https://arxiv.org/abs/2303.09975
MedNeXt: Transformer-driven Scaling of ConvNets for Medical Image Segmentation
There has been exploding interest in embracing Transformer-based architectures for medical image segmentation. However, the lack of large-scale annotated medical datasets make achieving performances equivalent to those in natural images challenging. Convol
arxiv.org
https://github.com/MIC-DKFZ/MedNeXt/tree/0b78ed869fbd1cc2fd38754d2f8519f1b72d43ba
GitHub - MIC-DKFZ/MedNeXt: [MICCAI 2023] MedNeXt is a fully ConvNeXt architecture for 3D medical image segmentation.
[MICCAI 2023] MedNeXt is a fully ConvNeXt architecture for 3D medical image segmentation. - MIC-DKFZ/MedNeXt
github.com
초록(Abstract)
의료 영상 분할을 위해 트랜스포머(Transformer) 기반 아키텍처를 적용하려는 관심이 최근 폭발적으로 늘어나고 있다. 그러나 대규모로 주석된 의료 데이터셋이 부족하여, 자연 이미지 분야와 유사한 수준의 성능을 내기에는 여전히 어려움이 있다. 반면 합성곱 신경망(Convolutional Neural Network)은 더 높은 귀납적 편향(inductive bias)을 지니고 있어, 상대적으로 간단한 학습 과정으로도 높은 성능을 달성하기 쉽다. 최근에 발표된 ConvNeXt 아키텍처는 트랜스포머 블록을 반영함으로써 전통적인 ConvNet을 현대적으로 재설계하려는 시도를 보여주었다.
본 연구에서는 이를 한 단계 발전시켜, 데이터가 부족한 의료 환경의 특수성을 고려한 확장 가능하고 현대화된 합성곱 기반 아키텍처를 설계한다. 구체적으로, 우리는 트랜스포머로부터 영감을 받은 대형 커널(large kernel) 분할 네트워크인 MedNeXt를 제안하며, 다음과 같은 주요 기여점을 갖는다.
- 3D ConvNeXt 기반 인코더-디코더(Encoder-Decoder) 네트워크: 의료 영상 분할을 위해 완전히 ConvNeXt 구조로 구성된 3D 인코더-디코더를 제안한다.
- Residual ConvNeXt 업샘플링·다운샘플링 블록: 다중 스케일에서의 의미 정보를 풍부하게 유지하기 위해 잔차(residual) 구조를 적용한 ConvNeXt 기반 업·다운샘플링 블록을 도입한다.
- 점진적 커널 확장 기법: 한정된 의료 데이터로 인한 성능 포화를 방지하기 위해, 작은 커널 크기를 갖는 네트워크를 업샘플링하여 커널 크기를 단계적으로 키우는 새로운 학습 전략을 제안한다.
- 복합적 스케일링(Compound Scaling): MedNeXt의 깊이(depth), 너비(width), 커널 크기(kernel size) 등 여러 측면에서 동시에 확장하는 복합 스케일링 방식을 채택한다.
제안된 MedNeXt 모델은 CT와 MRI 등 서로 다른 영상 기법, 다양한 데이터셋 크기를 포함한 네 가지 과제에서 최신 수준(state-of-the-art)의 성능을 달성하였다. 이는 의료 영상 분할을 위한 현대화된 딥러닝 아키텍처로서의 가능성을 보여준다. 해당 연구의 코드는 다음 링크에서 공개되어 있다: https://github.com/MIC-DKFZ/MedNeXt.
키워드(Keywords): 의료 영상 분할, 트랜스포머, MedNeXt, 대형 커널(large kernels), ConvNeXt
1 서론(Introduction)
트랜스포머(Transformers) [30, 7, 21]는 의료 영상 분할 분야에서, 하이브리드 아키텍처의 일부 [3, 9, 33, 2, 8, 31] 혹은 독립적인 기법 자체 [34, 25, 15]로 활용되어 최신 성능(state-of-the-art)을 달성하는 사례가 급격히 늘어나고 있다. 트랜스포머가 시각적 과업에서 제공하는 주요 장점 중 하나는 장거리(long-range) 공간적 종속성을 학습할 수 있다는 점이다. 그러나 트랜스포머는 본질적으로 귀납적 편향(inductive bias)이 제한적이기 때문에, 대규모 주석(annotated) 데이터셋이 필요하다는 문제가 있다. 자연 이미지 분야에는 대규모 데이터셋(ImageNet-1k [6], ImageNet-21k [26])이 풍부하지만, 의료 영상 분야는 일반적으로 고품질 주석 데이터의 부족으로 어려움을 겪는다 [19].
이를 해결하기 위해, 합성곱(Convolution) 본연의 귀납적 편향을 유지하면서도 트랜스포머 아키텍처의 이점을 동시에 누릴 수 있는 방법이 모색되고 있다. 최근 ConvNeXt [22]가 제안되어, 자연 이미지 분류 분야에서 합성곱 기반 네트워크(ConvNet)가 트랜스포머에 버금가는 경쟁력을 다시 확보할 수 있음을 입증하였다. ConvNeXt는 트랜스포머와 유사하게 깊이별 합성곱(depthwise convolution), 채널 확장 층(expansion layer), 채널 축소 층(contraction layer)으로 구성된 인버티드 보틀넥(inverted bottleneck) 구조를 채택한다(섹션 2.1). 여기에 더해, 큰 커널(large depthwise kernels)을 통해 트랜스포머가 갖는 확장성 및 장거리 표현 학습 능력을 모방한다. ConvNeXt 저자들은 방대한 데이터셋과 결합된 큰 커널 ConvNeXt 네트워크를 활용해, 기존에 제시된 트랜스포머 기반 네트워크보다 뛰어난 성능을 보고하였다.
