https://ar5iv.labs.arxiv.org/html/2301.12503
AudioLDM: Text-to-Audio Generation with Latent Diffusion Models
Text-to-audio (TTA) systems have recently gained attention for their ability to synthesize general audio based on text descriptions. However, previous studies in TTA have limited generation quality with high computatio…
ar5iv.labs.arxiv.org
요약
텍스트를 기반으로 오디오를 합성하는 텍스트-투-오디오(TTA) 시스템은 최근 들어 많은 주목을 받고 있습니다. 하지만 기존의 TTA 연구는 높은 계산 비용으로 인해 생성 품질에 한계가 있었습니다. 본 연구에서는 AudioLDM이라는 TTA 시스템을 제안합니다. 이 시스템은 잠재 공간(latent space)을 기반으로 구축되어, 대조적 언어-오디오 사전 학습(Contrastive Language-Audio Pretraining, CLAP) 임베딩에서 연속적인 오디오 표현을 학습합니다. 사전 학습된 CLAP 모델은 오디오 임베딩으로 LDMs(잠재 확산 모델)을 훈련할 수 있게 하며, 샘플링 시 텍스트 임베딩을 조건으로 제공합니다. 오디오 신호의 잠재적 표현을 학습하면서 크로스 모달 관계를 모델링하지 않음으로써, AudioLDM은 생성 품질과 계산 효율성을 모두 향상시킵니다. AudioCaps 데이터셋에서 단일 GPU로 훈련된 AudioLDM은 객관적 및 주관적 지표로 측정된 바, 다른 오픈 소스 시스템과 비교했을 때 최첨단 TTA 성능을 달성했습니다. 또한 AudioLDM은 다양한 텍스트 기반 오디오 조작(예: 스타일 변환)을 제로샷 방식으로 수행할 수 있는 최초의 TTA 시스템입니다. 우리의 구현 및 데모는 https://audioldm.github.io에서 확인할 수 있습니다.
기계 학습, ICML
1. 서론
개인화된 요구 사항에 따라 효과음, 음악 또는 음성을 생성하는 것은 증강 현실(AR) 및 가상 현실(VR), 게임 개발, 비디오 편집과 같은 응용 프로그램에서 매우 중요합니다. 전통적으로 오디오 생성은 신호 처리 기술(Andresen, 1979; Karplus & Strong, 1983)을 통해 이루어졌습니다. 최근 들어서는 무조건적 또는 다른 모달리티에 조건을 거는 생성 모델(Oord et al., 2016; Ho et al., 2020; Song et al., 2021; Tan et al., 2022)이 이 작업을 혁신적으로 변화시키고 있습니다. 이전 연구들은 주로 UrbanSound8K 데이터셋(Salamon et al., 2014)의 10가지 사운드 클래스와 같은 소수의 레이블에 의존한 레이블-투-사운드(label-to-sound) 설정에 중점을 두었습니다(Liu et al., 2021b; Pascual et al., 2022). 반면에, 자연어는 레이블보다 훨씬 더 유연하여 피치(pitch), 음향 환경, 시간 순서와 같은 오디오 신호의 세밀한 설명을 포함할 수 있습니다. 자연어 설명으로 촉발된 오디오를 생성하는 작업은 텍스트-투-오디오(Text-to-Audio, TTA) 생성이라고 알려져 있습니다.
TTA 시스템은 고차원 오디오 신호의 광범위한 범위를 생성하기 위해 설계되었습니다. 데이터를 효율적으로 모델링하기 위해, 우리는 DiffSound(Yang et al., 2022)와 유사한 접근 방식을 채택하여 학습된 이산 표현(discrete representation)을 사용해 고차원 오디오 신호를 효율적으로 모델링합니다. 또한, 파형에서 학습된 이산 표현의 자기회귀 모델링에서 최근의 발전, 예를 들어 DiffSound의 능력을 능가한 AudioGen(Kreuk et al., 2022)에서 영감을 얻었습니다. 고품질 이미지 생성을 위한 잠재 확산 모델(LDMs)을 사용하는 StableDiffusion(Rombach et al., 2022)의 성공을 바탕으로, 우리는 이전 TTA 접근법을 이산 표현을 학습하는 대신 연속적인 잠재 표현(continuous latent representations)으로 확장합니다. 추가적으로, 게임과 같은 응용 프로그램에서 스타일 변환(Engel et al., 2020; Pascual et al., 2022)과 같은 오디오 조작이 필요한 경우, 우리는 LDMs를 사용하여 이전에 시도되지 않은 다양한 제로샷 텍스트 기반 오디오 조작을 탐구하고 이를 달성합니다.

그림 1: 텍스트-투-오디오 생성용 AudioLDM 시스템 개요 (a)
훈련 중에는 잠재 확산 모델(LDM)이 오디오 임베딩 E_x에 조건화되어, VAE(변분 오토인코더)가 학습한 연속 공간 z_0에서 훈련됩니다. 샘플링 과정에서는 텍스트 임베딩 E_y가 조건으로 사용됩니다. 사전 학습된 LDM을 사용하면, 제로샷 오디오 인페인팅(b) 및 스타일 전환(c)이 LDM의 역방향 확산 과정에서 실현됩니다. Forward Diffusion 블록은 가우시안 노이즈로 데이터를 손상시키는 과정을 나타냅니다(Equation 2 참조).
이전 TTA 연구의 경우, 생성 품질의 잠재적 제한 요인은 대규모 고품질 오디오-텍스트 데이터 쌍의 필요성입니다. 이러한 데이터 쌍은 일반적으로 쉽게 구할 수 없으며, 구할 수 있더라도 품질과 양이 제한적입니다(Liu et al., 2022f). 저품질 데이터를 보다 효과적으로 활용하기 위해 여러 텍스트 전처리 방법이 제안되었습니다(Kreuk et al., 2022; Yang et al., 2022). 그러나 이러한 전처리 단계는 사운드 이벤트의 관계를 간과하여 생성 성능을 제한합니다(예: "개가 짖고 있다"가 "개 짖다 공원"으로 변환됨). 이에 비해, 우리가 제안한 방법은 생성 모델 훈련을 위해 오디오 데이터만 필요로 하며, 텍스트 전처리의 어려움을 피하면서 오디오-텍스트 쌍 데이터 사용보다 더 나은 성능을 발휘합니다. 이는 이후에 논의할 것입니다.
