https://github.com/ShihuaHuang95/DEIM
GitHub - ShihuaHuang95/DEIM: [CVPR 2025] DEIM: DETR with Improved Matching for Fast Convergence
[CVPR 2025] DEIM: DETR with Improved Matching for Fast Convergence - ShihuaHuang95/DEIM
github.com
초록(Abstract)
우리는 실시간 객체 탐지를 위한 Transformer 기반 아키텍처(DETR)의 수렴 속도를 가속화하기 위해 고안된 혁신적이고 효율적인 학습 프레임워크 DEIM을 소개한다. DETR 모델의 1:1 매칭(one‑to‑one, O2O)에서 발생하는 희소(supervision) 문제를 완화하기 위해, DEIM은 Dense O2O 매칭(Dense O2O matching) 전략을 채택한다. 이 방법은 표준 데이터 증강 기법을 활용해 추가 목표(타깃)를 도입함으로써 이미지당 양성(positive) 샘플의 수를 늘린다. Dense O2O 매칭은 수렴을 가속하지만, 동시에 성능에 악영향을 줄 수 있는 다수의 저품질 매칭을 유발하기도 한다. 이를 해결하기 위해 우리는 다양한 품질 수준의 매칭을 최적화하도록 설계된 새로운 손실 함수 MAL(Matchability‑Aware Loss)을 제안한다.
COCO 데이터셋에서 수행한 광범위한 실험 결과, DEIM의 효용성이 입증되었다. RT‑DETR 및 D‑FINE과 결합할 경우, 학습 시간을 50 % 줄이면서도 일관되게 성능을 향상시킨다. 특히 RT‑DETRv2와 함께 사용할 때, NVIDIA 4090 GPU에서 단 하루 학습만으로 53.2 % AP를 달성하였다. 또한 DEIM으로 학습한 실시간 모델들은 최신(real‑time) 객체 탐지기들을 능가했으며, DEIM‑D‑FINE‑L과 DEIM‑D‑FINE‑X는 추가 데이터 없이도 NVIDIA T4 GPU에서 각각 124 FPS에서 54.7 % AP, 78 FPS에서 56.5 % AP를 기록했다. 우리는 DEIM이 실시간 객체 탐지 분야의 새로운 기준(baseline)을 제시한다고 믿는다. 코드와 사전 학습 모델은 https://www.shihuahuang.cn/DEIM/에서 공개되어 있다.
(a) 더 빠르게: 학습이 계산 자원(연산량) 대비 효율적임
(b) 더 우수하게: 평균 정밀도(AP)와 지연(latency) 면에서 모든 실시간 탐지기를 능가
