https://arxiv.org/abs/1707.01083
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
We introduce an extremely computation-efficient CNN architecture named ShuffleNet, which is designed specially for mobile devices with very limited computing power (e.g., 10-150 MFLOPs). The new architecture utilizes two new operations, pointwise group con
arxiv.org
요약
우리는 매우 계산 효율적인 CNN 구조인 ShuffleNet을 소개합니다. 이 구조는 매우 제한된 계산 성능을 가진 모바일 장치(예: 10-150 MFLOPs)를 위해 특별히 설계되었습니다. 새로운 아키텍처는 연산 비용을 크게 줄이면서도 정확도를 유지하기 위해 두 가지 새로운 연산, 즉 포인트와이즈 그룹 컨볼루션과 채널 셔플을 사용합니다. ImageNet 분류 및 MS COCO 객체 검출 실험에서 ShuffleNet은 다른 구조에 비해 우수한 성능을 보여줍니다. 예를 들어, 40 MFLOPs의 연산 예산 내에서 ImageNet 분류 작업에서 최근 MobileNet[12]보다 절대적으로 7.8% 더 낮은 top-1 오류율을 기록했습니다. ARM 기반 모바일 장치에서 ShuffleNet은 AlexNet에 비해 약 13배의 실제 속도 향상을 이루면서도 유사한 정확도를 유지합니다.
1. 서론
깊고 큰 컨볼루션 신경망(CNN)을 구축하는 것은 주요 시각 인식 과제를 해결하는 데 있어 주요한 추세입니다 [21, 9, 33, 5, 28, 24]. 가장 정확한 CNN은 일반적으로 수백 개의 레이어와 수천 개의 채널을 가지고 있으며 [9, 34, 32, 40], 수십억 FLOPs의 연산을 필요로 합니다. 이 보고서는 그 반대 극단을 다룹니다: 수십 또는 수백 MFLOPs의 매우 제한된 연산 예산 내에서 최고의 정확도를 추구하며, 드론, 로봇, 스마트폰과 같은 일반적인 모바일 플랫폼에 초점을 맞춥니다. 많은 기존 연구 [16, 22, 43, 42, 38, 27]는 "기본" 네트워크 아키텍처를 가지치기, 압축 또는 저비트 표현에 초점을 맞추고 있습니다. 그러나 여기서는 우리가 원하는 연산 범위에 맞춰 특별히 설계된 매우 효율적인 기본 아키텍처를 탐구하고자 합니다.
우리는 Xception [3]과 ResNeXt [40]과 같은 최신 기본 아키텍처가 매우 작은 네트워크에서는 비효율적이게 된다는 점을 주목했습니다. 이는 비용이 많이 드는 밀집된 1 × 1 컨볼루션 때문입니다. 우리는 1 × 1 컨볼루션의 연산 복잡성을 줄이기 위해 포인트와이즈 그룹 컨볼루션을 사용하는 것을 제안합니다. 그룹 컨볼루션이 가져오는 부작용을 극복하기 위해, 우리는 피처 채널 간의 정보 흐름을 돕기 위한 새로운 채널 셔플 연산을 고안했습니다. 이 두 가지 기술을 기반으로 ShuffleNet이라는 매우 효율적인 아키텍처를 구축했습니다. [30, 9, 40]과 같은 인기 있는 구조와 비교했을 때, 주어진 연산 복잡성 예산 내에서 ShuffleNet은 더 많은 피처 맵 채널을 허용하며, 이는 더 많은 정보를 인코딩하는 데 도움을 주며 특히 매우 작은 네트워크의 성능에 중요합니다.
우리는 우리의 모델을 도전적인 ImageNet 분류 [4, 29]와 MS COCO 객체 검출 [23] 작업에서 평가했습니다. 일련의 통제된 실험은 우리의 설계 원칙의 효과와 다른 구조들보다 우수한 성능을 보여줍니다. 최신 아키텍처인 MobileNet [12]과 비교했을 때, ShuffleNet은 절대적으로 7.8% 더 낮은 ImageNet top-1 오류율을 40 MFLOPs 수준에서 달성하며, 현저히 더 나은 성능을 보여줍니다.
또한 실제 하드웨어, 즉 상용 ARM 기반 컴퓨팅 코어에서의 속도 향상도 살펴보았습니다. ShuffleNet 모델은 AlexNet [21]에 비해 실제로 약 13 배의 속도 향상(이론적으로는 18배)을 달성하면서도 유사한 정확도를 유지합니다.

그림 1: 두 개의 그룹 컨볼루션이 쌓인 채널 셔플.
GConv는 그룹 컨볼루션을 의미합니다.
a) 동일한 그룹 수를 가진 두 개의 쌓인 컨볼루션 레이어. 각 출력 채널은 그룹 내의 입력 채널과만 연관되며, 그룹 간 상호작용이 없습니다.
b) GConv1 이후 다른 그룹에서 데이터를 가져가는 GConv2로 인해 입력 및 출력 채널이 완전히 연결됩니다.
c) b와 동등한 구현으로, 채널 셔플을 사용한 방식입니다.
