취업이 쉽지 않아 지원서만 쓰다보니 너무 오래되었다...
https://nvlabs.github.io/Sana/Sprint/
Sana
• Stabilizing Continuous-Time Distillation: To stabilize continuous-time consistency distillation, we address two key challenges: training instabilities and excessively large gradient norms that occur when scaling up the model size and increa
nvlabs.github.io
초록(Abstract)
본 논문에서는 초고속 텍스트-이미지(T2I, Text-to-Image) 생성을 위한 효율적인 확산 모델(diffusion model)인 SANA-Sprint를 제안한다. SANA-Sprint는 사전 훈련된 기초 모델을 기반으로 하이브리드 증류(distillation)를 추가하여, 이미지 생성에 필요한 추론 단계를 기존의 20단계에서 단 1-4단계로 획기적으로 축소하였다. 이를 위해 세 가지 주요 혁신을 도입하였다. 첫째, 훈련이 필요 없는(training-free) 접근 방식을 통해 사전 훈련된 플로우 매칭(flow-matching) 모델을 연속 시간 일관성 증류(continuous-time consistency distillation, sCM)로 전환하여, 처음부터 훈련하는 비용을 제거하고 훈련 효율을 크게 높였다. 제안된 하이브리드 증류 전략은 sCM과 잠재적 적대 증류(Latent Adversarial Distillation, LADD)를 결합하는 방식으로, sCM은 교사 모델과의 정합성을 유지하며 LADD는 단일 단계(single-step) 생성 품질을 높인다. 둘째, SANA-Sprint는 단계에 따라 개별적으로 훈련할 필요 없이 1-4단계 모두에서 고품질의 결과를 생성할 수 있는 통합된 단계 적응 모델(unified step-adaptive model)로, 효율성을 더욱 개선하였다. 셋째, 실시간 인터랙티브 이미지 생성을 위해 ControlNet을 SANA-Sprint와 결합하여 사용자의 입력에 따라 즉각적인 시각적 피드백을 제공한다. SANA-Sprint는 속도-품질의 트레이드오프 측면에서 새로운 파레토 최적(Pareto frontier)을 달성하며, 단 1단계 추론으로도 최신 성능(state-of-the-art)인 7.59 FID 및 0.74 GenEval 지표를 기록하였다. 이는 기존의 최고 성능 모델인 FLUX-schnell(7.94 FID, 0.71 GenEval) 대비 10배 빠른 속도(H100 GPU에서 1.1초 vs 0.1초)로 더 우수한 성능이다. 또한 H100 GPU를 기준으로 1024×1024 크기 이미지에 대해 텍스트-이미지 변환 시 0.1초, ControlNet 활용 시 0.25초의 지연시간을 기록하였으며, RTX 4090에서도 텍스트-이미지 변환 시 0.31초의 우수한 효율성을 보였다. 이는 AI 기반 소비자 애플리케이션(AIPC)에 매우 적합한 성능임을 보여준다. 제안된 코드와 사전 훈련 모델은 공개될 예정이다.
링크: Github 코드 | 프로젝트 페이지
- 서론(Introduction)

