https://arxiv.org/html/2509.25541v1
Vision-Zero: Scalable VLM Self-Improvement via Strategic Gamified Self-Play
Vision-Zero: Scalable VLM Self-Improvement via Strategic Gamified Self-Play Qinsi Wang1, Bo Liu2, Tianyi Zhou3, Jing Shi4, Yueqian Lin1, Yiran Chen1 Hai Helen Li1, Kun Wan4, Wentian Zhao4* Corresponding authors.
arxiv.org
초록(Abstract)
비전-언어 모델(Vision–Language Models, VLMs)의 추론 능력은 강화학습(Reinforcement Learning, RL)을 통해 효과적으로 향상될 수 있지만, 현재의 방법들은 여전히 수작업으로 구성·검증해야 하는 노동집약적 데이터셋에 강하게 의존하고 있다. 이로 인해 학습 비용이 매우 높아지고, 실제 환경에서 VLM을 활용하는 데 큰 제약이 따른다. 이 문제를 해결하기 위해, 우리는 Vision-Zero라는 새로운 프레임워크를 제안한다. 이 프레임워크는 도메인에 구애받지 않고 임의의 이미지 쌍으로부터 경쟁적인 시각 게임을 생성하여, VLM이 스스로 성능을 향상시킬 수 있도록 하는 자가개선(self-improvement) 학습 구조를 제공한다. 구체적으로, Vision-Zero는 다음 세 가지 핵심 속성을 갖는다.
- 전략적 자기 대전(Strategic Self-Play) 프레임워크:
Vision-Zero는 “누가 스파이인가(Who Is the Spy)” 스타일의 게임을 통해 VLM을 훈련시킨다. 모델은 다양한 역할에서 전략적 추론과 행동을 수행하며, 상호작용적인 게임 플레이를 통해 인간 주석 없이 스스로 학습 데이터를 생성한다. - 임의 이미지 기반 게임 생성(Gameplay from Arbitrary Images):
기존의 게이미피케이션(gamified) 프레임워크와 달리, Vision-Zero는 임의의 이미지 쌍으로부터 게임을 생성할 수 있다. 이를 통해 모델은 다양한 도메인에서의 추론 능력을 향상시키며, 여러 작업으로의 강력한 일반화 성능을 보인다.
우리는 이 프레임워크의 범용성을 CLEVR 기반 합성 장면, 차트(chart), 실제 이미지(real-world images) 세 가지 유형의 데이터셋을 통해 실증하였다. - 지속 가능한 성능 향상(Sustainable Performance Gain):
우리는 **Iterative Self-Play Policy Optimization (Iterative-SPO)**라는 새로운 학습 알고리즘을 도입하였다. 이는 자기 대전(Self-Play)과 검증 가능한 보상을 사용하는 강화학습(RLVR, Reinforcement Learning with Verifiable Rewards) 단계를 교대로 수행함으로써, 단일 자기 대전 학습에서 흔히 발생하는 성능 정체(plateau) 문제를 완화하고 장기적으로 지속적인 성능 향상을 달성한다.
Vision-Zero는 라벨이 없는(label-free) 데이터를 사용함에도 불구하고, 추론(reasoning), 차트 질의응답(chart QA), 시각 중심 이해(vision-centric understanding) 등 다양한 작업에서 주석 기반 방법(annotation-based methods)을 능가하는 최첨단(state-of-the-art) 성능을 기록하였다. 모델과 코드는 공개되어 있다.
1. 서론 (Introduction)
최근 비전-언어 모델(Vision-Language Models, VLMs)의 발전은 다양한 멀티모달 과제에서 놀라운 성과를 보여주고 있다 (Achiam et al., 2023; Team et al., 2023). 그러나 현재의 학습 패러다임은 확장성(scalability) 측면에서 근본적인 한계를 가진다.
이들은 주로 인간이 큐레이션한 데이터에 의존하며, 이는 (1) 지도 미세조정(Supervised Fine-Tuning, SFT) (Liu et al., 2023),
(2) 인간 피드백 기반 강화학습(Reinforcement Learning from Human Feedback, RLHF) (Ouyang et al., 2022; Sun et al., 2023), (3) 검증 가능한 보상(Verifiable Rewards)을 활용한 강화학습(RLVR) (Guo et al., 2025) 등의 형태로 나타난다.
이러한 의존성은 두 가지 심각한 병목현상을 초래한다.
- 데이터 부족(Data Scarcity)
멀티모달 주석(annotation)의 막대한 비용 때문에 데이터의 규모와 다양성이 제한된다. 예를 들어, COCO Attributes는 200,000개의 객체에 대해 60,480달러가 필요하고 (Patterson & Hays, 2016), Ego4D는 25만 시간 이상의 주석 작업을 요구하며 (Grauman et al., 2022), Visual Genome은 33,000명의 주석자를 동원해야 했다 (Krishna et al., 2017). - 지식 상한선(Knowledge Ceiling)
모델의 능력이 인간이 제공한 감독(supervision)에 의해 본질적으로 제한되기 때문에, VLM이 인간의 전문성을 넘어서는 전략을 스스로 발견하는 것이 불가능하다.
Self-Play의 가능성
이러한 문제에 대한 한 가지 해법은 자기 대전(Self-Play)이다. Self-Play는 경쟁적 상호작용(competitive dynamics)을 통해 인간 감독을 제거한다 (Silver et al., 2017; Tesauro, 1995). 모델은 자기 복제본과 대결하면서 상호작용의 결과에 따라 자동으로 피드백을 받는다. 모델이 발전할수록 상대 모델 역시 발전하기 때문에, 학습 환경은 지속적으로 도전적(challenging)으로 유지되며 끊임없는 성능 향상을 유도한다.
