https://qwenlm.github.io/blog/qwen2.5/
Qwen2.5: A Party of Foundation Models!
GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD Introduction In the past three months since Qwen2’s release, numerous developers have built new models on the Qwen2 language models, providing us with valuable feedback. During this period, we have focused on c
qwenlm.github.io
소개
지난 3개월 동안 Qwen2가 출시된 이후, 수많은 개발자들이 Qwen2 언어 모델을 바탕으로 새로운 모델을 구축하며 우리에게 귀중한 피드백을 제공해 주었습니다. 이 기간 동안 우리는 더욱 스마트하고 지식이 풍부한 언어 모델을 만드는 데 집중해 왔습니다. 오늘, 우리는 Qwen 패밀리의 최신 추가 모델인 Qwen2.5를 소개하게 되어 매우 기쁩니다. 이것은 역사상 가장 큰 오픈소스 공개 중 하나가 될 수도 있습니다! 축제를 시작해볼까요?
이번 최신 릴리스에는 LLM Qwen2.5와 함께 코딩에 특화된 모델 Qwen2.5-Coder, 수학에 특화된 모델 Qwen2.5-Math가 포함되어 있습니다. 모든 공개 가중치 모델은 조밀한(dense) 디코더 전용 언어 모델이며, 다양한 크기로 제공됩니다. 모델들은 다음과 같습니다:
- Qwen2.5: 0.5B, 1.5B, 3B, 7B, 14B, 32B, 72B
- Qwen2.5-Coder: 1.5B, 7B, 그리고 32B(곧 제공 예정)
- Qwen2.5-Math: 1.5B, 7B, 72B
모든 오픈소스 모델은 3B 및 72B 변형을 제외하고 Apache 2.0 라이선스 하에 제공됩니다. 해당 라이선스 파일은 각각의 Hugging Face 저장소에서 찾을 수 있습니다. 이러한 모델들 외에도 우리는 Model Studio를 통해 Qwen-Plus와 Qwen-Turbo라는 플래그십 언어 모델에 대한 API를 제공하고 있으니 꼭 한 번 탐색해보시기 바랍니다. 또한 지난달 릴리스에 비해 성능이 향상된 Qwen2-VL-72B도 오픈소스로 공개하였습니다.
Qwen2.5, Qwen2.5-Coder, Qwen2.5-Math에 대한 자세한 정보는 아래 링크를 통해 확인해 보세요:
우리의 광범위한 모델 라인업을 통해 무한한 가능성을 열어볼 준비를 하세요! 여러분과 함께 이 최첨단 모델들을 공유하게 되어 기쁘며, 여러분이 이루어낼 멋진 성과들을 매우 기대하고 있습니다!
주요 내용
Qwen2.5 언어 모델에 대해 모든 모델은 최신 대규모 데이터셋으로 사전 학습되었으며, 최대 18조 토큰을 포함하고 있습니다. Qwen2와 비교했을 때, Qwen2.5는 훨씬 더 많은 지식을 습득하였으며(MMLU: 85+), 코딩 능력(HumanEval: 85+)과 수학 능력(MATH: 80+)이 크게 향상되었습니다. 또한 새로운 모델들은 명령어 따르기, 긴 텍스트 생성(8K 토큰 이상), 구조화된 데이터(예: 테이블) 이해, 그리고 특히 JSON과 같은 구조화된 출력 생성에서 큰 개선을 이루었습니다. Qwen2.5 모델은 시스템 프롬프트의 다양성에 더 잘 대응하며, 역할극 구현 및 챗봇의 조건 설정에서도 향상된 성능을 보입니다.
