https://arxiv.org/abs/2404.19737
Better & Faster Large Language Models via Multi-token Prediction
Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in higher sample efficiency. More specifically, at each posi
arxiv.org
GPT 및 Llama와 같은 대규모 언어 모델은 다음 토큰 예측 손실을 사용하여 훈련됩니다. 본 연구에서는 언어 모델이 한 번에 여러 개의 미래 토큰을 예측하도록 훈련하면 샘플 효율성이 향상됨을 제안합니다. 더 구체적으로, 훈련 말뭉치의 각 위치에서 모델은 공유 모델 트렁크 위에서 작동하는 n개의 독립적인 출력 헤드를 사용하여 다음 n개의 토큰을 예측하도록 요청합니다. 다중 토큰 예측을 보조 훈련 작업으로 고려하여 코드 및 자연어 모델 모두에서 훈련 시간 오버헤드 없이 다운스트림 기능이 향상됨을 측정합니다. 이 방법은 모델 크기가 클수록 유용하며 여러 epoch에 대해 훈련할 때에도 매력적입니다. 특히 코딩과 같은 생성 벤치마크에서 이점이 두드러지며, 본 모델은 여러 백분율 포인트만큼 강력한 기준선을 지속적으로 능가합니다. 본 연구의 13B 매개변수 모델은 HumanEval에서 12%, MBPP에서 17% 더 많은 문제를 해결합니다. 소규모 알고리즘 작업에 대한 실험은 다중 토큰 예측이 유도 헤드 및 알고리즘 추론 기능 개발에 유리함을 보여줍니다. 추가적인 이점으로, 4-토큰 예측으로 훈련된 모델은 대규모 배치 크기에서도 추론 속도가 최대 3배 더 빠릅니다.

그림 1: 다중 토큰 예측 개요. (위) 훈련하는 동안 모델은 공유 트렁크와 4개의 전용 출력 헤드를 통해 한 번에 4개의 미래 토큰을 예측합니다. 추론하는 동안에는 다음 토큰 출력 헤드만 사용합니다. 선택적으로 다른 세 개의 헤드를 사용하여 추론 시간을 단축할 수 있습니다. (아래) 다중 토큰 예측은 MBPP 코드 작업의 pass@1을 향상시키며, 모델 크기가 증가함에 따라 그 효과는 더욱 커집니다. 오차 막대는 데이터 세트 샘플에 대한 부트스트래핑을 통해 계산된 90% 신뢰 구간입니다.
1. 서론
인류는 가장 독창적인 업적, 놀라운 발견, 아름다운 창작물을 텍스트 형태로 응축해 왔습니다. 이러한 모든 말뭉치에 대해 훈련된 대규모 언어 모델(LLM)은 방대한 양의 세상 지식과 기본적인 추론 능력을 추출할 수 있습니다. 이는 단순하지만 강력한 비지도 학습 작업인 다음 토큰 예측을 통해 이루어집니다. 최근 인상적인 성과(OpenAI, 2023)에도 불구하고, 다음 토큰 예측은 언어, 세상 지식, 추론 능력을 습득하는 비효율적인 방식으로 남아 있습니다. 더 정확히 말하면, 다음 토큰 예측을 이용한 교사 강요 방식은 지역적인 패턴에 집착하고 "어려운" 결정을 간과합니다. 결과적으로, 최첨단 다음 토큰 예측 모델은 인간 어린이와 동일한 수준의 유창성에 도달하기 위해 훨씬 더 많은 데이터를 필요로 합니다 (Frank, 2023).
본 연구에서는 LLM이 한 번에 여러 토큰을 예측하도록 훈련하면 샘플 효율성이 향상될 것이라고 주장합니다. 그림 1에서 예상한 바와 같이, 다중 토큰 예측은 LLM이 훈련 말뭉치의 각 위치에서 n개의 미래 토큰을 동시에 병렬로 예측하도록 지시합니다(Qi et al., 2020).
기여 다중 토큰 예측은 이전 문헌에서 연구되었지만(Qi et al., 2020), 본 연구는 다음과 같은 기여를 합니다.
- 훈련 시간이나 메모리 오버헤드가 없는 간단한 다중 토큰 예측 아키텍처를 제안합니다(섹션 2).
- 이 훈련 패러다임이 최대 13B 매개변수를 가진 모델에서 평균적으로 약 15% 더 많은 코드 문제를 해결하는 등 대규모로 유익하다는 실험적 증거를 제공합니다(섹션 3).
- 다중 토큰 예측은 자기 추측 디코딩을 가능하게 하여 광범위한 배치 크기에서 추론 시간을 최대 3배까지 단축합니다(섹션 3.2).
다중 토큰 예측은 비용이 들지 않고 간단하지만 더 강력하고 빠른 트랜스포머 모델을 훈련하기 위한 효과적인 수정 방법입니다. 본 연구가 다음 토큰 예측을 넘어 LLM을 위한 새로운 보조 손실에 대한 관심을 불러일으켜 이러한 흥미로운 모델의 성능, 일관성 및 추론 능력을 향상시키는 데 도움이 되기를 바랍니다.
그림 2: n = 2 헤드를 가진 n-토큰 예측 모델의 순방향/역방향 순서. 헤드에서 순방향/역방향을 순차적으로 수행함으로써 모든 임베딩 해제 레이어 기울기를 메모리에 동시에 구체화하지 않고 최대 GPU 메모리 사용량을 줄입니다.
메모리 효율적인 구현
다중 토큰 예측 모델 훈련의 큰 과제 중 하나는 GPU 메모리 사용량을 줄이는 것입니다. 이유를 이해하기 위해, 현재 LLM에서 어휘 크기 V는 잠재 표현의 차원 d보다 훨씬 크다는 점을 상기하십시오. 따라서 로짓 벡터가 GPU 메모리 사용량의 병목 현상이 됩니다. 모든 로짓과 그 기울기를 (n, V) 형태로 구체화하는 순진한 다중 토큰 예측 구현은 허용 가능한 배치 크기와 평균 GPU 메모리 사용률을 심각하게 제한합니다. 이러한 이유로, 본 연구의 아키텍처에서는 그림 2에 설명된 대로 순방향 및 역방향 연산 순서를 신중하게 조정할 것을 제안합니다. 특히, 공유 트렁크 (f_{s})를 통한 순방향 전달 후 각 독립 출력 헤드 (f_{i})의 순방향 및 역방향 전달을 순차적으로 계산하여 트렁크에 기울기를 누적합니다. 이렇게 하면 출력 헤드 (f_{i})에 대한 로짓(및 해당 기울기)이 생성되지만, 다음 출력 헤드 (f_{i+1})로 계속하기 전에 해제되어 d차원 트렁크 기울기
(\frac{\partial L_{n}}{\partial f_{s}})만 장기 저장하면 됩니다. 요약하면, 런타임 비용 없이 최대 GPU 메모리 사용량을 O(nV + d)에서 O(V + d)로 줄였습니다(표 S5).