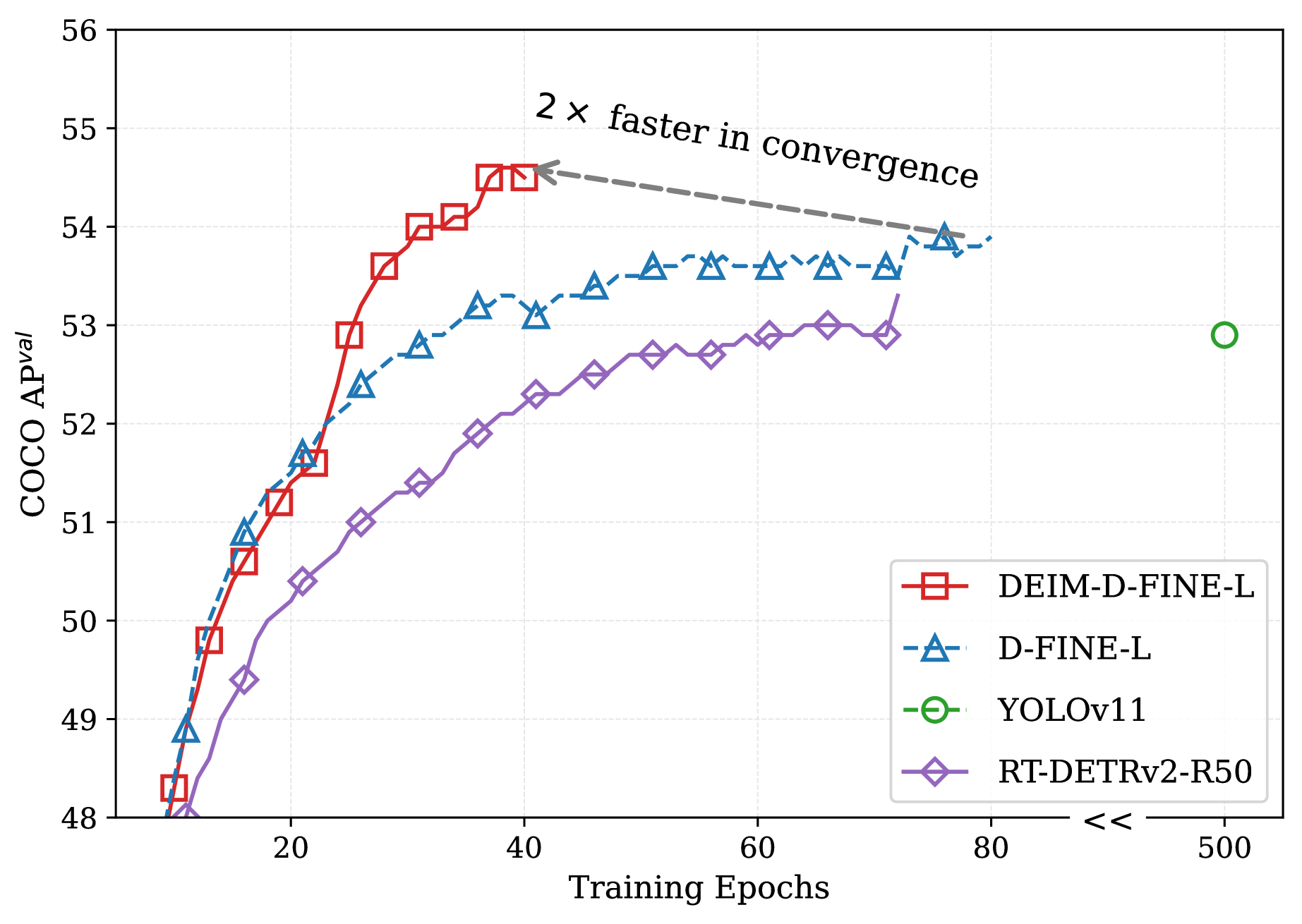
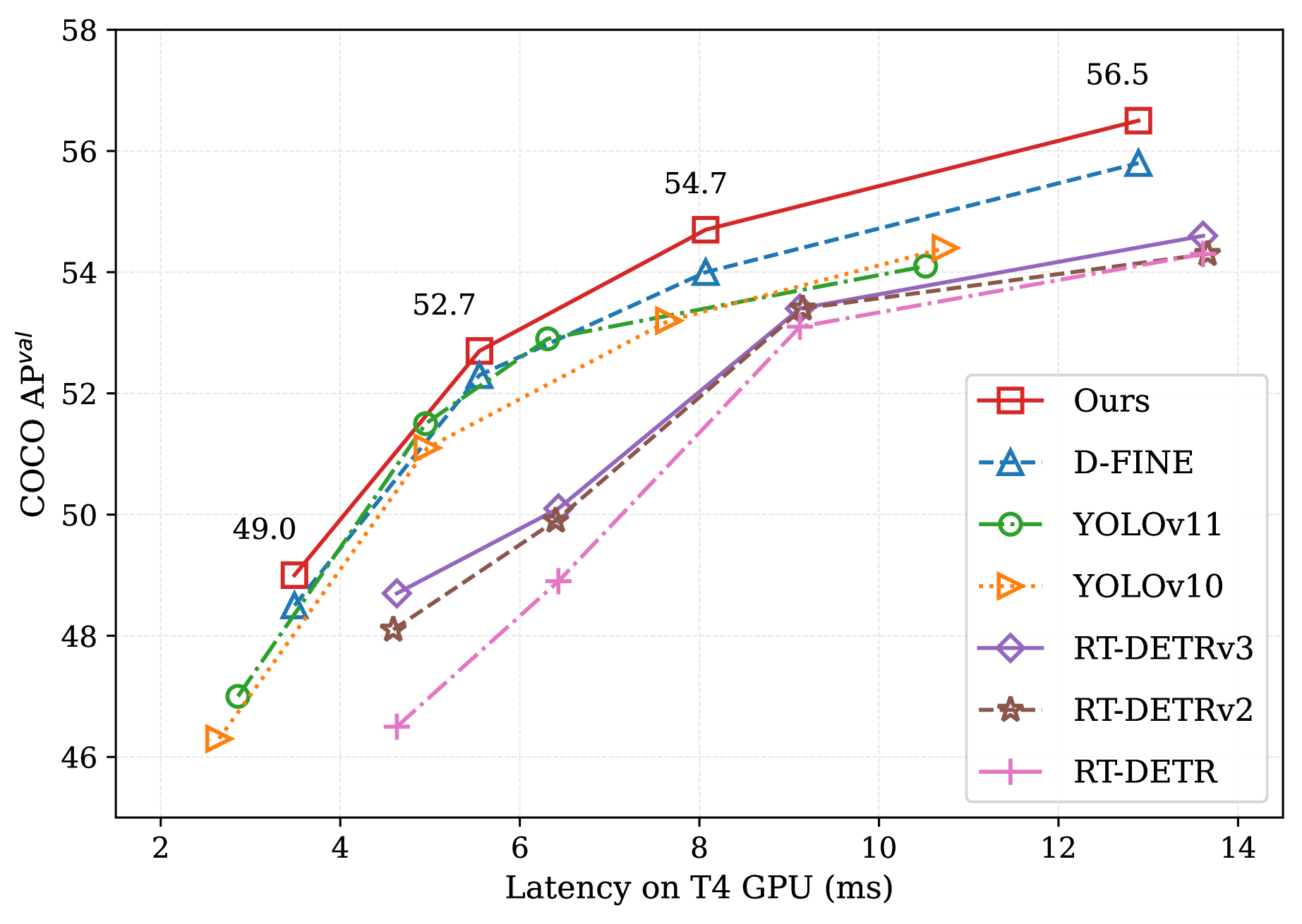
그림 0 | COCO 데이터셋에서 최첨단 실시간 객체 탐지기들과의 비교
1 서론 (Introduction)
객체 탐지(Object Detection)는 컴퓨터 비전의 기본 과제로, 자율주행 [6, 5], 로봇 내비게이션 [9] 등 다양한 분야에 널리 활용된다. 고효율 탐지기에 대한 수요가 증가하면서 실시간(real‑time) 탐지 방법이 급속히 발전해 왔다. 그중에서도 YOLO (You Only Look Once)는 지연(latency)과 정확도(accuracy)의 뛰어난 균형 [34, 32, 44, 1, 28] 덕분에 실시간 객체 탐지의 핵심 패러다임으로 부상했다.
YOLO 모델은 컨볼루션 신경망(Convolutional Neural Network, CNN)을 기반으로 한 원‑스테이지(one‑stage) 탐지기로 잘 알려져 있으며, 시리즈 전반 [28, 1, 44, 34]에서 원‑투‑매니(one‑to‑many, O2M) 할당 전략을 채택한다. 즉, 하나의 타깃 박스(target box)가 여러 앵커(anchor)에 매칭되는데, 이 전략은 조밀한(supervision) 학습 신호를 제공해 수렴 속도를 높이고 성능을 향상시키는 것으로 입증되었다 [44]. 그러나 객체마다 중첩되는 바운딩 박스가 다수 생성되므로, 중복을 제거하기 위해 수작업으로 설계된 비최대 억제(Non‑Maximum Suppression, NMS)가 필요하며, 이는 추가적인 지연과 불안정성을 야기한다 [43, 32].
Transformer 기반 탐지(DETR) 패러다임 [3]의 등장은 멀티‑헤드 어텐션(multi‑head attention)을 통해 전역 문맥(global context)을 포착함으로써 위치 추정과 분류 성능을 향상시키며 큰 주목을 받았다 [4, 39, 46]. DETR은 학습 과정에서 헝가리(Hungarian) 알고리즘 [16]을 이용해 예측 박스와 GT 객체를 1 : 1로 매칭하는 원‑투‑원(one‑to‑one, O2O) 전략을 채용하여, 후처리 단계인 비최대 억제(Non‑Maximum Suppression, NMS)가 필요 없다. 이러한 엔드‑투‑엔드(end‑to‑end) 구조는 실시간 객체 탐지를 위한 매력적인 대안을 제시한다.
그러나 느린 수렴은 여전히 DETR의 주요 한계이며, 그 이유는 두 가지로 추정된다.