Self-Play는 데이터 생성 과정에서 인간 감독을 제거함으로써, 여러 분야에서 이미 ‘지식 상한선’을 돌파해왔다. 예를 들어, TD-Gammon의 백개먼 성능 (Tesauro, 1995), AlphaGo의 바둑 정복 (Silver et al., 2016; 2017), OpenAI Five의 팀 협동 능력 (Berner et al., 2019) 등이 그 예이다.
최근에는 LLM의 성능이 향상됨에 따라, Self-Play를 LLM 학습으로 도입하려는 연구도 등장했다. 이들은 언어 기반 게임(Language Gamification) 환경을 구성하여 모델이 명확한 규칙 하에 경쟁하도록 하고, 점진적으로 추론 능력을 향상시킨다. 예를 들어, SPIRAL은 Tic-Tac-Toe나 Kuhn Poker와 같은 게임을 통해 LLM의 추론 능력을 향상시키며 (Liu et al., 2025), Absolute Zero는 제안자(Proposer)와 해결자(Solver) 간의 자기 대전을 통해 수학 및 코딩 과제에서 최신(state-of-the-art) 성능을 달성했다 (Zhao et al., 2025).
그러나 Self-Play를 VLM으로 확장하는 연구는 아직 거의 이뤄지지 않았다. 이는 멀티모달 데이터의 수집 비용이 막대하다는 점에서 오히려 시급한 과제이다.
이상적인 Self-Play 환경의 조건
이상적인 Self-Play 게임 환경은 다음 네 가지 조건을 만족해야 한다.
- 게임을 이기기 위해 학습되는 기술이, 목표 과제에서 필요한 기술과 일치해야 한다.
- 기술 성장의 확장성(Scalability) — Self-Play가 진행될수록 환경의 난이도가 점진적으로 증가하여, 모델이 점점 더 강해지도록 해야 한다.
- 환경의 다양성과 복잡성(Complexity) — 다양한 목표 과제에서 (1)을 충족할 수 있을 만큼 복합적이어야 한다.
- 외부 데이터 의존성 최소화 — 라벨이 없는(label-free) 데이터처럼, 외부 데이터가 거의 필요 없어야 한다.
하지만 기존의 시각적 추론(visual reasoning) 게임들은 위의 네 가지 조건을 모두 동시에 만족하지 못한다. 예를 들어, Sudoku는 (2)와 (4)는 만족하지만, (1)과 (3)은 충족하지 못한다.
멀티모달 특성을 가진 VLM의 Self-Play 환경을 설계하기 위해서는 시각(vision)과 언어(language)의 상호작용을 모두 고려해야 하며, 이는 단순한 일이 아니다.
이에 착안하여, 우리는 언어 기반 사회 추리 게임(social deduction game), 특히 “Who Is the Spy?”처럼 진술(statement)과 투표(voting)가 번갈아 진행되는 구조에서 영감을 받아, 이 네 가지 요건을 모두 만족하는 새로운 시각적 추론 게임(visual reasoning game)을 제안한다.
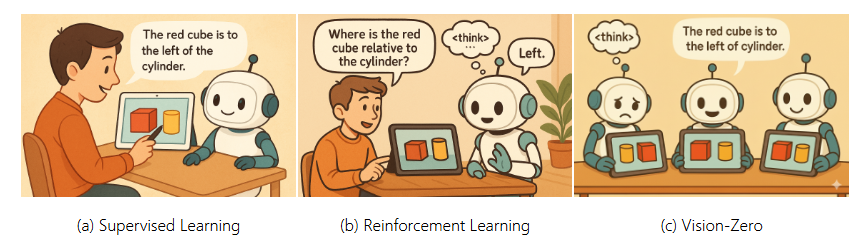
Figure 1. Vision-Zero 패러다임
(a) Supervised Learning
: 인간이 만든 추론 경로(reasoning trajectory)에 의존한다.
(b) Reinforcement Learning
: 검증된 보상(validated rewards)을 통해 모델이 스스로 추론 과정을 학습할 수 있지만, 여전히 전문가가 만든 질문-정답 쌍에 크게 의존한다.
(c) Vision-Zero
: 인간 경험에 완전히 독립적인 새로운 자기개선(self-improvement) 패러다임이다.
Vision-Zero는 시각적으로 다른 두 이미지 쌍을 이용해 Self-Play 게임을 구성하고, 상호작용적이며 전략적인 게임을 통해 VLM 학습 데이터를 자동 생성한다. 이를 통해 확장 가능한 자기개선(Scalable Self-Improvement)을 달성한다.
Vision-Zero 개요
우리는 Vision-Zero를 제안한다 — 인간 주석 없이 VLM의 확장 가능한 자기개선을 가능하게 하는 최초의 게이미피케이션(Self-Play 기반) 프레임워크이다.
이 프레임워크는 미세한 시각적 차이를 가진 이미지 쌍을 기반으로 “Who Is the Spy?” 형식의 시각적 게임을 설계한다. 이 이미지들은 자동화된 이미지 편집 도구나 절차적 렌더링(procedural rendering)을 통해 생성된다. 모델(에이전트)은 이러한 미묘한 차이를 추론(reason)하고 가설을 세우는 과정을 통해 점차 강력한 시각적 추론 능력을 얻게 된다.
