https://arxiv.org/abs/2105.15203
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
We present SegFormer, a simple, efficient yet powerful semantic segmentation framework which unifies Transformers with lightweight multilayer perception (MLP) decoders. SegFormer has two appealing features: 1) SegFormer comprises a novel hierarchically str
arxiv.org
요약:
우리는 SegFormer라는 단순하고 효율적이면서도 강력한 의미론적 분할 프레임워크를 제안합니다. SegFormer는 경량 다층 퍼셉트론(MLP) 디코더와 트랜스포머를 통합한 것입니다. SegFormer는 두 가지 매력적인 특징을 가지고 있습니다: 1) SegFormer는 다중 스케일 특징을 출력하는 새로운 계층 구조의 트랜스포머 인코더로 구성되어 있습니다. 이는 위치 인코딩을 필요로 하지 않아, 테스트 해상도가 학습 해상도와 다를 때 성능이 저하되는 위치 코드 보간을 피할 수 있습니다. 2) SegFormer는 복잡한 디코더를 피합니다. 제안된 MLP 디코더는 다양한 층에서 정보를 집계하여 로컬 주의와 글로벌 주의를 결합해 강력한 표현을 제공합니다. 우리는 이 단순하고 경량의 디자인이 트랜스포머에서 효율적인 분할의 핵심임을 보여줍니다. 우리는 SegFormer-B0에서 SegFormer-B5까지 일련의 모델을 확장하여 이전의 방법들보다 성능과 효율성이 훨씬 뛰어난 결과를 얻었습니다. 예를 들어, SegFormer-B4는 ADE20K에서 64M 파라미터로 50.3% mIoU를 달성하며, 이전 최고 방법보다 5배 작고 2.2% 더 나은 성능을 보입니다. 우리의 최고 모델인 SegFormer-B5는 Cityscapes 검증 세트에서 84.0% mIoU를 달성하고 Cityscapes-C에서 뛰어난 제로샷 견고성을 보여줍니다. 코드는 github.com/NVlabs/SegFormer에서 제공될 예정입니다.

그림 1: ADE20K에서의 성능 vs. 모델 효율성. 모든 결과는 단일 모델과 단일 스케일 추론으로 보고됩니다. SegFormer는 이전 방법보다 훨씬 더 효율적이면서도 새로운 최첨단 51.0% mIoU를 달성합니다.
1. 소개
의미론적 분할은 컴퓨터 비전에서 기본적인 과제로, 여러 다운스트림 애플리케이션을 가능하게 합니다. 이는 이미지 수준의 예측 대신 픽셀 단위의 카테고리 예측을 생성하므로 이미지 분류와 관련이 있습니다. 이러한 관계는 선구적인 연구 [1]에서 지적되고 체계적으로 연구되었습니다. 이 연구에서 저자들은 의미론적 분할 작업에 완전한 컨볼루션 네트워크(FCN)를 사용했습니다. 그 이후로 FCN은 많은 후속 연구에 영감을 주었고, 밀도 예측을 위한 주요 설계 선택이 되었습니다.
분류와 의미론적 분할 사이에는 강한 관계가 있기 때문에, 최첨단 의미론적 분할 프레임워크의 많은 부분이 ImageNet의 이미지 분류를 위한 인기 있는 아키텍처의 변형입니다. 따라서 백본 아키텍처 설계는 의미론적 분할에서 활발한 연구 분야로 남아 있습니다. 초기 방법에서 VGGs [1, 2]를 사용한 방법부터 훨씬 더 깊고 강력한 백본을 사용하는 최신 방법까지, 백본의 진화는 의미론적 분할의 성능 경계를 극적으로 밀어 올렸습니다. 백본 아키텍처 외에도 의미론적 분할을 구조화된 예측 문제로 공식화하고 맥락 정보를 효과적으로 포착할 수 있는 모듈과 연산자를 설계하는 또 다른 연구가 있습니다. 이 분야의 대표적인 예는 커널에 구멍을 내어 수용장을 확장하는 팽창 컨볼루션 [4, 5]입니다.
자연어 처리(NLP)에서의 큰 성공을 목격한 후, 비전 작업에 트랜스포머를 도입하려는 최근의 관심이 급증했습니다. Dosovitskiy 등 [6]은 이미지 분류를 위한 비전 트랜스포머(ViT)를 제안했습니다. NLP에서의 트랜스포머 설계를 따르며, 저자들은 이미지를 여러 개의 선형으로 임베딩된 패치로 나누고 위치 임베딩(PE)을 사용하여 표준 트랜스포머에 입력하여 ImageNet에서 인상적인 성능을 이끌어냈습니다. 의미론적 분할에서는 Zheng 등 [7]이 이 작업에 트랜스포머를 사용하는 가능성을 보여주기 위해 SETR을 제안했습니다. SETR은 백본으로 ViT를 채택하고 여러 CNN 디코더를 포함하여 특징 해상도를 확장합니다.