❶ 희소한 감독(Sparse supervision) : O2O 매칭은 타깃당 양성 샘플이 단 하나뿐이어서 양성 샘플 수가 극히 제한된다. 반면 O2M은 수 배 많은 양성 샘플을 제공한다. 특히 작은 객체에서는 조밀한 감독이 성능에 필수적이므로, 양성 샘플 부족은 효과적인 학습을 저해한다.
❷ 저품질 매칭(Low‑quality matches) : 전통적인 탐지기가 보통 8,000개 이상의 조밀한 앵커를 사용하는 것과 달리, DETR은 무작위로 초기화된 100 ~ 300개의 쿼리(query)만 활용한다. 이들 쿼리는 타깃과 공간적으로 정렬되어 있지 않기 때문에, 학습 과정에서 IoU는 낮지만 신뢰도(confidence)는 높은 저품질 매칭이 다수 발생하게 된다.
감독 신호의 부족을 해소하기 위해, 최근 DETR 관련 연구들은 O2O 매칭의 제약을 완화하고 O2M 할당을 보조적으로 도입하여 타깃당 추가 양성 샘플(auxiliary positive samples)을 생성하였다. 예를 들어 Group DETR [4]는 여러 쿼리 그룹을 두어 각 그룹마다 독립적으로 O2O 매칭을 수행하고, Co‑DETR [46]는 Faster R‑CNN [29]·FCOS [31] 같은 O2M 방법을 결합한다. 이러한 방식은 양성 샘플 수를 늘리는 데에는 성공했지만, 추가 디코더가 필요해 계산량이 증가하고, 전통 탐지기와 유사하게 중복된 고품질 예측이 발생할 위험이 있다.
이에 비해 우리는 Dense O2O 매칭이라는 간단하면서도 새로운 접근을 제안한다. 핵심 아이디어는 훈련 이미지 내 타깃 수를 늘려 학습 과정에서 자연스럽게 더 많은 양성 샘플을 얻는 것이다. 이는 mosaic [1]·mixup [38]과 같은 고전적인 증강 기법만으로도 쉽게 구현 가능하며, 1 : 1 매칭 구조를 그대로 유지하면서 이미지당 양성 샘플을 추가로 생성한다. 결과적으로 Dense O2O는 O2M에 필적하는 감독 수준을 제공하면서도, O2M 방식이 수반하는 복잡성과 오버헤드는 피할 수 있다.
또한 쿼리 초기화를 개선하기 위해 priors를 활용한 연구들 [45, 18, 39, 43]이 있었지만, 이들은 인코더에서 추출한 제한적 특징 정보에 의존해 쿼리가 소수의 두드러진 객체 주변에만 밀집되는 경향이 있다. 그 결과, 눈에 덜 띄는(non‑salient) 객체 주변에는 쿼리가 부족해 저품질 매칭이 발생한다. Dense O2O를 사용할 때 이 문제는 더욱 두드러진다. 타깃 수가 늘어날수록 두드러진 객체와 그렇지 않은 객체 간의 격차가 커져, 매칭 총량은 증가해도 저품질 매칭 비율이 상승하기 때문이다. 손실 함수가 이러한 저품질 매칭을 충분히 처리하지 못하면, 성능 향상에 걸림돌이 될 수 있다.
기존 DETR에서 사용되는 손실 함수 [19, 40]—대표적으로 Varifocal Loss( VFL ) [40]—는 저품질 매칭이 상대적으로 적은 조밀한 앵커(dense anchor) 환경에 맞춰 설계되었다. 이러한 함수들은 주로 고품질 매칭, 특히 IoU는 높지만 신뢰도(confidence)가 낮은 경우를 강하게 페널티하고, 저품질 매칭은 거의 무시한다. 저품질 매칭 문제를 해결하고 Dense O2O를 더욱 향상시키기 위해 우리는 Matchability‑Aware Loss( MAL , 매치어빌리티 기반 손실)를 제안한다. MAL은 매칭된 쿼리와 타깃 간의 IoU와 분류 신뢰도를 함께 반영해 매치어빌리티(matchability)에 따라 페널티를 조정한다. 따라서 고품질 매칭에 대해서는 VFL과 유사하게 동작하지만, 저품질 매칭에는 더 큰 가중치를 부여하여 제한된 양성 샘플의 효용을 높여 준다. 또한 MAL은 VFL보다 수식이 간결하다.
제안한 DEIM은 Dense O2O와 MAL을 결합해 효과적인 학습 프레임워크를 구성한다. COCO [20] 데이터셋에서 광범위한 실험을 수행한 결과(그림 0) DEIM은 RT‑DETRv2 [24]와 D‑FINE [27]의 수렴을 크게 가속하면서 성능도 향상시켰다. 구체적으로, 절반의 학습 에포크만으로 RT‑DETRv2보다 +0.2 AP, D‑FINE보다 +0.6 AP를 기록했다. 또한 단일 4090 GPU로 ResNet‑50 기반 DETR을 약 24 에포크(하루 이내) 학습해 53.2 % mAP를 달성할 수 있었다. 더 효율적인 모델을 통합함으로써, 우리는 최신 YOLOv11 [13]을 포함한 기존 실시간 탐지기를 능가하는 새로운 실시간 탐지기 세트를 제시하여, 실시간 객체 탐지 분야의 새로운 SoTA(state‑of‑the‑art)를 수립하였다(그림 0(b)).

그림 1 | 제안하는 DEIM 개념도. 노란색, 빨간색, 초록색 박스는 각각 GT(Ground Truth), 양성(positive) 샘플, 음성(negative) 샘플을 나타낸다. ‘pos.’는 양성 샘플을 의미한다. 위: 우리 방법인 Dense O2O(그림 1(c))는 O2M(그림 1(a))과 동등한 품질의 양성 샘플을 제공한다. 아래: 저품질 매칭의 경우, VFL [40]과 MAL을 사용했을 때의 손실 값이 ★로 표시되어 있으며, MAL이 이러한 사례를 더 효과적으로 최적화함을 보여 준다.
본 연구의 주요 기여
• DEIM: 실시간 객체 탐지를 위한 간단하고 유연한 학습 프레임워크를 제안한다.
• 수렴 가속: Dense O2O로 매칭 양(quantity)을, MAL로 매칭 질(quality)을 향상시켜 학습 수렴 속도를 크게 높인다.