이 연구에서는 연속적인 LDM을 사용하여 높은 생성 품질과 우수한 계산 효율성을 달성하며, 텍스트 조건부 오디오 조작을 가능하게 하는 TTA 시스템인 AudioLDM을 제시합니다. TTA 생성과 텍스트 기반 오디오 조작을 위한 AudioLDM 설계 개요는 그림 1에 나와 있습니다. 특히, AudioLDM은 멜 스펙트로그램 기반의 변분 오토인코더(VAE)가 인코딩한 잠재 공간에서 표현을 생성하는 법을 학습합니다. CLAP(대조적 언어-오디오 사전 학습) 임베딩에 조건화된 LDM은 VAE 잠재 생성용으로 개발되었습니다. CLAP의 오디오-텍스트 정렬 임베딩 공간을 활용하여, LDM을 훈련하는 동안 짝을 이루는 오디오-텍스트 데이터의 필요성을 제거했습니다. VAE 잠재 생성 조건은 오디오 자체에서 직접 가져올 수 있기 때문입니다. 오디오 데이터만을 사용하여 LDM을 훈련하는 것이 오디오-텍스트 데이터 쌍을 사용하는 것보다 더 나은 결과를 얻을 수 있음을 실험적으로 증명했습니다. 제안된 AudioLDM은 AudioCaps 데이터셋에서 Freshet 거리(FD) 23.31을 기록하며, DiffSound 기준선(FD 47.68)보다 크게 앞서는 성과를 달성했습니다. 또한, 우리 시스템은 샘플링 과정에서 제로샷 오디오 조작을 가능하게 합니다. 요약하자면, 우리의 기여는 다음과 같습니다:
- 우리는 TTA 생성을 위해 연속적인 LDM을 개발한 첫 번째 시도를 시연했습니다. 우리의 AudioLDM 방법은 주관적 평가와 객관적 지표 모두에서 기존 방법을 능가합니다.
- 우리는 CLAP 임베딩을 활용하여 LDM을 훈련할 때 언어-오디오 쌍을 사용하지 않고도 TTA 생성을 가능하게 했습니다.
- 우리는 오디오 데이터만을 사용하여 LDM을 훈련할 때 고품질의 계산 효율적인 TTA 시스템을 얻을 수 있음을 실험적으로 보여주었습니다.
- 우리는 제안된 TTA 시스템이 모델을 특정 작업에 맞춰 미세 조정하지 않고도, 오디오 스타일 전환, 슈퍼 해상도, 인페인팅과 같은 텍스트 기반 오디오 스타일 조작을 수행할 수 있음을 보여주었습니다.
2. 관련 연구
텍스트-투-오디오(TTA) 생성은 최근 많은 관심을 받고 있습니다. 두 가지 연구(Yang et al., 2022; Kreuk et al., 2022)는 자연어 설명을 기반으로 이산 공간에서 오디오 표현을 학습한 후, 이 표현을 오디오 파형으로 디코딩하는 방법을 탐구합니다. 두 연구 모두 잠재 생성 모델을 훈련하기 위해 오디오-텍스트 쌍 데이터를 필요로 하며, 이들은 낮은 품질과 희소한 데이터 쌍 문제를 해결하기 위한 방법을 제안했습니다.
DiffSound(Yang et al., 2022)은 텍스트 인코더, 디코더, 벡터 양자화 변분 오토인코더(VQ-VAE), 그리고 보코더로 구성됩니다. 오디오-텍스트 쌍 데이터의 부족을 완화하기 위해, 그들은 오디오 레이블에서 텍스트 설명을 생성하는 마스크 기반 텍스트 생성 전략(MBTG)을 제안했습니다. 예를 들어, "dog bark, a man speaking"이라는 레이블은 "[M] [M] dog bark [M] man speaking [M]"로 표현되며, 여기서 [M]은 마스크 토큰을 나타냅니다. 그러나 MBTG가 생성한 텍스트는 여전히 레이블 정보만 포함하므로, 이는 모델 성능을 잠재적으로 제한할 수 있습니다.
AudioGen(Kreuk et al., 2022)은 Transformer 기반 디코더를 사용하여 파형에서 직접 압축된 목표 이산 토큰을 생성하는 방법을 학습합니다. AudioGen은 10개의 데이터셋에서 훈련되었으며, 훈련 데이터의 다양성을 높이기 위해 데이터 증강 방법을 제안합니다. 언어-오디오 쌍을 생성할 때, 그들은 언어 설명을 레이블로 사전 처리하여 클래스-레이블 주석 분포와 더 잘 맞추고 작업을 단순화합니다. 예를 들어, "a dog is barking at the park"이라는 텍스트 설명은 "dog bark park"으로 변환됩니다. 데이터 증강을 위해, 그들은 다양한 신호 대 잡음비(SNR)에 따라 오디오 샘플을 혼합하고 변환된 언어 설명을 연결합니다. 이는 공간적 및 시간적 관계를 보여주는 세부적인 텍스트 설명이 삭제된다는 것을 의미합니다.
확산 모델(Ho et al., 2020; Song et al., 2021)은 이미지 생성(Dhariwal & Nichol, 2021; Ramesh et al., 2022; Saharia et al., 2022), 이미지 복원(Saharia et al., 2021), 음성 생성(Chen et al., 2021; Kong et al., 2021b; Leng et al., 2022), 비디오 생성(Singer et al., 2022; Ho et al., 2022)과 같은 작업에서 최첨단 샘플 품질을 달성했습니다. 음성 또는 오디오 합성의 경우, 확산 모델은 멜 스펙트로그램 생성(Popov et al., 2021; Chen et al., 2022c)과 파형 생성(Lam et al., 2022; Lee et al., 2022; Chen et al., 2022b) 모두에 대해 연구되었습니다.
