https://arxiv.org/abs/2409.06666
LLaMA-Omni: Seamless Speech Interaction with Large Language Models
Models like GPT-4o enable real-time interaction with large language models (LLMs) through speech, significantly enhancing user experience compared to traditional text-based interaction. However, there is still a lack of exploration on how to build speech i
arxiv.org
요약
GPT-4와 같은 모델들은 실시간 음성 상호작용을 통해 대형 언어 모델(LLM)과의 상호작용을 가능하게 하여 전통적인 텍스트 기반 상호작용에 비해 사용자 경험을 크게 향상시킨다. 그러나 여전히 오픈소스 LLM을 기반으로 한 음성 상호작용 모델의 구축에 대한 탐구는 부족하다. 이를 해결하기 위해 우리는 LLaMA-Omni라는 새로운 모델 아키텍처를 제안한다. 이 모델은 LLM과의 저지연, 고품질 음성 상호작용을 위해 설계되었다. LLaMA-Omni는 미리 학습된 음성 인코더, 음성 어댑터, LLM, 스트리밍 음성 디코더를 통합하고 있다. 이 모델은 음성 전사를 필요로 하지 않으며, 음성 지시로부터 텍스트와 음성 응답을 동시에 극히 낮은 지연 시간으로 생성할 수 있다. 우리는 최신 Llama-3.1-8B-Instruct 모델을 기반으로 이 모델을 구축하였다. 음성 상호작용 시나리오에 맞추기 위해 20만 개의 음성 지시와 이에 대응하는 음성 응답으로 구성된 InstructS2S-200K라는 데이터셋을 구축하였다. 실험 결과에 따르면 LLaMA-Omni는 이전 음성-언어 모델에 비해 콘텐츠와 스타일 모두에서 더 나은 응답을 제공하며, 응답 지연 시간은 226ms에 불과하다. 또한, LLaMA-Omni의 훈련은 4개의 GPU로 3일 이내에 완료될 수 있어 향후 효율적인 음성-언어 모델 개발의 가능성을 열어준다.
코드와 모델은 https://github.com/ictnlp/LLaMA-Omni에서 확인할 수 있다.
1. 소개
대형 언어 모델(LLMs), 예를 들어 ChatGPT(OpenAI, 2022)는 강력한 범용 작업 해결사가 되어 대화형 상호작용을 통해 사람들을 일상생활에서 돕고 있다. 그러나 현재 대부분의 LLM은 텍스트 기반 상호작용만 지원하기 때문에 텍스트 입력과 출력을 사용하는 것이 이상적이지 않은 상황에서 그 적용이 제한된다. 최근 등장한 GPT-4o(OpenAI, 2024)는 음성을 통해 LLM과 상호작용할 수 있게 만들어 매우 낮은 지연 시간으로 사용자의 지시에 응답하며 사용자 경험을 크게 향상시켰다. 그러나 오픈 소스 커뮤니티에서는 이러한 음성 상호작용 모델을 LLM 기반으로 구축하는 것에 대한 탐구가 여전히 부족하다. 따라서 LLM과의 저지연, 고품질 음성 상호작용을 어떻게 실현할 것인가는 해결해야 할 시급한 과제이다.
LLM과의 음성 상호작용을 가능하게 하는 가장 간단한 방법은 자동 음성 인식(ASR)과 텍스트-음성 변환(TTS) 모델을 기반으로 한 연쇄 시스템을 사용하는 것이다. 이 방식에서는 ASR 모델이 사용자의 음성 지시를 텍스트로 변환하고, TTS 모델이 LLM의 응답을 음성으로 합성한다. 그러나 연쇄 시스템은 전사된 텍스트, 텍스트 응답, 음성 응답을 순차적으로 출력하기 때문에 전체 시스템의 지연 시간이 높아질 수 있다. 이에 반해 일부 다중 모달 음성-언어 모델이 제안되었는데(Zhang 등, 2023; Rubenstein 등, 2023), 이러한 모델은 음성을 토큰으로 분할하고 LLM의 어휘를 확장하여 음성 입력과 출력을 지원한다. 이론적으로 이러한 음성-언어 모델은 중간 텍스트를 생성하지 않고도 음성 지시로부터 직접 음성 응답을 생성할 수 있어 매우 낮은 응답 지연 시간을 달성할 수 있다. 그러나 실제로 음성에서 음성으로의 직접 생성은 복잡한 매핑 문제로 인해 어려울 수 있으며, 생성 품질을 높이기 위해 중간 텍스트를 생성하는 경우가 일반적이다(Zhang 등, 2023). 이는 일부 응답 지연을 희생하는 것이다.
본 논문에서는 저지연, 고품질 상호작용을 가능하게 하는 새로운 모델 아키텍처인 LLaMA-Omni를 제안한다. LLaMA-Omni는 음성 인코더, 음성 어댑터, LLM, 스트리밍 음성 디코더로 구성된다. 사용자의 음성 지시는 음성 인코더를 거쳐 음성 어댑터에서 처리되고, 이후 LLM에 입력된다. LLM은 음성을 텍스트로 먼저 전사하지 않고 직접 텍스트 응답을 디코딩한다. 음성 디코더는 비자기회귀(NAR) 스트리밍 Transformer(Ma 등, 2023)로, LLM의 출력 은닉 상태를 입력으로 받아 연결주의 시계열 분류(CTC; Graves 등, 2006a)를 사용하여 음성 응답에 해당하는 이산 단위의 시퀀스를 예측한다. 추론 과정에서 LLM이 텍스트 응답을 자동 회귀적으로 생성하는 동시에 음성 디코더는 이에 해당하는 이산 단위를 생성한다. 음성 상호작용 시나리오의 특성과 더 잘 일치하도록 하기 위해, 기존의 텍스트 지시 데이터를 재작성하고 음성 합성을 수행하여 InstructS2S-200K라는 데이터셋을 구축하였다. 실험 결과, LLaMA-Omni는 고품질의 텍스트와 음성 응답을 동시에 매우 낮은 226ms의 지연 시간으로 생성할 수 있음을 보여준다. 또한, 이전 음성-언어 모델인 SpeechGPT(Zhang 등, 2023)와 비교할 때, LLaMA-Omni는 필요한 훈련 데이터와 계산 자원을 크게 줄여 최신 LLM을 기반으로 강력한 음성 상호작용 모델을 효율적으로 개발할 수 있다.