추론
추론 시간 동안 제안된 아키텍처의 가장 기본적인 사용은 다른 모든 헤드를 버리고 다음 토큰 예측 헤드 (P_{\theta}(x_{t+1} | x_{t:1}))를 사용하는 일반적인 다음 토큰 자기 회귀 예측입니다. 그러나 추가 출력 헤드는 블록 단위 병렬 디코딩(Stern et al., 2018)(추가 초안 모델이 필요 없는 추측 디코딩(Leviathan et al., 2023)의 변형) 및 Medusa와 같은 트리 어텐션을 사용한 추측 디코딩(Cai et al., 2024)과 같은 자기 추측 디코딩 방법을 통해 다음 토큰 예측 헤드의 디코딩 속도를 높이는 데 활용할 수 있습니다.
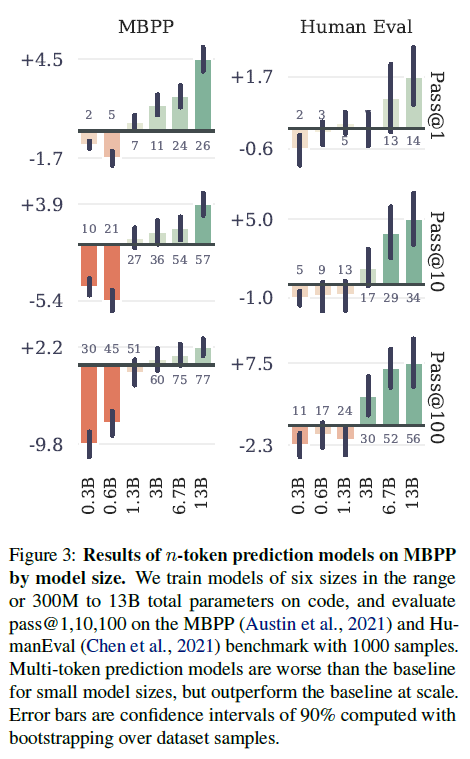
그림 3: 모델 크기별 MBPP에서 n-토큰 예측 모델의 결과. 코드에서 총 300M~13B 매개변수 범위의 6가지 크기 모델을 학습하고 1000개 샘플을 사용하여 MBPP(Austin et al., 2021) 및 HumanEval(Chen et al., 2021) 벤치마크에서 pass@1,10,100을 평가했습니다. 다중 토큰 예측 모델은 작은 모델 크기에서는 기준선보다 성능이 떨어지지만, 대규모에서는 기준선을 능가합니다. 오차 막대는 데이터 세트 샘플에 대한 부트스트래핑을 통해 계산된 90% 신뢰 구간입니다.
3. 실제 데이터에 대한 실험
본 연구에서는 7가지 대규모 실험을 통해 다중 토큰 예측 손실의 효능을 입증합니다. 3.1절에서는 모델 크기가 커짐에 따라 다중 토큰 예측이 점점 더 유용해지는 방식을 보여줍니다. 3.2절에서는 추측 디코딩을 사용하여 추가 예측 헤드가 추론 속도를 3배까지 높일 수 있는 방법을 보여줍니다. 3.3절에서는 다중 토큰 예측이 더 장기적인 패턴 학습을 촉진하는 방법을 보여주며, 이는 바이트 수준 토큰화의 극단적인 경우에 가장 분명하게 나타납니다. 3.4절에서는 4-토큰 예측 모델이 크기 32k의 토크나이저를 사용하여 큰 이득을 가져온다는 것을 보여줍니다. 3.5절에서는 여러 epoch으로 훈련을 실행할 때 다중 토큰 예측의 이점이 유지된다는 것을 보여줍니다. 3.6절에서는 Code-Contests 데이터 세트(Li et al., 2022)에 대한 미세 조정을 통해 다중 토큰 예측 손실을 사용한 사전 훈련으로 촉진되는 풍부한 표현을 보여줍니다. 3.7절에서는 다중 토큰 예측의 이점이 자연어 모델에도 적용되어 요약과 같은 생성 평가를 개선하는 동시에 객관식 질문 및 음의 로그 우도를 기반으로 하는 표준 벤치마크에서 크게 회귀하지 않음을 보여줍니다.
다음 토큰 예측 모델과 n-토큰 예측 모델 간의 공정한 비교를 위해, 이후 실험에서는 항상 동일한 양의 매개변수를 가진 모델을 비교합니다. 즉, 미래 예측 헤드에 n-1개의 레이어를 추가할 때 공유 모델 트렁크에서 n-1개의 레이어를 제거합니다. 모델 아키텍처는 표 S14를, 실험에 사용된 하이퍼파라미터 개요는 표 S13을 참조하십시오.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
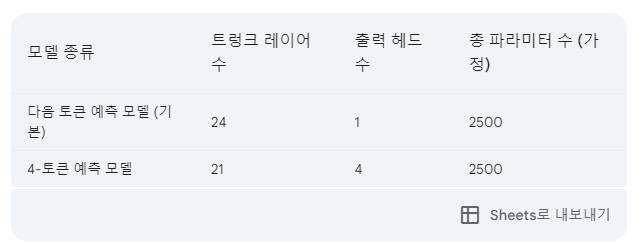
다음 토큰 예측 모델과 n-토큰 예측 모델을 공정하게 비교하기 위해 두 모델의 총 파라미터 수를 동일하게 유지하는 것이 중요합니다. 왜냐하면 모델의 파라미터 수는 모델의 복잡도와 성능에 직접적인 영향을 미치기 때문입니다. 만약 파라미터 수가 다르다면, 단순히 모델 크기 차이로 인해 성능 차이가 발생할 수 있습니다.
본 논문에서는 n-토큰 예측 모델을 만들 때 단순히 출력 헤드(output head)를 추가하는 것이 아니라, 공유 모델 트렁크(shared model trunk)에서 n-1개의 레이어를 제거합니다.
예를 들어, 다음 토큰 예측 모델에 24개의 레이어가 있다고 가정해 봅시다. 이 모델을 4-토큰 예측 모델로 변경한다면, 3개의 출력 헤드(4-1=3)를 추가하고, 공유 모델 트렁크에서 3개의 레이어를 제거합니다. 결과적으로, 4-토큰 예측 모델은 3개의 출력 헤드와 21개의 공유 트렁크 레이어를 가지게 되어 총 파라미터 수는 다음 토큰 예측 모델과 동일하게 유지됩니다.
이러한 방식으로 모델의 파라미터 수를 동일하게 유지함으로써, 다중 토큰 예측 자체의 효과를 모델 크기의 영향과 분리하여 분석할 수 있습니다. 즉, 모델 성능 차이가 순수하게 다중 토큰 예측으로 인한 것인지 확인할 수 있습니다.
