https://github.com/eqimp/hogwild_llm?_bhlid=d0e43178b4d426d6b68fdb2f5c141720a923cacc
GitHub - eqimp/hogwild_llm: Official PyTorch implementation for Hogwild! Inference: Parallel LLM Generation with a Concurrent At
Official PyTorch implementation for Hogwild! Inference: Parallel LLM Generation with a Concurrent Attention Cache - eqimp/hogwild_llm
github.com
https://www.arxiv.org/abs/2504.06261?_bhlid=eead2d61bcbd2ce1f827d441dfc16b82f2fa7798
Hogwild! Inference: Parallel LLM Generation via Concurrent Attention
Large Language Models (LLMs) have demonstrated the ability to tackle increasingly complex tasks through advanced reasoning, long-form content generation, and tool use. Solving these tasks often involves long inference-time computations. In human problem so
arxiv.org
초록(Abstract)
대형 언어 모델 (Large Language Models, LLMs)은 고급 추론 (advanced reasoning), 장문의 콘텐츠 생성 (long‑form content generation), 그리고 도구 활용 (tool use)을 통해 갈수록 복잡한 과제까지 해결할 수 있음을 보여 주었다. 이러한 과제를 풀려면 종종 긴 추론 시간이 필요한 계산이 뒤따른다. 사람의 문제 해결 과정에서 작업 속도를 높이는 흔한 전략은 협업(collaboration)이다. 문제를 하위 과제로 나누거나, 여러 전략을 동시에 탐색하는 식이다. 최근 연구에 따르면 LLM 역시 명시적인 협력 프레임워크—예컨대 투표 메커니즘(voting mechanisms) 또는 병렬로 실행 가능한 독립적 하위 과제의 명시적 생성—를 통해 병렬로 동작할 수 있다. 그러나 이러한 각 프레임워크가 모든 과제 유형에 적합한 것은 아니어서 적용성이 제한될 수 있다.
본 연구에서는 다른 설계를 제안한다. 우리는 여러 LLM “작업자(worker)”를 병렬로 실행하면서, 동시에 업데이트되는 어텐션 캐시(attention cache)를 통해 동기화하도록 하고, 각 작업자가 어떻게 협업할지 스스로 결정하도록 프롬프트한다. 이렇게 하면 각 인스턴스가 서로의 부분 진행 상황을 공유 캐시로 “보면서” 당면 과제에 맞는 협업 전략을 스스로 고안할 수 있다.
이를 위해 우리는 Hogwild! Inference를 구현했다. 이는 동일한 LLM 인스턴스 여러 개가 동일한 어텐션 캐시를 공유하며 병렬로 실행되고, 서로가 생성한 토큰에 즉각적으로(“instant”) 접근할 수 있는 병렬 LLM 추론 엔진이다.<sup>1</sup> Hogwild! Inference는 회전 위치 임베딩(Rotary Position Embeddings, RoPE)을 활용해 재계산을 피하면서 하드웨어 병렬 활용도를 높인다. 우리는 최신의 고급 추론 능력을 갖춘 LLM이 추가 미세 조정(fine‑tuning) 없이도 공유 Key‑Value 캐시(shared Key‑Value cache)로 추론을 수행할 수 있음을 확인했다.
<sup>1</sup> 구현 코드는 https://github.com/eqimp/hogwild_llm에서 확인할 수 있다.
† 교신 저자(Corresponding author): rodionovgleb@yandex‑team.ru
* 공동 1저자(Equal contribution)
