https://arxiv.org/abs/2205.14756
EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction
High-resolution dense prediction enables many appealing real-world applications, such as computational photography, autonomous driving, etc. However, the vast computational cost makes deploying state-of-the-art high-resolution dense prediction models on ha
arxiv.org
초록
고해상도 밀집 예측(high-resolution dense prediction)은 계산 사진학(computational photography), 자율 주행(autonomous driving) 등 다양한 실세계 응용에 매력적인 가능성을 제공합니다. 그러나 최신 고해상도 밀집 예측 모델은 막대한 연산 비용으로 인해 실제 하드웨어에 배포하기 어렵습니다. 본 논문에서는 EfficientViT라는 새로운 고해상도 비전 모델 계열을 제안하며, 다중 스케일 선형 어텐션(multi-scale linear attention)이라는 새로운 기법을 도입합니다. 기존 고해상도 밀집 예측 모델들이 높은 성능을 달성하기 위해 무거운 softmax 어텐션, 하드웨어 비효율적인 대형 커널 합성곱, 복잡한 토폴로지 구조에 의존한 반면, EfficientViT의 다중 스케일 선형 어텐션은 경량이면서도 하드웨어 효율적인 연산만으로 글로벌 수용 영역(global receptive field)과 다중 스케일 학습(multi-scale learning)을 모두 달성합니다.
이러한 특성 덕분에 EfficientViT는 모바일 CPU, 엣지 GPU, 클라우드 GPU 등 다양한 하드웨어 플랫폼에서 기존 최고 성능 모델 대비 획기적인 속도 향상과 성능 향상을 동시에 제공합니다.
- Cityscapes 데이터셋에서는 성능 손실 없이 SegFormer 대비 최대 13.9배, SegNeXt 대비 6.2배 GPU 지연 시간(latency)을 줄였습니다.
- 초해상도(super-resolution) 작업에서는 Restormer 대비 최대 6.4배 속도 향상과 함께 PSNR 0.11dB 증가를 달성했습니다.
- Segment Anything 작업에서는 A100 GPU에서 48.9배 높은 처리량(throughput)을 기록하면서도 COCO 데이터셋에서 제로샷 인스턴스 분할(zero-shot instance segmentation) 성능을 소폭 상회하였습니다.
1. 서론 (Introduction)
고해상도 밀집 예측(high-resolution dense prediction)은 컴퓨터 비전에서 근본적인 과제로, 자율 주행, 의료 영상 처리, 계산 사진학(computational photography) 등 다양한 실제 분야에서 널리 활용됩니다. 따라서, 최신 고해상도 밀집 예측 모델(state-of-the-art, 이하 SOTA 모델)을 하드웨어 장치에 배포할 수 있다면 많은 응용 분야에서 실질적인 이점을 얻을 수 있습니다.
하지만 이러한 SOTA 모델들이 요구하는 막대한 연산량은 실제 하드웨어 장치의 한정된 자원과 큰 격차를 보이며, 이는 현실적인 응용을 어렵게 만듭니다. 특히, 고해상도 밀집 예측 모델은 고해상도 입력 이미지와 강력한 문맥 정보 추출 능력이 필요합니다 [1~6]. 따라서 기존의 이미지 분류용 효율적인 모델 구조를 단순히 가져다 쓰는 것은 적절하지 않습니다.
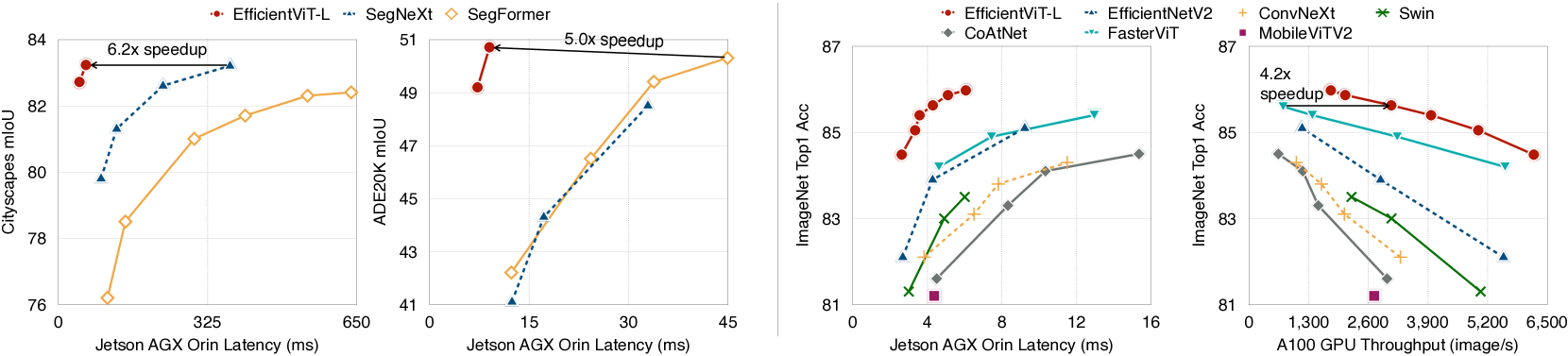
[그림 1: Latency/Throughput vs. Performance]
다양한 하드웨어 플랫폼(Jetson AGX Orin, A100 GPU)에서 TensorRT와 FP16으로 추론 시, EfficientViT는 기존 분할/분류 모델 대비 뛰어난 성능을 유지하면서도 지속적으로 향상된 속도를 보여줍니다.
