Open Assistant 참여와 Pytorch based DQN을 코드 작성등 개인적인 일정이 겹쳐 조금 늦게 작성을 시작하게 되었다.
추가적으로 CNN을 어떤 식으로 설명할까 고민하다 전통적인 방식으로 진행하게 될 것 같다.
사람은 사물을 판단할 때, 컴퓨터와 달리 픽셀이 완전히 일치해야 동일한 사물이라고 하지 않는다. 이는 극단적인 예지만, 일반적으로 CNN의 시작은 다음의 O, X Classifier 문제를 푸는 방식으로 시작한다.
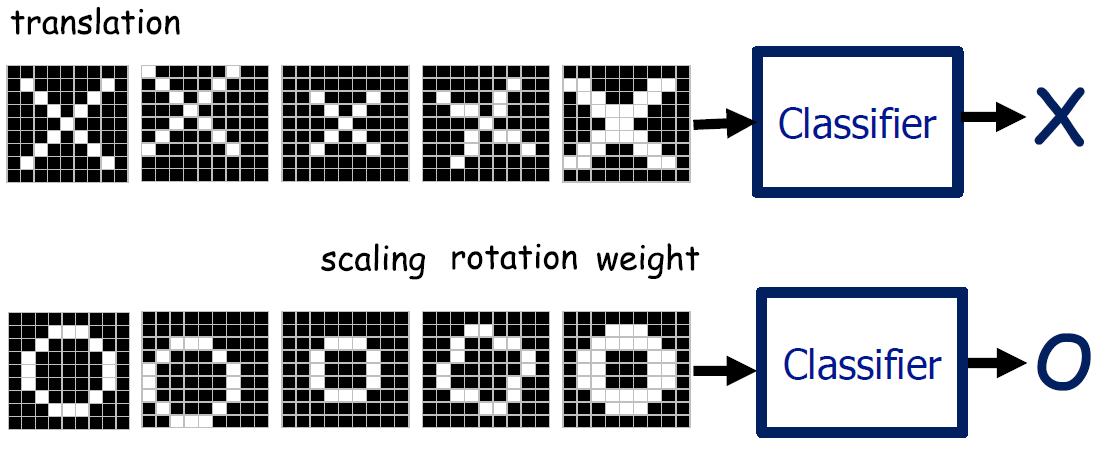
우리는 위와 아래의 구분이 명확하지만 컴퓨터는 그렇지 않다. 입력자체가 숫자로 들어오기 때문에, 다음의 그림이 일치하는지 알지 못한다.
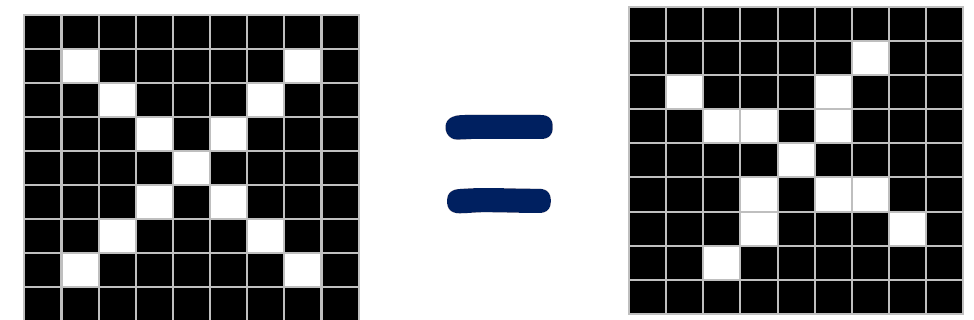
그러면 컴퓨터에게 어떻게 이 둘이 동일한 X인지 설명인지 시키게 할 것인가? 이것은 참 어려운 문제이다.
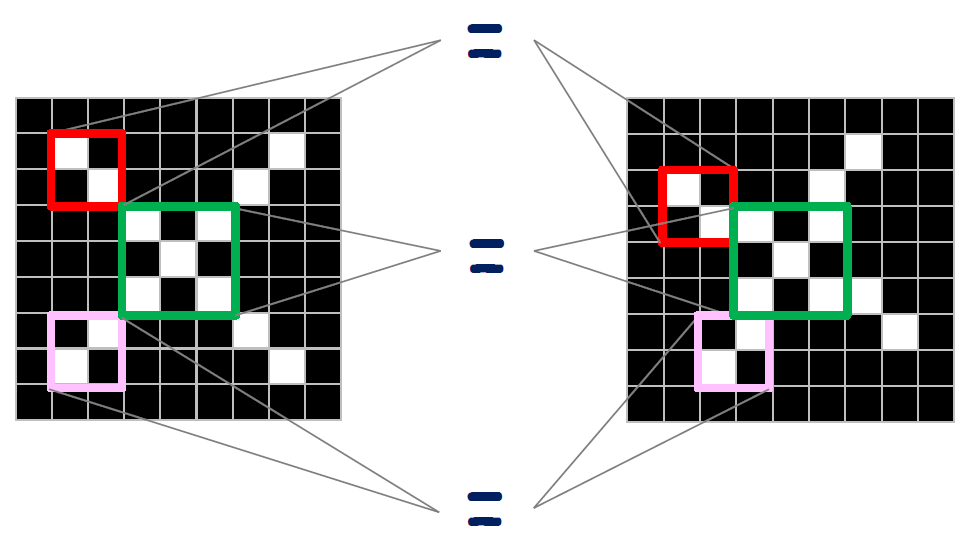
컴퓨터에서 이미지는 픽셀의 집합으로 표현된다. 따라서 픽셀이 동일한 로컬 features를 찾아주고 이를 같은 부분끼리 매칭시켜준다면 동일한 그림으로 인식할 것이다.
그렇다면 로컬 features는 어떻게 찾을 수 있을까?
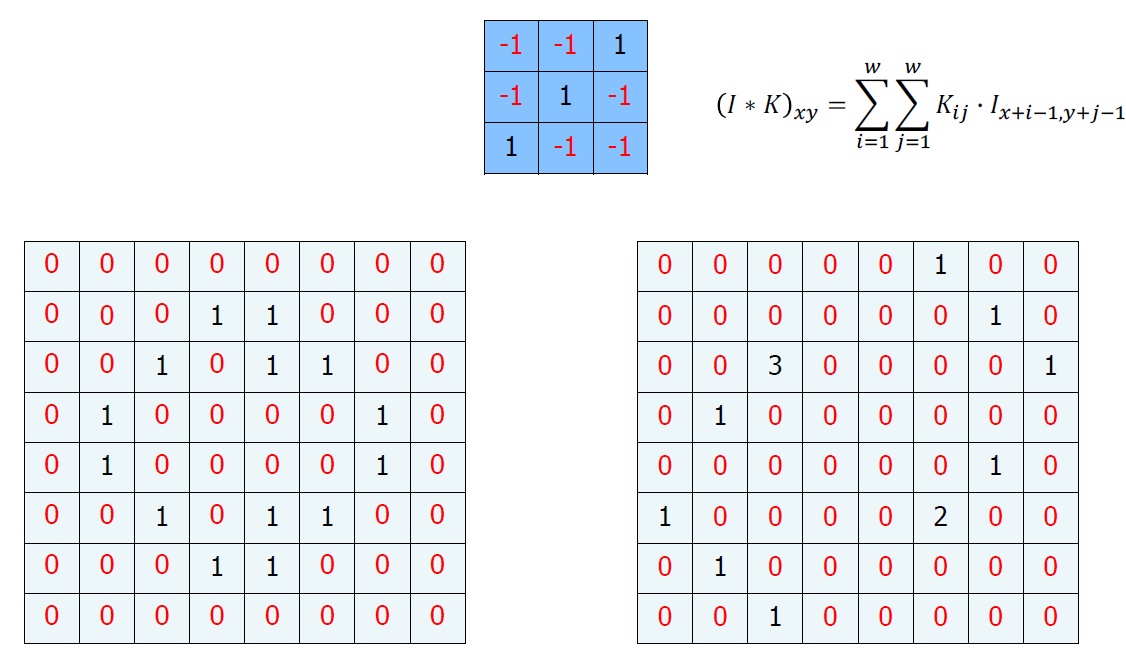
우리는 이를 위해서 Convolution이란 하나의 함수와 또 다른 함수를 반전 이동한 값을 곱한 다음, 구간에 대해 적분하여 새로운 함수를 구하는 수학 연산자이다.
