https://arxiv.org/abs/2305.15272
ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers
Recently, plain vision Transformers (ViTs) have shown impressive performance on various computer vision tasks, thanks to their strong modeling capacity and large-scale pretraining. However, they have not yet conquered the problem of image matting. We hypot
arxiv.org
요약
최근 순수 비전 트랜스포머(ViTs)는 강력한 모델링 능력과 대규모 사전 학습 덕분에 다양한 컴퓨터 비전 작업에서 인상적인 성능을 보여주고 있습니다. 그러나 이들은 아직 이미지 매팅 문제를 완전히 해결하지 못했습니다. 우리는 ViT가 이미지 매팅 성능을 향상시킬 수 있을 것이라고 가정하고, 새로운 효율적이고 강력한 ViT 기반 매팅 시스템인 ViTMatte를 제안합니다. 우리의 방법은 다음을 활용합니다: (i) ViT가 매팅 작업에서 성능과 계산 효율성 간의 뛰어난 균형을 달성할 수 있도록 하는 컨볼루션 넥과 결합된 하이브리드 어텐션 메커니즘, (ii) 매팅에 필요한 세부 정보를 보완하기 위해 간단하고 가벼운 컨볼루션으로만 구성된 디테일 캡처 모듈. 우리가 아는 한, ViTMatte는 이미지 매팅에 ViT의 잠재력을 간결하게 적용한 최초의 연구입니다. ViTMatte는 사전 학습 전략, 간결한 아키텍처 설계, 유연한 추론 전략 등 ViT가 가진 많은 우수한 특성을 매팅 작업에 적용합니다. 우리는 ViTMatte를 이미지 매팅에서 가장 널리 사용되는 벤치마크인 Composition-1k와 Distinctions-646에서 평가했으며, 그 결과 우리 방법이 최첨단 성능을 달성하며 이전 매팅 연구들을 큰 차이로 능가했습니다. 우리의 코드와 모델은 이 링크에서 이용할 수 있습니다.
1. 소개

