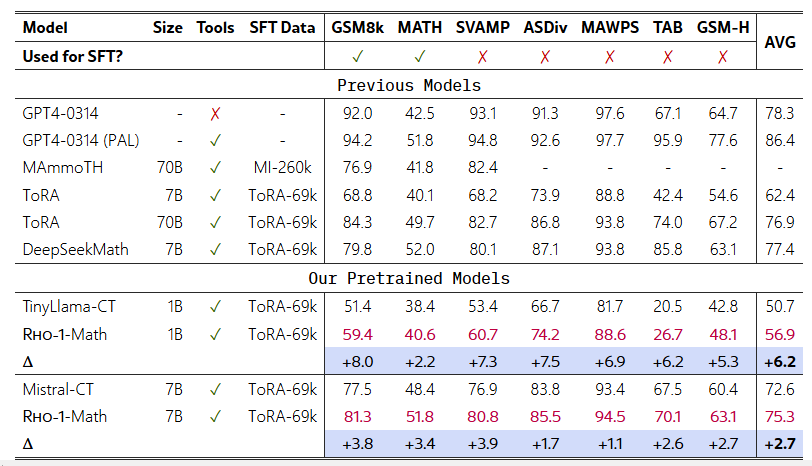
3.2 수학 분야 사전 학습 결과
Few-shot CoT 추론 결과
우리는 기존 연구들(Lewkowycz et al., 2022; Azerbayev et al., 2023; Shao et al., 2024)을 참고하여, base 모델에 대해 few-shot chain-of-thought (CoT) 예시(Wei et al., 2022a)를 사용해 평가했습니다. 표 1에 나타난 결과를 보면, 일반적인 방식으로 사전 학습을 단순 연장하는 경우와 비교했을 때, Rho-1-Math는 1B 모델에서 평균 16.5%, 7B 모델에서 평균 10.4%의 few-shot 정확도 향상을 달성했습니다. 추가로 OpenWebMath에서 여러 에폭에 걸쳐 훈련했더니, Rho-1은 평균 few-shot 정확도를 40.9%까지 끌어올릴 수 있었습니다. 또한 5000억(500B) 개의 수학 토큰으로 사전 학습한 DeepSeekMath-7B와 비교해볼 때, 단 150억(15B) 개 토큰(이 중 10.5억 개를 선택 학습)으로 사전 학습한 Rho-1-7B가 유사한 결과를 얻어, 본 접근법의 효율성을 입증했습니다.
툴 통합 추론(Tool-Integrated Reasoning) 결과
우리는 69k ToRA 코퍼스(Gou et al., 2024)를 활용하여 Rho-1과 베이스라인 모델들을 파인튜닝했습니다. 이 코퍼스는 GPT-4로 생성된 16k개의 툴 통합 추론 형식(tool-integrated reasoning) 트래젝터리와, LLaMA를 이용해 답안이 포함되도록 보강한 53k 샘플로 구성됩니다. 표 2에서 볼 수 있듯, Rho-1-1B와 Rho-1-7B는 MATH 데이터셋에서 각각 40.6%, 51.8%의 최신 최고 성능(state-of-the-art)을 달성했습니다. 또한 TabMWP나 GSM-Hard 같은 일부 미공개 과제(unseen tasks)에서도, Rho-1은 Rho-1-Math-1B에서 6.2%, Rho-1-Math-7B에서 2.7%의 평균 few-shot 정확도 향상을 보이며 일정 수준의 일반화 능력을 입증했습니다.
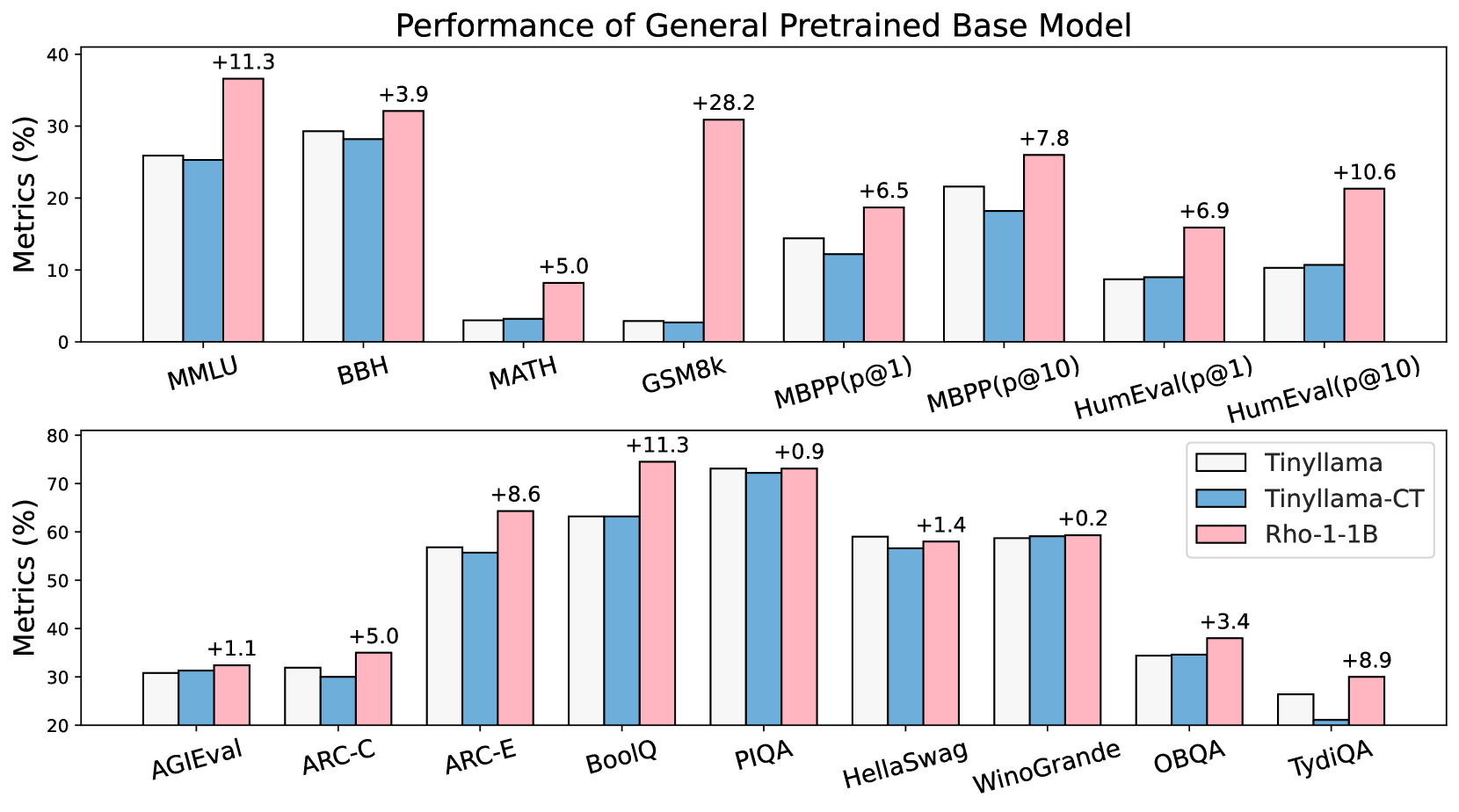
그림 5: 일반 도메인 사전 학습 결과.
우리는 Tinyllama-1B 모델을 대상으로 800억(80B) 개의 일반 도메인 토큰으로 지속적 사전 학습을 진행했습니다. Tinyllama-CT는 CLM 방식을 사용했고, Rho-1은 제안된 SLM 방식으로 학습되었습니다.
