참조영상: https://www.youtube.com/watch?v=uFoGaIVHfoE
https://www.youtube.com/watch?v=nthpXARTduk
https://github.com/kwonminki/One-sentence_Diffusion_summary
GitHub - kwonminki/One-sentence_Diffusion_summary: The repo for studying and sharing diffusion models.
The repo for studying and sharing diffusion models. - GitHub - kwonminki/One-sentence_Diffusion_summary: The repo for studying and sharing diffusion models.
github.com
내용
시작전 참고
U-Net은 컴퓨터 비전과 의료 영상 처리 분야에서 널리 사용되는 딥러닝 기반의 이미지 분할(segmentation) 알고리즘입니다. U-Net은 2015년 Olaf Ronneberger, Philipp Fischer, Thomas Brox가 제안한 구조로, 특히 의료 영상 처리에서 세포 구조나 세부 특징을 정확하게 분할하는 데 높은 성능을 보여줍니다. 이 구조는 일반적인 이미지 분할 작업에서도 널리 사용되고 있습니다.
U-Net의 구조는 이름에서 알 수 있듯이 대략 'U'자 형태를 띄고 있으며, 이는 인코더와 디코더 두 부분으로 구성되어 있습니다.
인코더 (contracting path): 인코더는 이미지의 특징을 추출하고 추상화하는 역할을 합니다. 인코더는 일련의 컨볼루션 레이어(Convolutional layers), 활성화 함수(Activation functions), 및 풀링 레이어(Pooling layers)로 구성되어 있습니다. 각 레이어를 거치면서 이미지의 차원이 줄어들고, 고수준의 특징이 추출됩니다.
디코더 (expanding path): 디코더는 인코더에서 추출된 고수준 특징을 사용하여 원본 이미지와 동일한 크기의 세분화된 이미지를 생성합니다. 디코더는 컨볼루션 레이어, 활성화 함수, 업샘플링 레이어(Up-sampling layers)로 구성되어 있으며, 각 레이어를 거치면서 이미지의 차원이 점차 확장됩니다.
스킵 커넥션 (skip connections): U-Net의 중요한 특징인 스킵 커넥션은 인코더와 디코더의 대칭적인 레이어 사이에 존재합니다. 스킵 커넥션은 인코더의 각 레이어에서 나온 특징 맵(Feature maps)을 디코더의 대응하는 레이어와 연결하여, 디코더에서 입력 이미지의 세부 정보를 더 잘 재구성할 수 있도록 돕습니다.
U-Net은 특히 훈련 데이터가 부족한 상황에서도 높은 성능을 보여주는 것으로 알려져 있으며, 다양한 이미지 분할 문제에서 사용되고 있습니다.
셀프 어텐션(Self-attention)은 특히 자연어 처리(NLP) 분야에서 널리 사용되는 메커니즘으로, 입력 시퀀스의 다른 위치에 있는 요소들 간의 상호 관계를 모델링합니다. 이 메커니즘은 트랜스포머(Transformer) 아키텍처에서 핵심적인 역할을 하며, 효율적인 문맥 인식 및 긴거리 종속성 학습을 가능하게 합니다.
셀프 어텐션 메커니즘은 쿼리(Query), 키(Key), 밸류(Value)라는 세 가지 요소를 사용하여 작동합니다. 각각의 역할은 다음과 같습니다:
쿼리(Query): 쿼리는 입력 시퀀스의 각 위치에서 관심을 가져야 할 다른 위치를 결정하는 역할을 합니다. 쿼리는 입력 시퀀스를 어텐션 메커니즘에 적용하기 전에 생성되며, 학습 과정에서 최적화됩니다.
키(Key): 키는 입력 시퀀스의 각 위치의 중요성을 표현하는 역할을 합니다. 키는 쿼리와 함께 사용되어, 어텐션 메커니즘에서 각 위치에 얼마나 집중할지 결정하는 가중치를 계산하는 데 도움을 줍니다.