- (a) 본 논문에서 제안하는 SANA-Sprint는 1024×1024 이미지 생성의 추론 속도를 획기적으로 가속하여, 기존 최고 성능 모델인 FLUX-Schnell의 1.94초 대비 0.03초로 단축하였다. 이는 NVIDIA A100 GPU 상에서 배치 사이즈 1을 기준으로 Transformer의 지연시간(latency)을 측정한 결과이며, 현존하는 단계 증류(step-distillation) 기반 최신 모델인 FLUX-Schnell과 비교하여 64배의 성능 향상이다. (b) 추가로, 본 모델은 훈련 시 GPU 메모리를 효율적으로 활용하며, 공식 코드를 사용해 측정한 결과 기존의 다른 증류(distillation) 방법들에 비해 뛰어난 메모리 효율성을 보였다(1024×1024 이미지 기준, 단일 A100 GPU 사용).
확산 생성 모델(diffusion generative models)[1, 2]은 일반적으로 이미지를 생성하기 위해 50-100회의 반복적 잡음 제거(iterative denoising) 단계를 요구하는 높은 연산 강도를 가지며, 이에 따라 효율적인 추론을 위한 시간 단계 증류(time-step distillation)가 중요한 연구 주제로 자리 잡았다. 현재 관련 기법은 크게 두 가지 대표적인 패러다임으로 나눌 수 있다. (1) GAN[3] 기반의 분포 증류(distribution-based distillation) 기법(e.g., ADD[4], LADD[5])과 변분 점수 증류(variational score distillation, VSD)[6,7,8]는 단일 단계의 결과를 다단계 교사 모델의 분포와 정합시키기 위해 공동 훈련(joint training)을 활용한다. (2) 직접 증류(Direct Distillation)[9], 점진적 증류(Progressive Distillation)[10,11], 일관성 모델(Consistency Models, CM)[12] 계열(e.g., LCM[13], CTM[14], MCM[15], PCM[16], sCM[17])의 궤적 기반 증류(trajectory-based distillation)는 축소된 샘플링 간격에서 ODE 해를 학습하여 빠른 생성 속도를 구현한다. 이러한 방법들은 이미지 생성 속도를 10-100배까지 단축하면서도 경쟁력 있는 생성 품질을 유지하여, 증류 기법을 실용적 응용을 위한 필수적인 접근법으로 자리 잡게 하였다.
그러나 이와 같은 기법들은 잠재적 한계를 지니고 있어 더 넓은 분야로 확장하는 데 어려움을 겪고 있다. GAN 기반의 방법들은 적대적(adversarial) 학습 과정에서 발생하는 불안정성과 모드 붕괴(mode collapse) 현상으로 인해 훈련 안정성이 낮다. 특히 GAN은 노이즈에서 자연 이미지를 지도(supervision) 없이 매핑해야 하는 비쌍 학습(unpaired learning)의 근본적인 어려움 때문에 더 심각한 문제가 발생한다[18,19]. 또한 아키텍처의 경직성으로 인해 새로운 백본 모델이나 환경에 적용할 때 매우 까다로운 하이퍼파라미터 조정이 필요하다. VSD 기반의 방법들은 추가적인 확산 모델을 공동 훈련해야 하는 과정에서 계산 비용이 증가하고 GPU 메모리에 큰 부담을 주며, 세심한 튜닝이 필요하다[20]. 일관성 모델(CM)의 경우 안정적이지만, 극소 단계(예: 4단계 미만)의 상황에서는 품질 저하가 일어난다. 특히 텍스트-이미지 생성에서는 궤적 단축(trajectory truncation)으로 인해 의미론적 정합성(semantic alignment)이 떨어진다. 이와 같은 문제점들은 효율성, 유연성, 품질을 동시에 확보할 수 있는 새로운 증류 프레임워크의 필요성을 부각시킨다.
------
분포 기반 증류:
- 여기서 GAN이 언급되는 이유는 GAN의 구조와 학습 방식을 차용했기 때문입니다.
- ADD(Adversarial Diffusion Distillation), LADD 같은 방법들은 GAN의 생성기-판별기 구조를 활용해 확산 모델의 분포를 학습합니다.
- 이는 "GAN을 사용한 확산 모델 증류"라고 볼 수 있습니다.
- 즉, DDPM/DDIM 자체가 GAN을 사용하는 것이 아니라, 이들을 빠르게 만들기 위한 증류 과정에서 GAN 구조가 활용되는 것입니다.
B. 궤적 기반 증류:
- 이 방법은 확산 모델의 다단계 과정(궤적)을 직접 학습합니다.
- Consistency Models(CM)나 Progressive Distillation과 같은 방법들이 여기에 속합니다.
- ODE 해법을 통해 연속적 흐름을 더 적은 단계로 근사합니다.
------
본 논문에서는 단일 단계로 고품질 텍스트-이미지(T2I) 생성을 수행할 수 있는 효율적 확산 모델인 SANA-Sprint를 제안한다. 제안하는 방법은 사전 훈련된 이미지 생성 모델인 SANA와 최근 제안된 연속 시간 일관성 모델(continuous-time consistency model, sCM)[17]을 기반으로 하며, 기존 일관성 모델의 장점을 유지하면서도 이산 시간 모델의 이산화(discretization) 오차 문제를 완화하였다. 우선 단일 단계 생성을 위해 SANA(Flow Matching 모델)를 손실 없는(lossless) 수학적 변환을 통해 sCM 증류에 적합한 TrigFlow 모델로 변환한다. 그 후 증류 과정에서의 불안정성을 완화하기 위해, 교사 모델을 재훈련하지 않고 사전 훈련된 모델로부터 효율적으로 지식을 이전할 수 있도록 SANA의 셀프 어텐션 및 교차 어텐션에서 QK norm을 조정하고 조밀한(dense) 시간 임베딩을 도입하였다. 또한 sCM과 LADD 기반 적대 증류(adversarial distillation)를 결합하여 빠른 수렴 속도와 고충실도의 생성 결과를 얻으면서 sCM의 장점 역시 유지하였다. 본 방법은 주로 SANA 모델 기반으로 검증되었으나, FLUX[21], SD3[22]과 같은 다른 플로우 매칭(flow matching) 기반 모델에도 효과적으로 적용될 수 있다.
그 결과, SANA-Sprint는 하이브리드 목적함수를 활용하여 속도와 품질 간 뛰어난 균형을 달성하였다. 특히, 단독 sCM에 비해 2단계 생성에서 FID를 0.6, CLIP-Score를 0.4 향상시켰으며, 순수한 LADD 기반 접근법보다 FID를 3.9, CLIP-Score를 0.9 향상시켰다. 그림 1에서 보듯이, SANA-Sprint는 SD3.5-Turbo, SDXL-DMD2, Flux-schnell 등 최근의 최신 방법론을 뛰어넘는 FID 및 GenEval 벤치마크 성능을 기록하였다. 특히 Flux-schnell 모델 대비 64.7배 빠른 속도를 보이면서도 더 뛰어난 FID(7.59 vs 7.94)와 GenEval(0.74 vs 0.71)을 달성했다.
또한, SANA-Sprint는 소비자급 GPU를 탑재한 랩탑(NVIDIA RTX 4090)에서 1024×1024 이미지 생성 시 0.31초, H100 GPU에서는 0.1초 만에 이미지를 생성하며, 교사 모델인 SANA보다 8.4배 빠른 추론 속도를 기록했다. 이 효율성은 즉각적 시각 피드백이 요구되는 ControlNet 기반의 이미지 생성/편집 등의 응용 분야에 적합하며, 특히 인간-컴퓨터 상호작용이 필요한 창의적 워크플로우, AI 기반 소비자 응용(AIPC), 몰입형 AR/VR 인터페이스에 이상적이다.
요약하면, 본 논문의 기여점은 다음과 같다:
- 하이브리드 증류 프레임워크 제안
- 탁월한 속도/품질 균형 달성
- 실시간 인터랙티브 이미지 생성 실현
2. 예비 지식(Preliminaries)
2.1 확산 모델(Diffusion Model) 및 그 변형들

