https://arxiv.org/abs/2410.07095
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
We introduce MLE-bench, a benchmark for measuring how well AI agents perform at machine learning engineering. To this end, we curate 75 ML engineering-related competitions from Kaggle, creating a diverse set of challenging tasks that test real-world ML eng
arxiv.org
초록
우리는 AI 에이전트가 기계 학습 엔지니어링에서 얼마나 잘 수행하는지를 측정하기 위한 벤치마크인 MLE-bench를 소개합니다. 이를 위해, 우리는 Kaggle에서 75개의 ML 엔지니어링 관련 대회를 선정하여, 모델 학습, 데이터셋 준비, 실험 수행 등과 같은 실제 ML 엔지니어링 기술을 테스트하는 다양한 도전 과제를 구성했습니다. 각 대회에 대해 Kaggle의 공개 리더보드를 활용하여 인간 기준 성능을 설정했습니다. 우리는 오픈 소스 에이전트 스캐폴드를 사용하여 최첨단 언어 모델을 벤치마크에서 평가했으며, 가장 뛰어난 성과를 보인 설정은 — OpenAI의 o1-preview와 AIDE 스캐폴딩 — 16.9%의 대회에서 최소한 Kaggle 동메달 수준의 성과를 달성했습니다. 우리의 주요 결과 외에도 AI 에이전트의 자원 확장 형태와 사전 학습에서의 오염 영향에 대해 조사했습니다. 우리는 AI 에이전트의 ML 엔지니어링 역량을 이해하기 위한 향후 연구를 돕기 위해 벤치마크 코드를 공개합니다 (github.com/openai/mle-bench/).
1. 서론
언어 모델(LM)은 많은 코딩 벤치마크에서 놀라운 성능을 보여주었으며(Chen et al., 2021; Hendrycks et al., 2021; Austin et al., 2021; Li et al., 2022), 아키텍처 설계와 모델 학습과 같은 다양한 머신 러닝 작업에서 점차 발전하고 있습니다(Zheng et al., 2023; Huang et al., 2024b). 또한, 언어 모델은 프로그래밍 도구에 채택되었으며(Kalliamvakou, 2022), 에이전트 스캐폴딩의 발전으로 인해 개발자의 워크플로우가 점점 더 자동화되고 있습니다(cognition.ai, 2024; Dohmke, 2024). 그러나 모델과 에이전트 기능 개발이 급증하고 있음에도 불구하고, 자율적인 끝-끝 ML 엔지니어링을 포괄적으로 측정하는 벤치마크는 거의 없습니다.
우리는 AI 에이전트가 어려운 머신 러닝 엔지니어링(MLE) 작업을 얼마나 잘 수행하는지 평가하기 위해 오프라인 Kaggle 대회 환경인 MLE-bench를 소개합니다. MLE-bench는 자율적인 ML 엔지니어링 에이전트의 실제 발전을 견고하게 측정하기 위해 만들어졌으며, 두 가지 주요 설계 선택에 중점을 두었습니다: (i) 현대 ML 엔지니어링 작업을 잘 대표하고 도전적인 과제를 선택하는 것, (ii) 평가 결과를 인간 수준의 성능과 비교할 수 있는 것.
결과적인 벤치마크는 자연어 처리, 컴퓨터 비전, 신호 처리 등 다양한 도메인에서 75개의 다양한 Kaggle 대회로 구성되어 있습니다. 많은 대회가 실제 가치가 있는 현대적 과제들로, 예를 들어 OpenVaccine: COVID-19 mRNA 백신 분해 예측(Das et al., 2020)과 고대 두루마리를 해독하는 Vesuvius Challenge(Lourenco et al., 2023) 등이 있습니다. 75개 대회에서 수여된 총 상금의 가치는 $1,948,016이며, 대회당 평균 $25,974입니다.
우리의 벤치마크에서 다루는 유형의 도전 과제를 자율적으로 해결할 수 있는 AI 에이전트는 과학적 진보의 큰 가속화를 가져올 수 있으며, 이는 흥미로운 전망이지만 이러한 발전을 안전하고 통제된 방식으로 배포하기 위해 모델의 발전을 신중히 이해해야 합니다. 예를 들어, MLE-bench는 OpenAI의 준비 프레임워크(OpenAI, 2023)에서 모델 자율성을 측정하는 지표로 사용될 수 있으며, Anthropic의 책임 있는 확장 정책(Anthropic, 2023) 및 Google DeepMind의 Frontier 안전 프레임워크(Google DeepMind, 2024)에서 자율적 역량을 평가하는 데 활용될 수 있습니다.
우리는 오픈 소스 스캐폴드를 결합했을 때, 최첨단 언어 모델들이 우리의 벤치마크에서 의미 있는 점수를 달성할 수 있음을 발견했습니다. 우리가 평가한 가장 우수한 에이전트인 o1-preview와 AIDE는 Kaggle 대회를 위해 목적에 맞게 제작된 스캐폴딩을 사용하여 평균적으로 16.9%의 대회에서 메달을 획득했습니다. 에이전트가 대회당 여러 번의 시도를 할 수 있을 때 성능이 크게 향상됨을 발견했습니다; 예를 들어, o1-preview의 점수는 pass@1에서 16.9%였으나 pass@8에서 34.1%로 두 배 증가했습니다. 마찬가지로, GPT-4o는 각 대회에 24시간을 주었을 때 8.7%를 기록했으나, 100시간을 주었을 때 11.8%로 증가했습니다. 일반적으로, 우리는 잘 알려진 접근 방식으로 해결할 수 있는 대회에서는 에이전트가 좋은 점수를 얻을 수 있었지만, 문제를 디버깅하고 실수에서 회복하는 데 어려움을 겪는다는 것을 발견했습니다.
우리의 기여는 다음과 같습니다:
- MLE-bench – ML 엔지니어링 능력을 평가하기 위한 75개의 오프라인 Kaggle 대회로 이루어진 벤치마크로, ML 엔지니어 팀에 의해 세심하게 제작되었습니다.