3.3 일반 도메인 사전 학습 결과
우리는 Tinyllama-1.1B 모델을 대상으로 800억(80B) 개 토큰을 추가로 학습함으로써, 일반적인(pretraining) 환경에서도 SLM이 효율적임을 검증했습니다. 그림 5에 나타난 결과에 따르면, Tinyllama 모델이 이미 이 토큰 중 상당 부분을 사전 학습한 상태임에도 불구하고, SLM을 적용했을 때 직접적인 지속적 사전 학습 대비 평균 6.8%(15개 벤치마크 기준)의 성능 향상을 얻을 수 있었습니다. 특히 코드와 수학 과제에서 10% 이상의 유의미한 개선폭이 확인되었습니다.
3.4 자기 참조(Self-Reference) 결과
표 3: 자기 참조(Self-Reference) 결과. 여기서 우리는 OpenWebMath(OWM)를 사용해 참조 모델을 학습했습니다.
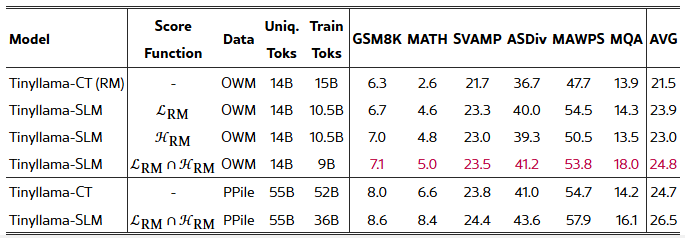
이 절에서는 추가적인 고품질 데이터 없이, 사전 학습 코퍼스만으로도 SLM이 모델 사전 학습 효과를 높일 수 있음을 보입니다. 구체적으로, 우리는 Proof-Pile-2(PPile)의 부분 집합인 OpenWebMath(OWM) 코퍼스에 대해 먼저 참조 모델을 학습했습니다. 그런 뒤, 학습된 참조 모델을 이용해 OWM과 PPile을 평가하고, 선택된 토큰들만으로 모델을 학습했습니다. 이때 다운스트림 과제와 관련된 데이터가 전혀 없는 상황(현실적 응용에서 흔히 벌어지는 경우)을 가정합니다. 우리는 “핵심은 원하는 분포를 점수화하는 것이라기보다, 노이즈 토큰을 제거하는 데 있다”고 가정했으며, 이에 따라 참조 모델의 손실 과 다음 토큰의 불확실성을 나타내는 정보 엔트로피 H_RM — 두 가지 점수 함수를 사용해 필터링을 시도했습니다. 자세한 내용은 부록 H를 참고하십시오.
표 3에 요약된 실험 결과를 보면, OWM으로 학습한 참조 모델만을 사용해 동일한 코퍼스에 대해 사전 학습을 진행해도 평균 다운스트림 성능에서 +2.4%의 향상을 얻을 수 있었습니다. 또한 참조 모델 손실 대신 “정보 엔트로피”만 점수 함수로 활용해도 유사한 향상폭을 확인했습니다. 더 나아가, 두 점수 함수가 공통으로 선택한 토큰들의 교집합에 대해서만 학습했더니, 전체 토큰이 40% 줄었음에도 +3.3%의 성능 향상을 얻을 수 있었습니다. 한편, 참조 모델은 OWM 부분집합만으로 학습했음에도 PPile 전체에 대해 SLM을 적용한 결과, 토큰 30% 절감과 함께 1.8%의 향상을 달성했습니다. 구체적인 내용은 부록 H를 참고하십시오.