확산 모델에서 주요 관심사는 고차원 데이터 공간에서 반복적인 생성 과정이 낮은 추론 속도로 이어질 수 있다는 점입니다. 그 해결책 중 하나는 예를 들어 이미지 생성에서 사용된 것처럼 작은 잠재 공간에서 확산 모델을 사용하는 것입니다(Vahdat et al., 2021; Sinha et al., 2021; Rombach et al., 2022). TTA 생성의 경우, 오디오 파형은 불필요한 정보(Liu et al., 2022e, c)를 가지고 있어 모델링 복잡성을 증가시키고 추론 속도를 저하시킵니다. 이를 극복하기 위해 DiffSound(Yang et al., 2022)는 멜 스펙트로그램의 압축된 표현으로 이산 토큰을 생성하기 위해 텍스트 조건부 이산 확산 모델을 사용합니다. 그러나 그들의 방법으로 생성된 사운드의 품질은 한계가 있으며, 오디오 조작 방법은 탐구되지 않았습니다.
3. 텍스트 조건부 오디오 생성
3.1 대조적 언어-오디오 사전 학습 (CLAP)
텍스트-투-이미지 생성 모델은 이미지 생성을 위해 대조적 언어-이미지 사전 학습(CLIP)을 활용하여 놀라운 샘플 품질을 보여주었습니다(Radford et al., 2021). 이에 영감을 받아, 우리는 텍스트-투-오디오(TTA) 생성을 촉진하기 위해 대조적 언어-오디오 사전 학습(CLAP)(Wu et al., 2022)을 활용합니다.

CLAP 모델을 훈련한 후, 오디오 샘플 x는 정렬된 오디오 및 텍스트 임베딩 공간 내에서 임베딩 E_x로 변환될 수 있습니다. CLAP 모델의 일반화 능력은 제로샷 오디오 분류(Wu et al., 2022)와 같은 다양한 다운스트림 작업에서 입증되었습니다. 따라서, 보지 못한 언어 또는 오디오 샘플에 대해서도 CLAP 임베딩은 크로스 모달 정보를 제공합니다.
3.2 조건부 잠재 확산 모델


-----------------------------------------------------------------------------------------------------------------------------------------------------------------
일반적인 encoder, decoder 과정
-----------------------------------------------------------------------------------------------------------------------------------------------------------------



3.3 조건 강화(Conditioning Augmentation)
텍스트-투-이미지 생성에서, 확산 기반 모델은 객체와 배경 사이의 세밀한 디테일을 포착하는 능력을 보여주었습니다(Ramesh et al., 2022; Saharia et al., 2022; Liu et al., 2022d). 이러한 성공의 이유 중 하나는 LAION 데이터셋(Schuhmann et al., 2021)에 있는 4억 개의 이미지-텍스트 쌍과 같은 대규모 언어-이미지 학습 쌍 덕분입니다. TTA 생성에서도 자연어 설명과 일관된 관계를 가지는 구성적 오디오 신호를 생성하는 것이 바람직합니다. 그러나 사용 가능한 언어-오디오 데이터셋의 규모는 언어-이미지 데이터셋에 비해 상당히 적습니다. 데이터 증강을 위해, AudioGen(Kreuk et al., 2022)은 오디오 샘플 쌍을 혼합하고 각각의 처리된 텍스트 캡션을 연결하여 새로운 쌍 데이터를 형성하는 믹스업 전략을 사용합니다. 우리의 작업에서는, Equation 3에서 보여준 바와 같이, LDMs를 훈련할 때 오직 오디오 임베딩 E_x만을 조건부 정보로 제공함으로써 언어-오디오 쌍을 증강할 필요 없이 오디오 신호에만 데이터 증강을 구현할 수 있습니다. 구체적으로, 우리는 오디오 x_1과 x_2에 대해 믹스업 증강을 다음과 같이 수행합니다:

여기서 λ는 베타 분포 B(5,5)(Gong et al., 2021)에서 샘플링된 [0, 1]사이의 스케일링 팩터입니다. 여기서 우리는 해당 텍스트 설명 y_{1,2}를 고려할 필요가 없습니다. 왜냐하면 LDM 훈련 시 텍스트 정보가 필요하지 않기 때문입니다. 오디오 쌍을 혼합함으로써, 우리는 LDMs를 위한 훈련 데이터 쌍 (z0,Ex)의 수를 증가시키며, 이는 LDMs가 CLAP 임베딩에 대해 더 강건해지도록 만듭니다. 샘플링 과정에서, 이전에 보지 못한 언어 설명으로부터 얻은 텍스트 임베딩 E_y를 제공하면, LDMs는 이에 상응하는 오디오 사전 z_0를 생성할 것으로 기대됩니다.
3.4 분류기 없는 가이던스(Classifier-free Guidance)

그림 2: 분류기 없는 가이던스의 다양한 스케일로 생성된 샘플들. 텍스트 프롬프트는 "고양이가 야옹거리고 있다"입니다.

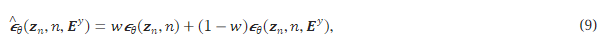
여기서 w는 가이던스 스케일을 결정합니다. AudioGen(Kreuk et al., 2022)과 비교했을 때, 우리는 두 가지 차이점이 있습니다. 첫째, 그들은 CFG를 기반으로 한 Transformer 기반의 자기회귀 모델을 활용한 반면, 우리의 LDMs는 CFG 뒤에 있는 이론적 공식화를 유지합니다(Ho & Salimans, 2021). 둘째, 우리의 텍스트 임베딩 E_y는 처리되지 않은 자연어에서 추출되므로, CFG가 오디오 생성에 대한 안내로 상세한 텍스트 설명을 활용할 수 있습니다. 그러나 AudioGen은 텍스트 전처리 방법을 통해 공간적 또는 시간적 관계를 나타내는 텍스트 세부 사항을 제거했습니다.
