https://arxiv.org/abs/2411.13476
When Precision Meets Position: BFloat16 Breaks Down RoPE in Long-Context Training
Extending context window sizes allows large language models (LLMs) to process longer sequences and handle more complex tasks. Rotary Positional Embedding (RoPE) has become the de facto standard due to its relative positional encoding properties that benefi
arxiv.org
초록
확장된 컨텍스트 윈도우(context window)를 이용하면 대규모 언어 모델(LLMs)이 더 긴 시퀀스를 처리하고 복잡한 작업을 수행할 수 있다. 이와 관련해 Rotary Positional Embedding (RoPE)은 상대적 위치 인코딩(relative positional encoding)의 장점을 활용해 긴 컨텍스트를 효과적으로 처리할 수 있어 사실상 표준 기법으로 자리 잡았다. 그러나 본 연구는 RoPE를 BFloat16 포맷으로 사용할 때 수치적 문제(numerical issues)가 발생하여, 특히 긴 컨텍스트 시나리오에서 의도한 상대적 위치 인코딩에서 벗어난 결과를 초래한다는 점을 발견하였다. 이러한 문제는 BFloat16의 제한된 정밀도로 인해 발생하며, 컨텍스트의 길이가 길어질수록 누적되는데, 특히 첫 번째 토큰이 이 문제에 크게 기여한다.
이를 해결하기 위해 본 연구에서는 AnchorAttention을 제안한다. AnchorAttention은 플러그 앤 플레이(plug-and-play) 방식의 어텐션 방법으로, BFloat16으로 인해 발생하는 수치적 문제를 완화하고, 긴 컨텍스트 처리 성능을 향상시키며, 훈련 속도를 가속화한다. AnchorAttention은 첫 번째 토큰을 모든 문서에 공통적으로 보이는 '앵커(anchor)'로 취급하고 고정된 위치 ID를 부여함으로써 불필요한 어텐션 계산을 줄이고 의미적 일관성(semantic coherence)을 유지하는 동시에 계산 효율성을 높인다.
세 가지 유형의 대규모 언어 모델(LLM)을 대상으로 진행한 실험 결과, AnchorAttention은 기존의 전체 어텐션(full attention) 방식과 비교했을 때 긴 컨텍스트에서의 성능을 크게 향상시키고, 훈련 소요 시간을 50% 이상 단축하면서도 일반적인 작업에서 원래 모델의 성능을 유지하는 것으로 나타났다.
* AnchorAttention의 구현체인 AnchorContext는 FlashAttention2와 FlexAttention을 활용하여 여러 인기 있는 모델을 지원하며, 코드는 https://github.com/haonan3/AnchorContext 에서 확인할 수 있다.
1 서론
최근 자연어 처리(Natural Language Processing, NLP) 분야에서는 더 긴 시퀀스를 처리할 수 있는 모델의 연구가 활발히 진행되고 있다(Yang et al., 2024; Dubey et al., 2024; Jiang et al., 2023; Team et al., 2024). 128K 토큰(token) 규모의 긴 컨텍스트 윈도우(context window)는 다중 문서 질의응답(multi-document question answering) (Wang et al., 2024a), 저장소 수준의 코드 이해(repository-level code comprehension) (Jimenez et al., 2024), 긴 범위 의존성(long-range dependencies)을 포착하는 다중 사례 학습(many-shot learning) (Agarwal et al., 2024) 등 복잡한 작업들을 처리할 수 있게 하여 더욱 일관되고 상황에 적합한 출력을 가능하게 한다(Mazumder & Liu, 2022).
대규모 언어 모델(Large Language Models, LLMs)이 긴 컨텍스트를 처리할 수 있도록 하기 위해, 위치 인코딩(positional encoding)의 주요한 기법으로 Rotary Positional Embedding (RoPE) (Su et al., 2021)이 널리 사용되고 있다(Liu et al., 2023b). RoPE의 성공은 주로 삼각함수(trigonometric) 기반의 회전(rotational) 특성과 상대적 위치 인코딩(relative positional encoding) 방식 덕분인데, 이를 통해 모델이 분포 밖(out-of-distribution, OOD)의 회전 각도(rotation angles)를 효과적으로 피할 수 있게 한다(Wang et al., 2024b; Chen et al., 2023a; Peng et al., 2023; LocalLLaMA, 2023; Men et al., 2024). 이론적으로는, 회전 주파수(rotary frequencies)를 조정함으로써 확장된 컨텍스트의 위치 ID(position IDs, OOD)를 훈련이 잘 이루어진 범위(in-distribution)로 매핑할 수 있으며, 상대적 위치 특성 덕분에 모델이 확장된 컨텍스트 내 입력 토큰의 상대적 위치를 인식할 수 있도록 원래 익숙한 범위로 보간(interpolation)이 가능하다. 그 결과, 비교적 적은 양의 추가적인 긴 컨텍스트 훈련을 통해 LLM들이 확장된 컨텍스트 길이에 효과적으로 적응할 수 있다(Zhao et al., 2024a; Fu et al., 2024; Zhang, 2023). 그러나 최소한의 긴 컨텍스트 훈련(minimal long-context training)은 컨텍스트 길이가 늘어남에 따라 GPU 메모리 소비가 이차적으로(quadratic) 증가하기 때문에 여전히 도전적이다(Xiong et al., 2023). 이를 해결하기 위해 사전 훈련(pre-training) 단계에서 널리 사용되는 브레인 부동소수점(Brain Floating Point, BFloat16) 형식이 긴 컨텍스트 훈련 단계에서도 채택되고 있다. BFloat16은 모델 정확도에 큰 영향을 미치지 않으면서 메모리 대역폭 요구사항을 감소시키기 때문에(Kalamkar et al., 2019) 긴 컨텍스트 모델의 계산 부담을 관리하는 데 이상적이다.

그림 1: 서로 다른 설정에서 위치 이동(positional shift)이 어텐션(attention) 계산에 미치는 영향.
왼쪽: 어텐션 차이(D, Eq.4)는 위치 이동 Δ₁을 변화시키며 측정(Δ₂=16 고정). 사전 훈련된 모델이 BFloat16(파란색)일 때는 Float32(노란색), 무작위 초기화(초록색)와 비교하여 상당한 불일치를 보이며, BFloat16에서는 RoPE의 상대적 위치 인코딩 특성이 깨지고, 사전 훈련으로 인해 이 현상이 더욱 심화됨을 나타낸다.
가운데: 토큰별 어텐션 차이(Δ₁=0 vs Δ₂=16). 첫 번째 토큰이 전체 어텐션 차이 대부분을 차지함을 보여줌.
오른쪽: 시퀀스 길이가 증가함에 따라 첫 번째 토큰의 어텐션 로짓(logit) 차이(Eq.5). 길이가 길어질수록 차이가 증가함.
그러나 BFloat16의 계산적 이점에도 불구하고, 본 연구는 BFloat16과 RoPE를 함께 사용했을 때 RoPE의 상대적 위치 인코딩 특성이 무너지는 심각한 문제를 발견하였다. 그림 1에서 보여지듯, 이 문제는 BFloat16의 제한된 정밀도(limited precision)로 인해 발생한다. 훈련 컨텍스트 길이가 길어질수록 수치적 오류(numerical errors)가 누적되어 이 현상을 악화시키고, 결과적으로 더 큰 불일치를 유발한다. 반면 Float32 형식을 사용하면 이와 같은 열화 현상은 발생하지 않으며, RoPE의 상대적 위치 인코딩 특성이 그대로 유지된다. 본 연구의 실험적 관찰은 이러한 붕괴가 긴 컨텍스트 훈련에서 RoPE가 제공하는 이점을 감소시킨다는 사실을 입증하였다.
긴 컨텍스트 훈련을 개선하기 위해 본 연구에서는 RoPE의 상대적 위치 인코딩 붕괴 원인을 조사했고, 어텐션 윈도우(attention window)의 첫 번째 토큰이 이 현상에 가장 크게 기여함을 관찰했다. 하지만 기존 방식들은 이러한 문제를 특별히 고려하지 않고 있다. 전체 어텐션(full attention) 방식에서는 각 토큰이 이전 모든 토큰을 참조하기 때문에 윈도우 크기가 증가할수록 편차가 누적된다. 표준 문서 내 어텐션(intra-document attention, 그림 2 왼쪽)은 교차 문서 마스킹(cross-document masking)을 통해 큰 윈도우를 여러 작은 윈도우로 분할하는데, 이로 인해 각 작은 윈도우마다 여러 개의 첫 번째 토큰이 등장하며, 이들에게 각기 다른 위치 ID를 할당하면 모델의 위치 이해에 불일치가 발생한다.
그림 2: 다양한 어텐션 기법의 도식화.
왼쪽: 표준 문서 내 어텐션 방식.
가운데: 본 연구에서 개선한 방식(문서별로 위치 ID를 리셋하는 방식).
오른쪽: 본 연구가 제안한 AnchorAttention 방식(공유 앵커 토큰 𝒜 사용).
