https://arxiv.org/abs/2305.07027
EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention
Vision transformers have shown great success due to their high model capabilities. However, their remarkable performance is accompanied by heavy computation costs, which makes them unsuitable for real-time applications. In this paper, we propose a family o
arxiv.org
초록
비전 트랜스포머(Vision Transformer)는 뛰어난 모델 성능으로 인해 큰 성공을 거두었지만, 이들의 우수한 성능은 막대한 계산 비용을 수반하여 실시간 응용 분야에는 적합하지 않다는 문제점이 있다. 본 논문에서는 EfficientViT라는 이름의 고속 비전 트랜스포머 모델군을 제안한다. 기존 트랜스포머 모델의 속도는 주로 비효율적인 메모리 연산, 특히 MHSA(Multi-Head Self-Attention) 내의 텐서 재구성(reshaping) 및 원소 단위 연산(element-wise operations)에 의해 제한된다는 점을 발견했다. 이에 따라 메모리 효율성과 채널 간 소통을 개선하기 위해 효율적인 FFN(Feed-Forward Network) 레이어 사이에 메모리 집약적인 MHSA를 하나만 배치하는 샌드위치 형태의 블록 구조를 설계하였다. 또한, 서로 다른 어텐션 헤드 간에 유사도가 높아 연산의 중복이 많다는 점을 확인하고, 이를 해결하기 위해 전체 특징(full feature)을 여러 그룹으로 나누어 각각의 어텐션 헤드에 전달하는 Cascaded Group Attention 모듈을 도입했다. 이는 계산 비용을 절감할 뿐 아니라 어텐션의 다양성(attention diversity)을 향상시키는 효과가 있다.
종합적인 실험을 통해 EfficientViT가 기존의 효율적인 모델들을 능가하며, 속도와 정확도 간에 우수한 균형을 달성함을 입증했다. 예를 들어 EfficientViT-M5 모델은 MobileNetV3-Large 대비 정확도에서 1.9% 앞서며, Nvidia V100 GPU 및 Intel Xeon CPU 환경에서 각각 40.4%, 45.2% 더 높은 처리량(throughput)을 보였다. 최근의 효율적 모델인 MobileViT-XXS와 비교하여 EfficientViT-M2는 정확도에서 1.8% 더 우수하면서도 GPU와 CPU에서 각각 5.8배, 3.7배 더 빠르게 작동했으며, ONNX 포맷으로 변환한 경우 7.4배 더 빠른 속도를 기록했다. 코드와 모델은 이곳에서 제공된다.
이 연구는 Xinyu가 Microsoft Research의 인턴으로 재직할 때 수행되었다.
1 서론

그림 1: Nvidia V100 GPU에서 ImageNet-1K 데이터셋 [17]을 사용하여 테스트한 EfficientViT (본 논문 제안 모델)와 기존 효율적인 CNN 및 ViT 모델의 속도 및 정확도 비교 결과.
비전 트랜스포머(Vision Transformers, ViTs)는 우수한 모델 표현력과 뛰어난 성능 덕분에 컴퓨터 비전 분야에서 큰 주목을 받고 있다[18, 69, 44]. 하지만 정확도가 지속적으로 향상될수록 모델 크기와 계산량도 급격히 증가한다는 문제가 있다. 예를 들어, 최신 성능을 달성한 SwinV2 [43]는 30억 개의 파라미터를 사용하며, V-MoE [62]는 무려 147억 개의 파라미터를 필요로 한다. 이와 같이 막대한 모델 크기와 계산 비용으로 인해 이러한 모델들은 실시간 응용 분야에서는 사용이 어렵다[86, 40, 78].
최근 들어 가볍고 효율적인 비전 트랜스포머 모델을 설계하려는 시도들이 있었다[81, 9, 50, 19, 56, 49, 79, 29]. 그러나 이러한 연구들 대부분은 모델 파라미터나 Flops를 줄이는 데 집중했는데, 이 지표들은 실제 속도를 직접적으로 나타내지 않고 간접적인 지표일 뿐이다. 예를 들어, Nvidia V100 GPU 상에서 MobileViT-XS [50]는 700M Flops를 사용하지만, 1,220M Flops를 사용하는 DeiT-T [69]보다 실제로 훨씬 느리게 동작한다. 비록 이러한 방식들이 적은 Flops나 파라미터로 좋은 성능을 달성하긴 했지만, 많은 경우 DeiT [69]와 Swin [44]과 같은 표준 트랜스포머 모델에 비해 실제 시간 상의 속도(wall-clock speed) 향상은 크지 않아, 널리 채택되지 못하고 있다.
본 논문에서는 이 문제를 해결하기 위해 비전 트랜스포머의 속도를 높이는 방법을 탐구하고, 효율적인 트랜스포머 아키텍처 설계 원칙을 제안한다. 우리는 대표적인 비전 트랜스포머인 DeiT [69]와 Swin [44]을 기반으로 메모리 접근(memory access), 계산의 중복성(computation redundancy), 파라미터 사용(parameter usage)이라는 세 가지 주요 요소가 모델의 추론 속도에 영향을 미친다는 점을 체계적으로 분석하였다. 특히, 트랜스포머 모델의 속도가 주로 메모리에 의해 제한된다는 점을 확인했다. 즉, 메모리 접근 지연(memory accessing delay)이 GPU나 CPU의 계산 성능을 완전히 활용하지 못하게 하여, 트랜스포머 모델의 실행 속도에 매우 부정적인 영향을 끼친다[21, 32, 72, 31, 15]. 특히 MHSA(Multi-Head Self-Attention) 내의 빈번한 텐서 재구성과 원소 단위(element-wise) 연산이 가장 비효율적인 메모리 연산이다. 우리는 MHSA와 FFN(Feed-Forward Network) 레이어 간의 비율을 적절히 조정하면, 성능 손실 없이 메모리 접근 시간을 크게 줄일 수 있음을 발견하였다. 또한 일부 어텐션 헤드가 유사한 선형 사상(linear projection)을 학습해 어텐션 맵(attention maps)에 중복성이 발생하는 것을 발견했다. 이를 해결하기 위해, 서로 다른 특징을 각각의 헤드에 제공하여 계산을 명확히 분리하면, 중복성을 감소시키고 계산 효율성을 향상시킬 수 있다는 점을 보였다. 추가로, 기존의 가벼운 모델들은 파라미터 배치를 소홀히 하고 표준 트랜스포머 모델의 구성을 주로 따르는 경향이 있었다[69, 44]. 우리는 파라미터 효율성을 높이기 위해 구조적 가지치기(structured pruning) [45]를 활용하여 네트워크에서 중요한 부분을 파악하고, 실험적으로 파라미터를 재배치하는 가이드라인을 제시했다.
