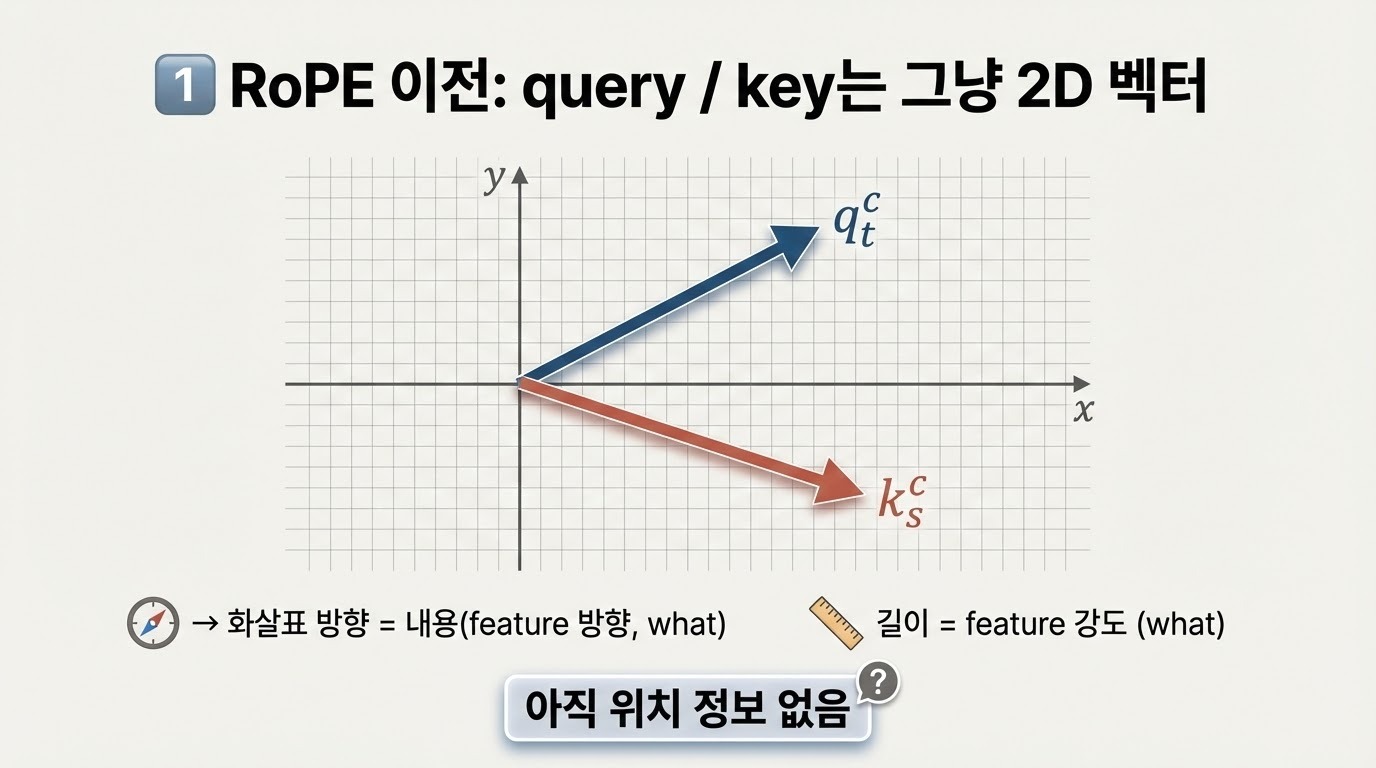
Decoupling the "What" and "Where" With Polar Coordinate Positional Embeddings
The attention mechanism in a Transformer architecture matches key to query based on both content -- the what -- and position in a sequence -- the where. We present an analysis indicating that what and where are entangled in the popular RoPE rotary position
arxiv.org
초록 (Abstract)
Transformer 아키텍처에서의 어텐션 메커니즘은 시퀀스 내에서의 내용(the what)과 위치(the where)라는 두 요소를 모두 기반으로 key와 query를 매칭한다. 본 논문에서는 널리 사용되는 회전 위치 임베딩(Rotary Position Embedding, RoPE)에서 이 두 요소가 서로 얽혀(entangled) 있음을 보이는 분석을 제시한다. 이러한 얽힘은 특히 내용과 위치에 대해 독립적인 매칭이 요구되는 결정 문제에서 성능 저하를 초래할 수 있다.
우리는 이 문제를 해결하기 위해 극좌표 위치 임베딩(Polar Coordinate Position Embedding, PoPE)이라 명명한 RoPE의 개선안을 제안하며, 이를 통해 what–where 간의 혼동(confound)을 제거한다. PoPE는 오직 위치 또는 내용만으로 인덱싱해야 하는 진단 과제에서 기존 방법 대비 월등한 성능을 보인다.
음악, 유전체, 자연어 도메인의 자기회귀 시퀀스 모델링에서, 위치 인코딩으로 PoPE를 사용하는 Transformer는 RoPE를 사용하는 기준 모델 대비 평가 손실(퍼플렉시티)과 다운스트림 과제 성능 모두에서 우수하다. 언어 모델링에서는 이러한 성능 향상이 124M에서 774M 파라미터 규모에 이르기까지 모델 크기 전반에 걸쳐 일관되게 유지된다. 특히 PoPE는 추가적인 파인튜닝과 주파수 보간이 필요한 길이 외삽(length extrapolation) 전용 방법인 YaRN과 비교하더라도, RoPE는 물론 YaRN보다도 강력한 제로샷 길이 외삽 능력을 보여준다.
1. 서론 (Introduction)
딥러닝의 초기 단계에서 중요한 도전 과제 중 하나는 순차적 데이터 또는 위치가 부여된 데이터(position-coded data)를 어떻게 표현할 것인가였다. 당시 관심의 대상이 된 과제들로는 문자 순서로부터 단어를 인식하는 문제(McClelland & Rumelhart, 1981), 파워 스펙트럼으로부터 음성을 인식하는 문제(Waibel et al., 1989), 예측 가능한 이벤트들 사이에 시간 지연이 존재하는 긴 시퀀스를 압축하는 문제(Schmidhuber et al., 1993), 스트로크 정보로부터 손글씨 기호를 분류하는 문제(Yaeger, 1996), 그리고 샘플로부터 시계열을 예측하는 문제(Mozer, 1993) 등이 있었다.
