https://arxiv.org/abs/2410.07718
Hallo2: Long-Duration and High-Resolution Audio-Driven Portrait Image Animation
Recent advances in latent diffusion-based generative models for portrait image animation, such as Hallo, have achieved impressive results in short-duration video synthesis. In this paper, we present updates to Hallo, introducing several design enhancements
arxiv.org
초록
최근에 Hallo와 같은 잠재 확산 기반 생성 모델을 이용한 인물 이미지 애니메이션의 발전은 짧은 길이의 비디오 합성에서 인상적인 성과를 이뤄냈습니다. 본 논문에서는 Hallo의 기능을 확장하기 위해 여러 디자인 개선을 적용한 업데이트를 소개합니다. 첫째, 방법을 확장하여 장시간 비디오를 생성할 수 있도록 했습니다. 이러한 확장 과정에서 발생할 수 있는 외형 드리프트(appearance drift)와 시간적 아티팩트(temporal artifacts)와 같은 주요 도전을 해결하기 위해, 우리는 조건부 모션 프레임의 이미지 공간에서 증강 전략을 연구했습니다. 구체적으로, 시각적 일관성과 장시간 동안의 시간적 일관성을 강화하기 위해 가우시안 노이즈가 추가된 패치 드롭(patch-drop) 기법을 도입했습니다. 둘째, 우리는 4K 해상도의 인물 비디오 생성에 성공했습니다. 이를 위해 잠재 코드의 벡터 양자화를 구현하고, 시간 축의 일관성을 유지하기 위해 시간 정렬 기술을 적용했습니다. 고품질 디코더를 통합하여 4K 해상도에서 시각적 합성을 실현했습니다. 셋째, 인물 표정을 조건부 입력으로 제어할 수 있도록 조정 가능한 의미적 텍스트 레이블을 도입했습니다. 이를 통해 기존의 오디오 신호만을 사용하던 방식에서 확장하여 생성된 콘텐츠의 제어 가능성과 다양성을 높였습니다. 우리의 지식에 따르면, 본 논문에서 제안하는 Hallo2는 4K 해상도에서 시간당 생성되는 오디오 기반 인물 이미지 애니메이션을 텍스트 프롬프트로 강화하여 생성할 수 있는 최초의 방법입니다. 우리는 HDTF, CelebV, 그리고 새로 도입한 “Wild” 데이터셋을 포함한 공개 데이터셋을 사용하여 방법을 평가하는 광범위한 실험을 수행했습니다. 실험 결과는 본 접근 방식이 장시간 인물 비디오 애니메이션에서 최첨단 성능을 달성하며, 4K 해상도에서 수십 분까지 확장 가능한 풍부하고 제어 가능한 콘텐츠를 성공적으로 생성함을 보여줍니다. 프로젝트 페이지: https://fudan-generative-vision.github.io/hallo2
Homepage
fudan-generative-vision.github.io
-----
패치 드롭(Patch-Drop)은 컴퓨터 비전 분야에서 사용되는 데이터 증강(data augmentation) 및 모델 성능 향상 기법입니다. 이 기법의 주요 특징과 작동 방식을 설명해드리겠습니다.
핵심 개념: 패치 드롭은 입력 이미지의 특정 패치(영역)들을 무작위로 제거하는 방식으로 작동합니다. 이미지에서 일부 영역을 의도적으로 누락시킴으로써 모델이 더 강건하게 학습할 수 있도록 돕습니다.
작동 방식:
- 이미지를 일정한 크기의 패치들로 분할합니다
- 설정된 확률에 따라 일부 패치들을 무작위로 선택합니다
- 선택된 패치들을 제거하거나 0으로 마스킹 처리합니다
- 나머지 패치들만으로 모델 학습을 진행합니다
주요 장점:
- 모델의 과적합을 방지하는데 도움이 됩니다
- 부분적인 정보만으로도 전체를 이해할 수 있는 능력을 향상시킵니다
- 노이즈나 가려짐에 대한 모델의 견고성을 높여줍니다
활용 분야:
- 이미지 분류
- 객체 탐지
- 세그멘테이션
- 자기 지도 학습
이 기법은 특히 제한된 데이터셋으로 학습할 때 유용하며, 다른 데이터 증강 기법들과 함께 사용하면 더 좋은 효과를 얻을 수 있습니다.
-----
1. 서론
인물 이미지 애니메이션—음성 Prajwal 등(2020); Tian 등(2024); Xu 등(2024a); Zhang 등(2023), 얼굴 랜드마크 Wei 등(2024); Chen 등(2024), 또는 텍스트 설명 Xu 등(2024b)과 같은 다양한 입력 신호를 이용하여 참조 인물로부터 애니메이션 비디오를 생성하는 과정—은 여러 도메인에서 큰 잠재력을 가지고 있는 빠르게 발전하는 분야입니다. 이러한 도메인에는 고품질 영화 및 애니메이션 제작, 가상 비서 개발, 맞춤형 고객 서비스 솔루션, 상호작용 교육 콘텐츠 제작, 게임 산업의 현실적인 캐릭터 애니메이션 등이 포함됩니다. 따라서 긴 지속 시간의 고해상도, 오디오 기반 인물 애니메이션을 생성하는 능력, 특히 텍스트 프롬프트로 지원되는 경우, 이러한 응용 프로그램에 매우 중요합니다. 최근 잠재 확산 모델(latent diffusion models)에서의 기술 발전은 이 분야를 크게 진보시켰습니다.