이러한 분석과 발견을 기반으로, 우리는 EfficientViT라는 새로운 메모리 효율적 트랜스포머 모델군을 제안한다. 구체적으로, 모델을 구성하기 위해 샌드위치 구조의 새로운 블록을 설계했다. 이 샌드위치 구조 블록은 효율적인 FFN 레이어들 사이에 단 하나의 메모리 집중적인 MHSA 레이어를 배치함으로써 MHSA의 메모리 연산으로 인한 시간 소모를 감소시키고, 채널 간의 소통을 증가시키는 FFN 레이어를 더욱 많이 활용해 메모리 효율성을 향상시킨다. 또한 계산 효율성을 높이기 위한 새로운 Cascaded Group Attention(CGA) 모듈을 제안했다. CGA의 핵심 아이디어는 어텐션 헤드로 입력되는 특징(feature)의 다양성을 증가시키는 것이다. 모든 헤드에 동일한 특징을 주입하는 기존의 셀프 어텐션과 달리, CGA는 각 헤드에 서로 다른 입력 분할을 제공하며 헤드 간 출력 특징을 순차적으로 연결(cascade)한다. 이 모듈은 다중 헤드 어텐션의 계산 중복을 줄일 뿐 아니라, 네트워크 깊이를 증가시켜 모델의 용량(capacity)도 향상시킨다. 마지막으로, 우리는 Value projection과 같은 핵심 네트워크 요소의 채널 폭(channel width)을 확장하고 FFN 내부의 숨겨진 차원(hidden dimension) 등 상대적으로 중요도가 낮은 요소를 축소하는 방식으로 파라미터를 재배치하여, 최종적으로 모델의 파라미터 효율성을 증가시켰다.
실험 결과, 제안한 모델은 그림 1에서 보듯이 기존 효율적인 CNN 및 ViT 모델들보다 속도와 정확도 모두에서 뚜렷한 성능 향상을 보였다. 예컨대, EfficientViT-M5는 ImageNet 데이터셋에서 77.1%의 top-1 정확도와 Nvidia V100 GPU 환경에서 초당 10,621장, Intel Xeon E5-2690 v4 CPU @ 2.60GHz에서 초당 56.8장의 처리량을 달성했다. 이는 MobileNetV3-Large [26]보다 정확도는 1.9%, GPU 속도는 40.4%, CPU 속도는 45.2% 높은 수치이다. EfficientViT-M2 모델은 70.8%의 정확도를 달성하여 MobileViT-XXS [50]보다 1.8% 높았으며, GPU와 CPU 환경에서는 각각 5.8배, 3.7배 빠른 속도를 보였고, ONNX [3]로 변환 시 7.4배 빠르게 동작했다. 모바일 칩셋(아이폰 11의 Apple A13 Bionic 칩)에 CoreML[1]을 통해 배포했을 때 EfficientViT-M2는 MobileViT-XXS [50]보다 2.3배 더 빨리 동작했다.
본 연구의 주요 기여는 다음과 같이 요약할 수 있다.
- 비전 트랜스포머의 추론 속도에 영향을 미치는 요소들을 체계적으로 분석하고, 효율적 모델 설계를 위한 가이드라인을 제시했다.
- 효율성과 정확도를 잘 균형 잡은 새로운 비전 트랜스포머 모델군을 제안했으며, 다양한 다운스트림 태스크에서 우수한 성능을 보였다.

그림 2: Swin-T와 DeiT-T 두 가지 대표적인 비전 트랜스포머의 실행 프로파일링(runtime profiling) 결과. 빨간색 텍스트는 메모리 병목(memory-bound) 연산을 의미하며, 주로 메모리 접근으로 인해 시간이 소요됨을 나타낸다.
2 비전 트랜스포머의 속도 향상
본 절에서는 비전 트랜스포머의 효율성을 메모리 접근(memory access), 계산 중복(computation redundancy), 파라미터 사용(parameter usage)이라는 세 가지 관점에서 살펴본다. 실험적 분석을 통해 속도의 주요 병목 지점을 찾아내고, 효과적인 모델 설계를 위한 가이드라인을 제시한다.
2.1 메모리 효율성
모델의 속도에 영향을 미치는 핵심 요소 중 하나는 메모리 접근 오버헤드(memory access overhead)이다[15, 31, 65, 28]. 트랜스포머 모델[71] 내의 많은 연산들, 특히 빈번한 텐서 재구성(reshaping), 원소 단위 덧셈(element-wise addition), 정규화(normalization)와 같은 연산들은 메모리 효율성이 떨어진다. 이로 인해 다양한 메모리 유닛에 걸친 접근 시간이 크게 늘어나며, 이는 그림 2에서 볼 수 있다. 이를 해결하기 위해 기존 연구들은 sparse attention[34, 75, 61, 57]이나 low-rank approximation[11, 74, 51]과 같이 표준적인 softmax self-attention 연산을 단순화하는 방식을 제안하기도 했지만, 이러한 접근 방식은 흔히 정확도 저하를 가져오거나 가속화 효과가 제한적이라는 문제점을 지닌다.
본 연구에서는 메모리 비효율적인 레이어의 수를 줄이는 방식으로 메모리 접근 비용을 절약하고자 한다. 최근 연구에 따르면, 메모리 비효율적인 연산의 대부분은 FFN 레이어가 아닌 MHSA 레이어에서 발생한다고 보고되고 있다[31, 33]. 그러나 현재 널리 쓰이는 ViT 모델들[18, 69, 44]은 주로 MHSA와 FFN 레이어를 거의 같은 비율로 사용하고 있어, 최적의 효율성을 달성하지 못하고 있다. 따라서 우리는 빠른 추론이 가능한 소형 모델에서 MHSA와 FFN 레이어의 최적 배분을 탐색하였다. 구체적으로 Swin-T[44]와 DeiT-T[69] 모델을 1.25배, 1.5배 더 빠르게 동작하는 여러 작은 서브 네트워크로 축소한 뒤, 다양한 MHSA 레이어 비율을 적용한 모델들의 성능을 비교했다. 그림 3에서 볼 수 있듯이, MHSA 레이어 비율이 전체 모델 대비 20%-40% 수준일 때 더 좋은 정확도를 얻는 경향이 나타났다. 이는 일반적인 ViT 모델들이 MHSA 레이어를 약 50% 비율로 사용하는 것과 비교해 상당히 낮은 비율이다. 또한 메모리 접근 효율성을 비교하기 위해, 메모리 병목 연산(memory-bound operations)에 소요되는 시간을 측정하였다. 여기에는 텐서 재구성, 원소 단위 덧셈, 복사(copying), 정규화가 포함된다. 그 결과, Swin-T를 1.25배 빠르게 한 모델(Swin-T-1.25×)에서 MHSA 레이어 비율을 20%로 낮추었을 때, 메모리 병목 연산 비율이 전체 실행 시간의 44.26%로 크게 감소했다. 이러한 관찰은 DeiT 모델 및 1.5배 속도로 작동하는 더 작은 모델에도 동일하게 적용됨을 확인했다. 따라서 MHSA 레이어의 비율을 적절하게 줄이면 모델 성능을 향상시키면서 메모리 효율성도 높일 수 있다는 점이 입증되었다.