“두 가지 점수 함수(참조 모델 손실 L_RM\과 정보 엔트로피 H_RM로 토큰을 각각 선별하고, 그 교집합만 골라 학습했는데 어떻게 더 적은 토큰으로도 성능이 향상되었는가?”라는 부분일 텐데요. 이를 간단히 요약해 보면 다음과 같은 논리가 숨어 있습니다.
- 각 점수 함수가 ‘유의미하다고 판단한 토큰’을 찾는다.
- L_RM이 큰 토큰은 ‘참조 모델 대비 학습 가치가 큰’ 토큰으로 간주됩니다.
- H_RM이 큰 토큰은 ‘참조 모델이 해당 위치를 불확실하게 보고 있다(즉, 여러 가능한 정답이 있을 수 있다)’고 해석할 수 있어, 역시 학습할 가치가 있다고 볼 수 있습니다.
- 두 점수 함수를 동시에 만족하는 토큰은 ‘둘 다 중요하다고 본 토큰’이 됩니다.
- 즉, L_RM 기준으로도 학습 가치가 높고, H_RM 기준으로도 변별력이 있다고 여겨지는 토큰이 교집합에 속하겠죠.
- 이 교집합은 자연스럽게 양쪽 기준에서 “가장 소음(노이즈)이 적거나, 학습 효과가 클 것”으로 기대되는 토큰 집합입니다.
- “가장 요긴한 토큰만 추려서 학습”하게 되면, 일반적으로 노이즈가 많은 토큰 혹은 학습 효용이 낮은 토큰을 배제하게 됩니다.
- 전체 토큰 수는 줄어들지만, 남은 토큰들은 사실상 “핵심 정보만” 남았을 가능성이 커집니다.
- 이는 학습 효율을 끌어올릴 수 있으며, 모델이 한정된 학습 용량(파라미터·GPU 시간 등)을 가장 필요한 정보에 집중할 수 있게 만들어 결과적으로 성능 향상을 야기할 수 있습니다.
- 실제 사례에서도, 데이터 필터링을 적절히 진행해 노이즈를 제거하면 “적은 양의 데이터로 더 좋은 결과”가 종종 일어납니다.
- 예컨대 고퀄리티로 선별된 100만 개 샘플이 잡다한 500만 개 샘플보다 학습 성능을 높이는 경우는 연구 사례가 많습니다.
- 여기서는 “ L_RM ∩ H_RM ”이라는 2중 기준이 고품질 필터 역할을 한다고 이해할 수 있습니다.
즉, 교집합이 전체 토큰 수를 줄였음에도 성능이 더 좋아진 이유는, “” 모델이 노이즈에 방해받지 않고 학습할 수 있게 됐기 때문이라고 볼 수 있습니다. 일반적인 논문 실험에서도 데이터 필터링·선별 기법이 노이즈를 줄이면, 오히려 데이터 양이 감소해도 모델 성능이 좋아지는 경우가 흔히 관찰됩니다.
결론 : 필터링 기법의 타당성이 상당하다
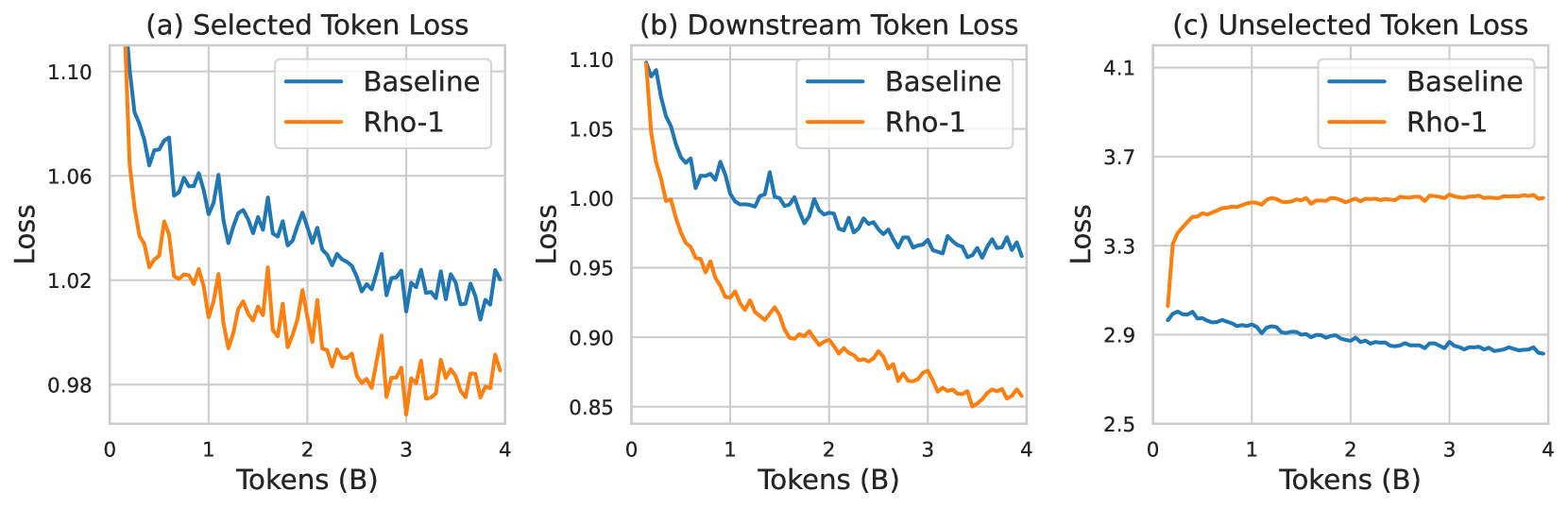
그림 6: 사전 학습 손실과 다운스트림 손실의 동태.
