https://arxiv.org/abs/2410.18967
Ferret-UI 2: Mastering Universal User Interface Understanding Across Platforms
Building a generalist model for user interface (UI) understanding is challenging due to various foundational issues, such as platform diversity, resolution variation, and data limitation. In this paper, we introduce Ferret-UI 2, a multimodal large language
arxiv.org
초록(Abstract)
플랫폼의 다양성, 해상도의 차이, 그리고 데이터 제한 등의 근본적인 문제로 인해 사용자 인터페이스(UI)를 이해하는 범용 모델을 구축하는 일은 쉽지 않습니다. 본 논문에서는 iPhone, Android, iPad, 웹페이지, 그리고 AppleTV 등 광범위한 플랫폼에서 보편적인 UI 이해를 수행하도록 설계된 멀티모달 대규모 언어 모델(MLLM)인 Ferret-UI 2를 소개합니다. 기존 Ferret-UI를 기반으로 한 Ferret-UI 2는 △다양한 플랫폼 유형 지원, △적응형 스케일링을 통한 고해상도 인식, △GPT-4o와 표식 세트 시각 프롬프트(set-of-mark visual prompting)를 활용한 고급 태스크 학습 데이터 생성이라는 세 가지 핵심 혁신을 제시합니다. 이러한 발전 덕분에 Ferret-UI 2는 복잡하고 사용자 중심적인 상호작용을 수행할 수 있으며, 점차 늘어나는 플랫폼 생태계의 다양성에 대한 높은 유연성과 적응력을 확보합니다. 참조(Referring)·그라운딩(Grounding), 사용자 중심 고급 태스크(9가지 하위 태스크 × 5개 플랫폼), GUIDE 다음 액션 예측 데이터셋, 그리고 GUI-World 멀티 플랫폼 벤치마크에 대한 광범위한 실험 결과, Ferret-UI 2는 Ferret-UI를 크게 능가할 뿐 아니라 강력한 플랫폼 간 전이 성능도 보임을 확인했습니다.
†University of Texas at Austin. Apple 인턴십 기간 중 진행한 연구.
1 서론(Introduction)
사용자 인터페이스(UI)는 인간-컴퓨터 상호작용에서 핵심 역할을 하며, 사용자가 디지털 시스템과 소통하는 방식을 결정합니다. 스마트폰, 태블릿, 웹 플랫폼, 스마트 TV 등이 급속도로 확산되면서 UI의 복잡도 역시 증가해왔습니다. 이러한 플랫폼 다양성이 커지고 있음에도 불구하고, 특히 멀티 플랫폼 환경에서의 UI 이해와 상호작용(Hong et al., 2023; Wang et al., 2024b; Kapoor et al., 2024)을 다루는 많은 현재 접근 방식들은 여러 한계를 보입니다.
이 분야에서 주목할 만한 연구 중 하나로 **Ferret-UI(You et al., 2024)**가 있습니다. 이는 UI를 지칭(referring)하고 그라운딩하는 분야를 발전시켰습니다. 그러나 Ferret-UI는 (Liu et al., 2024a)에서 제시된 “어떤 해상도라도 처리 가능(any-resolution)”한 접근 방식을 표방함에도 불구하고, 실제로는 336×672 또는 672×336으로 고정된 해상도에 묶여 있습니다. 또한 Ferret-UI는 아이폰이나 안드로이드와 같은 단일 유형의 모바일 플랫폼에만 집중하고 있어, 현재처럼 다양성이 극대화된 플랫폼 환경에서는 활용도가 제한적입니다. 예컨대 그림 1에서 보듯이 아이폰, 아이패드, 웹 UI, 그리고 AppleTV는 각각 기기의 해상도가 전혀 달라, 이들과 직접적으로 호환하여 Ferret-UI를 적용하기가 매우 까다롭습니다.
또 다른 주요 문제는 서로 다른 플랫폼별로 특화된 고품질 데이터가 충분하지 않다는 점입니다. Ferret-UI의 데이터 생성 방법은 이들 플랫폼에도 확장 가능하긴 하지만, 대부분 텍스트 기반 GPT-4 프롬프트에 의존하며 바운딩 박스가 순수하게 텍스트 형식으로만 표현됩니다. 이러한 방식에는 UI 요소 간의 시각적 정보와 공간적 관계가 부족해, 학습 데이터 품질을 저하시킵니다. 이로 인해 최종적으로 모델 성능과 효율성 역시 제한을 받게 됩니다.

그림 1: 하나의 Ferret-UI 2 모델이 UI 이해를 위해 서로 다른 네 가지 플랫폼(iPhone, iPad, 웹페이지, AppleTV)에서 상호작용하는 실제 예시입니다. 여러 단계의 상호작용을 포함한 더 많은 예시는 부록 D를 참고하세요.
이러한 한계점을 극복하기 위해, 우리는 Ferret-UI 2를 소개합니다. Ferret-UI 2는 다양한 UI 화면을 이해하고, 여러 플랫폼에서 단일 단계(single-step) 상호작용을 통해 사용자 의도에 대응하도록 설계된 멀티모달 대규모 언어 모델(MLLM)입니다. Ferret-UI(You et al., 2024)를 기반으로 발전된 Ferret-UI 2는 다음 세 가지 핵심 개선을 통해 UI 인식과 사용자 상호작용 역량을 크게 강화합니다: (1) 멀티 플랫폼 지원, (2) 동적인 고해상도 이미지 인코딩, (3) 고품질 멀티모달 학습 데이터 생성.
첫째, Ferret-UI 2는 모바일 플랫폼(iPhone과 Android)뿐만 아니라 태블릿, 웹페이지, 스마트 TV 등으로 범위를 확장합니다. 그림 1은 네 가지 대표적인 화면 유형에서 Ferret-UI 2가 사용자와 상호작용하는 시각적 예시를 보여줍니다. 이를 통해 플랫폼 다양성이 한층 넓어졌으며, 다양한 사용자 환경에 원활하게 확장 적용할 수 있게 되었습니다.
둘째, Ferret-UI 2는 any-resolution 방식(Liu et al., 2024a; Zhang et al., 2024c)을 적용해 고해상도 이미지를 인코딩합니다. 나아가 UI 스크린샷의 원본 해상도를 유지하면서 시각 인식을 강화하기 위해 개선된 적응형 그리딩(adaptive gridding) 기법을 도입했습니다. 이는 사람이 직접 수집한 바운딩 박스 주석 정보를 활용해 UI 요소를 지칭(referring)하고 그라운딩하는 정확도를 높여, UI 구성 요소와 그 관계를 더욱 세밀하게 파악할 수 있게 해줍니다.