최근 몇 년간 인물 이미지 애니메이션을 위한 잠재 확산 모델을 활용한 여러 방법들이 등장했습니다. 예를 들어, VASA-1 Xu 등(2024b)은 DiT 모델 Peebles & Xie (2023)을 확산 과정의 디노이저로 사용하여 단일 정적 이미지와 오디오 세그먼트를 현실적인 대화 얼굴 애니메이션으로 변환합니다. 유사하게, EMO 프레임워크 Tian 등(2024)은 높은 표현력과 사실성을 지닌 애니메이션, 매끄러운 프레임 전환, 정체성 보존을 가능하게 하는 U-Net 기반 확산 모델 Blattmann 등(2023)로 단 하나의 참조 이미지와 오디오 입력만을 사용하여 애니메이션을 생성하는 최초의 종단 간 시스템을 나타냅니다. 이 분야의 다른 주요 발전에는 AniPortrait Wei 등(2024), EchoMimic Chen 등(2024), V-Express Wang 등(2024a), Loopy Jiang 등(2024), CyberHost Lin 등(2024) 등이 있으며, 각각 인물 이미지 애니메이션의 기능 및 응용을 향상시키는데 기여하고 있습니다. 또 다른 주목할만한 기여인 Hallo Xu 등(2024a)은 얼굴 표정 생성, 머리 자세 제어, 맞춤형 애니메이션 사용자화를 이루기 위해 계층적 오디오 기반 시각 합성을 도입했습니다. 본 논문에서는 Hallo Xu 등(2024a)의 기능을 확장하기 위한 여러 디자인 개선을 통해 Hallo의 업데이트를 제시합니다.
-----
EMO 프레임워크에서 Masking 단계의 구체적인 탐지 및 제거 방법을 설명해드리겠습니다.
- 토큰 레벨 마스킹 구현 방법
- 키워드 기반 필터링
- 사전에 정의된 키워드 목록 활용
- 정규표현식을 통한 패턴 매칭
- 단어 임베딩 유사도 계산을 통한 유사 키워드 탐지
- 토큰 중요도 평가
- Attention 가중치 분석
- Gradient-based 중요도 계산
- SHAP(SHapley Additive exPlanations) 값 활용
- 문장 레벨 마스킹 기술
- 문장 분류기 활용
- BERT나 RoBERTa 같은 사전학습 모델을 파인튜닝하여 부적절한 문장 분류
- 문장 임베딩을 통한 유사도 기반 필터링
- 감성 분석을 통한 부정적/편향된 문장 탐지
- 문장 구조 분석
- 구문 분석을 통한 복잡성 평가
- 의존성 파싱을 통한 관계 분석
- 문장 길이와 구조의 적절성 판단
- 컨텍스트 기반 마스킹 방법
- 맥락 이해 모델
- 이전/이후 문장과의 관계 분석
- 주제 일관성 검사
- 담화 구조 분석
- 시맨틱 필터링
- 개체명 인식(NER)을 통한 중요 정보 보존
- 의미역 분석을 통한 핵심 정보 식별
- 문맥상 부적절한 내용 탐지
구체적인 구현 예시:
def token_level_masking(text, keywords, threshold=0.7):
# 토큰화
tokens = tokenizer(text)
# 키워드 기반 마스킹
masked_tokens = []
for token in tokens:
# 임베딩 유사도 계산
similarity = calculate_embedding_similarity(token, keywords)
if similarity > threshold:
masked_tokens.append('[MASK]')
else:
masked_tokens.append(token)
return ' '.join(masked_tokens)
def sentence_level_masking(text, classifier_model):
# 문장 분리
sentences = sentence_tokenizer(text)
# 부적절한 문장 분류
masked_sentences = []
for sentence in sentences:
# 분류 점수 계산
inappropriateness_score = classifier_model.predict(sentence)
if inappropriateness_score < threshold:
masked_sentences.append(sentence)
return ' '.join(masked_sentences)- 마스킹 최적화 전략
- 적응적 임계값 설정
- 문서 특성에 따른 동적 임계값 조정
- 컨텍스트별 마스킹 강도 조절
- 피드백 기반 파라미터 최적화
- 선택적 마스킹
- 중요도에 따른 차등적 마스킹
- 대체 표현 제안
- 부분적 수정 옵션 제공
이러한 마스킹 기법들은 실제 구현 시 다음과 같은 고려사항이 필요합니다:
- 계산 효율성
- 실시간 처리 가능성
- 오탐지 최소화
- 맥락 보존의 중요성
실제 환경에서는 이러한 여러 기법들을 조합하여 사용하며, 특정 도메인이나 용도에 맞게 커스터마이징하는 것이 일반적입니다.
-----
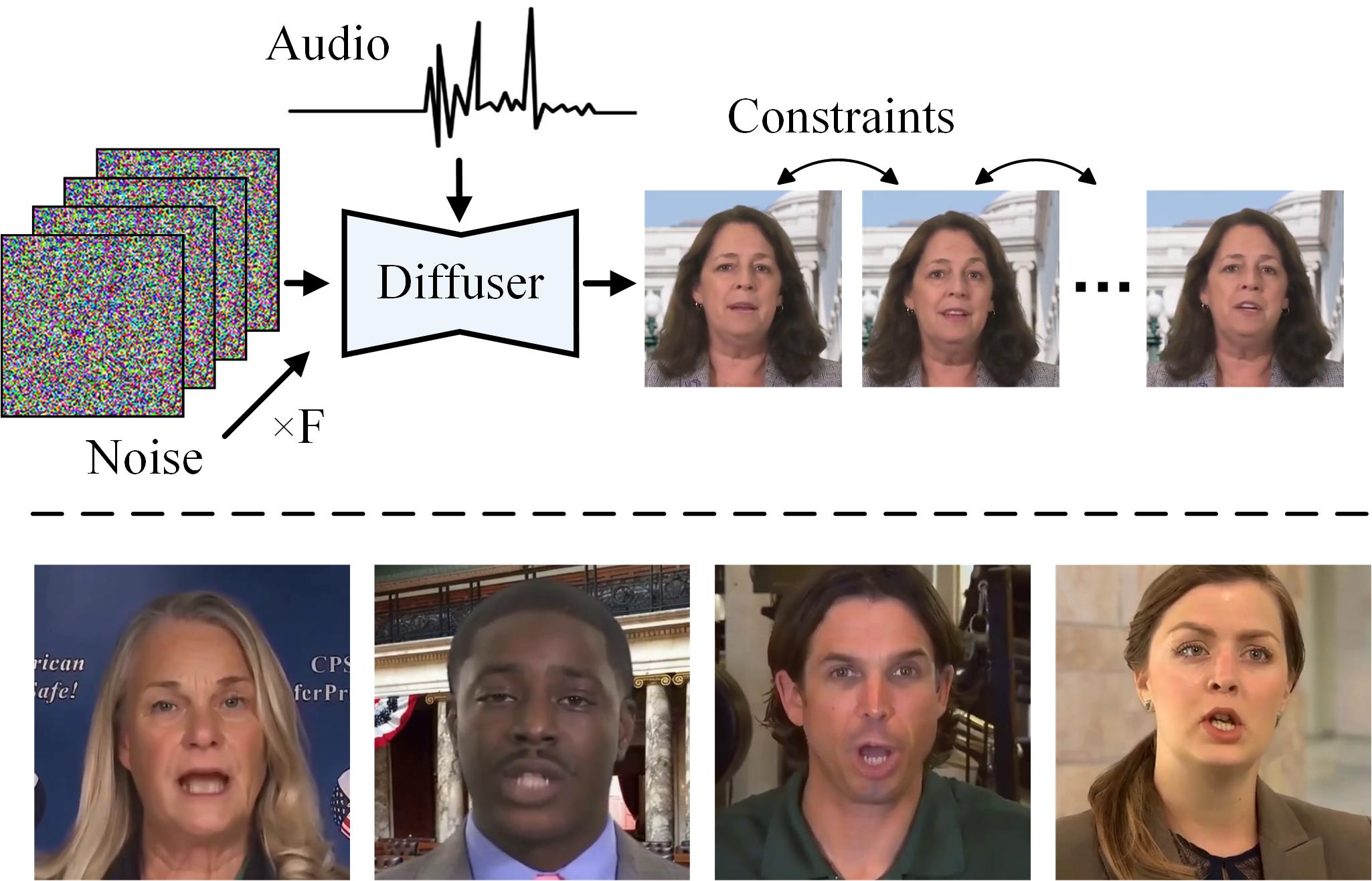
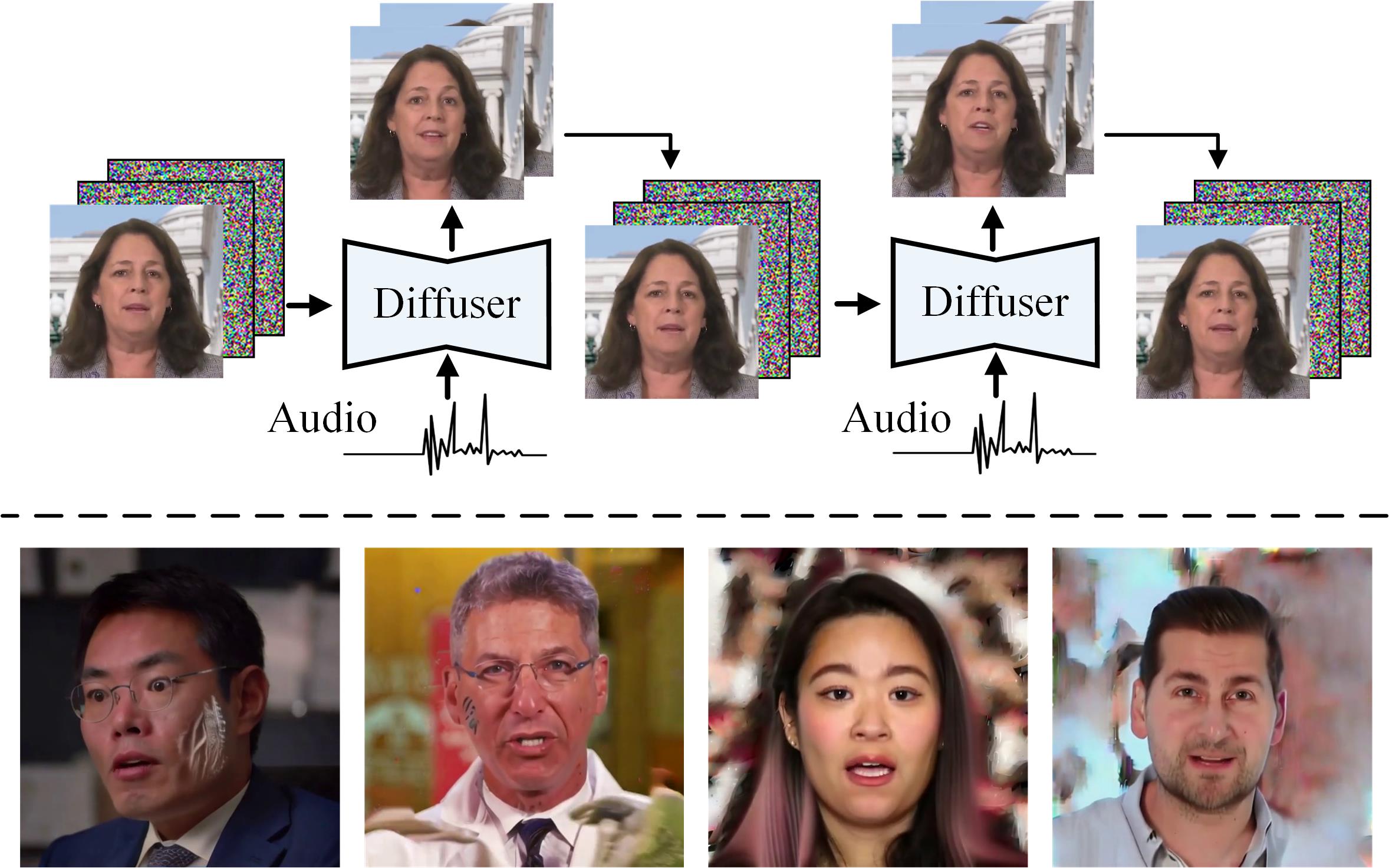
첫째, Hallo를 기존의 짧은 몇 초짜리 인물 애니메이션 생성에서 수십 분에 이르는 지속 시간을 지원하는 방식으로 확장했습니다. 그림 2에서 볼 수 있듯이, 장기 비디오 생성에는 일반적으로 두 가지 주요 접근법이 사용됩니다. 첫 번째 접근법은 제어 신호에 의해 오디오 기반 비디오 클립을 병렬로 생성한 후 이러한 클립의 인접한 프레임 사이에 외형과 모션 제약을 적용하는 것입니다 Wei 등(2024); Chen 등(2024). 이 방법의 주요 한계는 생성된 클립들 사이의 외형과 모션 차이를 최소화해야 한다는 점으로, 이로 인해 입술 움직임, 얼굴 표정, 자세의 큰 변화를 방해하며, 연속성 제약으로 인해 흐릿해지거나 왜곡된 표현과 자세를 초래할 수 있습니다. 두 번째 접근법은 이전 프레임을 조건부 정보로 활용하여 새로운 비디오 콘텐츠를 점진적으로 생성하는 방식입니다 Xu 등(2024a); Tian 등(2024); Wang 등(2021). 이 방법은 연속적인 모션을 가능하게 하지만 오류 누적에 취약합니다. 참조 이미지와의 왜곡, 변형, 노이즈 아티팩트, 또는 이전 프레임의 모션 불일치가 후속 프레임에 전파되어 전체 비디오 품질을 저하시킬 수 있습니다.

