https://www.arxiv.org/abs/2408.11039
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
We introduce Transfusion, a recipe for training a multi-modal model over discrete and continuous data. Transfusion combines the language modeling loss function (next token prediction) with diffusion to train a single transformer over mixed-modality sequenc
arxiv.org
초록
우리는 이산 및 연속 데이터를 처리하는 다중 모달 모델을 훈련하기 위한 방법인 Transfusion을 소개합니다. Transfusion은 언어 모델링 손실 함수(다음 토큰 예측)와 확산(diffusion)을 결합하여 혼합 모달리티 시퀀스에서 단일 트랜스포머를 훈련시킵니다. 우리는 텍스트와 이미지 데이터를 혼합하여 여러 Transfusion 모델을 최대 70억 개의 매개변수로 처음부터 사전 훈련하였으며, 다양한 단일 모달 및 교차 모달 벤치마크와 관련된 확장 법칙을 확립했습니다. 실험 결과, Transfusion은 이미지를 양자화하고 이산 이미지 토큰을 통해 언어 모델을 훈련시키는 것보다 훨씬 더 효율적으로 확장된다는 것을 보여줍니다. 모달리티별 인코딩 및 디코딩 레이어를 도입함으로써 Transfusion 모델의 성능을 더욱 향상시킬 수 있으며, 각 이미지를 단 16개의 패치로 압축할 수 있습니다. 우리는 또한 Transfusion 방법을 70억 개의 매개변수와 2조 개의 다중 모달 토큰으로 확장함으로써, 유사한 규모의 확산 모델 및 언어 모델과 동등한 수준으로 이미지와 텍스트를 생성할 수 있는 모델을 만들 수 있음을 증명하였으며, 두 세계의 이점을 모두 얻을 수 있음을 보여줍니다.
1. 소개
다중 모달 생성 모델은 이산적인 요소(예: 텍스트나 코드)와 연속적인 요소(예: 이미지, 오디오, 비디오 데이터)를 인식하고 처리하며 생성할 수 있어야 합니다. 다음 토큰 예측 목표로 훈련된 언어 모델이 이산 모달리티에서 우세한 반면(OpenAI et al., 2024; Dubey et al., 2024), 확산 모델(Ho et al., 2020; Rombach et al., 2022a)과 그 일반화 모델(Lipman et al., 2022)은 연속 모달리티를 생성하는 데 있어서 최첨단 기술로 평가받고 있습니다(Dai et al., 2023; Esser et al., 2024b; Bar-Tal et al., 2024). 이러한 접근법을 결합하려는 많은 시도가 있었으며, 여기에는 언어 모델이 확산 모델을 도구로 사용하도록 확장하거나(Liu et al., 2023), 사전 훈련된 확산 모델을 언어 모델에 접목시키는 방법(Dong et al., 2023; Koh et al., 2024) 등이 포함됩니다. 또 다른 방법으로는 연속 모달리티를 양자화하여(Van Den Oord et al., 2017) 이산 토큰으로 표준 언어 모델을 훈련시키는 것인데(Ramesh et al., 2021; Yu et al., 2022, 2023), 이는 모델의 아키텍처를 단순화하지만 정보 손실이 발생할 수 있습니다. 이번 연구에서는 이산 텍스트 토큰을 예측하고 연속적인 이미지를 확산시키는 단일 모델을 훈련시킴으로써 정보 손실 없이 두 가지 모달리티를 완전히 통합할 수 있음을 보여줍니다.
우리는 이산 및 연속 모달리티를 원활하게 생성할 수 있는 모델을 훈련하기 위한 방법인 Transfusion을 소개합니다. 우리는 Transfusion을 텍스트와 이미지 데이터를 각각 50%씩 사용하여 각 모달리티에 대해 다른 목표(텍스트에 대해서는 다음 토큰 예측, 이미지에 대해서는 확산)를 사용해 트랜스포머 모델을 사전 훈련시킴으로써 구현합니다. 모델은 각 훈련 단계에서 두 가지 모달리티와 손실 함수에 노출됩니다. 표준 임베딩 레이어는 텍스트 토큰을 벡터로 변환하고, 패치화(patchification) 레이어는 각 이미지를 패치 벡터의 시퀀스로 나타냅니다. 우리는 텍스트 토큰에는 인과적 주의(causal attention)를, 이미지 패치에는 양방향 주의(bidirectional attention)를 적용합니다. 추론을 위해, 우리는 언어 모델에서의 텍스트 생성과 확산 모델에서의 이미지 생성의 표준적인 방식을 결합한 디코딩 알고리즘을 도입합니다. 그림 1은 Transfusion의 개요를 보여줍니다.
Chameleon의 양자화 접근법(Chameleon Team, 2024)과의 통제된 비교에서, Transfusion 모델은 모든 모달리티 조합에서 더 잘 확장된다는 것을 보여줍니다. 텍스트에서 이미지로의 생성에서, Transfusion은 계산 비용이 3분의 1 이하로 줄어든 상황에서 Chameleon 접근법을 능가한다는 것이 FID 및 CLIP 점수로 측정되었습니다. FLOPs를 기준으로 조정할 때, Transfusion은 Chameleon 모델보다 약 2배 낮은 FID 점수를 기록했습니다. 이미지에서 텍스트로의 생성에서도 유사한 경향이 나타났으며, Transfusion은 Chameleon의 21.8%의 FLOPs로 유사한 성능을 보였습니다. 놀랍게도, Transfusion은 텍스트에서 텍스트로의 예측 학습에서도 더 효율적이었으며, Chameleon의 FLOPs의 50%에서 60%로 텍스트 작업에서 동등한 수준의 퍼플렉시티를 달성했습니다.
소거(ablation) 실험을 통해 Transfusion의 중요한 구성 요소와 잠재적인 개선점을 밝혀냈습니다. 우리는 이미지 내 양방향 주의가 중요하며, 이를 인과적 주의로 대체하면 텍스트에서 이미지로의 생성 성능이 저하된다는 것을 관찰했습니다. 또한, 이미지 인코딩 및 디코딩을 위해 U-Net 다운 및 업 블록을 추가하면 더 큰 이미지 패치를 성능 저하 없이 압축할 수 있으며, 이는 서비스 비용을 최대 64배까지 줄일 수 있다는 점도 발견했습니다.
마지막으로, Transfusion이 다른 확산 모델과 유사한 품질의 이미지를 생성할 수 있음을 입증했습니다. 우리는 U-Net 다운/업 레이어(2.7억 매개변수)로 강화된 70억 매개변수의 트랜스포머를 처음부터 훈련시켰으며, 2조 개의 토큰(1조 개의 텍스트 토큰과 약 6억 9천 2백만 개의 이미지와 그 캡션을 5회 반복한 데이터로 이루어진 1조 개의 패치/토큰)으로 모델을 학습시켰습니다. 그림 2는 모델에서 샘플링한 일부 생성 이미지를 보여줍니다. GenEval 벤치마크(Ghosh et al., 2023)에서, 우리 모델은 DALL-E 2와 SDXL과 같은 다른 인기 모델들을 능가했으며, 이러한 이미지 생성 모델들과 달리 텍스트도 생성할 수 있습니다. 텍스트 벤치마크에서 Llama 1과 동일한 수준의 성능에 도달했습니다. 우리의 실험은 Transfusion이 진정한 다중 모달 모델을 훈련시키기 위한 유망한 접근법임을 보여줍니다.
