Automating GPU Kernel Generation with DeepSeek-R1 and Inference Time Scaling | NVIDIA Technical Blog
As AI models extend their capabilities to solve more sophisticated challenges, a new scaling law known as test-time scaling or inference-time scaling is emerging. Also known as AI reasoning or long…
developer.nvidia.com

AI 모델이 점점 더 복잡한 문제를 해결할 수 있는 능력을 확장함에 따라, 추론 시점 스케일링(test-time scaling, inference-time scaling)이라는 새로운 스케일링 법칙이 등장하고 있습니다. AI 추론 또는 롱-씽킹(long-thinking)이라고도 불리는 이 기법은 추론 과정에서 더 많은 계산 리소스를 할당하여 여러 가능한 결과를 평가한 뒤 최적의 결과를 선택함으로써 모델의 성능을 높입니다. 이 방법을 통해 AI는 복잡한 문제를 인간이 문제를 쪼개고 각 부분을 해결하여 최종 답안을 도출하는 방식과 유사하게 전략적으로 접근하고 체계적으로 문제를 해결할 수 있게 됩니다.
이 글에서는 NVIDIA 엔지니어들이 최신 오픈소스 모델 중 하나인 DeepSeek-R1 모델에, 추론 중 추가 계산 자원을 투입해 복잡한 문제를 해결하는 실험을 다룹니다. 이 실험의 목표는 주어진 주의(attention) 연산의 여러 변형에 대해, 명시적 프로그래밍 없이도 수치적으로 정확하고 최적화된 GPU 주의 커널(attention kernel)을 자동 생성하는 것이었습니다.
실험 결과, 어떤 경우에는 숙련된 엔지니어들이 개발한 최적화 커널보다도 더 나은 성능을 보였습니다.
최적화된 주의 커널의 필요성과 관련 과제
주의(attention)는 대규모 언어 모델(LLM)의 발전을 획기적으로 이끈 핵심 개념입니다. 모델이 작업을 수행할 때 입력 데이터에서 가장 중요한 부분에 선택적으로 집중할 수 있게 해주며, 이를 통해 모델은 더욱 정확한 예측을 하고 데이터에 내재된 패턴을 찾아낼 수 있습니다.
NVIDIA GTC 2025
주의 연산의 계산 복잡도는 입력 시퀀스 길이에 대해 이차적으로 증가합니다. 이는 단순한 구현에서 발생할 수 있는 런타임 에러(예: 메모리 부족) 등을 방지하고 계산 효율성을 확보하기 위해, 하위 수준(GPU 커널)의 최적화된 구현을 개발해야 한다는 필요성을 일깨웁니다.
주의에는 인과(causal), 상대적 위치 임베딩(relative positional embeddings), alibi 등 다양한 변형이 있으며, 실제 작업에서는 이들 중 여러 변형을 혼합해서 사용하는 경우가 많습니다.
멀티모달 모델(예: 비전 트랜스포머)은 공간-시간(spatio-temporal) 정보를 유지해야 하는 컴퓨터 비전·영상 생성 모델 등에서 주로 다뤄지는 공간 이웃 주의(Spatial Neighborhood Attention) 같은 특수 주의 기법이 필요하기 때문에 또 다른 난관이 생깁니다.
공간 이웃 주의(Spatial Neighborhood Attention)는 이미지나 영상 같은 2D(또는 3D) 입력에서 특정 공간 영역(이웃 범위)에 한정하여 집중하는 주의 메커니즘입니다. 예컨대 영상 속 한 지점 주변의 픽셀만을 우선적으로 살펴보는 방식으로, 국소적으로 관련성이 높은 부분에 초점을 맞춰 효율적으로 정보를 처리할 수 있습니다.
일반적인(글로벌) 주의는 입력 전체를 대상으로 하기 때문에 시퀀스 길이가 길어지면 계산 복잡도가 급격히 증가합니다. 반면 이웃 주의는 주변 영역만 고려하여 연산하므로, 특히 영상·비디오 등에서 자주 나타나는 공간적·시간적 특성을 잘 포착하면서도 비교적 계산 부담을 줄일 수 있습니다. 이런 이유로 멀티모달 모델(예: 비전 트랜스포머)에서 이미지나 영상 내 공간적 구조를 유지하고, 중요한 영역을 놓치지 않도록 하는 데에 자주 활용됩니다.
예를 들어, 여러 dilation(확장) 값을 적용해 입력 이미지를 단계적으로 더 넓은 이웃 영역까지 주의 범위를 확대함으로써, 처음에는 제한된 범위만 보다가 점차 전체 영상을 파악하는 방식으로 활용하기도 합니다. 이를 통해 모델은 영상 내 국소적 특징에서 시작해 전체 맥락까지 다룰 수 있게 됩니다.