본 연구에서는 고해상도 밀집 예측을 위한 새로운 비전 트랜스포머 계열 모델인 EfficientViT를 제안합니다. EfficientViT의 핵심은, 하드웨어 효율적인 연산만으로도 글로벌 수용 영역(global receptive field)과 다중 스케일 학습(multi-scale learning)을 가능하게 하는 새로운 다중 스케일 선형 어텐션(multi-scale linear attention) 모듈입니다.
기존의 SOTA 모델들은 다중 스케일 학습 [3, 4]과 글로벌 수용 영역 [7]이 성능 향상에 핵심이라는 사실을 보여주었지만, 실제 하드웨어 효율성은 고려하지 않았습니다.
예를 들어, SegFormer [7]는 softmax 어텐션 [8]을 백본(backbone)에 적용하여 글로벌 수용 영역을 확보하였지만, 연산 복잡도가 입력 해상도에 대해 이차적(quadratic)으로 증가하여 고해상도 이미지를 처리하기 어렵습니다.
또한 SegNeXt [9]는 커널 크기 최대 21의 대형 커널 합성곱을 다중 브랜치 모듈로 도입했지만, 이는 하드웨어에서 최적화되기 어려운 연산이어서 실제 장치에서 비효율적입니다 [10, 11].
따라서, 우리는 이러한 두 가지 핵심 요소(글로벌 수용 영역, 다중 스케일 학습)를 지원하면서도 하드웨어에 비효율적인 연산은 피하는 방향으로 모듈을 설계하였습니다.
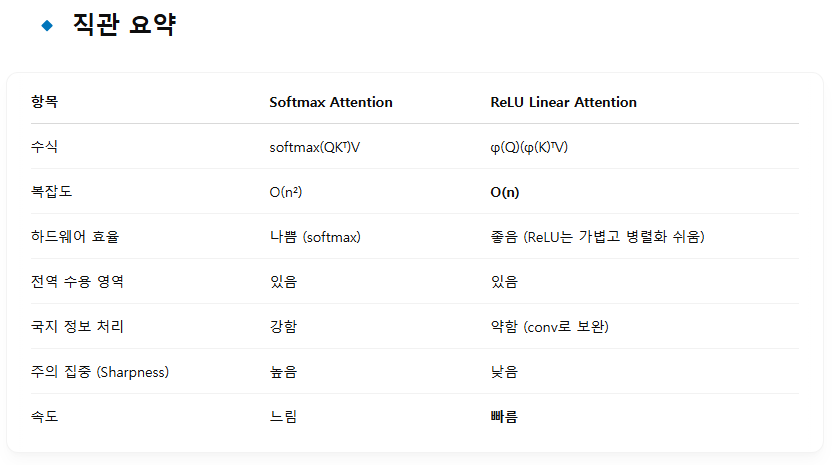
구체적으로, softmax 어텐션을 경량화된 ReLU 기반 선형 어텐션(ReLU linear attention)으로 대체하여 글로벌 수용 영역을 확보합니다.
ReLU 선형 어텐션은 행렬곱의 결합 법칙(associative property)을 활용하여 연산 복잡도를 이차 → 선형(linear)으로 줄일 수 있으며, softmax와 같은 하드웨어 비우호적 연산을 제거해 하드웨어 배포에 적합합니다 (그림 4 참조).
하지만 ReLU 선형 어텐션만으로는 국지적(local) 정보 추출과 다중 스케일 학습이 부족해 성능에 한계가 있습니다. 이를 보완하기 위해,
- 우리는 소형 커널 합성곱을 통해 인접 토큰들을 집계하여 다중 스케일 토큰(multi-scale tokens)을 생성하고,
- 여기에 ReLU 선형 어텐션을 적용해 글로벌 수용 영역 + 다중 스케일 학습을 결합합니다 (그림 2 참조).
- 또한 FFN(feed-forward network) 레이어에 depthwise convolution을 삽입하여 국지적 정보 추출 능력을 강화했습니다.
우리는 EfficientViT를 두 가지 대표적인 고해상도 밀집 예측 과제, 즉 시맨틱 분할(semantic segmentation)과 초해상도(super-resolution)에 대해 폭넓게 평가하였습니다. 그 결과, 기존 SOTA 모델 대비 성능 향상은 물론, 하드웨어 비효율 연산의 배제 덕분에 연산량(FLOPs) 감소가 실제 하드웨어 지연 시간(latency) 감소로 이어졌습니다 (그림 1 참조).
또한, 우리는 EfficientViT를 최근 주목받는 Segment Anything [13]에도 적용해 보았습니다. 이 작업은 다양한 비전 과제에 제로샷 전이(zero-shot transfer)를 가능하게 하는 prompt 기반 분할 과제입니다. EfficientViT는 SAM-ViT-Huge [13] 대비 A100 GPU에서 48.9배 빠른 속도를 보이면서도 성능 저하 없이 작업을 수행했습니다.
본 논문의 주요 기여는 다음과 같습니다:
- 다중 스케일 선형 어텐션 모듈을 새롭게 도입하여, 글로벌 수용 영역과 다중 스케일 학습을 모두 달성하면서도 하드웨어 효율성을 유지했습니다. 본 연구는 선형 어텐션을 고해상도 밀집 예측에 효과적으로 적용한 최초의 사례입니다.
- 제안한 모듈을 바탕으로 한 새로운 고해상도 비전 모델 계열인 EfficientViT를 설계하였습니다.
- EfficientViT는 시맨틱 분할, 초해상도, Segment Anything, ImageNet 분류 등 다양한 과제에서 기존 SOTA 모델 대비 획기적인 속도 향상을 달성했습니다. 또한 모바일 CPU, 엣지 GPU, 클라우드 GPU 등 다양한 하드웨어 플랫폼에서 우수한 성능을 보였습니다.

