https://arxiv.org/abs/2410.13842
D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement
We introduce D-FINE, a powerful real-time object detector that achieves outstanding localization precision by redefining the bounding box regression task in DETR models. D-FINE comprises two key components: Fine-grained Distribution Refinement (FDR) and Gl
arxiv.org
D-FINE: DETR에서 회귀(regression) 과제를 세밀한 분포 정제(Fine-grained Distribution Refinement)로 재정의
Yansong Peng¹, Hebei Li¹, Peixi Wu¹, Yueyi Zhang¹, Xiaoyan Sun¹˒²*, Feng Wu¹˒²
¹ 중국과학기술대학교 (University of Science and Technology of China)
² 허페이 종합국가과학센터 인공지능연구소 (Institute of Artificial Intelligence, Hefei Comprehensive National Science Center)
{pengyansong, lihebei, wupeixi}@mail.ustc.edu.cn
{zhyuey, sunxiaoyan, fengwu}@ustc.edu.cn
*교신 저자 (Corresponding authors)
초록 (Abstract)
본 논문에서는 DETR 모델에서 바운딩 박스 회귀(bounding box regression) 과제를 재정의함으로써 뛰어난 위치 추정 정밀도를 달성하는 강력한 실시간 객체 검출기 D-FINE을 제안한다. D-FINE은 두 가지 핵심 구성 요소로 이루어져 있다. 첫째는 세밀한 분포 정제(Fine-grained Distribution Refinement, FDR)이고, 둘째는 전역 최적 위치 자기 증류(Global Optimal Localization Self-Distillation, GO-LSD)이다.
FDR은 고정된 좌표를 직접 예측하는 기존 회귀 방식을, 확률 분포를 반복적으로 정제하는 과정으로 전환한다. 이를 통해 세밀한 중간 표현(fine-grained intermediate representation)을 제공하며, 결과적으로 위치 추정 정확도를 크게 향상시킨다. GO-LSD는 양방향 최적화 전략으로, 정제된 분포에서 얻은 위치 정보를 자기 증류(self-distillation)를 통해 얕은 계층으로 전달하는 동시에, 깊은 계층에서는 잔차(residual) 예측 과제를 단순화한다.
또한 D-FINE은 연산 비용이 큰 모듈과 연산에 대해 경량화 최적화를 적용하여, 속도와 정확도 사이의 균형을 더욱 개선한다. 구체적으로, D-FINE-L / X는 NVIDIA T4 GPU에서 124 / 78 FPS의 속도로 COCO 데이터셋 기준 54.0% / 55.8% AP를 달성한다. Objects365 데이터셋으로 사전학습(pretraining)한 경우, D-FINE-L / X는 각각 57.1% / 59.3% AP를 기록하며, 기존의 모든 실시간 객체 검출기를 능가한다.
더 나아가, 제안한 방법은 추가 파라미터와 학습 비용을 거의 증가시키지 않으면서도, 다양한 DETR 계열 모델의 성능을 최대 5.3% AP까지 향상시킨다. 코드 및 사전학습 모델은 다음 링크에서 확인할 수 있다.
https://github.com/Peterande/D-FINE
GitHub - Peterande/D-FINE: D-FINE: Redefine Regression Task of DETRs as Fine-grained Distribution Refinement [ICLR 2025 Spotlig
D-FINE: Redefine Regression Task of DETRs as Fine-grained Distribution Refinement [ICLR 2025 Spotlight] - Peterande/D-FINE
github.com

그림 1: 지연 시간(latency, 좌), 모델 크기(model size, 중), 계산 비용(computational cost, 우) 측면에서 다른 검출기들과의 비교. 엔드투엔드 지연 시간은 NVIDIA T4 GPU에서 TensorRT FP16을 사용하여 측정하였다.
1. 서론 (Introduction)
실시간 객체 검출(real-time object detection)에 대한 수요는 다양한 응용 분야 전반에서 지속적으로 증가하고 있다 (Arani et al., 2022). 실시간 검출기 중 가장 영향력 있는 계열로는 YOLO 시리즈(Redmon et al., 2016a; Wang et al., 2023a; b; Glenn., 2023; Wang & Liao, 2024; Wang et al., 2024a; Glenn., 2024)가 있으며, 이는 높은 효율성과 견고한 커뮤니티 생태계로 널리 인정받고 있다. 강력한 경쟁자로서 Detection Transformer (DETR) 계열(Carion et al., 2020; Zhu et al., 2020; Liu et al., 2021; Li et al., 2022; Zhang et al., 2022)은 트랜스포머 기반 아키텍처를 통해 전역 문맥(global context)을 모델링할 수 있고, Non-Maximum Suppression(NMS)이나 앵커 박스(anchor box)에 의존하지 않는 직접적인 집합 예측(direct set prediction)이 가능하다는 점에서 뚜렷한 장점을 제공한다. 그러나 DETR 계열은 높은 지연 시간(latency)과 계산량이라는 한계로 인해 실사용에 제약을 받는 경우가 많다 (Zhu et al., 2020; Liu et al., 2021; Li et al., 2022; Zhang et al., 2022).
RT-DETR(Zhao et al., 2024)은 이러한 한계를 해결하기 위해 실시간 변형(real-time variant)을 제안함으로써, YOLO 계열 검출기에 대한 엔드투엔드(end-to-end) 대안을 제시한다. 더 나아가 LW-DETR(Chen et al., 2024)은 DETR이 YOLO보다 더 높은 성능 상한(performance ceiling)을 달성할 수 있음을 보여주었으며, 특히 Objects365(Shao et al., 2019)와 같은 대규모 데이터셋으로 학습할 경우 그 차이가 더욱 두드러진다는 점을 입증하였다.