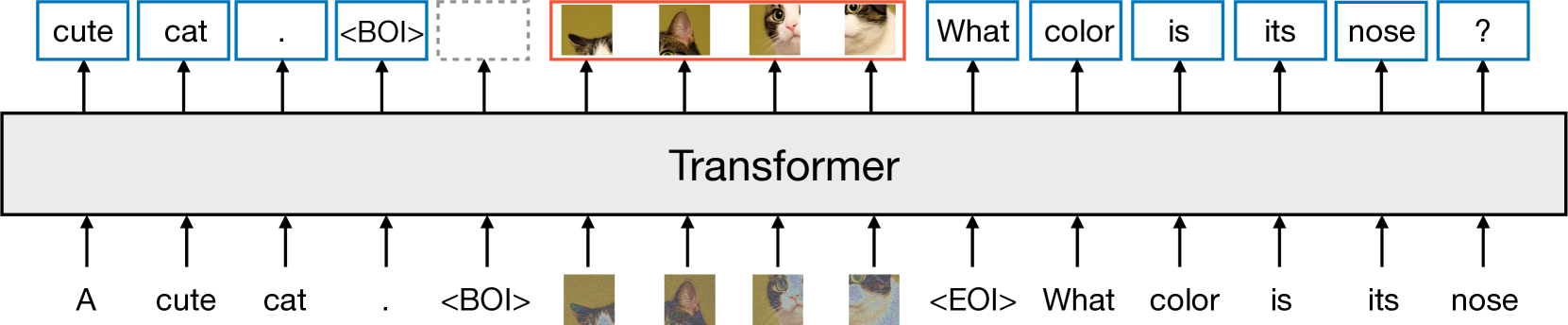
그림 1: Transfusion의 고수준 개요를 보여주는 그림입니다. 단일 트랜스포머가 모든 모달리티의 데이터를 인식하고 처리하며 생성합니다. 이산적(텍스트) 토큰은 자동회귀적으로 처리되며 다음 토큰 예측 목표에 따라 훈련됩니다. 연속적(이미지) 벡터는 병렬로 함께 처리되며 확산 목표에 따라 훈련됩니다. BOI(Beginning Of Input) 및 EOI(End Of Input) 토큰이 모달리티를 구분합니다.

그림 2: 2조 개의 다중 모달 토큰으로 훈련된 70억 매개변수 Transfusion 모델이 생성한 이미지들입니다.
2. 배경
Transfusion은 언어 모델링과 확산이라는 두 가지 목표로 훈련된 단일 모델입니다. 이 두 가지 목표는 각각 이산적 데이터와 연속적 데이터 모델링에서 최첨단 기술을 대표합니다. 이 섹션에서는 이러한 목표와 잠재적 이미지 표현에 대한 배경을 간략히 정의합니다.

2.2 확산(Diffusion)
잡음 제거 확산 확률 모델(일명 DDPM 또는 확산 모델)은 점진적인 잡음 추가 과정을 역으로 되돌리는 방법을 학습하는 원칙에 따라 작동합니다(Ho et al., 2020). 이산적인 토큰(예: 텍스트)으로 작업하는 언어 모델과 달리, 확산 모델은 연속적인 벡터(예: 이미지) 위에서 작동하여 연속적인 데이터와 관련된 작업에 특히 적합합니다. 확산 프레임워크는 원래 데이터를 잡음으로 변환하는 정방향 과정과, 모델이 수행하는 방법을 학습하는 역방향 과정이라는 두 가지 과정을 포함합니다.




2.3 잠재 이미지 표현
초기 확산 모델들은 픽셀 공간에서 직접 작업했지만(Ho et al., 2020), 이는 계산 비용이 많이 들었습니다. 변분 오토인코더(VAE)(Kingma and Welling, 2013)는 이미지를 더 낮은 차원의 잠재 공간으로 인코딩하여 계산을 절약할 수 있습니다. 딥 CNN으로 구현된 현대의 VAE는 재구성 손실과 정규화 손실의 조합으로 훈련되며(Esser et al., 2021), 잠재 확산 모델(LDM)(Rombach et al., 2022a)과 같은 후속 모델들이 컴팩트한 이미지 패치 임베딩을 효율적으로 처리할 수 있도록 합니다. 예를 들어, 8×8 픽셀 패치를 8차원 벡터로 표현할 수 있습니다. 자동회귀 언어 모델링 접근 방식(Ramesh et al., 2021; Yu et al., 2022)을 위해서는 이미지를 이산화해야 합니다. 벡터 양자화 VAE(VQ-VAE)(Van Den Oord et al., 2017)와 같은 이산 오토인코더는 연속적인 잠재 임베딩을 이산 토큰으로 매핑하는 양자화 레이어(및 관련 정규화 손실)를 도입함으로써 이를 달성합니다.
3. Transfusion
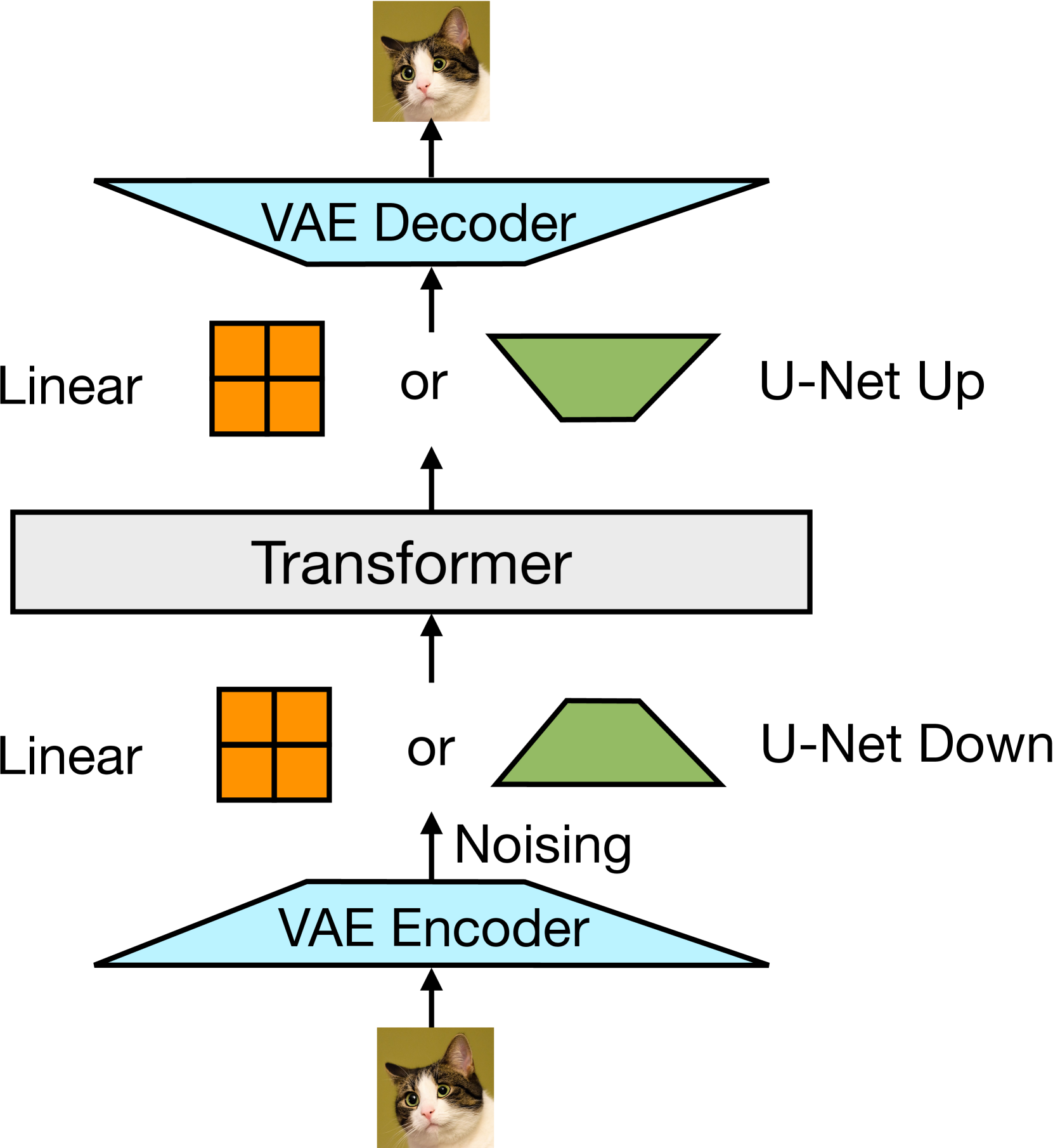
그림 3: 우리는 사전 훈련된 VAE를 사용하여 이미지를 잠재 표현으로 변환한 후, 단순한 선형 레이어 또는 U-Net 다운 블록을 사용해 패치 표현으로 변환합니다.