그림 1: 이미지 매팅 파이프라인. 전경 F와 그에 해당하는 트리맵 T를 ViTMatte에 입력하여 알파 매트 α를 예측합니다. 그런 다음, 이들을 사용해 식 I=αF+(1−α)B를 통해 새로운 합성 이미지를 만들 수 있습니다. 이미지들은 AIM-500 [29]와 인터넷에서 가져온 것입니다. 더 나은 시야를 위해 확대해서 보세요.
이미지 매팅은 오랜 역사를 가진 기본적인 컴퓨터 비전 연구 문제입니다 [28, 1]. 그림 1에서 볼 수 있듯이, 이미지 매팅은 알파 매트를 예측하여 전경 객체와 배경을 정밀하게 분리하는 것을 목표로 합니다(알파 매팅이라고도 알려져 있습니다). 이 기술은 영화 특수 효과, 디지털 인물 생성, 화상 회의 등 수많은 핵심 응용 분야에 적용될 수 있습니다.
최근 몇 년 동안, 이미지 매팅의 성능은 딥 러닝 기반 방법들 [56, 47, 59, 36]에 의해 크게 향상되었습니다. 이 방법들은 전통적인 샘플링 [44, 23] 또는 전파 기반 방법 [46, 27, 7]에 비해 강력한 의미 표현을 활용하여 의미 있는 컨텍스트를 포착할 수 있습니다. 주류 CNN 기반 이미지 매팅은 일반적으로 다음과 같은 패러다임을 따릅니다: 계층적 백본을 사용하여 이미지의 특징을 추출한 다음, 다중 수준의 특징을 융합하기 위해 사전 정보를 주입한 디코더를 사용합니다. 일반적으로 디코더는 두 가지 작업을 동시에 수행해야 한다고 가정됩니다: (i) 다중 수준의 특징을 융합하고 (ii) 세부 정보를 포착하는 것입니다 [41, 30, 59]. 이는 디코더와 전체 시스템의 설계를 복잡하게 만듭니다.
그림 2: ViTMatte와 다른 평범한 비전 트랜스포머(plain vision transformers) 응용의 개요 [31, 57, 51]. 이들은 ViTDet [31]에 의해 설계된 간단한 특징 피라미드를 사용합니다. 이와 달리, 우리는 이미지 매팅을 위해 특별히 설계된 새로운 적응 전략인 ViTMatte를 제안합니다. 우리는 단순한 컨볼루션 층을 사용하여 이미지의 세부 정보를 얻고, 평범한 비전 트랜스포머가 출력하는 특징 맵은 한 번만 사용됩니다.
다른 한편으로, 평범한 비전 트랜스포머(ViT)는 다양한 컴퓨터 비전 작업의 강력한 백본이 되었습니다 [14, 31, 57]. 일반적으로 사용되는 계층적 백본과 달리 [24, 37], ViT는 최소주의적이고 비계층적입니다. 최근 몇몇 연구들은 평범한 비전 트랜스포머를 객체 탐지 [31]와 자세 추정 [57]에 사용하여 놀라운 결과를 달성했습니다. 이러한 연구의 핵심 통찰은, 작업에 무관한 사전 학습된 트랜스포머 구조가 이미 충분히 풍부한 의미 표현을 인코딩할 수 있어, 하위 작업의 적응을 단순화할 수 있다는 점입니다. 예를 들어, ViTDet [31]는 특징 피라미드 네트워크(FPN) [34]의 특징 융합 과정 없이도, 단순한 디컨볼루션으로 생성된 특징 피라미드로도 인상적인 성능을 달성할 수 있음을 발견했습니다. 비슷한 패러다임 변화는 다른 도메인에서도 관찰되며, 여기서 기본 모델들(예: GPT-3 [3]와 Florence [60])이 대부분의 무거운 작업을 수행하도록 설계되었습니다. 이러한 이전 연구들에 영감을 받아, 평범한 ViT가 간단한 적응만으로 이미지 매팅을 해결하기에 충분히 '기반적'인지에 대한 질문을 제기하는 것이 흥미로울 것입니다.
이 논문에서는 ViT를 매팅 작업에 미세 조정하여 그 잠재력을 발휘할 수 있도록 시도합니다. 우리의 목표는 이미지 매팅에 특화된 복잡한 새로운 모듈을 설계하는 것이 아니라, 최소한의 적응으로 더 일반적이고 효과적인 매팅 아키텍처를 추구하는 것입니다. 성공한다면, 이는 패러다임의 변화를 더욱 확증하고, 작업에 무관한 사전 학습과 작업에 특화된 적응을 분리할 수 있을 것입니다. 그러나 이미지 매팅을 위해 ViT를 탐구하려면 두 가지 특정한 도전 과제가 있습니다. (1) 고해상도 이미지를 처리하는 데 필요한 과도한 계산 비용을 어떻게 줄일 것인가 [58]? 평범한 ViT는 이미지의 모든 패치 간의 셀프 어텐션을 계산하며, 이로 인해 긴 패치 시퀀스와 과도한 계산 부담이 발생합니다. (2) 비계층적 ViT 표현에서 가장 미세한 세부 사항을 어떻게 포착할 것인가. 앞서 논의한 동기를 고려할 때, 이전 연구들처럼 [30, 59, 40, 47] 복잡한 계층적 특징 융합 메커니즘을 신중히 설계하지 않는 것이 좋습니다.
위의 도전 과제를 해결하기 위해, 우리는 평범한 비전 트랜스포머를 사용하는 효율적이고 효과적인 이미지 매팅 시스템인 ViTMatte를 제안합니다. 우리의 분석에 따르면, 사전 학습된 ViT 모델은 이미지 매팅에 필요한 대부분의 기능을 이미 제공하며, 이를 위해 간결하고 가벼운 적응만 필요하다고 믿습니다. 한편으로, 평범한 ViT는 동일한 트랜스포머 블록으로 쌓여 있으며, 각각이 높은 비용을 요구하는 글로벌 셀프 어텐션을 계산합니다. 우리는 이것이 불필요하다고 주장하며, 매팅 문제를 해결하기 위해 ViT에 특화된 간단한 적응 전략을 제안합니다. 구체적으로, 우리는 계산의 균형을 맞추기 위해 윈도우 어텐션과 글로벌 어텐션을 모두 사용합니다. 또한, 컨볼루션 모듈이 ViT의 글로벌 어텐션을 효과적으로 강화할 수 있으며, 잔여 컨볼루션 넥(residual convolutional neck)이 매팅 성능을 더욱 향상시킬 수 있음을 발견했습니다. 다른 한편으로, 평범한 ViT는 고정된 패치 임베딩 과정을 가지고 있어, 특히 매우 미세한 세부 사항에서 정보 손실이 발생할 수 있습니다. 매팅을 위해 세부 사항을 완전히 모델링하기 위해, 우리는 ViT에 특화된 세부 캡처 모듈을 도입했으며, 이는 3M 미만의 매개변수로만 구성됩니다.
이전의 ViT 기반 작업 및 매팅 시스템과 비교할 때, ViTMatte는 이미지 매팅을 위해 특별히 설계된 최초의 ViT 적응 방법입니다. 그림 2에서 볼 수 있듯이, 이전의 적응 전략 [31]과 비교하여, 더 적은 매개변수로 더 나은 결과를 얻습니다. 고해상도 이미지를 처리할 때 70%의 FLOP를 절약할 수 있습니다. ViTMatte는 또한 최초의 ViT 기반 이미지 매팅 방법이며, 다양한 자기지도 학습 사전 학습된 ViT로 이미지 매팅 성능을 향상시킵니다. 우리는 ViTMatte를 가장 널리 사용되는 벤치마크인 Composition-1k와 Distinctions-646에서 평가했으며, 더 적은 매개변수로 새로운 최첨단 결과를 달성했습니다. 우리의 기여는 다음과 같이 요약될 수 있습니다:
- ViTMatte를 제안합니다. 이는 첫 번째 평범한 ViT 기반 매팅 시스템으로, 도전 과제를 해결하기 위해 ViT 적응 전략과 세부 캡처 모듈을 도입했습니다. 처음으로, 평범한 비전 트랜스포머가 다른 백본보다 적은 매개변수로도 매팅 성능을 크게 향상시킬 수 있음을 증명했습니다.
- ViTMatte를 가장 널리 사용되는 벤치마크에서 평가했습니다. 이전의 최첨단 방법과 비교하여, 우리의 모델은 Composition-1k에서 SAD 2.54 및 Connectivity 3.06, Distinctions-646에서 SAD 8.60 및 Connectivity 8.50의 향상을 각각 달성했으며, 더 작은 모델 크기로 새로운 최첨단 시스템이 되었습니다.
- ViTMatte는 ViT의 장점을 잘 계승했습니다. 이전의 ViT 적응 전략 및 매팅 시스템과 비교하기 위해 많은 포괄적인 실험과 분석이 수행되었습니다. 이는 ViTMatte의 독특한 통찰을 드러냈으며, 평범한 비전 트랜스포머를 사용하는 다음 매팅 작업에 영감을 줄 수 있기를 바랍니다.
2. 관련 연구
여기에서는 주로 가장 관련성이 높은 연구들을 검토하며, 이미지 매팅 문제에 대한 자세한 논의는 [1, 32, 40]을 참조하십시오.
2.1 트랜스포머 기반 이미지 매팅
기존의 학습 기반 이미지 매팅은 오랫동안 컨볼루션 신경망(CNN)에 의해 주도되어 왔습니다 [56, 26, 41, 30, 59, 48, 62, 32, 33, 52]. 그러나 최근에 이르러, CNN과 비교하여 강력한 장거리 모델링 능력을 가진 트랜스포머 기반 방법들이 다양한 비전 작업에서 혁신을 일으켰습니다 [49, 14]. 이러한 패러다임 전환에 영감을 받아, 몇몇 최신 연구들은 매팅 작업을 해결하기 위해 트랜스포머를 사용하기 시작했고 [40, 10, 5], 유망한 결과를 보여주었습니다. 예를 들어 Swin Transformer [37]와 SegFormer [55]가 있습니다. 그러나 이들 특화된 비주얼 트랜스포머는 CNN과 유사한 계층적 구조를 가지며, CNN 백본의 직접적인 대체물로 설계되었습니다. 기술이 빠르게 발전함에 따라, 최근의 연구 [31]는 최소주의적이고 비계층적인 성질에도 불구하고 평범한 ViT가 예상보다 더 강력할 수 있음을 시사합니다. [31]은 비전 기반 모델 [2]이 평범한 ViT를 기반으로 학습될 수 있으며, 하위 작업은 작업 특화된 적응을 통해 수행될 수 있다는 중요한 메시지를 전합니다. 본 논문에서는, 이미지 매팅 작업이 상세한 시각 정보를 필요로 하므로, 이는 기반 모델에서 쉽게 학습되지 않는다는 점에서 이 어려운 문제를 연구하고자 합니다.
2.2 평범한 ViT의 사전 학습
사전 학습과 미세 조정은 많은 시각적 이해 작업에서 사실상의 패러다임이 되어 왔습니다. 대부분의 비전 트랜스포머는 일반적으로 ImageNet [12]에서 지도 학습으로 사전 학습됩니다. 최근에는 자기 지도 학습 전략이 자연어 처리(NLP) [13, 43, 4, 42]에서 비전으로 도입되었습니다. 이들은 레이블이 없는 데이터를 사용하여 데이터 문제를 해결합니다. 이들 중 많은 것들, 예를 들어 MAE [22], DINO [6], iBOT [63] 등은 주로 평범한 비전 트랜스포머 구조와 사전 학습된 모델들을 자기 지도 방식으로 타겟팅합니다. 이 방법들은 의미론적 분할, 객체 탐지, 인스턴스 분할과 같은 많은 하위 작업을 촉진할 수 있는 것으로 나타났습니다. 그러나 매팅에 이러한 사전 학습된 표현을 어떻게 가장 잘 활용할 수 있는지는 여전히 계산 비용과 정확도 관점에서 많이 탐구되지 않은 상태입니다.
2.3 평범한 ViT의 하위 작업 적용
평범한 비전 트랜스포머는 원래 이미지 분류를 위한 강력한 백본으로 사용되었습니다 [14]. 그러나 비계층적 구조 설계로 인해 많은 하위 작업에서 일반적인 디코더 또는 헤드와의 호환성이 좋지 않습니다. 사람들은 비전 작업을 위해 특별히 설계된 트랜스포머 [37, 53, 61, 25, 16]를 선호합니다. 이들의 다중 수준 아키텍처는 많은 컨볼루션 기반 작업에 직접적으로 적용될 수 있습니다. 그러나 평범한 ViT에 대한 자기 지도 사전 학습이 부상하면서(i.e., [22]), 이 비계층적 구조에 대한 관심이 다시 집중되었습니다. 예를 들어, ViTDet [31]은 무거운 특징 피라미드 네트워크(FPN) [34] 없이 병렬 디컨볼루션만으로 간단한 특징 피라미드를 생성하여 평범한 ViT가 객체 탐지 작업에서 인상적인 결과를 달성할 수 있음을 발견했습니다. ViTPose [57]는 ViT가 컨볼루션 신경망보다 간단한 디코더 설계와 더 호환성이 높음을 발견했습니다. 우리는 ViT의 이 간결한 속성이 이미지 매팅 문제를 해결하기 위한 새로운 구조적 설계를 촉진할 수 있을 것이라고 추측합니다.
3. 방법론
3.1 기초 개념
명확성을 높이기 위해, 이미지 매팅에서의 트리맵(trimap)과 평범한 비전 트랜스포머(plain vision transformers)의 개념을 간결하게 설명합니다.
이미지 매팅에서의 트리맵
자연 이미지 매팅에서 연구자들은 항상 트리맵을 사전 정보로 사용하여 전경과 배경을 구분합니다.