‡ 책임 저자(Senior author)
1 서론(Introduction)
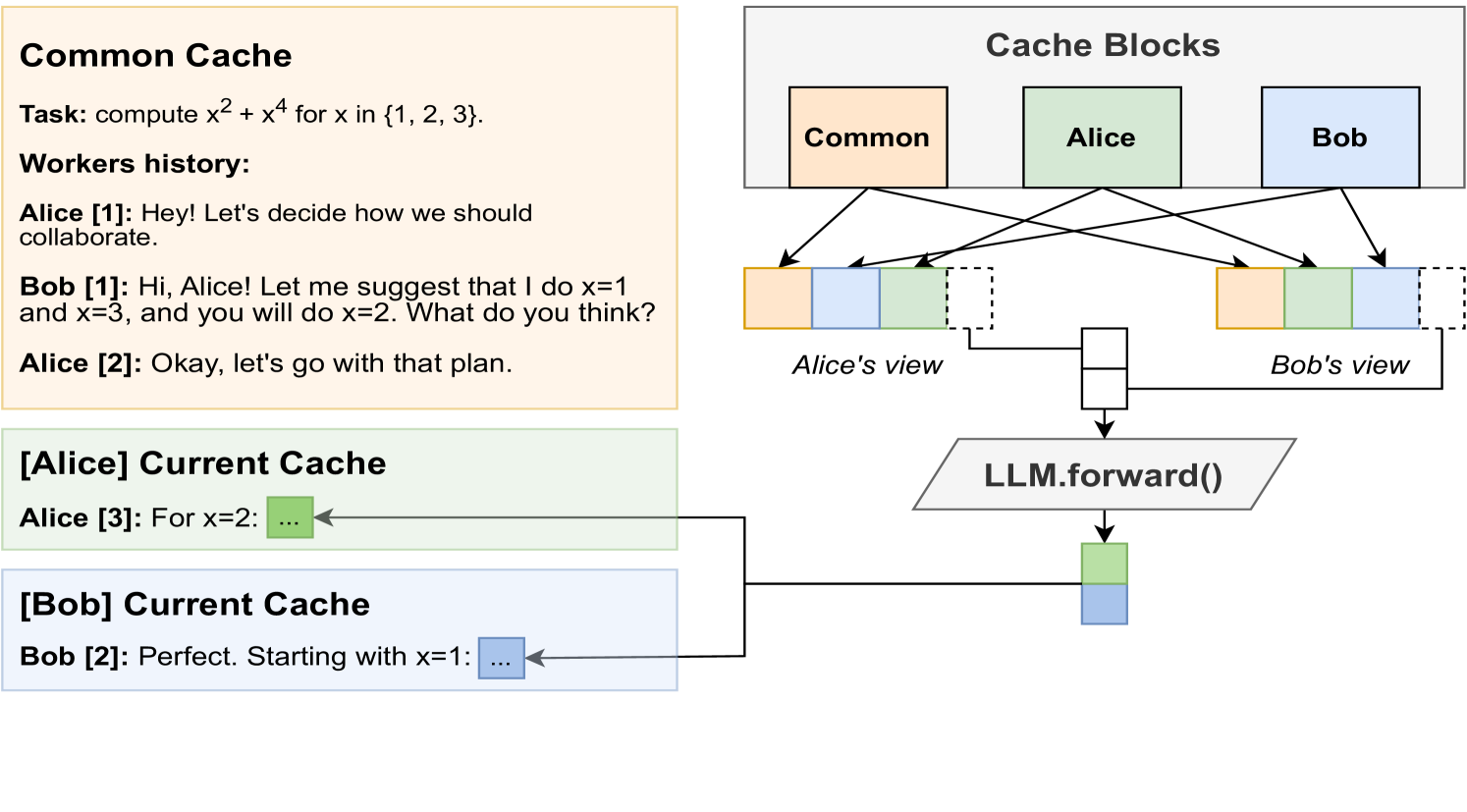
그림 1: Hogwild! Inference의 직관적 설명. 두 개의 워커(worker)가 병렬로 텍스트를 생성하고, 세 개의 공유 캐시 블록(shared cache block)을 사용한다. 색상마다 하나의 캐시 블록을 나타낸다. 실제 동작 예시는 ‘example generation’에서 확인할 수 있다.
최근 대형 언어 모델(Large Language Models, LLMs) 연구에서는 추론(inference) 단계에서 추가적인 계산을 수행해 성능을 높이는 방법이 주목받고 있다 (Suzgun et al., 2022; Snell et al., 2024; Beeching et al.; Muennighoff et al., 2025). 이러한 방법은 고급 추론(advanced reasoning) (Wei et al., 2022; Kojima et al., 2022; Zhang et al., 2022; Yao et al., 2023; Lightman et al., 2023), 장문 생성(long‑form generation) (Bai et al., 2024), 외부 도구 활용(tool use) (Schick et al., 2023; Qin et al., 2023; Yao et al., 2022; Shen et al., 2023) 등에서 두각을 드러낸다. 실제 서비스에서도 장문‑추론 능력을 갖춘 모델이 등장하고 있으며(OpenAI et al., 2024; Google DeepMind, 2025; Anthropic, 2024), DeepSeek‑AI et al. (2025), Qwen Team (2025), Yang et al. (2024), Touvron et al. (2023), Dubey et al. (2024), Muennighoff et al. (2025), Ye et al. (2025) 등 공개 모델도 속속 등장하고 있다.
그러나 복잡한 문제를 해결하려면 토큰을 하나씩 생성하는 순차적(sequential) 계산이 길어지는 경우가 많다. 한편 많은 추론 문제는 본질적으로 순차적이지 않다. 이를 활용해 여러 연구는 병렬 추론(parallel inference) 전략을 제안했다. 예를 들어, 여러 LLM이 독립적으로 문제를 풀고 투표(Wang et al., 2022)하거나 서로의 출력을 교차 검증(cross‑reference)하여(Du et al., 2023; Wang et al., 2024a) 정확도를 높일 수 있다. 다른 접근은 LLM이 문제를 여러 독립적 하위 과제(sub‑task)로 분할한 뒤 이를 병렬로 해결하고 결과를 합치는 방식이다(Ning et al., 2024; Kim et al., 2024; Jin et al., 2025). 이러한 전략은 하드웨어 병렬성을 활용해 품질과 효율을 동시에 개선한다.
하지만 단일 협업 전략이 모든 문제에 효과적인 것은 아니다. 예컨대 독립적인 병렬 “스레드”로 문제를 풀면, 특정 스레드가 특히 오래 걸릴 때 나머지 에이전트는 지연(straggler)을 기다리느라 계산 자원을 낭비할 수 있다(Wang et al., 2022, 2024a). 반면 하위 과제 기반 추론은 문제를 곧바로 여러 과제로 쪼갤 수 있어야만 동작한다. 계획이 잘못됐음을 발견해도 재계획(re‑plan)을 할 수 없어 불필요한 과제를 계속 수행할 위험도 있다(Ning et al., 2024; Ding et al., 2025; Jin et al., 2025).
이는 인간 협업 방식과 대조적이다. 인간 문제 해결자는 고정된 전략을 따르기보다는 상황에 따라 계획을 수정하거나, 진행 중인 작업을 포기하고 더 유망한 접근으로 전환하며, 전략을 토론·논쟁하기도 한다(Hutchins, 1995; Entin and Serfaty, 1999). 이러한 동적 협업(dynamic collaboration)은 정의하기 어렵지만, 참여자가 충분히 유기적이라면 더 유연하고 효율적일 수 있다.