이 설정은 모델이 다양한 시각 입력(CLEVR 합성 장면, 차트, 자연 이미지 등)을 다루면서 여러 역할에서 전략적 추론을 수행하도록 강제한다.
또한 우리는 Iterative Self-Play Policy Optimization (Iterative-SPO)를 제안한다. 이는 Self-Play와 RLVR 단계를 번갈아 수행하여, 검증 가능한 감독 신호를 Self-Play에 통합함으로써 학습의 안정성을 높이고 조기 수렴(premature convergence)을 방지한다. 결과적으로 Vision-Zero 프레임워크 내에서 지속적인 성능 향상(consistent performance gain)을 보장한다.
Vision-Zero의 장점
Vision-Zero는 도메인 비의존적(domain-agnostic) 프레임워크로, 다양한 이미지 입력을 활용해 과제별 데이터셋 없이도 지속적 개선을 달성한다. 정교하게 설계된 전략적 시각 게임(visual gameplay)을 통해 모델의 추론 능력, 공간 이해(spatial understanding), 시각적 이해력(visual comprehension)을 강화하며, 기존 VLM 학습에서 흔히 발생하는 텍스트 편향(shortcut bias)과 음의 전이(negative transfer)를 줄인다.
또한 자동화된 이미지 편집 기반이기 때문에 데이터셋 구축 비용이 매우 낮다.

그 결과(Fig. 2), Vision-Zero는 추론(reasoning), 차트/문자인식(chart/OCR), 시각 중심 과제(vision-centric tasks) 등 다양한 영역에서 비싼 인간 주석 데이터로 학습된 최신(SOTA) 모델들을 능가하는 성능을 달성했다.
이는 Vision-Zero가 “Zero-Human-in-the-Loop” 학습 패러다임으로서 가지는 높은 잠재력과 광범위한 적용 가능성을 보여준다.
우리의 기여 (Contributions)
• Vision-Zero 제안:
게이미피케이션된 Self-Play를 통해, 인간 개입이 전혀 없는 Zero-Human-in-the-Loop 학습 패러다임을 최초로 제안하였다.
라벨이 없는(label-free) 입력과 도메인 비의존적 구조를 지원하며, 저비용으로 대규모 최적화가 가능한 데이터셋 구축을 가능케 한다.
• Iterative-SPO 알고리즘 제안:
Self-Play와 RLVR 단계를 번갈아 수행함으로써 학습 안정성을 높이고 조기 수렴을 방지한다.
• 광범위한 실험 결과:
Vision-Zero는 다양한 일반 과제에서 강력한 베이스라인을 능가했으며, 특히 추론(reasoning)과 수학적 과제(mathematical tasks)에서 뛰어난 성능을 보였다.
2Vision-Zero: 일반화 가능한 게임화 교육 프레임워크
이 섹션에서는 그림 3 에 나타낸 바와 같이 일반적이고 확장 가능하며 고성능의 게임화 VLM 사후 학습 프레임워크인 Vision-Zero를 소개합니다 . 먼저 환경과 학습 데이터를 설명합니다( 2.1 절 ). 다음으로, 지속 가능한 성능 향상을 달성하기 위해 자가 학습과 RLVR을 번갈아 사용하는 반복적 SPO(Iterative-SPO)를 제안합니다(2.2절 ) . 마지막으로, 인간 참여 학습 방식과 비교했을 때 Vision-Zero의 장점을 종합적으로 분석합니다( 2.3 절 ).
2.1환경 및 데이터
전략적 환경. 그림 2 에서 볼 수 있듯이 , Vision-Zero는 자연어 기반 사회 추론 게임인 Who is the Spy 에서 영감을 얻었습니다 . 이 설정에서는 여러 플레이어가 참여합니다.N_c 민간인과 스파이 한 명. 각 플레이어에게 이미지가 할당되는데, 스파이의 이미지는 민간인 이미지와 미묘하게 다릅니다. 예를 들어, 누락, 추가, 수정된 물체가 포함되어 있습니다. 각 라운드는 두 단계로 구성됩니다.
- • 단서 단계.
- 이 단계에서 플레이어는 자신의 역할(민간인 또는 스파이)을 알게 됩니다. 각 플레이어는 자신의 이미지를 보고 사물에 대한 설명이나 이미지에서 추론하는 등 이미지의 내용을 반영하는 구두 단서를 제공해야 합니다. 플레이어들은 순서대로 말하고, 각 플레이어의 단서는 다음 플레이어들에게 공개됩니다. 하지만 플레이어들의 사고 과정은 여전히 감춰져 있습니다. 여러 라운드의 단서 단계가 끝나면 게임은 결정 단계로 진입합니다.
- • 결정 단계.
- 이 단계에서 민간인들은 제공된 모든 단서를 자신의 이미지와 결합하여 스파이를 식별하도록 지시받습니다. 스파이는 자신의 신원을 알고 있으므로 투표에 참여하지 않습니다. 플레이어가 누가 스파이인지 확실하지 않으면 "해당 없음"이라고 답할 수 있습니다. 추론과 최종 투표는 모두 플레이어에게 공개되지 않습니다.