셋째, Ferret-UI 2는 기초 과제와 고급 과제 모두에 대해 고품질 학습 데이터를 활용합니다. 기초 과제에서는 단순 referring·grounding 데이터를 대화 형식으로 변환하여, 모델이 다양한 UI 화면에 대한 기초 이해를 구축하도록 합니다. 고급 과제에서는 사용자 중심의 자유로운 대화를 다루기 위해, 텍스트 기반 GPT-4 프롬프트(바운딩 박스가 텍스트로만 표현되는 방식)를 대체하여 GPT-4o와 ‘표식 세트 시각 프롬프트(set-of-mark visual prompting)’(Yang et al., 2023)를 사용해 학습 데이터를 생성합니다. 이를 통해 UI 요소의 공간적 이해를 강화하여 더욱 높은 품질의 학습 데이터를 얻을 수 있습니다. 또한 기존처럼 “[바운딩 박스 위치]를 클릭해라” 같은 단순 지시를 따르는 대신, Ferret-UI 2는 사용자 중심의 단일 단계 상호작용을 수행합니다. 예를 들어 “제출을 확인해 주세요”라는 명령을 받았을 때, 단순 클릭이 아닌 실제 사용자가 원하는 동작의 의도를 이해하고 실행합니다. 우리의 기여 사항을 간단히 요약하면 다음과 같습니다.
- Ferret-UI 2를 제시합니다. iPhone, Android, iPad, 웹페이지, AppleTV를 비롯해 폭넓은 플랫폼을 지원하는 멀티모달 LLM으로, 기존 모델과 달리 학습에 활용되는 지도 데이터(instruction-tuning data)를 개선하고, 고해상도 이미지 인코딩을 도입했으며, 플랫폼별 특성에 맞춰 새롭게 설계한 referring·grounding 벤치마크를 제공합니다.
- Ferret-UI 2는 플랫폼별 UI referring·grounding 성능을 크게 향상시킵니다. 3가지 범주의 과제(Referring, Grounding, 사용자 중심 고급 과제로 구성된 9개 하위 태스크 × 5개 플랫폼)에서 Ferret-UI 2는 기존 Ferret-UI보다 뛰어난 성능을 보였으며, GPT-4o와 견줄 만한 경쟁력을 보여줍니다. 또한 Ferret-UI 2는 플랫폼 간 전이 능력도 강력하게 발휘합니다. 마지막으로 GUIDE(Chawla et al., 2024)나 GUI-World(Chen et al., 2024a) 같은 최신 벤치마크에서도 우수한 성능을 달성했습니다.
요약하자면 **“여러 플랫폼에서 돌아가는 다양한 UI 화면을 제대로 이해하고 사용자 의도에 맞춰 동작하도록 만드는 모델을 개발하려는 것”**이 Ferret-UI 2의 목표입니다. 이를 위해 고품질 데이터(특히 UI의 시각적 요소와 공간 정보를 포함한 멀티모달 데이터)를 대량으로 생성하고, 이 데이터를 활용해 모델을 학습시킵니다. 그렇게 학습된 Ferret-UI 2는 사용자가 “이 버튼 눌러줘”라고 하면 실제로 화면에서 그 버튼이 어디에 있는지 인식하고 눌러주거나, “설정을 열어줘” 같은 명령을 이해해 해당 기능을 수행하게 되는 식이죠.
좀 더 구체적으로는,
- 여러 플랫폼(iPhone, Android, iPad, Web, AppleTV 등)에 대응하기 위해, 서로 다른 해상도·레이아웃을 지닌 UI 스크린샷을 고해상도로 정확히 인식할 수 있도록 만들고,
- **사용자가 말하는 명령(“사용자 의도”)**을 제대로 이해하여, 단순 클릭 이상으로 “어떤 동작이 필요한지”를 파악하고 실행할 수 있도록 설계하며,
- 이를 위한 학습 데이터를 직접 생성(특히 GPT-4o + 시각 정보 활용)해 기존 모델의 한계를 뛰어넘는 성능을 추구합니다.
결국 “다양한 기기와 UI 환경에서도 사용자가 말하는 것을 이해하고 그에 맞춰 조작할 수 있는 범용 UI 이해 모델”을 만들고자 하는 거라고 보시면 됩니다.
2 관련 연구(Related Work)
사용자 인터페이스(UI) 에이전트는 다양한 플랫폼에서 복합적인 UI 태스크를 자동화하고자 하는 멀티모달 모델 분야에서 최근 큰 주목을 받고 있습니다. 여러 연구들이 단일 플랫폼과 멀티 플랫폼 환경에서의 UI 이해, 상호작용, 자동화와 관련된 특정 과제를 다루며 이 분야를 발전시켜 왔습니다.
단일 플랫폼 UI 에이전트(Single-Platform UI Agents)
단일 플랫폼 UI 에이전트는 Android, iOS, 데스크톱 환경, 웹페이지 등 특정 기기 환경에서 자동화를 구현하는 데 집중합니다. 모바일 분야에서는, 인간에 가까운 상호작용을 목표로 하는 DigiRL(Bai et al., 2024), AppAgent V2(Li et al., 2024c), AutoDroid(Wen et al., 2024), MobileFlow(Nong et al., 2024) 등이 Android 에이전트를 제안하였습니다. 웹 기반 에이전트로는 WebShop(Yao et al., 2022), WebArena(Zhou et al., 2023), LASER(Ma et al., 2023), WebAgent(Gur et al., 2023), AutoWebGLM(Lai et al., 2024), WebVoyager(He et al., 2024), Agent-E(Abuelsaad et al., 2024) 등이 웹 환경에서의 탐색과 태스크 수행을 다루었으며, MindSearch(Chen et al., 2024b)는 웹 검색을 위한 AI 엔진에 집중했습니다. AssistGUI(Gao et al., 2023), OS-Copilot(Wu et al., 2024), SYNAPSE(Zheng et al., 2023), UFO(Zhang et al., 2024a) 등은 컴퓨터 OS 상호작용처럼 더 복잡한 분야에 도전했습니다. 이러한 연구들은 특정 플랫폼 내에서의 자동화 성능을 크게 향상시켰지만, 단일 플랫폼에 국한되어 있어 플랫폼 간 유연성은 다소 제한적이라는 한계를 지닙니다.
