https://arxiv.org/abs/2510.25616
Don't Blind Your VLA: Aligning Visual Representations for OOD Generalization
The growing success of Vision-Language-Action (VLA) models stems from the promise that pretrained Vision-Language Models (VLMs) can endow agents with transferable world knowledge and vision-language (VL) grounding, laying a foundation for action models wit
arxiv.org
초록
시각-언어-행동(VLA, Vision-Language-Action) 모델의 성공이 확대되고 있는 것은, 사전 학습된 시각-언어 모델(VLM)이 에이전트에게 전이 가능한 세계 지식과 시각-언어(VL) 그라운딩(grounding)을 부여하여, 보다 폭넓은 일반화가 가능한 행동 모델의 기반을 마련해 줄 수 있다는 기대에서 비롯됩니다. 그러나 이러한 VLM이 행동 모달리티(action modality)에 적용될 때, 원래의 시각-언어 표현과 지식이 어느 정도까지 보존되는지는 여전히 불분명합니다.
본 연구에서는 VLA 미세 조정(fine-tuning) 과정에서의 표현 보존에 대해 체계적으로 연구하여, 단순한 행동 미세 조정이 시각적 표현의 저하를 초래한다는 것을 보여줍니다. 이러한 효과를 특성화하고 측정하기 위해, 우리는 VLA의 은닉 표현(hidden representation)을 조사하고 어텐션 맵(attention map)을 분석합니다. 또한, VLA 모델과 그 기반이 되는 VLM을 대조하는 일련의 타겟 작업을 설계하여, 행동 미세 조정으로 인해 유발된 VL 능력의 변화를 분리해냅니다.
더 나아가 시각적 표현을 정렬(align)하기 위한 다양한 전략을 평가하고, 성능 저하를 완화하면서 분포 외(OOD, Out-Of-Distribution) 시나리오에 대한 일반화를 개선하는 간단하면서도 효과적인 방법을 제안합니다. 종합적으로, 우리의 분석은 행동 미세 조정과 VL 표현 저하 사이의 상충 관계(trade-off)를 명확히 하고, 상속된 VL 능력을 회복하기 위한 실용적인 접근 방식을 제시합니다. 코드는 blind-vla-paper.github.io에 공개되어 있습니다.
1. 서론 (Introduction)
시각-언어 모델(VLM)은 대규모 멀티모달 데이터셋을 통합하는 능력 덕분에 놀라운 성공을 거두었으며, 이를 통해 의미적 그라운딩(semantic grounding)과 일반화 가능한 시각-언어(VL) 표현을 획득했습니다(NVIDIA et al., 2025a; Bai et al., 2025; Wang et al., 2025b; Beyer et al., 2024; Driess et al., 2023; Awadalla et al., 2023). 이러한 모델은 새로운 시각적 또는 언어적 맥락에 노출되었을 때 견고한 교차 모달(cross-modal) 이해와 구성적 인식(compositional perception) 능력을 보여주는데, 이는 학습 데이터의 분포를 벗어난 상황에서도 강력한 제로샷(zero-shot) 및 퓨샷(few-shot) 일반화 성능을 뒷받침하는 핵심 속성입니다. 이러한 발전은 자연스럽게 VLM을 임바디드(embodied) 도메인으로 확장하려는 시도로 이어졌습니다.

그림 1. 시각적 정렬(Visual alignment) 방법 개요. 중간 단계의 VLA 특징(features)들을 정규화된 구면(normalized sphere)에 투영하고 교사(teacher) 임베딩과 정렬시킴으로써, 시각적 의미를 보존하고 OOD(분포 외) 일반화 성능을 향상시킵니다. 하단 플롯은 Simpler 기반 벤치마크(Liu et al., 2025)에서 세 가지 일반화 축에 대해 표준 SFT(지도 미세 조정)와 비교한 결과를 보여줍니다.
시각-언어-행동(VLA, Vision-Language-Action) 모델은 이러한 연구 흐름에서 중요한 방향성을 제시합니다. 이 모델들은 대규모 시각-언어 사전 학습에서 물려받은 의미론적 사전 지식(semantic priors)과 인지 능력을 활용하려는 목표를 가지고, 사전 학습된 VLM을 로봇 환경의 행동 예측 작업에 적용합니다.
이에 깔린 기본 가설은, 적절하게 조정될 경우 VLA 모델이 초기 VLM의 시각-의미적(visual-semantic) 표현을 행동 도메인으로 전이시켜, 이전에 본 적 없는 장면, 지시 사항 및 시나리오에 대해서도 일반화가 가능할 것이라는 점입니다.
그러나 실제로는 VLM을 행동 모달리티(action modality)에 적용하는 과정에서 종종 새로운 문제들에 직면하게 됩니다. 최근의 여러 연구들(Pugacheva et al., 2025; Driess et al., 2025; Liu et al., 2023; Mees et al., 2022; Chen et al., 2023)은 현재의 VLA 모델들이 시각적, 언어적으로 복잡한 작업에서 일반화 성능을 유지하는 데 어려움을 겪고 있음을 보여주었으며, 이는 VLM의 강력한 VL 능력이 과연 임바디드(embodied) 환경으로 온전히 전이되는지에 대한 의문을 제기합니다. 이러한 문제는 작업별 미세 조정(task-specific fine-tuning) 과정에서 가장 두드러지게 나타나는데, 이 과정에서 데이터의 다양성 부족과 제한된 데이터셋이 빈번하게 과적합(overfitting)을 유발하기 때문입니다(Zang et al., 2024; Staroverov et al., 2023; Ding et al., 2024; Pugacheva et al., 2025; Cherepanov et al., 2025b).

그림 2. 제안하는 방법의 개요. (a, b) 시각적 정렬(visual alignment) 손실을 포함한 학습 파이프라인 – 추가적인 오버헤드 없이, SFT(지도 미세 조정) 과정에서 미리 계산된 교사 특징(teacher features)과 경량화된 정규화 항(regularization term)만을 사용합니다. (c) VL 작업에 대한 손실 지형(loss landscape)의 개념적 예시: 핵심 아이디어는 VL 이해 성능을 보존하면서 행동 목표(action objective)에 맞춰 모델을 최적화하는 것입니다.
대규모 로봇 사전 학습 과정에서, 최근 연구들은 멀티모달 이해 능력을 보존함으로써 이러한 저하(degradation)를 완화하고자 시도해 왔습니다. 이전의 전략들로는 보조 추론(auxiliary reasoning) 목표를 통합하거나(Chen et al., 2025), 웹 스케일 데이터에 대해 멀티모달 공동 학습(co-training)을 적용하거나(Yang et al., 2025), 또는 VL 표현을 보존하고 지시 이행 성능을 향상시키기 위해 사전 학습된 시각-언어 백본(backbone)을 동결하는 방법(NVIDIA et al., 2025b; Driess et al., 2025) 등이 있습니다.