(a)와 (c)는 SLM 방식과 CLM 방식에서, 사전 학습 중 SLM이 “선택/비선택”한 토큰들 각각에 대한 손실 변화를,
(b)는 MetaMath(Yu et al., 2024) 과제에서 SLM과 CLM이 달성한 손실을 보여줍니다. 위 결과는 총 40억(4B) 개의 토큰을 사용한 사전 학습 과정을 통해 검증되었습니다.
3.5 에블레이션 연구(Ablation Study) 및 분석(Analysis)
선택된 토큰 손실은 다운스트림 성능과 더 잘 정렬된다
우리는 참조 모델을 사용해 토큰을 필터링하고, 학습 후 검증 세트 및 다운스트림 손실에 미치는 영향을 살펴봤습니다. 그림 6에 나타난 바와 같이, 우리는 총 40억(4B) 개 토큰으로 사전 학습을 수행한 뒤, 각 기법과 검증 세트별 손실 변화를 추적했습니다. 그 결과, Rho-1은 선택된 토큰에 대해 기존 사전 학습보다 더 큰 폭의 손실 감소를 보였습니다. 그림 (a), (b), (c)를 교차로 살펴보면, 선택된 토큰 중심으로 사전 학습을 진행했을 때 다운스트림 손실이 크게 줄어드는 반면, 기존 사전 학습은 초기 손실이 줄었음에도 다운스트림 손실에는 그다지 큰 변화가 없었습니다. 따라서 사전 학습에 사용할 토큰을 선별하는 전략이 더 효율적임을 예상할 수 있습니다.

그림 7: SLM에서 선택된 토큰/선택되지 않은 토큰 손실과 다운스트림 과제 성능 간의 관계.
y축은 GSM8k와 MATH에서의 평균 few-shot 정확도를, x축은 각 체크포인트(20억, 50억, 80억, 110억, 140억 토큰 시점)에서 선택된 토큰/비선택 토큰의 평균 손실을 나타냅니다.
그림 7을 보면, 선택된 토큰의 손실은 최근 연구(Gadre et al., 2024)에서 확인된 것처럼 파워 법칙(power law) 형태로 다운스트림 과제 성능과 상관관계를 보입니다. 우리는 SLM이 선택한 토큰이 모델 성능을 긍정적으로 이끄는 반면, 선택되지 않은 토큰은 오히려 성능에 부정적 영향을 준다고 해석했습니다. 이는 모든 토큰의 손실을 일괄적으로 줄이는 것이 모델 성능 향상에 필수적이지 않음을 시사합니다. 자세한 내용은 부록 F를 참조하십시오.
논문에서 말하는 요점은 다음과 같습니다:
- “모든 토큰을 무조건 잘 맞히도록(=손실을 줄이도록) 노력하는 방식”과,
- “일부 토큰(즉, 모델에게 가치가 큰 토큰)만 집중적으로 맞히도록(=손실을 줄이도록) 하는 방식”
이 두 가지가 서로 다르다는 것입니다.
1. 모든 토큰의 손실을 골고루 줄이기
- 전통적인 인과적 언어 모델링(CLM)은 “코퍼스 안에 등장하는 모든 토큰”을 골고루 예측하려고 하면서, 각 토큰에 동일한 중요도를 부여합니다.
- 따라서 모든 토큰에 대해 손실을 줄여야 한다고 가정합니다.
그러나 실제로는 노이즈가 많거나, 예측 자체가 학습에 크게 기여하지 않는 토큰들도 있을 수 있습니다.
- 예를 들어, 반복적인 패턴, 문법적으로 별 의미가 없는 토큰, 혹은 데이터 내 오탈자(noise) 등.
- 이런 토큰을 맞히려고 모델이 리소스를 낭비하면, 정작 중요한 토큰에 더 집중하지 못할 수 있습니다.
2. 일부 “가치 있는 토큰”만 선택적으로 맞히기
- SLM(Selective Language Modeling)처럼 “특정 기준(참조 모델 손실, 정보 엔트로피 등)을 사용해, 토큰 중 가치가 높은 것들만 학습 대상에 포함”하는 방식에서는,
- 중요한 토큰에 대해서만 손실을 줄이려고 하므로, 모델이 불필요한 노이즈에 쓸데없이 신경 쓰지 않게 됩니다.
- 결과적으로, 덜 중요한 토큰의 손실은 충분히 줄이지 않았더라도(=그 토큰을 틀릴 때가 많더라도), 핵심 토큰을 더 정확히 학습함으로써 다운스트림 태스크 성능이 올라가는 경우가 나타납니다.
“선택되지 않은 토큰이 성능을 떨어뜨린다”는 의미
- “선택되지 않은 토큰”은 모델이 “굳이 맞힐 필요가 없다고(또는 학습 효율이 낮다고)” 간주한 토큰들입니다.
- CLM 방식이라면 이 토큰들을 맞히려 애쓰고, 손실을 줄이려고 할 텐데, 실제로 그 노력이 다운스트림 과제 성능으로 이어지지는 않는다는 것이죠.
- 오히려 이 토큰들로 인해 모델이 노이즈나 비효율적 패턴에 끌려다니게 될 가능성이 높아집니다.