멀티 플랫폼 UI 에이전트(Multi-Platform UI Agents)
멀티 플랫폼 UI 에이전트는 모바일·웹·데스크톱 환경 등 다양한 기기와 플랫폼을 동시에 지원해, 복잡해져 가는 디바이스 생태계를 다루고자 등장했습니다. 예를 들어, **Zheng et al. (2024a); Cheng et al. (2024)**는 시각 정보를 활용한 GPT-4V를 범용 에이전트로 제시했습니다. OmniACT(Kapoor et al., 2024)는 데스크톱과 웹 인터페이스를 모두 지원하며, CogAgent(Hong et al., 2023)는 PC 웹페이지와 안드로이드 기기를 아우르는 UI 내비게이션을 수행합니다. 또한 Mind2Web(Deng et al., 2024)과 Mobile-Agent(Wang et al., 2024b) 역시 여러 플랫폼에서 에이전트가 매끄럽게 동작하도록 하는 연구입니다. Mobile-Agent V2(Wang et al., 2024a)는 비영어권과 영어권 시나리오를 위해 Harmony OS와 Android OS를 모두 지원합니다. Ferret-UI(You et al., 2024)는 멀티모달 LLM(McKinzie et al., 2024; Zhang et al., 2024b)을 활용해 Android와 iPhone 스크린샷을 대상으로 UI를 이해하고, 특히 **지칭(referring)**과 그라운딩(grounding) 역량에 중점을 둡니다. 이들 에이전트는 복잡하고 사용자 의도 중심적인 상호작용을 여러 기기 유형에 걸쳐 수행함으로써, 진정한 범용 멀티모달 에이전트를 향한 길을 열고 있습니다.
UI 에이전트 벤치마크(UI-Agent Benchmarks)
UI 에이전트를 평가하려면 태스크 수행, 내비게이션, 상호작용 이해 등 다양한 UI 상호작용 요소를 검증하는 특화된 벤치마크가 필요합니다. Rico(Deka et al., 2017)는 모바일 앱 상호작용 연구에서 기반이 되는 데이터셋으로, 이후 Mobile-Env(Zhang et al., 2023), AndroidEnv(Toyama et al., 2021), AndroidWorld(Rawles et al., 2024a), Android in-the-Wild(Rawles et al., 2024b), AndroidControl(Li et al., 2024b), AMEX(Chai et al., 2024) 등이 모바일 디바이스 제어를 위한 벤치마크를 제시했습니다. Windows Agent Arena(Bonatti et al., 2024)는 PC 윈도우 환경에 집중한 벤치마크를, OSWorld(Xie et al., 2024)는 Ubuntu, MacOS, Windows 등 실제 컴퓨터 환경 전반을 다루는 광범위한 벤치마크를 마련했습니다.
웹 상호작용 벤치마크로는 WebSRC(Chen et al., 2021), Mind2Web(Deng et al., 2024), WebCanvas(Pan et al., 2024) 등이 웹 환경에서 구조적 독해와 태스크 수행 능력을 평가합니다. 최근에는 MobileAgentBench(Wang et al., 2024c)와 VisualWebBench(Liu et al., 2024b)가 모바일 및 웹 인터페이스 전반에서 멀티모달 에이전트 성능을 측정하는 분류 체계를 도입했습니다. VisualAgentBench(Liu et al., 2024c)는 멀티모달 LLM을 시각 기반 에이전트로 활용하는 데 초점을 맞춰 이를 확장합니다. GUI Odyssey(Lu et al., 2024)는 앱 간 내비게이션(cross-App navigation)에 대한 벤치마크를 제공하고, GUI-World(Chen et al., 2024a)는 여러 플랫폼을 아우르는 GUI 에이전트 벤치마크를 처음으로 시도했습니다. CRAB(Xu et al., 2024)은 여기서 더 나아가 크로스-환경 태스크를 다루어, GUI 에이전트의 한계를 시험합니다. 이런 벤치마크들은 단일하고 통합된 멀티 플랫폼 평가가 필요한 상황에서, UI 에이전트의 적응성·정확성·효율성을 측정할 수 있는 중요한 기반을 제공합니다.
이에 비해 Ferret-UI 2는 스마트폰, 태블릿, 웹 인터페이스, 스마트 TV 등 다양한 플랫폼에 걸쳐 범용 UI 이해를 목표로 한 첫 번째 모델입니다. Ferret-UI 2는 미세 단위의 지칭·그라운딩·추론 등 기본 역량에 집중하며, 다양한 UI 내비게이션 시나리오에서도 활용될 수 있는 범용 에이전트를 구현하고자 합니다.
3 Ferret-UI 2

그림 2: Core-set 데이터 생성 파이프라인 개요.
본 섹션에서는 먼저 원시(raw) 주석(annotations)으로부터 학습 데이터셋을 어떻게 구성하는지(3.1절) 설명하고, 이어서 모델 아키텍처를 소개합니다(3.2절).
3.1 데이터셋 구성(Dataset Construction)
우리는 멀티플랫폼 UI 이해 모델을 효과적으로 학습하기 위해 자체 데이터셋을 구축했습니다. 그림 2는 전체 데이터셋 생성 파이프라인의 흐름도를 나타냅니다.
원시 주석 수집(Raw Annotation Collection)
Ferret-UI 2 학습에 사용되는 주 데이터셋은 iPhone, Android, iPad, Webpage, AppleTV 등 다양한 플랫폼 유형에서 수집한 데이터를 결합한 것입니다. 각 플랫폼에 따라 데이터 수집 방식이 달라집니다.
- iPhone, iPad, AppleTV:
- 실제 사용 사례를 다양하게 반영한 iPhone, iPad, AppleTV 데이터를 수집하고, 사람(human annotator)이 직접 위젯의 바운딩 박스 좌표와 라벨을 달았습니다.
- 라벨링 비용을 절감하기 위해 텍스트 주석을 따로 수집하지 않고, 화면 전체(Screen-wide)에서 OCR(광학 문자 인식)로 검출된 텍스트 및 바운딩 박스를 사용했습니다. 이때 OCR 신뢰도(confidence) 임계값은 0.5로 설정했습니다.
- Webpage:
- 웹 데이터는 WebUI 데이터셋(Wu et al., 2023)에서 가져왔습니다.
- 모든 유형의 UI 위젯 바운딩 박스와, 이미지가 아닌 위젯에 대한 텍스트 주석은 원본 HTML의 뷰 계층 구조를 바로 파싱해 얻어, 고품질의 주석 정보를 확보했습니다.
- 이미지 위젯의 경우, 이미지 내부 텍스트를 OCR로 추가 감지해 주석을 보완했습니다.
- Android:
- Android 스크린샷, 바운딩 박스, 텍스트 주석 데이터는 RICO 데이터셋(Deka et al., 2017)을 변환해 활용했습니다.
- WebUI 데이터셋과 마찬가지로, 이미지에만 해당하는 OCR 작업을 수행하여, 이미지 위젯에 빠져 있는 텍스트 주석을 보완했습니다.
수집한 모든 데이터에 대해 다음과 같은 데이터 필터링을 진행했습니다.
- (i) 화면 범위를 벗어나는 바운딩 박스를 제거하거나 축소하고, 필터링 후 남은 바운딩 박스가 하나도 없는 스크린샷은 삭제했습니다.
- (ii) Ferret-UI 2 모델이 다국어를 지원하도록 설계된 것은 아니므로, 텍스트 주석 중 비ASCII(non-ASCII) 문자가 5% 이상 포함된 스크린샷도 제거했습니다.
표 1: Ferret-UI 2를 학습하기 위해 사용된 다양한 플랫폼별 데이터셋 요약. 각 스크린샷 해상도 통계는 부록 E에 제시했습니다.