이런 정의보다 그림을 보면 바로 이해가 될 것이다.
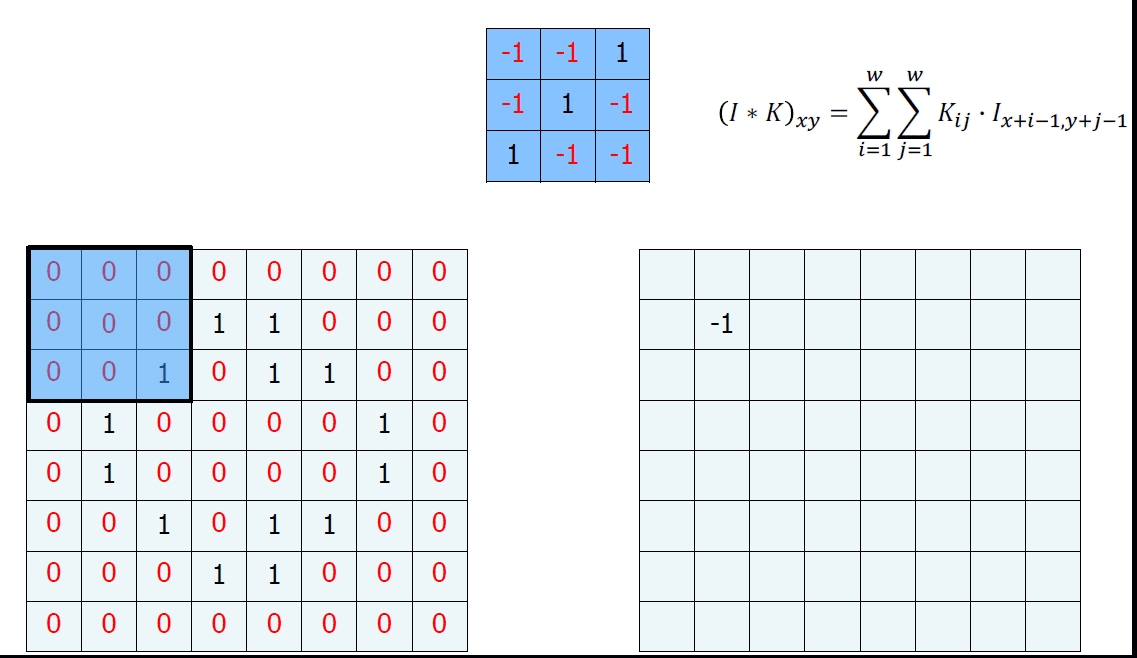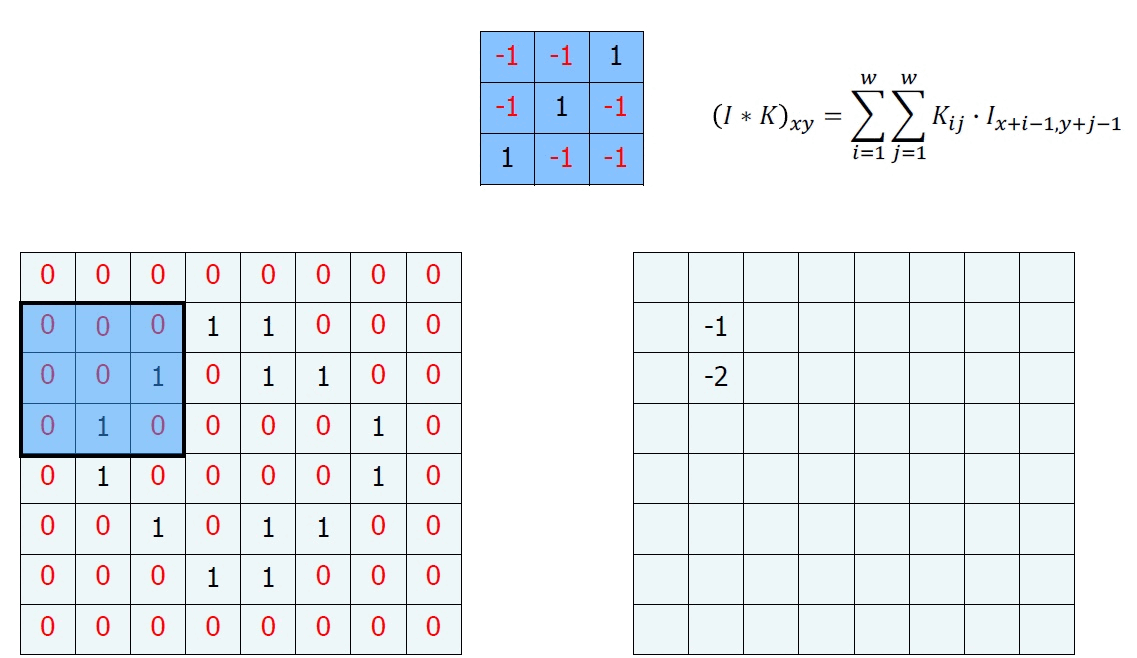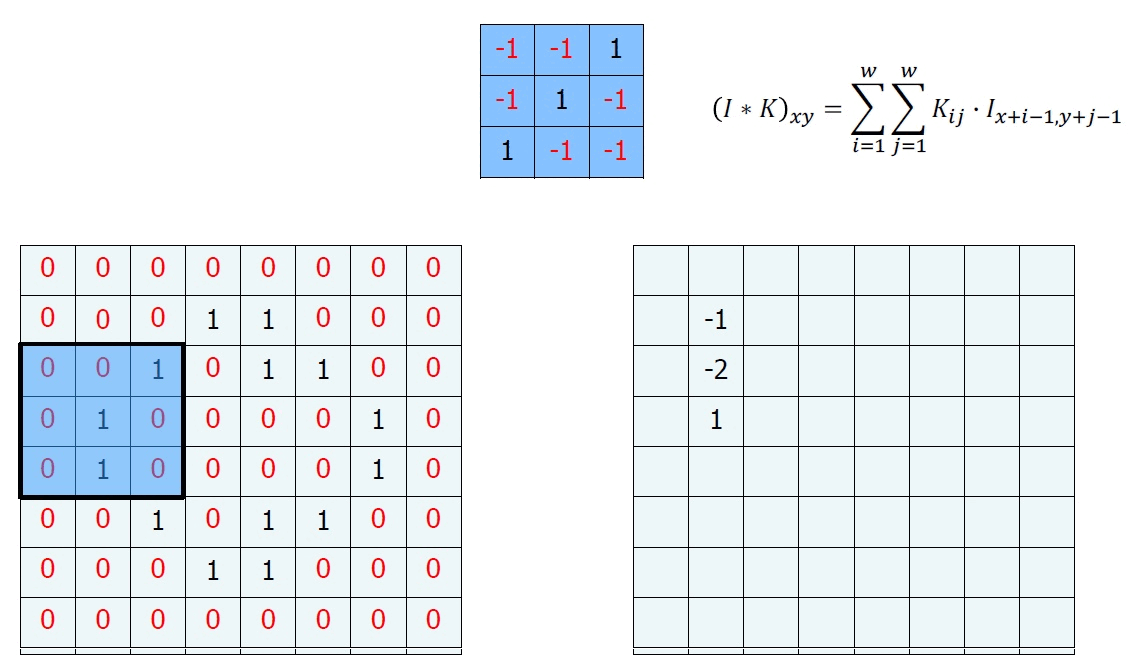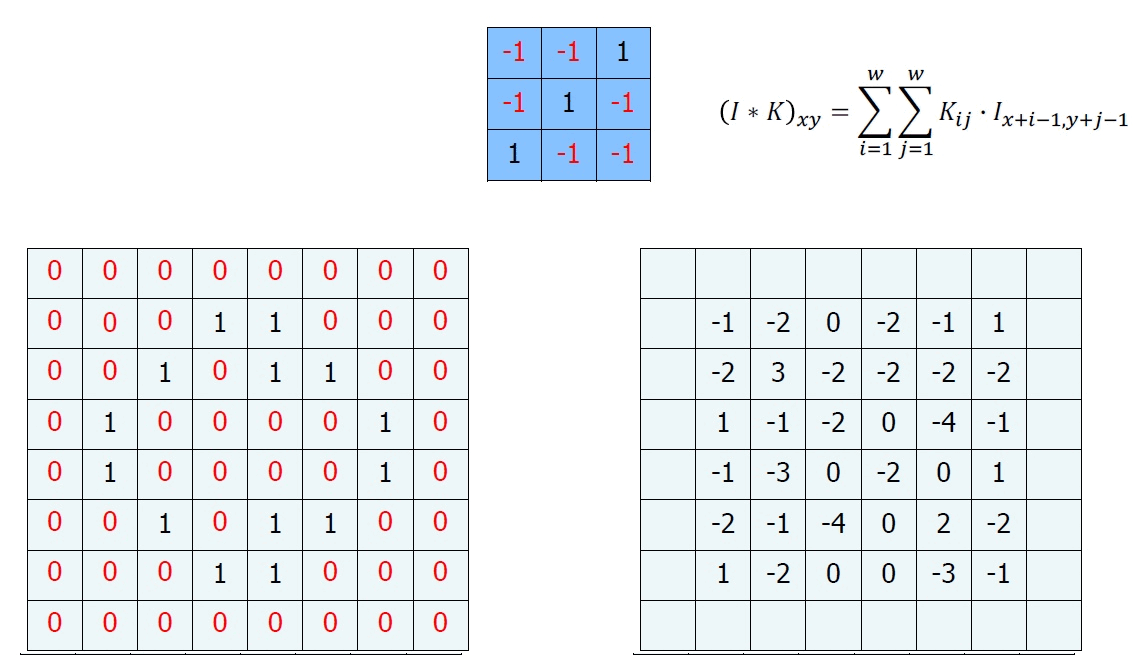
이런 행렬 연산을 Convolution이라고 한다. 마지막 계산을 하고 남는 부분이 있는데, 이는 일반적으로 다음과 같이 하여 매꾸어준다.