2. 관련 연구
효율적인 모델 설계
최근 몇 년 동안 딥 러닝 신경망이 컴퓨터 비전 과제에서 큰 성공을 거두었으며 [21, 36, 28], 그중 모델 설계가 중요한 역할을 합니다. 고품질의 딥 러닝 신경망을 임베디드 장치에서 실행해야 할 필요성이 증가하면서 효율적인 모델 설계 연구가 촉진되었습니다 [8]. 예를 들어, GoogLeNet [33]은 단순히 컨볼루션 레이어를 쌓는 것보다 훨씬 낮은 복잡성으로 네트워크의 깊이를 증가시킵니다. SqueezeNet [14]은 파라미터와 연산을 크게 줄이면서도 정확도를 유지합니다. ResNet [9, 10]은 효율적인 병목 구조를 사용하여 인상적인 성능을 달성합니다. SENet [13]은 약간의 연산 비용으로 성능을 향상시키는 구조 단위를 도입했습니다. 우리와 동시에 최근의 연구 [46]는 강화 학습과 모델 검색을 사용하여 효율적인 모델 설계를 탐구합니다. 제안된 모바일 NASNet 모델은 우리의 ShuffleNet 모델과 비슷한 성능을 보입니다 (ImageNet 분류 오류 기준으로 26.0% @ 564 MFLOPs 대 26.3% @ 524 MFLOPs). 그러나 [46]에서는 매우 작은 모델(예: 복잡도가 150 MFLOPs 이하인 모델)에 대한 결과를 보고하지 않았으며, 모바일 장치에서 실제 추론 시간을 평가하지 않았습니다.
그룹 컨볼루션
그룹 컨볼루션의 개념은 처음 AlexNet [21]에서 모델을 두 개의 GPU에 분산시키기 위해 도입되었으며, ResNeXt [40]에서 그 효과가 잘 입증되었습니다. Xception [3]에서 제안된 깊이별 분리 컨볼루션은 Inception 시리즈 [34, 32]에서 사용된 분리 컨볼루션 아이디어를 일반화한 것입니다. 최근에는 MobileNet [12]이 깊이별 분리 컨볼루션을 활용하여 경량 모델 중에서 최신 성과를 달성했습니다. 우리의 연구는 그룹 컨볼루션과 깊이별 분리 컨볼루션을 새로운 형태로 일반화했습니다.
채널 셔플 연산
우리가 아는 한, 채널 셔플 연산의 아이디어는 효율적인 모델 설계와 관련된 이전 연구에서는 거의 언급되지 않았습니다. 다만, CNN 라이브러리 cuda-convnet [20]은 "랜덤 희소 컨볼루션" 레이어를 지원하며, 이는 그룹 컨볼루션 레이어 뒤에 랜덤 채널 셔플을 수행하는 것과 동등합니다. 이러한 "랜덤 셔플" 연산은 목적이 다르며 이후로 거의 활용되지 않았습니다. 매우 최근의 또 다른 연구 [41]도 이 아이디어를 두 단계 컨볼루션에 채택했지만, [41]은 채널 셔플 자체의 효과와 작은 모델 설계에서의 사용에 대해 특별히 조사하지 않았습니다.
모델 가속화
이 연구 방향은 미리 학습된 모델의 정확도를 유지하면서 추론 속도를 가속화하는 것을 목표로 합니다. 네트워크 연결 [6, 7] 또는 채널 [38]을 가지치기하여 미리 학습된 모델의 불필요한 연결을 줄이면서 성능을 유지합니다. 양자화 [31, 27, 39, 45, 44]와 행렬 분해 [22, 16, 18, 37]는 계산의 중복성을 줄여 추론 속도를 높이기 위해 문헌에서 제안되었습니다. 파라미터를 수정하지 않고 FFT [25, 35] 및 기타 방법 [2]을 사용한 최적화된 컨볼루션 알고리즘은 실제로 시간 소모를 줄입니다. Distilling [11]은 대형 모델에서 소형 모델로 지식을 전이하여 소형 모델의 학습을 더 쉽게 만듭니다.
3. 접근 방법
그림 2: ShuffleNet 유닛.
a) 깊이별 컨볼루션(DWConv) [3, 12]이 포함된 병목 유닛 [9];
b) 포인트와이즈 그룹 컨볼루션(GConv)과 채널 셔플이 포함된 ShuffleNet 유닛;
c) 스트라이드(stride) = 2를 갖는 ShuffleNet 유닛.