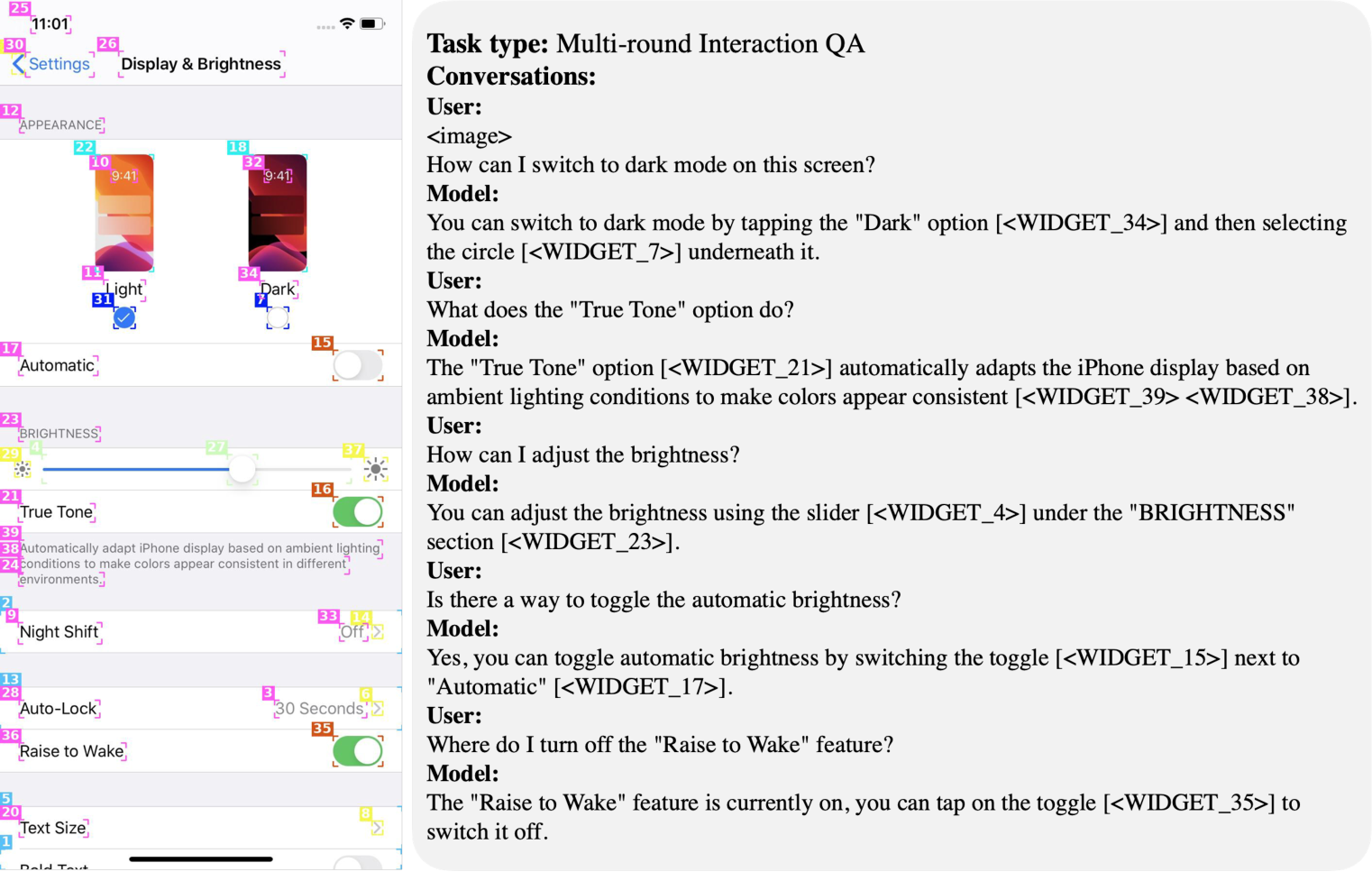
그림 3: Set-of-mark 시각 프롬프트(Yang et al., 2023) 예시(왼쪽)와 이를 통해 생성된 고급 과제 학습 예시(오른쪽).
다양한 소스에서 온 여러 종류의 라벨 공간을 다루기 위해, 우리는 관련성이 낮은 라벨(예: 특정 UI 타입)에 매핑된 바운딩 박스를 제거하고, 남은 라벨들을 ‘Checkbox’, ‘Button’, ‘Container’, ‘Dialog’, ‘Icon’, ‘PageControl’, ‘Picture’, ‘SegmentedControl’, ‘Slider’, ‘TabBar’, ‘Text’, ‘TextField’, ‘Toggle’로 구성된 공통 라벨 공간에 일관되게 대응시켰습니다. 이 과정을 통해 여러 플랫폼에 걸친 일관된 UI 위젯 주석(raw UI widget annotations) 데이터셋을 얻었습니다. 원본 라벨 통계와 변환된 라벨에 대한 자세한 내용은 부록 F에 제시합니다.
위 과정을 통해 수집한 스크린샷 데이터셋을 Core-set이라 명명하며, 이 데이터셋으로 기초 태스크와 고급 태스크 데이터를 구성합니다. 또한, 사전 정의한 태스크에 과도하게 맞춰진 학습을 피하기 위해, 서드파티 학습 데이터셋도 활용해 데이터 소스를 다양화했습니다. 표 1에서 Ferret-UI 2의 전체 학습 데이터셋 통계를 요약했는데, 플랫폼별로 매우 불균형한 데이터 분포를 보임을 확인할 수 있습니다. 특히 iPad와 AppleTV 스크린샷 수는 다른 플랫폼에 비해 현저히 적습니다. 이를 해결하기 위해,
- 학습 시 플랫폼마다 다른 손실 가중치(loss weight)를 적용하고,
- iPad와 AppleTV 플랫폼 예시에는 3가지 유형의 고급 태스크를 전부 생성하며, 그 외 플랫폼 예시에는 1가지 유형만 생성하도록 했습니다.
Ferret-UI는 모델이 감지한 바운딩 박스에 의존해 학습 데이터셋을 구성했던 데 반해, Ferret-UI 2의 학습 데이터셋은 주로 사람이 직접 수집한 주석이나 원본 HTML에서 바로 파싱한 바운딩 박스를 활용하여, 4.2절에서 제시할 정량 평가에서 확인할 수 있듯 주석 품질이 크게 향상되었습니다.
태스크 데이터 생성(Task Data Generation)
태스크 데이터 생성은 Ferret-UI의 데이터 구성 방식을 따르며, 여기에는 기초 태스크와 고급 태스크가 모두 포함됩니다.
- 기초 태스크(그림 2)는 3가지 지칭(referring) 태스크와 3가지 그라운딩(grounding) 태스크로 구성됩니다.
