https://arxiv.org/abs/1611.05431
Aggregated Residual Transformations for Deep Neural Networks
We present a simple, highly modularized network architecture for image classification. Our network is constructed by repeating a building block that aggregates a set of transformations with the same topology. Our simple design results in a homogeneous, mul
arxiv.org
초록
우리는 이미지 분류를 위한 간단하고 고도로 모듈화된 네트워크 아키텍처를 제시합니다. 우리의 네트워크는 동일한 토폴로지를 가진 일련의 변환들을 집합적으로 결합한 빌딩 블록을 반복하여 구성됩니다. 이 간단한 설계는 소수의 하이퍼파라미터만을 설정해야 하는 동질적이고 다중 브랜치 구조를 갖는 아키텍처를 만들어냅니다. 이 전략은 '카디널리티' (변환 집합의 크기)라는 새로운 차원을 깊이와 너비 차원 외에도 필수적인 요소로 노출시킵니다. ImageNet-1K 데이터셋에서 우리는 복잡성을 유지하는 제한된 조건 하에서도 카디널리티를 증가시키면 분류 정확도가 향상될 수 있음을 실험적으로 보여주었습니다. 더 나아가, 카디널리티를 증가시키는 것이 네트워크의 용량을 늘릴 때 더 깊거나 더 넓게 만드는 것보다 효과적임을 확인했습니다. 우리의 모델인 ResNeXt는 ILSVRC 2016 분류 과제에서 2위를 차지한 우리의 출품작의 기초가 되었습니다. 우리는 또한 ImageNet-5K 세트와 COCO 검출 세트에서 ResNeXt를 추가로 연구하였으며, ResNet과 비교하여 더 나은 결과를 보여주었습니다. 코드와 모델은 온라인에서 공개적으로 이용 가능합니다.
1 https://github.com/facebookresearch/ResNeXt
GitHub - facebookresearch/ResNeXt: Implementation of a classification framework from the paper Aggregated Residual Transformatio
Implementation of a classification framework from the paper Aggregated Residual Transformations for Deep Neural Networks - facebookresearch/ResNeXt
github.com
1. 서론
시각 인식에 대한 연구는 "특징 공학"에서 "네트워크 공학"으로의 전환을 겪고 있습니다 [25, 24, 44, 34, 36, 38, 14]. 전통적인 수작업으로 설계된 특징들(e.g., SIFT [29]와 HOG [5])과는 달리, 대규모 데이터로부터 신경망이 학습한 특징들은 훈련 과정에서 최소한의 인간 개입만을 필요로 하며, 다양한 인식 작업에 전이될 수 있습니다 [7, 10, 28]. 그러나 인간의 노력은 이제 더 나은 표현 학습을 위한 네트워크 아키텍처 설계로 전환되었습니다.
아키텍처 설계는 하이퍼파라미터(너비, 필터 크기, 스트라이드 등)의 수가 증가함에 따라 점점 더 어려워지고 있으며, 특히 많은 층이 있는 경우 더욱 그렇습니다. VGG-net [36]은 동일한 형태의 빌딩 블록을 쌓아 매우 깊은 네트워크를 구성하는 간단하지만 효과적인 전략을 보여줍니다. 이 전략은 ResNet [14]에도 계승되어 동일한 토폴로지를 가진 모듈을 쌓는 방식으로 사용됩니다. 이 간단한 규칙은 하이퍼파라미터 선택의 자유도를 줄이며, 깊이를 신경망에서 필수적인 차원으로 노출시킵니다. 또한, 우리는 이 규칙의 단순성이 특정 데이터셋에 하이퍼파라미터를 과도하게 적응시키는 위험을 줄일 수 있다고 주장합니다. VGG-net과 ResNet의 견고함은 다양한 시각 인식 작업 [7, 10, 9, 28, 31, 14]뿐만 아니라, 음성 [42, 30]과 언어 [4, 41, 20]를 포함한 비시각적 작업에서도 입증되었습니다.
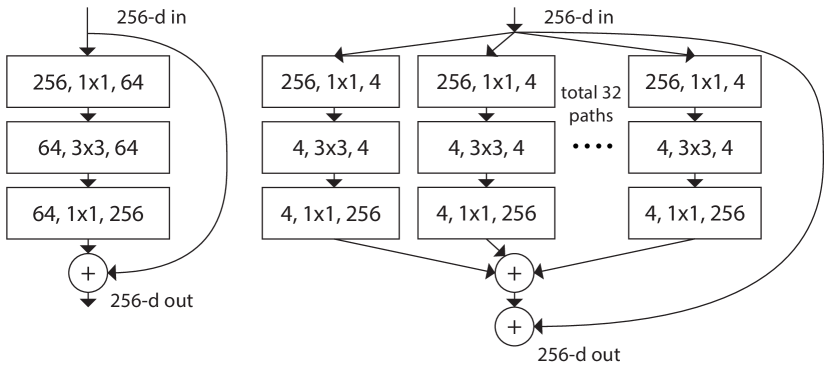
그림 1: 왼쪽: ResNet [14]의 블록.
오른쪽: ResNeXt의 블록 (카디널리티 = 32)으로, 대략적으로 동일한 복잡도를 가집니다. 각 레이어는 (# 입력 채널, 필터 크기, # 출력 채널)로 표시됩니다.
VGG-net과 달리, Inception 모델 군 [38, 17, 39, 37]은 신중하게 설계된 토폴로지가 낮은 이론적 복잡도와 함께 뛰어난 정확도를 달성할 수 있음을 보여주었습니다. Inception 모델은 시간이 지남에 따라 발전해 왔지만 [38, 39], 중요한 공통 속성은 분할-변환-병합(split-transform-merge) 전략입니다. Inception 모듈에서는 입력이 몇 가지 저차원 임베딩(1×1 합성곱에 의해)으로 분할되고, 일련의 특수화된 필터(3×3, 5×5 등)에 의해 변환된 후, 병합(연결)됩니다. 이 아키텍처의 솔루션 공간은 고차원 임베딩에서 동작하는 단일 큰 레이어(e.g., 5×5)의 솔루션 공간의 엄격한 부분 공간임을 보여줄 수 있습니다. Inception 모듈의 분할-변환-병합 행동은 큰 밀집 레이어의 표현력을 낮은 계산 복잡도로 접근할 수 있게 합니다.
좋은 정확도에도 불구하고, Inception 모델을 구현하는 과정에서는 몇 가지 복잡한 요소들이 동반되었습니다. 필터의 수와 크기는 각각의 개별 변환에 맞게 조정되고, 모듈은 단계별로 맞춤 설계되었습니다. 이러한 구성 요소들을 신중하게 조합하면 우수한 신경망 레시피를 만들 수 있지만, 일반적으로 Inception 아키텍처를 새로운 데이터셋/작업에 어떻게 적응시킬지는 불분명하며, 특히 설계해야 할 요인과 하이퍼파라미터가 많을 때 그렇습니다.