그림 1. 2D 입력에서의 이웃 주의(Neighborhood Attention)
스키 점프를 보는 사람들 사진 4장이 dilation 값을 1~4까지 달리 적용한 예시를 보여주고 있습니다. dilation=1일 때는 스키어 한 명만 포함되는 bounding box가, dilation=4일 때는 사진 대부분을 포함할 정도로 크게 확장된 모습을 보입니다.
이처럼 주의를 위한 최적화된 GPU 커널을 만드는 일은 숙련된 소프트웨어 엔지니어에게도 많은 기술과 시간이 필요한 작업입니다.
최근 LLM인 DeepSeek-R1은 코드 생성 능력에서 많은 가능성을 보여주고 있으나, 아직 첫 시도에서 최적화된 코드를 생성하는 데에는 어려움을 겪습니다. 따라서 추론 과정에서 다른 전략을 활용해 최적화된 코드를 생성할 필요가 있습니다.
아래는 상대적 위치 임베딩(relative positional embeddings) 주의 커널을 작성하기 위한 예시 사용자 프롬프트(prompt)입니다.
Please write a GPU attention kernel to support relative position encodings. Implement the relative positional encoding on the fly within the kernel. The complete code should be returned, including the necessary modifications.
Use the following function to compute the relative positional encoding:
def relative_positional(score, b, h, q_idx, kv_idx):
return score + (q_idx - kv_idx)
When implementing the kernel, keep in mind that a constant scaling factor 1.44269504 should be applied to the relative positional encoding due to qk_scale = sm_scale * 1.44269504. The PyTorch reference does not need to scale the relative positional encoding, but in the GPU kernel, use:
qk = qk * qk_scale + rel_pos * 1.44269504
Please provide the complete updated kernel code that incorporates these changes, ensuring that the relative positional encoding is applied efficiently within the kernel operations.LLM은 때때로 코드가 혼합된 문법이나 잘못된 정보를 포함하는 “환각(hallucinated)” 코드를 생성하기도 하며, 이는 즉시 코드 오류나 비효율성을 초래합니다. 최적의 GPU 스레드 매핑(thread mapping)을 찾는 것 또한 간단하지 않으며, 올바르고 효율적인 커널을 얻기 위해서는 보통 여러 차례의 반복적 개선이 필요합니다.
추론 시점 스케일링을 활용한 최적화 GPU 커널 생성
NVIDIA 엔지니어들은 DeepSeek-R1 모델과 함께 특수한 검증기(verifier)를 추가하여, 사전에 정해진 시간 동안 반복적으로 코드 생성과 검증을 수행하는 새로운 워크플로우를 만들었습니다.

그림 2. NVIDIA Hopper 플랫폼에서 DeepSeek-R1을 활용한 추론 시점 스케일링
이 그림은 첫 번째 프롬프트로부터 주의 커널을 생성하고, DeepSeek-R1이 생성한 GPU 코드를 검증기가 검사한 뒤, 조건을 충족하지 않을 경우 Hopper GPU가 프롬프트를 보강·재구성하여 다시 DeepSeek-R1 모델에 입력하는 과정을 보여줍니다. 최종적으로 GPU 최적화 커널이 만들어집니다.
이 워크플로우는 먼저 수동으로 작성한 프롬프트로 DeepSeek-R1 모델이 첫 번째 버전의 GPU 코드를 생성하게 합니다. 그런 다음, 검증기는 NVIDIA H100 GPU에서 해당 커널을 실행·분석하고, 새 프롬프트를 생성해 DeepSeek-R1 모델에 다시 입력합니다.
이 폐쇄 루프(closed-loop) 방식을 통해 매번 다른 방식으로 코드를 유도함으로써 코드 생성 과정을 점진적으로 개선합니다. 연구팀은 이 과정을 약 15분 동안 반복하면 주의 커널의 성능이 향상된다는 사실을 발견했습니다.

그림 3. Flex Attention 환경에서 자동 생성된 최적화 주의 커널의 성능
이 막대 그래프는 Hopper GPU에서 다양한 주의 커널 유형에 대한 평균 속도 향상을 보여줍니다. 주황색 막대는 PyTorch API(Flex Attention)의 성능을 1배수로 기준 삼았고, 녹색 막대는 NVIDIA 워크플로우(DeepSeek-R1)를 적용했을 때의 속도를 나타냅니다. 예컨대 문서 마스크(Document Mask)나 인과 마스크(Causal Mask)는 약 1.1배, 상대적 위치(Relative Positional)는 1.5배, 알리바이 바이어스(Alibi Bias)와 풀 마스크(Full Mask)는 1.6배, 그리고 소프트캡(Softcap)은 2.1배가량의 속도 향상을 보였습니다.
이 워크플로우는 Stanford의 KernelBench 벤치마크에서 테스트했을 때, Level-1 문제에서 100%의 정답률(수치적으로 정확한 커널), Level-2 문제에서 96%의 정답률을 달성했습니다.