이러한 접근법들이 시각-언어 지식을 유지하고 일반화를 향상시키는 데 도움은 되지만, 종종 강도 높은 지도(heavy supervision), 높은 계산 비용, 또는 제한된 모델 아키텍처에 의존해야 한다는 단점이 있습니다. 그러나 사전 학습 단계에서의 이러한 발전에도 불구하고, 작업별 지도 미세 조정(SFT) 단계에서의 표현 저하를 해결할 효과적인 방법은 여전히 존재하지 않습니다. SFT는 VLA 모델이 의미적 그라운딩(semantic grounding)과 VL 능력을 잃지 않으면서 특정 로봇 도메인에 적응해야 하는 중요한 단계입니다.
본 연구에서 우리는 현실적인 VLA 배포 설정을 채택합니다. 즉, 사전 학습된 VLA에서 시작하여 선택된 임바디먼트(embodiment)와 도메인에서 제한된 데이터로 지도 미세 조정을 수행하여 적응시키는 것입니다. 이러한 제약 하에서, 우리는 VLA 모델의 VL 표현 및 멀티모달 이해 능력 저하에 대해 체계적인 조사를 수행하고 다음과 같은 핵심 질문을 던집니다: 로봇 행동에 대해 미세 조정하는 동안 상속된 VL 표현을 복구할 수 있는 간단하면서도 효과적인 방법을 설계할 수 있을까?
이 질문에 답하기 위해, 우리는 먼저 로봇 도메인의 매칭된 이미지-지시(instruction) 쌍에 대해 VLM과 비교하여 VLA 모델의 어텐션 맵(attention map)과 특징 활성화(feature activation)를 조사했습니다. 어텐션 맵 분석 결과, 사전 학습된 VLM은 작업 관련 객체에 정확히 집중하는 반면, 미세 조정된 VLA 모델은 종종 확산되거나 잘못된 위치의 활성화를 생성하여, 분포 외(OOD) 조건에서 주요 개체에 주목하지 못한다는 사실이 밝혀졌습니다(그림 4).
다음으로, 우리는 VLM과 VLA 레이어 전반의 중간 표현에 대해 t-SNE(van der Maaten and Hinton, 2008a) 분석을 수행했습니다. 이는 VLA 모델에서 명확한 표현 붕괴(representation collapse)(Barbero et al., 2024; Arefin et al., 2024)를 드러냈는데, 이는 표준 행동 미세 조정이 다양한 내부 특징들을 좁은 표현 공간으로 압축시켜 표현의 다양성과 일반화 용량을 감소시킨다는 것을 나타냅니다.
그다음으로, 우리는 VLM에서 VLA 모델로의 VL 지식 전이를 평가하기 위해 VL-Think 작업 세트(섹션 4)를 제안하고, 몇몇 강력한 VLM을 벤치마킹하며, OpenVLA-7B(Kim et al., 2024)를 그 사전 학습 기반인 PrismaticVLM(Karamcheti et al., 2024)과 비교합니다. 우리는 행동 미세 조정 후 체계적이고 도메인 특화적인 망각(forgetting) 현상을 관찰했으며, 이는 VLA가 로봇 미세 조정 데이터에 없는 도메인에 대한 VL 지식을 소실한다는 것을 보여줍니다.
이러한 표현 저하를 해결하기 위해, 우리는 플라톤 표현 가설(Platonic Representation Hypothesis)(Huh et al., 2024)에서 영감을 받은 경량화된 시각적 표현 정렬(Visual Representation Alignment) 방법을 도입합니다. 이 가설은 대규모 시각 및 언어 모델들이 범용 모델(generalist models) 전반에 걸쳐 일반적인 시각 및 의미 표현을 인코딩하는 공유 잠재 표현 공간으로 수렴하는 경향이 있음을 시사합니다.
우리의 방법은 미세 조정 내내 VLA의 시각적 표현이 범용 비전 모델과 정렬된 상태를 유지하도록 명시적으로 제약합니다. 이 연결을 유지함으로써, VLA는 행동 정책을 새로운 작업에 적응시키면서 의미적 일관성을 보존합니다. 이 방법은 무시할 만한 수준의 계산 오버헤드만 추가하며 SFT와 매끄럽게 통합됩니다(그림 2). Simpler 벤치마크(Li et al., 2024)의 다양한 변형에 대한 광범위한 실험은 이 정렬 방식이 분포 외 일반화(OOD generalization)를 일관되게 향상시킨다는 것을 보여주며, 단순 SFT 대비 최대 10%의 상대적 성능 이득을 기록했습니다(LABEL:tab:ood_performance).
우리의 주요 기여는 다음과 같습니다: (1) 단순한 VLA 미세 조정이 초기 VLM과 비교하여 표현 붕괴(representation collapse)와 어텐션 싱크(attention sink)를 유발한다는 것을 체계적으로 입증합니다. (2) VLM에서 VLA 모델로의 VL 지식 전이를 평가하기 위한 진단 작업 세트인 VL-Think를 소개하고, VLA 행동 미세 조정이 도메인 특화적 망각을 초래함을 보여줍니다. (3) VLA의 시각 표현을 강력한 시각적 교사 특징(teacher features)에 고정(anchor)시켜, 복잡성을 더하지 않고도 멀티모달 이해를 보존하고 OOD 일반화를 향상시키는 간단하고 효율적인 시각적 정렬 방법을 제안합니다(그림 2).
종합하면, 우리의 발견은 VLA 모델에서 행동 미세 조정과 표현 저하 사이의 상충 관계(trade-off)에 대한 새로운 통찰력을 제공합니다. 이는 미세 조정 중 시각-언어 정렬 유지의 중요성을 강조하며, 모델이 의존하는 사전 학습된 지각 지식을 "눈멀게(blind)" 하지 않는 VLA를 구축하기 위한 실용적인 방안을 제시합니다.

그림 3. VL-Think 작업 세트 예시. 각 패널은 에이전트가 지시된 개념(예: 색상, 숫자, 기호 또는 범주)과 일치하는 보드 위에 물체를 놓아야 하는 집고 놓기(pick-and-place) 에피소드를 보여줍니다.
2. 관련 연구 (Related Works)
2.1. 시각-언어-행동 모델 (Vision-Language-Action models)
VLA 모델은 대규모 멀티모달 학습을 통해 지각(perception), 추론(reasoning), 제어(control)를 통합하는 것을 목표로 합니다. RT-1(Brohan et al., 2023b) 및 RT-2(Brohan et al., 2023a)와 같은 초기 접근 방식은 시각-언어(VL) 사전 학습을 로봇 데이터로 확장함으로써 다양한 조작 작업에 걸쳐 일반화가 가능함을 입증했습니다.
OpenVLA(Kim et al., 2024), Octo(Team et al., 2024), MolmoAct(Lee et al., 2025), OneTwoVLA(Lin et al., 2025b), $\pi_0$(Black et al., 2024)를 포함한 후속 연구들은 대규모 로봇 사전 학습, 경량화된 디퓨전(diffusion) 기반 정책, 모듈형 추론 아키텍처, 토큰 기반 의사결정 시퀀싱(sequencing), 그리고 연속 플로우 매칭(continuous flow-matching) 정책 등을 탐구했습니다.