3.5 디코더(Decoder)

4. 텍스트 기반 오디오 조작
스타일 전환(Style Transfer)

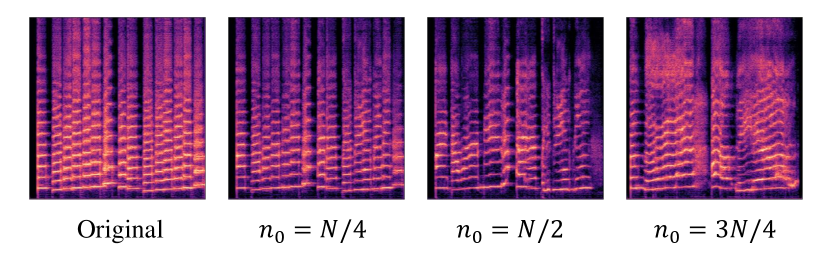
그림 3: 얕은 역방향 과정의 시작 지점 n_0에 따른 조작 결과. 원본 신호는 트럼펫이며, 스타일 전환을 위한 텍스트 프롬프트는 "어린이들이 노래하고 있다"입니다.
인페인팅(Inpainting) 및 초해상도(Super-Resolution)

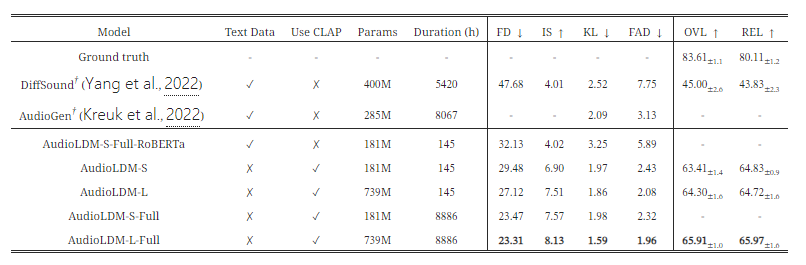
표 1: AudioLDM과 기준 TTA(텍스트-투-오디오) 생성 모델 간의 비교. 평가는 AudioCaps 테스트 세트에서 수행되었습니다. † 기호는 산업 수준의 계산을 나타냅니다. DiffSound는 32개의 V100 GPU에서 훈련되었고, AudioGen은 64개의 A100 GPU에서 훈련된 반면, AudioLDM 모델은 RTX 3090 또는 A100 단일 GPU에서 훈련되었습니다. AS와 AC는 각각 AudioSet과 AudioCaps 데이터셋을 나타냅니다. AudioGen의 결과는 그 구현이 공개적으로 제공되지 않았기 때문에 (Kreuk et al., 2022)에서 가져왔습니다.
5. 실험
훈련 데이터셋
이 논문에서 사용된 데이터셋에는 AudioSet(AS) (Gemmeke et al., 2017), AudioCaps(AC) (Kim et al., 2019), Freesound(FS) 및 BBC Sound Effect 라이브러리(SFX)가 포함됩니다. AS는 현재 527개의 레이블과 5,000시간 이상의 오디오 데이터를 포함하는 가장 큰 오디오 데이터셋입니다. AC는 약 49,000개의 오디오 클립과 텍스트 설명을 포함하는 훨씬 작은 데이터셋입니다. AudioSet과 AudioCaps의 대부분의 데이터는 YouTube에서 수집된 in-the-wild 오디오이기 때문에 오디오의 품질이 보장되지 않습니다. 데이터셋을 확장하고 특히 고품질의 오디오 데이터를 확보하기 위해, 우리는 다양한 범주의 음악, 음성 및 사운드 효과를 포함하는 FreeSound 및 BBC SFX 데이터셋에서 데이터를 크롤링했습니다. 데이터 처리 방법과 훈련 구성에 대한 자세한 내용은 부록 E에 나와 있습니다.
평가 데이터셋
모델 평가는 AC와 AS에서 수행되었습니다. AC의 각 오디오 클립에는 5개의 텍스트 캡션이 있습니다. 우리는 이들 중 하나를 무작위로 선택하여 텍스트 조건으로 사용하는 평가 세트를 생성했습니다. AC의 저자들이 의도적으로 음악과 관련된 레이블의 오디오를 제거했기 때문에(Kim et al., 2019), 더 넓은 범위의 사운드로 모델 성능을 평가하기 위해, AS에서 10%의 오디오 샘플을 무작위로 선택하여 또 다른 평가 세트를 만들었습니다. AS는 텍스트 설명을 포함하지 않기 때문에, 우리는 레이블을 연결하여 텍스트 설명으로 사용했습니다(예: Speech, hip hop music, crowd cheering).