[그림 2: EfficientViT의 구성 블록 및 다중 스케일 선형 어텐션]
좌측: EfficientViT는 다중 스케일 선형 어텐션 + depthwise convolution이 결합된 FFN으로 구성됩니다.
우측: Q/K/V 토큰을 선형 투영 후, 소형 커널 합성곱으로 다중 스케일 토큰을 만들고, 각 스케일에 대해 ReLU 선형 어텐션을 수행한 후 결과를 결합합니다.

[그림 3: Softmax 어텐션 vs. ReLU 선형 어텐션]
ReLU 선형 어텐션은 비선형 유사도 함수가 없어 날카로운 주의 분포(sharp attention)를 만들지 못해, softmax 어텐션보다 국지 정보 추출력이 약할 수 있습니다.

[그림 4: Softmax vs. ReLU 어텐션의 지연 시간 비교]
ReLU 선형 어텐션은 softmax보다 3.3~4.5배 빠른 속도를 기록하였으며, Qualcomm Snapdragon 855 CPU + TensorFlow Lite에서 실측하였습니다.

[그림 5: EfficientViT의 전체 구조]
표준 backbone-head (encoder-decoder) 구조를 따르며, EfficientViT 모듈은 stage 3, 4에 삽입됩니다. 마지막 세 단계(P2, P3, P4)의 피처들을 단순히 더해(head) 출력으로 활용합니다.


2. 방법론 (Method)
이 장에서는 먼저 다중 스케일 선형 어텐션(Multi-Scale Linear Attention) 모듈을 소개합니다. 기존 연구들과 달리, 본 모듈은 하드웨어 친화적인 연산만으로 글로벌 수용 영역(global receptive field)과 다중 스케일 학습(multi-scale learning)을 동시에 달성합니다. 이후, 이를 기반으로 한 고해상도 밀집 예측을 위한 비전 트랜스포머 계열 모델인 EfficientViT를 제안합니다.
2.1 다중 스케일 선형 어텐션
우리의 다중 스케일 선형 어텐션 모듈은 고해상도 밀집 예측에서 요구되는 성능과 효율성을 균형 있게 만족시키기 위해 설계되었습니다. 성능 측면에서는 글로벌 수용 영역과 다중 스케일 학습이 핵심 요소이며, 기존 SOTA 모델들도 이를 통해 높은 성능을 달성했지만, 하드웨어 효율성은 고려되지 않았습니다. 본 모듈은 약간의 용량(capacity) 손실을 감수하고 하드웨어 효율을 극대화하는 방식으로 이 문제를 해결합니다.
[그림 2 오른쪽]에 제안된 모듈이 시각화되어 있습니다.