좋은 성능에도 불구하고, ViT에는 몇 가지 제한이 있습니다: 1) ViT는 단일 스케일 저해상도 특징을 출력하며 다중 스케일 특징을 제공하지 않습니다. 2) 큰 이미지에서 높은 계산 비용이 발생합니다. 이러한 제한을 해결하기 위해 Wang 등 [8]은 밀도 예측을 위한 피라미드 구조의 자연스러운 확장으로 피라미드 비전 트랜스포머(PVT)를 제안했습니다. PVT는 객체 감지와 의미론적 분할에서 ResNet 대비 상당한 개선을 보여줍니다. 그러나 Swin Transformer [9] 및 Twins [10]과 같은 다른 새로운 방법과 함께, 이러한 방법은 주로 트랜스포머 인코더 설계를 고려하고 디코더의 기여를 무시하여 추가 개선을 이끌어내지 못합니다.
이 논문은 효율성, 정확성 및 강건성을 고려한 최첨단 트랜스포머 프레임워크인 SegFormer를 소개합니다. 이전 방법과 달리, 우리의 프레임워크는 인코더와 디코더 모두를 재설계했습니다. 우리의 접근 방식의 주요 혁신은 다음과 같습니다:
- 새로운 위치 인코딩이 없는 계층적 트랜스포머 인코더.
- 복잡하고 계산 집약적인 모듈 없이 강력한 표현을 제공하는 경량의 All-MLP 디코더 디자인.
- 그림 1에서 보여지듯이 SegFormer는 효율성, 정확성 및 강건성 측면에서 세 가지 공개적으로 사용 가능한 의미론적 분할 데이터셋에서 새로운 최첨단을 설정합니다.
첫째, 제안된 인코더는 학습 해상도와 다른 해상도의 이미지에 대한 추론을 수행할 때 위치 코드를 보간하지 않도록 합니다. 그 결과, 우리의 인코더는 성능에 영향을 주지 않고 임의의 테스트 해상도에 쉽게 적응할 수 있습니다. 또한, 계층적 부분은 인코더가 고해상도 미세 특징과 저해상도 거친 특징을 모두 생성할 수 있도록 합니다. 이는 고정된 해상도의 단일 저해상도 특징 맵만을 생성할 수 있는 ViT와 대조됩니다.
둘째, 우리는 경량의 MLP 디코더를 제안하며, 주요 아이디어는 하위 계층의 주의는 로컬에 머무르고, 최고 계층의 주의는 매우 넌로컬한 트랜스포머 유도 특징을 활용하는 것입니다. 다양한 계층의 정보를 집계함으로써, MLP 디코더는 로컬 및 글로벌 주의를 결합합니다. 그 결과, 강력한 표현을 제공하는 단순하고 직관적인 디코더를 얻을 수 있습니다.
우리는 모델 크기, 실행 시간 및 정확성 측면에서 SegFormer의 장점을 세 가지 공개적으로 사용 가능한 데이터셋인 ADE20K, Cityscapes 및 COCO-Stuff에서 입증합니다. Cityscapes에서 우리의 경량 모델인 SegFormer-B0는 TensorRT와 같은 가속화된 구현 없이 48 FPS에서 71.9% mIoU를 달성하여 ICNet [11]과 비교하여 지연 시간과 성능에서 각각 60%와 4.2%의 상대적 개선을 나타냅니다. 우리의 가장 큰 모델인 SegFormer-B5는 84.0% mIoU를 달성하여 SETR [7]보다 상대적으로 1.8% mIoU 개선을 나타내면서 5배 더 빠릅니다. ADE20K에서 이 모델은 SETR보다 4배 작으면서도 51.8% mIoU의 새로운 최첨단을 설정합니다. 또한, 우리의 접근 방식은 기존 방법보다 공통적인 손상 및 교란에 대해 훨씬 더 강력하여 안전이 중요한 애플리케이션에 적합합니다. 코드는 공개적으로 제공될 예정입니다.
