https://www.mdpi.com/2079-9292/13/15/2969
Improved YOLOv7-Tiny for Object Detection Based on UAV Aerial Images | MDPI
The core task of target detection is to accurately identify and localize the object of interest from a multitude of interfering factors.
www.mdpi.com
UAV 항공 영상 기반 객체 탐지를 위한 개선된 YOLOv7-Tiny
Zitong Zhang¹, Xiaolan Xie¹,* , Qiang Guo²,* , Jinfan Xu¹
¹ 중국 계림이공대학교 컴퓨터과학및공학대학, Guilin 541006, China
² 중국 계림이공대학교 광시 임베디드 기술 및 지능 시스템 핵심 실험실, Guilin 541006, China
* 교신저자
Electronics 2024, 13(15), 2969
https://doi.org/10.3390/electronics13152969
접수: 2024년 6월 29일 / 수정: 2024년 7월 24일 / 게재 승인: 2024년 7월 26일 / 출판: 2024년 7월 27일
초록 (Abstract)
객체 탐지의 핵심 과제는 다양한 방해 요인 속에서 관심 객체를 정확하게 식별하고 위치를 추정하는 것이다. 이 과제는 대상 객체가 매우 작고 배경이 극도로 복잡한 경우가 많은 UAV 항공 영상 환경에서 특히 어렵다. 이러한 문제를 해결하기 위해, 본 연구에서는 YOLOv7-tiny 네트워크를 기반으로 한 UAV 항공 영상용 향상된 객체 탐지 알고리즘을 제안한다.
네트워크 백본(backbone)의 합성곱 모듈을 강화하기 위해, 기존의 전통적인 합성곱 대신 Receptive Field Coordinate Attention Convolution(RFCAConv)을 도입하여 핵심 영상 영역에서의 특징 추출 능력을 향상시켰다. 또한, 소형 객체 탐지 레이어(tiny object detection layer)를 추가함으로써 작은 객체에 대한 탐지 성능을 효과적으로 강화하였다. 더 나아가, 새롭게 제안된 BSAM 주의(attention) 메커니즘은 주의 분포를 동적으로 조정하여, 특히 객체 간 유사성이 높은 경우에도 객체와 배경을 정밀하게 구분할 수 있도록 한다.
마지막으로, 기존의 CIoU를 대체하는 혁신적인 inner-MPDIoU 손실 함수(loss function)를 도입하여 종횡비(aspect ratio) 변화에 대한 모델의 민감도를 높였으며, 이를 통해 탐지 정확도를 크게 향상시켰다. VisDrone2019 데이터셋에서 수행한 실험 결과, 기존 YOLOv7-tiny 모델 대비 개선된 YOLOv7-tiny 모델은 정밀도(Precision, P), 재현율(Recall, R), 평균 정밀도(mAP)를 각각 4.1%, 5.5%, 6.5% 향상시켰다. 이는 제안한 알고리즘이 기존의 주류 방법들보다 우수함을 입증한다.
키워드: UAV 영상, 객체 탐지, YOLOv7-tiny, BSAM 주의 메커니즘
1. 서론 (Introduction)
드론 기술이 지속적으로 발전함에 따라, 다양한 분야에서의 활용 가능성이 점차 드러나고 있다. 드론은 초기의 첨단 장난감이라는 인식을 넘어, 현대 사회에서 다목적이며 필수적인 도구로 자리 잡고 있다 [1]. 기술 발전과 드론 가격 하락에 힘입어, 드론은 실험실 단계를 넘어 상업 분야와 일상생활로 빠르게 확산되었다. 드론의 활용 영역 또한 군사 정찰을 넘어 농업 점검, 물류, 환경 모니터링, 재난 대응 등으로 확대되었으며, 사회 전반에서 그 중요성이 점점 커지고 있다 [2,3].
지상 관측, 수동 점검, 항공 및 위성 원격 탐사와 같은 기존 방식과 비교했을 때, 드론 기술은 여러 가지 뚜렷한 장점을 지닌다. 예를 들어 산불 감시 시나리오에서 드론은 신속한 배치와 실시간 데이터 전송을 가능하게 하여 [4], 긴급 대응 효율을 높이고 인력 의존도를 줄이며 장기적인 운영 비용을 절감할 수 있다. 그러나 UAV의 활용 범위가 넓어지고 보급률이 증가함에도 불구하고, 운용 환경의 복잡성과 사용자 요구의 다양성은 여전히 기존 UAV 객체 인식 기술에 큰 도전 과제로 남아 있다.
UAV 플랫폼 기반 객체 탐지는 여러 중대한 문제에 직면해 있으며 [5,6,7], 이는 주로 다음과 같은 측면에서 나타난다. 첫째, 직사광선에서 그림자 영역으로의 전환과 같은 빈번한 조명 변화는 영상의 밝기 범위에 큰 변화를 초래한다. 이러한 고동적 범위(high dynamic range) 환경에서는 객체 경계의 대비가 과도하게 강조되는 반면, 음영 영역 내부의 세부 정보는 사라질 수 있어 탐지 난이도가 크게 증가한다. UAV가 다양한 복잡 지형과 배경을 비행할 경우, 이러한 환경은 객체와 배경을 분리하는 과정을 더욱 어렵게 만들며, 객체가 다른 물체나 지형 요소에 의해 가려질 가능성도 높아진다 [8]. 또한 UAV 장비는 일반적으로 연산 자원이 제한적이기 때문에, 제한된 계산 능력 하에서 효율적인 객체 탐지 알고리즘을 구현하는 문제는 현재 연구자들이 직면한 핵심 과제 중 하나이다.
이러한 문제들을 해결하기 위해, 본 논문에서는 YOLOv7-tiny 아키텍처를 기반으로 한 향상된 네트워크 모델을 제안한다. 제안한 알고리즘은 VisDrone2019 데이터셋에서 실험되었으며, 우수한 탐지 성능을 입증하였다. 본 논문의 주요 기여는 다음과 같이 정리할 수 있다.
- ELAN-S 백본(backbone) 구조에서 부분 합성곱(partial convolution)을 Receptive Field Coordinate Attention Convolution(RFCAConv)으로 대체하였다. 이를 통해 합성곱 커널의 파라미터 공유로 인한 문제를 해결함과 동시에, 좌표 주의 메커니즘을 활용하여 핵심 영상 영역을 보다 정밀하게 포착하고 중요한 특징에 집중할 수 있도록 하였다. 이러한 개선은 파라미터 증가를 최소화하면서도 탐지 성능을 크게 향상시킨다.
- 소형 객체(tiny object) 탐지를 위한 전용 레이어를 추가하고 샘플링 스케일을 확장하였으며, 모델의 neck 단계에서 다중 스케일 특징 융합(multi-scale feature fusion)을 적용하였다. 이를 통해 기존 객체 탐지 모델에서 빈번히 발생하던 소형 객체의 누락 또는 오탐 문제를 효과적으로 해결하였고, 알고리즘의 일반화 성능을 크게 향상시켰다.
- CBAM과 BiFormer 어텐션을 결합하여 강화한 BSAM 주의 메커니즘을 프레임워크의 특징 통합 단계에 도입하였다. 이 메커니즘은 주의 분포를 동적으로 조정하여 네트워크가 객체와 배경을 보다 정확하게 구분할 수 있도록 하며, 특히 소형 객체에 대한 판별 능력을 크게 향상시킨다.