실시간 객체 검출 분야에서 상당한 진전이 이루어졌음에도 불구하고, 여전히 여러 미해결 문제가 검출기의 성능을 제한하고 있다. 그중 핵심적인 과제 중 하나는 바운딩 박스 회귀(bounding box regression)의 문제 설정이다. 대부분의 검출기는 고정된 좌표를 직접 회귀하는 방식으로 바운딩 박스를 예측하며, 각 경계(edge)를 디랙 델타 분포(Dirac delta distribution)로 모델링된 정확한 값으로 취급한다 (Liu et al., 2016; Ren et al., 2015; Tian et al., 2019; Lyu et al., 2022). 이 방식은 직관적이기는 하지만, 위치 추정의 불확실성(localization uncertainty)을 모델링하지 못한다는 한계를 가진다. 그 결과, 모델은 L1 손실과 IoU 손실에 의존하게 되며, 이는 각 경계를 독립적으로 조정하는 데 충분한 지침을 제공하지 못한다 (Girshick, 2015). 이로 인해 최적화 과정이 작은 좌표 변화에도 민감해지고, 수렴 속도가 느려지며, 궁극적으로는 성능 저하로 이어진다.
GFocal(Li et al., 2020; 2021)과 같은 방법은 확률 분포를 통해 불확실성을 다루고자 시도하였으나, 여전히 앵커 의존성, 거친 위치 추정(coarse localization), 반복적 정제(iterative refinement)의 부재라는 한계를 벗어나지 못하고 있다. 또 다른 도전 과제는 실시간 검출기의 효율성 극대화이다. 실시간 성능을 유지하기 위해서는 제한된 계산 자원과 파라미터 예산 내에서 동작해야 한다. 이러한 맥락에서 지식 증류(Knowledge Distillation, KD)는 대형 교사 모델(teacher)로부터 소형 학생 모델(student)로 지식을 이전하여, 추가 비용 없이 성능을 향상시킬 수 있는 유망한 해결책으로 주목받고 있다 (Hinton et al., 2015). 그러나 Logit Mimicking이나 Feature Imitation과 같은 기존 KD 기법은 객체 검출 과제에서는 비효율적인 것으로 밝혀졌으며, 최신 성능의 모델에서는 오히려 성능 저하를 초래하기도 한다 (Zheng et al., 2022).
이에 반해 위치 증류(Localization Distillation, LD)는 검출 과제에서 더 나은 성과를 보이고 있다. 그럼에도 불구하고, LD는 상당한 학습 오버헤드를 요구하며, 앵커 프리(anchor-free) 검출기와의 비호환성 문제로 인해 실제 적용에는 여전히 많은 어려움이 존재한다.
이러한 문제들을 해결하기 위해, 우리는 바운딩 박스 회귀를 재정의하고 효과적인 자기 증류 전략을 도입한 새로운 실시간 객체 검출기 D-FINE을 제안한다. 본 접근법은 고정 좌표 회귀 방식에서 발생하는 최적화의 어려움, 위치 추정 불확실성을 모델링하지 못하는 한계, 그리고 낮은 학습 비용으로 효과적인 증류가 필요하다는 문제를 동시에 해결하고자 한다. 이를 위해 우리는 세밀한 분포 정제(Fine-grained Distribution Refinement, FDR)를 도입하여, 바운딩 박스 회귀를 고정된 좌표 예측 문제에서 확률 분포를 모델링하는 문제로 전환한다. FDR은 보다 세밀한 중간 표현을 제공하며, 잔차(residual) 형태로 확률 분포를 반복적으로 정제함으로써 점진적으로 더 정교한 조정을 가능하게 하고 위치 추정 정밀도를 향상시킨다.
더 깊은 계층이 확률 분포 안에 더 풍부한 위치 정보를 포착함으로써 더 정확한 예측을 생성한다는 점에 착안하여, 우리는 전역 최적 위치 자기 증류(Global Optimal Localization Self-Distillation, GO-LSD)를 제안한다. GO-LSD는 추가적인 학습 비용을 거의 증가시키지 않으면서, 깊은 계층에서 학습된 위치 정보를 얕은 계층으로 전달한다. 이후 계층에서 정제된 출력과 얕은 계층의 예측을 정렬함으로써, 모델은 초기 단계에서 더 나은 보정 값을 생성하도록 학습되며, 이는 수렴 속도를 가속하고 전체 성능을 향상시킨다. 또한 기존의 실시간 DETR 아키텍처(Zhao et al., 2024; Chen et al., 2024)에서 계산 비용이 큰 모듈과 연산을 간소화하여, D-FINE을 더 빠르고 경량화된 구조로 설계하였다. 일반적으로 이러한 수정은 성능 저하를 초래하기 쉽지만, FDR과 GO-LSD는 이러한 성능 감소를 효과적으로 상쇄하여 속도와 정확도 사이에서 더 나은 균형을 달성한다.
