https://www.liquid.ai/blog/liquid-foundation-models-v2-our-second-series-of-generative-ai-models
Introducing LFM2: The Fastest On-Device Foundation Models on the Market | Liquid AI
Today, we release LFM2, a new class of Liquid Foundation Models (LFMs) that sets a new standard in quality, speed, and memory efficiency for on-device deployment. Built on a hybrid architecture, LFM2 delivers 200% faster decode and prefill performance than
www.liquid.ai


오늘 우리는 LFM2를 공개한다. LFM2는 품질, 속도, 그리고 메모리 효율적 배포 측면에서 새로운 기준을 제시하는 차세대 Liquid Foundation Models (LFMs) 계열이다. LFM2는 산업 전반에서 가장 빠른 온디바이스 생성형 AI 경험을 제공하도록 특별히 설계되었으며, 이를 통해 방대한 수의 디바이스에서 생성형 AI 워크로드를 실행할 수 있는 가능성을 연다.
새로운 하이브리드 아키텍처를 기반으로 구축된 LFM2는 CPU 환경에서 Qwen3 대비 디코딩과 프리필 성능이 2배 빠르다. 또한 각 모델 크기 구간별로 기존 모델들을 크게 상회하는 성능을 보여주며, 효율적인 AI 에이전트를 구동하는 데 이상적인 선택지이다.
이러한 성능 향상은 LFM2를 로컬 및 엣지 환경 활용에 최적의 모델로 만든다. 배포 측면의 이점뿐 아니라, 새로운 아키텍처와 학습 인프라는 이전 LFM 세대 대비 학습 효율을 3배 개선하여, LFM2를 범용적이고 강력한 AI 시스템을 구축하는 데 있어 가장 비용 효율적인 경로로 자리매김하게 한다.
Liquid는 특정 작업과 하드웨어 요구사항에 맞춰 품질, 지연 시간, 메모리 사용량 간의 최적 균형을 달성하는 파운데이션 모델을 개발한다. 이러한 균형을 완전히 제어할 수 있는 능력은 어떤 디바이스에서도 최고 수준의 생성형 모델을 배포하는 데 필수적이며, 바로 이 점이 엔터프라이즈를 위한 Liquid 제품이 제공하는 핵심 가치이다.
대규모 생성형 모델을 원격 클라우드에서 경량의 온디바이스 LLM으로 이전하면 밀리초 단위의 지연 시간, 디바이스 자체의 복원력, 그리고 데이터 주권을 보장하는 프라이버시를 확보할 수 있다. 이러한 특성은 휴대폰, 노트북, 차량, 로봇, 웨어러블, 위성 등 실시간 추론이 요구되는 다양한 엔드포인트에 필수적이다. 소비자 전자제품, 로보틱스, 스마트 가전, 금융, 이커머스, 교육 등 고성장 엣지 AI 스택 중심의 수직 시장을 고려하고, 여기에 국방, 우주, 사이버보안 분야까지 포함하면, 소형이면서 프라이버시를 보장하는 파운데이션 모델의 총 시장 규모(TAM)는 2035년까지 약 1조 달러에 이를 것으로 전망된다.
Liquid는 이러한 분야에서 다수의 포춘 500대 기업과 협력하고 있다. 우리는 모든 디바이스를 로컬에서 AI 디바이스로 전환할 수 있는, 보안이 강화된 엔터프라이즈급 배포 스택과 함께 초고효율 소형 멀티모달 파운데이션 모델을 제공한다. 이는 기업들이 클라우드 LLM에서 비용 효율적이고, 빠르며, 프라이버시를 보장하는 온프레미스 인텔리전스로 전환하는 과정에서, 시장에서 압도적인 점유율을 확보할 수 있는 기회를 제공한다.
LFM2 핵심 요약
빠른 학습 및 추론
LFM2는 이전 세대 대비 학습 속도가 3배 빠르다. 또한 CPU 환경에서 Qwen3와 비교했을 때 디코딩(decode) 및 프리필(prefill) 속도가 최대 2배 향상되었다.