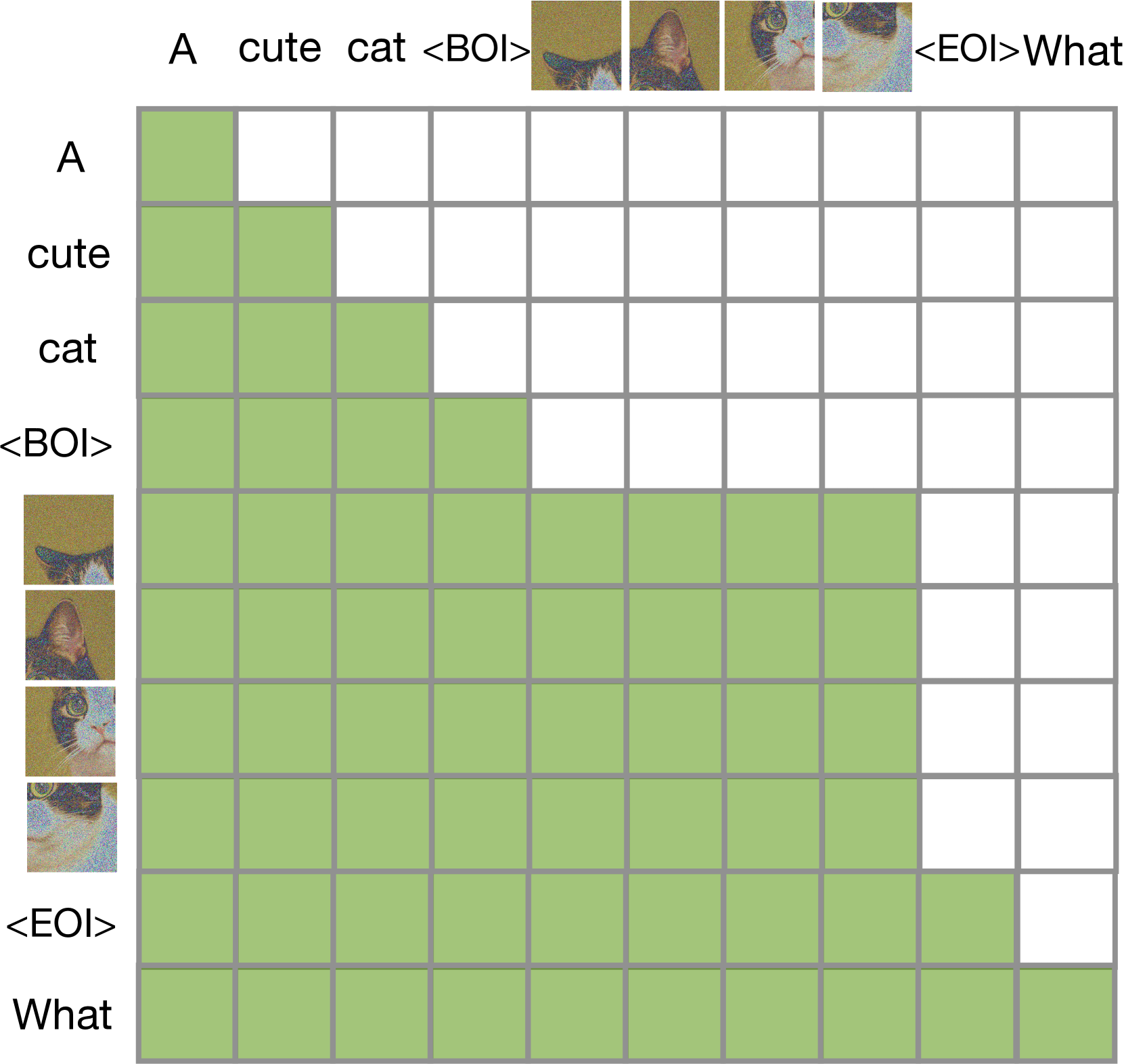
그림 4: 인과 마스크(causal mask)를 확장하여, Transfusion은 동일한 이미지의 패치들이 서로 조건화할 수 있도록 합니다.
Transfusion은 이산적 모달리티(예: 텍스트)와 연속적 모달리티(예: 이미지)를 모두 이해하고 생성할 수 있는 단일 통합 모델을 훈련하는 방법입니다. 우리의 주요 혁신은 텍스트에 대해 언어 모델링, 이미지에 대해 확산과 같은 다른 모달리티에 대해 별도의 손실 함수를 사용하면서도, 이를 공통된 데이터와 매개변수로 처리할 수 있음을 입증한 것입니다. 그림 1은 Transfusion의 개념을 보여줍니다.
데이터 표현
우리는 두 가지 모달리티, 즉 이산적 텍스트와 연속적 이미지를 포함하는 데이터를 실험합니다. 각 텍스트 문자열은 고정된 어휘에서 이산적 토큰 시퀀스로 토크나이즈되며, 각 토큰은 정수로 표현됩니다. 각 이미지는 VAE(§2.3 참조)를 사용하여 잠재 패치로 인코딩되며, 각 패치는 연속적인 벡터로 표현됩니다. 패치들은 왼쪽에서 오른쪽, 위에서 아래로 순서대로 배열되어 각 이미지로부터 패치 벡터 시퀀스를 만듭니다.
※ 우리의 표준 설정에서는 잠재 확산 모델을 따르는 VAE를 사용하지만, 초기 실험에서 원시 픽셀 표현을 사용하여 Transfusion을 구현할 수 있음을 입증했습니다.
혼합 모달 예제의 경우, 각 이미지 시퀀스를 텍스트 시퀀스에 삽입하기 전에 이미지의 시작(BOI)과 끝(EOI)을 나타내는 특별한 토큰으로 둘러쌉니다. 이로써 이산적 요소(텍스트 토큰을 나타내는 정수)와 연속적 요소(이미지 패치를 나타내는 벡터)를 모두 포함할 수 있는 단일 시퀀스를 얻을 수 있습니다.
모델 아키텍처
모델의 대부분의 매개변수는 모든 시퀀스를 처리하는 단일 트랜스포머에 속하며, 이는 모달리티와 관계없이 처리합니다.
※ 우리는 SwiGLU 활성화 함수(Shazeer, 2020)와 RoPE(Su et al., 2024)를 포함하는 Llama(Touvron et al., 2023a)의 트랜스포머 블록 스타일을 따릅니다.
※ 이 연구에서는 트랜스포머 아키텍처를 사용하지만, Transfusion은 이름과 상관없이 다른 아키텍처와도 잠재적으로 작동할 수 있습니다.

그림 4는 전체 아키텍처를 보여줍니다.