본 연구는 이 원칙을 인공 추론기(artificial reasoner)에도 적용해 본다. 현대 LLM은 이미 어느 정도 계획 수립(planning)과 추론(reasoning) 능력을 갖추었으므로(Zhou et al., 2024; Gao et al., 2024; Wang et al., 2024c), 여러 인스턴스 간 동적 상호작용이 도움이 될 것이라는 가설을 세웠다.
이를 검증하기 위해 Hogwild! Inference를 제안한다. 이는 사전 정의된 협업 프레임워크 없이(no pre‑defined framework of collaboration) 수행하는 병렬 LLM 추론 프로토콜이다.² 여러 LLM 인스턴스가 병렬로 토큰을 생성하면, 각 인스턴스는 다른 인스턴스가 방금 생성한 토큰을 즉시 확인할 수 있다. 그런 다음, 최신 상황을 반영해 각자 다음 행동(하위 과제 해결, 상호 검증, 전략 토론, 계획 전환 등)을 스스로 결정하도록 프롬프트한다.
이를 위해 Hogwild! Inference는 동일한 가중치(weights)를 공유하는 여러 LLM 인스턴스를 실행하되, 맞춤형 Key‑Value 캐시(custom Key‑Value cache)를 사용해 토큰 표현을 공유하고 동시에 교차 어텐션(cross‑attention)을 가능하게 한다. 구체적으로는 각 워커의 KV 메모리를 추적한 뒤, 위치 임베딩(position embeddings)을 보정해 워커마다 다른 순서로 “이어 붙여(stitch)” 사용한다(그림 1 참조).
최신 공개 모델인 QwQ(Qwen Team, 2025)와 DeepSeek‑R1(DeepSeek‑AI et al., 2025)으로 실험한 결과, 별도 미세 조정 없이도 “협업 조정에 대한 추론(reason about coordinating)”이 가능했다. 구체적으로, 병렬 에이전트들은 계획을 세우고, 초기 계획이 실패하면 적응하며, 서로의 오류를 지적하고, 핵심 관찰을 공유한다. 어느 워커가 이미 끝낸 하위 과제를 다른 워커가 중복 수행하거나, 계획 변경 후 불필요해진 문제를 풀고 있을 때 “중복 작업(redundant work)” 여부를 확인하도록 지시하면, 종종(항상은 아님) 이를 감지하고 다른 전략으로 전환했다.
우리는 이러한 관찰을 기반으로 세 가지 메모리 레이아웃(memory layout)을 시험했다.
i) 단순 레이아웃(naive layout): 각 인스턴스가 연속적인 메모리 구역에 진행 상황을 기록.
ii) 채팅형 레이아웃(chat‑like layout): 각 인스턴스가 비공개 버퍼에 작성하다가 주기적으로 공유 메모리에 커밋(commit).
iii) 하이브리드(hybrid) 전략: 공유 채팅형 히스토리를 사용하되, 메시지를 보내기 전 서로의 현재 메시지를 볼 수 있음.
우리는 긴 추론 체인이 필요한 수학 문제에 대해 Hogwild! Inference를 평가하여 레이아웃별 효과를 비교했다. 예비 실험 결과, 모든 캐시 설정에서 병렬 인스턴스는 자신만의 추론 경로를 유지하면서도 다른 인스턴스의 진행 상황을 동적으로 통합했다. 또한 문제 유형에 따라 협업 행동(collaborative behavior)을 스스로 조정하는 징후를 보였다.
이 초기 결과는 공유 Key‑Value 캐시(shared Key‑Value cache)를 활용한 병렬 추론이 여러 LLM 인스턴스 간 효과적인 협업을 가능케 하는 유망한 방법임을 시사한다.
² 우리 접근은 비동기적으로 업데이트를 적용하는 Hogwild! SGD (Recht et al., 2011)에서 영감을 받았다. 느낌표는 원래 이름의 일부다(Stanford HAI, 2023).
2 배경(Background)
최근 연구에서는 병렬 추론(parallel reasoning)·도구 사용(tool use)을 위한 다양한 프레임워크가 제안되었다(Zhang et al., 2025). 이들 프레임워크는 ▲병렬 인스턴스의 조직 방식, ▲서로 주고받는 정보, ▲교환 빈도 등 여러 축에서 차이를 보인다. 본 절에서는 주요 방법을 간략히 정리한다.
토론 및 집계 (Discussion & aggregation)
체인‑오브‑쏘트 추론(chain‑of‑thought reasoning)을 병렬화하는 가장 단순한 방법은 Self‑Consistency(Wang et al., 2022)이다. 여러 LLM 인스턴스가 독립적으로(reason independently) 추론한 뒤, 최종 해답에 대해 투표(vote)를 실시한다. Du et al.(2023)는 이 접근을 확장해, 독립 투표 대신 텍스트 기반 의사소통 라운드(text‑based communication rounds)를 도입했다. 이후 연구들은 서로 다른 종류의 LLM을 조합하거나(Wang et al., 2024a) 더 많은 에이전트까지 확장(Li et al., 2024a)하였다. 또 다른 계열의 연구는 디버거(Debugger)(Talebirad & Nadiri, 2023), 시험관(Examiner)(Cohen et al., 2023), 수학 교사(Math Teacher)(Kong et al., 2024), 판사(Judge)(Chen et al., 2024) 등 특화된 “역할(role)”을 추가해 추론 능력을 보강한다.