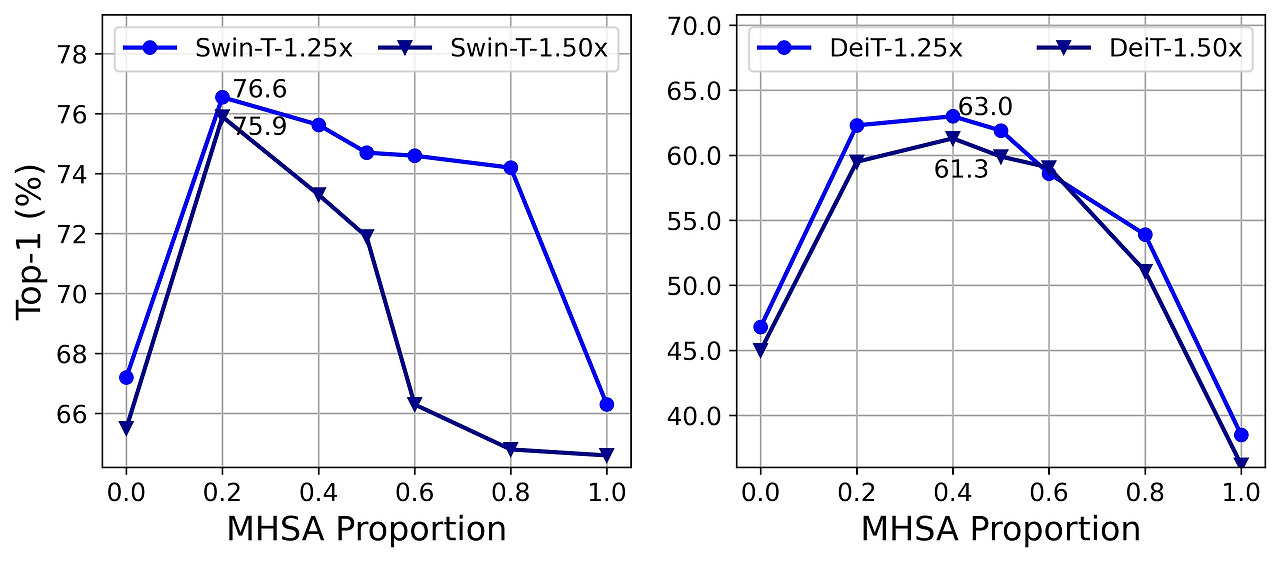
그림 3: MHSA 레이어 비율을 다양하게 설정한 축소된 모델들의 정확도 비교. 각 라인의 점(dot)은 유사한 처리량(throughput)을 가진 서브 네트워크를 나타낸다. 왼쪽: Swin-T를 기준으로 함. 오른쪽: DeiT-T를 기준으로 함. 1.25×/1.5×는 각각 기준 모델보다 1.25배 및 1.5배 빠르게 동작하도록 가속한 것을 의미한다.
2.2 계산 효율성
MHSA(Multi-Head Self-Attention)는 입력 시퀀스를 여러 개의 서브공간(subspace, 헤드)으로 임베딩한 뒤 별도의 어텐션 맵을 계산하는 방식으로 성능 향상에 효과적인 것으로 증명되었다[71, 18, 69]. 그러나 어텐션 맵 계산은 많은 연산을 필요로 하며, 기존 연구에서는 상당수의 어텐션 헤드가 실제로는 중요하지 않다는 점을 보였다[52, 73]. 따라서 우리는 소형 ViT 모델에서 중복된 어텐션 계산을 줄이는 방안을 모색했다. 이를 위해 너비(width)를 축소해 1.25배 빠른 추론 속도를 가지도록 조정한 Swin-T[44] 및 DeiT-T[69] 모델을 학습시킨 후, 각 블록 내 어텐션 헤드 사이의 최대 코사인 유사도(cosine similarity)를 측정했다.
그림 4에서 볼 수 있듯이, 특히 마지막 블록들에서 어텐션 헤드 간의 높은 유사도가 관찰되었다. 이러한 현상은 다수의 헤드가 같은 전체 특징(full feature)에 대해 유사한 프로젝션(projection)을 학습하여 계산상의 중복을 일으키고 있음을 시사한다. 각 헤드가 서로 다른 패턴을 학습하도록 명시적으로 유도하기 위해, 전체 특징을 여러 채널로 나누어 각각의 헤드에 별도의 부분 특징(split feature)만 입력하는 직관적인 방식을 적용했다. 이는 기존 CNN에서 그룹 컨볼루션(group convolution)의 아이디어[87, 10]와 유사하다. 수정된 MHSA 구조로 축소된 모델을 학습한 뒤 다시 어텐션 유사도를 측정한 결과를 그림 4에 제시하였다. 결과에 따르면 모든 헤드에 동일한 전체 특징을 입력하는 기존 MHSA 방식 대신, 서로 다른 헤드에 채널 단위로 구분한 별도의 부분 특징을 입력하는 방식이 어텐션 연산의 중복을 효과적으로 줄일 수 있음을 알 수 있다.

그림 4: 서로 다른 블록에서 각 헤드의 평균 최대 코사인 유사도를 나타낸다. 왼쪽은 축소된 Swin-T 모델, 오른쪽은 축소된 DeiT-T 모델을 나타낸다. 파란색 선은 Swin-T-1.25× 및 DeiT-T-1.25× 모델을 나타내고, 진한 파란색 선은 전체 특징을 헤드별로 분할(split)하여 입력한 변형 모델을 나타낸다.

그림 5: Swin-T 모델에 가지치기(pruning)를 적용하기 전후 입력 임베딩(input embedding)에 대한 채널 비율을 나타낸다. 베이스라인 정확도는 79.1%이고, 가지치기 후 정확도는 76.5%이다. DeiT-T 모델의 결과는 부록(supplementary)에 제공되어 있다.