그림 1: LLaMA-Omni는 매우 낮은 응답 지연 시간으로 음성 지시에 기반하여 텍스트와 음성 응답을 동시에 생성할 수 있다.
2. 모델: LLaMA-Omni
본 섹션에서는 LLaMA-Omni의 모델 아키텍처를 소개한다. 그림 2에서 볼 수 있듯이, LLaMA-Omni는 음성 인코더, 음성 어댑터, LLM, 음성 디코더로 구성되어 있다. 사용자의 음성 지시, 텍스트 응답, 음성 응답을 각각 XS, YT, YS로 표기한다.
2.1 음성 인코더
우리는 Whisper-large-v3 (Radford et al., 2023)의 인코더를 음성 인코더 ℰ로 사용한다. Whisper는 다량의 오디오 데이터를 학습한 범용 음성 인식 모델로, 음성으로부터 의미 있는 표현을 추출할 수 있는 능력을 가지고 있다. 특히, 사용자의 음성 지시 XS에 대해 인코딩된 음성 표현은 𝐇 = ℰ(XS)로 주어지며, 여기서 𝐇 = [𝐡1, …, 𝐡N]는 길이 N의 음성 표현 시퀀스를 나타낸다. 우리는 전체 학습 과정 동안 음성 인코더의 파라미터를 고정시킨다.
2.2 음성 어댑터
LLM이 입력된 음성을 이해할 수 있도록, 우리는 음성 표현을 LLM의 임베딩 공간으로 매핑하는 학습 가능한 음성 어댑터 𝒜를 추가한다. Ma et al. (2024c)을 따라, 음성 어댑터는 먼저 음성 표현 𝐇을 다운샘플링하여 시퀀스 길이를 줄인다. 구체적으로, 매 k개의 연속적인 프레임을 특성 차원에서 연결한다:
𝐇′ = [𝐡′1, …, 𝐡′⌊N/k⌋],여기서
𝐡i′ = [𝐡k×(i−1)+1 ⊕ 𝐡k×(i−1)+2 ⊕ ⋯ ⊕ 𝐡k×i].다음으로, 𝐇′는 선형 레이어 사이에 ReLU 활성화 함수를 사용하는 2층 퍼셉트론을 통과하며, 최종 음성 표현 𝐒를 생성한다. 위 과정을 다음과 같이 공식화할 수 있다:
𝐒 = 𝒜(𝐇) = Linear(ReLU(Linear(DownSample(𝐇)))).
그림 2: 왼쪽: LLaMA-Omni의 모델 아키텍처. 오른쪽: LLaMA-Omni의 두 단계 학습 전략의 일러스트레이션.
2.3 대형 언어 모델(LLM)
2.4 음성 디코더(Speech Decoder)
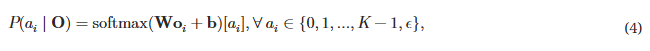

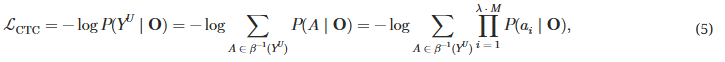


그림 3: LLaMA-Omni의 프롬프트 템플릿
2.5 학습(Training)

2.6 추론(Inference)


3. 음성 명령 데이터 구성: InstructS2S-200K
LLaMA-Omni를 학습시키기 위해, 우리는 <음성 명령, 텍스트 응답, 음성 응답>으로 구성된 삼중 데이터가 필요하다. 그러나 대부분의 공개된 명령 데이터는 텍스트 형태로 제공된다. 따라서 우리는 기존 텍스트 명령 데이터를 기반으로 음성 명령 데이터를 다음 과정에 따라 구성하였다:
단계 1: 명령 재작성 음성 입력은 텍스트 입력과 다른 특성을 가지기 때문에, 우리는 텍스트 명령을 다음 규칙에 따라 재작성한다: (1) 자연스러운 음성 패턴을 시뮬레이션하기 위해 명령에 적절한 필러 단어(예: "이봐", "그래서", "어", "음" 등)를 추가한다. (2) 명령 내의 비텍스트 기호(예: 숫자)를 해당 발음 형태로 변환하여 TTS가 정확하게 합성할 수 있도록 한다. (3) 명령을 불필요한 수식어 없이 간결하게 수정한다. 우리는 Llama-3-70B-Instruct (모델 링크)을 사용해 이러한 규칙에 따라 명령을 재작성한다. 프롬프트는 부록 A에 나와 있다.
단계 2: 응답 생성 음성 상호작용에서, 기존 텍스트 명령의 응답은 음성 명령 응답으로 직접 사용하기에 적합하지 않다. 이는 텍스트 기반 상호작용에서 모델이 복잡한 문장을 사용하거나 괄호나 순서 목록과 같은 비언어적 요소를 포함하여 길고 상세한 응답을 생성하는 경향이 있기 때문이다. 그러나 음성 상호작용에서는 간결하면서도 정보가 풍부한 응답이 선호된다(익명, 2024). 따라서 우리는 Llama-3-70B-Instruct 모델을 사용해 다음 규칙에 따라 음성 명령에 대한 응답을 생성한다: (1) 응답에는 괄호, 순서 목록 등 TTS 모델이 합성할 수 없는 내용이 포함되어서는 안 된다. (2) 응답은 매우 간결하고 핵심을 짚어야 하며, 지나치게 긴 설명은 피해야 한다. 프롬프트는 부록 A에 나와 있다.
단계 3: 음성 합성 음성 상호작용에 적합한 명령과 응답을 얻은 후, 우리는 이를 TTS 모델을 사용해 음성으로 변환해야 한다. 명령의 경우, 합성된 음성이 보다 자연스럽게 들리도록 하기 위해 CosyVoice-300M-SFT (Du et al., 2024) 모델 (모델 링크)을 사용하여, 각 명령에 대해 무작위로 남성 또는 여성 음성을 선택한다. 응답의 경우, LJSpeech (Ito & Johnson, 2017) 데이터셋으로 학습된 VITS (Kim et al., 2021) 모델 (모델 링크)을 사용해 표준 음성으로 응답을 합성한다.