Qwen2와 마찬가지로 Qwen2.5 언어 모델도 최대 128K 토큰을 지원하며 최대 8K 토큰을 생성할 수 있습니다. 또한 중국어, 영어, 프랑스어, 스페인어, 포르투갈어, 독일어, 이탈리아어, 러시아어, 일본어, 한국어, 베트남어, 태국어, 아랍어 등을 포함한 29개 이상의 언어를 다중 언어로 지원합니다. 아래에 모델에 대한 기본 정보와 지원되는 언어에 대한 자세한 내용을 제공합니다.
전문화된 언어 모델인 Qwen2.5-Coder(코딩용)와 Qwen2.5-Math(수학용) 역시 이전 모델인 CodeQwen1.5와 Qwen2-Math에 비해 상당한 개선이 이루어졌습니다. 특히 Qwen2.5-Coder는 코드 관련 데이터 5.5조 토큰으로 학습되었으며, 이 덕분에 작은 규모의 코딩 전용 모델조차도 코딩 평가 벤치마크에서 더 큰 언어 모델과 비교해 경쟁력 있는 성능을 발휘할 수 있습니다. 한편 Qwen2.5-Math는 중국어와 영어를 모두 지원하며, 연쇄 사고(Chain-of-Thought, CoT), 사고 기반 프로그램 작성(Program-of-Thought, PoT), 도구 통합 추론(Tool-Integrated Reasoning, TIR) 등 다양한 추론 방법을 포함하고 있습니다.

성능
Qwen2.5
Qwen2.5의 성능을 보여주기 위해, 우리는 가장 큰 오픈소스 모델인 Qwen2.5-72B(매개변수 72B의 조밀한 디코더 전용 언어 모델)를 Llama-3.1-70B, Mistral-Large-V2와 같은 주요 오픈소스 모델들과 비교하여 벤치마크했습니다. 우리는 다양한 벤치마크에서 명령어 조정이 된 버전들의 종합적인 결과를 제시하며, 모델의 능력과 인간의 선호도를 평가하였습니다.
Qwen2.5-72B 명령어 조정 성능
명령어 조정된 언어 모델 외에도, 우리는 오픈소스 플래그십 모델인 Qwen2.5-72B의 기본 언어 모델이 Llama-3-405B와 같은 더 큰 모델들과 비교해도 상위 성능을 달성한다는 것을 확인했습니다.
Qwen2.5-72B 기본 모델 성능
또한, 우리는 최신 API 기반 모델인 Qwen-Plus를 GPT4-o, Claude-3.5-Sonnet, Llama-3.1-405B, DeepSeek-V2.5 등의 주요 독점 및 오픈소스 모델들과 비교하여 벤치마크를 진행했습니다. 이 비교는 현재의 대형 언어 모델 환경에서 Qwen-Plus의 경쟁력을 보여줍니다. Qwen-Plus는 DeepSeek-V2.5를 상당히 능가하며 Llama-3.1-405B와 경쟁력 있는 성능을 보여주는 반면, 일부 측면에서는 GPT4-o 및 Claude-3.5-Sonnet에 비해 낮은 성능을 보였습니다. 이러한 벤치마킹은 Qwen-Plus의 강점을 강조하는 동시에, 향후 개선이 필요한 영역을 확인하여 대형 언어 모델 분야에서 지속적인 개선과 혁신에 대한 우리의 의지를 강화합니다.
Qwen-Plus 명령어 조정 성능
Qwen2.5에서 중요한 업데이트 중 하나는 Qwen2.5-14B와 Qwen2.5-32B와 같은 14B 및 32B 모델의 재도입입니다. 이러한 모델들은 다양한 작업에서 Phi-3.5-MoE-Instruct, Gemma2-27B-IT 등과 같은 동등하거나 더 큰 크기의 기본 모델들을 능가하는 성능을 보입니다. 이들은 모델 크기와 성능 간의 최적 균형을 이루며, 일부 더 큰 모델들에 버금가거나 그 이상의 성능을 제공합니다. 추가로, 우리의 API 기반 모델인 Qwen-Turbo는 두 오픈소스 모델과 비교하여 비용 효율적이고 신속한 서비스를 제공하면서도 높은 경쟁력을 자랑합니다.