결국 논문이 말하고자 하는 핵심은
“모든 토큰의 예측 정확도를 높여 손실을 줄이는 것이 반드시
다운스트림 과제 성능 향상과 1:1로 이어지지는 않는다.”
라는 점입니다.
- 대신, 정말 ‘유용한 토큰’만 선택해 집중적으로 학습했을 때,
- 모델이 필요한 지식이나 패턴을 더 효율적으로 습득하고 다운스트림 과제 성능을 높일 수 있다는 겁니다.
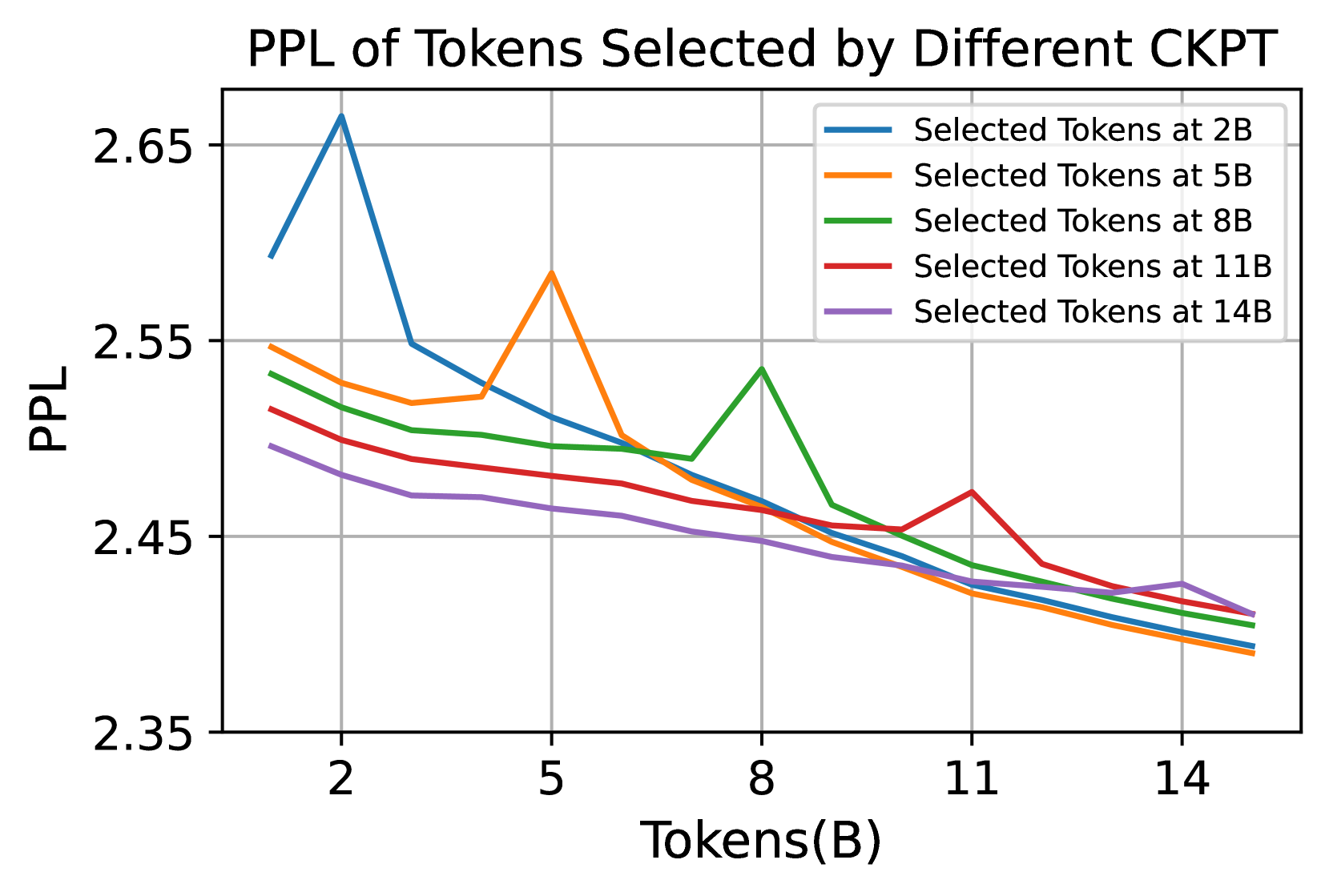
그림 8: 체크포인트별로 선택된 토큰들의 PPL.
2B, 5B, 8B, 11B, 14B 시점에서 선택된 토큰들에 대한 PPL을 측정했습니다.
