https://github.com/kyutai-labs/moshi
GitHub - kyutai-labs/moshi
Contribute to kyutai-labs/moshi development by creating an account on GitHub.
github.com
https://arxiv.org/abs/2410.00037
Moshi: a speech-text foundation model for real-time dialogue
We introduce Moshi, a speech-text foundation model and full-duplex spoken dialogue framework. Current systems for spoken dialogue rely on pipelines of independent components, namely voice activity detection, speech recognition, textual dialogue and text-to
arxiv.org
moshi.chat
moshi.chat
초록
우리는 Moshi라는 음성-텍스트 기초 모델과 풀-듀플렉스 음성 대화 프레임워크를 소개합니다. 현재의 음성 대화 시스템은 음성 활동 감지, 음성 인식, 텍스트 기반 대화, 텍스트-음성 변환과 같은 독립적인 구성 요소들의 파이프라인에 의존하고 있습니다. 이러한 프레임워크는 실제 대화의 경험을 재현하지 못합니다. 첫째, 이러한 시스템의 복잡성은 상호작용 간에 몇 초의 지연을 초래합니다. 둘째, 텍스트가 대화의 중간 매개체로 사용되면서 감정이나 비언어적 소리와 같은 의미를 수정하는 비언어적 정보가 상호작용에서 손실됩니다. 마지막으로, 이러한 시스템은 화자의 턴(turn)으로 대화를 구분하며, 이는 겹치는 발화, 중단, 삽입 발화를 고려하지 못합니다.
Moshi는 이러한 독립적인 문제들을 모두 해결하기 위해 음성 대화를 음성-대-음성 생성으로 재구성합니다. 텍스트 언어 모델을 기반으로 한 Moshi는 신경 오디오 코덱의 잔여 양자화기로부터 음성을 토큰 형태로 생성하며, 자신의 음성과 사용자의 음성을 별도의 병렬 스트림으로 모델링합니다. 이를 통해 명시적인 화자 턴을 제거하고 임의의 대화 역동성을 모델링할 수 있게 됩니다.
또한, 우리는 이전 연구의 계층적 의미-음향 토큰 생성을 확장하여, 오디오 토큰의 접두사로서 시간 정렬된 텍스트 토큰을 먼저 예측합니다. 이러한 "내적 독백(Inner Monologue)" 방식은 생성된 음성의 언어적 품질을 크게 향상시킬 뿐만 아니라, 스트리밍 음성 인식과 텍스트-음성 변환 기능도 제공할 수 있음을 보여줍니다. 결과적으로 우리의 모델은 이론상 160ms, 실제로 200ms의 지연을 가지는 최초의 실시간 풀-듀플렉스 음성 대형 언어 모델이며, GitHub(github.com/kyutai-labs/moshi)에서 이용할 수 있습니다.
키워드: 음성, 텍스트, 멀티모달, 기초 모델, 음성 대화
1. 도입
음성은 Alexa, Siri, Google Assistant와 같은 초기 대화 시스템에 편리한 인터페이스를 제공해 왔습니다. 이러한 시스템에서 사용자가 발화한 "웨이크 워드(깨우는 단어)"는 일반적으로 자동 음성 인식(ASR) 시스템을 트리거하며, 사용자의 요청을 텍스트로 전사합니다. 이후 자연어 이해(NLU) 파이프라인은 이 쿼리를 구조화된 형식으로 변환하여 자연어 생성(NLG)을 통해 텍스트 응답을 생성합니다. 마지막으로 텍스트-음성 변환(TTS) 시스템이 사용자가 들을 수 있도록 응답을 전달합니다. 이러한 프로세스는 짧고 제한된 상호작용(예: 행동 트리거, 정보 검색)에는 적합하지만, 대형 언어 모델(LLM)의 등장으로 인해 음성 인터페이스가 여러 턴에 걸친 개방형 대화를 처리할 필요성이 생겼습니다. 이러한 과제에 대한 해결책은 LLM을 이용해 NLU와 NLG를 처리하고, 사용자의 턴과 시스템의 턴 각각에서 ASR과 TTS가 음성 인터페이스를 제공하는 것입니다(Llama, 2024). 이 프레임워크는 현재의 음성 대화 시스템인 Gemini나 ChatGPT 같은 시스템에서 사용됩니다.
그럼에도 불구하고, 이러한 인터페이스가 제공하는 경험은 자연스러운 대화와는 거리가 멉니다. 첫째, 이러한 파이프라인의 여러 구성 요소에서 지연이 누적되어 보통 몇 초의 전체 지연을 초래합니다. 이는 몇 백 밀리초 안에 반응이 이루어지는 자연스러운 대화와는 다릅니다. 둘째, 언어 이해와 생성이 텍스트 영역에서 이루어지기 때문에, 비언어적 정보는 모델에서 무시됩니다. 이는 감정이나 억양과 같은 준언어적 정보부터 주변 소리와 같은 비음성 오디오까지 포함됩니다. 마지막으로 이러한 모델은 근본적으로 턴 기반으로 동작하며, 대화를 하나의 화자가 말하는 잘 정의된 연속적인 턴의 집합으로 간주합니다. 이러한 접근 방식은 텍스트 대화에는 적합하지만, 방해, 겹치는 발화(전체 발화 시간의 10%에서 20%를 차지함), 백채널링(예: "알겠어"나 "그래"와 같은 끼어들지 않는 반응)과 같은 구어적 대화의 측면을 모델링하는 데에는 한계가 있습니다.
이 연구에서는 앞서 언급한 지연 문제, 텍스트 정보 병목 현상, 턴 기반 모델링의 한계를 해결하기 위해 Moshi라는 음성-텍스트 기초 모델과 실시간 음성 대화 시스템을 소개합니다. Moshi는 텍스트 LLM 백본에 더 작은 오디오 언어 모델(Borsos et al., 2022; Yang et al., 2023)을 추가하여 이산 오디오 유닛을 처리하고 예측합니다. 이를 통해 입력을 이해하고 출력을 생성할 때 텍스트를 중간 매개로 사용하지 않고 오디오 도메인에서 직접 처리함으로써 텍스트의 정보 병목 현상을 제거하고, 기반 텍스트 LLM의 지식과 추론 능력을 활용할 수 있습니다. 우리는 이전 오디오 언어 모델 연구를 확장하여 스트리밍 가능한 계층적 아키텍처를 설계했으며, 이론상 160ms의 지연을 달성합니다—이는 10개 언어에서 측정한 자연 대화 평균 지연인 230ms보다 낮은 수치입니다(Stivers et al., 2009). 또한, 입력 및 출력 오디오 스트림을 두 개의 자가 회귀 토큰 스트림으로 명시적으로 처리하는 최초의 다중 스트림 오디오 언어 모델을 소개합니다. 이를 통해 화자 턴의 개념을 제거하고, 겹치는 발화나 중단을 포함한 임의의 대화 역동성을 가진 자연 대화를 모델 학습에 사용할 수 있습니다. 결과적으로 우리의 모델은 첫 번째 풀-듀플렉스—항상 듣고 항상 음성을 생성하는, 실시간 대화형 LLM입니다. 우리의 기여는 아래와 같습니다:
- Helium을 제안합니다. 70억 개의 파라미터를 가진 텍스트 LLM으로, 2.1조 개의 공개된 영어 토큰으로 사전 학습되었습니다. 모델의 아키텍처와 학습은 3.2절에서 설명하고, 사전 학습 데이터 수집 및 필터링은 4.1절에서 다룹니다.
- Mimi를 훈련합니다. Moshi가 예측하는 이산 토큰으로 오디오를 변환하고 다시 복원하는 신경 오디오 코덱으로, 잔여 벡터 양자화(RVQ)를 사용합니다. 일반적으로 오디오 언어 모델은 음향 토큰과 자기 지도 학습 음성 모델의 의미적 토큰을 결합해야 텍스트 조건 없이도 이해 가능한 음성을 생성합니다(Borsos et al., 2022). 우리는 Zhang et al. (2024b)의 접근 방식을 확장하여 의미 정보를 음향 토큰의 첫 번째 레벨에 증류하고, 개선된 학습 기법을 도입합니다. Mimi의 아키텍처와 학습은 3.3절에서 설명하며, 세부 실험은 5.2절에서 다룹니다.
- Moshi를 제안합니다. 오디오 토큰을 계층적이며 스트리밍 방식으로 예측하기 위해 Helium과 더 작은 Transformer(Vaswani et al., 2017) 모델을 결합한 새로운 아키텍처입니다. 이러한 비조건 오디오 언어 모델이 이해 가능한 음성을 생성하는 데 얼마나 어려운지를 보여주고, 스트리밍 방식으로 오디오를 생성하면서 비스트리밍 모델보다 음성의 명료도와 품질을 초과하는 솔루션을 제공합니다. 또한 이 아키텍처를 확장하여 여러 오디오 스트림을 병렬로 모델링하며, 임의의 동적 특성을 가진 풀-듀플렉스 대화를 단순하고 실용적으로 처리할 수 있게 합니다. 이 아키텍처는 3.4절에서 설명합니다.
- 내적 독백(Inner Monologue)을 도입합니다. 오디오 언어 모델의 학습과 추론 설정으로, 오디오 토큰 예측 전에 시간 정렬된 텍스트 토큰을 예측함으로써 생성된 음성의 사실성과 언어적 품질을 크게 향상시킵니다. Moshi는 사용자 오디오와 Moshi의 오디오 모두에서 비언어적 정보를 추론할 수 있는 음성-대-음성 모델이지만, 이는 Moshi가 음성을 출력할 때 텍스트를 생성하는 것과 양립할 수 있습니다. 과거 연구(Borsos et al., 2022; Zhang et al., 2024b)에 따르면 의미에서 음향 토큰으로의 생성 과정이 일관된 음성을 생성하는 데 중요하다는 점을 감안하여, 이 계층을 텍스트 토큰을 의미적 토큰의 시간 단계별 접두사로 사용하도록 확장했습니다. 실험 결과, 이 접근 방식이 생성된 음성의 길이와 품질을 크게 향상시키며, 텍스트와 오디오 토큰 사이의 지연을 강제하여 Moshi 모델로부터 스트리밍 ASR 및 스트리밍 TTS를 도출할 수 있음을 보여줍니다.
- Moshi의 모든 구성 요소를 여러 축을 따라 평가합니다. 텍스트 이해, 음성 명료도 및 일관성, 오디오 품질, 음성 질의 응답 등을 포함하여 평가합니다. 5장에서 보고된 실험 결과, 우리의 모델이 스트리밍 호환성을 가지면서 기존의 음성-텍스트 모델들 중에서 음성 모델링 및 음성 질의 응답에서 최고 성능을 보이며, 몇 분의 맥락(우리의 실험에서는 5분)을 모델링할 수 있음을 보여줍니다.
우리는 독자들이 웹 데모를 통해 Moshi와 대화해보기를 권장합니다.
https://moshi.chat/
moshi.chat
moshi.chat
2. 관련 연구
오디오 언어 모델링
초기의 음성 기초 모델 개발은 자동 음성 인식(ASR) (Baevski et al., 2020; Radford et al., 2023; Zhang et al., 2023b), 화자 검증(Chen et al., 2022), 음성 분류(Yang et al., 2021) 등 여러 판별 작업에서 음성 이해를 향상시켰습니다. 이러한 발전의 주요 요소는 자가 지도 학습(Hsu et al., 2021; Baevski et al., 2020; Chen et al., 2022)으로, 일반적이고 판별적인 음성 표현을 학습할 수 있게 합니다. 이러한 음성 이해 모델들은 텍스트의 마스킹 언어 모델링(Devlin et al., 2019) 연구를 바탕으로 하며, 생성적 텍스트 사전 학습(Radford et al., 2018)은 유사하게 많은 음성 생성 모델의 영감을 주었습니다. 특히 Lakhotia et al. (2021)은 앞서 언급한 자가 지도 표현을 양자화하는 것을 제안했습니다. 결과적으로 얻어진 이산 오디오 토큰들은 음성 구간을 범주형 변수의 시퀀스로 표현하여 음성 생성을 언어 모델링 작업으로 재구성합니다. AudioLM(Borsos et al., 2022)은 이러한 의미 토큰을 신경 오디오 코덱(Zeghidour et al., 2022)의 음향 토큰과 결합하여 임의의 목소리, 녹음 조건 및 비음성 소리까지 모델링할 수 있게 합니다. 이러한 오디오 언어 모델들은 텍스트-음성 변환(Wang et al., 2023; Kharitonov et al., 2023)에서 음성-대-음성 번역(Rubenstein et al., 2023; Reid et al., 2024), 음성 개선(Yang et al., 2023)에 이르기까지 음성 생성의 최첨단을 재정의했습니다. 이러한 지도 학습 작업을 넘어서 자율적인 오디오 전용 모델을 자가 회귀 음성 생성으로 학습하고 확장하는 연구(Dunbar et al., 2021; Lakhotia et al., 2021; Borsos et al., 2022)도 병행되었습니다. 