Generative Adverislal Network, 흔히 GAN이라고 불리며 현재는 잘 사용되지 않는 모델이다. Diffusion 모델이 현재 생성 이미지를 꽉 잡고 있기 때문이다. GAN에 대한 정리 영상과 Diffusion 모델 영상은 다음을 추천드린다.
GAN: https://www.youtube.com/watch?v=vZdEGcLU_8U
Diffusion: https://youtu.be/jaPPALsUZo8
우리는 지금까지 discriminative models 보았다. (CNN 기준으로) 이는 이미지 X가 주어지면 레이블 Y를 예측한다(P(Y|X)). 하지만 discriminative model에는 몇 가지 주요 제한 사항이 있다. P(X), 즉 특정 이미지를 볼 확률을 모델링할 수 없다. 따라서 P(X)에서 샘플링할 수 없다. 즉, 새 이미지를 생성할 수 없다. 우리는 GAN을 통해 새로운 이미지 생성 가능한 모델에 대해서 알아볼 것이다.
생성모델이 무엇이냐하면 간단하게 주어진 데이터의 전체 확률 분포를 모델링하여 기존 데이터와 유사한 새로운 데이터를 생성하는 것이다.
입력이 고양이사진으로 주어졌다면 다음과 같이 나와야한다.

우리는 생성모델을 왜 사용해야될까?
이는 다음의 그림을 확인하면 명확하게 알 수 있다.

해상도를 높여줄 수 있고, 없는 style을 만들어줄 수 있어 창의적인 행동을 간단하게 컴퓨터로 할 수 있게해주기 때문이다.
자, 그러면 GAN으로 들어가보자.

GAN의 구조는 간단하다. G는 generator, D는 discriminator로 G는 D가 속을때까지 계속학습하고, D는 계속 생성된 이미지를 간파하는 것이다. 즉, 경찰과 위조 지폐범이 지폐의 위조 유무를 두고 싸우는 것과 같다.
그렇기 때문에 목적함수(Objective Function)를 살펴보면 다음과 같다.
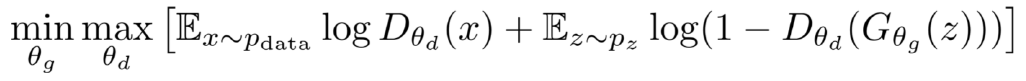
D의 경우 𝑫(𝒙)가 1에 가깝고 𝑫(𝑮𝒛)가 0에 가까워지도록 하여 목표를 최대화한다. G 의 경우 𝑫(𝑮𝒛)를 만들어 목표를 최소화합니다. 이 식으로는 이해가 어려울 수 있으니 조금 더 자세히 보자.
목적함수는 Training에 사용된다. 그리고 θd, θg를 보기 편하게 다음과 같이 하이라이트하자.
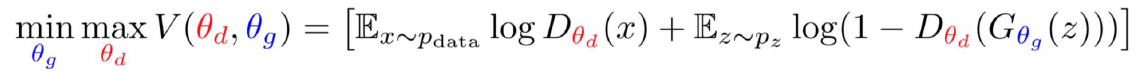
각각의 D와 G의 부분을 식으로서 분리하면 다음과 같아질 것이다.
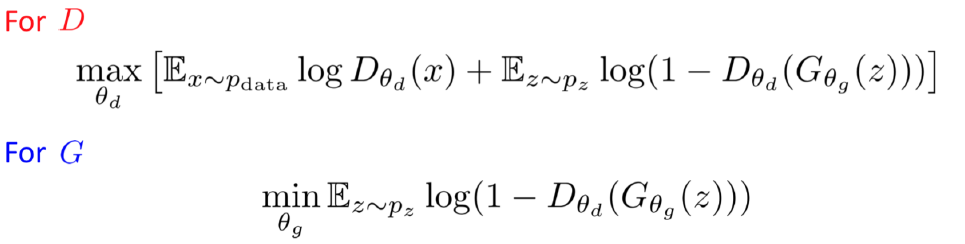
따라서 우리는 𝑫(𝒙)는 1에 가깝게 될 수록 , 그리고 𝑫(𝑮𝒛)가 최소화 될 수록 높은 reward를 받는 것을 알 수 있다.
반대로 G는 𝑫(𝑮𝒛)를 만들어 목표를 최소화해야 높은 reward를 받는 것을 알 수 있다.
Discriminator를 속이는 최고의 전략이 존재할까? 즉, input 이미지처럼 만들수 있는 최고의 방향성이 있냐는 말이다.
이를 한번 찾아보자. 이를 해를 찾기위해, G는 fix하고 D를 minimize하자. 그러면 다음의 식으로 변경될 것이다.
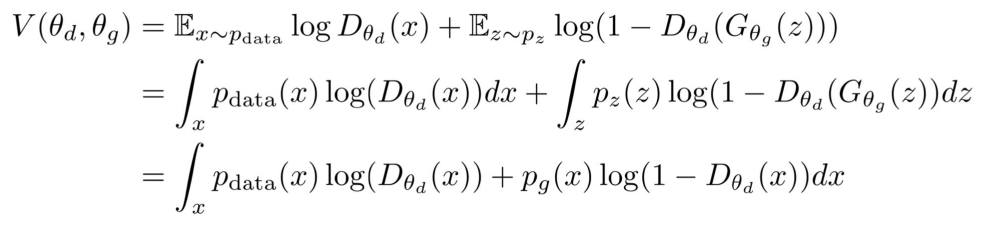
여기서 x에 대한 미분을 때리고, D(x)에 대한 해를 구하면 V가 0이 되기 때문에 다음과 같이 나온다.

