우리는 지금까지 모델에 layer들이 추가되는 방식에 대해서 설명했다. 얼마나 더 큰 모델을 만들고 이것들이 잘작동하는지 말이다. 하지만 큰 모델들은 컴퓨터나 클라우드에서 사용가능하다. 이는 어디에서나 해당 모델을 사용할 수 없다는 말이다. 가령 인터넷이 끊기는 지역이라던가 컴퓨터가 없는 밖에서는 말이다. 그렇다면 핸드폰에서 인공지능을 사용하면 어떨까? 왠만한 곳에서 학습도 가능하고 실제 사용도 가능하지 않을까? 이렇게 해서 나온 것이 MobileNet이다.
MobileNet-V1
MobileNet-V1을 이해하려면 이전에 설명했던 것들을 기억해야한다.
먼저, Depthwise Separable Convolution이다.
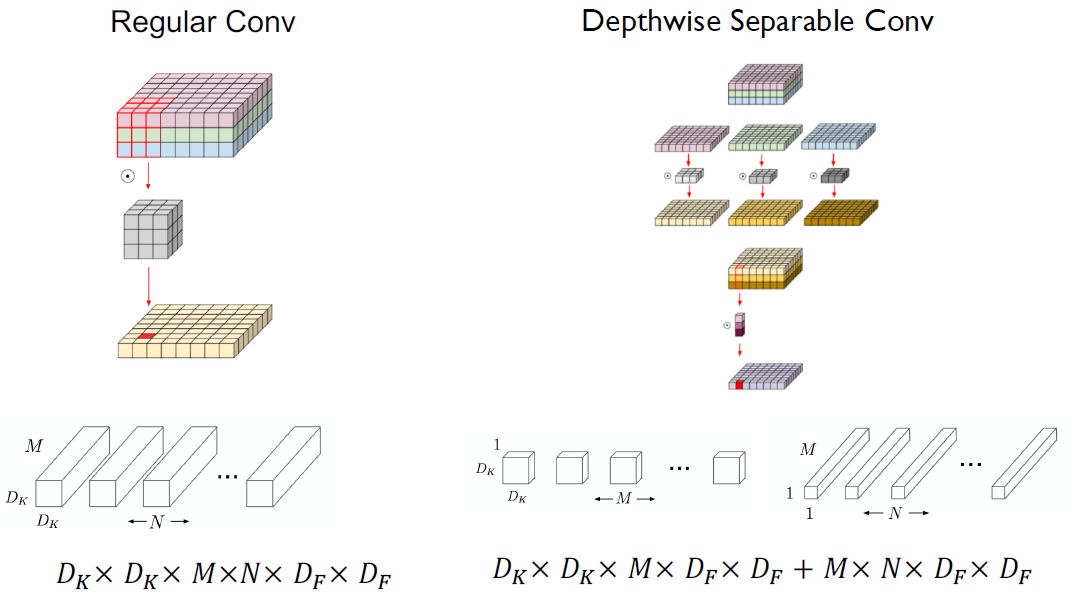
우리는 이를 통해 총 연산을 줄이는 것을 알고 있다.
이를 활용하면 아래 그림의 왼쪽이 오른쪽처럼 구조가 바뀐다는 것을 알 수 있다.

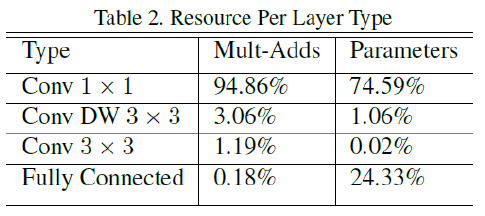
이를 통해 줄인 Model Structure를 보면 다음과 같다.