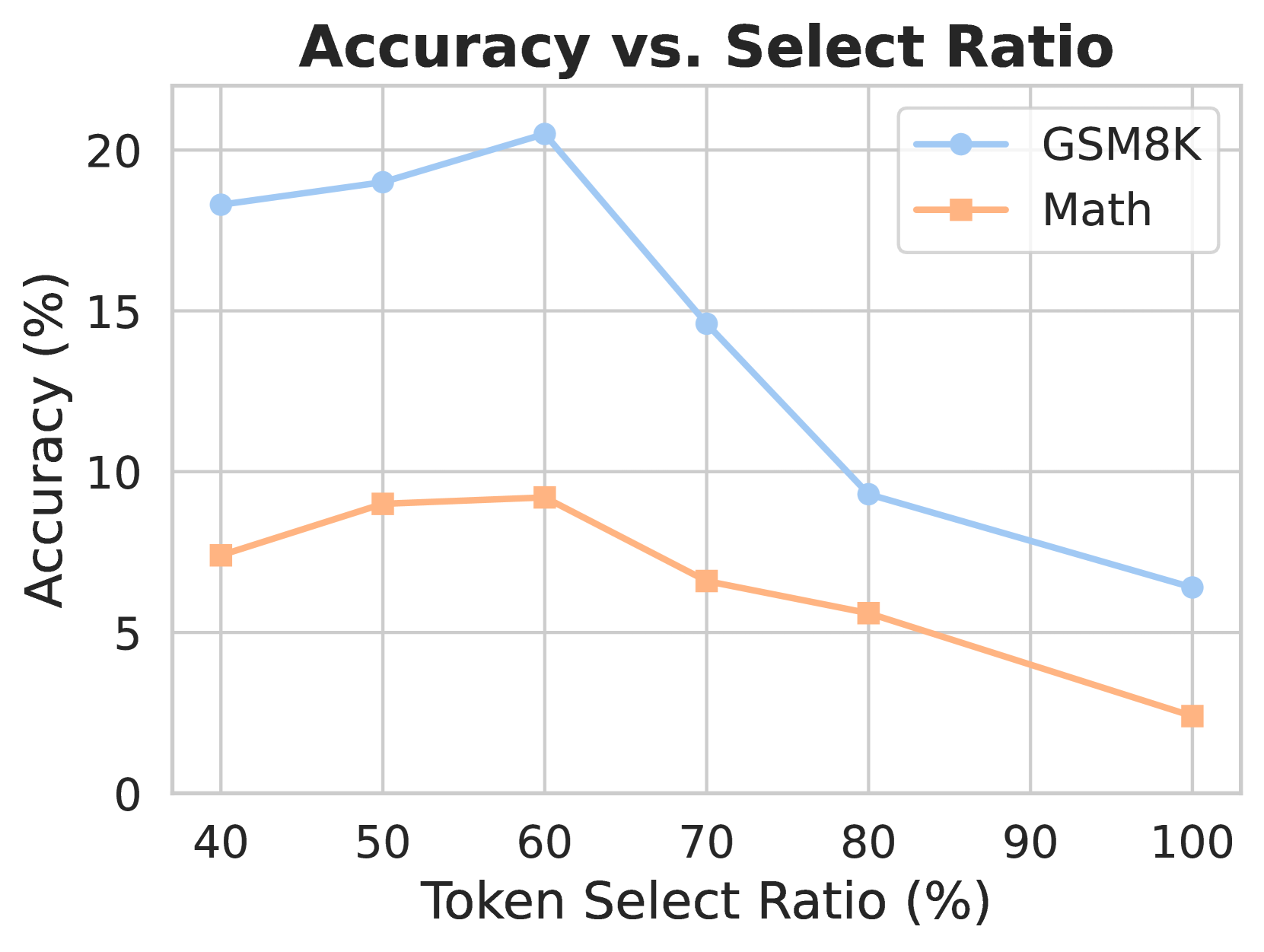
그림 9: 토큰 선택 비율(Token Select Ratio)의 영향.
우리는 50억(5B) 개 토큰으로 10억(1B) 파라미터 모델을 SLM 방식으로 학습하며, 다양한 선택 비율이 성능에 어떤 영향을 미치는지 실험했습니다.
어떤 토큰이 SLM으로 선택되는가?
우리는 SLM 방법이 사전 학습 과정에서 선택한 토큰들이 어떤 특징을 갖는지 분석하여, 그 작동 메커니즘을 더 깊이 이해하고자 합니다. 이를 위해 OpenWebMath로 Rho-1 모델을 학습하는 중 SLM의 토큰 선택 과정을 시각화했습니다. §G.1에서는 실제 사전 학습에서 유지된(선택된) 토큰을 파란색으로 표시했습니다. 관찰 결과, SLM이 고른 토큰 대다수는 수학과 밀접한 관련이 있으며, 원본 코퍼스 중 수학적 내용에 해당하는 부분에 효과적으로 모델이 집중하게 만드는 것으로 보였습니다.
또한 우리는 학습 과정 중 여러 체크포인트에서 토큰 필터링이 어떻게 달라지는지 살펴보고, 다른 체크포인트에 대해 이 토큰들의 퍼플렉시(perplexity)를 테스트했습니다. 그림 8에 나타난 바와 같이, 후반부 체크포인트가 선택한 토큰들은 학습 후반부에서 퍼플렉시가 더 높고, 학습 초반에는 퍼플렉시가 더 낮았습니다. 이는 모델이 먼저 학습 여지가 큰 토큰부터 최적화함으로써 학습 효율을 높인다는 것을 시사할 수 있습니다. 또한 선택된 토큰의 손실에서 샘플 단위의 “더블 디센트(double descent)”(Nakkiran et al., 2021) 현상을 확인했는데, 이는 초기에 선택된 토큰들의 퍼플렉시가 잠시 높아졌다가 이후 감소하는 양상을 의미합니다. 이는 초과 손실(excess loss)에 기반해 매 체크포인트마다 “가장 필요로 하는” 토큰들을 선택했기 때문일 수 있습니다.
더블 디센트(double descent)는 머신 러닝 모델(특히 심층 신경망 등 ‘오버파라미터화’된 모델을 다룰 때)에서 관찰되는 독특한 학습 곡선 현상을 가리킵니다. 전통적인 머신 러닝 이론에서는 “모델 복잡도(파라미터 수)를 늘릴수록 학습 오차는 줄지만 테스트 오차는 처음에 감소하다가 중간쯤에서 다시 증가(오버피팅 구간), 그 뒤엔 증가만 한다”는 식의 U자형(또는 역U자형)의 손실 곡선을 예상했습니다.