평가 방법
우리는 객관적 평가와 인간의 주관적 평가를 모두 수행했습니다. 객관적 평가를 위한 주요 지표로는 프레셋 거리(FD), 인셉션 점수(IS), 쿨백-라이블러(KL) 발산이 포함됩니다. 이미지 생성에서의 프레셋 인셉션 거리와 유사하게, 오디오에서의 FD는 생성된 샘플과 목표 샘플 간의 유사성을 나타냅니다. IS는 샘플의 품질과 다양성을 평가하는 데 효과적입니다. KL은 쌍을 이룬 샘플 수준에서 측정되어 최종 결과로 평균화됩니다. 이 세 가지 지표는 모두 최신 오디오 분류기인 PANNs(Kong et al., 2020b)를 기반으로 합니다. (Kreuk et al., 2022)와 비교하기 위해, 우리는 또한 프레셋 오디오 거리(FAD) (Kilgour et al., 2019)를 채택했습니다. FAD는 FD와 유사한 아이디어를 가지고 있지만, 분류기로 VGGish(Hershey et al., 2017)를 사용하며, 이는 PANNs보다 성능이 낮을 수 있습니다. 생성 품질을 더 잘 측정하기 위해, 우리는 이 논문에서 FD를 주요 평가 지표로 선택했습니다. 주관적 평가를 위해, 우리는 6명의 오디오 전문가를 모집하여 (Kreuk et al., 2022; Yang et al., 2022)를 따르는 평가 과정을 진행했습니다. 구체적으로, 생성된 샘플은 i) 전반적인 품질(OVL)과 ii) 입력 텍스트와의 관련성(REL)을 1에서 100 사이의 척도로 평가받았습니다. 인간 평가의 세부 사항은 부록 E에 포함되어 있습니다. 우리는 재현성을 높이기 위해 우리의 평가 파이프라인을 오픈소스화했습니다.
모델
우리는 최근 제안된 두 가지 TTA 시스템인 DiffSound(Yang et al., 2022)와 AudioGen(Kreuk et al., 2022)를 기준 모델로 사용했습니다. DiffSound는 AS 및 AC 데이터셋에서 약 4억 개의 파라미터로 훈련되었습니다. AudioGen은 AS, AC 및 여덟 개의 다른 데이터셋에서 약 2억 8,500만 개의 파라미터로 훈련되었습니다. AudioGen의 구현이 공개적으로 제공되지 않았기 때문에, 우리는 그들의 논문에 보고된 KL 및 FAD 결과를 재사용했습니다. 우리는 두 가지 AudioLDM 모델을 훈련했습니다. 하나는 AudioLDM-S라는 작은 모델로, 1억 8,100만 개의 파라미터를 가지고 있으며, 다른 하나는 AudioLDM-L이라는 큰 모델로, 7억 3,900만 개의 파라미터를 가지고 있습니다. UNet 아키텍처의 세부 사항은 부록 B에 설명되어 있습니다. 우리의 방법의 장점을 입증하기 위해, 우리는 이 두 모델을 오직 AC 데이터셋만으로 훈련했습니다. 또한, 훈련 데이터 규모의 효과를 탐구하기 위해, AC, AS, FreeSound, BBC SFX 데이터셋에서 훈련된 AudioLDM-L-Full 모델을 개발했습니다.
5.1 결과
우리는 표 1에서 AC 테스트 세트에 대한 주요 평가 결과를 보여줍니다. 단일 훈련 데이터셋인 AC를 기준으로 했을 때, AudioLDM-S는 더 작은 모델 크기에도 불구하고, 객관적 및 주관적 평가에서 기준 모델들보다 더 나은 생성 결과를 달성할 수 있었습니다. AudioLDM-L로 모델 용량을 확장함으로써, 우리는 전반적인 결과를 더욱 향상시켰습니다. 그런 다음 AS와 두 개의 다른 데이터셋을 훈련에 통합하여, 우리 모델 AudioLDM-L-Full은 23.31의 FD로 최고의 품질을 달성했습니다. 비록 RoBERTa와 CLAP이 동일한 텍스트 인코더 구조를 가지고 있지만, CLAP은 오디오-텍스트 관계 학습을 생성 모델 훈련에서 분리할 수 있다는 이점을 가지고 있습니다. 이 분리는 직관적이며, CLAP이 이미 임베딩 공간을 정렬하여 오디오와 텍스트 간의 관계를 모델링했기 때문입니다. 반면, AudioLDM-S-Full-RoBERTa에서는 텍스트 인코더가 텍스트 정보를 나타내는 역할만 하기 때문에, 모델이 오디오 생성 과정을 학습하는 동시에 텍스트-오디오 관계를 학습해야 합니다. 또한, CLAP 기반 방법은 오디오 데이터만을 사용하여 모델 훈련이 가능하게 합니다. 따라서 CLAP으로 사전 학습되지 않은 RoBERTa를 사용하는 것은 훈련의 난이도를 증가시킬 수 있습니다.

그림 4: 인간 평가 결과의 히스토그램. 가로축과 세로축은 각각 평가 점수와 빈도를 나타냅니다. OVL은 오디오 파일의 전반적인 품질을, REL은 텍스트와 생성된 오디오 간의 관련성을 나타냅니다. OVL과 REL 모두 1에서 100까지의 척도로 평가됩니다. 각 평가 파일의 점수는 모든 평가자의 점수를 평균한 것입니다.
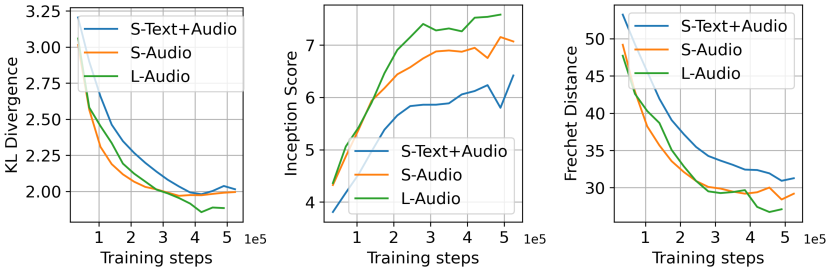
그림 5: i) 텍스트 임베딩으로 훈련된 AudioLDM-S (S-Text+Audio), ii) AudioLDM-S (S-Audio), 그리고 iii) AudioLDM-L (L-Audio)의 훈련 과정에서 평가된 다양한 평가 지표의 비교.