⚠ ReLU 선형 어텐션의 한계와 해결
ReLU 선형 어텐션은 연산량과 지연 시간 측면에서 매우 우수하지만, 한계도 존재합니다:
- Sharp한 attention map을 생성하지 못함: non-linear similarity function이 없기 때문에 특정 위치에 집중하지 못하고, 지역(local) 정보 추출이 약함
→ [그림 3] 참조
이를 보완하기 위해 다음을 제안합니다:
- FFN 레이어에 depthwise convolution 추가 → 지역 정보 처리 능력 향상
- Q/K/V 각각에 대해 다중 스케일 토큰 생성
- 인접 토큰들을 작은 커널의 depthwise separable convolution을 통해 집계
- 효율성 유지를 위해 각 Q/K/V에 대해 독립적인 집계를 수행
- GPU 효율을 위해 DWConv들을 하나의 DWConv로, 1×1 Conv는 그룹 convolution으로 합침 → [그림 2 오른쪽] 참조
- 다중 스케일 토큰 위에 ReLU 선형 어텐션 수행
- 각 head별로 결과를 concat하고, 마지막 선형 계층으로 피처를 융합
2.2 EfficientViT 아키텍처
우리는 위에서 제안한 다중 스케일 선형 어텐션 모듈을 기반으로 새로운 EfficientViT 모델 계열을 설계하였습니다. 주요 구성은 [그림 2 왼쪽]에, 전체 구조는 [그림 5]에 제시되어 있습니다.
✅ Backbone
- 입력 stem과 4단계로 구성된 일반적인 비전 트랜스포머 구조
- 각 stage에서 feature map 해상도는 줄이고 채널 수는 증가
- EfficientViT 모듈은 Stage 3와 4에 삽입
- 다운샘플링은 stride 2의 MBConv( Mobile Inverted Bottleneck Convolution )를 사용
✅ Head
- P2, P3, P4는 Stage 2, 3, 4의 출력을 의미 (pyramid 구조)
- 각각을 1×1 convolution과 bilinear/bicubic upsampling으로 통일된 형태로 만든 후 단순한 add 연산으로 융합
- 간단한 MBConv 기반 head만으로도 충분한 성능을 달성함
실험 결과, 복잡한 head 없이도 높은 성능을 달성함을 확인하였음
✅ 다양한 크기의 EfficientViT 모델 계열
서로 다른 효율성 요구를 충족하기 위해 다음과 같은 계열을 설계하였습니다:
- EfficientViT-B0, B1, B2, B3: 일반 장치용
- EfficientViT-L 시리즈: 클라우드용 (고성능 버전)
모델 세부 구조는 GitHub에서 확인 가능:
🔗 https://github.com/mit-han-lab/efficientvit
GitHub - mit-han-lab/efficientvit: Efficient vision foundation models for high-resolution generation and perception.
Efficient vision foundation models for high-resolution generation and perception. - mit-han-lab/efficientvit
github.com
3. 실험 (Experiments)
3.1 실험 설정 (Setups)
✅ Ablation Study (구성요소 제거 실험)

표 1: Cityscapes 데이터셋 (1024×2048 입력)에서의 Ablation Study 결과.
MACs(Multiply–accumulate operations)는 동일하게 유지하며 width를 조정함.
→ 다중 스케일 학습과 글로벌 수용 영역이 시맨틱 분할 성능 향상에 필수적임을 확인할 수 있음.

