https://arxiv.org/abs/2410.07073
Pixtral 12B
We introduce Pixtral-12B, a 12--billion-parameter multimodal language model. Pixtral-12B is trained to understand both natural images and documents, achieving leading performance on various multimodal benchmarks, surpassing a number of larger models. Unlik
arxiv.org
초록
우리는 Pixtral 12B를 소개합니다. Pixtral 12B는 120억 개의 파라미터를 가진 멀티모달 언어 모델로, 자연 이미지와 문서를 모두 이해하도록 훈련되었습니다. Pixtral 12B는 다양한 멀티모달 벤치마크에서 탁월한 성능을 보여주며, 더 큰 모델들을 능가합니다. 많은 오픈 소스 모델들과 달리, Pixtral은 멀티모달 작업에서 우수한 성능을 보이면서도 자연어 처리 성능을 포기하지 않은 최첨단 텍스트 모델입니다. Pixtral은 처음부터 새롭게 훈련된 비전 인코더를 사용하여 이미지를 자연 해상도와 비율 그대로 처리할 수 있습니다. 이를 통해 사용자는 이미지를 처리하는 데 사용되는 토큰 수에 대한 유연성을 가질 수 있습니다. Pixtral은 또한 128K 토큰의 긴 컨텍스트 창에서 여러 개의 이미지를 처리할 수 있습니다. Pixtral 12B는 유사한 크기의 다른 오픈 모델들(Llama-3.2 11B 및 Qwen-2-VL 7B)을 상당히 능가하며, 훨씬 더 큰 오픈 모델인 Llama-3.2 90B보다도 7배 더 작으면서도 더 나은 성능을 보입니다. 우리는 또한 실용적인 시나리오에서 비전-언어 모델을 평가하기 위한 오픈 소스 벤치마크인 MM-MT-Bench를 제공하고, 멀티모달 LLM의 표준화된 평가 프로토콜을 위한 상세 분석 및 코드를 제공합니다. Pixtral 12B는 Apache 2.0 라이선스 하에 공개됩니다.
웹페이지: https://mistral.ai/news/pixtral-12b/
추론 코드: https://github.com/mistralai/mistral-inference/
평가 코드: https://github.com/mistralai/mistral-evals/
GitHub - mistralai/mistral-evals
Contribute to mistralai/mistral-evals development by creating an account on GitHub.
github.com

1 서론


그림 1: Pixtral의 성능. Pixtral은 멀티모달 작업에서 동일한 파라미터 범위 내 모든 오픈 모델들을 큰 차이로 능가합니다. 왼쪽: MM-MT-Bench에서의 성능, MM-MT-Bench는 멀티모달 언어 모델의 실제 사용을 반영하도록 설계된 새로운 멀티모달, 멀티턴, 명령 수행 벤치마크입니다. 오른쪽: 공개 LMSys 리더보드에서의 성능 (Vision arena, 2024년 10월).
이 논문은 Pixtral 12B에 대해 설명합니다. Pixtral 12B는 이미지와 텍스트를 모두 이해할 수 있도록 훈련된 멀티모달 언어 모델로, Apache 2.0 라이선스 하에 공개된 가중치와 함께 제공됩니다. Pixtral은 대규모 이미지와 텍스트 문서가 혼합된 데이터에 사전 학습된 명령 조정 모델로, 멀티턴 및 멀티 이미지 대화를 수행할 수 있습니다.
Pixtral은 새롭게 훈련된 RoPE-2D 구현을 사용한 비전 인코더를 갖추고 있어, 이미지를 본래 해상도와 비율 그대로 처리할 수 있습니다. 이를 통해 모델은 지연이 제한된 환경에서 저해상도로 이미지를 유연하게 처리하거나, 세부적인 추론이 필요할 때 고해상도로 이미지를 처리할 수 있습니다.
동일한 평가 환경에서 유사한 크기의 모델과 비교했을 때, Pixtral은 텍스트 전용 추론 성능을 저하하지 않으면서 강력한 멀티모달 추론 능력을 보여줍니다. 예를 들어, Pixtral은 Qwen2-VL 7B [23] 및 Llama-3.2 11B [6] 같은 모델의 성능을 MMU [24] 및 MathVista [14]와 같은 인기 있는 멀티모달 벤치마크에서 일치하거나 능가하며, MATH [7] 및 HumanEval [26]과 같은 인기 있는 텍스트 전용 작업에서도 대부분의 오픈 소스 모델을 능가합니다. Pixtral은 훨씬 더 큰 모델인 Llama-3.2 90B [6] 및 Claude-3 Haiku [1]나 Gemini-1.5 Flash 8B [18]와 같은 폐쇄형 모델조차 멀티모달 벤치마크에서 능가합니다.
Pixtral과 기준 모델들을 평가하는 동안, 멀티모달 언어 모델에 대한 평가 프로토콜이 표준화되지 않았으며, 설정의 작은 변경이 일부 모델의 성능에 큰 영향을 줄 수 있다는 것을 발견했습니다. 우리는 공통된 평가 프로토콜 하에서 비전-언어 모델을 재평가한 경험을 철저히 분석합니다.
구체적으로, 우리는 평가에서 두 가지 문제를 확인했습니다:
• 프롬프트: 여러 벤치마크의 기본 프롬프트가 명확하게 명시되지 않아, 주요 폐쇄형 모델 [16, 1]의 성능이 보고된 수치에 비해 크게 감소하는 경우가 많습니다.
• 평가 메트릭: 공식 메트릭은 일반적으로 정확한 일치를 요구하여, 모델이 생성한 답변이 참조 답변과 정확히 일치해야만 올바른 것으로 평가됩니다. 그러나 이 메트릭은 실질적으로 맞지만 약간 다른 형식(예: "6.0" vs "6")의 답변을 불이익을 줍니다.
이러한 문제를 해결하기 위해, 우리는 참조 답변에서 요구하는 형식을 명시적으로 지정하는 'Explicit' 프롬프트를 제안합니다. 우리는 또한 다양한 모델에 대한 유연한 구문 분석의 영향을 분석하고, 공정하고 표준화된 평가 프로토콜을 확립하기 위해 평가 코드와 프롬프트를 공개합니다.
https://github.com/mistralai/mistral-evals/
게다가, 현재의 멀티모달 벤치마크는 주로 주어진 입력 이미지에 대해 짧은 형태 또는 다중 선택 질문에 대한 답변을 평가하지만, 실제 사용 사례(예: 멀티턴, 장문 어시스턴트 환경)에서 모델의 활용도를 완전히 포착하지 못합니다. 이를 해결하기 위해, 우리는 새로운 멀티모달, 멀티턴 평가인 MM-MT-Bench를 오픈소스로 공개합니다.
https://huggingface.co/datasets/mistralai/MM-MT-Bench
우리는 MM-MT-Bench에서의 성능이 LMSys Vision 리더보드의 ELO 순위와 높은 상관관계를 가진다는 것을 발견했습니다.
Pixtral은 멀티모달 명령 수행에서 뛰어나며, MM-MT-Bench 벤치마크에서 유사한 오픈 소스 모델들을 능가합니다(그림 1 참조). LMSys Vision 리더보드에서의 인간 선호도에 따르면, Pixtral 12B는 현재 Apache 2.0 라이선스 모델 중 가장 높은 순위를 차지하며, Llama-3.2 11B [6] 및 Qwen2-VL 7B [23] 같은 다른 오픈 모델들을 크게 능가합니다. 또한, Claude-3 Opus 및 Claude-3 Sonnet [1]과 같은 일부 폐쇄형 모델, 그리고 Llama-3.2 90B [6]와 같은 더 큰 모델보다도 높은 순위를 기록하고 있습니다.
2. 아키텍처 세부사항

표 1: 디코더와 인코더 매개변수.
Pixtral 12B는 Transformer 아키텍처 [22]를 기반으로 하며, 고급 추론을 수행하기 위한 멀티모달 디코더와 이미지를 입력할 수 있도록 하는 비전 인코더로 구성되어 있습니다. 모델의 주요 매개변수는 표 1에 요약되어 있습니다.
2.1 멀티모달 디코더
Pixtral 12B는 Mistral Nemo 12B [15]를 기반으로 구축된 120억 개의 파라미터를 가진 디코더 전용 언어 모델이며, 다양한 지식 및 추론 작업에서 강력한 성능을 발휘합니다.