모델 1: 다음 토큰 예측 모델 (기본)
- 트렁크 레이어 수: 24
- 출력 헤드 수: 1
- 총 파라미터 수: 2500
입력
|
V
[트렁크 레이어 1]
|
V
[트렁크 레이어 2]
|
V
...
|
V
[트렁크 레이어 24]
|
V
[출력 헤드 1]
|
V
출력
모델 2: 4-토큰 예측 모델
- 트렁크 레이어 수: 21
- 출력 헤드 수: 4
- 총 파라미터 수: 2500
입력
|
V
[트렁크 레이어 1]
|
V
[트렁크 레이어 2]
|
V
...
|
V
[트렁크 레이어 21]
|
V
+-----------------------+
| | |
V V V
[출력 헤드 1] [출력 헤드 2] [출력 헤드 3] [출력 헤드 4]
| | |
V V V
출력 출력 출력 출력-----------------------------------------------------------------------------------------------------------------------------------------------------------------
3.1. 모델 크기에 따른 이점 확대
이 현상을 연구하기 위해 300M에서 13B 매개변수 범위의 6가지 크기의 모델을 최소 91B 토큰의 코드에서 처음부터 학습합니다. MBPP(Austin et al., 2021) 및 HumanEval(Chen et al., 2021)에 대한 그림 3의 평가 결과는 정확히 동일한 계산 예산으로 다중 토큰 예측을 사용하여 고정된 데이터 세트에서 대규모 언어 모델의 성능을 훨씬 더 많이 끌어낼 수 있음을 보여줍니다.
본 연구는 이러한 유용성이 대규모에서만 나타나는 것이 지금까지 다중 토큰 예측이 대규모 언어 모델 훈련을 위한 유망한 훈련 손실로 간과된 가능성 있는 이유라고 생각합니다.
3.2. 더 빠른 추론
본 연구에서는 xFormers(Lefaudeux et al., 2022)를 사용하여 이질적인 배치 크기를 가진 탐욕적 자기 추측 디코딩(Stern et al., 2018)을 구현하고, 훈련 중에 보지 못한 코드 및 자연어 테스트 데이터 세트(표 S2)에서 가져온 프롬프트를 완성하는 데 있어 7B 매개변수를 가진 최고의 4-토큰 예측 모델의 디코딩 속도를 측정합니다. 코드에서는 평균적으로 3개의 제안 중 2.5개의 토큰이 허용되어 3.0배의 속도 향상을, 텍스트에서는 2.7배의 속도 향상을 관찰했습니다. 8-바이트 예측 모델에서는 추론 속도가 6.4배 향상되었습니다(표 S3). 다중 토큰 예측을 사용한 사전 훈련을 통해 추가 헤드는 다음 토큰 예측 모델의 단순 미세 조정보다 훨씬 더 정확할 수 있으므로, 본 모델은 자기 추측 디코딩의 잠재력을 최대한 발휘할 수 있습니다.
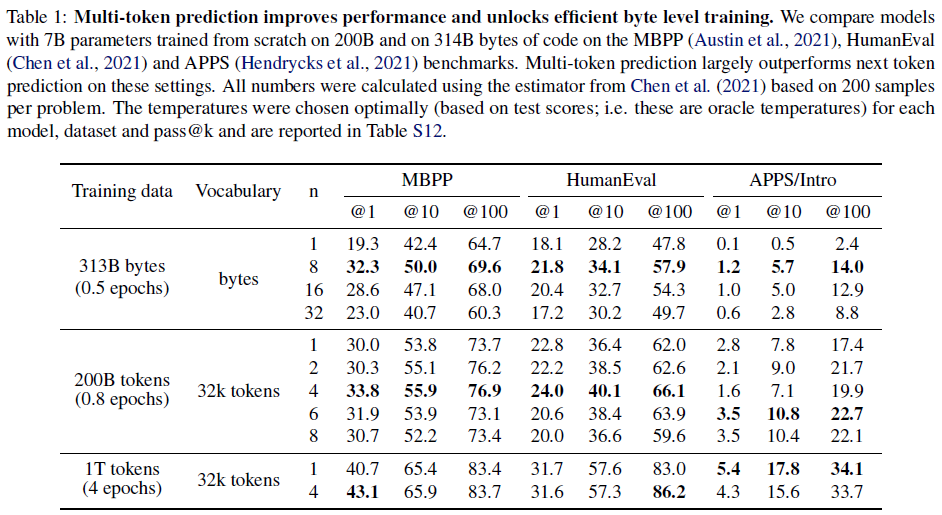
표 1: 다중 토큰 예측은 성능을 향상시키고 효율적인 바이트 수준 훈련을 가능하게 합니다. 200B 및 314B 바이트 코드에서 처음부터 훈련된 7B 매개변수를 가진 모델을 MBPP(Austin et al., 2021), HumanEval(Chen et al., 2021) 및 APPS(Hendrycks et al., 2021) 벤치마크에서 비교합니다. 다중 토큰 예측은 이러한 설정에서 다음 토큰 예측보다 훨씬 뛰어난 성능을 보입니다. 모든 수치는 문제당 200개 샘플을 기반으로 Chen et al. (2021)의 추정기를 사용하여 계산되었습니다. 각 모델, 데이터 세트 및 pass@k에 대해 온도를 최적으로 선택(테스트 점수 기준, 즉 오라클 온도)했으며 표 S12에 보고되어 있습니다.
3.3. 다중 바이트 예측으로 글로벌 패턴 학습
다음 토큰 예측 작업이 지역 패턴에 집착한다는 것을 보여주기 위해, 314B 바이트(약 116B 토큰에 해당)에 대해 7B 매개변수 바이트 레벨 트랜스포머를 훈련하여 바이트 레벨 토큰화의 극단적인 경우를 살펴보았습니다. 8-바이트 예측 모델은 다음 바이트 예측과 비교하여 놀라운 개선을 달성하여 MBPP pass@1에서 67% 더 많은 문제를 해결하고 HumanEval pass@1에서 20% 더 많은 문제를 해결했습니다.
따라서 다중 바이트 예측은 바이트 레벨 모델의 효율적인 훈련을 가능하게 하는 매우 유망한 방법입니다. 자기 추측 디코딩은 8-바이트 예측 모델에서 6배의 속도 향상을 달성할 수 있으며, 이는 추론 시 더 긴 바이트 레벨 시퀀스의 비용을 완전히 보상하고 다음 토큰 예측 모델보다 거의 2배 빠를 수 있게 해줍니다. 8-바이트 예측 모델은 강력한 바이트 기반 모델로, 1.7배 적은 데이터로 학습되었음에도 불구하고 토큰 기반 모델의 성능에 근접합니다.
