https://arxiv.org/abs/2411.05003
ReCapture: Generative Video Camera Controls for User-Provided Videos using Masked Video Fine-Tuning
Recently, breakthroughs in video modeling have allowed for controllable camera trajectories in generated videos. However, these methods cannot be directly applied to user-provided videos that are not generated by a video model. In this paper, we present Re
arxiv.org
요약
최근 비디오 모델링의 돌파구는 생성된 비디오에서 제어 가능한 카메라 궤적을 가능하게 했습니다. 하지만 이러한 방법들은 비디오 모델에 의해 생성되지 않은 사용자가 제공한 비디오에는 직접적으로 적용할 수 없습니다. 본 논문에서는 ReCapture라는, 사용자가 제공한 단일 비디오로부터 새로운 카메라 궤적을 가진 새로운 비디오를 생성하는 방법을 제시합니다. 우리의 방법은 참조 비디오에 있는 모든 기존 장면 움직임을 유지하면서도, 완전히 다른 각도와 시네마틱한 카메라 움직임으로 재생성할 수 있습니다. 특히, 우리의 방법을 사용하면 참조 비디오에서 관찰할 수 없었던 장면 일부를 그럴듯하게 추론해낼 수도 있습니다. 우리의 방법은 (1) 다중 시점 확산 모델 또는 깊이 기반 포인트 클라우드 렌더링을 사용하여 새로운 카메라 궤적을 가진 노이즈가 있는 앵커 비디오를 생성하고, (2) 제안한 마스크 비디오 미세 조정 기법을 통해 앵커 비디오를 깨끗하고 시간적으로 일관된 새로운 각도의 비디오로 재생성하는 방식으로 작동합니다.

그림 1: 사용자가 제공한 소스 비디오가 주어졌을 때, ReCapture를 사용하여 새로운 맞춤형 카메라 궤적을 가진 새로운 버전의 비디오를 생성할 수 있습니다. 비디오 속 피사체와 장면의 움직임이 그대로 유지되며, 소스 비디오에는 없는 각도에서 장면을 관찰할 수 있습니다.
1. 서론
최근 확산 모델(Diffusion Models)은 비디오 생성 및 편집 [35, 76, 31, 105, 103, 32, 94, 10, 109, 66, 107, 55, 99, 27]에서 중요한 진전을 이루며, 디지털 콘텐츠 제작의 작업 흐름을 혁신하고 있습니다. 카메라 제어는 비디오 생성과 편집의 실용적인 응용에서 매우 중요한 역할을 하며, 이를 통해 사용자 맞춤성과 사용자 경험을 강화할 수 있습니다. 최근 연구들은 비디오 확산 모델에 카메라 제어 기능을 도입하였지만 [29, 2, 89, 38], 이 경우 비디오는 텍스트 프롬프트로부터 비디오 모델에 의해 완전히 생성되며, 실제 세계에서 촬영된 것도 아니고 사용자가 제공한 것도 아닙니다. 복잡한 장면 움직임을 포함하는 기존 사용자 제공 비디오로부터 사용자 지정 카메라 움직임을 가진 새로운 비디오를 효과적으로 생성하는 것은 여전히 열려 있고 어려운 문제입니다.
이 과제는 참조 비디오에서 제한된 정보량 때문에 본질적으로 제대로 정의되지 않은 문제입니다. 장면의 4D 콘텐츠에 대한 완전한 지식이 없으면 모든 각도에서 장면이 어떻게 보일지 정확히 알 수 없습니다. 그러나 이것이 사용자가 충분히 받아들일 수 있는 그럴듯한 대략적인 해결책을 배제하지는 않습니다. 이전 연구들은 동기화된 다중 시점 비디오가 사용 가능하다는 가정 하에 유망한 결과를 보였습니다 [64], 이는 4D 신경 표현을 구축하는 방식입니다. 이후의 연구들 [87, 53, 45, 92, 80]은 단일 단안 비디오를 사용하여 4D 재구성을 가능하게 했지만, 정확한 카메라 자세와 깊이 추정이 필요하며 원래 시야 밖의 콘텐츠를 캡처할 수는 없습니다. 본 논문에서는 이 문제를 비디오 간 번역 작업(video-to-video translation task)으로 재구성합니다. Camera Dolly [82] 역시 비디오 간 파이프라인을 개발했지만, 시뮬레이션을 통해 얻은 다른 카메라 자세를 가진 4D 비디오 데이터가 필요하여 운전이나 정육면체 물체와 같은 도메인 내 장면으로 제한됩니다. 야외에서 다양한 카메라 움직임을 가진 페어 비디오를 얻는 도전 때문에 이 문제를 비디오 간 파이프라인으로 종단 간 해결하는 것은 어렵고, 우리는 이를 두 단계로 나누어 해결합니다. 우리의 접근 방식은 이미지 및 비디오 도메인에서 확산 생성 모델의 사전 지식을 활용하여, 요청된 카메라 궤적에서 촬영한 것처럼 비디오를 효과적으로 새로운 각도로 재각도화(reangle)합니다.