본 연구는 문서별로 위치 ID를 리셋하여 윈도우 간의 일관성을 유지하는 것(본 연구가 개선한 방식, 그림 2 가운데)이 긴 컨텍스트 성능을 향상시킨다는 것을 경험적으로 확인하였다. 이는 위치 ID의 불일치가 핵심 문제임을 입증한다. 그러나 위치 ID를 리셋하면 최대 컨텍스트 길이에 도달하거나 초과하는 데이터 시퀀스를 처리할 때만 전체 회전 각도(rotational angles)를 학습할 수 있다는 새로운 문제가 발생한다. 이러한 관찰을 바탕으로 본 연구는 긴 컨텍스트 처리 능력을 강화하고 훈련 속도를 높이는 유연한 플러그 앤 플레이 방식의 어텐션 기법인 AnchorAttention을 제안한다(그림 2 오른쪽).
AnchorAttention의 핵심 아이디어는 첫 번째 토큰을 모든 문서에서 공유하는 '앵커(anchor)'로 취급하여 항상 동일한 위치 ID를 부여하고 문서 간에는 서로 보이지 않게 하는 방식이다. 이렇게 함으로써 AnchorAttention은 모델이 짧은 시퀀스로부터도 모든 회전 각도를 학습할 수 있게 하며, 위치 ID의 불일치를 제거할 뿐 아니라 수치 오류의 누적을 방지하여 긴 컨텍스트 벤치마크(RULER, LongBench)에서 기존 방식 대비 일관된 성능 향상을 달성하였다.
본 연구의 주요 기여점은 다음과 같다:
- BFloat16에서 RoPE의 상대적 위치 인코딩 특성이 깨짐을 발견하였다.
- 시퀀스의 첫 번째 토큰이 이 현상의 주요 원인임을 밝혔으며, 긴 컨텍스트일수록 편차가 더 심해짐을 확인하였다.
- 이를 기반으로 긴 컨텍스트 훈련을 위한 AnchorAttention을 제안했으며, 표준 어텐션 대비 훈련 시간을 절반 이하로 단축하고 기존 훈련 파이프라인에 쉽게 적용 가능함을 입증하였다.
2. RoPE의 상대적 위치 인코딩에서 발생하는 불일치
2.1 Rotary Position Embedding (RoPE)의 배경
최신 대규모 언어 모델(LLM)의 구조는 주로 트랜스포머(Transformer; Vaswani et al., 2017)에 기반하고 있다. 트랜스포머의 핵심 구성요소 중 하나는 어텐션(attention) 메커니즘으로, 수식은 다음과 같이 표현할 수 있다:
2.2 BFloat16이 RoPE의 상대적 위치 특성을 손상시키는 문제 (특히 긴 컨텍스트에서)


요약
BFloat16 정밀도를 사용할 경우, RoPE의 상대적 위치 인코딩 특성이 깨진다. 특히 첫 번째 토큰이 이 불일치의 주요 원인이며, 긴 컨텍스트로 갈수록 이 문제는 더욱 심각해진다.
3. AnchorAttention (앵커 어텐션)
앞선 섹션에서, 우리는 BFloat16 정밀도로 인해 RoPE의 상대적 위치 인코딩(relative positional encoding)에 문제가 발생하며, 시퀀스 길이가 증가할수록 이 문제가 더욱 심화된다는 점을 확인하였다. 그럼에도 불구하고, BFloat16은 계산 효율성 때문에 긴 컨텍스트를 처리하는 현실적 상황에서는 여전히 매력적인 선택이다. 긴 컨텍스트 성능 향상을 위한 가장 효과적인 전략 중 하나는 긴 컨텍스트 데이터를 기반으로 추가적인 사전 훈련(pre-training)을 수행하는 것이다(Fu et al., 2024; Gao et al., 2024). 그러나 이 방법은 어텐션 메커니즘의 계산량이 컨텍스트 길이에 따라 이차적(quadratic)으로 증가하여 실질적으로 어려움이 크다. 따라서 우리는 긴 시퀀스로 인해 증가하는 오차를 줄이고 BFloat16의 장점을 유지하기 위해 AnchorAttention을 제안한다.
3.1 작은 윈도우 크기로 긴 컨텍스트 모델 훈련하기
긴 컨텍스트 모델을 훈련하는 전통적 방식은 긴 시퀀스를 직접 처리하는 것이다. 그러나 이는 BFloat16의 정밀도 문제를 악화시키며, 처리되는 토큰 수가 증가할수록 오차가 커진다는 점이 그림 1(오른쪽)에서도 나타난다. 시퀀스 길이를 줄이면 정밀도 문제를 완화할 수 있지만, 긴 컨텍스트 모델을 짧은 시퀀스로 훈련하는 것은 모순적으로 보일 수 있다.
이 모순을 해결하기 위해 기존 문헌의 방법을 검토한 결과, 문서 간 어텐션(cross-document attention)을 마스킹하여 문서 내 어텐션(intra-document attention)만 사용하는 방법(Zhao et al., 2024b; 그림 2 왼쪽)을 활용하면 전체 어텐션보다 훨씬 짧은 길이로 긴 컨텍스트 모델을 효과적으로 훈련할 수 있음을 알게 되었다. 실제로 문서 내 어텐션 기법은 오픈 소스 LLM인 LLaMA-3 시리즈에서 성공적으로 사용되었으며, Gao et al. (2024)는 문서 경계를 넘는 어텐션을 마스킹하면 단기 및 장기 컨텍스트 성능이 모두 개선됨을 검증하였다.
3.2 BFloat16에서 발생한 RoPE의 편차가 실제 긴 컨텍스트 성능에 미치는 영향은?
앞서 우리는 BFloat16 사용 시 RoPE의 상대적 위치 인코딩에 편차가 발생함을 어텐션 점수 차이로 확인했다. 이 편차가 실제 긴 컨텍스트 성능에도 유의미한 영향을 미칠까? 특히 문서 내 어텐션이 어텐션 점수의 편차를 완화시키므로, 문서 내 어텐션 방식으로 훈련된 모델에서는 BFloat16의 영향이 미미할 가능성도 있다. 이를 확인하기 위해 두 가지 위치 인덱스 방식을 비교하였다:
- 첫 번째 방식(기존 방식): 시퀀스 처음부터 끝까지 위치 ID를 연속적으로 부여 (그림 2 왼쪽).
- 두 번째 방식(개선된 방식): 각 문서별로 위치 ID를 1로 리셋하여 재부여 (그림 2 가운데).
이론적으로는 두 방식이 같은 성능을 보여야 하므로, 이 실험을 통해 RoPE의 편차가 성능에 미치는 영향을 평가하였다.
실험 구성 및 결과
LLaMA-2-7B 아키텍처를 기반으로 Slimpajama 데이터셋에서 문서 내 어텐션으로 128K 모델을 훈련하고, 널리 사용되는 긴 컨텍스트 벤치마크인 RULER에서 평가하였다. 위치 ID를 리셋한 경우와 그렇지 않은 경우의 성능을 비교하였다(구체적인 훈련 및 평가 프로토콜은 섹션 5에서 논의됨).
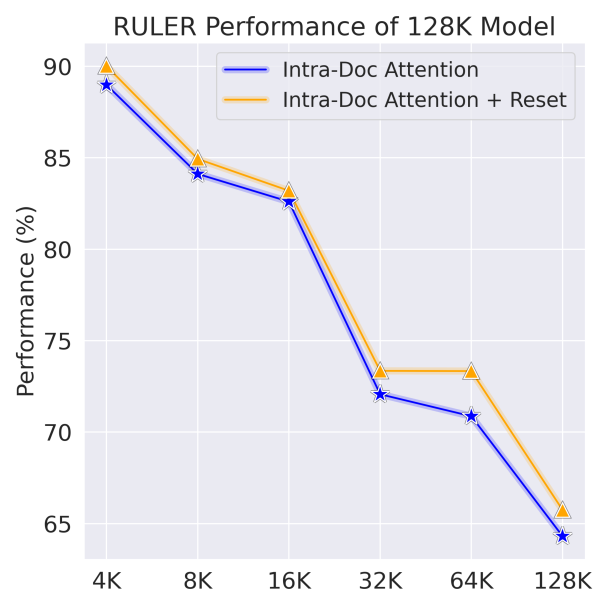
그림 3: 위치 ID를 리셋하면 성능이 향상되며, 이는 RoPE의 이론적 예측과 상반된다.
결과는 그림 3에 제시되어 있다. 위치 ID를 문서마다 리셋하면 일관되게 긴 컨텍스트 성능이 향상되었다. 반면, 기존의 방식(리셋하지 않은 방식)은 상대적으로 성능이 떨어졌다. 이러한 성능 차이는 각 문서의 첫 번째 토큰에 서로 다른 위치 ID를 부여할 때 모델이 혼란을 느껴 일관성이 깨지기 때문일 수 있다. 위치 ID를 리셋하면 모든 문서가 일관된 위치 관계(첫 번째 토큰은 항상 위치 ID 1)를 유지할 수 있다. 이 분석은 BFloat16 환경에서 RoPE가 절대 위치 인코딩의 성격을 가지게 된다는 가정 하에 이루어진 것이므로, 추가적인 연구를 통해 이 가정에 대한 엄밀한 검증이 필요하다.
이 가정이 중요한 이유는 다음과 같습니다:
1. RoPE의 이론적 전제와의 충돌
RoPE(Rotary Positional Embedding)는 원래 **상대적 위치 인코딩(relative positional encoding)**으로 설계되었습니다. 즉, 두 토큰 사이의 상대적 거리만 중요하고, 각 토큰의 절대적 위치는 의미가 없어야 합니다. 하지만 BFloat16 환경에서는 이 특성이 깨지고, RoPE가 마치 **절대 위치 인코딩(absolute positional encoding)**처럼 동작하게 된다는 것이 본 논문의 관찰입니다.