이처럼 역할 기반 토론은 특정 과제에서 LLM의 사실성(factuality)을 크게 향상시키는 것으로 나타났으며(Wang et al., 2022; Du et al., 2023), 여러 약한 LLM이 협력해 단일 최첨단 모델을 능가하도록 만들 수도 있다(Wang et al., 2024a). 그러나 이러한 향상은 다중 에이전트에만 국한되지 않으며, 더 정교한 단일 에이전트 프롬프트(single‑agent prompting)로 상쇄될 수 있다(Wang et al., 2024b; Muennighoff et al., 2025). 또한 해당 방식은 모든 에이전트 중 일부가 문제 전체를 순차적으로 풀고 서로의 결과를 재인코딩(re‑encode)해야 하므로 추론 속도를 반드시 높여 주지는 못한다. 이는 실행 시간과 메모리 측면 모두에서 추가 계산 부하(computational overhead)를 초래한다(Wang et al., 2024a; Du et al., 2023).
효율을 위한 병렬성 (Parallelism for efficiency)
다른 연구 흐름은 여러 LLM을 활용해 작업을 더 빠르게 병렬로 해결한다. 대표적으로 Skeleton‑of‑Thought(SoT)(Ning et al., 2024)가 있다. SoT는 단일 LLM으로 문제 해결 계획(plan)을 세우고, 이를 독립적 하위 과제(sub‑task)로 나눈 뒤 각 과제를 수행할 병렬 LLM 인스턴스를 실행한다. 이후 연구들은 동적 병렬 트리 탐색(dynamic parallel tree search)(Ding et al., 2025), 하나의 에이전트가 비동기 하위 과제를 백그라운드 LLM “스레드”로 생성하는 방식(PASTA; Jin et al., 2025) 등 더 복잡한 전략을 제안했다. 함수 호출(function calling)이 포함된 문제라면, 해당 함수들도 병렬 실행이 가능하다(Kim et al., 2024; Gim et al., 2024).
이러한 기술은 특정 유형의 병렬성이 잘 맞는 문제에서 추론 시간을 크게 단축한다. 그러나 이는 동시에 주요 한계이기도 하다. 특정 병렬 전략을 강제함으로써, 해당 프레임워크와 맞지 않는 문제에서는 오히려 추론 성능을 떨어뜨릴 수 있다. 예를 들어 복잡한 추론 문제는 초기 계획이 잘못되었거나 불완전한 경우가 흔하다(Muennighoff et al., 2025; DeepSeek‑AI et al., 2025). 이는 고정된 계획‑실행‑통합(plan‑execute‑aggregate) 절차를 따르는 SoT류 방법(Ning et al., 2024; Yu, 2025)과 충돌한다. 또한 일부 하위 과제는 예상보다 복잡해져 작업량이 크게 늘 수 있는데, 이 경우 PASTA(Jin et al., 2025) 같은 방법은 그 과제가 끝날 때까지 대기해야 한다. 반면 더 정교한 추론기는 계획을 동적으로 조정해 병렬 효율을 높일 수 있다. 개별 문제마다 새로운, 더 복잡한 병렬 프레임워크를 추가해 해결할 수도 있겠지만, 이런 사례가 너무 많아 근본적인 해결책이 되기 어렵다.
본 연구는 여러 LLM 인스턴스가 즉시 서로의 진행 상황을 관찰하고, 명시적 또는 암묵적으로 상호작용하며 자체 협업 전략을 수립·조정하도록 하는 접근을 제안한다. 놀랍게도, 기존의 추론 특화 LLM들은 이미 이러한 능력을 어느 정도 활용할 수 있음을 보여 준다.
3 Hogwild! 추론(Hogwild! Inference)
우리의 핵심 가설은 현대 LLM은 추론 시 병렬성(inference‑time parallelism)을 위해 미리 정해진 프레임워크가 없어도 스스로 협업 구조를 조직할 수 있다는 것이다. 이를 검증하기 위해, 여러 LLM 인스턴스가 최대한 유연하게 협력할 수 있도록 설계한 병렬 추론 프로토콜을 제안한다. 각 작업자(worker)에게 특정 역할이나 하위 과제(sub‑task)를 고정으로 배정하는 대신, 이들을 병렬로 실행하고 자체적인 협업 방식을 고안하도록 프롬프트(prompt)한다.
이 접근은 두 가지 핵심 요소로 이루어진다.
- 동일한 Key‑Value 메모리(Key‑Value memory)에서 다수의 추론 스레드(inference thread)를 어떻게 실행할 것인가.
- 그 메모리 위에서 LLM ‘작업자’들이 어떻게 협업하도록 프롬프트할 것인가.
이에 따라 본 절의 구성을 다음과 같이 제시한다.
- 3.1절에서는 공유 캐시(shared cache)를 사용해 LLM 추론을 수행하는 방법을 설명한다.
- 3.2절에서는 가능한 여러 메모리 레이아웃(memory layout)과 그 의미를 논의한다.
- 3.3절에서는 LLM 간 협업을 유도하기 위한 프롬프트 전략(prompting strategy)을 소개한다.
3.1 공유 Key‑Value 캐시를 이용한 동시 어텐션
Hogwild! 추론의 핵심 구성 요소는 모든 워커(worker)가 접근할 수 있는 공유 Key‑Value 메모리(KV cache)이다. 이 캐시는 여러 블록(block)으로 이루어져 있으며, 각 워커 사이에서 재사용되어 동시형(concurrent) 어텐션 메커니즘 (Bahdanau et al., 2015; Vaswani, 2017)을 구현한다.