우리 방법의 첫 번째 단계에서는 사용자 제공 카메라 궤적과 참조 비디오를 조건으로 불완전한 앵커 비디오를 생성하고자 합니다. 우리는 초기 단계에서 대상 비디오의 프레임별 깊이 추정을 부분적으로 수행합니다. 각 프레임을 깊이 추정기를 사용하여 3D 공간으로 투사해 포인트 클라우드 시퀀스를 얻습니다. 그런 다음 확대(zoom), 팬(pan), 기울기(tilt)와 같은 사용자가 지정한 카메라 움직임을 시뮬레이션하고, 새로운 카메라 궤적에 따라 포인트 클라우드 시퀀스를 렌더링합니다. 이 추정은 부분적인 것인데, 그림 4에서 볼 수 있듯이 이러한 카메라 움직임은 원래 비디오 경계 밖의 검은 영역을 도입하거나 포인트 클라우드 투사의 특성상 일부 블러링을 일으키며, 프레임별로 생성되기 때문에 시간적 일관성이 떨어지기 때문입니다. 최근의 3D 재구성 발전을 활용하는 또 다른 방식은 카메라 자세와 개별 비디오 프레임을 조건으로 하는 다중 시점 확산 모델(multiview diffusion model) [24]을 사용하는 것입니다. 이 방법 역시 시간적 일관성이 떨어지고, 블러와 장면 외부의 검은 영역, 그리고 기타 잡음이 있는 앵커 비디오를 생성하게 됩니다.
이 앵커 비디오를 사용하여 우리는 원하는 카메라 궤적을 가진 깨끗한 출력을 생성할 수 있습니다. 이를 위해 우리는 새로운 기법인 마스크 비디오 미세 조정(masked video fine-tuning)을 제안합니다. 이 기법은 생성된 앵커 비디오의 알려진 픽셀과 추가 참조 프레임 데이터에 대해 컨텍스트 인지(context-aware) 공간 LoRA와 시간적 모션 LoRA를 학습하는 방식으로 이루어집니다. 구체적으로, 공간 LoRA는 비디오 확산 모델의 공간 레이어에 포함되며, 소스 비디오에서 추출된 증강된 프레임에 대해 미세 조정됩니다. 이를 통해 모델이 소스 비디오의 피사체 외형과 배경 맥락을 학습할 수 있게 합니다. 시간적 LoRA는 새로운 카메라 궤적에 따른 장면 움직임을 학습할 수 있게 하며, 비디오 확산 모델의 시간 레이어에 삽입되어 앵커 비디오에 대해 마스크된 손실(masked loss)을 사용해 미세 조정됩니다. 알려지지 않은 영역은 마스크 처리되어 손실 계산에서 제외되며, 모델이 의미 있고 알려진 영역과 움직임에 집중할 수 있게 합니다.
추론 단계에서, 비디오에 특정한 공간 및 시간적 LoRA를 갖춘 확산 모델은 앵커 비디오의 알려지지 않은 영역을 그럴듯한 콘텐츠로 자동으로 채울 수 있으며, 확산 모델의 사전 지식과 공간 LoRA로 제공된 맥락을 활용합니다. 이는 시간적 일관성을 크게 개선하고 앵커 비디오의 흔들림을 제거합니다. 그 결과로서, 원래 앵커 비디오에서 학습한 시간적 LoRA 훈련을 통해 움직임과 레이아웃을 보존하는 일관되고 의미 있는 비디오 출력이 생성됩니다. 마지막으로, 정제 단계로서 시간적 LoRA를 제거하고 컨텍스트 인지 공간 LoRA만 유지하여 생성된 비디오에 SDEdit [56]을 적용함으로써 블러링을 줄이고 시간적 일관성을 더욱 개선할 수 있습니다.
결국, 우리는 원본의 복잡한 장면 움직임과 전체 내용을 보존하면서 새로운 카메라 궤적을 가진 비디오를 생성할 수 있습니다. 특히, 페어 비디오 데이터가 필요 없이 이를 달성합니다. 궁극적으로, 우리의 방법은 훈련 데이터로 페어 비디오를 필요로 하는 Generative Camera Dolly [82]와 기타 4D 재구성 방법 [93, 48]보다 Kubric 데이터셋 [82]에서 우수한 성능을 보입니다. 또한, 제안한 방법의 각 구성 요소는 VBench [40]에서의 절단 연구(ablation studies)를 통해 검증되었습니다.
2. 관련 연구
그림 2: ReCapture는 설정 단계에서 (a) 앵커 비디오 생성, (b) 공간 및 시간적 LoRA를 사용한 마스크 비디오 미세 조정으로 구성됩니다. 새로운 카메라 궤적을 가진 깨끗한 출력 비디오를 생성하기 위해 우리는 비디오 모델의 추론을 수행하기만 하면 됩니다.
------
결국 그림으로만 봐도 확실하게 이해 가능하다. Trajectory를 이어주는 방향으로 생성해주는 것이다.
------
비디오 확산 모델(Video Diffusion Model)
최근 비디오 생성 방법들 [41, 70, 105, 30, 15, 37, 4, 16, 97, 25]은 최첨단 성능과 강력한 오픈 소스 커뮤니티 덕분에 주로 확산 모델 [34, 79, 60]을 활용합니다. 몇몇 접근법은 3D-UNet 아키텍처를 사용하여, 이미지 확산 모델을 학습 가능한 시간 레이어로 확장하기도 합니다 [37, 10, 26, 4, 7]. 다른 연구들에서는 이산(discrete) [43] 및 연속(continuous) 토큰 [54, 27, 11]을 사용하는 트랜스포머 아키텍처를 탐구했습니다. 본 논문에서는 오픈 소스인 Stable Video Diffusion (SVD) [7]을 비디오 확산 모델로 사용합니다.