기존 모델에서 사용되던 CIoU를 대체하여, 개선된 inner-MPDIoU 손실 함수를 적용하였다. 이는 예측 박스와 실제 박스 간 종횡비 유사성에 둔감한 CIoU의 한계를 해결하며, 결과적으로 모델의 객체 탐지 성능을 크게 향상시킨다.
2. 관련 연구 (Related Work)
전통적인 객체 탐지 방법은 인공 특징 기반 객체 탐지 기법으로도 알려져 있다. 이 방법의 핵심 원리는 Haar, LBP(Local Binary Pattern), HOG(Histogram of Oriented Gradients)와 같은 인위적으로 설계된 특징을 활용하여 영상 내 객체 영역을 표현하고, 이후 머신러닝 기법을 적용해 객체 탐지 성능을 향상시키는 것이다. 그러나 이러한 접근 방식에는 명확한 한계가 존재한다. 우선, 특징 선택과 추출 과정에 전문적인 지식과 경험이 요구되어 전체 파이프라인을 구축하고 운영하기가 어렵다. 또한 모델의 특징이 특정 데이터셋에 대해서만 수작업으로 설계되기 때문에 일반화 성능이 제한적이며, 만족스러운 결과를 얻기 어려운 경우가 많다.
신경망과 연산 성능의 지속적인 발전에 따라 객체 탐지는 심층 학습 기반의 고도화 단계로 진입하였다. 전통적인 객체 탐지 방식과 비교했을 때, 딥러닝 기법은 신경망이 특징을 자동으로 학습하도록 함으로써 객체 탐지에 수반되는 학습 난이도를 크게 낮춘다. 초기에는 RCNN [9], Fast-RCNN [10], Faster R-CNN [11]과 같은 2단계(two-stage) 객체 탐지 알고리즘이 주를 이루었다. 이들의 핵심 아이디어는 객체 탐지 과정을 객체 분류와 후보 영역 생성이라는 두 단계로 분리하는 것이다. 이러한 방식은 높은 탐지 정확도를 제공하지만, 각 후보 영역에 대해 합성곱 연산을 수행해야 하므로 계산량이 매우 크다는 단점이 있다. 그 결과, 실시간 탐지 응용에는 적합하지 않다. 이러한 한계를 극복하기 위해 SSD [12]와 YOLO 계열 [13–18]로 대표되는 1단계(single-stage) 객체 탐지 알고리즘이 등장하였다. 이들 방법은 복잡한 영역 분할 및 분류 단계를 거치지 않고 단 한 번의 특징 추출 후, 분류 점수와 위치 좌표를 직접 예측한다. 이러한 종단 간(end-to-end) 객체 탐지 방식은 처리 속도와 효율성을 크게 향상시켰다.
전통적인 객체 탐지와 비교했을 때, UAV 항공 영상은 배경이 더욱 복잡하고 객체 간 가림(occlusion) 발생 가능성이 높아 탐지 난이도가 크게 증가한다. 또한 드론은 제한된 연산 성능을 가진 칩을 탑재하고 있기 때문에, 실시간 처리와 계산 자원 소모에 대한 고려가 필수적이다. 이러한 문제를 해결하기 위해 지금까지 다양한 효과적인 전략들이 제안되어 왔다.
2020년 Liu 등 [19]은 YOLOv3 구조를 개선하여 Darknet 백본에 동일한 차원의 ResNet 유닛 두 개를 통합함으로써 네트워크의 수용 영역(receptive field)을 크게 확장하였다. 또한 데이터 증강과 k-means 알고리즘을 활용하여 앵커 박스를 클러스터링함으로써 탐지 정확도를 향상시켰다. 이 전략은 UAV 영상에서 다양한 크기와 형태의 객체를 처리하는 능력을 개선한다.
2021년 Tan 등 [20]은 YOLOv4의 특징 추출 단계에 RFB 모듈을 도입하여 샘플링 및 합성곱 과정에서의 특징 추출 능력을 강화하였다. 특징 피라미드 단계에서는 ULSAM(Ultra Lightweight Subspace Attention Mechanism)을 적용하여 각 특징 맵 서브스페이스마다 서로 다른 주의 특징 맵을 생성함으로써 다중 스케일 특징 표현을 구현하고, 복잡한 배경에서의 소형 객체 탐지 성능을 향상시켰다. 또한 Soft-NMS를 활용하여 검출 박스의 점수와 중첩 정도를 평가하고, 중첩 박스의 점수를 동적으로 조정함으로써 가림 현상으로 인한 탐지 누락을 줄였다.
2022년 Luo 등 [21]은 YOLOv4에 개선된 효율적 채널 주의(IECA) 모듈을 추가하여, 최대 풀링과 전역 평균 풀링을 통해 채널 간 상호작용 정보를 보다 효율적으로 학습할 수 있도록 하였다. 더불어 적응형 공간 특징 융합 모듈을 설계하여 서로 다른 스케일의 특징 맵 통합을 최적화함으로써, 다중 스케일 객체 탐지 성능을 향상시켰다.
2023년 Zhao 등 [22]은 Swin Transformer 유닛과 다중 스케일 탐지 헤드, CBAM 주의 모듈을 결합하여 전역 정보를 효과적으로 포착하였다. 또한 새로운 SPPFS 피라미드 풀링 모듈을 도입하여 특징 간 상호작용을 강화하고, Soft-NMS와 Mish 활성화 함수를 통합함으로써 UAV 항공 영상에서 소형·밀집 객체 탐지 성능을 크게 개선하였다.
같은 해 Zhai 등 [23]은 기존 합성곱을 대체하는 SPD-Conv를 적용하여 소형 객체 특징 보존 능력을 강화하고, 소형 객체 탐지 성능을 향상시켰다. 아울러 모델의 neck 부분에 GAM 주의 메커니즘을 도입하여 오탐 발생 확률을 크게 줄였다.
2024년 Bai 등 [24]은 객체 형태 변화에 대응하기 위해 동적 스네이크 합성곱(dynamic snake convolution) 기술을 제안하였다. 이 기법은 합성곱 커널의 형태를 유연하게 조정하여 도로, 하천과 같은 가늘고 긴 구조를 효과적으로 포착할 수 있으며, UAV 데이터셋의 특성에 잘 부합한다.
또한 2024년 Zeng 등 [25]은 YOLOv5 기반의 혼합 주의 모듈을 제안하여 공간 및 좌표 주의(SCA) 메커니즘을 결합함으로써 소형 객체에 대한 특징 추출 능력을 강화하였다. 채널 스플라이싱 기법을 활용한 다층 특징 융합 구조를 구성하여 얕은 특징 맵과 깊은 특징 맵을 통합함으로써, 얕은 특징의 의미 정보를 풍부하게 하고 소형 객체 인식 성능을 향상시켰다.
3. 방법 및 개선 사항 (Methods and Improvements)
3.1. YOLOv7-Tiny 네트워크 구조
YOLOv7은 현재 사용 가능한 1단계(one-stage) 객체 탐지 알고리즘 중에서도 선도적인 성능을 보이는 모델 중 하나이다. YOLOv7-tiny는 엣지 디바이스를 위해 특별히 설계된 YOLOv7의 경량화 버전이다. YOLOv7의 다른 버전들과 비교했을 때, YOLOv7-tiny는 더 빠른 탐지 속도와 더 적은 파라미터 수를 갖는다. 비록 YOLOv7-tiny 모델의 탐지 성능이 다른 버전들에 비해 다소 낮기는 하지만, UAV 플랫폼의 제한된 연산 자원과 항공 영상 응용에서 요구되는 높은 실시간성 요구를 고려할 때, 본 연구에서는 YOLOv7-tiny 알고리즘을 기본 방법(base method)으로 선택하였다.