그래서 layer의 비율을 보면 1x1 Conv가 가장 많이 차지하는 것을 알 수 있다.
- 너비 승수 Thinner 모델 (Width Multiplier Thinner Models)
주어진 레이어 및 폭 승수 α에 대해 입력 채널 수 M은 αM이 되고 출력 채널 수 N은 αN이 된다
일반적인 설정이 1, 0.75, 0.6 및 0.25인 α
- 분해능 승수 감소 표현 (Resolution Multiplier Reduced Representation)
신경망의 계산 비용을 줄이기 위한 두 번째 하이퍼 매개변수는 해상도 승수 ρ
0< ρ≤ 1, 일반적으로 네트워크의 입력 해상도가 224, 192, 160 또는 128( ρ = 1, 0.857, 0.714, 0.571)이 되도록 암시적으로 설정된다
- 계산 비용:
𝐷k×𝐷k×𝜶𝑀×𝝆𝐷F×𝝆𝐷F + 𝑀×𝑁×𝝆𝐷F×𝝆𝐷F
추가적으로 구조중에 Fully Connected Layer도 기억해야한다.
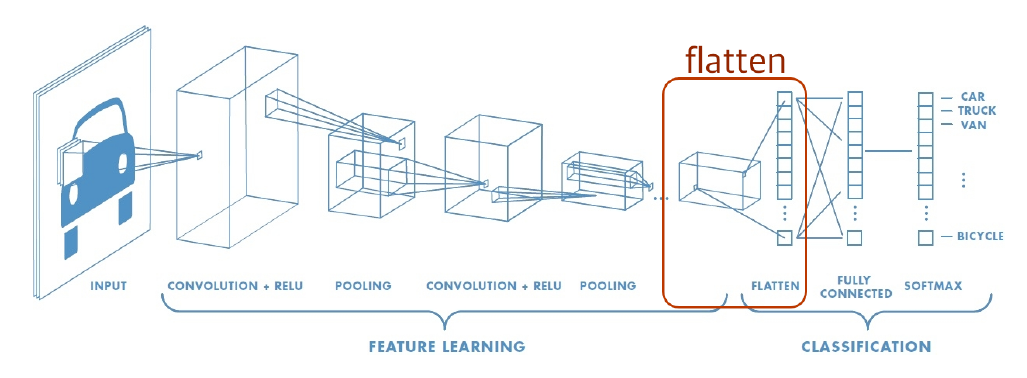
특징 맵의 모든 픽셀은 Fully Connected Layer에 연결된다.
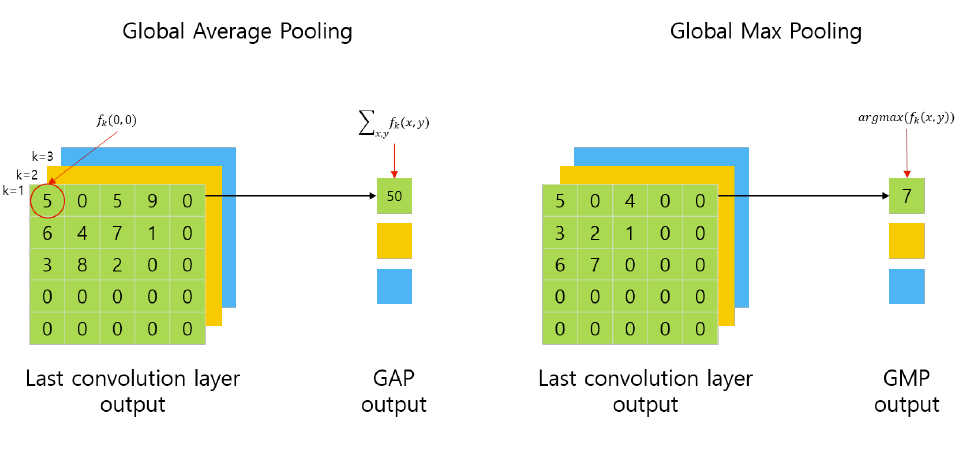
추가적으로 Global Average Pooling을 마지막 부분에 사용한다. Global Average Pooling이란 네트워크의 출력을 하나의 고정된 크기의 벡터로 변환하는 역할을 수행한다. 이는 네트워크의 출력 특성 맵의 공간적인 정보를 간결하게 압축하고, 분류 작업과 같은 최종 출력을 위한 특징 벡터를 생성하는 데 사용된다.
그리고 종합하여 다음의 결과를 보여준다.


파라미터는 줄었지만 정확도는 비슷하다.
MobileNet-V2
MobileNet-V2는 Depthwise Separable Convolution block을 Bottleneck Residual block으로 업그레이드했다.