pdata = pg면 우리는 data와 generator를 구분할 수 없는 것이기 때문에, 다음의 최적 해가 나온다.
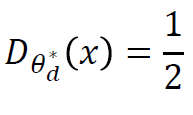
실제 GAN의 trainging alforithm은 다음과 같다.

빨강 부분이 discriminator, 파랑 부분이 generator에 관련된 것임을 확인할 수 있다.
그렇다면 우리는 discriminator에 대해서만 봤는데, generator는 어떻게 training시켜야 될까?
일단 Generator의 식을 살펴보자.
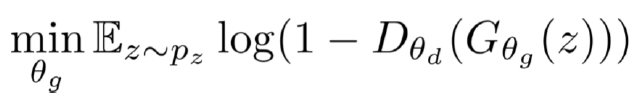
이걸 함수로 먼저보자.

초기에 생성된 샘플이 좋지 않은 경우(훈련 시작 시) 그래디언트가 상대적으로 평평하기 때문에, 생성기 목표 최적화가 제대로 작동하지 않을 가능성이 높다. 하지만 기다리면 결국 잘 작동한다는 것을 알 수 있다.
추가적인 이득으로는 GAN의 generator는 최대 우도 추정(Maximum Likelihood Estimation, MLE)와 같은 전통적인 학습 방법을 사용하지 않기 때문에, 훈련 과정은 간단하다. 생성자와 판별자라는 두 개의 신경망이 적대적인 경쟁을 통해 동시에 학습된다. GAN은 생성자가 훈련 데이터를 직접 보지 않기 때문에 과적합에 강하며, 데이터 분포의 다양한 모드를 잘 포착할 수 있다.
이를 보면 GAN은 하나의 게임같지 않은가? Discriminator와 Generator가 각각의 게임에서 최대의 이득을 보려고하는 점이 말이다. 이는 Nash equilibrium이라 하며 더 정확하게는 게임에서 플레이어들이 최선의 선택을 한다고 가정할 때, 어떤 플레이어도 단독으로 전략을 변경할 경우 자신의 이익을 개선할 수 없는 상태를 의미한다. 그러나 GAN에서 Nash equilibrium을 달성하는 것은 어렵다. GAN의 학습 과정이 적대적이기 때문이다. 생성자와 판별자가 서로 경쟁하며 동시에 학습되는데, 한 쪽이 학습을 앞서게 되면 다른 쪽이 따라잡기 위해 전략을 변경할 수 있다. 이러한 상황에서 균형 상태를 유지하고 최적 해에 도달하는 것은 어렵기 때문에, GAN의 학습은 종종 균형이 불안정하고 수렴하기 어려운 문제를 가지게 된다. 추가적으로 SGD는 Nash equilibrium을 타겟으로 디자인되지 않았기 때문이다.
이런 수렴하기 어려운 부분 때문에 Mode collapse가 다음과 같이 일어난다. 즉, 퀄리티가 좋지않은 비슷해 보이는 이미지를 많이 뽑아낸다는 것이다.