이 모델들의 능력은 점진적으로 확장되어 단일 화자의 짧은 문장을 생성하는 것(Lakhotia et al., 2021)에서 임의의 목소리와 조건으로 수십 초 동안 의미 있고 일관된 음성을 생성하는 것까지 발전했습니다(Borsos et al., 2022). 이 과정에서 의미와 음향 토큰의 계층적 모델링이 중요한 역할을 했습니다. 주요 도전 과제는 의미 있는 출력물을 생성하기 위해 몇 분에 달하는 긴 시퀀스를 모델링해야 하는 오디오의 특성입니다. 그러나 오디오에 대한 잠재 표현은 일반적으로 텍스트에 대한 표현보다 덜 압축됩니다. 따라서 신경 오디오 코덱의 이산 표현은 자가 회귀적으로 모델링할 때 시간 단계마다 여러 예측을 필요로 합니다. Liu et al. (2023b)와 Evans et al. (2024)은 일반 오디오 및 음악 모델링을 위해 잠재 확산(Ho et al., 2020)을 사용하여 계층적 이산 토큰의 필요성을 줄이려 하였지만, 이러한 방법은 스트리밍 방식으로 사용할 수 없으며 일관된 음성을 생성할 수 있는지 여부도 명확하지 않습니다. 대신 Copet et al. (2023)은 다른 레벨의 토큰 간에 지연을 도입하고 이를 통해 병렬 예측을 수행하여 자가 회귀 단계 수를 줄일 수 있음을 보여주었습니다. Lee et al. (2022)의 RQ-Transformer 방법과 계층적 MegaByte Transformer 모델(Yu et al., 2024)에서 영감을 받은 Yang et al. (2023)과 Zhu et al. (2024)은 작은 중첩된 트랜스포머를 활용하여 단일 시간 단계에서 서로 다른 토큰을 모델링했습니다. 본 연구에서는 오디오 토큰의 계층적 모델링을 제안하여 여러 분의 맥락을 처리하면서 실시간으로 오디오를 생성할 수 있는 자가 회귀 음성 생성의 한계를 극복하고자 합니다. 음성 전용 모델이 원시 음성에서 언어적 구조(어휘, 구문, 의미)를 학습하더라도(Dunbar et al., 2021) 일반적으로 사실적 지식과 추론 능력이 부족하거나 거의 없습니다. 이러한 문제를 해결하기 위해 텍스트 모델의 지식과 추론 능력을 오디오 모델의 생성 능력과 결합하려는 음성-텍스트 모델이 개발되었습니다.
음성-텍스트 모델
이러한 모델들은 일반적으로 사전 학습된 텍스트 언어 모델에서 시작하여 오디오를 예측하도록 미세 조정하거나(Hassid et al., 2023), 음성-텍스트 미세 조정 작업을 제안합니다(Rubenstein et al., 2023; Maiti et al., 2023; Nachmani et al., 2024; Nguyen et al., 2024; Mitsui et al., 2024; Zhang et al., 2024a). 예를 들어, AudioPALM(Rubenstein et al., 2023)은 사전 학습된 PALM(Chowdhery et al., 2022) 모델에서 시작하여 의미적 오디오 토큰을 텍스트 어휘에 추가합니다. 이후, 모델은 TTS, ASR 및 음성-대-음성 번역을 포함하는 다양한 음성-텍스트 작업을 수행하도록 훈련됩니다. VoxTLM(Maiti et al., 2023)도 TTS와 ASR을 위한 유사한 접근 방식을 채택합니다. 이러한 모델들은 특정 입력과 출력 시퀀스와 함께 지도 학습되지만, Spirit-LM(Nguyen et al., 2024)은 음성과 해당 전사 간의 시간 정렬을 사용하여 시퀀스 내부에서 모달리티 전환(음성 토큰에서 텍스트 토큰으로, 또는 그 반대)을 수행합니다. 이를 통해 텍스트나 음성으로 표현되었는지에 관계없이 일관된 언어의 내부 표현을 학습할 수 있습니다. Spectron(Nachmani et al., 2024), SpeechGPT(Zhang et al., 2023a), PSLM(Mitsui et al., 2024)과 같은 또 다른 접근 방식은 음성과 텍스트를 교환 가능한 표현으로 다루기보다는 계층적으로 결합합니다. AudioLM(Borsos et al., 2022)이 음성 생성을 의미 토큰 예측 후 음향 토큰 예측으로 나누는 것처럼, Spectron과 SpeechGPT도 "모달리티의 연쇄(Chain-of-Modality)" 방식을 사용해 먼저 발화를 텍스트 토큰으로 생성하고, 이후 이를 접두사로 사용해 음성을 생성합니다. 이는 기저 텍스트 LLM의 출력을 이용해 음성 생성을 유도할 수 있지만, 모델이 텍스트로 전체 응답을 생성한 후에만 음성을 생성하기 때문에 실시간 상호작용과는 근본적으로 호환되지 않습니다. PSLM은 텍스트와 음성 토큰을 병렬로 모델링하여 이러한 제한을 완화하지만, Inner Monologue는 계층적 방식으로 텍스트, 의미, 음향 토큰의 연쇄를 분해해 학습하고 실시간 생성이 가능하도록 설계되었습니다.
음성 대화 모델
음성 대화는 음성 생성에서 덜 탐구된 작업 중 하나로, 몇 가지 도전 과제를 해결해야 합니다: 1) 모델은 실시간으로 실행되며 풀-듀플렉스 방식으로 긴 대화를 지원해야 합니다—모델은 항상 듣고 언제든지 말할 수 있어야 합니다; 2) 비언어적 소통을 처리하기 위해 음성-대-음성이어야 합니다; 3) 유용하고 즐거운 대화를 가능하게 하는 지식과 추론 능력을 보여주어야 합니다. Spectron은 기본 텍스트 LLM 덕분에 지식을 갖추고 있으나, 모달리티의 연쇄 방식으로 인해 실시간 생성과는 호환되지 않습니다. PSLM은 지연을 줄이기 위해 음성과 텍스트 토큰을 병렬로 생성하는 것을 제안하지만, 응답의 품질을 저하시키며 여전히 ASR에 의존하여 준언어적 정보를 잃게 됩니다. 중요한 것은 이러한 모델들은 화자 턴의 경계가 없는 풀-듀플렉스 통신을 처리할 수 없다는 것입니다. Moshi는 이러한 모든 한계를 극복하고자 하며, 사용자로부터 얻은 모든 정보(언어적 및 비언어적)를 실시간으로 처리하고 발화하는 풀-듀플렉스 모델입니다.
3. 모델
3.1 개요