표 2: 다양한 모델과의 ImageNet 분류 정확도 및 연산 효율 비교.
'r224', 'r288'은 입력 해상도(예: 224×224)를 의미함.
EfficientViT는 더 적은 연산량과 낮은 지연 시간으로 더 높은 정확도를 달성함.
✅ 평가에 사용한 데이터셋
EfficientViT는 세 가지 대표적인 고해상도 밀집 예측 과제에서 평가됨:
- 시맨틱 분할 (Semantic Segmentation)
- 데이터셋: Cityscapes [24], ADE20K [25]
- 초해상도 (Super-resolution)
- 경량화 SR: DIV2K [26]에서 학습, BSD100 [27]에서 평가
- 고해상도 SR: FFHQ [28]의 첫 3000개 이미지로 학습, 첫 500개 이미지로 평가
- Segment Anything
- 새로운 prompt 기반 segmentation 작업 (zero-shot 성능 평가)
추가로, ImageNet [29]을 사용하여 이미지 분류 성능도 분석함.
✅ 지연 시간 측정 기준
- 모바일 CPU: Qualcomm Snapdragon 8Gen1 + TensorFlow Lite, batch size = 1, fp32
- 엣지 및 클라우드 GPU: TensorRT + fp16 사용 (지연 시간 및 처리량 계산 시 전송 시간 포함)
✅ 구현 및 학습 세부사항
- 프레임워크: PyTorch 기반 구현
- Optimizer: AdamW
- Learning rate 스케줄: Cosine decay 사용
- 다중 스케일 어텐션에서는 5×5 영역의 토큰을 집계하여 2-branch 구조로 학습 효율성 향상
✦ 과제별 설정:
- 시맨틱 분할: mIoU (mean Intersection over Union)를 평가 지표로 사용
- 백본은 ImageNet 사전학습(pretrained), head는 무작위 초기화
- 초해상도: Y 채널 기준으로 PSNR / SSIM 사용
- 모델은 무작위 초기화로 학습
3.2 Ablation Study (구성요소 제거 실험)
✅ EfficientViT 모듈의 효과 분석
Cityscapes 데이터셋에서 EfficientViT 모듈의 두 핵심 설계 요소인
- 다중 스케일 학습(Multi-scale learning)
- 글로벌 어텐션(Global attention)
의 중요성을 검증하기 위해 ablation 실험을 수행했습니다.
- 모든 실험은 사전학습(pretraining) 없이 무작위 초기화 상태에서 진행
- MACs 수를 동일하게 맞추기 위해 모델의 width를 조정
- 결과는 표 1에 정리되어 있으며, 어떤 구성 요소를 제거하더라도 성능이 크게 하락함을 확인할 수 있음
→ 두 요소 모두 성능-효율 트레이드오프 달성에 필수적
✅ ImageNet 분류 성능 평가
EfficientViT는 고해상도 밀집 예측을 목표로 설계되었지만, ImageNet 분류에서도 강력한 성능을 보입니다:
- 예: EfficientViT-L2-r384
- Top-1 정확도: 86.0%
- EfficientNetV2-L 대비 +0.3% 향상
- A100 GPU에서 2.6배 빠름
→ 이는 EfficientViT 백본의 범용성과 성능을 보여줍니다 (표 2 참조).
🔍 성능 비교: Semantic Segmentation
✅ Cityscapes (1024×2048 해상도 기준)
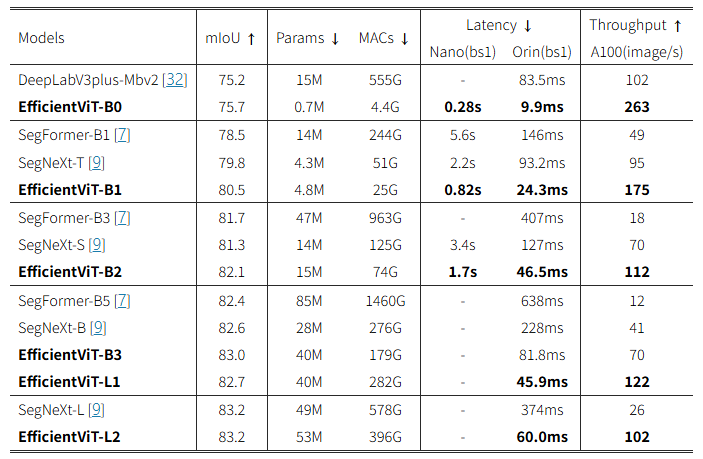
→ 같은 mIoU에서 훨씬 낮은 연산량과 지연 시간을 달성
✅ ADE20K (짧은 변 기준 512로 리사이즈)
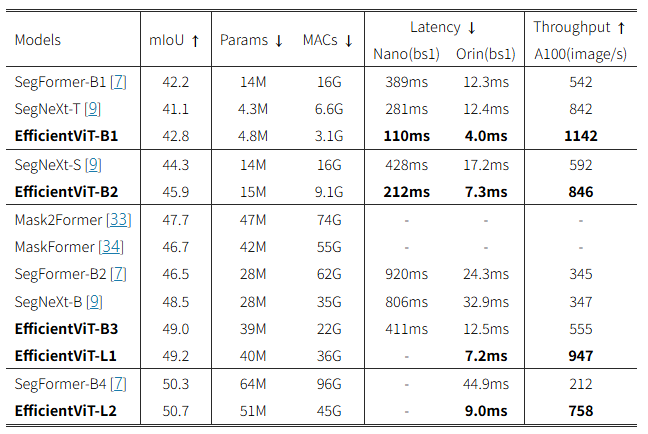
→ ADE20K에서도 압도적인 효율-성능 균형을 보여줌
🔍 성능 비교: Super-Resolution

→ 고해상도 FFHQ, 저해상도 BSD100 모두에서 기존 SOTA 대비 PSNR/SSIM 상승 + 수 배 빠른 속도 확보
3.3 시맨틱 분할 (Semantic Segmentation)
🔹 Cityscapes
표 3은 Cityscapes 데이터셋에서 EfficientViT와 기존 SOTA 시맨틱 분할 모델 간의 비교 결과를 보여줍니다.
EfficientViT는 기존 모델들과 유사하거나 더 나은 정확도(mIoU)를 달성하면서도, 놀라운 수준의 연산량 절감 및 지연 시간 개선을 달성합니다.
📌 주요 성과 요약:
- SegFormer 대비:
- 최대 13배 적은 MACs (연산량)
- 8.8배 빠른 GPU 지연 시간(Jetson AGX Orin 기준)
- 더 높은 mIoU
- SegNeXt 대비:
- 최대 2배 적은 연산량(MACs)
- 3.8배 빠른 GPU 속도
- 더 높은 mIoU 유지
- A100 GPU 기준 처리량 (throughput):
- SegNeXt 대비 최대 3.9배 향상
- SegFormer 대비 10.2배 향상
- 성능(mIoU)은 동일하거나 더 높음
- 예시:
- EfficientViT-B3는 연산량이 더 적음에도 불구하고, SegFormer-B1보다 mIoU가 +4.5 높음