우리의 인간 평가 결과는 다른 평가 지표와 유사한 경향을 보입니다. 제안된 방법은 약 64점의 OVL(전반적인 품질)과 REL(텍스트와 생성된 오디오의 관련성) 점수를 기록하여, 각각 45.00점과 43.83점을 기록한 DiffSound보다 훨씬 우수한 성능을 보여줍니다. AudioLDM 모델의 크기에 대해, 우리는 더 큰 모델이 전반적인 오디오 품질에 유리하다는 것을 알게 되었습니다. 훈련 데이터를 확장한 후, OVL과 REL 모두에서 상당한 개선이 나타났습니다. 그림 4는 모든 평가자의 점수를 평균한 다양한 모델의 점수 통계를 보여줍니다. 우리의 모델이 DiffSound에 비해 더 높은 점수에 집중되어 있음을 알 수 있습니다. 무작위로 선택된 실제 녹음인 스팸 케이스도 높은 점수를 보여, 평가 결과가 신뢰할 만하다는 것을 나타냅니다.
음악을 포함할 수 있는 오디오 데이터를 평가하기 위해, 우리는 AS 평가 세트에서 모델을 추가로 평가했습니다. 우리의 방법을 DiffSound와 비교했으며, 그 결과를 표 2에 보여줍니다. 우리의 세 가지 AudioLDM 모델은 AC 테스트 세트에서와 유사한 경향을 보였습니다. 우리는 모든 지표에서 DiffSound 기준 모델을 크게 능가할 수 있었습니다.
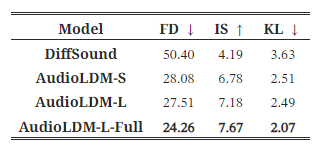
표 2: AudioSet 평가 세트에서의 평가 결과.
조건부 정보
LDMs를 오디오 임베딩 E_x에 조건을 두고 훈련하고 있지만, TTA 생성 시에는 LDMs에 텍스트 임베딩 E_y를 제공하기 때문에, 텍스트 임베딩을 훈련 조건으로 직접 사용하는 것이 더 강력한 결과를 가져올 수 있는지에 대한 자연스러운 의문이 생깁니다. 우리는 이에 대한 실험을 진행하였으며, 결과를 표 3에 제시합니다. 공정한 비교를 위해, 우리는 데이터 증강을 수행하고, AudioGen에서 사용된 전략을 채택했습니다. 구체적으로, 섹션 3.3에서 설명한 것과 같은 오디오 쌍에 대한 동일한 믹싱 방법을 사용하고, 두 개의 텍스트 캡션을 결합하여 조건부 정보로 사용했습니다. 표 3은 LDMs를 E_x에 대해 훈련함으로써 E_y로 훈련하는 것보다 더 나은 결과를 얻을 수 있음을 보여줍니다.
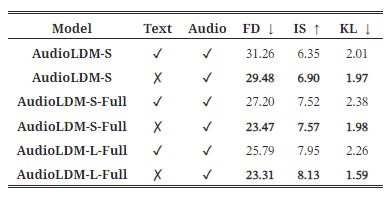
표 3: LDMs 훈련 시 조건부 정보로서 텍스트 임베딩과 오디오 임베딩의 비교.
우리는 표 3의 결과에 대한 주요 이유가 텍스트 임베딩이 오디오 임베딩만큼 생성 목표를 잘 표현하지 못하기 때문이라고 믿습니다. 첫째, 소리의 모호함과 복잡성 때문에 텍스트 캡션은 정확하고 포괄적으로 표현되기 어렵습니다. 서로 다른 인간 주석자들은 동일한 오디오에 대해 서로 다른 인식과 설명을 가질 수 있으며, 이는 텍스트-오디오 쌍으로 훈련하는 것이 오디오만으로 훈련하는 것보다 덜 안정적이게 만듭니다. 게다가, 일부 캡션은 매우 추상적인 수준에 머물러 있어 오디오 내용을 정확하게 설명하지 못할 수 있습니다. 예를 들어, BBC SFX 데이터셋에는 "Boats: Battleships-5.25 conveyor space"라는 캡션이 있는 오디오가 있는데, 이는 사람이 듣고 상상하기에도 어렵습니다. 이러한 언어-오디오 쌍의 품질은 모델 최적화를 방해할 수 있습니다. 이에 비해, CLAP 잠재 표현에서 E_x를 조건으로 사용하면, 이는 오디오 신호에서 직접 추출되며, 이상적으로는 최고의 텍스트 캡션과 정렬됩니다. 이는 LDMs에 강력한 조건부 정보를 제공할 수 있게 하며, 잡음이 섞인 텍스트 설명을 고려할 필요가 없습니다. 그림 5는 훈련 진행에 따른 샘플 품질을 보여줍니다. 우리는 다음과 같은 사실을 확인했습니다: i) 오디오 임베딩으로 훈련할 때 텍스트 임베딩보다 훈련 전반에 걸쳐 훨씬 더 나은 결과를 얻을 수 있으며, ii) 더 큰 모델은 수렴 속도가 더 느리지만 최종 성능이 더 우수할 수 있습니다.
압축 수준
우리는 압축 수준 r이 생성 품질에 미치는 영향을 연구했습니다. 표 4는 r=4,8,16 설정에서의 성능 비교를 보여줍니다. 압축 수준이 증가함에 따라 성능이 감소하는 경향을 관찰했습니다. 그럼에도 불구하고, 주파수 축에서 64 밴드 멜-스펙트로그램을 단지 4차원으로 압축하는 r=16 설정에서도, 우리의 성능은 KL 측면에서 AudioGen과 비슷하며, 모든 지표에서 DiffSound보다 우수합니다.

표 4: AudioLDM에서 압축 수준이 미치는 영향.
압축 수준을 r=1로 설정하면, 이는 CLAP 임베딩에서 직접 멜-스펙트로그램을 생성한다는 의미이며, 이 경우 훈련 과정은 단일 RTX 3090 GPU에서 구현하기 어렵습니다. 유사한 결과가 r=2에서도 발생합니다. 게다가, r=1과 r=2의 경우 추론 속도가 느려질 것입니다. 우리의 연구에서 r=4는 높은 생성 품질을 유지하면서도 계산 부담을 합리적인 수준으로 줄이는 데 성공했습니다. 따라서, 우리는 실험에서 기본 설정으로 r=4를 사용합니다.