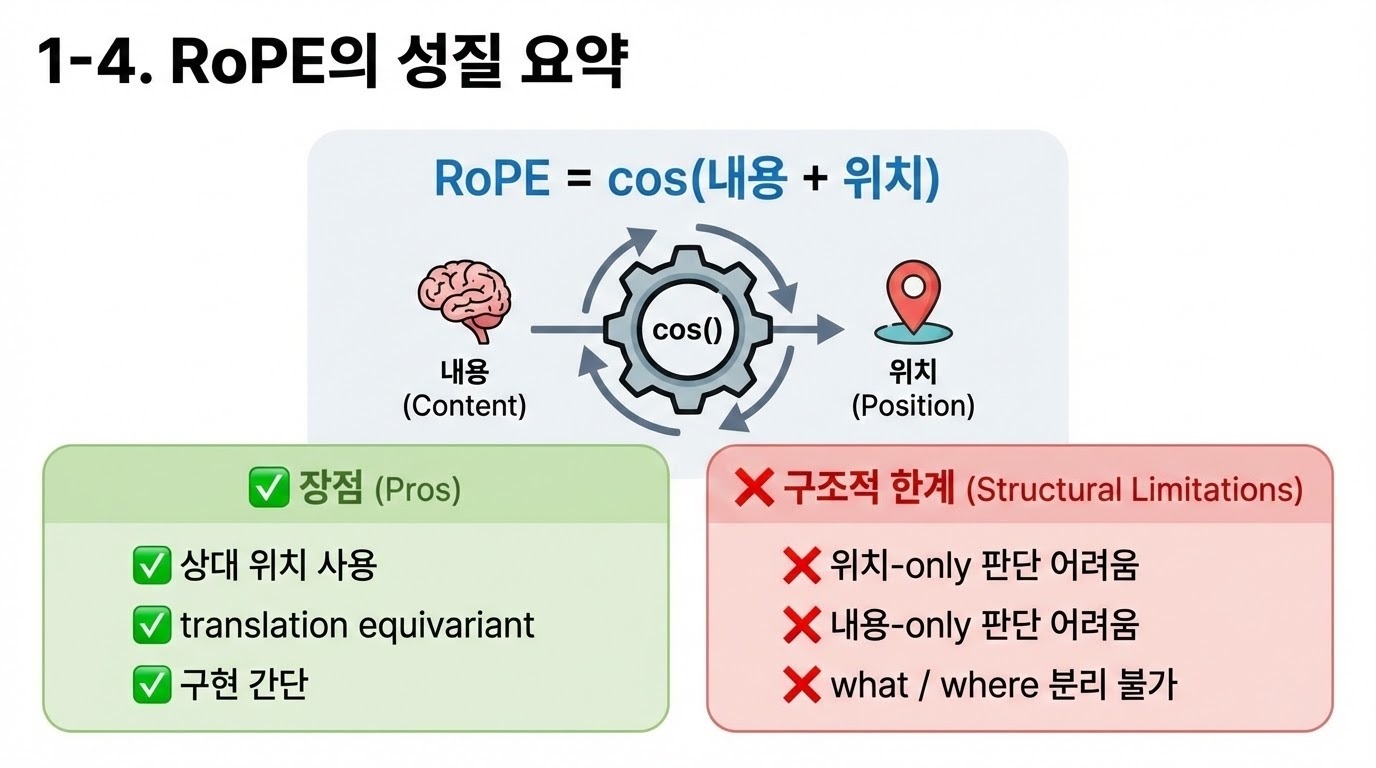
1980년대에는 두 가지 접근법이 주로 사용되었다. 하나는 순환 신경망(Recurrent Neural Networks, RNNs)이고, 다른 하나는 슬롯 기반 인코딩(slot-based encodings)이다. RNN은 입력의 순서를 통해 시퀀스상의 위치 정보를 암묵적으로 인코딩하는 방식이다. 반면, 슬롯 기반 인코딩은 입력 벡터를 시퀀스의 각 단계(step)에 대응되는 개별 구성 요소들로 분할한다. RNN의 중요한 장점 중 하나는 근사적인 이동 등변성(translation equivariance)을 가진다는 점인데, 이는 입력 내에서 어떤 부분 시퀀스의 절대 위치를 이동시키면 모델 상태 역시 이에 상응하는 방식으로 이동함을 의미한다. 슬롯 기반 표현은 이러한 성질을 공유하지 않는다. 즉, 하나의 슬롯에서 특정 내용에 반응하도록 학습되더라도, 동일한 내용이 다른 슬롯에 나타났을 때 그 지식이 일반화되지 않는다.
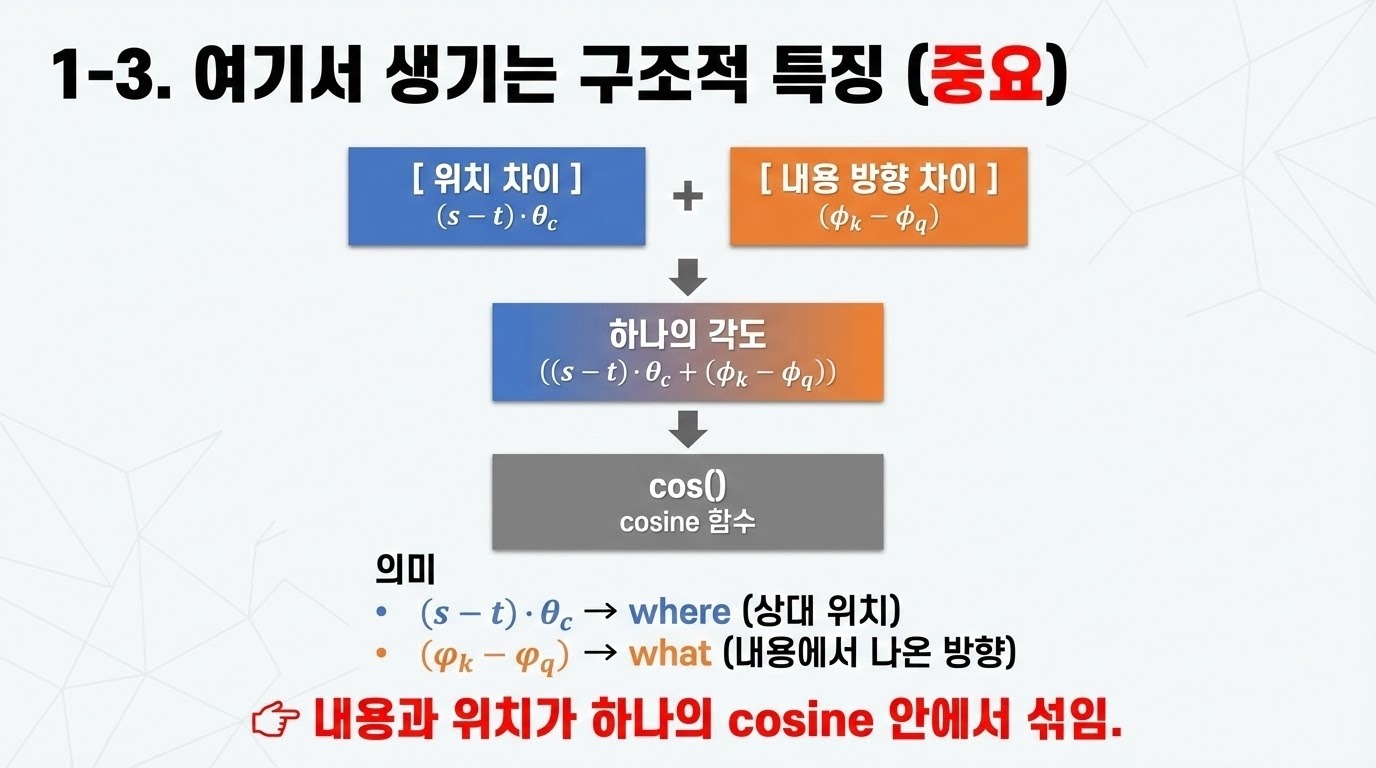
Transformer 아키텍처(Vaswani et al., 2017)는 슬롯 기반 표현의 판도를 바꾸었다. 자기 어텐션(self-attention) 메커니즘을 통해, 기본적인 Transformer는 (인과적 어텐션 경계를 고려할 경우) 이동 등변성뿐 아니라 이동 불변성(translation invariance)과 순열 불변성(permutation invariance)까지 갖는다. 따라서 Transformer에서의 핵심 과제는, 입력 요소들의 상대적 위치에 대한 민감성을 유지하면서도 이동 등변성을 어떻게 확보할 것인가가 되었다. 이를 해결하기 위해 등장한 방법들은 잠재 표현(latent representation)을 확장하여, 단순히 내용(the what)뿐만 아니라 시퀀스 위치 간의 관계, 즉 위치(the where)까지 함께 인코딩하도록 설계되었다(Vaswani et al., 2017; Dai et al., 2019; Su et al., 2024). 이러한 접근들은 언어와 같은 복잡한 시퀀스를 모델링하는 데 있어 내용과 위치가 모두 필수적이라는 점을 올바르게 전제하고 있다.