본 논문에서는 VGG/ResNet의 층 반복 전략을 채택하면서, 분할-변환-병합 전략을 쉽게 확장 가능한 방식으로 활용하는 간단한 아키텍처를 제시합니다. 우리 네트워크의 모듈은 저차원 임베딩에서 각각의 변환을 수행하고, 그 출력이 합산되어 집계됩니다. 이 아이디어의 간단한 구현을 추구하는데, 집계될 변환들은 모두 동일한 토폴로지를 가집니다(e.g., 그림 1 오른쪽). 이 설계는 특수한 설계 없이도 많은 수의 변환으로 확장할 수 있게 해줍니다.
흥미롭게도, 이러한 단순화된 상황에서 우리의 모델은 두 가지 다른 동등한 형태를 가집니다(그림 3). 그림 3(b)의 재구성은 다수의 경로를 연결하는 Inception-ResNet 모듈 [37]과 유사해 보이지만, 우리의 모듈은 모든 경로가 동일한 토폴로지를 공유한다는 점에서 기존의 모든 Inception 모듈과 다르며, 따라서 경로의 수를 독립된 연구 요인으로 쉽게 분리할 수 있습니다. 더 간결한 재구성에서, 우리의 모듈은 Krizhevsky 등 [24]의 그룹화된 합성곱에 의해 재형성될 수 있습니다(그림 3(c)). 그러나 이 그룹화된 합성곱은 기술적 타협의 결과로 개발되었습니다.
우리는 계산 복잡도와 모델 크기를 유지하는 제한된 조건 하에서도, 우리의 집계된 변환이 원래의 ResNet 모듈보다 뛰어나다는 것을 실험적으로 입증합니다 — 예를 들어, 그림 1(오른쪽)은 FLOP 복잡도와 그림 1(왼쪽)의 매개변수 수를 유지하도록 설계되었습니다. 우리는 용량을 증가시켜(깊게 하거나 넓게 하여) 정확도를 높이는 것이 상대적으로 쉽지만, 복잡도를 유지하거나 줄이면서 정확도를 높이는 방법은 문헌에서 드물다는 점을 강조합니다.
우리의 방법은 카디널리티(변환 집합의 크기)가 너비와 깊이 차원 외에도 중요한 중심 차원임을 나타냅니다. 실험 결과, 카디널리티를 증가시키는 것이 깊게 하거나 넓게 만드는 것보다 정확도를 높이는 데 더 효과적이며, 특히 기존 모델에서 깊이와 너비가 수익 감소를 보이기 시작할 때 그렇습니다.
우리의 신경망, ResNeXt는 ImageNet 분류 데이터셋에서 ResNet-101/152 [14], ResNet-200 [15], Inception-v3 [39], Inception-ResNet-v2 [37]보다 우수한 성능을 보입니다. 특히, 101층 ResNeXt는 ResNet-200 [15]보다 더 나은 정확도를 달성하지만, 복잡도는 50%에 불과합니다. 또한, ResNeXt는 모든 Inception 모델보다 훨씬 간단한 설계를 가지고 있습니다. ResNeXt는 ILSVRC 2016 분류 과제에서 우리가 2위를 차지한 출품작의 기초가 되었습니다. 이 논문은 또한 ImageNet-5K 세트와 COCO 객체 탐지 데이터셋 [27]에서 ResNeXt를 추가로 평가하며, ResNet보다 일관되게 더 나은 정확도를 보여줍니다. 우리는 ResNeXt가 다른 시각적(그리고 비시각적) 인식 작업에도 잘 일반화될 것이라고 기대합니다.
2. 관련 연구
다중 분기 합성곱 네트워크
Inception 모델 [38, 17, 39, 37]은 각 분기가 신중하게 맞춤 설계된 성공적인 다중 분기 아키텍처입니다. ResNet [14]은 한 분기가 항등 매핑(identity mapping)인 두 분기 네트워크로 볼 수 있습니다. Deep Neural Decision Forests [22]는 학습된 분할 함수를 사용하는 나무 패턴의 다중 분기 네트워크입니다.
그룹화된 합성곱
그룹화된 합성곱의 사용은 최소한 AlexNet 논문 [24]까지 거슬러 올라갑니다. Krizhevsky 등 [24]에 따르면, 그룹화된 합성곱의 동기는 모델을 두 개의 GPU에 분산시키기 위함이었습니다. 그룹화된 합성곱은 주로 AlexNet의 호환성을 위해 Caffe [19], Torch [3], 및 기타 라이브러리에서 지원됩니다. 우리가 아는 한, 그룹화된 합성곱을 활용하여 정확도를 향상시킨다는 증거는 거의 없습니다. 그룹화된 합성곱의 특수한 경우는 채널 수가 그룹 수와 동일한 경우의 채널 단위 합성곱입니다. 채널 단위 합성곱은 [35]에서 분리 가능한 합성곱의 일부입니다.
합성곱 네트워크 압축
분해(공간 [6, 18] 및/또는 채널 [6, 21, 16] 수준)는 심층 합성곱 네트워크의 중복성을 줄이고 이를 가속화/압축하는 데 널리 사용되는 기술입니다. Ioannou 등 [16]은 계산을 줄이기 위한 "루트" 패턴 네트워크를 제시했으며, 루트의 분기는 그룹화된 합성곱으로 구현됩니다. 이러한 방법들 [6, 18, 21, 16]은 정확성을 유지하면서도 낮은 복잡도와 작은 모델 크기를 제공하는 우아한 절충안을 제시합니다. 우리의 방법은 압축 대신에, 실험적으로 더 강한 표현력을 보여주는 아키텍처입니다.
앙상블
독립적으로 훈련된 네트워크 집합을 평균화하는 것은 정확도를 향상시키는 효과적인 방법이며 [24], 인식 대회에서 널리 사용됩니다 [33]. Veit 등 [40]은 단일 ResNet을 ResNet의 덧셈적 동작 [15]에서 비롯된 얕은 네트워크들의 앙상블로 해석합니다. 우리의 방법은 변환 집합을 집계하기 위해 덧셈을 활용합니다. 그러나 우리의 방법을 앙상블로 보는 것은 부정확하다고 주장합니다. 왜냐하면 집계될 구성원들이 독립적으로 훈련된 것이 아니라, 함께 훈련되기 때문입니다.
3. 방법
3.1 템플릿
우리는 VGG/ResNet을 따르는 고도로 모듈화된 설계를 채택합니다. 우리의 네트워크는 잔차 블록(residual blocks)으로 구성된 스택으로 이루어져 있습니다. 이 블록들은 동일한 토폴로지를 가지고 있으며, VGG/ResNet에서 영감을 받은 두 가지 간단한 규칙을 따릅니다: (i) 동일한 크기의 공간적 맵을 생성할 때, 블록들은 동일한 하이퍼파라미터(너비와 필터 크기)를 공유합니다. (ii) 각 블록이 공간적 맵을 2배로 다운샘플링할 때마다, 블록의 너비가 2배로 증가합니다. 이 두 번째 규칙은 모든 블록의 계산 복잡도가 FLOPs(부동 소수점 연산, 곱셈-덧셈의 수) 측면에서 대략 동일하도록 보장합니다.
이 두 가지 규칙을 따르면, 우리는 템플릿 모듈을 설계하기만 하면 되며, 네트워크의 모든 모듈은 이에 따라 결정될 수 있습니다. 따라서 이 두 규칙은 설계 공간을 크게 좁혀주며, 몇 가지 주요 요소에 집중할 수 있게 해줍니다. 이러한 규칙에 따라 구성된 네트워크는 표 1에 나와 있습니다.