2.3 파라미터 효율성
일반적인 비전 트랜스포머(ViT) 모델은 대부분 NLP 분야의 트랜스포머[71]에서 사용된 설계 방식을 그대로 가져온다. 예를 들어, Q, K, V 프로젝션에 동일한 채널 폭을 사용하거나, 스테이지(stage)가 진행될수록 헤드 수를 늘리며, FFN의 확장 비율(expansion ratio)을 4로 고정하는 방식이 대표적이다. 하지만 경량(lightweight) 모델에서는 이러한 구성 요소를 보다 신중하게 재설계할 필요가 있다[7, 39, 8]. 본 연구에서는 [45, 82]를 참고하여 Taylor 구조적 가지치기(Taylor structured pruning)[53]를 적용해 Swin-T와 DeiT-T 모델에서 중요한 구성 요소를 자동으로 찾아내고, 파라미터 할당의 근본적인 원리를 탐색하였다. 이 가지치기 방법은 정해진 자원 제한 하에서 중요하지 않은 채널을 제거하고, 정확도 손실을 최소화하기 위해 가장 중요한 채널만을 유지한다. 여기서 채널의 중요도는 그레이디언트(gradient)와 가중치(weight)의 곱을 사용하여 결정되며, 이는 채널 제거 시 손실의 변화(loss fluctuation)를 근사화한 것이다[38].
그림 5에서는 입력 채널 대비 가지치기 후 남은 출력 채널의 비율을 나타냈으며, 비교를 위해 가지치기 전 모델의 원래 비율도 함께 나타냈다. 여기에서 다음과 같은 현상을 확인할 수 있다:
- 앞의 두 스테이지(stage)에서는 더 많은 채널 차원을 유지하는 반면, 마지막 스테이지에서는 훨씬 적은 차원을 유지한다.
- Q, K 및 FFN 차원은 크게 축소되는 반면, V의 차원은 거의 유지되다가 마지막 몇 블록에서만 감소한다.
이러한 현상으로부터 다음의 결론을 얻을 수 있다:
- 스테이지마다 채널 폭을 두 배씩 증가시키는 방식[44]이나, 모든 블록에 동일한 채널 폭을 사용하는 방식[69]은 마지막 블록에서 상당한 중복을 발생시킬 수 있다.
- 동일한 차원을 사용할 때, Q와 K의 중복성이 V보다 훨씬 크며, V는 입력 임베딩(input embedding) 차원과 유사한 비교적 큰 채널 폭을 유지하는 것을 선호한다.

그림 6: EfficientViT 구조 개요. (a) EfficientViT의 아키텍처; (b) 샌드위치 레이아웃(Sandwich Layout) 블록; (c) Cascaded Group Attention 모듈.
3 Efficient Vision Transformer
앞선 분석을 기반으로 본 절에서는 빠른 추론 속도를 갖는 새로운 계층적 모델인 EfficientViT를 제안한다. 전체 아키텍처 개요는 그림 6에서 확인할 수 있다.
3.1 EfficientViT 빌딩 블록
우리는 비전 트랜스포머를 위한 새로운 효율적 빌딩 블록(building block)을 제안하며, 이는 그림 6(b)에 나타나 있다. 이 블록은 메모리 효율적인 샌드위치 레이아웃(sandwich layout), Cascaded Group Attention 모듈, 파라미터 재배치(parameter reallocation) 전략으로 구성되며, 각각 메모리, 계산, 파라미터 효율성을 향상시키는 데 초점을 맞추고 있다.
샌드위치 레이아웃(Sandwich Layout)
메모리 효율성을 높이기 위해, 메모리에 병목을 일으키는 셀프 어텐션(self-attention) 레이어 수는 줄이고, 메모리 효율적인 FFN 레이어를 늘려 채널 간 소통(channel communication)을 수행하는 샌드위치 형태의 블록 구조를 설계하였다. 구체적으로, 공간적 혼합(spatial mixing)을 담당하는 단일 셀프 어텐션 레이어(Φᵢᴬ)를 두고, 그 앞뒤로 FFN 레이어(Φᵢᶠ)를 배치하는 방식이다. 계산 과정은 다음과 같다.
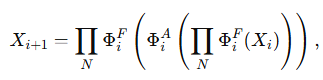

Cascaded Group Attention (캐스케이드 그룹 어텐션)
MHSA의 주요 문제 중 하나는 어텐션 헤드 간의 중복성으로 인한 계산 비효율성이다. 효율적인 CNN에서 활용되는 그룹 컨볼루션(group convolution)의 아이디어[37, 10, 87, 64]에 착안하여, 우리는 비전 트랜스포머를 위한 새로운 어텐션 모듈인 Cascaded Group Attention(CGA)을 제안한다. 이 모듈은 전체 특징(full features)을 여러 부분으로 나누어 각 헤드(head)에 별도의 부분 특징(split features)을 입력함으로써, 어텐션 계산을 명확히 헤드 단위로 나눈다. 이 연산을 수식화하면 다음과 같다.

각 헤드가 전체 특징이 아닌 특징의 일부만을 사용하는 것이 더 효율적이고 계산 오버헤드를 줄이지만, 우리는 각 헤드의 용량(capacity)을 더욱 높이기 위해 Q,K,V 레이어가 더욱 풍부한 정보를 가진 특징을 학습할 수 있도록 했다. 이를 위해 각 헤드의 어텐션 맵을 연속적으로 계산하는 캐스케이드 방식(cascaded manner)을 도입하여, 각 헤드의 출력을 다음 헤드의 입력에 더함으로써 특징 표현(feature representation)을 점진적으로 개선했다(그림 6(c) 참고).
표 1: EfficientViT 모델 변형들의 아키텍처 세부사항
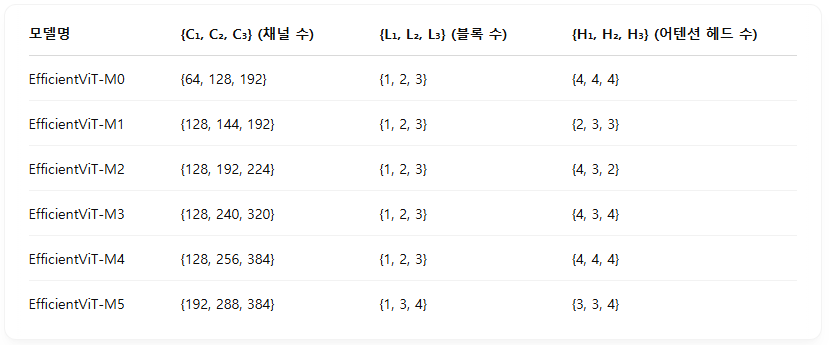
표 2: ImageNet-1K [17] 데이터셋에 대한 EfficientViT의 이미지 분류 성능 (추가 데이터 없이 학습된 최신 효율적인 CNN 및 ViT 모델들과의 비교)
- 처리량(Throughput)은 Nvidia V100 GPU와 Intel Xeon E5-2690 v4 CPU @2.60 GHz 및 ONNX 환경에서 측정된 것으로, 수치가 클수록 추론 속도가 빠름을 나타냄.