비디오 확산 모델의 개인화(Personalization of Video Diffusion Models)
현재 이미지 생성 모델의 개인화 문제는 지난 몇 년 동안 잘 탐구되어 왔으며, 주제 중심 생성 [71, 22, 72, 18, 100], 스타일 중심 생성 [78, 86, 33, 69], 스타일+주제 중심 생성 [75, 73], 그리고 이미지 레벨 개인화를 통한 인페인팅 [81]에 대한 연구가 진행되었습니다. 비디오 모델의 개인화 연구는 더 드물지만, Dreamix [58]처럼 주어진 비디오에 대해 비디오 모델을 미세 조정하는 것, Still-Moving [14]처럼 맞춤형 이미지 모델을 공간 및 시간 어댑터를 사용해 비디오 도메인으로 확장하는 것, Movie Gen [62]처럼 비디오 모델의 조건 경로를 직접 학습시키는 최근 연구들이 있습니다. 우리의 방법은 이와는 전혀 다른 응용 프로그램을 목표로 하지만, 이러한 방법들은 중요하며 관련이 있습니다.
카메라 제어를 통한 비디오 생성(Video Generation with Camera Control)
최근 연구들은 입력 텍스트와 일치하며 지정된 카메라 궤적과 일치하는 비디오를 생성하기 위해 비디오 생성 모델에 명시적인 카메라 제어 기능을 추가하는 것을 연구했습니다. 대부분의 방법들 [89, 29, 2, 98, 44]은 카메라 매개변수를 수락하는 추가 모듈을 도입하고 이를 감독 학습 방식으로 훈련합니다. Viewcrafter [102]와 Training-Free [38] 같은 접근법은 렌더링 사전(기존의 경험적 지식)을 입력으로 활용해 카메라 제어를 달성합니다.
이전 연구들이 비디오 생성 과정에 카메라 제어를 통합하는 것과 달리, 우리 방법은 사용자 제공 비디오의 카메라 궤적을 변경하면서 원래의 콘텐츠와 역학을 보존합니다.
동적 장면의 새로운 시점 합성(Novel View Synthesis of Dynamic Scene)
새로운 시점 합성은 오랜 과제로, 장면의 몇몇 희소한 시점을 가지고 모델이 관찰되지 않은 카메라 위치에서 새로운 시점을 예측하는 것입니다 [52, 63, 49, 85, 88, 17, 28, 61, 106, 36, 95, 83]. 그러나 이러한 방법을 비디오에 확장하는 것은 매우 까다롭습니다. 왜냐하면 이러한 방법들은 다중 시점 학습 데이터를 필요로 하기 때문입니다. 장면의 다양한 시점을 얻는 것이 어렵긴 하지만, 다양한 카메라 궤적을 가진 동기화된 비디오 쌍을 얻는 것보다는 훨씬 더 실현 가능성이 높습니다.
최근에는 동적 장면(즉, 비디오)의 새로운 시점을 생성하는 방법들이 도입되었습니다. 초기에는 이러한 방법들이 여러 개의 동기화된 입력 비디오에 의존했으며 [3, 5, 46], 이는 실용적인 적용을 제한했습니다. NeRF [57]의 발명으로, 새로운 방법들이 장면의 4D 부피 표현을 구축하고 시간 변화 NeRF를 사용하여 다른 시점을 렌더링하는 방식으로 발전했습니다 [47, 96, 20, 47, 65, 59]. 이러한 방법들은 입력 비디오에 다양한 카메라 시점이 포함되어야 하며, 원래 비디오에 존재하는 시야 밖으로 일반화하는 데 어려움을 겪습니다.
최근의 접근법은 보다 자연스러운 단안 비디오(monocular video)를 지원합니다. DynIBaR [48]은 단안 비디오에서 인접한 시점의 특징을 카메라 인지 방식으로 집계하는 부피 기반 이미지 렌더링 프레임워크를 사용합니다. DpDy [84]는 이미지 기반 확산 모델을 활용해 정적 및 동적 NeRF 구성 요소를 결합한 하이브리드 4D 표현을 생성합니다. 더 최근에는 동적 3D 가우시안 분할 [91, 21]을 사용해 4D 장면을 재구성하고 실시간 렌더링을 달성하는 접근법도 있습니다.
이 방법들은 매력적인 결과를 생성하지만, 종종 카메라 이동으로 생성된 효과적인 다중 시점 큐에 의존하며, 이는 카메라 텔레포테이션이나 준정적(quasi-static) 장면이 필요하거나 단안 비디오에서 부족할 수 있습니다 [23]. 또한, 종종 제공된 시야 밖으로 외삽하는 데 어려움을 겪습니다. 최근에는 텍스트-4D 및 이미지-4D 관련 논문들이 등장했지만, 결과는 주로 개별 객체나 동물의 애니메이션에 국한되어 있습니다 [77, 1, 50, 108, 68, 67, 104]. 다른 연구들은 [101, 90] 더 복잡한 장면을 다루지만, 4D 학습 데이터 또는 정교한 4D 재구성을 필요로 합니다.