2. 관련 연구
의미론적 분할
의미론적 분할은 이미지 수준에서 픽셀 수준으로 확장된 이미지 분류로 볼 수 있습니다. 딥러닝 시대 [12-16]에서, FCN [1]은 의미론적 분할의 기본 작업으로, 픽셀 대 픽셀 분류를 엔드 투 엔드 방식으로 수행하는 완전한 컨볼루션 네트워크입니다. 이후 연구자들은 수용 영역 확장 [17-19, 5, 2, 4, 20], 맥락 정보 정제 [21-29], 경계 정보 도입 [30-37], 다양한 주의 모듈 설계 [38-46], AutoML 기술 사용 [47-51] 등 여러 측면에서 FCN을 개선하는 데 집중했습니다. 이러한 방법들은 많은 경험적 모듈을 도입하여 의미론적 분할 성능을 크게 향상시켰지만, 결과적으로 계산 요구량이 많고 복잡해졌습니다. 더 최근의 방법들은 트랜스포머 기반 아키텍처가 의미론적 분할에 효과적임을 입증했습니다 [7, 46]. 그러나 이러한 방법들도 여전히 계산 요구량이 큽니다.
트랜스포머 백본
ViT [6]는 순수 트랜스포머가 이미지 분류에서 최첨단 성능을 달성할 수 있음을 처음으로 증명한 연구입니다. ViT는 각 이미지를 토큰 시퀀스로 처리한 다음, 이를 여러 트랜스포머 레이어에 입력하여 분류를 수행합니다. 이후, DeiT [52]는 데이터 효율적인 훈련 전략과 ViT를 위한 증류 접근 방식을 추가로 탐구했습니다. T2T ViT [53], CPVT [54], TNT [55], CrossViT [56], LocalViT [57]와 같은 더 최근의 방법들은 ViT에 맞춤형 변화를 도입하여 이미지 분류 성능을 더욱 향상시켰습니다.
분류를 넘어, PVT [8]는 트랜스포머에 피라미드 구조를 도입한 최초의 연구로, 밀도 예측 작업에서 CNN 대비 순수 트랜스포머 백본의 잠재력을 입증했습니다. 이후, Swin [9], CvT [58], CoaT [59], LeViT [60], Twins [10] 등의 방법들은 특징의 지역 연속성을 강화하고 고정 크기 위치 임베딩을 제거하여 밀도 예측 작업에서 트랜스포머의 성능을 향상시켰습니다.
특정 작업을 위한 트랜스포머
DETR [52]는 비최대 억제(NMS) 없이 트랜스포머를 사용하여 엔드 투 엔드 객체 탐지 프레임워크를 구축한 최초의 연구입니다. 그 외에도 트랜스포머를 다양한 작업에 사용하는 연구들이 있습니다. 예를 들어, 추적 [61, 62], 초해상도 [63], ReID [64], 색상화 [65], 검색 [66], 다중 모달 학습 [67, 68] 등이 있습니다. 의미론적 분할에서는 SETR [7]이 ViT [6]를 백본으로 채택하여 특징을 추출하고, 인상적인 성능을 달성했습니다. 그러나 이러한 트랜스포머 기반 방법들은 효율성이 매우 낮아 실시간 애플리케이션에 배포하기 어렵습니다.
SegFormer는 두 가지 주요 모듈로 구성됩니다: 거친 특징과 미세 특징을 추출하는 계층적 트랜스포머 인코더와 이러한 다중 수준의 특징을 직접 융합하여 의미론적 분할 마스크를 예측하는 경량의 All-MLP 디코더입니다. "FFN"은 피드포워드 네트워크를 나타냅니다.
그림 2: 제안된 세그포머 프레임워크는 두 가지 주요 모듈로 구성됩니다: 거친 특징과 미세 특징을 추출하는 계층적 Transformer 인코더와 이러한 다단계 특징을 직접 융합하고 의미적 분할 마스크를 예측하는 경량 All-MLP 디코더입니다. "FFN"은 피드 포워드 네트워크를 나타냅니다.




그림 3: 도시 풍경의 유효 수신 필드(ERF)(평균 100개 이상의 이미지). 맨 윗줄: Deeplabv3+. 맨 아래 줄: 세그-포머. 네 단계의 ERF와 두 아키텍처의 디코더 헤드가 시각화되어 있습니다. 확대하면 가장 잘 보입니다.
효과적 수용 영역(ERF) 분석
의미론적 분할에서 맥락 정보를 포함하기 위해 큰 수용 영역을 유지하는 것은 중요한 문제입니다 [5, 19, 20]. 여기서 우리는 우리의 MLP 디코더 설계가 트랜스포머에서 효과적인 이유를 시각화하고 해석하기 위한 도구로 ERF(Effective Receptive Field) [70]를 사용합니다. 그림 3에서는 DeepLabv3+와 SegFormer의 네 가지 인코더 단계와 디코더 헤드의 ERF를 시각화합니다. 우리는 다음과 같은 관찰을 할 수 있습니다:
- DeepLabv3+의 ERF는 가장 깊은 단계인 Stage-4에서도 상대적으로 작습니다.