본 논문에서는 널리 채택되고 있는 방법인 회전 위치 임베딩(Rotary Position Embedding, RoPE)(Su et al., 2024)가 내용과 위치, 즉 what과 where를 서로 얽히게(entangle) 만들어, 특히 이 두 요소에 대해 독립적인 매칭이 필요한 의사결정 상황에서 모델 성능을 저하시킬 수 있음을 주장한다. 이에 대한 대안으로, 우리는 PoPE라 부르는 새로운 기법을 제안한다. PoPE는 다른 위치 인코딩 방식들에 비해 RoPE가 갖는 장점들을 그대로 유지하면서도, key–query 매칭을 what 매칭과 where 매칭의 결합(conjunction)으로 명확히 분리하여 규칙을 구현할 수 있도록 Transformer를 설계한다. PoPE는 RoPE에 대한 비교적 작은 수정에 불과하지만, 데이터 효율성, 점근적 정확도(asymptotic accuracy)를 향상시키고, 최신 방법들보다 우수한 컨텍스트 길이 일반화(context-length generalization) 성능을 제공하는 강력한 귀납적 편향(inductive bias)을 도입한다.
2. 배경 (Background)
RoPE(Su et al., 2024)는 Llama 3(Grattafiori et al., 2024), DeepSeekv3(Liu et al., 2024), Gemma 3(Team et al., 2025), Qwen3(Yang et al., 2025) 등을 포함한 다수의 최신 언어 모델에서 위치 정보를 통합하는 지배적인 접근법이다. RoPE는 각 query–key 쌍에 대해, 두 벡터가 얼마나 잘 매칭되는지뿐만 아니라 입력 시퀀스 내에서의 상대적 위치를 함께 반영한 어텐션 점수를 생성한다.

이며, θ는 기본 파장(base wavelength)이라 불린다. Query(또는 key) 성분의 구성과 2차원 회전 과정은 그림 1의 왼쪽에 도식화되어 있다.

RoPE에 대한 우리의 관점은 key와 query 성분을 데카르트 좌표계(Cartesian coordinates)에서 극좌표계(polar coordinates)로 재표현하는 것에서 출발한다. 즉,

이 표기를 사용하면 회전을 합성할 수 있고, 어텐션 점수는 다음과 같이 쓸 수 있다.












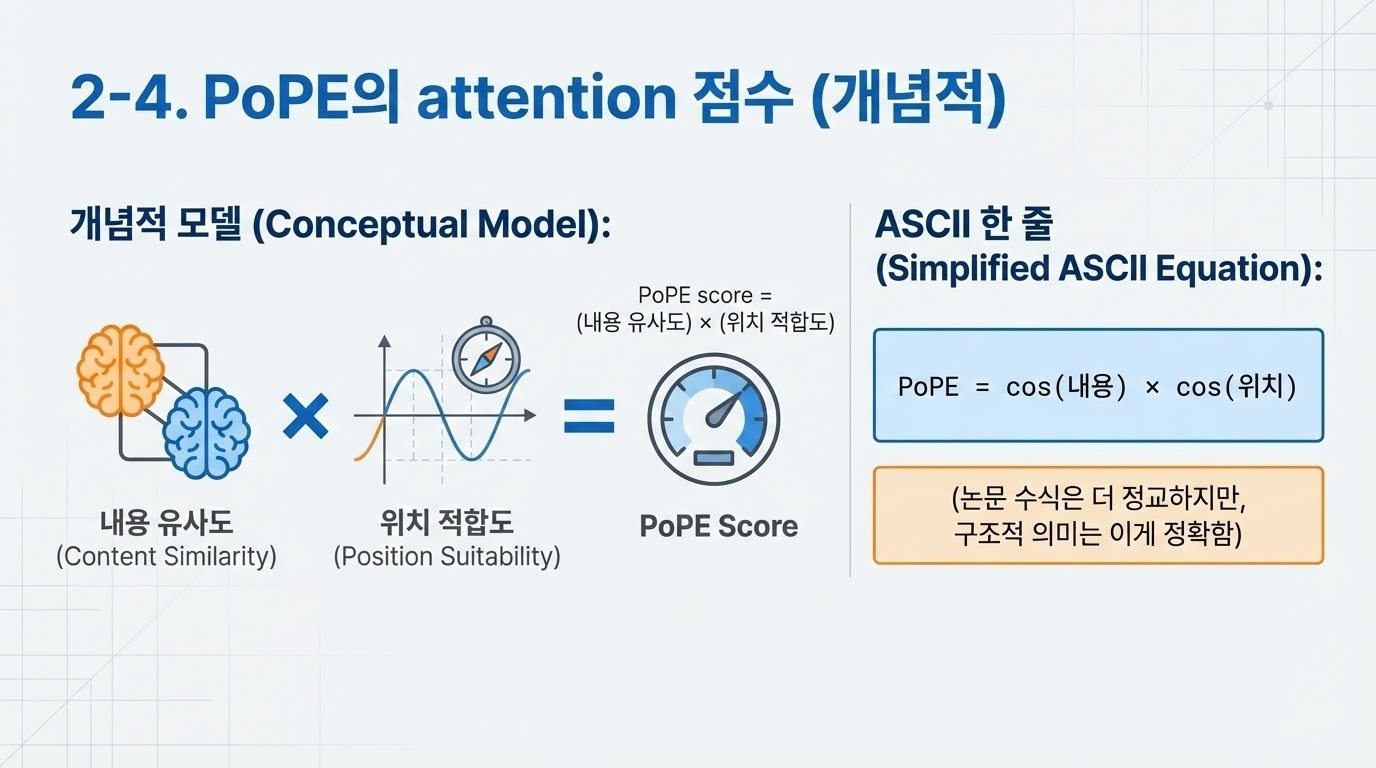
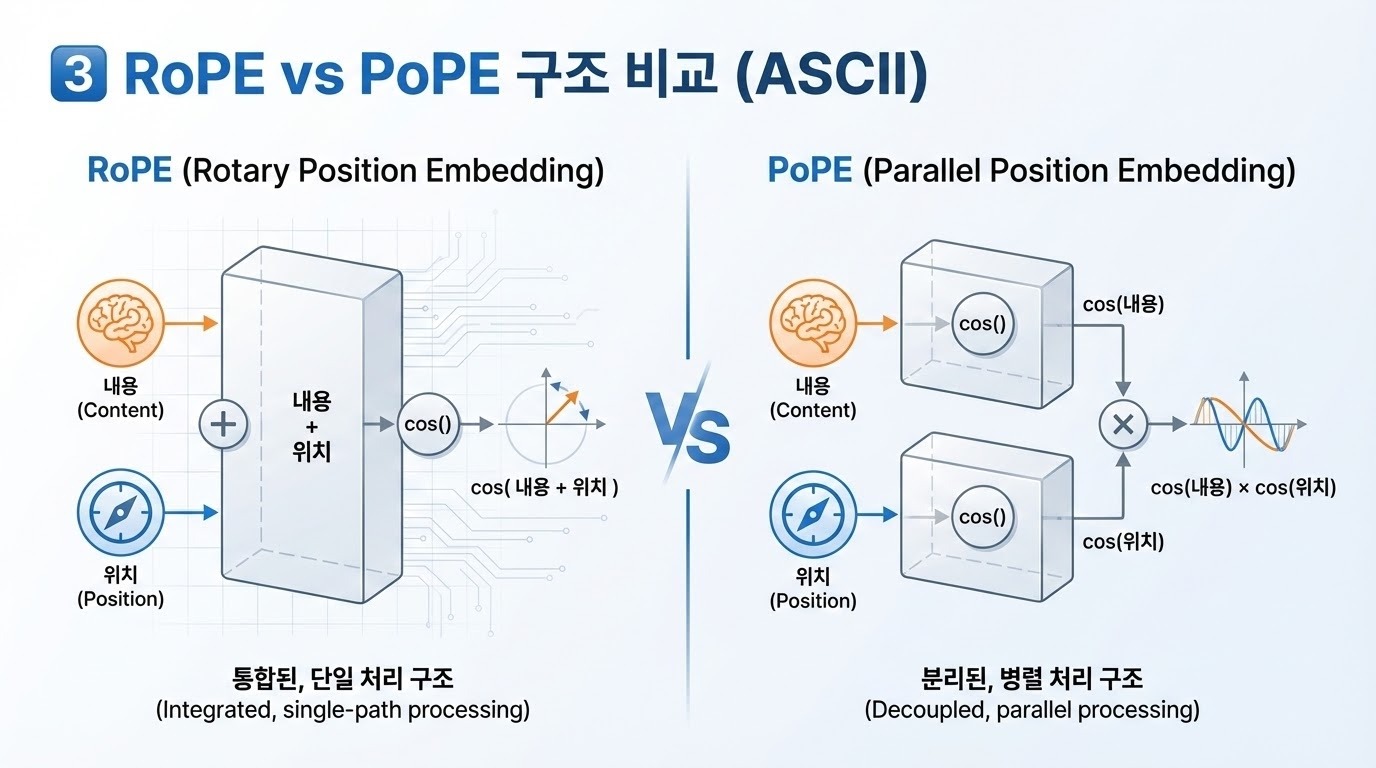

3. 방법 (Method)
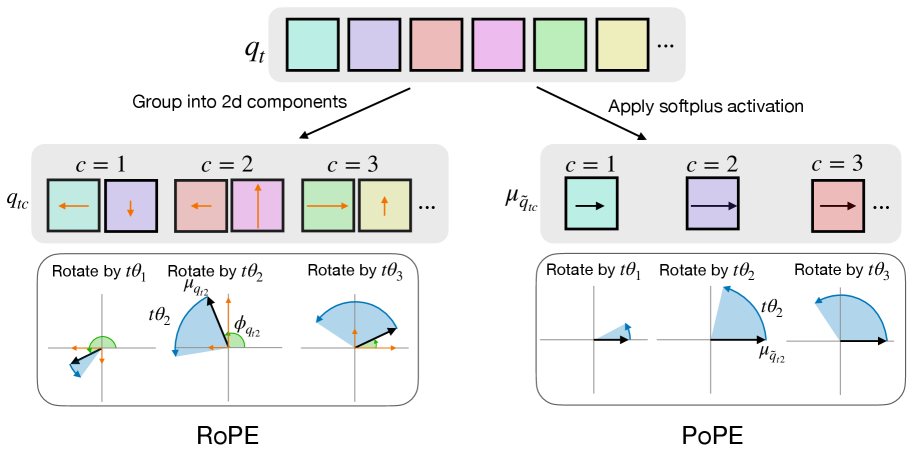

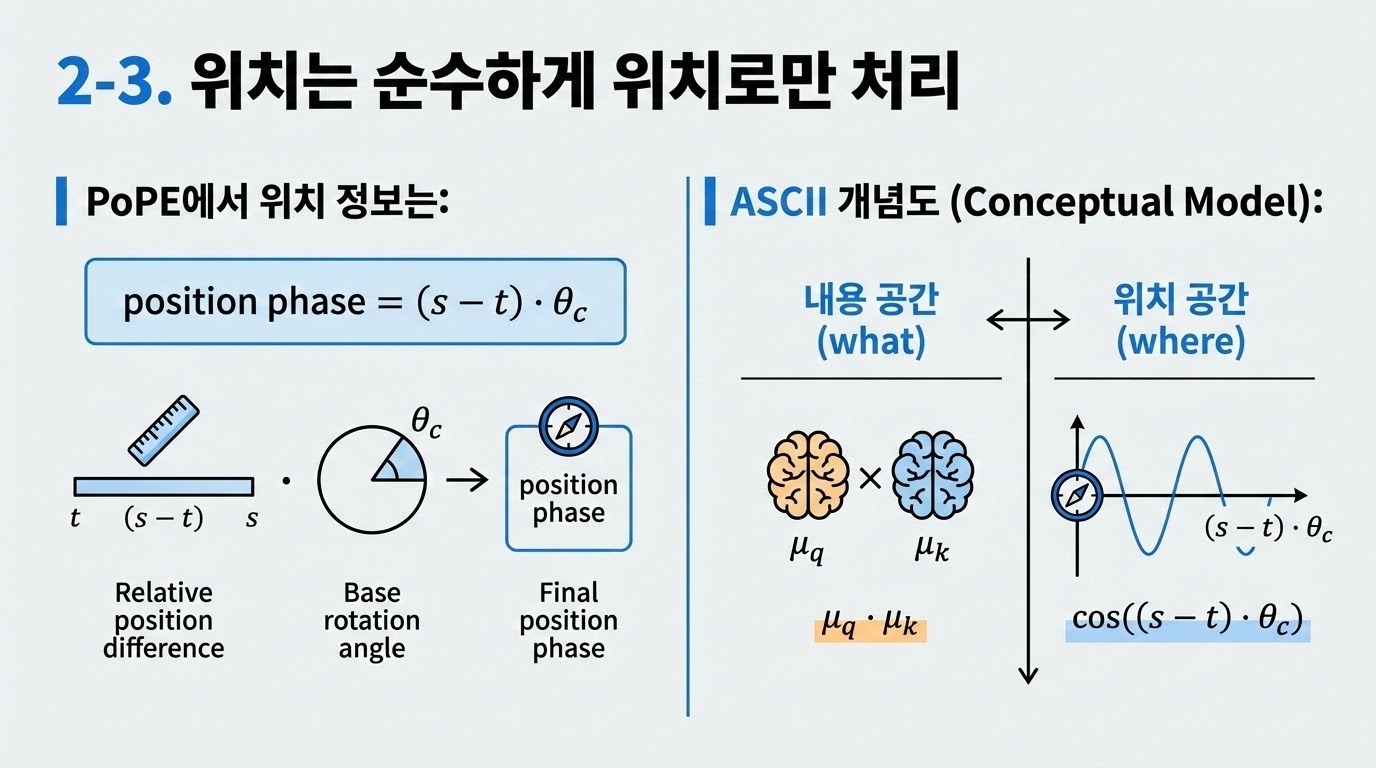