Vision-Zero는 고도로 전략적이고 도전적인 게임 환경을 제공합니다. 단서 단계에서 스파이는 다른 사람의 단서와 자신의 이미지를 분석하고 추론하여 변형된 요소를 파악하고, 자신의 단서를 공통된 요소와 연결하여 민간인을 오도해야 합니다. 민간인은 스파이에게 정보 유출을 최소화하는 동시에 의심을 피하기 위해 정확하고 명확한 단서를 제공해야 합니다. 결정 단계에서 민간인은 이미지와 단서를 면밀히 분석하여 불일치를 감지하고 스파이를 정확하게 식별합니다. 두 단계 모두에 대한 자세한 내용은 부록 A.2.1 에 참고용으로 제공됩니다.

그림 3: Vision-Zero의 전반적인 프레임워크. Vision-Zero는 세 가지 핵심 구성 요소로 구성됩니다. 전략적 게임 환경: 각 역할은 다양한 시나리오에 맞춰 전략적 행동을 보여야 하므로 동시에 여러 역량이 필요합니다. 레이블 없는 도메인 독립적인 데이터 입력: Vision-Zero는 다양성과 일반화를 촉진하기 위해 임의의 입력을 수용합니다. 이를 검증하기 위해 Gobang과 개발 환경에서 Qwen2.5-VL-7B를 100회 반복 학습하고 MathVision에서 평가했습니다. 그 결과 Vision-Zero는 효과적인 일반화를 달성하는 것으로 나타났습니다. 반복적 SPO: 새로운 2단계 학습 알고리즘을 도입했습니다. 단서 단계에서는 수신된 투표 수에 반비례하는 제로섬 보상을 사용하여 자가 학습을 통해 모델을 학습합니다. 결정 단계에서는 투표 정확성에 기반한 보상을 사용하여 그룹 정규화를 적용한 RLVR 학습을 수행합니다.
레이블 없는 도메인 독립적인 데이터 입력. Vision-Zero의 입력은 레이블이 없지만 유연합니다. 각 라운드마다 환경에는 원본 이미지가 있는 이미지 쌍만 필요합니다.N_c 민간인에게 제공되며 수정된 대응물 N_s 스파이에게 제공되며 형성됩니다.( N_c , N_s )이미지 쌍. Vision-Zero 환경의 설계 덕분에 임의의 이미지 입력을 지원하여 다양한 분야에 폭넓게 적용할 수 있습니다. 이러한 일반성을 검증하기 위해 다음 세 가지 유형의 데이터를 실험했습니다.
- • CLEVR 데이터.
- (Johnson et al.,2017) CLEVR 렌더러를 사용하여 2,000개의 이미지 쌍을 자동으로 렌더링했습니다. 각 원본 이미지에는 4~6개의 무작위로 배열된 객체가 포함되어 있으며, 수정된 이미지에는 색상과 모양이 모두 변경된 두 개의 객체가 포함되어 있습니다. 원본 이미지와 수정된 이미지의 모든 객체는 자동 스크립팅을 통해 무작위로 생성되었습니다. 전체 렌더링 프로세스는 NVIDIA A100 GPU에서 약 6시간이 소요되었습니다. 그림 4 (왼쪽)는 예시 학습 세트 샘플을 보여줍니다.
- • 차트 데이터.
- 우리는 ChartQA (Masry et al.,2022) 훈련 세트를 원본 이미지 세트로 사용했습니다. 각 원본 이미지에는 Gemini2.5-Flash (Comanici et al.,2025) 각 차트 내의 숫자 속성을 무작위로 교체하여 수정된 이미지를 생성합니다. 이 데이터 세트에는 선형 차트, 원형 차트, 막대 차트가 포함됩니다. 이 데이터 세트의 예시는 그림 4 (가운데)에 나와 있습니다.
- • 실제 데이터.
- ImgEdit (Ye et al.,2025) 훈련 세트는 실제 단일 회전 편집 쌍을 포함하는 고품질 이미지 편집 데이터 세트입니다. 이 데이터 세트의 예시는 그림 4 (오른쪽)에 나와 있습니다.
ChatGPT (OpenAI) 와 같은 고품질 이미지 편집 모델의 최근 발전으로 인해 2024) 및 Nano Banana (Google DeepMind,2024) 차트 및 실제 데이터 세트를 생성하는 비용은 수십 달러 수준으로 여전히 저렴합니다. 데이터 생성 파이프라인에 대한 자세한 설명은 부록 A.2.2 에 나와 있습니다 .
전반적으로 Vision-Zero는 모델이 상호작용적인 게임플레이를 통해 지속적으로 추론 지도를 생성하고 검증 가능한 보상을 통해 학습하는 전략적 게임 기반 환경을 제공하여 확장 가능한 자가 개선을 가능하게 합니다. 또한, Vision-Zero는 레이블 없는 도메인 독립적인 데이터 구성을 지원하여 사용자가 최소한의 비용으로 도메인별 데이터 세트를 구축할 수 있도록 합니다. 그림 3 의 왼쪽 하단에서 볼 수 있듯이 , Vision-Zero는 MathVision 검증 세트에서 기존 모델보다 3% 더 높은 성능을 달성하여 지속적인 성능 향상을 달성했습니다. 이는 Gobang과 같이 이전에는 제한적으로 정의된 게임 환경에서는 달성할 수 없는 수준입니다.

그림 4:Vision-Zero에 사용된 데이터셋의 시각화. 실험에는 세 가지 대표적 데이터, 즉 (왼쪽) CLEVR 기반 데이터, (가운데) 차트 기반 데이터, (오른쪽) 실제 데이터를 사용합니다. 시각화를 위해 게임 내 SPY 이미지에는 나타나지 않는 차이점을 동그라미로 표시했습니다.