이러한 모델들의 공통된 목표는 실세계 환경에서의 효율성과 일반화 성능을 유지하면서, 단일 통합 정책 내에서 의미적 그라운딩(semantic grounding)과 저수준 모터 제어를 결합하는 것입니다. 그러나 로봇 데이터에 대한 미세 조정(fine-tuning) 과정에서 VL 이해 능력을 보존하고 유지하는 것은 여전히 핵심 과제로 남아 있습니다.
2.2. 표현 정렬 (Representation alignment)
최근 연구들은 모델의 파라미터, 데이터, 그리고 작업의 규모가 커짐에 따라, 그 표현(representation)들이 아키텍처와 모달리티 전반에 걸쳐 점점 더 정렬되는 일관된 패턴을 보여줍니다. '플라톤 표현 가설(Platonic Representation Hypothesis, Huh et al., 2024)'은 이러한 현상을 현실에 대한 공유된 통계적 모델로 수렴하는 것으로 설명합니다. 독립적으로 훈련된 비전 및 언어 인코더들이 의미적으로 호환되는 공간을 형성하며, 대규모의 언어 비의존적(language-free) 시각 모델들이 텍스트와 자연스럽게 정렬되면서도 CLIP 수준의 성능에 도달한다는 것입니다(Maniparambil et al., 2024; Fan et al., 2025, 2025).
최근의 표현 학습 방법론들은 이러한 추세를 더욱 강화하고 있습니다. REPA(Yu et al., 2025)는 디퓨전(diffusion) 모델의 은닉 상태를 강력한 이미지 인코더에 정렬하여 학습 속도를 높이고 ImageNet 품질을 개선합니다. OLA-VLM(Jain et al., 2025)은 예측 임베딩 손실(predictive embedding losses)을 통해 다중 교사(multi-teacher) 타겟을 LLM의 중간 레이어로 증류(distill)합니다. 3DRS(Huang et al., 2025)는 다시점 대응(multi-view correspondence)을 이용해 3D 인식 지도(supervision) 정보를 주입합니다. 그리고 Geometry Forcing(Wu et al., 2025)은 시간적으로 일관된 생성을 위해 각도 및 스케일 목적함수(objectives)를 사용하여 비디오 디퓨전 특징을 3D 백본과 정렬시킵니다.


4. VL-Think 작업 세트 (VL-Think Task Suite)
현재의 VLA 모델 평가들(Liu et al., 2023; Mees et al., 2022; Cherepanov et al., 2025a)은 주로 객체, 장면, 회상 기반(recall-based) 요구사항 또는 질감의 변화와 같은 분포 변화(distribution shifts) 상황에서의 작업 수행 능력에 중점을 두고 있습니다. 그러나 이러한 평가들은 사전 학습된 VLM으로부터 상속받은 시각-언어(VL) 능력과 지식이 행동 미세 조정(action fine-tuning) 이후에도 보존되는지에 대해서는 거의 통찰을 제공하지 못합니다.
이러한 한계를 극복하기 위해, 우리는 VL-Think 작업 세트(Task Suite)를 소개합니다. 이는 저수준 제어 성능과는 독립적으로, VLM에서 VLA로의 VL 능력 전이를 평가하도록 설계된 진단용 도구 모음입니다.
이 작업 세트는 모델이 '잡기(grasp)'나 '놓기(placement)' 동작을 성공적으로 수행할 수 있는지가 아니라, VLM 데이터셋에서는 흔히 평가되지만 로봇 도메인에서는 비중이 낮은 시각적 기호, 구성적 단서(compositional cues), 범주적 구분을 모델이 여전히 이해하고 있는지를 테스트하는 데 중점을 둡니다. 우리는 관찰되는 성능 저하가 행동 실행 능력의 문제가 아닌 VL 이해 능력의 손실을 반영하도록 보장하기 위해, 제어 복잡성을 의도적으로 최소화했습니다.
4.1. 평가 프로토콜 (Evaluation protocol)
시각-언어(VL) 능력의 격차를 정량화하기 위해, 우리는 VLA 모델과 VLM 모델 모두에 대해 평가를 수행합니다.
VLA 평가. 에이전트는 RGB 프레임과 언어 지시사항을 관찰합니다. 잘 알려진 물체가 올바른 목표 보드 위에 놓일 경우 성공률이 기록됩니다. 동작의 복잡도가 고정되어 있기 때문에, 이는 모델의 조작 기술보다는 언어를 시각적 범주에 그라운딩(grounding)하는 용량을 직접적으로 측정합니다.
VLM 평가. 행동(action)이 없는 상태에서 로봇 설정 내의 추론 능력을 평가하기 위해, 동일한 장면들이 정적인 초기 이미지로 제시되며 다음과 같은 질문(probe)이 주어집니다: “<보드_이름>이 보입니까? ‘예’ 또는 ‘아니오’로 답하시오. 만약 ‘예’라면, 위치를 ‘왼쪽’, ‘중앙’, 또는 ‘오른쪽’ 중에서 명시하시오.” 예측된 보드의 존재 여부와 그 목표 위치가 모두 정답(ground truth)과 일치할 때만 성공적인 응답으로 간주되며, 이를 통해 산출된 성공률은 의미적 그라운딩에 대한 행동이 배제된(action-free) 척도 역할을 합니다.
4.2. VL-Think 설명 (VL-Think description)
임바디먼트(embodiment) 및 설정 특화 적응(setup-specific adaptation)에 따른 병목 현상을 줄이기 위해, VL-Think 작업 세트는 WidowX-250S 로봇 팔의 집고 놓기(pick-and-place) 작업을 사용하는 현실적인 Simpler(Li et al., 2024) 벤치마크를 기반으로 합니다.
각 에피소드는 100%의 잡기 신뢰도(grasp reliability)를 보장하는 위치에 놓인, 잘 알려진 단일 소스 물체(당근) 하나와 추상적인 범주(예: 아이콘, 도형, 숫자)로 텍스처링된 여러 개의 평면 "보드"를 생성합니다. 언어 지시사항은 하나의 목표 개념(모양, 색상, 아이콘 종류, 방향 또는 홀짝성)을 지정합니다. 에이전트가 지시된 개념과 일치하는 보드 위에 당근을 올려놓으면 성공한 것입니다. 물체와 행동의 복잡도를 고정함으로써, 이 평가는 실행 복잡도를 제한한 상태에서 VL(시각-언어) 기술만을 분리하여 측정합니다.
VL-Think 세트는 지식의 다양한 측면을 탐색하는 8가지 보드 선택 작업으로 구성됩니다(그림 3 참조). 각 작업에서 에이전트는 지시된 개념과 일치하는 보드 위에 물체를 놓아야 합니다.
- 도형 (Shape): 그래픽이 지정된 기하학적 도형인 보드 (예: "별(star) 위에 물체를 놓으시오.")
- 색상 (Color): 도형이 지정된 색상을 가진 보드 (예: "파란색(blue) 도형 위에 물체를 놓으시오.")