최고 수준의 성능
LFM2는 지식, 수학, 지시 수행(instruction following), 다국어 처리 등 여러 벤치마크 범주에서 동일 규모의 모델들을 전반적으로 능가하는 성능을 보인다.
새로운 아키텍처
LFM2는 곱셈 게이트(multiplicative gates)와 짧은 컨볼루션(short convolutions)을 결합한 하이브리드 Liquid 모델이다. 전체 구조는 16개 블록으로 구성되며, 이 중 10개는 이중 게이트(short-range convolution) 블록이고, 나머지 6개는 그룹드 쿼리 어텐션(grouped query attention) 블록이다.
유연한 배포
스마트폰, 노트북, 차량 등 어떤 환경에 배포하더라도 LFM2는 CPU, GPU, NPU 하드웨어에서 효율적으로 동작한다. 아키텍처, 최적화, 배포 엔진을 포함한 풀스택 솔루션을 통해 프로토타입에서 제품으로 전환되는 과정을 빠르게 가속한다.
지금 바로 사용해보기
0.35B, 0.7B, 1.2B 파라미터 규모의 세 가지 Dense 체크포인트 가중치를 공개한다. Liquid Playground, Hugging Face, OpenRouter에서 지금 바로 사용해볼 수 있다.
LFMs 사용해보기
https://playground.liquid.ai/login
Login
We are excited to announce the LFM2.5-1.2B model family, our most capable release yet for edge AI deployment. It builds on the LFM2 device-optimized architecture and represents a significant leap forward in building reliable agents on the edge. We have ext
playground.liquid.ai
https://huggingface.co/LiquidAI
LiquidAI (Liquid AI)
A new generation of foundation models from first principles.
huggingface.co
https://github.com/ggml-org/llama.cpp
GitHub - ggml-org/llama.cpp: LLM inference in C/C++
LLM inference in C/C++. Contribute to ggml-org/llama.cpp development by creating an account on GitHub.
github.com
벤치마크
LFM2의 성능을 종합적으로 파악하기 위해 자동화된 벤치마크와 LLM-as-a-Judge 프레임워크를 함께 활용하여 평가를 수행했다.
자동화된 벤치마크
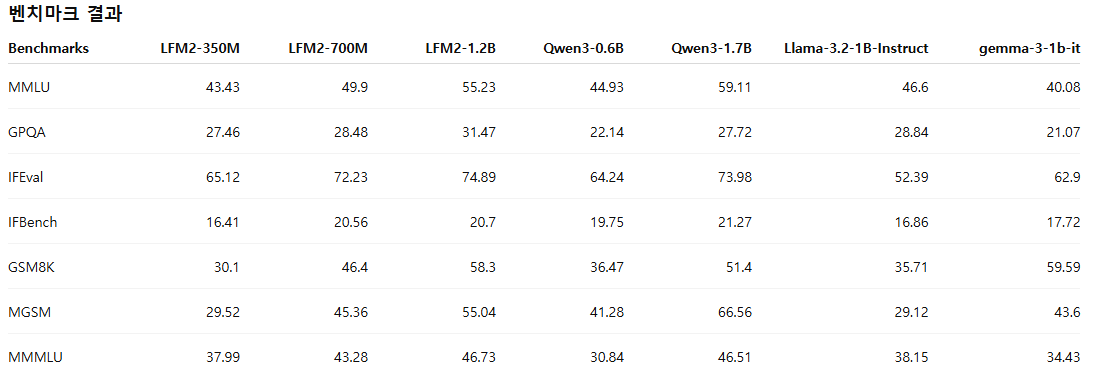
LFM2는 다양한 평가 범주에서 동일 규모의 모델들을 전반적으로 능가하는 성능을 보였다. 본 평가에서는 지식(5-shot MMLU, 0-shot GPQA), 지시 수행(instruction following, IFEval, IFBench), 수학(0-shot GSM8K, 5-shot MGSM), 다국어 능력(5-shot OpenAI MMMLU, 5-shot MGSM 재사용)을 포함하는 총 7개의 널리 사용되는 벤치마크를 사용했다. 다국어 평가는 아랍어, 프랑스어, 독일어, 스페인어, 일본어, 한국어, 중국어 등 7개 언어를 대상으로 수행되었다.