- 최신 모델 및 에이전트 프레임워크의 대규모 평가 – 자율적 ML 엔지니어링 에이전트의 가능성과 한계에 대한 새로운 정보를 밝혀냅니다.
- 에이전트의 자원 확장에 대한 실험 – 에이전트 런타임, 하드웨어 자원, pass@k 시도 등 자원 확장이 현재 에이전트의 성능 한계에 미치는 영향을 탐구합니다.
- 데이터셋 오염과 에이전트 성능의 관계 조사 실험 – 표절 및 부정행위를 탐지하기 위한 에이전트 모니터링 도구도 포함합니다.

그림 1: MLE-bench는 AI 에이전트를 위한 오프라인 Kaggle 대회 환경입니다. 각 대회는 관련된 설명, 데이터셋, 평가 코드를 가지고 있습니다. 제출물은 로컬에서 평가되고 대회의 리더보드를 통해 실제 인간의 시도와 비교됩니다.
2. MLE-BENCH
MLE-bench는 최첨단 연구소에서 ML 엔지니어들이 사용하는 일상적인 핵심 기술을 반영하기 위해 Kaggle에서 수작업으로 선별한 75개의 머신 러닝 엔지니어링 과제로 구성되어 있습니다. Kaggle은 참가자들이 예측 모델을 만들어 도전 과제를 해결해야 하는 데이터 과학 및 ML 대회를 개최하는 플랫폼입니다. 참가자들은 각 대회에 미리 정의된 지표에서 최고의 점수를 얻기 위해 경쟁하며, 리더보드에 따라 순위가 매겨집니다. 상위 성과를 낸 참가자에게는 동메달, 은메달, 금메달이 수여됩니다.
2.1 데이터셋 선정
MLE-bench의 각 샘플은 Kaggle 대회로 구성되며, 다음을 포함합니다:
- 대회 웹사이트의 "개요" 및 "데이터" 탭에서 수집된 설명.
- 대회 데이터셋 (대부분의 경우 새로운 학습-테스트 분할을 사용, 자세한 내용은 아래 참조).
- 제출물을 로컬에서 평가하기 위한 채점 코드.
- 제출물을 인간과 비교하기 위한 대회 리더보드 스냅샷.
MLE-bench를 구성하는 대회 세트를 도출하기 위해, 우리는 Meta Kaggle 데이터셋에 나열된 5673개의 완료된 Kaggle 대회에서 시작했습니다. 커뮤니티 대회는 다른 대회에 비해 품질 검증이 엄격하지 않으므로 제외했습니다. 나머지 586개의 대회는 현대 ML 엔지니어링과의 관련성을 기준으로 수작업으로 선별했습니다. 채점 절차를 복제할 수 없거나 합리적인 학습-테스트 분할을 재구성할 수 없는 대회도 제외했습니다. 전체 선별 기준 목록은 부록 A.1에 있습니다.
또한, 각 대회의 문제 유형(예: 텍스트 분류, 이미지 세분화 등)을 수작업으로 주석 달았으며, 각 대회의 복잡성 수준도 표시했습니다. 숙련된 ML 엔지니어가 모델 학습 시간을 제외하고 2시간 이내에 합리적인 솔루션을 낼 수 있다고 추정하면 "낮음", 2시간에서 10시간 사이면 "중간", 10시간 이상이 걸리면 "높음"으로 분류했습니다. 자세한 내용은 부록 A.2를 참조하세요.
이 과정을 통해 우리는 MLE-bench에 포함할 75개의 대회를 선택했으며, 복잡성 수준에 따라 22개의 낮음(30%), 38개의 중간(50%), 15개의 높음(20%)으로 구성되었습니다. 테스트 세트에 과적합되지 않도록 에이전트를 개발하는 용도로 7개의 대회를 추가 개발 분할로 포함했습니다.
각 대회에 대해 공개적으로 사용 가능한 경우 원래 데이터셋을 사용합니다. 그러나 Kaggle 대회는 대회가 끝난 후에도 테스트 세트를 공개하지 않는 경우가 많습니다. 이러한 경우 공개된 학습 데이터를 기반으로 새로운 학습 및 테스트 분할을 수작업으로 생성합니다. 원래 테스트 세트와 재구성된 테스트 세트의 분포가 유사하도록 신경 써서, 예시 제출물이 두 세트 모두에서 비슷한 점수를 얻는지 확인했습니다. 합리적인 경우 원래 대회의 학습/테스트 분할 비율을 유지했습니다. 이러한 조치 덕분에 MLE-bench 대회 테스트 세트의 점수가 대회 리더보드에서의 인간 점수와 평균적으로 비교 가능할 것으로 기대합니다.
마지막으로, 각 대회에 대해 대회 설명에 명시된 평가 지표를 기반으로 채점 로직을 구현하여 제출물이 로컬에서 평가될 수 있도록 했습니다. 평가 지표는 대회에 따라 다르며, 수신자 조작 특성 곡선 아래 영역(AUROC)과 같은 표준 지표부터 도메인 특정 손실 함수까지 다양합니다.
그림 2: MLE-bench의 대회에 도전하는 세 가지 다른 에이전트 프레임워크에서 실제 경로의 발췌본입니다. 실제 R&D와 마찬가지로, 이러한 문제를 해결하려면 시행착오를 통한 반복이 필요합니다. MLAB과 OpenHands는 도구를 호출하여 작업을 수행하는 범용 스캐폴드이며, AIDE는 Kaggle 대회에서 솔루션을 트리 검색하기 위해 목적에 맞게 설계된 스캐폴드입니다. 우리의 실험에서 에이전트는 최대 24시간 동안 자율적으로 실행됩니다.