기본 텍스트 명령의 경우, 우리는 다양한 주제를 다루는 Alpaca 데이터셋 (데이터셋 링크) (Taori et al., 2023)에서 약 50K 명령을 수집하였다. 추가적으로, 주로 세상에 대한 질문으로 구성된 UltraChat 데이터셋 (데이터셋 링크) (Ding et al., 2023)에서 약 150K 명령을 수집하였다. UltraChat은 대규모 다중 턴 대화 데이터셋이지만, 우리는 처음 150K 항목만 선택하고 첫 번째 라운드의 명령만 사용하였다. 위 데이터셋과 데이터 처리 파이프라인을 사용하여, 최종적으로 200K 개의 음성 명령 데이터를 얻었으며, 이를 InstructS2S-200K라 한다.
4. 실험 (Experiments)
4.1 실험 설정 (Experimental Setups)
데이터셋 학습 데이터로는 3장에서 언급된 InstructS2S-200K 데이터셋을 사용하였으며, 여기에는 200K개의 음성 명령 데이터가 포함되어 있다. 목표 음성에 해당하는 이산 단위를 추출하기 위해, HuBERT 특징에서 1000개의 클러스터를 학습한 사전 학습된 K-means 양자화기 (모델 링크)를 사용하였다. HiFi-GAN 보코더 (Kong et al., 2020; Polyak et al., 2021)를 이용해 이산 단위를 파형으로 합성하였다. 평가 데이터로는 Alpaca-Eval (데이터셋 링크) (Li et al., 2023)에서 helpful_base와 vicuna 두 하위 집합을 선택하였다. 이 질문들은 음성 상호작용 시나리오에 더 적합하다. 수학 및 코드와 관련된 질문들을 제거하여 총 199개의 명령을 남겼다. 음성 버전을 얻기 위해, CosyVoice-300M-SFT 모델을 사용해 명령을 음성으로 합성하였다. 이후 섹션에서 이 테스트 세트를 InstructS2S-Eval이라 부른다.
모델 구성 (Model Configuration) Whisper-large-v3의 인코더를 음성 인코더로 사용하고, Llama-3.1-8B-Instruct를 LLM으로 사용하였다. 음성 어댑터는 음성 표현을 5배 다운샘플링한다. 음성 디코더는 LLaMA와 동일한 아키텍처를 가진 2개의 Transformer 레이어로 구성되며, 히든 차원은 4096, 어텐션 헤드는 32개, 피드포워드 네트워크 차원은 11008로, 총 425M개의 파라미터를 가진다. 업샘플링 비율 λ는 25로 설정하였다. 보코더에 입력되는 최소 단위 청크 크기 Ω는 주 실험에서 Ω=+∞로 설정하여, 전체 단위 시퀀스가 생성된 후 보코더에 입력해 음성을 합성하도록 하였다. 이후 실험에서는 Ω값을 조정하여 응답 지연 시간과 지연 및 음성 품질 간의 절충점을 분석할 예정이다.
학습 (Training) LLaMA-Omni는 두 단계의 학습 과정을 따른다. 첫 번째 단계에서는 배치 크기 32로 음성 어댑터와 LLM을 3 에폭 동안 학습한다. 첫 3% 단계는 워밍업으로 사용하고, 코사인 학습률 스케줄러를 사용하며, 최고 학습률은 2e−5로 설정하였다. 두 번째 단계에서는 동일한 배치 크기, 단계 수, 학습률 스케줄러를 사용하지만, 최고 학습률은 2e−4로 설정하여 음성 디코더를 학습한다. 전체 학습 과정은 4개의 NVIDIA L40 GPU에서 약 65시간이 소요되었다.
4.2 평가 (Evaluation)
LLaMA-Omni는 음성 명령을 바탕으로 텍스트와 음성 응답을 모두 생성할 수 있으므로, 우리는 모델의 성능을 음성-텍스트 명령 수행(S2TIF)과 음성-음성 명령 수행(S2SIF) 두 가지 작업에 대해 평가하였다. 실험 결과의 재현성을 보장하기 위해 탐욕적 탐색(greedy search)을 사용하였다. 모델은 다음 측면에서 평가되었다:
ChatGPT 점수 (ChatGPT Score) 모델의 음성 명령 수행 능력을 평가하기 위해, GPT-4o (OpenAI, 2024)를 사용해 모델의 응답을 점수화하였다. S2TIF 작업에서는 음성 명령의 텍스트 변환과 모델의 텍스트 응답을 바탕으로 점수를 매겼다. S2SIF 작업에서는 먼저 모델의 음성 응답을 Whisper-large-v3 모델을 사용해 텍스트로 변환한 후, S2TIF 작업과 동일한 방식으로 점수화하였다. GPT-4o는 내용과 스타일 두 가지 측면에서 점수를 제공한다. 내용 점수는 모델의 응답이 사용자의 명령을 충분히 처리했는지 평가하며, 스타일 점수는 모델의 응답 스타일이 음성 상호작용 시나리오에 적합한지를 평가한다. 자세한 프롬프트는 부록 A에 나와 있다.
음성-텍스트 정렬 (Speech-Text Alignment) 텍스트 응답과 음성 응답 간의 정렬을 평가하기 위해, Whisper-large-v3 모델을 사용해 음성 응답을 텍스트로 변환한 후, 변환된 텍스트와 텍스트 응답 간의 단어 오류율(WER) 및 문자 오류율(CER)을 계산하였다. 이 지표들을 각각 ASR-WER 및 ASR-CER이라 한다.
음성 품질 (Speech Quality) 생성된 음성의 품질을 평가하기 위해, UTMOS (모델 링크) (Saeki et al., 2022)라는 평균 의견 점수(MOS) 예측 모델을 사용하여 음성의 자연스러움을 평가하였다. 이를 UTMOS 점수라 한다.