밸류(Value): 밸류는 입력 시퀀스의 각 위치에서 실제로 사용되는 정보를 나타냅니다. 밸류는 어텐션 가중치와 함께 사용되어, 최종적으로 어텐션 메커니즘의 출력을 계산하는 데 사용됩니다.
셀프 어텐션 메커니즘은 쿼리, 키, 밸류를 사용하여 입력 시퀀스의 각 위치에서 다른 위치에 대한 정보를 얻습니다. 이를 통해, 모델은 시퀀스 내의 단어나 토큰 간의 상호 작용과 종속성을 효과적으로 학습할 수 있습니다. 이러한 메커니즘은 트랜스포머 아키텍처의 성능 향상에 크게 기여하며, 현재 NLP 분야의 다양한 응용 사례에서 사용되고 있습니다.
트랜스포머(Transformer) 모델은 자연어 처리(NLP) 분야에서 혁신적인 발전을 이룬 딥러닝 아키텍처입니다. 2017년 Vaswani et al.에 의해 제안되었으며, 기존의 순환 신경망(RNN)과 합성곱 신경망(CNN)에 대한 새로운 대안으로 빠르게 인기를 얻었습니다. 트랜스포머는 효과적인 문맥 인식 및 병렬 처리 능력을 활용하여 현존하는 대부분의 NLP 작업에서 최고의 성능을 기록하고 있습니다.
트랜스포머 모델의 핵심 구성 요소는 다음과 같습니다:
셀프 어텐션 메커니즘 (Self-attention mechanism): 트랜스포머는 셀프 어텐션 메커니즘을 사용하여 입력 시퀀스의 각 위치에서 다른 위치의 정보를 포착할 수 있습니다. 이를 통해 모델은 단어나 토큰 간의 상호 작용 및 종속성을 효과적으로 학습할 수 있습니다.
포지션 인코딩 (Position encoding): 트랜스포머는 순서 정보를 포착하기 위해 포지션 인코딩을 사용합니다. 이를 통해 모델은 입력 시퀀스의 순서 정보를 유지하면서도 효과적인 병렬 처리를 수행할 수 있습니다.
인코더-디코더 아키텍처 (Encoder-decoder architecture): 트랜스포머는 인코더와 디코더로 구성된 아키텍처를 사용합니다. 인코더는 입력 시퀀스를 고차원의 문맥 정보로 변환하고, 디코더는 이 문맥 정보를 사용하여 출력 시퀀스를 생성합니다.
멀티-헤드 어텐션 (Multi-head attention): 트랜스포머는 여러 개의 어텐션 헤드를 사용하여 서로 다른 표현 공간에서의 정보를 동시에 포착할 수 있습니다. 이를 통해 모델은 다양한 관점에서 입력 시퀀스를 분석하고 이해할 수 있습니다.
층별 정규화 (Layer normalization): 트랜스포머는 층별 정규화를 사용하여 학습 과정을 안정화하고 빠르게 수렴하도록 돕습니다. 이는 기술은 각 층의 출력을 정규화하여 그래디언트 소실(vanishing gradient) 및 폭주(exploding gradient) 문제를 완화하는 데 도움이 됩니다.
위치별 피드포워드 네트워크 (Position-wise Feed-Forward Networks): 트랜스포머 모델은 각 인코더 및 디코더 층에서 위치별 피드포워드 네트워크를 사용하여 비선형 변환을 적용합니다. 이렇게 함으로써 모델은 입력 시퀀스의 다양한 구조와 관계를 학습할 수 있습니다.
잔차 연결 (Residual connections): 트랜스포머는 각 층의 출력에 잔차 연결을 사용하여 그래디언트 흐름을 개선하고, 깊은 아키텍처에서의 학습을 용이하게 합니다.
트랜스포머 모델은 위와 같은 구성 요소들을 통해 높은 성능을 달성하며, NLP 분야에서 많은 발전을 이끌어 왔습니다. GPT, BERT, T5 등 다양한 대규모 사전 훈련된 모델들이 트랜스포머 아키텍처를 기반으로 구축되어 있으며, 이러한 모델들은 현재 다양한 NLP 작업에서 최고의 성능을 보여주고 있습니다.