그림 1은 YOLOv7-tiny의 네트워크 아키텍처를 보여주며, 전체 구조는 크게 백본(backbone), 넥(neck), 헤드(head) 세 부분으로 구성된다.

그림 1. YOLOv7-tiny 각 구성 요소의 네트워크 구조도
(a) YOLOv7-tiny의 전체 네트워크 구조
(b) SPPCSPC-S의 네트워크 구조
(c) ELAN-S의 네트워크 구조
(d) CBL의 네트워크 구조
(e) MP의 네트워크 구조
백본 네트워크는 CBL 레이어, 경량 고효율 원격 집계 네트워크(Lightweight Efficient Layer Aggregation Network, ELAN-S) 레이어, 그리고 MPConv 레이어로 구성된다. 이 부분의 주요 목적은 탐지 대상 객체의 특징을 추출하는 것이다. ELAN-S 구조는 특징 추출 속도를 크게 가속화하며, 모델이 보다 쉽게 수렴하도록 돕는다.
YOLOv7-tiny의 넥(neck) 부분에는 PAFPN(Path Aggregation Feature Pyramid Network) 구조가 적용되어 있다. 이 구조는 특징 피라미드 네트워크(FPN) [26]의 상향식(top–down) 강건한 의미 정보와, 경로 집계 네트워크(PANet) [27]의 하향식(bottom–up) 정밀한 위치 정보 결합 능력을 효과적으로 융합한다. 해당 모듈은 8배, 16배, 32배 다운샘플링 이후의 특징 맵에 대해 다중 스케일 특징 융합을 수행함으로써, 서로 다른 크기의 객체를 탐지하는 능력을 크게 향상시킨다. 이를 통해 다중 스케일 학습 목표를 실현하고, 탐지의 유연성과 정확도를 동시에 개선한다.
헤드(head) 모듈에서는 YOLOv7과 달리, YOLOv7-tiny는 특징 융합을 위해 RepConv를 사용하지 않고 표준 합성곱(standard convolution)만을 사용한다. 이러한 전략은 모델의 탐지 효율을 일정 부분 감소시킬 수 있다. 그러나 표준 합성곱을 채택함으로써, RepConv로 인해 발생할 수 있는 파라미터 수 증가 문제와 기울기 소실(vanishing gradient) 문제를 효과적으로 회피할 수 있다. 세 번의 표준 합성곱을 거친 특징 맵은 서로 다른 크기의 세 가지 탐지 헤드로 입력되며, 이를 통해 다양한 크기의 객체에 대한 예측과 함께 객체의 위치 및 신뢰도 점수를 산출한다.
3.2. 개선된 YOLOv7-Tiny UAV 네트워크 모델
3.2.1. 수용 영역 좌표 주의 합성곱
(Receptive Field Coordinate Attention Convolution)
Receptive Field Attention Convolution(RFAConv) [28]은 수용 영역(receptive field)의 공간적 특징에 집중함으로써 합성곱 커널 파라미터 공유로 인해 발생하는 문제를 효과적으로 해결한다. RFAConv에서는 수용 영역 특징으로부터 생성된 주의(attention) 맵 간의 상호 학습을 통해 네트워크 성능을 향상시킨다. 그러나 이러한 방식은 추가적인 연산 비용을 수반할 수 있다. 이를 완화하기 위해, 각 수용 영역 특징으로부터 전역 정보를 집계하는 데 평균 풀링(average pooling)을 사용한다. 또한 softmax 함수를 적용하여 수용 영역 내부 각 구성 요소 간의 상관성을 강화한다. RFA의 계산 과정은 다음과 같이 표현된다.
𝐹 = Softmax(g₁×₁(AvgPool(X))) × ReLU(Norm(gₖ×ₖ(X))) (1)
여기서 기호 gᵢ×ᵢ는 크기가 i×i인 그룹 합성곱(grouped convolution) 연산을 의미한다. k는 사용되는 합성곱 커널의 크기를 나타내며, Norm은 정규화(normalization) 과정을 의미한다. X는 입력 특징 맵(input feature map)이다. F는 수용 영역 공간 특징(field space features)을 나타내며, 이는 주의 맵과 적절히 변환된 지각(perceptual) 맵 간의 곱 연산을 통해 얻어진다.
좌표 주의(Coordinate Attention, CA) [29]는 채널(channel) 자체에만 주의를 기울이는 것이 아니라, 채널의 공간적 위치 관계까지 함께 고려함으로써 채널 주의와 공간 주의를 효과적으로 결합한다.
Receptive Field Coordinate Attention Convolution(RFCAConv) [28]의 설계는 합성곱 파라미터 공유 문제를 해결함과 동시에, 좌표 주의 메커니즘을 통합함으로써 입력 특징의 공간적 연관성에 대한 네트워크의 이해 능력을 크게 향상시킨다. 이러한 개선을 통해 네트워크는 영상 내 핵심 영역을 보다 정확하게 식별할 수 있으며, 중요한 특징에 집중한 분석이 가능해진다. RFCAConv는 자기 주의(self-attention) 메커니즘과 유사한 방식으로 동작하여, 정보 내의 장거리 의존성(long-range dependency)을 효과적으로 포착할 수 있다. 기존의 자기 주의 메커니즘과 비교했을 때, RFCAConv는 연산량과 파라미터 수를 현저히 줄이면서도 합성곱 과정의 효율성을 동시에 향상시킨다는 장점을 지닌다.
그림 2는 개선된 RFCA 모듈과 기존 CA 모듈의 구조적 차이를 비교하여 보여준다.

그림 2. CA와 RFCAConv의 상세 구조 비교도
(a) CA의 구조
(b) RFCA의 구조
3.2.2. 다중 스케일 샘플링 특징 융합
소형 객체 탐지 레이어 추가
UAV 객체 탐지 과제에서는 특히 장거리 촬영, 고속 이동, 저고도 비행과 같은 조건에서 소형 객체를 정확하게 탐지하는 것이 매우 큰 도전 과제로 작용한다. 이러한 어려움의 주된 원인은 소형 객체가 갖는 특징 수 자체가 매우 제한적인 데다, 풀링 레이어와 합성곱 커널 연산 과정에서 특징 정보가 추가적으로 감소하기 때문이다. 이로 인해 소형 객체 인식의 난이도가 크게 증가하며, 오탐이나 미탐 발생 가능성도 높아진다.
또한 기존 Feature Pyramid Network(FPN) 구조는 특징 융합 단계에서 백본(backbone)으로부터 출력되는 특징 맵을 충분히 활용하지 못하는 한계가 있다. 이로 인해 업샘플링 과정에서 일부 정보 손실이나 간섭이 발생할 수 있으며, 이는 결과적으로 초소형(tiny) 객체 탐지 성능을 저하시킨다. 이러한 문제를 해결하기 위해, 본 연구에서는 YOLOv7-tiny 모델의 neck 모듈에 새로운 탐지 레이어인 P2 레이어를 추가하였다. 이 레이어는 깊은 수준의 전역 정보와 얕은 특징을 융합함으로써 영상의 세부 정보를 보다 많이 보존하고, 소형 객체를 탐지하고 인식하는 모델의 능력을 크게 향상시킨다.