그림 1: Moshi의 개요. Moshi는 실시간 음성 대화를 가능하게 하는 음성-텍스트 기초 모델입니다. Moshi의 아키텍처 주요 구성 요소는 다음과 같습니다: 맞춤형 텍스트 언어 모델 백본(Helium, 3.2절 참조); 자가 지도 학습 음성 모델에서 추출된 의미적 지식을 잔여 벡터 양자화와 결합한 신경 오디오 코덱(Mimi, 3.3절 참조); 사용자와 Moshi의 의미 및 음향 토큰의 스트리밍, 계층적 생성, 그리고 Inner Monologue 사용 시 Moshi의 시간 정렬된 텍스트 토큰(3.4절).
Moshi는 다중 스트림 음성-대-음성 트랜스포머 모델로, 그림 1에 요약된 혁신적인 아키텍처 덕분에 사용자와의 풀-듀플렉스 음성 대화를 가능하게 합니다. Moshi는 Helium을 기반으로 구축되었으며, 이는 우리가 처음부터 고품질의 텍스트 데이터를 사용하여 강력한 추론 능력을 제공하도록 설계한 텍스트 LLM입니다(3.2절 참조). 또한, Inner Monologue(3.4.4절 참조)라는 훈련 및 추론 절차를 제안하여 텍스트와 오디오 토큰을 공동으로 모델링합니다. 이를 통해 모델이 텍스트 모달리티에서 전달받은 지식을 최대한 활용하면서도 음성-대-음성 시스템으로 유지될 수 있습니다. 실시간 대화를 가능하게 하기 위해 Moshi는 처음부터 다중 스트림 아키텍처로 설계되었습니다(3.4.3절 참조). 이 모델은 사용자와 동시에 말하고 들을 수 있으며, 화자의 턴을 명시적으로 모델링할 필요가 없습니다. 또한, 사용자 오디오 입력과 Moshi의 음성 출력을 고품질로 효율적으로 캡처하기 위해, 우리는 잔여 벡터 양자화와 지식 증류를 사용해 의미적 정보와 음향 정보를 하나의 토크나이저로 결합한 신경 오디오 코덱인 Mimi(3.3절 참조)를 제안합니다. Moshi와 사용자의 오디오 스트림, 그리고 Moshi의 텍스트 토큰을 공동으로 모델링하기 위해, 스트리밍 추론과 호환되는 Depth Transformer를 사용합니다(3.4.1, 3.4.2절).
이 섹션에서는 각 구성 요소에 대해 더욱 상세히 설명합니다. 이후 4절에서는 Moshi를 학습시키기 위해 사용된 학습 데이터셋과 여러 학습 단계에 대해 설명합니다. 마지막으로 5절에서는 Moshi의 언어적, 음향적 능력에 대한 평가 결과와 주요 구성 요소에 대한 세부 실험 결과를 보고하며, 6절에서는 시스템의 안전성에 대한 분석을 제공합니다.
3.2 Helium 텍스트 언어 모델
3.2.1 아키텍처
Helium은 트랜스포머 아키텍처(Vaswani et al., 2017)를 기반으로 한 자가 회귀 언어 모델입니다. 이전 연구를 따라 원래 아키텍처에 다음과 같은 변경을 가했습니다. 첫째, 모델의 주의 블록, 피드포워드 블록, 출력 선형 층의 입력에 RMS 정규화(Zhang and Sennrich, 2019)를 사용했습니다. 우리는 회전 위치 임베딩(Su et al., 2024, RoPE)을 사용하며, 4,096 토큰의 문맥 길이와 효율적인 학습을 위해 FlashAttention(Dao et al., 2022)을 사용합니다. 마지막으로 피드포워드 블록의 아키텍처를 변경하여 Gated Linear Units(Shazeer, 2020)을 사용하며, SiLU 활성화 함수(Hendrycks and Gimpel, 2016b)를 게이팅 함수로 사용합니다. 토크나이저는 SentencePiece(Kudo and Richardson, 2018)의 유니그램 모델을 기반으로 하며, 대부분 영어를 대상으로 하는 32,000개의 요소를 포함합니다. 모든 숫자는 한 자리 숫자로 분할하며, byte-backoff를 사용하여 토크나이저가 정보를 잃지 않도록 보장합니다. 모델은 AdamW(Loshchilov and Hutter, 2017) 옵티마이저를 사용해 학습하며, 고정 학습률 이후 코사인 학습률 감쇠(Loshchilov and Hutter, 2016)를 적용합니다.
표 1: 모델의 하이퍼파라미터. Helium 언어 모델(70억 개의 파라미터)과 Moshi 음성-텍스트 대화 모델의 아키텍처와 학습 하이퍼파라미터입니다. Moshi의 학습은 다음 네 가지 단계로 진행됩니다: 1) 비지도 데이터로의 사전 학습(Helium에서 초기화된 Temporal Transformer 사용), 2) 다이어리제이션 기반의 시뮬레이션된 다중 스트림을 이용한 후속 학습, 3) Fisher 데이터셋(Cieri et al., 2004)으로 풀 듀플렉스 기능을 습득하기 위한 미세 조정, 4) 합성 상호작용 스크립트로 만든 커스텀 데이터셋을 사용한 명령어 미세 조정. 사전 학습 단계에서 Helium에 사용된 동일한 데이터셋에서 전체 텍스트 배치를 학습하는 시간을 절반으로 유지하며, 별도의 옵티마이저 상태를 사용합니다.