응답 지연 (Response Latency) 응답 지연은 음성 상호작용 모델의 주요 지표로, 음성 명령 입력과 음성 응답 시작 사이의 시간 간격을 나타내며, 이는 사용자 경험에 큰 영향을 미친다. 또한, 음성 응답이 시작될 때 텍스트 응답에서 이미 생성된 단어의 수를 계산하여 #lagging word라 한다.
4.3 기준 시스템 (Baseline Systems)
다음과 같은 음성-언어 모델들을 기준 시스템으로 포함하였다:
SpeechGPT SpeechGPT (Zhang et al., 2023)는 음성 입력과 출력을 모두 지원하는 음성-언어 모델이다. 우리는 원 논문에서 채택한 모달리티 체인 프롬프트(chain-of-modality prompting)를 디코딩에 사용하여, 음성 명령에 기반해 텍스트 명령, 텍스트 응답, 음성 응답을 순차적으로 출력한다.
SALMONN (+TTS) SALMONN (Tang et al., 2024)는 음성과 오디오 입력을 받아 텍스트로 응답할 수 있는 LLM으로, S2TIF 작업을 수행할 수 있다. S2SIF 작업을 위해서는 SALMONN 이후에 VITS TTS 모델을 추가하여, 음성 응답을 계단식 방식(cascaded manner)으로 생성하도록 하였다.
Qwen2-Audio (+TTS) Qwen2-Audio (Chu et al., 2024)는 S2TIF 작업을 포함한 다양한 오디오 관련 작업을 수행할 수 있는 강력한 범용 오디오 이해 모델이다. 우리는 Qwen2-Audio와 VITS를 계단식 시스템으로 구축하여 S2SIF 작업을 완료하였다.
4.4 주요 결과 (Main Results)
표 1: InstructS2S-Eval 벤치마크에서 S2TIF와 S2SIF 작업에 대한 ChatGPT 점수 및 음성-텍스트 응답 간의 정렬 점수. 여기서 S2SIF 작업을 위해 Ω=+∞로 설정하였다.
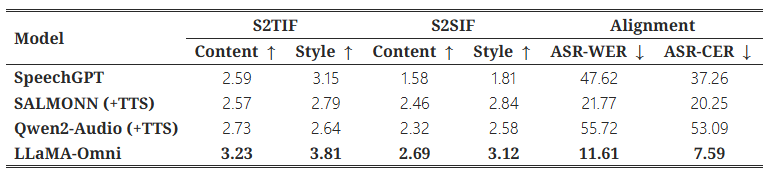
표 1에는 InstructS2S-Eval 벤치마크에 대한 주요 결과가 나와 있다. 먼저, S2TIF 작업에서 콘텐츠 관점에서 보면 LLaMA-Omni는 이전 모델들에 비해 상당한 개선을 보인다. 이는 주로 LLaMA-Omni가 최신 Llama-3.1-8B-Instruct 모델을 기반으로 개발되어 강력한 텍스트 명령 수행 능력을 활용했기 때문이다. 스타일 관점에서 보면, SALMONN과 Qwen2-Audio는 낮은 점수를 받았는데, 이는 이들이 음성-텍스트 모델이기 때문이다. 이들의 출력 스타일은 음성 상호작용 시나리오와 맞지 않아 포맷된 콘텐츠나 불필요한 설명을 자주 포함한다. 반면, SpeechGPT는 음성-음성 모델로서 더 높은 스타일 점수를 얻었고, 마찬가지로 우리 LLaMA-Omni도 가장 높은 스타일 점수를 얻어 InstructS2S-200K 데이터셋에서 학습된 후, 출력 스타일이 음성 상호작용 시나리오에 잘 맞춰졌음을 보여준다.
S2SIF 작업에서도 LLaMA-Omni는 콘텐츠와 스타일 점수에서 모두 이전 모델들을 능가한다. 이는 LLaMA-Omni가 사용자 명령을 음성으로 간결하고 효율적으로 처리할 수 있음을 다시 한 번 확인시켜 준다.
또한, 음성 및 텍스트 응답 간의 정렬 측면에서 LLaMA-Omni는 가장 낮은 ASR-WER 및 ASR-CER 점수를 기록하였다. 반면, SpeechGPT는 텍스트와 음성을 순차적으로 생성하기 때문에 음성 및 텍스트 응답 정렬이 좋지 않았다. SALMONN+TTS 및 Qwen2-Audio+TTS와 같은 계단식 시스템의 음성-텍스트 정렬도 최적이 아닌데, 이는 주로 생성된 텍스트 응답에 음성으로 합성할 수 없는 문자가 포함될 수 있기 때문이다. 이 문제는 특히 Qwen2-Audio에서 두드러지는데, 때때로 중국어 문자를 출력하여 음성 응답에서 오류를 유발하였다. 이에 비해, LLaMA-Omni는 가장 낮은 ASR-WER 및 ASR-CER 점수를 달성하여 생성된 음성과 텍스트 응답 간의 높은 정렬도를 보여주며, 텍스트와 음성을 동시에 생성하는 우리의 접근 방식의 장점을 추가로 검증하였다.
-----
이 표는 S2TIF (음성-텍스트 명령 수행)와 S2SIF (음성-음성 명령 수행) 작업에서 네 가지 모델의 성능을 평가한 것이다. 평가 지표로는 콘텐츠(Content)와 스타일(Style) 점수, 그리고 음성 및 텍스트 응답 간의 정렬을 평가하는 ASR-WER 및 ASR-CER을 사용한다.
- S2TIF (음성-텍스트 명령 수행): 음성 명령을 텍스트로 변환하여 응답을 생성하는 작업.
- S2SIF (음성-음성 명령 수행): 음성 명령에 대해 음성으로 응답을 생성하는 작업.
- ASR-WER (단어 오류율): 음성에서 생성된 텍스트와 텍스트 응답 간의 일치도를 단어 수준에서 평가하는 지표. 낮을수록 좋음.
- ASR-CER (문자 오류율): 음성에서 생성된 텍스트와 텍스트 응답 간의 일치도를 문자 수준에서 평가하는 지표. 낮을수록 좋음.