📸 [그림 6] 시각적 비교 결과:
Cityscapes의 예시 시각화 결과에서 EfficientViT는 기존 모델들보다
- 경계선(boundary)과
- 작은 객체(small object)를 더 정확하게 인식함을 보여줍니다.
이와 동시에 GPU 지연 시간은 더 낮습니다.
🔹 ADE20K
표 4는 ADE20K 데이터셋에서 EfficientViT와 기존 SOTA 시맨틱 분할 모델들을 비교한 결과입니다.
Cityscapes와 마찬가지로, EfficientViT는 성능과 효율성 면에서 모두 우수한 결과를 달성합니다.
📌 주요 성과 요약:
- SegFormer-B1 대비:
- mIoU +0.6 향상
- 연산량 5.2배 감소
- GPU 지연 시간 최대 3.5배 빠름
- SegNeXt-S 대비:
- mIoU +1.6 향상
- 연산량 1.8배 감소
- Jetson AGX Orin 기준 2.4배 빠른 속도
3.4 초해상도 (Super-Resolution)
표 5는 EfficientViT를 기존의 SOTA ViT 기반 초해상도(SR) 방법론(SwinIR [31], Restormer [35]) 및 CNN 기반 초해상도 방법론(VapSR [36], BSRN [37])과 비교한 결과입니다.
EfficientViT는 모든 기존 모델들에 비해 더욱 뛰어난 성능-지연 시간(latency) trade-off를 달성합니다.
🔹 경량 초해상도 (Lightweight SR)
- EfficientViT는 BSD100 데이터셋에서:
- 기존 CNN 기반 초해상도 모델들과 비교하여:
- GPU latency는 동일하거나 더 낮게 유지하면서, 최대 +0.09 dB의 PSNR 향상
- 기존 ViT 기반 모델들과 비교하여:
- PSNR을 유지하면서 최대 5.4배의 GPU 속도 향상을 제공합니다.
- 기존 CNN 기반 초해상도 모델들과 비교하여:

그림 7: 처리량과 COCO 제로샷 인스턴스 세분화 mAP 비교. EfficientViT-SAM은 SAM-ViT-H의 제로샷 성능[13]과 일치하거나 이를 능가하는 최초의 가속화된 SAM 모델로, SOTA 성능-효율성 트레이드오프를 제공합니다
🔹 고해상도 초해상도 (High-resolution SR)
고해상도 초해상도 작업에서는 EfficientViT의 강점이 더욱 뚜렷하게 나타납니다.
- Restormer 대비:
- GPU에서 최대 6.4배 속도 향상
- PSNR 기준으로 FFHQ 데이터셋에서 0.11 dB의 성능 향상 달성

🔹 EfficientViT 기반 SAM의 Zero-Shot Instance Segmentation 결과 (표 6)
EfficientViT를 기반으로 Segment Anything (SAM) 모델을 가속화한 결과입니다. 기존 SAM-ViT-H [13] 모델의 zero-shot 성능을 달성하거나 초과하는 최초의 효율적인 SAM 모델로서, 뛰어난 성능-효율 균형을 보여줍니다.
- SAM-ViT-H 대비 EfficientViT 기반 모델은:
- 파라미터 수와 연산량(MACs)을 최대 10배 이상 크게 감소시키면서도,
- 처리량(throughput)을 최대 69배 향상 (11→762 img/s) 시켰습니다.
- mAP는 비슷하거나 더 높음

🔹 Zero-Shot Point-Prompted Segmentation 결과 (표 7)
하나 또는 여러 개의 클릭 기반(point-prompted) 제로샷 세그멘테이션 성능 비교:
- EfficientViT-SAM-XL1 모델은 클릭 기반 프로프팅에서도 기존 SAM-ViT-H를 능가하거나 유사한 성능을 보였습니다.
🚩 결론 및 시사점
EfficientViT는 다양한 비전 작업(초해상도, 시맨틱 분할, 제로샷 세그멘테이션 등)에서 뛰어난 성능과 극히 높은 연산 효율을 보이며, 특히 GPU 등 실제 하드웨어 환경에서 크게 뛰어난 속도와 효율성을 입증하였습니다. 이는 EfficientViT가 다양한 고해상도 밀집 예측 작업에서 효과적이고 실질적인 모델로 자리 잡을 수 있음을 나타냅니다.
3.5 Segment Anything (SAM) 성능 평가
EfficientViT를 기반으로 SAM의 이미지 인코더를 대체하여 EfficientViT-SAM이라는 새로운 고속 Segment Anything 모델군을 개발했습니다.
Prompt 인코더와 Mask 디코더는 기존 SAM의 경량 구조를 그대로 유지하였습니다.
학습은 두 단계로 구성됩니다.
- 1단계: SAM의 이미지 인코더를 교사(teacher)로 사용하여 EfficientViT-SAM의 이미지 인코더를 학습.
- 2단계: SA-1B 전체 데이터셋[13]을 사용해 EfficientViT-SAM 모델을 end-to-end로 학습.
🔹 다양한 제로샷 성능 평가
COCO[38] 및 LVIS[39] 데이터셋에서 EfficientViT-SAM의 제로샷 인스턴스 세그멘테이션 성능을 면밀히 평가하였습니다.
Prompt는 ViTDet[40]으로 예측된 바운딩 박스를 사용했습니다 (표 6).
- EfficientViT-SAM은 기존의 SAM-ViT-H[13] 대비 성능-효율성이 매우 뛰어남
- 특히 EfficientViT-SAM-XL1 모델은 COCO와 LVIS에서 SAM-ViT-H를 능가하며, A100 GPU에서 처리량(throughput)이 16.5배 더 높습니다.
📌 주요 성과 요약 (표 6):