• 새로운 SoTA: 제안 방법을 적용한 기존 실시간 DETR 모델들은 학습 비용을 절반으로 줄이면서도 성능이 향상된다. 특히 D‑FINE의 효율적 모델들과 결합할 때 YOLO 계열을 넘어서는 실시간 객체 탐지의 새로운 State‑of‑the‑Art를 달성한다.
2 관련 연구 (Related Work)
Transformer 기반 객체 탐지(DETR) [3]는 전통적인 CNN 아키텍처에서 Transformer로의 전환을 보여준다. DETR는 1 : 1 매칭을 위해 헝가리(Hungarian) 알고리즘 [16]을 사용함으로써, 후처리 단계의 수작업 비최대 억제(NMS)가 필요 없으며 엔드‑투‑엔드 객체 탐지가 가능하다. 하지만 느린 수렴과 높은 연산량이라는 한계를 지닌다.
양성(Positive) 샘플 수 늘리기
원‑투‑원(O2O) 매칭에서는 각 타깃이 하나의 양성 샘플만 갖기 때문에, 원‑투‑매니(O2M)에 비해 감독(supervision)이 크게 부족해 최적화를 방해한다. 이를 보완하기 위해 O2O 틀 안에서 감독을 늘리는 여러 방법이 연구되었다. 예를 들어 Group DETR [4]는 “그룹(groups)” 개념을 도입해 O2M을 근사한다. 쿼리를 K (> 1)개 그룹으로 나누고, 각 그룹 내부에서 독립적으로 O2O 매칭을 수행해 타깃마다 K개의 양성 샘플을 할당한다. 단, 그룹 간 정보 교류를 막기 위해 그룹마다 별도의 디코더 층이 필요하므로 최종적으로 K개의 병렬 디코더가 생긴다. H‑DETR [15]의 하이브리드 매칭 방식도 Group DETR와 유사하다. Co‑DETR [46]는 원‑투‑매니 할당이 모델이 더 구별력 있는 특징을 학습하도록 돕는다는 점을 밝혀, Faster R‑CNN [29]·FCOS [31]처럼 O2M 라벨을 갖는 보조 헤드(auxiliary head)를 통해 인코더 표현을 강화하는 협업적 하이브리드 할당을 제안했다. 이들 기존 방법은 모두 타깃당 양성 샘플 수를 늘려 감독을 강화하려 한다. 반면, 우리의 Dense O2O는 이미지당 타깃 수 자체를 늘려 감독을 효과적으로 높이는 다른 방향을 탐구한다. 추가 디코더나 헤드가 필요 없어 학습 자원 소모가 증가하지 않는 연산 부담이 없는(computation‑free) 접근이다.
저품질 매칭 (optimizing low‑quality matches) 최적화
무작위로 초기화된 희소 쿼리(query)는 타깃과 공간적으로 정렬되지 않아 저품질 매칭(low‑quality matches) 비율이 높아지고, 이는 모델 수렴을 저해한다. 이를 완화하기 위해 다양한 방법이 쿼리 초기화 단계에 사전 지식(prior)을 도입했다. 예를 들어 Anchor Queries [35], DAB‑DETR [21], DN‑DETR [18], Dense Distinct Queries [41] 등이 있다. 최근에는 2‑스테이지(two‑stage) 탐지기 [29, 45]에서 영감을 받아, DINO [39]와 RT‑DETR [43]가 인코더의 조밀한 출력에서 상위 랭크(top‑ranked)의 예측을 추출해 디코더 쿼리를 정제(refine)하는 방식을 활용한다 [36]. 이러한 전략은 타깃 영역에 더 가까운 효과적인 쿼리 초기화를 가능하게 한다.
그럼에도 저품질 매칭은 여전히 큰 도전 과제다 [22]. RT‑DETR [43]는 Varifocal Loss(VFL)를 사용해 분류 신뢰도(classification confidence)와 박스 품질(box quality) 간 불확실성을 줄여 실시간 성능을 향상시켰다. 그러나 VFL은 저품질 매칭이 상대적으로 적은 전통적 탐지기를 위해 설계되어 고 IoU 최적화에 집중하며, 낮은 IoU의 매칭은 손실 값이 작고 평평해 충분히 최적화되지 못한다. 이러한 고급 초기화 기법을 기반으로, 우리는 Matchability‑Aware Loss(MAL)를 도입해 품질 수준이 서로 다른 매칭을 효과적으로 최적화함으로써 Dense O2O 매칭의 효율을 크게 향상시킨다.
연산 비용 감소 (Reducing computation cost)
표준 어텐션 메커니즘은 연산 밀도가 높다. 효율을 높이고 다중 스케일 특징 간 상호작용을 촉진하기 위해 변형 어텐션(deformable attention) [45], 다중 스케일 변형 어텐션(multi‑scale deformable attention) [42], 동적 어텐션(dynamic attention) [7], 계단식 윈도우 어텐션(cascade window attention) [37] 등 고급 어텐션 기법이 제안되었다.
최근에는 더 효율적인 인코더(encoder) 설계에도 관심이 집중되고 있다. 예를 들어 Lite DETR [17]는 고수준(high‑level)과 저수준(low‑level) 특징을 교차로 업데이트하는 인코더 블록을 도입했으며, RT‑DETR [43]는 CNN과 자기 어텐션(self‑attention)을 결합한 하이브리드 인코더를 사용해 자원 소비를 크게 줄였다. RT‑DETR는 DETR 계열 최초의 실시간 객체 탐지 모델이기도 하다.
이 하이브리드 인코더를 기반으로 D‑FINE [27]는 추가 모듈을 통해 RT‑DETR를 한층 최적화하고, 고정 좌표를 예측하는 대신 확률 분포를 반복적으로 갱신(iterative distribution refinement)하여 회귀(regression)를 개선했다. 그 결과 D‑FINE은 지연(latency)과 성능(performance)의 균형에서 최신 YOLO 모델을 소폭 앞선다.
실시간 DETR에서 이 같은 발전을 활용한 우리의 방법은 학습 비용을 줄이면서도 실시간 객체 탐지에서 YOLO 계열 모델을 큰 폭으로 능가하는 인상적인 성능을 달성하였다.
3 방법 (Method)
3.1 사전 지식 (Preliminaries)
O2M vs. O2O
전통적 객체 탐지기에서는 O2M(one‑to‑many) 할당 전략 [44, 10]이 널리 쓰이며, 그 감독 (supervision)은 다음과 같이 표현된다.