모델 별 상세 결과
- SpeechGPT
- S2TIF 콘텐츠: 2.59, 스타일: 3.15
- SpeechGPT는 S2TIF 작업에서 평균 수준의 콘텐츠 점수를 기록했다. 텍스트 기반 명령에 대해 생성된 응답의 적절성은 약간 부족했지만, 스타일 점수는 비교적 높아 음성 명령의 자연스러운 상호작용 스타일을 잘 반영하였다.
- S2SIF 콘텐츠: 1.58, 스타일: 1.81
- 음성-음성 명령 수행에서 콘텐츠와 스타일 점수가 매우 낮았다. 이는 SpeechGPT가 음성 상호작용을 위한 최적화가 부족했음을 시사한다.
- ASR-WER: 47.62, ASR-CER: 37.26
- SpeechGPT는 음성과 텍스트 간의 정렬 측면에서도 상대적으로 높은 오류율을 기록하였다. 이는 음성과 텍스트 간의 일치도가 낮아 사용자에게 일관된 경험을 제공하는 데 어려움이 있었음을 보여준다.
- S2TIF 콘텐츠: 2.59, 스타일: 3.15
- SALMONN (+TTS)
- S2TIF 콘텐츠: 2.57, 스타일: 2.79
- SALMONN은 S2TIF 작업에서 콘텐츠 점수가 2.57로, 다소 부족한 응답 품질을 보였지만, 스타일 점수는 2.79로 양호했다. 이는 텍스트 기반 응답이 다소 형식적이거나 불필요한 설명을 포함할 수 있음을 반영한다.
- S2SIF 콘텐츠: 2.46, 스타일: 2.84
- S2SIF 작업에서는 음성 응답의 품질이 개선되어 콘텐츠와 스타일 점수가 각각 2.46, 2.84로 기록되었다. 이는 음성 응답 생성이 SALMONN의 텍스트 기반 응답 스타일보다 더 나은 상호작용 경험을 제공했음을 의미한다.
- ASR-WER: 21.77, ASR-CER: 20.25
- SALMONN은 음성과 텍스트 응답 간의 정렬 측면에서 상대적으로 낮은 오류율을 기록하며, 일관된 음성 및 텍스트 응답을 생성하는 데 성공적이었다.
- S2TIF 콘텐츠: 2.57, 스타일: 2.79
- Qwen2-Audio (+TTS)
- S2TIF 콘텐츠: 2.73, 스타일: 2.64
- Qwen2-Audio는 콘텐츠 점수 2.73, 스타일 점수 2.64로 비교적 준수한 성능을 보였다. 콘텐츠 측면에서는 다른 기준 시스템보다 약간 더 좋은 응답을 생성했으나, 스타일에서는 일부 다소 딱딱한 형식의 응답을 보였다.
- S2SIF 콘텐츠: 2.32, 스타일: 2.58
- 음성 응답의 경우, 콘텐츠와 스타일 점수가 S2TIF보다 약간 낮아졌으며, 스타일 점수는 여전히 음성 상호작용에 최적화되지 않았음을 보여준다.
- ASR-WER: 55.72, ASR-CER: 53.09
- 음성과 텍스트 응답 간의 정렬에서 Qwen2-Audio는 상당히 높은 오류율을 기록했다. 이는 텍스트 응답에 중국어 문자가 포함되는 경우가 있어 음성으로 정확히 합성하기 어려웠기 때문으로 보인다.
- S2TIF 콘텐츠: 2.73, 스타일: 2.64
- LLaMA-Omni
- S2TIF 콘텐츠: 3.23, 스타일: 3.81
- LLaMA-Omni는 S2TIF 작업에서 콘텐츠와 스타일 모두에서 가장 높은 점수를 기록하였다. 이는 최신 Llama-3.1-8B-Instruct 모델을 기반으로 강력한 명령 수행 능력을 잘 활용했으며, 스타일 측면에서도 매우 자연스러운 음성 상호작용을 반영했음을 보여준다.
- S2SIF 콘텐츠: 2.69, 스타일: 3.12
- S2SIF 작업에서도 콘텐츠와 스타일 모두 높은 점수를 기록하였다. 특히 스타일 점수가 3.12로, 음성 상호작용에 매우 적합한 응답을 생성하였다. 이 결과는 LLaMA-Omni가 음성 상호작용 시나리오에서 우수한 성능을 보임을 나타낸다.
- ASR-WER: 11.61, ASR-CER: 7.59
- 음성과 텍스트 간의 정렬 측면에서 LLaMA-Omni는 가장 낮은 오류율을 기록하며, 생성된 음성과 텍스트 응답 간의 높은 일치도를 보여주었다. 이는 LLaMA-Omni가 텍스트와 음성을 동시에 생성하는 접근 방식에서 큰 장점을 가지고 있음을 시사한다.
- S2TIF 콘텐츠: 3.23, 스타일: 3.81
주요 분석
- 콘텐츠 및 스타일 점수: LLaMA-Omni는 콘텐츠와 스타일 모두에서 최고의 성능을 보였다. 특히 스타일 점수는 다른 모델들에 비해 큰 차이를 보였으며, 이는 LLaMA-Omni가 음성 상호작용에 잘 맞춰졌음을 의미한다.
- 음성-텍스트 정렬: LLaMA-Omni는 가장 낮은 ASR-WER 및 ASR-CER을 기록하였다. 이는 음성 응답이 텍스트 응답과 매우 잘 일치하여 사용자에게 일관된 경험을 제공할 수 있음을 보여준다. 반면, Qwen2-Audio와 같은 모델은 생성된 텍스트에 포함된 비음성적 요소로 인해 정렬 품질이 떨어졌다.
- SALMONN과 SpeechGPT: SALMONN은 텍스트 기반 응답 스타일에서 문제가 있었지만 음성 응답에서는 개선된 모습을 보였으며, SpeechGPT는 음성 상호작용에 적합하지 않은 경우가 많았다. LLaMA-Omni는 이러한 모델들이 가지고 있는 약점을 모두 극복하였다.
요약하자면, LLaMA-Omni는 콘텐츠와 스타일, 그리고 음성-텍스트 정렬 측면에서 가장 우수한 성능을 보여주었으며, 사용자 경험을 위한 음성 상호작용에 최적화된 모델임을 확인할 수 있었다.