우리 방법은 명시적인 4D 표현을 구축하는 대신, 비디오 생성 모델의 움직임 사전 지식을 활용하여 이 작업을 비디오 간 번역(video-to-video translation)으로 재구성합니다. 즉, 요청된 카메라 궤적에서 주어진 비디오를 재생성하는 것입니다. 우리는 우리의 방법이 실제 비디오에서도 효과적으로 작동하며, 카메라가 원래 시야를 넘어 움직일 때도 의미 있는 콘텐츠를 생성할 수 있음을 보여줍니다.
3. 방법(Method)
우리 방법은 두 단계로 이루어져 있습니다. 첫 번째 단계에서는 새로운 카메라 궤적에 따라 불완전하고 노이즈가 있는 앵커 비디오를 생성하고, 두 번째 단계에서는 제안된 마스크 비디오 미세 조정 기법을 사용해 이 앵커 비디오를 깨끗하고 시간적으로 일관된 새로운 각도의 비디오로 재생성합니다.
좀 더 구체적으로, 첫 번째 단계는 이미지 기반 시점 합성으로 구성되며, 각 입력 비디오 프레임을 독립적으로 변환하여 새로운 카메라 자세를 가진 노이즈가 있는 앵커 프레임과 그 유효성 마스크를 생성합니다. 이러한 프레임들은 일반적으로 불완전합니다. 드러난 폐색으로 인해 누락된 정보와 같은 결함을 가지며, 구조적 변형과 깜빡임과 같은 시간적 불일치가 있습니다.
우리의 전체 방법은 첫 번째 단계에서 앵커 프레임을 생성하는 특정 기술에 독립적이며, 본 연구에서는 두 가지 기술을 탐구합니다: 포인트 클라우드 시퀀스 렌더링과 다중 시점 프레임별 이미지 확산. 우리의 전체 방법은 앵커 비디오의 오류를 수정하고 시간적 불일치를 해결하며 누락된 정보를 완성할 수 있습니다.
두 번째 단계에서는 새로운 마스크 비디오 미세 조정 전략을 적용합니다. 우리는 앵커 비디오의 손상된 부분을 마스크하는 마스크된 손실(masked loss)을 사용해 시간적 모션 LoRA를 훈련시킵니다. 이 과정은 모델이 앵커 비디오의 카메라 움직임과 역학을 따르면서도 모델의 사전 지식을 기반으로 누락된 부분을 완성하는 비디오를 생성하도록 합니다. 또한, 소스 비디오의 프레임으로부터 생성된 증강 이미지를 사용해 컨텍스트 인지 공간 LoRA를 훈련합니다. 이를 위해 비디오 모델의 시간 레이어를 비활성화하고 이미지를 대상으로 훈련할 수 있게 합니다. 이 단계는 앵커 비디오의 구조적 결함을 수정하는 데 도움을 줍니다.
미세 조정 이후, 비디오 확산 모델은 앵커 비디오를 재생성하여 누락된 영역을 시간적 및 공간적으로 일관된 비디오 콘텐츠로 자연스럽게 채울 수 있게 됩니다. 더불어, 원래 비디오의 일관성, 콘텐츠, 역학을 유지하며 첫 번째 단계에서 발생한 결함을 제거하고, 새로운 카메라 움직임에 적응합니다. 최종 출력은 단순히 새로운 카메라 궤적을 가진 소스 비디오로, 이는 종종 소스 비디오에서 볼 수 없었던 장면의 시점을 포함합니다.
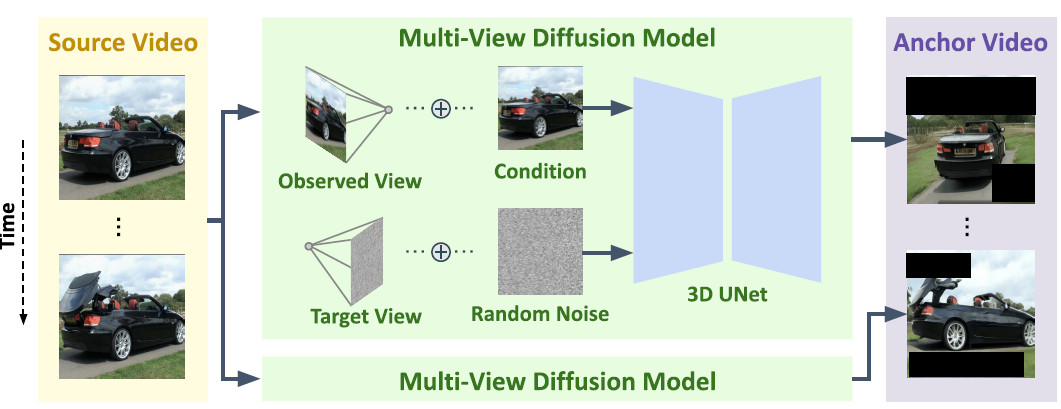
그림 3: 이미지 레벨 다중 시점 확산 모델을 사용하여 새로운 시점을 프레임별로 생성하는 앵커 비디오 생성.