그림 1: 제안된 접근 방식의 데모입니다. 이 접근 방식은 몇 분간의 오디오 입력과 함께 단일 참조 이미지를 처리합니다. 또한 선택적으로 텍스트 프롬프트를 다양한 간격에서 도입하여 초상화의 표현을 조정할 수 있습니다. 결과 출력은 오디오와 동기화되며 선택적 표현 프롬프트의 영향을 받는 4K 고해상도 비디오로, 비디오의 연장된 지속 시간 동안 일관성을 유지합니다.
높은 표현력, 사실성, 풍부한 모션 역학을 달성하기 위해, 우리는 두 번째 접근법을 따릅니다. 우리의 방법은 주로 참조 이미지로부터 외형을 도출하고, 생성된 이전 프레임들은 모션 역학—입술 움직임, 얼굴 표정, 자세 등을 전달하기 위해서만 사용합니다. 이전 프레임으로부터 외형 정보가 오염되지 않도록 하기 위해, 조건부 프레임에서 외형 정보를 통제된 방식으로 손상시키면서 모션 특성을 유지하는 패치 드롭 데이터 증강 기법을 적용했습니다. 이 접근법은 애니메이션 동안 외형이 주로 참조 초상 이미지에서 비롯되도록 하여 견고한 정체성 일관성을 유지하며, 지속적인 모션을 갖춘 긴 비디오 생성을 가능하게 합니다. 또한, 외형 오염에 대한 탄력성을 높이기 위해 조건부 프레임에 추가적인 데이터 증강 기법으로 가우시안 노이즈를 도입하여 참조 이미지에 대한 충실도를 더욱 강화하면서 모션 정보를 효과적으로 활용합니다.
둘째, 4K 비디오 해상도를 달성하기 위해 Vector Quantized Generative Adversarial Network (VQGAN) Esser 등(2021)의 이산 코드북 공간 방법을 코드 시퀀스 예측 작업의 시간 축으로 확장했습니다. 코드 시퀀스 예측 네트워크에 시간 정렬을 통합함으로써 생성된 비디오의 예측된 코드 시퀀스에서 부드러운 전환을 달성했습니다. 고품질 디코더를 적용한 결과, 외형과 모션 모두에서 강력한 일관성이 유지되어 고해상도 세부 사항의 시간적 일관성을 강화할 수 있었습니다.
셋째, 장기 인물 비디오 생성의 의미 제어를 강화하기 위해, 인물 표정에 대한 조정 가능한 의미적 텍스트 프롬프트를 오디오 신호와 함께 조건부 입력으로 도입했습니다. 다양한 시간 간격에서 텍스트 프롬프트를 주입함으로써 얼굴 표정과 머리 자세를 조정할 수 있으며, 이를 통해 애니메이션을 더욱 생동감 있고 표현력 있게 만듭니다.
제안된 방법의 효과를 평가하기 위해, 우리는 HDTF, CelebV, 그리고 새로 도입한 "Wild" 데이터셋을 포함한 공개 데이터셋에서 포괄적인 실험을 수행했습니다. 우리가 아는 한, 우리의 접근법은 초상화 이미지 애니메이션에서 최대 10분 또는 몇 시간에 이르는 지속 시간을 가지며 4K 해상도를 달성한 최초의 방법입니다. 또한, 얼굴 특징에 대한 정확한 제어를 가능하게 하는 조정 가능한 텍스트 프롬프트를 통합함으로써, 생성 과정 동안 높은 수준의 사실성과 다양성을 보장할 수 있었습니다.
(a) 병렬 생성
(b) 점진적 생성
그림 2: 장기 인물 이미지 애니메이션을 위한 병렬 및 점진적 확산 기반 생성 모델 비교. (a) 병렬 생성 접근법은 프레임 간의 연속성 제약으로 인해 흐릿하거나 왜곡된 표현을 초래할 수 있습니다. (b) 점진적 생성 방법은 얼굴 특징 및 배경의 오류 누적에 취약합니다.
2. 관련 연구
비디오 확산 모델. 확산 기반 모델은 텍스트 및 이미지 입력으로부터 고품질의 현실적인 비디오를 생성하는 데 있어 탁월한 능력을 입증했습니다(Hu et al., 2023; Zhu et al., 2024; Zhang et al., 2024). Stable Video Diffusion(Blattmann et al., 2023)은 잠재 비디오 확산 접근을 강조하며, 사전 학습, 미세 조정, 그리고 큐레이팅된 데이터셋을 활용해 비디오 품질을 향상시켰습니다. Make-A-Video(Singer et al., 2022)는 텍스트-이미지 합성 기술을 활용해 페어링된 데이터 없이도 텍스트-비디오 생성을 최적화했습니다. MagicVideo(Zhou et al., 2022a)는 새로운 3D U-Net 설계를 통해 효율적인 프레임워크를 도입하여 계산 비용을 줄였습니다. AnimateDiff(Guo et al., 2023)는 플러그 앤 플레이 모션 모듈을 통해 개인화된 텍스트-이미지 모델의 애니메이션을 가능하게 했습니다. VideoComposer(Wang et al., 2024b)와 VideoCrafter(Chen et al., 2023a)와 같은 추가 연구들은 비디오 생성에서 제어 가능성과 품질을 강조합니다. VideoComposer는 동적 지도를 위해 모션 벡터를 통합하고, VideoCrafter는 오픈 소스 모델을 제공합니다. CogVideoX(Yang et al., 2024)는 전문 트랜스포머를 통해 텍스트-비디오 정렬을 향상시켰으며, MagicTime(Yuan et al., 2024)은 변형 타임랩스 모델을 통해 물리적 지식의 인코딩을 다룹니다. 이러한 발전들을 기반으로, 우리의 접근법은 장기간 및 고해상도 합성에 특화된 우수한 사전 학습된 확산 모델을 초상화 이미지 애니메이션에 적용합니다.
그림 3: 제안된 접근 방식의 프레임워크. 제안된 패치 드롭 데이터 증강 및 텍스트 프롬프트 제어의 세부 사항은 오른쪽에 표시되어 있습니다. c_와 c_는 참조 이미지와 모션 프레임의 특징을 나타냅니다.
초상화 이미지 애니메이션. 오디오 기반의 얼굴 애니메이션 생성 및 초상화 이미지 애니메이션에서 큰 진전이 이루어졌으며, 특히 사실성과 오디오 입력과의 동기화에 중점을 두고 있습니다. LipSyncExpert(Prajwal et al., 2020)는 판별자와 새로운 평가 벤치마크를 사용하여 입술 동기화 정확도를 개선했습니다. 그 후속 방법인 SadTalker(Zhang et al., 2023)와 VividTalk(Sun et al., 2023)는 3D 모션 모델링과 머리 자세 생성을 통합하여 표현력과 시간적 동기화를 향상시켰습니다. 확산 기반 기술들은 이 분야를 더욱 발전시켰습니다. DiffTalk(Shen et al., 2023)와 DreamTalk(Ma et al., 2023)는 다양한 정체성 간의 동기화를 유지하면서 비디오 품질을 향상시켰습니다. VASA-1(Xu et al., 2024b)과 AniTalker(Liu et al., 2024)는 미세한 얼굴 표현과 범용 모션 표현을 통합하여 생동감 있고 동기화된 애니메이션을 생성했습니다. AniPortrait(Wei et al., 2024), EchoMimic(Chen et al., 2024), V-Express(Wang et al., 2024a), Loopy(Jiang et al., 2024), CyberHost(Lin et al., 2024), EMO(Tian et al., 2024)는 표현력, 사실성, 정체성 보존을 중점으로 기능을 향상시켰습니다. 이러한 발전에도 불구하고, 긴 지속 시간과 고해상도의 초상화 비디오를 시각적 품질과 시간적 일관성을 유지하며 생성하는 것은 여전히 어려운 과제입니다. 우리의 방법은 Hallo(Xu et al., 2024a)를 기반으로 하여 이 격차를 메우고, 장기간 초상화 이미지 애니메이션에서 현실적인 고해상도 모션 역학을 달성하고자 합니다.
장기 및 고해상도 비디오 생성. 최근 비디오 확산 모델의 발전은 긴 지속 시간과 고해상도 비디오의 생성을 크게 향상시켰습니다. Flexible Diffusion Modeling(Harvey et al., 2022) 및 Gen-L-Video(Harvey et al., 2022)와 같은 프레임워크는 시간적 일관성을 향상시키고 추가 학습 없이 텍스트 기반 비디오 생성을 가능하게 합니다. SEINE(Chen et al., 2023b) 및 StoryDiffusion(Zhou et al., 2024)은 장면 전환과 시각적 스토리텔링을 부드럽게 만들기 위해 생성적 전환 및 의미적 모션 예측기를 도입했습니다. StreamingT2V(Henschel et al., 2024) 및 MovieDreamer(Zhao et al., 2024)는 확장된 서사 비디오를 위해 오토리그레시브 전략과 확산 렌더링을 사용하며, 원활한 전환을 제공합니다. Video-Infinity(Tan et al., 2024)는 분산 추론을 통해 긴 비디오 합성을 최적화하며, FreeLong(Lu et al., 2024)은 훈련 없이 전역 및 지역 비디오 특징을 통합하여 일관성을 유지합니다. 본 논문에서는 패치 드롭 및 가우시안 노이즈 증강을 사용하여 장기간 초상화 이미지 애니메이션을 가능하게 합니다.
학습된 사전을 사용하는 이산 사전 표현은 이미지 복원에 효과적임이 입증되었습니다. VQ-VAE(Razavi et al., 2019)는 벡터 양자화를 통한 이산 잠재 공간을 도입하여 VAE를 향상시키고, 포스터리어 붕괴를 해결하며, 고품질 이미지, 비디오 및 음성 생성을 가능하게 했습니다. 이를 기반으로 VQ-GAN(Lee et al., 2022)은 CNN과 트랜스포머를 결합하여 이미지 구성 요소의 풍부한 맥락을 담은 어휘를 생성하고, 조건부 이미지 생성에서 최첨단 결과를 달성했습니다. CodeFormer(Zhou et al., 2022b)는 학습된 이산 코드북을 사용하여 블라인드 얼굴 복원을 수행하며, 트랜스포머 기반 네트워크를 사용해 열화에 대한 강력한 내성을 제공합니다. 본 논문에서는 잠재 코드의 벡터 양자화와 시간 정렬 기법을 도입하여 4K 합성을 위한 시간적 고해상도 일관성을 유지하고자 합니다.
3. 기초 개념
3.1 잠재 확산 모델 (Latent Diffusion Models)
잠재 확산 모델(LDMs)은 Rombach 등(2022)에 의해 도입된 생성 모델링의 중요한 발전을 나타내며, 고차원 이미지 공간이 아닌 압축된 잠재 공간에서 확산 및 디노이징 과정을 수행합니다. 이 접근 방식은 생성된 이미지의 품질을 유지하면서도 계산 복잡도를 크게 줄여줍니다.
구체적으로, 사전 학습된 변분 오토인코더(VAE, Variational Autoencoder) Kingma & Welling (2013)이 입력 이미지를 저차원 잠재 표현으로 인코딩하는 데 사용됩니다. 주어진 입력 이미지 II에 대해, 인코더 E(⋅)는 이를 잠재 벡터로 매핑합니다:
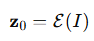
그 후, 전방 확산 과정 Sohl-Dickstein 등(2015); Ho 등(2020); Song 등(2020)이 잠재 벡터 z_0에 적용되며, 시간 단계 T 동안 가우시안 노이즈를 추가하여 일련의 노이즈 잠재 변수를 생성합니다:
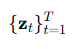
이 과정은 다음과 같이 정의됩니다:
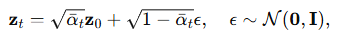

