https://developers.googleblog.com/en/t5gemma/
T5Gemma: A new collection of encoder-decoder Gemma models- Google Developers Blog
In the rapidly evolving landscape of large language models (LLMs), the spotlight has largely focused on the decoder-only architecture. While these models have shown impressive capabilities across a wide range of generation tasks, the classic encoder-decode
developers.googleblog.com

빠르게 진화하는 대규모 언어 모델(LLM)의 흐름 속에서, 지금까지는 주로 디코더 전용(decoder-only) 아키텍처에 관심이 집중되어 왔습니다. 이러한 모델들은 다양한 생성(generation) 과제에서 인상적인 성과를 보여주었지만, T5(The Text-to-Text Transfer Transformer)와 같은 고전적인 인코더-디코더(encoder-decoder) 아키텍처는 여전히 많은 실제 응용 분야에서 선호되고 있습니다. 인코더-디코더 모델은 입력에 대한 이해를 위한 풍부한 인코더 표현, 설계 유연성, 높은 추론 효율 덕분에 요약, 번역, 질의응답(QA) 등 다양한 작업에서 강점을 보입니다. 그럼에도 불구하고, 이러한 강력한 인코더-디코더 구조는 상대적으로 적은 주목을 받아왔습니다.
이에 오늘, 우리는 이 아키텍처를 재조명하며, T5Gemma라는 새로운 인코더-디코더 LLM 컬렉션을 소개합니다. T5Gemma는 기존에 사전학습된 디코더 전용 모델을 어댑테이션(adaptation)이라는 기법을 통해 인코더-디코더 아키텍처로 변환하여 개발되었습니다. T5Gemma는 Gemma 2 프레임워크를 기반으로 하며, 어댑트된 Gemma 2 2B 및 9B 모델뿐만 아니라 새롭게 학습된 T5 사이즈 모델들(Small, Base, Large, XL) 도 포함하고 있습니다. 우리는 사전학습(pretrained) 및 명령어 튜닝(instruction-tuned)된 T5Gemma 모델을 커뮤니티에 공개함으로써, 연구 및 개발의 새로운 가능성을 열고자 합니다.
디코더 전용에서 인코더-디코더로
T5Gemma에서는 다음과 같은 질문을 던집니다: 사전학습된 디코더 전용(decoder-only) 모델을 기반으로 최고 수준의 인코더-디코더(encoder-decoder) 모델을 만들 수 있을까? 우리는 이를 모델 어댑테이션(model adaptation)이라는 기법을 탐구함으로써 답하고자 합니다. 핵심 아이디어는, 이미 사전학습이 완료된 디코더 전용 모델의 가중치를 활용하여 인코더-디코더 모델의 파라미터를 초기화한 뒤, UL2 또는 PrefixLM 기반 사전학습을 통해 추가로 적응시키는 것입니다.