-----
Flow Matching의 등장과 확산
- 최초 등장: Flow Matching은 일반적인 Diffusion 모델의 변형으로, 2022년 초반부터 학술계에서 주목받기 시작했습니다.
- 특히, "Flow Matching for Generative Modeling" (Lipman et al., 2022) 논문(arXiv:2210.02747)을 기점으로 본격적으로 주목받았습니다.
- 이후 2023년 중반부터 후속 논문들이 활발히 발표되며, 이미지 및 텍스트 생성 분야에서 빠르게 퍼졌습니다. 대표적으로 FLUX(Flow Matching with Latent Diffusion) 같은 모델이 제안되면서 특히 2023년 이후 이미지 생성 분야에서 빈번히 활용되고 있습니다.
2. TrigFlow의 등장과 확산
- 최초 등장: TrigFlow는 Flow Matching의 변형으로, 구면 선형 보간(SLERP)을 사용하여 각도 기반의 보간을 적용한 방법입니다.
- TrigFlow의 최초 논문으로 간주되는 논문은 "TrigFlow: Rethinking Velocity Prediction for Efficient Generative Flow Matching" (Gu et al., 2023) (arXiv:2310.02667)이며, 2023년 10월에 공개되었습니다.
- TrigFlow가 Flow Matching에 비해 비교적 최근(2023년 하반기)에 등장했으며, 특히 2024년에 들어서면서 이미지 생성 모델의 초고속 증류(distillation) 기법과 결합해 주목받고 있습니다.
-----
2.2 일관성 모델(Consistency Models)

이산 시간 일관성 모델 (Discrete-time CMs)

연속 시간 일관성 모델 (Continuous-time CMs)

TrigFlow 기반 연속 시간 일관성 모델 (sCM)의 구체적 표현

3 방법(Method)
연속 시간 일관성 모델(Continuous-time consistency models, CMs)은 sCM[17]에서 제안된 TrigFlow 형식을 통해 단순화될 수 있다. 이는 매우 깔끔한 프레임워크를 제공하지만, 현재 대부분의 스코어 기반(score-based) 생성 모델들은 diffusion 또는 flow matching 형식에 기반을 두고 있다. 따라서 이를 활용하려면 두 가지 접근이 가능하다. 첫 번째 접근법은 이러한 기존 formulation 각각에 따라 별도의 연속 시간 CM 훈련 알고리즘을 개발하는 것인데, 이는 별개의 알고리즘 설계 및 하이퍼파라미터 튜닝을 요구하므로 복잡성을 증가시킨다. 두 번째 방법은 [17]에서와 같이 별도의 TrigFlow 모델을 사전 훈련(pretrain)하는 것이지만, 이 방법은 계산 비용을 크게 증가시킨다.
이러한 문제를 해결하기 위해 우리는 이미 사전 훈련된 flow matching 모델을 간단한 수학적 변환을 통해 TrigFlow 모델로 변환하는 간편한 방법을 제안한다. 본 접근법은 기존의 사전 훈련된 모델을 완전히 활용하면서도 별도의 알고리즘 설계를 필요로 하지 않으므로, [17]에서 제안된 훈련 알고리즘을 그대로 적용 가능하게 한다. 일반적인 확산(diffusion) 모델의 경우에도 이와 유사한 방식으로 변환을 수행할 수 있으나, 본 논문에서는 간결함을 위해 이를 생략한다.
3.1 TrigFlow로의 훈련이 필요 없는 변환(Training-Free Transformation to TrigFlow)
스코어 기반 생성 모델(score-based generative models)인 diffusion, flow matching, TrigFlow 등은 적절한 데이터 스케일과 신호대잡음비(SNR, Signal-to-Noise Ratio)에 따라 데이터를 디노이징(denoising)할 수 있다¹. 하지만, flow matching 모델을 TrigFlow 스케줄로 생성된 데이터에 직접 적용할 경우 다음과 같은 세 가지 주요 불일치가 발생한다.

이와 관련된 이론적으로 손실이 없는(lossless) 변환법을 다음 명제로 제시한다.

Remark:
우리는 기존의 flow matching과 같은 노이즈 스케줄을 최대한 원활하게 TrigFlow로 변환하여, sCM 프레임워크를 최소한의 변경만으로 통합할 수 있도록 했다. 본 접근법은 [17]에서처럼 별도의 TrigFlow 모델을 사전 훈련하는 과정을 회피하는 대신, [28, 17]의 unit variance 원칙으로부터의 약간의 일탈을 허용한다.