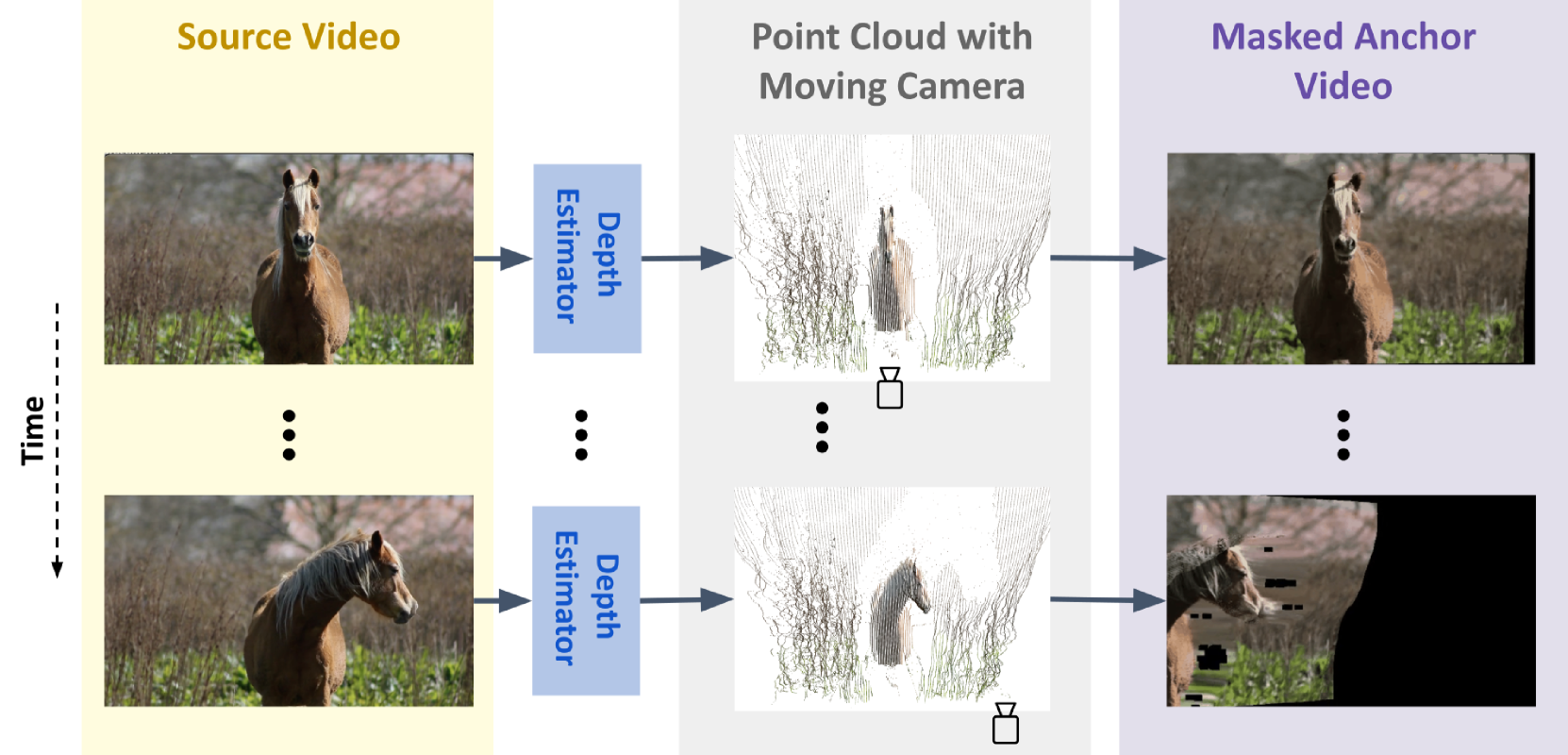
그림 4: 깊이 추정을 사용하여 각 프레임을 포인트 클라우드로 변환하고, 카메라 자세를 제어하여 새로운 시점을 생성하는 앵커 비디오 생성.
3.1 사전 지식(Preliminaries)
3D U-Net
비디오 확산 모델은 3D U-Net(공간-시간적 3D)을 훈련하여, 텍스트나 이미지 프롬프트로 안내받아 가우시안 노이즈 샘플의 시퀀스를 제거하고 비디오를 생성합니다 [10, 8]. 3D U-Net 아키텍처는 다운샘플링 블록, 중간 블록, 업샘플링 블록으로 구성되어 있습니다. 각 블록에는 다수의 공간적 합성곱 레이어, 공간 트랜스포머, 교차 주의(cross-attention) 레이어, 그리고 시간적 트랜스포머나 합성곱 레이어가 포함됩니다.
저랭크 적응(Low-Rank Adaptation, LoRA)
저랭크 적응(LoRA)은 대규모 사전 훈련된 언어 모델을 미세 조정하기 위해 도입되었습니다 [39]. 이후로 텍스트-이미지 및 텍스트-비디오 작업에서 외형 맞춤화를 위해 적용되었습니다 [71, 14]. LoRA는 가중치 행렬 W을 저랭크 분해를 통해 업데이트합니다:

3.2 새로운 카메라 움직임을 가진 앵커 비디오(Anchor Video with New Camera Motion)

우리는 새로운 카메라 궤적을 기반으로 앵커 비디오를 얻기 위해 두 가지 접근법을 제시합니다. 첫 번째 방법은 포인트 클라우드 렌더링 기법을 사용하며, 이는 팬(panning), 틸트(tilting), 줌(zoom)과 같이 단순한 이동과 소규모 회전을 포함하는 일반적인 카메라 움직임에 적합합니다. 두 번째 접근법은 궤도 회전과 같이 더 큰 회전을 포함하는 카메라 움직임을 위해 설계되었습니다. 이 방법에서는 다중 시점 확산 모델(multiview diffusion model) [24]을 사용하여 장면의 새로운 시점을 생성합니다.