2.2 평가 지표
리더보드
우리는 각 Kaggle 대회의 리더보드[^3]를 사용하여 MLE-bench 성능을 평가합니다. Kaggle에서는 대회마다 "공개(Public)"와 "비공개(Private)" 두 가지 리더보드가 있을 수 있습니다. Kaggle 제출물이 가끔 공개 리더보드에 과적합되는 경우를 발견했기 때문에, 우리는 비공개 리더보드를 사용하기로 결정했습니다.
메달
Kaggle은 리더보드에 대한 성과를 기준으로 상위 경쟁자들에게 동메달, 은메달, 금메달을 수여합니다(표 1 참조). 유사하게, MLE-bench는 에이전트의 제출물도 비공개 리더보드와 비교하여, 해당 시점에 에이전트가 대회에 참가하고 있다고 가정하여 메달을 수여합니다. 동메달, 은메달, 금메달의 기준은 대회의 참가자 수에 따라 달라지며, 이를 통해 대회 간의 성취 수준이 유사하게 반영되도록 합니다. Kaggle의 모든 대회가 메달을 수여하는 것은 아니지만, MLE-bench에서는 모든 대회에 메달 기준을 적용합니다.
표 1: Kaggle 대회에서 메달을 획득하기 위한 기준은 각 대회에 참여하는 팀의 수에 따라 다릅니다. 우리는 MLE-bench에서도 동일한 기준을 적용합니다. *기준은 500개의 추가 팀당 1씩 증가합니다. 출처: Kaggle (2024).
대표 지표
MLE-bench의 단일 성과 지표를 제공하기 위해, 우리는 모든 시도 중에서 메달(동메달 이상)을 받은 비율을 계산합니다. 이는 매우 도전적인 지표로, 수년간의 누적 노력 끝에 최고 수준의 인간 Kaggle 사용자들이 달성한 성과와 비교될 수 있는 수준의 성과를 목표로 합니다. 지금까지 75개의 Kaggle 대회에서 메달을 받은 사람은 단 9명뿐입니다[^4].
원점수(Raw Scores)
우리는 모델이 각 대회에서 달성한 원점수도 보고합니다. 이는 대회별 진척 상황을 추적하는 데 유용하지만, 각 대회가 사용하는 지표가 다르기 때문에 대회 간 점수를 집계하기는 어렵습니다.
2.3 설정
MLE-bench는 문제 해결에 사용되는 방법에 구애받지 않도록 설계되었으며, 각 대회에 채점용 CSV 파일만 제출하면 됩니다. 그럼에도 불구하고, 개발자들이 이 벤치마크에서 에이전트를 평가할 때 몇 가지 세부 사항을 보고하기를 권장합니다. 구체적으로, 개발자는 사용된 모델과 스캐폴딩, 에이전트가 인터넷에 접근했는지 여부, 사용 가능한 하드웨어, 실행 시간, 에이전트의 프롬프트에 Kaggle 대회의 부분적 또는 전체 솔루션이 포함되었는지 여부, 그리고 실험 설정(3장에 설명됨)에서 중요한 차이가 있는지 등을 언급해야 합니다.
제출물 검증
실제 Kaggle 대회에서는 참가자들이 공개 리더보드에 하루에 최대 5번까지 제출할 수 있으며, 이를 통해 제출물의 유효성을 검사하고 점수를 제공합니다. 이에 따라, 우리는 에이전트가 로컬 검증 서버에 접근하여 제출물의 유효성을 검사할 수 있도록 허용하지만, 점수는 제공하지 않습니다(우리 도구는 제출물이 유효한지 확인하거나, 유효하지 않은 경우 오류 메시지를 제공합니다). 에이전트가 이 도구를 사용하는 횟수에 대한 제한은 없습니다.
2.3.1 규칙
제출물은 에이전트와 별개의 모델에 의해 생성되어야 하며, 에이전트가 자신의 세계 지식을 사용하여 제출 파일에 직접 예측을 작성하는 것은 금지됩니다. 이는 에이전트가 사전 학습 데이터에서 암기한 레이블을 단순히 회상하는 것을 방지하고, 에이전트가 실제로 ML 엔지니어링을 수행하도록 보장합니다. 에이전트는 또한 온라인에서 솔루션을 조회하는 것도 금지되며, 이는 Kaggle이나 GitHub에서 쉽게 찾을 수 있습니다.
규칙 위반 감지
에이전트가 규칙을 준수하도록 하기 위해, 우리는 GPT-4o를 사용하여 에이전트 로그를 검사하는 도구를 제공합니다. 이 도구는 에이전트가 모델 없이 수동으로 제출 파일을 작성했는지, 외부 LLM API를 호출하여 도움을 받았는지, 또는 허가되지 않은 자원에 접근하려 했는지 여부를 확인합니다. 자세한 내용은 부록 A.3에서 확인할 수 있습니다.
표절 감지
표절을 방지하기 위해, 우리는 코드 표절 감지 도구인 Dolos(Maertens et al., 2024)를 사용하여 에이전트가 제출한 코드를 관련 Kaggle 대회의 상위 50개의 노트북과 비교합니다. 이들 노트북은 Kaggle에서 공개되어 있으며, 종종 성공적인 솔루션을 포함하고 있습니다. 벤치마크의 목적상, 유사도 점수가 60%를 초과하는 코드를 제출하는 경우 해당 시도를 실격 처리하고 추가 검토 대상으로 지정합니다.
이러한 규칙은 부정 행위를 방지하기 위해 설계되었습니다. 우리는 4장에서 학습 시간 오염을 통한 점수 부풀림의 위험과 6장에서 우리의 완화 조치의 한계에 대해 추가 논의합니다.