Focal Loss
Focal loss(FL) [19]는 훈련 과정에서 쉬운 음성(negative) 샘플이 탐지기를 압도하지 못하도록 하여, 어려운(hard) 샘플에 더 집중하도록 고안된 손실 함수이다. DETR류 [45, 39]에서 기본 분류 손실로 사용되며, 다음과 같이 정의된다.

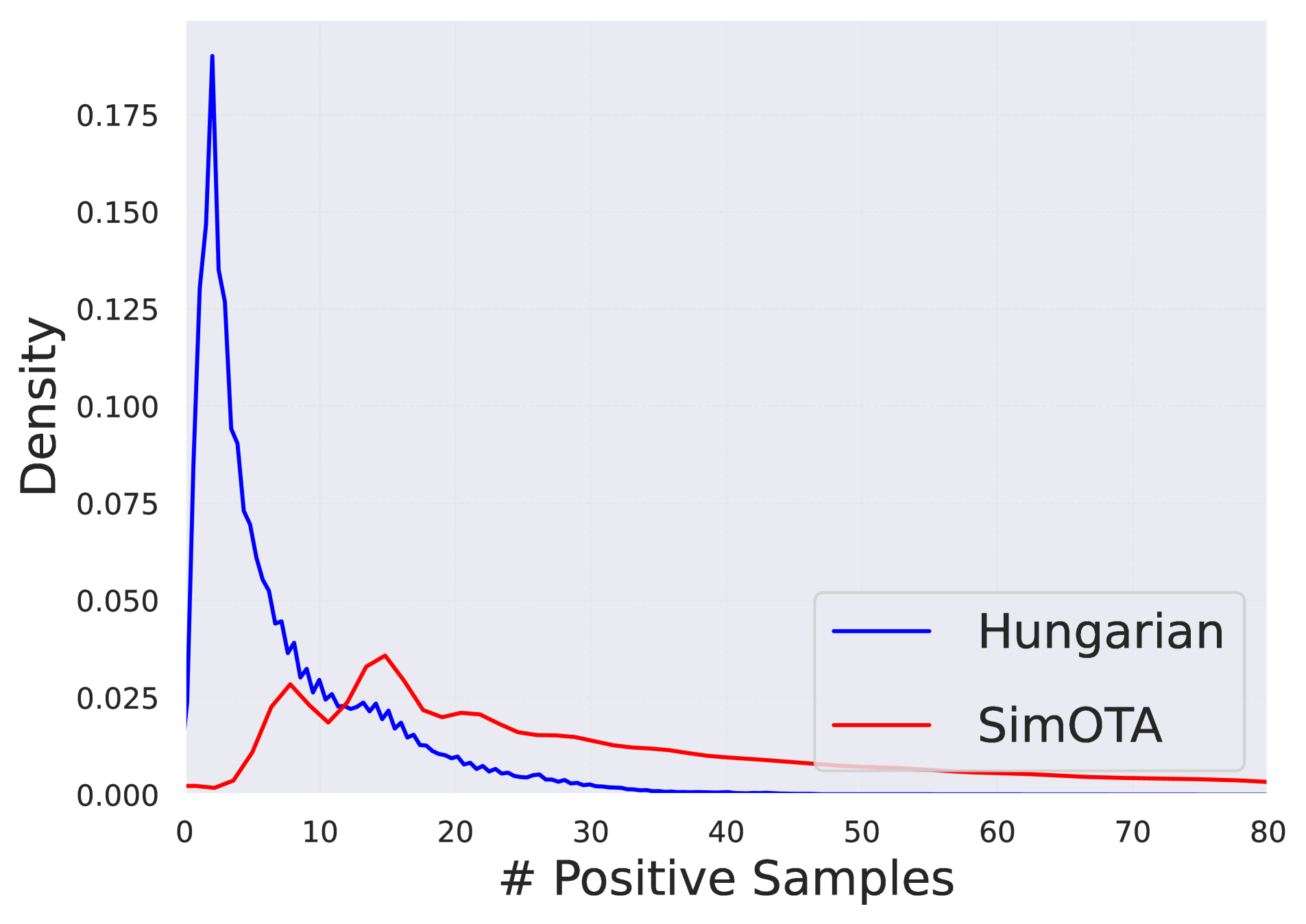
(a) 매칭 분포
(b) O2M과 O2O의 비율
그림 2 | 앵커/쿼리 매칭 비교
SimOTA [44]의 원‑투‑매니(one‑to‑many) 매칭과 Hungarian [3]의 원‑투‑원(one‑to‑one) 매칭 방식을 사용해, COCO 데이터셋 1 에포크 동안 이미지당 매칭된 앵커/쿼리 개수를 비교한 결과.
3.2 매칭 효율 향상: Dense O2O
DETR 계열 모델에서 일반적으로 사용되는 원‑투‑원(O2O) 매칭은 각 타깃(target)을 하나의 예측 쿼리(query)에만 대응시킨다. 이는 헝가리(Hungarian) 알고리즘 [16]으로 구현되어 NMS가 필요 없는 엔드‑투‑엔드 학습이 가능하지만, SimOTA [44]와 같은 전통적 원‑투‑매니(O2M) 방식에 비해 양성(positive) 샘플 수가 현저히 적다는 한계가 있다. 양성 샘플이 부족하면 감독(supervision)이 희소해져 학습 수렴이 느려질 수 있다.
이 문제를 구체적으로 파악하기 위해, 우리는 RT‑DETRv2 [24]를 ResNet‑50 백본과 함께 MS COCO 데이터셋 [20]에서 학습시켰다. 그리고 O2O(Hungarian)와 O2M(SimOTA) 전략이 생성하는 양성 매칭 수를 비교하였다. 그림 2(a)에서 보듯, O2O는 이미지당 양성 매칭이 10개 미만으로 날카롭게 집중된 반면, O2M은 80개를 넘기도 하는 훨씬 넓은 분포를 보인다. 그림 2(b)는 SimOTA가 극단적인 경우 O2O보다 약 10배 많은 매칭을 생성함을 강조한다. 이는 O2O가 양성 매칭이 부족해 최적화 속도가 느려질 수 있음을 시사한다.