표 1:
(왼쪽) ResNet-50.
(오른쪽) ResNeXt-50의 32×4d 템플릿(그림 3(c)에서 재구성한 것). 대괄호 안에는 잔차 블록의 형태가, 대괄호 밖에는 단계별로 쌓인 블록의 수가 표시되어 있습니다. "C=32"는 32개의 그룹으로 구성된 그룹화된 합성곱 [24]을 나타냅니다. 이 두 모델 사이의 매개변수와 FLOPs 수는 비슷합니다.
3.2 간단한 뉴런 재고
인공 신경망에서 가장 간단한 뉴런은 내적(가중 합산)을 수행하며, 이는 완전 연결층과 합성곱층에서 수행되는 기본적인 변환입니다. 내적은 변환 집합을 집계하는 한 형태로 생각될 수 있습니다:



그림 2: 내적(가중 합산)을 수행하는 간단한 뉴런.

그림 3: ResNeXt의 동등한 빌딩 블록들.
(a): 집계된 잔차 변환, 그림 1 오른쪽과 동일합니다.
(b): (a)와 동등한 블록으로, 조기 연결(early concatenation)로 구현되었습니다.
(c): (a, b)와 동등한 블록으로, 그룹화된 합성곱 [24]으로 구현되었습니다. 굵은 글씨로 된 표기는 재구성된 변화를 강조합니다. 각 레이어는 (# 입력 채널, 필터 크기, # 출력 채널)로 표시됩니다.
3.3 집계된 변환