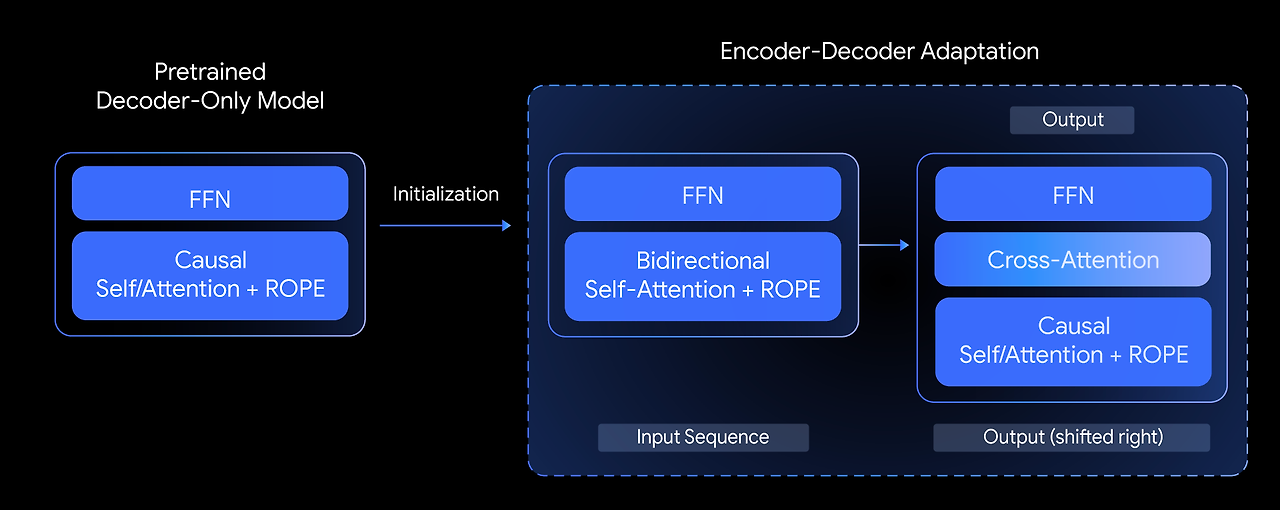
decoder-only model
아래 그림은 사전학습된 디코더 전용 모델의 파라미터를 이용해 새로운 인코더-디코더 모델을 어떻게 초기화하는지를 보여줍니다.
이 어댑테이션 방식은 매우 유연하여, 모델 크기를 창의적으로 조합할 수 있다는 장점이 있습니다. 예를 들어, 큰 인코더(예: 9B)와 작은 디코더(예: 2B)를 짝지어 비대칭(unbalanced) 모델을 구성할 수 있습니다. 이러한 조합은 특정 작업에 맞춰 품질과 효율 사이의 균형을 조정하는 데 유용합니다. 예를 들어 요약(summarization)과 같은 작업에서는 출력의 복잡성보다는 입력에 대한 깊은 이해가 더 중요하기 때문에, 이런 비대칭 구조가 효과적일 수 있습니다.
더 나은 품질-효율 균형을 향하여
T5Gemma의 성능은 어떨까요?
실험 결과, T5Gemma 모델은 기존 디코더 전용 Gemma 모델들과 비교해 동등하거나 더 나은 성능을 달성했으며, SuperGLUE와 같은 벤치마크에서 품질-추론 효율(pareto frontier) 면에서 거의 우위를 점했습니다. SuperGLUE는 모델이 학습한 표현의 품질을 평가하는 대표적인 벤치마크입니다.

Encoder-decoder 모델 벤치마크
인코더-디코더 모델은 주어진 추론 계산량(inference compute) 하에서 일관되게 더 나은 성능을 보여주며, 여러 벤치마크에서 품질-효율 경계의 선두를 차지하고 있습니다.
이러한 성능 우위는 단지 이론에 그치지 않습니다. 실제 상황에서도 품질과 속도 면에서의 장점이 분명히 나타났습니다. 예를 들어 수학적 추론 과제인 GSM8K에서 실제 지연 시간(latency)을 측정한 결과, T5Gemma는 명확한 우위를 보였습니다.
- 예를 들어, T5Gemma 9B-9B는 Gemma 2 9B보다 더 높은 정확도를 기록하면서도 지연 시간은 유사했습니다.
- 더 인상적인 사례로, T5Gemma 9B-2B는 2B-2B 모델보다 훨씬 높은 정확도를 보이면서도, 지연 시간은 훨씬 작은 Gemma 2 2B 모델과 거의 동일했습니다.
이러한 실험 결과는 인코더-디코더 어댑테이션이 품질과 추론 속도 사이에서 유연하면서도 강력한 균형 조정 방식을 제공함을 잘 보여줍니다.
기초 능력과 미세조정 능력의 확장
인코더-디코더 LLM도 디코더 전용 모델과 유사한 능력을 가질 수 있을까요?