포인트 클라우드 시퀀스 렌더링(Point Cloud Sequence Rendering)



그림 5: 궤도 카메라 궤적을 사용하는 Generative Camera Dolly [82]와의 비교.
각 프레임을 위한 다중 시점 이미지 확산(Multiview Image Diffusion for Each Frame)


3.3 마스크 비디오 미세 조정(Masked Video Fine-tuning)
이 단계에서 우리의 목표는 아티팩트와 불일치가 많은 불완전한 앵커 비디오를 입력으로 받아 깨끗하고 고품질의 출력을 생성하는 것입니다. 이를 달성하기 위해, 우리는 비디오 확산 모델의 마스크 미세 조정 기법을 도입하였으며, 여기에는 컨텍스트 인지 공간 LoRA와 시간적 모션 LoRA가 포함됩니다. 비디오 확산 모델의 강력한 사전 지식을 활용함으로써 앵커 비디오를 조건으로 고품질의 비디오를 생성할 수 있습니다. 다음은 우리의 구성 요소들에 대한 설명입니다:
시간적 LoRA와 마스크 비디오 미세 조정(Temporal LoRAs with Masked Video Fine-tuning)
첫 번째 단계의 앵커 비디오는 카메라 움직임으로 인한 폐색의 노출, 깜박임과 같은 시간적 불일치 등의 아티팩트를 나타낼 수 있습니다. 이러한 문제를 해결하기 위해, 우리는 시간적 모션 LoRA를 사용한 마스크 비디오 미세 조정 전략을 제안합니다. LoRA는 비디오 확산 모델의 시간 변환기 블록 내의 선형 레이어에 적용됩니다. LoRA는 저랭크 공간에서 작동하며 공간 레이어는 손대지 않기 때문에, 앵커 비디오에서 기본적인 움직임 패턴을 학습하는 데 집중하고 전체 비디오에 과적합되지 않습니다. 비디오 확산 모델의 강력한 시간적 일관성 사전 지식은 시간적 불일치를 최소화하는 데 도움을 줍니다. 우리는 앵커 비디오의 유효하지 않은 영역을 손실 계산에서 제외하여 모델이 의미 있는 픽셀만 학습하도록 하는 마스크 확산 손실(masked diffusion loss)을 도입합니다. 추론 과정에서 비디오 확산 모델은 비디오를 재생성하고, 앵커 비디오의 원래 움직임을 유지하면서 유효하지 않은 영역을 자동으로 채웁니다. 확산 훈련의 시간적 손실은 다음과 같이 정의됩니다:

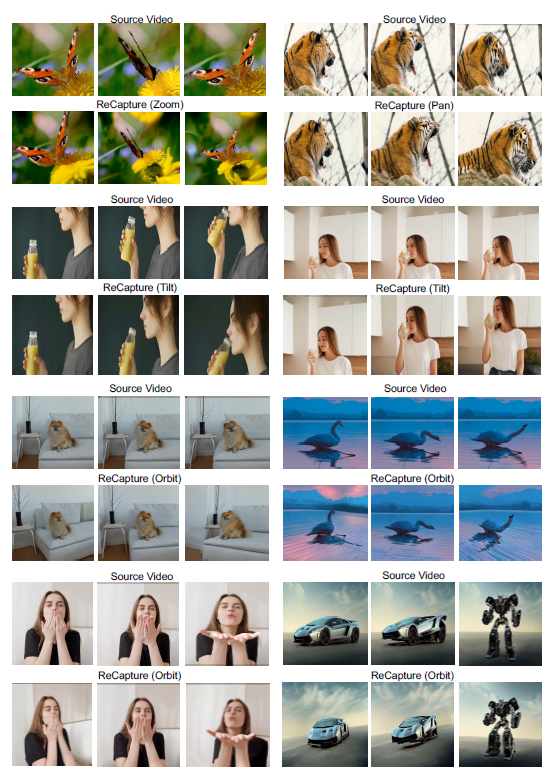
그림 6: ReCapture를 사용하여 새로운 사용자가 제공한 카메라 궤적과 함께 생성된 비디오 갤러리.
컨텍스트 인지 공간 LoRA(Context-Aware Spatial LoRAs)
마스크 미세 조정을 사용한 비디오 확산 모델은 앵커 비디오의 유효하지 않은 영역을 자동으로 채우지만, 이 채움이 원래의 맥락이나 외형과 일치하지 않을 수 있으며, 픽셀화되어 보일 수 있습니다 (그림 8의 2번째 줄 참조). 이러한 문제를 해결하기 위해 우리는 비디오 확산 모델의 공간 주의(attention) 레이어를 강화하고, 소스 비디오의 프레임에 대해 미세 조정된 공간 LoRA를 통합하는 방식을 제안합니다. 각 학습 단계에서 소스 비디오로부터 프레임이 무작위로 선택되고, 시간 레이어는 우회됩니다. 공간 LoRA 손실은 다음과 같이 정의됩니다:

표 1: VBench에서 Generative Camera Dolly와의 정량적 비교.