가장 단순한 경우(그림 1)로, 워커가 두 개이고 캐시 블록이 세 개라고 가정하자. 첫 번째 블록은 프롬프트(prompt)를 담고, 나머지 두 블록은 각각 워커 A와 B(그림에서는 Alice와 Bob)가 생성한 “생각(thoughts)”—즉 토큰—을 저장한다. 워커가 새 토큰을 생성할 때마다 서로의 어텐션 캐시에 접근하는데, 이는 마치 그 토큰이 자신이 이전에 생성한 것처럼 동작한다. 예컨대 그림 1에서 Alice는 공통 프롬프트 → Bob의 토큰 표현 → 자신의 토큰 순으로 캐시를 본다. 반대로 Bob은 같은 프롬프트 → Alice의 토큰 → 자신의 토큰 순으로 본다.³
이렇게 하면 동일한 Key‑Value 쌍이 각 워커에게 서로 다른 위치에 나타난다. 또한 같은 두 토큰(예: Alice와 Bob이 각각 처음 생성한 토큰) 사이의 상대 거리가 새 토큰이 추가될 때마다 달라진다. 이런 토큰을 각 워커의 새 위치에 맞춰 다시 인코딩(re‑encode)할 수도 있지만, 이는 계산량이 세제곱으로 증가하는 과부하를 초래한다.⁴
우리는 각 워커 간에 기존 토큰 표현을 재사용하고자 한다. 문제는 워커·스텝마다 위치가 달라지므로 위치 임베딩(positional embedding)을 보정해야 한다는 점이다. 현대 LLM은 대개 RoPE(Rotary Position Embeddings) (Su et al., 2021)을 사용한다. RoPE에서는 각 key와 query 벡터를 절대 위치에 비례한 각도로 회전시킨다. 선행 연구는 RoPE 임베딩을 스케일링(scaling) (Peng et al., 2023), 슬라이싱(slicing) (Xiao et al., 2024), 프루닝(pruning) (Zhang et al., 2023)으로 조작할 수 있음을 보였다. RoPE의 매우 유용한 성질은 평행 이동(parallel shift)에 불변이라는 점이다. 즉 query와 key를 같은 각도로 회전시키면 두 벡터의 내적(dot product)이 변하지 않는다.
Hogwild! 추론에서는 이 성질을 이용해 KV 블록 전체를 해당 위치에 맞춰 회전한다. 그림 1(오른쪽)처럼 동일한 캐시 블록이 워커마다 다른 순서로 배열되지만, 블록 내부 토큰 간 상대 각도는 그대로 유지된다. 결과적으로 Alice의 마지막 토큰과 그 이전 토큰들 사이의 어텐션 점수는 변하지 않으면서도, Alice는 Bob의 토큰에도 즉시 어텐션을 줄 수 있고 Bob도 마찬가지다.
새 토큰을 생성할 때 우리는 모든 워커를 하나의 배치(batch)처럼 병렬로 전방 패스(forward pass)한다. 새로 생성된 토큰은 각자의 캐시 블록 끝에 KV 표현을 삽입한 뒤, 워커별로 블록을 재배열한다. 이렇게 하면 모델의 모든 층을 통과하기 전에도 워커들이 서로의 최신 토큰에 곧바로 어텐션할 수 있다. 캐시 재배열은 워커마다 메모리를 소모하므로, 우리는 필요한 어텐션 층 하나씩 재배열된 KV 캐시를 지연‑생성(just‑in‑time)한다.
³ 설명의 명료성을 위해 두 병렬 에이전트에 인명 대명사를 부여했다.
⁴ 만약 워커가 n 개이고 각 워커가 새 토큰을 하나씩 생성한 후, 이를 각 워커에 대해 다른 위치로 다시 인코딩해야 하며, 각 워커가 O(n) 개의 추가 토큰에 어텐션해야 한다면, 한 스텝의 총 계산 복잡도는 O(n³)이다.

그림 2: 3.2절에서 설명한 세 가지 캐시 레이아웃. 왼쪽부터 (i) 스텝 단위 동기화(step‑wise synchrony)가 있는 인터리브드(interleaved), (ii) 단순 연속(contiguous) 레이아웃, (iii) 토큰 단위 동기화(token‑wise synchrony)가 있는 혼합(combined) 레이아웃. 모두 Alice 관점에서 표시하였다.
3.2 캐시 레이아웃(Cache Layouts)
앞 절에서 캐시를 여러 블록(block)으로 나눈 뒤 실시간으로 재배열할 수 있음을 살펴보았다. 그렇다면 블록을 어떻게 배치하는 것이 가장 좋을까? 본 예비 연구에서는 그림 2에 제시된 세 가지 레이아웃을 비교한다.
① 연속 레이아웃 (Contiguous layout, token‑wise)
가장 단순한 형태로, 각 워커가 자신만의 토큰 시퀀스 뒤에 새 토큰을 덧붙이고, 다른 워커의 토큰 표현을 과거의 key‑value로 본다. Google Docs나 Overleaf 같은 협업 문서 편집기에서 영감을 받은 구조다.
Section 3.1에서 설명했듯, 워커마다 다른 순서로 캐시를 배열한다. 공통 프롬프트 캐시 → 다른 모든 워커의 캐시 → 자신의 캐시 순으로 본다. 이렇게 하면 각 워커는 자신의 캐시 뒤에 올 다음 토큰을 예측하게 된다.
<sup>5</sup> 워커가 2명보다 많을 때도 동일하다. 예를 들어 A, B, C 세 워커가 있을 때, B는 프롬프트와 A·C의 출력, 마지막으로 자신의 메모리를 본다. A 역시 B·C, 그다음 A 자신의 메모리를 본다.
② 교차 레이아웃 (Interleaved layout, step‑wise)
Slack이나 Discord 같은 그룹 채팅과 유사하다. 워커는 먼저 개인 영역에서 토큰을 생성하다가 추론 스텝(reasoning step)을 마치면 결과를 공유 히스토리(shared history)에 추가한다. 히스토리는 각 워커가 완료한 순서대로 스텝을 기록한다.