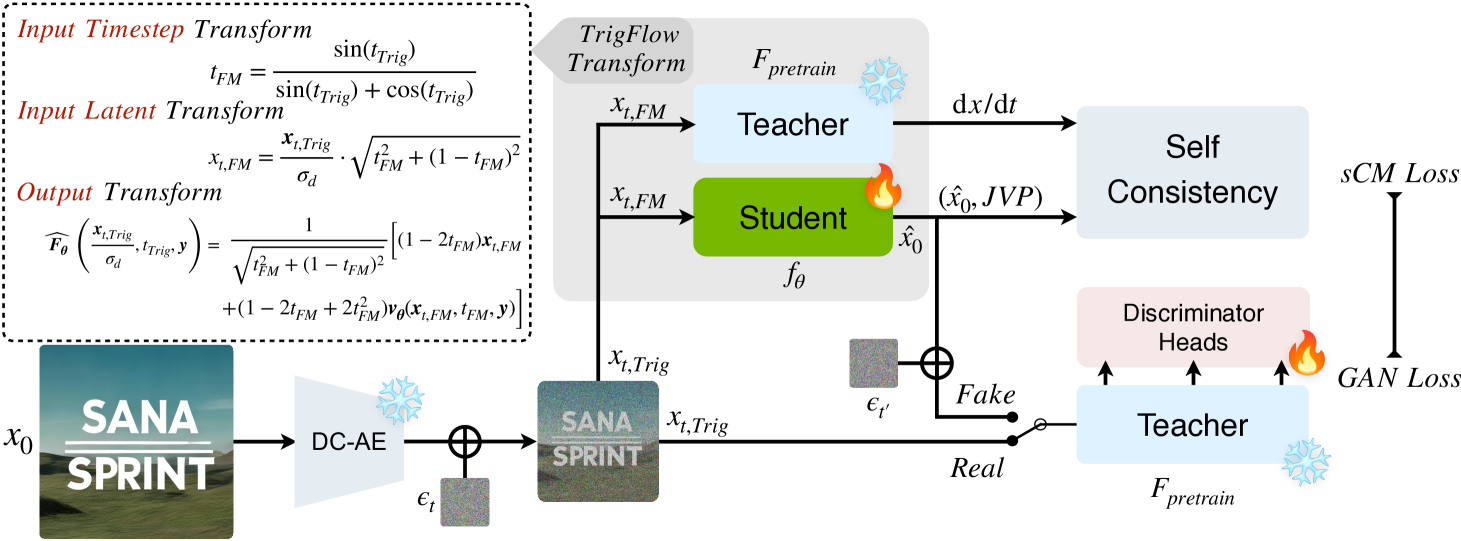
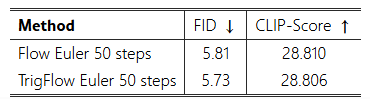
위 명제 3.1의 구체적인 증명 및 세부사항은 부록(Appendix) D에 제시되어 있다. 입력과 출력 변환 모두 미분 가능하며, 자동 미분(auto-differentiation)과 완벽히 호환된다. 본 변환은 이론 및 실제 실험(표 1) 모두에서 손실이 없음을 확인하였다. 본 논문에서 제안한 훈련이 필요 없는(training-free) 변환은 그림 2의 회색 박스(gray box)에 나타나 있다.
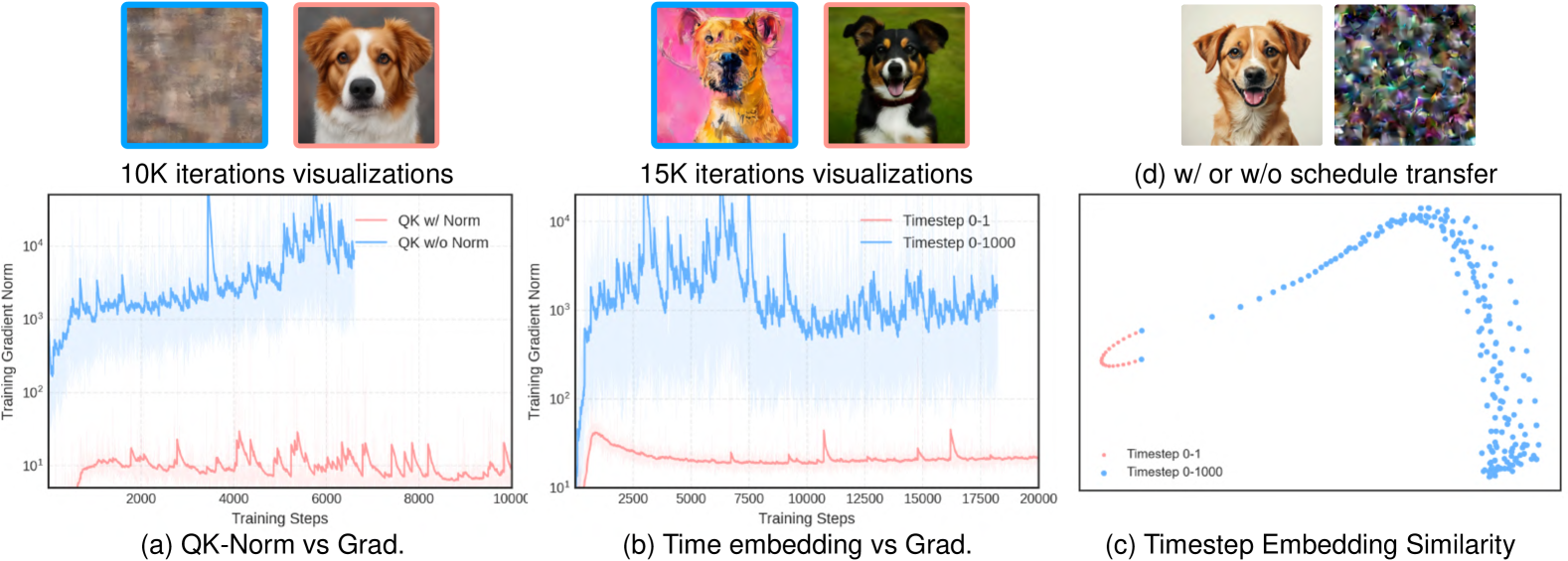
그림 3 설명:
효율적인 증류(Distillation)를 위한 QK Normalization, 조밀한(dense) 시간 임베딩, 훈련이 필요 없는 스케줄 변환을 나타낸다.
- (a) QK Normalization의 유무에 따른 그래디언트 노름과 시각화 비교. QK Normalization의 안정화 효과를 보여준다.
- (b) timestep 스케일(0-1 vs 0-1000)에 따른 그래디언트 노름 곡선을 비교하여 안정성 및 품질에 미치는 영향을 시각화.
- (c) timestep 임베딩의 PCA 기반 유사성 분석.
- (d) 5000번의 미세조정(fine-tuning) 반복(iteration) 후의 이미지 결과 비교. (왼쪽: 제안한 스케줄 변환(Sec. 3.1) 적용, 오른쪽: 미적용)
표 1:
기존의 Flow 기반 SANA 모델과 본 논문의 훈련이 필요 없는 변환(TrigFlow 기반 SANA-Sprint 모델)을 비교하여, 변환 전후의 성능을 FID와 CLIP-Score로 평가했다.