추가된 소형 객체 탐지 레이어의 구조는 그림 3에 제시되어 있다.

그림 3. 개선된 YOLOv7-tiny의 각 구성 요소 네트워크 구조도
(a) 개선된 YOLOv7-tiny의 전체 네트워크 구조
(b) SPPCSPC-S의 네트워크 구조
(c) ELAN-S′의 네트워크 구조
(d) CBL의 네트워크 구조
(e) MP의 네트워크 구조
그림 3은 업데이트된 YOLOv7-tiny 네트워크 구조를 나타낸다.
3.2.3. 이중 단계 공간 주의 모듈
(Bilevel Spatial Attention Module)
주의(attention) 메커니즘의 도입은 객체 탐지 연구에서 핵심적인 기술적 진보로 입증되었으며, 탐지 정확도를 크게 향상시켜 왔다. 이 메커니즘의 기본 원리는 특징 맵의 서로 다른 영역에 서로 다른 가중치를 부여하여, 관심 있는 특징을 강조하는 데 있다. 특히 원격 탐사 영상 분석 과정에서는 객체 정보가 복잡한 배경 정보에 비해 상대적으로 작기 때문에, 기존의 합성곱 신경망은 특징 추출 단계에서 비객체 영역의 영향을 쉽게 받아 탐지 성능이 저하되는 문제가 발생한다.
이러한 문제를 해결하기 위해, 연구자들은 네트워크의 객체 특징 추출 능력을 최적화하기 위한 다양한 주의 메커니즘 전략을 제안해 왔다. 일반적으로 이러한 전략은 두 가지 주요 차원을 포함한다. 하나는 채널 주의(channel attention)로, 특징 채널에 서로 다른 가중치를 부여함으로써 객체 특징의 표현력을 강화하여 “무엇(what)”이 객체인지를 식별하는 데 초점을 둔다. 다른 하나는 공간 주의(spatial attention)로, 객체가 “어디(where)”에 위치하는지를 정확히 찾아내는 역할을 담당한다.
본 연구에서는 BiFormer [30]의 Bilevel Routing Attention Module과 CBAM [31]의 Spatial Attention Module(SAM)을 결합하여, 영상 내 소형 객체 인식 성능을 향상시키는 동시에 불필요한 정보는 효과적으로 제거하고자 한다. 두 모듈을 병렬로 통합함으로써 Bilevel Spatial Attention Module(BSAM)을 구성하였으며, 이를 통해 모델의 전반적인 주의 표현 능력을 강화하였다. BSAM 모듈은 BiFormer의 동적 희소 주의(dynamic sparse attention)와 공간 주의 메커니즘을 결합한 구조로, 기존 CBAM 주의 모듈과 비교했을 때 특히 위치 민감도 측면에서 우수한 특징 추출 성능을 보인다. 이 모듈은 콘텐츠에 따라 주의 할당을 유연하게 조절하여, 관련 없는 토큰들에 주의를 분산시키는 대신 소수의 핵심 토큰에 집중함으로써, 높은 특징 추출 정확도를 유지하면서도 계산 효율성을 향상시킨다.
BSAM 모듈의 동작 원리는 먼저 입력 특징 맵을 다수의 작은 영역으로 세분화하는 것에서 시작된다. 이후 query(Q), key(K), value(V) 세 가지 벡터를 계산하고, 인접 행렬(adjacency matrix)을 활용하여 의미적 연관성이 높은 영역을 식별한다. 그 다음, 이러한 의미적으로 연결된 영역들 간의 토큰-대-토큰(token-to-token) 주의 메커니즘(𝐾𝑔, 𝑉𝑔)을 구현하기 위해 인덱싱된 라우팅 행렬을 구성한다.
𝐾𝑔 = gather(K, 𝐼𝑟) (2)
𝑉𝑔 = gather(V, 𝐼𝑟) (3)
여기서 𝐾𝑔와 𝑉𝑔는 각각 집계된(gathered) key 텐서와 value 텐서를 의미하며, 𝐼𝑟은 주의 메커니즘에서 가장 관련성이 높거나 중요한 영역 또는 요소를 포함하는 인덱스를 나타낸다.
이중 단계 주의 메커니즘을 통해 처리된 특징 맵은 전역 최대 풀링(global max pooling)과 전역 평균 풀링(global average pooling)을 거쳐 2차원 표현으로 변환된다. 이후 채널 차원에서 이들 특징 맵을 연결(concatenation)한 뒤, 합성곱 레이어를 통해 단일 채널로 압축함으로써 특징 통합 과정을 간소화한다. 이어서 sigmoid 활성화 함수를 적용하여 공간 주의 특징 맵을 생성하고, 이를 통해 관련 특징에 대한 집중도를 정제한다. 마지막으로 공간 주의 특징 맵을 입력 특징 맵과 요소별(element-wise)로 곱하여 최종 출력을 생성한다.
BSAM 모듈의 구조는 그림 4에 제시되어 있다.

그림 4. 이중 단계 공간 주의 모듈(Bilevel Spatial Attention Module)의 상세 구조도
3.2.4. 손실 함수 최적화
(Optimization of Loss Function)
YOLOv7-tiny는 바운딩 박스 예측을 위해 CIoU [32] 손실 함수를 사용한다. CIoU는 기존 IoU를 확장한 형태로, 바운딩 박스 중심점 간의 유클리드 거리와 종횡비(aspect ratio)를 고려한 패널티 항을 포함한다. 그러나 탐지된 객체의 종횡비가 예측 박스의 종횡비와 유사한 경우, 이러한 패널티 메커니즘은 충분히 효과적으로 작동하지 못할 수 있다.
반면, inner-IoU [33]는 서로 다른 스케일을 갖는 데이터셋 전반에 걸쳐 손실 함수를 계산하기 위한 새로운 방법을 제안하여, 적응성과 효율성을 향상시킨다. 다양한 스케일의 보조(auxiliary) 프레임을 도입하고, 스케일 팩터 비율을 통해 그 크기를 조절함으로써 손실 함수 계산의 효율을 최적화한다. inner-IoU의 계산식은 다음과 같다.
𝑏𝑙 = 𝑥𝑐 − 𝑤 ∗ 𝑟𝑎𝑡𝑖𝑜 / 2, 𝑏𝑟 = 𝑥𝑐 + 𝑤 ∗ 𝑟𝑎𝑡𝑖𝑜 / 2 (4)
𝑏𝑡 = 𝑦𝑐 − ℎ ∗ 𝑟𝑎𝑡𝑖𝑜 / 2, 𝑏𝑏 = 𝑦𝑐 + ℎ ∗ 𝑟𝑎𝑡𝑖𝑜 / 2 (5)
𝑖𝑛𝑡𝑒𝑟 = (min(𝑏𝑔𝑡𝑟, 𝑏𝑟) − max(𝑏𝑔𝑡𝑙, 𝑏𝑙)) × (min(𝑏𝑔𝑡𝑏, 𝑏𝑏) − max(𝑏𝑔𝑡𝑡, 𝑏𝑡)) (6)
𝑢𝑛𝑖𝑜𝑛 = (𝑤𝑔𝑡 ∗ ℎ𝑔𝑡) ∗ (𝑟𝑎𝑡𝑖𝑜)² + (𝑤 ∗ ℎ) (7)
𝐼𝑜𝑈ᵢₙₙₑᵣ = 𝑖𝑛𝑡𝑒𝑟 / 𝑢𝑛𝑖𝑜𝑛 (8)
보조 바운딩 박스를 도입함으로써, inner-IoU는 이 보조 박스와 실제(target) 바운딩 박스 간의 IoU를 손실 계산의 한 요소로 활용한다. 예측 박스가 실제 박스와 높은 교차 비율을 보이는 경우에는, 더 작은 보조 바운딩 박스를 사용하여 손실을 계산함으로써 학습 수렴 속도를 가속한다. 반대로 예측 박스와 실제 박스 간의 교차 비율이 낮은 경우에는, 더 큰 보조 바운딩 박스를 사용하여 유효 회귀 범위를 확장함으로써 낮은 IoU 영역에서의 회귀를 보조하고 IoU 지표의 일반화 성능을 향상시킨다.