이러한 상황은 RoPE의 이론적 전제와 정면으로 충돌합니다. 따라서 이 가정이 사실이라면, RoPE의 설계 목적과 실제 동작 사이의 괴리를 명확히 밝혀야 합니다.
2. 모델 성능 및 일반화 능력에 미치는 영향
만약 RoPE가 BFloat16 환경에서 절대 위치 인코딩의 성격을 갖는다면, 모델이 특정 위치에만 고정된 패턴을 학습하게 될 위험이 큽니다. 이는 긴 컨텍스트 환경에서 모델의 일반화 능력(generalization)을 제한할 가능성이 큽니다. 위치에 대한 절대적 의존성이 모델의 예측력을 떨어뜨리고, 긴 컨텍스트 환경에서의 성능을 오히려 악화시킬 수 있기 때문입니다.
3. 후속 연구 방향에 대한 명확성 제공
이 가정이 맞다면 후속 연구자들이 RoPE와 BFloat16의 조합에서 발생하는 문제를 해결하기 위해 절대 위치 특성을 고려한 새로운 포지션 인코딩 방법을 개발하거나, 혹은 RoPE의 연산을 BFloat16 환경에서 보다 안정적으로 유지하는 개선 방식을 연구할 필요가 있습니다. 이 가정이 사실인지 아닌지에 따라 후속 연구 방향이 완전히 달라질 수 있습니다.
결론적으로,
이 가정의 검증은 RoPE의 이론적 정합성, 모델의 실제 성능 및 효율성, 나아가 후속 연구 및 적용 방향을 결정하는 매우 중요한 요소이므로 추가적인 엄밀한 연구가 반드시 필요합니다.
3.3 효율적인 긴 컨텍스트 훈련을 위한 공유 앵커 토큰(anchor token)
위치 ID 리셋 방식은 성능을 높여주지만 중요한 단점이 있다. 모델이 전체 회전 각도(rotational angles)를 학습하려면 컨텍스트 길이를 초과하거나 이에 근접하는 긴 시퀀스를 반드시 처리해야 한다는 것이다. 긴 컨텍스트로 확장할수록 충분한 길이의 시퀀스를 확보하는 것은 현실적으로 어려워지며, 이는 모델의 일반화 능력을 제한하게 된다.
이 문제를 해결하기 위해 본 논문은 긴 컨텍스트 윈도우 내의 모든 문서가 공유하는 공통의 앵커 토큰(anchor token)을 도입하는 AnchorAttention을 제안한다. 이 방법은 문서 간 불필요한 어텐션 연결을 무시하여 일관된 정보에만 모델이 집중하게 한다(그림 2 오른쪽).
AnchorAttention에서 앵커 토큰 A는 모든 문서의 공통 출발점 역할을 한다. 이는 RoPE의 상대적 위치 인코딩 편차가 주로 첫 번째 토큰에서 발생한다는 관찰에서 영감을 얻은 것이다. 첫 번째 토큰을 제외하면 나머지 토큰은 RoPE의 상대적 위치 인코딩 특성을 유지하므로, 공통된 앵커 토큰을 도입하여 첫 번째 위치 ID를 고정하면, 모델이 문서 시작점과 위치 ID 사이의 관계에 혼란을 겪지 않게 된다. 구체적으로, 시퀀스 시작 토큰(<bos>)을 앵커로 사용한다. <bos> 토큰은 일반적으로 명시적인 의미가 없기 때문에, BFloat16에 의한 정밀도 오차가 집중되더라도 모델 성능에 미치는 영향은 최소화된다.
공통 앵커 토큰을 사용하면 위치 ID를 문서마다 리셋할 필요가 없으며(그림 2 오른쪽 방식), 매 훈련 반복에서 모든 회전 각도를 학습할 수 있게 된다. 결과적으로 긴 시퀀스를 대량으로 확보할 필요성이 줄어들며, 데이터 수집 및 업샘플링의 의존도를 낮출 수 있다.
요약
- BFloat16에서 발생하는 RoPE의 편차는 긴 컨텍스트 성능에도 실질적 영향을 미친다.
- 문서 내 어텐션에서 위치 ID를 리셋하면 일관된 위치 관계를 유지하여 긴 컨텍스트 성능을 개선할 수 있다.
- 공통 앵커 토큰(anchor token) 도입은 긴 컨텍스트 훈련을 위한 간단하면서도 강력한 해결책을 제공한다.
4 긴 컨텍스트 확장 프로토콜
본 절에서는 최적화된 훈련 전략과 신뢰성 있는 평가 방법에 초점을 맞추어, 기초 모델(Base Model)의 선정, 긴 컨텍스트 훈련 데이터셋 구성, 훈련 설정, 벤치마크 구성 방법을 자세히 설명한다.
4.1 기초 모델, 데이터셋 및 훈련 설정
기초 모델(Base Models)
본 연구의 실험에서는 주로 LLaMA-2-7B 모델을 기본 모델로 사용하였다. 또한, 제안한 방식의 일반화 성능을 확인하기 위해 추가적으로 LLaMA-3-8B (Dubey et al., 2024), Qwen-1.5 (1.8B) (Yang et al., 2024), 그리고 Mistral-7B-v0.3 (Jiang et al., 2023) 모델을 사용하여 성능을 비교 평가하였다(자세한 비교는 5.3절 참고). 이 모델들은 다양한 아키텍처와 사전 훈련 방식을 대표하며, 제안 방식의 범용성을 검증하는 데 적합하다.
데이터셋(Dataset)
긴 컨텍스트 훈련을 위한 데이터셋으로 SlimPajama(Soboleva et al., 2023)를 사용했다. 이 데이터셋은 LLaMA 사전 훈련 데이터 혼합(LLaMA pretraining data mixture; Touvron et al., 2023)을 오픈소스로 재구성한 것으로, Common Crawl(CC), C4, GitHub, ArXiv, Books, Wikipedia(Wiki), StackExchange 등 다양한 텍스트 소스를 포함한다.
원본 SlimPajama 데이터셋 이외에 Fu et al.(2024)가 제안한 긴 시퀀스 업샘플링(data mixture) 방식을 적용하여 각 소스에서 긴 시퀀스 데이터를 더 자주 등장시키되, 원본 데이터셋의 전체 분포는 유지하도록 하였다. 이 업샘플링은 훈련 시 모델이 긴 컨텍스트 시나리오를 더 많이 경험하게 하여 긴 컨텍스트 성능을 향상시키는 데 목적이 있다.
실험에서는 원본과 업샘플링한 SlimPajama 데이터에서 각각 총 20억 개의 토큰을 샘플링하였다.
- SlimPajama-64K: 최대 길이 64K 토큰
- SlimPajama-128K: 최대 길이 128K 토큰
- UpSampledMix-128K: 업샘플링된 128K 토큰 데이터
각 데이터셋에 대한 상세한 통계는 부록(Appendix C)에 포함되어 있다.

<표 1> 훈련 설정 요약

4.2 의미 있는 평가를 위한 통제된 연구 설계
본 절에서는 긴 컨텍스트 처리 능력을 정확하게 평가할 수 있는 적합하고 신뢰성 있는 평가 지표의 중요성을 강조하고, 이를 활용한 통제된 평가 전략을 설명한다.
긴 컨텍스트 능력을 측정하기 위한 적합한 평가 지표
제안된 어텐션 방식이 기초 모델(base model)의 긴 컨텍스트 능력을 얼마나 효과적으로 향상시키는지 명확히 평가하려면 견고하고 적합한 평가 지표를 사용하는 것이 매우 중요하다.
기존 연구에서는 흔히 퍼플렉서티(Perplexity, PPL)를 사용해 긴 컨텍스트 모델을 평가했다. 그러나 최근 연구들은 퍼플렉서티의 신뢰성에 의문을 제기한다. Hu et al.(2024)는 PPL이 모델의 장거리 의존성(long-range dependencies)을 이해하는 능력과 낮은 상관성을 보이며, 주로 국지적인(local) 정보 포착 능력만을 측정한다고 밝혔다. Fang et al.(2024) 또한 PPL이 긴 컨텍스트에서 중요한 의미를 가진 핵심 토큰을 제대로 평가하지 못해 부정확한 평가를 초래한다고 실험적으로 입증하였다. 더 나아가 Gao et al.(2024)는 긴 데이터를 늘리는 것이 PPL을 향상시킬 수 있지만, 오히려 긴 데이터만을 사용하는 것이 실제 긴 컨텍스트 성능을 저하시킬 수 있음을 보고하였다.
본 연구에서도 유사한 현상을 확인하였다. 그림 4에서 보듯 초기 몇 스텝 이후 PPL 값은 크게 변화하지 않지만, 실제 긴 컨텍스트 능력을 평가하는 RULER 벤치마크(Hsieh et al., 2024)에서의 성능은 지속적으로 향상되는 것으로 나타났다. 이는 PPL이 긴 컨텍스트 능력의 개선을 제대로 반영하지 못함을 보여준다.