3.2 연속 시간 증류의 안정화(Stabilizing Continuous-Time Distillation)
연속 시간 일관성 증류(continuous-time consistency distillation)의 안정성을 높이기 위해, 우리는 모델 크기와 해상도가 증가할 때 나타나는 두 가지 주요 문제를 해결했다. 즉, 훈련의 불안정성(training instabilities)과 지나치게 큰 그래디언트 노름(gradient norms)으로 인해 발생하는 모델 붕괴(model collapse)를 극복하였다. 이를 위해 더 조밀한(dense) 시간 임베딩을 설계하고, 셀프 어텐션(self-attention) 및 크로스 어텐션(cross-attention) 모듈에 QK-Normalization을 적용하였다. 이 수정 사항들은 높은 해상도 및 대규모 모델에서도 효율적이고 안정적인 훈련이 가능하도록 만들어, 견고한 성능을 유지할 수 있게 하였다.



그림 4 설명
SANA-Sprint와 다양한 경쟁 모델의 생성 이미지 시각적 비교.
† 표시는 각 추론 단계에 따라 별도의 모델을 필요로 하는 방법을 나타내며, 모델명 아래 시간은 A100 GPU에서 4단계 추론 시 측정된 지연시간(latency)을 의미한다.
SANA-Sprint는 모든 추론 단계에서 가장 빠른 속도를 유지하면서도 경쟁 모델들 대비 더 현실적이며, 텍스트와의 정합성이 뛰어난 이미지를 생성하였다.
3.3 GAN을 통한 연속 시간 CM 성능 향상(Improving Continuous-Time CMs with GAN)
CTM[14]에 따르면, 일관성 모델(CMs)은 교사 모델(teacher)의 정보를 국지적(local)으로 증류(distill)한다. 즉, 각 반복(iteration)마다 학생 모델(student)은 좁은 시간 구간(interval)의 정보만을 학습하기 때문에, 시간 단계를 초월한(cross timestep) 전역적(global) 정보는 암묵적인 외삽법(implicit extrapolation)에만 의존하게 되어 수렴 속도가 느려질 수 있다. 이를 해결하기 위해 우리는 시간 단계를 뛰어넘어 전역적으로 직접적인 감독(supervision)을 제공하는 추가적인 적대적 손실(adversarial loss)[5]을 도입하여, 수렴 속도와 출력 품질 모두를 개선하였다.
GAN[3]은 생성자(Generator) G와 판별자(Discriminator) D가 서로 경쟁하며 사실적인 데이터를 생성하는 제로섬(zero-sum) 게임 구조를 갖는다. Diffusion-GAN[34] 및 LADD[5]는 이를 확장하여 판별자가 노이즈가 추가된 실제(real)와 가짜(fake) 샘플을 구분하도록 설계하였다. 특히 LADD는 고정된(frozen) 교사 모델을 특징(feature) 추출기로 활용하고, 다중 판별자 헤드(head)를 교사 모델 위에 훈련하는 방식을 제안하였다. 이로 인해 픽셀(pixel) 공간이 아니라 잠재(latent) 공간에서 직접적인 적대적 감독을 제공하여 더 효율적이고 효과적인 훈련을 가능케 했다.
본 논문에서는 LADD의 방식을 따라, 다음과 같은 힌지 손실(Hinge loss)[35]을 이용하여 학생 모델과 판별자를 훈련하였다.