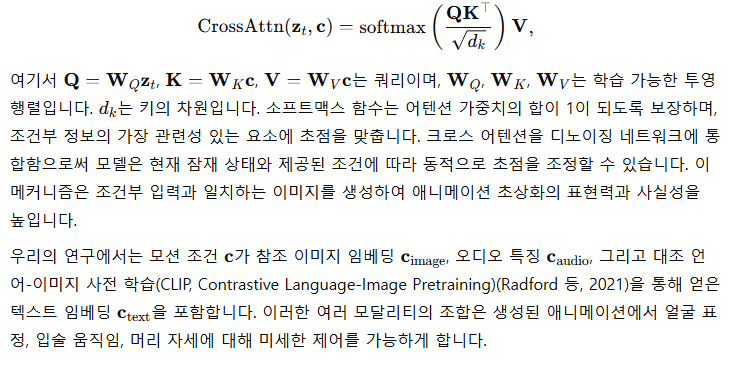
3.2 크로스 어텐션을 통한 모션 조건 통합
잠재 확산 모델에서 생성 과정을 제어하기 위해 조건부 정보를 통합하는 것은 매우 중요합니다. 크로스 어텐션 메커니즘(Vaswani, 2017)은 모션 조건을 모델에 효과적으로 통합하는 데 사용됩니다. 어텐션 레이어는 노이즈 잠재 변수 z_와 임베딩된 모션 조건 c을 처리하여 디노이징 과정을 안내합니다. 크로스 어텐션 연산은 다음과 같이 정의됩니다:
4. 방법
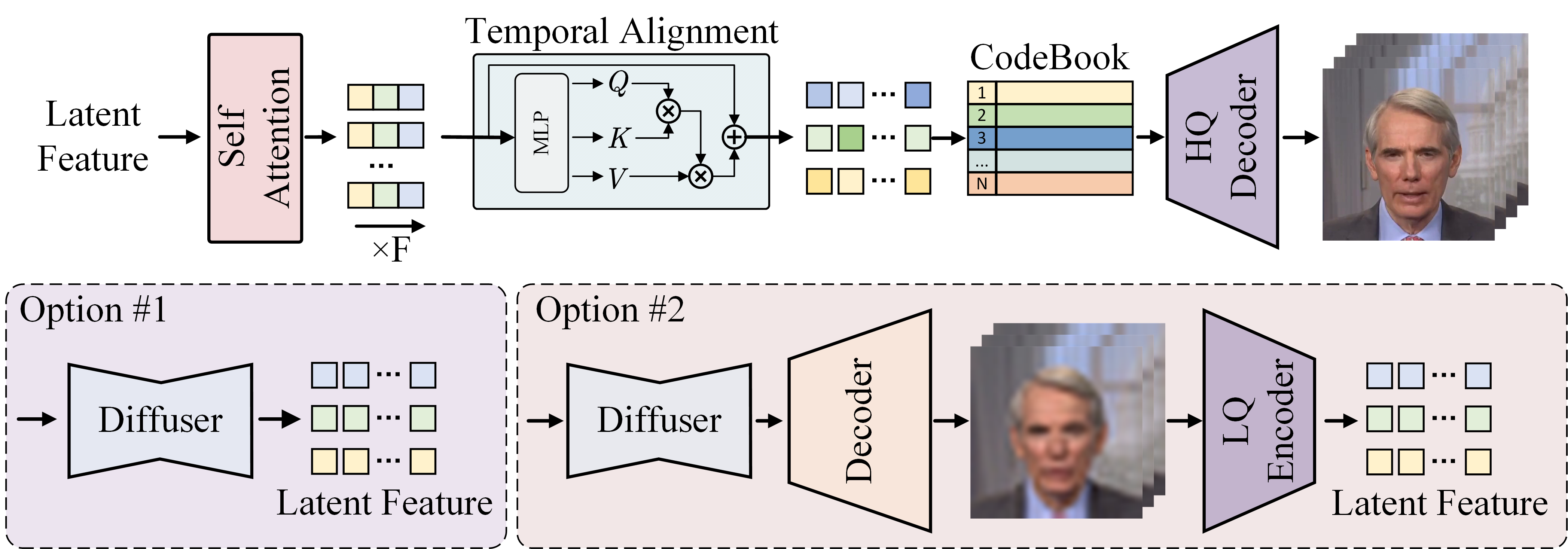
그림 4: 제안된 고해상도 향상 모듈의 그림. 입력 잠재 특징을 추출하는 두 가지 대체 설계가 보여집니다.
이 섹션에서는 인물 이미지 애니메이션을 위한 확장된 기술을 소개합니다. 이 기술은 장기간, 고해상도 비디오를 생성하는 데 있어서 복잡한 모션 역학을 효과적으로 처리하며, 오디오 기반 및 텍스트로 제어 가능한 조작을 가능하게 합니다. 제안된 방법은 주로 하나의 참조 이미지로부터 주제의 외형을 도출하면서 이전에 생성된 프레임들을 조건부 입력으로 사용하여 모션 정보를 포착합니다. 참조 이미지의 외형 세부 사항을 유지하고 이전 프레임으로부터의 오염을 방지하기 위해, 패치 드롭 데이터 증강 기법과 가우시안 노이즈 주입을 결합한 기법을 도입했습니다(섹션 4.1 참조). 추가적으로, VQGAN 이산 코드북 예측을 시간 축으로 확장하여 고해상도 비디오 생성을 촉진하고 시간적 일관성을 향상시켰습니다(섹션 4.2 참조). 또한, 오디오 신호와 함께 텍스트 조건을 통합하여 장기 비디오 생성 중 얼굴 표정과 모션에 대한 다양한 제어를 가능하게 합니다(섹션 4.3 참조). 마지막으로, 네트워크 구조와 학습 및 추론 전략에 대해 섹션 4.4에서 설명합니다.
4.1 장기 애니메이션
패치 드롭 증강. 일관된 외형을 유지하면서 풍부한 모션 역학을 보여주는 장기 초상화 비디오를 생성하기 위해, 우리는 조건부 프레임에 적용되는 패치 드롭 데이터 증강 기법을 도입합니다. 이 기법의 핵심 아이디어는 이전 프레임의 외형 정보를 손상시키는 동시에 그들의 모션 단서를 유지함으로써 모델이 외형 특징을 참조 이미지에 주로 의존하고, 시간적 역학을 포착하기 위해 이전 프레임을 활용하도록 하는 것입니다.