3.4. 최적의 n 탐색
예측된 토큰 수의 영향을 더 잘 이해하기 위해 200B 토큰 코드로 학습된 7B 규모 모델에 대한 포괄적인 절제 연구를 수행했습니다. 이 설정에서 n = 1, 2, 4, 6, 8을 시도했습니다. 표 1의 결과는 4개의 미래 토큰으로 훈련하면 HumanEval 및 MBPP 전체에서 pass@1, 10, 100 지표에 대해 다른 모든 모델보다 지속적으로 성능이 우수함을 보여줍니다: MBPP의 경우 +3.8%, +2.1%, +3.2%, HumanEval의 경우 +1.2%, +3.7%, +4.1%. 흥미롭게도 APPS/Intro의 경우 n = 6이 +0.7%, +3.0%, +5.3%로 앞서 있습니다. 최적의 창 크기는 입력 데이터 분포에 따라 달라질 가능성이 매우 높습니다. 바이트 레벨 모델의 경우 이러한 벤치마크에서 최적의 창 크기가 8바이트로 더 일관됩니다.
3.5. 여러 epoch 훈련
동일한 데이터에 대해 여러 epoch으로 훈련할 때 다중 토큰 훈련은 여전히 다음 토큰 예측보다 우위를 유지합니다. 개선 효과는 줄어들지만 MBPP에서 pass@1은 +2.4%, HumanEval에서 pass@100은 +3.2% 증가하는 반면 나머지는 비슷한 성능을 보입니다. APPS/Intro의 경우 200B 토큰 훈련에서는 창 크기 4가 이미 최적이 아니었습니다.
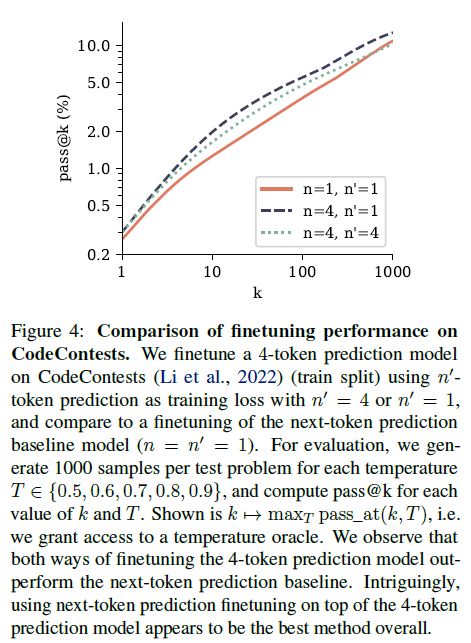
그림 4: CodeContests에 대한 미세 조정 성능 비교. n' = 4 또는 n' = 1인 n'-토큰 예측을 훈련 손실로 사용하여 CodeContests(Li et al., 2022)(훈련 분할)에서 4-토큰 예측 모델을 미세 조정하고 다음 토큰 예측 기준 모델(n = n' = 1)의 미세 조정과 비교합니다. 평가를 위해 각 온도 T ∈ {0.5, 0.6, 0.7, 0.8, 0.9}에 대해 테스트 문제당 1000개의 샘플을 생성하고 각 k 및 T 값에 대해 pass@k를 계산합니다. k 7→ maxT pass_at(k, T)가 표시됩니다. 즉, 온도 오라클에 대한 액세스 권한을 부여합니다. 4-토큰 예측 모델을 미세 조정하는 두 가지 방법 모두 다음 토큰 예측 기준선보다 성능이 뛰어남을 알 수 있습니다. 흥미롭게도 4-토큰 예측 모델 위에 다음 토큰 예측 미세 조정을 사용하는 것이 전반적으로 가장 좋은 방법으로 보입니다.
3.6. 다중 토큰 예측 모델의 미세 조정
다중 토큰 예측 손실로 사전 훈련된 모델은 미세 조정에 사용될 때도 다음 토큰 예측 모델보다 성능이 뛰어납니다. 이를 평가하기 위해 3.3절의 7B 매개변수 모델을 CodeContests 데이터셋(Li et al., 2022)에 대해 미세 조정했습니다. 4-토큰 예측 모델과 다음 토큰 예측 기준선을 비교하고, 4-토큰 예측 모델에서 추가 예측 헤드를 제거하고 기존 다음 토큰 예측 목표를 사용하여 미세 조정하는 설정도 포함했습니다.
그림 4의 결과에 따르면, 두 가지 방법으로 미세 조정된 4-토큰 예측 모델 모두 k에 대한 pass@k에서 다음 토큰 예측 모델보다 성능이 뛰어납니다. 이는 모델이 작업을 이해하고 해결하는 데 더 능숙하며 다양한 답변을 생성하는 데 더 능숙하다는 것을 의미합니다. CodeContests는 본 연구에서 평가한 코딩 벤치마크 중 가장 어려운 벤치마크임을 참고하십시오. 다음 토큰 예측 사전 훈련에 이어 작업별 미세 조정이라는 고전적인 패러다임과 일치하게, 4-토큰 예측 사전 훈련 위에 다음 토큰 예측 미세 조정을 수행하는 것이 전반적으로 가장 좋은 방법으로 보입니다. 자세한 내용은 부록 F를 참조하십시오.
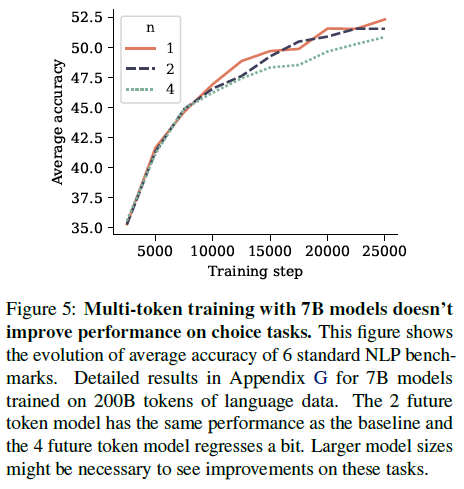
그림 5: 7B 모델을 사용한 다중 토큰 훈련은 선택 작업 성능을 향상시키지 않습니다. 이 그림은 6가지 표준 NLP 벤치마크의 평균 정확도 변화를 보여줍니다. 200B 토큰의 언어 데이터에 대해 훈련된 7B 모델에 대한 자세한 결과는 부록 G를 참조하십시오. 2개의 미래 토큰 모델은 기준선과 동일한 성능을 가지며 4개의 미래 토큰 모델은 약간 회귀합니다. 이러한 작업에서 개선을 확인하려면 더 큰 모델 크기가 필요할 수 있습니다.
3.7. 자연어에 대한 다중 토큰 예측
자연어에 대한 다중 토큰 예측 훈련을 평가하기 위해 4-토큰, 2-토큰 및 다음 토큰 예측 손실을 각각 사용하여 200B 토큰의 자연어에 대해 크기가 7B 매개변수인 모델을 훈련했습니다. 그림 5에서는 6가지 표준 NLP 벤치마크에서 결과 체크포인트를 평가합니다. 이러한 벤치마크에서 2-미래 토큰 예측 모델은 훈련 과정 전반에 걸쳐 다음 토큰 예측 기준선과 동등한 성능을 보입니다. 4-미래 토큰 예측 모델은 성능 저하를 겪습니다. 자세한 수치는 부록 G에 보고되어 있습니다.