COCO 데이터셋(Lin et al., 2014a)에서 수행한 실험 결과는 D-FINE이 실시간 객체 검출 분야에서 최첨단(state-of-the-art) 성능을 달성하며, 정확도와 효율성 측면에서 기존 모델들을 능가함을 보여준다. D-FINE-L과 D-FINE-X는 COCO val2017 기준으로 각각 54.0%와 55.8% AP를 달성하였으며, NVIDIA T4 GPU에서 각각 124 FPS와 78 FPS로 동작한다. Objects365(Shao et al., 2019)와 같은 대규모 데이터셋으로 사전학습한 이후에는, D-FINE 계열이 최대 59.3% AP에 도달하여 기존의 모든 실시간 검출기를 뛰어넘는 성능을 기록하였고, 이를 통해 확장성(scalability)과 강건성(robustness)을 모두 입증하였다. 더 나아가, 제안한 방법은 추가 파라미터와 학습 비용을 거의 증가시키지 않으면서도 다양한 DETR 모델의 성능을 최대 5.3% AP까지 향상시켜, 높은 유연성과 일반화 성능을 보여준다.
결론적으로, D-FINE은 실시간 객체 검출기의 성능 한계를 한 단계 더 끌어올린다. FDR과 GO-LSD를 통해 바운딩 박스 회귀와 증류 효율성의 핵심 문제를 해결함으로써, 본 연구는 객체 검출 분야에서 의미 있는 진전을 제시하며, 향후 연구에 새로운 방향을 제시한다.
2. 관련 연구 (Related Work)
실시간 / 엔드투엔드 객체 검출기 (Real-Time / End-to-End Object Detectors)
YOLO 시리즈는 아키텍처, 데이터 증강, 학습 기법의 지속적인 혁신을 통해 실시간 객체 검출 분야를 선도해 왔다 (Redmon et al., 2016a; Wang et al., 2023a; b; Glenn., 2023; Wang & Liao, 2024; Glenn., 2024). 높은 효율성에도 불구하고, YOLO 계열은 일반적으로 Non-Maximum Suppression(NMS)에 의존하며, 이는 속도와 정확도 사이에서 지연(latency)과 불안정성을 유발한다. DETR(Carion et al., 2020)는 NMS와 앵커(anchor)와 같은 수작업 기반 구성 요소를 제거함으로써 객체 검출 패러다임에 혁신을 가져왔다. 전통적인 DETR 계열(Zhu et al., 2020; Meng et al., 2021; Zhang et al., 2022; Wang et al., 2022; Liu et al., 2021; Li et al., 2022; Chen et al., 2022a; c)은 뛰어난 성능을 달성했으나, 높은 계산 비용을 요구하여 실시간 응용에는 부적합했다.
최근에는 RT-DETR(Zhao et al., 2024)과 LW-DETR(Chen et al., 2024)이 DETR을 실시간 환경에 성공적으로 적용하였다. 동시에 YOLOv10(Wang et al., 2024a) 역시 NMS를 제거하여, YOLO 계열 내에서 엔드투엔드 객체 검출로의 중요한 전환점을 제시하고 있다.
분포 기반 객체 검출 (Distribution-Based Object Detection)
전통적인 바운딩 박스 회귀 방식(Redmon et al., 2016b; Liu et al., 2016; Ren et al., 2015)은 디랙 델타 분포(Dirac delta distribution)에 의존하여 바운딩 박스의 경계를 정확하고 고정된 값으로 취급하므로, 위치 추정 불확실성을 모델링하기 어렵다. 이를 해결하기 위해 최근 연구들은 가우시안 분포 또는 이산(discrete) 분포를 사용하여 바운딩 박스를 표현함으로써 불확실성 모델링을 강화하고 있다 (Choi et al., 2019; Li et al., 2020; Qiu et al., 2020; Li et al., 2021). 그러나 이러한 방법들은 모두 앵커 기반 프레임워크에 의존하기 때문에, YOLOX(Ge et al., 2021)나 DETR(Carion et al., 2020)와 같은 최신 앵커 프리(anchor-free) 검출기와의 호환성이 제한적이다. 또한 이들의 분포 표현은 대체로 거친(coarse-grained) 형태로 설계되어 있으며, 효과적인 정제(refinement) 과정이 부족하여 보다 정확한 예측을 달성하는 데 한계를 가진다.
지식 증류 (Knowledge Distillation)
지식 증류(Knowledge Distillation, KD)는 강력한 모델 압축 기법이다 (Hinton et al., 2015). 전통적인 KD는 주로 Logit Mimicking을 통해 지식을 전달하는 데 초점을 맞춰왔다 (Zagoruyko & Komodakis, 2017; Mirzadeh et al., 2020; Son et al., 2021). FitNets(Romero et al., 2015)는 특징 모방(Feature Imitation)을 최초로 제안하였으며, 이후 이를 확장한 다양한 연구들이 제시되었다 (Chen et al., 2017; Dai et al., 2021; Guo et al., 2021; Li et al., 2017; Wang et al., 2019). DETR 계열을 대상으로 한 대부분의 접근법(Chang et al., 2023; Wang et al., 2024b)은 로짓과 다양한 중간 표현을 결합한 하이브리드 증류 방식을 채택하고 있다.
최근에는 위치 증류(Localization Distillation, LD)(Zheng et al., 2022)가 객체 검출 과제에서 위치 정보를 전달하는 것이 더 효과적임을 입증하였다. 또한 자기 증류(Self-Distillation)(Zhang et al., 2019; 2021)는 KD의 특수한 형태로, 별도의 교사 모델을 학습할 필요 없이 모델 자신의 정제된 출력으로부터 얕은 계층이 학습할 수 있도록 하여, 추가 학습 비용을 크게 줄일 수 있다는 장점을 가진다.