Transfusion의 어텐션(Attention)
언어 모델은 일반적으로 인과 마스킹(causal masking)을 사용하여, 시퀀스 전체에 걸쳐 손실과 기울기를 단일 순방향-역방향 패스로 효율적으로 계산하며, 미래 토큰의 정보가 누출되지 않도록 합니다. 텍스트는 자연스럽게 순차적이지만, 이미지는 그렇지 않으며 보통은 제한 없는(양방향) 어텐션으로 모델링됩니다. Transfusion은 시퀀스의 모든 요소에 인과적 어텐션을 적용하고, 각 개별 이미지의 요소 내에서는 양방향 어텐션을 적용하여 이 두 가지 어텐션 패턴을 결합합니다. 이를 통해 각 이미지 패치는 동일한 이미지 내의 다른 모든 패치에 주의를 기울일 수 있지만, 시퀀스에서 이전에 나타난 텍스트나 다른 이미지의 패치에만 주의를 기울일 수 있습니다. 우리는 이미지 내 어텐션을 활성화하면 모델 성능이 크게 향상된다는 것을 발견했습니다(§4.3 참조). 그림 4는 Transfusion 어텐션 마스크의 예를 보여줍니다.


4. 실험(Experiments)
우리는 일련의 통제된 실험을 통해 Transfusion이 통합된 다중 모달 모델을 훈련하기 위한 실용적이고 확장 가능한 방법임을 입증합니다.
4.1 설정(Setup)
평가
우리는 표준 단일 모달 및 교차 모달 벤치마크 모음에서 모델 성능을 평가합니다(표 2 참조). 텍스트에서 텍스트로의 생성에서는, Wikipedia와 C4 코퍼스(Raffel et al., 2019)에서 2천만 개의 제외된 토큰에 대한 퍼플렉시티(perplexity)를 측정하고, Llama 2(Touvron et al., 2023b)의 사전 훈련 평가 스위트에서 정확도를 측정합니다.
※ Llama 2 평가 스위트에는 HellaSwag(Zellers et al., 2019), PIQA(Bisk et al., 2020), SIQA(Sap et al., 2019), WinoGrande(Sakaguchi et al., 2021), ARC-e 및 -c(Clark et al., 2018), BoolQ(Clark et al., 2019)이 포함됩니다. 우리는 이러한 벤치마크에서 0-샷 태스크의 평균 정확도를 보고합니다.
텍스트에서 이미지로의 생성에서는 MS-COCO 벤치마크(Lin et al., 2014)를 사용하여 검증 세트에서 무작위로 선택된 3만 개의 프롬프트에 대해 이미지를 생성하고, 제로샷 Frechet Inception Distance(FID)(Heusel et al., 2017)를 사용해 이미지의 사진 현실감을 측정하며, CLIP 점수(Radford et al., 2021)를 사용해 프롬프트와의 일치도를 측정합니다.
※ 우리는 소거(ablations) 실험에서 일반적으로 사용하는 방식에 따라 FID와 CLIP을 계산할 때 §4.3에서 5천 개의 예제만 사용합니다.
또한 모델의 이미지 캡션 생성 능력을 평가하며, MS-COCO(Karpathy 테스트 분할)에서 CIDEr(Vedantam et al., 2015) 점수를 보고합니다. 이러한 평가들은 확장 법칙 연구(§4.2) 및 소거 실험(§4.3)을 위한 신호를 제공합니다. 최근 확산 모델 관련 문헌과 비교하기 위해, 우리는 가장 큰 규모의 모델(§4.4)을 GenEval(Ghosh et al., 2023)에서 평가하며, 이는 모델이 프롬프트의 정확한 묘사를 생성할 수 있는 능력을 검토하는 벤치마크입니다.
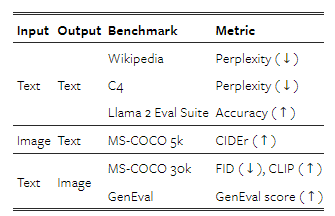
표 1: 이 연구에서 사용된 평가 스위트에 대한 개요입니다.
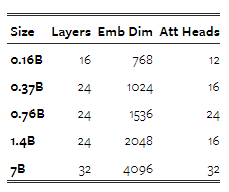
표 2: Transfusion과 기준 모델들에 대한 모델 크기와 구성에 대한 정보입니다.
기준 모델(Baseline)
이 글을 작성하는 시점에서 텍스트와 이미지를 모두 생성할 수 있는 단일 혼합 모달 모델을 훈련하기 위한 저명한 오픈 사이언스 방법은 이미지를 이산 토큰으로 양자화한 후, 전체 토큰 시퀀스를 표준 언어 모델로 모델링하는 것입니다(Ramesh et al., 2021; Yu et al., 2022, 2023). 우리는 Chameleon(Chameleon 팀, 2024)의 방법을 따라 데이터와 계산량을 제어하는 기준 모델들을 훈련하여 Transfusion 모델과 직접 비교할 수 있도록 했습니다. Chameleon과 Transfusion의 주요 차이점은 Chameleon이 이미지를 이산화하여 토큰으로 처리하는 반면, Transfusion은 이미지를 연속 공간에서 유지하여 양자화 정보 병목 현상을 제거한다는 점입니다. 혼란을 최소화하기 위해, Chameleon과 Transfusion의 VAE는 동일한 데이터, 계산량, 아키텍처를 사용하여 훈련되었으며, Chameleon의 VQ-VAE의 양자화 레이어와 코드북 손실만이 차이점입니다(아래 세부 정보 참조). Chameleon은 또한 Llama 트랜스포머 아키텍처와 다르게, 쿼리-키 정규화, 사후 정규화(post-normalization), 분모 손실(denominator loss), 1e-4의 낮은 학습률을 추가하여 훈련 불안정을 관리하는데, 이는 효율성 비용을 초래합니다(§4.2 참조).※ 이러한 변경 사항을 제거한 초기 실험에서는 Chameleon에서 최적화 불안정성이 발생했습니다.
데이터
거의 모든 실험에서 우리는 두 개의 데이터셋에서 1:1 토큰 비율로 0.5조 개의 토큰(패치)을 샘플링합니다. 텍스트의 경우, 우리는 다양한 도메인에서 2조 개의 토큰을 포함하는 Llama 2 토크나이저와 코퍼스(Touvron et al., 2023b)를 사용합니다. 이미지의 경우, 3억 8천만 개의 라이선스가 있는 Shutterstock 이미지와 캡션을 사용합니다. 각 이미지는 중심을 잘라내고 크기를 조정하여 256×256 픽셀 이미지로 만듭니다.
※ 패치 인코더의 압축률에 따라(§3 모델 아키텍처 참조), 각 이미지는 시퀀스에서 1024, 256, 64, 또는 16개의 요소로 표현될 수 있습니다. 텍스트/이미지 비율은 훈련 중에 일정하게 유지되므로, 더 높은 압축률은 이미지 당 계산량을 줄이는 대가로 총 훈련 가능한 이미지 수를 증가시킵니다.
한 실험(§4.4)에서는 총 훈련 데이터를 2조 개의 토큰(1조 개의 텍스트 토큰과 이미지당 256개의 패치로 구성된 약 35억 개의 캡션-이미지 쌍)으로 확장합니다. 다양성을 높이기 위해, 사람을 포함하지 않도록 필터링된 2억 2천만 개의 공개적으로 이용 가능한 이미지와 캡션을 추가합니다. 분포를 재조정하기 위해, 사람을 포함하는 8천만 개의 Shutterstock 이미지를 오버샘플링합니다. 또한 Conceptual 12M(CC12M)(Changpinyo et al., 2021) 데이터도 추가하여 에포크당 총 6억 9천 2백만 개의 이미지-캡션 쌍의 혼합물을 달성합니다. 마지막으로, 훈련 일정의 마지막 1% 동안 고도 미적 이미지를 더 높은 비율로 가중치를 부여합니다.