텍스트 기반 오디오 조작
우리는 텍스트 기반 오디오 조작 방법의 성능을 두 가지 작업, 즉 초해상도(super-resolution)와 인페인팅(inpainting)에서 보여줍니다. 구체적으로, 초해상도의 경우, 오디오 신호를 8kHz 샘플링 속도에서 16kHz로 업샘플링합니다. 인페인팅 작업에서는, 2.5초에서 7.5초 사이의 오디오 신호를 제거하고 이 부분을 인페인팅으로 채웁니다. 오디오 초해상도에 대한 대부분의 연구는 음성 신호에 집중되어 있으므로(Liu et al., 2021a, 2022a), 우리는 AudioCaps와 다중 화자 음성 데이터셋인 VCTK(Yamagishi et al., 2019)에서 결과를 보여줍니다. 초해상도를 위해, 우리는 AudioUNet(Kuleshov et al., 2017)과 NVSR(Liu et al., 2022a) 두 가지 모델을 기준 모델로 사용하고, 비교를 위해 로그 스펙트럴 거리(LSD)(Wang & Wang, 2021)를 평가 지표로 사용합니다. 인페인팅 작업에서는 FAD를 지표로 사용하여 이 작업의 기준선을 설정합니다.
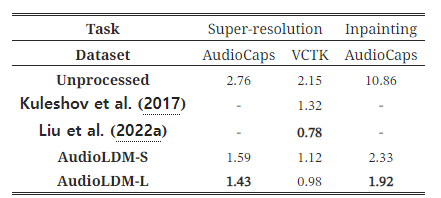
표 5: LSD와 FAD로 각각 평가된 제로샷 초해상도 및 인페인팅 성능 비교.
표 5는 AudioLDM이 강력한 AudioUNet 기준 모델을 능가할 수 있지만, NVSR(Liu et al., 2022a)만큼 좋은 결과를 내지는 못했음을 보여줍니다. AudioLDM은 다양한 오디오 신호 세트, 특히 강한 배경 소음을 포함하는 신호들로 훈련된 모델이라는 점을 상기해보면, 이는 초해상도 과정의 출력에서 화이트 노이즈나 기타 비음성 소리 이벤트가 발생할 가능성을 높여 성능이 저하될 수 있습니다. 그럼에도 불구하고, 우리의 기여는 TTA 시스템을 사용하여 제로샷 방식으로 텍스트 기반 오디오 조작을 달성하는 데 새로운 가능성을 열어줄 수 있습니다. 우리의 벤치마크 결과를 바탕으로 추가적인 개선이 기대됩니다. 우리는 부록 I에 여러 결과 샘플을 제공합니다.
5.2 소거 연구(Ablation Study)
표 6은 AudioLDM-S에 대한 소거 연구 결과를 보여줍니다. UNet의 어텐션 메커니즘을 한 층의 다중 헤드 자기 어텐션으로 단순화하면(w. Simple attn), 각 지표에서 성능이 눈에 띄게 감소하는데, 이는 복잡한 어텐션 메커니즘이 선호된다는 것을 나타냅니다. 또한, 오디오 분류에서 널리 사용되는 균형 샘플링 전략(Gong et al., 2021; Liu et al., 2022b)이 TTA에서는 개선 효과를 보이지 않는다는 것을 확인했습니다(w. Balance samp). 조건부 증강(3.3절 참조)은 주관적 평가에서 개선을 보여주지만, 객관적 평가 지표에서는 개선을 보이지 않습니다(w. Cond aug). 그 이유는 조건부 증강이 AudioCaps 데이터셋을 잘 대표하지 못하는 훈련 데이터를 생성하여, 모델 출력이 평가 데이터와 잘 일치하지 않아 지표 점수가 낮아지는 결과를 초래할 수 있기 때문입니다. 그럼에도 불구하고, 조건부 증강은 두 가지 주관적 지표를 개선할 수 있으므로, 데이터 증강 기술로 사용하는 것을 여전히 권장합니다.

표 6: 어텐션 메커니즘, 훈련 데이터에 대한 균형 샘플링 기법, 그리고 조건부 증강 알고리즘에 대한 소거 연구 결과.
DDIM 샘플링 단계
DDPMs의 역방향 과정에서 샘플링 단계 수는 생성 품질에 직접적인 영향을 미칠 수 있습니다(Ho et al., 2020; Song et al., 2021). 일반적으로, 샘플링 단계 수를 증가시키면 샘플 품질이 향상되지만, 동시에 계산 부하도 증가합니다. 우리는 잠재 확산 모델에서 DDIM(Song et al., 2020) 샘플링 단계가 미치는 영향을 탐구했습니다. 표 7은 샘플링 단계가 많아질수록 품질이 향상된다는 것을 보여줍니다. 100단계와 같은 충분한 샘플링 단계에서는 샘플링 단계를 추가하는 이득이 덜 중요해집니다. 200단계의 결과는 100단계의 결과보다 약간 더 나은 정도입니다.