이는 수식으로도 확인 가능하다.

결국 생성기가 다양한 샘플을 출력하지 못하기 때문에 발생하는 것이다.

따라서 이를 해결하기 위해서는 다양성을 추가해주는 수식이 필요하다.

위의 식의 유도과정은 따로 찾아보길 권한다.
KL divergence의 수식은 다음과 같다.
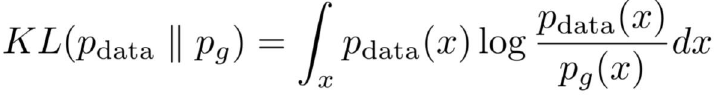
Jensen Shannon divergence의 수식은 다음과 같다.
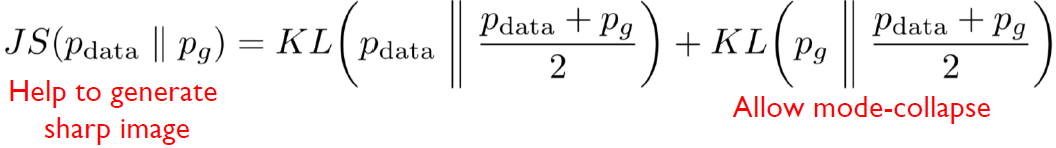
KL divergence는 두 확률 분포 사이의 거리를 측정하는 방법 중 하나이다. 생성된 분포와 실제 데이터 분포 간의 KL divergence를 최소화하면, 생성자는 실제 데이터의 다양성을 잘 포착하도록 학습된다. KL divergence는 생성자가 다양한 모드를 포함한 분포를 생성할 수 있도록 돕는 역할을 한다.
Jensen-Shannon divergence는 KL divergence의 대칭적인 형태로, 두 분포 사이의 유사성을 계산한다. Jensen-Shannon divergence를 최소화하면, 생성된 분포와 실제 데이터 분포 사이의 유사성을 개선하고 모드 붕괴를 완화할 수 있다.
KL divergence나 Jensen-Shannon divergence를 사용하여 모드 붕괴를 방지하려면, 생성자와 판별자의 학습 과정에서 해당 지표를 손실 함수에 추가한다. 이를 통해 생성자는 실제 데이터 분포와 유사한 분포를 생성하고 다양한 모드를 포착하는 데 더 집중할 수 있다.
하지만 주의할 점은 KL divergence나 Jensen-Shannon divergence를 사용하면 모드 붕괴를 완전히 제거할 수는 없다는 것이다.
적용하면 아래의 그림과 같이 나온다.
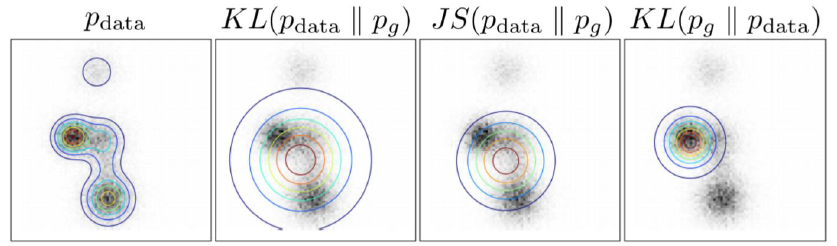
그렇다면 추가적으로 개선할 수 있는 방식은 무엇이 있을까?
Feature matching, Historical averaging, Minibatch Discrimination이 있다.
Feature Matching (특징 매칭): Feature Matching은 생성자의 손실 함수를 조정하여 안정성을 향상시키는 방법이다. 일반적으로 생성자의 목표는 판별자를 속이기 위해 실제 데이터 분포의 특징을 잘 맞추는 것이다. Feature Matching은 생성자의 출력과 실제 데이터의 중간 표현(feature) 사이의 차이를 최소화하는 방식으로 손실을 계산한다. 이를 통해 생성자는 특징 매칭을 통해 실제 데이터 분포의 특징을 더 잘 반영하도록 학습된다.