3.2.2 사전 학습 데이터 필터링
학습 데이터는 LLM을 훈련하는 데 있어 중요한 요소 중 하나입니다. 이제 우리는 대형 고품질 텍스트 데이터셋을 얻기 위한 방법을 설명합니다. 우리는 Wikipedia, Stack Exchange, 대규모 과학 논문 모음 등 고품질 데이터 출처로부터 시작합니다. 이러한 출처의 데이터 양만으로는 LLM을 학습시키기에는 부족하기 때문에, 데이터셋을 확장하기 위해 CommonCrawl에서 크롤링한 웹 데이터를 사용합니다. 데이터 출처에 대한 자세한 내용은 4.1절을 참조하십시오. 웹 데이터는 고품질의 학습 세트를 얻기 위해 광범위한 처리가 필요합니다: 중복 제거, 언어 식별, 품질 필터링을 수행합니다. 다음에서 각 작업에 대해 더 자세히 설명합니다.
중복 제거
우리는 CommonCrawl 프로젝트에서 추출한 웹 페이지의 텍스트 콘텐츠만 포함된 WET 파일에서 시작합니다. 이 형식은 페이지의 모든 텍스트를 포함하고 있기 때문에 탐색 메뉴와 같은 많은 불필요한 요소들도 포함됩니다. 따라서 우리의 파이프라인 첫 번째 단계는 각 샤드(크롤당 100개의 샤드 있음)에서 라인 단위로 중복을 제거하여 이러한 불필요한 요소들을 제거하는 것입니다. 이를 위해 각 라인의 FNV-1a 해시를 계산하고, Bloom 필터를 사용해 중복을 제거합니다. 또한, 중복 데이터와 비중복 데이터를 구분하기 위해 fastText(Joulin et al., 2016) 분류기를 훈련하여 퍼지 중복 제거를 수행합니다. 여기서 우리는 중복으로 분류된 연속된 3줄 이상의 블록만 제거합니다.
언어 식별
중복 제거가 수행된 후, fastText를 기반으로 한 언어 식별기를 사용하여 영어 데이터만 유지합니다. 언어 식별은 문서 단위로 수행되며, 우리는 특정 임계값(0.85) 이상인 문서만 유지합니다.
품질 필터링
마지막 단계는 나머지 데이터를 필터링하여 고품질 웹페이지만 유지하는 것입니다. 이 단계를 수행하기 위해 우리는 고품질 데이터 출처와 CommonCrawl에서 무작위로 선택한 웹페이지의 라인을 이용해 fastText 분류기를 훈련합니다. 우리는 Wikipedia, Wikibooks와 같은 고품질 출처 및 StackExchange의 STEM이나 인문학과 같은 하위 집합을 나타내는 9개의 범주를 가지는 분류기를 얻었습니다. 이 접근 방식의 목적은 고품질 출처와의 유사성뿐만 아니라 그들의 도메인에 기반하여 어느 문서를 유지할지에 대한 세밀한 통제를 얻는 것입니다. 이 분류기는 라인 단위로 적용되며, 각 라인의 점수를 길이에 따라 가중치를 주어 평균을 내어 집계된 점수를 얻습니다. 또한, 우리는 특정 임계값 이상의 점수를 가진 문서만 유지합니다.
3.3 오디오 토큰화
파형을 오디오 토큰으로 이산화하기 위해, 우리는 Mimi라는 신경 오디오 코덱(Zeghidour et al., 2022; Défossez et al., 2023)을 도입합니다. Mimi는 이산 병목을 가진 오토인코더로 작동합니다(van den Oord et al., 2017). 문헌에서는 Borsos et al. (2022)이 정의한 용어를 따르며, 이러한 토큰을 '음향 토큰(acoustic tokens)'이라 부르는데, 이는 세밀한 오디오 세부 사항을 모델링하며 고품질의 재구성을 위해 최적화된 토큰입니다. 이 음향 토큰은 텍스트-오디오 모델(e.g., 텍스트-음성(Wang et al., 2023) 또는 텍스트-음악(Copet et al., 2023))에 적합한 타겟을 제공하지만, 비조건 음성 생성을 위해서는 자가 지도 학습 음성 모델(Baevski et al., 2020; Hsu et al., 2021; Chung et al., 2021)에서 추출한 의미 토큰과 결합해야 합니다. 음향 토큰과 달리 의미 토큰은 고품질 오디오를 재구성할 수 없지만, 언어적 콘텐츠와 강하게 상관관계가 있습니다. 이러한 언어와의 유사성 덕분에 의미 오디오 토큰을 음향 토큰 예측의 접두사로 사용하면 텍스트 조건 없이도 이해 가능하고 일관된 음성을 생성할 수 있습니다. 그러나 이러한 하이브리드 토큰화 접근법은 실시간 생성과는 호환되지 않습니다. 의미 토큰은 일반적으로 인과적이지 않아 오프라인 방식에서만 계산이 가능합니다. 또한, 별도의 인코더를 사용해 음향 및 의미 토큰을 생성하는 것은 무시할 수 없는 계산 부담을 초래합니다. 따라서, 이전의 SpeechTokenizer 연구(Zhang et al., 2024b)에서 영감을 받아, Mimi는 비인과적 고수준 의미 정보를 인과적 모델이 생성한 토큰으로 증류하여 의미-음향 토큰의 스트리밍 인코딩 및 디코딩을 가능하게 합니다.
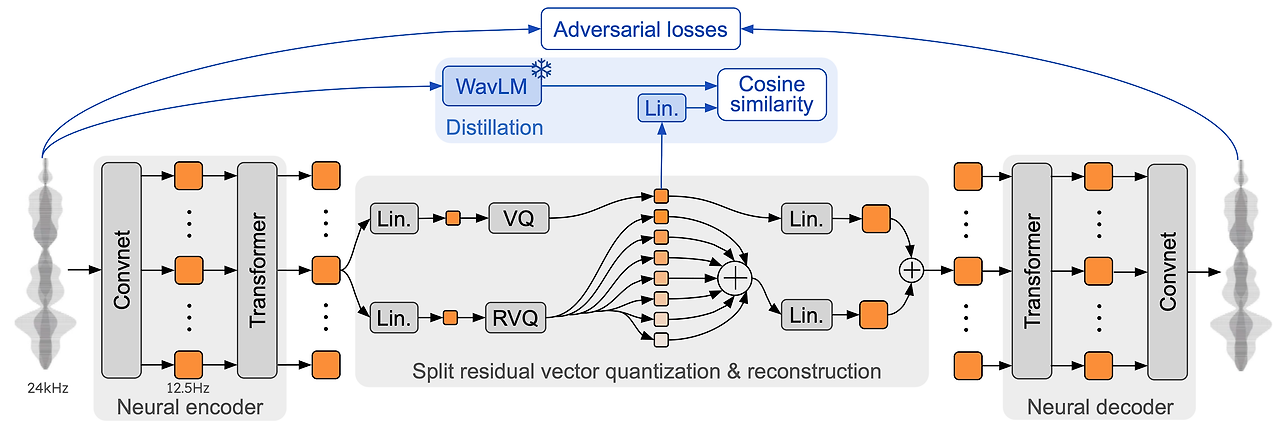
그림 2: 우리의 신경 오디오 코덱 Mimi의 아키텍처와 학습 과정, 그리고 분할 잔여 벡터 양자화. 학습 중(파란 부분, 상단), 우리는 WavLM(Chen et al., 2022)으로부터 비인과적 임베딩을 하나의 벡터 양자화기로 증류하여 의미 토큰을 생성하고, 이는 별도의 음향 토큰과 결합되어 재구성을 수행합니다.
3.3.1 아키텍처