반면, 의료 영상 분할 분야에서는 VGGNet [28]이 제시한 방식인 작은 커널을 여러 층으로 쌓는 전통적인 합성곱 설계가 여전히 주류를 이루고 있다. 범용적이고 데이터 효율적인 기법인 nnUNet [13] 또한 표준적인 UNet [5]의 변형을 사용하며, 폭넓은 과업에서 여전히 뛰어난 성능을 보이고 있다.
ConvNeXt 아키텍처는 Vision Transformer [7]와 Swin Transformer [21]의 확장 가능성(scalability)과 장거리 공간 표현 학습 능력을, ConvNet의 본질적 귀납적 편향과 결합한 형태다. 특히 인버티드 보틀넥 디자인은 커널 크기에 구애받지 않고 너비(채널 수)를 확장할 수 있게 해준다. 의료 영상 분할에서 이를 적극적으로 활용할 경우, 1) 큰 커널을 통해 장거리 공간 정보를 학습할 수 있고, 2) 여러 네트워크 차원을 동시에 확장(scale)할 수 있다는 장점이 있다. 하지만, 이러한 대형 네트워크는 제한된 의료 데이터로 학습할 때 과적합(overfitting)이 발생하기 쉽기 때문에, 이를 방지할 기법이 필요하다.
ConvNeXt가 “Vision Transformer와 Swin Transformer의 확장 가능성(scalability)과 장거리 공간 표현 학습 능력을, 동시에 ConvNet의 귀납적 편향과 결합했다”는 말은 다음과 같은 맥락을 담고 있습니다:
- 트랜스포머의 특성
- 장거리(long-range) 관계 학습: 트랜스포머는 self-attention 메커니즘을 통해 입력 전체에서 중요한 정보들을 주고받으면서, 매우 먼 거리의 특징 간 상호 작용도 쉽게 학습할 수 있습니다.
- 우수한 확장성(scalability): Vision Transformer(ViT)나 Swin Transformer 등은 모델 규모(레이어 수, 채널 수 등)를 매우 크게 확장해도 비교적 안정적으로 학습이 가능합니다. 즉, 데이터나 모델 크기를 늘릴 때 적절한 하드웨어 환경이 주어지면 성능이 더 좋아지는 경향이 있습니다.
- CNN(ConvNet)의 ‘본질적 귀납적 편향(inductive bias)’
- CNN은 이미지 같은 2차원 입력에서 ‘지역성(locality)’을 자연스럽게 가정합니다. 즉, 인접 픽셀들끼리는 관련성이 높을 것이라는 가정이 있으며, 필터를 이동시키며 동일한 연산을 반복(파라미터 공유)하기 때문에 지역적 특징 탐색에 최적화되어 있습니다.
- 이러한 귀납적 편향 덕분에, 상대적으로 적은 양의 데이터로도 학습을 잘해낼 수 있고, 시각적으로 의미 있는 에지(edge)나 영역 등의 지역 패턴을 빠르게 잡아낼 수 있습니다.
- ConvNeXt에서의 결합 아이디어
- ConvNeXt는 CNN을 기반으로 하지만, 인버티드 보틀넥(inverted bottleneck) 구조, 깊이별 합성곱(depthwise convolution), 큰 커널(large kernel) 적용 등 트랜스포머 블록에서 착안한 설계를 활용합니다.
- 이를 통해 장거리 공간 정보를 좀 더 폭넓게 학습할 수 있도록 수용영역(receptive field)을 늘리고, 네트워크 규모(깊이, 너비 등)도 원활히 확장할 수 있도록 했습니다.
- 동시에 CNN 특유의 지역 패턴 학습 능력, 적은 데이터로도 학습 성능이 안정적이라는 장점을 최대한 살렸습니다.
정리하자면,
- 트랜스포머의 장점: 이미지를 전역적(global)으로 바라보면서 네트워크를 크게 키워도 학습이 잘 된다(확장성).
- CNN의 장점: 지역적 특성을 빠르게 잡아내는 데 특화되어 있고, 데이터가 풍부하지 않아도 비교적 안정적으로 학습이 가능하다.
이 두 가지가 절묘하게 융합된 것이 ConvNeXt이며, “트랜스포머의 확장성과 장거리 표현 학습” + “CNN의 본질적 귀납적 편향”이 서로 보완적인 강점으로 작용한다는 의미입니다.
그럼에도 최근에는 의료 영상 분야에 큰 커널 개념을 적용하려는 시도가 이루어지고 있다. 예를 들어 [18]에서는, 장기(organ) 및 뇌 종양 분할 성능 향상을 위해, 3D-UNet [5]에 큰 커널을 적용하되 이를 깊이별 합성곱(depthwise)과 dilated 커널로 분해하는 방식을 사용하였다. 이 연구에서는 레이어 수나 채널 수는 고정하되 커널 크기를 확장하는 방식을 시도했다. 한편 3D-UX-Net [17]에서는 SwinUNETR [8]의 트랜스포머를 ConvNeXt 블록으로 교체하여 여러 분할 과업에서 높은 성능을 거두었다. 그러나 3D-UX-Net은 표준적인 합성곱 기반 인코더 구조에 ConvNeXt 블록을 부분적으로만 적용하여, ConvNeXt가 제공할 수 있는 전체 이점을 완전히 활용하지는 못했다.
본 논문에서는 ConvNeXt 디자인이 지닌 잠재력을 최대한 활용하면서, 동시에 의료 영상 분할의 제한된 데이터 문제를 해결하기 위한 전략을 제안한다. 우리는 완전히 ConvNeXt 블록으로 구성된 최초의 3D 분할 네트워크인 MedNeXt를 제안하며, 이는 확장 가능한(Scalable) 인코더-디코더 구조이다.
구체적으로, 다음과 같은 기여점을 제시한다.