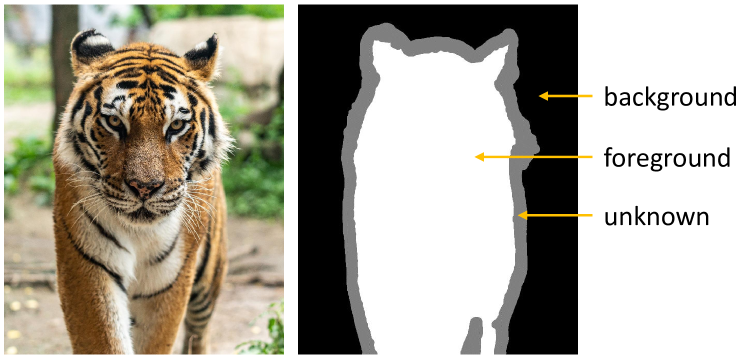
그림 3: 원본 이미지(왼쪽)와 해당하는 트리맵(오른쪽). 트리맵은 이미지 매팅에서 가장 널리 사용되는 수동으로 그려진 힌트 맵입니다.
트리맵 T(x,y)는 다음과 같이 정의됩니다:

이는 각각 배경, 전경, 알 수 없는 영역을 나타냅니다.
평범한 비전 트랜스포머
여기서 '평범한 비전 트랜스포머'는 Dosovitskiy 등 [14]이 제안한 아키텍처를 가리키며, 다른 비전용 변형은 포함하지 않습니다. 이 아키텍처는 비계층적이며 입력과 동일한 크기의 출력을 제공합니다.



3.2 전체 아키텍처

3.3 비전 트랜스포머 적응
ViTMatte는 이미지 매팅을 위해 비전 트랜스포머를 향상시키기 위해 하이브리드 어텐션 메커니즘을 사용하고, 트랜스포머 블록 사이에 컨볼루션 넥을 추가합니다. 그림 4는 우리의 적응 전략을 보여줍니다.
우리는 고해상도 이미지의 경우 전역 셀프 어텐션을 계산하는 것이 불필요하며, 이는 과도하게 높은 계산 복잡도를 초래할 수 있다고 가정합니다. 이는 **식 (4)**에 나타난 바와 같습니다. Li 등 [31]의 연구에서 영감을 받아, 우리는 평범한 비전 트랜스포머를 위해 하이브리드 어텐션 메커니즘을 제안합니다.


이와 같은 방식으로 트랜스포머 블록을 적응시킴으로써, 특히 고해상도 이미지에서 ViT의 계산 복잡도를 크게 줄일 수 있습니다.

우리는 어텐션 메커니즘이 저주파수 정보에 더 많은 주의를 기울이는 경향이 있다는 가정을 하고 있습니다 [45]. 이 경우, 컨볼루션 블록은 경계나 텍스처와 같은 고주파수 정보를 추출하는 고역 필터(high-pass filter) 역할을 할 수 있으며, 이는 정확한 매팅에 매우 중요합니다. 잔여 연결을 이용함으로써, 트랜스포머 블록이 포착한 저주파수 정보를 유지하면서, 컨볼루션 블록을 통해 고주파수 정보를 강화할 수 있습니다.
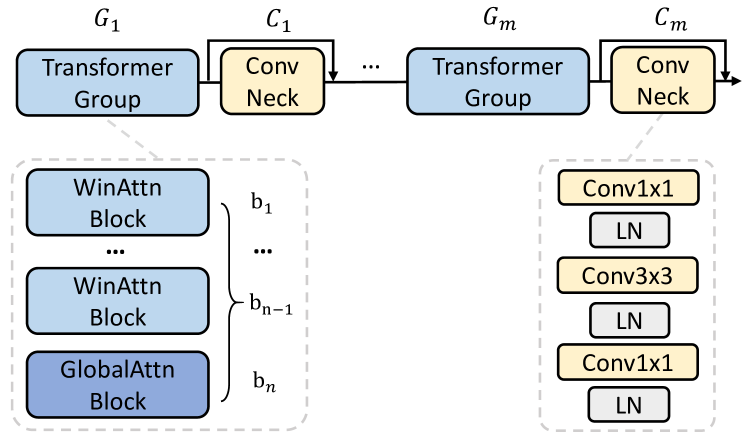
그림 4: ViTMatte의 백본 적응. 계산 부담을 줄이기 위해 비전 트랜스포머 레이어에서 윈도우 어텐션과 전역 어텐션을 균등하게 사용하고, 매팅을 위한 세부 정보 강화를 위해 컨볼루션 넥을 추가합니다.
3.4 디테일 캡처 모듈
비전 트랜스포머가 대부분의 필요한 작업을 수행하기 때문에, 우리는 가벼운 디테일 캡처 모듈을 추가하여 더 세밀한 디테일을 효과적으로 포착하도록 했습니다. 이 모듈은 컨볼루션 스트림과 간단한 융합 전략으로 구성되어, 부족한 세부 정보를 보완하는 역할을 합니다.


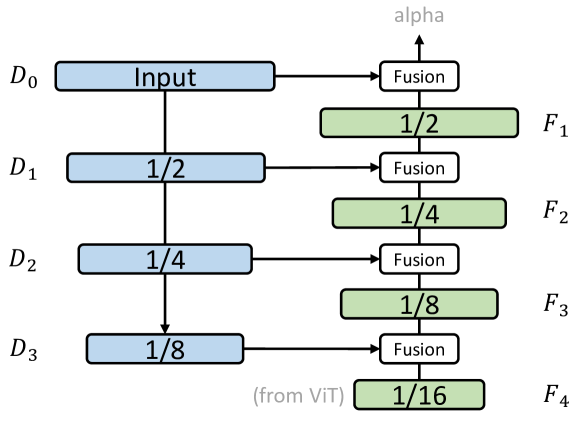
그림 5: 비전 트랜스포머와 컨브스트림(convstream)이 출력한 특징 맵을 융합하는 과정.
융합(Fusion) 과정은 다음과 같이 정의됩니다:


우리는 강력한 기반 모델을 사용할 때, 단순한 디코더로도 좋은 성능을 달성할 수 있음을 보여주며, ViT의 매팅 작업에서의 큰 잠재력을 입증하고자 합니다.
3.5 학습 스킴
앞서 논의한 바와 같이, ViTMatte의 장점 중 하나는 ViTs로부터 다양한 사전 학습 가중치 [6, 63, 22]를 상속할 수 있다는 것입니다. 그러나 백본과 트리맵 입력의 적응으로 인해, ViTMatte의 비전 트랜스포머는 원래의 ViT와 약간 다릅니다.

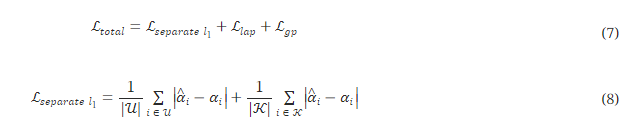

데이터 증강을 위해, 우리는 **[30]**에서 제안한 전략을 따릅니다. 입력 이미지에 대해, 먼저 무작위로 회전, 무작위 스케일, 무작위 쉐어, 무작위 뒤집기 등 무작위 어핀 변환을 적용합니다. 그 후 이미지를 무작위로 자르고, 크기를 512×512로 맞춥니다. 또한, 이미지를 무작위로 자극하여 이미지의 색조를 변경합니다.
4. 실험
우리의 제안 방법인 ViTMatte는 기존의 다른 매팅 방법들을 능가하며, 널리 사용되는 Composition-1k와 Distinctions-646 벤치마크에서 새로운 최첨단 성능을 달성했습니다. 또한, ViTMatte-S 모델은 이전 매팅 방법들보다 더 적은 매개변수로도 더 나은 결과를 얻었습니다.