4. 실험(Experiments)
4.1 실험 환경(Experimental Setup)
우리는 두 단계로 구성된 훈련 전략(two-phase training strategy)을 사용하였으며, 구체적인 설정과 평가 프로토콜은 부록 F.1에 자세히 기술하였다. 교사 모델(teacher models)은 대규모 모델인 SANA-1.5 4.8B[42] 모델에서 가지치기(pruning)와 미세조정(fine-tuning)을 거쳐 얻어졌으며, 이어서 제안된 훈련 방법을 이용한 증류(distillation)를 수행하였다. 성능 평가를 위해 MJHQ-30K[43] 데이터셋에서 FID, CLIP Score 및 GenEval[44]과 같은 지표를 사용하였다.
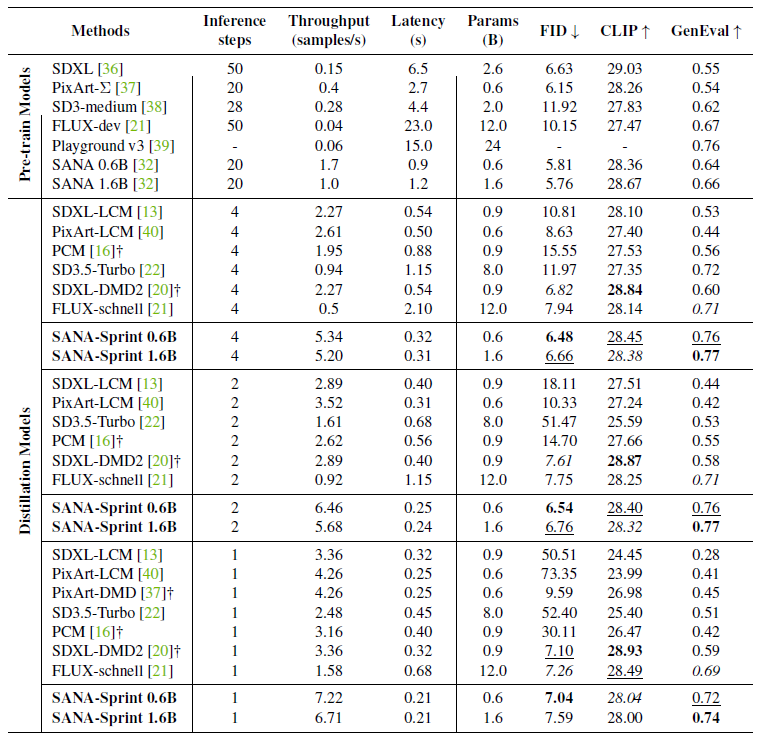
표 2 | 효율성 및 성능 측면에서 SANA-Sprint와 최신(SOTA) 방법들을 종합적으로 비교한 결과.
속도는 BF16 정밀도로 설정된 A100 GPU 1개에서 측정하였다. 처리량(Throughput)은 배치 크기(batch size) 10을 기준으로 측정하였고, 지연시간(Latency)은 배치 크기 1로 측정하였다. 가장 좋은 결과는 굵게 강조하고, 두 번째로 좋은 결과는 밑줄을 쳤다. † 표시는 각기 다른 추론 단계에 대해 별도의 모델이 필요함을 의미한다.
4.2 효율성 및 성능 비교(Efficiency and Performance Comparison)
우리는 표 2와 그림 4에서 SANA-Sprint를 최신(text-to-image) 확산 모델 및 타임스텝 증류 방법(timestep distillation methods)들과 비교하였다. SANA-Sprint 모델은 타임스텝 증류에 초점을 맞추었으며, 그림 5에서 보이듯이 단지 1~4단계의 추론만으로도 20단계의 교사 모델과 경쟁할 정도로 높은 품질의 결과를 생성할 수 있었다. 타임스텝 설정에 대한 더 자세한 사항은 부록 F.2에 설명되어 있다.
구체적으로, 4단계(steps) 추론 시 SANA-Sprint 0.6B 모델은 5.34 samples/s의 처리량(throughput)과 0.32초의 지연시간(latency)을 기록하며, FID는 6.48, GenEval은 0.76을 달성했다.
SANA-Sprint 1.6B 모델은 약간 낮은 처리량(5.20 samples/s)을 기록하였지만, GenEval 점수를 0.77로 향상시켰으며, 이는 훨씬 더 큰 모델인 FLUX-schnell(12B, 0.5 samples/s, 2.10초 latency)보다 뛰어난 결과였다.
2단계 추론에서도 SANA-Sprint 모델은 뛰어난 효율성을 유지했다.
- SANA-Sprint 0.6B는 6.46 samples/s의 처리량과 0.25초의 지연시간을 기록하며 FID는 6.54였다.
- SANA-Sprint 1.6B는 5.68 samples/s의 처리량과 0.24초의 지연시간을 기록하며 FID는 6.76을 달성하였다.
단 1단계(single-step) 추론에서는 SANA-Sprint 0.6B가 7.22 samples/s의 높은 처리량과 0.21초의 짧은 지연시간을 기록하며, FID 7.04 및 GenEval 0.72를 유지하였다. 이는 FLUX-schnell과 유사한 품질 수준이면서도 훨씬 더 뛰어난 효율성을 보인 것이다.
이러한 결과들은 SANA-Sprint 모델이 빠른 추론 속도와 강력한 성능 지표를 동시에 갖추고 있어, 실시간(real-time) 응용 분야에 실용적으로 활용 가능함을 입증한다.