<sup>6</sup> 본 연구에서는 “완결된 문장(마침표·물음표 등으로 끝남) 뒤에 두 줄 개행 \n\n”을 한 스텝으로 정의했지만, 모델에 따라 달라질 수 있다.
워커들은 토큰마다 동기화하지 않고, 완료된 스텝 단위로만 서로의 출력을 본다. 그렇다고 상대를 기다리지는 않는다. 각 워커는 토큰을 계속 생성하며, 때때로 캐시에 삽입된 새 key‑value를 받아들인다.
③ 결합 레이아웃 (Combined layout, token‑wise)
앞의 두 방식을 혼합한 형태다. 워커들은 교차 레이아웃처럼 스텝을 쌓아 공유 히스토리를 만들지만, 스텝을 비공개로 작성하지 않고 실시간으로 서로의 진행 상황을 확인한다는 점이 연속 레이아웃과 같다.
연속 레이아웃은 공유 히스토리가 없고, 교차 레이아웃은 즉각적 동기화가 없는 부분 제거(ablated) 버전으로 볼 수 있다. Section 4에서는 세 레이아웃을 실험적으로 비교해 각 설계 요소가 성능에 미치는 영향을 정량화한다.
3.3 협업을 유도하는 프롬프트 (Prompting to Collaborate)
앞서 설명한 공유 Key‑Value 캐시 추론(shared key‑value cache inference)을 통해 현대 LLM들은 서로의 토큰에 접근하며 협력적 추론(collaborative reasoning)을 수행할 수 있다. 그러나 LLM이 실제로 협업하도록 유도(prompt)하지 않으면, 그런 능력이 있어도 자동으로 발휘되지는 않는다. 원하는 LLM 행동을 끌어내는 방법은 두 가지가 있다.
- 협업적으로 토큰을 생성하도록 모델을 학습시키거나,
- 문맥 내 프롬프트(in‑context prompting)로 유도하는 것이다.
본 연구에서는 후자를 택해 Hogwild! Inference를 새로운 모델·과제에도 쉽게 일반화할 수 있도록 했다.
우리의 프롬프트 전략은 세 부분으로 이뤄진다.
- 시스템 프롬프트(System prompt)
- 공유 캐시 레이아웃이 작동하는 “규칙”을 기술한다.
- 부분적 인컨텍스트 예시(Partial in‑context examples)
- 기본적인 인스턴스 간 협업(cross‑instance collaboration)을 보여 주는 발췌 예시를 제공한다. 예를 들어, 한 워커가 다른 워커의 최신 업데이트 때문에 수행 중인 작업이 중복(redundant)임을 인지하는 장면 등이다.
- s1‑형 협업 질문 삽입(s1‑like collaboration prompts)
- 몇 스텝마다 새 문단의 시작에 다음과 같은 질문을 삽입한다.
- “Wait, am I doing redundant work? (yes/no):”
- 이 전략은 Muennighoff et al.(2025)의 아이디어에서 착안했다.
이 마지막 s1‑형 프롬프트가 특히 흥미롭다. 사전 학습된 추론형 LLM은 종종 자신이 작성 중인 내용에 과도하게 집중해, 다른 인스턴스가 오류를 발견했거나 문제를 이미 해결했음을 눈치채지 못한다. 그러나 이렇게 직접 질문을 던지면, 중복 작업을 식별하고 접근 방식을 바꾸는 경우가 많다.
이 부분은 엔트로픽의 연구를 보면 당연한 것
종합하면, 위와 같이 프롬프트를 구성했을 때 LLM들은 꽤 높은 빈도(항상은 아님)로 자신이 중복 작업을 하고 있는지 감지하고, 최선의 행동 방침을 추론한다는 사실을 확인했다.
물론 이러한 프롬프트가 협업적 추론을 완벽히 이끌어내는 최적 방법은 아니다. 다만 합리적인 범위에서 효과가 있음을 Section 4에서 보인다. 향후 연구 과제로는 지도형 미세 조정(supervised fine‑tuning)이나 강화 학습(reinforcement learning) 등 다른 방법을 통해 협업 추론을 유도하는 방안이 있다. LLM들이 함께 추론할 수 있음을 확인했다면, 다음 목표는 일관성 있게 협업하도록 만드는 것이다.
4 초기 실험 (Initial Experiments)
본 장에서는 Hogwild! 추론(Hogwild! Inference)을 여러 조건에서 초기에 평가한다.
주요 평가는 QwQ‑32B 모델<sup>7</sup>을 사용하고, 다음 두 가지 실험 설정을 검토한다.
- 의사소통이 거의 필요 없는 단순 합성 과제(synthetic tasks),
- 더 복잡한 협업 패턴이 요구되는 도전적 추론 문제.
합성 과제에서의 정상 동작 확인 (Sanity checks with synthetic tasks)
복잡한 문제로 넘어가기 전에 Hogwild! 추론이 기본 협업을 수행할 수 있는지 확인한다.
이를 위해 GSM8k 테스트셋(Cobbe et al., 2021)에서 질문 5개를 추출해 한 샘플을 구성하고, 모델이 256 토큰 내에 해결할 수 있는 문제만 걸러냈다. 이렇게 준비한 100개 세트(각 3개 과제, 교집합 없음)에 대해 모델은 다음과 같이 프롬프트를 받는다<sup>8</sup>.
“다음 문제를 풀고 쉼표로 구분된 값 \boxed{answer1,…,answer5} 형태로 답을 반환하세요:
- {task1} … 5. {task5}”
모델이 한 세트에서 5개 중 4개를 맞히면 0.8로 채점한다.