그림 1. 모델 크기 대비 평균 점수 (MMLU, IFEval, IFBench, GSM8K, MMMLU)
LFM2-1.2B는 파라미터 수가 47% 더 많은 Qwen3-1.7B와 경쟁력 있는 성능을 보인다. LFM2-700M은 Gemma 3 1B IT를 능가하며, 가장 작은 체크포인트인 LFM2-350M 역시 Qwen3-0.6B 및 Llama 3.2 1B Instruct와 견줄 만한 성능을 보인다.
* 모든 벤치마크 점수는 일관성을 위해 내부 평가 스위트(internal evaluation suite)를 사용해 계산되었다.
또한 EleutherAI의 lm-evaluation-harness 대비 다음과 같은 변경 사항을 적용했다.
- MMLU와 같은 로그잇(logit) 기반 평가에서는 가장 가능성이 높은 로그잇을 디코딩한 뒤 불필요한 공백을 제거했다. 이를 통해 “ A” 대신 “A”와 같이 공백으로 인한 차이를 제거하여 공정한 비교가 가능하도록 했다.
- 추론(reasoning) 모델 관련 선행 연구를 바탕으로 수학 벤치마크에서의 정답 추출(answer extraction) 방식을 통합했다. 이로 인해 특히 Gemma 3 1B IT의 성능이 크게 개선되었다.
- Qwen3는 비추론(non-reasoning) 모드로만 평가했다. 추론 트레이스는 엣지 배포에서 현실적인 출력 토큰 예산(<4,096 토큰)보다 길어지는 경향이 있으며, 비추론 모드가 일관되게 더 높은 점수를 보였기 때문이다.
LLM-as-a-Judge
추가로, 우리는 특히 다중 턴 대화(multi-turn dialogue) 환경에서의 성능에 초점을 맞추어 LFM2-1.2B의 대화 능력을 평가했다. 이를 위해 WildChat 데이터셋에서 추출한 1,000개의 실제 대화 사례를 사용하였고, 각 모델이 이에 대한 응답을 생성하도록 했다. 이후 다섯 개의 LLM으로 구성된 심사단(jury)이 쌍대 비교(pairwise comparison) 방식으로 응답을 검토하여 선호도를 산출했다.

그 결과, LFM2-1.2B는 Llama 3.2 1B Instruct와 Gemma 3 1B IT 대비 유의미하게 높은 선호도를 보였다. 또한 모델 크기가 훨씬 작고 실행 속도가 더 빠름에도 불구하고, Qwen3-1.7B와 동등한 수준의 성능을 나타냈다.

한편 LFM2-700M의 응답은 Qwen3-0.6B보다 유의미하게 더 선호되었다. 가장 작은 모델인 LFM2-350M 역시 크기가 더 작음에도 불구하고 Qwen3-0.6B와 비교해 거의 균형에 가까운 선호도 점수를 기록하며 경쟁력 있는 성능을 보였다.
추론(Inference)
다양한 배포 시나리오를 지원하기 위해 LFM2를 여러 추론 프레임워크로 내보냈다(export). 온디바이스 추론을 위해 ExecuTorch를 통한 PyTorch 생태계와 오픈소스 llama.cpp 라이브러리를 모두 활용했다. LFM2 모델들은 각 플랫폼에서 권장하는 양자화(quantization) 방식인 ExecuTorch의 8da4w, llama.cpp의 Q4_0 설정을 적용하여 평가되었으며, 해당 생태계에서 사용 가능한 기존 모델들과 성능을 비교했다. 타깃 하드웨어로는 Samsung Galaxy S24 Ultra(Qualcomm Snapdragon SoC)와 AMD Ryzen (HX370) 플랫폼을 사용했다.