- SegFormer의 인코더는 낮은 단계에서 컨볼루션과 유사한 로컬 주의를 자연스럽게 생성하면서, Stage-4에서는 맥락을 효과적으로 포착하는 매우 넌로컬한 주의를 출력할 수 있습니다.
- 그림 3의 확대된 패치에서 볼 수 있듯이, MLP 헤드의 ERF(파란색 상자)는 Stage-4(빨간색 상자)와는 달리 강한 로컬 주의를 보여줍니다.
CNN의 제한된 수용 영역은 ASPP [18]와 같은 컨텍스트 모듈을 사용하여 수용 영역을 확장해야 하지만, 이는 필연적으로 무거워집니다. 우리의 디코더 설계는 트랜스포머의 넌로컬 주의로부터 이점을 얻어, 복잡하지 않으면서도 더 큰 수용 영역을 제공합니다. 그러나 동일한 디코더 설계는 CNN 백본에서는 잘 작동하지 않는데, 이는 전체 수용 영역이 Stage-4의 제한된 수용 영역에 의해 상한이 정해지기 때문이며, 이는 나중에 표 1d에서 확인할 것입니다.
더 중요한 것은, 우리의 디코더 설계가 본질적으로 트랜스포머 유도 특징의 이점을 활용하여 동시에 매우 로컬한 주의와 넌로컬한 주의를 생성한다는 것입니다. 이를 통합함으로써, 우리의 MLP 디코더는 몇 가지 파라미터만 추가하여 보완적이고 강력한 표현을 제공합니다. 이것이 우리의 설계를 동기 부여한 또 다른 중요한 이유입니다. Stage-4의 넌로컬 주의만으로는 좋은 결과를 생성하기에 충분하지 않으며, 이는 표 1d에서 확인할 수 있습니다.
4 실험
4.1 실험 설정
데이터셋: 우리는 세 가지 공개 데이터셋을 사용했습니다: Cityscapes [71], ADE20K [72], COCO-Stuff [73]. ADE20K는 150개의 세밀한 의미론적 개념을 다루는 장면 파싱 데이터셋으로 20,210개의 이미지를 포함합니다. Cityscapes는 의미론적 분할을 위한 운전 데이터셋으로 19개 카테고리의 고해상도 이미지 5,000장을 포함합니다. COCO-Stuff는 172개의 레이블을 다루며, 총 164,000개의 이미지를 포함합니다: 118,000개의 학습용 이미지, 5,000개의 검증용 이미지, 20,000개의 테스트-데브 이미지, 20,000개의 테스트-챌린지 이미지를 포함합니다.
구현 세부 사항: 우리는 mmsegmentation 코드베이스를 사용하여 8개의 Tesla V100을 가진 서버에서 학습을 진행했습니다. 인코더는 Imagenet-1K 데이터셋에서 사전 학습되었고, 디코더는 무작위로 초기화되었습니다. 학습 중에는 0.5-2.0 비율로 무작위 크기 조정, 무작위 가로 뒤집기, ADE20K, Cityscapes, COCO-Stuff 각각에 대해 512×512, 1024×1024, 512×512로 무작위 자르기를 통해 데이터 증강을 적용했습니다. [9]를 따라 우리의 가장 큰 모델 B5에 대해 ADE20K에서 자르기 크기를 640×640으로 설정했습니다. 우리는 AdamW 옵티마이저를 사용하여 ADE20K와 Cityscapes에서 160K 반복, COCO-Stuff에서 80K 반복 동안 모델을 학습시켰습니다. 예외적으로, 절제 연구에서는 모델을 40K 반복 동안 학습시켰습니다. ADE20K와 COCO-Stuff에는 배치 크기 16을, Cityscapes에는 배치 크기 8을 사용했습니다. 학습률은 초기값 0.00006으로 설정된 후 기본값으로 1.0 인자와 함께 "poly" 학습률 스케줄을 사용했습니다. 단순성을 위해, OHEM, 보조 손실 또는 클래스 균형 손실과 같은 널리 사용되는 트릭을 채택하지 않았습니다. 평가 중에는 ADE20K와 COCO-Stuff의 경우 이미지의 짧은 쪽을 학습 자르기 크기로 재조정하고 종횡비를 유지했습니다. Cityscapes의 경우, 1024×1024 윈도우로 자르기 하여 슬라이딩 윈도우 테스트를 사용하여 추론을 수행했습니다. 의미론적 분할 성능은 평균 교차 겹침(mIoU)을 사용하여 보고합니다.