3.1 그룹 컨볼루션을 위한 채널 셔플
최신 컨볼루션 신경망 [30, 33, 34, 32, 9, 10]은 일반적으로 동일한 구조를 가진 반복적인 빌딩 블록들로 구성됩니다. 그 중 Xception [3]과 ResNeXt [40] 같은 최신 네트워크들은 효율적인 깊이별 분리 컨볼루션 또는 그룹 컨볼루션을 빌딩 블록에 도입하여 표현 능력과 연산 비용 간의 탁월한 균형을 맞추고 있습니다. 하지만 이들 설계는 1 × 1 컨볼루션(또는 포인트와이즈 컨볼루션 [12]에서 언급됨)을 충분히 고려하지 않았다는 점을 우리는 발견했습니다. 이는 상당한 연산 복잡성을 요구합니다. 예를 들어, ResNeXt [40]에서는 3 × 3 레이어만 그룹 컨볼루션으로 장착되어 있습니다. 그 결과, ResNeXt의 각 잔차 유닛에서 포인트와이즈 컨볼루션이 93.4%의 곱셈-덧셈 연산을 차지하게 됩니다(카디널리티 = 32는 [40]에서 제안됨). 작은 네트워크에서는 비싼 포인트와이즈 컨볼루션으로 인해 제한된 채널 수를 사용할 수밖에 없으며, 이는 정확도에 큰 타격을 줄 수 있습니다.
이 문제를 해결하기 위한 간단한 해결책은 1 × 1 레이어에도 그룹 컨볼루션과 같은 채널 희소 연결을 적용하는 것입니다. 각 컨볼루션이 해당 입력 채널 그룹에 대해서만 연산을 수행하게 하여, 그룹 컨볼루션은 연산 비용을 크게 줄일 수 있습니다. 하지만 여러 그룹 컨볼루션을 쌓으면 부작용이 발생할 수 있습니다: 특정 채널의 출력이 입력 채널의 작은 부분에서만 도출된다는 점입니다. 그림 1 (a)는 두 개의 쌓인 그룹 컨볼루션 레이어의 상황을 보여줍니다. 특정 그룹의 출력은 해당 그룹 내의 입력과만 연관이 있음을 알 수 있습니다. 이 속성은 채널 그룹 간 정보 흐름을 차단하고 표현 능력을 약화시킵니다.
이 문제를 해결하기 위해 그룹 컨볼루션이 다른 그룹에서 입력 데이터를 가져올 수 있게 허용하면(그림 1 (b) 참조), 입력과 출력 채널이 완전히 연관될 수 있습니다. 구체적으로는, 이전 그룹 레이어에서 생성된 피처 맵의 채널을 각 그룹으로 나누고, 다음 레이어에서 각 그룹에 다른 하위 그룹을 입력으로 제공할 수 있습니다. 이는 채널 셔플 연산을 통해 효율적이고 우아하게 구현할 수 있습니다(그림 1 (c)). 예를 들어, g 그룹을 가진 컨볼루션 레이어에서 출력이 g × n 채널일 때, 먼저 출력 채널 차원을 ( g , n ) 으로 재구성하고, 이를 전치한 후 다시 평탄화하여 다음 레이어의 입력으로 사용합니다. 이 연산은 두 컨볼루션이 다른 그룹 수를 가지고 있어도 여전히 효과적입니다. 또한 채널 셔플은 미분 가능하므로 네트워크 구조에 포함되어 끝에서 끝으로 학습이 가능합니다.
채널 셔플 연산은 여러 그룹 컨볼루션 레이어로 더 강력한 구조를 구축하는 것을 가능하게 합니다. 다음 절에서는 채널 셔플과 그룹 컨볼루션을 사용한 효율적인 네트워크 유닛을 소개하겠습니다.
3.2 ShuffleNet 유닛
표 1: ShuffleNet 아키텍처.
복잡도는 FLOPs, 즉 부동소수점 곱셈-덧셈 연산의 개수로 평가됩니다. 2단계(Stage 2)의 경우, 입력 채널 수가 상대적으로 적기 때문에 첫 번째 포인트와이즈 레이어에 그룹 컨볼루션을 적용하지 않았음을 유의하세요.
표 2: 분류 오류 대 그룹 수 g (작은 숫자가 더 나은 성능을 나타냅니다)
채널 셔플 연산을 활용하여, 우리는 작은 네트워크를 위해 특별히 설계된 새로운 ShuffleNet 유닛을 제안합니다. 우리는 먼저 그림 2 (a)에 있는 병목 유닛 [9]의 설계 원칙에서 시작합니다. 이는 잔차 블록(residual block)입니다. 이 잔차 분기에서 3 × 3 레이어의 경우, 병목 피처 맵에 계산 비용이 적은 3 × 3 깊이별 컨볼루션 [3]을 적용합니다. 그런 다음 첫 번째 1 × 1 레이어를 포인트와이즈 그룹 컨볼루션으로 대체하고, 그 뒤에 채널 셔플 연산을 추가하여 ShuffleNet 유닛을 구성합니다(그림 2 (b) 참조). 두 번째 포인트와이즈 그룹 컨볼루션의 목적은 채널 차원을 복원하여 숏컷 경로와 일치시키는 것입니다. 간단함을 위해 두 번째 포인트와이즈 레이어 이후에는 추가적인 채널 셔플 연산을 적용하지 않았으며, 이로 인해 유사한 성능 점수를 얻을 수 있었습니다. 배치 정규화(BN) [15]와 비선형성 사용 방식은 [9, 40]과 유사하지만, [3]에서 제안한 것처럼 깊이별 컨볼루션 이후에는 ReLU를 사용하지 않았습니다. ShuffleNet을 스트라이드와 함께 적용하는 경우, 우리는 두 가지 간단한 수정 사항을 적용했습니다(그림 2 (c) 참조): (i) 숏컷 경로에 3 × 3 평균 풀링을 추가; (ii) 요소별 덧셈을 채널 연결로 대체하여 적은 연산 비용으로 채널 차원을 확장할 수 있게 했습니다.