RoPE에서는 key와 query의 d/2개 성분을 복소수(complex numbers)로 해석하였다. 우리가 제안하는 방법에서는, key와 query를 표현하기 위해 극좌표 기반 표현(polar-coordinate representation)의 또 다른 형태를 사용한다. 우리는 이 방법을 PoPE(Polar Coordinate Positional Embedding)라고 부른다.



효율적인 구현 (Efficient Implementation)
우리는 Triton을 사용하여 PoPE를 구현하였으며, Flash Attention 2의 예제 코드(Dao, 2024)를 출발점으로 삼았다.¹
¹ https://triton-lang.org/main/getting-started/tutorials/06-fused-attention.html
구체적으로, 커널(kernel)을 수정하여 복소수 값의 key와 query를 데카르트 좌표계(Cartesian form)로 입력받고, query–key 내적에서 생성되는 복소수 행렬을 실제로 물리화(materialize)하지 않은 채, 커널 내부에서 그 실수부(real part)만 계산하도록 하였다.

그럼에도 불구하고, 우리는 다양한 PoPE 변형을 손쉽게 프로토타이핑할 수 있도록, 메모리 최적화를 수행하지 않고 데카르트 좌표계의 복소수 key와 query를 직접 입력으로 받는, 더 느리지만 일반적인 구현 방식을 선택하였다.
4. 실험 결과 (Results)
모든 실험에서 우리는 제안한 방법인 PoPE를, 널리 사용되는 RoPE(Su et al., 2024) 방식과 비교한다. 이를 위해 모델 구조와 학습 하이퍼파라미터가 완전히 동일한 두 개의 Transformer를 사용하며, 두 모델 간의 유일한 차이점은 위치 인코딩 방식뿐이다. 데이터셋의 생성, 전처리, 토크나이징 방법에 대한 자세한 내용은 부록 A.1절을 참조하라.
모든 실험에서는 자기회귀 시퀀스 모델링을 위해 인과적 마스킹(causal masking)을 적용한 디코더 전용 Transformer 아키텍처(Vaswani et al., 2017; Radford et al., 2018)를 사용한다. 이때 적용된 유일한 구조적 변경 사항은, 최신 대규모 모델들에서 일반적으로 사용되는 방식에 따라, 정규화 기법으로 LayerNorm(Ba et al., 2016) 대신 RMSNorm(Zhang & Sennrich, 2019)을 사용했다는 점이다. 각 실험에서 사용된 모델 구성과 학습 하이퍼파라미터에 대한 상세한 내용은 각각 부록 A.2절과 부록 A.3절을 참고하라.