- 완전한 ConvNeXt 블록만으로 구성된 아키텍처: 네트워크 전반에 걸쳐 ConvNeXt 블록을 활용함으로써, ConvNeXt가 제공하는 이점을 네트워크 전체에서 고르게 누릴 수 있도록 설계한다(섹션 2.1).
- Residual Inverted Bottleneck을 활용한 업샘플링·다운샘플링 블록: 치밀한 분할(dense segmentation)을 위해 해상도를 재조정(resample)하는 과정에서 맥락 정보를 보존하고자, 기존의 업·다운샘플링 블록을 Residual Inverted Bottleneck으로 대체한다. 특히 잔차(residual) 연결을 변형하여, 학습 시 그라디언트 흐름(gradient flow)이 개선되도록 설계한다(섹션 2.2).
- 단계별 커널 크기 증가 기법(UpKern): 큰 커널의 MedNeXt가 제한된 데이터로 학습할 때 성능이 정체되는(saturation) 현상을 방지하기 위해, 작은 커널로 사전학습한 네트워크를 업샘플링하여 점진적으로 커널 크기를 늘려가는 간단하지만 효과적인 기법을 제안한다(섹션 2.3).
- 복합적 스케일링(Compound Scaling) 적용: 우리의 네트워크 구조는 너비(채널 수), 수용영역(커널 크기), 깊이(레이어 수)를 상호 독립적으로 확장할 수 있게 설계되어 있다. 이를 기반으로 [29]에서 제안된 복합적 스케일링(Compound Scaling)을 적용하여 네트워크의 여러 매개변수를 동시 확장한다(섹션 2.4).
제안하는 MedNeXt는 트랜스포머 기반, 합성곱 기반, 그리고 큰 커널 기반 네트워크를 아우르는 다양한 베이스라인과의 비교 실험에서 최신 수준의 성능을 달성하였다. 우리는 CT·MRI 등 서로 다른 영상 기법과 데이터 크기(30개에서 1251개까지 다양)를 포함한 4가지 과업(장기 및 종양 분할)에서 MedNeXt의 성능 향상을 시연한다. 궁극적으로, MedNeXt는 의료 영상 분할 분야에서 표준적인 합성곱 기반 네트워크를 대체할 수 있는 강력하고 현대적인 아키텍처로 자리매김할 것이다.
2 제안 기법(Proposed Method)
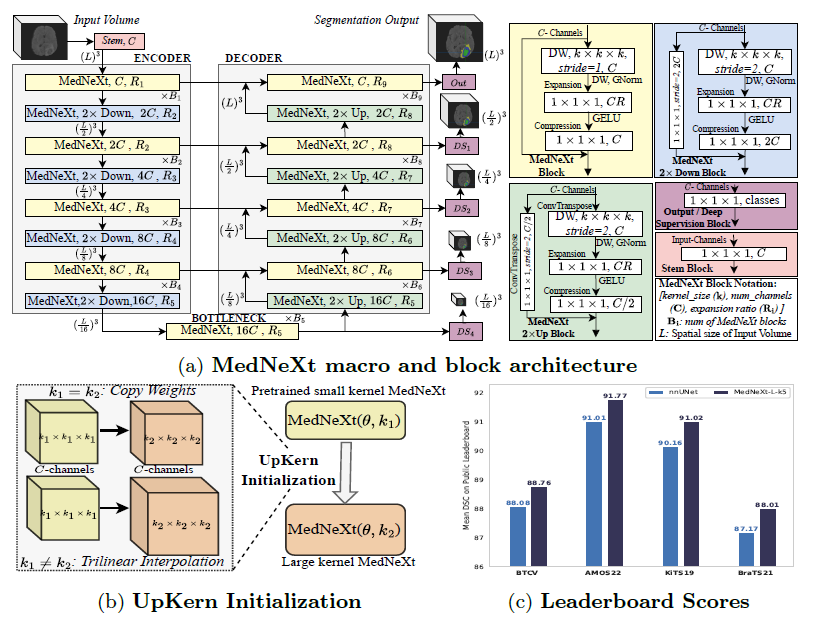
그림 1: (a) MedNeXt의 아키텍처 설계. 네트워크는 인코더(Encoder)와 디코더(Decoder)를 각각 4개 층으로 구성하고, 이들 사이에 보틀넥(bottleneck) 층을 둔다. 업샘플링(Up)과 다운샘플링(Down) 층에도 MedNeXt 블록이 적용된다. 각 디코더 층에서는 딥 수퍼비전(Deep Supervision)을 사용하되, 해상도가 낮아질수록 손실(loss) 가중치를 작게 부여한다. 모든 잔차(residual)는 단순 합산 방식으로 처리하며, 합성곱 연산에는 패딩(padding)을 적용해 텐서 크기가 유지되도록 한다. (b) 업샘플드 커널(UpKern) 초기화를 적용한 MedNeXt 아키텍처 쌍의 개념도. 이 두 아키텍처는 커널 크기( k_1, k_2 )를 제외하고는 동일한 구성( θ )을 지닌다. (c) MedNeXt-L( 5×5×5 )의 리더보드 성능.
딥 수퍼비전(Deep Supervision)은 신경망 내부의 여러 중간 단계(예: 중간 디코더 층이나 보틀넥 직후 등)에서 직접적인 학습 신호(loss)를 주어 학습을 진행하는 기법입니다. 전형적인 네트워크는 출력층에서만 손실 함수를 계산하고 그라디언트를 역전파하지만, 딥 수퍼비전을 활용하면 중간 출력들에도 각각 손실 함수를 적용해 다중 경로로 학습을 진행할 수 있습니다.
예를 들어 UNet 같은 인코더-디코더 구조에서, 보통은 최종 디코더 출력에만 분할(segmentation) 결과를 내고 손실을 구합니다. 하지만 딥 수퍼비전을 사용하면, 각 디코더 단계에서 축소된 해상도의 분할 결과를 생성하고, 이들 결과에 대해서도 별도의(또는 가중치가 조정된) 손실을 계산하여 네트워크를 학습시킵니다.