- 지칭 태스크는 (i) OCR: 텍스트 바운딩 박스에 주어진 텍스트 인식하기, (ii) 위젯 분류: UI 요소의 유형 예측하기, (iii) 탭 가능성(tapperbility): 선택된 위젯이 상호작용(탭) 가능한지 예측하기로 나뉩니다.
- 그라운딩 태스크는 (i) 위젯 나열(widget listing): 화면에 있는 모든 위젯 나열하기, (ii) 텍스트 찾기(find text): 특정 텍스트가 있는 위치 찾기, (iii) 위젯 찾기(find widget): 주어진 위젯 설명을 바탕으로 해당 위젯 위치 찾기로 구성됩니다.

그림 4: 고해상도 지원을 통해 매끄러운 UI 이해와 사용자 중심의 단일 단계(single-step) 상호작용을 가능케 하는 Ferret-UI 2 모델 아키텍처 개요.
고급(advanced) 태스크의 경우, 우리는 스크린샷에 대한 바운딩 박스 주석을 GPT-4o에 입력한 뒤, 해당 스크린에 포함된 UI 위젯과 관련된 QA 태스크를 생성하도록 요구합니다. 기존 Ferret-UI는 이미지 정보(스크린샷) 없이 텍스트 기반 프롬프트만을 사용해 바운딩 박스를 주석했기 때문에 주로 공간적 묘사에 집중했지만, Ferret-UI 2는 GPT-4o를 활용하여 UI 이해 전반에 걸친 고급 태스크 데이터를 생성합니다. 이는 GPT-4o가 스크린샷을 입력받을 때 UI 위젯들 간의 공간적 관계를 보다 효과적으로 파악할 수 있게 되었기 때문입니다. 구체적으로, Ferret-UI 2에서는 (그림 2 참조) GPT-4o에게 다음 3가지 유형의 고급 태스크 생성을 요청합니다:
- (i) 전반적 기술(comprehensive description): 화면의 전역 및 국소적 기능 설명
- (ii) 멀티 라운드 인지(perception) QA: UI 인식 역량과 관련된 다중 라운드 질의응답
- (iii) 멀티 라운드 상호작용(interaction) QA: 현재 화면 상태를 기반으로, 단일 단계·사용자 중심 UI 상호작용과 관련된 다중 라운드 질의응답
GPT-4o가 이러한 고급 태스크를 생성할 때의 세부 요구사항과 프롬프트 구성은 부록 B에 제시했습니다.
실험 결과, 스크린샷 원본 이미지를 그대로 입력했을 때 GPT-4o가 지칭된 UI 위젯의 위치를 찾는 것(그라운딩)이 어렵다는 점을 확인했습니다. 이를 해결하기 위해, 우리는 멀티 라운드 인지·상호작용 QA 학습 샘플을 생성할 때 Set-of-Mark(SoM) 시각 프롬프트(Yang et al., 2023)를 사용합니다. 그 예시와 함께 생성된 데이터 샘플은 그림 3에 나와 있으며, 각 UI 위젯마다 모서리(corner-style) 형태의 바운딩 박스와 고유 번호 태그를 부여해 식별을 쉽게 했습니다. 또한 같은 클래스의 UI 위젯은 동일한 색상으로 표시해, GPT-4o가 공간적으로 가까이 있거나 중첩된 위젯을 보다 확실하게 구분하도록 도왔습니다. 다른 플랫폼에서의 시각 프롬프트 예시는 그림 5를, 고급 태스크의 추가 데이터 예시는 부록 C를 참고하세요.
마지막으로, 표 1에서 언급했듯이 우리는 Core-set에서 생성한 태스크 외에도 GroundUI-18k(Zheng et al., 2024b), GUIDE(Chawla et al., 2024), Spotlight(Li & Li, 2023) 등의 서드파티 데이터셋을 추가로 활용해 학습 데이터를 증강(augment)했습니다.
3.2 모델 아키텍처(Model Architecture)

그림 4에서 보이듯, Ferret-UI 2의 모델 아키텍처는 Ferret-UI(You et al., 2024)를 직접 계승합니다. Ferret-UI는 Any-Resolution(AnyRes) 기법(Liu et al., 2024a)을 사용해 지칭(referring) 및 그라운딩(grounding)을 강화함으로써, 인코더가 다양한 해상도의 이미지를 처리할 수 있도록 했습니다.
구체적으로는, CLIP 이미지 인코더가 먼저 UI 스크린샷에서 저해상도 전체 이미지를 통해 추출한 글로벌(global) 특징과, 고해상도 부분 이미지를 통해 추출한 로컬(local) 특징을 모두 얻어냅니다. 이후 이 이미지 특징들을 일렬화(flatten)하여 LLM에 입력합니다. 그런 다음 Visual Sampler는 사용자 지시사항에 따라 적절한 UI 영역을 식별하고 선택합니다. 최종적으로 모델은 UI 요소에 대한 인식(perception) 또는 상호작용(interaction)을 위한 그라운딩된(grounded) 설명을 출력합니다.
모델이 UI 요소에 대한 인식(perception) 혹은 **상호작용(interaction)**을 수행하려면, 단순히 “이 위젯은 버튼이다”와 같은 고정된 답만 내놓는 것이 아니라, “어떤 위젯(또는 텍스트)이 어디에 있으며, 어떤 맥락에서 어떻게 활용되는지”를 구체적으로 파악해야 합니다.
여기서 “그라운딩된(grounded) 설명”은,
- “바운딩 박스 정보”나 “시각적·공간적 위치”,
- “해당 요소가 텍스트인지, 버튼인지, 체크박스인지” 등 객관적인 UI 요소 정보를 토대로
- 사용자가 원하는 작업(예: ‘이 버튼 눌러줘’)을 실행하기 위해 필요한 인식/설명을 말합니다.
즉, 모델이 “사용자가 지칭하는 요소가 어디에 있고, 무슨 종류이며, 어떻게 동작하는지”를 명확히 이해(grounding)해서,
- 인식(perception) 관점에서는 “이 위젯은 x,y 좌표에 있는 버튼이며 ‘로그인’ 기능과 관련되어 있다”와 같은 식으로 설명하고,
- 상호작용(interaction) 관점에서는 “사용자가 ‘로그인’ 버튼을 눌러달라고 하면 실제로 그 위치를 찾아 클릭 동작을 수행”할 수 있게 된다는 의미입니다.
결국 이 “그라운딩된 설명”이란, 화면 속 UI 요소를 올바른 맥락과 위치에 연결(ground)한 상태에서, 모델이 이해한 내용을 설명하거나 동작으로 옮길 수 있게끔 표현해주는 것을 뜻한다고 보면 됩니다.