그림 6: Composition-1k에서 이전 최첨단(SOTA) 방법들과 비교한 시각적 결과입니다. 더 나은 확인을 위해 확대해 보세요.
4.1 데이터셋과 평가 지표
Composition-1k [56]는 50개의 고유한 전경 이미지를 포함하고 있습니다. 각 전경 이미지는 VOC2012 [15] 데이터셋의 20개의 배경 이미지와 함께 합성되어 1000개의 서로 다른 합성 이미지로 구성된 테스트 세트를 만듭니다. 학습 세트인 Adobe Image Matting에는 431개의 고유한 전경 이미지가 있습니다. Composition-1k와 유사하게, 각 전경은 COCO [35] 데이터셋의 100개의 배경 이미지와 합성되어 43100개의 서로 다른 합성 이미지로 구성된 학습 세트를 만듭니다.
Distinctions-646는 [41]에서 제공된 이미지 매팅 데이터셋입니다. 이 데이터셋은 Composition-1k와 동일한 합성 전략을 사용합니다. 646개의 고유한 전경 이미지는 596개와 50개의 이미지로 나뉩니다. 우리는 위에서 설명한 것과 동일한 방식으로 59600개의 이미지로 구성된 학습 세트와 1000개의 이미지로 구성된 테스트 세트를 만듭니다.
우리의 접근법을 평가하기 위해, 우리는 일반적으로 사용되는 네 가지 지표를 사용합니다: 절대 차이 합계(SAD), 평균 제곱 오차(MSE), 그라디언트 손실(Grad), 및 연결 손실(Conn). 이 지표들의 값이 낮을수록 알파 매트의 품질이 높음을 나타냅니다. 참고로, 읽기 편하게 하기 위해 MSE 값은 1e-3로 조정했습니다.
4.2 구현 세부사항
훈련 데이터에 대해, 우리는 먼저 앞서 설명한 방식으로 훈련 이미지를 합성하고, 무작위 커널 크기 [1,30]를 사용한 확장-침식(dilation-erosion) 연산으로 트리맵을 생성합니다. 그런 다음, RGB 이미지와 트리맵을 연결하여 모델에 입력합니다. 모델 구조로는 ViT-S와 ViT-B 백본 [14]을 기반으로 크기가 다른 두 가지 모델, ViTMatte-S와 ViTMatte-B를 구축했습니다. 모델 초기화는 각각 DINO [6]와 MAE [22] 사전 학습 가중치를 사용하여 ViTMatte-S와 ViTMatte-B를 초기화했습니다. 모델은 두 개의 V100 GPU에서 100 에포크 동안 훈련됩니다. ViTMatte-S와 ViTMatte-B의 배치 크기는 각각 32와 20으로 설정되었습니다. 우리는 AdamW 옵티마이저를 사용하며, 학습률은 초기 값으로 5e-4로 설정하고, 가중치 감소율은 0.1로 설정했습니다. 학습률은 30번째 에포크와 90번째 에포크에서 각각 원래 값의 0.1과 0.05로 감소합니다. 미세 조정 동안에는 층별 학습률(layerwise learning rate)이 적용되어 사전 학습된 ViT를 최적화하며, 감소율은 0.65로 설정됩니다.
4.3 주요 결과
Composition-1k에서의 결과
Composition-1k에 대한 정량적 결과는 표 1에 나와 있습니다. 우리는 이러한 지표들을 트리맵의 알 수 없는 영역에서만 측정했습니다. 이전 방법들과 비교했을 때, 우리의 모델은 모두를 능가하며 새로운 최첨단(SOTA) 성능을 달성했습니다. 표 3은 우리 ViTMatte-S의 성능과 매개변수 수를 이전의 SOTA 방법들과 비교한 것입니다. 보시다시피, 우리 방법은 더 작은 모델 크기로도 더 나은 성능을 달성했습니다. 그림 6은 우리 접근법과 이전 SOTA 방법들 간의 질적 비교를 보여줍니다. 복잡한 경우에서도 ViTMatte는 이미지의 세부 사항을 효과적으로 포착하여 우수한 성능을 보여줍니다.
Distinctions-646에서의 결과
Composition-1k와 달리, Distinctions-646은 테스트를 위한 공식 트리맵을 제공하지 않습니다. 이전 연구들은 일반적으로 테스트를 위해 무작위로 생성된 트리맵을 사용하였는데, 이는 공정한 비교를 어렵게 만듭니다. 우리의 연구에서는, 알파 매트를 기반으로 무작위 커널 크기 [1,30]를 사용하여 침식 연산으로 트리맵을 무작위로 생성했습니다. 우리는 **[41]**에 따라 전체 이미지 영역에서 지표를 평가했으며, 정량적 결과는 표 2에 나와 있습니다. 트리맵에 따라 결과가 어느 정도 영향을 받겠지만, 우리의 방법은 여전히 이전 방법들을 크게 능가하며, 최고의 결과를 달성했습니다.
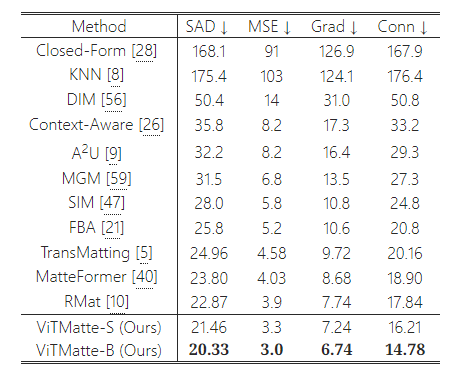
표 1: Composition-1k에 대한 정량적 결과.
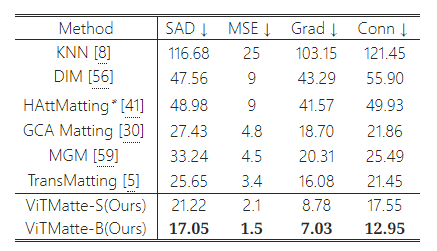
표 2: Distinctions-646에 대한 정량적 결과.
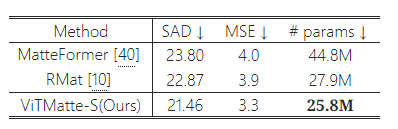
표 3: 매개변수 수 비교. ViTMatte-S는 더 적은 매개변수로 이전 매팅 방법들보다 더 나은 결과를 얻었습니다.
5. 절삭 실험 및 분석: 이전 ViT 기반 작업들과의 비교
우리가 ViT를 하위 비전 작업에 활용한 첫 사례는 아니지만, 우리의 연구는 이전 연구들 [31, 57, 51]에 영향을 받았으며, ViT를 매팅 작업에 직접적으로 적용한 첫 사례를 제시합니다. 이 섹션에서는 ViT를 매팅 작업에 적용하는 것과 다른 작업에 적용하는 것의 유사점과 차이점을 조사하기 위해 종합적인 구조 분석을 수행합니다.
기본적으로 우리는 ViT-S를 백본으로 사용하며, DINO [6] 사전 학습 가중치로 초기화합니다. Adobe Image Matting [56] 데이터셋에서 10 에포크 동안 모델을 훈련하고, 이를 Composition-1k [56] 벤치마크에서 평가했습니다. 각 설계 전략의 성능을 평가하기 위해, 우리는 절대 차이 합계(SAD)와 평균 제곱 오차(MSE) 지표를 사용합니다.
5.1 매팅을 위한 하이브리드 어텐션
글로벌 어텐션은 평범한 비전 트랜스포머에서 매우 강력한 도구입니다. Dosovitskiy 등 [14]은 글로벌 어텐션이 분류 작업에서 매우 효과적이며, ViT 모델이 뛰어난 분류 성능을 달성하는 데 크게 기여한다고 밝혔습니다. 그러나 각 층에서 글로벌 어텐션을 계산하는 것은 상당한 계산 오버헤드를 초래할 수 있으며, 이는 대규모 애플리케이션에서 알고리즘의 확장성을 저해할 수 있습니다. 이로 인해 매팅 작업에서 각 수준에서 글로벌 어텐션을 계산하는 것이 정말로 필요한지에 대한 의문이 제기됩니다.
경험적으로, 트리맵은 이미 충분한 글로벌 의미 정보를 제공하기 때문에, 매팅 작업을 위한 네트워크는 이미지의 작은 영역 내에서 세부 정보에 더 집중하는 경향이 있을 것으로 예상됩니다. 이는 윈도우 어텐션의 메커니즘과 일치합니다. Li 등 [31]에서 영감을 받아, 우리는 원래 ViT에서 각 층에서 글로벌 어텐션을 계산하는 대신, ViTMatte의 ViT 백본에서 글로벌 어텐션과 윈도우 어텐션을 번갈아 사용하는 새로운 접근 방식을 도입했습니다. 이 새로운 어텐션 메커니즘을 하이브리드 어텐션이라고 합니다. 이 어텐션 메커니즘에 대한 우리의 정량적 및 정성적 분석은 우리의 가설을 뒷받침합니다.
성능에 미치는 영향을 정량적으로 조사하면서 계산 노력을 줄이기 위해, 우리는 ViT 백본의 일부 블록에서 글로벌 어텐션을 윈도우 어텐션으로 대체했습니다. 표 4는 계산 비용과 정확성 측면에서 하이브리드 어텐션 메커니즘의 우수성을 보여줍니다. 놀랍게도, 계산적으로 비싼 글로벌 어텐션을 덜 복잡한 윈도우 어텐션으로 대체하면 네트워크 성능이 오히려 향상되는 결과가 나타났습니다. 네 개의 층에서 윈도우 어텐션을 사용함으로써 계산 비용이 전체 글로벌 어텐션에 비해 50% 감소하면서도 최적의 성능을 유지했습니다. SAD에서 1.52, MSE에서 0.74의 개선이 이루어졌습니다.
그러나 [31]과는 달리, 매팅 작업에서 글로벌 어텐션에만 의존하는 것이 반드시 최적의 성능을 제공하지는 않았습니다. 이 문제를 해결하기 위해, 우리는 윈도우 어텐션과 글로벌 어텐션의 윈도우 맵을 시각화하여 정성적 분석을 수행했습니다. 결과적인 어텐션 맵은 그림 7에 제시되었습니다. 그림에서 알 수 있듯이, 윈도우 어텐션의 어텐션 맵은 트랜스포머에서 더 뚜렷하게 활성화된 반면, 글로벌 어텐션은 상대적으로 덜 활성화된 상태로 남아 있었습니다. 이 관찰은 우리의 경험적 발견과 일치하며, 글로벌 어텐션의 과도한 사용이 네트워크가 이미지의 세부 사항에 효과적으로 집중하는 능력을 저해하여 이미지 매팅 성능이 저하되는 결과를 초래함을 보여줍니다.
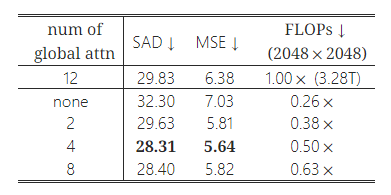
표 4: 하이브리드 어텐션 메커니즘. 이를 기반으로, 평범한 비전 트랜스포머는 더 적은 계산 부담으로 더 나은 매팅 성능을 달성할 수 있습니다. 이 메커니즘은 고해상도 이미지를 처리할 때 약 50%의 FLOP를 절약하는 데 도움이 됩니다.
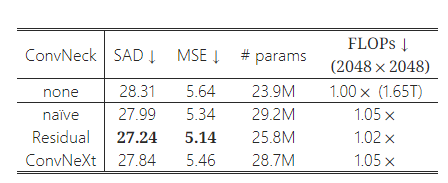
표 5: 다양한 컨볼루션 넥(Convolution Neck)의 성능. 컨볼루션 넥은 ViT의 매팅 성능을 거의 무시할 수 있는 정도의 FLOP 증가(2%-5%)로 향상시킬 수 있습니다. 실험에서 잔차 블록(Residual Block)이 가장 우수한 성능을 보였습니다.