채널 셔플이 포함된 포인트와이즈 그룹 컨볼루션 덕분에, ShuffleNet 유닛의 모든 구성 요소는 효율적으로 계산될 수 있습니다. ResNet [9]의 병목 설계와 ResNeXt [40]와 비교했을 때, 같은 조건에서 우리의 구조는 더 적은 복잡도를 가집니다. 예를 들어, 입력 크기가 c × h × w 이고 병목 채널이 m 일 경우, ResNet 유닛은 h w ( 2 c m + 9 m 2 ) FLOPs가 필요하고 ResNeXt는 h w ( 2 c m + 9 m 2 / g ) FLOPs가 필요합니다. 반면, 우리의 ShuffleNet 유닛은 h w ( 2 c m / g + 9 m ) FLOPs만 필요합니다. 여기서 g 는 컨볼루션의 그룹 수를 의미합니다. 즉, 주어진 연산 예산에서 ShuffleNet은 더 넓은 피처 맵을 사용할 수 있습니다. 이는 작은 네트워크에 매우 중요하다는 것을 발견했는데, 작은 네트워크는 보통 정보를 처리할 충분한 채널 수가 부족하기 때문입니다.
추가적으로, ShuffleNet에서 깊이별 컨볼루션은 병목 피처 맵에만 적용됩니다. 깊이별 컨볼루션은 일반적으로 이론상 매우 낮은 복잡성을 가지지만, 저전력 모바일 장치에서 효율적으로 구현하기 어렵다는 점을 발견했습니다. 이는 다른 밀집 연산과 비교했을 때, 계산/메모리 접근 비율이 더 나쁘기 때문일 수 있습니다. 이와 같은 단점은 TensorFlow [1] 기반의 런타임 라이브러리를 사용하는 [3]에서도 언급된 바 있습니다. ShuffleNet 유닛에서는 오버헤드를 최대한 줄이기 위해 병목 부분에만 깊이별 컨볼루션을 의도적으로 사용했습니다.
3.3 네트워크 아키텍처
ShuffleNet 유닛을 기반으로, 우리는 전체 ShuffleNet 아키텍처를 표 1에 제시합니다. 제안된 네트워크는 주로 세 단계로 그룹화된 ShuffleNet 유닛의 스택으로 구성됩니다. 각 단계의 첫 번째 빌딩 블록에는 스트라이드(stride) = 2가 적용됩니다. 각 단계 내의 다른 하이퍼파라미터는 동일하게 유지되며, 다음 단계로 갈 때 출력 채널이 두 배로 늘어납니다. [9]와 유사하게, 우리는 각 ShuffleNet 유닛의 병목 채널 수를 출력 채널의 1/4로 설정했습니다. 우리는 가능한 한 간단한 참조 설계를 제공하고자 했으나, 추가적인 하이퍼파라미터 튜닝을 통해 더 나은 결과를 얻을 수 있음을 발견했습니다.
ShuffleNet 유닛에서 그룹 수 g 는 포인트와이즈 컨볼루션의 연결 희소성을 제어합니다. 표 1에서는 다양한 그룹 수를 탐색하며, 우리는 전체 연산 비용을 대략 일정하게 유지하기 위해 출력 채널 수를 조정했습니다(대략 140 MFLOPs). 명확히, 더 큰 그룹 수는 주어진 복잡성 제약 내에서 더 많은 출력 채널(즉, 더 많은 컨볼루션 필터)을 생성하며, 이는 더 많은 정보를 인코딩하는 데 도움이 됩니다. 그러나 이는 제한된 입력 채널 때문에 개별 컨볼루션 필터의 성능 저하를 초래할 수 있습니다. 섹션 4.1.1에서는 이 숫자가 다양한 연산 제약에 미치는 영향을 연구할 것입니다.