→ 기존 SAM-ViT-H 모델 대비 파라미터 및 MACs를 크게 줄이면서도 성능을 상회
🔹 기존 SAM 모델들과의 성능 효율성 비교 (그림 7)
- EfficientViT-SAM은 기존의 가속화된 SAM 모델 중 최초로 SAM-ViT-H의 제로샷 성능을 달성하거나 능가
- 따라서 성능-효율성 trade-off 측면에서 SOTA (state-of-the-art) 모델임을 확인할 수 있음
🔹 포인트 기반 세그멘테이션 성능 평가 (표 7)
바운딩 박스가 아니라 포인트 기반(prompted) 세그멘테이션에서도 EfficientViT-SAM을 평가하였습니다.

- EfficientViT-SAM-XL1 모델은 대부분 상황에서 기존 SAM-ViT-H 모델보다 뛰어난 성능을 보이며, 특히 여러 포인트가 주어졌을 때 큰 성능 향상 달성.
- 다만, LVIS 데이터셋에서 한 개의 포인트만 주어진 상황에서는 SAM-ViT-H가 더 나은 성능을 보임.
- 이는 학습 과정(end-to-end 학습)에서 상호작용(interactive segmentation) 설정이 없었기 때문으로 추정되며,
향후 한 개의 포인트 설정에서의 성능 향상을 위해 추가적인 연구가 필요합니다.
4. 관련 연구 (Related Work)
🔹 고해상도 밀집 예측 (High-Resolution Dense Prediction)
밀집 예측(dense prediction) 이란, 입력 이미지가 주어졌을 때 모든 픽셀에 대한 예측값을 생성하는 작업으로, 이미지 분류를 이미지 단위 예측에서 픽셀 단위 예측으로 확장한 것으로 볼 수 있습니다.
기존 CNN 기반 고해상도 밀집 예측 모델의 성능을 개선하기 위한 광범위한 연구들이 진행되어 왔습니다 [1, 2, 3, 4, 5, 6].
또한, 일부 연구에서는 고해상도 밀집 예측 모델의 효율성 개선에 초점을 맞추었습니다 [41, 42, 43, 44].
하지만 이들 효율성 중심의 모델들은, 성능 측면에서 SOTA 고해상도 밀집 예측 모델에 비해 여전히 크게 뒤처져 있습니다.
이들과 비교하여, 본 논문의 모델(EfficientViT)은 글로벌 수용 영역(global receptive field)과 다중 스케일 학습(multi-scale learning)을 하드웨어 친화적인 가벼운 연산으로 구현함으로써, 성능과 효율성 간의 더 나은 균형을 제공합니다.
🔹 효율적인 비전 트랜스포머 (Efficient Vision Transformer)
ViT(Vision Transformer)는 연산량이 매우 큰 영역(high-computation region)에서 인상적인 성능을 보였지만, 연산량이 제한된 저연산 영역(low-computation region)에서는 기존 효율적 CNN 모델보다 성능이 떨어지는 경우가 많습니다 [45, 46, 47, 48].
이를 극복하기 위해 몇몇 모델이 제안되었습니다:
- MobileViT [49]: CNN의 지역적(local) 처리 방식을 트랜스포머 기반의 글로벌 처리 방식으로 대체하여 CNN과 ViT의 장점을 결합.
- MobileFormer [50]: MobileNet과 Transformer를 병렬적으로 구성하고 양방향 브릿지를 통해 피처를 융합.
- NASViT [51]: Neural Architecture Search(NAS)를 활용하여 효율적인 ViT 아키텍처를 자동 탐색.
하지만 이 모델들은 주로 이미지 분류 작업에 집중되어 있으며, 여전히 계산 복잡도가 이차(quadratic)인 softmax 어텐션에 의존하기 때문에, 고해상도 밀집 예측과 같은 작업에는 적합하지 않습니다.
🔹 효율적인 딥러닝 (Efficient Deep Learning)
본 논문은 효율적인 딥러닝 분야와도 관련이 있습니다. 효율적인 딥러닝이란 모바일, IoT와 같이 자원이 제한된 하드웨어 플랫폼에 배포 가능하도록 딥 뉴럴 네트워크의 효율성을 개선하는 연구 분야입니다.
대표적인 효율화 기술로는 네트워크 프루닝(pruning) [52, 53, 54], 양자화(quantization) [55], 효율적인 모델 설계 [18, 56], 학습 기법 [57, 58, 59] 등이 있습니다.
수작업(manual design)뿐 아니라, 최근에는 AutoML 기법[60, 61, 62]을 활용하여 신경망의 아키텍처 설계[47], 프루닝[63], 양자화[64]를 자동화하는 연구들이 활발히 이루어지고 있습니다.
5. 결론 (Conclusion)
본 연구에서는 고해상도 밀집 예측을 위한 효율적인 아키텍처 설계에 대해 연구했습니다.
글로벌 수용 영역과 다중 스케일 학습을 동시에 달성하는 가벼운 다중 스케일 선형 어텐션 모듈을 제안하였으며,
이는 경량이며 하드웨어 효율적인 연산만으로 구현되어 다양한 하드웨어 장치에서 최신 고해상도 밀집 예측 모델과 성능 손실 없이 획기적인 속도 향상을 제공합니다.
향후 연구로는 EfficientViT를 다른 비전 작업에도 적용하고, EfficientViT 모델의 규모를 더욱 확장(scaling-up)하는 방향을 탐구할 예정입니다.
✨ 감사의 글 (Acknowledgments)
본 연구를 지원해주신 MIT-IBM Watson AI Lab, MIT AI Hardware Program, Amazon and MIT Science Hub, Qualcomm Innovation Fellowship, National Science Foundation에 깊은 감사를 드립니다.
🔹 기본 아이디어:
기존 방식 (예: EfficientViT):
- Transformer → Attention → FFN 구조
- 여기서 attention만 바꿔도 효과가 크지만, 여전히 "attention 프레임워크" 자체에 갇혀 있음
(예: Q/K/V projection, 토큰 간 상호작용 기반)
새로운 방식 (예: DeepSeek-VL, RWKV, RetNet 등):
- Attention 없이도 long-range dependency 학습 가능
- 순차적, 재귀적, 컨볼루션 기반 등의 방식으로 Transformer 구조 자체를 근본적으로 교체
- 기존 Q/K/V가 필요 없는 구조도 있음
🔹 EfficientViT 스타일에 적용하면?
✅ 1. Backbone 구조 교체:
EfficientViT는 기본적으로 ViT-style이지만, softmax 대신 ReLU attention만 교체한 형태였죠.
- 대체 방식: attention 자체를 제거하고
예를 들어, RetNet 블록이나 RWKV 블록, Hyena operator로 backbone block을 대체
class EfficientRetNetBlock(nn.Module):
def __init__(self, dim, ...):
super().__init__()
self.retnet = RetNetCore(dim, ...) # 또는 Hyena1D 같은 operator
self.conv = DepthwiseConv(...)
self.norm = LayerNorm(dim)
def forward(self, x):
x = self.retnet(x)
x = self.norm(x + self.conv(x))
return xFFN+DWConv는 그대로 두고, Attention module 자리에 새로운 block을 넣는 방식.
✅ 2. Pretraining 방식 수정:
- 기존 ViT나 Swin은 ImageNet-pretrained weights를 사용하는 경우가 많음.
- 만약 DeepSeek-style 구조를 쓰려면, 처음부터 고해상도 dense prediction을 위한 pretraining을 새로 해야 함.
- 특히 구조가 완전히 다르면 (예: Hyena는 Convolutional Long Kernel Operator), 기존 weight를 쓸 수 없기 때문에:
(1) 대규모 unlabeled 데이터셋에서 self-supervised pretraining →
(2) downstream task (semantic segmentation 등) fine-tuning🔹 이런 구조를 쓰면 어떤 장점이 생기나?