MPDIoU 손실 함수는 예측 박스와 실제 박스의 수직 방향 에지 간 최소 거리를 고려함으로써 겹침(overlap) 측정의 정확도를 개선한다.
𝑀𝑃𝐷𝐼𝑜𝑈 = 𝐼𝑜𝑈 − 𝜌²(𝑃ₚᵣₑ𝑑1, 𝑃𝑔𝑡1) / (𝑤² + ℎ²) − 𝜌²(𝑃ₚᵣₑ𝑑2, 𝑃𝑔𝑡2) / (𝑤² + ℎ²) (9)
여기서 𝑃ₚᵣₑ𝑑1, 𝑃ₚᵣₑ𝑑2는 각각 예측 박스의 좌상단과 우하단 점을 의미하며, 𝑃𝑔𝑡1, 𝑃𝑔𝑡2는 실제 박스의 좌상단과 우하단 점을 의미한다. 𝜌²(𝑃ₚᵣₑ𝑑1, 𝑃𝑔𝑡1)은 해당 점들 간의 거리 제곱을 계산하는 함수이다.
inner-MPDIoU는 inner-IoU를 활용하여 MPDIoU를 확장한 손실 함수로, 바운딩 박스 간 겹침 평가를 보다 정교하게 수행함으로써 복잡하거나 객체가 밀집된 장면에서도 효과적으로 동작한다. 이 방법은 바운딩 박스 위치 변화에 대한 모델의 반응 속도를 향상시키고, 복잡한 시각적 환경에 대한 적응 능력을 강화한다. inner-MPDIoU의 수식은 다음과 같다.
𝑀𝑃𝐷𝐼𝑜𝑈ᵢₙₙₑᵣ = 𝐼𝑜𝑈ᵢₙₙₑᵣ − 𝜌²(𝑃ₚᵣₑ𝑑1, 𝑃𝑔𝑡1) / (𝑤² + ℎ²) − 𝜌²(𝑃ₚᵣₑ𝑑2, 𝑃𝑔𝑡2) / (𝑤² + ℎ²) (10)
4. 실험 결과 분석 (Analysis of Experimental Results)
4.1. 데이터셋 (Dataset)
VisDrone2019 [34] 데이터셋은 톈진대학교(Tianjin University)에서 제공한 UAV 비전 과제를 위한 데이터셋으로, 객체 탐지를 목적으로 한 10,209장의 정적 이미지로 구성되어 있다. 이 중 6471장은 학습용(training set), 548장은 검증용(validation set), 나머지 3190장은 테스트용(testing set)으로 할당되었다. 해당 데이터셋은 다양한 실제 환경을 포괄하며, 서로 다른 기상 조건과 시간대에서 촬영된 도시 도로, 농촌 지역, 공원 등의 장면을 포함하고 있다. 또한 객체 탐지 모델의 평가 및 성능 향상을 지원하기 위해 10개의 객체 범주에 대한 주석(annotation)이 제공된다.
YOLOv7-tiny 모델을 활용한 객체 탐지에 앞서, VisDrone2019 데이터셋의 이미지들에 대해 일련의 전처리 과정을 수행하였다. 먼저 모든 이미지를 640 × 640 픽셀 크기로 리사이즈하였으며, 이후 픽셀 값을 [0, 1] 범위로 정규화하여 네트워크의 학습 효율을 향상시켰다. 또한 데이터 증강을 위해 랜덤 회전(random rotation) 기법을 적용하여, 복잡한 배경 환경에서도 모델의 강건성을 높였다. 이러한 전처리 단계들은 입력 데이터의 일관성과 품질을 보장함으로써, YOLOv7-tiny 모델이 영상 내 객체를 보다 정확하게 인식하고 위치를 추정할 수 있도록 한다.
4.2. 실험 환경 (Experimental Environment)
본 연구의 실험 구성에서는 Intel(R) Xeon(R) Bronze 3106 CPU @ 1.70 GHz, 256 GB RAM을 탑재하고 CentOS 7.6 운영체제를 실행하는 컴퓨팅 플랫폼을 사용하였다. 딥러닝 실험은 PyTorch 프레임워크 기반에서 수행되었으며, NVIDIA Tesla V100 GPU와 CUDA 11.8 환경을 활용하였다. 또한 실험 조건의 일관성을 보장하기 위해, 모든 학습 프로그램에 동일한 하이퍼파라미터 설정을 적용하였다. 모델 사전 학습(pre-training)을 위해 COCO 데이터셋에서 학습된 가중치를 사용하였다.
표 1은 학습 과정에서 사용된 실험 환경 구성과 주요 하이퍼파라미터 설정을 나타낸다.

4.3. 평가 지표 (Assessment Metrics)
모델 성능 향상과 예측 정확도를 객관적으로 평가하기 위해, 본 연구에서는 정밀도(Precision, P), 재현율(Recall, R), 그리고 평균 정밀도(mean Average Precision, mAP)와 같은 주요 지표를 사용하였다. 특히 mAP@0.5는 예측된 바운딩 박스와 실제 바운딩 박스 간의 중첩 비율이 최소 50% 이상일 경우 해당 예측을 올바른 탐지로 간주하는 지표로, 모델의 예측 효과를 평가하는 데 널리 사용되는 중요한 척도이다.
𝑃 = 𝑇𝑃 / (𝑇𝑃 + 𝐹𝑃) (11)
𝑅 = 𝑇𝑃 / (𝑇𝑃 + 𝐹𝑁) (12)
𝐴𝑃 = ∫₀¹ 𝑝(𝑟) 𝑑𝑟 (13)
𝑚𝐴𝑃 = (1 / 𝑘) ∑ᵢ₌₁ᵏ 𝐴𝑃ᵢ (14)
여기서 𝑇𝑃(True Positive)는 모델이 양성(positive) 클래스를 양성으로 정확히 예측한 경우를 의미하고, 𝐹𝑃(False Positive)는 음성(negative) 클래스를 양성으로 잘못 분류한 경우를 의미한다. 𝑇𝑁(True Negative)는 음성 클래스를 음성으로 정확히 예측한 경우를, 𝐹𝑁(False Negative)은 양성 클래스를 음성으로 잘못 판단한 경우를 나타낸다.
또한 𝑝(𝑟)는 특정 재현율(recall)에서의 정밀도를 의미하며, 𝐴𝑃는 서로 다른 재현율 구간에서의 정밀도를 적분하여 계산한 평균 정밀도이다. 이는 다양한 재현율 수준에서의 정밀도를 통합적으로 고려함으로써 모델 성능을 종합적으로 평가한다.