네트워크를 원하는 복잡성으로 맞추기 위해, 우리는 간단히 채널 수에 대해 스케일 팩터 s 를 적용할 수 있습니다. 예를 들어, 표 1의 네트워크를 "ShuffleNet 1 × "라고 명명하면, "ShuffleNet s × "는 ShuffleNet 1 × 에서 필터 수를 s 배로 확장한 것으로, 따라서 전체 복잡성은 대략 ShuffleNet 1 × 의 s ^2 배가 됩니다.
4. 실험
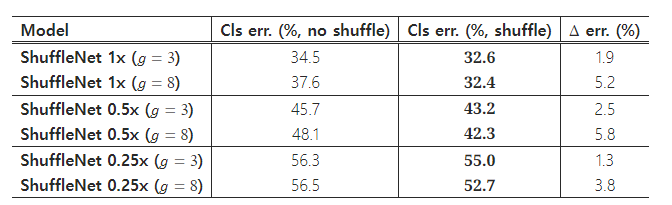
표 3: 채널 셔플 적용 여부에 따른 ShuffleNet 성능 비교 (작은 숫자가 더 나은 성능을 나타냅니다)
우리는 주로 ImageNet 2012 분류 데이터셋 [29, 4]에서 모델을 평가합니다. 대부분의 훈련 설정과 하이퍼파라미터는 [40]에서 사용된 것을 따르며, 두 가지 예외가 있습니다: (i) 우리는 가중치 감쇠(weight decay)를 1e-4 대신 4e-5로 설정하고 선형 감쇠 학습률 정책을 사용합니다(0.5에서 0으로 감소); (ii) 데이터 전처리를 위해 조금 덜 공격적인 스케일 증강(scale augmentation)을 사용합니다. 이러한 작은 네트워크들은 일반적으로 과적합보다 과소적합 문제를 겪기 때문에 [12]에서도 비슷한 수정이 참조되었습니다. 4개의 GPU에서 배치 크기를 1024로 설정하여 모델을 훈련하는 데 약 1~2일이 소요되며, 3×10^5 번의 반복(iterations)을 수행합니다. 성능 비교를 위해, 우리는 ImageNet 검증 세트에서 싱글 크롭 top-1 성능을 비교합니다. 즉, 256×256 입력 이미지에서 224×224 크기의 중앙 뷰를 잘라내고 분류 정확도를 평가합니다. 모든 모델에 대해 동일한 설정을 사용하여 공정한 비교를 보장합니다.
4.1 소거 연구(Ablation Study)
ShuffleNet의 핵심 아이디어는 포인트와이즈 그룹 컨볼루션과 채널 셔플 연산에 있습니다. 이 절에서는 각각의 요소를 평가합니다.
4.1.1 포인트와이즈 그룹 컨볼루션
포인트와이즈 그룹 컨볼루션의 중요성을 평가하기 위해, 그룹 수가 1에서 8까지 범위인 동일한 복잡도의 ShuffleNet 모델들을 비교합니다. 그룹 수가 1인 경우, 포인트와이즈 그룹 컨볼루션이 사용되지 않으며 ShuffleNet 유닛은 "Xception과 유사한" [3] 구조가 됩니다. 이해를 돕기 위해, 네트워크의 너비를 3개의 서로 다른 복잡도로 확장하고 각각의 분류 성능을 비교합니다. 결과는 표 2에 나와 있습니다.
결과에서 알 수 있듯이, 그룹 컨볼루션을 사용한 모델( g = 1 )은 포인트와이즈 그룹 컨볼루션이 없는 모델( g = 1 )보다 일관되게 더 나은 성능을 보입니다. 특히 작은 모델들이 그룹의 이점을 더 많이 누리는 경향이 있습니다. 예를 들어, ShuffleNet 1×에서 최고의 성능( g = 8 )은 비교 모델보다 1.2% 더 우수하며, ShuffleNet 0.5×와 0.25×에서는 그 차이가 각각 3.5%와 4.4%로 더 커집니다. 그룹 컨볼루션이 주어진 복잡성 제약 내에서 더 많은 피처 맵 채널을 허용하기 때문에 이러한 성능 향상은 더 넓은 피처 맵에서 오는 이점 때문이라고 가정할 수 있습니다. 또한 작은 네트워크는 더 얇은 피처 맵을 가지므로, 피처 맵이 확장될수록 더 많은 이점을 얻습니다.
표 2는 또한 일부 모델(예: ShuffleNet 0.5×)의 경우 그룹 수가 상대적으로 클 때(예: g = 8 ) 성능이 포화 상태에 이르거나 오히려 하락한다는 점을 보여줍니다. 그룹 수가 증가하면(즉, 더 넓은 피처 맵을 가지면) 각 컨볼루션 필터에 대한 입력 채널 수가 줄어들어 표현 능력에 악영향을 미칠 수 있습니다. 흥미롭게도, ShuffleNet 0.25×와 같은 작은 모델에서는 더 큰 그룹 수가 일관되게 더 나은 결과를 나타내며, 이는 더 작은 모델일수록 더 넓은 피처 맵에서 더 많은 이점을 얻음을 시사합니다.