가우시안 노이즈 증강. 점진적인 생성 과정에서, 이전에 생성된 비디오 프레임은 얼굴 영역과 배경의 노이즈, 입술 움직임과 얼굴 표정의 미세한 왜곡 등 외형과 동작 모두에 오염을 일으킬 수 있습니다. 이 과정이 계속되면 이러한 오염이 후속 프레임에 전파되어 점진적으로 아티팩트가 누적되고 증폭될 수 있습니다. 이러한 문제를 완화하기 위해, 우리는 모션 프레임에 가우시안 노이즈를 추가하여, 잠재 공간에서 외형과 동작의 오염을 복구하는 디노이저의 능력을 향상시켰습니다. 구체적으로, 증강된 잠재 표현에 가우시안 노이즈를 도입합니다:

4.2 고해상도 향상
고해상도 비디오 생성에서 시간적 일관성을 향상시키기 위해, 우리는 Zhou 등(2022c)에 의해 제안된 코드북 예측 접근을 채택하고, 도입된 시간 정렬 메커니즘을 통합합니다.


그림 4에서 볼 수 있듯이, 우리는 입력 잠재 특징을 추출하기 위한 두 가지 구현을 제안합니다. 첫 번째 접근법은 초해상도 모듈을 위해 확산 모델에서 직접 잠재 특징을 활용하며, 이는 간단하지만 전체 모듈의 엔드 투 엔드 학습이 필요합니다. 두 번째 접근법은 확산 모델의 디코더와 저해상도 디코더를 통해 잠재 특징을 처리하여, 가벼운 시간 정렬 모듈만 학습이 필요합니다. 초해상도 비디오 데이터의 희소성을 고려할 때, 두 번째 접근법은 제한된 학습 조건에서 우수한 성능을 보입니다.
트랜스포머 모듈 내의 공간적 및 시간적 어텐션 메커니즘을 통합함으로써, 네트워크는 프레임 내 및 프레임 간의 종속성을 효과적으로 포착하여 고해상도 비디오 출력에서 시간적 일관성과 시각적 충실도를 모두 향상시킵니다.
4.3 텍스트 프롬프트 제어