Historical Averaging (과거 평균화): Historical Averaging은 생성자와 판별자의 파라미터를 업데이트하는 방식을 개선하는 방법이다. 일반적으로 GAN에서 생성자와 판별자는 각각의 손실 함수에 대한 그래디언트를 계산하여 모델 파라미터를 업데이트한다. Historical Averaging은 이러한 그래디언트를 이전에 계산된 그래디언트의 평균과 결합하여 파라미터 업데이트를 수행한다. 이를 통해 모델 파라미터의 업데이트를 부드럽게 하고 안정성을 향상시키는 효과를 얻을 수 있다.
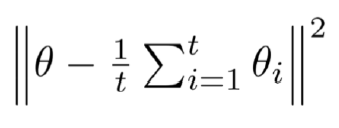
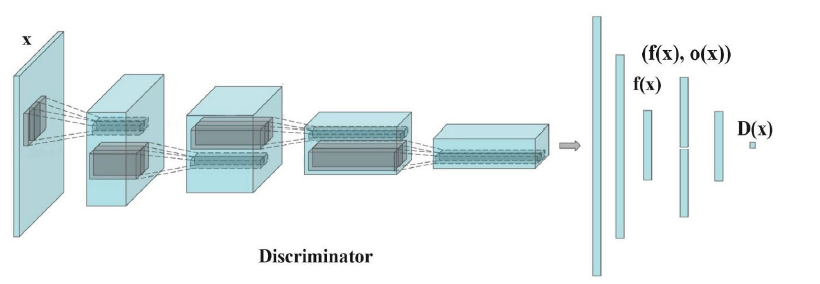
Minibatch Discrimination (미니배치 디스크리미네이션): Minibatch Discrimination은 생성자가 다양한 샘플을 생성하는 데 도움을 주는 기법이다. 일반적으로 판별자는 개별 샘플을 판별하는 데 사용된다. Minibatch Discrimination은 이 개별적인 판별 대신 미니배치에 대한 정보를 사용하여 생성자를 훈련한다. 판별자는 미니배치의 다양한 샘플 간의 관계를 학습하고, 생성자는 이 정보를 활용하여 다양한 샘플을 생성할 수 있도록 돕는다. 이를 통해 생성된 결과의 다양성을 증가시키는 효과를 얻을 수 있다.
그러면 GAN의 기본에 대한 설명은 끝났다. 다양한 유형의 GAN을 살펴보자.
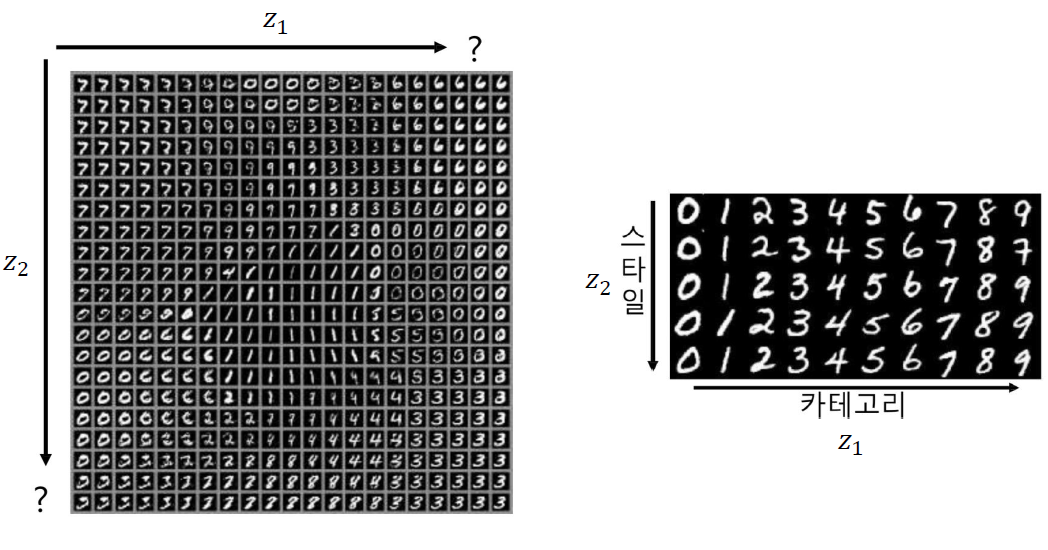
InfoGAN은 생성된 데이터는 일반적으로 아래 그림의 왼쪽 같이 되어있는데, 이를 오른쪽처럼 continuous하게 정렬하는 것이다.