- 교통 (Traffic): 24가지 일반적인 교통 표지판 중 하나를 묘사한 보드 (예: "양보(yield) 표지판")
- 세탁 기호 (Laundry care): 17가지 표준 세탁 기호 중 하나를 묘사한 보드 (예: "표백 금지(Do not bleach)")
- 날씨 (Weather): 9가지 일반적인 날씨 아이콘 중 하나를 묘사한 보드 (예: "맑음(sunny)", "흐림(cloudy)")
- 방향 화살표 (Directional arrow): 화살표가 지정된 방향을 가리키는 보드 ("위", "아래", "왼쪽", "오른쪽")
- 공공 정보 (Public information): 14가지 공공 정보 표지판 중 하나를 묘사한 보드 (예: "애완견 출입 금지(no dogs allowed)")
- 숫자 홀짝성 (Numeral parity): 인쇄된 숫자가 요청된 홀짝성("홀수" 또는 "짝수")과 일치하는 보드 (예: "홀수(odd number) 위에 물체를 놓으시오")
5. VL 표현 분석 (VL representations analysis)
이 섹션에서는 다음과 같은 질문을 던집니다: 행동 미세 조정(action fine-tuning) 이후 VLA 모델 내의 VL 표현과 지식에는 어떤 변화가 발생하는가? VLM으로부터의 지식 전이(knowledge transfer)가 실제로 일어나는지, 그리고 강력한 의미적 그라운딩(semantic grounding)이 유지되는지 확인해 봅니다.
VLA 모델에서 VL 표현이 얼마나 심각하게 저하되는지 조사하기 위해, 우리는 상호 보완적인 분석들을 수행합니다.
첫째, t-SNE(van der Maaten and Hinton, 2008b) 시각화를 사용하여 모델이 지시(instruction) 관련 토큰들에 대해 구조적이고 분리 가능한 잠재 공간(latent space)을 보존하고 있는지 평가합니다.
둘째, 어텐션 맵(attention maps)을 분석하여 모델이 입력 지시사항에서 언급된 객체에 얼마나 정확하게 집중하는지 평가합니다.
마지막으로, VL-Think 세트를 사용하여 VLM의 VL 기술이 VLA 정책(policy)으로 전이 가능한지 평가합니다.
종합하면, 이러한 방법들은 VL 표현 저하와 도메인 망각(domain forgetting)에 대한 직관적이고 해석 가능한 진단을 제공합니다. 즉, 행동 미세 조정 이후에도 모델이 집중된 시각적 그라운딩과 일관된 잠재적 구성(latent organization)을 유지하는지, 아니면 도메인 특화 지식을 소실하는지를 밝혀냅니다.
5.1. 어텐션 싱크 (Attention sink)
미세 조정(fine-tuning)이 VLA 모델의 VL 그라운딩(grounding) 능력에 미치는 영향을 더욱 깊이 조사하기 위해, 우리는 텍스트 지시(instruction)에서 언급된 객체에 모델이 얼마나 효과적으로 집중하는지를 보여주는 어텐션 맵(attention maps)을 검사합니다. 이 분석은 모델이 시각적 특징과 언어적 특징 사이의 연결을 얼마나 잘 유지하고 있는지를 직접적으로 파악할 수 있게 해줍니다.
각 모델에 대해, 우리는 중간 레이어에서 추출한 시각적 패치 임베딩의 어텐션 맵을 시각화합니다. 이전 연구들(Zhang et al., 2025)에 따라, 우리는 가장 강력하고 의미론적으로 유의미한 어텐션 패턴이 주로 시각-언어 융합이 가장 활발하게 일어나는 중간 트랜스포머 레이어(14~24번 레이어)에서 나타난다는 것을 관찰했습니다(그림 4).
평가된 모델 중 Qwen2.5-VL은 명확하고 적절한 객체 정렬(object-aligned) 어텐션을 보여주는데, 이는 어텐션이 공간적 노이즈를 최소화한 상태로 질의된(queried) 객체에 정확히 국소화되어 있음을 나타냅니다.
이와 대조적으로 OpenVLA는 어텐션 품질에서 상당한 저하를 보입니다. 맵은 확산되고 노이즈가 많아지며 타겟 객체와의 상관관계가 약해지는데, 이는 어텐션 싱크(attention sink) 현상(Kang et al., 2025; Lin et al., 2025a)을 나타냅니다. OpenVLA의 어텐션 맵은 관련된 이미지 영역에 집중하는 대신, 빈번하게 관련 없는 배경 영역으로 새어 나가거나 방해 객체(distractor objects)에 집중합니다 (더 많은 결과는 섹션 A.2 참조).
반면, 우리가 제안한 시각적 표현 정렬(Visual Representation Alignment) 접근법은 이 문제를 해결합니다. 이 방법으로 학습된 OpenVLA (Align)는 선명하고 객체 중심적인 어텐션 맵을 생성합니다 (상세 내용은 섹션 A.2 참조).

그림 4. 어텐션 맵 비교: 가장 강력하고 의미론적으로 그라운딩된 어텐션은 중간 레이어 부근에서 나타납니다. 제안된 방법으로 미세 조정된 OpenVLA (OpenVLA Align)는 어텐션 맵에서 객체 정렬 초점을 유지하는 반면, 기본 OpenVLA SFT는 확산되고 노이즈가 많은 패턴을 보여 시각-언어 그라운딩의 손실을 나타냅니다 (더 많은 결과는 부록 그림 6 참조).

그림 5. Qwen2.5-VL, PrismaticVLM, OpenVLA의 토큰 임베딩에 대한 t-SNE 시각화. PrismaticVLM과 Qwen2.5-VL은 타겟 객체들에 대해 잘 분리된 클러스터를 유지하는 반면, OpenVLA는 클래스 간에 거대한 중첩을 보여주며, 이는 행동 미세 조정이 표현 붕괴(representation collapse)를 초래함을 나타냅니다.
5.2. 표현 붕괴 (Representations collapse)
행동 미세 조정(action fine-tuning)이 VLA 모델의 내부 VL 표현에 어떤 영향을 미치는지 분석하기 위해, 우리는 Qwen2.5-VL(Bai et al., 2025), PrismaticVLM(Karamcheti et al., 2024), 그리고 OpenVLA(Kim et al., 2024)를 비교하는 t-SNE 표현 조사를 수행했습니다. 이 실험은 행동 학습 과정을 통해 잠재 공간(latent space) 내의 의미적 구조가 어떻게 진화하는지에 대한 정성적인 관점을 제공합니다.
우리는 COCO 데이터셋(Lin et al., 2014)을 사용하고, 세 가지 일반적인 가정용 객체 클래스인 컵(cup), 병(bottle), 칼(knife)에서 샘플을 선택했습니다. 각 이미지에 대해, 모델은 "Do you see <object_name>?" 형태의 텍스트 질의를 받습니다. 그 후 우리는 트랜스포머 레이어에서 `<object_name>` 토큰에 해당하는 임베딩을 추출하고, t-SNE 알고리즘을 사용하여 이 임베딩들을 2차원으로 투영합니다. 시각화의 각 점은 객체 클래스별로 색상 코드화되어 있어, 범주 클러스터들이 얼마나 뚜렷하게 구별되는지 혹은 뒤엉켜(entangled) 있는지를 관찰할 수 있게 합니다.