이 방식의 장점은 다음과 같습니다:
- 그라디언트 소실(Vanishing Gradient) 완화: 중간층에서도 직접 손실을 구하므로, 깊은 네트워크 구조에서도 학습 신호가 뒤쪽(초기 인코더 단계)까지 잘 전달되어 학습이 원활해집니다.
- 다중 스케일 정보 반영: 각 단계별 예측 결과는 해상도가 서로 다르기 때문에, 네트워크가 서로 다른 스케일(크기)의 특징을 효과적으로 학습할 수 있습니다.
- 학습 가속화: 최종 출력만 학습 신호를 받는 방식보다, 중간 출력들을 함께 학습하는 방식을 쓰면 초기 학습이 빨라지고, 분류나 분할 등 목적 과업에 필요한 특성이 다양한 수준에서 잘 정착됩니다.
이처럼 딥 수퍼비전은 딥러닝 모델 내부의 여러 지점에서 학습 책임을 분산함으로써, 학습 안정성·속도·성능을 향상시키는 대표적인 기법으로 알려져 있습니다.
2.1 완전 ConvNeXt 기반 3D 분할 아키텍처 (Fully ConvNeXt 3D Segmentation Architecture)
이전 연구 [22]에서 ConvNeXt는 Vision Transformer [7]와 Swin Transformer [21]로부터 건축적(architectural) 인사이트를 추출하여 합성곱(Convolution) 아키텍처로 구현되었다. ConvNeXt 블록은 트랜스포머의 여러 설계 요소를 물려받았으며, 네트워크를 확장하는 과정에서 연산량을 제한하도록 고안되어 있어, 표준 ResNet [10] 대비 성능 향상을 보였다.
본 연구에서는 이러한 강점을 활용하기 위해, ConvNeXt의 전반적인 설계를 3D-UNet [5]-유사 매크로 아키텍처에 빌딩 블록으로 채택하여 MedNeXt를 구현한다. 또한 업/다운샘플링 층까지 이를 확장(섹션 2.2)함으로써, 의료 영상 분할을 위한 최초의 완전 ConvNeXt 아키텍처를 완성하였다. 매크로 아키텍처는 그림 1(a)에 요약되어 있다.
MedNeXt 블록(ConvNeXt 블록과 유사)은 트랜스포머 블록을 모방한 3개 층으로 구성되며,
CC 채널의 입력에 대해 다음과 같이 작동한다:
- Depthwise Convolution Layer
- 커널 크기가 k×k×k 인 Depthwise Convolution을 수행한 뒤, 정규화(normalization)를 적용한다. 출력 채널 수는 C 로 동일하다.
- 원본 ConvNeXt와 달리, 소량의 배치(batch)에도 안정적인 학습을 위해 LayerNorm 대신 채널 단위의 GroupNorm [32]을 사용한다 [27].
- Depthwise Convolution 특성상, 커널 크기가 커져도 계산량을 제한하면서 Swin Transformer와 유사한 ‘넓은 주의(attention) 영역’을 모방할 수 있다. 따라서 무거운 연산은 이후에 등장할 Expansion Layer로 넘기도록 설계되었다.
- Expansion Layer
- 트랜스포머의 설계를 참고하여, 출력 채널 수를 C×R로 확장하는(Overcomplete) 합성곱 층을 배치하고, 그 뒤 GELU [12] 활성화 함수를 적용한다.
- 이때 (expansion ratio)이 클수록 네트워크가 너비(채널 수) 측면에서 확장되지만, 커널 크기는 1×1×1로 고정되어 있어 연산량 증가는 제한적이다.
- 즉, 이 레이어는 이전 레이어의 ‘수용영역(커널 크기) 스케일링’과 ‘너비 스케일링’을 효과적으로 분리(decouple)하는 역할을 담당한다.
- Compression Layer
- 1×1×1 커널을 사용하는 합성곱으로, 채널 수를 C로 다시 압축(compress)하여 출력한다.
결국 MedNeXt는 합성곱 방식의 모델로서, 의료 영상처럼 데이터가 부족한 환경에서도 학습이 용이하도록 하는 CNN 고유의 귀납적 편향(inductive bias)을 유지한다. 더 나아가 업샘플링·다운샘플링 층에서도 너비(채널 수 확장)와 수용영역(큰 커널) 스케일링이 가능하도록 전면적으로 ConvNeXt 구조를 적용하였다. 또한 깊이(레이어 수) 확장과 더불어, 이 3가지(너비·커널 크기·깊이)를 상호 독립적으로 확장할 수 있는 복합적 스케일링(Compound Scaling) 방식을 도입하여(섹션 2.4), 의료 영상 분할에 효과적인 확장 가능한(scalable) MedNeXt를 설계한다.
BatchNorm(Batch Normalization)은 미니배치(batch) 단위로 입력의 평균과 분산(variance)을 구해 정규화하는 방법이고, GroupNorm(Group Normalization)은 채널(Channel)을 여러 그룹으로 묶어 각 그룹마다 평균과 분산을 구해 정규화한다는 점에서 큰 차이가 있습니다.
1. BatchNorm과 배치 크기(미니배치)의 문제
- BatchNorm
- 같은 미니배치 내에서 평균과 분산을 구합니다.
- 따라서 배치 크기가 매우 작아지면, 평균과 분산 추정치가 불안정해져 성능이 저하되거나 학습이 흔들릴 수 있습니다.
- 예를 들어, 매우 작은 배치(예: 1~2장)로 학습하면, 각 배치별로 지엽적인 통계량이 추정돼 과도한 편향이 생길 수 있습니다.
- GroupNorm
- 배치의 크기와 상관없이, 각 샘플의 채널들을 특정 개수의 그룹으로 묶은 후 평균과 분산을 계산해 정규화합니다.