이를 해결하기 위해 Dense O2O를 제안한다. 이 전략은 매칭 구조는 그대로(O2O, 즉 M_i=1) 유지하면서, 이미지당 타깃 수 N를 늘려 감독을 조밀하게 한다. 예를 들어 그림 1(c)처럼 원본 이미지를 네 구역으로 복제해 하나의 합성 이미지로 결합하되, 최종 해상도는 그대로 유지한다. 이렇게 하면 타깃 수가 1개에서 4개로 늘어나 식 (1)의 감독 강도가 높아지면서도 매칭 구조는 변하지 않는다. Dense O2O는 O2M 수준의 감독을 제공하면서도 추가적인 복잡도나 연산 오버헤드가 거의 없다.
3.3 매칭 품질 향상: Matchability‑Aware Loss
VFL의 한계
VariFocal Loss(VFL) [40]는 Focal Loss(FL) [19]를 기반으로 하여 DETR 모델 [43, 24, 2]에서 객체 탐지 성능을 개선하는 것으로 알려져 있다. VFL은 다음과 같이 정의된다.

전경 샘플(q>0)의 타깃 레이블은 q로 설정되고, 배경 샘플(q=0)은 0으로 설정된다. DETR [43]에서는 IoU를 손실에 포함시켜 쿼리 품질을 개선한다.
그러나 VFL은 저품질 매칭(low‑quality matches) 최적화에서 두 가지 한계를 지닌다.
- 저품질 매칭: VFL은 주로 고품질 매칭(high IoU)에 집중한다. 저 IoU 매칭에서는 손실 값이 매우 작아 모델이 해당 박스를 충분히 개선하지 못한다(그림 1(d)의 예시와, 그림 1(e)에서 ★로 표시된 손실 값 참조).
- 음성 샘플 처리: VFL은 겹침이 전혀 없는 매칭을 음성(negative) 샘플로 간주해 양성 샘플 수를 줄이므로, 효과적인 학습이 제한된다.
전통적인 탐지기는 조밀한 앵커와 O2M 할당 덕분에 이러한 문제가 크지 않지만, 쿼리가 희소하고 매칭이 엄격한 DETR 프레임워크에서는 위 한계가 더욱 두드러진다.
Matchability‑Aware Loss
이러한 한계를 극복하기 위해 우리는 Matchability‑Aware Loss (MAL)을 제안한다. MAL은 VFL의 이점을 유지하되 단점을 완화하며, 매칭 품질(matchability)을 손실 함수에 직접 반영해 저품질 매칭에 더욱 민감하게 반응한다. MAL은 다음과 같이 정의된다:



그림 3 | VFL과 MAL 비교
낮은 품질 매칭 사례(IoU = 0.05, 그림 3(a))와 높은 품질 매칭 사례(IoU = 0.95, 그림 3(b))에서 VFL과 본 논문의 MAL을 비교한 결과.
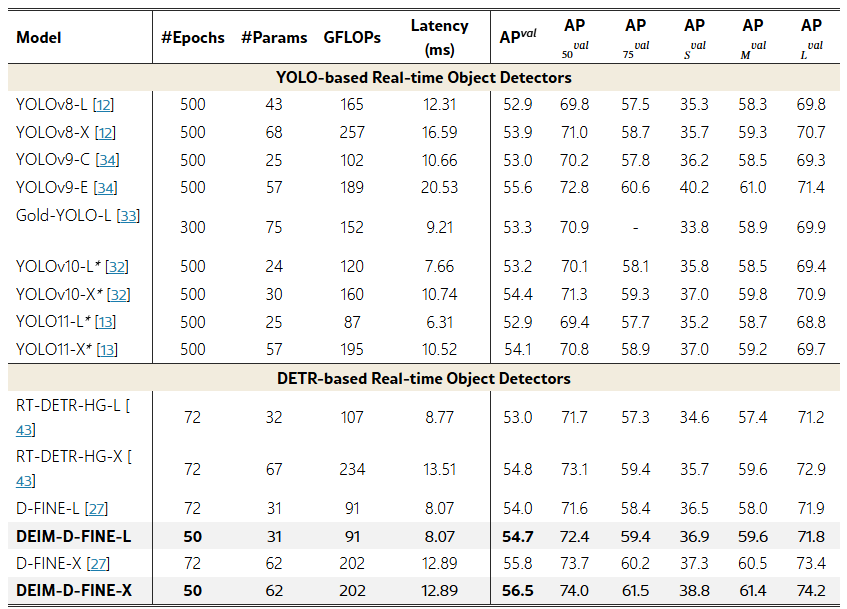
표 1 | COCO [20] val2017에서 실시간 객체 탐지기 성능 비교
제안한 방법을 D‑FINE‑L [27]과 D‑FINE‑X [27]에 통합해 DEIM‑D‑FINE‑L 및 DEIM‑D‑FINE‑X를 구현하였다. 이를 YOLO 기반 및 DETR 기반 실시간 객체 탐지기와 비교하였다.
⋆ 표시는 NMS의 confidence 임계값을 0.01로 조정했음을 의미한다.
4 실험 (Experiments)
4.1 학습 세부사항 (Training details)
Dense O2O를 위해 mosaic augmentation [1]과 mixup augmentation [38]을 적용하여 이미지당 추가 양성 샘플을 생성한다. 이러한 증강의 영향은 4.5절에서 논의한다. 모든 모델은 MS‑COCO 데이터셋 [20]에서 AdamW 옵티마이저 [23]로 학습하였다. color jitter, zoom‑out 등 표준 데이터 증강은 RT‑DETR [24, 43] 및 D‑FINE [27]과 동일하게 사용한다. 학습률은 flat cosine scheduler [25]를, 데이터 증강 강도는 새롭게 제안한 Data Augmentation Scheduler로 조절한다. 주로 초기 4 에포크 동안 data‑augmentation warm‑up 전략을 적용해 어텐션 학습을 단순화하며, 전체 학습의 50 % 이후에는 Dense O2O를 비활성화하면 더 나은 결과가 나온다. 또한 RT‑DETRv2 [43]와 같이 마지막 두 에포크에서는 데이터 증강을 끈다. 우리의 LR 및 DataAug 스케줄러는 그림 4에 자세히 나와 있다. 백본(backbone)은 ImageNet‑1k [8] 사전학습 가중치를 사용한다. 평가는 해상도 640 × 640에서 MS‑COCO validation 셋으로 수행하였다. 추가 하이퍼파라미터 설정은 부록에 제공된다.
표 2 | COCO val2017에서 ResNet 기반 DETR 성능 비교
ResNet50 [14]과 ResNet101 [14] 백본에 제안 방법을 통합하여 DEIM‑RT‑DETRv2‑R50 및 DEIM‑RT‑DETRv2‑R101을 구현하였다. 동일한 백본(ResNet50 또는 ResNet101)을 사용하는 주요 DETR 기반 객체 탐지기와 성능을 비교한다.