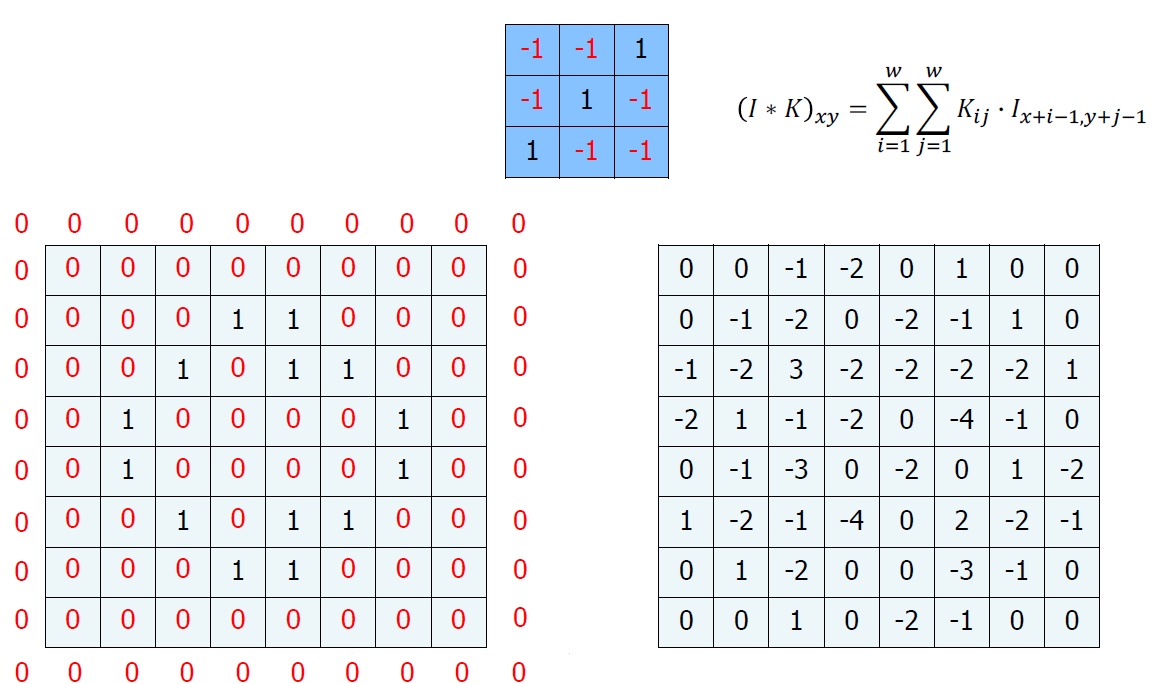
0을 추가하여 행렬을 완성시킨다. 이를 Zero padding이라고 부른다. (나중에 또 설명할 것이다.)
우리는 현재 계산에서 0과 1만을 사용하고 있었다. 따라서 0이하의 값들은 다른 의미가 없을 것임으로 0으로 통일해도 무방할 것이다. 이게 바로 Threshold(임계값)이다.
import numpy as np
import cv2
# 이미지를 불러옵니다.
img = cv2.imread('image.jpg', 0)
# Gaussian 필터를 적용하여 이미지를 스무딩합니다.
img_smooth = cv2.GaussianBlur(img, (5,5), 0)
# Sobel 필터를 적용하여 이미지의 경계선을 검출합니다.
sobelx = cv2.Sobel(img_smooth,cv2.CV_64F,1,0,ksize=5)
sobely = cv2.Sobel(img_smooth,cv2.CV_64F,0,1,ksize=5)
img_edge = np.sqrt(sobelx**2 + sobely**2)
# Harris 코너 검출을 수행합니다.
dst = cv2.cornerHarris(img_edge, 2, 3, 0.04)
dst = cv2.dilate(dst, None)
# 코너 위치를 찾습니다.
corners = np.where(dst > 0.01 * dst.max())
# 이미지에 코너를 표시합니다.
for i in range(len(corners[0])):
x = corners[1][i]
y = corners[0][i]
cv2.circle(img, (x,y), 5, (0,0,255), 2)
# 결과를 출력합니다.
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()image.jpg 파일을 통해 Convolution 연산을 해볼 수 있다.
우리는 1차원적인 행렬 계산을 진행했지만, 실제 우리 모니터, 사진 등에서 나오는 색상은 RGB의 조화로 이루어져있다.
따라서 우리는 Feature Extraction을 위해 필터를 RGB 3개의 행렬에 계산해야 한다. 이를 일반적으로 3D Convolution이라고 하는데, Convolution이라고 해도 이것과 동일한 것으로 이해해도 무방하다. 나중에 1D Convolution을 오히려 따로 정의하기 때문이다.
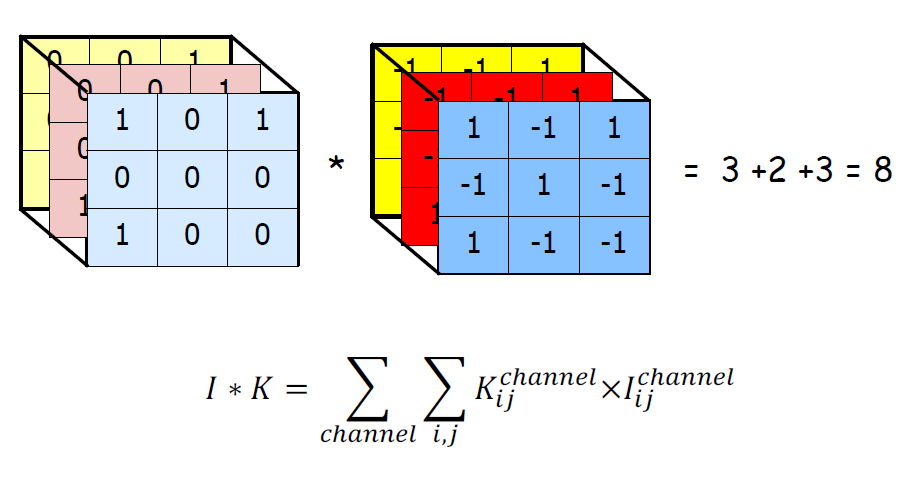
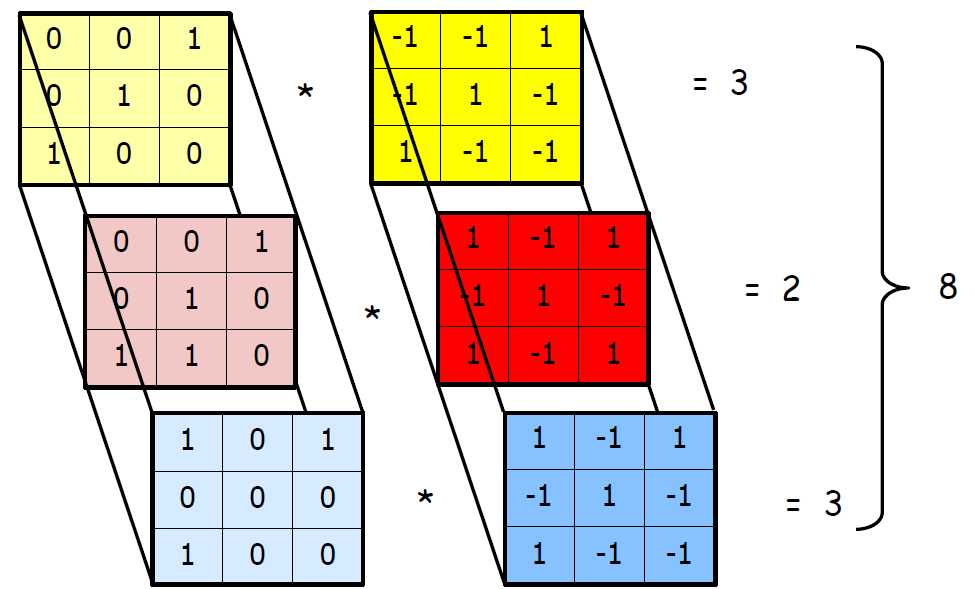
3D Convolution 행렬 연산 예시를 하나 더 보면 다음과 같다.