그림 5는 중간 레이어에 대한 이러한 비교를 보여주며, 서로 다른 모델의 레이어 전반에 걸쳐 잠재 공간이 어떻게 구성되어 있는지를 드러냅니다. PrismaticVLM과 Qwen2.5-VL에서, 세 가지 범주에 대한 임베딩은 대규모 VLM의 전형적인 특징인 일관되고 의미적으로 조직된 잠재 공간을 반영하며 잘 분리된 클러스터를 형성합니다.
이와 대조적으로, OpenVLA는 흐릿하고 중첩된 클러스터를 보여주는데, 이는 로봇 제어를 위한 미세 조정이 상속된 표현의 구조적 조직을 무너뜨림을 나타냅니다. 이러한 분리 가능성(separability)의 상실은 표현 붕괴(representation collapse)(Barbero et al., 2024; Arefin et al., 2024)와 유사한 현상에 해당하며, 여기서 이전에 뚜렷했던 VL 표현들은 변별력이 떨어지는(less discriminative) 부분 공간으로 수렴하게 됩니다.
5.3. VLA 모델에서의 도메인 망각 (Domain forgetting in VLA models)
VL-Think 작업 세트(섹션 4)를 사용하여, 우리는 InternVL3.5(Wang et al., 2025b), Ovis2.5(Lu et al., 2025), Qwen2.5-VL(Bai et al., 2025)과 같은 여러 최첨단 VLM 전반의 VL 능력을 평가하고, 특히 OpenVLA-7B(Kim et al., 2024)와 우리가 근사적 상한선(approximate upper bound)으로 사용하는 그 사전 학습 기반인 PrismaticVLM(Karamcheti et al., 2024) 간의 비교에 중점을 둡니다. 이 비교는 행동 미세 조정(action fine-tuning) 이후에 VL 지식과 의미적 그라운딩(semantic grounding) 기술이 얼마나 유지되는지를 조사합니다.
여기서 두 가지 뚜렷한 경향이 나타납니다.
첫째, 강력한 VLM들은 모든 도메인에 걸쳐 높은 성공률을 달성하며, 이는 견고한 의미적 그라운딩 능력을 반영합니다.
둘째, 행동 미세 조정은 VLA 모델에서 체계적이고 도메인 특화적인 망각(domain-specific forgetting)을 유발합니다. 사전 학습된 대응 모델과 비교할 때, OpenVLA-7B는 거의 모든 도메인에서 상당한 성능 하락을 보이며, 특히 기호적이고 추상적인 범주(교통, 화살표, 공공 정보, 날씨)에서 가장 큰 감소를 보입니다.
우리는 VLA 모델이 로봇 미세 조정 데이터셋에 존재하지 않는 도메인에 대한 지식을 잃어버린다고 가설을 세웁니다. 지식 전이가 유지되는 유일한 도메인은 색상(Color)입니다. 이 도메인의 성공률은 초기 VLM 수준으로 유지되는데, 이는 색상 단서가 제어(control) 작업에 직접적으로 유용하며 로봇 데이터셋 내에 암시적으로 존재하기 때문일 가능성이 높습니다.
6. 방법론 (Method)
플라톤 표현 가설(Platonic Representation Hypothesis)(Huh et al., 2024)에 기반하여, 우리는 고성능의 시각, 언어, 그리고 멀티모달 모델들이 서로 다른 모달리티(modality) 전반에 걸쳐 일반적인 의미적, 지각적 구조를 포착하는 공유 잠재 표현 공간(shared latent representation space)으로 수렴하는 경향이 있다고 가정합니다. 각 모달리티는 이 공유 공간에 대해 구별되면서도 호환 가능한 관점을 제공하며, 동일한 기저의 시각-언어(VL) 규칙성 중 상호 보완적인 측면들을 인코딩합니다.
이러한 관점에서 볼 때, VLA 모델은 자신의 의사결정을 이러한 멀티모달 표현의 부분집합(subset)에 그라운딩(grounding)하는 하나의 정책으로 간주할 수 있습니다. 그러나 작업별 미세 조정(task-specific fine-tuning) 과정에서 정책의 내부 특징(features)들이 이 일반화된 표현 공간으로부터 벗어나게(drift away) 될 수 있으며, 이로 인해 광범위하고 전이 가능한(transferable) 의미와의 연결고리를 잃게 됩니다.
이러한 효과를 완화하기 위해, 우리는 VLA의 시각적 표현을 일관되고 범용적인 시각적 의미를 인코딩하는 안정적인 외부 참조(stable external reference)에 고정(anchor)시키는 시각적 표현 정렬(Visual Representation Alignment) 목표를 도입합니다 (그림 1).
표 1. 평가 환경 전반에 걸친 OOD 일반화 성능 (평균 ± 표준편차). 제안된 정렬(alignment) 목표는 SFT 및 인코더 동결(frozen-encoder) 베이스라인보다 일관된 성능 향상을 보여주며, 이는 OOD(분포 외) 도메인 변화에 대해 향상된 견고성을 나타냅니다.
| Method | Semantic | Vision | Execution | ||||||||||
| Carrot | Instruct | MultiCarrot | MultiPlate | Plate | VisionImg | Tex03 | Tex05 | Whole03 | Whole05 | Position | EEPose | PosChangeTo | |
| Default | 0.49±0.02 | 0.74±0.02 | 0.28±0.02 | 0.43±0.02 | 0.73±0.02¯ | 0.81±0.01 | 0.67±0.01 | 0.55±0.03 | 0.71±0.02 | 0.56±0.01 | 0.43±0.02 | 0.34±0.01 | 0.23±0.01 |
| Freeze | 0.03±0.01 | 0.05±0.01 | 0.01±0.01 | 0.02±0.01 | 0.03±0.01 | 0.02±0.01 | 0.03±0.01 | 0.01±0.01 | 0.01±0.01 | 0.01±0.01 | 0.03±0.01 | 0.03±0.01 | 0.04±0.01 |
| Align (ours) | 0.61±0.01 | 0.83±0.03 | 0.35±0.02 | 0.49±0.02 | 0.75±0.01 | 0.86±0.02 | 0.70±0.02 | 0.67±0.02 | 0.79±0.02 | 0.60±0.02 | 0.58±0.02 | 0.38±0.02 | 0.20±0.03¯ |
6.1. 시각적 표현 정렬 (Visual representation alignment)
우리는 VLA 모델 내부의 임베딩이 동결된(frozen) 사전 학습 비전 교사(vision teacher)의 임베딩과 가깝게 유지되도록 정규화(regularizing)함으로써, VLA 모델 내에서 일반화되고 의미적으로 일관된 시각적 표현을 복구하는 경량화된 시각적 정렬 방법을 제안합니다.
플라톤적 해석(Platonic interpretation)에 따르면, 교사 인코더(teacher encoder)는 일반화된 표현 공간에 대해 더 안정적이고 의미적으로 정밀한 투영(projection)을 제공하는 반면, VLA 자체의 표현은 이 공간에 대한 작업 적응적(task-adapted) 근사를 형성합니다. 이들 간의 불일치를 최소화함으로써, 모델은 공통된 의미 구조로 다시 유도됩니다.