추론 시간(inference time, 또는 response time)은 밀리초(ms) 단위로 측정되며, 모델이 객체 탐지를 완료하는 데 소요되는 시간을 평가하는 지표이다. 모델의 성능을 보다 포괄적으로 분석하기 위해, 본 연구에서는 추론 시간뿐만 아니라 모델 파라미터 수와 GFLOPS를 함께 고려하여 연산 복잡도 및 계산 자원 소모 수준을 평가하였다.
4.4. 소거 실험 (Ablation Experiment)
향상된 모듈들이 모델 성능에 미치는 영향을 검증하기 위해, VisDrone2019 데이터셋에서 단일 개선 모듈 또는 여러 개선 모듈을 조합한 실험을 수행하였다. 실험 결과는 표 2에 제시되어 있다.

표 2에서 볼 수 있듯이, 초기 실험에서는 YOLOv7-tiny를 기준 모델로 설정하여 VisDrone2019 데이터셋에서 실험을 수행하였으며, 그 결과 mAP@0.5는 35.0%로 나타났다. 이후 실험 A, B, C, D는 YOLOv7-tiny 모델을 기반으로 각각 RFCA, TODL, BSAM, inner-MPDIoU 모듈을 단독으로 추가하여, 각 모듈이 프레임워크 성능에 미치는 영향을 분석하였다.
실험 A에서는 ELAN-S 구조의 일부 합성곱을 RFCAConv로 대체함으로써 합성곱 커널 공유 문제를 해결하였으며, 기준 모델 대비 mAP@0.5가 2.8% 향상되었다. 실험 B에서는 소형 객체 탐지 레이어를 도입하여 모델 파라미터 수는 증가했으나, 성능 향상 효과가 가장 뚜렷하게 나타났다. 기준 모델과 비교했을 때 정밀도(P), 재현율(R), mAP@0.5가 각각 1.9%, 4.6%, 3.5% 증가하였다. 실험 C에서는 BiFormer의 BRA 어텐션과 CBAM의 공간 어텐션을 결합한 BSAM 어텐션 메커니즘을 모델의 neck 부분에 통합하였으며, 그 결과 소형 객체 탐지 능력이 크게 향상되어 기준 모델 대비 mAP@0.5가 1.7% 증가하였다. 실험 D에서는 손실 함수를 inner-MPDIoU로 교체하였으며, 기존 모델의 파라미터 수 변화는 거의 없이 mAP@0.5가 0.8% 향상되었다.
실험 E, F, G는 기존의 개선 사항을 바탕으로 서로 다른 개선 전략을 조합하여 모델 성능을 추가로 최적화한 결과이다. 실험 H에서는 네 가지 개선 전략을 모두 통합하였으며, 이전 모델 대비 파라미터 수는 단 0.36 M만 증가했음에도 불구하고, 정밀도(P), 재현율(R), mAP@0.5가 각각 4.1%, 5.5%, 6.5% 크게 향상되었다.
inner-MPDIoU 손실 함수에서 ratio 값의 변화가 실험 결과에 미치는 영향을 분석하기 위해, 서로 다른 ratio 값을 적용한 소거 실험을 추가로 수행하였으며, 그 결과는 표 3에 제시되어 있다.

ratio = 1일 때, inner-MPDIoU 손실 함수는 사실상 MPDIoU 손실 함수와 동일해진다. 실험 결과에 따르면, UAV 항공 영상에는 주로 소형 객체가 많이 포함되어 있기 때문에 ratio 값이 1보다 클 경우 보조 프레임이 실제 프레임보다 커지며, 이는 낮은 IoU 영역에서의 회귀에 유리하게 작용한다. 가장 우수한 실험 결과는 ratio = 1.3일 때 얻어졌다. 반면 ratio = 1.2 또는 1.4일 경우에는 성능이 다소 감소하였다. 따라서 최적의 ratio 값은 실험 데이터셋의 특성에 따라 조정되어야 한다. 일반적으로 데이터셋 내 객체 크기가 큰 경우에는 ratio를 1보다 작게 설정하고, 객체 크기가 작은 경우에는 1보다 크게 설정하는 것이 바람직하다.
TODL이란?
TODL = Tiny Object Detection Layer
즉, 소형 객체 탐지 레이어를 의미합니다.
논문에서의 TODL 의미 정리
이 논문에서 TODL은 YOLOv7-tiny의 neck 부분에 추가된 새로운 탐지 레이어(P2 layer)를 가리킵니다.
- 기존 YOLOv7-tiny
- P3, P4, P5 레벨에서만 detection head 사용
- stride 8 / 16 / 32 기준
- 개선된 구조 (TODL 추가)
- P2 레벨(stride 4) 에 detection head 추가
- 얕은(shallow) feature + 깊은(global) feature 융합
- 작은 객체에 더 많은 공간 해상도 제공
즉 TODL은 “작은 객체를 위해 더 높은 해상도의 feature map에서 바로 탐지하도록 만든 전용 detection head”입니다.
왜 TODL이 중요한가?
UAV 항공 영상에서는 다음 특성이 두드러집니다.
- 객체 크기가 매우 작음 (차량, 보행자 등)
- 원거리 촬영
- 배경 대비 객체 픽셀 수가 극히 적음
기존 YOLO 계열 구조에서는:
- backbone을 거치며 downsampling이 반복됨
- 작은 객체의 feature가 소실되기 쉬움
→ P2 레벨에서 바로 detection을 수행하는 TODL이 이를 보완
Ablation Table에서 TODL의 역할
Table 2에서:
- B 실험 = TODL만 추가
- mAP@0.5: +3.5%
- Recall: +4.6%
→ 단일 모듈 중 가장 큰 성능 개선 효과
이 결과는 TODL이 UAV small object detection에서 핵심적인 기여 요소임을 보여줍니다.
한 줄 요약
TODL은 Tiny Object Detection Layer의 약자로,
YOLOv7-tiny에 P2 detection head를 추가하여 소형 객체 탐지를 강화하는 구조적 개선 요소이다.
4.5. 비교 실험 (Comparative Experiments)
모델의 neck 부분에 주의(attention) 메커니즘을 도입하는 것이 성능에 미치는 영향을 검증하기 위해, 본 연구에서는 제안한 BSAM 모듈을 기존에 널리 사용되는 SENet, CBAM, BiFormer 주의 메커니즘과 비교하는 네 가지 비교 실험을 수행하였다. 표 4는 다양한 주의 메커니즘 모듈을 추가하기 전후의 YOLOv7-tiny 탐지 성능을 비교한 결과를 보여준다. 실험 결과, 서로 다른 주의 메커니즘을 추가하면 네트워크 모델의 전체 정확도가 향상되는 것을 확인할 수 있었다. 그중에서도 YOLOv7-tiny 모델에 BSAM 주의 메커니즘을 적용했을 때, 다른 주의 메커니즘들보다 더 우수한 탐지 성능을 보였다.