표 2: Kubric-4D에서의 비교 결과. 우리는 [82]를 따르는 점진적 동적 시점 합성 모델을 평가하기 위해 해상도 384×256의 비디오를 사용합니다. 우리의 방법은 다른 재구성 및 생성 방법들에 비해 우수한 성능을 달성합니다.
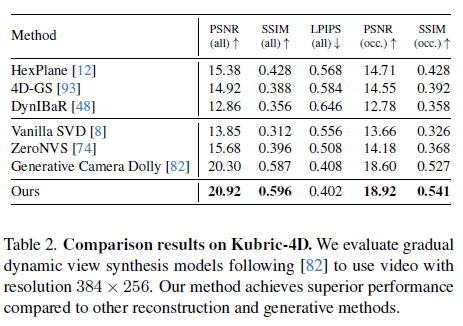
표 3: 마스크 비디오 확산 미세 조정의 각 구성 요소에 대한 절단 연구. '+ Temporal LoRAs'는 시간적 LoRA만을 사용하여 마스크 비디오 미세 조정을 적용합니다. '++ Spatial LoRAs'는 추가적인 컨텍스트 인지 LoRA를 도입하여 공간 및 시간적 LoRA 모두를 사용해 미세 조정을 수행합니다. '+++ SD-Edit'는 두 LoRA 모두로 훈련을 완료한 후 SD 편집을 적용하여 블러를 제거합니다.
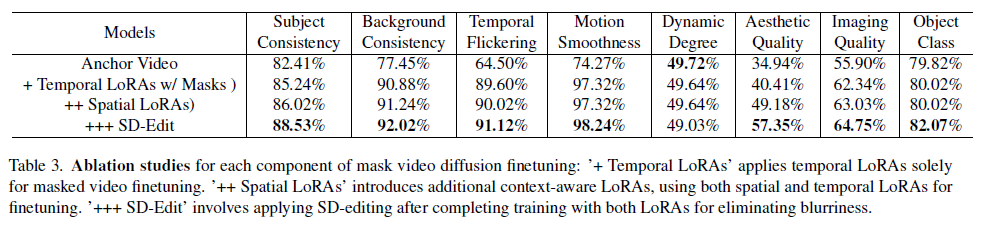
그림 7: 마스크 비디오 미세 조정(2단계)의 효과를 시각화하여 노이즈가 있는 앵커 비디오에서 공간적 및 시간적으로 일관된 출력을 생성하는 모습을 보여줍니다.

블러 제거(Eliminating Blurriness)
두 LoRA 훈련을 완료한 후, 우리는 비디오 확산 모델을 직접 사용하여 새로운 카메라 움직임을 가진 원하는 비디오를 높은 시각적 품질로 생성할 수 있습니다. 마지막으로, 그림 8의 3번째 줄에서 보여지듯이, 마스크 비디오 미세 조정으로는 완전히 해결할 수 없는 블러를 더 제거하기 위한 후처리 단계로서, 우리는 시간적 LoRA를 생략하고 공간 LoRA만을 사용하여 출력 비디오에 SD 편집(SD-editing) [56]을 수행합니다. 일반적으로 SD 편집은 피사체의 외형을 변경하는 무작위성을 도입하지만, 우리의 공간 LoRA는 소스 비디오에 대해 미세 조정되었기 때문에 원래 외형을 보존하면서 동시에 블러를 제거합니다.
우리의 방법은 대규모 4D 다중 시점 비디오 데이터에 대한 훈련 없이도 기존 비디오에 동적인 카메라 움직임을 성공적으로 추가하며, 다양한 비디오와 카메라 궤적에 일반화할 수 있습니다. 다음으로, 우리의 실험, 데이터셋, 평가 및 비교 결과를 제시합니다.
4. 실험(Experiments)
우리는 기존 비디오에서 새로운 시점 합성 작업에 대한 성능을 평가하기 위해, 주요 베이스라인과 비교하여 종합적인 정성적 및 정량적 평가를 수행합니다. 섹션 4.1에서의 정량적 분석은 자동 메트릭의 두 가지 보완적인 하위 집합을 포함합니다: PSNR 및 SSIM과 같은 저수준 통계와, 주제 일관성 같은 고수준 의미적 측정입니다. 추가적으로, 자동화되지 않은 평가를 위해 사용자 연구를 포함하였습니다. 섹션 4.3에서는 절단 연구(ablation study)를 통해 우리 접근 방식의 각 구성 요소의 중요성을 입증합니다. 섹션 4.2에서는 정성적 결과를 제시하여, 우리의 방법이 시각적으로 우수함을 보여주며, 구현 세부 사항은 섹션 4.4에서 제공됩니다.