Adaptive Gridding
로컬 이미지 특징(local image features)은, 우리가 제안한 Adaptive N-gridding 기법을 통해 최적의 격자(grid) 크기를 계산한 뒤, 각 격자를 리사이즈하고 시각적 특징을 인코딩함으로써 추출됩니다. 이는 기존 Ferret-UI와 비교했을 때 Ferret-UI 2가 도입한 핵심적인 모델 혁신 중 하나입니다.

결과적으로, Adaptive Gridding 기법을 통해 Ferret-UI 2는 주어진 추론 비용 한도(크기 제한 ) 내에서 어떤 해상도에서도 최적 구성으로 UI 화면을 이해하고, 사용자 중심의 상호작용을 제공할 수 있게 됩니다.
4 실험(Experiments)
4.1 실험 설정(Experiment Setup)
학습 데이터(Training Data). 표 1에 정리된 학습 데이터셋은 다음 두 가지 범주로 나눌 수 있습니다.
- 직접 구축한 데이터셋: 3.1절에서 설명한 대로, 모든 플랫폼에서 확보한 기초 태스크 데이터와 고급 태스크 데이터를 포함합니다.
- 공개 데이터셋: 웹페이지 스크린샷을 활용해 사용자 중심의 간단한 상호작용을 다루는 GroundUI-18k(Zheng et al., 2024b), 웹페이지 스크린샷을 대상으로 한 다음 액션 예측(next-action prediction) 데이터셋인 GUIDE(Chawla et al., 2024), 안드로이드 UI 이해와 상호작용을 위한 Spotlight(Li & Li, 2023)가 이에 해당합니다.
표 2: 우리가 구성한 벤치마크(기초 태스크와 고급 태스크) 및 GUIDE 벤치마크(Chawla et al., 2024)에서의 결과. 기초 태스크와 고급 태스크 결과는 iPhone, Android, iPad, Webpage, AppleTV 전 플랫폼에 대한 평균치이며, 각 플랫폼마다 6개의 기초 태스크와 3개의 고급 태스크로 구성됩니다.
(†) 지칭(referring)이 필요한 태스크에서 GPT-4o는 스크린샷에 붉은 사각형을 표시하는 set-of-mark(SoM) 프롬프트를 사용해 위젯을 지칭합니다. Ferret-UI와 Ferret-UI 2는 SoM 시각 프롬프트를 사용하지 않았음을 유의하세요.

표 2에는 다음과 같은 내용을 담고 있습니다:
- 비교 대상 및 평가 지표
- Ferret-UI 2를 포함한 여러 모델(예: Ferret-UI, GPT-4o 등)이 기초 태스크와 고급 태스크(총 6+3=9개의 태스크)에서 어떤 성능을 보이는지를 iPhone, Android, iPad, Webpage, AppleTV 플랫폼별로 평가한 뒤, 그 결과를 평균치로 요약해놓았습니다.
- 또한, **GUIDE 벤치마크(Chawla et al., 2024)**라는 별도의 벤치마크(‘다음 액션 예측’ 과제) 결과도 함께 표기해, 모델 간 성능을 비교할 수 있게 했습니다.
- 기초 태스크 vs 고급 태스크
- 표 2에서 언급하는 ‘기초 태스크’는 주로 간단한 UI 요소 식별이나 텍스트 찾기, 위젯 분류 같은 과제이고,
- ‘고급 태스크’는 사용자 의도에 맞춰 여러 라운드로 물어보고 대답하는 등 좀 더 복잡한 대화를 포함한 과제입니다.
- 각 플랫폼마다 기초 6개, 고급 3개로 나뉘어 있고, 이를 전부 합산해 평균 성능으로 표에 제시합니다.
- SoM(“set-of-mark”) 프롬프트란?
- 지칭(referring)이 필요한 태스크에서, GPT-4o 모델은 스크린샷에 붉은 사각형을 표시해 “이 위젯을 가리킨다”는 사실을 ‘시각적으로’ 나타내줍니다(SoM 시각 프롬프트).
- Ferret-UI나 Ferret-UI 2는 이런 식으로 붉은 사각형을 미리 표시해주지 않고, 오직 모델 자체가 위젯의 위치를 찾아야 하는 방식으로 평가합니다. 즉, GPT-4o가 좀 더 ‘힌트’를 받는 셈인 거죠.
즉, 표 2는 “기초 및 고급 태스크를 다양한 플랫폼(iPhone, Android, iPad, Webpage, AppleTV)에서 수행했을 때, Ferret-UI 2가 어느 정도 성능을 내는지”를 보여주고, 동시에 “GUIDE 같은 추가 벤치마크에서도 얼마나 잘하는지”를 다른 모델들과 비교하는 표입니다. 그리고 각주에서 (†\dagger†\dagger)라고 표시된 부분은 GPT-4o만 특별히 SoM(붉은 박스) 방식으로 지칭 정보를 얻는다는 사실을 주지시키는 것입니다. 이는 SoM 힌트를 받는 모델과 받지 않는 모델 사이에는 일정한 차이가 있음을 알아두라는 의미입니다.
모델(Model). Ferret-UI(You et al., 2024)와 마찬가지로, Ferret-UI 2는 CLIP ViT-L/14 모델을 이미지 인코더로 사용합니다. LLM 백본으로는 기존 Ferret-UI에서 사용했던 Vicuna-13B(Chiang et al., 2023) 외에도, 모바일 스케일 모델인 Gemma-2B(Team et al., 2024)와 Llama3-8B(Dubey et al., 2024) 두 가지를 추가로 시도해 보았습니다. 동적인 고해상도 이미지 인코딩을 위해 크기 제한 N을 8로 설정했으며, 이에 따라 Adaptive Gridding의 최대 격자(grid) 수는 16이 됩니다.
평가(Evaluation). 전반적으로 모델 평가는 다음 두 범주로 구분됩니다: (1) 우리가 직접 구축한 벤치마크, (2) 공개 벤치마크.
- 직접 구축한 벤치마크의 경우, 5가지 플랫폼 각각에 대해 6개의 기초 태스크와 3개의 고급 태스크로 구성된 총 45개 태스크를 마련했습니다. 기초 태스크는 You et al.(2023)에서 제시한 평가 지표를 따르며, 고급 태스크는 GPT-4o를 활용해 스크린샷과 사용자 질의를 대상으로 생성된 답변을 채점합니다(해당 위젯을 붉은 사각형 바운딩 박스로 표시하여 GPT-4o에게 시각적 힌트를 제공합니다). 고급 태스크 평가는 GPT-4o 평가 점수와 Multi-IoU 방식으로 이루어지는데, Multi-IoU는 예측된 바운딩 박스와 정답 바운딩 박스를 먼저 매칭한 뒤, 각 쌍의 IoU(교집합-합집합비, Intersection over Union)를 평균낸 값입니다(매칭 실패 시 IoU=0).