3. 기초 배경 (Preliminaries)
객체 검출에서의 바운딩 박스 회귀(bounding box regression)는 전통적으로 디랙 델타 분포(Dirac delta distribution)를 모델링하는 방식에 의존해 왔으며, 이는 중심점 기반 표현

이러한 문제를 해결하기 위해 GFocal(Li et al., 2020; 2021)은 앵커 포인트로부터 네 개 경계까지의 거리를 이산화된 확률 분포(discretized probability distribution)로 회귀함으로써, 바운딩 박스를 보다 유연하게 모델링한다. 구체적으로, 바운딩 박스 거리

(1) 앵커 의존성(Anchor Dependency): 회귀가 앵커 박스 중심에 묶여 있어 예측의 다양성이 제한되며, 앵커 프리(anchor-free) 프레임워크와의 호환성이 떨어진다.
(2) 반복적 정제의 부재(No Iterative Refinement): 예측이 단 한 번(one-shot)으로 이루어지며, 반복적인 정제 과정이 없어 회귀의 강건성이 감소한다.
(3) 거친 위치 추정(Coarse Localization): 고정된 거리 범위와 균일한 bin 간격은, 각 bin이 넓은 값의 범위를 대표하게 되어 특히 소형 객체(small objects)에 대해 위치 추정이 거칠어지는 문제를 초래한다.
위치 증류(Localization Distillation, LD)는 위치 정보를 전달하는 것이 객체 검출 과제에서 더 효과적임을 보여주는 유망한 접근법이다 (Zheng et al., 2022). GFocal을 기반으로 한 LD는, 분류 로짓이나 특징 맵을 단순히 모방하는 대신, 교사 모델로부터 유용한 위치 추정 지식을 증류하여 학생 모델의 성능을 향상시킨다. 이러한 장점에도 불구하고, 해당 방법은 여전히 앵커 기반 아키텍처에 의존하며, 추가적인 학습 비용을 요구한다는 한계를 가진다.
4. 방법 (Method)
우리는 속도, 모델 크기, 계산 비용, 정확도 측면에서 모두 우수한 성능을 보이는 강력한 실시간 객체 검출기 D-FINE을 제안한다. D-FINE은 기존 바운딩 박스 회귀 방식의 한계를 해결하기 위해 두 가지 핵심 구성 요소인 세밀한 분포 정제(Fine-grained Distribution Refinement, FDR)와 전역 최적 위치 자기 증류(Global Optimal Localization Self-Distillation, GO-LSD)를 활용하며, 이 두 모듈은 거의 추가적인 파라미터나 학습 시간 증가 없이도 성능을 크게 향상시키도록 상호 보완적으로 작동한다.
(1) FDR은 바운딩 박스 예측에 대한 보정값으로 작용하는 확률 분포를 반복적으로 최적화하여, 보다 세밀한 중간 표현을 제공한다. 이 접근법은 각 경계(edge)의 불확실성을 독립적으로 포착하고 최적화할 수 있도록 설계되었다. 비균일 가중 함수(non-uniform weighting function)를 활용함으로써, FDR은 각 디코더 계층(decoder layer)에서 보다 정밀하고 점진적인 조정을 가능하게 하여 위치 추정 정확도를 향상시키고 예측 오차를 줄인다. 또한 FDR은 앵커 프리(anchor-free) 엔드투엔드(end-to-end) 프레임워크 내에서 동작하므로, 보다 유연하고 강건한 최적화 과정을 가능하게 한다.
(2) GO-LSD는 정제된 확률 분포로부터 위치 정보를 증류하여 얕은 계층으로 전달한다. 학습이 진행됨에 따라 최종 계층은 점점 더 정밀한 소프트 레이블(soft label)을 생성하며, 얕은 계층들은 GO-LSD를 통해 자신의 예측을 이러한 레이블에 정렬시킨다. 그 결과, 얕은 계층에서도 보다 정확한 예측이 가능해진다. 초기 단계의 예측이 개선되면, 이후 계층들은 더 작은 잔차(residual)를 정제하는 데 집중할 수 있게 된다. 이러한 상호 강화 과정은 시너지 효과를 만들어내며, 점진적으로 더 정확한 위치 추정을 가능하게 한다.
D-FINE의 효율성을 더욱 향상시키기 위해, 기존 실시간 DETR 아키텍처(Zhao et al., 2024)에서 계산 비용이 큰 모듈과 연산을 간소화하여 D-FINE을 더 빠르고 경량화된 구조로 설계하였다. 일반적으로 이러한 수정은 일정 수준의 성능 저하를 동반하지만, FDR과 GO-LSD는 이러한 성능 감소를 효과적으로 상쇄한다. 구체적인 구조 및 연산 수정 사항은 표 3(Table 3)에 정리되어 있다.
4.1 세밀한 분포 정제 (Fine-grained Distribution Refinement)
세밀한 분포 정제(Fine-grained Distribution Refinement, FDR)는 그림 2에 나타난 바와 같이, 디코더 계층(decoder layers)에서 생성된 세밀한 확률 분포를 반복적으로 최적화하는 방식이다. 먼저 첫 번째 디코더 계층은 전통적인 바운딩 박스 회귀 헤드와 D-FINE 헤드를 통해 초기 바운딩 박스와 초기 확률 분포를 예측한다(두 헤드는 모두 MLP 구조이며, 출력 차원만 다르다). 각 바운딩 박스는 네 개의 분포와 연결되며, 이는 각각 상단, 하단, 좌측, 우측 경계(edge)에 대응한다. 초기 바운딩 박스는 기준(reference) 박스로 사용되고, 이후의 디코더 계층들은 잔차(residual) 방식으로 분포를 조정하면서 이를 점진적으로 정제한다. 이렇게 정제된 분포는 초기 바운딩 박스의 네 경계를 조정하는 데 적용되며, 반복이 진행될수록 위치 추정 정확도가 점차 향상된다.