트랜스포머 기반 병목 구조
Mimi의 고품질 오디오 재구성과 음성을 압축된 표현으로 인코딩하는 능력을 향상시키기 위해, 우리는 양자화 바로 전과 후에 트랜스포머 모듈을 병목 구조에 추가했습니다. 이 트랜스포머는 8개의 층과 8개의 헤드, RoPE 위치 인코딩, 250 프레임(20초)의 유한한 문맥, GELU(Hendrycks and Gimpel, 2016a) 활성화 함수, 모델 차원 512 및 MLP 차원 2048을 가집니다. 학습을 안정화하기 위해, 우리는 대각선 값의 초기값을 0.01로 설정한 LayerScale(Touvron et al., 2021)을 사용합니다. 두 트랜스포머는 모두 인과적 마스킹을 사용하여 전체 아키텍처가 스트리밍 추론과 호환되도록 합니다. 인코더의 트랜스포머는 아래에서 설명하는 의미 정보의 증류에도 도움을 주며(테이블 3의 실험 결과 참조), 두 트랜스포머 모두 인식된 오디오 품질을 높이는 데 기여합니다.
인과성 및 스트리밍
언급된 하이퍼파라미터로 인해 Mimi는 인과적이며 인코딩 및 디코딩 모두에 스트리밍 방식으로 사용할 수 있습니다. 초기 프레임 크기와 전체 보폭이 80ms로 설정되어 있어, 첫 번째 오디오 프레임(80ms)을 받으면 Mimi는 첫 번째 잠재 시간 단계를 출력하며, 이를 통해 80ms의 출력 오디오를 디코딩할 수 있습니다.
최적화
순전히 컨볼루션으로 구성된 코덱이 Adam(Kingma and Ba, 2015)을 사용하는 것과 달리, 아키텍처에 트랜스포머를 도입하면 가중치 감쇠(weight decay)를 사용하는 추가적인 정규화와 AdamW(Loshchilov and Hutter, 2019) 옵티마이저가 필요합니다. 더 정확히는, 우리는 가중치 감쇠를 트랜스포머의 파라미터에만 적용하며, 그 가중치는 5⋅10^{-2}입니다. 학습률은 8⋅10^{-4}, 모멘텀 감쇠는 0.5, 제곱 기울기 감쇠는 0.9, 가중치에 대한 지수 이동 평균은 0.99로 설정합니다. 우리는 배치 크기 128로 12초 길이의 임의 창을 사용하여 4M 스텝 동안 학습하며, 트랜스포머의 문맥은 10초(인코더의 마지막 다운샘플링 층 이전에 250 프레임, 디코더도 대칭적으로 적용)로 제한됩니다.
양자화 비율
Q=8개의 양자화기를 사용하며, 각 코드북의 크기는 N_A = 2048입니다. 12.5Hz에서 이는 1.1kbps의 비트레이트를 나타냅니다. 잠재 차원이 512이지만 RVQ를 적용하기 전에 임베딩을 256 차원으로 투영하고, 디코더 전에 다시 512로 투영합니다. 이전 연구와 일관되게, 우리는 코덱에 비트레이트 확장성을 제공하기 위해 양자화기 드롭아웃(Zeghidour et al., 2022)을 사용합니다. 또한, Kumar et al. (2023)의 관찰을 따라 학습 중 일정 확률로 양자화를 적용하지 않는 것이 오디오 품질을 개선함을 발견했습니다. 구체적으로, 학습 중에 시퀀스마다 50%의 확률로 양자화를 적용합니다. 이는 Kumar et al. (2023)과 달리 모든 양자화기로 양자화된 임베딩을 전달하는 대신, 양자화되지 않은 임베딩을 디코더로 전달하는 것을 의미합니다. 테이블 3은 이것이 객관적인 품질 지표를 크게 향상시킴을 보여주지만, 사람들의 평가에서는 명확한 결론이 나오지 않았습니다. 우리의 실험에서 이 이득은 비트레이트를 낮출수록 더욱 중요해짐을 알 수 있었습니다.
적대적 손실만을 사용한 학습
기본적으로, 우리는 Défossez et al. (2023)과 동일한 재구성 및 적대적 손실의 조합으로 Mimi를 학습하며, 여기에는 멀티 스케일 멜-스펙트로그램 재구성 손실과 멀티 스케일 STFT 판별자가 포함됩니다. 정확한 파라미터는 Audiocraft 리포지토리에서 찾을 수 있습니다(https://github.com/facebookresearch/audiocraft/blob/main/config/solver/compression/default.yaml). 이전의 신경 코덱들이 재구성과 적대적 손실의 조합에 의존한 반면, 우리는 오직 피처 손실과 판별자 손실만 유지하여 순수한 적대적 학습을 실험합니다. 이는 이전에 Tagliasacchi et al. (2020)와 Hauret et al. (2023)이 대역폭 확장 연구에서 실험했던 것입니다. 재구성 손실을 제거하면 객관적 지표가 크게 저하되지만, 개발 중에 우리는 생성된 오디오가 위의 지표에 비해 예상보다 훨씬 좋게 들린다는 것을 관찰했습니다. 테이블 4에 보고된 주관적 평가도 이러한 관찰을 확인하며, 적대적 손실만으로 학습했을 때 오디오 품질이 크게 향상됨을 보여줍니다.
3.3.2 분할 RVQ를 통한 의미-음향 토큰 학습
SpeechTokenizer(Zhang et al., 2024b)와 마찬가지로, 우리는 자가 지도 모델(WavLM8 (Chen et al., 2022))에서 의미 정보를 추출하여 RVQ의 첫 번째 레벨로 증류합니다. WavLM은 16kHz 파형을 50Hz로 샘플링한 1024차원 임베딩으로 투영하고, Mimi는 24kHz 파형을 12.5Hz에서 512차원으로 투영합니다. 학습 중 입력 파형을 16kHz로 다운샘플링한 후, WavLM 임베딩을 계산하고 커널 크기 8, 보폭 4로 평균 풀링을 적용하여 12.5Hz로 맞춤으로써 증류 타겟을 생성합니다. 흥미롭게도, 비인과적으로 이 평균 풀링을 수행하는 것이 성능에 매우 중요했으며, 이러한 임베딩은 학습 중에만 사용되므로 스트리밍 추론과 호환됩니다. 우리는 첫 번째 RVQ 레벨의 출력에 대해 실제 임베딩과 병렬로 1024 차원의 선형 투영을 적용합니다. 그런 다음 첫 번째 양자화기 출력과 변환된 WavLM 임베딩 사이의 코사인 거리를 계산하여 증류를 수행합니다. 테이블 3은 이 증류 손실이 품질을 목표로 하는 재구성 및 적대적 손실과 충돌함을 보여줍니다. 실제로 증류는 첫 번째 양자화기의 음성 구별력을 크게 향상시키지만(ABX (Schatz et al., 2013)로 측정), 오디오 품질에는 부정적인 영향을 미칩니다. 우리는 이것이 단일 RVQ의 첫 번째 레벨에 의미 정보를 증류한 결과라고 가정합니다. 상위 양자화기가 첫 번째 양자화기의 잔여에 작용하기 때문에, 후자는 음질과 음소 구별력 사이에서 타협해야 합니다. 우리는 8레벨의 단일 RVQ 대신 평범한 VQ에 의미 정보를 증류하고, 7레벨의 RVQ를 병렬로 적용하여 이 문제를 해결합니다. 우리는 그들의 출력을 합산하여, 둘 다 재구성에 사용될 수 있으면서도 의미 양자화기의 잔여에 음향 정보가 보존되어야 한다는 제약을 제거했습니다. 그림 2는 이 아키텍처를 설명하며, 테이블 3은 이 솔루션이 전체적으로 더 나은 의미-음향 균형을 제공함을 보여줍니다.
3.4 생성적 오디오 모델링
이제 우리는 Helium 모델을 확장하여 Mimi 코덱이 제공하는 오디오 토큰을 모델링하는 방법을 설명합니다. 현실감 있는 음성 대화 상호작용을 달성하기 위한 목표로, 단일 오디오 스트림뿐만 아니라 사용자와 시스템을 동시에 나타내는 두 개의 스트림을 어떻게 모델링할 수 있는지도 보여줍니다. 마지막으로, 상호작용의 품질을 개선하기 위해 시스템 측에서 텍스트와 오디오 모달리티를 공동으로 모델링하는 '내적 독백(Inner Monologue)'이라는 새로운 기능을 상세히 설명합니다.
3.4.1 RQ-Transformer를 이용한 계층적 자가 회귀 모델링