이 모듈은 먼저 high dim으로 확장되고 가벼운 깊이 방향 컨볼루션으로 필터링되는 low dim 압축 표현을 입력으로 사용한다. 즉, Bottleneck Residual 블록은 ResNet에서 사용되는 Bottleneck 구조를 적용한 것으로 Bottleneck Residual 블록은 입력 데이터를 더 낮은 차원으로 압축한 후, 중간 차원에서 컨볼루션 연산을 수행하고, 다시 원래 차원으로 확장하는 방식이다. 그림으로 표현되면 다음과 같다.
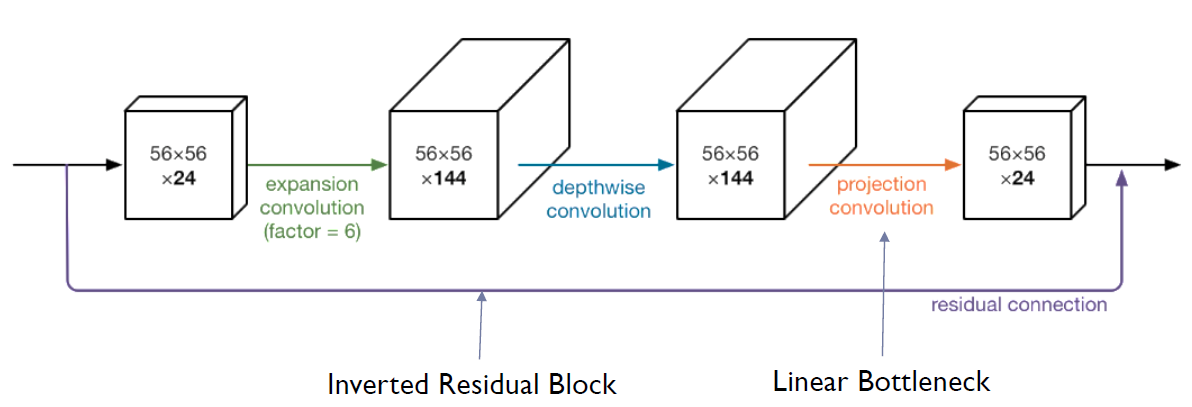
이를 2개의 Bottleneck Residual layer가 연결된 것으로 표현되면 다음과 같다.
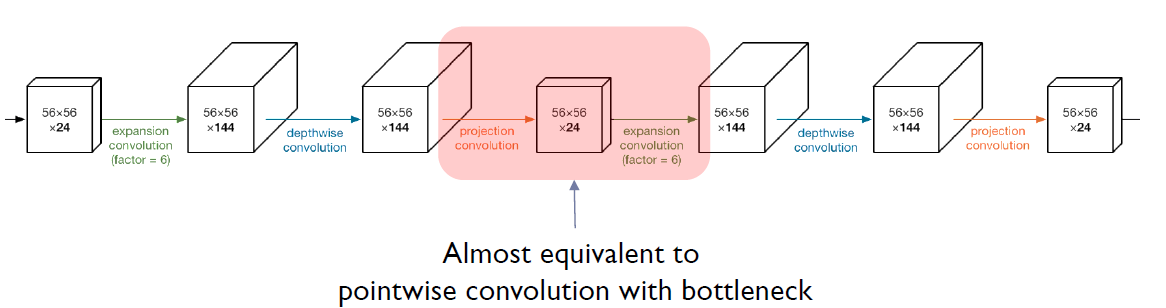
즉, 2개를 연결하면 bottleneck이 있는 pointwise convolution과 거의 동일하게 보인다. 왜 이렇게 사용했을까?
- Manifold의 Dimension은 Input의 Dimension보다 훨씬 낮은 것으로 판단되었다
- 중요한 정보를 효과적으로 추출하기 위해 사용되었다
어떻게 보면 encoder의 역활을 수행한다고 봐도 될 것 같다.
그렇다면 이렇게 사용하면 안될까?

이는 목적에 부합하지 않기 때문에 안된다.
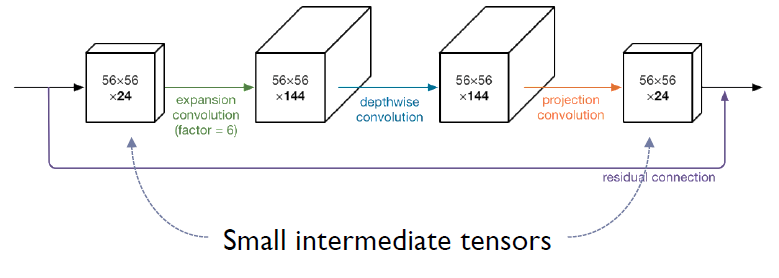
Small Intermediate Tensors가 다음의 목적에 더 부합하기 때문이다.
- 모바일 장치의 작지만 매우 빠른 캐시 메모리에 맞출 수 있다.
- 추론 중에 필요한 메모리 공간을 크게 줄일 수 있다.
- 많은 임베디드 하드웨어 설계에서 메인 메모리 액세스의 필요성을 줄인다.
그렇다면 GoogleNet과 달리 왜 Mobilenet-V2는 linear하게 쓸까?
선형 변환(linear transformation)을 통해 차원을 조정하는 역할을 진행하며, 이를 통해 차원 축소를 진행하여 중요한 정보를 효율적으로 캡처해야 하기 때문이다. 그러나 장점만 있는 것은 아니다. ReLU는 몇 가지 중요한 기능을 잃을 수 있다. 평균적으로 특징 맵의 절반은 정보가 없는 ZERO다.