4.2 실시간 탐지기와의 비교
우리는 제안 방법을 D‑FINE‑L [27]과 D‑FINE‑X [27]에 적용하여 DEIM‑D‑FINE‑L과 DEIM‑D‑FINE‑X를 구축하였다. 그런 다음 이 모델들을 YOLOv8 [12], YOLOv9 [34], YOLOv10 [34], YOLOv11 [13]과 같은 최신 YOLO 계열 모델 및 RT‑DETRv2 [24], D‑FINE [27] 등 DETR 기반 모델과 비교 평가하였다. 표 1에는 각 모델의 학습 에포크 수, 파라미터 규모, GFLOPs, 지연(latency), 탐지 정확도(AP)가 정리되어 있다. 더 작은 크기(S, M)의 모델 변종 비교는 부록에 포함하였다.
우리 방법은 학습 비용, 추론 지연, 탐지 정확도 면에서 현존 SoTA(state‑of‑the‑art) 모델을 능가하며, 실시간 객체 탐지의 새로운 기준을 제시한다. 특히 D‑FINE [27]은 지식 증류(distillation)와 바운딩 박스 정제(refinement)를 결합해 RT‑DETRv2 [24] 성능을 끌어올린 최신 실시간 탐지기인데, DEIM을 적용하면 추가 지연 없이 학습 비용을 30 % 절감하면서 0.7 AP 향상을 달성한다. 작은 객체 탐지 성능이 가장 크게 향상되어, DEIM‑D‑FINE‑X는 원본 D‑FINE‑X보다 1.5 AP 높다.
YOLOv11‑X [13]과 직접 비교하면, DEIM‑D‑FINE‑L은 더 높은 정확도(54.7 AP vs. 54.1 AP)를 기록하면서도 추론 속도를 20 % 단축한다(8.07 ms vs. 10.74 ms). 하이브리드 O2M+O2O 할당 전략을 사용하는 YOLOv10 [34]과 비교해도, 우리의 모델은 일관되게 더 나은 성능을 보여 Dense O2O의 효과를 입증한다.
한편 다른 DETR 기반 모델에 비해 작은 객체 AP는 크게 향상되었으나, YOLO 계열과 비교하면 소폭 낮다. 예를 들어 YOLOv9‑E [34]는 작은 객체에서 D‑FINE‑L보다 약 1.4 AP 높지만, 전체 AP는 우리 모델이 앞선다(56.5 vs. 55.6). 이는 DETR 아키텍처에서 지속적인 과제인 작은 객체 탐지 성능 개선의 여지를 시사한다.
4.3 ResNet [14] 기반 DETR와의 비교
대부분의 DETR 연구는 ResNet [14]을 백본으로 사용한다. 이에 우리는 기존 DETR 변종 전반과 공정하게 비교하기 위해 최신 변종인 RT‑DETRv2 [24]에도 제안 기법을 적용하였다. 결과는 표 2에 요약되어 있다. 원본 DETR가 효과적인 학습에 500 에포크를 필요로 하는 반면, 최근 DETR 변종(본 연구 포함)은 학습 시간을 단축하면서 성능을 향상시키고 있다. 그중에서도 DEIM은 단 36 에포크 만에 모든 변종을 뛰어넘는 가장 큰 개선 폭을 보인다. 구체적으로, ResNet‑50 [14] 백본에서는 0.5 AP를, ResNet‑101 [14] 백본에서는 0.9 AP를 추가로 확보하면서 학습 시간을 절반으로 줄였다. 또한 ResNet‑50 백본 기준으로 DINO‑Deformable‑DETR [39]보다 2.7 AP 높다.
DEIM은 소형 객체(small object) 탐지 성능도 크게 개선한다. 예를 들어, 전체 AP는 RT‑DETRv2 [24]와 비슷하지만 DEIM‑RT‑DETRv2‑R50은 작은 객체에서 1.3 AP 더 높다. ResNet‑101 백본에서는 그 격차가 2.1 AP로 더욱 커진다. 학습을 72 에포크로 연장하면, 특히 ResNet‑50 백본에서 전체 성능이 추가로 상승해 소형 모델이 더 긴 학습으로 이득을 본다는 점을 시사한다.
표 3 | CrowdHuman [30]에서 D‑FINE과 DEIM‑적용 D‑FINE 성능 비교
두 모델 모두 120 에포크로 학습하였다.

4.4 CrowdHuman 벤치마크 비교
CrowdHuman [30]은 밀집 군중(dense crowd) 환경에서 객체 탐지기의 성능을 평가하기 위해 설계된 벤치마크 데이터셋이다. 우리는 D‑FINE 기본 설정을 그대로 따르면서 CrowdHuman에 D‑FINE과 제안한 방법(DEIM을 적용한 D‑FINE)을 모두 적용하였다. 표 3에서 알 수 있듯, DEIM이 결합된 D‑FINE‑L은 원본 D‑FINE‑L 대비 1.5 AP의 두드러진 성능 향상을 보였다. 특히 작은 객체(APs)와 고품질 검출(AP75)에서 3 % 이상의 성능 상승을 기록하며, 복잡한 상황에서도 보다 정확한 객체 탐지가 가능함을 입증했다. 이 실험 결과는 DEIM이 다양한 데이터셋에서도 강력한 일반화(generalization) 능력을 보유하고 있음을 보여 주며, 그 견고성(robustness)을 확인해 준다.
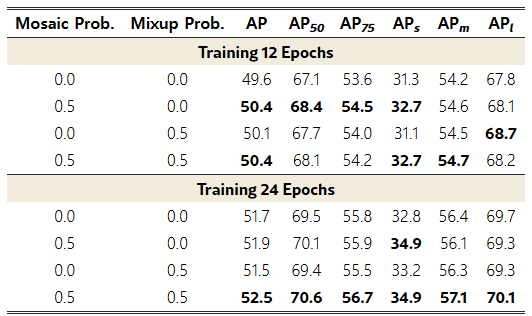
표 4 | Dense O2O에서 mosaic / mixup 조합 비교
서로 다른 mosaic 및 mixup 증강 전략을 조합한 Dense O2O 방법들의 성능을 비교하였다. 표의 확률 값은 학습 중 각 미니배치에서 mosaic과 mixup을 적용할 확률(likelihood)을 의미한다.