- ↑ : 더 높은 해상도에서 추가로 파인튜닝한 모델.


이러한 캐스케이드 설계는 두 가지 장점이 있다. 첫째, 각 헤드에 서로 다른 특징 부분을 입력하면 어텐션 맵의 다양성이 증가하여 계산 중복을 줄일 수 있다(Sec. 2.2에서 입증됨). 이는 그룹 컨볼루션과 유사하게 Q,K,V 레이어의 입출력 채널이 h배 감소하여 Flops와 파라미터도 약 h배 절약된다. 둘째, 어텐션 헤드를 캐스케이드 방식으로 연결하면 네트워크의 깊이가 증가되어, 파라미터 수는 늘리지 않으면서 모델 용량을 효과적으로 향상시킨다. 이 경우, Q,K 채널의 크기가 작아 각 헤드에서 어텐션 맵 계산에 따른 추가 지연 시간(latency overhead)은 미미한 수준이다.
파라미터 재배치 (Parameter Reallocation)
파라미터 효율성을 높이기 위해, 네트워크 내 중요한 모듈의 채널 폭(channel width)은 확장하고 덜 중요한 모듈의 채널 폭은 축소하여 파라미터를 재배치했다. 구체적으로, 섹션 2.3의 테일러 중요도 분석을 기반으로 모든 스테이지에서 각 헤드의 Q,K 프로젝션 차원을 작게 설정하고, V 프로젝션의 차원은 입력 임베딩(input embedding)과 동일하게 유지했다. 또한 FFN 레이어의 확장 비율을 기존 4에서 2로 축소하여 파라미터 중복을 줄였다. 이 전략을 통해 중요한 모듈이 높은 차원에서 풍부한 표현을 학습하여 특징 정보의 손실을 최소화하는 한편, 중요하지 않은 모듈의 중복 파라미터를 제거해 모델 추론 속도를 높이고 효율성을 개선했다.
3.2 EfficientViT 네트워크 아키텍처
EfficientViT의 전체 네트워크 아키텍처는 그림 6(a)에 나타나 있다. 구체적으로, 16×16 크기의 패치를 중첩 패치 임베딩(overlapping patch embedding)[80, 20]을 사용하여 C_1 차원을 가진 토큰으로 변환하며, 이는 저수준(low-level)의 시각적 표현(visual representation) 학습 능력을 향상시킨다. 네트워크는 총 세 개의 스테이지(stage)로 구성된다. 각 스테이지는 앞서 제안한 EfficientViT 빌딩 블록을 여러 개 쌓아 구성되며, 서브샘플링(subsampling)을 수행하는 레이어마다 토큰 수를 4배(해상도 기준 2배 축소)씩 감소시킨다. 효율적인 서브샘플링을 위해 EfficientViT 서브샘플 블록(subsample block)을 제안하였으며, 이는 기존의 샌드위치 레이아웃을 유지하면서 셀프 어텐션(self-attention) 레이어 대신 inverted residual 블록[63, 26]을 사용하여 서브샘플링 과정에서 정보 손실을 최소화하였다.
또한, 모델 전체에 걸쳐 LayerNorm(LN)[2] 대신 BatchNorm(BN)[30]을 사용했는데, BN은 이전의 컨볼루션(convolution) 또는 선형(linear) 레이어에 통합(folded)할 수 있어 런타임(runtime) 측면에서 LN보다 유리하기 때문이다. 활성화 함수로는 ReLU[54]를 사용했다. 일반적으로 사용되는 GELU[25]나 HardSwish[26] 활성화 함수는 속도가 느리고, 일부 추론 배포 플랫폼에서는 충분히 지원되지 않는 경우가 있기 때문이다[3, 1].
우리는 모델을 총 여섯 가지의 서로 다른 너비(width)와 깊이(depth) 스케일로 구성했으며, 각 스테이지마다 어텐션 헤드(head)의 수를 다르게 설정했다. 특히 해상도가 높은 초기 스테이지에서는 처리 시간이 오래 걸리기 때문에 MobileNetV3[26]나 LeViT[20]와 유사하게 초기 스테이지에서 블록을 적게 사용하고, 후반 스테이지에서는 블록 수를 증가시켰다. 또한, 2.3절에서 분석한 바와 같이, 후반부 스테이지에서의 중복성을 완화하기 위해 스테이지가 진행될수록 채널 폭(width)을 약간씩 (최대 2배 이하로) 증가시키는 방식을 채택하였다. 모델 아키텍처의 세부사항은 표 1에서 확인할 수 있으며, 여기서 C_i, L_i, H_i는 각각 -번째 스테이지의 채널 폭(width), 깊이(depth, 블록 개수), 어텐션 헤드(head) 수를 나타낸다.
4 실험
4.1 구현 세부사항
우리는 ImageNet-1K [17] 데이터셋을 이용하여 이미지 분류(image classification) 실험을 수행하였다. 모델은 PyTorch 1.11.0 [59] 및 Timm 0.5.4 [77]로 구현되었으며, 8개의 Nvidia V100 GPU에서 AdamW [46] 옵티마이저와 코사인 학습률 스케줄러(cosine learning rate scheduler)를 사용하여 총 300 에폭(epoch) 동안 처음부터 학습하였다. 전체 배치 크기(batch size)는 2,048로 설정하였다. 입력 이미지는 크기를 조정(resize)한 후 224×224로 무작위로 잘라(random cropping) 사용하였다. 초기 학습률(learning rate)은 1×10^-3으로 설정하였으며, 가중치 감쇠(weight decay)는 2.5×10^-2을 사용하였다. 데이터 증강(data augmentation)은 Mixup [85], Auto-Augmentation [13], Random Erasing [88]을 포함하여 [69]의 방법과 동일하게 적용하였다.
또한 다양한 하드웨어 환경에서의 처리량(throughput)을 평가하였다. GPU 환경의 경우 Nvidia V100 GPU를 사용하여 처리량을 측정하였으며, 최대한의 배치 크기를 메모리에 맞게 2의 거듭제곱(power-of-two) 단위로 설정하여 측정하였다[69, 20]. CPU 및 ONNX 환경에서는 Intel Xeon E5-2690 v4 @2.60GHz 프로세서를 사용하여 배치 크기를 16으로 설정하고 단일 스레드(single thread)에서 모델을 실행하여 처리 시간을 측정하였다[20].