그림 3: RQ-Transformer의 아키텍처. RQ-Transformer는 길이 K⋅S의 평탄화된 시퀀스를 대형 Temporal Transformer에서 사용하는 문맥 임베딩을 생성하는 S개의 시간 단계로 나눕니다. 이 문맥 임베딩은 K 단계 동안 작은 Depth Transformer의 조건으로 사용됩니다. 이 방식은 단일 모델로 평탄화된 시퀀스를 모델링하는 것보다 S를 증가시켜 더 긴 시퀀스를 모델링하거나, K를 증가시켜 더 깊이 있는 모델링이 가능하게 합니다. 그림에서는 K=4를 예시로 사용합니다.
음성 언어를 모델링할 때, 토큰화된 텍스트를 사용하는 것은 오디오 토큰보다 훨씬 더 압축된 표현을 제공합니다. 섹션 3.3에서 소개한 Mimi 코덱을 사용할 경우, 프레임 속도 12.5Hz에서 코드북 수 Q=8을 가질 때, 오디오 1초를 생성하기 위해 100단계의 시퀀스 길이가 필요합니다. 5분의 오디오를 모델링하려면 30,000개의 시간 단계가 필요하며, 이는 상당한 계산 비용을 초래하며 초당 100개의 토큰을 생성하는 것은 스트리밍 추론과 호환되지 않습니다. 이에 비해 영어 음성 샘플은 초당 약 3~4개의 텍스트 토큰으로 표현될 수 있습니다.