아래와 같이 사용될 수 있다.
구조는 다음과 같다. 왼쪽이 GAN, 오른쪽이 InfoGAN이다.

노이즈 벡터를 두 부분으로 분할하면 다음과 같다.
Z 벡터는 이미지의 약간의 변화를 캡처한다. C 벡터는 이미지의 주요 속성을 캡처한다.
여기서는 C과 x=G(Z,C) 간의 상호 정보를 극대화하고자 하기 때문에 다음의 식을 사용할 수 있다.
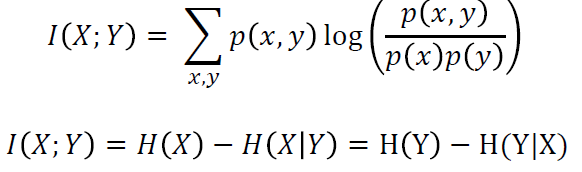
H는 상호 정보 엔트로피(Mutual Information Entropy)이다.일반적으로 상호 정보를 계산하기 위해 사용되는 지표 중 하나로, 잠재 변수의 분포와 생성된 데이터의 분포 사이의 차이를 계산하는 방법으로 사용되기 때문에 여기에 적절하다.
미니맥스 게임의 가치 함수에 통합하면 다음과 같이 식이 될 것이다.
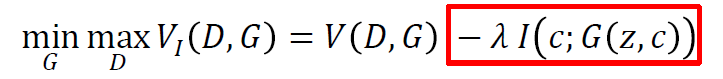
이를 조금 더 변경하면 다음의 식들이 전개된다.

이를 통해 InfoGAN을 생성할 수 있다.
다음은 Conditional GAN을 살펴보자.

Conditional GAN은 GAN의 변형으로, 추가적인 조건 정보를 활용하여 생성자와 판별자를 조건부로 학습시키는 방법이다. 이를 통해 원하는 조건에 맞는 특정한 결과를 생성할 수 있다.
일반적인 GAN은 잠재 공간의 무작위한 노이즈 벡터로부터 데이터를 생성한다. 하지만 Conditional GAN은 이 노이즈 벡터에 추가적인 조건 정보를 입력으로 제공한다. 이 조건 정보는 생성된 데이터의 특성이나 분류 정보와 같은 것일 수 있다.
조건부 GAN의 구조는 생성자와 판별자 사이에 추가적인 조건 정보를 전달하기 위한 입력층이 추가된다. 생성자는 이 조건 정보를 활용하여 원하는 조건에 맞는 데이터를 생성하고, 판별자는 생성된 데이터와 실제 데이터를 판별할 때 이 조건 정보를 함께 고려한다.
Image to Image Translation에서 사용될 수 있다.


다음은 CycleGAN이다.
콘텐츠를 유지하면서 이미지 스타일을 변경하고자 만들어졌다. 다음 그림을 보면 이해하기 쉽다.