간접 인덱싱 (Indirect Indexing)
우리는 가변 길이의 소스 문자열 안에서 목표 문자(target character)를 식별해야 하는 과제를 도입한다. 목표 문자는 특정 소스 문자(source character)로부터 지정된 상대적 오프셋(왼쪽 또는 오른쪽)에 위치한 문자로 정의된다. 예를 들어, 입력이
QEOHoUbKfeSrMVNlCzXu, z, -3, N
이라면, 문자열에서 문자 z를 기준으로 왼쪽으로 세 칸에 위치한 문자인 N이 목표가 된다.
이 시퀀스의 마지막(목표) 문자를 예측하기 위해서는, 모델이 토큰의 내용 정보(content)와 위치 정보(positional information)를 서로 독립적으로 조작할 수 있어야 하며, 일종의 포인터 산술(pointer arithmetic) 연산을 학습해야 한다. 데이터셋은 소스 문자열, 소스 기호, 그리고 상대적 이동량(relative shift)을 절차적으로 생성하여 구성된다.
우리는 RoPE(Su et al., 2024)와 PoPE를 비교하기 위해, 동일한 Transformer 모델 두 개를 학습시키되, 마지막(목표) 토큰에 대해서만 교차 엔트로피 손실(cross-entropy loss)을 적용하고, 최종 토큰의 정확도(accuracy)로 성능을 평가한다. 표 1은 테스트 세트에서의 최종 토큰 정확도에 대한 평균과 표준편차(3개 시드)를 보여준다.
표 1: 간접 인덱싱(Indirect Indexing) 과제의 테스트 분할에서의 정확도(표준편차 포함)

RoPE는 이 과제를 학습하는 데 어려움을 겪으며 평균 정확도가 약 11%에 불과한 반면, 제안한 방법인 PoPE는 거의 완벽하게 과제를 해결하여 평균 약 95%의 정확도에 도달한다. 이 결과는 RoPE가 ‘무엇(what)’과 ‘어디(where)’ 정보, 즉 특정 내용의 위치를 식별하고 특정 상대적 위치에 있는 내용을 결정하는 과정을 분리해 학습하는 데 어려움이 있음을 분명히 보여준다. 반면 PoPE는 key–query 매칭 과정에서 what과 where 정보를 분리(disentangle)할 수 있기 때문에, 이 과제에 대해 일반화 가능한 해결책을 효율적으로 학습하는 것으로 보인다.
다음으로, 우리는 음악 및 유전체(genomic) 데이터 도메인에서의 시퀀스 모델링에 대해 제안한 방법을 평가한다. 인간 언어와 마찬가지로, 이 두 도메인 역시 계층적 구조(hierarchical organization)를 가지며 규칙에 의해 지배되는 시스템이다. 다만 인간 언어와 달리, 이들 도메인에서는 구조적 규칙이 매우 엄격할 수 있고, 정확한 위치 정보가 특히 중요하다. 음악 작품은 코드(chord), 프레이즈(phrase), 모티프(motif)와 같은 계층적 반복 구조를 포함하며, 절대적인 값보다 상대적인 음정과 타이밍 변화가 더 예측력이 높다(Huang et al., 2019). 또한 Huang et al. (2019)는 피아노 제스처에서 나타나는 고유한 문법(grammar)이 절대 위치보다 상대적 간격(interval)에 더 크게 의존함을 지적한다. 이와 유사하게, 유전체 시퀀스 역시 요소들의 상대적 위치와 순서에 의존하는 국소적 패턴을 포함한다.
표 2: 음악 데이터셋(JSB, MAESTRO)에서 RoPE 또는 PoPE 위치 인코딩을 사용한 Transformer 모델의 테스트 분할 기준 최적 음의 로그우도(NLL)

PoPE를 사용한 모델은 두 음악 데이터셋 모두에서 RoPE 대비 더 낮은 NLL을 달성하며, 시퀀스 모델링 성능의 일관된 개선을 보여준다.
기호적 음악 시퀀스 모델링 (Sequence Modeling of Symbolic Music)
우리는 두 개의 널리 사용되는 음악 데이터셋, 즉 Bach 코랄(JSB, Bach-Chorales) (Boulanger-Lewandowski et al., 2012)과 MAESTRO (Hawthorne et al., 2019)를 사용하여, 최대 길이 2048의 MIDI 기반 입력에 대해 교차 엔트로피 손실(cross-entropy loss)을 적용해 Transformer 모델을 학습시킨다. 전처리 과정은 Huang et al. (2019)의 방법을 충실히 따른다. 표 2에서 확인할 수 있듯이, PoPE는 두 데이터셋 모두에서 RoPE 대비 음의 로그우도(NLL)를 감소시키는 성과를 보인다.
표 3: 인간 참조 유전체(Human Reference Genome) 데이터셋의 테스트 분할에서의 최적 음의 로그우도(NLL)

인간 유전체 시퀀스 모델링 (Sequence Modeling of Human Genome)
우리는 인간 참조 유전체(Human Reference Genome) 데이터셋(Dalla-Torre et al., 2025)의 시퀀스를 대상으로, 표준 다음 토큰 예측 손실(next-token prediction loss)을 사용해 Transformer 모델을 학습시킨다. 시퀀스의 최대 길이를 1000 토큰, 어휘 크기를 4107로 설정하기 위해, 최근 최고 성능을 보인 Nucleotide Transformer(Dalla-Torre et al., 2025)의 전처리 및 토크나이징 절차를 따른다. 그 결과, PoPE 기반 모델은 기준선인 RoPE 모델에 비해 NLL을 유의미하게 감소시키는 성능을 달성한다(표 3).
음악 및 유전체 시퀀스와 같은 다양한 도메인에서 Transformer에 PoPE를 도입함으로써 이점을 확인했지만, 우리는 이 도메인들을 의도적으로 선택했다. 그 이유는 이들 도메인이 내용(content)과 위치(position)의 분리뿐만 아니라 정확한 위치 정보를 요구하는 특성을 뚜렷하게 가지기 때문이다. 반면, 이러한 특성이 인간 언어에도 동일하게 적용되는지는 그리 명확하지 않다. 이에 따라 다음 실험에서는, 서로 다른 크기의 Transformer 모델을 OpenWebText 데이터셋에서 사전학습(pretraining)한다.
표 4: RoPE 또는 PoPE 위치 인코딩을 사용한 Transformer 모델의 OpenWebText 검증 분할 기준 퍼플렉시티(Perplexity)

PoPE를 적용한 모델은 모든 모델 규모에서 RoPE 대비 일관되게 더 낮은 퍼플렉시티를 기록하며, 언어 모델링에서도 성능 향상이 유지됨을 보여준다.
OpenWebText에서의 언어 모델링 (Language Modeling on OpenWebText)
우리는 OpenWebText 데이터셋(Gokaslan & Cohen, 2019)에서 세 가지 크기의 Transformer 모델을 학습시켜, 언어 모델링에서의 PoPE의 효용성을 평가한다. 각 모델 크기에서 두 모델은 아키텍처와 학습 파라미터가 완전히 동일하며, 위치 인코딩 방식만 다르다. 모든 모델 규모에 걸쳐 PoPE는 RoPE 대비 일관되게 더 낮은 퍼플렉시티(perplexity)를 달성한다(표 4). 특히, 모델 크기가 커질수록 RoPE와 PoPE 간의 성능 격차가 유지되거나 오히려 확대되는 경향을 보인다는 점은 주목할 만하다.