기존 긴 컨텍스트 벤치마크들의 한계점 및 RULER의 활용
현재 긴 컨텍스트 모델을 위한 주요 벤치마크들(HELMET, LongBench, LongBench-Cite, InfiniteBench, NoCha 등)은 대부분 지시 기반(instruction-following) 과제를 중심으로 설계되어 있어, 기초 모델의 순수한 긴 컨텍스트 성능을 평가하는 데 한계가 있다. 특히, LongBench는 주로 16K 토큰 내외의 중간 길이의 컨텍스트 과제로 구성되어 있어서, 본 연구처럼 64K 또는 128K까지 처리 가능한 모델들을 평가하기에는 충분히 도전적이지 않다. 그럼에도 불구하고, LongBench가 실제 상황에서의 긴 컨텍스트 작업을 일부 포함하고 있으며, 소수 샷 인-컨텍스트 학습(few-shot ICL)을 통해 기초 모델의 성능을 평가할 수 있다는 장점이 있어 보조적으로 활용하였다. Gao et al.(2024)의 동시 연구에서도 소수 샷 ICL이 기초 모델 평가에 효과적임이 보고된 바 있다.
긴 컨텍스트 능력을 더 정확하게 평가하기 위해, 본 연구에서는 특별히 긴 컨텍스트를 평가할 목적으로 설계된 RULER 벤치마크를 주요 평가 지표로 활용하였다. RULER 벤치마크는 다음과 같은 능력을 평가한다.
- (1) 방대한 콘텐츠에서 특정 정보를 찾는 능력(Needle-in-a-Haystack, NIAH)
- (2) 긴 컨텍스트 전반에서 변수 간의 관계를 추적하는 능력(Variable Tracing, VT)
- (3) 흩어진 정보를 집계하고 정량화하는 능력(Aggregation)
- (4) 복잡한 질의에서 관련 정보를 불필요한 정보와 구분하는 능력(Question Answering, QA)
이러한 다양한 범주의 과제들은 긴 컨텍스트 처리 능력을 보다 정확하게 측정할 수 있게 한다.
평가 성능 보고의 신뢰성 향상을 위한 권장 사항
공식 RULER 평가에서는 총 13개의 작업에 대한 종합 성능을 측정하지만, 본 연구에서는 LLaMA-2-7B 모델의 경우 특정 두 작업(NIAH-Multikey 3, Common Word Extraction)을 제외하였다. 이는 긴 컨텍스트 훈련이 본래 모델이 가진 능력을 더 긴 시퀀스로 확장하는 데 초점을 맞추고 있으며, LLaMA-2-7B가 원래 4K 길이에서도 이 두 작업을 잘 수행하지 못했기 때문에, 기존에 없는 새로운 능력을 긴 컨텍스트 환경에서 갑자기 획득할 것을 기대하는 것은 합리적이지 않기 때문이다(자세한 결과는 부록 D 참조). 다만, 다른 고급 모델(LLaMA-3-8B, Mistral-7B-v0.3, Qwen-1.5-1.8B)의 경우에는 모든 13개 작업을 사용하였다.
또한 기존 연구들은 RULER 성능을 하나의 특정 체크포인트에서만 보고하는 경향이 있으나, 본 연구에서는 마지막 50스텝에서 10스텝마다 저장한 5개의 체크포인트의 성능을 평균하여 보고할 것을 제안한다. 모델을 여러 번 재훈련하여 평균을 내는 것도 방법이지만, 비용이 과도하게 높아진다. 그림 4에서 보듯 RULER 성능이 훈련 중 변동성을 보이므로, 특정 체크포인트만 선택적으로 제시하는 문제(cherry-picking)를 방지하기 위해 평균 성능 보고를 권장한다.
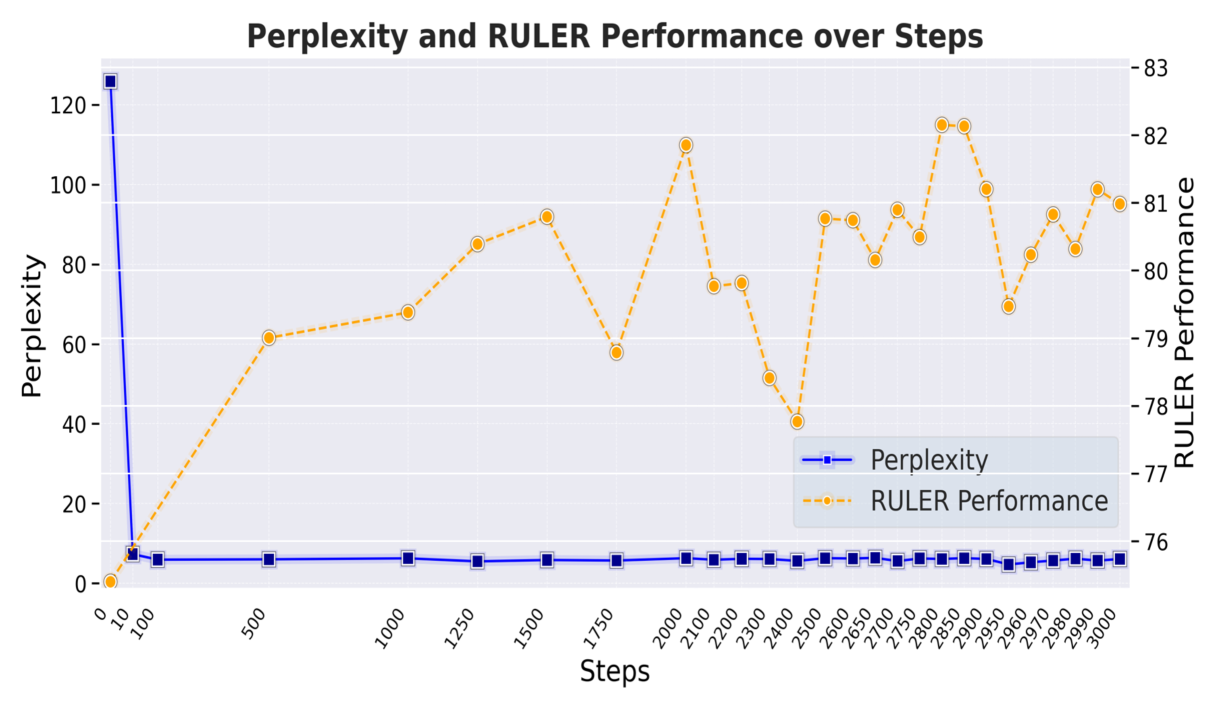
그림 4: 긴 컨텍스트 훈련 과정에서의 RULER 성능 변화.
훈련 중 RULER 벤치마크 성능은 지속적으로 변동하므로, 최종 훈련 스텝의 결과만을 보고하기보다는 마지막 여러 체크포인트의 평균 성능을 보고하는 것이 신뢰할 만한 평가 방식이다. 반면, 퍼플렉서티(PPL)는 초기 몇 스텝 이후 거의 변화하지 않아 긴 컨텍스트 능력의 실제 개선을 제대로 반영하지 못함을 확인할 수 있다.
기초 모델의 일반 성능 보존 검증
지속적 사전 훈련(continual pretraining)이 모델의 기본적인 능력을 훼손하지 않고 유지하는지 확인하기 위해, 본 연구에서는 모델의 일반적 능력 평가를 위해 MMLU(Hendrycks et al., 2021)와 HellaSwag(Zellers et al., 2019) 벤치마크를 활용하였다.
- MMLU는 STEM, 인문학, 사회과학, 철학, 법, 의학 등 57개의 다양한 주제에서 지식과 추론 능력을 평가하여 모델의 폭넓은 이해력을 측정한다.
- HellaSwag는 주어진 상황에서 가장 그럴듯한 후속 내용을 선택하도록 하여, 상식적인 추론과 문맥 이해 능력을 측정한다.
이 두 벤치마크는 기초 모델이 원래의 성능을 유지하는지 평가하는 데 표준적으로 사용되는 지표이며, 본 연구에서도 채팅 모델과 기초 모델 간 성능 차이가 크지 않아 적합한 평가 방법임을 확인하였다.
요약
- 긴 컨텍스트 능력 평가에는 PPL보다 RULER 벤치마크가 효과적이다.
- RULER 평가 시, 체크포인트 변동성을 고려하여 평균 성능을 보고하는 것이 신뢰성을 높인다.
- 기초 모델의 일반 능력 유지 여부는 MMLU와 HellaSwag를 통해 확인하였다.
4.3 긴 컨텍스트 훈련을 위한 위치 임베딩 최적화
긴 컨텍스트 훈련에 가장 적합한 위치 임베딩(positional embedding)을 찾기 위해, 본 연구에서는 LLaMA-2-7B 모델을 SlimPajama-64K 데이터셋에서 최대 64K 토큰 시퀀스로 분할하여 훈련하였다. 이 과정에서 RoPE(Su et al., 2021), NTK-aware(LocalLLaMA, 2023), YaRN(Peng et al., 2023)의 세 가지 방법을 평가하였다. Men et al.(2024)의 연구를 따라, 위치 임베딩의 각도 계산 공식(수식 6)의 base 값을 변화시키며 최적의 조건을 탐색하였다. 이 공식은 트랜스포머 구현(Wolf et al., 2020)의 rope-theta 파라미터에 대응된다.