2.2 비전 인코더

그림 2: Pixtral 비전 인코더. Pixtral은 가변 이미지 크기와 비율을 본래 지원할 수 있도록 처음부터 새롭게 훈련된 비전 인코더를 사용합니다. 블록 대각선 어텐션 마스크는 배칭을 위한 시퀀스 패킹을 가능하게 하고, RoPE-2D 인코딩은 가변 이미지 크기를 지원합니다. 어텐션 마스크와 위치 인코딩은 비전 트랜스포머에 추가 입력으로 제공되며, 오직 자기-어텐션 계층에서만 사용됩니다.
Pixtral 12B가 이미지를 입력할 수 있도록 우리는 Pixtral-ViT라는 새로운 비전 인코더를 처음부터 훈련했습니다. 여기서 우리의 목표는 다양한 해상도와 비율의 이미지를 처리할 수 있는 간단한 아키텍처를 구현하는 것이었습니다. 이를 위해 우리는 4억 개의 파라미터를 가진 비전 트랜스포머 [5]를 구축하고, 표준 아키텍처 [17]에 네 가지 주요 변경 사항을 적용했습니다.
- 토큰 분리 (Break tokens): 동일한 패치 수(같은 면적)를 가지지만 다른 비율을 가진 이미지를 구분하기 위해 이미지 행 사이에 [IMAGE BREAK] 토큰을 추가하였습니다. 또한 이미지 시퀀스 끝에 [IMAGE END] 토큰을 추가했습니다 [2].
- FFN의 게이팅 (Gating in FFN): 주의 블록에서 표준 피드포워드 계층 대신, 숨겨진 계층에 게이팅을 사용하였습니다 [19].
- 시퀀스 패킹 (Sequence packing): 단일 배치 내에서 이미지를 효율적으로 처리하기 위해 시퀀스 차원을 따라 이미지를 평면화하고 이를 연결했습니다 [3]. 우리는 서로 다른 이미지의 패치 간 주의 누출을 방지하기 위해 블록 대각선 마스크를 구성했습니다.
- RoPE-2D (Rotary Position Encoding 2D): 우리는 이미지 패치에 대해 전통적으로 사용되던 학습된 절대 위치 인코딩 대신, 상대적인 회전 위치 인코딩(RoPE)을 자기-어텐션 계층에 사용합니다 [11, 20]. 학습된 위치 인코딩은 새로운 이미지 크기에 대응하기 위해 보간을 필요로 하며, 이로 인해 성능이 저하될 수 있습니다. 그러나 상대적인 위치 인코딩은 가변적인 이미지 크기에 자연스럽게 적용될 수 있습니다.

중요하게도, 우리의 RoPE-2D 변환의 단순한 구현은 "상대적" 특성을 만족합니다. 즉, 두 벡터 간의 내적이 그들의 높이와 너비 위치 간의 상대적 차이에만 의존하고, 절대 위치에는 의존하지 않는다는 것을 의미합니다 (자세한 내용은 부록 B를 참조).
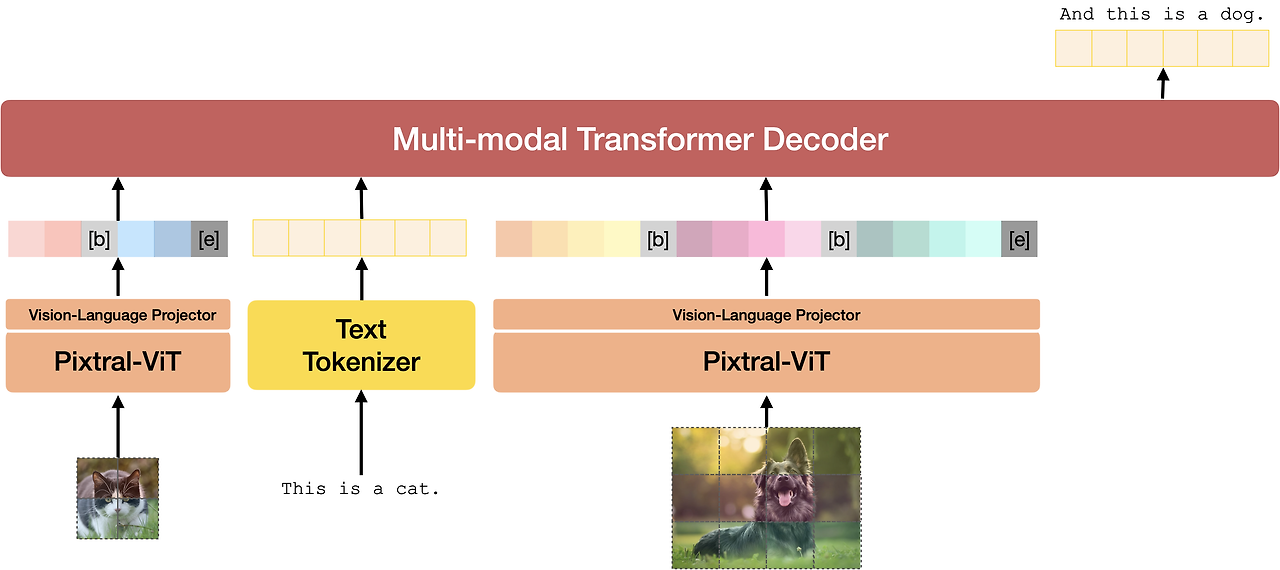
그림 3: Pixtral 전체 아키텍처. Pixtral은 이미지를 토큰화하는 비전 인코더와 텍스트 및 이미지 시퀀스가 주어졌을 때 다음 텍스트 토큰을 예측하는 멀티모달 디코더의 두 구성요소로 이루어져 있습니다. Pixtral은 128K 컨텍스트 창 내에 맞는 한도 내에서 임의의 수의 이미지를 입력으로 받을 수 있습니다.
논의: 우리의 비전 인코더는 멀티모달 모델링을 위해 특별히 설계되었습니다. 기존의 인코더는 일반적으로 ImageNet 성능을 기준으로 해상도 224×224 또는 336×336 픽셀에서 최적화됩니다. 멀티모달 언어 모델에 통합될 때는, 이전 작업들은 이미지 전체를 작은 (정사각형) 타일로 나눈 뒤 각 타일을 독립적으로 비전 인코더에 입력했습니다. 대신, 우리의 비전 인코더는 원래 비율로 고해상도와 저해상도 이미지를 모두 처리할 수 있으며, 멀티모달 작업에서 상당한 성능 향상을 제공합니다 (4.4절 참조).
2.3 전체 아키텍처
Pixtral 비전 인코더는 멀티모달 디코더와 2계층 완전 연결 네트워크를 통해 연결됩니다. 이 네트워크는 비전 인코더의 출력을 디코더가 필요로 하는 입력 임베딩 크기로 변환하며, 중간 숨겨진 계층에는 GeLU 활성화 함수 [8]를 사용합니다. 이미지 토큰은 텍스트 토큰과 동일하게 RoPE-1D [20] 위치 인코딩을 포함하여 멀티모달 디코더에 의해 처리됩니다. 특히, 우리의 디코더는 인과적 자기-어텐션 메커니즘을 사용하여 멀티 이미지 대화와 같은 기능을 매끄럽게 수행할 수 있도록 합니다. 아키텍처는 그림 3에 나와 있습니다.
3. MM-MT-Bench: 멀티모달 명령 수행을 위한 벤치마크
대부분의 기존 멀티모달 벤치마크는 주어진 입력 이미지에 대해 다중 선택 질문에 답하는 모델의 능력을 측정합니다. 이러한 평가 방식은 모델이 이미지를 이해하는 능력을 측정하는 데 유용하지만, 사용자에게 실제로 얼마나 유용한지(예를 들어, 멀티모달 어시스턴트나 챗봇으로서의 역할)는 충분히 평가하지 못합니다. 이러한 품질을 측정하기 위해 명령 조정된 텍스트 전용 모델은 일반적으로 MT-Bench [25]에서 평가되며, 독립적인 LLM 심판이 모델의 출력을 참조 답변에 대해 평가합니다. 우리는 텍스트 전용 변형과 유사하게 명령 조정된 멀티모달 모델의 성능을 평가하기 위해 '멀티모달 MT-Bench(MM-MT-Bench)'라는 새로운 벤치마크를 설계하고 공개합니다.