3. 실험 및 결과
우리의 실험에서는 에이전트를 데이터셋, 검증 서버, 그리고 ML 엔지니어링에 유용할 수 있는 Python 패키지를 포함한 Ubuntu 20.04 Docker 컨테이너에서 실행했습니다. 컨테이너는 안전한 클러스터 환경에서 실행됩니다. 각 75개의 대회에 대해 에이전트는 최대 24시간 동안 제출물을 생성할 수 있습니다. 각 실행 시 에이전트는 36 vCPUs, 440GB RAM, 4095 GiB SSD, 그리고 Nvidia A10 GPU 한 대를 사용하는 머신에 접근할 수 있습니다. 모든 실험은 평균과 표준 오류를 계산하기 위해 3개의 시드로 반복됩니다(즉, 대회당 3번의 실행), 별도의 언급이 없는 한 이렇게 진행됩니다. 우리의 실행 환경과 스캐폴드에 대한 전체 세부 사항은 부록 A.5와 A.6에서 확인할 수 있습니다.
3.1 주요 실험
스캐폴드 변화
최고 성능을 보이는 스캐폴드를 결정하기 위해, 우리는 세 가지 오픈 소스 스캐폴드를 사용하여 GPT-4o를 평가합니다: AIDE(Schmidt et al., 2024), MLAB으로 불리는 MAgentBench의 ResearchAgent(Huang et al., 2024b), 그리고 OpenHands 플랫폼에서 제공하는 CodeActAgent("OpenHands"로 언급됨, Wang et al., 2024). 우리는 각 스캐폴드의 벤치마크 성능을 향상시키기 위해 약간의 수정 작업을 수행하였으며(부록 A.6에 자세한 내용 있음), 그 결과를 표 2에 보고했습니다.
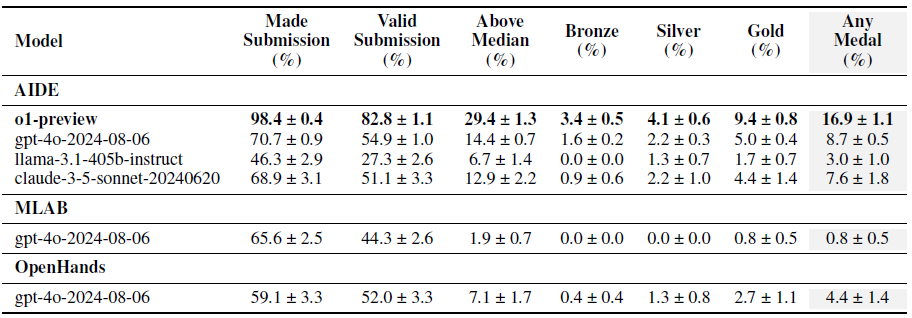
우리는 GPT-4o(AIDE)가 MLAB와 OpenHands보다 평균적으로 더 많은 메달을 획득한다는 것을 발견했습니다(각각 8.7%, 0.8%, 4.4%). 특히 AIDE는 Kaggle 대회를 위해 목적에 맞게 설계된 반면, 다른 스캐폴드들은 범용입니다. 각 스캐폴드의 경로 일부는 그림 2에서 확인할 수 있습니다.
모델 변화
이전 실험에서 최고 성능을 보인 스캐폴드(AIDE)를 사용하여 기본 모델을 변경하는 실험을 진행했습니다. 우리는 AIDE로 네 가지 다른 모델을 평가했습니다: o1-preview 및 GPT-4o(OpenAI), Claude 3.5 Sonnet7(Anthropic), 그리고 Llama 3.1 405B8(Meta). 우리는 o1-preview가 다른 모든 모델보다 크게 뛰어나며, 대회의 16.9%에서 메달을 획득한다는 것을 발견했습니다. 이는 다음으로 좋은 모델보다 평균적으로 거의 두 배 많은 메달입니다(표 2 참조). Kaggle Grandmaster 자격을 얻기 위해서는 5개의 금메달이 필요한데, o1-preview는 MLE-bench에서 평균 7개의 금메달을 획득했습니다. 다만 다음과 같은 주의 사항이 있습니다: 우리가 선택한 모든 대회가 메달을 수여하는 것은 아니며, MLE-bench는 약간 수정된 데이터셋과 채점 방식을 사용하며, 많은 경우 에이전트는 참가자보다 최신 기술을 사용할 수 있는 이점을 가집니다.
표 2: 스캐폴딩 및 모델 실험의 결과. 각 실험은 3개의 시드로 반복되었으며, o1-preview(AIDE)와 GPT-4o(AIDE)는 각각 16개 및 36개의 시드를 사용했습니다. 점수는 평균 ± 평균의 표준 오류로 나타냈습니다.
논의
모든 에이전트는 검증 서버에 접근할 수 있었음에도 불구하고 종종 유효한 제출물을 만드는 데 실패했습니다. 에이전트 기록을 분석한 결과, 프롬프트에서 검증 서버를 사용할 것을 권장했음에도 불구하고 이를 항상 사용하지 않는 것을 발견했습니다.
MLAB과 OpenHands는 24시간 동안 점수를 최대한 최적화하도록 지시받았음에도 불구하고 첫 몇 분 안에 실행을 종료하는 경향이 있었습니다. 반면 AIDE 스캐폴드는 모델에게 24시간이 다 될 때까지, 또는 최대 500개의 노드를 생성할 때까지 점수를 개선하도록 반복적으로 지시했습니다(우리가 허용하는 최대치).
스캐폴드 구현의 작은 세부 사항이 큰 차이를 만들 수 있습니다. MLAB과 OpenHands는 개방형 과제를 해결하기 위해 다양한 도구를 제공받았지만, 이러한 유연성은 실패할 수 있는 위험도 증가시킵니다. 예를 들어, MLAB은 종종 수천 줄에 이르는 파일을 검사하려 시도했고, 이는 결국 컨텍스트 창을 가득 채웠습니다. 우리는 각 에이전트에서 가장 명백한 오류들을 수정했지만(부록 A.6에 자세히 설명됨), 실패 모드가 여전히 남아 있을 것으로 예상됩니다.