그림 7: 우리는 윈도우 어텐션 블록과 글로벌 어텐션 블록에서 어텐션 맵을 평균화하고 시각화했습니다. 이 결과는 로컬 어텐션이 글로벌 어텐션보다 더 강하게 활성화되는 경향이 있음을 보여줍니다.
5.2 컨볼루션 넥을 사용한 트랜스포머 백본 강화
[45]에 따르면, 트랜스포머는 저주파수 정보에 더 많은 주의를 기울이는 경향이 있습니다. 반면에, 최근 연구 [54, 11]에서는 컨볼루션 블록이 독특한 장점을 가지고 있다는 것이 입증되었습니다. 컨볼루션 레이어를 통합하면 평범한 ViT를 사용할 때 이미지 매팅의 성능이 향상되는 것으로 나타났으며, 잘 훈련된 컨볼루션 블록은 엣지나 텍스처와 같은 고주파수 세부 정보를 효과적으로 추출할 수 있습니다 [20]. 이러한 특징을 성공적으로 추출하는 것은 이미지 매팅 작업에서 ViT 기반 모델의 성능을 향상시키는 데 중요한 요소입니다.
우리의 하이브리드 어텐션 설계를 바탕으로, 각 글로벌 어텐션 블록 후에 컨볼루션 블록을 추가하는 실험을 수행했습니다. 이를 통해 네트워크 전체 성능에 대한 컨볼루션의 영향을 조사할 수 있었습니다. 그림 8에서 볼 수 있듯이, 빨간 점들이 파란 점들보다 일관되게 낮게 나타났는데, 이는 컨볼루션 블록의 추가가 네트워크의 전체 성능에 크게 기여했음을 의미합니다. 이 결과는 우리의 가설을 더욱 뒷받침하며, 매팅 네트워크의 아키텍처에 컨볼루션 블록을 통합하는 것이 중요하다는 점을 강조합니다.
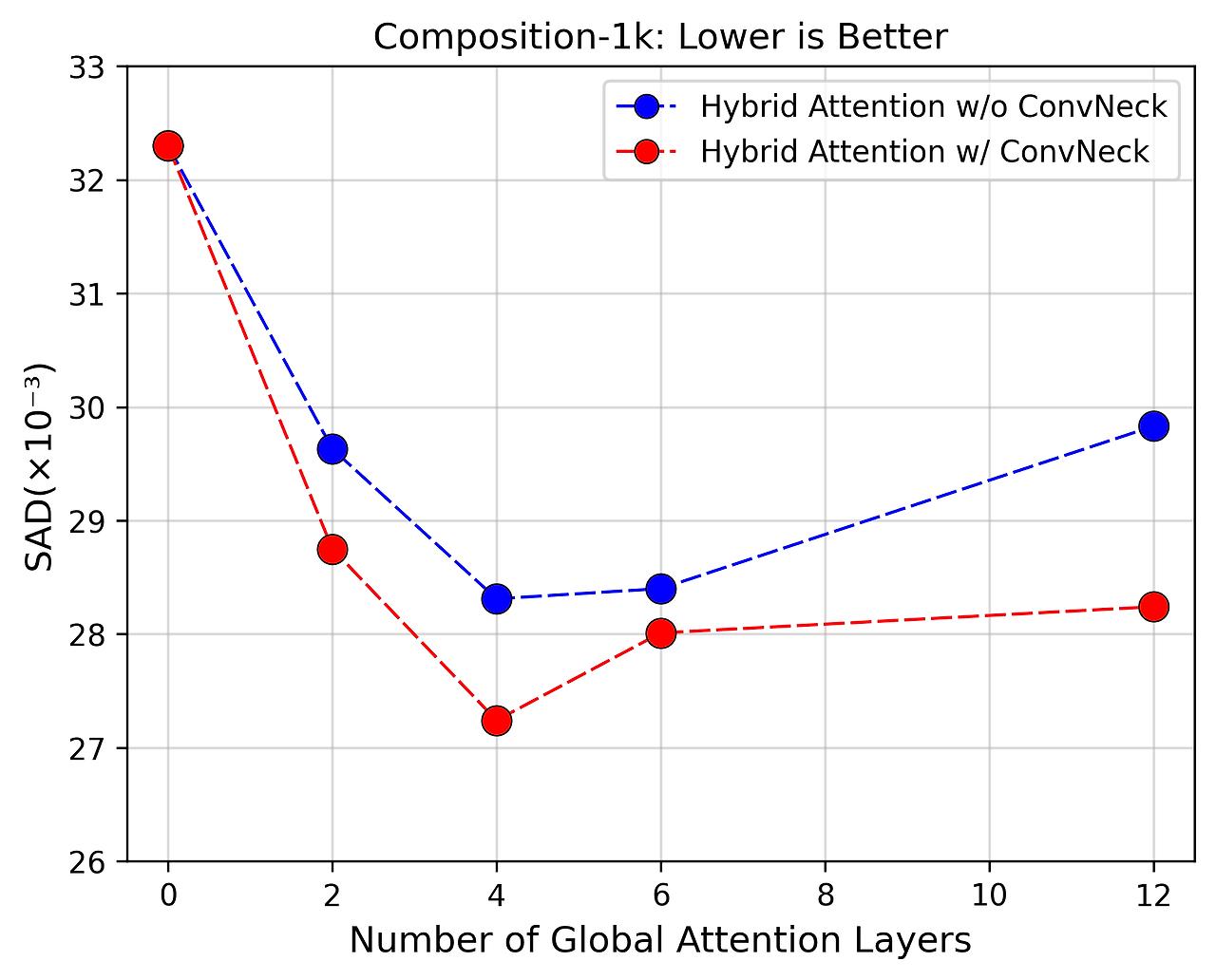
그림 8: 이 그림은 ViT를 매팅 작업에 맞게 개선한 내용을 보여줍니다. (i) 가벼운 컨볼루션 넥의 추가만으로도 모델 성능을 효과적으로 향상시킬 수 있으며, (ii) 글로벌 어텐션의 수를 줄이고 이를 윈도우 어텐션으로 대체하면 모델 성능을 더욱 향상시킬 수 있음을 나타냅니다. 이는 이미지 매팅 작업이 이미지의 국소적인 세부 사항에 더 큰 비중을 두는 설계에서 이점을 얻는다는 우리의 관찰과 일치합니다.
표 5는 평범한 비전 트랜스포머의 이미지 매팅 성능을 향상시킬 수 있는 다양한 컨볼루션 블록을 비교한 내용을 제시합니다. 우리는 글로벌 어텐션 레이어의 수를 최적의 4개로 고정하고, 각 레이어 후에 다른 컨볼루션 블록을 추가했습니다. 실험에서 사용된 세 가지 유형의 컨볼루션 블록은 다음과 같습니다: 하나의 3×3 컨볼루션만 포함된 단순한 컨볼루션 블록, 잔여 병목 블록(Residual Bottleneck) [24], 그리고 ConvNeXt 블록 [38]입니다. 우리는 세 가지 컨볼루션 블록 모두가 기본 성능에 비해 매팅 성능을 향상시켰으며, FLOP 증가가 2%에서 5%로 미미하다는 것을 발견했습니다. 잔여 병목 블록이 가장 우수한 성능을 보여주었으며, 2%의 추가 FLOP로 SAD에서 1.07의 향상을 이루었고, 우리는 이 블록을 모델에 통합하여 성능을 향상시켰습니다.
5.3 디테일 캡처 모듈 (DCM)
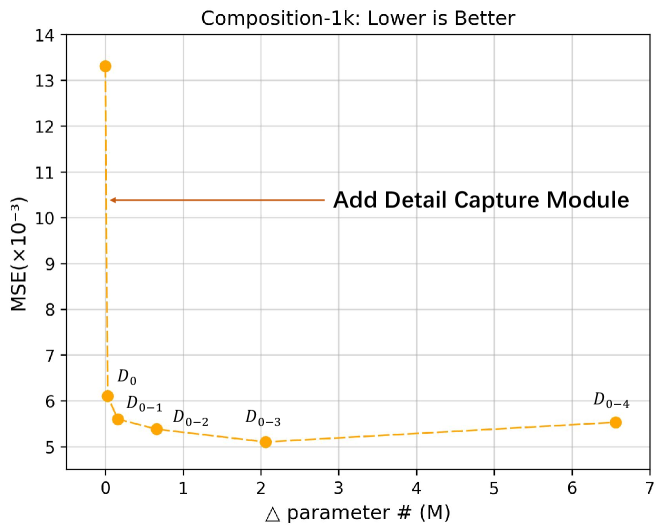
그림 9: 이 그림은 디테일 캡처 모듈(DCM)의 효과를 입증하고, DCM의 최적 깊이를 탐색한 결과를 보여줍니다. 실험 결과, DCM이 최소한의 매개변수 추가로 이미지 매팅 성능을 크게 향상시킬 수 있음을 확인했습니다.