디자인. MM-MT-Bench는 총 92개의 대화를 포함합니다. 이 벤치마크는 5개의 이미지 카테고리(차트(21개), 테이블(19개), PDF 페이지(24개), 다이어그램(20개), 기타(8개))를 아우르는 다양한 실용적인 사용 사례를 포함하고 있습니다. 69개의 단일 턴 대화와 18개의 2턴 대화, 4개의 3턴 대화, 1개의 4턴 대화로 구성되어 있습니다. 모델을 평가하기 위해, 우리는 대화의 모든 턴을 병렬로 모델에게 질의하며, 이전 턴에 대한 참조 답변을 히스토리로 제공합니다. 각 턴은 심판에 의해 제공된 전체 대화 히스토리를 바탕으로 독립적으로 평가됩니다. 심판은 정확성(즉, 추출된 정보가 정확한가)과 완전성(즉, 모델의 답변이 참조에서 제시된 모든 점을 다루고 있는가)에 따라 1에서 10까지의 점수를 부여하도록 유도됩니다. 평가 과정은 그림 4에 설명되어 있으며, 심판 프롬프트는 부록 A.5에 제공됩니다. 표 2에 제시된 결과에 따르면, MM-MT-Bench는 LMSys-Vision ELO 등급과 0.91의 피어슨 상관 계수를 보입니다.
예제. MM-MT-Bench는 비전-언어 모델의 실제 사용을 모방하도록 설계되었으며, 이미지의 내용을 추출, 요약 및 추론하는 작업을 포함합니다. 각 카테고리에서 대표적인 이미지는 그림 12에 제공되었으며, 비전-언어 모델에서 평가된 답변의 예는 그림 11에 제공됩니다. 우리는 수동으로 이미지, 프롬프트 및 답변을 큐레이션하였으며, 두 번째 라벨러 그룹이 답변을 검증했습니다. 모든 프롬프트는 이미지 입력을 참조해야만 올바르게 답할 수 있도록 설계되어 있습니다.
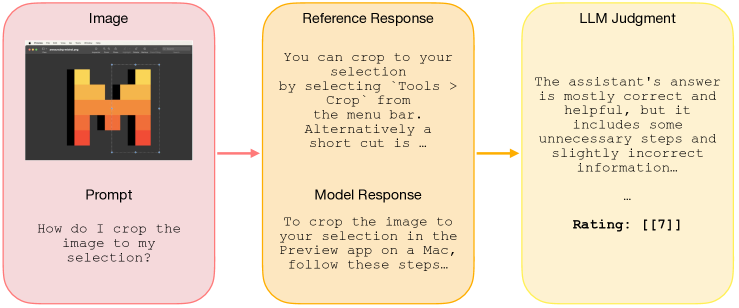
그림 4: MM-MT-Bench: 우리는 멀티모달 모델을 위한 새로운 명령 수행 벤치마크를 오픈 소스로 공개하며, 이 벤치마크는 LMSys ELO 등급과 높은 상관관계를 가집니다. 입력 이미지, 참조 답변 및 모델의 응답을 제공한 상태에서 독립적인 LLM 심판이 모델의 응답을 1에서 10까지의 점수로 평가하도록 합니다.
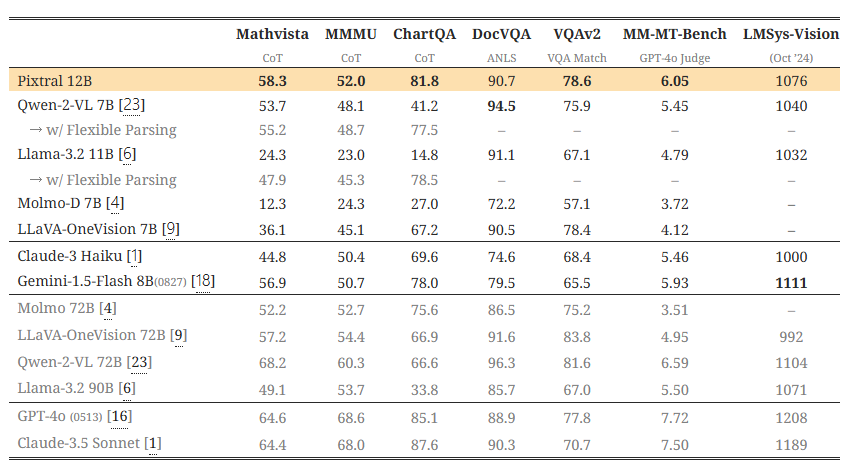
표 2: 멀티모달 벤치마크. Pixtral은 유사한 크기의 오픈 모델들뿐만 아니라 일부 폐쇄형 모델들을 상당히 능가합니다. 우리는 모든 모델을 동일한 프롬프트와 평가 메트릭으로 다시 평가했습니다(4.2절 참조). Qwen2-VL 7B [23] 및 Llama-3.2 11B [6]와의 공정한 비교를 위해, 이들의 성능을 완화된 평가 조건 하에서도 (회색으로) 추가 보고합니다(4.3절 참조). 일부 오픈 소스 모델의 보고된 수치와의 차이를 더 조사하기 위해 분석을 E절에 제공하였습니다.
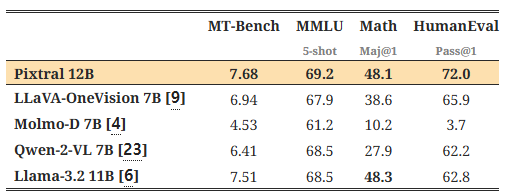
표 3: 언어 벤치마크. Pixtral 12B는 텍스트 전용 벤치마크에서 유사한 크기의 오픈 소스 모델들을 지속적으로 능가하며, 기존 텍스트 전용 배포를 위한 멀티모달 대체제로 사용할 수 있습니다.
4. 결과
이 섹션에서는 Pixtral 12B를 다양한 모델 크기에 걸쳐 폐쇄형 및 오픈 소스 모델들과 비교 평가한 결과를 제공합니다. 모든 모델을 동일한 평가 하네스를 통해 다시 평가했습니다. 특히, 각 데이터셋에 대해, 선도적인 멀티모달 모델(GPT-4o [16] 및 Claude-3.5 Sonnet [1])의 결과를 재현할 수 있도록 프롬프트를 설계하였습니다. 이 프롬프트는 'Explicit'하고 출력 형식을 완전히 명시합니다 (4.2절 참조), 이를 통해 프롬프트 지침을 따르는 모델들이 테스트 시 정확하게 평가될 수 있습니다. 모든 모델은 동일한 프롬프트로 평가되었으며, 이 프롬프트는 부록 A에 명시되어 있습니다. 다양한 프롬프트와 메트릭으로 모델을 재평가한 추가 분석은 4.2절과 4.3절, 그리고 부록 D와 E에 제공합니다.
4.1 주요 결과
멀티모달 성능: 표 2에 따르면, Pixtral은 멀티모달 벤치마크에서 그 규모에 있는 모든 오픈 모델뿐만 아니라 Claude-3 Haiku [1] 및 Gemini-1.5 Flash 8B [18]과 같은 폐쇄형 모델들을 상당히 능가합니다. 특히, Pixtral은 실제 사용 사례를 목표로 하는 MM-MT-Bench에서 유사한 크기의 모든 모델을 능가하는 성능을 보였으며, 이는 LMSys Vision Arena에서의 강력한 성능에 의해 뒷받침됩니다. 이 공개 리더보드에서 Pixtral 12B는 Qwen2-VL 72B [23] 및 Llama-3.2 90B [6]과 같은 가장 큰 오픈 가중치 모델들의 성능에 근접하고 있습니다.