위의 그림처럼 더 많은 정보를 만들 수 있어야하지만 RELU의 중요기능을 잃어 정보가 부족할 수 있다.
다음은 Mobilenet-V2의 구조와 결과를 보고 Mobilenet-V2를 마친다.


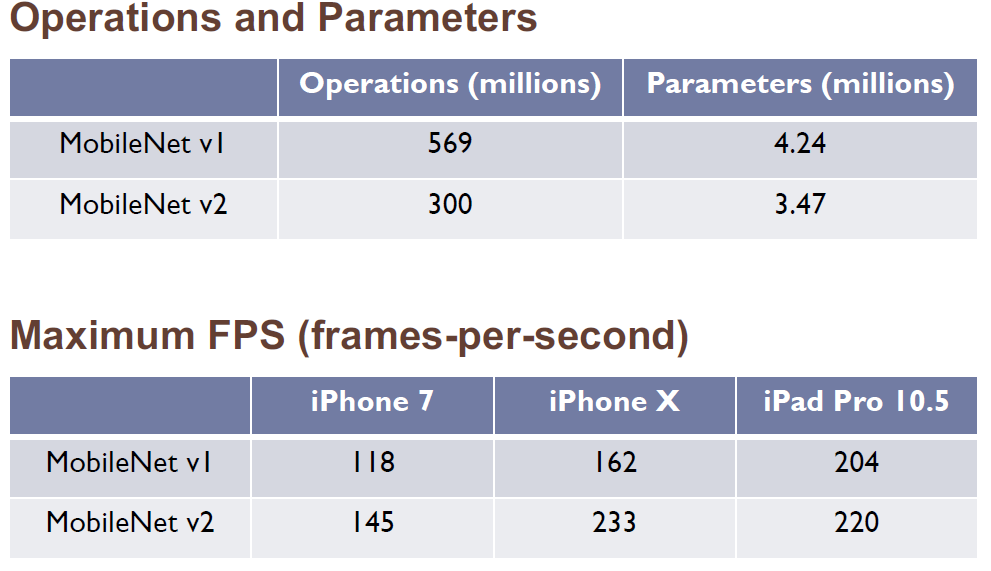
ImageNet Classification 결과

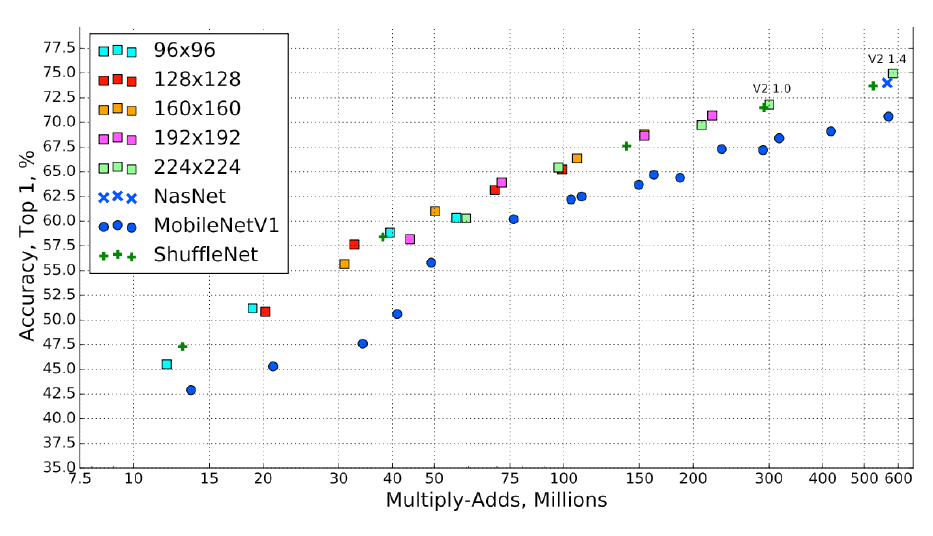
몇가지 추가적으로 보고 Small Nets를 마치려고 한다.
ShuffleNet
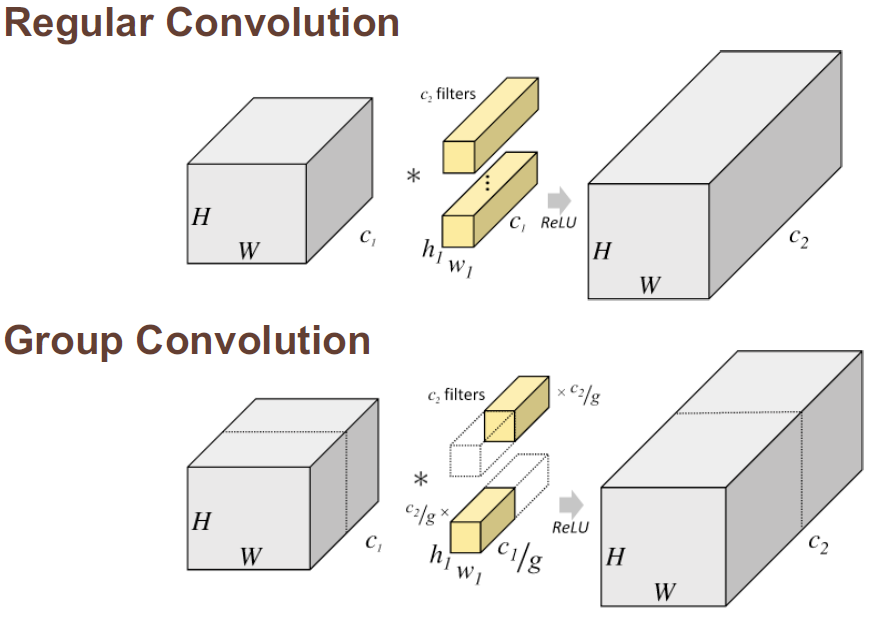
ShuffleNet은 Group Convolution을 사용한다.Group Convolution은 입력 채널을 그룹으로 나누어 각 그룹에 대해 독립적으로 컨볼루션 연산을 수행하는 방법이다. 기존의 컨볼루션은 입력 채널 전체에 대해 연산을 수행하는 반면, Group Convolution은 채널을 그룹으로 나누어 그룹 간에 독립적인 연산을 수행한다.
Group Convolution의 주요 목적은 모델의 연산 비용을 줄이는 것이다. 기존의 컨볼루션 연산은 입력 채널의 크기에 비례하여 연산 비용이 증가하는 문제가 있다. 그러나 Group Convolution은 채널을 그룹으로 나누어 각 그룹에 대해 독립적으로 연산을 수행하므로, 입력 채널의 크기에 상관없이 일정한 연산 비용을 유지할 수 있다.