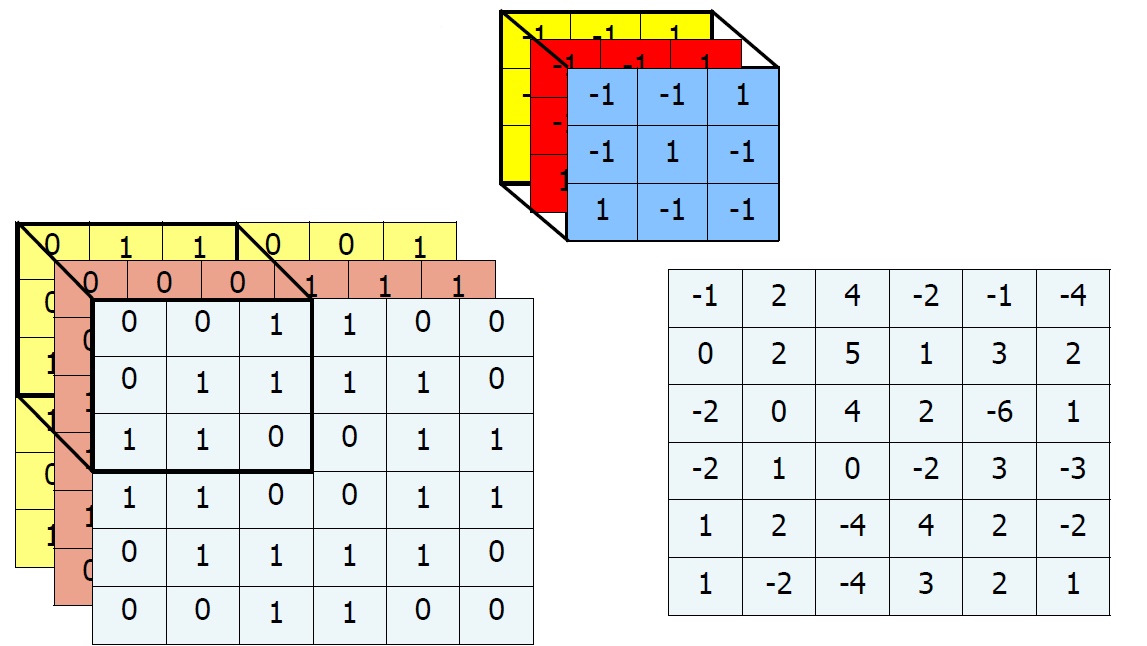
우리는 이런 연산을 통해 필터들을 만들 수 있다. 대표적인 예시는 다음과 같다.

우리가 앞에서 배웠던 연산을 통해 다음의 Feature map을 얻었다고 해보자.
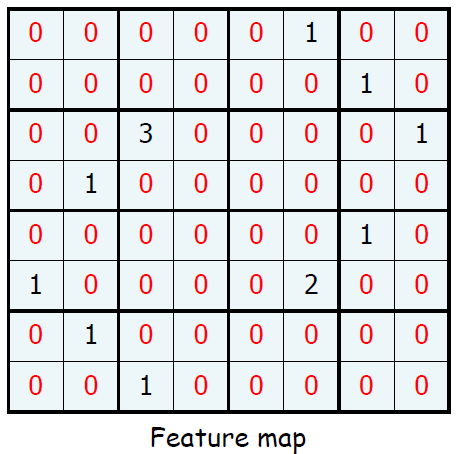
우리는 임계값을 설명할 때, 양수가 filter를 거치면서 어떤 정보를 가지고 있다는 것을 직관 적으로 알게된다. 그렇다면 0을 줄일 수 있다면 우리의 데이터 크기도 줄면서 처리 속도도 증가하지 않을까?
이런 방향으로 나온 것이 Pooling이다.
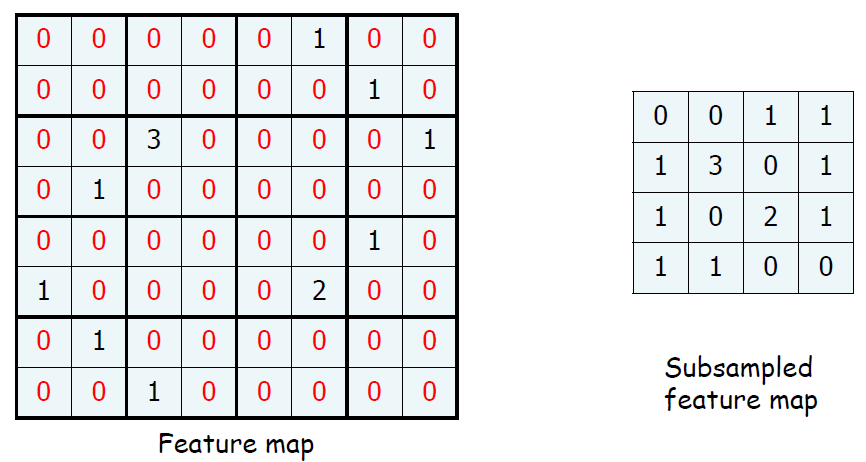
추가적으로 입력 이미지나 영상에서 특정 위치에서 발생한 특징이 다른 위치에서도 같은 방식으로 감지될 수 있도록 하는 효과를 가지고 있다. 아래의 그림에서 우리는 그림을 한칸 내렸지만 0이 아닌 값이 더 많이 일치한다.
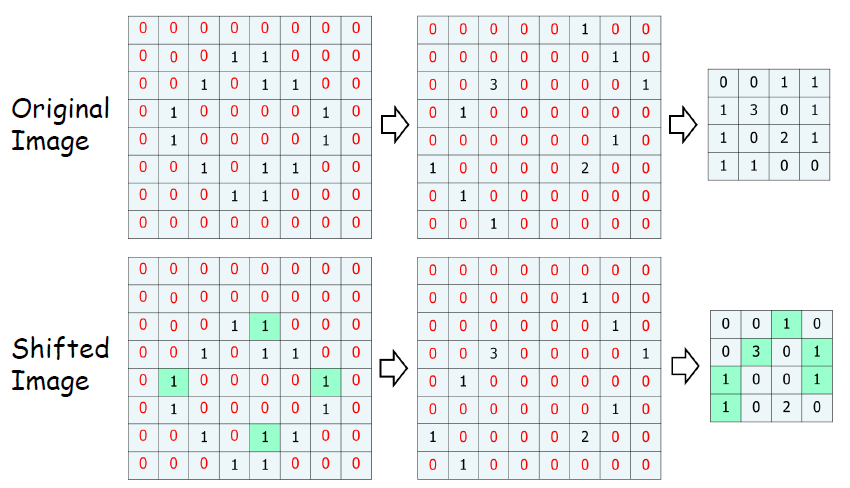
Shift Invariant를 우리는 앞에서 들어 봤었다. 바로 과적합(overfitting)을 방지에 도움을 주는 것으로 말이다. 따라서 Pooling의 장점을 정리하면 다음과 같다.