Qwen2.5-32B 명령어 조정 성능
최근 들어 소형 언어 모델(SLM)에 대한 관심이 두드러지고 있습니다. 소형 언어 모델은 역사적으로 더 큰 모델(LLM)에 비해 성능이 떨어지는 경향이 있었지만, 그 격차가 빠르게 줄어들고 있습니다. 특히, 매개변수가 단 30억 개에 불과한 모델들도 이제 매우 경쟁력 있는 결과를 내고 있습니다. 첨부된 그림은 중요한 추세를 보여줍니다: 최신 모델들이 MMLU에서 65 이상의 점수를 달성하는 경향이 있으며, 이는 점점 더 작은 모델들에서 나타나고 있다는 점입니다. 이는 언어 모델 간 지식 밀도의 급격한 성장을 의미하며, 특히 우리 Qwen2.5-3B는 단 30억 개의 매개변수만으로도 인상적인 성능을 발휘하여 이전 모델들과 비교했을 때 효율성과 역량을 입증합니다.
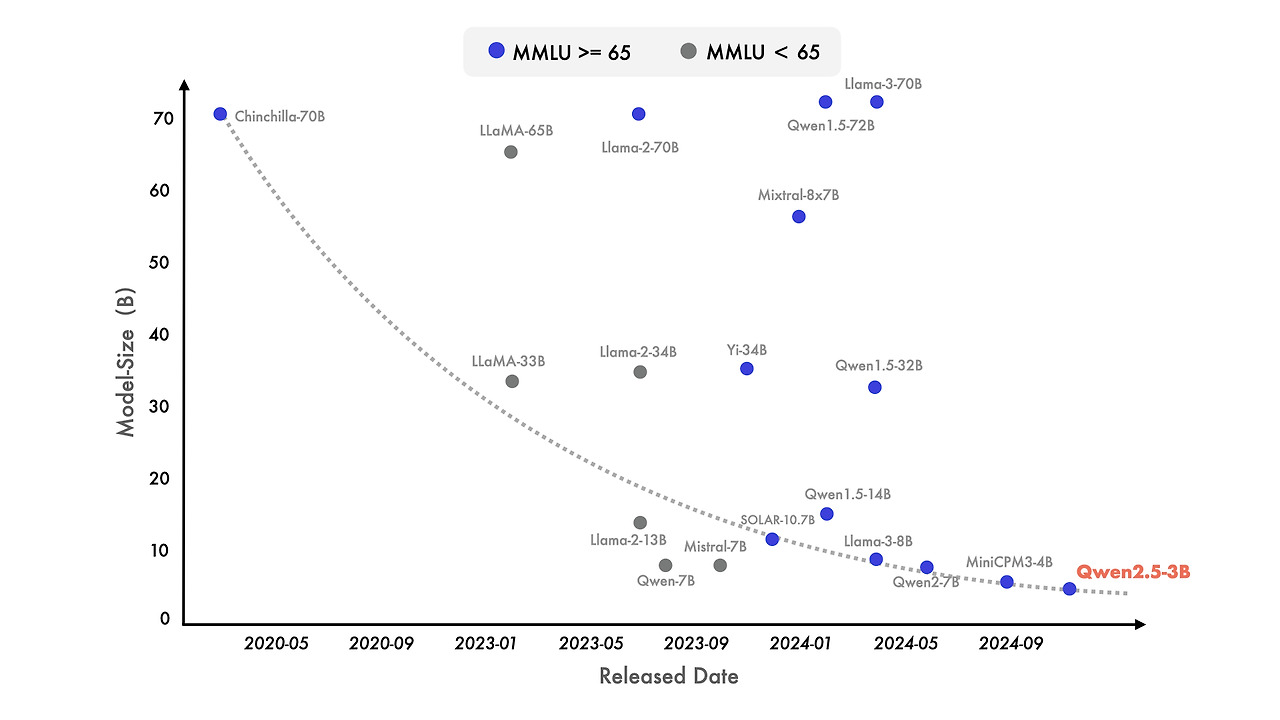
Qwen2.5 소형 모델
이러한 벤치마크 평가의 상당한 개선 외에도 우리는 후속 학습 방법론을 정교화하였습니다. 우리의 네 가지 주요 업데이트는 최대 8K 토큰에 이르는 긴 텍스트 생성을 지원, 구조화된 데이터에 대한 이해 능력의 상당한 향상, JSON 형식을 포함한 구조화된 출력 생성의 신뢰성 향상, 그리고 다양한 시스템 프롬프트에 대한 성능 개선을 통해 효과적인 역할극을 가능하게 한 것입니다. 이러한 기능들을 어떻게 활용할 수 있는지에 대한 자세한 내용은 LLM 블로그를 확인해 보세요.