그러나 본 연구에서는 객관식 및 가능성 기반 벤치마크가 언어 모델의 생성 능력을 효과적으로 식별하는 데 적합하지 않다고 생각합니다. 생성 품질 또는 언어 모델 판단에 대한 인간 주석의 필요성을 피하기 위해(Koo et al. (2023)에서 지적한 것처럼 자체적인 함정이 있음) 요약 및 자연어 수학 벤치마크에 대한 평가를 수행하고 각각 200B 및 500B 토큰의 훈련 세트 크기와 다음 토큰 및 다중 토큰 예측 손실을 사용하여 사전 훈련된 모델을 비교합니다.
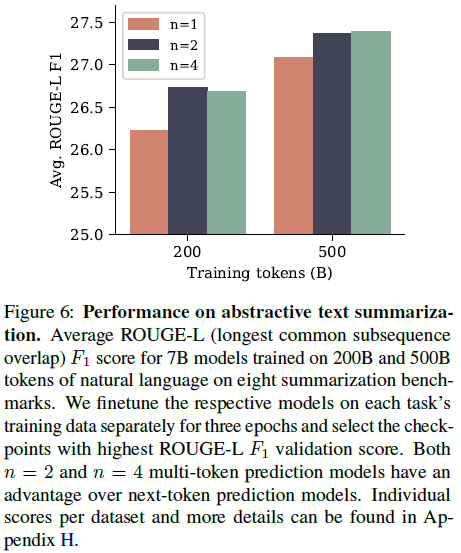
그림 6: 추상 텍스트 요약 성능. 8개의 요약 벤치마크에서 200B 및 500B 토큰의 자연어에 대해 훈련된 7B 모델에 대한 평균 ROUGE-L(가장 긴 공통 부분 시퀀스 겹침) F1 점수. 각 작업의 훈련 데이터에 대해 각 모델을 별도로 3 epoch 동안 미세 조정하고 가장 높은 ROUGE-L F1 유효성 검사 점수를 가진 체크포인트를 선택합니다. n = 2 및 n = 4 다중 토큰 예측 모델 모두 다음 토큰 예측 모델보다 우수합니다. 데이터 세트별 개별 점수 및 자세한 내용은 부록 H에서 확인할 수 있습니다.
요약의 경우 ROUGE 메트릭(Lin, 2004)을 기준 진리 요약과 비교하여 생성된 텍스트를 자동으로 평가할 수 있는 8개의 벤치마크를 사용합니다. 각 사전 훈련된 모델을 각 벤치마크의 훈련 데이터 세트에서 3 epoch 동안 미세 조정하고 검증 데이터 세트에서 가장 높은 ROUGE-L F1 점수를 가진 체크포인트를 선택합니다. 그림 6은 n = 2 및 n = 4를 사용하는 다중 토큰 예측 모델이 두 훈련 데이터 세트 크기 모두에 대해 ROUGE-L F1 점수에서 다음 토큰 기준선보다 개선되었으며 데이터 세트 크기가 커짐에 따라 성능 격차가 줄어드는 것을 보여줍니다. 모든 메트릭은 부록 H에서 찾을 수 있습니다.
자연어 수학의 경우 GSM8K 벤치마크(Cobbe et al., 2021)에서 사전 훈련된 모델을 8-shot 모드로 평가하고 few-shot 예제에서 유도된 사고 연쇄 후 생성된 최종 답변의 정확도를 측정합니다. 코드 평가와 같이 답변의 다양성과 정확성을 정량화하기 위해 pass@k 메트릭을 평가하고 0.2에서 1.4 사이의 샘플링 온도를 사용합니다. 결과는 부록 I의 그림 S13에 나와 있습니다. 200B 훈련 토큰의 경우 n = 2 모델이 다음 토큰 예측 기준선을 분명히 능가하지만 500B 토큰 이후에는 패턴이 반전되고 n = 4는 전체적으로 더 나쁩니다.
4. 합성 데이터에 대한 절제 실험
우리가 고려한 모든 작업에서 다중 토큰 예측 모델의 다운스트림 성능이 향상되는 원인은 무엇일까요? 통제된 훈련 데이터 세트 및 평가 작업에 대한 토이 실험을 수행함으로써 다중 토큰 예측이 모델 기능 및 일반화 동작에 질적인 변화를 가져온다는 것을 입증합니다. 특히, 4.1절에서는 Olsson et al. (2022)에서 논의된 바와 같이 작은 모델 크기의 경우 유도 능력이 다중 토큰 예측을 훈련 손실로 사용할 때만 형성되거나 크게 향상됨을 보여줍니다. 또한, 4.2절에서는 다중 토큰 예측이 산술 작업에 대한 일반화를 향상시키며, 모델 크기를 세 배 늘리는 것보다 더 큰 효과를 보여줍니다.
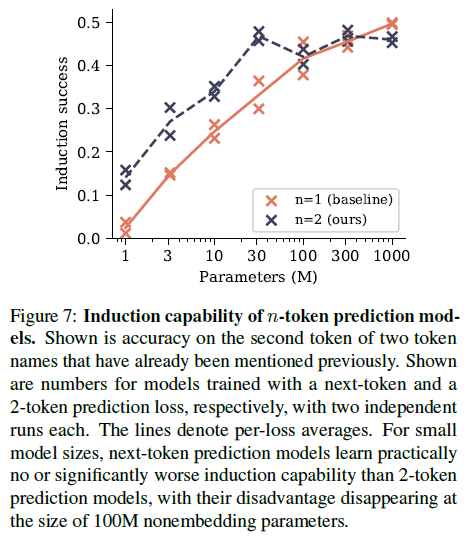
그림 7: n-토큰 예측 모델의 유도 능력. 이전에 이미 언급된 두 토큰 이름의 두 번째 토큰에 대한 정확도를 보여줍니다. 각각 두 번의 독립적인 실행을 통해 다음 토큰 및 2-토큰 예측 손실로 훈련된 모델에 대한 수치가 표시됩니다. 선은 손실별 평균을 나타냅니다. 작은 모델 크기의 경우 다음 토큰 예측 모델은 2-토큰 예측 모델보다 실질적으로 유도 능력을 배우지 못하거나 크게 떨어지며, 100M 비임베딩 매개변수 크기에서 이러한 단점은 사라집니다.