ExecuTorch에서의 CPU 처리량(Throughput) 비교

llama.cpp에서의 CPU 처리량(Throughput) 비교

그림에서 보이듯이, LFM2는 모델 크기 대비 프리필(prefill, 프롬프트 처리)과 디코드(decode, 토큰 생성) 추론 속도 모두에서 파레토 프런티어(Pareto frontier)를 지배한다. 예를 들어 LFM2-700M은 파라미터 수가 16% 더 큼에도 불구하고, ExecuTorch와 llama.cpp 환경 모두에서 디코드 및 프리필 속도 측면에서 Qwen-0.6B보다 일관되게 빠른 성능을 보였다. 이러한 LFM2의 강력한 CPU 성능은 커널 최적화 이후 GPU와 NPU와 같은 가속기 환경으로도 자연스럽게 이전될 것이다.
LFM2 아키텍처
이 절에서는 Liquid 시간 상수 네트워크(Liquid Time-constant Networks) 계열을 바탕으로 Liquid Foundation Models를 어떻게 설계했는지를 설명한다.
배경
[Hasani & Lechner et al., 2018; 2020]에서 우리는 Liquid Time-constant Networks (LTCs) 를 소개했다. LTC는 비선형 입력 상호연결 게이트(nonlinear input interlinked gates)에 의해 조절되는 선형 동적 시스템(linear dynamical systems) 기반의 새로운 연속시간 순환 신경망(continuous-time recurrent neural networks, RNNs) 계열이다. 이는 다음과 같이 정의된다.

Liquid Time-constant Networks (LTCs)는 비선형 입력 상호연결 게이트에 의해 조절되는 선형 동적 시스템으로 구성된 연속시간 RNN의 한 종류이다.
여기서 x(t)는 입력, y(t)는 상태(state)를 의미하며, T(·)와 F(·)는 비선형 매핑(non-linear maps), A는 상수 조절자(constant regulator)이다.
특히 LTC에서 사용되는 게이트는 시퀀스 모델링을 위한 기존 RNN에서의 입력 의존(input-dependent) 및 상태 의존(state-dependent) 게이팅을 연속시간 영역으로 일반화한 것이다. 이러한 특성은 시스템의 시간적 진화를 보다 정밀하게 제어할 수 있도록 하며, 데이터로부터 복잡한 “액체적(liquid)” 동역학을 학습할 수 있게 해준다.
이후 수년간 우리 연구팀과 머신러닝 커뮤니티의 다수 연구에서는 이러한 개념을 RNN, 상태공간 모델(state-space models) [Hasani & Lechner et al., 2022], 그리고 컨볼루션(convolutions) [Poli & Massaroli et al., 2023]에까지 확장·통합해 왔다.
LIV 연산자에서의 체계적인 신경 아키텍처 탐색
효율적인 Liquid 시스템의 아키텍처 설계 공간을 통합하기 위해, 우리는 선형 입력 가변(linear input-varying, LIV) 연산자 개념을 개발했다 [Thomas et al., 2024]. LIV 시스템(Linear Input-Varying system) 이란, 작용 대상이 되는 입력으로부터 가중치가 실시간(on-the-fly)으로 생성되는 선형 연산자를 의미하며, 이를 통해 컨볼루션(convolutions), 순환 구조(recurrences), 어텐션(attention), 그리고 기타 구조화된 레이어들을 하나의 입력 인지(input-aware) 통합 프레임워크로 묶을 수 있다.
보다 형식적으로, LIV 연산자는 다음과 같은 식으로 표현할 수 있다.

Linear Input-Varying (LIV) 시스템은 입력으로부터 동적으로 생성된 가중치를 사용하는 선형 연산자이며, 이를 통해 컨볼루션, 순환 구조, 어텐션 및 기타 구조화된 레이어들을 하나의 통합된 입력 인지 프레임워크로 표현할 수 있다.