만약 우리에게 짝지어진 데이터가 있다면, 이는 지도 학습 문제가 될 것이다. 하지만 이러한 데이터를 찾는 것은 어렵다.
CycleGAN 구조는 짝지어지지 않은 데이터에서 이를 수행할 수 있도록 학습한다.
두 개의 서로 다른 생성자 네트워크를 훈련시켜 스타일 1에서 스타일 2로 가는 매핑과 그 반대의 매핑을 수행한다.
스타일 2의 생성된 샘플이 실제 이미지와 구별할 수 없도록 판별자 네트워크를 통해 확인한다.
생성자 네트워크가 사이클 일관성을 가지도록 한다: 스타일 1에서 스타일 2로의 매핑과 다시 역으로 스타일 2에서 스타일 1로의 매핑은 거의 원본 이미지를 얻어야 한다.
아래 그림은 CycleGAN의 작동 방식이다.
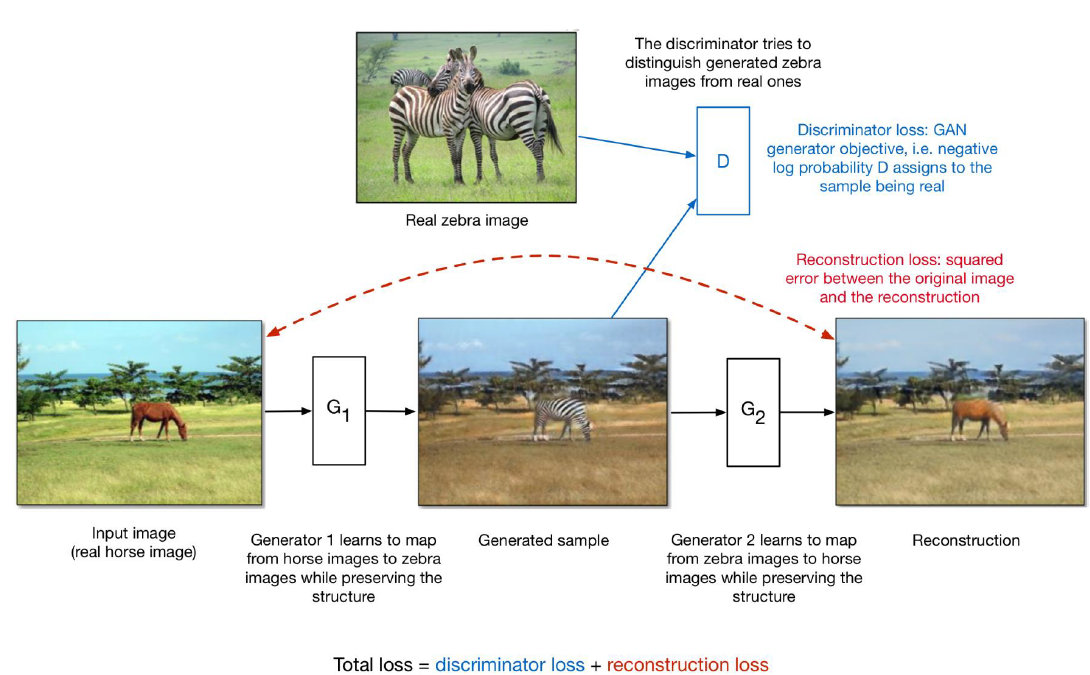
이런 식으로도 활용 가능하다.

Text to Image Synthesis를 알아보자. 이는 최근에 prompt를 통해 그림을 생성하는 stable diffusion, dalle2의 형태이다.(물론 구조는 아예다르다.) 텍스트를 이미지로 합성시켜주는 것으로 텍스트 설명이 주어지면 밀접하게 관련된 이미지를 생성한다. Dense 텍스트 임베딩을 조건으로 하는 생성기와 판별자와 함께 조건부 GAN을 사용하여 만든다.