4.1. 유도 능력
유도는 부분 패턴을 가장 최근의 연속으로 완성하는 간단한 추론 패턴을 설명합니다(Olsson et al., 2022). 다시 말해, 문장에 "AB"가 포함되어 있고 나중에 "A"가 언급되는 경우, 유도는 연속이 "B"라는 예측입니다. 통제된 방식으로 유도 능력을 측정하기 위한 설정을 설계했습니다. 1M에서 1B의 비임베딩 매개변수를 가진 작은 모델을 어린이 이야기 데이터 세트로 훈련하고, 조정된 테스트 세트를 통해 유도 능력을 측정합니다: 원래 테스트 분할에서 100개의 이야기에서 문자 이름을 사용하는 토크나이저로 두 개의 토큰으로 구성된 임의로 생성된 이름으로 바꿉니다. 이 두 토큰 중 첫 번째 토큰을 예측하는 것은 이전 텍스트의 의미와 연결되지만, 각 이름이 적어도 한 번 언급된 후 두 번째 토큰을 예측하는 것은 순수한 유도 작업으로 볼 수 있습니다. 실험에서는 최대 90 epoch 동안 훈련하고 테스트 메트릭과 관련하여 조기 중지를 수행합니다(즉, epoch 오라클을 허용합니다). 그림 7은 두 개의 서로 다른 시드를 사용하여 두 번 실행하여 모델 크기와 관련하여 이름의 두 번째 토큰에 대한 정확도로 측정한 유도 능력을 보고합니다.
2-토큰 예측 손실은 30M 비임베딩 매개변수 이하 크기의 모델에서 유도 능력 형성을 크게 향상시키지만, 100M 비임베딩 매개변수 이상 크기에서는 이러한 이점이 사라짐을 발견했습니다. 이러한 결과는 다음과 같이 해석합니다. 다중 토큰 예측 손실은 모델이 시퀀스 위치 간에 정보를 전달하는 것을 학습하는 데 도움이 되며, 이는 유도 헤드 및 기타 컨텍스트 내 학습 메커니즘 형성에 도움이 됩니다. 그러나 유도 능력이 형성되면 이러한 학습된 기능은 유도를 현재 토큰에서 로컬로 해결하고 다음 토큰 예측만으로 학습할 수 있는 작업으로 변환합니다. 이 시점부터 다중 토큰 예측은 실제로 이 제한된 벤치마크에서 성능을 저하시키지만, 3.1절의 결과에서 입증된 바와 같이 더 높은 형태의 컨텍스트 내 추론에 기여한다고 추측합니다. 그림 S14에서는 이러한 설명에 대한 증거를 제시합니다. 어린이 이야기 데이터 세트를 책 데이터 세트와 어린이 이야기를 9:1 비율로 혼합한 고품질 데이터 세트로 대체하여 데이터 세트만으로 훈련 초기에 유도 능력 형성을 강제합니다. 결과적으로, 두 가지 가장 작은 모델 크기를 제외하고 작업에 대한 다중 토큰 예측의 이점은 사라집니다. 유도 기능의 기능 학습은 작업을 순수한 다음 토큰 예측 작업으로 변환했기 때문입니다.
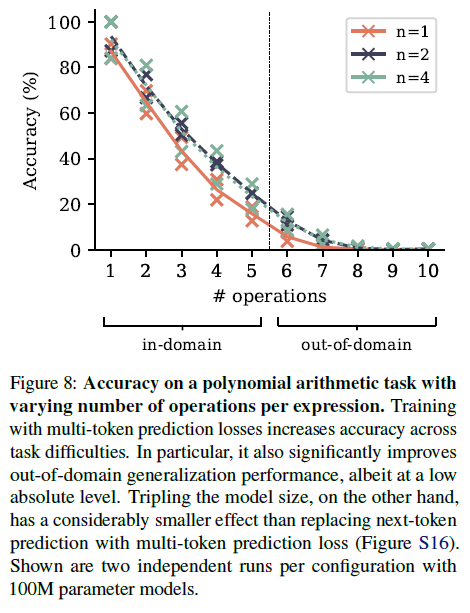
그림 8: 표현식당 연산 수가 다양한 다항식 산술 작업에 대한 정확도. 다중 토큰 예측 손실로 훈련하면 작업 난이도에 따라 정확도가 높아집니다. 특히 절대적인 수준은 낮지만 도메인 외 일반화 성능도 크게 향상됩니다. 반면에 모델 크기를 세 배 늘리는 것은 다음 토큰 예측을 다중 토큰 예측 손실로 대체하는 것보다 훨씬 더 작은 효과를 나타냅니다(그림 S16). 구성당 100M 매개변수 모델을 사용한 두 번의 독립적인 실행 결과가 표시됩니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
모델 크기를 세 배 늘리는 것은 다음 토큰 예측을 다중 토큰 예측 손실로 대체하는 것보다 훨씬 더 작은 효과를 나타냅니다(그림 S16).
- 모델의 크기를 세 배로 늘리는 것(예: 파라미터 수를 세 배로 증가시키는 것)은 다음 토큰 예측 손실을 다중 토큰 예측 손실로 바꾸는 것보다 성능 향상에 훨씬 작은 효과를 미친다는 것입니다. 이 내용은 그림 S16에서 자세히 설명되어 있습니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
4.2. 알고리즘 추론
알고리즘 추론 작업은 유도만으로는 측정할 수 없는 더 복잡한 형태의 맥락 내 추론을 측정할 수 있게 해줍니다. 본 연구에서는 단항 부정, 덧셈, 곱셈, 다항식 구성을 연산으로 하는
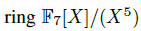
ring F7[X]/(X5)에서 다항식 산술에 대한 작업을 수행하는 모델을 훈련하고 평가합니다. 피연산자와 연산자의 계수는 균일하게 샘플링됩니다. 작업은 결과 표현식에 해당하는 다항식의 계수를 반환하는 것입니다. 표현식에 포함된 연산 수 m은 훈련 시 1에서 5 사이의 범위에서 균일하게 선택되며, 도메인 내(m ≤ 5) 및 도메인 외(m > 5) 일반화 평가의 난이도를 조정하는 데 사용할 수 있습니다. 평가는 연산 수당 2000개 샘플의 고정 테스트 세트에서 탐욕적 샘플링을 사용하여 수행됩니다. 각각 30M 및 100M 비임베딩 매개변수를 가진 두 가지 작은 크기의 모델을 학습합니다. 이는 마찬가지로 매개변수가 부족하고 전체 훈련 데이터 세트를 기억할 수 없는 대규모 텍스트 말뭉치에 대해 훈련된 대규모 언어 모델의 조건을 시뮬레이션합니다.
다중 토큰 예측은 이 작업으로 측정한 알고리즘 추론 능력을 작업 난이도에 따라 향상시킵니다(그림 8). 특히, 절대적인 수치는 낮지만 분포 외 일반화에서 인상적인 이득을 가져옵니다. 반면에 모델 크기를 30M 매개변수에서 100M 매개변수로 늘리는 것은 다음 토큰 예측을 다중 토큰 예측으로 대체하는 것만큼 평가 정확도를 향상시키지 못합니다(그림 S16). 또한 부록 K에서는 일시 중지 토큰(Goyal et al., 2023)으로 훈련하고 평가할 때 다중 토큰 예측 모델이 이 작업에서 다음 토큰 예측 모델보다 우위를 유지함을 보여줍니다.