그런데 실제로는 모델 복잡도가 일정 수준(‘인터폴레이션(interpolation) 임계점’)을 넘어가면,
- 학습 오차가 거의 0에 가까워지고(모델이 데이터를 ‘과하게’ 기억),
- 테스트 오차도 한 번 크게 올라갔다가(오버피팅),
- 이후 모델 규모를 더 키우면 테스트 오차가 다시 내려가는
이런 두 번의 하강(“double descent”) 패턴이 나타나기도 합니다.
즉,
- 첫 번째 하강: 모델 복잡도가 어느 정도까지 증가하여, 점차 데이터를 잘 맞추면서 발생하는 일반적인 오차 감소 구간.
- 이후 오차가 다시 상승: 모델이 너무 복잡해져서 오버피팅 문제나 잡음에 대한 민감도가 증가하는 시점.
- 두 번째 하강: 모델을 ‘매우’ 크게 만들고(오버파라미터화), 적절한 정규화·학습 기법을 적용하면 오히려 테스트 성능이 다시 좋아지는 현상.
이 “double descent”는 Nakkiran et al.(2021), Belkin et al.(2019) 등의 연구를 통해 체계적으로 보고되었으며, 데이터셋 크기, 모델 크기, 학습 과정 등 여러 요인에 의해 좌우됩니다. 최근 대형 언어 모델(LLM)의 학습 과정에서도 토큰 수, 파라미터 수 등에 따라 이중 하강 현상이 부분적으로 발견되곤 합니다. 이렇듯 한 번 오차가 줄었다가 다시 늘어났다 또 줄어드는 두 번의 하강 곡선이 “더블 디센트” 현상입니다.
그래프 설명:
- 언더파라미터화 영역: 모델의 복잡도가 낮을 때, 에러가 높다가 점차 감소
- 임계 영역: 기존 이론상 최적점. 테스트 에러가 일시적으로 증가
- 오버파라미터화 영역: 파라미터가 더 증가하면서 테스트 에러가 다시 감소
토큰 선택 비율의 영향
우리는 SLM의 토큰 선택 비율(token select ratio)이 모델 학습에 미치는 영향을 조사했습니다. 대체로 선택 비율은 Masked Language Model(MLM) 학습(Devlin et al., 2019; Liu et al., 2019) 등 이전 기법에서처럼 휴리스틱 규칙으로 결정됩니다. 그림 9에서 볼 수 있듯, 원본 토큰 중 약 60%를 선택하는 비율이 모델에 적절한 것으로 보입니다.
4 결론(Conclusion)
본 논문에서는 Selective Language Modeling(SLM) 기법을 통해 Rho-1을 학습하는 방법을 제안하며, 현재 사전 학습 단계에 보다 적합한 토큰을 선별하는 아이디어를 제시했습니다. 사전 학습 과정에서 나타나는 토큰 손실 변화를 상세히 분석한 결과, 모든 토큰이 동일하게 중요한 것은 아니라는 사실을 발견했습니다. 수학 및 일반 도메인에서 진행된 실험과 분석은 SLM의 효용을 입증했으며, 대형 언어 모델(LLM)의 사전 학습 프로세스에서 “토큰 단위 접근”의 중요성을 강조합니다. 앞으로는 토큰 단위 관점에서 LLM 사전 학습을 개선하는 방법에 대한 심층 연구가 더욱 필요하리라 봅니다.
Acknowledgments(감사의 글)
Zhenghao Lin과 Chen Lin은 중국 국가 중점 R&D 프로그램(No. 2022ZD0160501)과 국가 자연과학기금(No. 62372390, 62432011)의 지원을 받았습니다. Zhibin Gou와 Yujiu Yang은 Shenzhen Science and Technology Program(JCYJ20220818101001004) 및 Ping An Technology (Shenzhen) Co., Ltd.의 “Graph Neural Network Project” 지원을 받았습니다.
배경: 모든 토큰이 똑같이 중요할까?
최근 대형 언어 모델(LLM)들은 파라미터 수와 데이터셋 크기를 마구 늘림으로써 놀라운 결과를 얻어 왔습니다. 하지만 무작정 방대한 데이터를 ‘전부’ 학습시키는 게 늘 최선인 건 아니죠. 예를 들어, 데이터 안에 노이즈(오탈자나 무의미한 토큰, 불필요하거나 질이 낮은 정보)가 많을 때, 오히려 모델이 엉뚱한 데 자원을 낭비할 수 있습니다.
이 논문에서는 “모든 토큰이 똑같이 중요하지 않다”는 전제하에, 토큰 단위 수준에서 노이즈를 필터링하고, 학습 가치가 높은 토큰에만 집중하자는 발상을 제시합니다. 이를 Selective Language Modeling(SLM)이라 부르는데, 간단히 말하면 ‘학습할 가치가 큰 토큰만 골라 모델이 집중 학습’ 하는 방법입니다.
SLM의 핵심 아이디어: 참조 모델과 초과 손실(Excess Loss)
SLM이 작동하는 과정은 크게 세 단계입니다.
- 참조 모델(Reference Model) 학습:
- 먼저, 고품질(혹은 원하는 목표 분포에 부합하는) 데이터로 참조 모델을 훈련합니다.
- 이 모델은 각 토큰에 대해, “참조 모델이라면 얼마나 쉽게/어렵게 예측하는지”를 알려주는 기준점이 됩니다.