비전 작업의 백본으로 ViT를 사용할 때, [31]에서 도입된 간단한 특징 피라미드(SFP)는 ViT의 단일 스케일 특징을 다중 스케일 특징으로 변환하는 일반적인 기술입니다 [22, 19, 18]. SFP는 풀링과 디컨볼루션 연산을 사용하여 ViT가 다양한 수준에서 특징을 추출할 수 있도록 하여 복잡한 시각적 장면을 처리하는 성능을 향상시킵니다. 그러나 SFP는 고해상도 특징 맵이 필요한 매팅 작업에는 적합하지 않을 수 있습니다. SFP에서 고해상도 특징 맵을 얻기 위해 사용하는 디컨볼루션 연산은 세부 사항의 손실과 불필요한 계산 오버헤드를 초래할 수 있어, 매팅 작업에는 적합하지 않을 수 있습니다. 이러한 문제를 해결하기 위해, ViTMatte는 경량의 컨브스트림(convstream)을 사용하여 고해상도 특징 맵을 추출합니다.

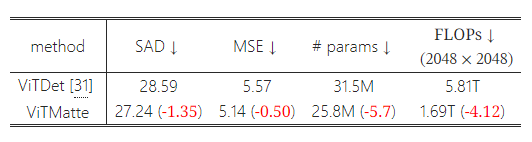
표 6: 다중 스케일 특징 맵을 얻는 방법. ViTMatte는 ViTDet [31]에서 사용된 SFP 대신 DCM을 사용하여 다중 스케일 특징을 얻습니다. DCM을 사용하여, 우리는 더 적은 매개변수로 성능을 향상시켰으며, 고해상도 이미지를 처리할 때 약 71%의 FLOP를 절약할 수 있습니다.
6. 절삭 실험 및 분석: 이전 매팅 시스템과의 비교
ViTMatte는 사전 학습된 ViT 모델을 사용하여 매팅 성능을 향상시킨 최초의 연구입니다. 이전 섹션에서 우리는 매팅 작업에 대해 일반적인 ViT 기반 시스템보다 ViTMatte의 뛰어난 적응성을 입증했습니다. 그러나 자연스럽게 제기되는 질문은 다음과 같습니다: 왜 매팅 작업에 ViT를 사용해야 하며, ViT를 매팅 작업에 적용하는 것이 새로운 통찰을 제공할 수 있을까요? 이 섹션에서는 이 질문을 다루고자 합니다. 구체적으로, 우리는 이전의 매팅 방법들과 우리 접근법을 비교하고 분석하여, ViT 도입이 매팅 작업에 가져오는 새로운 관점을 보여주고자 합니다.
6.1 유연한 사전 학습 전략
비전 작업에서 기본 모델의 중요성은 자명합니다. 이러한 모델들 [22, 19, 18, 6, 63]은 일반적으로 고급 기술, 방대한 데이터, 그리고 강력한 컴퓨팅 자원을 사용하여 사전 학습됩니다. 그 결과, 하위 작업에 적용될 때 뛰어난 능력을 발휘합니다. 그러나 이전의 매팅 방법들 [30, 59, 40, 10]은 종종 이 점을 간과했습니다. 일반적으로, 이들은 ResNet [24] 또는 SwinTransformer [37]와 같은 백본을 사용하여 ImageNet에서 사전 학습된 모델을 매팅 작업에 단순히 적용했습니다. 반면에, 우리는 다양한 강력한 사전 학습 전략과 쉽게 호환되는 매우 적응력이 뛰어난 ViT 구조를 채택했습니다. 이는 모델 아키텍처를 근본적으로 변경하지 않고도, 매팅 작업이 다양한 사전 학습 전략의 이점을 상속할 수 있음을 의미합니다.
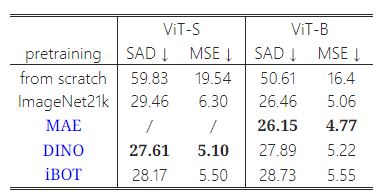
표 7: 다양한 사전 학습 전략에 따른 성능. ViTMatte는 지도 학습과 자기 지도 학습을 포함한 다양한 사전 학습 전략을 상속할 수 있습니다. 우리는 ViTMatte가 자기 지도 학습인 DINO [6]와 MAE [22]를 사용했을 때 최고의 성능을 얻는 것을 관찰했습니다.
표 7에 나타난 바와 같이, 우리는 다양한 사전 학습 전략을 사용하여 ViTMatte를 훈련했습니다. 비전 트랜스포머의 수렴이 대량의 훈련 데이터에 크게 의존한다는 것은 잘 알려져 있습니다 [14]. 그러나 사용 가능한 매팅 데이터셋은 다양성과 크기가 제한적이기 때문에, ViT 모델을 사전 학습하는 것은 이 문제를 완화하고 전체 성능을 향상시킬 수 있습니다. 표 7에서 볼 수 있듯이, ViTMatte를 처음부터 훈련하면 성능이 크게 저하됩니다. 그럼에도 불구하고, ViTMatte는 지도 학습과 자기 지도 학습을 포함한 다양한 사전 학습 전략을 쉽게 상속할 수 있습니다. 우리의 실험 결과, MAE [22]와 DINO [6]와 같은 자기 지도 학습을 통해 사전 학습된 ViT 모델이 ViTMatte에 대해 최고의 성능을 발휘한다는 것을 확인했습니다. 이 관찰은 우리의 방법이 다른 매팅 기술보다 우수하다는 것을 강조합니다. 앞으로 더 나은 사전 학습 가중치를 통해 ViTMatte를 사용하여 매팅 성능을 지속적으로 향상시킬 수 있을 것입니다.