1. 매개변수 수 감소에 따른 처리속도 증가
2. 시프트 불변성으로 더욱 강력한 피처 맵 생성 및 과적합 방지
장점을 꼭 기억해둘 필요는 없다. 그때 그때 찾아 쓰는것이지. 하지만 Pooling의 경우는 많이 사용함으로 1번을 주로 사용되는 이유로 알고 있으면 좋다.
추가적으로 Pooling에도 Max Pooling과 Average Pooling이 존재한다. 우리가 앞서 사용한 것은 Max Pooling으로 윈도우 내에서 가장 큰 값을 선택하여 출력하는 방식이고 Average Pooling은 윈도우 내의 모든 값을 평균하여 출력한다. Average Pooling이 사용되었다면 다음과 같이 변했을 것이다.
| 0 | 0 | 1 | 1 |
| 1 | 3 | 0 | 1 |
| 1 | 0 | 2 | 1 |
| 1 | 1 | 0 | 0 |
Max Pooling
| 0 | 0 | 0.25 | 0.25 |
| 0.25 | 0.75 | 0 | 0.25 |
| 0.25 | 0 | 0.5 | 0.25 |
| 0.25 | 0.25 | 0 | 0 |
Average Pooling
일반적으로 Max Pooling이 더 좋은 성능을 보이며, 이는 입력 데이터에서 가장 강한 신호를 찾아서 보존하는 효과가 있기 때문이다.
그러면 우리가 하나의 이미지로 부터 Feature map을 뽑은 과정을 정리해보자.
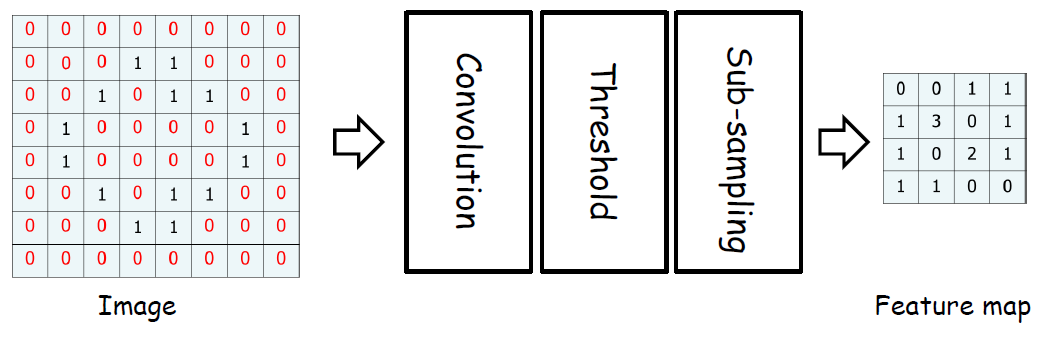
Sub-sampling은 설명하지 않았는데, 이는 입력 데이터의 크기를 줄이는 작업을 의미한다. 즉, 우리가 한 Max Pooling, Average Pooling이 이에 해당된다. 따라서 굳이 기를 쓰며 기억할 필요 없다. 우리가 원하는 것은 저런 단계를 거쳐 결국 Freature map을 뽑는다는 사실에 집중해야한다.
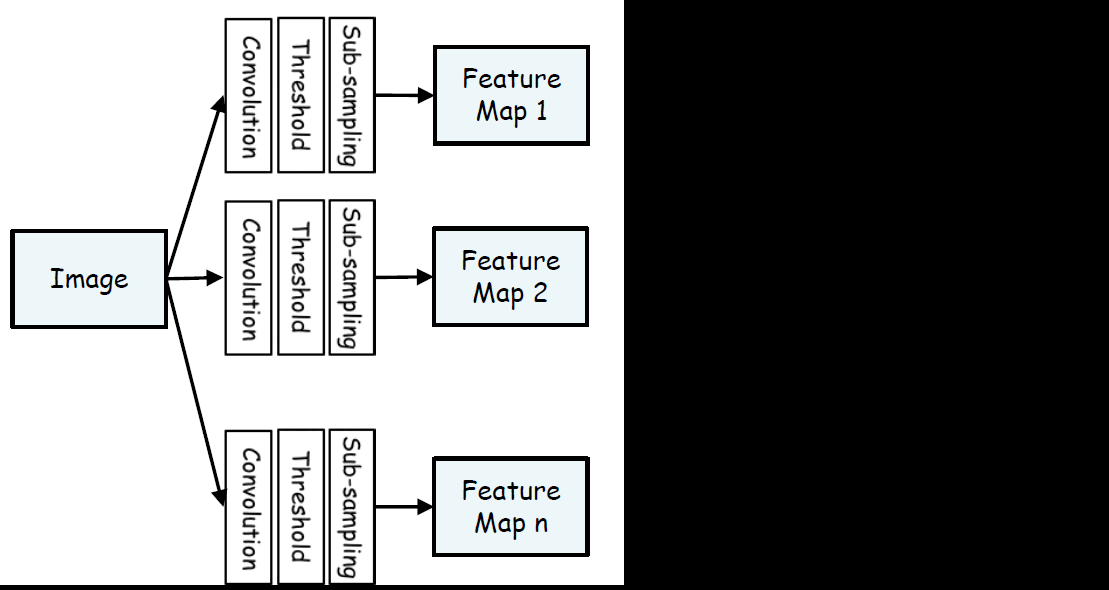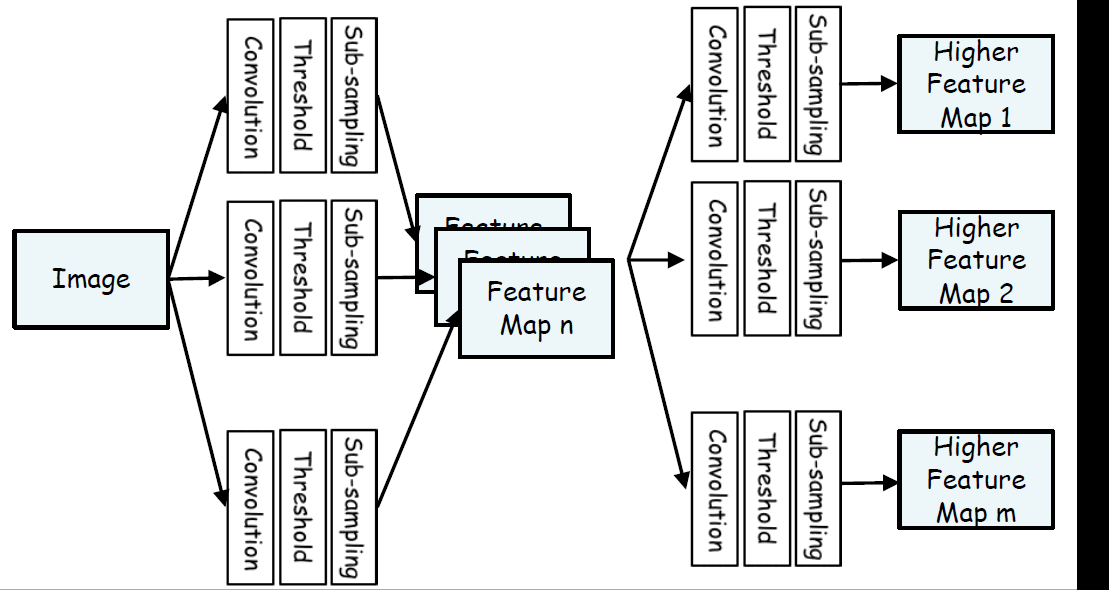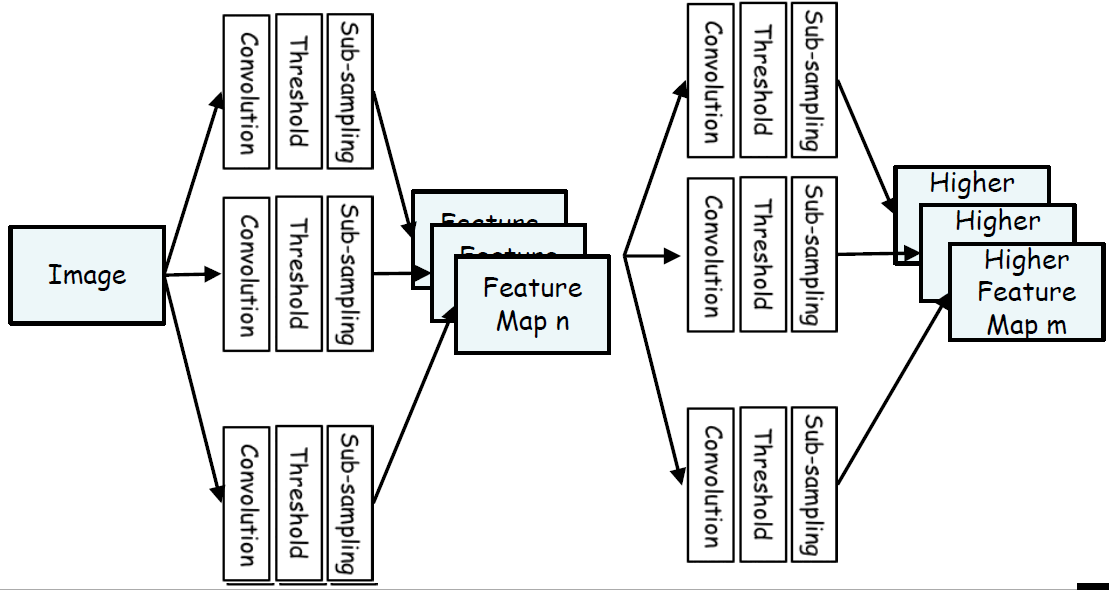
따라서 Freature map 위의 그림과 같이 계속 응축시킬 수 있다.