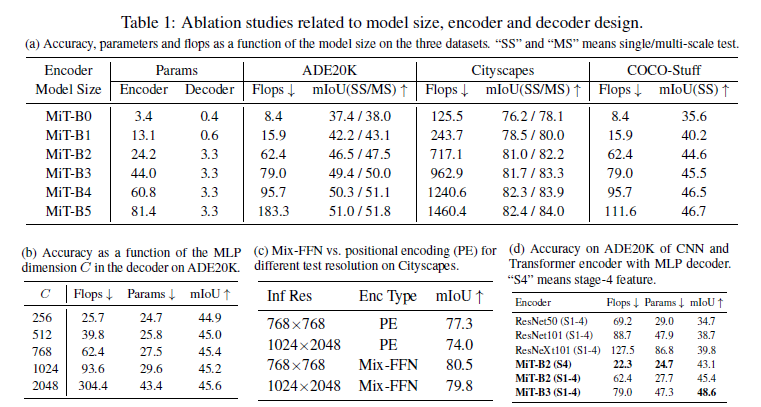
표 1: 모델 크기, 인코더 및 디코더 설계와 관련된 절제 연구. (a) 세 가지 데이터셋에서 모델 크기에 따른 정확도, 파라미터 및 FLOPs. "SS"와 "MS"는 단일/다중 스케일 테스트를 의미합니다. (b) ADE20K에서 디코더의 MLP 차원 CC에 따른 정확도. (c) Cityscapes에서 다른 테스트 해상도에 대한 Mix-FFN 대 위치 인코딩(PE). (d) MLP 디코더가 있는 CNN 및 트랜스포머 인코더의 ADE20K 정확도. "S4"는 4단계 특징을 의미합니다.
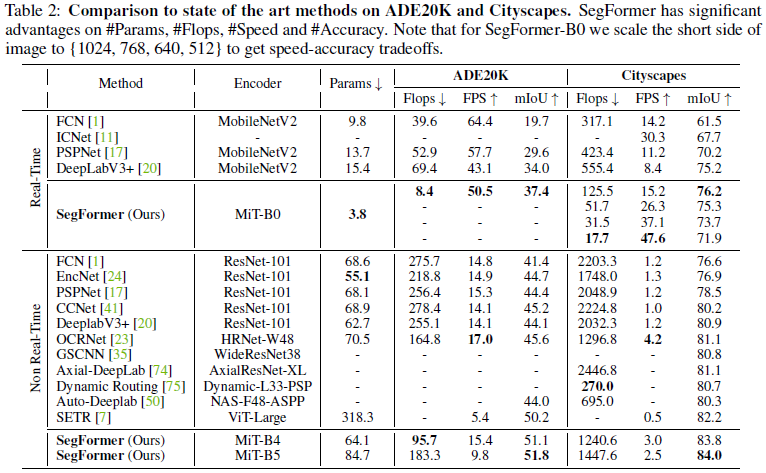
표 2: ADE20K와 Cityscapes에서 최첨단 방법과의 비교. SegFormer는 파라미터 수, FLOPs, 속도 및 정확도에서 중요한 이점을 가지고 있습니다. SegFormer-B0의 경우, 성능-속도 균형을 맞추기 위해 이미지의 짧은 측면을 {1024, 768, 640, 512}로 조정합니다.
4.2 절제 연구
모델 크기의 영향
우선 인코더 크기를 증가시키는 것이 성능과 모델 효율성에 미치는 영향을 분석했습니다. 그림 1은 인코더 크기에 따른 ADE20K의 성능 대 모델 효율성을 보여주며, 표 1a는 세 가지 데이터셋에 대한 결과를 요약합니다. 여기서 주목할 첫 번째 점은 인코더에 비해 디코더의 크기입니다. 표시된 바와 같이, 경량 모델의 경우 디코더는 단지 0.4M 파라미터만을 가지고 있습니다. MiT-B5 인코더의 경우, 디코더는 모델 전체 파라미터의 최대 4%만 차지합니다. 성능 측면에서 보면, 전체적으로 인코더 크기를 증가시키면 모든 데이터셋에서 일관된 성능 향상을 얻을 수 있습니다. 우리의 경량 모델인 SegFormer-B0는 작고 효율적이면서도 경쟁력 있는 성능을 유지하여 실시간 애플리케이션에 매우 적합함을 보여줍니다. 반면, 가장 큰 모델인 SegFormer-B5는 세 가지 데이터셋 모두에서 최첨단 결과를 달성하여 우리의 트랜스포머 인코더의 잠재력을 보여줍니다.