또한 우리는 절제(ablation) 실험을 수행하여, 124M 모델에 대해 PoPE 변형 중 softplus 활성화 함수 σ(⋅)를 사용하지 않는 경우와, 학습 가능한 편향 벡터 δ를 제거한 경우를 각각 학습시켰다. 그 결과, 이 두 요소 모두가 성능 향상에 각각 독립적으로 기여함을 확인했다(자세한 내용은 부록 B 참조). 이후 퍼플렉시티를 넘어, 표준적인 다운스트림 과제 세트에서 모델의 실제 활용 성능을 평가한다.
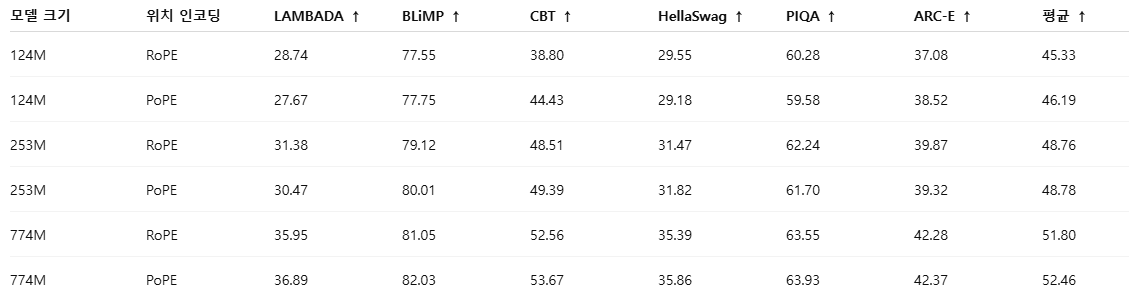
표 5: RoPE 또는 PoPE 위치 인코딩을 사용하여 OpenWebText에서 사전학습된 Transformer 모델의 다운스트림 과제 제로샷(Zero-shot) 성능
다운스트림 과제에서의 제로샷 성능 (Zero-shot Performance on Downstream Tasks)
우리는 OpenWebText에서 사전학습된 Transformer 모델들의 제로샷 성능을 다음의 여섯 가지 다운스트림 과제에서 평가한다:
LAMBADA (Paperno et al., 2016), BLiMP (Warstadt et al., 2020), Children’s Book Test(CBT) (Hill et al., 2016), HellaSwag (Zellers et al., 2019), PIQA (Bisk et al., 2020), 그리고 ARC-E (Clark et al., 2018).
Gao et al. (2024)를 따라, LAMBADA의 경우 OpenAI에서 제공하는 디토크나이즈(detokenized) 버전을 사용하고, 마지막 단어에 대한 top-1 정확도를 평가한다. (마지막 단어는 여러 토큰으로 구성될 수 있으며, 이때 그리디 디코딩을 사용한다.) CBT와 BLiMP에 대해서는 각 하위 과제별 정확도를 측정한 뒤, 모든 과제에 대한 평균 정확도를 보고한다. 표 5는 세 가지 모델 크기에 대해, 여섯 개 다운스트림 과제 각각의 정확도를 제시하며, 마지막 열에는 과제 전반에 대한 평균 정확도가 제시되어 있다. 모든 모델 규모에서, PoPE 기반 Transformer는 RoPE 기반 Transformer보다 더 높은 평균 정확도를 기록한다.
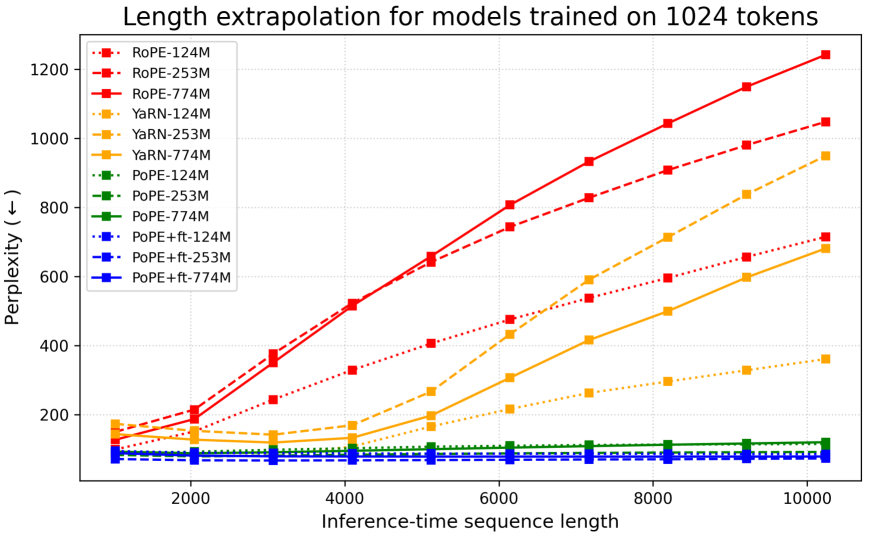
그림 2: 서로 다른 모델 크기에 대해 PG-19 데이터셋에서 테스트 시점의 길이 외삽(length extrapolation) 성능을 비교한 결과. RoPE를 사용하는 기준선 모델(빨간색)과, 길이 외삽을 위해 설계된 YaRN(노란색)을, 추가적인 파인튜닝이나 보간(interpolation) 기법을 전혀 사용하지 않는 PoPE(초록색) 및 파인튜닝만 적용한 PoPE+ft(파란색)와 비교한다. 테스트 시퀀스 길이는 1024의 배수로 최대 10240까지 확장된다.
테스트 시점 길이 외삽 (Test-time Length Extrapolation)
우리는 학습 시에 보지 못한 더 긴 시퀀스에 대해 PoPE가 얼마나 잘 일반화되는지를 측정한다. 구체적으로, 컨텍스트 길이(context window) 1024 토큰으로 OpenWebText에서 사전학습된 모델들을 대상으로, PG-19 데이터셋(Rae et al., 2020) 테스트 분할에서 최대 10240 토큰에 이르는 훨씬 더 긴 시퀀스에 대해 제로샷 퍼플렉시티(zero-shot perplexity)를 평가한다.
또한 우리는 RoPE의 길이 외삽 능력을 개선하기 위해 제안된 최신(state-of-the-art) 방법인 YaRN(Peng et al., 2024)과도 비교한다. YaRN은 RoPE의 기본 주파수 θ_c에 보간(interpolation) 기법을 적용하고, 더 긴 시퀀스에 대해 모델을 파인튜닝함으로써 길이 외삽 성능을 향상시키는 방식이다. 이에 비해 PoPE의 경우, 주파수 성분에 대한 보간은 수행하지 않고 더 긴 시퀀스에 대해 단순히 파인튜닝만 적용하며, 이 변형을 그림 2에서는 PoPE+ft로 표기한다.
YaRN과 PoPE+ft 모델은 모두 OpenWebText 데이터셋에서 길이 4096의 시퀀스를 사용해, 500 스텝 동안 파인튜닝되었으며, 워밍업 20 스텝, 배치 크기 64, 학습률 6e-5, 학습률 감소(decay) 없음의 설정을 사용한다.
그림 2에서 확인할 수 있듯이, RoPE는 테스트 시점에서 시퀀스 길이가 길어질수록 성능이 급격히 저하된다. YaRN은 파인튜닝에 사용된 컨텍스트 길이(최대 4096)를 넘지 않는 범위의 시퀀스에서는 이러한 성능 저하를 완화하지만, 파인튜닝에 사용된 길이를 초과하는 테스트 시퀀스로 확장하면 YaRN 역시 성능이 크게 저하된다.
이에 비해 PoPE는 테스트 시점에서 어떠한 파인튜닝이나 위치 보간 기법도 사용하지 않고도, 학습 시 컨텍스트보다 10배 더 긴 시퀀스에 대해 강력한 즉시 사용 가능한(out-of-the-box) 길이 외삽 성능을 보여주며, 그림 2에서 보듯이 YaRN과 같은 특화된 기준선 방법들보다도 우수한 성능을 달성한다. 또한 파인튜닝된 PoPE 변형(PoPE+ft)은 기본 PoPE 대비 더 긴 시퀀스에서 퍼플렉시티가 눈에 띄게 개선되는데, 이는 파인튜닝 과정에서 저주파(low-frequency) 성분들이 더 긴 시퀀스에 맞게 적응되었음을 시사한다.