4.1 정량적 평가(Quantitative Evaluation)
저수준 평가 메트릭(Low-level evaluation metrics)
우리는 Kubric-4D 데이터셋을 사용하여 3,000개의 장면을 평가하며, 이 중 100개의 장면은 평가 하위 집합으로 구성됩니다. 이러한 장면들은 Kubric 시뮬레이터를 사용해 생성되었으며, 복잡한 다중 객체 상호작용과 동적 움직임 패턴을 보여줍니다. 각 장면은 16개의 고정된 카메라 관점에서 동기화된 비디오를 포함하고 있으며, 해상도는 576 x 384, 60 프레임, 24 FPS로 구성되어 있습니다. 추가적으로 각 장면에는 7개에서 22개의 크기가 다양한 객체들이 포함되어 있으며, 대략 3분의 1은 초기 공중에 위치하여 복잡한 동적 요소를 도입합니다. 이러한 구성은 빈번하고 복잡한 폐색을 유도하며, 정확한 새로운 시점 합성에 상당한 도전을 제공합니다. 일관성을 위해, 우리는 [82]에서 설명된 평가 프로토콜을 따르며, 비디오를 해상도 384×256, 14 프레임으로 다운샘플링했습니다.
표 2에 나타난 바와 같이, 우리 방법은 기존의 4D 재구성 방법들을 능가하며, 생성 모델을 사용해 카메라 제어를 비디오 간 번역 작업으로 설정하는 접근 방식의 효과를 강조합니다. 특히, 우리 접근법은 4D 학습 데이터 없이도 우수한 결과를 달성하며, 대규모 4D 데이터를 훈련에 사용하는 Generative Camera Dolly를 능가합니다.
고수준 의미적 평가 메트릭(High-level semantic evaluation metrics)
[51]에서 언급한 바와 같이, 저수준 평가 메트릭은 종종 비디오의 실제 품질을 정확히 반영하지 못합니다. 예를 들어, PSNR 값이 비슷하더라도 Dolly의 시각적 품질(그림 5 참조)은 훨씬 더 흐릿하고 우리보다 열등합니다. 비디오 품질에 대한 보다 종합적이고 공정한 평가를 제공하기 위해, 우리는 VBench 데이터셋 [40]을 사용한 평가를 수행합니다. 이 벤치마크는 35개의 비디오를 포함하며, 주제 정체성 일관성, 움직임의 부드러움, 시간적 깜박임과 같은 비디오 생성의 일곱 가지 중요한 차원을 평가합니다. 이러한 세분화된 평가 메트릭은 DINO [13]와 같은 특징 추출기를 사용해 일관성을 평가하고, MUSIQ [42]로 이미지 품질을 측정합니다. 이러한 접근법은 고수준의 평가를 가능하게 하며, 각 모델의 뚜렷한 강점과 개선이 필요한 부분에 대한 깊은 통찰을 제공합니다. 우리는 각 비디오에 연관된 특정 프롬프트를 제공하여 객체 클래스 평가를 용이하게 합니다.
표 1에 나타난 바와 같이, 우리의 방법은 대부분의 평가 차원에서 큰 차이로 우수한 성과를 보였습니다. 이러한 접근법은 고수준 평가를 가능하게 하며, 각 모델의 뚜렷한 강점과 개선이 필요한 부분에 대한 깊은 통찰을 제공합니다.
4.2 정성적 비교(Qualitative Comparisons)
정성적 결과에 대해, 우리는 그림 4에서 제시된 바와 같이 Generative Camera Dolly [82]와 우리의 방법을 비교합니다. 비교 결과, 우리의 방법이 카메라 궤적을 더 정확히 따르고, Dolly보다 적은 아티팩트를 생성하며, 블러 현상도 덜 나타나는 것을 확인할 수 있습니다. 특히, 카메라 위치가 원래 비디오와 크게 다를 때에도, 우리의 방법은 피사체의 움직임과 외형을 충실히 보존하는 반면, Dolly는 이러한 조건에서 심각한 아티팩트가 발생합니다.
4.3 절단 연구(Ablation Studies)
표 3에서 우리는 우리 방법의 각 구성 요소의 영향을 평가합니다. 실험 결과, 시간적 LoRA를 마스킹과 함께 미세 조정하면 시간적 일관성과 시각적 품질이 크게 개선되는 것을 확인했습니다. 이러한 효과는 그림 8에서도 볼 수 있는데, 시간적 LoRA를 사용해 비디오를 생성하면 앵커 비디오에서 보이지 않는 영역을 채우는 데 도움이 되어 시각적 품질과 시간적 일관성을 모두 향상시킵니다. 추가적으로, 컨텍스트 인지 공간 LoRA를 통합하면 원래 비디오에 대한 사전 지식을 활용하여 시각적 품질과 피사체의 일관성을 더욱 높일 수 있습니다. 마지막으로, SDEdit을 통합하면 아티팩트를 줄임으로써 전반적인 품질을 더욱 향상시킵니다. 이러한 결과는 우리 방법의 각 구성 요소가 효과적임을 입증합니다.

그림 8: 우리 방법의 모든 구성 요소에 대한 상세한 절단 연구.
4.4 구현 세부 사항(Implementation Details)

5. 결론(Conclusion)
본 연구에서는 ReCapture를 제시하며, 기존 사용자 제공 비디오로부터 새로운 카메라 궤적을 가진 비디오를 생성하는 방법을 제안합니다. 이전 연구와 비교할 때, 비디오 모델의 강력한 사전 지식 덕분에 ReCapture는 매우 다양한 비디오와 장면에 놀라울 정도로 잘 일반화할 수 있는 능력을 가지며, 많은 경우 복잡한 장면과 피사체의 움직임을 충실하게 보존하며 장면의 세부 사항도 유지합니다.