러나, 로컬 특징 추출만으로는 이미지 분류나 객체 감지와 같은 고차원적인 작업으로 변경하게 되면 다음의 이미지화 될 것이다.
상황에 맞는 필터를 계속 전문가인 사람의 손으로 할 순 없다. 따라서 convolution mask(이전에는 filter라고 했던 것)를 연결 가중치로 변환하고 앞선 Convolution, Threshold, Sub-sampling을 신경망으로 변화시켜 convolution mask를 경사 하강 방법으로 찾는 방법이 고안 되었고 이를 Convolutional Neural Networks, 즉 CNN이라고 한다.
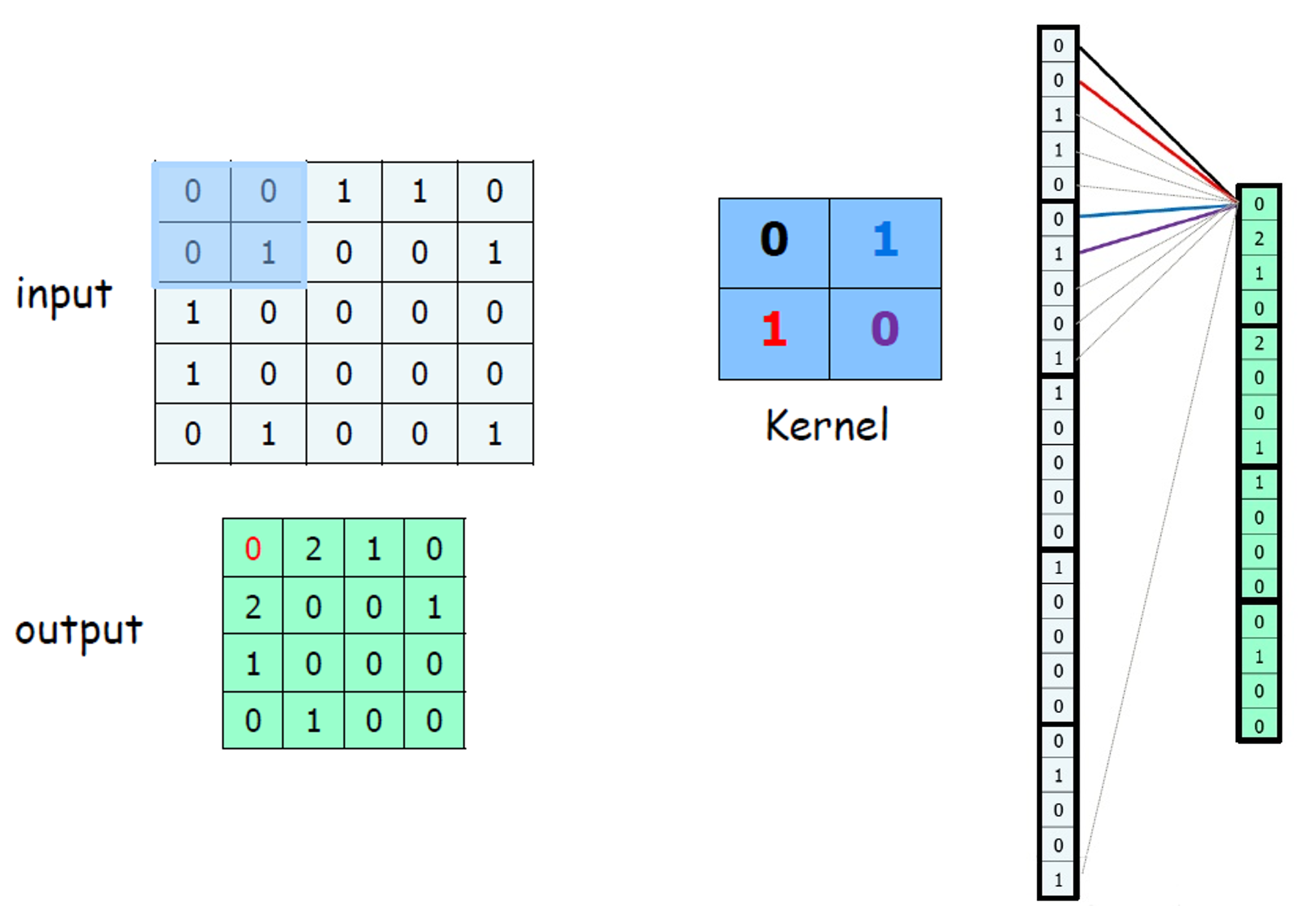 |
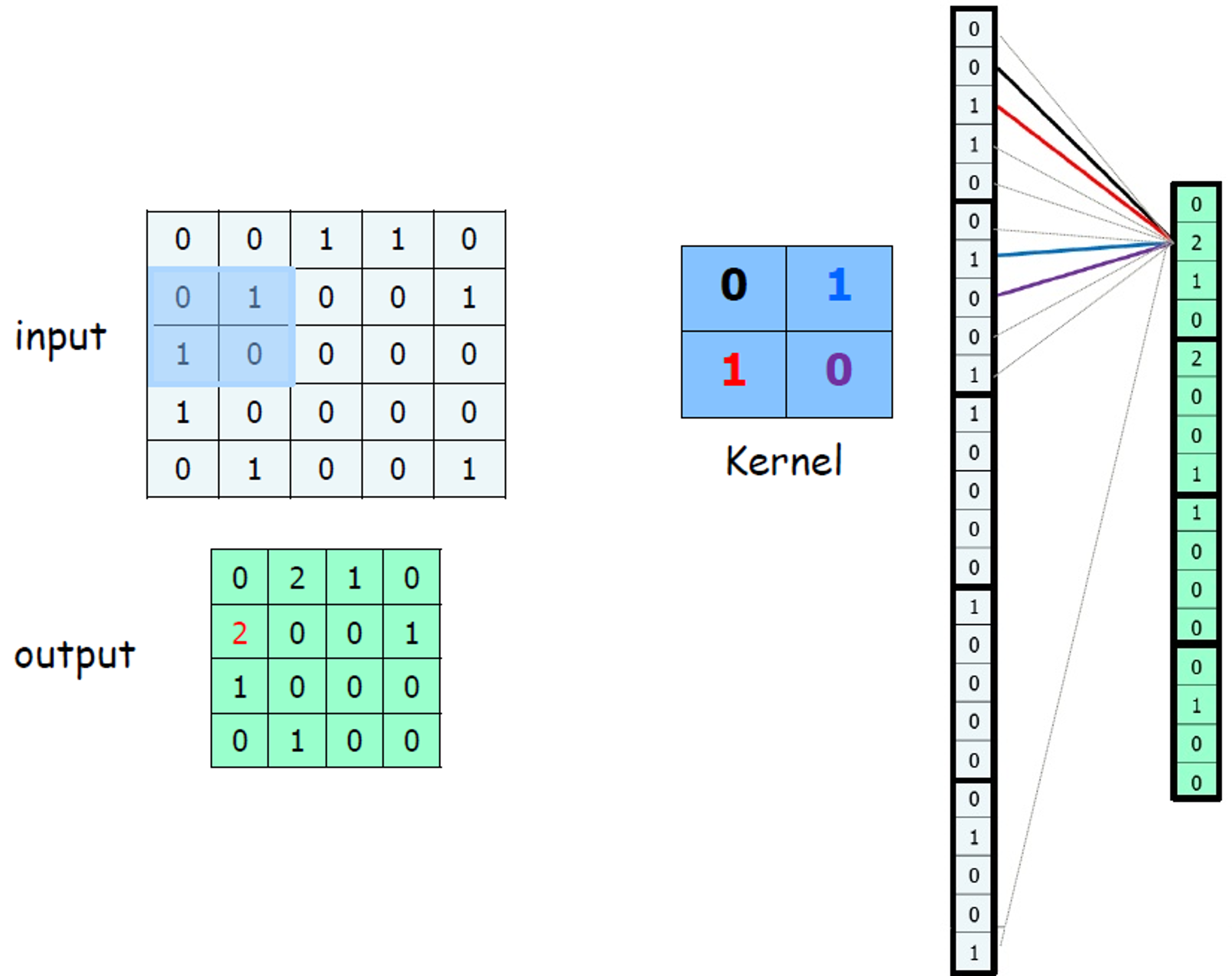 |
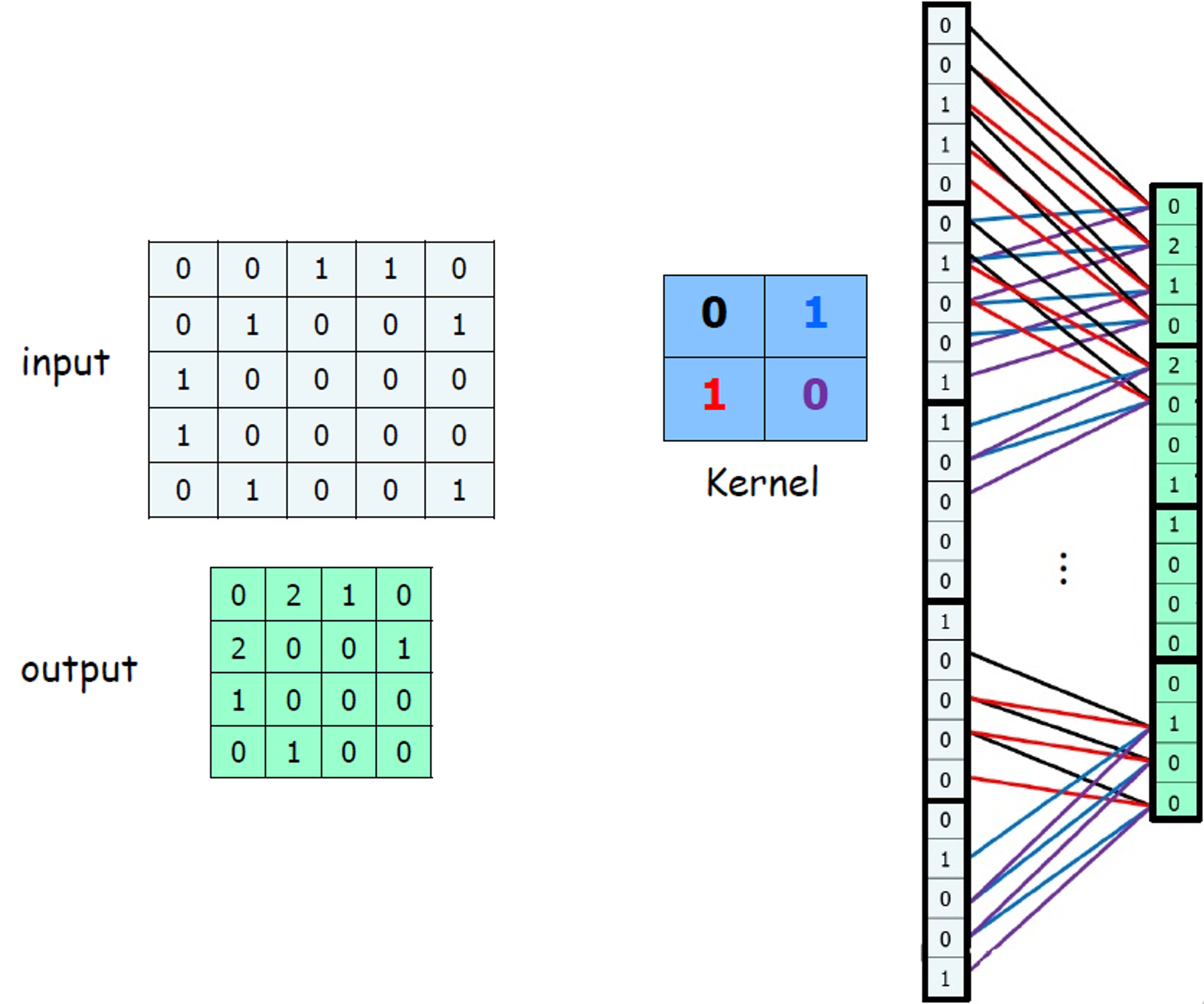 |
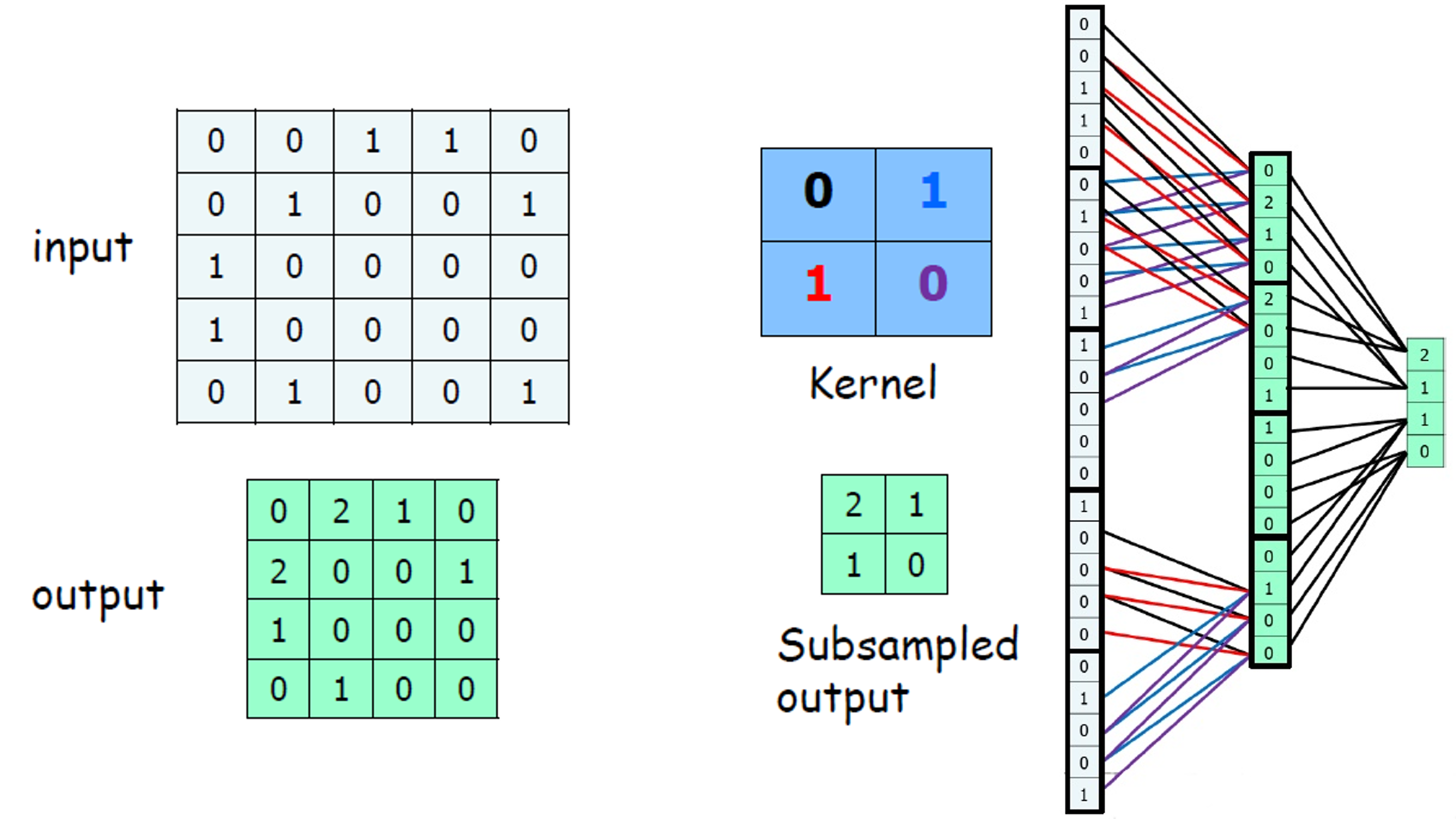 |
1 -> 2 -> 3 -> 4와 같은 뉴런망이 만들어 질수 있다. 따라서 이를 Convolutional Neural Networks이라 부르는 것이다.