-----
4.5 음성 품질과 응답 지연 간의 트레이드오프
표 2: 다양한 단위 청크 크기에서 지연 시간, 음성-텍스트 정렬 및 음성 품질
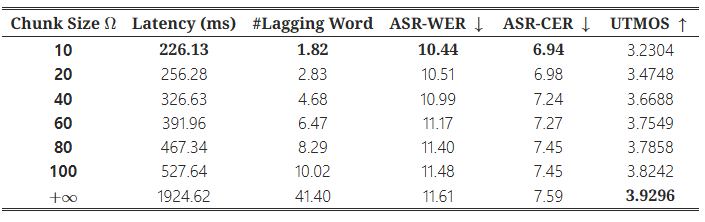
LLaMA-Omni는 텍스트 응답과 음성 응답에 해당하는 이산 단위를 동시에 생성할 수 있다. 2.6절에서 설명한 대로, 파형을 스트리밍 방식으로 생성하기 위해 생성된 이산 단위의 수가 일정한 청크 크기 Ω에 도달하면, 해당 단위 청크를 보코더에 입력하여 음성을 합성하고 재생한다. Ω 값을 조정함으로써 시스템의 지연 시간을 제어할 수 있으며, 작은 Ω값은 낮은 시스템 지연에 해당한다. Ω=+∞로 설정하면 모든 단위가 생성될 때까지 기다렸다가 음성을 합성하게 된다. 동시에, 값은 생성된 음성의 품질에도 영향을 미친다. 작은 값은 음성이 더 많은 부분으로 나뉘어 합성됨을 의미하며, 이는 각 구간 간의 불연속성을 유발하여 전체적인 음성의 일관성을 떨어뜨릴 수 있다.
값의 영향을 더 잘 이해하기 위해, 우리는 시스템의 지연 시간, 음성 및 텍스트 응답 간의 정렬, 그리고 생성된 음성의 품질을 다양한 Ω 설정에서 탐구하였다. 표 2에 나와 있듯이, Ω를 10으로 설정했을 때 시스템의 응답 지연은 226ms로, 이는 GPT-4o의 평균 오디오 지연 시간 320ms보다 낮다. 이 시점에서 음성 응답은 평균 1.82 단어의 지연을 보인다. 반면, Ω=+∞로 설정하면 지연 시간이 약 2초로 증가한다.
ASR-WER 및 ASR-CER 지표를 보면, 청크 크기가 증가함에 따라 오류율도 증가하는 것을 확인할 수 있다. 우리는 그 이유가 두 가지일 것이라 생각한다. 첫째, 보코더는 짧은 단위 시퀀스를 긴 시퀀스보다 더 안정적으로 처리할 수 있는데, 이는 보통 보코더가 짧은 시퀀스로 학습되기 때문이다. 둘째, 우리가 사용하는 ASR 모델인 Whisper-large-v3는 강력한 견고성을 가지고 있어, Ω가 작아 음성에 다소 불연속성이 있더라도 ASR 인식 정확도에 큰 영향을 미치지 않는다.
따라서 우리는 UTMOS 지표를 사용하여 생성된 음성의 자연스러움을 추가로 평가하였다. 결과적으로, Ω 값이 커질수록 음성의 자연스러움이 개선되었다. 이는 음성의 불연속성이 줄어들기 때문으로 볼 수 있다. 요약하자면, 우리는 서로 다른 시나리오에 따라 Ω 값을 조정함으로써 응답 지연과 음성 품질 간의 트레이드오프를 달성할 수 있다.
4.6 디코딩 시간 (Decoding Time)
표 3: S2TIF와 S2SIF 작업에서 다양한 모델의 평균 디코딩 시간 (초)
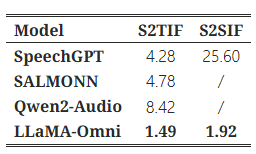
표 3은 S2TIF와 S2SIF 작업에서 각 모델의 평균 디코딩 시간을 보여준다. S2TIF 작업에서 SpeechGPT는 텍스트 명령을 먼저 출력하고 그 후에 텍스트 응답을 생성해야 하므로 디코딩 시간이 비교적 길다. 반면, SALMONN과 Qwen2-Audio는 대체로 길고 상세한 응답을 생성하는 경향이 있어 시간이 오래 걸린다. 이에 비해, LLaMA-Omni는 간결한 답변을 직접 제공하여 명령당 평균 1.49초로 상당히 낮은 디코딩 시간을 기록하였다. (확인 필요)
S2SIF 작업에서는 SpeechGPT가 텍스트와 음성 응답을 순차적으로 출력하므로, 텍스트 응답만 생성할 때보다 디코딩 시간이 약 6배 더 길어져 25.60초에 달한다. 반면, LLaMA-Omni는 텍스트와 음성 응답을 동시에 출력하며, 이산 단위를 생성할 때 비자기회귀(non-autoregressive) 아키텍처를 사용한다. 그 결과, 전체 생성 시간은 1.28배만 증가하여, 디코딩 속도 측면에서 LLaMA-Omni의 우월함을 보여주고 있다.
-----
논문에서 제공하는 데이터를 바탕으로 보면, LLaMA-Omni는 여러 기준에서 성능과 품질 간의 균형을 잘 맞춘 모델임을 주장하고 있음을 확인 가능
-----
4.7 사례 연구 (Case Study)
표 4: "How do I wrap a present neatly?"라는 명령에 대한 다양한 모델의 응답

표 4에서 다양한 모델이 "선물을 깔끔하게 포장하는 방법"에 대해 어떻게 응답하는지 살펴볼 수 있다. Qwen2-Audio의 응답은 상당히 길고, 줄 바꿈과 괄호와 같은 음성으로 합성하기 어려운 요소들을 포함하고 있다. SALMOON의 응답도 다소 긴 편이다. SpeechGPT의 응답은 음성 상호작용 시나리오에 더 적합한 스타일이지만, 포함된 정보의 양이 적다. 반면, LLaMA-Omni의 응답은 간결한 스타일을 유지하면서도 보다 상세하고 유용하여, 음성 상호작용 시나리오에서 이전 모델들보다 뛰어난 성능을 보인다.