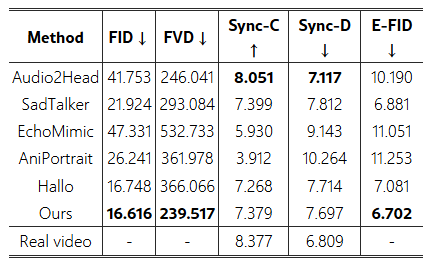
그림 5: HDTF 데이터셋에서 기존 초상화 이미지 애니메이션 접근법과의 정량적 비교. 우리의 평가에서는 4분 길이의 생성된 비디오를 대상으로 하며, 이후의 정량적 실험에서도 일관된 설정을 유지합니다.
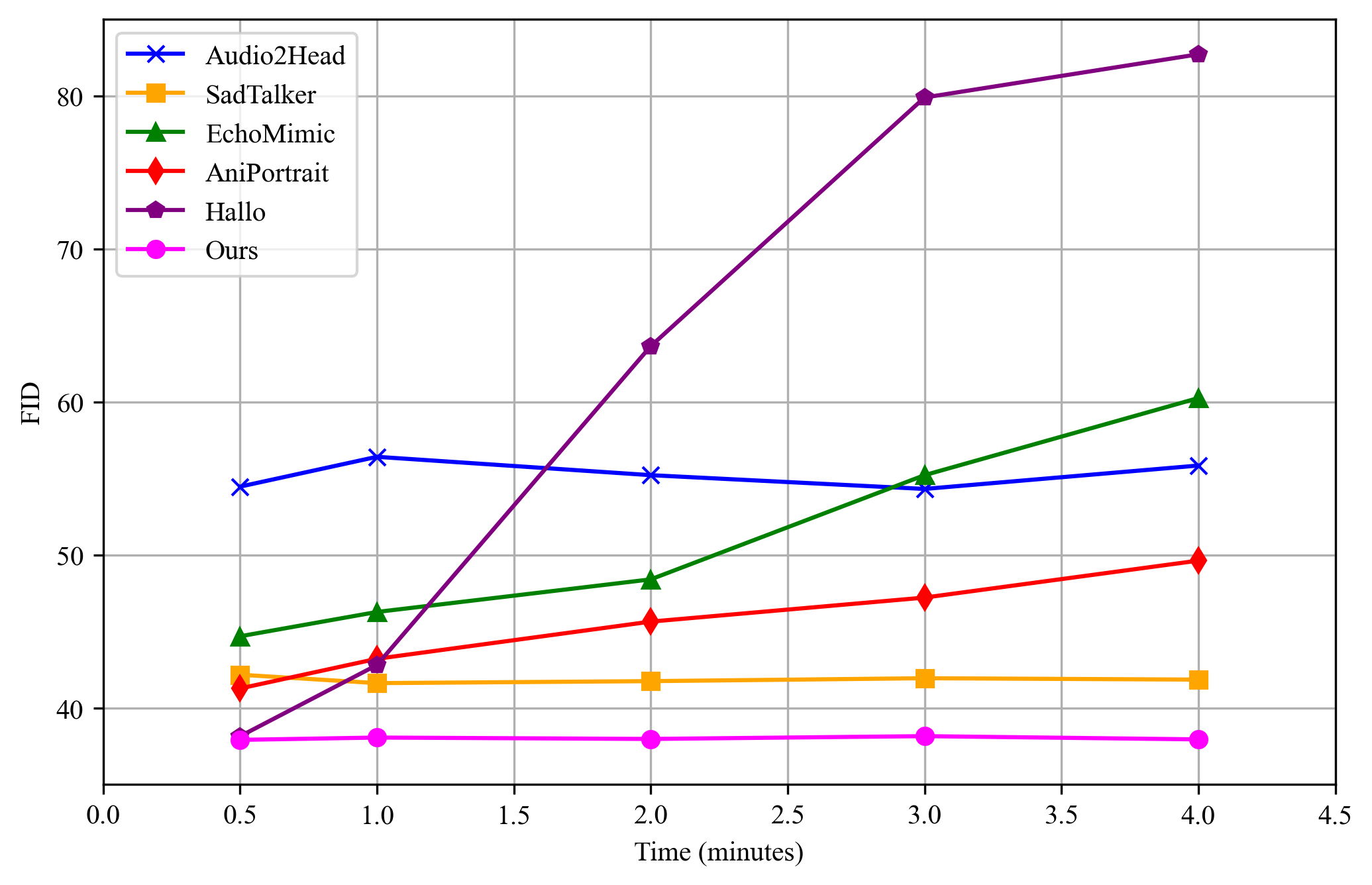
그림 6: 추론 시간이 증가함에 따라 서로 다른 방법들의 FID 지표.

그림 7: HDTF 데이터셋에서 기존 접근법과의 질적 비교.
4.4 네트워크
네트워크 아키텍처. 그림 3은 제안된 접근법의 아키텍처를 보여줍니다. ReferenceNet은 참조 이미지 z_를 임베딩하여 초상화와 해당 배경의 시각적 외형을 포착합니다. 시간적 역학을 모델링하면서도 이전 프레임으로부터의 외형 오염을 완화하기 위해, 모션 프레임 z^t−i에 패치 드롭과 가우시안 노이즈 증강을 적용합니다. 우리의 확장된 프레임워크는 각 확산 시간 단계 t에서 노이즈 잠재 벡터 z_t를 처리하는 디노이징 U-Net 아키텍처를 사용합니다. 입력 오디오 임베딩 c_{는 12층 wav2vec 네트워크(Schneider 등, 2019)로부터 도출되며, 텍스트 프롬프트 임베딩 c_{은 CLIP(Radford 등, 2021)을 통해 얻습니다. 이러한 다양한 조건부 입력들을 디노이징 U-Net 내의 크로스 어텐션 레이어(Blattmann 등, 2023)를 통해 합성하여 모델은 참조 이미지와 시각적으로 일관성을 유지하면서도 역동적이고 미묘한 입술 움직임과 얼굴 표정을 표현하는 프레임을 생성합니다. 마지막으로, 고해상도 향상 모듈은 잠재 코드의 벡터 양자화를 시간 정렬 기법과 함께 사용하여 4K 해상도로 최종 비디오를 생성합니다.
훈련. 본 연구에서는 전체 프레임워크의 다양한 구성 요소를 최적화하기 위해 두 단계로 구성된 훈련 과정을 구현했습니다.
첫 번째 단계에서는 참조 이미지, 입력 오디오, 목표 비디오 프레임을 사용하여 비디오 프레임을 생성하도록 모델을 훈련합니다. 이 단계에서는 변분 오토인코더(VAE) 인코더와 디코더의 파라미터, 그리고 얼굴 이미지 인코더의 파라미터를 고정한 상태로 유지합니다. 최적화 과정은 ReferenceNet과 디노이징 U-Net의 공간적 크로스 어텐션 모듈에 초점을 맞추며, 모델의 초상화 비디오 생성 능력을 향상시키는 것을 목표로 합니다. 구체적으로, 입력 비디오 클립에서 랜덤 이미지를 선택하여 참조 이미지로 사용하고, 인접한 프레임을 목표 이미지로 지정하여 훈련합니다. 또한 모션 모듈을 도입하여 모델의 시간적 일관성과 부드러움을 개선합니다.
두 번째 단계에서는 패치 드롭과 가우시안 노이즈 증강 기법을 모션 프레임에 적용하여, 시간적 일관성과 부드러운 전환이 특징인 장기간 비디오를 생성하도록 모델을 훈련합니다. 이 단계에서는 오염된 모션 프레임을 조건부 집합에 통합하여 시간적 역학의 모델링을 개선하고, 모델이 장시간 시퀀스에서 모션 연속성을 포착하는 능력을 강화합니다. 동시에, 이 단계에서 텍스트 프롬프트를 활용하여 텍스트 지시에 따라 얼굴 표정과 움직임을 정밀하게 조절할 수 있도록 합니다. 초해상도 모델에서는 VAE 인코더의 파라미터를 최적화하여 코드북 예측에 책임이 있는 가중치들을 세밀하게 조정하는 데 집중합니다. 시간 정렬은 트랜스포머 기반 아키텍처 내에서 사용되어 프레임 간의 일관성과 고품질 출력을 보장함으로써, 고해상도 세부사항에서 시간적 일관성을 강화합니다.
추론. 추론 과정에서 비디오 생성 네트워크는 단일 참조 이미지, 드라이빙 오디오, 선택적인 텍스트 프롬프트, 그리고 패치 드롭과 가우시안 노이즈 기법으로 증강된 모션 프레임을 입력으로 받습니다. 네트워크는 제공된 오디오와 텍스트 프롬프트에 따라 참조 이미지를 애니메이션화하여, 오디오 출력과 동기화된 현실적인 입술 움직임과 표정을 합성한 비디오 시퀀스를 생성합니다. 이후, 고해상도 향상 모듈이 생성된 비디오를 처리하여 고해상도 프레임을 생성함으로써 시각적 품질과 세밀한 얼굴 디테일을 향상시킵니다.
5.1 실험 설정
구현. 모든 실험은 8개의 NVIDIA A100 GPU가 장착된 GPU 서버에서 수행되었습니다. 훈련 과정은 두 단계로 진행되었습니다. 첫 번째 단계는 30,000단계로, 단계 크기 4를 사용하여 512 × 512 픽셀의 비디오 해상도를 목표로 했습니다. 두 번째 단계는 배치 크기 4로 28,000단계로 구성되었으며, 모션 모듈은 Animatediff의 가중치로 초기화되었습니다. 두 단계 모두에서 약 160시간 분량의 비디오 데이터를 사용하였으며, 학습률은 1e-5로 설정되었습니다. 초해상도 구성 요소의 경우, 시간 정렬을 위한 훈련은 550,000단계까지 연장되었으며, CodeFormer의 초기 가중치를 활용하고 학습률은 1e-4로 설정되었습니다. VFHQ 데이터셋이 초해상도 훈련 데이터로 사용되었습니다. 두 번째 단계에서는 각 인스턴스에서 모션 프레임으로 지정된 첫 4개의 실제 프레임과 모션 모듈의 잠재 변수들을 통합하여 16개의 비디오 프레임이 생성되었습니다. 추론 과정에서 출력 비디오 해상도는 최대 4096 × 4096 픽셀로 증가됩니다.
데이터셋. 제안된 방법을 평가하기 위해 HDTF, CelebV, 그리고 새로 도입한 “Wild” 데이터셋을 포함한 여러 공개 데이터셋을 사용했습니다. “Wild” 데이터셋은 총 155.9시간 분량의 약 2019개 클립으로 구성되어 있으며, 다양한 입술 움직임, 얼굴 표정, 머리 자세가 포함되어 있습니다. 이 광범위한 데이터셋은 우리의 초상화 이미지 애니메이션 프레임워크의 훈련 및 테스트를 위한 견고한 기반을 제공하며, 다양한 상황에서 고품질의 표현력 있는 애니메이션을 생성할 수 있는 능력을 종합적으로 평가하는 데 기여합니다.
평가 지표. 우리는 초상화 이미지 애니메이션 프레임워크를 엄격하게 평가하기 위해 여러 평가 지표를 사용합니다. 프레셰 인셉션 거리(FID, Fréchet Inception Distance)는 생성된 이미지와 실제 이미지 간의 통계적 거리를 측정하며, 값이 낮을수록 더 높은 품질을 의미합니다. 프레셰 비디오 거리(FVD, Fréchet Video Distance)는 이를 비디오로 확장하여 생성된 비디오와 실제 비디오 간의 유사성을 평가하며, 값이 낮을수록 시각적 품질이 우수함을 나타냅니다. Sync-C 지표는 오디오와의 입술 동기화 일관성을 측정하며, 점수가 높을수록 더 나은 정렬을 반영합니다. 반면에 Sync-D 지표는 동적 입술 움직임의 시간적 일관성을 평가하며, 값이 낮을수록 개선된 모션 충실도를 의미합니다. 마지막으로, Expression-FID(E-FID)는 생성된 콘텐츠와 실제 비디오 간의 표정 동기화 차이를 정량적으로 평가하여 표정 정확성에 대한 정량적 평가를 제공합니다.