5. 작동 원리에 대한 추측
코딩 평가 벤치마크와 소규모 알고리즘 추론 작업에서 다중 토큰 예측이 더 우수한 성능을 제공하는 이유는 무엇일까요? 이 섹션에서 개발된 본 연구의 직관은 다중 토큰 예측이 훈련 시간 교사 강요와 추론 시간 자기회귀 생성 사이의 분포 불일치를 완화한다는 것입니다. 텍스트 연속과 관련된 토큰에 대한 암묵적인 가중치와 다중 토큰 예측 손실의 정보 이론적 분해를 통해 이러한 견해를 뒷받침합니다.

그림 9: 다중 토큰 예측 손실은 결과 토큰에 더 높은 암묵적 가중치를 할당합니다. "5 → A"를 제외한 모든 전환이 예측하기 쉬운 시퀀스와 3-토큰 예측에서 해당 예측 대상이 표시됩니다. 어려운 전환 "5 → A"의 결과도 마찬가지로 예측하기 어렵기 때문에 이 전환은 "3 → A", ..., "5 → C"와의 상관관계를 통해 전체 손실에서 더 높은 암묵적 가중치를 받습니다.
5.1. 룩어헤드(lookahead)는 선택 지점을 강화합니다.
모든 토큰 결정이 언어 모델에서 유용한 텍스트를 생성하는 데 동일하게 중요한 것은 아닙니다(Bachmann and Nagarajan, 2024; Lin et al., 2024). 일부 토큰은 텍스트의 나머지 부분을 제약하지 않는 문체적 변형을 허용하는 반면, 다른 토큰은 텍스트의 상위 수준 의미 속성과 연결된 선택 지점을 나타내며 답변이 유용한지 또는 탈선하는지 결정할 수 있습니다.
다중 토큰 예측은 훈련 토큰에 후속 토큰과 얼마나 밀접하게 관련되어 있는지에 따라 암묵적으로 가중치를 부여합니다. 예를 들어, 그림 9와 같이 한 전환은 예측하기 어려운 선택 지점이고 다른 전환은 "중요하지 않은" 것으로 간주되는 시퀀스를 생각해 보십시오. 선택 지점 다음에 오는 중요하지 않은 전환도 마찬가지로 미리 예측하기 어렵습니다. 손실 항을 표시하고 계산함으로써 n-토큰 예측은 상관관계를 통해 선택 지점에 n(n+1)/2 가중치를 할당하고 중요하지 않은 지점에는 n보다 작은 가중치를 할당한다는 것을 알 수 있습니다. 자세한 내용은 부록 L.3을 참조하십시오. 일반적으로 텍스트 생성의 품질은 선택 지점에서 올바른 결정을 내리는 데 달려 있으며, n-토큰 예측 손실은 이러한 결정을 촉진한다고 생각합니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
어려운 선택 지점이 더 높은 가중치를 받는다는 점을 강조
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
5.2. 정보 이론적 논증
언어 모델은 일반적으로 교사 강요 방식으로 훈련됩니다. 이 방식에서는 모델이 훈련 중에 각 미래 토큰에 대한 정답(ground truth)을 제공받습니다. 하지만 테스트 시에는 생성 과정이 안내 없이 자기회귀적으로 진행되므로 오류가 누적될 수 있습니다. 따라서 교사 강요 방식은 모델이 단기적인 예측에만 집중하도록 유도하여 생성된 시퀀스 전체 구조의 장기적인 의존성을 무시할 가능성이 있습니다.
다중 토큰 예측의 영향을 설명하기 위해 다음과 같은 정보 이론적 논증을 고려해 봅시다. 여기서 X는 다음에 올 토큰을, Y는 그 다음에 올 토큰을 나타냅니다. 두 토큰의 생성은 관찰된 입력 맥락 C에 조건부로 결정되지만, 간단하게 하기 위해 방정식에서는 C를 생략합니다. 토큰 X 앞에서, 기존의 다음 토큰 예측은 H(X)라는 양에 관심을 둡니다. 반면, n=2인 다중 토큰 예측은 H(X) + H(Y)를 목표로 합니다. 이 두 양은 다음과 같이 분해할 수 있습니다.

여기서 H(Y | X)는 다음 위치에서 예측할 때 다시 나타나므로 무시합니다. 이를 통해 2-토큰 예측은 I(X; Y)의 중요도를 2배 증가시킨다는 것을 알 수 있습니다. 따라서 다중 토큰 예측 모델은 텍스트의 나머지 부분과 관련성이 높은 토큰 X를 예측하는 데 더 정확합니다. 부록 L.2에서는 2-토큰 예측 손실의 손실 분해에서 상대적 상호 정보의 가중치 증가를 보여주는 위 방정식의 상대적 버전을 제공합니다.
6. 관련 연구
언어 모델링 손실
Dong et al. (2019) 및 Tay et al. (2022)은 생성 작업에서 다음 토큰 사전 훈련과의 성능 격차를 해소하기 위해 다양한 어텐션 마스크(전체, 인과 및 접두사 어텐션)를 사용하는 노이즈 제거 작업을 혼합하여 훈련합니다. Tay et al. (2022)는 스팬 손상(span corruption) 목표를 사용하여 토큰 범위를 특수 토큰으로 대체하고 인코더 및 디코더가 해당 범위의 내용을 예측하도록 합니다. UniLM과 달리 이 방법은 교사 강요를 사용하여 완전한 인과 관계 훈련을 허용합니다. 유사하게, Yang et al. (2019)은 원래 위치 임베딩을 유지하면서 순열된 시퀀스에 대해 훈련하여 과거 및 미래 정보를 혼합하여 시퀀스의 다양한 부분을 예측하도록 모델을 효과적으로 훈련합니다. 이 순열된 언어 모델링은 다음 토큰을 넘어 예측할 수 있도록 허용하므로 본 연구의 작업과 가장 유사합니다. 그러나 이러한 모든 언어 모델링 작업은 입력 텍스트의 작은 비율에 대해 훈련합니다. 평균적으로 토큰의 15%만 역방향으로 전달됩니다. Dong et al. (2019)의 경우 BERT 스타일로 마스킹을 수행하므로 너무 많은 정보를 파괴하기 때문에 15% 이상 마스킹하기 어렵습니다. Tay et al. (2022)의 경우 기술적으로 더 큰 비율을 가질 수 있지만 실제로는 마스크된 토큰이 15%에서 25% 사이인 설정을 사용합니다. (Yang et al., 2019)는 순열만 하고 정보가 손실되지 않기 때문에 전체 시퀀스에 대해 훈련할 수 있도록 합니다. 그러나 실제로는 완전히 무작위 순열을 재구성하기가 매우 어렵기 때문에 훈련 안정성을 위해 15%만 예측합니다.