- 배치 크기가 작아져도 정규화가 안정적으로 작동합니다. (각 샘플 내부의 채널끼리만 계산하므로 배치 간 상호 의존성이 거의 없음)
2. LayerNorm과의 차이
- LayerNorm
- 한 샘플(이미지) 내에서 모든 채널과 공간 위치를 통째로 묶어 평균과 분산을 구합니다.
- 이미지의 모든 채널과 픽셀 위치를 한 번에 정규화하기 때문에, 특정 채널이 다른 채널에 비해 유리하거나 불리하게 작동할 수 있습니다.
- GroupNorm
- LayerNorm보다는 완화된 형태로, 채널을 일정 개수의 그룹으로 나눈 다음(예: 32채널씩), 그룹별로 독립적으로 평균과 분산을 구합니다.
- LayerNorm 대비 채널 간 독립성이 더 높아지고, 동시에 BatchNorm의 배치 크기 의존 문제도 없애는 중간 형태입니다.
요약하자면, GroupNorm은 작은 배치 크기 환경에서도 안정적인 정규화가 가능하다는 장점이 있어, 대규모 배치를 쓰기 어려운 의료 영상 등 특수 도메인에서 BatchNorm 대신 자주 쓰이게 됩니다.
2.2 잔차형 인버티드 보틀넥을 활용한 리샘플링 (Resampling with Residual Inverted Bottlenecks)
기존 ConvNeXt 설계는 표준적인 스트라이드(strided) 합성곱으로 구성된 별도의 다운샘플링 레이어를 사용한다. 업샘플링도 이에 대응하는 방식으로 스트라이드 트랜스포즈 합성곱(strided transposed convolution)을 사용한다. 그러나 이러한 설계는 리샘플링 과정에서 ConvNeXt의 “너비 확장” 또는 “커널 기반 확장” 이점을 직접적으로 활용하지 못한다.
우리는 이를 개선하기 위해, MedNeXt의 리샘플링 블록에서도 인버티드 보틀넥(Inverted Bottleneck)을 확장 적용한다. 구체적으로, 다운샘플링 블록에는 첫 번째 Depthwise 층에 스트라이드 합성곱을, 업샘플링 블록에는 트랜스포즈 합성곱을 각각 배치한다. 채널 축소나 확장은 그림 1(a)에 나타난 것처럼 MedNeXt의 2× 업/다운(Up/Down) 블록 설계에서 마지막 압축(compression) 층에서 수행한다.
또한 그라디언트 흐름을 원활히 만들기 위해, 잔차(residual) 연결 경로에 1×1×1 스트라이드 2의 합성곱(또는 트랜스포즈 합성곱)을 추가한다. 이를 통해 MedNeXt는 다운샘플링 및 업샘플링을 포함한 모든 컴포넌트에서, 트랜스포머와 유사한 인버티드 보틀넥 구조가 제공하는 장점을 충분히 활용하게 된다. 결과적으로 낮은 해상도에서도 풍부한 의미 정보를 유지함으로써, 치밀(dense)한 의료 영상 분할 과업에 이바지할 것으로 기대된다.

표 1: (왼쪽) 그림 1(a)에서 블록 수( B )와 확장 비율( R )을 조정하여 스케일링한 MedNeXt 구성. (오른쪽) MedNext-B 관련 실험(ablation) 결과(섹션 4.1).
즉, “트랜스포머와 유사한 인버티드 보틀넥”이라 함은,
- 중간에서 채널을 크게 확장했다가 다시 축소하는 흐름,
- Depthwise Convolution + 확장/압축 설계,
가 결합되어 트랜스포머가 보여주는 넓은 표현력과 계산 효율이라는 특성을 CNN 구조 안에 녹였다는 점을 말합니다.
UNet의 기본 블록과는 달리 이러한 인버티드 보틀넥 구조를 다운/업샘플링에도 적용해주면,
- 각 해상도별로 풍부한 채널 표현을 학습
- 잔차 연결로 그라디언트 흐름 개선
- 커널 확장으로 넓은 수용영역 확보
같은 이점들이 네트워크 전반에 도입되어, “트랜스포머스럽게” CNN을 스케일링하고 성능을 끌어올릴 수 있게 되는 것입니다.
결국, 트랜스포머 FFN 구조가 입력 채널을 크게 확장했다가(예: 512 → 2048) 다시 축소하는 흐름을 갖는 것처럼, ConvNeXt(혹은 MedNeXt)의 인버티드 보틀넥도 비슷한 과정을 밟습니다. 이렇게 중간 단계에서 채널 수를 크게 늘림으로써 표현력을 확장하고, 이후 압축 과정을 거치면서 최종 출력 채널 수로 맞추는 형태죠.
2.3 UpKern: 성능 포화 없이 큰 커널 합성곱 활용하기 (Large Kernel Convolutions without Saturation)
큰 커널을 사용하는 합성곱은 트랜스포머에서의 넓은 어텐션 윈도(attention window)를 근사하는 효과가 있지만, 여전히 성능 포화(performance saturation)에 취약하다. 예를 들어 자연 이미지 분류 분야의 ConvNeXt 아키텍처는 ImageNet-1k, ImageNet-21k 같은 대규모 데이터셋의 이점이 있음에도, 커널 크기가 7×7×7에 이르면 성능이 정체되는 양상이 보고되었다 [22]. 의료 영상 분할에서는 사용할 데이터가 훨씬 적어, 큰 커널 네트워크에서 성능 포화가 더욱 문제가 될 수 있다.