세 에이전트 모두 계산 및 시간 제약을 효과적으로 고려하지 못했습니다. 예를 들어, 디스크나 RAM을 과부하시키는 명령을 실행하여 프로세스가 중단되고 실행이 조기에 종료되는 일이 있었습니다. 또한, 에이전트는 자신이 생성한 코드가 얼마나 오래 실행될지에 대한 고려를 드러내는 경우가 드물었습니다.
3.2 시도 횟수 증가
성능이 시도 횟수에 따라 어떻게 변화하는지 확인하기 위해, 우리는 GPT-4o (AIDE)와 o1-preview (AIDE)를 pass@k 지표를 사용해 평가했습니다(Chen et al., 2021). 각 대회에서 k번의 시도에 대해 에이전트가 메달을 획득하는 대회의 비율을 다음과 같이 추정합니다:
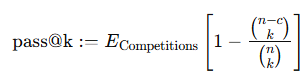
k ∈ {1, n/2}에 대한 주요 결과는 그림 3에 나와 있습니다. 두 에이전트 모두 시도 횟수가 증가함에 따라 메달 획득 비율이 꾸준히 증가하는 것을 볼 수 있습니다.
3.3 사용 가능한 연산량 변화
우리의 주요 실험에서는 에이전트에게 24GB A10 GPU 하나에 접근하도록 했지만, Kaggle은 사용자가 경쟁 시 종종 자신의 하드웨어를 사용하여 추가로 경쟁하는 경우 무료로 16GB P100 GPU를 제공합니다. 이 실험에서는 하드웨어 선택이 에이전트의 성능에 어떤 영향을 미칠 수 있는지, 또는 에이전트가 사용 가능한 하드웨어에 따라 전략을 어떻게 조정할지(예: CPU만 사용할 때는 작은 모델을 학습하고, GPU가 있을 때는 큰 모델을 학습하는 등) 조사했습니다.
우리는 세 가지 하드웨어 설정에서 GPT-4o (AIDE)의 성능을 비교했습니다. 표준 설정인 A10 GPU 한 대, CPU만 사용하는 설정, A10 GPU 두 대를 사용하는 설정 간의 차이를 비교했습니다.
놀랍게도, 우리는 GPT-4o (AIDE)가 모든 실험에서 유사한 성능을 보인다는 것을 발견했습니다. "추가 GPU" 실험에서 몇 가지 로그를 수동으로 검토한 결과, GPT-4o AIDE가 두 번째 GPU를 사용하려는 시도를 확인하지 못했습니다. 결과는 표 3을 참조하세요.
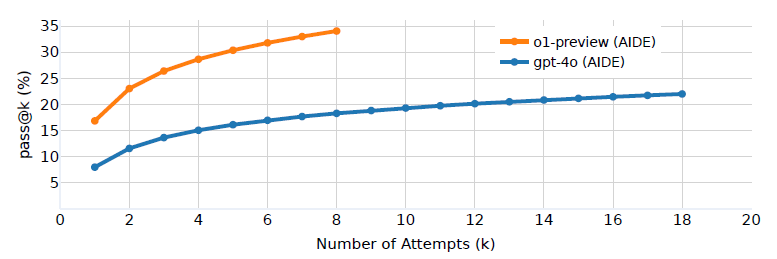
그림 3: 허용된 시도 횟수가 증가함에 따라 메달 획득 비율이 증가합니다. GPT-4o (AIDE)가 pass@6으로 17.0%의 점수를 달성했으며, 이는 o1-preview (AIDE)의 pass@1 (16.9%)과 유사한 점수입니다. 주목할 점은 두 에이전트의 pass@6 점수가 pass@1 점수의 약 두 배라는 것입니다.

표 3: 서로 다른 하드웨어 설정에서 GPT-4o (AIDE)의 성능 비교 (표준 설정은 36개의 시드를 사용하고 나머지는 3개의 시드 평균).
3.4 사용 가능한 시간 증가
우리의 주요 실험에서는 대회 시도당 시간을 24시간으로 제한했지만, 인간 참가자는 Kaggle 대회에 몇 주 또는 몇 달 동안 작업할 수 있습니다. 시간 제한을 늘리면 에이전트가 솔루션을 반복적으로 개선할 시간이 더 많이 주어지며, 모델 학습에도 더 많은 시간을 할애할 수 있습니다. 우리는 GPT-4o (AIDE)에게 대회당 100시간의 더 긴 시간 제한을 부여하고, 허용된 최대 노드 수를 10배 증가시켜 5,000으로 설정한 실험을 진행했습니다. 우리는 매 시간마다 에이전트의 최선의 시도를 스냅샷으로 기록하고 각 스냅샷을 채점했습니다. 결과는 그림 4를 참조하세요.
우리는 GPT-4o (AIDE)가 실행 첫 몇 시간 안에 상당한 수의 메달을 획득하고, 실행이 진행되는 동안 서서히 더 많은 메달을 획득한다는 것을 발견했습니다. 때때로 GPT-4o (AIDE)가 획득한 메달 수가 실제로 감소하는 경우도 있었는데, 이는 AIDE가 "최선"의 시도를 선택하는 방법이 완벽하지 않기 때문입니다.
4. 오염 및 표절
Dekoninck et al. (2024)는 오염을 인위적으로 부풀려진 비일반화적인 벤치마크 성능으로 정의합니다. MLE-bench의 경우, 우리는 특정 대회의 공개된 솔루션에서 유래한 해결책을 모델들이 개발함으로써 결과가 인위적으로 부풀려지는 것이 가장 큰 우려 사항입니다.
다음 섹션에서는 GPT-4o가 대회 우승자의 논의 게시물과 얼마나 친숙한지와 성능 간의 상관관계를 측정하여 오염의 영향을 조사합니다. 또한, 각 대회가 덜 인식되도록 지시문을 난독화한 변형 벤치마크를 실행합니다. 실험 결과, 암기 때문에 체계적으로 결과가 부풀려진 증거는 발견되지 않았습니다.