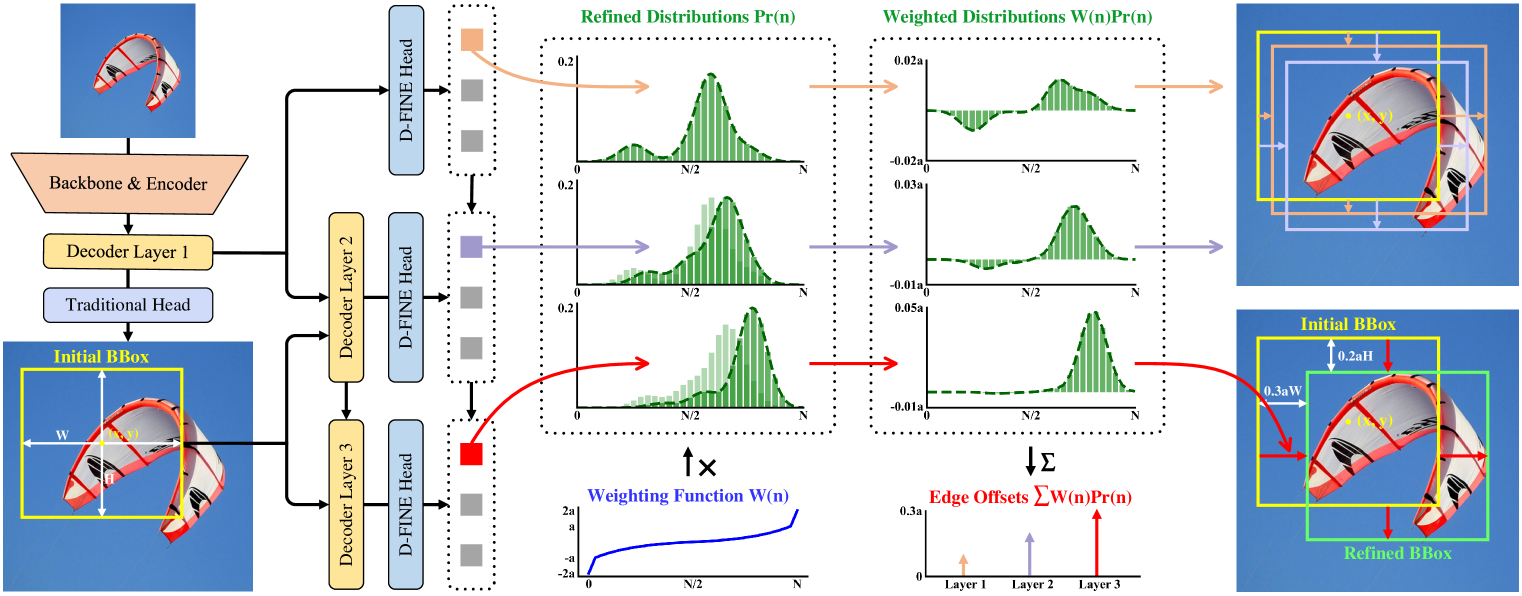
그림 2: FDR을 포함한 D-FINE의 개요. 보다 세밀한 중간 표현으로 작용하는 확률 분포는 디코더 계층에 의해 잔차 방식으로 반복적으로 정제된다. 비균일 가중 함수(non-uniform weighting function)를 적용하여 더 정밀한 위치 추정을 가능하게 한다.
수학적으로, 초기 바운딩 박스 예측을 𝐛₀ = {x, y, W, H}로 두자. 여기서 {x, y}는 바운딩 박스 중심 좌표를, {W, H}는 박스의 너비와 높이를 나타낸다. 이후 𝐛₀는 중심 좌표 𝐜₀ = {x, y} 와 중심으로부터 각 경계까지의 거리 𝐝₀ = {t, b, l, r} 로 변환될 수 있으며, 이는 각각 상단, 하단, 좌측, 우측 경계까지의 거리를 의미한다.
l번째 디코더 계층에서 정제된 경계 거리 𝐝_l = {t_l, b_l, l_l, r_l}는 다음과 같이 계산된다.
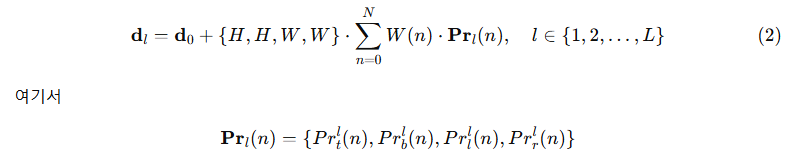
는 네 개의 독립적인 분포로 구성되며, 각각 하나의 경계에 대응한다. 각 분포는 해당 경계에 대해 가능한 오프셋(offset) 후보 값들이 선택될 확률을 예측한다. 이러한 후보 값들은 가중 함수 W(n)에 의해 결정되며, n은 전체 N개의 이산 bin 중 하나를 나타내고, 각 bin은 특정한 경계 오프셋 후보에 대응한다. 분포의 가중합(weighted sum)을 통해 경계 오프셋이 계산되며, 이후 초기 바운딩 박스의 높이 H와 너비 W로 스케일링된다. 이를 통해 조정 값이 박스 크기에 비례하도록 보장한다.