우리는 'Explicit' 프롬프트를 사용했을 때, 일부 오픈 소스 모델의 성능이 보고된 수치보다 상당히 낮아진다는 점을 강조합니다. 가장 유사한 오픈 소스 모델인 Qwen2-VL 7B [23]와 Llama-3.2 11B [6]의 경우, 이는 주로 모델이 답변 형식 지침을 따르지 않는 것에서 기인합니다 (예: "정답은 6입니다." 대신 "최종 답변: 6"을 생성). 이러한 모델들과의 공정한 비교를 위해, 보다 유연한 파싱을 적용한 완화된 메트릭으로 평가한 결과를 회색으로 추가 보고합니다 (4.3절 참조). 다양한 프롬프트에서 이러한 모델들의 성능에 대한 분석은 부록 D에서 다루고 있습니다. 부록 E에서는 각 모델에 맞게 평가를 맞춤 설정하여, 보고된 성능과의 격차를 메우기 위해 필요한 변경 사항을 설명합니다.
언어 성능: 표 3은 일반적인 텍스트 전용 벤치마크에서 유사한 크기의 오픈 소스 모델들과 비교하여 Pixtral 12B의 성능을 평가한 결과입니다 (역시 공통된 프롬프트와 평가 프로토콜을 사용하여). Pixtral은 멀티모달 기능을 추구하는 과정에서 텍스트 이해를 희생하지 않으며, 텍스트와 비전 작업 모두에 대한 적합한 대체 모델로 사용될 수 있습니다.
4.2 프롬프트 선택
여기서는 평가 프롬프트를 설계하기 위한 우리의 방법론에 대해 논의합니다. 평가 하네스에서 우리는 선도적인 폐쇄형 모델들(GPT-4o [16] 및 Claude-3.5-Sonnet [1])의 보고된 결과를 재현할 수 있는 프롬프트를 선택합니다. 이 프롬프트는 부록 A에 제공되며, 10개의 프롬프트에 대한 평균 결과는 부록 D에 보고됩니다.
우리는 일반적으로 사용되는 프롬프트가 출력 형식을 제대로 명시하지 않는다는 점을 발견했습니다. 예를 들어, 다중 선택 질문의 경우, 오픈 소스 프롬프트에는 "위의 선택지 중에서 정답을 선택하십시오"와 같은 모호한 지침이 포함되어 있는 것을 확인했습니다. 이러한 경우, 모델이 정답을 인덱스로 표시해야 하는지("옵션 A", "옵션 B" 등) 아니면 자연어 응답으로 표시해야 하는지를 알 수 없으며, 그로 인해 잘못된 형식으로 응답했을 때 불이익을 받습니다. 따라서, 선도적인 모델들은 필요한 출력 형식을 명시적으로 지정하는 프롬프트가 필요합니다. 우리는 그림 5에서 MMMU의 실제 예를 통해 이를 설명합니다.
표 4에서 우리는 'Explicit' 프롬프트가 'Naive' 프롬프트에 비해 선도적인 모델들의 성능을 크게 향상시킨다는 점을 보여줍니다. 또한, 일부 경우에는 작은 모델의 성능이 Explicit 프롬프트 형식에서 감소하는 것을 확인했는데, 이는 아마도 이 벤치마크의 훈련 세트에서의 프롬프트 스타일과의 불일치 때문일 수 있습니다. Pixtral 12B는 Explicit 프롬프트에서 일반적으로 더 나은 성능을 보이며, ChartQA에서만 소폭의 성능 감소가 있었습니다.

그림 5: 'Naive' 프롬프트와 'Explicit' 프롬프트가 선도적인 모델에 미치는 영향. 선도적인 모델들은 출력 형식에 대한 세부 사항을 제공하는 'Explicit' 프롬프트에서 크게 이득을 봅니다. 그렇지 않을 경우, 본질적으로 올바른 응답이 평가 과정에서 잘못된 것으로 표시됩니다(상단 행, 오른쪽).
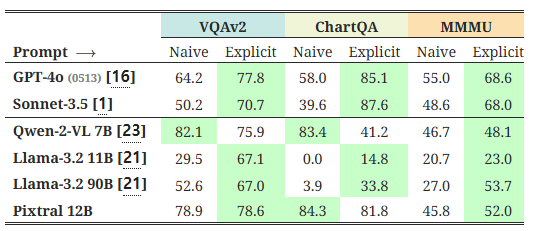
표 4: 프롬프트 실험. 선도적인 모델들은 좋은 성능을 내기 위해 출력 형식을 명시적으로 지정하는 프롬프트가 필요합니다. Pixtral 12B는 'Explicit' 및 'Naive' 프롬프트 모두에서 잘 작동하며, ChartQA에서만 소폭의 성능 감소를 보입니다.
4.3 평가 메트릭에 대한 민감도
4.2절에서, 출력 형식을 제대로 명시하는 프롬프트의 중요성에 대해 논의했습니다. 하지만 평가 과정에서, Explicit 프롬프트를 사용하더라도 여전히 많은 모델들이 다양한 형식으로 출력을 제공하며, 그 결과 참조 답변과 정확히 일치해야 한다는 메트릭에 의해 불이익을 받습니다.
이를 조사하기 위해, 우리는 모델이 생성한 답변을 점진적으로 더 유연한 파싱 제약 조건하에서 평가합니다. 예를 들어, 정답이 "6"일 때, 유연한 메트릭은 "6.0"이나 "정답은 6입니다"와 같은 답변에 대해 벌점을 주지 않습니다. 이러한 파싱 설정의 세부 사항은 부록 C에 제공됩니다. 여기서는 'Flexible Level 3'이 생성된 응답 어디에든 참조 답변이 포함되어 있다면 정답으로 표시하는 것을 의미한다는 점을 언급합니다. 이는 참조 답변이 "6"일 때 "6000"과 같은 답변도 정답으로 허용하는, 지나치게 관대한 메트릭으로 상한선을 설명하기 위한 용도로만 포함되었습니다.
우리의 분석 결과는 표 5에 나와 있습니다. 우리는 몇몇 모델의 성능이 더 유연한 파싱 메트릭을 사용했을 때 극적으로 개선되는 것을 확인하였으며, 이는 낮은 점수가 모델이 프롬프트 지침을 제대로 따르지 못하는 데 기인할 수 있음을 시사합니다. 또한, Pixtral 12B는 유연한 파싱에서 거의 이득을 보지 않으며(즉, 지침을 따르는 능력을 입증함), 유연한 메트릭이 사용된 이후에도 일반적으로 다른 모델들을 능가할 수 있음을 확인했습니다.
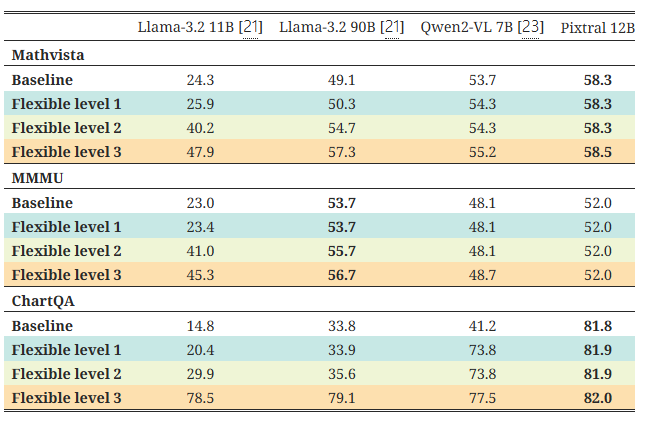
표 5: 유연한 파싱 실험. 우리는 모델들을 점진적으로 더 느슨한 파싱 제약 조건하에서 평가합니다(자세한 내용은 부록 C 참조). 느슨한 파싱 제약 조건에서 일부 모델의 성능은 극적으로 향상됩니다. Pixtral 12B의 성능은 모든 파싱 조건에서 안정적이며, 유연한 파싱이 적용된 이후에도 여전히 선두를 유지합니다. 'Flexible Level 3'은 일부 잘못된 답변도 정답으로 표시될 수 있기 때문에 설명 목적으로만 포함되었습니다.