추가적으로 Channel Shuffling도 사용한다. ShuffleNet은 컨볼루션 연산 후에 채널을 섞는 Channel Shuffle 작업을 수행한다. 이를 통해 다양한 그룹 간의 정보 교환을 촉진하고, 효과적인 특성 학습을 도모한다. Channel Shuffle은 입력 채널을 섞어 다양한 정보를 조합하고, 모델의 표현력을 향상시킨다.

이를 적용한 블럭을 보면 다음과 같다.

SqueezeNet
SqueezeNet의 핵심 아이디어는 "squeeze"와 "expand" 단계이다. 이 단계들은 입력 특성 맵의 차원을 조절하고 필터의 파라미터 수를 줄이는 역할을 수행한다.
"Squeeze" 단계에서는 입력 채널을 줄이기 위해 1x1 컨볼루션 연산을 수행한다.
"Expand" 단계에서는 압축된 특성 맵을 다시 원래 차원으로 확장한다. 이를 위해 1x1 컨볼루션 연산을 수행하고, 이어서 3x3 컨볼루션 연산을 수행한다. 이를 통해 입력 채널의 차원을 확장하고, 더 풍부한 특성 표현을 얻을 수 있다.
SqueezeNet은 또한 "fire module"이라고 불리는 구조를 사용한다. 이 모듈은 "squeeze" 단계와 "expand" 단계로 구성되어 있으며, 작은 모델 크기와 높은 효율성을 제공한다. SqueezeNet은 많은 파라미터를 공유하고, 효율적인 구조를 통해 고성능을 달성하는데 초점을 두고 있다.