실험 결과 및 분석
[Table 2] 는 4K부터 64K 토큰까지 다양한 컨텍스트 길이에 대한 RULER 벤치마크 성능을 나타낸다. 결과에 따르면, Vanilla RoPE 방식이 적절한 base 값 선택 시 훈련 컨텍스트 길이(64K) 내에서는 NTK-aware 및 YaRN 방식보다 우수한 성능을 보였다.
그러나 훈련에서 사용한 컨텍스트 길이를 초과한 범위(128K 컨텍스트)에서의 성능 일반화(generalization) 능력을 평가한 결과([Table 4] 참조), YaRN 임베딩이 보다 긴 미지의 컨텍스트에 대해 더 나은 일반화 성능을 보였다. Vanilla RoPE는 훈련한 컨텍스트 내에서는 좋은 성능을 보이지만, 훈련 컨텍스트 길이를 초과하면 성능이 저하되는 경향을 보였다.
RoPE의 base 값 선택이 중요함을 확인한 후, 훈련 자원 절약을 위해 32K 컨텍스트에서 추가 실험을 수행하여 rope-theta 값의 영향을 상세히 살펴보았다([Table 3] 참조). 특정 theta 값에서 성능이 최고점에 이르고, 이후 값을 더 높이면 성능 개선은 미미하거나 오히려 감소하는 경향을 보였다. 이는 Liu et al.(2023b) 및 Men et al.(2024)의 관찰과도 일치한다.
이러한 결과를 바탕으로 본 연구에서는 다음과 같이 컨텍스트 길이에 따라 최적의 base theta 값을 제안한다.
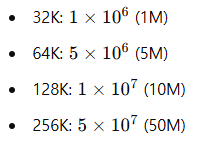
이 방식은 다양한 컨텍스트 길이에서 최적의 성능을 보장한다.
[Table 2] 긴 컨텍스트 훈련 방법 성능 비교 (64K 데이터셋 사용)
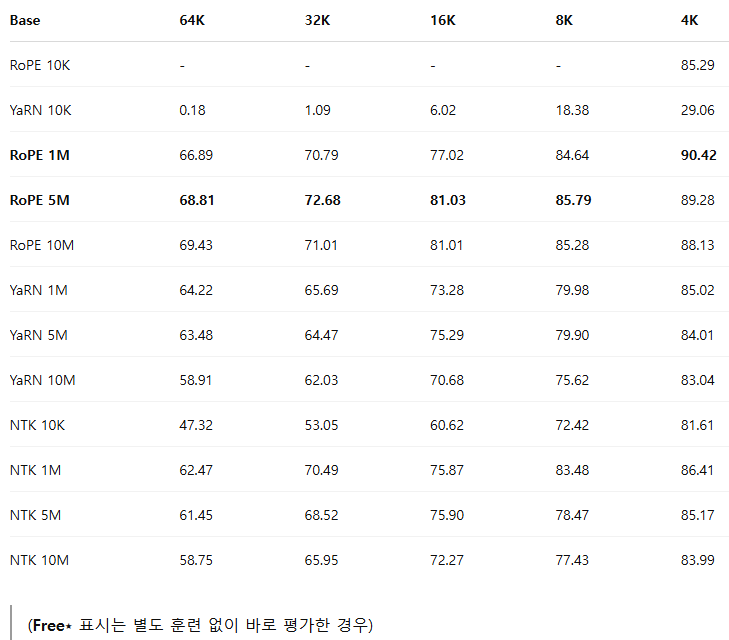
[Table 3] RoPE base 값의 중요성 (32K 데이터셋 사용)
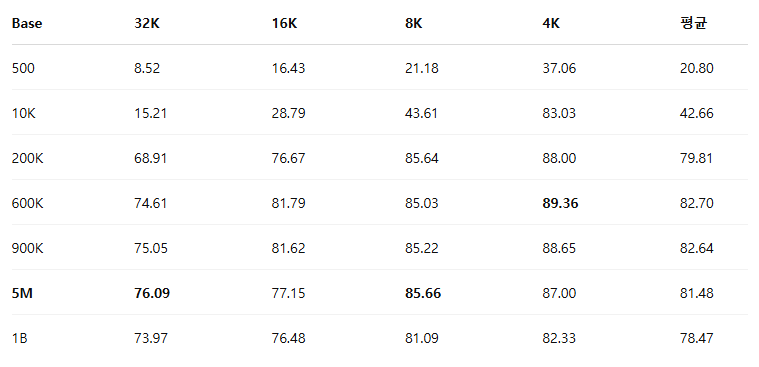
[Table 4] 훈련 컨텍스트를 초과한 길이에서의 일반화 성능 비교

요약
- RULER 벤치마크는 긴 컨텍스트 평가에 효과적이다.
- Vanilla RoPE는 훈련 범위 내에서는 우수하지만, 긴 컨텍스트 일반화에는 YaRN이 더 뛰어나다.
- RoPE 기반 위치 임베딩에서는 적절한 base 값 선정이 매우 중요하며, 지나치게 크거나 작은 값은 성능을 저하시킨다.
5 실험 결과
5.1 AnchorAttention의 RULER 벤치마크 성능
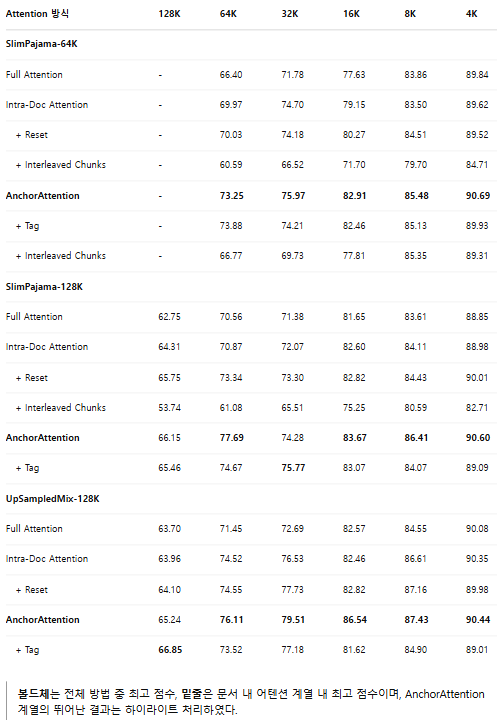
본 연구에서는 LLaMA-2-7B 모델을 대상으로 세 가지 데이터셋(SlimPajama-64K, SlimPajama-128K, UpSampledMix-128K)에서 지속적 사전 훈련(continuous pretraining)을 수행했다. 훈련에 사용된 어텐션 메커니즘은 전체 어텐션(Full Attention), 문서 내 어텐션(Intra-Document Attention), 그리고 본 논문에서 제안한 AnchorAttention이다. 이 모델들을 RULER 벤치마크에서 평가하여 그 결과를 [Table 5]에 나타냈다.
주요 관찰 결과는 다음과 같다.
- 위치 ID를 리셋하는 방식(Intra-Document Attention with Reset)이 일반적으로 문서 내 어텐션의 성능을 향상시켰다. 단, 일부 짧은 시퀀스(예: SlimPajama-64K 및 UpSampledMix-128K의 4K 토큰)의 경우 그 차이가 미미하였다.
- 제안한 AnchorAttention은 모든 데이터셋 및 컨텍스트 길이에 걸쳐 전체 어텐션과 문서 내 어텐션보다 일관되게 뛰어난 성능을 보였으며, 특히 긴 컨텍스트에서 두드러진 성능 향상을 기록하였다. AnchorAttention은 세 가지 데이터셋 모두에서 각 컨텍스트 길이에 대해 최고의 점수를 달성하며 모든 기존 방법을 능가하였다.
- 전체 어텐션 및 문서 내 어텐션으로 훈련했을 때는 긴 시퀀스를 업샘플링한 UpSampledMix-128K 데이터셋을 사용하는 것이 모델 성능 향상에 도움이 되었다. 그러나 AnchorAttention으로 훈련할 경우 SlimPajama-128K와 UpSampledMix-128K 사이의 성능 격차가 크게 줄어들었다.
이러한 결과는 AnchorAttention이 세심히 업샘플링된 데이터에 대한 의존성을 줄여, 향후 긴 컨텍스트 모델 훈련 시 데이터 준비 과정이 더 단순화될 가능성을 시사한다.
5.2 AnchorAttention의 부가 전략 평가: 도메인 태깅과 교차 청크(interleaved chunks)
AnchorAttention의 성능을 높일 수 있는 두 가지 데이터 활용 전략인 도메인 태깅(domain tagging)과 교차 청크(interleaved chunks)의 효과를 추가로 조사하였다([그림 5] 참고).