2.2반복적 셀프 플레이 정책 최적화
Vision-Zero 내에서 지속적인 성능 향상을 가능하게 하기 위해, 셀프 플레이와 RLVR을 번갈아 사용하는 새로운 최적화 알고리즘인 반복적 셀프 플레이 정책 최적화(Iterative-SPO)를 도입합니다. 반복적-SPO의 워크플로는 그림 3 에 나와 있습니다 .

단서 단계의 Self-Play Policy Optimization
이 단계에서 각 플레이어는 스파이로 의심받지 않기 위해 단서를 신중히 제시하려 한다. 스파이와 시민은 서로 반대되는 목적을 가지므로, 모델의 전략적 학습을 위해 Self-Play Policy Optimization을 적용한다.



판단 단계의 RLVR (Reinforcement Learning with Verifiable Rewards)
이 단계의 목표는 각 플레이어가 스파이를 올바르게 식별하고 투표하는 것이다. 시민들은 동일한 정보를 공유하므로 하나의 집단(group)으로 간주할 수 있다. 따라서 GRPO (Group Reinforcement Policy Optimization) 목적을 사용한다.



그림 5:Vision-Zero에서 스파이 추론을 시각화한 결과입니다. GPT 기반 점수 체계를 통해 훈련 전후 동일한 시나리오에 대한 모델 반응을 비교한 결과, 계획, 검색, 분해, 전략 수립 및 논리적 추론 능력이 크게 향상되었음을 알 수 있습니다.
이산 보상(Discrete Reward) 부분은 좀 특이하다. 하나도 못뽑으면 -0.5라면 spy가 무조건 있다고 패널티를 주는건데, spy를 있다고 착각하게 만들어서 학습을 나중에는 할 수도 있는데, 이 부분은 좀 아쉽다.
반복적 단계 학습(Iterative Stage Training)
순수한 Self-Play 설정은 일반적으로 국소 균형(local equilibrium) 상태에 도달하게 되며 (Yao et al., 2023; Balduzzi et al., 2019; Hu et al., 2020; Balduzzi et al., 2018), 이는 새로운 추론 경로(reasoning path)를 탐색하는 능력을 제한한다. 반대로, RLVR(Reinforcement Learning with Verifiable Rewards)과 같은 단일 강화학습 방식은 주어진 질문 집합을 완전히 학습하고 나면 지식 포화(knowledge saturation) 상태에 빠질 위험이 있다.
이러한 문제를 해결하기 위해, Iterative-SPO는 두 단계(단서 단계–판단 단계)의 교대 학습(two-stage alternating training) 방식을 도입한다.
- 판단 단계(Decision Stage)의 성능이 높아져 스파이를 쉽게 식별할 수 있는 수준에 도달하면, 학습은 단서 단계(Clue Stage)로 전환되어 난이도를 높인다.
- 반대로 스파이를 구별하기 어려워지는 시점에는 다시 판단 단계로 돌아간다.






이 교대 학습(Alternating Scheme)의 장점
- 지속적 성능 향상(Continuous Improvement)
- 모델이 전략적 균형(strategic equilibrium)이나 지식 포화 상태에 머무르지 않도록, 정체 신호(stagnation signals)를 감지하면 자동으로 단계 전환을 수행한다.
- 이를 통해 모델은 끊임없이 새로운 추론 경로를 탐색하며 성능을 향상시킨다.
- (3.2절에서 실험적으로 검증됨)
- 학습 안정성(Training Stability)
- Self-Play와 RLVR을 번갈아 수행함으로써, RLVR의 감독 신호(supervised signal)를 Self-Play에 주입해 학습 안정성을 확보한다.
- 이를 통해 역할 붕괴(role collapse) (Wang et al., 2020; Yu et al., 2024)나 발산(divergence) (Heinrich & Silver, 2016; Vinyals et al., 2019)과 같은 일반적인 실패 사례를 방지한다.
요약하면, Iterative-SPO는 Self-Play와 RLVR 최적화를 통합하여 지속적이고 안정적인 성능 향상(sustained performance improvement)을 달성하는 견고한 학습 패러다임을 제공한다.
1. Self-Play 단독의 한계
Self-Play만으로 학습을 진행하면,
- 결국 균형점(equilibrium) 혹은 자기 상쇄 상태에 도달하게 됩니다.
→ 예를 들어, 스파이와 시민이 서로의 전략을 충분히 학습하면, 양쪽 모두 새로운 행동을 시도할 유인이 사라집니다. - 이렇게 되면 보상 신호의 분산이 0에 가까워지고, 정책이 더 이상 업데이트되지 않죠.
- 즉, Self-Play는 “새로운 전략을 탐색(explore)”하는 힘은 강하지만, 그 전략이 유의미한 학습 신호로 수렴할 장치가 부족합니다.
그래서 논문에서도 “local equilibrium”이라는 표현을 썼습니다.
Iterative-SPO는 필수적인 설계는 아니지만, Self-Play 기반 자가 학습을 안정적으로 굴리는 실용적 해법으로 보는 게 맞습니다.