Xception
Xception은 "Extreme Inception"의 줄임말로, Inception 모듈을 발전시킨 네트워크 구조다. Xception은 컨볼루션 연산에서 극단적인 방식을 사용하는데, 기존의 Inception 모듈의 방식과는 다르다. Inception 모듈은 다양한 커널 크기를 동시에 적용하여 특성을 추출하는데 비해, Xception은 깊이 방향의 컨볼루션을 통해 특성을 추출할 수 있다.
기존의 컨볼루션은 입력 특성 맵의 공간 방향과 채널 방향을 동시에 학습하는 반면, Xception은 먼저 공간 방향의 컨볼루션을 수행한 후, 채널 방향의 컨볼루션을 수행합니다. 이를 통해 네트워크는 공간적인 정보와 채널 간의 관계를 독립적으로 학습할 수 있다. 이는 더 효율적인 파라미터 사용과 더 나은 표현력을 제공한다.
Xception은 파라미터 공유를 최소화하는 장점도 가지고 있다. 각각의 깊이 방향 컨볼루션은 독립된 파라미터를 가지기 때문에 효율적인 파라미터 사용이 가능하며, 이를 통해 모델의 크기와 계산 비용을 줄일 수 있다.

EfficientNet으로 넘어가자.
EfficientNet이 나올 2019년의 CNN의 trend는 Base Blocks을 반복사용하는 것이었다.
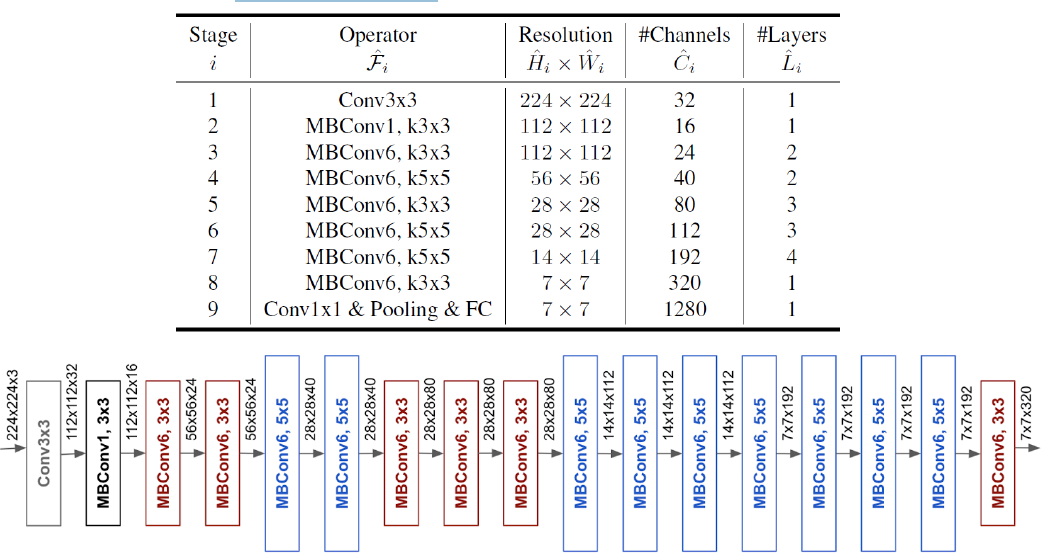
이를 통해 모델의 Scale이 커지고 이는 성능향상으로 이어졌다. 이를 통해, 더 좋은 image들이 생성되는 시기었다. Scale을 크게하는 방식은 다음과 같다.