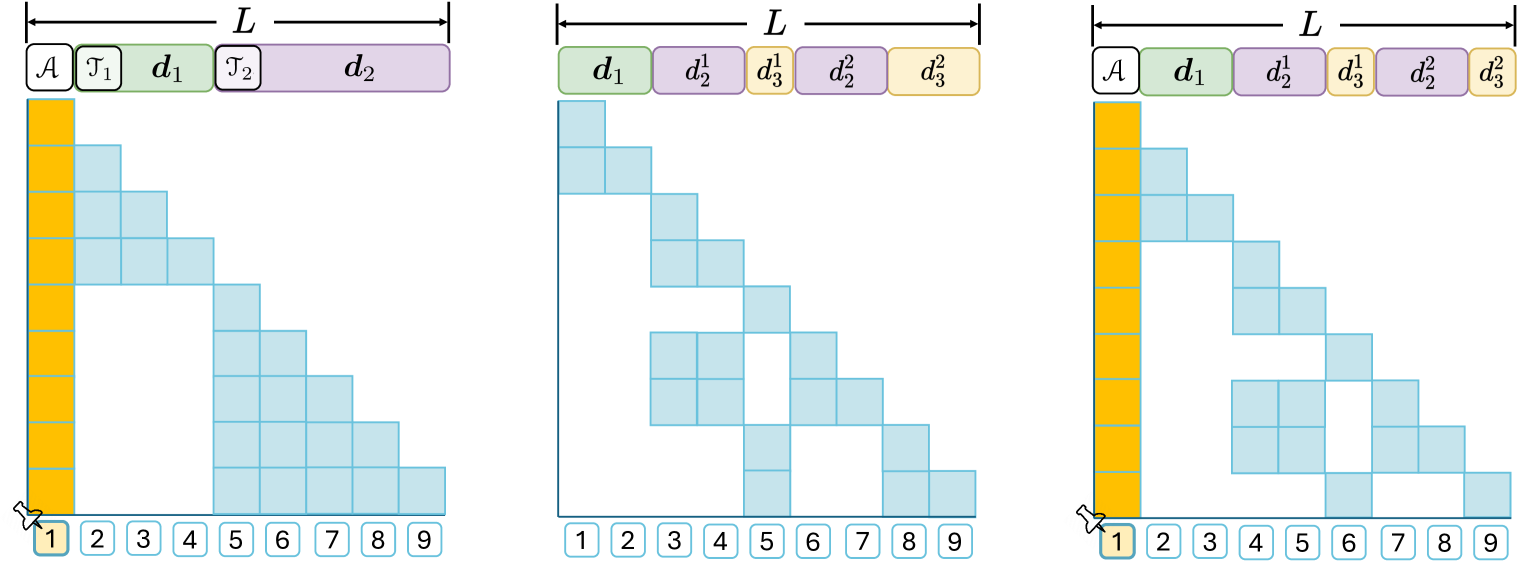
그림 5 설명
- 왼쪽: 도메인 태깅을 적용한 AnchorAttention. 각 문서 앞에 도메인 식별 태그(예: Wikipedia, CommonCrawl)를 추가하여 모델이 도메인 정보를 활용하도록 유도한다.
- 가운데: 교차 청크(interleaved chunks)를 사용한 문서 내 어텐션. 문서를 여러 개의 랜덤 청크로 나누고, 각 청크를 섞은 후 재구성하되, 동일 문서 내 청크의 원래 순서는 유지된다.
- 오른쪽: AnchorAttention에 교차 청크(interleaved chunks)를 적용한 경우.
도메인 태깅(Domain Tagging)
훈련 시각 텍스트 시퀀스의 시작점에 도메인 식별 태그를 추가하고, 학습 과정에서 이 태그에서 발생하는 손실(loss)을 마스킹한다. 이는 모델이 특정 도메인의 정보를 구분하고 우선적으로 학습할 수 있도록 돕는다. 이전 연구(Allen-Zhu & Li, 2024; Zhang et al., 2024b)에서도 도메인 태깅이 지식 저장 최적화 및 선택적 학습(selective learning)을 촉진하여 정보 간 충돌을 최소화하는 데 유용하다고 보고된 바 있다.
교차 청크(Interleaved Chunks)
문서를 무작위 지점에서 여러 개의 청크(chunk)로 나눈 뒤, 이들을 섞어 새로운 시퀀스로 결합하되 각 문서 내에서 원본 순서는 유지된다. Zhao et al.(2024a)는 이 방법으로 인공적인 긴 컨텍스트 데이터를 생성해 모델이 긴 컨텍스트를 잘 처리하도록 훈련하는 데 성공했다.
실험 결과 분석
[Table 5]의 실험 결과는 다음과 같다.
- 교차 청크(interleaved chunks)를 적용한 AnchorAttention(AnchorAttention + Interleaved Chunks)은 원본 AnchorAttention에 비해 성능이 일관되게 저하되었다.
- 이러한 성능 저하가 AnchorAttention과 교차 청크의 구조적 비호환성 때문인지 확인하기 위해, 문서 내 어텐션(Intra-document attention)에도 교차 청크를 적용하여 추가 실험을 진행하였다. 그 결과 역시 성능이 저하되었으며, 심지어 전체 어텐션(Full Attention)의 베이스라인보다도 성능이 떨어졌다.
- 참고로 Zhao et al.(2024a)의 기존 연구에서는 교차 청크가 전체 어텐션(Full Attention)과 결합했을 때는 성능 향상에 효과적이었다. 따라서 본 연구는 문서 간 어텐션 마스킹(cross-document attention masking)이 교차 청크 방식과 구조적으로 호환되지 않는 것으로 추정한다.
- 도메인 태깅(AnchorAttention + Tag)은 원본 AnchorAttention에 비해 성능이 일관되게 향상되지는 않았다.
- 예를 들어, SlimPajama-64K 데이터셋에서 64K 토큰 길이에서는 약간 더 높은 성능(73.88 vs. 73.25)을 보였으나, 32K 토큰에서는 오히려 성능이 떨어졌다.
- SlimPajama-128K와 UpSampledMix-128K 데이터셋에서도 특정 컨텍스트 길이에서 도메인 태깅이 원본 AnchorAttention보다 우수했지만, 전체적인 성능에서는 원본 AnchorAttention이 더 나은 경향이 나타났다.
종합 요약 및 결론
- 도메인 태깅(domain tagging)은 특정 상황에서 AnchorAttention의 긴 컨텍스트 성능을 미세하게 향상시킬 수 있으나, 일관되게 효과적이지는 않다.
- 교차 청크(interleaved chunks) 방식은 문서 간 어텐션 마스킹(cross-document attention masking) 방식(AnchorAttention, Intra-document attention)과 구조적으로 호환되지 않아 성능을 오히려 저하시킨다.
- AnchorAttention은 원본 문서의 일관성을 유지한 원본 데이터를 그대로 사용하는 것이 가장 효과적이다.
[Table 5] 64K 및 128K 토큰 데이터셋 성능 비교 (주요 결과 요약)
5.3 다양한 모델 아키텍처에 대한 AnchorAttention의 긴 컨텍스트 성능 평가
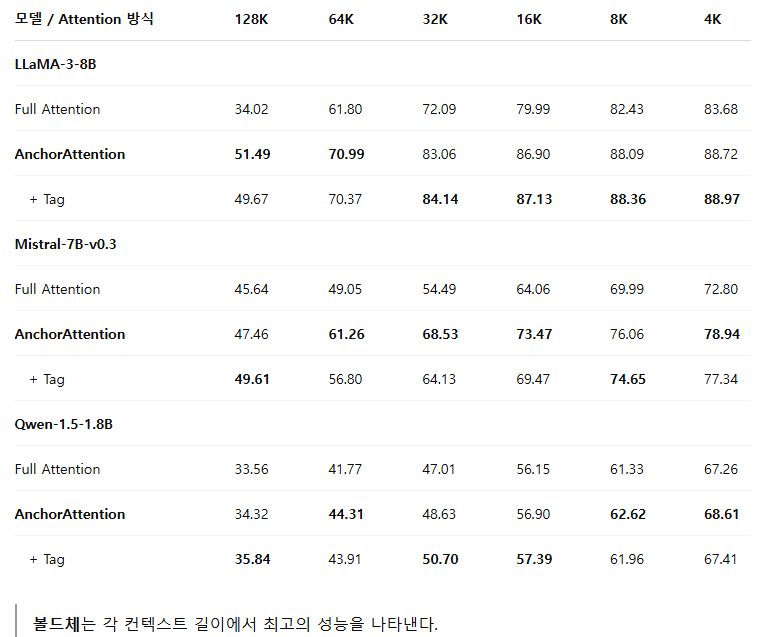
본 연구에서는 AnchorAttention의 일반화 성능을 평가하기 위해 다양한 사전 훈련 모델들을 대상으로 긴 컨텍스트 성능을 비교 실험하였다. 그 결과는 다음과 같다([Table 6] 참고).
주요 관찰 결과
- AnchorAttention 방식은 모든 모델(LLaMA-3-8B, Mistral-7B-v0.3, Qwen-1.5-1.8B)에서 표준 전체 어텐션(Full Attention) 방식에 비해 전반적으로 우수한 성능을 나타냈다. 특히 컨텍스트 길이가 길어질수록 그 성능 향상이 두드러졌다.
- LLaMA-3-8B 모델의 경우, 컨텍스트 길이가 128K 토큰일 때 AnchorAttention이 51.49점을 기록하여 전체 어텐션(34.02점) 대비 큰 폭의 성능 향상을 달성하였다.
- 도메인 태깅(AnchorAttention + Tag)을 추가할 경우, 특정 상황에서는 성능이 더 향상되기도 했다. 예를 들어, Mistral-7B-v0.3 모델의 128K 토큰에서 점수가 49.61로 증가하는 등, 선택적 상황에서 효과를 보였다.
- Qwen 시리즈는 별도의 bos 토큰을 사용하지 않으므로, eos 토큰을 공통 앵커로 사용하였다.
이러한 결과는 AnchorAttention 방식이 모델의 아키텍처에 상관없이 긴 컨텍스트 성능을 효과적으로 향상시킬 수 있는 견고성과 범용성을 가지고 있음을 증명한다.