6.2 경량 디코더
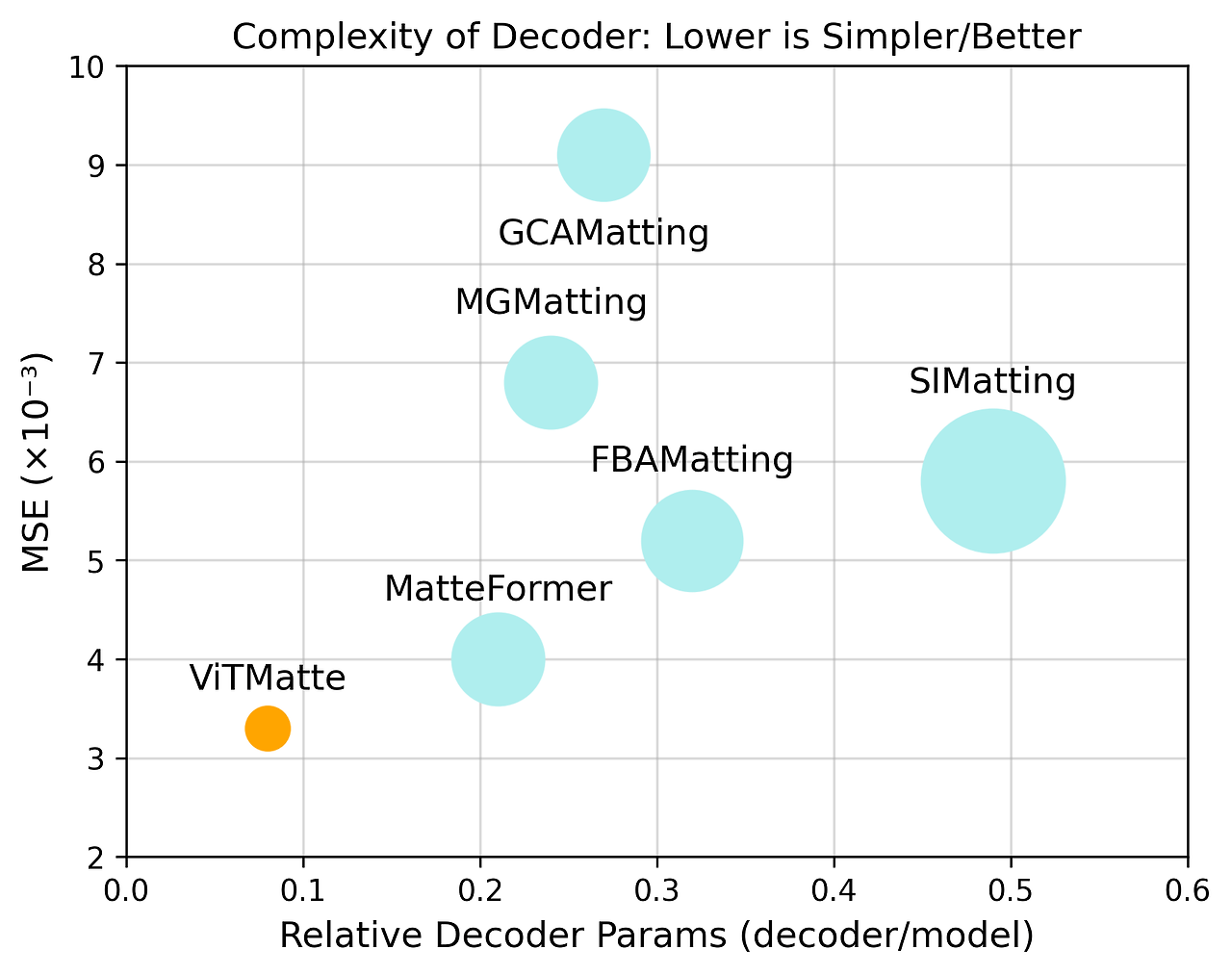
그림 10: 우리는 우리의 접근법과 기존 매팅 방법들의 디코더 크기와 복잡성을 비교합니다. 놀랍게도, ViTMatte는 가장 작고 간단한 디코더를 가지고 있으면서도 최고의 매팅 성능을 달성했습니다. 이는 "기본" 모델을 사용할 때, 복잡한 디코더 설계가 매팅 방법에 필수적이지 않을 수 있음을 시사합니다.
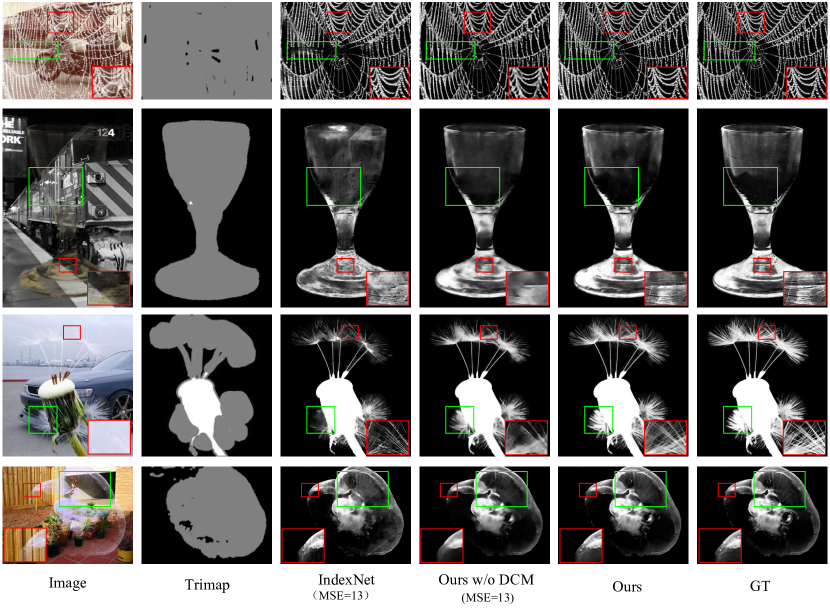
그림 11: IndexNet, DCM이 없는 ViTMatte, 그리고 ViTMatte의 시각적 결과를 비교한 것입니다. 더 나은 확인을 위해 확대해서 보세요.
ViTMatte는 지금까지 가장 가벼운 매팅 디코더를 채택했습니다. 다른 방법들이 매팅에 특화된 더 복잡한 디코더를 추구하는 반면, ViTMatte는 설계의 기본 부분에 더 많은 주의를 기울입니다. ViTMatte에서는 모든 디테일 캡처 모듈(DCM)을 디코더로 간주합니다. 섹션 5.3에서 논의된 것처럼, 우리는 DCM을 사용하여 일반적으로 사용되는 단순 특징 피라미드(Simple Feature Pyramid) ViT 기반 작업을 단순화했습니다. 그러나 이것이 여전히 다른 매팅 방법보다 우수한가요?
더 많은 통찰력을 제공하기 위해, 우리는 우리의 방법과 최근 다른 접근법들 [40, 21, 47, 59, 30]을 정량적으로 비교했습니다. MSE로 측정한 정확도 외에도, 우리는 인코더 매개변수의 수, 전체 모델의 매개변수 수, 그리고 그림 10에서 "Relative Decoder Params"로 표시된 비율도 평가했습니다. 보여진 바와 같이, 우리의 방법은 가장 높은 정확도를 달성하면서도 가장 적은 수의 디코더 매개변수를 사용합니다. 또한, 모델에서 디코더가 차지하는 비율 역시 가장 작다는 점(8%)이 중요합니다. 이는 이전 접근법들(21%에서 49% 사이)보다 상당히 작은 비율입니다. 이러한 결과는 원 논문에서 제기된 질문을 효과적으로 해결하며, 평범한 ViT 백본이 이미지 매팅에서 가장 중요한 역할을 한다는 것을 시사합니다. 더욱이, 이 발견은 작업 무관한 사전 학습과 작업 특화 경량 적응의 분리라는 새로운 패러다임을 강화합니다. 즉, 이전 방법에서 사용된 높은 유도 편향(inductive bias)을 가진 디코더는 이미지 매팅에 필수적이지 않을 수 있다는 결론을 내릴 수 있습니다.
우리는 결과를 시각화하고 디테일 캡처 모듈(DCM)이 모델의 시각적 성능에 미치는 영향을 비교합니다. DCM이 없는 ViTMatte는 IndexNet[39]과 유사한 정량적 결과를 보입니다. 그러나 시각화에서는 명백한 차이가 있습니다.
그림 11은 ViTMatte의 성능에 대한 디테일 캡처 모듈의 영향을 보여줍니다. 디코더가 없는 모델도 시각적으로 그럴듯한 알파 매트를 생성할 수 있지만, 빨간색 박스의 확대된 영역에서 결과를 더 자세히 살펴보면, 다른 두 그룹에 비해 과도하게 부드러워지고 시각적 디테일이 부족한 경향이 있음을 알 수 있습니다. 반면, 디코더가 장착된 ViTMatte의 두 변형은 더 많은 시각적 디테일을 보여줍니다. 또한, 녹색 박스는 ViTMatte가 디코더 없이도 IndexNet [39] 접근법에서 나타나는 배경 매핑이나 영역 손실과 같은 명백한 의미적 오류를 겪지 않음을 나타냅니다. 이러한 시각적 비교는 디테일 캡처 모듈이 매팅을 위해 세부 정보를 효과적으로 포착하고 통합할 수 있음을 보여주며, ViT 백본이 매팅 문제를 해결하는 데 주요한 계산 능력을 제공한다는 것을 증명합니다.
6.3 유연한 추론 전략
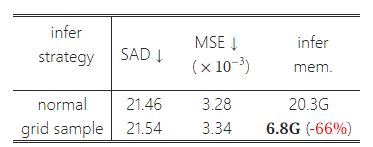
표 8: 그리드 샘플 추론(Grid Sample Inference). 그리드 샘플링은 고해상도 이미지를 추론할 때 성능 저하가 거의 없이 메모리 부담을 효과적으로 줄일 수 있습니다. 추론 메모리는 (2048, 2048) 크기의 이미지에서 테스트되었습니다.