플라톤적 관점에서 보면, 본 방법은 모델이 공유되고 일반화된 VL(vision–language) 지식에 대한 의미적 사전(prior)을 유지하도록 돕는다. 행동(action) 파인튜닝만 수행할 경우, 모델의 지각 공간이 특정 데이터셋이나 특정 로봇/환경의 통계에 과도하게 적응하게 되고, 그 결과 내부 표현이 보다 넓은 범위의 일반화된 표현에서 점차 벗어나게 된다.
정렬 손실은 강력한 사전학습 비전 모델이 가진 더 일반적이고 의미 기반의 시각–언어 관계에 대응하도록 학생 모델의 중간 표현을 일치시키며, 이 균형을 다시 회복하는 역할을 한다.
7. 실험 (Experiments)
7.1. 평가 설정 (Evaluation setup)
우리는 제안된 VL-Think 작업 세트(섹션 4)와 VLA 일반화를 세 가지 축(시각, 의미론, 실행)에 걸쳐 평가하기 위해 설계된 (Liu et al., 2025)에 도입된 벤치마크를 사용하여, Simpler(Li et al., 2024; Tao et al., 2025)에 기반한 여러 로봇 환경에서 우리의 접근 방식을 평가합니다.
- 시각 (Vision): 동적 텍스처와 이미지 수준의 노이즈를 통해 전경과 배경을 변경하여, 약하거나 강한 시각적 교란에 대한 견고성을 테스트합니다.
- 의미론 (Semantics): 보지 못한 물체와 용기(receptacles), 바꿔 쓴 지시사항(paraphrased instructions), 그리고 구성적 추론을 어렵게 하는 다중 객체 또는 방해 요소 시나리오를 도입합니다.
- 실행 (Execution): 무작위 초기 자세와 에피소드 중간의 물체 재배치를 통해 저수준 제어 조건을 변경하여, 행동 수준의 견고성을 조사합니다.
OOD(분포 외) 평가는 각 축마다 최소 하나의 변형 요인을 남겨두고(hold out) 진행하며, 여기에는 9개의 새로운 물체, 16개의 보지 못한 용기, 5개의 새로운 장면 텍스처, 16개의 방해 배경이 포함됩니다. 추가로, 우리는 다양한 방법으로 학습된 VLA 표현의 품질을 정량화하기 위해 ImageNet-100(Tian et al., 2020)에서 선형 프로빙(linear probing)을 수행합니다.
각 모델 변형은 128개의 무작위 시드에 대해 평가되며, 우리는 성공률을 평균 ± 표준편차(SD)로 보고합니다. 섹션 8에서는 단측 대립 가설(one-sided alternative)을 적용한 대응 표본 윌콕슨 부호 순위 검정(paired Wilcoxon signed-rank test)(Wilcoxon, 1945)을 사용하며, p-값을 보고합니다. 모든 모델은 공정한 비교를 보장하기 위해 동일한 하이퍼파라미터로 같은 수의 에포크 동안 학습됩니다.
7.2. 학습 설정 (Training setup)
지도 미세 조정(supervised fine-tuning)을 위해, 우리는 MPLib 모션 플래너(Guo et al., 2025)를 사용하여 1,400개의 전문가 시연 궤적(demonstration trajectories)을 수집합니다. 학습 무작위화(randomization)는 16개의 테이블, 16개의 물체(학습 변형당 평균 약 5개의 에피소드 산출), 그리고 다수의 자세 섭동(pose perturbations)을 포괄하여 진행됩니다. 모든 미세 조정 실행 과정에서, VLA의 모든 선형 레이어(linear layers)에 LoRA 어댑터(Hu et al., 2021)가 적용됩니다.
7.3. 베이스라인 (Baselines)
널리 채택된 오픈 소스 OpenVLA 모델을 사용하여, 우리는 제안된 정렬 방법을 몇 가지 미세 조정 베이스라인들과 비교합니다.
- 기본 (Default) – 시연 데이터에 대해 교차 엔트로피 손실을 사용하는 표준 지도 미세 조정(SFT)이며, 주된 베이스라인 역할을 합니다.
- 동결 (Freeze) – 학습 도중 VLA의 시각 인코더 가중치를 동결한 상태로 진행하는 SFT입니다. 이 설정은 동결된 표현이 일반화에 도움이 될 수 있다는 가설을 검증합니다.
- 정렬 (Align, 제안 방법) – 6.1절에서 설명된 보조 시각적 표현 정렬 손실(auxiliary visual representation alignment loss)과 결합된 SFT입니다. 이는 VLA의 비전 인코더를 사전 학습된 범용 비전 교사(teacher)에 명시적으로 고정(anchor)시킵니다.
표 2. 8개 도메인 전반에 걸친 VL-Think VLM 결과. 이 벤치마크는 VL(시각-언어) 이해 능력과 모델 규모 사이의 강력한 상관관계를 보여줍니다. 즉, 더 큰 VLM일수록 전반적으로 더 높은 성공률을 달성합니다. 그러나 행동(action)에 대해 미세 조정된 OpenVLA-7B는 명확한 VL 성능 저하를 나타냅니다. VL 기술이 대체로 보존된 색상(color) 도메인을 제외하고, 모든 도메인에서 원본 PrismaticVLM에 비해 성능이 현저하게 하락했습니다.

표 3. 선형 프로빙(Linear probing) 결과. OpenVLA Align은 사전 학습된 모델과 SFT 변형 모델 모두보다 더 강력한 특징(features)을 유지하며, C-RADIOv3 교사 모델과의 격차를 크게 좁히고 행동 미세 조정 후 향상된 의미적 일관성을 보여줍니다.

7.4. 결과: OOD 평가 (Results: OOD Evaluation)
LABEL:tab:ood_performance(표 1)의 결과는 우리의 시각적 정렬 방법이 의미론(Semantic), 시각(Vision), 실행(Execution)의 모든 평가 축에서 일관된 성능 향상을 가져옴을 보여줍니다. 이 결과는 실제 시나리오에서 빈번하게 발생하는 시각적 변화, 텍스트 지시 변형, 질감 변화, 그리고 배경 교란(perturbations)에 대한 견고성을 향상시키는 데 있어 시각적 표현 정렬이 효과적임을 강조합니다.
이러한 성능 향상은 내부 시각-언어 임베딩을 정렬하는 것이 지각(perception)을 안정화할 뿐만 아니라 의미적 그라운딩을 강화한다는 것을 나타냅니다.
반대로, 동결(Freeze) 베이스라인은 모든 범주에서 완전히 실패하여((Wang et al., 2025a)에서도 관찰된 바와 같이) 거의 0에 가까운 성능을 기록했습니다. 이는 사전 학습된 시각 인코더를 단순히 동결하는 것만으로는 적응(adaptation) 과정에서 유용한 표현들을 보존할 수 없음을 확인시켜 줍니다. 공동 최적화(joint optimization)가 없으면, 동결된 특징들이 학습에 따라 변화하는 행동 구성 요소들과 불일치하게 되어, 지각과 제어 능력 모두 심각하게 저하되는 결과를 초래합니다.