정제된 확률 분포는 다음과 같이 정의되는 잔차(residual) 보정을 통해 업데이트된다.



여기서 a와 c는 함수의 상한과 곡률(curvature)을 제어하는 하이퍼파라미터이다. 그림 2에서 보이듯이, W(n)의 형태는 바운딩 박스 예측이 이미 정확한 경우 작은 곡률을 통해 미세한 조정을 가능하게 한다. 반대로, 예측이 실제 값과 크게 어긋난 경우에는, 경계 근처에서의 큰 곡률과 W(n) 경계에서의 급격한 변화가 충분한 유연성을 제공하여 큰 보정이 가능하도록 한다.
분포 예측의 정확도를 더욱 향상시키고 이를 정답(ground truth)과 정렬하기 위해, Distribution Focal Loss(DFL)(Li et al., 2020)에서 영감을 받아 세밀한 위치 추정 손실(Fine-Grained Localization, FGL Loss)을 새롭게 제안한다. FGL 손실은 다음과 같이 계산된다.



그림 3: GO-LSD 과정의 개요. 최종 계층에서 정제된 분포로부터 얻은 위치 정보가, 분리된 가중 전략(decoupled weighting strategies)을 사용하는 DDF 손실을 통해 얕은 계층으로 증류된다.
4.2 전역 최적 위치 자기 증류 (Global Optimal Localization Self-Distillation)
전역 최적 위치 자기 증류(Global Optimal Localization Self-Distillation, GO-LSD)는 그림 3에 나타난 바와 같이, 최종 계층에서 정제된 확률 분포 예측을 활용하여 위치 추정 지식을 얕은 계층으로 증류한다. 이 과정은 먼저 각 계층의 예측 결과에 대해 헝가리안 매칭(Hungarian Matching)(Carion et al., 2020)을 적용하여, 모델의 각 단계에서 로컬 바운딩 박스 매칭을 식별하는 것으로 시작된다. 이후 전역 최적화를 수행하기 위해, GO-LSD는 모든 계층에서 얻어진 매칭 인덱스를 하나의 통합 합집합(union set)으로 결합한다. 이 합집합은 계층 전반에 걸쳐 가장 정확한 후보 예측들을 포함하며, 이를 통해 모든 계층이 증류 과정의 이점을 공유하도록 한다.
전역 매칭을 정제하는 것뿐만 아니라, GO-LSD는 학습 과정에서 매칭되지 않은(unmatched) 예측들 역시 함께 최적화하여 전체적인 안정성을 향상시키며, 이는 전반적인 성능 개선으로 이어진다. 위치 추정은 이러한 합집합을 통해 전역적으로 최적화되지만, 분류(classification) 과제는 여전히 일대일(one-to-one) 매칭 원칙을 따르므로 중복된 박스는 발생하지 않는다. 이러한 엄격한 매칭 구조로 인해, 합집합에 포함된 일부 예측들은 위치 추정은 정확하지만 신뢰도(confidence)가 낮은 경우가 존재한다. 이러한 저신뢰도 예측들은 정밀한 위치 정보를 담고 있는 중요한 후보들이므로, 효과적인 증류가 필요하다.
이를 해결하기 위해, 우리는 분리형 증류 포컬 손실(Decoupled Distillation Focal, DDF Loss)을 도입한다. DDF 손실은 분리된 가중 전략(decoupled weighting strategies)을 적용하여, IoU가 높지만 분류 신뢰도가 낮은 예측에도 적절한 가중치가 부여되도록 한다. 또한 DDF 손실은 매칭된 예측과 매칭되지 않은 예측의 개수에 따라 가중치를 조절하여, 전체 기여도와 개별 손실 간의 균형을 맞춘다. 이러한 설계는 보다 안정적이고 효과적인 증류를 가능하게 한다.

5. 실험 (Experiments)
5.1 실험 설정 (Experiment Setup)
제안한 방법의 효과를 검증하기 위해, 우리는 COCO(Lin et al., 2014a)와 Objects365(Shao et al., 2019) 데이터셋에서 실험을 수행한다. D-FINE의 성능 평가는 COCO 표준 지표를 사용하며, IoU 임계값 0.50부터 0.95까지 평균한 평균 정밀도(AP)를 비롯해, 특정 임계값에서의 AP50, AP75, 그리고 객체 크기별 성능 지표인 소형(APS), 중형(APM), 대형(APL) 객체에 대한 AP를 보고한다. 또한 모델 효율성을 비교하기 위해 파라미터 수(#Params.), 계산량(GFLOPs), 엔드투엔드 지연 시간(latency)을 함께 제시한다. 지연 시간은 NVIDIA T4 GPU에서 TensorRT FP16을 사용하여 측정하였다.