-----
SALMOON이 가장 나한테는 괜찮아보이는 답변....
-----
5 관련 연구 (Related Work)
음성/오디오 언어 모델 (Speech/Audio Language Models) 자연어 처리 분야에서 언어 모델이 성공을 거두면서 (Brown et al., 2020), 연구자들은 언어 모델을 사용하여 음성이나 오디오를 어떻게 모델링할 수 있을지 탐구하기 시작했다. 초기 연구들은 오디오의 의미적 토큰이나 음향 토큰에 언어 모델을 학습시켜, 텍스트 없이도 오디오를 생성할 수 있는 가능성을 탐구하였다 (Lakhotia et al., 2021; Nguyen et al., 2023; Borsos et al., 2023). 또한, 음성 토큰과 텍스트를 공동으로 학습하여 VALL-E (Wang et al., 2023b)와 VioLA (Wang et al., 2023c)와 같은 디코더 전용 모델들이 음성 인식, 음성 번역, 음성 합성과 같은 작업을 수행할 수 있게 되었다. 그러나 이러한 모델들은 대형 언어 모델(LLM)을 기반으로 구축되지 않았다. LLM의 강력한 성능을 활용하기 위해, LLaMA와 같은 LLM을 기반으로 한 음성-언어 모델을 구축하는 방법을 탐구하는 많은 연구들이 있다. 이는 두 가지 유형으로 나눌 수 있다. 첫 번째 유형은 SpeechGPT (Zhang et al., 2023; 2024a)와 AudioPaLM (Rubenstein et al., 2023)처럼 LLM의 어휘에 음성 토큰을 추가하고, 음성과 텍스트 데이터를 사용해 사전 학습을 계속함으로써 네이티브 다중 모달 음성-텍스트 모델을 만드는 것이다. 그러나 이러한 접근법은 대개 많은 데이터와 상당한 컴퓨팅 자원을 필요로 한다. 두 번째 유형은 LLM 앞에 음성 인코더를 추가하고 전체 모델을 미세 조정하여 음성 인식 (Fathullah et al., 2024a; Yu et al., 2024; Ma et al., 2024c; Hono et al., 2024), 음성 번역 (Wu et al., 2023; Wang et al., 2023a; Chen et al., 2024) 또는 기타 일반적인 음성-텍스트 작업 (Chu et al., 2023; Tang et al., 2024; Chu et al., 2024; Fathullah et al., 2024b; Das et al., 2024; Hu et al., 2024)을 수행할 수 있는 능력을 갖추는 것이다. 그러나 이러한 접근법들은 대개 음성 또는 오디오 이해에만 집중하며 이를 생성할 수 있는 능력은 부족하다. 이전 연구와 비교하여, LLaMA-Omni는 LLM에 음성 이해와 생성 능력을 모두 부여하여 일반적인 음성 명령 수행 작업을 수행할 수 있게 한다. 또한, LLaMA-Omni는 낮은 학습 비용을 가지고 있어 최신 LLM을 기반으로 빠르게 개발할 수 있는 장점이 있다.
동시 생성 (Simultaneous Generation) 스트리밍 생성은 전체 입력을 받기 전에 출력을 생성하기 시작하는 것을 목표로 한다. 이 기능은 스트리밍 음성 인식이나 동시 통역과 같은 여러 시나리오에서 화자와 청취자 간의 동기화를 유지하는 데 중요하다. 대형 언어 모델의 경우, 스트리밍 음성 합성 컴포넌트는 모델과 사용자 간의 지연 시간을 크게 줄일 수 있다. 일반적인 스트리밍 생성 방법은 세 가지 주요 카테고리로 나뉜다: 단조 주의 기반 방법(monotonic-attention-based methods) (Raffel et al., 2017), CTC 기반 방법 (Graves et al., 2006b), 그리고 트랜스듀서 기반 방법 (Graves, 2012)이다. 단조 주의 기반 방법은 전통적인 주의 기반 시퀀스-투-시퀀스 프레임워크 (Bahdanau, 2014)를 수정하여 스트리밍 생성을 지원한다. 이러한 방법들은 외부 모듈을 사용하여 READ/WRITE 정책을 관리하며, 고정형(e.g., Wait-k (Ma et al., 2018)) 또는 적응형(e.g., MMA (Ma et al., 2019), EDAtt (Papi et al., 2022), Seg2Seg (Zhang & Feng, 2024))일 수 있다. CTC 기반 방법은 대기 동작을 나타내기 위해 타겟 어휘에 빈(blank) 기호를 추가한다. 인접한 반복 토큰과 빈 기호를 제거함으로써 스트리밍 추론을 달성한다. 주의 기반 방법의 강점을 활용하기 위해, CTC 기반 접근법은 종종 청크 기반 비자기회귀 아키텍처를 사용하며 (Ma et al., 2023), 이는 동시 통역 및 스트리밍 음성 합성에서 효과적인 것으로 입증되었다 (Zhang et al., 2024b; Ma et al., 2024a). 트랜스듀서 기반 방법은 CTC 기반 방법의 비자기회귀 특성과 타겟 토큰 간의 자기회귀 의존성을 연결하기 위해 설계되었다. 이러한 접근법들은 토큰 의존성을 포착하기 위한 추가적인 예측기를 도입하며, 그 변형들은 동시 통역에서 강력한 성능을 보였다 (Liu et al., 2021; Tang et al., 2023). 최근에는 연구자들이 디코더 전용 대형 언어 모델을 스트리밍 생성 작업에 채택하기 시작했으며 (Seide et al., 2024; Guo et al., 2024), 이를 인터럽트 가능한 듀플렉스 모델로 확장하고 있다 (Ma et al., 2024b).