그렇습니다. T5Gemma는 사전학습 전후 모두에서 매우 유망한 성능을 보여줍니다. 사전학습 이후, T5Gemma는 추론 능력이 요구되는 복잡한 과제에서 인상적인 향상을 이룹니다.
예를 들어,
- T5Gemma 9B-9B는 수학적 추론 과제인 GSM8K에서 원래 Gemma 2 9B보다 9점 이상,
- 독해 과제인 DROP에서는 4점 이상 더 높은 점수를 기록했습니다.
이러한 결과는 어댑테이션(adaptation)을 통해 초기화된 인코더-디코더 아키텍처가 보다 강력하고 성능 높은 기초 모델(foundation model)로 발전할 수 있는 가능성을 보여줍니다.
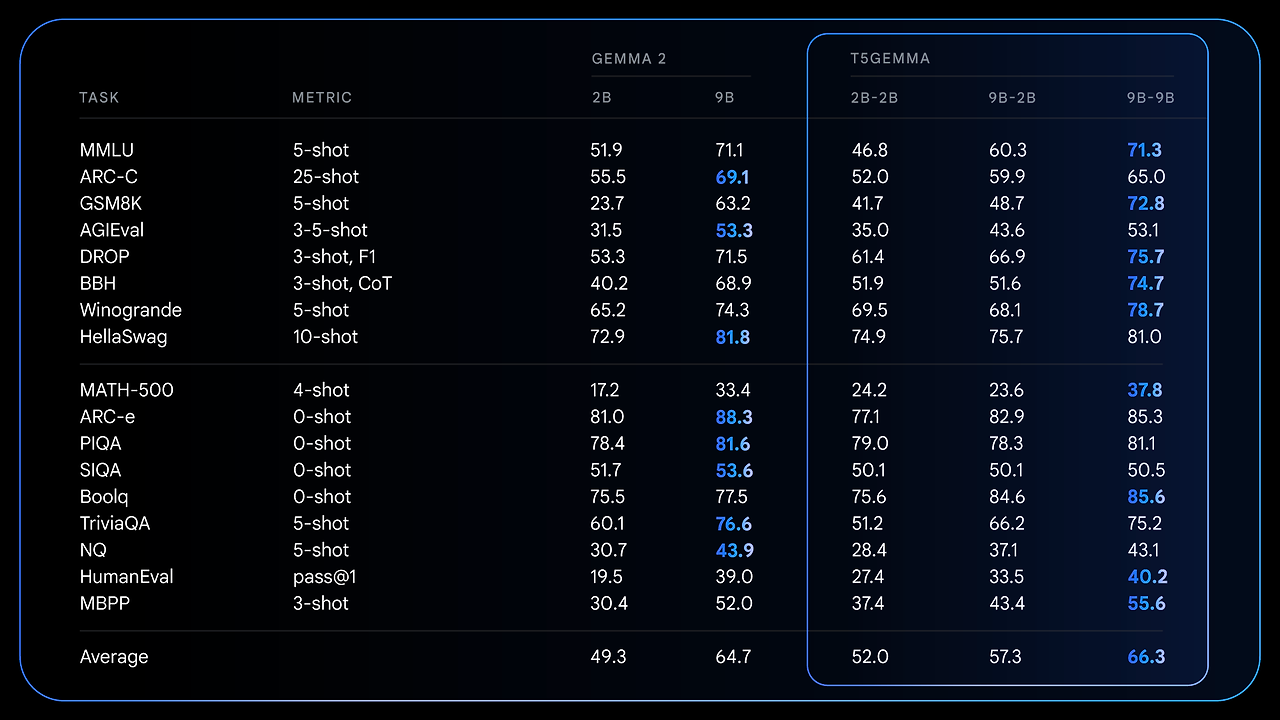
사전학습(pretrained) 모델의 상세 결과
어댑테이션된 모델이 디코더 전용 Gemma 2보다 추론 중심 벤치마크에서 얼마나 큰 성능 향상을 이뤘는지를 수치로 보여줍니다.