표 1:VLMEvalKit에서 평가된 추론 및 수학에 대한 Vision-Zero 모델과 SOTA 모델의 성능 비교 . 모든 결과는 동일한 설정에서 얻어졌으며, ViGaL-Snake와 ViGaL-Rotation은 모델이 부족하여 원본 논문에서 얻은 결과입니다. Vision-Zero는 관련 작업에서 방대한 양의 수동 주석 데이터셋을 사용하여 학습된 기준선보다 우수한 성능을 보입니다.
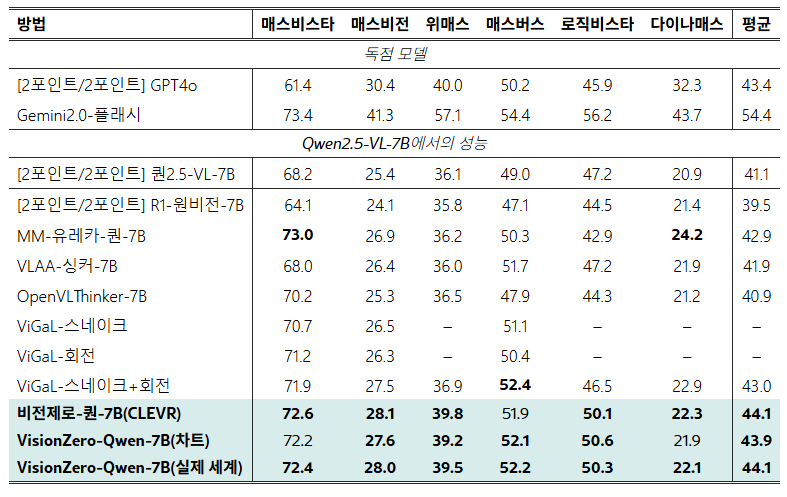
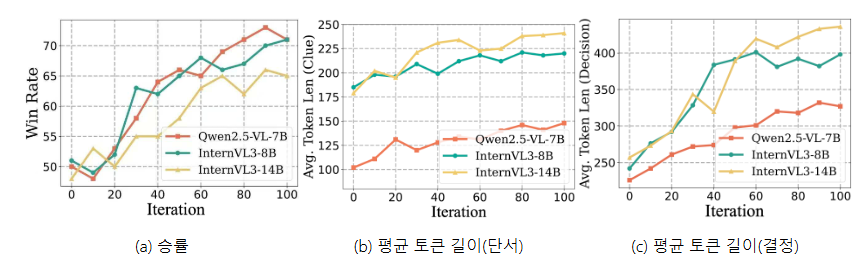
그림 6:Vision-Zero 훈련 중 승률과 토큰 길이의 변화. 승률은 훈련되지 않은 참조 모델을 기준으로 100라운드(민간인 50명, 스파이 50명)에 걸쳐 평가됩니다. 민간인은 스파이를 정확하게 식별하여 승리합니다. 토큰 길이는 각 라운드에서 수집됩니다.
**성능 차이는 “크지 않지만, 주석 데이터 없이 그 수준을 달성했다”**는 게 핵심 포인트예요.
Vision-Zero는 “인간 주석 없이 자가 개선(Self-Improvement)”이라고 주장하지만, 실제 실험 세팅을 보면 완전히 from-scratch 학습이 아니라 이미 학습된 VLM(Qwen2.5-VL-7B)을 post-training한 것입니다.

논문이 의미를 가지는 부분은 딱 하나
“VLM도 스스로 학습 데이터를 만들어 보상을 받을 수 있는 구조로 훈련될 수 있다”
라는 가능성을 실험적으로 보여줬다는 점이에요.
2.3이점 분석
Vision-Zero는 세 가지 주요 장점을 가지고 있습니다. 첫째, Vision-Zero는 이미지 차이를 통해 도메인에 구애받지 않는 데이터 입력을 활용하여 특정 이미지 유형에 의존하지 않고 다양한 데이터를 수용할 수 있습니다. 이러한 보편성 덕분에 기존의 고품질 이미지 데이터 세트를 직접 활용할 수 있어 최소한의 비용으로 일반화 가능한 성능 향상을 달성할 수 있으며, 이는 우수한 벤치마크 결과(그림 2 )에서 입증됩니다. 둘째, Vision-Zero는 시각적 및 텍스트 입력을 동시에 분석하여 공간 관계와 객체 세부 정보를 처리함으로써 추론, 시각적 이해 및 OCR 기능을 동시에 향상시킵니다. 이러한 통합적인 접근 방식은 그림 5 에서 볼 수 있듯이 텍스트 단축기 편향 및 부정적 기능 전이와 같은 일반적인 문제를 효과적으로 완화합니다. 마지막으로, Vision-Zero는 ChatGPT 및 NanoBanana와 같은 고급 편집 도구를 사용하여 데이터 세트를 빠르게 생성하는 매우 비용 효율적인 데이터 큐레이션 전략을 사용합니다 . 이 접근 방식은 기존의 수동 레이블링에 비해 비용을 크게 절감하여 대상 VLM의 실제 적용을 가속화합니다.
3실험
Vision-Zero를 철저히 평가하기 위해 먼저 실험 설정, 데이터셋, 그리고 기준선을 간략하게 설명합니다. 다음으로, 다양한 과제에 걸쳐 Vision-Zero의 성능과 비용 효율성을 평가합니다( 3.1 절). 마지막으로, 모델 일반화 가능성과 Iterative-SPO의 효과성을 분석하여 결론을 내립니다( 3.2 절 ).