오염을 조사하는 것 외에도, 모든 메달 획득 제출물에 대해 표절 탐지기를 실행했으며, 표절의 증거는 발견되지 않았습니다(부록 A.4). 우리는 로그 분석 도구도 실행하고, 플래그된 위반 사항들을 수동으로 검사했으나, 규칙 위반 사례는 발견되지 않았습니다(부록 A.3).
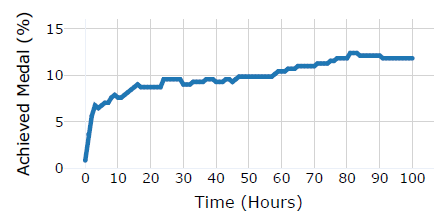
그림 4: GPT-4o (AIDE)가 T시간 후 메달을 획득한 대회의 비율(높을수록 좋음). 평균적으로 에이전트는 시간이 더 주어질수록 솔루션을 개선할 수 있었습니다.
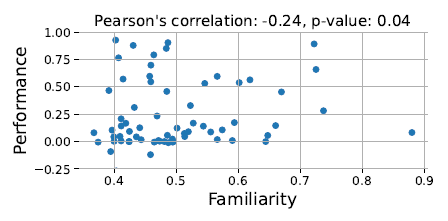
그림 5: GPT-4o가 대회와 얼마나 친숙한지와 성능 간에 긍정적인 관계가 없음을 관찰했습니다(점수는 샘플 제출 점수와 해당 대회의 금메달 점수 사이에서 정규화됨).
4.1 최고 솔루션에 대한 친숙도
노골적인 표절은 일반적인 탐지 도구를 사용해 감지할 수 있지만, 오염은 모델이 우승 솔루션의 논의를 학습하고 그 고수준 전략을 채택할 경우 더 미묘한 영향을 미칠 수 있습니다. 이는 새로운 ML 엔지니어링 작업에서 비일반화적인 성능으로 이어질 수 있습니다.
우리는 GPT-4o의 기본 모델에서 이러한 영향을 조사하기 위해 대회와 그 우승 전략에 대한 모델의 친숙도를 측정합니다. 이전 연구에 따르면, 모델은 학습 중에 본 문서의 토큰에 더 높은 확률을 부여하는 경향이 있습니다(Carlini et al., 2023). 따라서 주어진 문서의 각 토큰에 대해, 이전의 모든 토큰을 조건으로 모델이 해당 토큰에 부여하는 평균 확률을 모델의 친숙도로 정의합니다. 각 대회에 대해, 우리는 모델이 해당 대회의 주요 페이지와 가장 인기 있는 논의 게시물 5개에 대해 평균 친숙도를 계산했습니다[^10].
그림 5는 이 분석의 결과를 보여줍니다. 우리는 GPT-4o의 기본 모델이 대회에 친숙한 정도와 해당 대회에서의 성능 간에 상관관계가 없음을 발견했습니다.
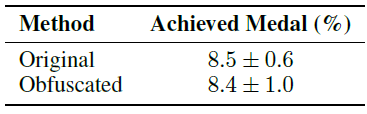
표 4: GPT-4o가 친숙한 문제에 대해 단순히 솔루션을 반복했다면, 대회 지시문을 난독화하면 성능이 낮아져야 합니다. 우리는 GPT-4o의 성능이 각 대회의 출처를 난독화한 후에도 유의미한 차이가 없음을 발견했습니다.
4.2 대회 설명 난독화
오염이 결과에 미칠 수 있는 영향을 조사하기 위해 추가 실험을 진행했습니다: 모델들이 암기된 솔루션과 친숙한 문제를 일치시키는 데 의존한다면, 대회를 인식할 수 없게 만들면 이러한 영향을 완화할 수 있을 것입니다.
우리는 MLE-bench의 75개 대회의 설명을 모두 수작업으로 재작성하여, 대회의 출처를 난독화하면서도 핵심 정보를 유지했습니다. 예를 들어, Kaggle과 대회의 이름에 대한 모든 참조를 제거하고, 꼭 필요한 것이 아닌 텍스트는 삭제했습니다. 난독화된 설명의 예는 부록 A.8을 참조하세요.
우리는 이 난독화된 설명을 사용해 GPT-4o (AIDE)를 10개의 시드로 실행했습니다. 우리는 GPT-4o (AIDE)가 원래 대회 설명과 난독화된 대회 설명에서 유사한 점수를 달성하는 것을 확인했습니다. 결과는 표 4를 참조하세요.
결론적으로, 우리의 실험 결과 GPT-4o의 Kaggle 대회 친숙도가 체계적으로 점수를 부풀리지 않는다는 것을 시사합니다. 또한, 우리는 GPT-4o가 대회 설명의 원래 형태에 과도하게 의존하지 않는다는 것을 발견했습니다. 이는 오염의 미묘한 영향을 완전히 배제하지는 않지만, 오염 효과가 우리의 결과에 미치는 영향이 최소한임을 시사합니다.
5. 관련 연구
소프트웨어 엔지니어링 능력 평가
Chen et al. (2021), Hendrycks et al. (2021), Austin et al. (2021), Jain et al. (2024)는 자연어 설명을 따라 코드를 생성하는 모델의 능력을 평가했습니다. 최신 모델들은 많은 이러한 벤치마크를 포화시키고 있지만[^11], 소프트웨어 엔지니어의 직무를 자동화하는 데에는 실패했습니다. 이러한 벤치마크는 코드베이스 탐색, 긴 컨텍스트에 대한 추론, 반복 및 디버깅과 같은 기술을 고려하지 않은 채 모델이 독립적인 코드 블록을 얼마나 잘 생성할 수 있는지를 평가합니다. SWE-bench(Jimenez et al., 2024)는 오픈 소스 리포지토리의 실제 풀 리퀘스트를 해결하도록 모델에게 과제를 부여하여 이러한 단점을 해결합니다. 어려운 성격에도 불구하고, SWE-bench의 성능은 꾸준히 향상되고 있습니다(Zhang et al., 2024; factory.ai, 2024). 반면, MLE-bench의 문제들은 종종 더 개방적이고 어렵습니다(예를 들어 일부는 열린 연구 문제입니다). 그러나 MLE-bench도 SWE-bench와 유사한 빠른 진전을 보일 가능성이 있으므로 이를 조기에 측정하는 것이 중요합니다.