종합하면, 이러한 결과는 RoPE의 핵심적인 한계를 원리적으로(principled way) 해결하는 데 있어 제안한 단순한 방법의 강점을 분명히 보여준다. 또한 흥미롭게도, RoPE의 외삽 성능은 모델 크기가 커질수록 오히려 악화되는 반면, PoPE의 외삽 성능은 전반적으로 안정적으로 유지된다. RoPE의 실패 원인은 what–where 상호작용을 허용한다는 점에 있는데, 이는 key와 query 표현의 일부 요소가 특정 성분의 위치 튜닝(position tuning)을 동적으로 이동시키는 것을 가능하게 한다. 이러한 이동은 특히 저주파 성분에서 문제가 되며, 컨텍스트 윈도우가 확장될 때에만 그 영향이 두드러지게 나타난다.
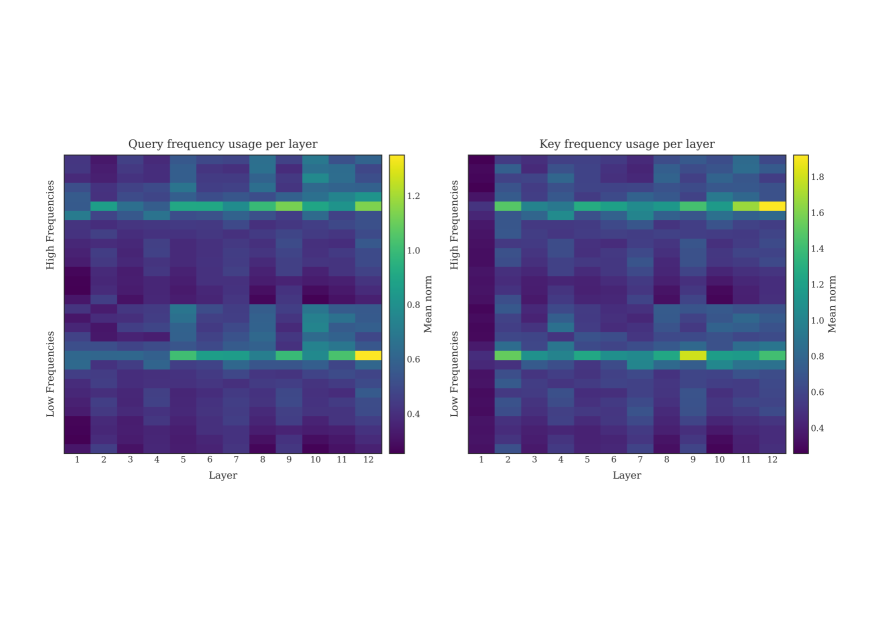
그림 3: 서로 다른 RoPE 주파수에 대해, 124M Transformer의 각 레이어에서 query(왼쪽)와 key(오른쪽)의 2차원 RoPE ‘청크(chunk)’에 대한 2-노름(ℓ2-norm)을 시각화한 결과. 각 레이어마다 셰익스피어 소네트 10편과 12개 어텐션 헤드에 대해 평균을 계산하였다.
주파수 사용 분석 (Frequency Usage Analysis)
Barbero et al. (2025)은 모든 레이어에 대해 2차원 RoPE 성분의 평균 노름(norm)을 시각화함으로써, RoPE가 서로 다른 주기 길이(period length)를 갖는 특징들을 어떻게 사용하는지를 분석하였다. 이들은 Gemma 7B 모델이 간섭(interference)을 최소화하기 위해 고주파 채널(high-frequency channels)에서 낮은 노름을 유지하려는 경향이 있음을 관찰했다. 이는 해당 채널들이 어텐션 내적(attention dot product)에 기여하는 방식이 무작위 노이즈(random noise)와 유사하게 동작하기 때문이다. 반면, Gemma는 희소한 일부 저주파(low-frequency) 특징들에 대해서만 높은 노름 값을 유지한다.
우리는 이들의 분석 방법을 OpenWebText에서 사전학습된 124M Transformer 모델(표 4)에 적용하였다. 그 결과, 우리 124M Transformer에서도 RoPE는 모든 레이어에 걸쳐 주파수 채널 중 극히 일부에 대해서만 높은 노름을 생성함을 확인했다(그림 3). Barbero et al. (2025)의 Gemma 7B 시각화 결과와 우리의 124M RoPE 기준 모델 사이에는 정성적 차이가 존재하지만, 이는 사전학습 데이터 규모와 모델 크기가 크게 다르다는 점에서 기인했을 가능성이 높다고 본다. 이러한 차이는 학습 데이터로부터 추출되는 행동 양상의 차이를 설명해줄 수 있다.
이에 비해 PoPE Transformer는 첫 번째 레이어를 제외한 모든 레이어에서 고주파 특징들에 대해 높은 노름 값을 할당한다(그림 4). 또한 PoPE는 RoPE와 비교했을 때, 전체 주파수 범위에 걸쳐 보다 분산된(distributed) 특징 사용 양상을 보인다. 특히 PoPE에서는 주파수의 개수가 두 배로 증가했음을 확인할 수 있는데, 이는 PoPE의 히트맵(그림 4)의 행(row) 수가 RoPE의 경우(그림 3)보다 두 배 많은 점에서 명확히 드러난다.

그림 4: 서로 다른 PoPE 주파수에 대해, 124M Transformer의 각 레이어에서 query(왼쪽)와 key(오른쪽)의 복소수 특징들의 크기(magnitude)를 시각화한 결과. 각 레이어마다 셰익스피어 소네트 10편과 12개 어텐션 헤드에 대해 평균을 계산하였다.
5. 관련 연구 (Related Work)
RoPE 및 그 확장 기법들
현재의 대규모 언어 모델(LLMs)에서 가장 널리 사용되는 위치 인코딩 방식은 RoPE(Su et al., 2024)이다(Touvron et al., 2023; Grattafiori et al., 2024; Liu et al., 2024; Team et al., 2025; Yang et al., 2025). 그러나 RoPE는 학습 시 사용된 길이보다 더 긴 시퀀스로 일반화하지 못한다는 한계가 잘 알려져 있다. 긴 시퀀스에 대한 사전학습은 비용이 매우 크기 때문에, 실제로는 비교적 짧은 컨텍스트 길이에서 모델을 학습한 뒤, 사후 학습(post-training) 단계에서 더 긴 컨텍스트로 확장하는 방식이 일반적으로 사용된다.
예를 들어, 각 위치에 대한 회전 주파수를 조정하여 최대 컨텍스트 길이에서 각 성분이 겪는 총 회전량이 사전학습 시와 동일하게 유지되도록 하는 방법이 있다(Chen et al., 2023). 이보다 더 성능이 좋은 대안으로는 YaRN(Peng et al., 2024)이 제안되었는데, 이는 고주파 성분을 저주파 성분보다 덜 스케일링함으로써, 작은 상대 거리 정보를 정밀하게 기억하는 능력을 유지한다. Ding et al. (2024)는 이러한 전략이, 초기 토큰 위치에 대해서는 스케일링을 건너뛰고, 유전 알고리즘(genetic algorithm)을 사용해 보다 최적의 스케일링 계수를 탐색함으로써 추가로 개선될 수 있음을 보였다. 더 나아가, 이들은 반복적인 스케일링과 이후의 튜닝 단계를 결합하여 컨텍스트 윈도우를 최대 200만(2M) 토큰까지 확장하는 데 성공했다.
Sun et al. (2023)는 다른 접근법을 취한다. 이들은 ALiBi(Press et al., 2022)와 유사한 감쇠(decay) 계수와 블록 단위 마스킹(block-wise masking)을 추가하여, 추론 시 어텐션이 참조할 수 있는 범위를 제한한다. 이러한 방식은 순수 RoPE에서 발생하는 급격한 성능 저하를 방지하는 데에는 도움이 되지만, 장거리 정보(long-range information)를 효과적으로 회상하는 것은 여전히 어렵다.