그림 5 | 서로 다른 추론 단계로 생성한 SANA-Sprint 이미지와 교사 모델 SANA의 시각적 비교.
SANA-Sprint는 단 1~2단계의 적은 추론 단계만으로도 고품질의 이미지를 생성할 수 있으며, 추론 단계 수를 증가시킬수록 이미지 품질이 더욱 향상됨을 확인할 수 있다.
4.3 분석(Analysis)

Schedule Transfer(스케줄 변환)의 효과
우리가 3.1절에서 제안한 스케줄 변환(schedule transfer)의 효과를 검증하기 위해 flow matching 기반 모델인 SANA[32]를 사용하여 TrigFlow[17]로의 스케줄 변환 적용 유무에 따른 성능 변화를 비교하는 실험을 진행하였다. 그림 3(d)에서 확인할 수 있듯, 스케줄 변환을 적용하지 않을 경우 부정확한 훈련 신호(signal)로 인해 훈련이 발산(divergence)하였다. 반면, 우리가 제안한 스케줄 변환을 적용한 경우 단지 5,000번의 훈련 반복(iteration)만으로도 안정적으로 양호한 결과를 얻었다. 이는 본 스케줄 변환이 flow matching 모델을 TrigFlow 기반의 일관성 모델로 효율적으로 전환하는 데 매우 중요한 역할을 수행하고 있음을 보여준다.
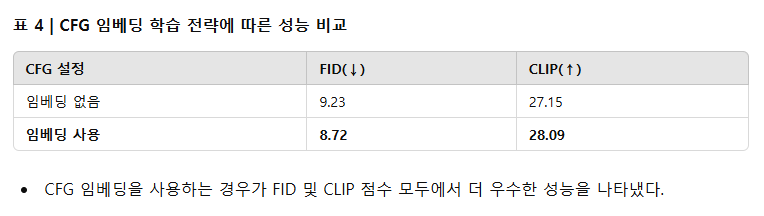
CFG Embedding의 영향 분석
우리 모델에서 Classifier-Free Guidance (CFG) 임베딩의 영향을 명확히 분석하기 위해, 이전 연구들[13, 17, 45]에서처럼 교사 모델에 CFG를 적용하는 설정을 유지하였다. 학생 모델의 훈련 과정에서는 교사 모델의 CFG scale을 {4.0, 4.5, 5.0} 중에서 균일하게 샘플링하였다. 학생 모델에 CFG 임베딩[11]을 통합하기 위해, 이를 시간 임베딩의 추가 조건으로 추가하고, 우리의 조밀한(dense) timestep 임베딩과의 정합성을 위해 CFG scale에 0.1을 곱해 사용하였다.
CFG 임베딩의 유무에 따른 성능 차이를 평가한 결과, 표 4에서 나타나듯이 CFG 임베딩을 적용한 경우 CLIP Score가 0.94나 향상되는 것을 확인하였다. 따라서 CFG 임베딩이 이미지 생성 품질에 크게 기여함을 입증하였다.
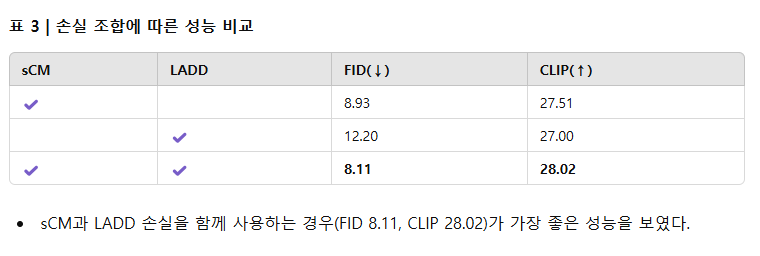
sCM과 LADD의 효과 분석
sCM 손실과 LADD 손실 각각의 효과를 평가하기 위해, sCM 손실만 또는 LADD 손실만 사용하여 훈련한 모델과 두 손실을 결합한 모델을 비교하였다(표 3 참조).
- LADD 손실만 사용하면 훈련 안정성이 떨어지고 성능이 크게 저하되어 FID 12.20, CLIP Score 27.00이라는 낮은 성능을 기록하였다.
- sCM 손실만 사용하는 경우에는 FID 8.93, CLIP Score 27.51을 기록하며 안정적이고 양호한 성능을 보였으나, 두 손실을 결합할 때의 성능에는 미치지 못하였다.
- sCM과 LADD 손실을 함께 사용하는 경우 가장 뛰어난 성능(FID 8.11, CLIP Score 28.02)을 얻어 두 손실의 상호보완적인 효과를 확인하였다.
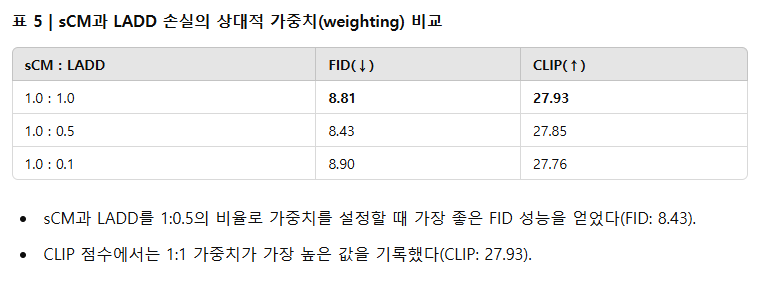
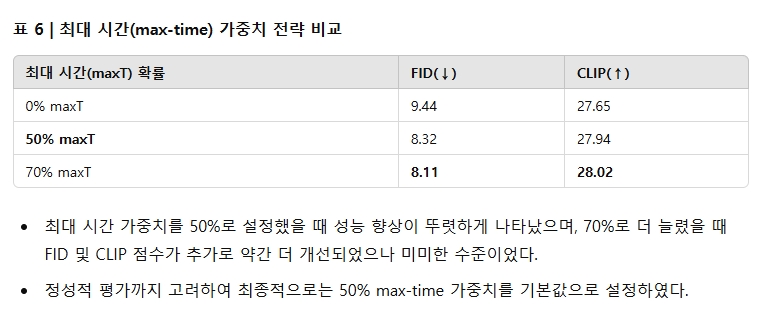
sCM과 LADD 손실의 상대적인 가중치 변화에 따른 성능 비교 결과는 표 5에 제시되어 있으며, 추가적인 timestep 분포 실험은 부록 F.2에서 다루었다.