언어 모델링에서의 다중 토큰 예측
Qi et al. (2020)은 다중 토큰 예측이 계획을 장려하고, 표현을 개선하며, 교사 강요 훈련으로 인해 발생할 수 있는 지역 패턴 과적합을 방지한다고 주장합니다. 그러나 이들의 기술적 접근 방식은 잔차 스트림을 n배 복제하는 반면, 본 연구의 접근 방식은 계산적으로 일치하는 비교를 허용하고 잔차 표현이 보조 손실 항에 보다 직접적으로 참여하도록 합니다. Stern et al. (2018) 및 Cai et al. (2024)은 더 빠른 추론을 위해 다중 토큰 예측을 사용한 모델 미세 조정을 제안하지만 사전 훈련 중 이러한 손실의 영향에 대해서는 연구하지 않습니다. Pal et al. (2023)은 프로빙 방법을 사용하여 다음 토큰 예측 모델이 어느 정도 추가적인 연속 토큰을 예측할 수 있음을 보여주지만, 이 작업을 위해 특별히 훈련된 본 연구의 모델만큼은 아닙니다. Jianyu Zhang (2024)은 미래에 어휘 단어가 발생하는 것에 대한 다중 레이블 이진 분류를 보조 학습 작업으로 사용하여 언어 모델링 작업을 개선했음을 관찰했습니다.
자기 추측 디코딩
Stern et al. (2018)은 본 연구가 알기로는 더 빠른 추론을 위한 추측 디코딩 방식을 처음 제안했습니다. 본 연구의 아키텍처는 선형 예측 헤드를 트랜스포머 레이어로 대체하지만, 그 외에는 유사합니다. 순방향/역방향 순서를 재구성함으로써 손실 계산을 위해 확률적으로 하나의 헤드를 선택하는 대신 모든 손실 항을 사용할 수 있습니다. Cai et al. (2024)는 최선의 예측만 사용하는 대신 각 헤드의 상위 k개 예측을 사용하는 보다 정교한 자기 추측 디코딩 방식을 제시합니다. 이는 본 연구에서 훈련한 다중 토큰 예측 모델과 함께 사용할 수 있습니다.
다중 목표 예측
다중 작업 학습은 관심 있는 작업의 성능을 향상시키기 위해 여러 작업에서 신경망을 공동으로 훈련하는 패러다임입니다(Caruana, 1997). 이러한 보조 작업을 통해 학습하면 모델이 대상 변수 간의 종속성을 활용할 수 있으며 독립적인 대상의 경우에도 더 바람직할 수 있습니다(Waegeman et al., 2019). 다중 목표 예측을 위한 보다 구체적으로 맞춤화된 아키텍처를 생각할 수 있지만(Spyromitros-Xioufis et al., 2016; Read et al., 2021), 최신 딥 러닝 접근 방식은 일반적으로 본 연구와 마찬가지로 각 작업에 대해 별도의 예측 헤드가 있는 대규모 공유 모델 트렁크를 사용합니다(Caruana, 1997; Silver et al., 2016; Lample et al., 2022). 다중 목표 예측은 다양한 영역에서 성공적인 전략으로 입증되었으며, 예를 들어 미래의 더 먼 시간 단계를 보조 목표로 사용하여 시계열 예측을 학습하거나(Vapnik and Vashist, 2009) 여러 미래 프레임(Mathieu et al., 2016; Srivastava et al., 2016) 또는 미래 프레임 표현(Vondrick et al., 2016)을 보조 목표로 사용하여 비디오에서 학습하는 경우가 있습니다.
7. 결론
본 연구에서는 생성 또는 추론 작업을 위한 언어 모델 훈련에서 다음 토큰 예측을 개선하는 방법으로 다중 토큰 예측을 제안했습니다. 본 연구의 실험(최대 7B 매개변수 및 1T 토큰)은 이 방법이 더 큰 모델에서 점점 더 유용하며 특히 코드 작업에서 큰 개선을 보여준다는 것을 보여줍니다. 본 연구에서는 이 방법이 교사 강요 훈련과 자기회귀 생성 사이의 분포 불일치를 줄인다고 주장합니다. 추측 디코딩과 함께 사용하면 정확한 추론 속도가 3배 빨라집니다.
향후 연구에서는 다중 토큰 예측 손실에서 n을 자동으로 선택하는 방법을 더 잘 이해하고자 합니다. 이를 수행하는 한 가지 가능성은 손실 스케일 및 손실 균형 조정(Défossez et al., 2022)을 사용하는 것입니다. 또한 다중 토큰 예측에 대한 최적의 어휘 크기는 다음 토큰 예측에 대한 최적의 어휘 크기와 다를 가능성이 높으며, 이를 조정하면 더 나은 결과를 얻을 수 있을 뿐만 아니라 압축된 시퀀스 길이와 바이트당 계산 비용 간의 절충점을 개선할 수 있습니다. 마지막으로, 임베딩 공간에서 작동하는 개선된 보조 예측 손실을 개발하고자 합니다(LeCun, 2022).
영향 보고서
본 논문의 목표는 언어 모델의 계산 및 데이터 효율성을 높이는 것입니다. 이는 원칙적으로 LLM 훈련의 환경적 영향을 줄일 수 있지만 반동 효과에 주의해야 합니다. 본 연구를 사용하는 동안 LLM의 모든 사회적 이점과 위험을 고려해야 합니다.
환경 영향
종합적으로, 논문에 보고된 모든 모델을 훈련하는 데 A100-80GB 및 H100 유형의 하드웨어에서 약 500K GPU 시간의 계산이 필요했습니다. 예상 총 배출량은 약 50 tCO2eq이며, 이 중 100%는 Meta의 지속 가능성 프로그램에 의해 상쇄되었습니다.
감사의 글
Jianyu Zhang, Léon Bottou, Emmanuel Dupoux, Pierre-Emmanuel Mazaré, Yann LeCun, Quentin Garrido, Megi Dervishi, Mathurin Videau, Timothée Darcet 및 기타 FAIR 박사 과정 학생 및 CodeGen 팀 구성원에게 유익한 토론에 감사드립니다. Jonas Gehring에게 그의 기술 전문 지식과 원래 Llama 팀 및 xFormers 팀에게 이러한 종류의 연구를 가능하게 해주셔서 감사합니다.
'인공지능' 카테고리의 다른 글
| Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling (1) | 2024.07.11 |
|---|---|
| SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers (2) | 2024.07.10 |
| BioCLIP: A Vision Foundation Model for the Tree of Life (1) | 2024.07.08 |
| Mip-Splatting: Alias-free 3D Gaussian Splatting (1) | 2024.07.07 |
| Rich Human Feedback for Text-to-Image Generation (1) | 2024.07.06 |