이를 해결하기 위해 우리는 Swin Transformer V2 [20]의 아이디어를 차용한다. Swin Transformer V2에서는 보다 작은 어텐션 윈도로 학습된 네트워크를 이용해, 보다 큰 어텐션 윈도를 지닌 네트워크를 초기화한다. 구체적으로, Swin Transformer는 학습된 상대적 위치 임베딩을 저장하기 위해
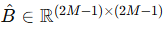
라는 바이어스(bias) 행렬을 사용하는데, 여기서 M은 어텐션 윈도 내 패치 수를 의미한다. 윈도 크기가 커지면
도 증가하여, B^의 크기가 더 커져야 한다. 저자들은 처음부터 새로 학습을 시작하지 않고, 기존 바이어스 행렬을 공간적으로 보간(spatial interpolation)하는 사전학습(pretraining) 과정을 제안해 성능을 끌어올렸다.
본 연구에서는 이러한 방식을 합성곱 커널에 맞추어 변형한 기법을 제안한다(그림 1(b)). UpKern은 서로 호환되지 않는(크기가 다른) 합성곱 커널(텐서 형태)을 삼중선형 보간(trilinear upsampling)으로 확장해, 작은 커널로 사전학습된 네트워크를 초기화용으로 활용하여 점진적으로 큰 커널 네트워크를 구성한다. 이때 정규화 층 등 텐서 크기가 변하지 않는 나머지 레이어들은 기존 사전학습 가중치를 그대로 복사해 쓴다. 이러한 초기화 방식은 간단하지만, 데이터가 제한적인 의료 영상 분할 환경에서도 큰 커널 네트워크의 성능 포화를 방지하고 학습 성능을 높이는 효과적 방법으로 작동한다.
Swin Transformer V2에서 사용하는 “상대적 위치 임베딩(relative position embedding)”은, 어텐션 윈도(attention window) 안에서 토큰(패치)들 간 상대적 거리에 따른 가중치를 학습하는 방식입니다. 일반적인 절대 위치 임베딩(absolute position embedding)과 달리, “어떤 토큰이 나와 얼마나 떨어져 있는가?”에 따라 attention 값에 bias(편향)를 추가해 주는 것이 핵심입니다.
한마디로 요약
- 윈도 크기가 커지면, 상대 거리를 표현해야 하는 범위도 커져서 행렬이 더 커져야 합니다.
- 그냥 새 행렬을 만들면, 이미 작은 윈도에서 학습한 ‘상대 위치 편향’ 지식을 버리는 꼴이 됩니다.
- 그래서 Swin Transformer V2는, 기존 행렬을 ‘공간 보간’해서 큰 크기의 행렬에 매핑함으로써, 학습된 지식을 효과적으로 재활용합니다.
- 이를 통해 **“작은 윈도 → 큰 윈도”**로 확장할 때 학습 성능 저하나 포화 문제를 크게 줄일 수 있습니다.
이것이 B 행렬을 공간적으로(interpolate) 보간하여 커진 윈도 크기에 맞춘다”는 말이 의미하는 핵심입니다.

2.4 깊이, 너비, 수용영역(Receptive Field)의 복합적 스케일링 (Compound Scaling of Depth, Width and Receptive Field)
복합적 스케일링(compound scaling) [29]은 깊이, 너비, 수용영역(커널 크기), 입력 해상도 등 여러 차원을 동시에 확장함으로써, 단일 차원만 확장할 때보다 더 큰 이점을 얻을 수 있다는 아이디어다. 특히 3D 네트워크에서 커널 크기를 무작정 늘리기만 하면 연산량이 급증하여 실현이 어렵기 때문에, 다른 차원과 함께 확장해보는 방식을 고려할 필요가 있다.
그림 1(a)에 나타난 구성에 맞추어, 우리는 블록 개수( B ), 확장 비율( R ), 커널 크기( )의 동시 스케일링을 실험한다. 이는 각각 네트워크의 깊이(depth), 너비(width), 수용영역(receptive field)을 나타낸다.
이를 위해 테이블 1(왼쪽)에 정리된 MedNeXt의 4가지 모델 구성을 사용하였다.
- 기본 구성(“MedNeXt-S”)은 채널 수( C )가 32, 확장 비율( R )이 2, 블록 수( B )가 2다.
- 변형 모델로는
- MedNeXt-B:
R만 증가 - MedNeXt-M:
R와 를 동시에 증가 - MedNeXt-L:
최대 62개의 MedNeXt 블록을 사용하며, 와 모두 큰 값을 취한다. 이는 커널 크기가 표준적일 때도 MedNeXt가 깊이 방향으로 크게 확장될 수 있음을 보여주기 위한 구성이다.
- MedNeXt-B:
추가로 우리는 큰 커널( k={3,5})을 각각의 구성에 대해 실험하여, MedNeXt 아키텍처에서 복합적 스케일링을 통해 성능을 극대화할 가능성을 탐색한다.
3 실험 설계(Experimental Design)
3.1 구성(Configurations), 구현(Implementation) 및 베이스라인(Baselines)
우리의 프레임워크 구현은 PyTorch [24]를 사용한다. 섹션 2.4에 자세히 설명된 대로, 우리는 MedNeXt의 4가지 구성과 2가지 커널 크기를 조합하여 실험을 진행한다. 스케일링으로 인해 커지는 GPU 메모리 요구사항은 1) PyTorch AMP를 활용한 혼합 정밀도(mixed precision) 학습, 2) Gradient Checkpointing [4] 기법을 사용해 제한한다.
실험 프레임워크는 nnUNet [13]을 백본으로 활용하며, 학습 스케줄(에포크=1000, 에포크당 배치=250), 추론(50% 패치 중첩), 데이터 증강(data augmentation) 설정은 그대로 유지한다. nnUNet을 제외한 모든 네트워크는 AdamW [23] 옵티마이저로 학습한다. 데이터는 학습 및 추론 시 1.0mm 등방성(isotropic) 해상도로 리샘플링되며, 최종 결과는 원본 해상도에 매핑해 평가한다. 입력 패치 크기는 3D 네트워크에 대해서는 128×128×128, 2D 네트워크에 대해서는 512×512를 사용하고, 배치 크기는 각각 2와 14로 설정한다.