Qwen2.5-Coder
CodeQwen1.5 출시 이후, 우리는 많은 사용자를 유치했으며 이들은 디버깅, 코딩 관련 질문에 대한 답변, 코드 제안 제공 등 다양한 코딩 작업에 이 모델을 활용하고 있습니다. 최신 버전인 Qwen2.5-Coder는 코딩 애플리케이션에 특화되어 설계되었습니다. 이번 섹션에서는 Qwen2.5-Coder-7B-Instruct의 성능 결과를 주요 오픈소스 모델들과 비교하여 제공합니다. 여기에는 매개변수 크기가 훨씬 큰 모델들도 포함됩니다.
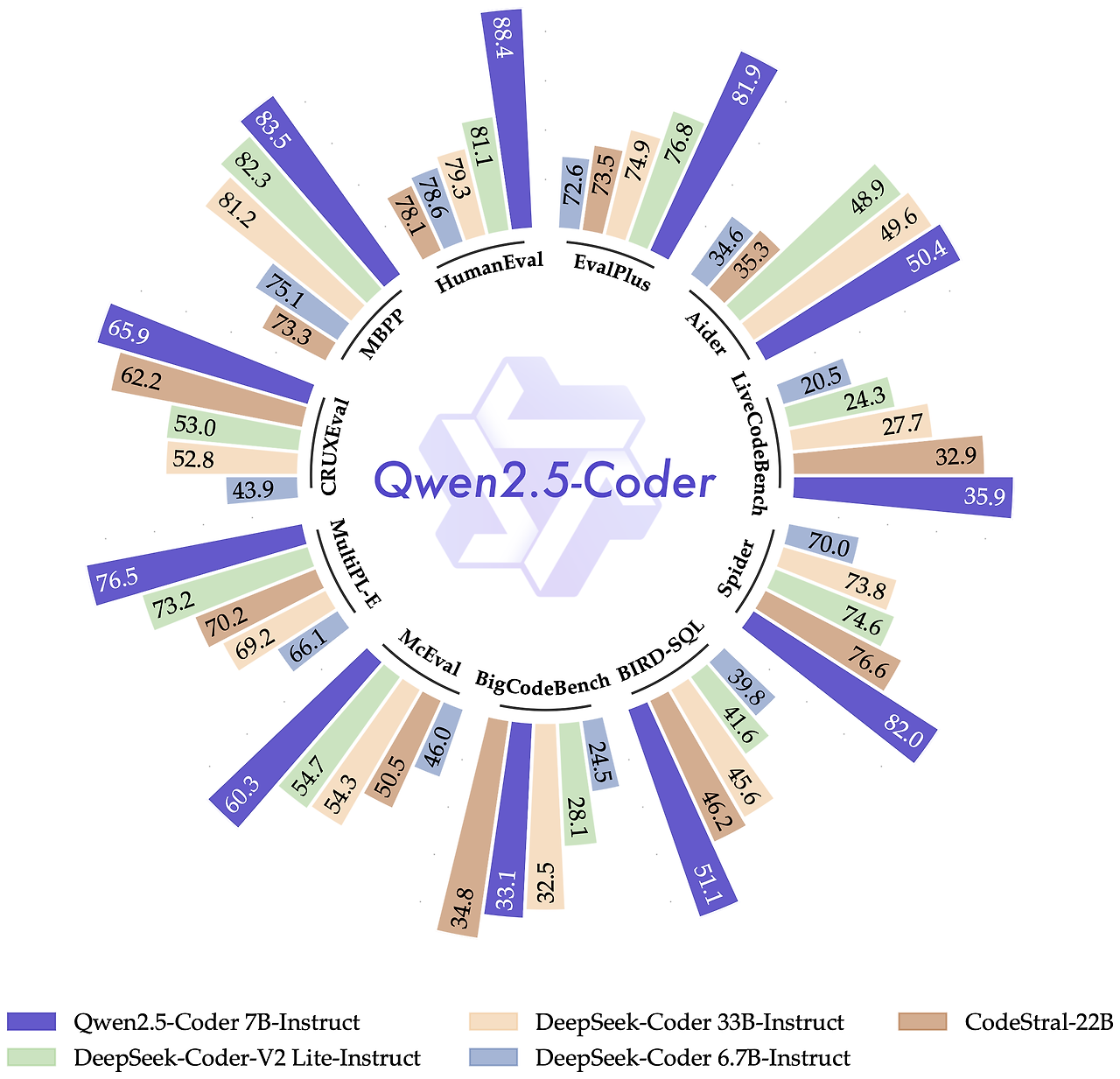
Qwen2.5-Coder 명령어 조정 성능
우리는 Qwen2.5-Coder가 개인 코딩 도우미로서 훌륭한 선택이라고 믿습니다. 크기가 작음에도 불구하고, 여러 프로그래밍 언어와 작업에서 더 큰 언어 모델들을 능가하며 탁월한 코딩 능력을 보여줍니다.
Qwen2.5-Math
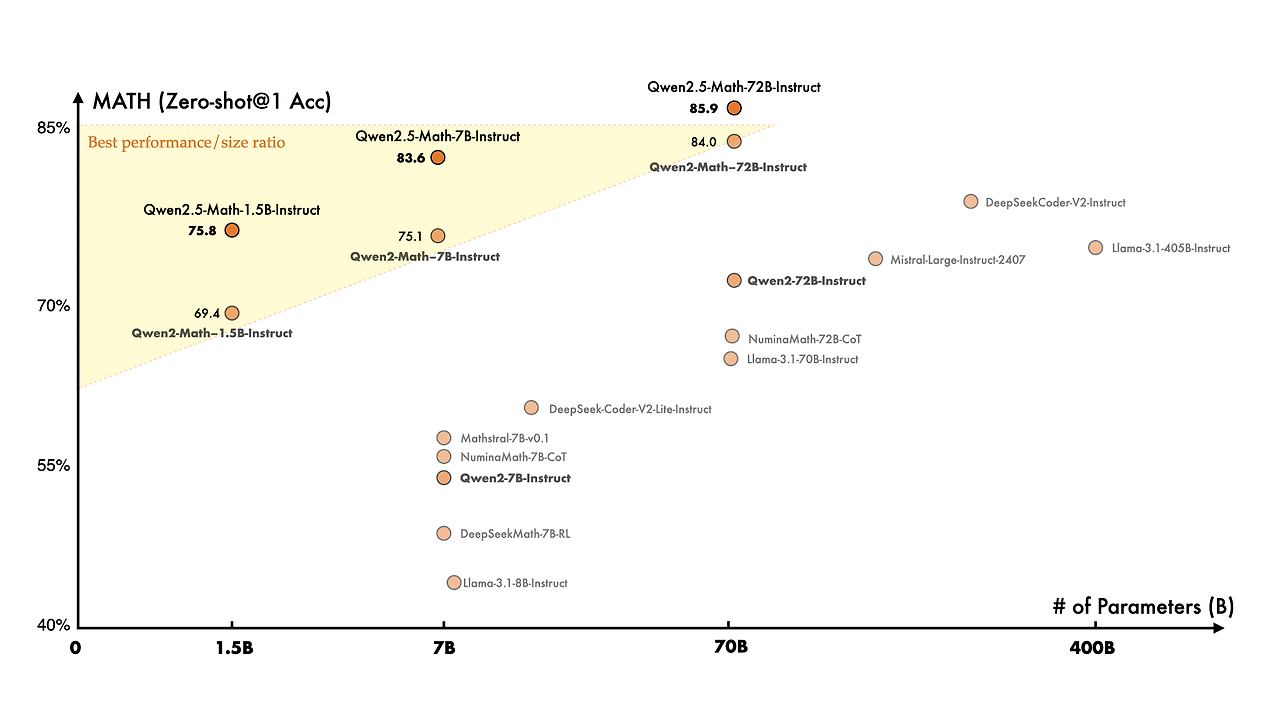
수학 특화 언어 모델과 관련하여, 지난달 처음으로 Qwen2-Math 모델을 출시했으며, 이번에는 Qwen2-Math와 비교하여 Qwen2.5-Math가 더욱 대규모의 수학 관련 데이터(예: Qwen2-Math가 생성한 합성 데이터)를 사전 학습한 상태로 공개되었습니다. 