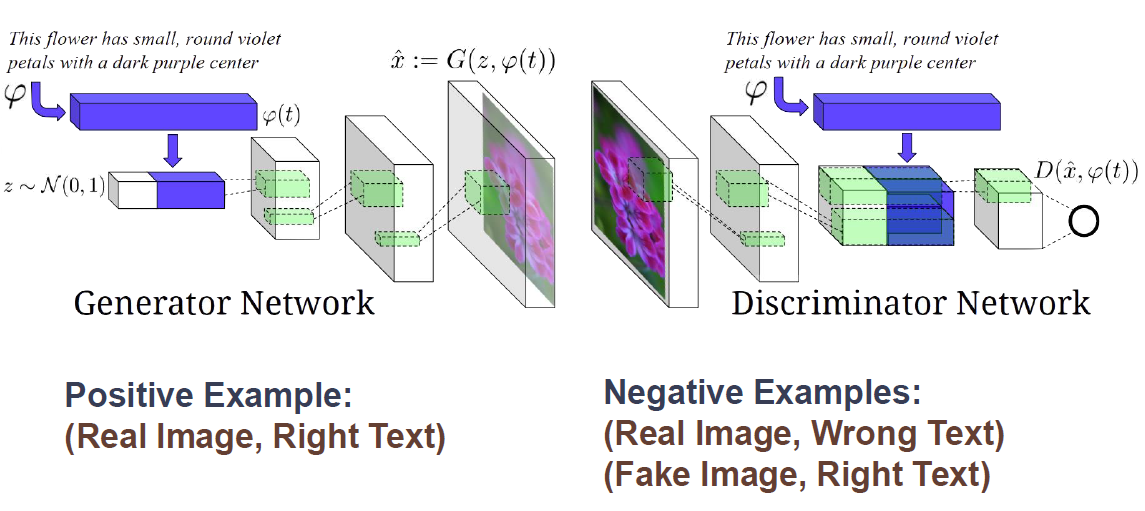
구조는 비슷하지만 안에 들어가는 네트워크가 다른것을 알 수 있다.
다음은 Progressive GAN에 대해서 알아보자.
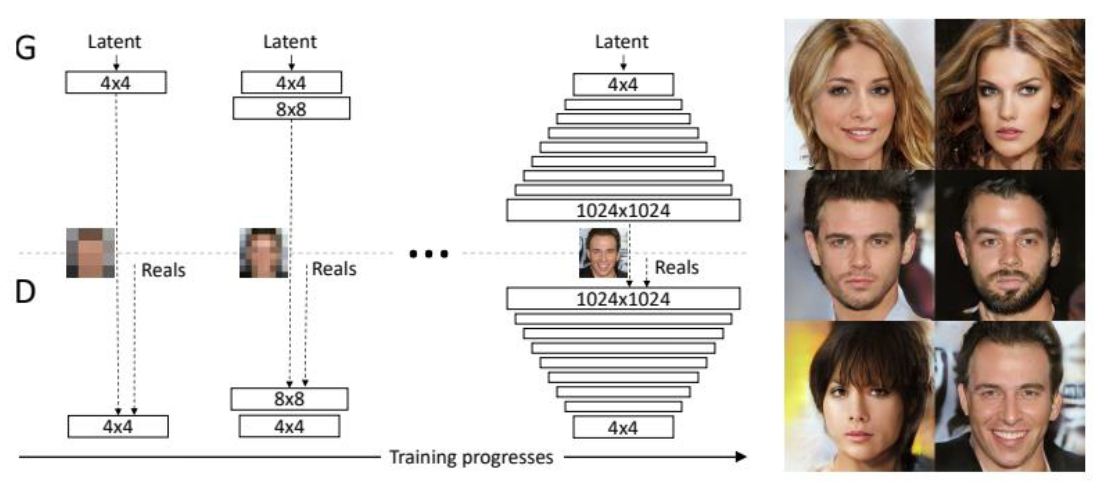
GAN은 선명한 이미지를 생성한다. 하지만 상대적으로 작은 해상도에서만 그리고 다소 제한된 변화로만 이루어지는 한계점이 있다. 이는 고해상도 이미지를 생성하는 것은 어렵다는 말이다. 이를 해결하기 위해서 생성자와 판별자를 점진적으로 키워나간다. 즉, 더 낮은 해상도의 이미지로부터 학습을 시작한다. 훈련 과정이 진행됨에 따라 더 높은 해상도 세부 정보를 도입하는 새로운 레이어를 추가하는 방식으로 진행된다. 아래 그림을 통해 이 과정을 이해할 수 있다.
다음의 Fade in the new layers smoothly 구조를 활용하여 이미 잘 훈련된 더 작은 해상도 레이어에 대한 갑작스러운 충격을 방지한다.
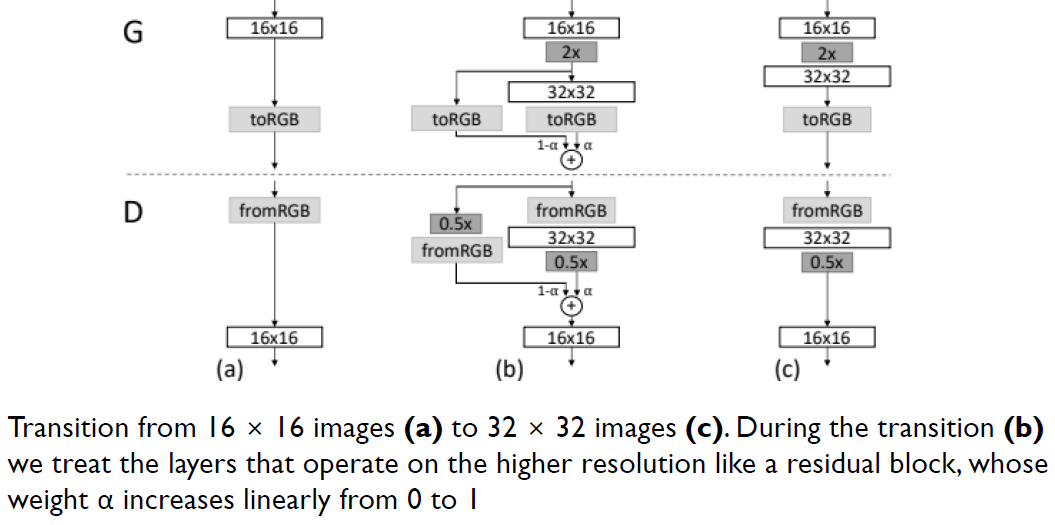
위 그림의 설명은 다음과 같다. 16 × 16 이미지(a)에서 32 × 32 이미지(c)로 전환합니다. 전환(b) 동안 우리는 가중치 α가 0에서 1로 선형적으로 증가하는 잔차 블록과 같이 더 높은 해상도에서 작동하는 레이어를 처리합니다.