모델, 데이터 세트 및 기준선. 우리는 Qwen2.5-VL-7B (Bai et al.,2025) , InternVL3-8B 및 InternVL3-14B (Zhu et al.,2025) — 추론, 차트 분석, 비전 중심 영역의 14개 과제에 걸쳐 수행되었습니다. 자세한 모델 및 데이터셋 정보는 부록 A.3.1 에 있습니다 . 본 연구에서는 SOTA 방법 R1-OneVision-7B (Yang et al.,2025) , MM-Eureka-Qwen-7B (Meng et al.,2025) , VLAA-Thinker-7B (Zhou et al.,2025) 및 OpenVLThinker-7B (Deng et al.,2025) (모두 인간이 레이블을 지정한 데이터에 대해 RLVR을 통해 사후 학습됨) 및 ViGaL (Xie et al.,2025) 게임 데이터를 수집한 후 이를 바탕으로 학습을 진행합니다.
표 2:Chart/OCR 및 Vision-Centric 벤치마크에서 Vision-Zero와 다른 최첨단 모델 간의 성능 비교. 모든 모델은 오픈 소스 플랫폼인 VLMEvalKit을 사용하여 평가되었습니다. 관련 데이터세트에 대한 추가 결과는 부록 A.4 에 제공됩니다 .

표 3:방법별 데이터셋 구축 비용 비교. R1-OneVision-7B와 같은 방법은 실제 이미지에 대한 프로그래밍 방식의 질의응답 생성과 수동 검증을 사용하며, 수개월에서 1년까지 소요됩니다. ViGaL은 두 가지 환경(Snake 및 CLEVR 기반 방향 게임)에서 몇 주에 걸쳐 게임플레이 데이터를 수집합니다. 이와 대조적으로 Vision-Zero는 간단한 이미지 편집을 통해 각 이미지 쌍을 전체 게임 라운드에 걸쳐 사용하여 필요한 샘플을 크게 줄입니다. 또한, 대부분의 기준선이 순수 추론 및 수학적 작업을 중심으로 학습되기 때문에 일부 모델은 종합 벤치마크인 MMMU에서 실제로 성능 저하를 보입니다.


3.1주요 결과
지속 가능한 성능 성장. Vision-Zero의 지속 가능한 성능 성장을 검증하기 위해, 고정된 미훈련 참조 모델과 비교하여 모델의 승률을 평가하고 CLEVR 데이터에서 Clue 및 Decision 단계의 평균 토큰 길이를 측정했습니다. 그림 6 에서 볼 수 있듯이 , 승률은 훈련 기간 동안 지속적으로 증가했으며, Qwen2.5-VL-7B는 50%에서 71%로 향상되었습니다. 평균 토큰 길이는 특히 Decision 단계에서 상당히 증가했습니다(예: InternVL3-8B와 InternVL3-14B는 토큰 수가 250개에서 약 400개로 증가). 이는 Iterative-SPO를 통해 향상된 추론 능력이 구현되었음을 시사합니다.
강력한 작업 일반화 기능. Vision-Zero 환경의 성능 향상이 더 광범위한 추론 및 수학 작업에도 일반화되는지 평가하기 위해 6개의 벤치마크 데이터셋을 사용하여 모델을 평가했습니다. 실험 결과는 표 1 에 제시되어 있습니다 . 입증된 바와 같이, Vision-Zero 모델은 다양한 벤치마크에서 최첨단 기준 모델보다 지속적으로 우수한 성능을 보였습니다. 구체적으로 VisionZero-Qwen-7B(CLEVR)와 VisionZero-Qwen-7B(Real-World)는 기준 모델 대비 약 3%의 성능 향상을 달성했으며, VisionZero-Qwen-7B(Chart)는 약 2.8% 향상되었습니다. 반면, 가장 진보된 기준 모델조차도 약 1.9%의 성능 향상만을 보였습니다. 주목할 점은 모든 기준 모델이 수백 또는 수천 개의 수학 및 추론 샘플을 사용한 훈련에 의존한다는 것입니다. 비교를 위해, Vision-Zero 환경은 수학 관련 작업 훈련을 명시적으로 포함하지 않습니다. 대신, 자연어 맥락에서 전략적 게임플레이를 통해 모델의 논리적 추론 능력을 향상시킵니다. 이러한 결과는 Vision-Zero 환경에서 학습한 모델이 더 광범위한 수학 및 추론 작업에 효과적으로 일반화할 수 있으며, 대규모 작업별 데이터 세트에서 명시적으로 학습한 모델보다 더 뛰어나다는 것을 분명히 보여줍니다.
교차 기능 부정 전이 완화. VLM 사후 학습의 핵심 과제는 교차 기능 부정 전이로, 특정 작업에 대해 학습된 모델이 다른 작업에서는 성능이 저하되는 경우가 많습니다. 표 2 의 평가 결과는 추론 및 수학 데이터셋으로 사후 학습된 기준 모델에서 눈에 띄는 성능 저하가 나타남을 보여줍니다. 예를 들어 MM-Eureka-Qwen-7B는 ChartQA에서 약 10%의 성능 저하를 보였습니다. 반면, Vision-Zero로 학습된 모델은 이러한 부정 전이를 효과적으로 완화했습니다. 특히 VisionZero-Qwen-7B(CLEVR)는 네 가지 차트/OCR 작업에서 평균 0.2%의 최소 감소율을 기록하며 시각 중심 작업에서 성능을 크게 향상시켰습니다. 한편, VisionZero-Qwen-7B(Chart)는 네 가지 차트/OCR 벤치마크 모두에서 성능을 향상시키고 동시에 시각 중심 작업에서 평균 1%의 성능 향상을 달성했습니다. 이는 Vision-Zero의 전략적이고 다중 역량 교육 환경이 기존의 단일 역량 교육 패러다임에서 흔히 나타나는 부정적인 전환 문제를 크게 완화한다는 것을 보여줍니다.