6 결론 (Conclusion)
이 논문에서는 LLM과의 낮은 지연 및 고품질 음성 상호작용을 가능하게 하는 혁신적인 모델 아키텍처인 LLaMA-Omni를 제안했다. LLaMA-Omni는 최신 Llama-3.1-8B-Instruct 모델을 기반으로, 음성 이해를 위한 음성 인코더와 텍스트 및 음성 응답을 동시에 생성할 수 있는 스트리밍 음성 디코더를 추가했다. 모델을 음성 상호작용 시나리오에 맞추기 위해, 200K개의 음성 명령과 그에 따른 음성 응답을 포함한 InstructionS2S-200K 데이터셋을 구성했다. 실험 결과, LLaMA-Omni는 이전 음성-언어 모델과 비교하여 콘텐츠와 스타일 모두에서 우수한 응답을 제공하였고, 지연 시간은 최소 226ms로 매우 낮았다. 또한, LLaMA-Omni의 학습은 4개의 GPU로 3일 이내에 완료되어 최신 LLM 기반 음성 상호작용 모델의 빠른 개발이 가능하다. 앞으로는 생성된 음성 응답의 표현력을 강화하고 실시간 상호작용 능력을 개선하는 연구를 진행할 계획이다.
A. 프롬프트 (PROMPT)
ChatGPT 평가 프롬프트 (모델: GPT-4o) 여러 모델의 음성 상호작용 시나리오에서의 성능을 평가하는 데 도움이 필요합니다. 모델들은 사용자의 음성 입력을 받고 이를 이해하여 음성 출력으로 응답해야 합니다. 당신의 과제는 제공된 사용자 입력 전사 [Instruction]과 모델의 출력 전사 [Response]를 바탕으로 모델의 응답을 평가하는 것입니다. 응답을 콘텐츠와 스타일 두 가지 관점에서 평가해 주시고, 각각 1에서 5점 사이로 점수를 매겨 주세요.
콘텐츠 (1-5점):
- 1점: 응답이 전반적으로 관련성이 없거나 잘못되었으며 사용자의 질문을 해결하지 못함. 주제가 벗어나거나 잘못된 정보를 제공함.
- 2점: 응답이 다소 관련성은 있지만 정확성이나 완전성이 부족함. 질문에 부분적으로만 답하거나 불필요한 정보를 포함함.
- 3점: 응답이 관련성 있고 대부분 정확하지만, 간결하지 않거나 메인 포인트에 기여하지 않는 불필요한 세부사항이 포함됨.
- 4점: 응답이 관련성 있고 정확하며, 간결하게 사용자의 질문에 명확한 답을 제공함. 불필요한 설명이 없음.
- 5점: 응답이 매우 관련성 있고 정확하며 핵심을 찌름. 사용자의 질문을 효과적이고 효율적으로 직접 해결하고 필요한 정보를 정확하게 제공함.
스타일 (1-5점):
- 1점: 음성 상호작용에 부적합한 응답이며, 목록 등 구조화된 요소를 포함하거나 지나치게 복잡하고, 분절되었거나 이해하기 어려움.
- 2점: 음성 상호작용에 다소 적합하지만, 지나치게 길거나 짧거나 어색한 표현이 있어 음성 상호작용에 덜 효과적임.
- 3점: 일반적으로 음성 상호작용에 적합하지만, 길이, 명확성 또는 유창성에 약간의 문제가 있어 전체적인 효과를 약간 떨어뜨림.
- 4점: 음성 상호작용에 적합하며, 적절한 길이와 명확한 언어, 자연스러운 흐름을 가지고 있음. 소리 내어 말할 때 이해하기 쉬움.
- 5점: 음성 상호작용에 완벽히 적합함. 이상적인 길이, 매우 명확하고 자연스럽게 흘러가며 소리 내어 말할 때 따라가기 쉽고 이해하기 쉬움.
아래에는 사용자의 명령과 모델의 응답 전사가 나와 있습니다:
### [Instruction]: {instruction}
### [Response]: {response}평가 후, 점수를 다음과 같은 JSON 형식으로 출력해 주세요: {"content": content score, "style": style score}. 추가적인 설명은 필요하지 않습니다.
명령 재작성 프롬프트 (모델: Llama-3-70B-Instruct) 아래는 사용자의 명령을 포함한 명령 데이터입니다. 음성 입력을 지원하는 대형 언어 모델을 학습하기 위해 이 명령 데이터의 음성 버전을 생성하고자 합니다. 따라서 다음 요구사항에 따라 명령 데이터를 재작성해 주세요:
- 인간의 음성을 시뮬레이션하기 위해 필러 단어를 적절히 추가해 주세요 (‘you know’, ‘like’ 등은 너무 많이 사용하지 않도록 주의해 주세요).
- 질문에는 TTS 모델이 합성할 수 없는 내용이 포함되어서는 안 됩니다. 숫자는 아라비아 숫자 대신 영어 단어로 작성해 주세요.
- 질문은 과도한 장황함 없이 비교적 간결해야 합니다.
[instruction]: {instruction}다음과 같은 JSON 형식으로 출력해 주세요: {"question": {question}}.
응답 생성 프롬프트 (모델: Llama-3-70B-Instruct) 아래는 사용자의 음성 질의에 대한 전사된 텍스트입니다. 이 질문에 대한 응답을 제공해 주세요. 응답은 TTS를 사용하여 음성으로 변환될 예정입니다. 응답을 작성할 때 다음 요구사항을 준수해 주세요:
- 응답에는 TTS 모델이 합성할 수 없는 내용(괄호, 순서 목록 등)이 포함되어서는 안 됩니다. 숫자는 아라비아 숫자 대신 영어 단어로 작성해 주세요.
- 응답은 매우 간결하고 핵심을 찌르며, 긴 설명은 피해야 합니다.
[instruction]: {instruction}다음과 같은 JSON 형식으로 출력해 주세요: {"response": {response}}.
'인공지능' 카테고리의 다른 글
| Qwen2.5: A Party of Foundation Models! (2) | 2024.11.26 |
|---|---|
| [모델까지만]Moshi: a speech-text foundation model for real-time dialogue (1) | 2024.11.26 |
| iTransformer: Inverted Transformers Are Effective for Time Series Forecasting (1) | 2024.11.25 |
| Pixtral 12B (1) | 2024.11.23 |
| DeepSeek-V2.5 (1) | 2024.11.23 |