그림 12: 그리드 샘플 추론.
우리의 백본 적응 전략 덕분에, 훈련 비용이 효과적으로 줄어들었고 ViTMatte는 대부분의 시나리오에 적용될 수 있습니다. 그러나 고해상도 이미지를 처리할 때, ViT의 글로벌 어텐션은 여전히 높은 계산 부담을 초래합니다. 이 문제를 해결하기 위해, 우리는 그림 12에 나타난 것처럼 간단한 추론 전략을 사용했습니다. 구체적으로, 글로벌 어텐션 전에 토큰을 그리드 샘플링(grid-sample)합니다. 각 그리드는 A, B, C, D로 표시된 4개의 이미지 토큰을 포함합니다. 우리는 모든 그리드의 토큰을 네 그룹으로 나누고, 각 그룹의 토큰에 대해 셀프 어텐션을 계산합니다.
표 8에서 볼 수 있듯이, 우리는 Composition-1k [56]에서 추론할 때 다른 전략을 사용했습니다. 주목할 점은, 그리드 샘플링은 추론 시에만 사용되며, 훈련 전략은 본문에서 논의된 것과 동일하다는 것입니다. 놀랍게도, 이 전략은 성능 저하가 거의 없이 GPU 메모리를 크게 절약합니다. ViTMatte는 추론에서 강력한 유연성을 보여줍니다.
7. 결론
이 논문에서는 평범한 비전 트랜스포머를 기반으로 한 간결하고 효율적인 매팅 시스템인 ViTMatte를 제시합니다. 우리는 하이브리드 메커니즘과 컨볼루션 넥을 사용하여 ViT를 이미지 매팅에 적응시켰습니다. 또한, 이전 매팅 방법들 중 가장 가벼운 디테일 캡처 모듈을 디코더로 설계하여 매팅에 필요한 세부 정보를 보완했습니다. 처음으로, 우리는 사전 학습된 ViT가 이미지 매팅 작업에서 큰 잠재력을 가지고 있음을 입증했습니다. 우리는 ViTMatte를 이전 ViT 적응 전략과 비교하여 매팅 작업에서의 우월성을 입증했습니다. 또한, 이전의 매팅 시스템들과 비교하여, 우리의 방법이 간결한 구조와 다양한 사전 학습 전략과 같은 여러 독특한 장점을 가지고 있음을 발견했습니다. ViT 기반 비전 기본 모델의 급속한 발전 덕분에, ViTMatte가 매팅 관련 산업 응용에서 표준 도구가 되기를 기대합니다.