잠재 이미지 표현
우리는 Esser et al. (2021)을 따라 8,600만 개의 매개변수를 가진 VAE를 훈련합니다. 우리는 CNN 인코더와 디코더를 사용하며, 잠재 차원은 8입니다. 훈련 목표는 재구성 손실과 정규화 손실을 결합한 것입니다.
※ 세부 사항은 부록 A를 참조하십시오.

모델 구성
확장 경향을 조사하기 위해, 우리는 Llama의 표준 설정(Touvron et al., 2023a)을 따라 1.6억, 3.7억, 7.6억, 14억, 70억 매개변수를 가진 다섯 가지 크기의 모델을 훈련합니다. 표 2에는 각 설정이 자세히 설명되어 있습니다. 선형 패치 인코딩을 사용하는 구성에서는 (§4.2 및 §4.3), 추가된 매개변수의 수는 미미하며, 모든 구성에서 총 매개변수의 0.5% 미만을 차지합니다. U-Net 패치 인코딩을 사용하는 경우(§4.3 및 §4.4), 이러한 매개변수는 모든 구성에서 총 2.7억 개의 추가 매개변수를 더합니다. 이는 작은 모델에 있어서는 상당한 추가이지만, 70억 매개변수 구성에서는 3.8%의 증가에 불과하며, 이는 임베딩 레이어의 매개변수 수와 거의 동일합니다.

추론
텍스트 모드에서는 텍스트 생성을 위해 탐욕적 디코딩을 사용합니다. Llama 평가 스위트에서는 순위가 매겨진 분류를 사용합니다. 이미지 생성에서는 250회의 확산 단계를 따르며(모델은 1,000단계로 훈련되었습니다), Chameleon을 따라 제어된 비교 실험(§4.2)에서 CFG 계수를 5로 사용합니다. 이 값은 Transfusion에는 최적화되어 있지 않으므로, 소거 실험(§4.3)에서는 CFG 계수를 3으로 사용하며, 대규모 실험(§4.4)에서는 각 벤치마크에 대해 계수를 조정하는 표준 방식을 따릅니다.
4.2 Chameleon과의 통제된 비교
우리는 Transfusion과 Chameleon을 서로 다른 모델 크기(N)와 토큰 수(D)에서 비교하는 일련의 통제된 실험을 수행합니다. 이 둘의 조합을 FLOPs(6ND)의 대리로 사용합니다.
※ Transfusion은 이미지를 연속적인 표현으로 사용하기 때문에, 단일 이미지를 훨씬 적은 토큰으로 표현할 수 있으며, 이로 인해 평균 문서 길이가 줄어들어 전체 어텐션의 계산 비용이 줄어듭니다. 이 사실이 Transfusion에 유리하기 때문에, 이 혼란 변수를 제거하기 위해 이론적인 FLOP 계산을 사용합니다.
단순성과 매개변수 제어를 위해, 이 실험에서 사용된 Transfusion 변형은 2×2 크기의 패치를 가진 단순한 선형 이미지 인코더/디코더와 양방향 어텐션을 사용합니다. 각 벤치마크에 대해, 우리는 모든 결과를 로그-FLOPs 곡선에서 로그-메트릭으로 나타내고 선형 추세선을 회귀 분석합니다.
※ 작은 Chameleon 모델들은 이미지 생성 및 이해 작업에서 성능이 저조하여, 결과가 상위 Chameleon 모델의 확장 법칙과 일치하지 않는 이상치(outlier) 결과를 초래합니다. 따라서 우리는 최소 성능 임계값을 정의하고, 그 이하의 데이터 포인트는 제거합니다: FID ≤ 100, CLIP ≥ 17, CIDEr ≥ 4.
또한, 동일한 성능 수준에 도달하기 위해 Transfusion과 Chameleon이 요구하는 FLOPs의 비율인 상대적 계산 효율성을 추정합니다.
그림 5는 확장 경향을 시각화한 것이며, 표 3은 이 통제된 설정에서 가장 큰 모델들의 결과와 추정된 상대 FLOP 비율을 보여줍니다. 모든 벤치마크에서 Transfusion은 Chameleon보다 일관되게 더 나은 확장 법칙을 나타냅니다. 추세선은 거의 평행하지만, Transfusion이 유리한 방향으로 상당한 차이가 있습니다. 특히 이미지 생성에서의 계산 효율성 차이는 매우 두드러지며, Transfusion이 Chameleon과 동등한 수준의 FID를 달성하는 데 34배 적은 계산을 사용합니다.
놀랍게도, 텍스트 전용 벤치마크에서도 Transfusion이 더 나은 성능을 보입니다. 이는 Transfusion과 Chameleon 모두 동일한 방식으로 텍스트를 모델링한다는 점에서 예상치 못한 결과입니다. 우리는 원래 Llama 2 레시피에서 Transfusion과 Chameleon으로 이어지는 다양한 변경 사항을 분석하여 이 현상을 조사합니다. 표 4에 따르면, Transfusion이 텍스트 성능에 어느 정도 비용을 발생시키지만, Chameleon 레시피는 아키텍처에 도입된 안정성 수정과 이미지 토큰의 도입으로 인해 더 큰 손실을 겪습니다. 양자화된 이미지 토큰으로 훈련하면 세 가지 벤치마크 모두에서 확산보다 텍스트 성능이 더 크게 저하됩니다. 이 현상에 대한 하나의 가설은 출력 분포에서 텍스트와 이미지 토큰 간의 경쟁에서 비롯된 것일 수 있습니다. 또 다른 가능성은 확산이 이미지 생성에서 더 효율적이어서, Transfusion 모델이 Chameleon보다 더 많은 용량을 텍스트 모델링에 사용할 수 있기 때문일 수 있습니다. 이 현상에 대한 추가 연구는 미래 연구로 남겨둡니다.
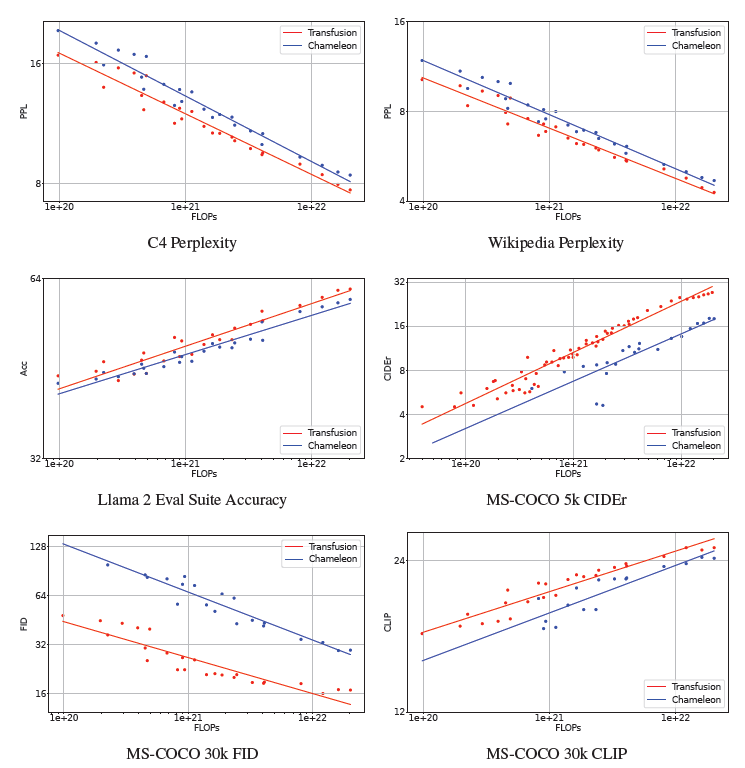
그림 5: Transfusion과 Chameleon 모델의 다양한 규모에서의 성능을 매개변수, 데이터, 계산량을 통제하여 비교한 그래프입니다. 모든 축은 로그 스케일입니다.