종합하면, 이러한 결과들은 시각적 정렬이 표현 저하를 막는 효과적인 정규화 기제(regularizer)로 작용하여, 모델이 새로운 로봇 환경에 적응하면서도 범용적인 시각적 의미를 회복할 수 있게 해준다는 것을 입증합니다.
7.5. 결과: 선형 프로빙 (Results: Linear probing)
우리 모델이 학습한 표현(representational) 품질을 추가로 평가하기 위해, 우리는 ImageNet-100 데이터셋(Tian et al., 2020)에 대해 선형 프로빙 분석을 수행합니다. 구체적으로, 우리는 C-RADIOv3(Heinrich et al., 2025) 교사(teacher) 모델의 마지막 레이어와 다양한 OpenVLA 변형 모델들의 중간 시각 레이어로부터 패치 임베딩을 추출합니다. 표현 학습의 표준 관행(Yu et al., 2025; Huh et al., 2024)을 따르며, 시각 인코더를 동결하고 그 동결된 특징들 위에 단일 선형 분류기를 학습시켜 의미론적 범주의 분리 가능성(separability)을 측정합니다. 이 설정은 행동 미세 조정 후 시각적 특징들이 얼마나 선형적으로 해독 가능한(linearly decodable) 상태로 남아 있는지를 직접적으로 정량화합니다.
7.6. 결과: VL-Think (Results: VL-Think)
5.3절의 실험에 이어, 우리는 제안된 시각적 표현 정렬 방법으로 미세 조정된 OpenVLA(OpenVLA-7B Align)를 동일한 데이터, 예산 및 평가 설정 하에서 평가합니다. 표 2의 결과는 SFT-Align이 기본 SFT에서 관찰된 도메인 망각 현상을 부분적으로 완화한다는 것을 보여줍니다.
특히, 색상(Color) 및 모양(Shape) 도메인에서의 성능은 일관되게 향상되어 PrismaticVLM 상한선조차 능가하는 모습을 보였으나, 다른 도메인들은 대체로 큰 변화가 없었습니다.
이러한 결과들은 제약된 설정 하에서 제안된 표현 정렬 방식이 지닌 가능성과 한계를 동시에 보여줍니다. 우리는 SFT 데이터셋의 제한적인 크기와 다양성, 그리고 LoRA 업데이트의 제한된 표현력이 로봇 데이터에서 비중이 낮고 빈도수가 적은 VL 개념들을 복구하기에는 불충분하다고 가정합니다.
또한, 데이터의 범위를 확장하고 파라미터 효율성 제약을 완화한다면, 흔히 다뤄지는 도메인을 넘어 더 폭넓은 성능 향상을 이끌어낼 수 있을 것이라 가정합니다. 이 가설을 검증하는 것은 향후 연구의 중요한 방향입니다.
8. 어블레이션 연구 (Ablations)
이 섹션에서는 다양한 설계 선택이 우리 시각적 정렬 방법의 성능에 어떤 영향을 미치는지 분석하기 위해 체계적인 어블레이션 연구를 수행합니다. 우리는 정렬에 사용되는 교사 모델(teacher model), 정렬 전략 및 타겟 레이어, 프로젝터 유형, 그리고 손실 함수의 영향을 조사합니다. 종합적으로, 이 실험들은 시각적 표현의 효과적인 정렬을 위해 어떤 구성 요소가 가장 결정적인지에 대한 통찰을 제공합니다.
8.1. 시각적 교사 모델 (Visual teacher models)
본 접근 방식에서 제기되는 핵심적인 질문은 정렬을 위한 참조 표현(reference representations)을 제공하는 교사 모델의 선택과 관련이 있습니다.
플라톤적 관점(Platonic perspective)에서 볼 때, 각 비전 파운데이션 인코더는 광범위하게 일반화 가능한 시각적 지식에 대한 서로 다른 투영(projection)을 포착하며, 더 강력한 교사 모델에 정렬하는 것은 미세 조정 과정에서 VLA 내에 이러한 고수준의 전이 가능한 추상화를 보존하는 데 도움이 됩니다. 따라서 우리는 대규모의 다양하고 다시점(multi-view) 데이터를 기반으로 학습된 파운데이션 모델이 더 나은 정렬과 더 강력한 전이 성능을 제공하는지 조사합니다.
이를 검증하기 위해, 우리는 DINOv2(Oquab et al., 2024), SigLIP(Zhai et al., 2023), C-RADIOv3(Heinrich et al., 2025), 그리고 Theia(Shang et al., 2024)를 포함한 여러 최첨단 비전 인코더를 평가했습니다.
LABEL:tab:teacher_backbone(해당 표)에서 볼 수 있듯이, C-RADIOv3가 전반적으로 가장 우수한 결과를 달성했습니다. 이는 대규모의 의미적으로 풍부한 멀티모달 데이터로 학습된 더 강력하고 뛰어난 성능의 비전 모델들이 정렬을 위해 보다 안정적이고 일반화 가능한 시각적 특징을 제공함을 시사합니다.
이러한 교사 모델들은 더 강력한 '플라톤적 앵커(Platonic anchors)' 역할을 수행하여, VLA가 작업 및 도메인 전반의 견고성을 향상시키는 전이 가능하고 의미적으로 일관된 표현과 정렬되도록 유도합니다.
표 4. 일반화 차원에 따른 사전 학습된 교사(Teacher) 비전 모델 비교. 값은 각 차원 내의 모든 환경에서 집계된 평균과 p-값을 나타냅니다. 각 열의 최고 결과는 굵게 표시되었습니다 (자세한 내용은 부록의 LABEL:tab:app_abb_vision_teacher 참조).
| 교사 모델 (Teacher) | 의미론 (Semantic) | 시각 (Vision) | 실행 (Execution) |
| C-RADIOv3 | 0.61 | 0.72 | 0.39 |
| DINOv2 | 0.57 (p=0.05) | 0.69 (p=0.12) | 0.37 (p=0.43) |
| SigLIP | 0.54 (p=0.01) | 0.65 (p=0.03) | 0.35 (p=0.09) |
| Theia | 0.56 (p=0.03) | 0.67 (p=0.05) | 0.36 (p=0.15) |
8.2. 정렬 방법 (Alignment method)
표 5. 일반화 차원에 따른 정렬 패러다임 비교. 차원별 평균 및 p-값으로 보고됨. 최고 결과는 굵게 표시되었습니다.
| 방법 (Method) | 의미론 (Semantic) | 시각 (Vision) | 실행 (Execution) |
| Backbone2Enc | 0.61 | 0.72 | 0.39 |
| Enc2Enc | 0.55 (p=0.01) | 0.66 (p=0.04) | 0.38 (p=0.64) |
다음으로, 우리는 VLA 모델의 어느 단계(level)가 시각적 표현 정렬로부터 가장 큰 이점을 얻는지 확인하기 위해 다양한 정렬 패러다임을 평가합니다. 두 가지 주요 전략이 테스트되었습니다.