RQ-Transformer


3.4.2 오디오 모델링

음향 지연(Acoustic Delay)


RQ-Transformers를 사용해 오디오를 모델링하는 것은 Yang et al. (2023)과 Zhu et al. (2024)에서도 성공적으로 사용된 바 있습니다. 우리는 여기서 Depth Transformer에 코드북별 매개변수를 사용하는 것과 음향 지연을 도입했습니다. Zhu et al. (2024)에서는 모든 의미 토큰을 먼저 생성한 반면, 우리는 의미 토큰과 음향 토큰을 동시에 생성하여 처음으로 의미와 음향 토큰을 스트리밍 방식으로 공동 모델링할 수 있게 했습니다.
3.4.3 다중 스트림 모델링

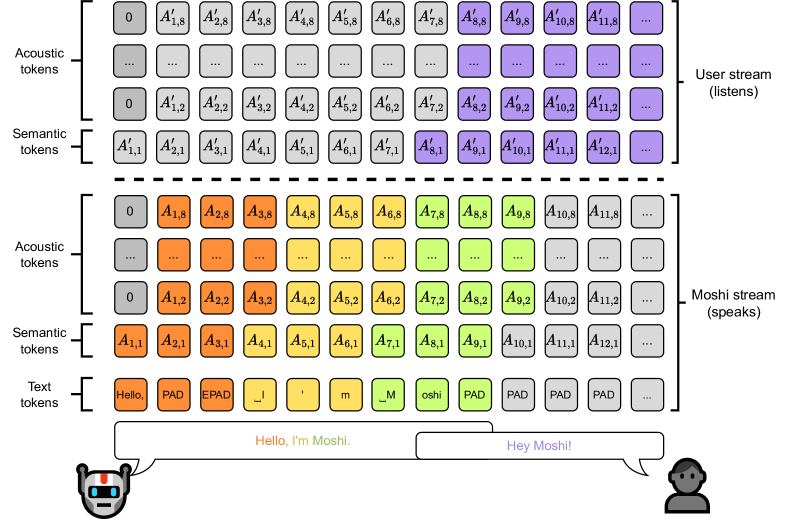

3.4.4 내적 독백(Inner Monologue)

텍스트와 오디오 토큰 정렬

스트리밍 ASR 및 TTS 도출

Moshi를 위한 결합 시퀀스 모델링

Moshi의 추론

'인공지능' 카테고리의 다른 글
| OpenAI Swarm (0) | 2024.11.26 |
|---|---|
| Qwen2.5: A Party of Foundation Models! (2) | 2024.11.26 |
| LLaMA-Omni: Seamless Speech Interaction with Large Language Models (2) | 2024.11.26 |
| iTransformer: Inverted Transformers Are Effective for Time Series Forecasting (1) | 2024.11.25 |
| Pixtral 12B (1) | 2024.11.23 |