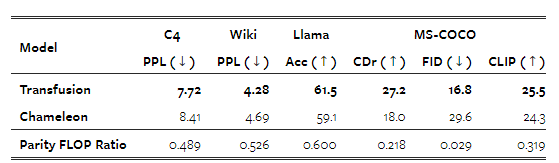
표 3: 통제된 환경에서 가장 큰 규모의(70억 매개변수) Transfusion과 Chameleon 모델의 성능입니다. 두 모델 모두 0.5조 개의 토큰으로 훈련되었습니다. Parity FLOP 비율은 Chameleon 70억 모델의 결과와 일치하는 성능을 내기 위해 Transfusion이 필요로 하는 FLOPs의 상대적인 양을 나타냅니다.
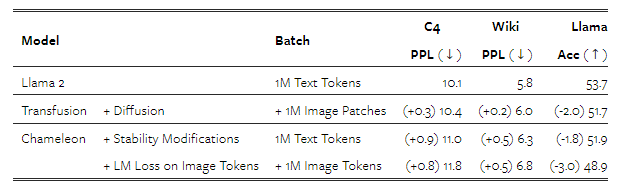
표 4: 텍스트 전용 벤치마크에서 7.6억 매개변수를 가진 Transfusion과 Chameleon 모델의 성능을 원래 Llama 2 레시피와 비교한 결과입니다.
4.3 아키텍처 소거 실험
우리가 통제된 환경에서 Transfusion이 다중 모달 모델링을 위한 실용적이고 확장 가능한 접근 방식임을 입증했으므로, 이제 Transfusion에만 적용할 수 있는 개선점과 확장 가능성을 탐구할 수 있습니다.
4.3.1 어텐션 마스킹(Attention Masking)
우리는 먼저 이미지 내 양방향 어텐션의 필요성을 조사합니다. 표 5는 표준 인과적 어텐션을 넘어 이 어텐션 패턴을 활성화하는 것이 모든 벤치마크에서, 그리고 두 가지 이미지 인코딩/디코딩 아키텍처를 사용하는 동안에도 유리하다는 것을 보여줍니다. 특히, 선형 인코딩 레이어를 사용할 때 FID가 크게 개선됨을 확인했습니다(61.3 → 20.3). 이 아키텍처의 인과적 어텐션만을 사용하는 버전에서는 시퀀스에서 나중에 등장하는 패치로부터 이전 패치로 정보가 전달되지 않습니다. U-Net 블록은 트랜스포머의 어텐션 마스크와 상관없이 양방향 어텐션을 포함하고 있기 때문에, 이 차이가 적용될 때 덜 두드러집니다.
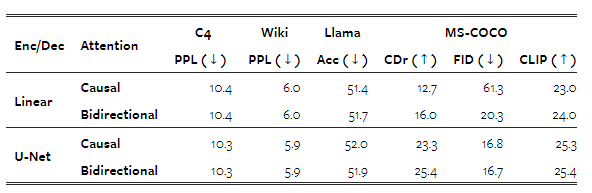
표 5: 이미지 내 양방향 어텐션의 유무에 따른 7.6억 매개변수 Transfusion 모델의 성능. 패치 크기는 2×2 잠재 픽셀로 설정되었습니다.
4.3.2 패치 크기
Transfusion 모델은 다양한 크기의 잠재 픽셀 패치를 기반으로 정의될 수 있습니다. 더 큰 패치 크기는 모델이 각 훈련 배치에 더 많은 이미지를 포함할 수 있게 하고, 추론 시 계산량을 크게 줄여주지만, 성능에 영향을 미칠 수 있습니다. 표 6은 이러한 성능 트레이드오프에 대한 정보를 제공합니다. 각 이미지가 선형 인코딩으로 더 적은 패치로 표현될수록 성능이 일관되게 감소하지만, U-Net 인코딩을 사용하는 모델은 이미지 모달리티와 관련된 작업에서 더 큰 패치의 이점을 얻습니다. 이는 훈련 중에 더 많은 이미지(및 확산 잡음)를 처리했기 때문이라고 추정됩니다. 또한, 텍스트 성능이 더 큰 패치와 함께 악화되는 것을 관찰할 수 있는데, 이는 Transfusion이 더 적은 패치로 이미지를 처리하는 방법을 학습하는 데 더 많은 자원(즉, 매개변수)을 투입해야 하고, 이로 인해 추론 시 계산량이 줄어들기 때문일 수 있습니다.
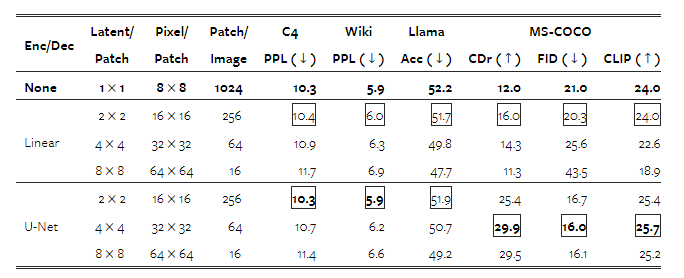
표 6: 다른 패치 크기를 가진 7.6억 매개변수 Transfusion 모델의 성능입니다. 굵게 표시된 숫자는 전반적인 최고 성능을 나타내며, 밑줄은 아키텍처 내에서의 최고 성능을 나타냅니다.
4.3.3 패치 인코딩/디코딩 아키텍처
지금까지의 실험에서는 단순한 선형 레이어 대신 U-Net 업 및 다운 블록을 사용하는 것이 이점이 있다는 것을 보여줍니다. 한 가지 가능한 이유는 모델이 U-Net 아키텍처의 귀납적 편향(inductive biases)에서 이익을 얻기 때문일 수 있습니다. 또 다른 가설은 이러한 이점이 U-Net 레이어에 의해 도입된 전체 모델 매개변수의 상당한 증가에서 비롯된 것일 수 있다는 것입니다. 이 두 가지 혼란 변수를 분리하기 위해, 우리는 핵심 트랜스포머를 70억 매개변수로 확장하면서, U-Net 매개변수의 양은 (거의) 일정하게 유지했습니다.
※ 이 실험에서는 트랜스포머와 함께 U-Net 레이어를 확장하지 않았지만, 이는 향후 연구에서 잠재적으로 유익한 연구 방향이 될 수 있습니다.
이 설정에서 추가된 인코더/디코더 매개변수는 총 모델 매개변수의 3.8% 증가에 불과하며, 이는 토큰 임베딩 매개변수의 양과 동일합니다.
표 7은 트랜스포머가 커질수록 U-Net 레이어의 상대적인 이점이 줄어들지만, 완전히 사라지지는 않는다는 것을 보여줍니다. 예를 들어, 이미지 생성에서는 U-Net 인코더/디코더를 사용하면 훨씬 작은 모델도 선형 패치화 레이어를 사용한 70억 모델보다 더 나은 FID 점수를 얻을 수 있습니다. 이미지 캡션 생성에서도 유사한 경향이 나타나며, U-Net 레이어를 추가하면 14억 매개변수 트랜스포머(총 16.7억 매개변수)의 CIDEr 점수가 선형 70억 모델의 성능을 능가합니다. 전반적으로, U-Net 인코딩 및 디코딩이 단순히 매개변수를 추가하는 것 이상의 귀납적 편향 이점을 제공한다는 점이 분명해 보입니다.