4.4 비전 인코더 실험
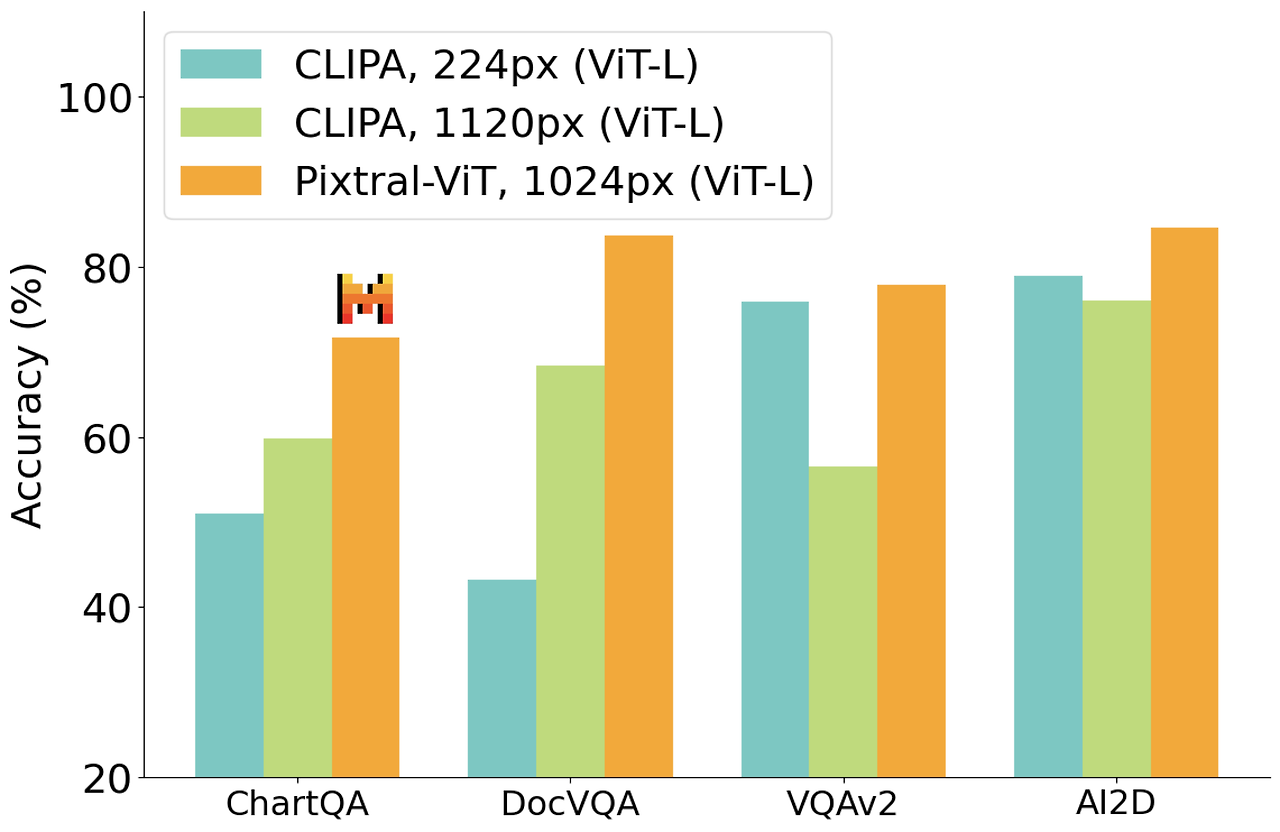
그림 6: 비전 인코더 실험: 우리의 인코더는 시각 명령 조정에 활용될 때, 세밀한 문서 이해가 필요한 작업에서 강력한 CLIPA [10] 기준 모델을 크게 능가하며, 자연 이미지에 대해서는 유사한 성능을 유지합니다.
비전 인코더에 대한 설계 선택을 검증하기 위해, 우리는 Visual Instruction Tuning [13]을 사용하여 소규모 실험을 수행했습니다. 우리는 멀티모달 명령 조정을 짧은 범위로 수행했으며, 이를 위해 우리 비전 인코더(Pixtral-ViT)와 CLIPA [10] 백본을 기준 모델로 사용했습니다. 두 비전 인코더 모두 멀티모달 디코더를 초기화하기 위해 Mistral-Nemo 12B-Instruct [15]를 사용했습니다.
다른 많은 오픈 소스 비전 인코더들처럼, CLIPA는 고정된 해상도 224×224 픽셀에서 훈련되었습니다. 비전-언어 모델에서 해상도를 높이기 위해, 기존 방법 [12]은 이미지를 여러 타일로 잘라내어, 각 타일을 사전 학습된 해상도로 비전 인코더에 독립적으로 전달합니다. 우리는 CLIPA와 함께 두 가지 실험을 진행했습니다: (a) 전체 이미지를 224×224로 리사이즈; (b) 입력 이미지를 25개의 타일로 구성하여 총 해상도가 1120×1120이 되도록 함. 이 모델들은 각각 224 픽셀 및 1120 픽셀에서 평가되었으며, 반면에 우리의 유연한 인코더는 최대 해상도 10241024 픽셀에서 가변적인 이미지 해상도로 평가되었습니다.
그림 6에서 우리는, 차트 및 문서 이해와 같이 세밀한 이해가 필요한 상황에서 우리의 모델이 CLIPA를 상당히 능가하는 반면, VQAv2와 같은 자연 언어 벤치마크에서는 유사한 성능을 보여주는 것을 확인했습니다.
5. 질적 예시
우리는 몇 가지 질적 예시를 살펴보며 Pixtral의 실제 응용에 대해 논의합니다. 특히, Pixtral은 복잡한 도형에 대한 추론(예: 그림 7), 다중 이미지 명령 수행(예: 그림 8), 차트 이해 및 분석(예: 그림 9), 그리고 이미지를 코드로 변환(예: 그림 10)하는 데 사용될 수 있습니다.
그림 11에서 우리는 MM-MT-Bench의 예시를 통해 Pixtral 12B를 QwenVL-7B와 Gemini-1.5 Flash-8B (0827)와 비교합니다. 이 예시는 미국의 직장 불안에 대한 복잡한 차트와, 차트에 대한 정확한 이해, 추론 및 분석을 요구하는 명령으로 구성되어 있습니다. Pixtral의 응답은 완전하고 정확했으며, 이에 따라 8점을 받았습니다. 반면 Gemini-Flash-8B는 잘못된 정보를 추출했고, QwenVL은 트렌드에 대한 상세한 설명을 하지 못했습니다.