이 식에서 C는 집계될 변환 집합의 크기를 나타냅니다. 우리는 C를 카디널리티라고 부릅니다 [2]. 이 식에서 C는 식 (1)에서의 D와 유사한 위치에 있지만, C는 D와 같을 필요는 없으며 임의의 값이 될 수 있습니다. 너비 차원이 단순한 변환(내적)의 수와 관련이 있는 반면, 우리는 카디널리티 차원이 더 복잡한 변환의 수를 제어한다고 주장합니다. 실험을 통해 카디널리티가 중요한 차원이며, 너비와 깊이 차원보다 더 효과적일 수 있음을 보여줍니다.
본 논문에서는 변환 함수들을 설계하는 간단한 방법을 고려합니다: 모든 T_i는 동일한 토폴로지를 가집니다. 이는 동일한 형태의 층을 반복하는 VGG 스타일의 전략을 확장하며, 몇 가지 요소를 분리하고 임의의 큰 수의 변환으로 확장하는 데 도움이 됩니다. 우리는 각 T_i 의 개별 변환을 병목 구조 [14]로 설정하며, 그림 1 (오른쪽)에 예시되어 있습니다. 이 경우, 각 T_i 의 첫 번째 1×1 레이어가 저차원 임베딩을 생성합니다.
식 (2)에서의 집계된 변환은 잔차 함수 [14]로 작용합니다 (그림 1 오른쪽):

여기서 는 출력입니다.
Inception-ResNet과의 관계
몇 가지 텐서 조작을 통해 그림 1(오른쪽) 모듈(그림 3(a)에도 표시됨)이 그림 3(b)와 동등함을 보여줄 수 있습니다.

그룹화된 합성곱과의 관계
위의 모듈은 그룹화된 합성곱 [24]의 표기법을 사용하여 더 간결해집니다.
그룹화된 합성곱 층에서는 입력 및 출력 채널이 C 그룹으로 나뉘며, 각 그룹 내에서 합성곱이 별도로 수행됩니다. 이 재구성은 그림 3(c)에서 설명됩니다. 모든 저차원 임베딩(첫 번째 1×1 레이어)은 하나의 더 넓은 레이어(e.g., 그림 3(c)에서 1×1, 128-d)로 대체될 수 있습니다. 분할은 본질적으로 입력 채널을 그룹으로 나누는 그룹화된 합성곱 층에 의해 수행됩니다. 그림 3(c)에서 그룹화된 합성곱 층은 입력 및 출력 채널이 4차원인 32개의 그룹의 합성곱을 수행하며, 그룹화된 합성곱 층은 이를 층의 출력으로 연결합니다. 그림 3(c)에서의 블록은 그림 1(왼쪽)의 원래 병목 잔차 블록과 비슷해 보이지만, 그림 3(c)는 더 넓고 드문 연결 모듈입니다.

그림 4:
(왼쪽): 깊이 인 변환 집합.
(오른쪽): 동등한 블록으로, 더 넓지만 단순합니다.
우리는 재구성이 비트리비얼한(topologically nontrivial) 토폴로지를 생성하는 경우는 블록의 깊이가 ≥3일 때뿐임을 주목합니다. 블록의 깊이가 =2인 경우(예: [14]의 기본 블록), 재구성은 간단하게 넓고 밀집된 모듈로 이어집니다. 그림 4의 예시를 참조하십시오.
논의
우리는 비록 연결(Fig. 3(b))이나 그룹화된 합성곱(Fig. 3(c))을 포함하는 재구성을 제시했지만, 이러한 재구성이 식 (3)의 일반적인 형태에 항상 적용되는 것은 아님을 주목합니다. 예를 들어, 변환 T_i가 임의의 형태를 취하고 이질적일 때 그렇습니다. 우리는 단순하고 확장 가능한 형태를 사용하기로 선택했습니다. 이 단순화된 경우에서는 그림 3(c)와 같은 형태의 그룹화된 합성곱이 구현을 용이하게 하는 데 유용합니다.
3.4 모델 용량
다음 섹션에서의 실험은 모델의 복잡도와 파라미터 수를 유지하면서도 우리의 모델이 정확도를 향상시킨다는 것을 보여줍니다. 이는 실제로 흥미로운 점일 뿐만 아니라, 복잡도와 파라미터 수는 모델의 내재된 용량을 나타내므로 종종 심층 네트워크의 기본 속성으로 연구됩니다 [8].
복잡도를 유지하면서 다양한 카디널리티 를 평가할 때, 다른 하이퍼파라미터의 수정을 최소화하고자 합니다. 우리는 병목 너비(e.g., 그림 1(오른쪽)에서 4-d)를 조정하기로 선택했는데, 이는 블록의 입력과 출력으로부터 독립적으로 조정될 수 있기 때문입니다. 이 전략은 다른 하이퍼파라미터(깊이 또는 블록의 입력/출력 너비)에는 변화를 주지 않으므로, 카디널리티의 영향에 집중할 수 있게 도와줍니다.

우리가 3.1절의 두 가지 규칙을 채택했기 때문에, 위의 근사적 동등성은 ResNet 병목 블록과 모든 단계에서의 ResNeXt 간에 유효합니다(특성 맵 크기가 변경되는 서브샘플링 레이어는 제외). 표 1은 원래 ResNet-50과 유사한 용량을 가진 우리의 ResNeXt-50을 비교합니다.5 5 파라미터 수가 약간 적고 FLOPs가 약간 더 높은 것은 주로 맵 크기가 변경되는 블록에서 발생합니다. 우리는 복잡도가 대략적으로만 유지될 수 있지만, 그 차이는 미미하며 우리의 결과에 편향을 주지 않는다고 주목합니다.

표 2:
카디널리티와 너비 간의 관계 (conv2 템플릿에 대해), 잔차 블록에서 대략적으로 복잡도가 유지됩니다. conv2 템플릿의 파라미터 수는 약 70k입니다. FLOPs 수는 약 0.22십억(파라미터 수 × 56 × 56 for conv2)입니다.