가장 유명한 사진. 원본 사이진에 가우시안 노이즈를 합성 후, 이를 되돌리는 학습법.
디퓨젼모델 대표 예시
DDPM
- U-net 사용
DDIM

Stable Diffusion



캡션을 같이 주는 형식 -> GAN 처럼
내 생각:
Stable diffusion은 딥러닝 및 인공지능 분야에서 연구되고 있는 새로운 개념으로, 이론적으로 안정적인 확산 과정을 통해 데이터의 다양한 특성을 학습하는 모델을 말합니다. Stable diffusion는 기존의 딥러닝 기술과 확률적 확산 이론을 결합하여 더욱 강력한 성능을 발휘합니다.
확률적 확산 이론: 확률적 확산 이론은 확률 과정을 사용하여 데이터의 변화와 불확실성을 모델링하는 이론입니다. 이를 통해 시간에 따른 데이터의 변동성을 파악하고 예측하는 것이 가능합니다.
딥러닝과 결합: Stable diffusion은 확률적 확산 이론을 딥러닝 기술과 결합하여 더욱 강력한 성능을 발휘합니다. 이를 통해 기존의 딥러닝 모델들이 가진 한계를 극복하고 더욱 복잡한 데이터 구조를 효과적으로 학습할 수 있습니다.
안정적인 학습: Stable diffusion의 핵심은 안정적인 학습 과정입니다. 확률적 확산 과정을 통해 데이터의 복잡한 특성을 차근차근 학습하면서, 과적합(overfitting) 문제를 방지하고 일반화 성능을 높이는 것이 목표입니다.
다양한 응용 분야: Stable diffusion은 다양한 인공지능 응용 분야에서 사용될 수 있습니다. 이미지 인식, 자연어 처리, 강화 학습 등 다양한 분야에서 이론과 기술을 활용하여 더욱 강력한 성능을 발휘할 수 있습니다.
요약하면, Stable diffusion은 확률적 확산 이론을 딥러닝과 결합하여 더욱 강력한 성능을 발휘하는 인공지능 기술입니다. 이를 통해 데이터의 복잡한 특성을 안정적으로 학습하고, 다양한 인공지능 응용 분야에서 높은 성능을 발휘할 수 있습니다.
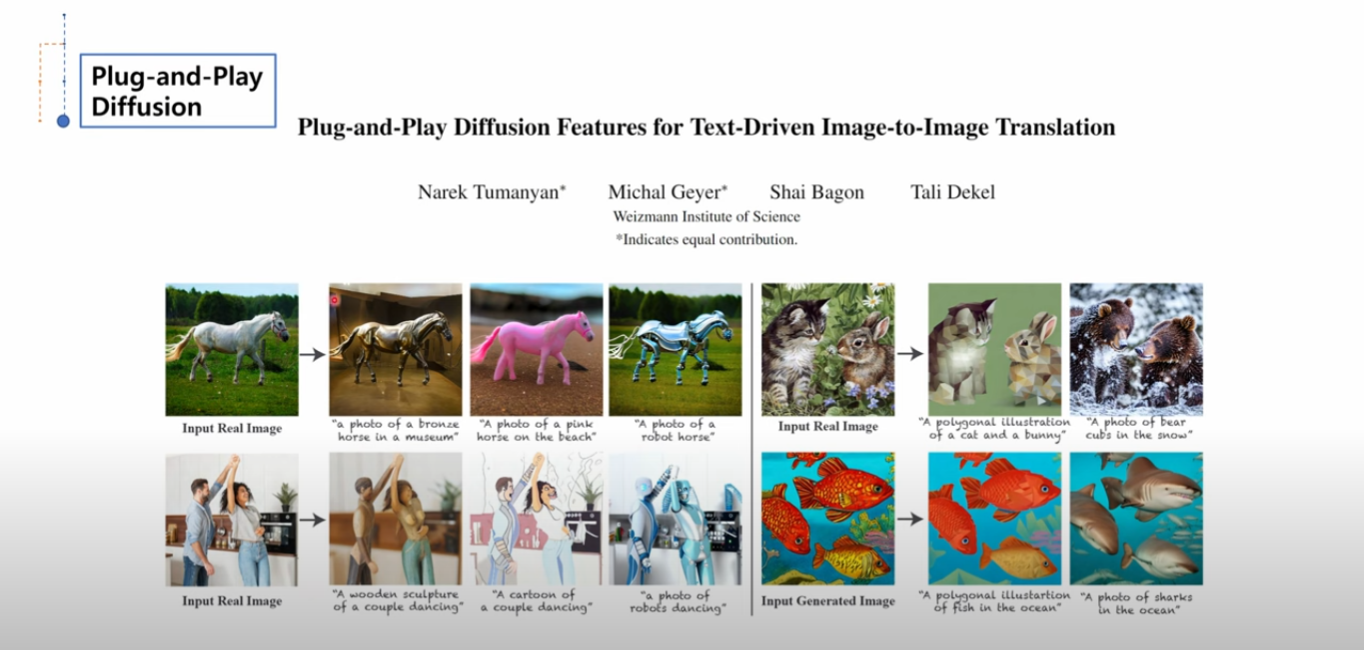
트레이닝을 안하고 바로 샘플링 하는 것이 중요 포인트
피봇형태라 생각하자.
내 생각:
Plug and Play Diffusion (PnP-Diffusion)은 이미지 생성과 복원과 같은 작업을 수행하는 인공지능 기반의 알고리즘입니다. 기본적으로, PnP-Diffusion은 확률적 확산 과정과 기존의 최적화 기반 알고리즘들을 결합하여 복잡한 이미지 생성 문제를 해결하려고 합니다. 이러한 접근 방식은 이미지 처리 분야에서 뛰어난 성능을 보여주고 있습니다.
Plug and Play Diffusion은 다음과 같은 방식으로 작동합니다:
확률적 확산 과정: PnP-Diffusion은 확률적 확산 과정을 사용하여 이미지의 노이즈를 점차적으로 제거합니다. 이 과정에서 이미지의 노이즈가 점차 감소하면서 원래 이미지의 정보가 점차 복원되는 방식으로 작동합니다.
최적화 기반 알고리즘: PnP-Diffusion은 기존의 최적화 기반 알고리즘들과 연계하여 이미지 복원을 수행합니다. 이러한 알고리즘들은 이미지의 일부분을 복원하거나 노이즈를 제거하는 데 도움이 되는 방식으로 작동합니다.
Plug and Play: PnP-Diffusion에서 "Plug and Play"라는 용어는 이러한 최적화 기반 알고리즘들을 쉽게 결합할 수 있는 방식을 의미합니다. 이를 통해 다양한 알고리즘들을 사용하여 이미지 복원을 수행할 수 있으며, 결과적으로 더욱 향상된 성능을 얻을 수 있습니다.
요약하면, Plug and Play Diffusion은 확률적 확산 과정과 최적화 기반 알고리즘을 결합하여 이미지 생성과 복원을 수행하는 인공지능 알고리즘입니다. 이러한 접근 방식은 이미지 처리 분야에서 높은 성능을 보여주며 다양한 응용 분야에서 활용되고 있습니다.

'인공지능' 카테고리의 다른 글
| Chapter 5 RNN, LSTM, GRU (1) | 2023.05.19 |
|---|---|
| Chapter 4 CNN Structures (1) | 2023.05.19 |
| Chapter 3 Convolutional Neural Networks (0) | 2023.02.13 |
| Chapter 2-2 Neural Networks (0) | 2023.02.05 |
| Chapter 2-1 Neural Networks (0) | 2023.01.27 |