4.1.2 채널 셔플 vs. 셔플 미적용
채널 셔플 연산의 목적은 여러 그룹 컨볼루션 레이어 간에 그룹 간 정보 흐름을 가능하게 하는 것입니다. 표 3은 채널 셔플을 적용한 ShuffleNet 구조와 적용하지 않은 구조의 성능을 비교합니다(그룹 수는 예로 3 또는 8로 설정됨). 이 평가는 세 가지 다른 복잡성 수준에서 수행되었습니다. 결과는 채널 셔플이 다양한 설정에서 일관되게 분류 점수를 향상시킨다는 것을 명확히 보여줍니다. 특히, 그룹 수가 상대적으로 클 때(예: g = 8 ), 채널 셔플을 적용한 모델이 적용하지 않은 모델보다 훨씬 더 나은 성능을 보이며, 이는 그룹 간 정보 교환의 중요성을 나타냅니다.
4.2 다른 구조 유닛과의 비교

표 4: 다양한 구조에 따른 분류 오류율(%, 작은 숫자가 더 나은 성능을 나타냅니다).
작은 네트워크에서는 정확도가 크게 떨어지기 때문에 VGG와 유사한 구조는 보고하지 않았습니다.
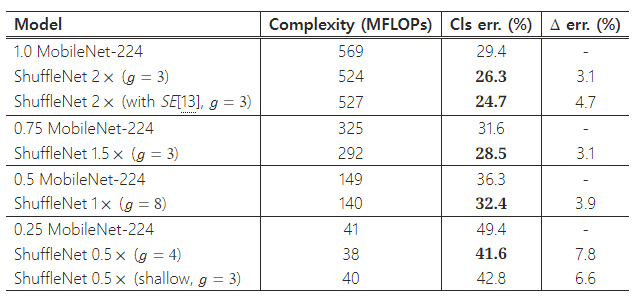
표 5: ImageNet 분류에서 ShuffleNet vs. MobileNet [12] 성능 비교
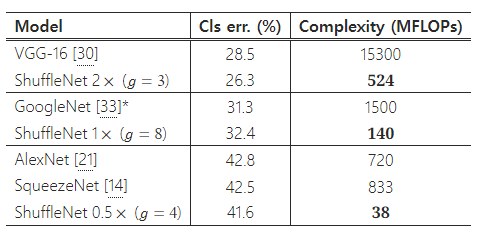
표 6: 복잡도 비교.
BVLC에서 구현됨 (https://github.com/BVLC/caffe/tree/master/models/bvlc_googlenet)
최근 VGG [30], ResNet [9], GoogleNet [33], ResNeXt [40], Xception [3]에서 제안된 최신 컨볼루션 유닛들은 대형 모델(예: ≥ 1 GFLOPs)을 사용하여 최첨단 결과를 추구했지만, 낮은 복잡성 조건을 충분히 탐구하지는 않았습니다. 이 섹션에서는 다양한 빌딩 블록을 조사하고, 동일한 복잡성 제약 하에서 ShuffleNet과 비교를 수행합니다.
공정한 비교를 위해, 우리는 표 1에 표시된 전체 네트워크 아키텍처를 사용합니다. Stage 2-4의 ShuffleNet 유닛을 다른 구조로 대체하고, 복잡성이 변하지 않도록 채널 수를 조정합니다. 우리가 탐구한 구조는 다음과 같습니다:
- VGG 유사 구조: VGG 네트워크 [30]의 설계 원칙을 따라, 3×3 컨볼루션 두 개를 기본 빌딩 블록으로 사용합니다. [30]과는 달리, 우리는 각 컨볼루션 이후에 배치 정규화(Batch Normalization) 레이어 [15]를 추가하여 엔드 투 엔드 학습을 용이하게 했습니다.
- ResNet: 우리는 실험에서 병목(bottleneck) 설계를 채택했으며, 이는 [9]에서 더 효율적임이 입증되었습니다. [9]와 동일하게, 병목 비율1도 1 : 4 입니다.
- 병목 비율: 병목 유닛(ResNet, ResNeXt 또는 ShuffleNet과 같은 구조)에서 병목 비율은 병목 채널 수와 출력 채널 수의 비율을 의미합니다. 예를 들어, 병목 비율이 1 : 4 라면, 출력 피처 맵의 너비는 병목 피처 맵의 너비보다 4배 큽니다.
- Xception 유사 구조: [3]에서 제안된 원래 구조는 서로 다른 단계에 대해 복잡한 설계 또는 하이퍼파라미터를 포함하며, 이는 작은 모델에서 공정한 비교를 어렵게 만듭니다. 대신에, 우리는 ShuffleNet에서 포인트와이즈 그룹 컨볼루션과 채널 셔플 연산을 제거했습니다(이는 또한 g = 1 인 ShuffleNet과 동일합니다). 이 파생된 구조는 [3]에서와 같은 "깊이별 분리 컨볼루션" 아이디어를 공유하며, 여기서는 이를 Xception 유사 구조라고 부릅니다.