그림 5:
ImageNet-1K에서의 훈련 곡선.
(왼쪽): 복잡도가 유지된 ResNet/ResNeXt-50 (약 41억 FLOPs, 약 2500만 파라미터);
(오른쪽): 복잡도가 유지된 ResNet/ResNeXt-101 (약 78억 FLOPs, 약 4400만 파라미터).
4. 구현 세부 사항
우리의 구현은 [14]와 공개된 fb.resnet.torch [11] 코드를 따릅니다. ImageNet 데이터셋에서는 입력 이미지가 [11]에 의해 구현된 [38]의 스케일 및 종횡비 증강을 사용하여 크기 조정된 이미지에서 224×224 크기로 무작위로 잘립니다. 단축(shortcuts)은 차원을 증가시키는 경우를 제외하고 항등 연결(identity connections)이며, 이 경우에는 프로젝션(type B in [14])이 사용됩니다. conv3, 4, 5의 다운샘플링은 [11]에서 제안한 대로 각 스테이지의 첫 번째 블록의 3×3 레이어에서 스트라이드-2 합성곱으로 수행됩니다. 우리는 8개의 GPU(각 GPU당 32개)에 대해 미니 배치 크기 256으로 SGD를 사용합니다. 가중치 감소율(weight decay)은 0.0001이고, 모멘텀(momentum)은 0.9입니다. 초기 학습률은 0.1로 시작하며, [11]의 일정에 따라 세 번 학습률을 10분의 1로 나눕니다. 가중치 초기화는 [13]을 채택합니다. 모든 제거 비교(ablation comparisons)에서는 짧은 변의 길이가 256인 이미지에서 단일 224×224 중심 자르기(center crop)를 통해 오류를 평가합니다.
우리의 모델은 그림 3(c)의 형태로 구현됩니다. 우리는 그림 3(c)의 합성곱 직후에 배치 정규화(BN) [17]를 수행합니다.6
6 BN을 사용할 때, 그림 3(a)에서 동등한 형태로 변환을 집계한 후 단축에 추가하기 전에 BN을 적용합니다.
ReLU는 각 BN 직후에 수행되며, 단축에 추가된 후의 블록 출력에 대해서는 [14]를 따릅니다.
우리는 BN과 ReLU가 위에서 언급한 대로 적절히 처리될 때 그림 3의 세 가지 형태가 엄밀히 동일함을 주목합니다. 우리는 세 가지 형태 모두를 훈련했으며 동일한 결과를 얻었습니다. 그림 3(c)를 구현하는 것을 선택한 이유는 다른 두 형태보다 더 간결하고 빠르기 때문입니다.
5. 실험
5.1 ImageNet-1K에서의 실험
우리는 1000개의 클래스가 있는 ImageNet 분류 과제 [33]에서 제거 실험(ablation experiments)을 수행합니다. [14]를 따라 50층과 101층 잔차 네트워크를 구성합니다. ResNet-50/101의 모든 블록을 우리 블록으로 단순히 교체합니다.
표기법
3.1절의 두 가지 규칙을 채택했기 때문에, 우리는 템플릿으로 아키텍처를 참조하는 것으로 충분합니다. 예를 들어, 표 1은 카디널리티 C=32와 병목 너비 =4d (그림 3)의 템플릿으로 구성된 ResNeXt-50을 보여줍니다. 이 네트워크는 간단히 ResNeXt-50 (32×4d)로 표기됩니다. 우리는 템플릿의 입력/출력 너비가 256-d로 고정되어 있으며(그림 3), 특성 맵이 다운샘플링될 때마다 너비가 두 배로 증가함을 주목합니다(표 1 참조).
카디널리티 vs. 너비
우리는 먼저 표 2에 나열된 대로 복잡도를 유지한 상태에서 카디널리티 C와 병목 너비 간의 절충(trade-off)을 평가합니다. 표 3은 결과를 보여주며, 그림 5는 에포크(epoch)에 따른 오류 곡선을 보여줍니다. ResNet-50과 비교했을 때(표 3 상단 및 그림 5 왼쪽), 32×4d ResNeXt-50은 검증 오류가 22.2%로, ResNet의 기준선인 23.9%보다 1.7% 낮습니다. 복잡도를 유지하면서 카디널리티 CC가 1에서 32로 증가함에 따라 오류율은 계속 감소합니다. 게다가, 32×4d ResNeXt는 ResNet보다 훈련 오류가 훨씬 낮으며, 이는 성능 향상이 정규화(regularization)에서 기인한 것이 아니라 더 강력한 표현력에서 기인한 것임을 시사합니다.
유사한 경향이 ResNet-101의 경우에도 관찰됩니다(그림 5 오른쪽, 표 3 하단). 여기서 32×4d ResNeXt-101은 ResNet-101보다 0.8% 더 우수한 성능을 보입니다. 비록 이 검증 오류의 향상이 50층 케이스보다 작지만, 훈련 오류의 향상은 여전히 큽니다(ResNet-101의 경우 20%, 32×4d ResNeXt-101의 경우 16%, 그림 5 오른쪽). 실제로, 더 많은 훈련 데이터는 검증 오류의 격차를 확대할 것입니다. 다음 절에서 ImageNet-5K 세트에서 이를 보여줍니다.
표 3은 또한 복잡도를 유지하면서 너비를 줄이는 대가로 카디널리티를 증가시키면 병목 너비가 작을 때 정확도가 포화되기 시작함을 시사합니다. 우리는 이러한 절충에서 너비를 계속 줄이는 것이 가치가 없다고 주장합니다. 따라서 우리는 다음에서 병목 너비를 4d 이상으로 유지합니다.