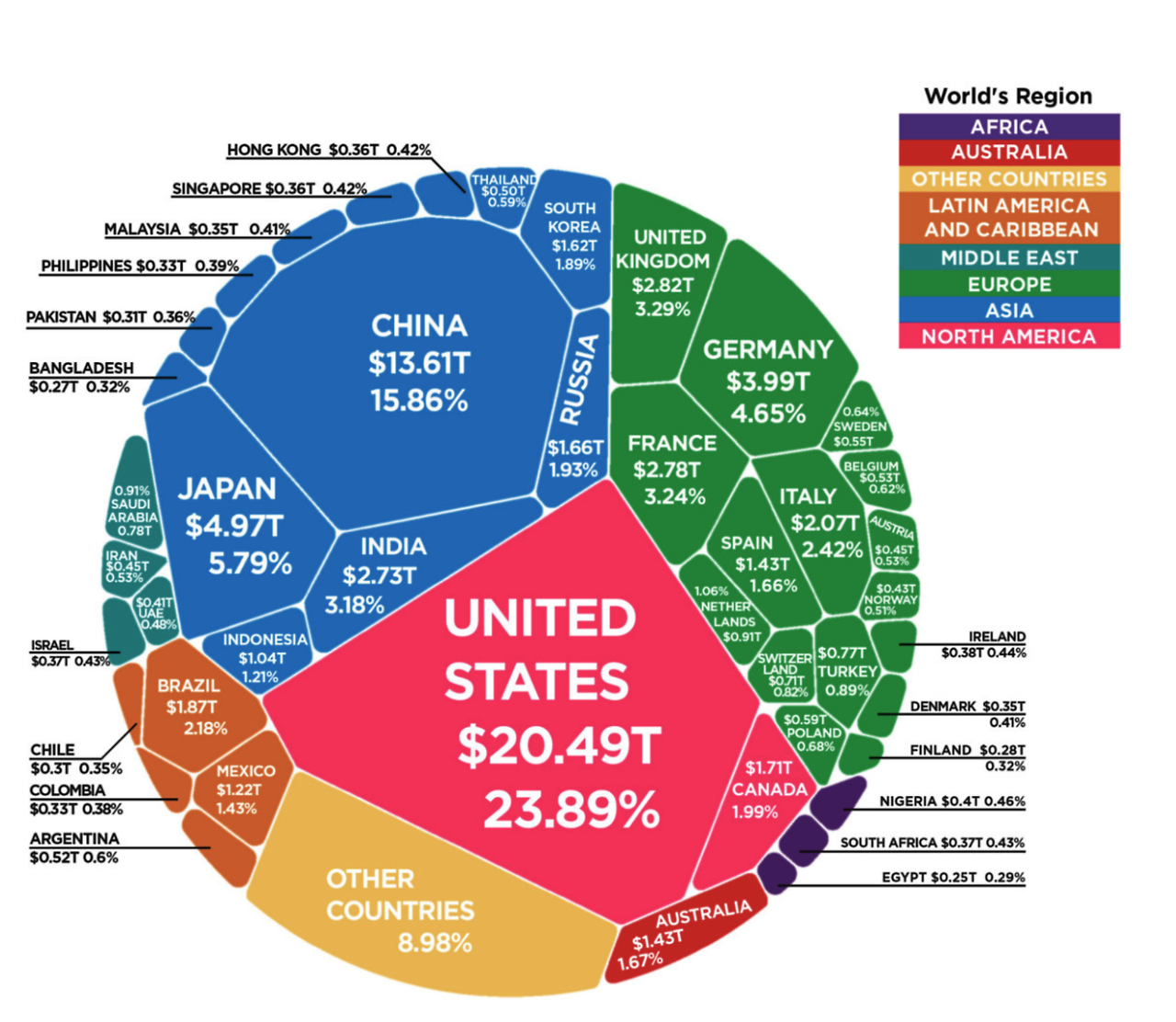
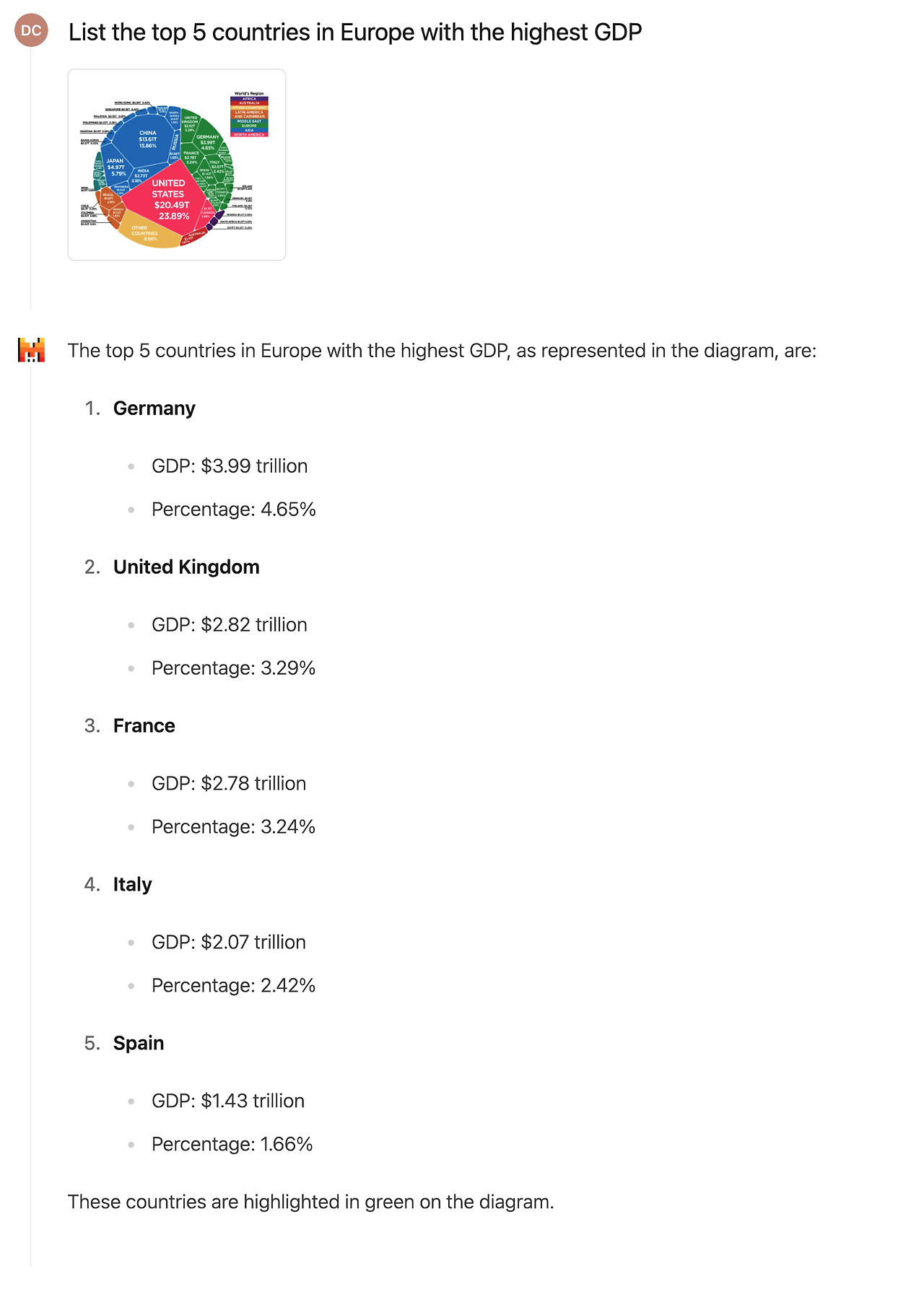
그림 7: 복잡한 도형에 대한 추론. Pixtral의 복잡한 도형을 이해하고 추론하는 능력을 보여주는 예시입니다. Pixtral은 초록색 상자가 유럽 국가들을 나타내고 있다는 것을 정확하게 식별한 후, 모든 유럽 국가의 GDP를 읽고 정렬하여 정확한 GDP 수치를 바탕으로 상위 5개 국가를 나열합니다.
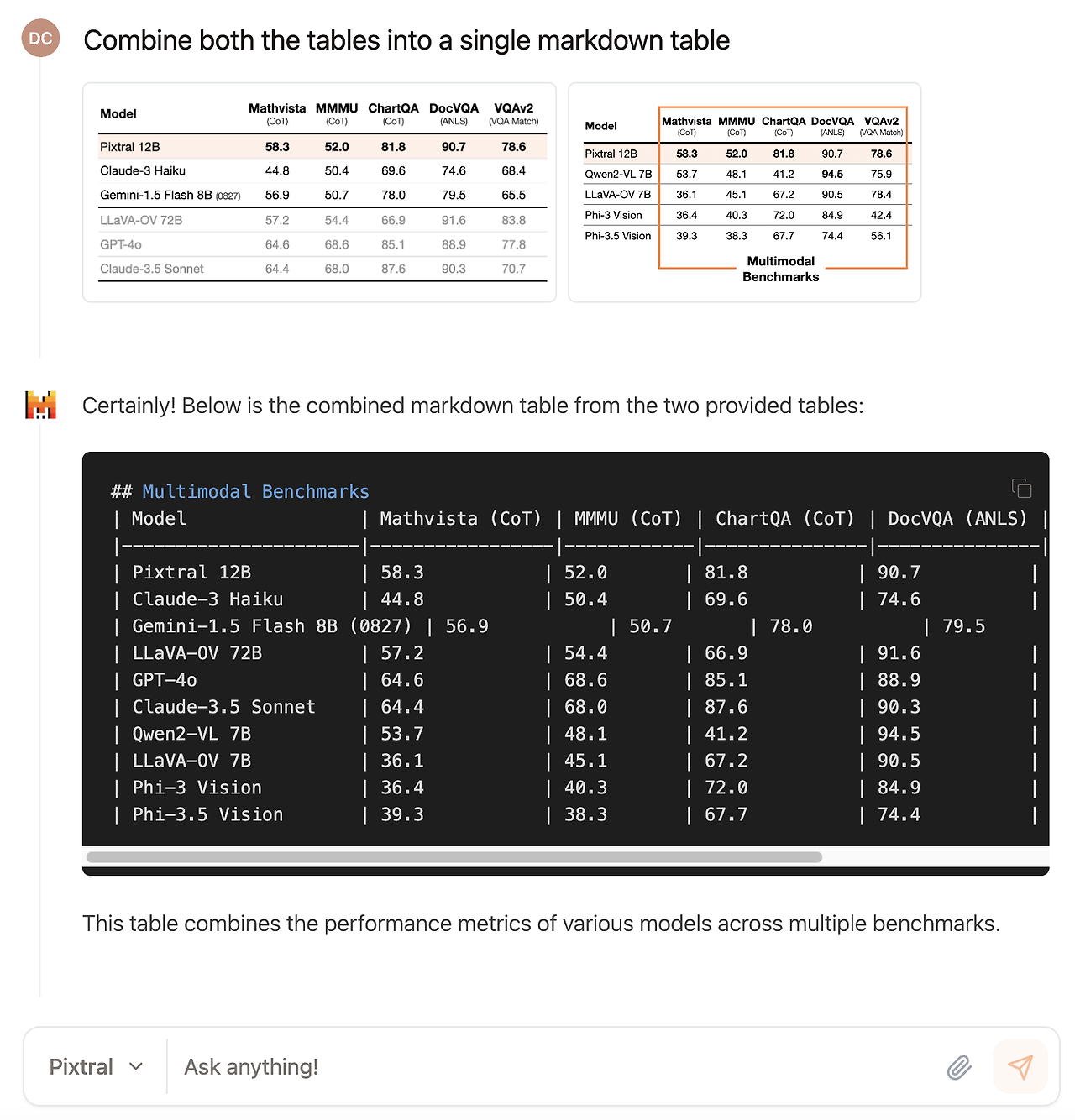
그림 8: 다중 이미지 명령 수행. Pixtral은 그 컨텍스트 창 내에서 임의의 수의 이미지를 처리할 수 있습니다. 이 예시는 Pixtral이 두 이미지의 정보를 성공적으로 결합하여 하나의 마크다운 표로 만드는 것을 보여줍니다.