BSAM, CBAM, BiFormer 주의 메커니즘 간의 차이를 보다 직관적으로 분석하기 위해, 본 연구에서는 gradient-weighted class activation mapping(Grad-CAM) [35] 기법을 사용하여 시각화를 수행하였다. 그 결과는 그림 5에 제시되어 있다. 그림 5에서 볼 수 있듯이, 주의 메커니즘을 적용하지 않은 모델과 비교했을 때, CBAM 및 BiFormer 주의 메커니즘을 통합한 모델은 영상 내 사람과 차량과 같은 객체에 대해 더 높은 주의 집중도를 보인다. 그림 5(d)는 기준 모델에 BSAM 주의 메커니즘을 결합한 결과를 나타내며, BSAM은 CBAM이나 BiFormer에 비해 더 넓은 객체 영역에 주의를 집중할 뿐만 아니라, 객체와 배경 정보를 효과적으로 구분하는 능력을 보여준다. 이는 BSAM 주의 메커니즘 모듈이 CBAM 및 BiFormer 대비 뚜렷한 장점을 가진다는 것을 시사한다.
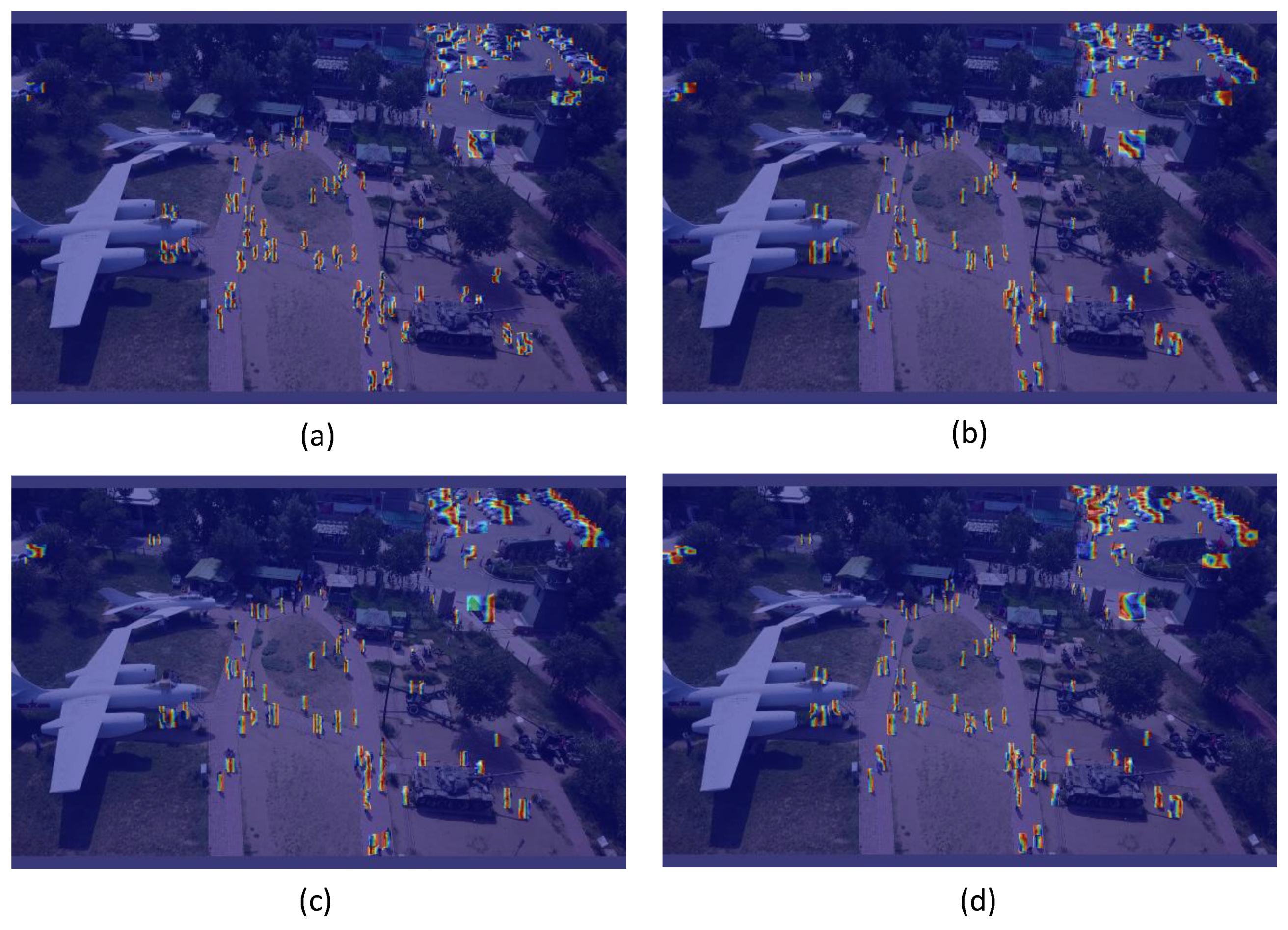
그림 5. 서로 다른 주의 메커니즘을 원래 네트워크 구조에 추가했을 때의 히트맵 비교
(a) 주의 메커니즘이 없는 경우
(b) CBAM을 적용한 경우
(c) BiFormer를 적용한 경우
(d) BSAM을 적용한 경우
개선된 모델의 성능 향상을 종합적으로 평가하기 위해, 본 연구에서는 현재 널리 사용되는 여러 경량 객체 탐지 알고리즘들과의 비교 분석을 수행하였다. 구체적인 실험 결과는 표 5에 제시되어 있다. 표 5의 분석 결과에 따르면, Faster R-CNN [10], Cascade R-CNN [36]과 같은 2단계 객체 탐지 알고리즘은 전반적으로 낮은 mAP 값을 보이는 반면, YOLO 계열 알고리즘은 상대적으로 높은 mAP 값을 달성하는 경향이 있다. 특히 본 논문에서 제안한 알고리즘은 YOLOv7-tiny 대비 mAP 값을 6.5% 향상시켜, RetinaNet [37], MSA-YOLO [38] 등 기존 알고리즘들보다 현저히 우수한 성능을 보였다.