🔹 실제 적용 예시 (Dense Prediction)
EfficientViT + Hyena 블록을 조합한 Semantic Segmentation 모델 (개념 예시):
class EfficientDensePredictor(nn.Module):
def __init__(self, config):
super().__init__()
self.stage1 = ConvStem(...)
self.stage2 = HyenaBlock(dim=64, ...)
self.stage3 = HyenaBlock(dim=128, ...)
self.stage4 = HyenaBlock(dim=256, ...)
self.decoder = FPNDecoder(...)
def forward(self, x):
x1 = self.stage1(x)
x2 = self.stage2(x1)
x3 = self.stage3(x2)
x4 = self.stage4(x3)
out = self.decoder([x2, x3, x4])
return out이처럼 attention 없이도 전체 semantic context를 처리할 수 있는 구조로 만들 수 있고,
memory-efficient + fast + scalable to high-resolution이라는 장점이 생깁니다.
🔸 결론: 앞으로의 방향
- attention 자체의 경량화 (EfficientViT) → 이미 좋은 효과
- 하지만 **attention이라는 개념 자체를 벗어나는 구조 (DeepSeek, Hyena)**는
진짜로 scalable하고 hardware-aware한 dense prediction을 가능하게 할 수 있음 - 문제는 아직 대부분 classification 위주로만 pretraining이 되어 있고, dense prediction에서는 구조를 바꾸는 만큼 데이터셋 + 파이프라인도 새로 구축해야 함
추가적으로 MBConv 대신 다른 경량 블록을 써보면 어떨까?