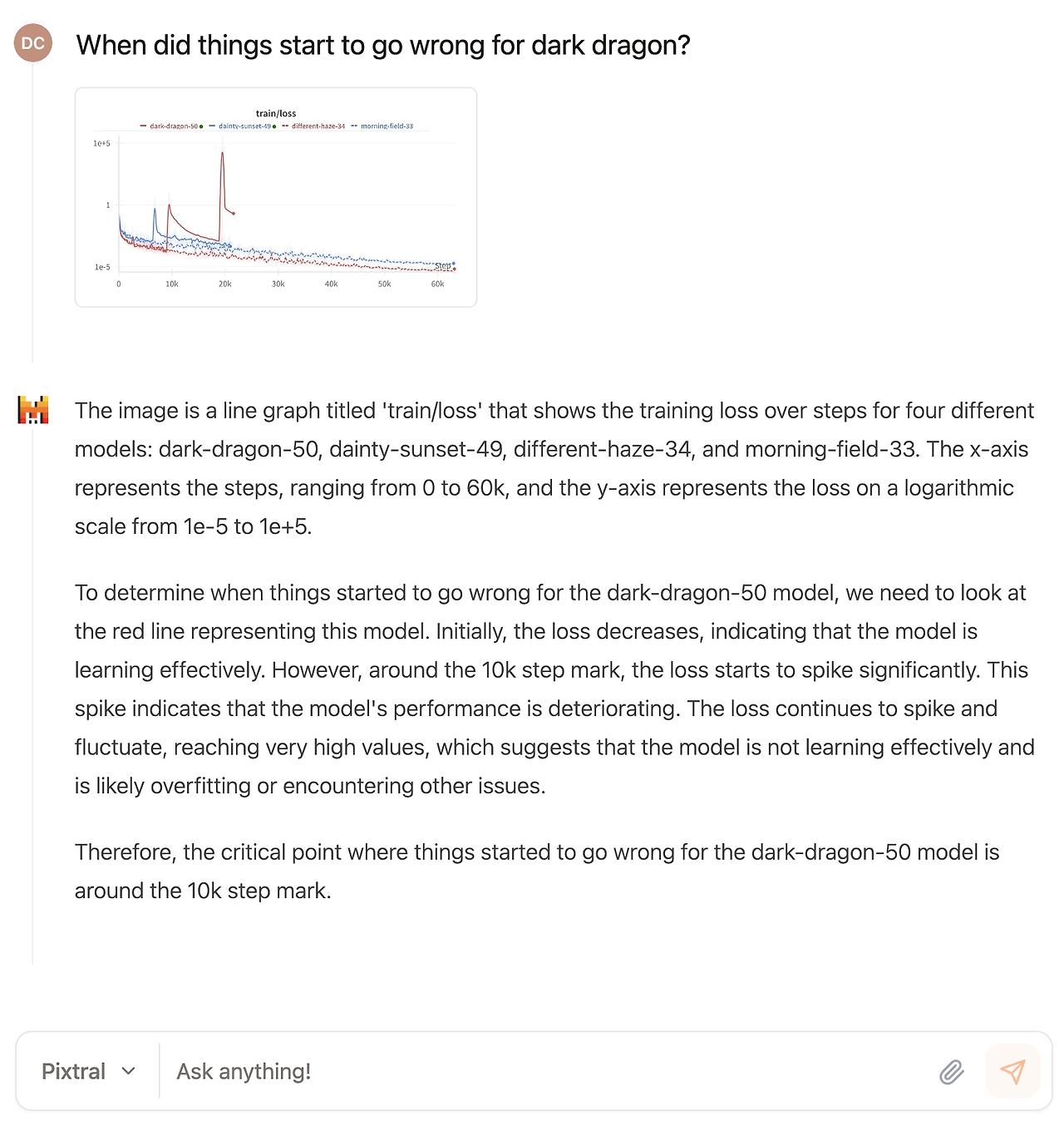
그림 9: 차트 이해 및 분석. Pixtral은 정교한 차트를 고도의 정확성으로 해석하고 분석하는 능력을 보여줍니다. 이 예시에서 Pixtral은 "dark-dragon"이 빨간 선과 일치한다는 것을 올바르게 식별하였으며, 훈련 손실이 부드럽게 감소할 것으로 예상된다는 점과 10K 스텝 부근에서 손실이 급격히 증가하여 훈련이 불안정해졌다는 점을 인지합니다.