또한 이번에는 중국어 지원을 확장하였고, 연쇄 사고(Chain-of-Thought, CoT), 사고 기반 프로그램 작성(Program-of-Thought, PoT), 도구 통합 추론(Tool-Integrated Reasoning, TIR)을 수행할 수 있는 능력을 부여하여 추론 능력을 강화하였습니다. Qwen2.5-Math-72B-Instruct의 전반적인 성능은 Qwen2-Math-72B-Instruct 및 GPT4-o를 능가하며, 심지어 매우 작은 전문 모델인 Qwen2.5-Math-1.5B-Instruct조차도 대형 언어 모델들과 비교해 매우 경쟁력 있는 성능을 보여줍니다.
Qwen2.5 개발하기
가장 간단한 사용 방법은 Hugging Face Transformer를 통해 모델 카드를 참고하여 사용하는 것입니다:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-7B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
Qwen2.5를 vLLM으로 사용하려면 다음 명령어를 실행하여 OpenAI API와 호환되는 서비스를 배포할 수 있습니다:
python -m vllm.entrypoints.openai.api_server \
--model Qwen/Qwen2.5-7B-Instruct
또는 vllm 버전이 0.5.3 이상인 경우 vllm serve를 사용할 수 있습니다. 그런 다음 curl을 사용하여 Qwen2.5와 통신할 수 있습니다:
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "Qwen/Qwen2.5-7B-Instruct",
"messages": [
{"role": "user", "content": "Tell me something about large language models."}
],
"temperature": 0.7,
"top_p": 0.8,
"repetition_penalty": 1.05,
"max_tokens": 512
}'
또한 Qwen2.5는 vLLM의 내장 도구 호출을 지원합니다. 이 기능은 vLLM 버전이 0.6 이상일 때 사용 가능하며, 이를 활성화하려면 다음 명령어로 vLLM의 OpenAI 호환 서비스를 시작하세요:
vllm serve Qwen/Qwen2.5-7B-Instruct --enable-auto-tool-choice --tool-call-parser hermes이제 GPT의 도구 호출 기능과 동일한 방식으로 사용할 수 있습니다.
Qwen2.5는 Ollama의 도구 호출도 지원합니다. Ollama의 OpenAI 호환 서비스를 시작하고, 이를 GPT의 도구 호출과 동일한 방식으로 사용할 수 있습니다.