[Table 6] 다양한 모델 및 토큰 길이에 따른 성능 비교
결론
- AnchorAttention은 모델 아키텍처와 관계없이 긴 컨텍스트 처리 성능을 안정적이고 효과적으로 향상시키며, 특히 긴 시퀀스에서 우수한 결과를 나타냈다.
- 도메인 태깅의 효과는 모델 및 컨텍스트 길이에 따라 달라질 수 있으나, 일부 상황에서는 성능을 추가로 개선할 수 있다.
- AnchorAttention은 다양한 사전 훈련 모델에 걸쳐 광범위한 적용 가능성을 보여준다.
5.4 중간 및 짧은 컨텍스트 작업에서의 일반 성능 평가
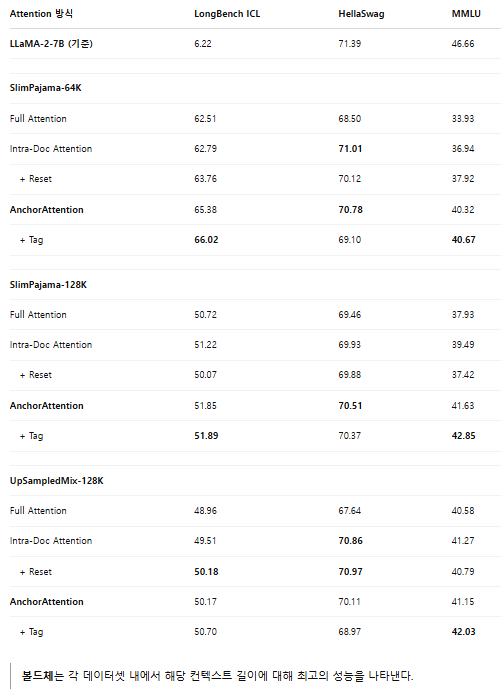
기존 연구(Xiong et al., 2023)에서는 긴 컨텍스트 능력을 향상시킬 경우 중간 및 짧은 컨텍스트 작업에서의 성능 저하(trade-off)가 발생할 수 있음을 지적한 바 있다. 본 연구의 목표는 긴 컨텍스트 처리 능력을 개선하면서도 짧거나 중간 길이 컨텍스트 작업에서의 우수한 성능을 유지하는 것이다. 이를 평가하기 위해 LongBench(중간 길이 컨텍스트), HellaSwag 및 MMLU(짧은 컨텍스트) 벤치마크를 사용하여 성능을 비교하였다([Table 7] 참조).
주요 결과 분석
- AnchorAttention을 사용하여 훈련한 모델은 전체 어텐션(Full Attention) 또는 문서 내 어텐션(Intra-Document Attention)으로 훈련한 모델들에 비해 사전 훈련 단계에서의 일반적인 능력을 더 잘 유지하는 것으로 나타났다.
- 특히 원본 LLaMA-2-7B 모델과 비교해도 AnchorAttention을 적용한 모델들은 짧은 컨텍스트 작업에서 경쟁력을 유지했다.
- HellaSwag 데이터셋에서, SlimPajama-64K에서 AnchorAttention 모델은 70.78의 점수를 기록하여, 원본 LLaMA-2-7B(71.39)와 매우 근접한 성능을 보였다.
- MMLU 벤치마크에서도 AnchorAttention + Tag 모델이 42.85의 점수를 기록해 원본 LLaMA-2-7B(46.66)에 근접하였다.
- 이는 AnchorAttention이 긴 컨텍스트 능력을 크게 향상시키는 동시에, 짧고 중간 길이 컨텍스트에서의 성능 저하를 최소화한다는 것을 의미한다.
- 추가로, 도메인 태깅(domain tagging)은 일반적인 모델의 능력을 유지하는 데 효과적이었다.
[Table 7] 중간 및 짧은 컨텍스트 성능 비교 (LongBench, HellaSwag, MMLU)
결론
- AnchorAttention 방식은 긴 컨텍스트 능력을 크게 개선하면서도 중간 및 짧은 컨텍스트 작업에서의 성능을 우수하게 유지하여, 성능 간의 트레이드오프(trade-off)를 효과적으로 최소화했다.
- 도메인 태깅 역시 짧고 중간 길이 컨텍스트에서 모델의 일반적 능력을 유지하는 데 긍정적 영향을 미쳤다.
5.5 인프라 및 엔지니어링
긴 컨텍스트 언어 모델을 효율적으로 훈련하려면 최적화된 구현이 필수적이다. 본 연구에서는 AnchorContext라는 코드베이스를 제공하며, 이를 통해 제안한 AnchorAttention 메커니즘을 LLaMA 시리즈, Mistral 시리즈, Qwen2 시리즈를 포함한 다양한 모델에 적용 가능하도록 하였다. 또한, 더 넓은 프레임워크와의 호환성을 높이기 위해 두 가지 연산 엔진 옵션을 제공한다.
- FlexAttention (PyTorch 2.5.0부터 네이티브 지원 예정)
- FlashAttention (현재 가장 널리 사용되는 방식)
본 연구의 실험적 결론의 신뢰성을 보장하기 위해 정확도, 속도, 통합 용이성 측면에서 기존 기법과 비교 평가하였다.
정확도 (Accuracy)
분산 훈련(distributed training)은 수치적 오차(numerical errors)를 발생시켜 모델 출력값(logits)에 영향을 줄 수 있다. 따라서 서로 다른 연산 환경에서도 수치적 일관성을 유지하는지 평가하는 것이 중요하다. 이를 위해 동일한 32K 토큰 길이 데이터를 8개의 A100 GPU 환경에서 처리했을 때의 로짓(logits) 차이를 측정하여 다음 세 가지 상황을 비교 평가하였다.
- FlashAttention2 단독 (기준): 분산 훈련 미사용.
- Zigzag-Ring attention (EasyContext 구현, Zhang, 2023): 분산 환경에서의 기존 방법.
- AnchorContext (제안 방식): DeepSpeed-Ulysses(Jacobs et al., 2023)를 이용한 시퀀스 병렬화(sequence parallelism) 기반의 분산 환경.
[Table 8] 분산 계산 환경의 로짓(logits) 차이 비교 (32K 시퀀스)

결과 해석:
- Zigzag-Ring 방식은 기준 대비 최대 0.75의 로짓(logits) 차이를 보였다.
- 반면 본 연구에서 제안한 AnchorContext 방식은 기준과 완벽하게 동일한 로짓을 출력하며 수치적 정확성을 유지하였다.
속도 및 효율성 (Speed and Efficiency)
본 연구의 방법은 수치적 정확성뿐 아니라 속도 측면에서도 뛰어난 성능을 나타냈다. 특히 AnchorContext 프레임워크 내에서 FlashAttention2를 통합하고 어텐션 메커니즘을 최적화하여 GPU 활용률을 높이고 훈련 시간을 크게 단축시켰다.
- [그림 6]에서 각 어텐션 메커니즘 별로 10억(1B) 토큰 처리에 필요한 훈련 시간을 비교했다.
- AnchorAttention은 동일한 시퀀스 병렬화 및 DeepSpeed-Ulysses 구성으로 전체 어텐션(Full Attention) 대비 훈련 시간을 50% 이상 단축하는 효율성을 보여준다.
통합 용이성 (Ease of Integration)
AnchorAttention은 FlashAttention(Dao, 2024) 및 Hugging Face transformers(Wolf et al., 2020)를 사용하는 기존의 다양한 훈련 코드베이스와 매우 간편하게 통합될 수 있도록 설계되었다. AnchorContext의 유연성 덕분에 연구자들은 자신의 코드베이스를 크게 수정하지 않고도 이 방법을 쉽게 도입할 수 있다.
고급 실험 지원 (Supporting Advanced Experiments)
추가로, AnchorContext를 FlexAttention 메커니즘과 결합하면 더 고급의 다양한 실험 환경을 지원할 수 있다. 예를 들어, 교차 청크(interleaved chunks)와 같은 복잡한 어텐션 마스크(flexible attention masks)를 지원할 수 있어 연구자들이 긴 컨텍스트 모델의 성능을 더욱 확장시키고 혁신적인 아이디어를 쉽게 탐구할 수 있도록 돕는다.
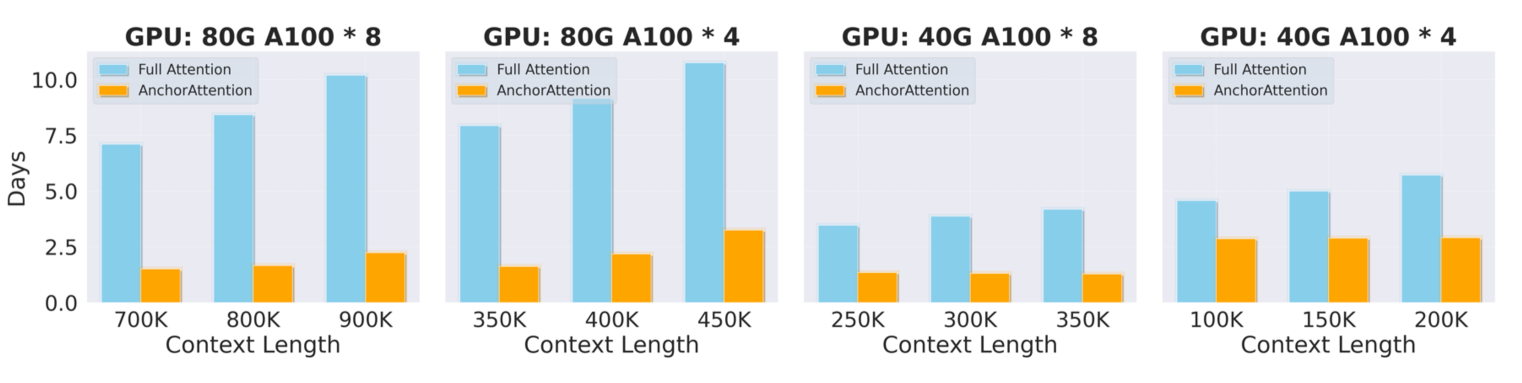
그림 6: 다양한 컨텍스트 길이에서 10억 토큰 처리에 필요한 훈련 시간(일) 비교
- AnchorAttention은 Full Attention 대비 훈련 시간을 50% 이상 단축시킨다.