여기서 x는 입력(input)을 의미하며, T는 입력에 의존하는 가중치 행렬(input-dependent weight matrix)이다.
LIV의 높은 유연성 덕분에, 우리는 다양한 신경망 연산자와 레이어를 공통된 계층적 표현(shared hierarchical format)으로 손쉽게 정의하고 기술할 수 있다. 이러한 기반 위에서, 우리는 배포 환경에서의 품질(quality), 메모리(memory), 지연 시간(latency) 기준을 동시에 만족하는 최적의 신경 아키텍처를 탐색하기 위해 자체 신경 아키텍처 탐색 엔진인 STAR를 구축했다.
LFM2
LFM2의 목표는 임베디드 SoC 환경에서 어떠한 타협도 없이 가장 빠른 생성형 AI 경험을 제공하는 것이었다. 이러한 비전을 실현하기 위해 우리는 STAR를 활용했으며, 다만 STAR의 학술 논문에 기술된 기본 알고리즘에 몇 가지 핵심적인 수정 사항을 적용했다.
- 언어 모델링 성능 평가에서는 기존의 검증 손실(validation loss)이나 퍼플렉서티(perplexity) 지표를 넘어선다. 대신 지식 회상(knowledge recall), 다중 홉 추론(multi-hop reasoning), 저자원 언어 이해(low-resource languages), 지시 수행(instruction following), 도구 사용(tool use) 등 다양한 능력을 평가하는 50개 이상의 내부 평가 스위트를 사용했다.
- 아키텍처 효율성 역시 KV 캐시 크기를 대리 지표로 사용하는 대신, 보다 직접적인 측정 방식을 채택했다. Qualcomm Snapdragon 임베디드 SoC CPU 환경에서 최대 메모리 사용량(peak memory usage)과 프리필+디코드 속도(prefill+decode speed)를 실제 테스트로 측정하고 최적화했다.
STAR를 통해 도출된 최종 아키텍처가 바로 LFM2이다. LFM2는 곱셈 게이트(multiplicative gates)와 짧은 컨볼루션(short convolutions)을 사용하는 Liquid 모델로, 유한한 시간 이후 0으로 수렴하는 선형 1차 시스템(linear first-order systems) 형태를 따른다. 구조적으로 LFM2는 컨볼루션 블록과 어텐션 블록을 결합한 하이브리드 모델이다. 전체 16개 블록 중 10개는 아래와 같은 형태의 이중 게이트(short-range) LIV 컨볼루션 블록으로 구성되어 있다.
def lfm2_conv(x):
B, C, x = linear(x) # 입력 프로젝션
x = B * x # 게이팅 (게이트는 입력에 의존)
x = conv(x) # 짧은 컨볼루션
x = C * x # 게이팅
x = linear(x)
return x
이와 더불어 그룹드 쿼리 어텐션(Grouped Query Attention, GQA) 블록이 6개 포함되어 있으며, 각 블록에는 SwiGLU와 RMSNorm 레이어가 함께 들어간다.
LFM2가 완전한 순환 구조나 전면적인 어텐션 레이어 대신 짧은 컨볼루션에 의존하는 구조를 채택한 것은, 목표 디바이스 클래스인 임베디드 SoC CPU와 해당 환경에서 사용되는 커널 라이브러리들이 이러한 연산과 워크로드에 최적화되어 있기 때문이다. 현재 우리는 GPU와 NPU와 같은 도메인 특화 가속기를 대상으로 LFMs를 적극적으로 최적화하고 있으며, 탐색 공간을 확장하고 궁극적으로는 모델 아키텍처와 하드웨어를 공동 진화(co-evolution)시키는 방향으로 나아가고 있다.