4.5 분석 (Analysis)
이하 실험에서는 별도 언급이 없는 한 RT‑DETRv2 [24]‑ResNet‑50 [14] 조합을 기본 설정으로 사용하며, 성능은 MS‑COCO val2017 기준으로 보고한다.
Dense O2O 달성을 위한 방법
Dense O2O를 구현하기 위해 mosaic [1]과 mixup [38] 두 가지 증강 방식을 실험하였다. mosaic은 네 장의 이미지를 하나로 결합하고, mixup은 두 장의 이미지를 임의 비율로 중첩한다. 두 기법 모두 이미지당 타깃 수를 효과적으로 늘려 학습 감독(supervision)을 강화한다.
표 4에 나타나듯, 타깃 증강(target augmentation) 없이 학습했을 때보다 mosaic과 mixup을 적용했을 때 12 에포크 만에 눈에 띄는 성능 향상이 확인되어 Dense O2O의 효용이 입증되었다. 특히 두 기법을 동시에 사용하면 모델 수렴이 더 빨라져, 증강된 감독의 이점을 더욱 강조한다. 또한 그림 5는 한 에포크 동안 이미지당 양성(positive) 샘플 수를 추적한 결과로, 전통적 O2O에 비해 Dense O2O가 양성 샘플 수를 크게 증가시킴을 보여 준다.
요약하면, Dense O2O는 이미지당 타깃 수를 늘려 감독 강도를 높여 모델 수렴 속도를 가속한다. mosaic과 mixup은 구현이 간단하고 연산 부담이 적은 방법으로, 향후 학습 중 타깃 수를 증대할 다른 기법 탐색 가능성을 시사한다.
표 5 | γ값이 MAL(식 4) 성능에 미치는 영향
COCO [20] val2017에서 24 에포크 학습 후 성능 변화를 보고한다.

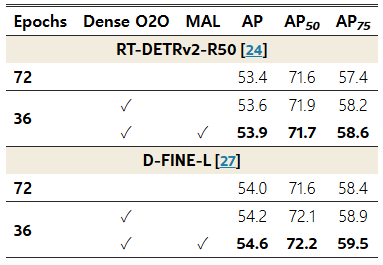
표 6: Dense O2O와 MAL의 영향
RT‑DETRv2‑R50 [24] 및 D‑FINE‑L [27]을 사용해 실험을 수행하였다.
MAL(식 4)의 γ 영향
표 5는 24 에포크 학습 후 서로 다른 γ 값이 MAL 성능에 미치는 영향을 보여준다. 실험 결과, γ=1.5가 가장 우수한 성능을 나타내어 본 연구에서는 경험적으로 γ=1.5를 사용한다.
Dense O2O와 MAL의 효과
표 6은 두 핵심 구성 요소인 Dense O2O와 MAL의 효과를 제시한다. Dense O2O는 모델 수렴을 크게 가속하여, 원본 모델이 72 에포크를 학습해야 달성하는 성능을 단 36 에포크 만에 달성한다. 여기에 MAL을 결합하면 성능이 추가로 향상된다. 이는 주로 박스 품질(box quality) 개선—특히 저품질 매칭을 최적화해 고품질 박스 예측을 향상—에 기인한다. 전반적으로 Dense O2O와 MAL은 RT‑DETRv2와 D‑FINE 모두에서 일관된 성능 향상을 제공하여, 두 기법의 견고성(robustness)과 범용성(generalizability)을 입증한다.
학습 속도(Training speed)
Mosaic 증강에 캐싱을 적용하고, Mixup을 배치 단위로 수행해 효율적인 구현을 제공한다. 표 7은 단일 4090 GPU에서 한 에포크당 학습 시간을 제시한다. DEIM은 기준선과 거의 동일한 속도(1.183 h vs. 1.181 h)를 유지하면서도 더 빠르게 수렴(71 h vs. 85 h)한다. 이는 제안 기법이 효율성을 유지하며 수렴을 가속함을 보여준다.
표 7: GPU 시간 기준 학습 소요 시간

Object365 파인튜닝(Finetuning from Object365)
우리는 D‑FINE에서 제공된 Object365 사전학습 가중치(pre‑trained weights)를 그대로 사용한 뒤, DEIM 적용 여부에 따라 파인튜닝 결과를 비교하였다. 표 8에서 보듯, DEIM을 적용하면 더 적은 파인튜닝 에포크로도 더 높은 성능을 달성한다. 이는 대규모 데이터셋으로 사전학습한 경우에도 DEIM이 일관된 성능 향상을 제공함을 추가로 입증한다.
표 8 | Object365 사전학습 가중치로 파인튜닝한 결과

5 결론(Conclusion)
본 논문에서는 매칭(matching)을 개선하여 DETR 기반 실시간 객체 탐지기의 수렴 속도를 가속화하는 DEIM을 제안하였다. DEIM은 이미지당 양성 샘플 수를 늘리는 Dense O2O 매칭과, 다양한 품질 수준—특히 저품질 매칭—을 효과적으로 최적화하도록 설계된 새로운 손실 함수 MAL을 결합한다. 이 조합은 훈련 효율을 대폭 향상시켜, 동일 에포크 수 기준 YOLOv11 등의 모델보다 우수한 성능을 달성한다. 또한 RT‑DETR·D‑FINE과 같은 최신 DETR 모델 대비 탐지 정확도와 학습 속도에서 확실한 이점을 보이며, 추론 지연(latency)에는 영향을 주지 않는다. 이러한 특성 덕분에 DEIM은 실시간 응용에 매우 효과적인 솔루션으로 자리매김하며, 차후 고성능 탐지 작업 전반으로 확장될 잠재력을 지닌다.
감사의 글(Acknowledgements)
본 연구는 Xuanlong Yu, Longfei Liu, Haiyang Xie의 귀중한 논의에 감사드린다. 또한 이 연구는 합肥사범대학교 산학협력 과제(과제번호 HXXM2022236)와 안후이성 대학 국가자연과학기금 중점 과제(과제번호 2023AH051302)의 지원을 받아 수행되었다.
DEIM-D-FINE과 DEIM-RT-DETRv2의 차이점
두 모델 모두 DEIM 훈련 전략을 적용했지만, _기본 탐지기(베이스라인) 구조_가 다르기 때문에 네트워크 구성·추론 속도·정확도 지점이 달라집니다.