모든 MedNeXt 모델의 학습률(learning rate)은 0.001이며, 단 KiTS19 데이터셋에서 커널 크기가 5일 경우는 안정성을 위해 0.0001을 사용한다. Swin 모델 및 3D-UX-Net의 학습률은 0.0025, ViT 모델은 0.0001을 사용한다.
평가 지표로는 체적 정확도를 측정하기 위한 Dice 유사도 계수(DSC)와 표면 정확도를 측정하기 위한 1.0mm 기준의 Surface Dice 유사도(SDC)를 사용한다. 모든 모델에 대해 80:20 분할을 적용한 뒤, 5-폴드 교차검증(CV)을 수행한 평균 성능을 보고한다. 또한 별도의 후처리 없이 5-폴드 앙상블한 MedNeXt-L (커널:5×5×5) 모델에 대해 테스트 세트 DSC 점수도 제시한다.
비교를 위한 베이스라인은 다음과 같다:
- 높은 성능의 합성곱 기반 네트워크인 nnUNet [13]
- 트랜스포머-합성곱 하이브리드 네트워크 4종
- UNETR [9], SwinUNETR [8] (트랜스포머를 인코더에 사용)
- TransBTS [31], TransUNet [3] (트랜스포머를 중간 층에 사용)
- 완전한 트랜스포머 네트워크인 nnFormer [34]
- 부분적으로 ConvNeXt를 사용하는 3D-UX-Net [17]
TransUNet은 2D 네트워크이고, 그 밖의 모델들은 모두 3D 네트워크다. 통일된 실험 프레임워크를 통해 패치 크기, 리샘플링, 증강, 학습 및 평가 등에서 어느 특정 모델이 이점을 얻지 않도록 동일 조건에서 비교를 수행한다.
3.2 데이터셋(Datasets)
MedNeXt 아키텍처의 이점을 종합적으로 입증하기 위해, 장기(organ) 및 종양(tumor) 분할 과업을 아우르는 다음 4가지 대표적인 과제에 대해 실험을 수행했다.
- Beyond-the-Cranial-Vault (BTCV) 복부 CT 장기 분할 [16]
- AMOS22 복부 CT 장기 분할 [14]
- 2019 신장 종양 분할 챌린지(KiTS19) [11]
- 2021 뇌종양 분할 챌린지(BraTS21) [1]
BTCV, AMOS22, KiTS19 데이터셋은 각각 CT 볼륨 30개, 200개, 210개로 구성되며, 분할 대상 클래스 수는 각각 13개, 15개, 2개다. 반면 BraTS21은 MRI 볼륨 1251개와 3개 클래스로 구성되어 있다. 이러한 데이터셋 구성이 CT와 MRI라는 다양한 영상 기법과 각기 다른 규모의 학습 데이터를 포함하고 있어, 본 연구에서 제안하는 기법이 폭넓은 상황에서 유효함을 확인할 수 있다.
4 결과 및 논의(Results and Discussion)
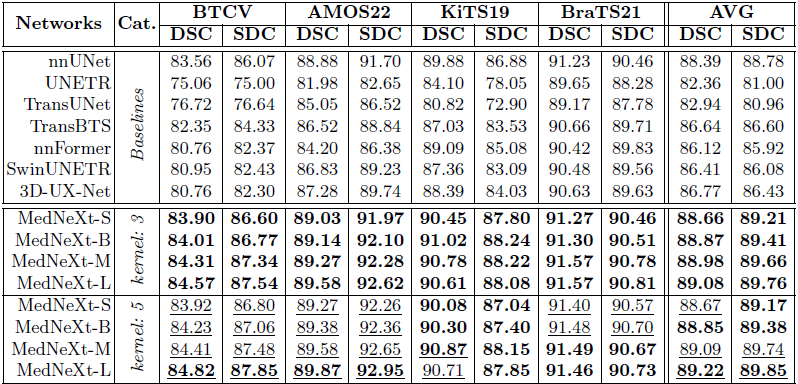
표 2: MedNeXt의 커널 크기 {3,5}에 대한 5-폴드 교차검증(CV) 결과로, 합성곱 기반·트랜스포머 기반·대형 커널 기반 등 7개의 베이스라인을 능가한다.
- val (굵게 표시): 최고 베이스라인과 같거나 그보다 우수(≥)
- val (밑줄): 동일 구성에서 커널이 33일 때보다 우수(>)
4.1 아키텍처 개선 요소의 성능 검증 (Performance ablation of architectural improvements)
우리는 MedNeXt-B 구성을 AMOS22 및 BTCV 데이터셋에 대해 절삭(ablation) 실험하여, 제안하는 개선 사항의 효과를 확인하고, 단순한 ConvNeXt가 nnUNet 같은 기존 분할 베이스라인과 견줄 수 없음을 보이고자 한다. 표 1(오른쪽)에 제시된 절삭 실험 결과에서 다음을 관찰할 수 있다.
- 다운/업샘플링 층에 적용된 잔차형 인버티드 보틀넥(Residual Inverted Bottlenecks)
- 이 수정 블록들이 존재해야만(“MedNeXt-B Resampling vs Standard Resampling”) 의료 영상 분할에서 MedNeXt가 효과적으로 작동한다.
- 반대로 이러한 수정 블록이 없으면 성능이 크게 하락한다. 이는 리샘플링 과정에서 피처 맵의 의미적 풍부함(semantic richness)을 보존하는 역할이 크기 때문으로 보인다.
- 의료 영상 분할에서 큰 커널 네트워크를 학습하는 것은 간단하지 않다
- 대형 커널 MedNeXt를 초기부터 학습(From Scratch)하면 성능이 떨어지는 반면, UpKern을 적용한 MedNeXt-B는 BTCV와 AMOS22 모두에서 5×5×5 커널의 성능을 향상시켰다(“UpKern vs From Scratch”).