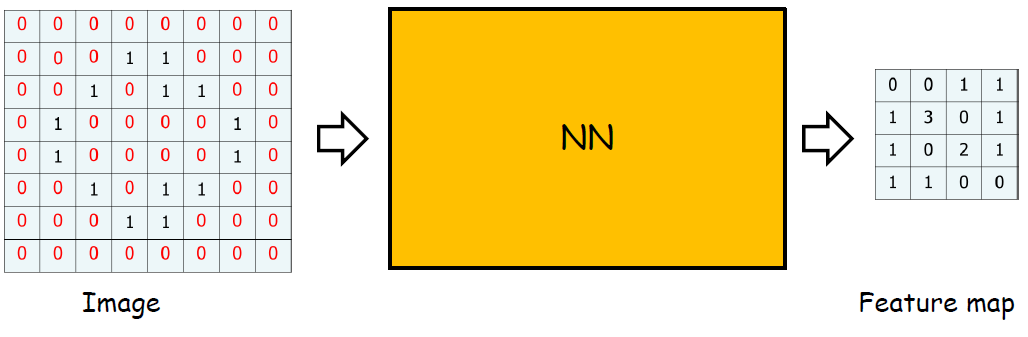
결국, 앞의 단계가 이렇게 간소화 되는 것이다.
따라서 앞에서 보여주었던 Structure도 이렇게 간소화하게 표현이 가능하다.
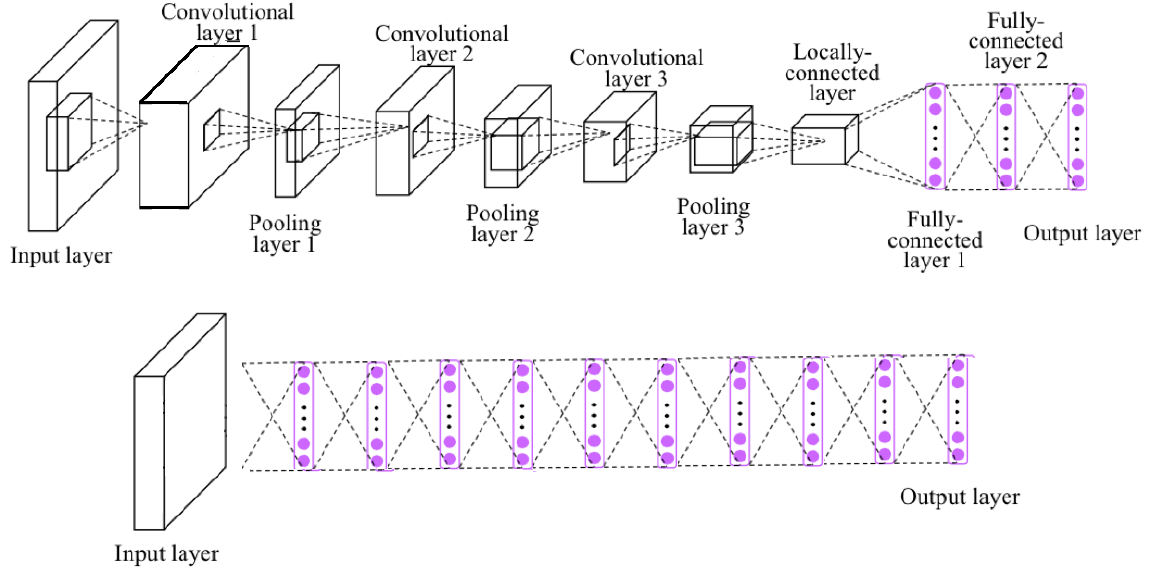
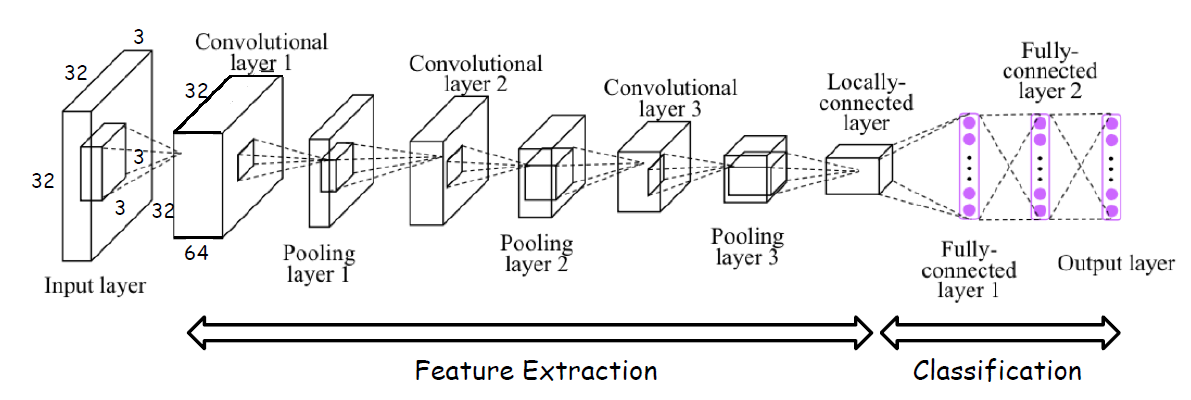
실제 사용되는 CNN 예시는 다음과 같다.

import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
# 데이터 불러오기
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# 입력 데이터 전처리
x_train = x_train.reshape(-1, 28, 28, 1).astype("float32") / 255.0
x_test = x_test.reshape(-1, 28, 28, 1).astype("float32") / 255.0
# 모델 생성
model = keras.Sequential(
[
layers.Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=(28, 28, 1)),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(10, activation="softmax"),
]
)
# 모델 컴파일
model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
# 모델 학습
model.fit(x_train, y_train, batch_size=128, epochs=5, validation_split=0.1)
# 모델 평가
model.evaluate(x_test, y_test, verbose=2)위 코드에서는 먼저 MNIST 숫자 데이터셋을 불러와 입력 데이터를 전처리한다. 그리고 layers 모듈을 사용하여 CNN 모델을 생성하고, compile() 함수를 사용하여 모델을 컴파일한다. 마지막으로 fit() 함수를 사용하여 모델을 학습하고, evaluate() 함수를 사용하여 모델을 평가를 진행한다.
모델은 입력 이미지를 Conv2D 레이어를 통해 feature map으로 변환하고, MaxPooling2D 레이어를 사용하여 subsampling을 수행합니다. 그리고 Flatten 레이어를 통해 1차원 벡터로 변환하고, Dense 레이어를 사용하여 분류를 수행한다.
'인공지능' 카테고리의 다른 글
| Chapter 4 CNN Structures (1) | 2023.05.19 |
|---|---|
| Diffusion Model (0) | 2023.04.01 |
| Chapter 2-2 Neural Networks (1) | 2023.02.05 |
| Chapter 2-1 Neural Networks (0) | 2023.01.27 |
| Chapter 1 Machine Learning (1) | 2023.01.20 |