- 공개 벤치마크로는 GUIDE(Chawla et al., 2024)에서 이전 액션 히스토리를 바탕으로 ‘다음 액션 예측’을 수행하고, 결과를 참조 답변과의 의미 유사도(semantic similarity)와 그라운딩 IoU 관점에서 평가합니다. 또한 GUI-World(Chen et al., 2024a)의 최근 버전을 지원되는 플랫폼별로 테스트했으며, Chen et al.(2024a)에서 사용한 GPT-4 평가 프로토콜을 그대로 따릅니다(이 평가에서는 상호작용 관련 UI 태스크에 대한 그라운딩 능력은 포함되지 않습니다).
4.2 실험 결과(Experiment Results)
표 3: Ferret-UI 2가 GUI-World 벤치마크(Chen et al., 2024a)에서 보여준 제로샷(zero-shot) 성능.

주요 결과(Main results)
표 2는 우리가 구성한 기초 태스크와 고급 태스크, 그리고 GUIDE 벤치마크(Chawla et al., 2024)에서 다양한 모델들의 성능을 비교한 결과를 요약한 것입니다. 이 중 기초 태스크와 고급 태스크에 해당하는 각 데이터 값은 모든 플랫폼에서의 평균 성능을 의미합니다. 플랫폼별 상세 성능은 부록 A의 표 6에서 확인할 수 있습니다. 아래에 핵심 관찰 내용을 정리합니다.
- Ferret-UI 2 + Llama-3-8B
- 대부분의 지표에서 최고 성능을 보였습니다. 특히 고급 태스크에서 GPT-4o 점수 89.73을 달성해, Ferret-UI보다 43.92점, GPT-4o보다 12.0점 더 높았습니다.
- GUIDE 벤치마크의 IoU 점수 55.78을 기록하여, 다른 모델보다 우수한 그라운딩(grounding) 능력을 입증했습니다.
- Ferret-UI 2 + Vicuna-13B
- 전반적으로 좋은 성능을 보여, 예컨대 고급 태스크에서 멀티 IoU(Multi-IoU) 점수 41.71을 달성했습니다.
- 파라미터 수가 6배 더 적은 Gemma-2B 버전 역시 전체적으로 경쟁력 있는 성능을 보입니다.
- GPT-4o
- 미세한 단위의 UI 이해 능력이 부족하다는 점이 드러납니다. 예컨대 기초 태스크에서 지칭(referring)은 56.47, 그라운딩(grounding)은 12.14로 낮은 점수를 기록했습니다.
- 고급 태스크와 GUIDE 벤치마크에서도 멀티 IoU와 IoU 점수가 낮게 나타났습니다.
종합적으로, Ferret-UI 2는 다양한 플랫폼에서 폭넓은 UI 이해 태스크를 수행하는 데에 있어 탁월한 범용성을 보여줍니다.
GUI-World에서의 결과(Results on GUI-World)
모델을 그대로 사용하는 제로샷(zero-shot) 설정 하에서 Ferret-UI 2의 성능을 추가로 검증하기 위해, 최근 발표된 **GUI-World 벤치마크(Chen et al., 2024a)**에서도 실험을 진행했습니다. 결과는 표 3에 요약되어 있습니다. 이로써 Ferret-UI 2가 학습 데이터에만 특화(overfitting)되지 않고, 실제 환경의 테스트 데이터에도 잘 **일반화(generalize)**됨을 확인할 수 있습니다. 특히 iOS, Android, Webpages 등의 지원 플랫폼에서, 해당 논문에서 제안된 GUI-Vid(Chen et al., 2024a) 모델보다 더 우수한 성능을 발휘했습니다.
표 4: Ferret-UI 2의 제로샷 크로스 플랫폼 전이(cross-platform transfer) 결과. 단순화를 위해, 여기서는 기초 태스크에 해당하는 데이터만 활용하여 모델을 학습 및 평가했습니다.

4.3 소거 연구(Ablation Study)
크로스 플랫폼 전이(Cross-Platform Transferability)
표 4는 Ferret-UI 2 모델을 한 플랫폼(도메인)의 기초 태스크로만 학습한 뒤, 다른 플랫폼에서 제로샷(Zero-Shot)으로 테스트했을 때의 성능을 보여줍니다. 이를 통해 모델이 서로 다른 플랫폼 간에 얼마나 잘 일반화하는지 알 수 있습니다. 지칭(referring)과 그라운딩(grounding) 태스크 모두에서 비슷한 성능 양상이 관찰되었는데, 구체적으로는 다음과 같습니다.
- iPhone
- 스크린샷 데이터의 양이 많고 화면 구성이 다양하며, 해상도와 종횡비도 iPad·Android와 유사한 편이어서, iPad나 Android로 전이할 때 지칭 태스크에서 최소 68.1, 71.2점을, 그라운딩 태스크에서도 65.2, 63.1점을 달성했습니다.
- iPad와 Android에서 iPhone 도메인으로 전이할 때도 모두 약 65점 정도를 기록하며, 비교적 안정적인 전이 성능을 보였습니다.
- AppleTV와 Web
- iPhone, Android, iPad 등 모바일 플랫폼(주로 세로 화면)과 달리, AppleTV·Web은 대부분 가로 화면이어서 전이가 원활하지 않았습니다. 지칭 태스크 최고 점수는 59.2, 그라운딩 태스크 최고 점수는 54.0에 그쳤습니다.
- 반대로, 다른 도메인에서 학습한 모델을 AppleTV에 적용했을 때도 성능이 좋지 않았으며, 두 태스크 모두 최고 점수가 약 40점에 불과했습니다. 이는 AppleTV의 콘텐츠 분포가 다른 도메인과 크게 달라서 발생한 것으로 보입니다.
이 결과로부터 다음과 같은 사실을 알 수 있습니다.
- iPhone, iPad, Android는 서로 유사한 콘텐츠 분포를 가져, 상호 간 전이 성능이 좋습니다.
- 다양한 콘텐츠(예: 10만 개에 달하는 iPhone 데이터 등)로 학습된 모델은 다른 플랫폼에도 더 잘 일반화합니다.
- 해상도와 종횡비가 유사한 플랫폼끼리는 전이 성능이 더 우수합니다.
- 일부 플랫폼 간 양호한 전이 성능이 Ferret-UI 2가 전체적으로 크로스 플랫폼 성능을 높이는 데 기여합니다.
표 5: Ferret-UI-anyRes (You et al., 2024) 대비 Ferret-UI 2의 아키텍처·데이터셋 개선 효과 소거 연구 결과. 즉, any-resolution 모듈을 탑재한 고해상도 버전의 Ferret-UI와 비교했을 때, Ferret-UI 2의 각 개선 요소가 고급(advanced) 태스크 성능에 어떤 영향을 미치는지를 보여줍니다. iPhone v1은 기존 Ferret-UI에서 사용하던 iPhone 데이터셋을, iPhone v2는 Ferret-UI 2에서 활용하는 iPhone 데이터를 의미합니다. 모델 평가는 고급 태스크를 기준으로 진행했습니다.