그림 8: CelebV 데이터셋에서 기존 접근법과의 질적 비교.
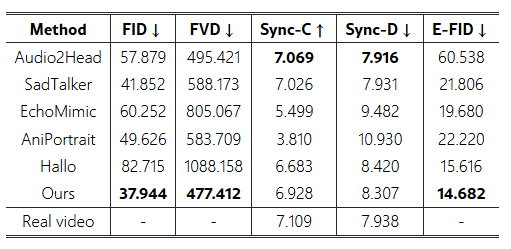
표 1: CelebV 데이터셋에서 기존 초상화 이미지 애니메이션 접근법과의 정량적 비교.
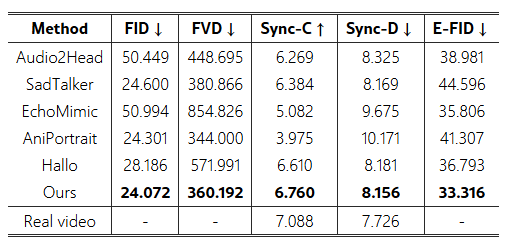
표 2: 제안된 "Wild" 데이터셋에서 기존 접근법과의 정량적 비교.

그림 9: 제안된 "Wild" 데이터셋에서 기존 접근법과의 질적 비교.

그림 10: 다양한 초상화 스타일에서 초상화 이미지 애니메이션 결과.
기준 접근법. 우리는 우리의 프레임워크를 비확산 모델과 확산 기반 모델 모두를 포함한 최신 기술들과 비교하여 평가합니다. 비확산 모델로는 Audio2Head와 SadTalker가 있으며, 확산 기반 모델로는 EchoMimic, AniPortrait, Hallo 등이 있습니다. 특히, EchoMimic과 AniPortrait는 장시간 출력 생성을 위한 병렬 생성 접근법을 사용하고, Hallo는 점진적 포뮬레이션을 사용합니다. 기존 연구들은 몇 초 길이의 짧은 비디오에 초점을 맞춘 반면, 우리의 평가는 벤치마크 데이터셋의 루프된 오디오를 드라이빙 오디오로 사용하여 4분 동안 생성된 비디오를 대상으로 이루어졌습니다. 공정한 비교를 위해, 우리는 고해상도 향상 모듈을 제외하고, 모든 정량적 비교에서 기존 접근법들과 동일한 출력 비디오 해상도(512 × 512 픽셀)를 유지했습니다.
5.2 최신 기술과의 비교
HDTF 데이터셋 비교. 표 6과 그림 7은 HDTF 데이터셋에서의 정량적 및 질적 비교를 보여줍니다. 우리의 프레임워크는 FID 16.616, E-FID 6.702를 기록하며, 탁월한 충실도와 인지적 품질을 입증했습니다. 추가로, 우리의 동기화 지표인 Sync-C (7.379)와 Sync-D (7.697)는 방법의 효과성을 더욱 검증해줍니다. 그림 6에서 볼 수 있듯이, 기존의 확산 기반 접근법에서 확장된 추론 시간은 FID 지표에 큰 영향을 미치며, 짧은 기간 성능에 비해 현저한 하락을 초래했습니다. 입술 및 표정 모션 동기화 측면에서, EchoMimic과 AniPortrait와 같은 병렬 방식들은 상당한 악화를 나타냅니다. 반면, 우리의 확장된 접근법은 추론 시간이 증가하더라도 이미지 및 비디오 품질, 모션 동기화 전반에 걸쳐 우수하고 안정적인 성능을 꾸준히 보여주었습니다.
CelebV 데이터셋 비교. 표 1과 그림 8은 CelebV 데이터셋에 대한 정량적 및 질적 비교를 제시합니다. 우리의 방법은 FID 37.944와 E-FID 14.682로, 우수한 애니메이션 품질을 나타냅니다. FVD 지표는 477.412를 기록하여 일관된 비디오 구조를 시사합니다. 추가로, 우리의 Sync-C 점수 6.928은 실제 비디오 표준에 비해 경쟁력 있는 성능을 보입니다. 특히, 추론 시간이 길어지면서 기존 방법들에서 FID와 FVD 점수 모두에 현저한 악화가 발생했으며, 특히 EchoMimic과 Hallo는 FVD 지표에서 눈에 띄는 열화를 나타냈습니다. Aniportrait 또한 입술 동기화와 표정 지표에서 현저한 저하를 보였습니다.
제안된 "Wild" 데이터셋 비교. 표 2와 그림 9는 새로 도입한 "Wild" 데이터셋에 대한 추가적인 정량적 및 질적 비교 결과를 제공합니다. 우리의 방법은 FID 24.072와 E-FID 33.316을 달성하며, 이는 모두 높은 이미지 품질을 나타냅니다. 또한, Sync-C 점수 6.760과 Sync-D 8.156을 기록하였으며, 가장 높은 FVD 360.192를 보여줌으로써 우수한 일관된 비디오 구조를 입증했습니다.
다양한 초상화 스타일의 애니메이션. 그림 10. 이 그림은 우리의 방법이 유화, 애니메이션 이미지, 생성 모델로부터의 초상화 등 다양한 입력 유형을 처리할 수 있음을 보여줍니다. 이러한 결과는 다양한 예술적 스타일을 수용할 수 있는 우리의 접근법의 다양성과 효과성을 강조합니다.
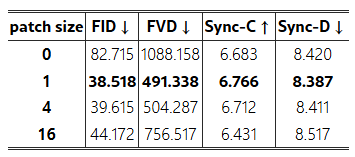
표 3: CelebV 데이터셋에서 패치 드롭 증강의 패치 크기별 정량적 비교. 패치 크기가 0인 경우 패치 드롭이 적용되지 않았음을 나타냅니다.
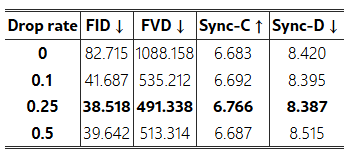
표 4: CelebV 데이터셋에서 패치 드롭 증강의 드롭 비율별 정량적 비교. 드롭 비율이 0인 경우 패치 드롭이 적용되지 않았음을 나타냅니다.
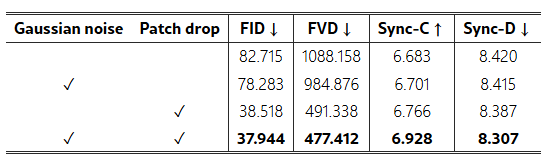
표 5: CelebV 데이터셋에서 패치 드롭 및 가우시안 노이즈 증강에 대한 소거 연구.
5.3 소거 연구
다양한 패치 드롭 크기. 표 4는 성능 지표에 미치는 다양한 패치 드롭 크기의 효과를 보여줍니다. 패치 크기가 0이면 패치 드롭이 적용되지 않음을 의미하며, 우리의 구현에서는 패치 크기 1을 사용합니다. 결과는 FID와 FVD 개선으로 시각적 결과가 향상되고, 모션 동기화 능력도 어느 정도 개선됨을 보여줍니다.
다양한 패치 드롭 비율. 표 4와 그림 12는 모션 프레임에 적용된 다양한 드롭 비율의 비교 분석을 제시합니다. 드롭 비율 0.25는 가장 낮은 FID 점수 38.518과 FVD 491.338을 달성하여 이미지 품질과 일관성이 향상되었음을 나타냅니다.
증강 전략의 효과. 표 5와 그림 12는 다양한 증강 전략을 평가합니다. 가우시안 노이즈만 사용한 경우 FID 82.715와 FVD 1088.158로 나타나, 최적의 품질을 달성하지 못했습니다. 패치 드롭 전략은 이러한 지표를 크게 개선하여 FID를 38.518, FVD를 491.338로 감소시켰습니다. 특히, 결합된 전략은 성능을 더욱 향상시켜 FID 37.944와 FVD 477.412, 그리고 Sync-C 최고 점수 6.928을 달성했습니다. 따라서 결합된 증강 방법이 고품질 모션 프레임을 생성하는 데 가장 효과적임을 입증합니다.