하지만 이는 곧 Saturation(포화) 현상을 보였다. ResNet 1000은 훨씬 더 많은 레이어를 가지고 있지만 ResNet 101과 비슷한 정확도를 가지고 있다. 그리고 네트워크가 넓더라도 네트워크가 얕으면 좋은 기능을 캡처하기 어려움을 겪었다. 아래는 해당 그림이다. d는 deeper, r은 resolution이다.
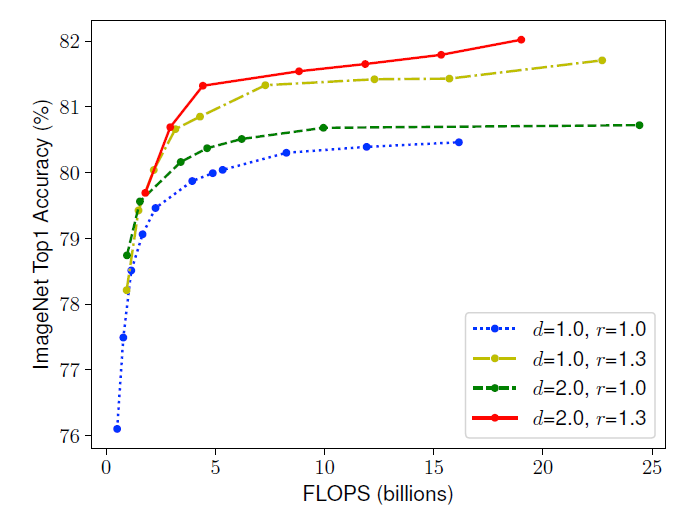
resolution

이를 피하기 위해서 다음의 아이디어가 나왔다.
1. 좋은 기준 모델 찾기
2. 스케일링을 위한 너비, 깊이 및 해상도의 황금 비율 찾기
3. 너비, 깊이 및 해상도의 황금 비율을 유지하면서 기본 모델의 각 차원을 확장
CNN을 공식화하면 이전의 표를 바탕으로 다음과 같이 나온다.

복합 스케일링을 적용하고 모든 단계와 레이어는 검색 공간을 줄이기 위해 배율 인수를 공유한다는 가정을 추가해보자.

그렇게 되면 CNN의 FLOPS( "floating-point operations"의 약어로, 모델이 수행하는 부동소수점 연산의 총량을 나타냅니다.)는 d, w^2, r^2에 비례하게 된다. 즉, 다음과 같은 형태가 나온다.

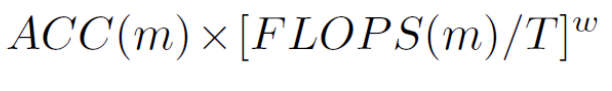
위의 공식과 이전의 Baseline Model을 통해 Golden Ratio를 찾았더니, 𝝓 = 𝟏일때, 𝜶 =1.2, 𝜷=1.1, 𝜸=1.15의 비율을 알게되었다.
이렇게 7개의 𝝓에 대한 𝑤 = 𝛼^𝝓, 𝑑 = 𝛽^𝝓, 𝑟 = 𝛾^𝝓를 구하여 만든 모델이 EfficientNet이다.
EfficientNet의 Performance를 보자.
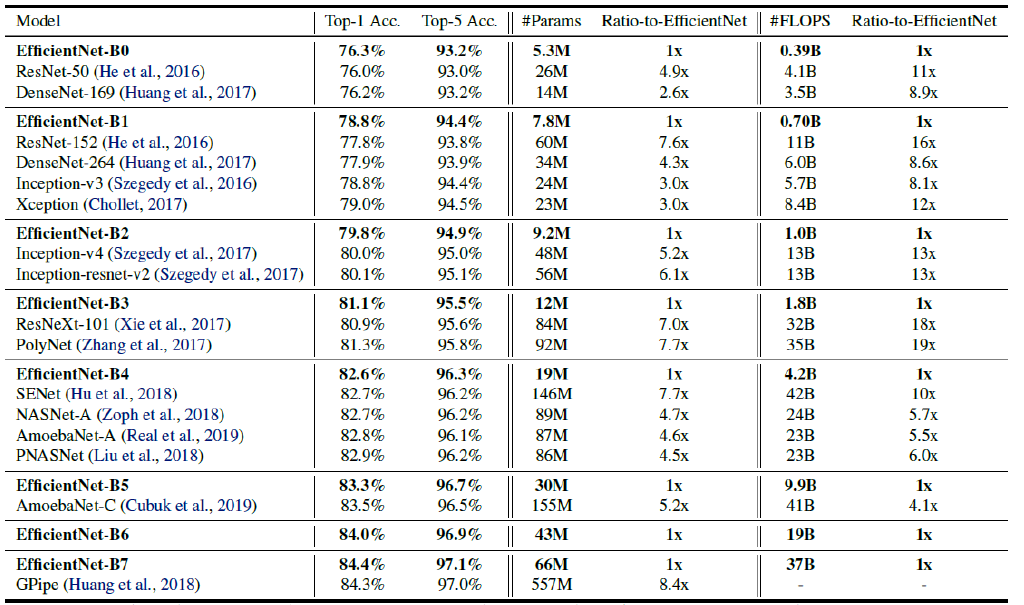
이제는 모델이 커질수록 ACC도 높아지는 것을 알 수 있다.
다른 모델들과의 비교도 다음과 같이 진행되었고, 파라미터와 성능이 다른 모델에 비해 좋은것을 확인할 수 있다.