본 sanity test에서는
- 순차적 생성(sequential generation)
- Hogwild! 추론 (+ combined layout, 워커 2 명 및 4 명)
을 비교한다. 모든 경우 전방 패스(forward pass) 횟수를 동일하게 맞추었다. 모델이 예산 내에 쉼표 구분 정답을 완전히 반환하면, 각 답의 정확도를 계산한다.
단, 예산이 빡빡하면 모델이 제때 답을 못 내놓을 수 있다. 부분 출력에서 답을 추출하기 위해, 모든 출력 뒤에 다음과 같은 특수 프롬프트<sup>9</sup>를 삽입해 조기 응답을 강제한다.
“\n\n시간이 부족하니 지금 바로 답을 줘야 합니다. 지금까지의 풀이를 고려할 때, 5개의 답은 \boxed{”
QwQ‑32B의 경우, 이미 계산한 답이 있으면 거의 항상 정확히 반환하며, 없을 때는 추측하거나 거부(unknown, n/a 등)한다. 이때는 병렬성을 끄고 탐욕적 디코딩(greedy decoding)으로 최대 32 토큰까지 답을 작성하게 했다. Hogwild! 추론 결과를 평가할 때는 모든 워커가 생성한 토큰<sup>10</sup>을 최종 모델이 볼 수 있게 했다.
결과 (Results)
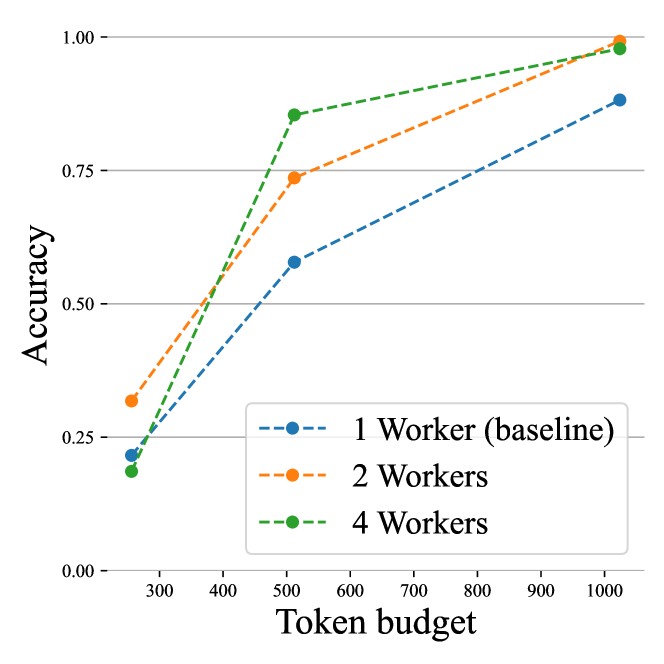
그림 3은 GSM8k 질문 5개로 구성된 합성 문제에서의 평가 결과를 보여 준다.
- Hogwild! 추론의 병렬 워커들은 실제로 협업할 수 있음을 확인했다.
- 생성 로그를 보면, 워커들은 보통 처음 몇 스텝 동안 작업 분할 방식을 “논의”한 뒤 각자 할당된 문제를 풀었다.
- 한 워커가 먼저 끝나고 남은 과제가 없으면 대부분 대기하거나 다른 워커의 풀이를 이중 확인(double‑check) 했다.
- 워커 4명 구성에서 256 토큰 예산을 줄 때 단일 워커보다 오히려 성능이 떨어졌는데, 이는 예산 대부분이 협의(coordination)에 소모되었기 때문이다.
- 반면 4 워커 + 넉넉한 토큰 예산에서는, 각 문제당 실제로 필요한 토큰 수가 256보다 훨씬 적은 경우가 많아 남는 자원을 맨 먼저 끝낸 워커가 다른 문제로 전환해 성능이 소폭 상승했다.
<sup>7</sup> https://huggingface.co/Qwen/QwQ‑32B
<sup>8</sup> 프롬프트 예시: “Solve these problems… \boxed{answer1,…,answer5}: …”
<sup>9</sup> 삽입 프롬프트: “Wait, given the limited time, I have to give an answer right now… \boxed{”
<sup>10</sup> 워커가 두 명일 경우 마지막 워커(Bob)의 관점과 동일.
LIMO 과제
다음으로는, 협업 패턴이 사전에 뚜렷하지 않은 보다 도전적인 문제 세트에서 Hogwild! 추론을 평가한다. 우리는 Ye et al.(2025)가 제안한 데이터셋을 사용했으며, 이 데이터셋은 신뢰할 만한 풀이를 위해 수천 토큰의 추론이 요구되는 수학 문제로 구성되어 있다. 앞선 합성 과제와 달리, 이 데이터셋의 문제들은 사전에 명확한 협업 전략이 존재하지 않는다. 그러나 LLM이 추론 사슬(chain‑of‑thought)을 시작하면, 병렬로 풀 수 있는 여러 경우(case)나 방정식이 나타나거나, 하나의 문제를 해결하기 위한 여러 전략이 동시에 떠오르는 상황을 자주 발견한다. 평가를 위해 원본 데이터셋에서 512개 샘플<sup>11</sup>을 선택했고(전체의 절반 조금 넘는 분량), 나머지는 개발용으로 사용했다.
여기서는 3.2절에서 소개한 세 가지 Hogwild! 캐시 레이아웃을 비교한다. 또한 다음 세 가지 기준선(baseline)도 평가했다.