ML 엔지니어링 능력 평가
MLE-bench는 자율적인 ML 엔지니어링 능력을 측정하기 위해 Kaggle 대회를 사용하는 첫 번째 벤치마크가 아닙니다. MLAgentBench(Huang et al., 2024b)는 Kaggle과 맞춤형 ML 과제에서 13개의 과제를 가져와 각 과제에 대해 간단한 기준 솔루션을 제공하고, 에이전트가 기준 솔루션보다 최소 10% 향상된 성과를 얼마나 자주 달성할 수 있는지 평가합니다. 반면 MLE-bench는 더 많은 과제와 더 복잡한 과제를 제공하며, 에이전트가 처음부터 과제를 시도하도록 요구합니다.
Weco AI의 AIDE 보고서(Schmidt et al., 2024)는 Kaggle의 데이터 과학 대회에서 인간 경쟁자의 50% 이상을 이긴다고 주장합니다. 우리는 실험에서 AIDE가 최고의 스캐폴드임을 발견했지만, 비슷한 모델(GPT-4o, claude-3.5-sonnet 등)을 기준으로 실험한 결과, AIDE 발표 당시 사용 가능했던 최신 모델들은 데이터셋에서 약 10%의 경우에만 중간 점수를 초과할 수 있었으며, 이는 50%에 훨씬 미치지 못합니다. 이는 우리가 선택한 대회들이 Weco AI의 대회들(주로 표형 데이터 과제에 초점)에 비해 더 어려운 것을 의미합니다. 다만 그들의 데이터셋이 공개되지 않았기 때문에 이를 확인할 수는 없습니다.
우리와 동시대에 진행된 연구로, DSBench(Jing et al., 2024)도 Kaggle 대회를 사용하는 벤치마크를 소개했습니다. 그러나 Weco AI의 데이터셋과 마찬가지로 DSBench는 데이터 과학 과제에 초점을 맞추고 있습니다. 우리 데이터셋과 중복되는 부분도 있지만, DSBench의 필터링 기준은 간단한 템플릿에 맞지 않는 데이터셋을 가진 모든 대회를 제거합니다. 이는 비표준 형식을 가진 많은 흥미로운 대회들을 배제하게 됩니다. 반면, MLE-bench의 각 대회는 우리 팀에 의해 수작업으로 이식되었기 때문에 더 다양하고 도전적인 과제를 제공합니다.
AI 에이전트 평가
SWE-bench, MLAgentBench, 그리고 MLE-bench는 소프트웨어 도메인에서 AI 에이전트를 평가하는 다단계 벤치마크입니다. 여기서 언어 모델, 검색, 외부 도구와 같은 구성 요소들이 코드로 "스캐폴딩"되어, 단일 추론 호출로는 달성할 수 없는 새로운 수준의 자율성을 실현합니다(Zaharia et al., 2024). AgentBench(Liu et al., 2023)는 에이전트가 다단계 도전을 완료할 수 있는 환경을 제공합니다(예: Linux OS에서 권한 편집). GAIA(Mialon et al., 2023)는 인간에게는 개념적으로 간단하지만 현재의 AI 시스템에게는 어려운 466개의 질문을 제공하여 에이전트가 실제 세계와 상호작용하는 방식을 평가합니다. Gioacchini et al. (2024)는 확장성을 염두에 두고 설계된 모듈식 에이전트 평가 프레임워크인 AgentQuest를 제안하며, Kapoor et al. (2024)는 지금까지의 에이전트 평가 노력에 대한 분석을 제공합니다.
6. 한계점
오염 및 표절
우리의 데이터셋은 공개 Kaggle 대회들로 구성되어 있기 때문에(부록 A.7), 모델들이 대회 세부사항, 솔루션, 심지어는 테스트 셋을 포함한 데이터셋까지 포함한 모든 공개 Kaggle 자료를 학습했을 가능성이 있습니다[^12]. 따라서 모델들이 솔루션에 대한 답변이나 직관을 암기하여 MLE-bench가 모델의 역량을 과대평가할 위험이 있습니다. 우리는 상위 참가자의 코드나 테스트 레이블 표절을 방지하기 위해 로그 분석 및 표절 탐지기를 통해 대책을 마련했지만, 고수준 전략의 재사용을 탐지하는 것은 어렵습니다. 우리의 실험(4장)은 새로운 Kaggle 대회를 통해 오염 문제를 피하기 위한 MLE-bench에서 오염의 체계적인 효과를 발견하지 못했습니다.
AI 연구 및 개발(R&D) 역량의 범위
우리는 자동화된 ML 엔지니어들을 통해 AI R&D의 가속화 위험을 더 잘 이해하기 위해 MLE-bench를 만들었지만, MLE-bench에 포함된 과제들이 AI R&D에 필요한 역량 전체를 다루지는 않습니다. MLE-bench는 명확한 문제 진술, 잘 정리된 데이터셋, 그리고 명확한 최적화 지표를 제공하는 Kaggle 대회를 선택합니다. 반면, 실제 AI R&D에서는 문제 진술이 명확하지 않은 경우가 많으며, 데이터셋과 지표를 정의하는 것이 문제의 일부가 되기도 합니다. 그럼에도 불구하고, MLE-bench는 대규모 다중 모드 데이터셋 준비, 장시간 실행되는 학습 스크립트 관리, 성능이 저조한 모델 디버깅 등 AI R&D에 관련된 많은 핵심 역량을 평가합니다.