- 초과 손실 계산:
- 실제로 모델이 학습할 때, 각 토큰에 대한 현재 모델의 손실(L_θ)과 참조 모델의 손실(L_RM)을 비교합니다.
- 초과 손실(LΔ)이 클수록 “내가 아직 많이 틀리는 토큰이지만, 참조 모델은 잘 맞추는 토큰” → 즉 학습 가치가 큰 토큰이라고 해석합니다.
- 선택적 학습:
- 초과 손실이 상위 k%에 드는 “유용한 토큰”만 골라, 교차 엔트로피 손실을 적용합니다.
- 이 과정을 통해 노이즈나 불필요한 토큰에 대한 학습 부담을 줄이고, 제한된 GPU 자원으로도 ‘진짜 배울 게 많은 토큰’에 집중할 수 있게 됩니다.
주요 실험 결과
논문에서는 크게 수학 분야와 일반 도메인으로 나누어 SLM의 효율성을 검증했습니다.
- 수학 분야 사전 학습
- Common Crawl에서 추출한 OpenWebMath(OWM) 데이터셋(대략 140억 토큰)을 사용.
- Rho-1 모델(1B, 7B 파라미터)을 SLM 방식으로 학습해본 결과, 기존 인과적 언어 모델(CLM)을 그대로 이어서 학습할 때보다 평균 10~16% 정도 few-shot 정확도가 올랐습니다.
- 특히, DeepSeekMath-7B가 5천억(500B) 토큰을 학습해 달성한 수준에, Rho-1-7B는 단 150억(15B) 토큰으로 도달해 “데이터 효율성”을 크게 입증했습니다.
- 툴 통합 추론(파인튜닝) 결과
- 69k 규모의 ToRA 데이터셋(GPT-4가 만든 ‘툴 사용 추론’ 포맷 등)을 이용해 파인튜닝했더니, Rho-1-1B와 Rho-1-7B가 수학 benchmark(MATH)에서 각각 40.6%, 51.8% 정확도를 기록하여 최신 최고 성능을 달성했습니다.
- 일부 처음 보는 유형의 과제에서도 일정 수준의 일반화 능력을 확인.
- 일반 도메인 사전 학습
- Tinyllama-1.1B 모델을 대상으로 800억(80B) 토큰을 추가 학습.
- 이미 거의 다 본 데이터임에도, SLM을 적용하자 평균 6.8% 성능이 향상되었고, 코드나 수학 과제에서는 10% 이상 큰 폭으로 개선되었습니다.
- 자기 참조(Self-Reference) 시나리오
- 별도의 고품질 데이터가 없고, OWM 같은 기존 코퍼스만으로 참조 모델을 학습 → 다시 본 코퍼스나 다른 코퍼스(PPile 등)에 SLM 적용.
- 그래도 성능이 2~3% 이상 높아지는 결과를 보였습니다. “꼭 고품질 외부 데이터가 있어야만 토큰을 필터링할 수 있는 건 아니다”를 보여주는 사례죠.
- 에블레이션(Ablation) 및 메커니즘 분석
- “선택된 토큰의 손실”이 다운스트림 과제 성능과 훨씬 더 밀접하게 맞물린다는 사실을, 토큰별 손실 추적 그래프 등을 통해 확인했습니다.
- 모든 토큰의 손실을 일괄적으로 낮추기보다, 핵심 토큰(‘가치가 큰 토큰’)만 먼저 잘 학습하는 편이 모델 최종 성능에 더 이롭다는 결론.
결론 & 시사점
결국 이 논문은 “데이터 전부를 학습하는 게 아니라, 목적과 분포에 맞춰 ‘토큰’을 선별해서 학습하는 방식”이 기존 대비 높은 효율과 성능을 가져올 수 있음을 보여줍니다. 특히:
- 다운스트림 과제에 직접적으로 기여하는 토큰에 집중
- 노이즈가 많은 토큰을 무리하게 맞히려 애쓰지 않음
- 데이터 효율성을 크게 개선 (적은 토큰으로도 비슷하거나 더 높은 성능 달성)
이라는 점을 다양한 실험으로 입증했습니다. 앞으로는 LLM 사전 학습에서 ‘토큰 단위 필터링·선택 전략’이 더 적극적으로 활용될 가능성이 높아 보입니다.
- 예를 들어 수학, 코드, 특정 도메인 지식이 필요한 경우, 노이즈를 걷어내고 중요한 토큰만 골라 학습함으로써 적은 리소스로도 좋은 모델을 만들어낼 수 있겠죠.
정리하면,
“모든 토큰이 같은 가치가 아니라, 학습할 가치가 높은 토큰에 집중해 모델의 역량을 극대화하자!”
는 슬로건이 이 논문의 핵심 메시지입니다. 앞으로 이 아이디어가 대형 언어 모델 분야에서 어떻게 확장·발전될지 기대해볼 만합니다.
'인공지능' 카테고리의 다른 글
| Titans: Learning to Memorize at Test Time (3) | 2025.01.16 |
|---|---|
| MedNeXt: Transformer-driven Scaling of ConvNets for Medical Image Segmentation (2) | 2025.01.13 |
| mochi-1-preview (3) | 2025.01.10 |
| Ferret-UI 2: Mastering Universal User Interface Understanding Across Platforms (2) | 2025.01.10 |
| Hallo2: Long-Duration and High-Resolution Audio-Driven Portrait Image Animation (3) | 2024.11.30 |