표 3: ImageNet-1K에서의 제거 실험 결과.
(상단): 복잡도를 유지한 ResNet-50 (약 41억 FLOPs);
(하단): 복잡도를 유지한 ResNet-101 (약 78억 FLOPs). 오류율은 224×224 픽셀의 단일 자르기(single crop)로 평가되었습니다.

표 4: FLOPs 수가 ResNet-101의 2배로 증가했을 때의 ImageNet-1K 비교. 오류율은 224×224 픽셀의 단일 자르기(single crop)로 평가되었습니다. 강조된 요소들은 복잡도를 증가시키는 요소들입니다.
카디널리티 증가 vs. 더 깊게/더 넓게
다음으로, 카디널리티 C를 증가시키거나 깊이 또는 너비를 증가시켜 복잡도를 증가시키는 방법을 조사합니다. 다음 비교는 ResNet-101 기준선의 2배 FLOPs에 대한 참조로도 볼 수 있습니다. 우리는 약 150억 FLOPs를 가진 다음 변형들을 비교합니다. (i) 200층으로 더 깊게 만들기. 우리는 [11]에서 구현된 ResNet-200 [15]을 채택합니다. (ii) 병목 너비를 증가시켜 더 넓게 만들기. (iii) 카디널리티 C를 두 배로 늘리기.
표 4는 복잡도를 2배로 증가시켜도 ResNet-101 기준선(22.0%)에 비해 오류가 꾸준히 감소함을 보여줍니다. 그러나 더 깊게 만들 경우(ResNet-200, 0.3% 감소)나 더 넓게 만들 경우(더 넓은 ResNet-101, 0.7% 감소)에는 개선이 적습니다.
반면에, 카디널리티 C를 증가시키는 것은 더 깊게 또는 더 넓게 만드는 것보다 훨씬 더 나은 결과를 보여줍니다. 2×64d ResNeXt-101(즉, 1×64d ResNet-101 기준선에서 CC를 두 배로 늘리고 너비를 유지)은 최상위-1(top-1) 오류를 1.3% 줄여 20.7%로 감소시킵니다. 64×4d ResNeXt-101(즉, 32×4d ResNeXt-101에서 CC를 두 배로 늘리고 너비를 유지)은 최상위-1 오류를 20.4%로 감소시킵니다.
또한, 32×4d ResNet-101(21.2%)이 더 깊은 ResNet-200과 더 넓은 ResNet-101보다 더 나은 성능을 보임을 주목할 필요가 있습니다. 이는 복잡도가 약 50%에 불과한 경우에도 그렇습니다. 이는 다시 한 번 카디널리티가 깊이와 너비의 차원보다 더 효과적인 차원임을 보여줍니다.
잔차 연결(Residual connections)
다음 표는 잔차(단축) 연결의 효과를 보여줍니다:

ResNeXt-50에서 단축(shortcuts)을 제거하면 오류율이 3.9% 증가하여 26.1%가 됩니다. 반면, ResNet-50에서 단축을 제거하면 훨씬 더 나쁜 결과(31.2%)를 보입니다. 이러한 비교는 잔차 연결(residual connections)이 최적화에 도움이 되며, 집계된 변환이 잔차 연결의 유무와 관계없이 일관되게 더 나은 성능을 보이는 강력한 표현임을 시사합니다.
성능
단순성을 위해 우리는 Torch의 기본 내장된 그룹화된 합성곱 구현을 사용하며, 특별한 최적화는 하지 않았습니다. 이 구현은 무작위로 진행되었으며 병렬 처리에 친화적이지 않았습니다. NVIDIA M40의 8개 GPU에서, 표 3의 32×4d ResNeXt-101을 훈련하는 데 미니배치 당 0.95초가 걸리며, 이는 유사한 FLOPs를 가진 ResNet-101 기준선의 0.70초와 비교됩니다. 우리는 이것이 합리적인 오버헤드라고 주장합니다. 신중하게 설계된 하위 수준의 구현(e.g., CUDA에서)은 이 오버헤드를 줄일 수 있을 것으로 기대합니다. 또한, CPU에서의 추론 시간은 더 적은 오버헤드를 보일 것으로 예상합니다. 2배 복잡도 모델(64×4d ResNeXt-101)을 훈련하는 데는 미니배치 당 1.7초가 걸리며, 8개 GPU에서 총 10일이 소요됩니다.
최신 결과와의 비교
표 5는 ImageNet 검증 세트에서 단일 자르기 테스트에 대한 추가 결과를 보여줍니다. 224×224 크기의 자르기 테스트 외에도, [15]를 따라 320×320 크기의 자르기 테스트도 평가했습니다. 우리의 결과는 ResNet, Inception-v3/v4, Inception-ResNet-v2와 비교해 우수한 성능을 보이며, 단일 자르기 top-5 오류율이 4.4%입니다. 또한, 우리의 아키텍처 설계는 모든 Inception 모델보다 훨씬 간단하며, 설정해야 할 하이퍼파라미터의 수가 크게 적습니다.
ResNeXt는 ILSVRC 2016 분류 과제에서 우리가 2위를 차지한 출품작의 기초가 되었습니다. 많은 모델(우리의 모델을 포함하여)이 이 데이터셋에서 다중 스케일 및/또는 다중 자르기 테스트를 사용한 후 포화 상태에 도달하기 시작한다는 점을 주목할 필요가 있습니다. 우리는 [14]에서 다중 스케일 밀집 테스트를 사용하여 단일 모델 기준으로 top-1/top-5 오류율이 17.7%/3.7%를 기록했으며, 이는 다중 스케일, 다중 자르기 테스트를 채택한 Inception-ResNet-v2의 단일 모델 결과인 17.8%/3.7%와 비슷한 수준입니다. 우리는 테스트 세트에서 3.03%의 top-5 오류율로 앙상블 결과를 얻었으며, 이는 우승자의 2.99%와 Inception-v4/Inception-ResNet-v2의 3.08%와 비슷한 수준입니다 [37].