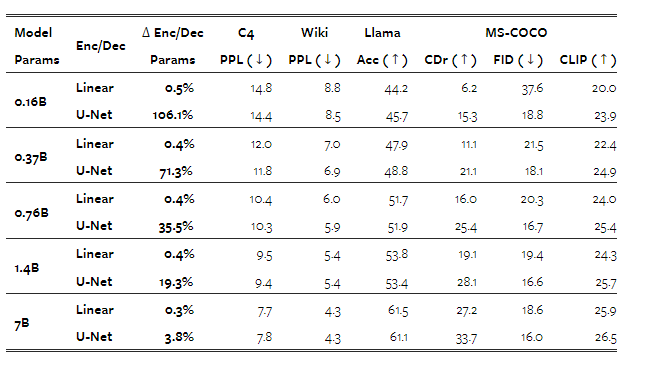
표 7: 다양한 모델 크기에서 선형 및 U-Net 변형 Transfusion의 성능입니다. 패치 크기는 2×2 잠재 픽셀로 설정되었습니다. "모델 매개변수"는 트랜스포머만을 의미합니다.
4.3.4 이미지 노이징(Image Noising)
우리의 실험에서는 80%의 이미지-캡션 쌍에서 캡션이 먼저 오고, 이미지는 캡션에 조건화되도록 배치합니다. 이는 이미지 생성이 이미지 이해보다 더 많은 데이터를 필요로 하는 작업일 수 있다는 직관을 따릅니다. 나머지 20%의 쌍에서는 캡션이 이미지에 조건화됩니다. 그러나 이러한 이미지들은 확산 목표의 일환으로 노이징됩니다. 따라서 우리는 이미지가 캡션보다 먼저 나타나는 20%의 경우에서 확산 노이즈를 최대 t=500 (노이즈 스케줄의 절반)으로 제한하는 효과를 측정합니다. 표 8은 노이즈 제한이 이미지 캡션 생성(CIDEr로 측정됨)을 상당히 개선하면서도, 다른 벤치마크에는 상대적으로 작은 영향을 미친다는 것(1% 미만)을 보여줍니다.
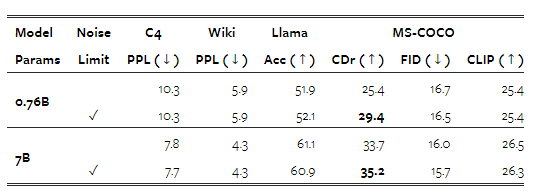
표 8: 이미지가 캡션보다 먼저 나타날 때 샘플링된 확산 노이즈를 최대 t=500으로 제한하는 경우와 제한하지 않은 경우의 Transfusion 성능입니다. 모델은 2×2 잠재 픽셀 패치를 인코딩하는 U-Net 변형입니다. 1% 이상 변화한 지표는 굵게 표시되었습니다.
4.4 이미지 생성 관련 문헌과의 비교
지금까지의 실험에서는 Chameleon과 Llama와의 통제된 비교를 다뤘지만, 아직 Transfusion의 이미지 생성 능력을 최첨단 이미지 생성 모델들과 비교하지 않았습니다. 이를 위해, 우리는 U-Net 인코딩/디코딩 레이어(2×2 잠재 픽셀 패치)를 사용하는 70억 매개변수 모델을 훈련했으며, 1조 개의 텍스트 코퍼스 토큰과 35억 개의 이미지와 그 캡션을 포함한 총 2조 개의 토큰에 해당하는 데이터를 사용했습니다. §4.2에서의 Transfusion 변형은 단순성과 실험 통제에 중점을 두었지만, 이 변형의 설계 선택과 데이터 혼합(§4.1)은 이미지 생성에 조금 더 중점을 둡니다. 그림 2와 부록 B는 이 모델에서 생성된 이미지를 보여줍니다.
우리는 다른 유사한 규모의 이미지 생성 모델들의 보고된 결과와, 참조용으로 일부 공개된 텍스트 생성 모델들과 우리의 모델 성능을 비교합니다. 표 9는 Transfusion이 DeepFloyd(Stability AI, 2024)와 같은 고성능 이미지 생성 모델들과 유사한 성능을 달성하며, SDXL(Podell et al., 2023)을 포함한 이전에 발표된 모델들을 능가함을 보여줍니다. Transfusion이 SD 3(Esser et al., 2024a)보다 성능이 뒤처지긴 하지만, 이 모델은 역번역(backtranslation)을 통해 생성된 이미지 캡션을 활용하여 GenEval 성능을 절대적으로 6.5% 향상시켰습니다(0.433 → 0.498). 간단하게 하기 위해, 우리의 실험 설정에는 자연 데이터만 포함되었습니다. 마지막으로, Transfusion 모델이 텍스트도 생성할 수 있으며, 동일한 텍스트 데이터 분포에서 훈련된 Llama 모델들과 동등한 성능을 보인다는 점을 언급합니다(§4.1).
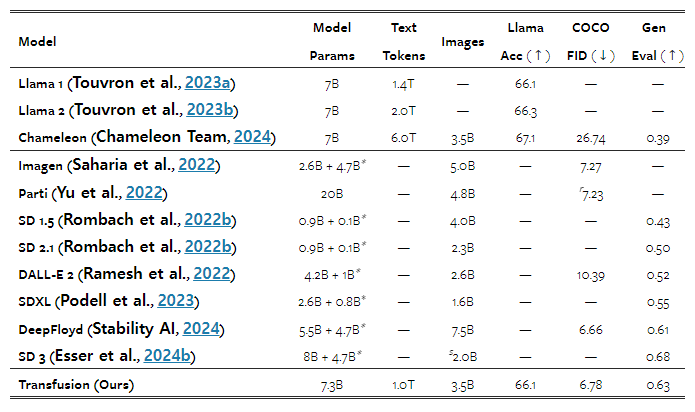
표 9: 2조 개의 토큰에 해당하는 데이터로 훈련된 70억 매개변수 Transfusion 모델(U-Net 인코더/디코더 레이어, 2×2 잠재 픽셀 패치)의 성능을 관련 문헌에 있는 유사한 규모의 모델들과 비교한 결과입니다. Chameleon을 제외한 모든 다른 모델들은 텍스트나 이미지 중 하나의 모달리티만 생성할 수 있습니다. * 텍스트 인코더 매개변수는 고정되어 있습니다. r Parti는 각 프롬프트에 대해 16개의 이미지를 샘플링한 후, 보조 스코어링 모델로 재정렬합니다. s SD 3은 GenEval 성능을 향상시키는 합성 캡션 데이터를 사용하여 훈련됩니다.
4.5 이미지 편집
우리의 Transfusion 모델들은 텍스트-텍스트, 이미지-텍스트, 텍스트-이미지 데이터에 대해 사전 훈련되어 이 모달리티 조합들에서 뛰어난 성능을 보입니다. 그렇다면 이러한 모델들이 다른 이미지를 기반으로 이미지를 생성하는 능력으로 확장될 수 있을까요? 이를 조사하기 위해, 우리는 8천 개의 공개된 이미지 편집 예제로만 구성된 데이터셋을 사용하여 70억 매개변수 모델(§4.4)을 미세 조정했습니다. 각 예제는 입력 이미지, 편집 프롬프트, 출력 이미지로 구성됩니다. 이 접근법은 LIMA(Zhou et al., 2024)에서 영감을 받아, 사전 훈련에서 다루지 않은 이미지-이미지 생성 시나리오에 대해 모델이 얼마나 잘 일반화할 수 있는지를 평가합니다.