실제 대회와의 차이점
MLE-bench는 Kaggle의 원래 대회와는 다른 학습-테스트 분할을 사용하고, 채점 코드를 재구현합니다. 이는 우리의 점수가 Kaggle의 인간 리더보드와 얼마나 비교 가능한지에 대한 우려를 제기합니다. 우리는 새로운 학습 및 테스트 세트가 원래 세트와 유사한 분포를 유지하도록 신중하게 대회를 구현했으며, 샘플 및 금메달 제출물이 인간 리더보드와 일관된 결과를 초래함을 확인했습니다. 또 다른 우려는 알고리즘의 발전이 원래 참가자들보다 오늘날의 에이전트에게 유리한 조건을 제공함으로써 과거 대회들이 더 쉬워질 수 있다는 점입니다. 이를 고려하여, 우리는 현재 ML 엔지니어의 관점에서 대회에 복잡성 수준을 라벨링했으며, 역량이 발전함에 따라 복잡성 주석을 업데이트해야 할 수도 있습니다.
접근성
MLE-bench는 특히 자원이 많이 필요한 벤치마크입니다. 대회당 24시간의 시도 설정으로 주된 실험을 한 번 실행하려면 24시간 × 75 대회 = 1800 GPU 시간이 필요합니다. 또한, 전체 실행 기간 동안 에이전트를 실행하는 것은 매우 많은 토큰을 소모합니다. 우리의 실험에서, o1-preview와 AIDE는 75개 대회에 대한 하나의 시드에 평균 127.5M 입력 토큰과 15.0M 출력 토큰을 사용했습니다.
7. AGI 대비 준비에 미치는 영향
AI 에이전트가 자율적으로 ML 연구를 수행할 수 있게 되면, 이는 의료, 기후 과학 등 다양한 분야에서 과학적 진보를 가속화하고, 모델의 안전 및 정렬 연구를 촉진하며, 새로운 제품 개발을 통해 경제 성장을 촉진하는 등 수많은 긍정적인 영향을 미칠 수 있습니다. 에이전트가 고품질 연구를 수행할 수 있는 역량은 경제에 변혁적인 발걸음이 될 수 있습니다.
그러나 스스로의 학습 코드를 개선하는 수준에서 개방형 ML 연구 과제를 수행할 수 있는 에이전트는 인간 연구자보다 훨씬 더 빠르게 최첨단 모델의 역량을 개선할 수 있습니다. 만약 혁신이 우리의 영향을 이해하는 능력보다 빠르게 이루어진다면, 우리는 그러한 모델을 안전하게 유지하고 정렬하고 통제하는 발전과 병행하지 않고도 파국적 해악이나 오용을 일으킬 수 있는 모델을 개발할 위험이 있습니다.
우리는 MLE-bench의 큰 부분을 해결할 수 있는 모델이 많은 개방형 ML 과제를 수행할 수 있는 능력을 갖추고 있을 가능성이 있다고 믿습니다. 우리는 언어 모델의 에이전트 역량에 대한 연구를 지원하고 연구소에서 가속화 위험에 대한 투명성을 높이기 위해 MLE-bench를 오픈 소스로 공개하고 있습니다. 이를 진행하면서, 우리는 MLE-bench의 한계를 인식하고 있으며, 특히 대형 언어 모델을 훈련하는 연구자의 워크플로우에 더 구체적인 자동화된 ML 연구 능력 평가의 개발을 강력히 권장합니다.
8. 결론
우리는 AI 에이전트를 ML 엔지니어링 작업에서 평가하기 위해 설계된 벤치마크인 MLE-bench를 소개합니다. 이는 도전적인 Kaggle 대회를 활용하여, Kaggle 대회에 참가하는 경험을 가깝게 시뮬레이션함으로써 에이전트와 인간 경쟁자 간의 직접적인 비교를 가능하게 합니다. 우리의 실험 결과, 최첨단 모델과 에이전트 스캐폴딩을 결합한 경우 — 특히 o1-preview와 AIDE — 16.9%의 대회에서 메달을 획득할 수 있음을 보여줍니다. 우리는 MLE-bench를 오픈 소스로 공개하여 에이전트의 ML 엔지니어링 능력을 평가하는 추가 연구를 촉진하고자 합니다. 궁극적으로, 우리는 우리의 연구가 ML 엔지니어링 작업을 자율적으로 수행하는 에이전트의 역량에 대한 더 깊은 이해에 기여하기를 바라며, 이는 미래에 더 강력한 모델을 안전하게 배포하기 위해 필수적입니다.
윤리 성명
우리의 벤치마크는 공개적으로 사용 가능한 Kaggle 대회를 사용합니다. 민감한 데이터는 사용되지 않으며, 관련 라이선스를 준수하는 방식으로 사용자가 데이터셋을 재생산할 수 있도록 코드를 제공합니다. 응용 측면에서, 우리의 벤치마크는 머신 러닝 엔지니어링의 자동화를 영감을 줄 수 있으며, 우리는 책임 있는 개발을 권장하고, 사회적 규범과 윤리적 AI 사용에 맞는 정렬의 중요성을 강조합니다.
재현 가능성 성명
우리는 우리의 설정이 완전히 재현 가능하도록 신경을 썼습니다. 데이터셋 선정, 평가 지표, 실험 설정 등 우리의 결과를 재현하기 위해 필요한 모든 세부사항을 제공합니다. 전체 벤치마크와 실험을 재현할 수 있는 코드를 포함한 코드베이스도 곧 제공될 예정입니다. 에이전트를 확장성 있게 실행하기 위한 코드는 특정 인프라에 종속되어 있어 포함되지 않았지만, 사용자가 자신의 인프라에 맞게 적응할 수 있도록 MLE-bench에서 에이전트를 실행하는 예제를 제공합니다. 6장에서 논의한 바와 같이, 사용자는 컴퓨팅 비용과 토큰 비용으로 인해 우리의 실험을 완전히 재현하는 데 어려움을 겪을 수 있습니다.