그림 11: CelebV 데이터셋에서 모션 프레임에 적용된 다양한 패치 드롭 비율에 대한 질적 비교.

그림 12: 패치 드롭, 가우시안 노이즈 증강 및 두 접근법의 결합에 대한 질적 소거 연구.
고해상도 향상의 효과. 고해상도 향상 기법의 효과는 그림 13에서 설명되며, 비디오 초해상도를 통해 애니메이션 품질이 향상되는 모습을 보여줍니다.

그림 13: 고해상도 향상 여부에 따른 초상화 이미지 애니메이션 결과의 질적 비교.

그림 14: 다양한 고해상도 향상 방법 간의 질적 비교.

그림 15: 텍스트 프롬프트 적용 전후의 초상화 애니메이션 질적 비교.

(a) 참조 이미지

(b) 모션 프레임
그림 16: 참조 이미지와 모션 프레임의 어텐션 맵 시각화.
다양한 고해상도 향상 방법 간의 비교. 그림 14는 다른 이미지 기반 향상 방법에 대한 질적 비교를 제공합니다. 분석 결과, 시간 정렬과 초해상도 통합은 시각적 충실도를 크게 향상시키고, 아티팩트를 줄이며, 이미지 선명도를 높여 얼굴 특징과 표정의 더 일관되고 사실적인 표현을 가능하게 함을 보여줍니다.
텍스트 프롬프트의 효과. 그림 15에서 보여지듯이, 우리의 초상화 이미지 애니메이션 프레임워크에 텍스트 프롬프트를 통합하면 생성된 애니메이션에 대한 제어가 크게 향상됩니다. 비교 분석 결과, 텍스트 프롬프트는 얼굴 표정과 감정적 뉘앙스를 정밀하게 조작할 수 있게 하여 더욱 맞춤화된 애니메이션 출력을 가능하게 합니다. 원하는 감정 상태에 대한 명확한 지시를 제공함으로써 모델은 주어진 프롬프트와 더 밀접하게 일치하는 애니메이션을 생성하는 데 있어 개선된 반응성을 보입니다.
어텐션 맵 시각화. 그림 16은 참조 이미지와 모션 프레임과 관련된 시간적 어텐션을 강조하는 어텐션 맵 시각화를 제공합니다. 결과는 참조 이미지가 패치 드롭 증강의 구현으로 인해 초상화와 배경의 전반적인 외형에 영향을 미친다는 것을 보여줍니다. 반면, 모션 프레임은 주로 얼굴 움직임과 관련된 영역에 집중하여 생성된 애니메이션에서 동적 속성을 포착하는 역할을 강조합니다.
5.4 한계점 및 향후 연구
장기간 고해상도 초상화 이미지 애니메이션을 위한 우리의 방법에는 몇 가지 한계가 있습니다. (1) 단일 참조 이미지에 의존하는 것은 생성된 표정과 자세의 다양성을 제한하므로, 여러 참조 이미지나 다양한 얼굴 특징을 합성할 수 있는 고급 모델의 필요성이 있습니다. (2) 패치 드롭 데이터 증강 기법이 모션 역학을 효과적으로 보존하지만, 아티팩트를 유발할 수 있으므로, 향후 연구에서는 콘텐츠에 특화된 적응형 메커니즘이나 대안적인 전략을 조사해야 합니다. (3) 4K 해상도 비디오를 생성하는 데 드는 막대한 계산 비용은 최적화와 하드웨어 가속을 통해 실시간 애플리케이션이 가능하도록 개선이 필요합니다.
6 결론
이 논문에서는 Hallo 프레임워크의 향상된 기능을 통해 초상화 이미지 애니메이션의 발전을 제시합니다. 애니메이션 지속 시간을 수십 분으로 확장하면서도 4K 고해상도를 유지함으로써 기존 방법의 주요 한계를 해결합니다. 구체적으로, 패치 드롭과 가우시안 노이즈를 포함한 혁신적인 데이터 증강 기법을 통해 정체성 일관성을 보장하고 외형 오염을 줄였습니다. 또한, 잠재 코드의 벡터 양자화와 시간 정렬 기법을 적용하여 시간적으로 일관된 4K 비디오를 달성하였습니다. 더불어, 조정 가능한 의미적 텍스트 프롬프트와 오디오 기반 신호를 통합하여 얼굴 표정과 모션 역학에 대한 정밀한 제어를 가능하게 함으로써 사실적이고 표현력 있는 애니메이션을 생성할 수 있었습니다. 공개 데이터셋에서 수행된 포괄적인 실험은 우리의 방법의 효과성을 검증하며, 장기간 고해상도 초상화 이미지 애니메이션 분야에 중요한 기여를 합니다.
'인공지능' 카테고리의 다른 글
| mochi-1-preview (3) | 2025.01.10 |
|---|---|
| Ferret-UI 2: Mastering Universal User Interface Understanding Across Platforms (2) | 2025.01.10 |
| MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering (5) | 2024.11.30 |
| GRIN: GRadient-INformed MoE (2) | 2024.11.29 |
| Introducing SynthID Text (이전에 한 것) (3) | 2024.11.29 |