표 5: ImageNet-1K 검증 세트에서의 최신(state-of-the-art) 모델들 (단일 자르기 테스트). ResNet/ResNeXt의 테스트 크기는 [15]에서와 같이 224×224 및 320×320이며, Inception 모델의 테스트 크기는 299×299입니다.

그림 6: ImageNet-5K 실험. 모델들은 5K 세트에서 훈련되고, 원래의 1K 검증 세트에서 평가됩니다. 이 평가에서는 1K 분류 과제로 플로팅됩니다. ResNeXt와 그 대응하는 ResNet 모델은 유사한 복잡도를 가지고 있습니다.

표 6: ImageNet-5K에서의 오류율 (%). 모델들은 ImageNet-5K에서 훈련되고, ImageNet-1K 검증 세트에서 테스트됩니다. 테스트 시 5K 분류 과제 또는 1K 분류 과제로 처리됩니다. ResNeXt와 그 대응하는 ResNet 모델은 유사한 복잡도를 가지고 있습니다. 오류율은 224×224 픽셀의 단일 자르기(single crop)로 평가됩니다.
5.2 ImageNet-5K에서의 실험
ImageNet-1K에서의 성능이 포화 상태에 도달한 것으로 보입니다. 그러나 이는 모델의 능력 때문이 아니라 데이터셋의 복잡성 때문이라고 주장합니다. 다음으로, 우리는 5000개의 카테고리를 가진 더 큰 ImageNet 부분 집합에서 우리의 모델을 평가합니다.
우리의 5K 데이터셋은 전체 ImageNet-22K 세트 [33]의 부분 집합입니다. 5000개의 카테고리는 원래의 ImageNet-1K 카테고리와 전체 ImageNet 세트에서 가장 많은 이미지를 가진 추가적인 4000개의 카테고리로 구성됩니다. 5K 세트는 680만 개의 이미지를 포함하며, 이는 1K 세트의 약 5배입니다. 공식적인 훈련/검증 분할은 제공되지 않으므로, 우리는 원래의 ImageNet-1K 검증 세트에서 평가하기로 했습니다. 이 1K 클래스 검증 세트에서 모델은 테스트 시 5K-way 분류 작업(다른 4K 클래스에서 예측된 모든 레이블은 자동으로 오류로 간주됨)으로 평가되거나, 1K-way 분류 작업(softmax가 1K 클래스에만 적용됨)으로 평가될 수 있습니다.
구현 세부 사항은 4절과 동일합니다. 5K 훈련 모델은 모두 처음부터 훈련되었으며, 1K 훈련 모델과 동일한 수의 미니배치로 훈련됩니다(따라서 1/5× 에포크). 표 6과 그림 6은 복잡도가 유지된 상태에서의 비교를 보여줍니다. ResNeXt-50은 ResNet-50과 비교하여 5K-way top-1 오류를 3.2% 줄였으며, ResNetXt-101은 ResNet-101과 비교하여 5K-way top-1 오류를 2.3% 줄였습니다. 유사한 격차가 1K-way 오류에서도 관찰됩니다. 이는 ResNeXt의 강력한 표현력을 입증합니다.
더욱이, 5K 세트에서 훈련된 모델들이(표 6에서 1K-way 오류율 22.2%/5.7%) 1K 세트에서 훈련된 모델들(표 3에서 21.2%/5.6%)과 경쟁할 만한 성능을 보이며, 동일한 1K-way 분류 작업에서 검증 세트로 평가되었습니다. 이 결과는 훈련 시간을 늘리지 않고(동일한 수의 미니배치 때문에) 미세 조정 없이 달성된 것입니다. 5K 카테고리를 분류하는 훈련 작업이 더 도전적인 과제임을 감안할 때, 이는 유망한 결과라고 주장합니다.
5.3 CIFAR에서의 실험
우리는 CIFAR-10과 100 데이터셋 [23]에서 추가 실험을 수행했습니다. 우리는 [14]에서와 같은 아키텍처를 사용하며, 기본 잔차 블록을

의 병목 템플릿으로 교체했습니다. 우리의 네트워크는 3×3의 단일 합성곱 레이어로 시작하여, 각각 3개의 잔차 블록을 가진 3단계를 거치고, 마지막으로 평균 풀링과 완전 연결된 분류기로 끝납니다(총 29층 깊이). 이는 [14]를 따릅니다. 데이터 증강은 [14]와 동일하게 번역 및 뒤집기를 사용합니다. 구현 세부 사항은 부록에 나와 있습니다.
우리는 위의 기준선을 바탕으로 복잡도를 증가시키는 두 가지 경우를 비교합니다: (i) 카디널리티를 증가시키고 모든 너비를 고정하거나, (ii) 병목의 너비를 증가시키고 카디널리티 =1 을 고정합니다. 우리는 이러한 변경 사항에 따라 일련의 네트워크를 훈련하고 평가했습니다. 그림 7은 테스트 오류율과 모델 크기의 비교를 보여줍니다. 우리는 카디널리티를 증가시키는 것이 너비를 증가시키는 것보다 더 효과적임을 발견했으며, 이는 ImageNet-1K에서 관찰한 바와 일치합니다. 표 7은 결과와 모델 크기를 보여주며, 가장 우수한 기록을 가진 Wide ResNet [43]과 비교한 것입니다. 유사한 모델 크기(34.4M)를 가진 우리의 모델은 Wide ResNet보다 더 나은 결과를 보입니다. 우리의 더 큰 모델은 CIFAR-10에서 3.58%의 테스트 오류(10회 실행 평균)와 CIFAR-100에서 17.31%의 오류율을 달성했습니다. 우리가 아는 한, 이는 문헌에 보고된(유사한 데이터 증강을 사용한) 최신 결과이며, 미발표된 기술 보고서를 포함합니다.