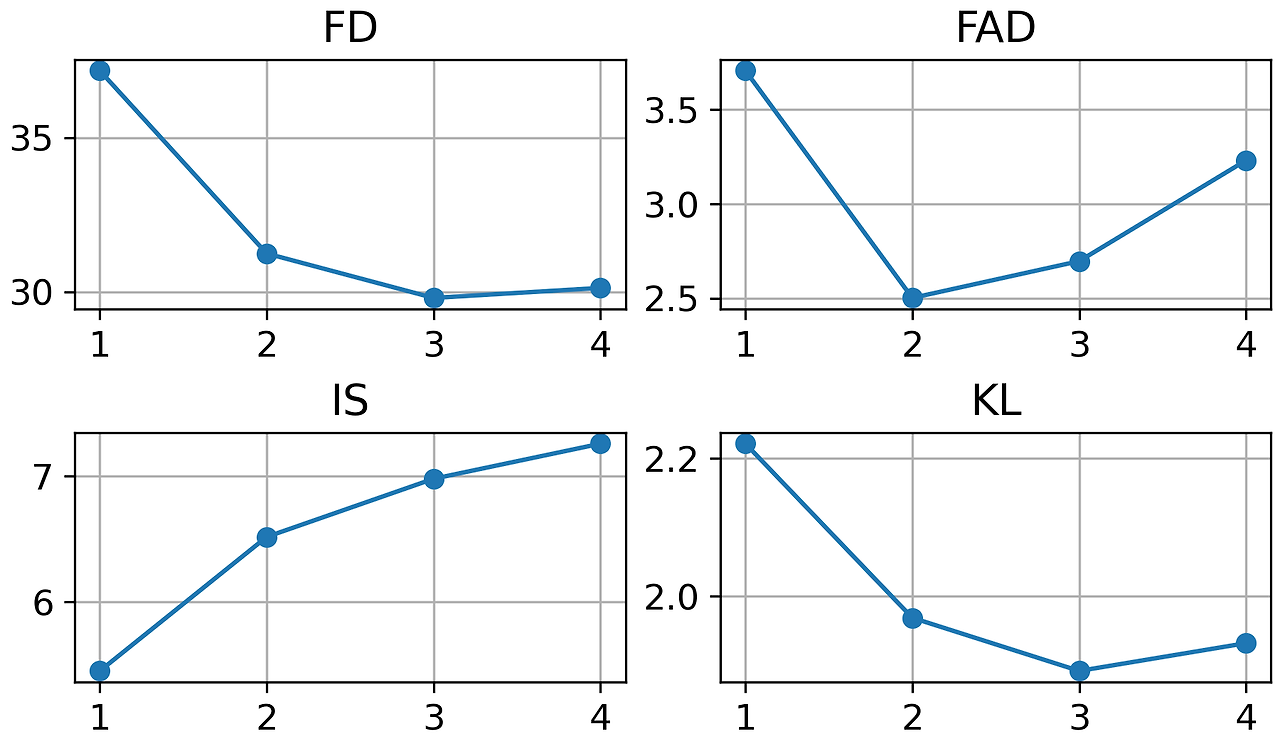
그림 6: AudioCaps에서 훈련된 AudioLDM-S 모델에 대해 다양한 분류기 없는 가이던스 스케일(가로축)의 비교.
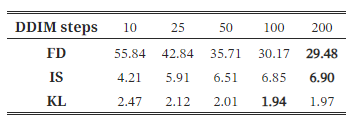
표 7: DDIM 샘플러를 사용한 LDMs의 샘플링 단계가 미치는 영향.
가이던스 스케일은 조건부 생성 품질과 샘플 다양성 사이의 균형을 나타냅니다. 적절한 가이던스 스케일은 생성된 샘플과 조건부 정보 간의 일관성을 생성 다양성의 수용 가능한 비용으로 개선할 수 있습니다. 우리는 그림 6에서 TTA에 대한 가이던스 스케일 w의 효과를 보여줍니다. w=3일 때, 우리는 FD와 KL에서 가장 좋은 결과를 얻었지만, FAD에서는 그렇지 않았습니다. 그 이유는 섹션 5에서 언급한 바와 같이, FAD의 오디오 분류기가 FD만큼 우수하지 않기 때문이라고 생각됩니다. 이 경우, 상세한 언어 설명에 대한 준수성이 개선되면 FAD의 분류기에는 오히려 혼란스러운 정보가 될 수 있습니다. 이전 연구들이 FD 대신 FAD 결과를 보고했기 때문에, 비교를 위해 w=2로 설정하였지만, w가 FAD, FD, IS, KL에 미치는 상세한 효과도 제공했습니다.
사례 연구
우리는 사례 연구를 수행하여 부록 I에 생성된 결과를 보여줍니다. 여기에는 스타일 전환(그림 9-11 참조), 초해상도(그림 12 참조), 인페인팅(그림 13-14 참조), 그리고 텍스트-투-오디오 생성(그림 15-22 참조)이 포함됩니다. 특히, 텍스트-투-오디오의 경우, AudioLDM의 제어 가능성을 보여주며, 이는 음향 환경, 재료, 소리 이벤트, 피치, 음악 장르, 시간 순서의 제어를 포함합니다.
6. 결론
우리는 텍스트-투-오디오(TTA) 생성을 위한 새로운 방법인 AudioLDM을 소개했습니다. 이 방법은 대조적 언어-오디오 사전 학습(CLAP) 모델과 잠재 확산 모델(LDM)을 활용합니다. 우리의 방법은 생성 품질, 계산 효율성, 오디오 조작에서 이점을 가지고 있습니다. 단일 훈련 데이터셋인 AudioCaps와 단일 GPU로, AudioLDM은 주관적 및 객관적 지표로 평가된 최첨단(SOTA) 생성 품질을 달성했습니다. 더욱이, AudioLDM은 제로샷 텍스트 기반 오디오 스타일 전환, 초해상도, 인페인팅을 가능하게 합니다.
7. 감사의 글
이 연구는 잠재 확산 모델에 대한 유용한 논의에 대해 James King과 Jinhua Liang에게 감사를 표합니다. 이 연구는 부분적으로 영국 방송공사 연구개발(BBC R&D), 공학 및 물리과학 연구위원회(EPSRC) Grant EP/T019751/1 "AI for Sound" 및 서리 대학교(University of Surrey) 시각, 음성 및 신호 처리 센터(CVSSP), 공학 및 물리과학 학부(FEPS)로부터의 박사과정 장학금의 지원을 받았습니다. 오픈 액세스의 목적을 위해, 저자들은 작성된 원고의 버전에 대해 크리에이티브 커먼즈 저작자 표시(CC BY) 라이선스를 적용했습니다.