MLP 디코더 채널 차원 C의 영향
이제 MLP 디코더의 채널 차원 C의 영향을 분석합니다. 3.2절을 참조하십시오. 표 1b에서는 이 차원에 따른 성능, FLOPs 및 파라미터를 보여줍니다. C=256으로 설정하면 매우 경쟁력 있는 성능과 계산 비용을 제공합니다. 채널 차원이 증가할수록 성능이 향상되지만, 더 크고 덜 효율적인 모델이 됩니다. 흥미롭게도, 채널 차원이 768을 초과하면 성능이 정체됩니다. 이러한 결과를 바탕으로, 우리는 실시간 모델 SegFormer-B0, B1에 대해 C=256, 나머지 모델에 대해 C=768을 선택했습니다.
Mix-FFN vs. 위치 인코더 (PE)
이 실험에서는 제안된 Mix-FFN을 사용하기 위해 트랜스포머 인코더에서 위치 인코딩을 제거하는 효과를 분석합니다. 이를 위해, 위치 인코딩(PE)과 제안된 Mix-FFN을 사용한 트랜스포머 인코더를 학습하고, 두 가지 다른 이미지 해상도(768×768의 슬라이딩 윈도우와 1024×2048의 전체 이미지)에서 Cityscapes에 대해 추론을 수행합니다.
표 1c는 이 실험의 결과를 보여줍니다. 보시다시피, 주어진 해상도에서 Mix-FFN을 사용하는 우리의 접근 방식이 위치 인코딩을 사용하는 것보다 명확히 우수합니다. 더욱이, 우리의 접근 방식은 테스트 해상도의 차이에 덜 민감합니다: 낮은 해상도에서 위치 인코딩을 사용할 때 정확도는 3.3% 떨어집니다. 반면, 제안된 Mix-FFN을 사용할 때 성능 저하는 단지 0.7%에 불과합니다. 이러한 결과로부터, 제안된 Mix-FFN을 사용하는 것이 위치 인코딩을 사용하는 것보다 더 우수하고 강력한 인코더를 생성함을 결론지을 수 있습니다.
효과적 수용 영역 평가
섹션 3.2에서, 우리의 MLP 디코더가 다른 CNN 모델에 비해 더 큰 효과적 수용 영역을 갖는 트랜스포머의 이점을 얻는다고 주장했습니다. 이 효과를 정량화하기 위해, 이 실험에서는 ResNet이나 ResNeXt와 같은 CNN 기반 인코더와 사용할 때 우리의 MLP 디코더의 성능을 비교합니다. 표 1d에서 볼 수 있듯이, CNN 기반 인코더와 MLP 디코더를 결합하면 제안된 트랜스포머 인코더와 결합한 것보다 훨씬 낮은 정확도를 나타냅니다. 직관적으로, CNN이 트랜스포머보다 작은 수용 영역을 가지므로(섹션 3.2의 분석 참조), MLP 디코더는 글로벌 추론에 충분하지 않습니다. 반면, 트랜스포머 인코더와 MLP 디코더를 결합하면 최고의 성능을 보여줍니다. 더욱이, 트랜스포머 인코더의 경우, 고수준의 특징만이 아닌 저수준의 로컬 특징과 고수준의 넌로컬 특징을 결합하는 것이 필요합니다.
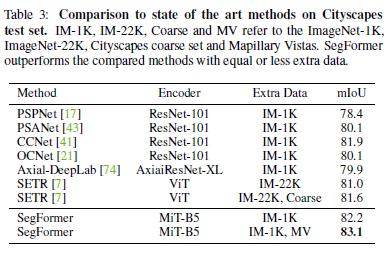
표 3: Cityscapes 테스트 세트에서 최첨단 방법과의 비교. IM-1K, IM-22K, Coarse 및 MV는 각각 ImageNet-1K, ImageNet-22K, Cityscapes 저품질 세트 및 Mapillary Vistas를 나타냅니다. SegFormer는 동등하거나 더 적은 추가 데이터를 사용하여 비교 방법을 능가합니다.
4.3 최첨단 방법과의 비교
이제 ADE20K [72], Cityscapes [71] 및 COCO-Stuff [73] 데이터셋에서 우리의 결과를 기존 접근 방식과 비교합니다.