EfficientViT의 전이성(transferability)을 평가하기 위해 다운스트림 작업(downstream tasks)에 대해서도 실험을 진행하였다. 다운스트림 이미지 분류(image classification)의 경우 [86]의 방식을 따라 모델을 300 에폭 동안 AdamW 옵티마이저를 이용해 파인튜닝(finetuning)하였으며, 배치 크기는 256, 학습률은 1×10^-3, 가중치 감쇠는 1×10^-8로 설정하였다. 객체 탐지(object detection)는 COCO [42] 데이터셋에서 RetinaNet [41] 모델을 사용하였으며, mmdetection [6] 프레임워크에서 [44]의 실험 설정과 동일하게 총 12 에폭(1× 스케줄) 동안 학습하였다. 인스턴스 분할(instance segmentation)에 대한 실험 세부사항은 부록(supplementary)을 참조하기 바란다.
4.2 ImageNet에서의 실험 결과
우리는 ImageNet 데이터셋 [17]에서 EfficientViT 모델을 최신의 효율적인 CNN 및 ViT 모델과 비교했으며, 결과는 표 2와 그림 1에 나타나 있다. 결과를 통해 대부분의 평가 조건에서 EfficientViT가 기존 모델들 대비 정확도와 속도의 최적 균형을 이루었음을 확인할 수 있다.
효율적인 CNN과의 비교
먼저 EfficientViT 모델을 MobileNet [26, 63] 및 EfficientNet [67]과 같은 대표적인 CNN 모델과 비교했다. 구체적으로, EfficientViT-M3는 MobileNetV2 1.0× [63]에 비해 top-1 정확도가 1.4% 더 높으면서도 Nvidia V100 GPU와 Intel CPU에서 각각 2.5배, 3.0배 더 빠른 속도를 보였다. 또한 최신의 MobileNetV3-Large [26]와 비교할 때, EfficientViT-M5는 정확도가 1.9% 높으면서도 속도 면에서도 크게 우수한 성능을 보였다. 구체적으로는 Nvidia V100 GPU에서 40.5%, Intel CPU에서 45.2% 더 빠른 처리 속도를 달성했으나, ONNX 모델로 변환 시에는 11.5% 더 느리게 나타났다. 이는 셀프 어텐션 연산에서 불가피하게 발생하는 reshaping 연산이 ONNX 구현에서는 상대적으로 느리기 때문인 것으로 보인다. 또한 EfficientViT-M5는 Neural Architecture Search를 통해 설계된 EfficientNet-B0 [67]과 유사한 정확도를 달성하면서도 Nvidia V100 GPU와 Intel CPU에서 각각 2.3배, 1.9배, ONNX 모델에서는 2.1배 더 빠르게 동작했다. EfficientViT가 비록 파라미터 수가 더 많지만, 메모리 비효율적인 연산을 줄여 추론 속도를 높임으로써 높은 처리량(throughput)을 달성했다.
효율적인 ViT와의 비교
또한 표 2에서 EfficientViT를 최근의 효율적인 ViT 모델들[9, 50, 51, 56, 5]과 비교하였다. 특히 ImageNet-1K [17]에서 유사한 성능을 보였을 때, EfficientViT-M4는 최근 모델인 EdgeViT-XXS [56]보다 CPU와 GPU 환경에서 각각 4.4배, 3.0배 빠른 속도를 보였다. ONNX 런타임 환경으로 변환 시에도 여전히 3.7배 더 높은 속도를 달성했다. 최신 모델인 MobileViTV2-0.5 [51]와 비교해도 EfficientViT-M2는 약간 더 우수한 정확도와 함께 Nvidia GPU와 Intel CPU 환경에서 각각 3.4배, 3.5배 더 높은 처리량을 기록하였다. 또한 표 3에서는 최신 대규모 ViT 모델들의 작은 버전(tiny variants)과도 비교했다. 예를 들어, PoolFormer-12S [83] 모델은 EfficientViT-M5와 비슷한 정확도를 보였지만, Nvidia V100 GPU 환경에서는 EfficientViT-M5가 3.0배 더 빨랐다. Swin-T [44] 모델과 비교하면 EfficientViT-M5는 정확도가 4.1% 낮지만, Intel CPU 환경에서는 12.3배 더 빠른 속도를 달성하여 본 연구에서 제안한 설계의 효율성을 입증했다. 추가적으로 모바일 칩셋 환경에서의 속도 평가 및 비교 결과는 부록에서 확인할 수 있다.
높은 해상도에서의 파인튜닝 성능
최근의 ViT 관련 연구들에서는 더 높은 해상도로 파인튜닝을 진행할 경우 모델의 성능이 추가적으로 향상됨을 보였다. 이에 따라 우리의 최대 모델인 EfficientViT-M5도 더 높은 해상도에서 파인튜닝하였다. EfficientViT-M5↑384는 Nvidia V100 GPU 환경에서 초당 3,986장의 처리량을 기록하면서 top-1 정확도 79.8%를 달성했고, EfficientViT-M5↑512는 top-1 정확도를 80.8%로 추가로 향상시켰다. 이를 통해 제안된 모델이 더 높은 해상도의 이미지를 처리할 때도 우수한 효율성과 뛰어난 모델 용량(capacity)을 가지고 있음을 입증했다.
표 3: ImageNet-1K [17]에서 최신 대규모 ViT 모델들의 tiny 버전들과의 성능 비교.
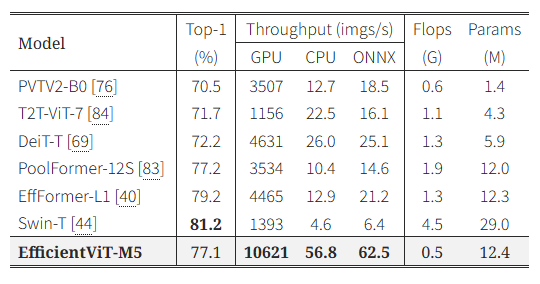
표 4: EfficientViT 및 다른 효율적인 모델들의 다운스트림 이미지 분류 데이터셋 성능 비교.

4.3 전이학습(Transfer Learning) 결과
EfficientViT의 전이 능력(transferability)을 보다 종합적으로 평가하기 위해 다양한 다운스트림(downstream) 태스크에서 성능을 측정하였다.
다운스트림 이미지 분류
EfficientViT 모델의 일반화 성능(generalization ability)을 확인하기 위해 다양한 다운스트림 이미지 분류 데이터셋에 적용하여 평가했다.
- 일반 이미지 분류 데이터셋: CIFAR-10 및 CIFAR-100 [36]
- 세부 클래스(fine-grained) 이미지 분류 데이터셋: Flowers [55], Stanford Cars [35], Oxford-IIIT Pets [58]
평가 결과는 표 4에 나타나 있다. 기존의 효율적인 모델들[27, 63, 26, 89, 18]과 비교할 때, 우리의 EfficientViT-M5 모델은 대부분의 데이터셋에서 더 높은 처리량(throughput)을 유지하면서도 비슷하거나 약간 더 우수한 정확도를 달성하였다. 단, Stanford Cars 데이터셋에서는 정확도가 다소 낮았는데, 이는 클래스 간의 미세한 차이점들이 주로 국소적(local) 디테일에 존재하여 컨볼루션(convolution) 기반의 모델들이 더 효과적으로 포착할 수 있기 때문으로 추정된다.