사전학습에서의 이러한 기반 향상은 instruction tuning을 거친 이후에 더욱 극적인 성능 향상으로 이어집니다. 예를 들어, Gemma 2 instruction-tuned(IT) 모델과 T5Gemma IT 모델을 비교해보면, T5Gemma는 전반적으로 훨씬 더 나은 성능을 보입니다.
- T5Gemma 2B-2B IT는 MMLU 점수가 거의 12점 상승하고,
- GSM8K 정확도는 58.0%에서 70.7%로 크게 증가합니다.
이처럼 어댑트된 인코더-디코더 구조는 더 나은 초기값을 제공할 뿐만 아니라, 명령어 튜닝(instruction-tuning)에도 더 효과적으로 반응하여 최종 모델의 성능과 유용성 모두를 크게 끌어올릴 수 있습니다.

Instruction tuning 및 RLHF 후의 모델 성능 결과
미세조정 및 보상 기반 학습(RLHF)을 거친 모델의 성능이 인코더-디코더 구조를 통해 얼마나 크게 증폭되는지를 보여주는 수치입니다.
모델 공개: T5Gemma 체크포인트를 만나보세요
우리는 사전학습된 디코더 전용 LLM(Gemma 2 등)에서 출발하여 강력하고 범용적인 인코더-디코더 모델을 만드는 새로운 방법을 소개하게 되어 매우 기쁩니다. 이번에 공개하는 T5Gemma 체크포인트는 이 연구를 바탕으로 커뮤니티가 더 다양한 실험과 응용을 시도할 수 있도록 돕기 위해 준비되었습니다.
공개 내용:
- 다양한 크기(Sizes)
T5 기반 모델(Small, Base, Large, XL)은 물론, Gemma 2 기반 모델(2B 및 9B)과 T5 Large와 XL 사이의 추가 모델도 포함되어 있습니다. - 여러 가지 변형(Variants)
사전학습(pretrained) 및 명령어 튜닝(instruction-tuned) 버전이 함께 제공됩니다. - 유연한 구성(Configurations)
9B 인코더 + 2B 디코더의 비대칭(unbalanced) 구성 체크포인트도 제공되어, 인코더와 디코더 크기 간의 trade-off를 실험해볼 수 있습니다. - 다양한 학습 목적(Objectives)
PrefixLM 또는 UL2 objective를 기반으로 학습된 모델이 포함되어 있으며, 이는 최신 생성 성능 또는 표현 품질 중 원하는 방향에 따라 선택할 수 있습니다.
우리는 이러한 체크포인트들이 모델 아키텍처, 효율성, 성능에 대한 연구에 유용한 자원이 되기를 기대합니다.
T5Gemma 시작하기
여러분이 T5Gemma로 어떤 것을 만들어낼지 매우 기대하고 있습니다. 아래 링크들을 통해 자세한 정보를 확인해보세요:
- 📄 논문 읽기: 이 프로젝트의 연구 배경과 방법론을 알아보세요.
- 💾 모델 다운로드: Hugging Face 또는 Kaggle에서 모델 가중치를 받으세요.
- 📓 Colab 실습: 모델의 성능을 확인하거나 여러분의 용도에 맞게 파인튜닝해보세요.
- 🚀 Vertex AI에서 추론 실행: 실제 애플리케이션에 바로 적용해보세요.
'Article' 카테고리의 다른 글
| MXFP8, MXFP4 및 NVFP4에 대한 자세한 설명 (0) | 2025.11.23 |
|---|---|
| Understanding and Coding the KV Cache in LLMs from Scratch (3) | 2025.06.19 |
| Qwen3: Think Deeper, Act Faster (1) | 2025.04.30 |
| Introducing OpenAI o3 and o4-mini (1) | 2025.04.17 |
| MONAI Integrates Advanced Agentic Architectures to Establish Multimodal Medical AI Ecosystem (1) | 2025.04.16 |