ADE20K와 Cityscapes
표 2는 ADE20K와 Cityscapes에 대한 파라미터, FLOPS, 지연 시간, 정확도를 포함한 우리의 결과를 요약합니다. 표의 상단 부분에서는 최신 방법과 우리의 MiT-B0 경량 인코더를 사용한 결과를 포함하여 실시간 접근 방식을 보고합니다. 하단 부분에서는 성능에 중점을 두고 더 강력한 인코더를 사용하는 우리의 접근 방식과 관련 작업의 결과를 보고합니다.
ADE20K에서 SegFormer-B0는 3.8M 파라미터와 8.4G FLOPs만 사용하여 37.4% mIoU를 달성하여, 파라미터, FLOPs 및 지연 시간 측면에서 모든 다른 실시간 대안을 능가합니다. 예를 들어, DeeplabV3+ (MobileNetV2)와 비교하여 SegFormer-B0는 7.4 FPS 더 빠르며 3.4% 더 나은 mIoU를 유지합니다. 더욱이, SegFormer-B5는 이전 최고였던 SETR을 포함한 모든 접근 방식을 능가하여 51.8%의 새로운 최첨단 성능을 달성하며, 이는 SETR보다 1.6% 더 나은 mIoU를 제공하면서 훨씬 더 효율적입니다.
Cityscapes에서도 우리의 결과는 유효합니다. SegFormer-B0는 15.2 FPS와 76.2% mIoU(입력 이미지의 짧은 측면이 1024일 때)를 달성하여, DeeplabV3+와 비교하여 1.3% mIoU 향상과 2배의 속도 향상을 나타냅니다. 또한, 입력 이미지의 짧은 측면이 512일 때, SegFormer-B0는 47.6 FPS로 실행되며 71.9% mIoU를 달성하여 ICNet보다 17.3 FPS 더 빠르고 4.2% 더 나은 성능을 보입니다. SegFormer-B5는 84.0%의 최고의 IoU를 달성하여 기존 모든 방법을 최소 1.8% mIoU로 능가하며, SETR [7]보다 5배 빠르고 4배 작습니다.
Cityscapes 테스트 세트에서는 공통 설정 [20]을 따르고 검증 이미지를 학습 세트에 병합하여, ImageNet-1K 사전 학습 및 Mapillary Vistas [76]를 사용한 결과를 보고합니다. 표 3에 보고된 바와 같이, Cityscapes의 고품질 데이터와 ImageNet-1K 사전 학습만 사용하여 우리의 방법은 82.2% mIoU를 달성하여, ImageNet-22K 사전 학습 및 추가 Cityscapes 저품질 데이터를 사용하는 SETR을 포함한 모든 다른 방법을 능가합니다. Mapillary 사전 학습을 사용하면, 우리의 방법은 83.1% mIoU의 새로운 최첨단 결과를 설정합니다. 그림 4는 Cityscapes의 정성적 결과를 보여주며, SegFormer는 SETR보다 더 나은 세부 정보를 제공하고 DeeplabV3+보다 더 부드러운 예측을 제공합니다.
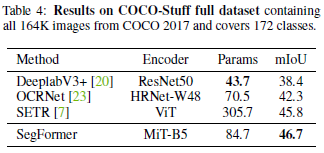
표 4: COCO-Stuff 전체 데이터셋의 결과로, COCO 2017의 모든 164K 이미지를 포함하며 172개의 클래스를 다룹니다.
COCO-Stuff
마지막으로, 우리는 전체 COCO-Stuff 데이터셋에서 SegFormer를 평가했습니다. 비교를 위해, 기존 방법들이 이 데이터셋에 대한 결과를 제공하지 않으므로, 우리는 DeeplabV3+, OCRNet, SETR과 같은 가장 대표적인 방법들을 재현했습니다. 이 경우, 이 데이터셋에서의 FLOPs는 ADE20K에서 보고된 것과 동일합니다. 표 4에서 보듯이, SegFormer-B5는 84.7M 파라미터만으로 46.7% mIoU를 달성하여 SETR보다 0.9% 더 좋고 4배 더 작습니다. 요약하자면, 이러한 결과는 정확도, 계산 비용 및 모델 크기 측면에서 SegFormer의 의미론적 분할에서의 우수성을 입증합니다.