- UpKern 없이는 큰 커널의 성능이 작은 커널과 거의 구분되지 않을 정도로 차이가 없다.
- 큰 커널 성능 향상의 핵심은 ‘UpKern + 대형 커널’의 조합
- 단순히 학습 스케줄을 길게(“Trained 2×”) 가져가는 것만으로는 동일 효과를 얻을 수 없다.
- 예를 들어, 이미 학습된 3×3×3커널 MedNeXt-B를 재학습해도, 대형 커널 모델만큼의 성능에는 도달하지 못했다.
이로써 제안하는 MedNeXt 구조적 수정 사항들이 ConvNeXt 아키텍처를 의료 영상 분할로 성공적으로 이식했음을 알 수 있다. 이후에는 합성곱·트랜스포머·대형 커널 기반 네트워크 등으로 이루어진 7가지 베이스라인과 비교하여, 4개 데이터셋 전반에서 MedNeXt 아키텍처의 성능 우수성을 검증한다. 아울러 MedNeXt가 여러 측면에서 어떠한 이점을 제공하는지 논의한다.
4.2 베이스라인과의 성능 비교 (Performance comparison to baselines)
MedNeXt는 5-폴드 교차검증(5-fold CV) 점수와 공식 테스트셋 리더보드라는 두 가지 측면에서 기존 베이스라인을 성공적으로 뛰어넘는다. 표 2에 제시된 5-폴드 CV 결과를 보면, 3×3×3커널을 사용하는 MedNeXt는 깊이(depth)와 너비(width)의 스케일링을 통해, 추가 학습 데이터 없이도 4개 전 과업(기관/장기 및 종양)에 걸쳐 모든 베이스라인 대비 최신 수준(state-of-the-art)의 분할 성능을 달성한다.
- 특히 MedNeXt-L은
- 과업의 다양성(뇌, 신장 종양, 장기),
- 영상 기법(CT, MRI),
- 데이터셋 크기(BTCV 18 샘플 vs BraTS21 1000 샘플)를 모두 아우르며, 작은 모델 변형들을 능가하거나 대등한 성능을 낸다.
- 이는 nnUNet 같은 기존 강력한 방법들을 대체할 만한 유망한 네트워크임을 시사한다.
- UpKern 기법과 5×5×5 커널을 추가로 적용하면 복합 스케일링(compound scaling) 이 완성되어, 작은 커널 기반의 MedNeXt 대비
- 장기 분할(BTCV, AMOS22)에서는 종합적인 성능 향상
- 종양 분할(KiTS19, BraTS21)에서는 다소 제한적이지만 의미 있는 개선을 달성한다.
게다가 공식 테스트셋 리더보드(그림 1(c)) 점수에서도, 5×5×5커널의 MedNeXt-L(5-폴드 앙상블)과 가장 강력한 경쟁자인 nnUNet(5-폴드 앙상블)을 비교해 보면 다음과 같다.
- BTCV: MedNeXt가 nnUNet을 능가했으며, 오직 지도학습(supervised training)만으로, 추가 학습 데이터 없이도 리더보드 최상위권(Dice=88.76, HD95=15.34)을 기록한다.
- AMOS22: MedNeXt가 nnUNet을 넘어섰을 뿐 아니라(DSC=91.77, NSD=84.00), (날짜: 09.03.23 기준) 현재 리더보드 1위에 올라 있다.
- KiTS19: MedNeXt가 nnUNet 성능(DSC=91.02)을 넘어선다.
- BraTS21: MedNeXt가 체적 정확도(DSC=88.01)는 물론 표면 정확도(HD95=10.69)에서도 nnUNet보다 우수하다.
특히 MedNeXt는 성능 향상을 위해 전이학습(transfer learning; 예: 3D-UX-Net)이나, 여러 번의 5-폴드 앙상블(UNETR, SwinUNETR) 같은 추가 기법을 사용하지 않았다. 즉, 전적으로 아키텍처만으로 이러한 성능을 달성하여, 의료 영상 분할의 새로운 최신 방법(state-of-the-art)으로 자리매김했다.
5 결론(Conclusion)
자연 이미지 분석과 달리, 의료 영상 분할 분야는 학습 데이터가 제한적이라는 고유의 문제로 인해 네트워크 규모 확장(scaling)을 활용하는 아키텍처가 상대적으로 부족하다. 본 연구에서는 이러한 환경에서 높은 성능을 낼 수 있도록, 트랜스포머에서 영감을 받은 확장 가능한(scalable) 완전 ConvNeXt 기반 3D 분할 아키텍처인 MedNeXt를 제안했다. MedNeXt는 제한된 의료 영상 데이터셋에서도 우수한 성능을 보이도록 맞춤화되었으며, 7가지 강력한 베이스라인과의 비교에서 4가지 난이도 높은 과업 전반에 걸쳐 최신 수준(state-of-the-art)의 성능을 달성함을 입증했다. 또한 자연 이미지에서 ConvNeXt가 수행한 것처럼 [22], MedNeXt 역시 표준 합성곱 블록을 현대화(modernization)하는 효과적인 설계를 제공하여, 의료 영상 분할을 위한 딥러닝 네트워크를 구축하는 데 있어 새로운 대안이 될 수 있음을 보여준다
'인공지능' 카테고리의 다른 글
| Titans: Learning to Memorize at Test Time (3) | 2025.01.16 |
|---|---|
| Rho-1: Not All Tokens Are What You Need (3) | 2025.01.10 |
| mochi-1-preview (3) | 2025.01.10 |
| Ferret-UI 2: Mastering Universal User Interface Understanding Across Platforms (2) | 2025.01.10 |
| Hallo2: Long-Duration and High-Resolution Audio-Driven Portrait Image Animation (3) | 2024.11.30 |