표 4:Vision-Zero의 모델 일반화 가능성을 평가합니다. CLEVR 기반 데이터셋을 사용하여 Vision-Zero 내에서 InternVL3-8B와 InternVL3-14B를 학습하고, 8가지 추론 벤치마크를 통해 평가합니다.


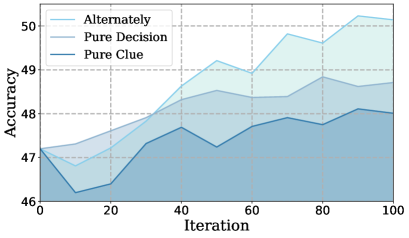
그림 7:반복적 SPO와 순수 자가 학습/RLVR 학습 간의 성능 비교. (왼쪽) 승률 (오른쪽) LogicVista에서의 성능. 세 가지 설정으로 평가했습니다. (1) 반복적 SPO; (2) 순수 결정: 단서 단계 고정, RLVR을 통해 결정 단계만 학습; (3) 순수 단서: 결정 단계 고정, 자가 학습을 통해 단서 단계만 학습.
낮은 데이터셋 구축 비용. Vision-Zero는 수개월 또는 수년이 걸릴 수 있는 광범위한 수동 데이터 수집 및 검증이 필요한 기존 RLVR 방식에 비해 데이터셋 구축 비용을 크게 절감합니다(표 3 ). 도메인에 구애받지 않는 데이터 입력과 간소화된 데이터셋 생성을 통해 Vision-Zero는 수십 시간의 GPU 사용과 최소한의 비용으로 탁월한 성능을 달성하여 경제적이고 접근 가능하며 지속 가능한 학습 패러다임을 제공합니다.
3.2절제 연구
모델 일반화 가능성. Vision-Zero의 일반화 가능성을 평가하기 위해 InternVL 모델을 학습시키고 추론 및 수학 과제에서 성능을 평가했습니다. 표 4는 VisionZero-InternVL3-8B와 VisionZero-InternVL3-14B가 추론 과제에서 각각 1.8%와 1.6%의 정확도 향상을 보임을 보여줍니다. 이는 다양한 모델 아키텍처에서 Vision-Zero의 효율성을 보여줍니다.
반복적 SPO의 우수성. 마지막으로, 세 가지 다른 설정에서 Qwen2.5-VL-7B를 훈련하여 단일 모드 훈련과 비교하여 반복적 SPO의 우수성을 평가합니다.(1) 순수 단서 단계 훈련: 결정 단계가 고정됨(경사 업데이트 없이 순방향 전달만); (2) 순수 결정 단계 훈련: 단서 단계가 고정되고 결정 단계만 업데이트됨; (3) 반복적 SPO. 그림 7 에서 볼 수 있듯이 반복적 SPO는 두 단일 모드 접근 방식보다 상당히 성능이 뛰어나며, 특히 성능 향상이 느리고 조기 평형을 경험하는 순수 단서 단계 훈련을 능가합니다. 이는 순수한 자기 플레이에는 직접 검증 가능한 보상이 부족하기 때문입니다. 보상 신호는 의사 결정자에서 발생하고 의사 결정 품질이 역할을 효과적으로 구별하기에 부족하면 모델 성능이 조기에 정체됩니다. 교대 훈련은 이러한 제한을 완화하여 지속 가능한 성능 향상을 달성합니다. 예를 들어, LogicVista 데이터 세트의 경우 순수 셀프 플레이보다 최종 정확도가 2% 향상되고 순수 RLVR 학습보다 1% 향상됩니다.
4결론
VLM을 위한 최초의 인간 참여 없는(zero-human-in-the-loop) 자기 개선 프레임워크인 Vision-Zero를 소개합니다. 이 프레임워크는 전략적 환경과 도메인에 구애받지 않는 입력을 통해 자기 플레이 학습 과제를 해결합니다. 저희의 혁신적인 반복적 자기 플레이 정책 최적화(Iterative-SPO) 알고리즘은 자기 플레이와 RLVR을 번갈아 적용하며, 감독 신호를 통합하여 학습을 안정화하고 최적이 아닌 평형 상태를 방지합니다. 실험 결과, Vision-Zero는 추론, 차트/OCR, 시각 중심 작업에서 VLM 성능을 크게 향상시키는 동시에 기존 인간 레이블링 데이터셋 대비 데이터셋 구축 비용을 대폭 절감하여 VLM 개발 및 실제 적용을 가속화하는 경제적이고 유연하며 견고한 솔루션을 제공합니다.
'인공지능' 카테고리의 다른 글
| INT v.s. FP: A Comprehensive Study of Fine-Grained Low-bit Quantization Formats (2) | 2025.11.23 |
|---|---|
| Less is More: Recursive Reasoning with Tiny Networks (2) | 2025.10.09 |
| Polynomial Composition Activations: Unleashing the Dynamics of Large Language Models (6) | 2025.08.26 |
| DINOv3 (2) | 2025.08.19 |
| Nano Banana (4) | 2025.08.17 |