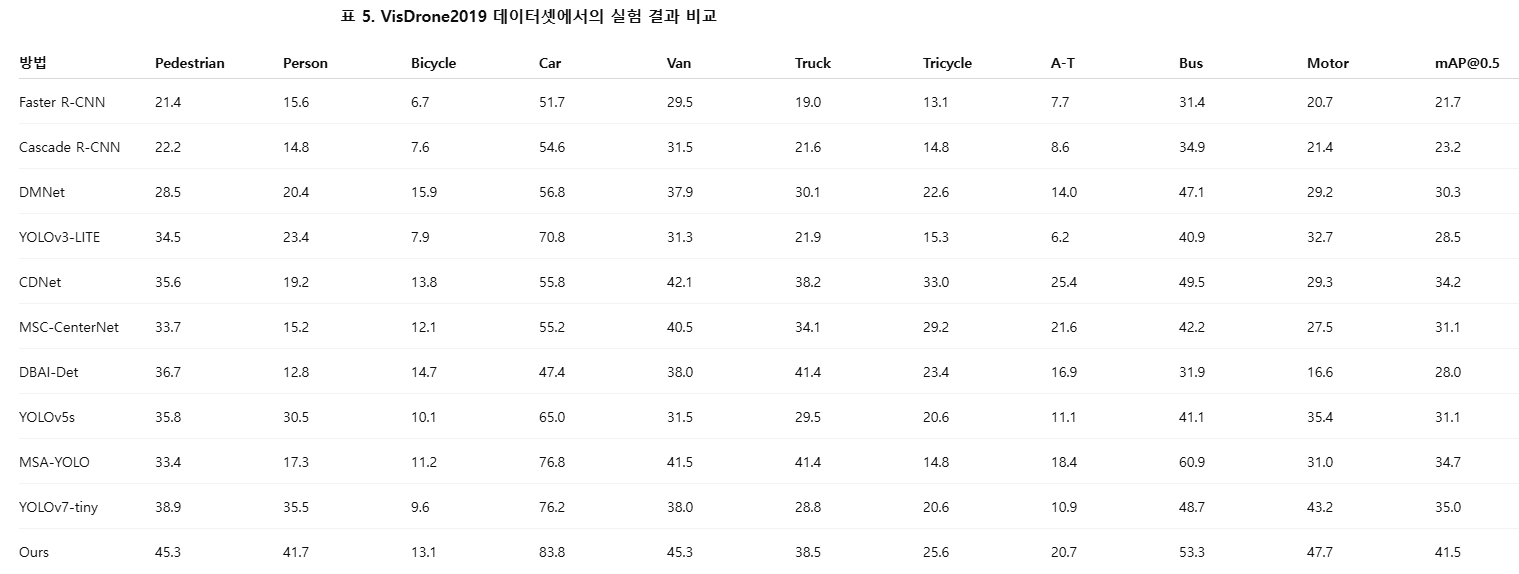
추가적으로, 실험 결과는 개선된 모델이 각 범주별 평균 정밀도(AP) 측면에서도 기존 모델을 크게 능가함을 보여준다. 구체적으로 10개 객체 범주에 대한 AP는 각각 6.4%, 6.2%, 3.5%, 7.6%, 7.3%, 9.7%, 5.0%, 9.8%, 4.6%, 4.5% 향상되었으며, 특히 트럭(truck)과 어닝 트라이시클(awning-tricycle) 범주에서 가장 큰 성능 향상이 관찰되었다. 이러한 실험 결과를 종합하면, 본 논문에서 제안한 알고리즘은 UAV 객체 탐지 과제에서 전반적으로 우수한 성능을 보이며, 실시간 UAV 탐지 시나리오에서의 적용 가능성과 효과성을 다시 한번 입증한다.
4.6. 탐지 효과 분석 (Detection Effect Analysis)
본 논문에서 제안한 알고리즘이 UAV 소형 객체 탐지에서 갖는 우수성을 시각적으로 확인하기 위해, 다양한 장면에서 본 연구의 알고리즘과 대표적인 기존 알고리즘들의 탐지 결과를 비교하였다.
그림 6은 주간 환경에서의 탐지 결과를 보여준다. 다른 알고리즘들과 비교했을 때, 개선된 YOLOv7-tiny 알고리즘은 원거리 보행자와 트럭과 같은 소형 객체를 더 많이 인식할 수 있으며, 객체 인식의 신뢰도(confidence) 또한 크게 향상된 것을 확인할 수 있다.


그림 6. (a–d)는 각각 주간 환경에서 YOLOv5s, MSA-YOLO, YOLOv7-tiny, 개선된 YOLOv7-tiny 알고리즘의 탐지 결과를 나타낸다.
그림 7은 야간 환경에서의 탐지 성능을 보여준다. 실험 결과, 제안한 모델은 조도가 낮은 환경에서도 더 많은 보행자를 효과적으로 탐지할 수 있었으며, 이는 저조도 환경에 대한 적응 능력이 우수함을 의미한다. 이러한 결과는 개선된 알고리즘이 조명 변화에 대해 상대적으로 낮은 민감도를 가지며, 그로 인해 더 강한 항간섭 능력과 높은 네트워크 강건성(robustness)을 갖는다는 점을 시사한다.


그림 7. (a–d)는 각각 어두운 조명 환경에서 YOLOv5s, MSA-YOLO, YOLOv7-tiny, 개선된 YOLOv7-tiny 알고리즘의 탐지 결과를 나타낸다.
그림 8과 그림 9는 각각 객체 밀집 환경과 객체 희소 환경에서 개선된 YOLOv7-tiny 알고리즘의 탐지 효과를 비교 분석한 결과를 보여준다. 객체가 밀집된 장면에서는 다수의 소형 객체와 이들 간의 상호 가림 현상으로 인해 UAV 영상의 탐지 난이도가 크게 증가한다. 그럼에도 불구하고, 최적화된 YOLOv7-tiny 알고리즘은 보행자 탐지 성능을 성공적으로 향상시키고, 오토바이 또한 정확하게 식별함으로써 고밀도 객체 환경에서도 효과적으로 동작함을 입증하였다. 반면 객체가 희소한 장면에서도, 본 모델은 차량, 트럭, 오토바이 인식에서 여전히 뚜렷한 장점을 보이며 우수한 일반화 성능을 보여준다.
종합적으로 볼 때, 제안한 모델은 다른 알고리즘들과 비교하여 미탐(miss detection)과 오탐(false detection)을 효과적으로 줄이는 데 있어 명확한 우위를 가진다. 이러한 실험 결과는 YOLOv7-tiny 알고리즘에 적용된 개선 사항들이 복잡한 환경에서의 객체 탐지 성능을 실질적으로 향상시킨다는 점을 충분히 검증한다.

그림 8. (a–d)는 각각 밀집 장면에서 YOLOv5s, MSA-YOLO, YOLOv7-tiny, 개선된 YOLOv7-tiny 알고리즘의 탐지 결과를 나타낸다.


그림 9. (a–d)는 각각 희소 장면에서 YOLOv5s, MSA-YOLO, YOLOv7-tiny, 개선된 YOLOv7-tiny 알고리즘의 탐지 결과를 나타낸다.
5. 결론 및 전망 (Conclusions and Outlook)
UAV 항공 영상에서 객체를 정확하게 인식하는 과정은 오탐과 미탐이 빈번하게 발생하는 어려운 과제이다. 본 연구에서는 이러한 문제를 해결하기 위해, 모델 백본(backbone)의 ELAN-S 합성곱 구조에 수용 영역 좌표 주의 합성곱(Receptive Field Coordinate Attention Convolution)을 통합하여 네트워크의 특징 포착 능력을 향상시켰다. 네트워크 구조 측면에서는, neck 부분에 소형 객체 탐지 레이어를 추가하여 샘플링 스케일을 확장하고, 이후 업샘플링 및 다운샘플링 과정에서 활용되는 특징 맵 정보를 더욱 풍부하게 하였다. 또한 BSAM 주의 메커니즘을 도입함으로써 소형 객체 탐지 영역에 대한 주의 집중을 강화하였다. 마지막으로 inner-MPDIoU 손실 함수를 적용하여, 소형 객체 및 난이도가 높은 샘플에 대한 모델의 학습 능력을 한층 더 향상시켰다.
VisDrone2019 데이터셋에서 수행한 실험 결과를 바탕으로, 본 연구에서 제안한 모델은 UAV 객체 탐지 과제에서 기존의 주요 모델들보다 우수한 성능을 보였다. 기존 UAV 객체 탐지 알고리즘 연구에서는 다양한 방식으로 성능 최적화를 시도해 왔으며, 본 연구에서 제시한 개선 사항 외에도 향후 연구에서는 다운샘플링 과정에서 더 많은 세부 정보를 유지할 수 있도록 다운샘플링 방법 자체를 개선함으로써 탐지 성능을 향상시키는 방향을 모색할 수 있을 것이다. 또한 탐지 정확도를 유지하면서도 모델 크기를 최적화하기 위해, 알고리즘 모듈에 대한 프루닝(pruning) 기법을 적용하는 방안 역시 향후 연구 주제로 고려될 수 있다.