(1) Backbone2Enc – VLA의 트랜스포머 백본(backbone) 표현을 교사(teacher) 시각 인코더의 마지막 레이어 특징(features)과 정렬하는 방식.
(2) Enc2Enc – VLA 자체 시각 인코더의 특징을 교사 모델의 최종 임베딩과 직접 정렬하는 방식.
우리의 실험 결과(표 5)는 Backbone2Enc가 일관되게 더 강력한 결과를 산출함을 보여줍니다. 이는 주된 표현 저하가 초기 인코더 레이어가 아닌, VL 통합 및 작업별 적응(task-specific adaptation)이 가장 활발한 중후반(middle-to-late) 융합 레이어에서 발생함을 나타냅니다. 이러한 더 깊은 표현들을 정규화하는 것이 시각-의미적 일관성을 유지하는 데 결정적인 것으로 보이며, 동시에 하위 레이어들이 도메인 특화적인 저수준 단서(cues)에 자유롭게 적응할 수 있도록 허용해 줍니다.
8.3. 프로젝터 유형 (Projector type)
표 6. 일반화 차원에 따른 다양한 투영 방법 비교 (차원별 평균, p-값). 각 투영 유형은 동결(Freeze) 및 학습 가능(Trainable) 변형 모두에서 평가되었습니다 (자세한 결과는 부록의 LABEL:
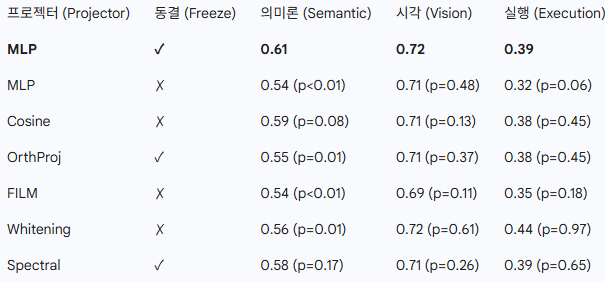

우리는 선형(linear), 코사인 유사도 기반, 직교(orthogonal), 스펙트럼 정규화(spectral-normalized), FiLM 조건부, 화이트닝-아핀(Whitening-affine), 그리고 MLP 기반 매핑을 포함한 다양한 투영 전략을 조사했습니다. 실험 결과, 동결된(frozen) MLP 프로젝터가 모든 평가 차원에 걸쳐 가장 신뢰할 수 있고 견고한 정렬을 제공하는 것으로 나타났습니다.
우리는 이 설정에서 프로젝터를 동결하는 것이 매우 중요하다고 가정합니다. 만약 프로젝터가 학습 가능하다면, 모델은 VLA의 내부 표현을 의미 있게 변화시키기보다는 주로 프로젝터를 적응(projector adaptation)시킴으로써 정렬 손실을 최소화하려 합니다. 이 경우, 프로젝터는 교사의 공간을 단순히 근사하는 임베딩을 출력하도록 빠르게 학습하여, 사실상 표현 교정(representational correction) 과정을 우회해 버립니다.
우리는 이를 두 가지 요인, 즉 비교적 적은 양의 정렬 데이터와 비전 교사와 VLA 백본 임베딩 간의 상당한 차원 격차($d_t=768$, $d_e=4096$) 때문으로 봅니다. 프로젝터를 동결하면 이러한 지름길(shortcut)이 차단되어, 정렬 목표(objective)가 학생 모델의 은닉 표현에 직접적으로 작용하도록 강제함으로써, 더 의미적으로 그라운딩되고 전이 가능한 특징 정렬을 산출하게 됩니다.
8.4. 정렬 레이어 (Alignment layers)
표 7. 일반화 차원에 따른 정렬 레이어 비교 (차원별 평균, p-값). (자세한 결과는 부록의 LABEL:tab:app_layers 참조).

우리는 가장 효과적인 표현 복구를 달성하기 위해 VLA 트랜스포머 백본 내의 어느 레이어를 정렬해야 하는지 추가로 조사합니다. VLM 해석 가능성에 관한 이전 연구(Zhang et al., 2025)와 본 연구의 분석(그림 4)은 중간 레이어(middle layers)들이 주로 VL 융합과 의미적 그라운딩(semantic grounding)을 담당하는 반면, 초기 레이어는 저수준 특징을 인코딩하고 후반 레이어는 행동 예측에 특화되어 있음을 시사합니다.
이에 따라 우리는 초기(Early), 중간(Middle), 후반(Late)의 서로 다른 레이어 유형을 정렬하는 실험을 수행합니다. 결과(표 7)는 중간 레이어가 의미적 그라운딩에 핵심적인 역할을 하며, 이들을 정렬하는 것이 일반화 축 전반에 걸쳐 가장 상당한 성능 향상을 가져옴을 확인시켜 줍니다.
8.5. 손실 함수 및 정렬 계수 (Loss functions and alignment coefficient)
표 8. 일반화 차원에 따른 다양한 손실 함수 비교 (차원별 평균, p-값).

마지막으로, 우리는 정렬 손실 함수와 그 가중치 계수의 영향을 평가합니다. 우리는 코사인 유사도(Cossim), L2, 그리고 대조 학습인 NT-Xent(Chen et al., 2020) 손실을 포함한 여러 변형을 정렬 계수 $\lambda = {0.2, 0.5, 1.0, 3.0}$에 걸쳐 테스트합니다.
결과(표 8)는 Cossim 손실이 가장 안정적이고 일관된 향상을 달성함을 보여주며, 특히 보조 가중치가 $\lambda = 0.2$로 설정될 때 그러했습니다. 이 설정은 작업 목표(task objective)를 압도하지 않으면서 표현의 이탈(drift)을 효과적으로 억제합니다.
9. 결론 (Conclusion)
본 연구에서 우리는 로봇 작업에 대해 VLA 모델을 미세 조정하는 것이 어떻게 VL 이해 능력과 표현 품질의 저하를 초래하는지 조사했습니다. 이러한 효과를 분석하기 위해, 우리는 행동 미세 조정 중 VL 기술이 어떻게 저하되는지를 밝혀내는 어텐션 맵 분석 및 선형 프로빙을 포함한 해석 가능성 프로브(interpretability probes)와 VL-Think 진단 세트를 도입했습니다.
이 문제를 해결하기 위해, 우리는 VLA를 사전 학습된 시각적 교사(teacher)에 고정(anchor)시키는 경량화된 시각적 정렬(Visual Alignment) 방법을 제안했습니다. 이 방법은 새로운 객체, 보지 못한 장면 구성, 텍스처 및 조명 변화, 지시어 바꾸어 쓰기(paraphrases)를 포함한 다양한 도메인 전반에서 OOD(분포 외) 일반화 성능을 일관되게 향상시켰습니다.
계산 자원의 제약으로 인해, 본 연구는 대규모 사전 학습보다는 미세 조정에 중점을 두었습니다. 우리는 이 연구가 확장 가능한 로봇 사전 학습과, VLA가 VLM으로부터 어떻게 VL 지식을 상속하고 유지하는지에 대한 체계적인 평가를 위한 향후 연구의 길잡이가 되기를 희망합니다.