- 기본 기준선: 주어진 토큰 예산만큼 추론을 수행한 뒤, 답을 \boxed{ } 안에 넣어 반환하도록 한 경우.
- 개선된 기준선: 만약 아직 정답을 출력하지 않았다면, “Wait, given limited time …”와 같은 프롬프트로 즉시 최종 답을 생성하도록 유도한 경우(위와 동일하되 “5 answers” → “the answer”, 최대 8 토큰).
- 순진한 병렬 전략: Wang et al.(2022)에서 영감을 얻은 방법으로, 두 워커가 의사소통 없이 각각 문제를 풀고, 같은 방식으로 정답을 추출하는 경우.
그 결과를 그림 4에 요약하였다. 어려운 과제임에도, 다수 워커가 참여한 Hogwild! 추론은 단일 스레드보다 더 빠르게 문제를 해결할 수 있었다. 스텝 단위(interleaved) 캐시와 토큰 단위 동기화(token‑wise synchrony)가 모두 품질 향상에 기여하는 것으로 보인다. 공유 히스토리가 없는 연속(contiguous) 레이아웃은 작은 예산에서는 잘 작동하지만, 토큰 수가 많아지면 효율이 떨어졌다. 워커가 수천 토큰을 생성하면 다른 어시스턴트의 행위를 파악하고 대응하기 어려워지기 때문일 수 있다. 반대로 즉각적 동기화가 없는 인터리브드 레이아웃은 작은 예산에서는 성능이 낮지만, 더 많은 토큰을 허용하면 따라잡았다. 스텝 단위 동기화 없이 협업 전략이 수렴하려면 “시간”이 더 필요하기 때문으로 추정된다. Hogwild! 추론의 생성 과정을 보여 주는 예시는 부록 A에, 예산별 세부 정확도는 부록 B에 제시하였다.
다만 이는 예비 실험에 불과하므로, 여러 중요한 질문이 남아 있다. 예를 들어 프롬프트 전략의 영향은 어떠한가? Hogwild! 추론이 다른 문제 유형(프로그래밍, 함수 호출 등)에도 효과적인가? 문제에 대한 모델의 추론 능력과 협업 능력 간 상관관계는? 지도형 미세 조정(supervised fine‑tuning)이나 강화 학습(reinforcement learning)으로 협업 성능을 더 높일 수 있을까? 이러한 부분은 향후 연구 과제로 남겨 둔다.
<sup>11</sup> 우리는 원본 LIMO 데이터셋 (https://huggingface.co/datasets/GAIR/LIMO)에서 512개 샘플을 사용했으며, 나머지는 개발용으로 활용하였다.

그림 4: 512개의 LIMO 과제 평가 결과. 가로의 검은 실선은 16 384 토큰 예산으로 단일 스레드 추론을 수행했을 때의 정확도(89.65 %)를 나타낸다. 더 많은 예산에 대한 결과는 부록 B(그림 5) 참조.
5 논의 (Discussion)
본 작업 논문에서는 고급 추론 LLM이 프롬프트에 따라 과제 해결 과정에서 병렬성(parallelism)을 구현할 수 있는지를 조사하였다. 놀랍게도, 몇 개의 few‑shot 예시만으로도 특수한 미세 조정(fine‑tuning) 없이 병렬 협업이 가능함을 확인했다. 개별 “병렬” LLM 스레드는 명시적으로 서로를 조율하며, 상대의 부분 진행 상황을 활용해 해답을 도출할 수 있었다. 나아가, 우리가 제안한 Hogwild! Inference 프로토타입은 여러 추론 스레드가 공유 어텐션 캐시(attention cache)를 동시에 읽고 쓸 수 있게 한다. 회전 위치 임베딩(Rotary Position Embeddings, RoPE)을 활용하여 오버헤드를 최소화하면서 하드웨어 활용도를 높인 것이 특징이다.
앞으로는 어텐션 동시성 메커니즘(attention concurrency mechanisms)의 정확도–병렬성(trade‑off)을 면밀히 분석하고, 지도형 미세 조정(supervised fine‑tuning)이 과제 병렬화에 미치는 영향을 검토할 예정이다. 또한 Hogwild! Inference의 효과는 과제 유형별로 달라질 수 있으므로, 과제 의존적 성능(task‑dependent performance)을 세부적으로 분석할 필요가 있다. 예컨대, 자연스럽게 독립·준독립 하위 과제로 분해되는 추론 문제는 큰 이점을 얻을 수 있지만, 엄격한 순차 논리(strict sequential logic)가 필요한 과제는 병렬화 이득이 작을 수 있다. 더불어 병렬 추론은 스레드 간 미묘한 타이밍 상호작용으로 인해 비결정성(non‑determinism)을 초래할 수 있다. 향후 연구에서는 사전 추론(speculative decoding; Leviathan et al., 2023), Medusa (Cai et al., 2024), EAGLE (Li et al., 2024b) 등 병렬 토큰 생성 기법과의 연계 가능성도 탐색하고자 한다.
감사의 말씀
초기 브레인스토밍과 유익한 제안, 향후 연구 방향 제시에 도움을 준 Vladimir Malinovskii께 깊이 감사드린다. 또한 원고 교정에 도움을 준 Philip Zmushko에게도 감사의 뜻을 전한다.
'인공지능' 카테고리의 다른 글
| BitNet b1.58 2B4T Technical Report (3) | 2025.04.24 |
|---|---|
| Gaussian Mixture Flow Matching Models (4) | 2025.04.22 |
| DEIM: DETR with Improved Matching for Fast Convergence (2) | 2025.04.17 |
| EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention (2) | 2025.04.16 |
| EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction (3) | 2025.04.14 |