객체 탐지(Object Detection)
COCO [42] 객체 탐지 태스크에서 EfficientViT-M4 모델과 다른 효율적인 모델들[63, 26, 22, 66, 12, 68]을 비교하였으며, 결과는 표 5에 나타나 있다. 구체적으로 EfficientViT-M4는 비슷한 Flops를 가진 MobileNetV2 [63]보다 AP(Average Precision)가 4.4% 더 높았다. 또한, 신경망 구조 탐색(neural architecture search)을 통해 설계된 SPOS [22]와 비교하면, EfficientViT-M4는 Flops를 18.1% 더 적게 사용하면서도 AP는 2.0% 더 높아, 다양한 컴퓨터 비전 태스크에서의 모델의 우수한 성능과 뛰어난 일반화 능력을 입증했다.
4.4 Ablation Study (요소별 성능 분석)
본 절에서는 EfficientViT 설계의 주요 구성요소가 성능에 미치는 영향을 ImageNet-1K 데이터셋 [17]에서 심층 분석한다. 실험에 사용된 모든 모델은 차이를 극대화하고 학습 시간을 단축하기 위해 100 에폭(epoch)만 학습하였다[20]. 결과는 표 6에 나타나 있다.
Sandwich Layout 블록의 영향
우선, 제안한 샌드위치 레이아웃의 효율성을 검증하기 위해 샌드위치 레이아웃 블록을 기존의 Swin 블록[44]으로 교체한 Ablation 실험을 진행했다. 공정한 비교를 위해 Swin 블록의 깊이를 {2, 2, 3}으로 조정하여 EfficientViT-M4와 비슷한 처리량(throughput)을 유지하였다. 그 결과, 속도는 비슷한 수준이었으나 정확도(top-1)는 3.0% 하락했다. 이는 메모리 병목을 유발하는 MHSA 대신 더 많은 FFN 레이어를 활용하는 것이 소형 모델에서는 더욱 효율적임을 보여준다. 또한, 셀프 어텐션 레이어 앞뒤로 사용하는 FFN의 개수(N)가 미치는 영향을 분석하기 위해 FFN의 개수를 1에서 2, 3개로 변경하고, 처리량을 유지하기 위해 전체 블록 수를 조정하였다. 표 6 (#3, #4)의 결과에 따르면, FFN의 개수를 추가로 늘리는 것은 장거리 공간 관계(long-range spatial relation)의 부족으로 인해 효과가 없었으며, N=1일 때 가장 높은 효율성을 보였다.
Cascaded Group Attention(CGA)의 영향
우리는 MHSA의 계산 효율성을 높이기 위해 CGA를 제안하였다. 표 6 (#5, #6)에 나타난 것처럼 CGA를 기존 MHSA로 교체하면 정확도가 1.1%, ONNX 속도가 5.9% 감소하여 헤드(head) 간 중복성을 처리하는 것이 모델 효율성 향상에 중요함을 나타냈다. 또한 cascade 연산 없이 단순히 헤드별 특징을 나눈(split) 모델의 경우 MHSA와 성능이 유사하지만 CGA보다는 성능이 낮아, 헤드별 특징 표현을 점진적으로 개선하는 CGA의 효과를 입증하였다.
파라미터 재배치의 영향
제안한 EfficientViT-M4는 QKV 채널의 차원 재배치(channel dimension reallocation) 또는 FFN 확장 비율 감소를 적용하지 않은 모델 대비 각각 1.4% 및 1.5% 더 높은 top-1 정확도를 보였으며, GPU 처리량 역시 각각 4.9%, 3.8% 더 높았다(표 6 #1 vs. #7, #8 참조). 이는 파라미터 재배치 전략의 효과성을 나타낸다. 추가로, 헤드별 QK 차원의 선택과 입력 임베딩(input embedding) 대비 V 차원의 비율이 미치는 영향을 그림 7에서 분석했다. 결과적으로 QK 차원이 4에서 16으로 증가할 때 성능이 점진적으로 향상되었으나, 그 이상에서는 성능이 오히려 저하되었다. 또한 V 차원을 입력 임베딩 대비 비율로 0.4에서 1.0으로 증가시킬 때 정확도가 70.3%에서 71.3%로 향상되었으나, 비율을 1.2로 더 증가시킬 때는 0.1%만 향상되었다. 따라서 입력 임베딩 차원과 비슷한 크기로 V 차원을 설정하는 것이 가장 효율적임을 확인할 수 있으며, 이는 2.3절에서의 분석 및 모델 설계 전략과 일치하는 결과이다.
기타 요소들의 영향
토큰 상호작용을 위한 DWConv, 정규화(normalization) 레이어, 활성화 함수(activation function)의 영향을 분석한 결과는 표 6 (#9, #10, #11)에 나타나 있다. DWConv를 사용할 경우 미미한 추가 지연 시간(latency overhead)이 있지만, 정확도는 1.4% 향상되어 국소적(local) 구조 정보를 도입하는 효과를 확인할 수 있었다. 정규화 레이어의 경우, BN을 LN으로 교체하면 정확도가 0.9%, GPU 속도는 2.9% 감소하였다. 활성화 함수의 경우 HardSwish를 사용하면 ReLU에 비해 정확도가 0.9% 증가하지만 ONNX 속도는 무려 20.0% 하락했다. 활성화 함수는 GPU 및 CPU 환경에서 상당한 처리 시간을 차지하는 원소 단위(element-wise) 연산이므로[48, 15, 72], 복잡한 활성화 함수보다는 ReLU를 사용하는 것이 효율성 면에서 더 낫다는 것을 입증했다.
표 7: ImageNet-1K [17] 및 ImageNet-ReaL [4]에서의 성능 비교.
(†\dagger: LeViT [20]와 동일하게 1,000 에폭 학습 및 지식 증류(knowledge distillation)를 적용한 결과.)
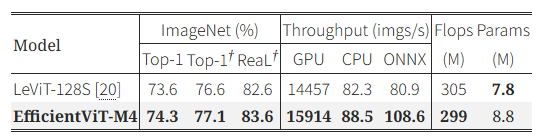
1,000 에폭 학습 및 지식 증류를 적용한 결과
표 7은 ImageNet-1K [17]와 ImageNet-ReaL [4]에서 LeViT [20]과 동일하게 1,000 에폭 학습하고 RegNetY-16GF [60] 모델을 교사 모델로 사용하여 지식 증류를 수행한 결과를 나타낸다. EfficientViT-M4는 LeViT-128S [20] 대비 ImageNet-1K에서 0.5%, ImageNet-ReaL에서 1.0% 더 높은 정확도를 보였다. 또한 ONNX 환경에서 처리량이 34.2% 더 높았으며, 다른 환경에서도 우수한 처리 속도를 기록하였다. 이 결과는 EfficientViT 모델이 장기간 학습을 진행할수록 더 강력한 표현력과 우수한 일반화 능력을 발휘할 수 있음을 보여준다.