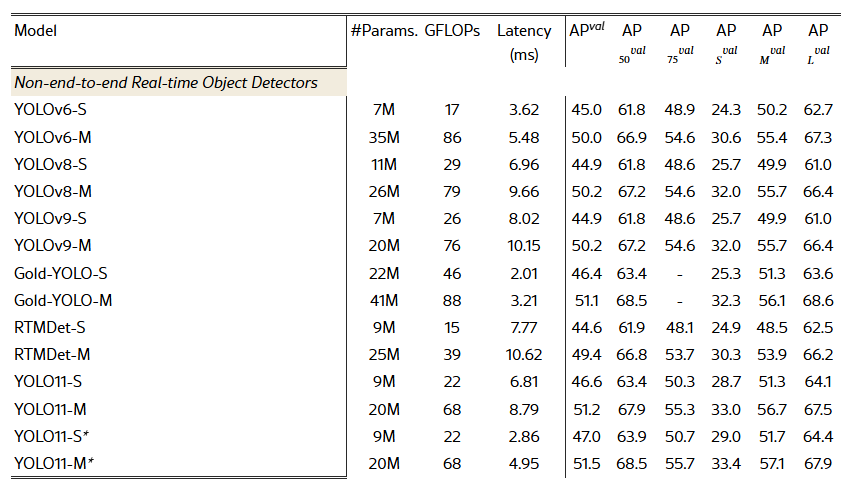
표 1. COCO val2017에서 다양한 실시간 객체 검출기의 성능 비교

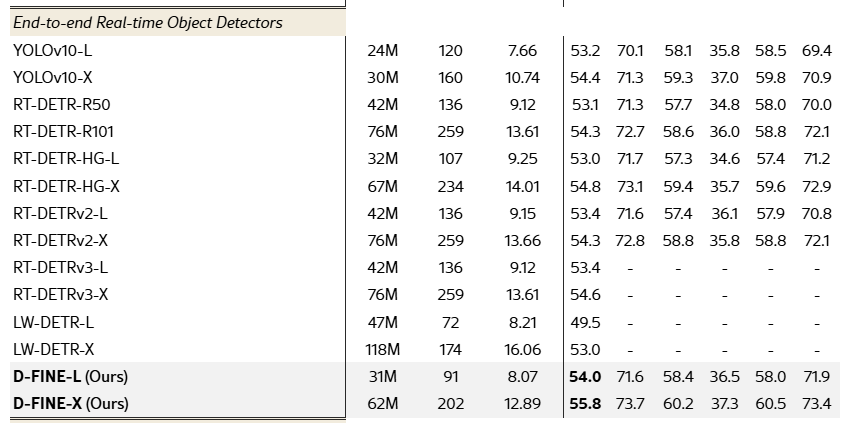

5.2 실시간 객체 검출기와의 비교 (Comparison with Real-Time Detectors)
표 1은 COCO val2017 데이터셋에서 D-FINE과 다양한 실시간 객체 검출기 간의 성능을 종합적으로 비교한 결과를 제시한다. D-FINE은 여러 지표 전반에 걸쳐 효율성과 정확도 사이에서 탁월한 균형을 달성한다. 구체적으로, D-FINE-L은 31M 파라미터와 91 GFLOPs 조건에서 54.0% AP를 기록하며, 8.07 ms의 낮은 지연 시간을 유지한다. 또한 D-FINE-X는 62M 파라미터와 202 GFLOPs로 55.8% AP를 달성하면서도, 12.89 ms의 지연 시간으로 동작한다.
지연 시간 대비 AP, 파라미터 수 대비 AP, FLOPs 대비 AP를 각각 산점도로 나타낸 그림 1에서 확인할 수 있듯이, D-FINE은 모든 핵심 차원에서 기존의 최첨단(state-of-the-art) 모델들을 지속적으로 능가한다. D-FINE-L은 YOLOv10-L(53.2%), RT-DETR-R50(53.1%), LW-DETR-X(53.0%)보다 높은 AP(54.0%)를 달성하는 동시에, 계산 자원 요구량은 더 적다(91 GFLOPs vs. 120, 136, 174). 마찬가지로 D-FINE-X 역시 YOLOv10-X와 RT-DETR-R101을 능가하여, 더 높은 성능(55.8% AP vs. 54.4%, 54.3%)을 기록함과 동시에 파라미터 수, GFLOPs, 지연 시간 측면에서도 더 우수한 효율성을 보인다.
추가로, 우리는 D-FINE과 YOLOv10을 Objects365 데이터셋(Shao et al., 2019)에서 사전학습한 후 COCO 데이터셋으로 미세조정(finetuning)을 수행하였다. 사전학습 이후, D-FINE-L과 D-FINE-X는 각각 57.1%와 59.3% AP를 달성하며 뚜렷한 성능 향상을 보였다. 이러한 성능 개선으로 인해, 두 모델은 YOLOv10-L과 YOLOv10-X를 각각 3.1%와 4.4% AP 차이로 앞서며, 본 비교에서 최고 성능 모델로 자리매김하였다.
더 나아가, YOLOv8의 사전학습 프로토콜(Glenn., 2023)을 따라 YOLOv10은 Objects365에서 300 에폭(epoch) 동안 사전학습을 수행한 반면, D-FINE은 단 21 에폭만으로도 상당한 성능 향상을 달성하였다. 이러한 결과는 LW-DETR(Chen et al., 2024)의 결론을 뒷받침하며, DETR 기반 모델이 YOLO 계열과 같은 다른 검출기들에 비해 사전학습으로부터 훨씬 더 큰 이득을 얻는다는 점을 보여준다.