1024x1024라는 고퀄리티 이미지를 뽑아내는 것을 알 수 있다.

GAN lecture를 요약하면 다음과 같다.
GAN은 두 개의 확률론적 신경망 모듈, 생성자(Generator)와 구분자(Discriminator)를 사용하여 구현되는 생성 모델이다.
Generator는 무작위 노이즈를 입력으로 받아 샘플을 생성하려고 시도한다.
Discriminator는 생성자로부터 생성된 샘플과 실제 데이터 분포로부터의 샘플을 구별하려고 한다.
두 신경망은 적대적으로(adversarially) 훈련되며 서로를 속이기 위해 함께 학습한다. 이 과정에서 두 모델은 각자의 작업을 더 잘 수행하게 된다.
하지만 최근에는 diffusion모델로 생성모델을 사용하고 있으니 diffusion 모델공부하시는게 더 도움될 것 같네요.
'인공지능' 카테고리의 다른 글
| Chapter 9 Hyperparameter Optimization (0) | 2023.05.20 |
|---|---|
| Chapter 8 Small Nets and EfficientNet (1) | 2023.05.20 |
| Chapter 6 Transformer Model (0) | 2023.05.20 |
| Chapter 5 RNN, LSTM, GRU (1) | 2023.05.19 |
| Chapter 4 CNN Structures (1) | 2023.05.19 |