5 관련 연구(Related Work)
효율적인 CNN 모델
리소스가 제한된 환경에서 CNN 모델을 배포하고자 하는 요구가 증가함에 따라, 효율적인 CNN 모델에 대한 연구가 활발히 이루어졌다[63, 26, 48, 67, 87, 23, 24]. Xception[10]은 depthwise separable convolution을 사용한 아키텍처를 제안하였다. MobileNetV2[63]는 입력 차원을 더 높은 차원으로 확장(expansion)한 inverted residual 구조를 제안하였다. MobileNetV3[26] 및 EfficientNet[67]은 신경망 구조 탐색(neural architecture search)을 통해 컴팩트한 모델을 설계했다. 하드웨어에서의 실제 속도를 향상시키기 위해 ShuffleNetV2[48]는 채널 분리(channel split) 및 셔플(shuffle) 연산을 통해 채널 그룹 간의 정보 교류를 개선했다. 하지만 CNN 모델은 컨볼루션 커널의 공간적 국소성(spatial locality) 때문에 장거리 의존성(long-range dependencies)을 잘 포착하지 못해 모델 표현력에 한계가 있다.
효율적인 비전 트랜스포머(ViT) 모델
ViT 및 그 변형 모델[18, 69, 44, 76]은 다양한 비전 태스크에서 뛰어난 성과를 보여왔다. 그러나 뛰어난 성능에도 불구하고, 대부분의 ViT는 추론 속도에서 전통적인 CNN 모델보다 열세였다. 최근 제안된 효율적인 트랜스포머 모델들은 크게 두 가지 범주로 나눌 수 있다.
- 효율적인 셀프 어텐션 방식
효율적 셀프 어텐션 접근법들은 sparse attention[34, 75, 61, 57] 또는 low-rank 근사화[11, 74, 51]를 통해 softmax 어텐션의 비용을 줄이려 했다. 하지만 이 접근법들은 softmax 어텐션[71] 대비 성능이 저하되거나 실제 추론 속도의 향상이 미미하거나 제한적인 문제가 있다. - 효율적인 아키텍처 설계 방식
또 다른 연구들은 가벼운 CNN과 ViT를 결합하여 효율적 아키텍처를 구성하였다[81, 50, 9, 49, 47]. LVT[81]는 dilated convolution과 강화된 어텐션 메커니즘을 도입하여 성능과 효율성을 동시에 개선했다. Mobile-Former[9]는 CNN과 트랜스포머 블록을 병렬로 구성해 지역적(local) 특징과 전역적(global) 상호작용을 모두 포착했다. 하지만 이 접근법들의 대부분은 Flops와 파라미터를 최소화하는 것을 목표로 하고 있어[16], 실제 추론 지연 시간(inference latency)과의 상관관계가 낮으며[70], 여전히 속도 면에서 효율적인 CNN 모델보다 못한 경향이 있다.
본 연구는 이러한 기존 연구와 달리, 다양한 하드웨어 및 배포 환경에서 실제 추론 처리량(throughput)을 직접 최적화하여 빠른 추론 속도를 가진 모델을 탐구하였으며, 속도와 정확도 간의 균형이 잘 잡힌 계층적(hierarchical) EfficientViT 모델군을 설계하였다.
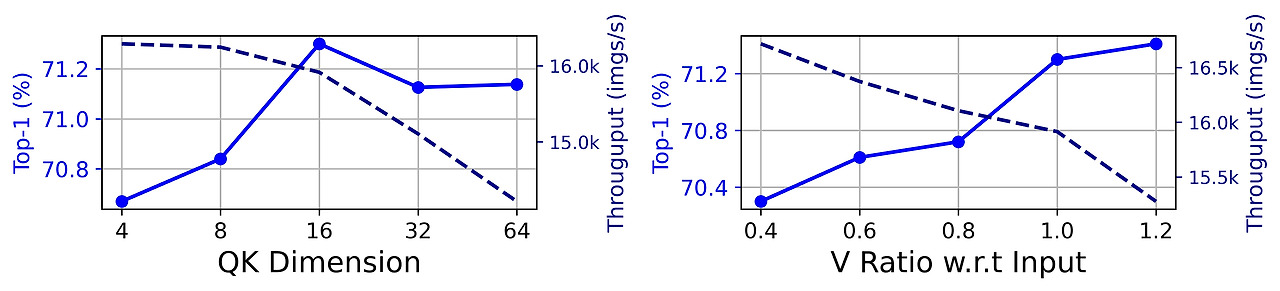
그림 7: 각 어텐션 헤드에서의 QK 차원과 입력 임베딩 대비 V 차원의 비율이 성능에 미치는 영향.
6 결론(Conclusion)
본 논문에서는 비전 트랜스포머의 추론 속도에 영향을 미치는 요소들을 체계적으로 분석하고, 메모리 효율적인 연산과 Cascaded Group Attention을 활용하여 고속 비전 트랜스포머 모델인 EfficientViT를 제안하였다. 다양한 실험을 통해 EfficientViT 모델이 높은 효율성과 우수한 성능을 달성했으며, 여러 다운스트림 벤치마크에서도 탁월한 성능을 보였음을 입증하였다.
한계점(Limitations)
EfficientViT 모델의 한 가지 한계점은 뛰어난 추론 속도에도 불구하고, 제안한 샌드위치 레이아웃에서 추가된 FFN 레이어로 인해 최신 효율적 CNN 모델[26]과 비교했을 때 모델 크기(model size)가 약간 더 크다는 것이다. 또한 EfficientViT 모델은 효율적인 비전 트랜스포머 설계에 대한 본 연구의 가이드라인을 기반으로 수동으로 설계되었다. 향후 연구에서는 모델 크기를 더 축소하는 방안과 자동화된 구조 탐색 기법을 도입하여 모델의 용량과 효율성을 추가적으로 높이는 방향을 탐색할 계획이다.
감사의 글(Acknowledgement)
Yuan 교수는 본 연구에 대해 홍콩 연구 보조금 위원회(Hong Kong Research Grants Council, RGC)의 General Research Fund (11211221)와 홍콩 혁신기술위원회(Innovation and Technology Commission)의 혁신기술기금(Innovation and Technology Fund, ITS/100/20)으로부터 부분적으로 지원을 받았습니다.