KernelBench의 Level-1 해결률(Level-1 solving rate)은 LLM이 특정 계산 작업을 위해 효율적인 GPU 커널을 생성할 수 있는 능력을 평가하기 위한 수치적 정확도 지표입니다. 이는 최신 LLM의 GPU 프로그래밍 능력을 시험하기 위한 일련의 과제 중 하나입니다.
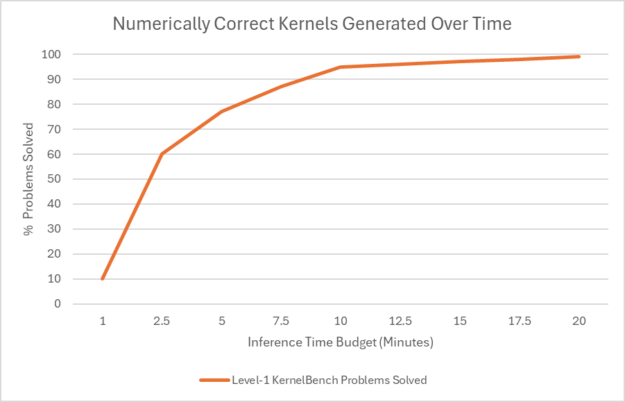
그림 4. 추론 시간 할당이 에이전트의 해결률에 미치는 영향
이 차트는 문제당 10분 이상의 시간을 할당할 경우, Level-1 카테고리의 100가지 문제 중 대부분에서 수치적으로 정확한 코드를 생성할 수 있게 됨을 보여줍니다. 그래프는 대략 10분쯤에서 95%에 도달하고, 20분에 100%에 다다릅니다.
DeepSeek-R1을 활용한 최적화된 GPU 커널
이 결과는 DeepSeek-R1 모델과 추론 과정에서 추가적인 계산 리소스를 투입함으로써 더 나은 GPU 커널을 얻을 수 있음을 보여줍니다. 아직은 연구 초기 단계로, 주의 커널을 자동 생성하는 유망한 접근법에서 나온 첫 결과라 할 수 있습니다.
비록 현재까지는 상당히 고무적인 성과를 거두고 있지만, 더 다양한 문제에 대해 안정적으로 개선된 결과를 얻기 위해서는 추가 연구가 필요합니다. DeepSeek-R1이 보여준 최신 발전과 그 잠재력에 대해 기대가 큽니다.
더 자세한 정보나 시작 방법을 알아보려면 **build.nvidia.com**에서 제공되는 DeepSeek-R1 NIM 마이크로서비스를 확인하십시오.
참고 자료
- DLI 코스: Deploying a Model for Inference at Production Scale
- GTC 세션: Accelerate Inference on NVIDIA GPUs
- GTC 세션: Kernel Optimization for AI and Beyond: Unlocking the Power of Nsight Compute
- GTC 세션: Generate and Optimize GPU Code for Deep Learning via Multi-Dimensional Homomorphisms
- NGC 컨테이너: NVIDIA MLPerf Inference
- NGC 컨테이너: NVIDIA MLPerf Inference
결론적으로는 문제를 deepseek - r1에 할당하고 r1 논문처럼 계속 RL을 돌린거군. 어떻게보면 local 문제에대한 rl이군
DeepSeek-R1에 문제를 계속 할당하면서, 마치 논문에 나온 RL(강화학습) 방식처럼 반복적으로 “결과 → 피드백 → 개선” 과정을 수행한다는 점에서 RL과 유사한 요소가 있습니다.
다만 전통적인 RL 알고리즘을 직접 적용하는 것과는 좀 다르게,
- **“검증기(verifier)”**가 코드의 정확성·성능을 평가하고,
- 이를 바탕으로 새로운 프롬프트(피드백)를 모델에 주어 다시 코드를 생성하도록 하는 폐쇄 루프(Closed-loop) 방식
으로 진행한다는 것이 특징입니다.
결국 결과물을 끊임없이 재생성해가며 “지역(local) 문제 최적화”를 반복하는 구조이므로, 일종의 **“작은 단위 문제에 대한 RL-like 프로세스”**라고도 볼 수 있습니다.
'Article' 카테고리의 다른 글
| On the Biology of a Large Language Model (2) | 2025.04.11 |
|---|---|
| Vibe coding: Your roadmap to becoming an AI developer 🤖 (1) | 2025.04.09 |
| 거의 2,000년 동안 읽히지 않았던 불에 탄 두루마리에서 해독된 첫 단어들 (1) | 2025.02.09 |
| o1 isn’t a chat model (and that’s the point) (4) | 2025.01.15 |
| Understanding Transformer reasoning capabilities via graph algorithms (1) | 2025.01.01 |