- 동일한 하드웨어 및 분산 설정에서도 뛰어난 효율성을 나타낸다.
6 관련 연구
위치 임베딩(Positional Embedding)
위치 임베딩은 Transformer 모델(Vaswani et al., 2017)이 입력 토큰의 순서를 효과적으로 포착하도록 하는 데 필수적인 요소이다. 초기 Transformer 모델은 절대 위치 임베딩(absolute positional embedding) 또는 학습된 위치 임베딩(learned positional embedding)을 사용하였으나(Vaswani et al., 2017; Devlin, 2018), 이러한 방법들은 긴 시퀀스로의 일반화가 어려웠다. 이후 가변 길이 시퀀스를 효과적으로 처리할 수 있는 상대 위치 임베딩(relative positional embedding)이 제안되었다(Shaw et al., 2018; Ke et al., 2021).
최근에는 특히 RoPE(Rotary Positional Embedding, Su et al., 2021)가 최소한의 파인튜닝으로 긴 컨텍스트를 효과적으로 확장할 수 있다는 장점으로 인해, 다양한 LLM에서 널리 채택되었다(Touvron et al., 2023; Dubey et al., 2024; Jiang et al., 2023; Yang et al., 2024; Abdin et al., 2024). 이를 기반으로 Position Interpolation(Chen et al., 2023a), NTK Interpolation(LocalLLaMA, 2023), YaRN(Peng et al., 2023), Resonance RoPE(Wang et al., 2024b), CLEX(Chen et al., 2024) 등 다양한 RoPE 변형 기법들이 등장해 긴 컨텍스트 처리 능력을 더욱 향상시켰다. 본 연구는 이러한 접근법과는 다른 방향에서, BFloat16의 정밀도가 RoPE의 상대 위치 인코딩 특성을 저하시킬 수 있음을 처음으로 분석하였다.
언어 모델 컨텍스트 길이 확장(Extending Language Model Context Lengths)
최근에는 별도의 추가 훈련 없이도 컨텍스트 길이를 확장하는 접근법들이 주목받았으나(Xiao et al., 2023; Han et al., 2023; Ruoss et al., 2023), 추가적인 긴 컨텍스트 훈련이 훨씬 더 좋은 성능을 보인다는 것이 최근 연구들에서 입증되고 있다(Fu et al., 2024; Xiong et al., 2023; Gao et al., 2024).
그러나 긴 컨텍스트 훈련은 두 가지 큰 도전을 제기한다.
- 컨텍스트 길이가 늘어날수록 계산 복잡도가 이차적으로 증가하는 문제.
- 사전 훈련 컨텍스트 길이를 초과하면 성능이 급격히 저하되는 문제.
이러한 문제를 해결하기 위해 다음과 같은 다양한 접근법이 제안되었다.
- RoPE 기반 방법
RoPE 매개변수를 변경해 최소한의 추가 훈련으로 컨텍스트를 확장하는 방식(Chen et al., 2023a; LocalLLaMA, 2023; Peng et al., 2023; Men et al., 2024). - 어텐션 패턴 조정
입력의 핵심적인 부분에만 집중하여 긴 컨텍스트의 연산 부담을 줄이는 전략(Chen et al., 2023b; Xiao et al., 2023, 2024; Bertsch et al., 2024; Jin et al., 2024; Ge et al., 2024; Yin et al., 2024). - 희소 어텐션 및 효율적인 구현
희소 어텐션(sparse attention, Lou et al., 2024; Ge et al., 2024) 또는 그룹 쿼리 어텐션(group query attention, Ainslie et al., 2023)을 활용한 연산 복잡도 감소, FlashAttention2와 같은 최적화 구현(Dao, 2024). - 하드웨어 한계를 극복하기 위한 분산 전략
시퀀스 병렬화(Sequence Parallelism, Li et al., 2021)로 데이터를 여러 장치에 분산하거나, Ring Attention(Liu et al., 2023a), DeepSpeed-Ulysses(Jacobs et al., 2023) 등을 통해 통신 효율을 높여 하드웨어 한계를 극복하는 방식.
본 연구는 지속적인 긴 컨텍스트 훈련 접근법을 효율적인 구현과 결합하면서도, 특히 RoPE가 BFloat16 정밀도 환경에서 발생시키는 문제점을 해결하기 위한 어텐션 설계에 초점을 맞추고 있다.
7 결론
본 논문에서는 RoPE와 BFloat16 정밀도의 결합이 특히 긴 컨텍스트 상황에서 RoPE의 상대적 위치 인코딩 특성을 훼손하는 중대한 문제점을 발견하였다. 분석 결과, 이 문제는 주로 시퀀스의 첫 번째 토큰에서 비롯되며, 긴 훈련 컨텍스트에서는 수치적 오류가 누적되어 더욱 심각해진다는 것을 확인하였다.
이 문제를 해결하기 위해 본 논문은 AnchorAttention이라는 새로운 어텐션 방식을 제안하였다. AnchorAttention은 시퀀스 내 첫 번째 토큰을 모든 문서가 공유하는 공통 앵커(anchor)로 취급하여, 이 앵커 토큰에 항상 일정한 위치 ID를 부여한다. 이를 통해 RoPE의 상대적 위치 특성을 유지하고, 불필요한 토큰 간의 어텐션 계산을 줄여 수치 오류의 누적을 최소화하였다.
실험 결과 AnchorAttention은 8K에서 128K에 이르는 다양한 컨텍스트 길이에서 기존의 전체 어텐션 및 문서 내 어텐션 방법들을 일관되게 능가하였다. 또한 실제 벤치마크(LongBench)에서도 긴 컨텍스트 성능을 향상시키면서도 MMLU 및 HellaSwag 같은 일반 작업에서의 성능을 효과적으로 유지하였다. AnchorAttention은 기존 훈련 파이프라인의 최소한의 수정만으로 도입할 수 있으며, 훈련 시간 또한 기존 방식 대비 50% 이상 절약하였다.
8 향후 연구 방향
본 연구의 경험적 분석에서 여러 샘플에 걸쳐 일관된 어텐션 차이를 관찰했으며(Appendix B 참조), 특히 첫 번째 토큰의 위치 ID가 사실상 절대 위치처럼 작동한다는 가설을 제기하였다. 향후 연구는 첫 번째 위치의 특성과 위치 인코딩에 미치는 영향을 더욱 엄밀히 조사할 필요가 있다.
또한 시퀀스의 첫 번째 토큰이 가지는 특이한 현상이 기존 연구에서 보고된 바 있는 어텐션 싱크(attention sinks)나 대규모 활성화(massive activation) 현상(Xiao et al., 2023; Han et al., 2023; Gu et al., 2024; Guo et al., 2024a; Sun et al., 2024; Guo et al., 2024b)과 관련 있을 가능성을 제기하였다. 이러한 연관성을 탐구하고 긴 컨텍스트 모델의 어텐션 메커니즘에 미치는 영향을 더 깊이 이해하는 것이 앞으로의 연구 과제가 될 것이다.
한계점(Limitations)
본 연구는 제안한 어텐션 메커니즘의 주요 구성 요소에 대해 면밀히 분석했지만, 자원 제약으로 인해 다음과 같은 일부 측면에서는 충분히 다루지 못하였다.
- 사전 훈련(pretraining) 단계에서의 AnchorAttention의 효용성 평가
- 다양한 최적화 하이퍼파라미터의 탐색 및 추가적인 데이터 혼합(data mixture) 연구
- 모델 크기를 10B 수준으로, 훈련 토큰 수를 2B 토큰으로 제한하여 더 큰 규모에서의 일반화 가능성을 충분히 검증하지 못한 점
향후 연구에서는 이와 같은 한계점을 보완하여 연구의 일반성과 실용성을 더욱 확장할 수 있을 것이다.
'인공지능' 카테고리의 다른 글
| ChatAnyone: Stylized Real-time Portrait Video Generation with Hierarchical Motion Diffusion Model (2) | 2025.04.04 |
|---|---|
| MusicInfuser: Making Video Diffusion Listen and Dance (3) | 2025.04.02 |
| Transformers without Normalization (2) | 2025.03.27 |
| SANA-Sprint: One-Step Diffusion with Continuous-TimeConsistency Distillation (3) | 2025.03.23 |
| Large Language Diffusion Models (2) | 2025.02.18 |