LFM2 학습(Training LFM2)
LFM2의 첫 번째 학습 스케일업 단계에서 우리는 저지연 온디바이스 언어 모델 워크로드를 목표로 세 가지 모델 크기(350M, 700M, 1.2B 파라미터)를 선택했다. 모든 모델은 웹과 라이선스 자료에서 수집된 사전학습 코퍼스를 기반으로 한 10조(10T) 토큰으로 학습되었으며, 데이터 구성은 약 영어 75%, 다국어 20%, 코드 5%이다. LFM2의 다국어 성능 강화를 위해 특히 일본어, 아랍어, 한국어, 스페인어, 프랑스어, 독일어에 중점을 두었다.
사전학습(pre-training) 과정에서는 기존의 LFM1-7B 모델을 교사 모델로 사용하는 지식 증류(knowledge distillation) 프레임워크를 활용했다. 전체 10T 토큰 학습 과정 동안, LFM2 학생 모델의 출력과 LFM1-7B 교사 모델의 출력 간 크로스 엔트로피(cross-entropy)를 주요 학습 신호로 사용했다. 또한 사전학습 중 컨텍스트 길이(context length)를 32k까지 확장했다.
사후 학습(post-training)은 범용적인 능력을 끌어내기 위해 다양한 데이터 혼합을 사용한 대규모 지도 미세조정(Supervised Fine-Tuning, SFT) 단계로 시작된다. 이러한 소형 모델의 경우, RAG나 함수 호출(function calling)과 같은 대표적인 다운스트림 태스크에 직접 학습시키는 것이 효과적임을 확인했다. 사용된 데이터셋은 오픈소스 데이터, 라이선스 데이터, 그리고 목적 지향적 합성 데이터(targeted synthetic data)로 구성되어 있으며, 정량적 샘플 점수화와 정성적 휴리스틱을 결합해 높은 품질을 보장했다.
이후 우리는 길이 정규화(length normalization)가 적용된 자체 Direct Preference Optimization(DPO) 알고리즘을 오프라인 데이터와 세미-온라인(semi-online) 데이터의 조합에 적용했다. 세미-온라인 데이터셋은 초기 SFT 데이터셋을 시드로 하여 모델로부터 여러 개의 응답을 샘플링해 생성된다. 이후 LLM 판별자(LLM judges)를 사용해 모든 응답을 점수화하고, SFT 샘플과 온폴리시(on-policy) 샘플 중에서 가장 높은 점수와 가장 낮은 점수를 받은 응답을 조합해 선호 쌍(preference pairs)을 생성한다. 오프라인 데이터와 세미-온라인 데이터 모두 점수 임계값을 기준으로 추가 필터링을 거친다. 우리는 하이퍼파라미터와 데이터 혼합 비율을 달리해 여러 후보 체크포인트를 생성하며, 마지막으로 다양한 모델 병합(model merging) 기법을 통해 최적의 체크포인트들을 결합해 최종 모델을 완성한다.
LFM2로 빌드하기(Build with LFM2)
LFM2 모델은 현재 Hugging Face에서 사용할 수 있다. 우리는 이를 Apache 2.0을 기반으로 한 오픈 라이선스로 공개한다. 해당 라이선스는 학술 및 연구 목적에 대해 LFM2 모델을 자유롭게 사용할 수 있도록 허용한다. 또한 연 매출 1천만 달러(USD 10m) 이하의 소규모 기업의 경우 상업적 사용도 가능하다. 이 기준을 초과하는 경우에는 sales@liquid.ai로 문의해 상업용 라이선스를 취득해야 한다. 라이선스에 대한 자세한 내용은 별도 안내 페이지에서 확인할 수 있다.
LFM2 모델은 온디바이스 효율성을 염두에 두고 설계되었기 때문에, llama.cpp와 같은 다양한 통합 환경을 통해 개인 디바이스에서 로컬로 테스트하는 것을 권장한다. 또한 TRL을 활용해 각자의 활용 사례(use case)에 맞게 미세조정(fine-tuning)하는 것도 가능하다.
엣지 배포를 포함한 맞춤형 솔루션에 관심이 있다면, sales@liquid.ai로 Liquid의 영업팀에 문의하기 바란다.