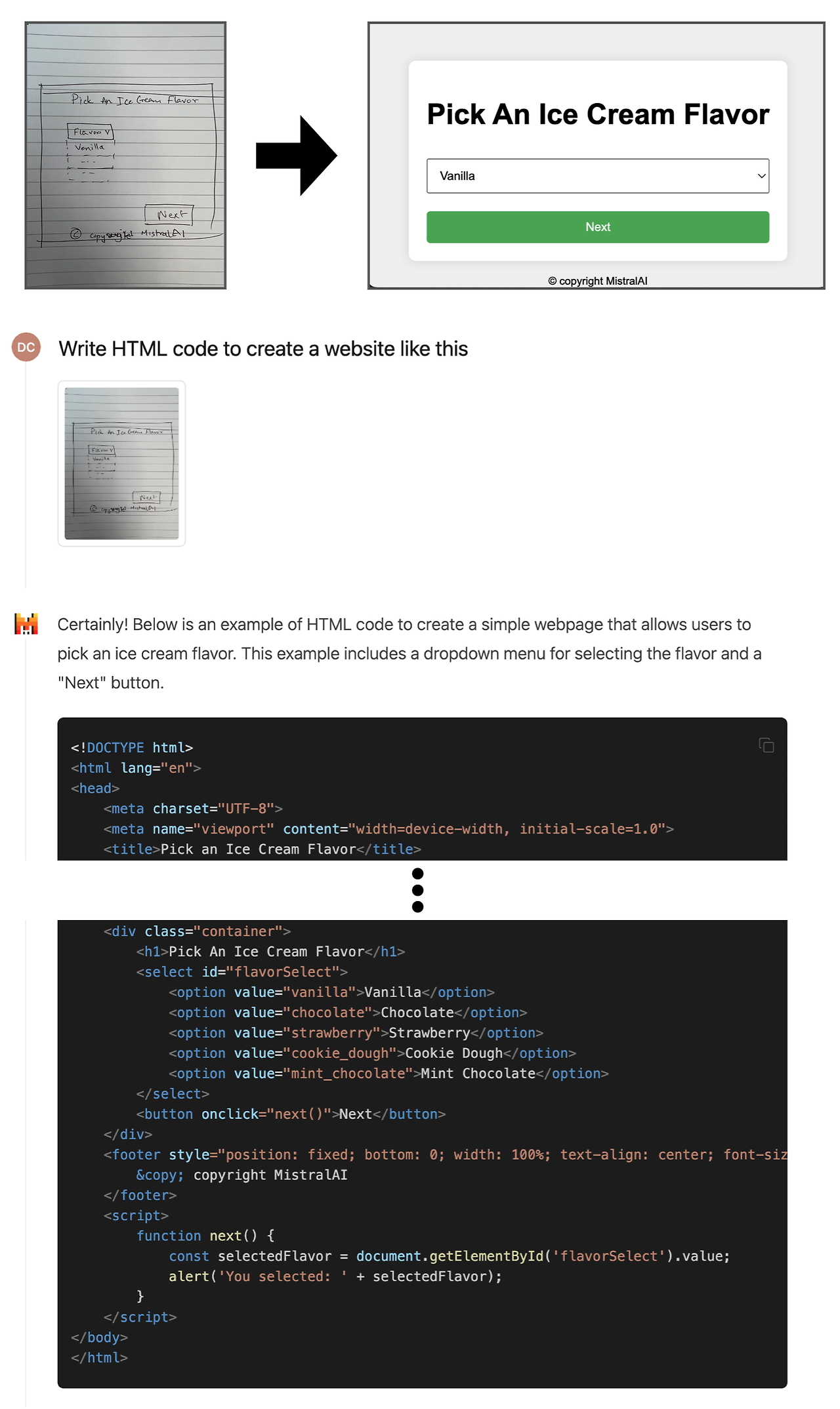
그림 10: 이미지를 코드로 변환. 이 예시는 Pixtral이 손으로 그린 웹사이트 인터페이스를 실행 가능한 HTML 코드로 변환하여, 손으로 그린 디자인을 완전한 기능의 웹사이트로 실현하는 능력을 보여줍니다.

그림 11: Pixtral-12B, QwenVL-7B 및 Gemini-1.5 Flash-8B (0827)의 모델 응답 예시 및 LLM 심판 점수. Pixtral의 응답은 완전하고 정확하여 8점을 받았으며, Gemini-Flash-8B는 잘못된 정보를 추출했고 QwenVL은 트렌드에 대해 자세히 설명하지 못했습니다.
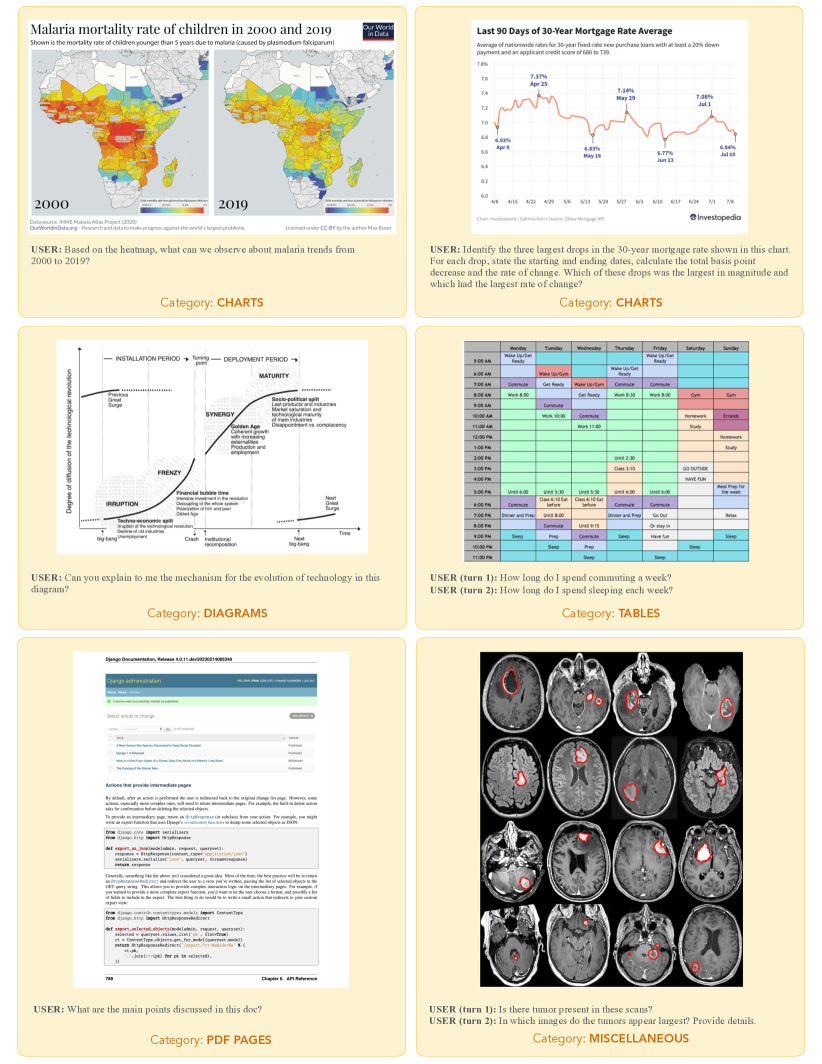
그림 12: MM-MT-Bench에서의 예시 이미지
6. 결론
이 논문에서는 Pixtral 12B를 소개했습니다. Pixtral 12B는 텍스트 전용 및 멀티모달 작업 모두에서 뛰어난 성능을 발휘하는 최첨단 멀티모달 모델입니다. 4억 개의 파라미터를 가진 비전 인코더와 120억 개의 파라미터를 가진 멀티모달 디코더로 구성된 새로운 아키텍처를 특징으로 하는 Pixtral 12B는 다양한 벤치마크에서 강력한 성능을 보여주며, 다른 오픈 모델을 능가하고 더 큰 모델들과 맞먹는 성능을 보입니다. 뛰어난 명령 수행 능력, 가변 이미지 크기 지원, 긴 컨텍스트 창 덕분에 복잡한 멀티모달 응용에 매우 유연하게 사용할 수 있습니다. Pixtral 12B는 Apache 2.0 라이선스 하에 공개됩니다.
7. 기여자
Mistral AI 과학 팀 (성에 따른 알파벳 순으로 나열됨):
Pravesh Agrawal, Szymon Antoniak, Emma Bou Hanna, Baptiste Bout, Devendra Chaplot, Jessica Chudnovsky, Diogo Costa, Baudouin De Monicault, Saurabh Garg, Theophile Gervet, Soham Ghosh, Amélie Héliou, Paul Jacob, Albert Q. Jiang, Kartik Khandelwal, Timothée Lacroix, Guillaume Lample, Diego Las Casas, Thibaut Lavril, Teven Le Scao, Andy Lo, William Marshall, Louis Martin, Arthur Mensch, Pavankumar Muddireddy, Valera Nemychnikova, Marie Pellat, Patrick Von Platen, Nikhil Raghuraman, Baptiste Rozière, Alexandre Sablayrolles, Lucile Saulnier, Romain Sauvestre, Wendy Shang, Roman Soletskyi, Lawrence Stewart, Pierre Stock, Joachim Studnia, Sandeep Subramanian, Sagar Vaze, Thomas Wang, Sophia Yang.
감사의 말씀
우리 모델을 LLM 아레나에 배포하는 데 도움을 주신 LMSys 팀과 Pixtral 12B를 추론 라이브러리에 통합하는 데 도움을 주신 vLLM 팀에게 감사의 인사를 전합니다.
'인공지능' 카테고리의 다른 글
| LLaMA-Omni: Seamless Speech Interaction with Large Language Models (2) | 2024.11.26 |
|---|---|
| iTransformer: Inverted Transformers Are Effective for Time Series Forecasting (1) | 2024.11.25 |
| DeepSeek-V2.5 (1) | 2024.11.23 |
| De novo design of high-affinity protein binders with AlphaProteo (3) | 2024.11.22 |
| AlphaProteo generates novel proteins for biology and health research (1) | 2024.11.22 |