5.관련 연구 (Related Work)
본 절에서는 관련된 연구를 간략히 개관하며, 더 상세한 내용은 부록에 기술하였다.
확산 모델(diffusion models)의 타임스텝 증류(step distillation) 기법은 크게 두 가지 접근법으로 나뉜다.
궤적 기반 증류 (Trajectory-based Distillation)
이 범주에는 직접 증류(direct distillation)[9]와 점진적 증류(progressive distillation)[10, 11]가 있다. 일관성 모델(consistency models, CMs)[12] 또한 이 범주에 속하며, 대표적인 변형으로는 LCM[13], CTM[14], MCM[15], PCM[16], sCM[17] 등이 제안되었다.
분포 기반 증류 (Distribution-based Distillation)
분포 기반 방법으로는 GAN 기반의 증류[3]와 변분 점수 증류(variational score distillation, VSD)의 변형[6,7,8,46,47]이 있다. 최근의 발전으로는 DINOv2를 활용한 적대적 학습[48,4], VSD의 안정화(stabilization)[49], 그리고 SID[50] 및 SIM[51]과 같은 향상된 알고리즘이 제안되었다.
실시간 이미지 생성 (Real-time Image Generation)
PaGoDA[52], Imagine-Flash 등은 확산 모델의 추론 속도를 대폭 개선한 방법이다. 모델 압축(Model Compression) 전략으로는 BitsFusion[53]과 Weight Dilation[54] 등이 있다. 모바일 환경에서는 MobileDiffusion[55], SnapFusion[56], SnapGen[57] 등이 활용된다. 또한, SVDQuant[58]와 SANA[32] 모델을 결합하여 소비자급 GPU에서 빠른 이미지 생성을 가능하게 하였다.
6. 결론 (Conclusion)
본 논문에서는 다단계(multi-step) 샘플링의 유연성을 유지하면서도 초고속 단일 단계 텍스트-이미지(text-to-image) 생성이 가능한 효율적인 확산 모델, SANA-Sprint를 제안하였다. 연속 시간 일관성 증류(sCM)와 잠재적 적대 증류(LADD)를 결합한 하이브리드 증류 전략을 통해 SANA-Sprint는 단 1단계의 추론으로 FID 7.04, GenEval 0.72라는 최첨단(SoTA)의 성능을 달성하였으며, 개별 단계별 훈련을 필요로 하지 않는다. 본 논문의 통합된 단계 적응(step-adaptive) 모델은 H100 GPU 환경에서 단 0.1초 만에 고품질의 1024×1024 이미지를 생성함으로써 속도-품질 트레이드오프(speed-quality tradeoffs)에서 새로운 표준을 제시하였다.
향후 SANA-Sprint의 즉각적인 시각적 피드백 기능은 실시간 인터랙티브 애플리케이션에 활용될 수 있으며, 확산 모델이 보다 응답성이 뛰어난 창의적 도구 및 AI 기반 소비자 애플리케이션(AIPC)으로 발전할 가능성을 보여준다. 우리는 효율적이고 실용적인 생성형 AI 시스템 연구를 더욱 촉진하기 위해 코드와 모델을 오픈 소스로 공개할 예정이다.
감사의 글(Acknowledgements)
본 연구의 sCM 파트 구현에 대한 귀중한 지도와 통찰력 있는 논의를 제공한 OpenAI의 Cheng Lu께 깊은 감사를 표한다. 또한 양자화(quantization) 분야에서 많은 공헌과 심도 있는 논의를 해 준 MIT의 Yujun Lin, Zhekai Zhang, Miyang Li에게도 진심으로 감사의 뜻을 전한다. 더불어 ControlNet 관련 전문 지식과 깊이 있는 의견을 제공해 준 Stanford의 Lvmin Zhang에게도 깊은 감사를 드린다. 이들의 협력과 건설적인 논의는 본 연구의 발전에 큰 역할을 하였다.
'인공지능' 카테고리의 다른 글
| MusicInfuser: Making Video Diffusion Listen and Dance (3) | 2025.04.02 |
|---|---|
| Transformers without Normalization (2) | 2025.03.27 |
| Large Language Diffusion Models (2) | 2025.02.18 |
| Layer Normalization (4) | 2025.02.17 |
| DeepSeek-V3 Technical Report (2) | 2025.02.14 |