그림 7: CIFAR-10에서의 테스트 오류와 모델 크기의 관계. 결과는 10회 실행한 후 계산되었으며, 표준 오차 막대와 함께 표시됩니다. 레이블은 템플릿의 설정을 나타냅니다.

표 7: CIFAR에서의 테스트 오류율 (%)과 모델 크기. 우리의 결과는 10회 실행의 평균입니다.

표 8: COCO minival 세트에서의 객체 탐지 결과. ResNeXt와 그 대응하는 ResNet 모델은 유사한 복잡도를 가지고 있습니다.
5.4 COCO 객체 탐지에서의 실험
다음으로, COCO 객체 탐지 세트 [27]에서 일반화 가능성을 평가합니다. 우리는 [1]을 따라 80k 훈련 세트와 35k 검증 세트의 하위 집합에서 모델을 훈련하고, 5k 검증 세트 하위 집합(minival)에서 평가합니다. COCO 스타일의 평균 정확도(AP)와 AP@IoU=0.5 [27]를 평가합니다. 우리는 기본 Faster R-CNN [32]을 채택하고, ResNet/ResNeXt를 여기에 적용하는 [14]의 방법을 따릅니다. 모델들은 ImageNet-1K에서 사전 훈련된 후, 탐지 세트에서 미세 조정(fine-tuning)됩니다. 구현 세부 사항은 부록에 나와 있습니다.
표 8은 비교 결과를 보여줍니다. 50층 기준선에서, ResNeXt는 복잡도를 증가시키지 않고도 AP@0.5를 2.1%, AP를 1.0% 향상시켰습니다. ResNeXt는 101층 기준선에서 더 작은 향상을 보였습니다. 우리는 ImageNet-5K 세트에서 관찰된 바와 같이, 더 많은 훈련 데이터가 더 큰 격차를 초래할 것이라고 추측합니다.
또한, 최근 ResNeXt가 Mask R-CNN [12]에 채택되어 COCO 인스턴스 분할 및 객체 탐지 작업에서 최신 결과를 달성했다는 점도 주목할 가치가 있습니다.
감사의 말 S.X.와 Z.T.의 연구는 부분적으로 NSF IIS-1618477의 지원을 받았습니다. 저자들은 귀중한 논의를 제공한 Tsung-Yi Lin과 Priya Goyal에게 감사를 표하고자 합니다.
부록 A: 구현 세부 사항 - CIFAR
우리는 50k 훈련 세트에서 모델을 훈련시키고 10k 테스트 세트에서 평가합니다. 입력 이미지는 32×32 크기로, 40×40 크기의 제로 패딩된 이미지나 그 뒤집힌 이미지에서 무작위로 잘립니다([14]를 따름). 다른 데이터 증강은 사용하지 않습니다. 첫 번째 레이어는 64개의 필터를 가진 3×3 합성곱입니다. 각 단계에는 3개의 잔차 블록이 있으며, 출력 맵 크기는 각 단계마다 32, 16, 8입니다([14]를 따름). 네트워크는 글로벌 평균 풀링과 완전 연결 레이어로 끝납니다. 3.1절에서 설명한 대로, 단계가 변경될 때(다운샘플링 시) 너비는 2배로 증가합니다. 모델은 8개의 GPU에서 미니 배치 크기 128로 훈련되며, 가중치 감소율(weight decay)은 0.0005이고, 모멘텀(momentum)은 0.9입니다. 학습률은 0.1로 시작하며, 300 에포크 동안 모델을 훈련시키고, 150번째와 225번째 에포크에서 학습률을 줄입니다. 다른 구현 세부 사항은 [11]과 동일합니다.
부록 B: 구현 세부 사항 - 객체 탐지
우리는 Faster R-CNN 시스템 [32]을 채택합니다. 단순성을 위해 RPN과 Fast R-CNN 간의 기능을 공유하지 않습니다. RPN 단계에서는 8개의 GPU에서 각 GPU가 미니 배치당 2개의 이미지를 처리하며, 각 이미지당 256개의 앵커를 사용합니다. 우리는 120k 미니 배치 동안 학습률 0.02로, 다음 60k 미니 배치 동안 학습률 0.002로 RPN 단계를 훈련합니다. Fast R-CNN 단계에서는 8개의 GPU에서 각 GPU가 미니 배치당 1개의 이미지와 64개의 영역을 처리합니다. 우리는 Fast R-CNN 단계를 120k 미니 배치 동안 학습률 0.005로, 다음 60k 미니 배치 동안 학습률 0.0005로 훈련합니다. 가중치 감소율(weight decay)은 0.0001이고, 모멘텀(momentum)은 0.9입니다. 다른 구현 세부 사항은 https://github.com/rbgirshick/py-faster-rcnn에서 확인할 수 있습니다.