마지막으로 Wang et al. (2024)는 모든 RoPE의 파장(wavelength)을 정수로 반올림하는 방법을 제안한다. 이를 통해 특정 채널이 한 주기를 돌아올 때마다 발생하는 회전 각도의 누적 이동(increasing shift)을 제거할 수 있다. 이 기법은 YaRN의 성능을 추가로 개선할 뿐만 아니라, 길이 확장 기법을 사용하지 않는 경우에도 효과적인 성능 향상을 보여준다.
대안적 위치 임베딩 (Alternative Positional Embeddings)
원래의 Transformer(Vaswani et al., 2017)는 절대 위치(absolute position)를 인코딩하기 위해 사인·코사인 기반(sinusoidal) 위치 임베딩을 사용하며, 이를 입력 레이어에서만 토큰 임베딩에 더한다. 그러나 이러한 사인파 위치 임베딩은, 위치 정보를 모든 레이어에 주입하는 상대적 위치 임베딩 방식과 비교했을 때 일반적으로 성능이 떨어진다(Su et al., 2024).
한편, 자기회귀 Transformer는 명시적인 위치 정보 인코딩 없이도 동작할 수 있음이 알려져 있다(Schmidhuber, 1992a; Irie et al., 2019; Irie, 2025). 이러한 Transformer들은 절대 및 상대 위치 임베딩을 사용하는 경우보다 길이 외삽(length extrapolation) 특성이 더 우수한 경향이 있지만, 그 대가로 분포 내(in-distribution) 성능은 저하되는 문제가 있다(Kazemnejad et al., 2023).
1990년대에는 Neural History Compressor(Schmidhuber, 1992b)와 같은 신경 시퀀스 모델들이, 마지막으로 예기치 않은 입력이 등장한 이후 경과한 시간의 역수(inverse time)에 기반한 상대적 위치 인코딩을 사용했다. Shaw et al. (2018)은 key와 query 사이의 거리에 따라 선택되는 별도의 key 집합을 사용하는 상대적 위치 임베딩을 도입했으며, Music Transformer(Huang et al., 2019)는 이를 보다 효율적으로 구현하는 방식을 제안했다. Dai et al. (2019)는 또 다른 변형을 제안했는데, 각 오프셋(offset)마다 별도의 key를 학습하는 대신, 절대 위치 임베딩에서 영감을 받은 사인파 기반 “오프셋 인코딩(offset encodings)”에 대한 학습된 투영(projection)을 사용한다. 이 접근법은 실제로 더 긴 시퀀스 길이에 대해 더 잘 일반화되는 것으로 알려져 있다. 또한 이들은 문서 단위로 순차 학습을 수행하고, 이전 배치에 대한 어텐션을 허용함으로써 모델의 장거리(long-range) 처리 능력을 더욱 향상시킨다.
Wang et al. (2020)은 이러한 “오프셋 인코딩” 개념을 확장하여, 입력을 복소수 임베딩(complex-valued embeddings)으로 표현함으로써 내용(content), 전역 위치(global position), 그리고 시퀀스 내 순서 관계(order relationships)에 대한 정보를 함께 인코딩하는 방법을 제안했다. 한편, T5(Raffel et al., 2020)는 전혀 다른 접근을 취한다. 이 방법은 토큰 쌍을 거리 기준으로 로그 크기의 버킷(log-sized buckets)으로 그룹화한 뒤, 각 버킷마다 학습 가능한 편향(bias)을 어텐션 로그릿에 더함으로써, 멀리 떨어진 컨텍스트의 중요도를 감소시킨다. ALiBi(Press et al., 2022)는 여기에서 영감을 받아, 상대 거리에 따라 감쇠(decay)되는 학습 가능한 점수를 어텐션 행렬에 추가한다.
마지막으로 Geometric Attention(Csordás et al., 2022)이나 stick-breaking attention(Tan et al., 2025)은 보다 급진적인 접근을 취한다. 이들은 위치나 오프셋을 명시적으로 인코딩하지 않고, softmax 활성화 함수 자체를 stick-breaking 과정으로 대체하여, 가까이 있으면서 잘 매칭되는 항목에 우선순위를 부여한다. 저자들은 이러한 방식이 우수한 길이 일반화 성능을 제공한다고 주장한다.
6. 결론 (Conclusion)
우리는 PoPE(Polar Coordinate Positional Embedding)라 불리는 새로운 상대적 위치 인코딩 기법을 제안하였다. PoPE는 query–key 어텐션 점수를 계산할 때 내용(content)에 기반한 매칭과 위치(position)에 기반한 매칭을 서로 분리(decouple)하여 처리한다. 이에 반해 RoPE는 key와 query 사이에서 ‘무엇(what)’과 ‘어디(where)’ 정보가 서로 얽히도록(confound) 설계되어 있어, 우리가 간접 인덱싱(Indirect Indexing)이라 명명한 진단 과제에서 보여주었듯이, 오직 내용만 또는 오직 위치만에 기반한 매칭 규칙을 학습하는 데 어려움을 겪는다. 실제로 RoPE 기반 Transformer는 이 과제를 해결하는 데 큰 어려움을 보이는 반면, PoPE 기반 Transformer는 이를 쉽게 학습한다.
음악, 유전체, 자연어 도메인에서의 자기회귀 시퀀스 모델링 전반에 걸쳐, PoPE를 위치 인코딩으로 사용하는 Transformer는 RoPE를 사용하는 기준선 모델 대비 학습 손실(퍼플렉시티)과 다운스트림 과제 성능 모두에서 우수한 결과를 달성한다. 언어 모델링에서도 이러한 성능 향상은 124M에서 774M 파라미터 규모에 이르기까지 모델 크기 전반에 걸쳐 일관되게 유지된다. 무엇보다도 PoPE는 강력한 제로샷 길이 외삽(zero-shot length extrapolation) 능력을 보여주는 반면, RoPE는 테스트 시점에서 시퀀스 길이가 길어질수록 성능이 크게 저하되며, 이를 보완하기 위해서는 추가적인 파인튜닝이나 위치 보간 기법이 필요하다.
7. 윤리적 고찰 (Ethics Statement)
본 연구는 Transformer 기반 시퀀스 모델링에 관한 기초 연구로서, 직접적인 사회적 영향을 목적으로 하지 않는다. 그러나 본 연구에서 제안한, Transformer의 시퀀스 모델링 능력을 향상시키는 새로운 상대적 위치 인코딩 기법은, 이중 용도(dual-use) 응용에서 잠재적인 이익뿐만 아니라 예기치 못한 위험이나 부작용을 초래할 가능성도 지닌다.
음악, 유전체, 자연어 등 다양한 도메인에서의 시퀀스 모델링 성능을 향상시킴으로써, 본 연구는 단백질 접힘 예측, 신약 개발, 음악 작곡, 대화형 어시스턴트와 같은 다운스트림 응용에 사용되는 파운데이션 모델(Foundation Models)의 성능을 잠재적으로 개선할 수 있다. 특히, 제안한 방법의 향상된 길이 외삽 능력은 테스트 시점에서 훨씬 긴 시퀀스를 처리해야 하는, 예를 들어 체인 오브 쏘트(chain-of-thought)를 활용하는 대규모 언어 모델의 실제 배포 환경에서 매우 중요한 가치를 지니며, 더 긴 시퀀스에 대한 파인튜닝과 그에 따른 연산 비용을 줄이는 데 기여할 수 있다.
그러나 파운데이션 모델의 성능 향상이 항상 긍정적인 결과만을 가져오는 것은 아니다. 다른 모든 성능 향상과 마찬가지로, 본 연구의 성과 역시 유해한 콘텐츠를 대규모로 생성하거나, 텍스트·오디오·이미지 등 다양한 형태의 보다 정교한 딥페이크를 생성하는 데 악용될 가능성을 내포하고 있다.