- ResNeXt: 우리는 [40]에서 제안된 대로 카드널리티 = 16 과 병목 비율 = 1 : 2 의 설정을 사용합니다. 우리는 또한 병목 비율 = 1 : 4 와 같은 다른 설정도 탐구했으며, 유사한 결과를 얻었습니다.
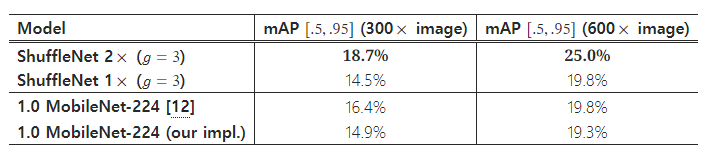
표 7: MS COCO에서의 객체 검출 결과(큰 숫자가 더 나은 성능을 나타냅니다).
MobileNet에 대해서는 두 가지 결과를 비교합니다: 1) [12]에서 보고된 COCO 검출 점수; 2) 우리 팀이 재구현한 MobileNet을 미세 조정한 결과로, 이때의 훈련 및 미세 조정 설정은 ShuffleNet과 정확히 동일하게 적용되었습니다.
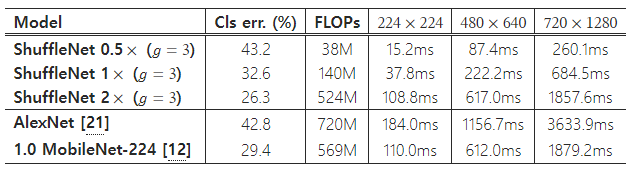
표 8: 모바일 장치에서 실제 추론 시간(작은 숫자가 더 나은 성능을 나타냅니다).
플랫폼은 Qualcomm Snapdragon 820 프로세서를 기반으로 하며, 모든 결과는 단일 스레드로 평가되었습니다.
우리는 동일한 설정을 사용하여 이러한 모델을 훈련시켰습니다. 결과는 표 4에 나와 있습니다. 우리의 ShuffleNet 모델은 다양한 복잡성 수준에서 대부분의 다른 모델을 상당한 차이로 능가합니다. 흥미롭게도, 피처 맵 채널 수와 분류 정확도 사이에 경험적인 관계가 있음을 발견했습니다. 예를 들어, 38 MFLOPs의 복잡성에서 VGG 유사 모델, ResNet, ResNeXt, Xception 유사 모델, ShuffleNet 모델의 Stage 4 출력 채널 수는 각각 50, 192, 192, 288, 576이며, 이는 정확도가 증가하는 것과 일치합니다. ShuffleNet의 효율적인 설계 덕분에 주어진 연산 예산 내에서 더 많은 채널을 사용할 수 있어 일반적으로 더 나은 성능을 얻을 수 있습니다.
위 비교에는 GoogleNet 또는 Inception 시리즈 [33, 34, 32]가 포함되어 있지 않음을 주목하세요. Inception 구조를 작은 네트워크로 생성하는 것은 간단하지 않습니다. 이는 Inception 모듈의 원래 설계가 너무 많은 하이퍼파라미터를 포함하기 때문입니다. 참고로, 첫 번째 GoogleNet 버전 [33]은 1.5 GFLOPs의 연산 비용으로 top-1 오류율이 31.3%입니다(표 6 참조). 더 정교한 Inception 버전 [34, 32]은 더 높은 정확도를 보이지만, 복잡성이 크게 증가합니다. 최근 Kim 등은 Inception 유닛을 채택한 경량 네트워크 구조인 PVANET [19]을 제안했습니다. 우리가 재구현한 PVANET(입력 크기 224×224)은 557 MFLOPs의 연산 복잡성으로 29.7%의 분류 오류율을 기록했으며, ShuffleNet 2x 모델( g = 3 )은 524 MFLOPs에서 26.3%의 오류율을 기록했습니다(표 6 참조).
4.3 MobileNets 및 기타 프레임워크와의 비교
최근 Howard 등은 모바일 장치를 위한 효율적인 네트워크 아키텍처인 MobileNets [12]를 제안했습니다. MobileNet은 [3]에서 제안된 깊이별 분리 컨볼루션 아이디어를 채택하여 작은 모델에서 최신 성과를 달성했습니다.