아키텍처 및 데이터셋 개선에 대한 소거 연구(Ablation on Architecture and Dataset Improvements).
표 5는 Ferret-UI와 Ferret-UI 2를 서로 다른 버전의 iPhone 데이터셋으로 학습시킨 뒤, 고급 태스크 테스트 세트에서 평가한 결과를 비교한 것입니다. 실험 결과, **적응형 N-그리딩(adaptive N-gridding)**을 비롯한 아키텍처 개선과 개선된 데이터셋(iPhone v2) 모두 성능 향상에 기여한다는 사실이 드러났습니다.
구체적으로 살펴보면, iPhone v1 테스트 세트에서 평가했을 때, Ferret-UI 2는 GPT4o 점수가 91.3에서 93.7로, Multi-IoU 점수가 36.89에서 37.12로 소폭 상승했습니다. 하지만 iPhone v2 데이터셋에서는 성능 개선 폭이 더 컸습니다. Ferret-UI 2는 GPT4o 점수 89.7을 기록하며 Ferret-UI의 85.97을 상회했으며, Multi-IoU 점수 역시 39.81에서 41.73으로 유의미하게 향상되었습니다. 이 결과는 아키텍처와 데이터셋의 개선 모두가 전체 성능을 끌어올리지만, 특히 새 데이터셋이 더 도전적인 태스크에서 더 큰 효과를 발휘한다는 점을 시사합니다.
5 결론(Conclusions)
본 논문에서는 서로 다른 플랫폼에서 UI를 이해하고 상호작용하는 능력을 향상하기 위해 고안된 멀티모달 대규모 언어 모델, Ferret-UI 2를 제시했습니다. Ferret-UI 2는 멀티 플랫폼 지원, 적응형 그리딩(adaptive gridding)을 이용한 고해상도 이미지 인코딩, 향상된 데이터 생성 과정을 통해, 기존 Ferret-UI를 모든 평가 벤치마크에서 능가하는 성능을 보여주었습니다. 또한, 강력한 제로샷(Zero-shot) 전이 능력을 보이며, 범용 UI 이해 모델로서의 가능성을 입증했습니다. 향후 연구에서는 더 많은 플랫폼 유형을 통합하고, 범용 UI 내비게이션을 수행할 수 있는 **범용 에이전트(generalist agent)**를 구축하는 데 집중할 예정입니다.
감사의 말(Acknowledgements)
저자들은 Forrest Huang, Zhen Yang, Haoxuan You, Amanda Swearngin, Alexander Toshev에게 귀중한 조언과 제안, 그리고 피드백을 제공해준 것에 대해 감사를 표합니다.
Ferret-UI 2: 범용 UI 이해와 상호작용을 위한 차세대 멀티모달 LLM
1. 소개
오늘 소개할 Ferret-UI 2는 아이폰, 안드로이드, 아이패드, 웹, 그리고 AppleTV 등 다양한 플랫폼의 UI를 이해하고 상호작용할 수 있도록 설계된 **멀티모달 대규모 언어 모델(MLLM)**이에요. 기존 Ferret-UI를 기반으로, 더 다양한 플랫폼 지원과 고해상도 이미지 인코딩, 그리고 고품질 데이터 생성을 통해 성능을 크게 끌어올렸다고 합니다.
2. 주요 특징
- 멀티 플랫폼 지원
- 스마트폰(iPhone/Android)뿐 아니라 태블릿(iPad), 웹 페이지, 스마트TV(AppleTV)까지 폭넓게 커버.
- 각 플랫폼별 다른 해상도·레이아웃을 효율적으로 처리하도록 설계되었어요.
- 고해상도 이미지 인코딩
- Adaptive Gridding이라는 새 기법을 통해, 스크린샷 이미지를 고해상도로 인식하면서도 추론 비용을 제한.
- 모델이 UI 화면의 디테일을 더 잘 파악할 수 있게 해 정확도가 대폭 향상됩니다.
- 고급 태스크 데이터 생성
- 기존엔 “버튼 위치 클릭” 같은 단순한 태스크 위주였다면, 이번에는 GPT-4o를 활용해 멀티 라운드 대화나 복잡한 상호작용 관련 데이터를 자동으로 생성.
- 사용자 의도를 더 풍부하게 반영한 학습 데이터를 확보해, 실제 유저와의 상호작용을 더욱 자연스럽게 처리합니다.
3. 성능 요약
- 다양한 벤치마크 시험에서 Ferret-UI 2는 이전 버전(Ferret-UI) 대비 모든 지표에서 우수한 성능을 달성했습니다.
- GUIDE(웹 기반 액션 예측)나 GUI-World(멀티 플랫폼 벤치마크)에서도 좋은 성적을 보여, 다른 모델 대비 뛰어난 제로샷(Zero-Shot) 전이 성능을 확인했다고 해요.
- 특히, iPhone, Android, iPad 같은 모바일 계열 플랫폼들 간에는 상호 전이가 잘 이루어지는 반면, AppleTV 같은 가로 화면 플랫폼에선 데이터 부족 등으로 인해 전이가 어려운 점도 발견되었습니다.
4. 의의 및 전망
- 범용 UI 이해: 화면 속 위젯(버튼, 텍스트 등)의 위치와 성격을 파악해, 다양한 플랫폼에서 복잡한 사용자 요구에 대응할 수 있는 길을 제시.
- 고해상도 처리: Adaptive Gridding을 통해, 해상도 왜곡이나 추론 비용 문제를 해결하면서도 시각 정보를 풍부하게 사용.
- 범용 에이전트의 토대: 향후 연구에서는 더 많은 플랫폼을 지원하고, 여러 단계의 상호작용까지 수행하는 “진짜 범용 UI 에이전트”를 만드는 데 집중할 계획이라고 해요.
마무리
결국 Ferret-UI 2는 사용자 인터페이스(UI) 자동화의 영역에서 한 단계 진화한 모델이라고 할 수 있습니다. 모바일·웹·스마트TV 등 다양한 플랫폼에 적용 가능하며, 고해상도 이미지를 더욱 효과적으로 처리해 복잡한 사용자 상호작용까지 다룰 수 있다는 점이 가장 큰 장점이죠. 앞으로 UI 에이전트를 개발하는 분들이라면, Ferret-UI 2가 어떤 식으로 모델을 확장하고 데이터를 구성했는지 살펴보시는 것이 좋겠습니다.
'인공지능' 카테고리의 다른 글
| Rho-1: Not All Tokens Are What You Need (4) | 2025.01.10 |
|---|---|
| mochi-1-preview (3) | 2025.01.10 |
| Hallo2: Long-Duration and High-Resolution Audio-Driven Portrait Image Animation (3) | 2024.11.30 |
| MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering (5) | 2024.11.30 |
| GRIN: GRadient-INformed MoE (2) | 2024.11.29 |