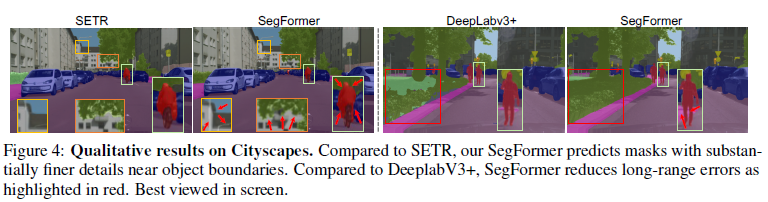
그림 4: 도시 경관에 대한 정성적 결과. SETR과 비교했을 때, 세그포머는 물체 경계 근처에서 훨씬 더 세밀한 디테일로 마스크를 예측합니다. DeeplabV3+와 비교하면 빨간색으로 강조 표시된 것처럼 SegFormer는 장거리 오류를 줄입니다. 화면에서 가장 잘 보입니다.
4.4 자연적인 손상에 대한 강건성
모델의 강건성은 자율 주행과 같은 안전이 중요한 작업에서 중요합니다 [77]. 이 실험에서는 SegFormer의 일반적인 손상과 교란에 대한 강건성을 평가합니다. 이를 위해 [77]을 따르며, 노이즈, 블러, 날씨 및 디지털 카테고리에서 알고리즘적으로 생성된 16가지 유형의 손상이 포함된 Cityscapes-C를 생성하여 Cityscapes 검증 세트를 확장했습니다. 우리는 DeeplabV3+와 다른 방법들의 변형과 우리의 방법을 비교했습니다. 이 실험의 결과는 표 5에 요약되어 있습니다.
우리의 방법은 이전 방법들을 크게 능가하며, 가우시안 노이즈에서 최대 588%, 눈 날씨에서 최대 295%의 상대적 개선을 보였습니다. 이러한 결과는 SegFormer의 강력한 강건성을 나타내며, 이는 강건성이 중요한 안전이 중요한 애플리케이션에 유익할 것으로 기대됩니다.
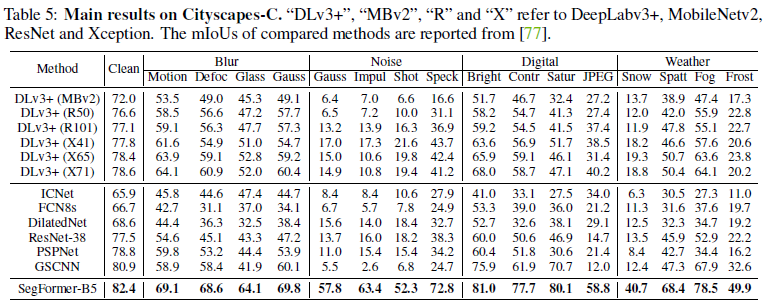
표 5: Cityscapes-C에 대한 주요 결과. "DLv3+", "MBv2", "R" 및 "X"는 각각 DeepLabv3+, MobileNetv2, ResNet 및 Xception을 나타냅니다. 비교된 방법들의 mIoU는 [77]에서 보고되었습니다.
5. 결론
이 논문에서는 단순하고 깔끔하면서도 강력한 의미론적 분할 방법인 SegFormer를 제안합니다. SegFormer는 위치 인코딩이 없는 계층적 트랜스포머 인코더와 경량의 All-MLP 디코더를 포함합니다. 이는 이전 방법의 복잡한 설계를 피하여 높은 효율성과 성능을 제공합니다. SegFormer는 일반적인 데이터셋에서 새로운 최첨단 결과를 달성할 뿐만 아니라 강력한 제로샷 강건성도 보여줍니다. 우리는 우리의 방법이 의미론적 분할을 위한 확고한 기준으로 작용하고 추가 연구를 자극하기를 바랍니다. 하나의 한계는 우리의 가장 작은 3.7M 파라미터 모델이 알려진 CNN 모델보다 작지만, 100k 메모리만 있는 엣지 디바이스 칩에서 잘 작동할 수 있을지는 불분명하다는 점입니다. 이는 향후 연구 과제로 남깁니다.
감사의 말
이 논문이 가능하지 않았을 통찰력 있는 토론을 제공한 Ding Liang, Zhe Chen, Yaojun Liu에게 감사드립니다.
'인공지능' 카테고리의 다른 글
| QLoRA: Efficient Finetuning of Quantized LLMs (1) | 2024.07.12 |
|---|---|
| Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling (1) | 2024.07.11 |
| Better & Faster Large Language Models via Multi-token Prediction (2) | 2024.07.09 |
| BioCLIP: A Vision Foundation Model for the Tree of Life (1) | 2024.07.08 |
| Mip-Splatting: Alias-free 3D Gaussian Splatting (1) | 2024.07.07 |