스케일링 비교는 다음과 같다.
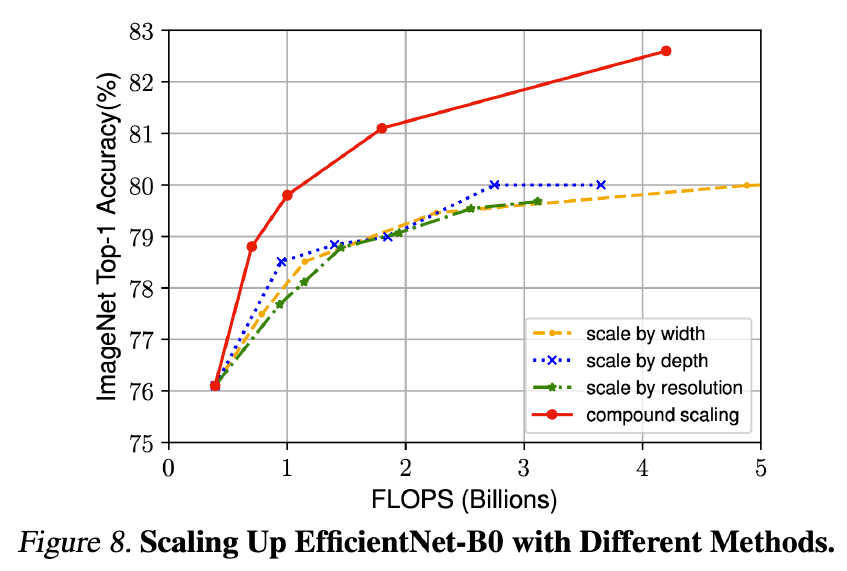
Compind scaling도 잘 적용되는 것을 볼 수 있다.

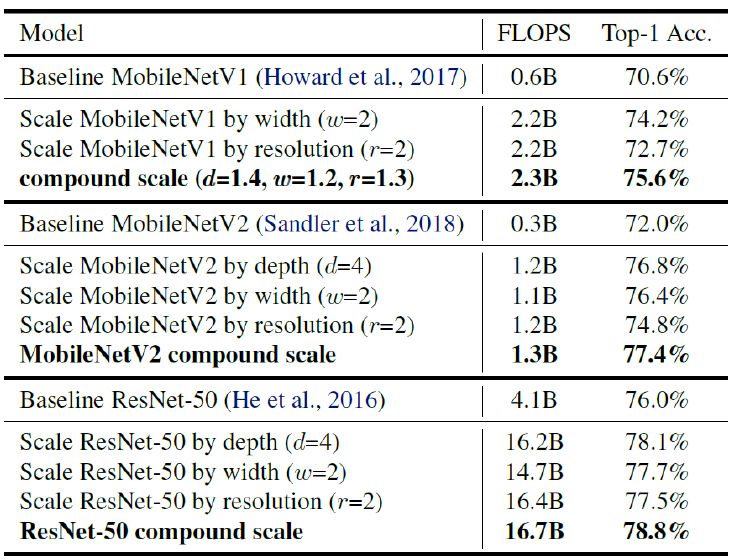
MobileNet 및 ResNet을 확장하기 위해 동일한 접근 방식을 적용해보면 다음과 같다.
'인공지능' 카테고리의 다른 글
| Chapter 10 Various artificial intelligence (0) | 2023.05.20 |
|---|---|
| Chapter 9 Hyperparameter Optimization (0) | 2023.05.20 |
| Chapter 7 Generative Adverislal Network (0) | 2023.05.20 |
| Chapter 6 Transformer Model (0) | 2023.05.20 |
| Chapter 5 RNN, LSTM, GRU (1) | 2023.05.19 |