표 5는 다양한 복잡성 수준에서 분류 점수를 비교한 것입니다. 우리의 ShuffleNet 모델이 모든 복잡성 수준에서 MobileNet보다 우수하다는 것이 명확합니다. 우리의 ShuffleNet 네트워크는 작은 모델( < 150 MFLOPs)용으로 특별히 설계되었지만, 더 높은 연산 비용이 드는 경우에도 MobileNet보다 우수합니다. 예를 들어, 500 MFLOPs의 연산 비용에서 ShuffleNet은 MobileNet 1×보다 3.1% 더 정확합니다. 더 작은 네트워크( ∼ 40 MFLOPs)에서는 ShuffleNet이 MobileNet보다 7.8% 더 우수합니다. 주목할 점은 ShuffleNet 아키텍처가 50개의 레이어를 가지고 있는 반면, MobileNet은 28개의 레이어만 가지고 있다는 점입니다. 이해를 돕기 위해, 우리는 Stage 2-4에서 블록의 절반을 제거하여 26개의 레이어로 구성된 ShuffleNet을 실험했습니다("ShuffleNet 0.5× shallow( g =3 )"로 표 5에 표시됨). 결과는 이 얕은 모델이 여전히 MobileNet보다 상당히 우수하다는 것을 보여주며, 이는 ShuffleNet의 효율성이 깊이보다는 그 구조에 기인한다는 것을 시사합니다.
표 6은 ShuffleNet과 몇몇 인기 있는 모델을 비교한 것입니다. 결과는 유사한 정확도를 가지고도 ShuffleNet이 다른 모델들보다 훨씬 더 효율적임을 보여줍니다. 예를 들어, ShuffleNet 0.5×는 이론적으로 AlexNet [21]보다 18배 더 빠르지만 비슷한 분류 점수를 얻습니다. 실제 실행 시간은 섹션 4.5에서 평가할 것입니다.
또한, 단순한 아키텍처 설계 덕분에 ShuffleNet에 [13, 26]과 같은 최신 기술을 쉽게 적용할 수 있다는 점도 주목할 만합니다. 예를 들어, [13]에서는 대형 ImageNet 모델에서 최신 성과를 달성한 Squeeze-and-Excitation(SE) 블록을 제안했습니다. SE 모듈은 ShuffleNet 백본과 결합했을 때도 효과를 발휘하여, 예를 들어 ShuffleNet 2x의 top-1 오류율을 24.7%로 향상시킵니다(표 5에 표시됨). 흥미롭게도, 이론적 복잡성의 증가가 미미함에도 불구하고, 모바일 장치에서 SE 모듈을 포함한 ShuffleNet은 "원본" ShuffleNet보다 25 ∼ 40 % 더 느리며, 이는 저비용 아키텍처 설계에서 실제 속도 평가가 중요함을 의미합니다. 섹션 4.5에서 이에 대해 추가로 논의할 것입니다.
4.4 일반화 능력
전이 학습의 일반화 능력을 평가하기 위해, 우리는 MS COCO 객체 검출 작업 [23]에서 ShuffleNet 모델을 테스트합니다. 우리는 Faster-RCNN [28]을 검출 프레임워크로 채택하고, 공개된 Caffe 코드 [28, 17]를 사용하여 기본 설정으로 훈련합니다. [12]와 유사하게, 모델은 5000개의 미니 검증(minival) 이미지를 제외한 COCO train+val 데이터셋에서 훈련되며, 테스트는 미니 검증 세트에서 수행됩니다. 표 7은 두 입력 해상도로 훈련되고 평가된 결과를 비교한 것입니다. 비슷한 복잡성을 가진 ShuffleNet 2×와 MobileNet(524 대 569 MFLOPs)을 비교하면, 우리의 ShuffleNet 2×는 두 해상도 모두에서 MobileNet을 상당한 차이로 능가합니다. 또한 ShuffleNet 1×는 600× 해상도에서 MobileNet과 유사한 결과를 달성하면서도 복잡성이 약 4 배 감소합니다. 이러한 큰 성능 향상은 ShuffleNet이 불필요한 복잡한 요소 없이 단순한 아키텍처 설계를 사용한 덕분이라고 추측됩니다.
4.5 실제 속도 향상 평가
마지막으로, ARM 플랫폼을 사용하는 모바일 장치에서 ShuffleNet 모델의 실제 추론 속도를 평가합니다. 그룹 수가 큰 ShuffleNet( g = 4 또는 g = 8 ) 모델이 일반적으로 더 나은 성능을 보이지만, 현재 구현에서는 비효율적임을 발견했습니다. 경험적으로 g = 3 이 정확도와 실제 추론 시간 간의 적절한 균형을 제공합니다. 표 8에 나와 있듯이, 세 가지 입력 해상도로 테스트가 수행되었습니다. 메모리 접근 및 기타 오버헤드 때문에, 이론적인 복잡성이 4배 감소할 때마다 실제 속도는 대략 2.6 배 빨라진다는 것을 발견했습니다. 그럼에도 불구하고, AlexNet [21]과 비교했을 때, 우리의 ShuffleNet 0.5× 모델은 여전히 유사한 분류 정확도에서 13 배의 실제 속도 향상을 달성했으며(이론적 속도 향상은 18배), 이는 이전의 AlexNet 수준 모델이나 속도 향상 접근 방식 [14, 16, 22, 42, 43, 38]보다 훨씬 빠릅니다.