Qwen2.5의 채팅 템플릿에는 도구 호출 템플릿도 포함되어 있어, Hugging Face Transformers의 도구 호출 지원을 사용할 수 있습니다.
vLLM / Ollama / Transformers의 도구 호출 지원은 Nous의 Hermes에서 영감을 받은 도구 호출 템플릿을 사용합니다. 이전에는 Qwen-Agent가 Qwen2의 고유한 도구 호출 템플릿을 사용하여 도구 호출 지원을 제공했지만, 이는 vLLM 및 Ollama와의 통합이 어려웠습니다. Qwen2.5는 Qwen2의 템플릿 및 Qwen-Agent와의 호환성을 유지하고 있습니다.
Qwen의 친구들
💗 Qwen은 친구들 없이는 존재할 수 없습니다! 이 오래된 동료들과 새로운 친구들의 지원에 깊은 감사를 드립니다:
- Hugging Face Transformers
- 파인튜닝: Peft, ChatLearn, Llama-Factory, Axolotl, Firefly, Swift, XTuner, Unsloth, Liger Kernel
- 양자화: AutoGPTQ, AutoAWQ, Neural Compressor
- 배포: vLLM, SGL, SkyPilot, TensorRT-LLM, OpenVino, TGI, Xinference
- API 플랫폼: Together, Fireworks, OpenRouter, Sillicon Flow
- 로컬 실행: MLX, Llama.cpp, Ollama, LM Studio, Jan
- 에이전트 및 RAG 프레임워크: Dify, LlamaIndex, CrewAI
- 평가: LMSys, OpenCompass, Open LLM Leaderboard
- 모델 학습: Arcee AI, Sailor, Dolphin, Openbuddy
Qwen에 기여해주신 수많은 팀과 개인들에게도 진심으로 감사의 말씀을 전합니다. 비록 모두가 구체적으로 언급되지 않았더라도, 여러분의 지원은 매우 소중합니다. 더 많은 친구들이 이 흥미진진한 여정에 동참해주길 따뜻하게 환영합니다. 함께 협력을 강화하고 오픈소스 AI 커뮤니티의 연구 개발을 촉진하여 그 어느 때보다 강하고 혁신적인 커뮤니티를 만들 수 있습니다.
앞으로의 계획
우리는 수많은 고품질 모델들을 동시에 출시하게 되어 기쁘지만, 여전히 해결해야 할 중요한 도전 과제가 남아 있음을 알고 있습니다. 최근의 릴리스는 언어, 비전-언어, 오디오-언어 영역 전반에 걸친 견고한 기초 모델 개발에 대한 우리의 헌신을 보여줍니다. 그러나 이들 서로 다른 모달리티를 하나의 모델에 통합하여 세 가지 모두에 걸친 정보의 원활한 엔드 투 엔드 처리를 가능하게 하는 것이 중요합니다. 또한 데이터 스케일링을 통해 추론 능력을 강화하는 데 진전을 이루었지만, 최근 강화 학습의 발전(예: o1)에 영감을 받아, 추론 계산을 확장함으로써 모델의 추론 능력을 더욱 향상시키는 데 전념하고 있습니다. 곧 차세대 모델을 소개하게 될 날을 기대하고 있습니다! 더 흥미로운 발전을 기대해 주세요!
'인공지능' 카테고리의 다른 글
| nivida/llama-3.1-nemotron-70B (0) | 2024.11.26 |
|---|---|
| OpenAI Swarm (0) | 2024.11.26 |
| [모델까지만]Moshi: a speech-text foundation model for real-time dialogue (1) | 2024.11.26 |
| LLaMA-Omni: Seamless Speech Interaction with Large Language Models (2) | 2024.11.26 |
| iTransformer: Inverted Transformers Are Effective for Time Series Forecasting (1) | 2024.11.25 |