EmuEdit 테스트 세트(Sheynin et al., 2024)에서 무작위로 선택한 예제를 수동으로 검사한 결과(그림 6 및 부록 4.5 참조), 미세 조정된 Transfusion 모델이 지시에 따라 이미지 편집을 수행하는 것으로 나타났습니다. 이 실험의 제한에도 불구하고, 이러한 결과는 Transfusion 모델이 새로운 모달리티 조합에 적응하고 일반화할 수 있음을 시사합니다. 이 유망한 연구 방향에 대한 추가 탐구는 향후 연구로 남겨둡니다.

그림 6: 미세 조정된 70억 매개변수 Transfusion 모델에서 편집된 이미지들.
5 관련 연구
대부분의 기존 다중 모달 모델들은 두 개 이상의 모달리티별 아키텍처를 결합하는 아이디어에 기반하여 구축되며, 각 구성 요소를 별도로 사전 훈련하는 경우가 많습니다. 예를 들어, 최첨단 이미지 및 비디오 생성 모델들은 큰 규모의 사전 훈련된 텍스트 인코더를 사용하여 입력 프롬프트를 잠재 공간에서 표현한 후, 이를 조건화된 확산 모델에 사용합니다(Saharia et al., 2022). 실제로, 최근 연구들은 여러 사전 훈련된 인코더의 표현을 결합하여 성능을 향상시키고 있습니다(Podell et al., 2023; Esser et al., 2024b). 시각 언어 모델 문헌에서도 유사한 패턴이 관찰되며, 일반적으로 사전 훈련된 언어 모델은 사전 훈련된 모달리티별 인코더/디코더와 결합되어 사전 훈련된 텍스트 공간으로 투영하는 레이어를 통해 보완됩니다. 예로는 시각적 이해를 위한 Flamingo(Alayrac et al., 2022)와 LLaVA(Liu et al., 2024), 시각적 생성을 위한 GILL(Koh et al., 2024), 시각적 이해와 생성을 모두 위한 DreamLLM(Dong et al., 2024)이 있습니다. 이에 반해, Transfusion은 텍스트와 이미지를 모두 생성할 수 있도록 하나의 통합된 아키텍처를 통해 엔드 투 엔드로 학습됩니다.
엔드 투 엔드 다중 모달 모델에 대한 이전 연구로는 Fuyu(Bavishi et al., 2023)가 있으며, 이는 시각적 이해를 위해 이미지 패치를 입력으로 사용하고, Chameleon(Chameleon Team, 2024)은 각 이미지를 이산화된 토큰 시퀀스로 변환한 후 결합된 텍스트-이미지 토큰 시퀀스에서 훈련합니다. 그러나 이러한 접근 방식은 입력 수준의 다중 모달 작업으로 제한되거나, 연속 데이터 생성에서 최첨단 모델(예: 확산 모델)보다 뒤처집니다. Transfusion은 고품질의 다중 모달 데이터를 이해하고 생성할 수 있는 간단하고 엔드 투 엔드 솔루션을 제공합니다.
최근의 흥미로운 연구 분야는 확산 모델과 그 일반화를 이산 텍스트 생성에 적용하는 것입니다(Li et al., 2022; Gat et al., 2024). 그러나 이 접근 방식은 아직 표준 자동회귀 언어 모델의 성능과 규모에 도달하지 못했습니다. 이 방향에서의 향후 연구는 하나의 모델에서 이산적 모달리티와 연속적 모달리티를 결합할 수 있는 새로운 방법을 열어줄 수 있을 것입니다.
6 결론
이 연구는 이산 시퀀스 모델링(다음 토큰 예측)과 연속 미디어 생성(확산)에서 최첨단 기술 간의 간극을 연결하는 방법을 탐구합니다. 우리는 두 가지 목표로 하나의 공동 모델을 훈련하는 간단하지만 이전에 탐구되지 않은 솔루션을 제안합니다. 각 모달리티를 그 선호하는 목표에 연결합니다. 우리의 실험은 Transfusion이 효율적으로 확장되며, 매개변수 공유 비용이 거의 또는 전혀 발생하지 않으면서도 모든 모달리티를 생성할 수 있음을 보여줍니다.
감사 인사 및 연구 자금 공개
이 프로젝트 전반에 걸쳐 유익한 논의를 나눠주신 Horace He, Songlin Yang, Jiatao Gu, Ishan Misra께 감사드립니다.

부록 B: 이미지 생성 예시
그림 7과 그림 8은 2조 개의 다중 모달 토큰으로 훈련된 70억 매개변수 Transfusion 모델에서 생성된 이미지 예시를 보여줍니다(§4.4 참조).
부록 C: 이미지 편집 예시
그림 9는 미세 조정된 70억 매개변수 Transfusion 모델에 의해 편집된 무작위 이미지 예시를 보여줍니다.
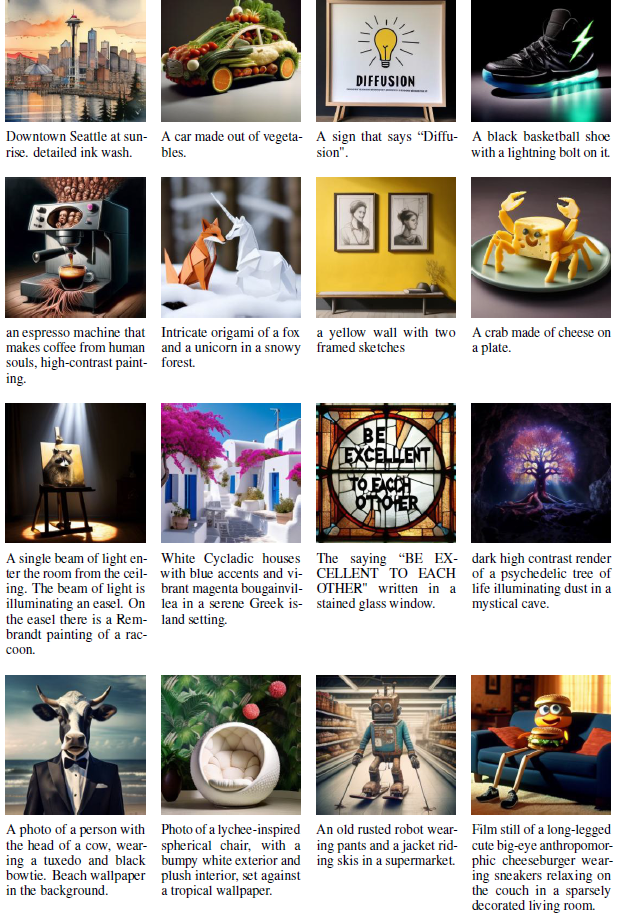
그림 7: 2조 개의 다중 모달 토큰으로 훈련된 70억 매개변수 Transfusion 모델에서 생성된 이미지들.

그림 8: 2조 개의 다중 모달 토큰으로 훈련된 70억 매개변수 Transfusion 모델에서 생성된 이미지들.

그림 9: 미세 조정된 70억 매개변수 Transfusion 모델에서 편집된 이미지들.
'인공지능' 카테고리의 다른 글
| Gaussian Error Linear Units (GELUs) (2) | 2024.09.04 |
|---|---|
| GLU Variants Improve Transformer (SwiGLU) (3) | 2024.09.03 |
| 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation (1) | 2024.09.01 |
| AudioLDM: Text-to-Audio Generation with Latent Diffusion Models (부록 추가 필요) (8) | 2024.08.31 |
| ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers (2) | 2024.08.30 |