5.3 다양한 DETR 모델에서의 효과성 (Effectiveness on various DETR models)
표 2는 COCO val2017 데이터셋에서 여러 DETR 기반 객체 검출기에 대해, 우리가 제안한 FDR과 GO-LSD 방법의 효과를 보여준다. 본 방법들은 높은 유연성을 목표로 설계되었으며, 어떠한 DETR 아키텍처에도 무리 없이 통합될 수 있고, 파라미터 수나 계산 비용을 증가시키지 않으면서도 성능을 크게 향상시킨다. FDR과 GO-LSD를 Deformable DETR, DAB-DETR, DN-DETR, DINO에 적용한 결과, 모든 경우에서 검출 정확도가 일관되게 향상되었으며, 그 성능 향상 폭은 2.0%에서 최대 5.3% AP에 이른다.
이러한 결과는 FDR과 GO-LSD가 위치 추정 정밀도를 효과적으로 개선하고, 효율성을 극대화하는 데 탁월함을 보여준다. 또한 다양한 엔드투엔드(end-to-end) 객체 검출 프레임워크 전반에 걸쳐 높은 적응성과 실질적인 성능 향상을 제공한다는 점을 입증한다.
표 2. COCO val2017에서 다양한 DETR 모델에 대한 FDR 및 GO-LSD의 효과

5.4 어블레이션 스터디 (Ablation Study)
5.4.1 D-FINE으로의 로드맵 (The Roadmap to D-FINE)
표 3은 기준 모델인 RT-DETR-HGNetv2-L(Zhao et al., 2024)에서 제안하는 D-FINE 프레임워크로 발전해 가는 단계별 과정을 보여준다. 기준 모델은 53.0% AP, 32M 파라미터, 110 GFLOPs, 9.25 ms 지연 시간의 성능을 가진다. 첫 번째 단계로 모든 디코더 프로젝션 레이어(decoder projection layers)를 제거하였다. 이 수정으로 GFLOPs는 97로 감소하고 지연 시간은 8.02 ms로 줄어들었지만, AP는 52.4%로 하락하였다. 이러한 성능 저하를 보완하기 위해 Target Gating Layer를 도입하였으며, 계산 비용을 거의 증가시키지 않으면서 AP를 52.8%까지 회복시켰다.
Target Gating Layer는 디코더의 크로스 어텐션(cross-attention) 모듈 이후에 전략적으로 배치되며, 기존의 잔차 연결(residual connection)을 대체한다. 이를 통해 쿼리(query)가 계층 간에서 서로 다른 타깃에 동적으로 집중할 수 있도록 하여, 정보가 뒤엉키는 문제를 효과적으로 방지한다. 해당 메커니즘은 다음과 같이 정의된다.

다음으로, 인코더의 CSP 레이어를 GELAN 레이어(Wang & Liao, 2024)로 대체하였다. 이 변경은 AP를 53.5%까지 향상시켰지만, 파라미터 수, GFLOPs, 지연 시간이 모두 증가하였다. 이러한 복잡도 증가를 완화하기 위해 GELAN의 히든 차원(hidden dimension)을 절반으로 줄였으며, 그 결과 효율성은 크게 개선되면서도 AP를 52.8% 수준으로 유지할 수 있었다. 이후 스케일별로 서로 다른 샘플링 포인트를 사용하는 비균일 샘플링(S: 3, M: 6, L: 3)을 적용하여 AP를 52.9%로 소폭 향상시켰다. 반면, (S: 6, M: 3, L: 3)이나 (S: 3, M: 3, L: 6)과 같은 다른 조합은 약 0.1% AP의 성능 저하를 보였다.
또한 RT-DETRv2 학습 전략(Lv et al., 2024)을 적용하면(자세한 내용은 Section A.1.1 참고), 파라미터 수나 지연 시간의 증가 없이 AP가 53.0%로 향상된다. 마지막으로 FDR과 GO-LSD 모듈을 통합함으로써 AP는 54.0%까지 상승하였으며, 이는 기준 모델 대비 지연 시간 13% 감소, GFLOPs 17% 감소라는 큰 효율 개선과 함께 달성된 결과이다. 이러한 점진적 수정들은 D-FINE 프레임워크의 강건성과 효과성을 명확히 보여준다.
표 3. 기준 모델에서 D-FINE까지의 단계별 수정 사항
각 단계별 AP, 파라미터 수, 지연 시간, FLOPs의 변화를 나타낸다.

표 4. D-FINE-L의 하이퍼파라미터 어블레이션 결과
ϵ은 매우 작은 값이며, a~,c~는 a,c가 학습 가능한 파라미터임을 의미한다.
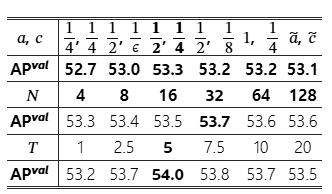
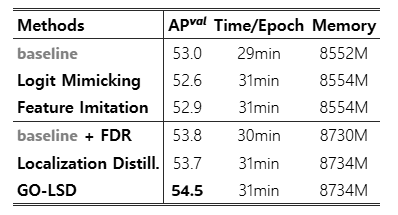
표 5. 증류 기법별 성능, 학습 시간, GPU 메모리 사용량 비교
GO-LSD는 최소한의 추가 학습 비용으로 가장 높은 AP_val을 달성한다.
5.4.2 하이퍼파라미터 민감도 분석 (Hyperparameter Sensitivity Analysis)
표 5는 FDR과 GO-LSD 모듈에서 사용되는 핵심 하이퍼파라미터에 대해, 모델 성능이 얼마나 민감하게 반응하는지를 평가한 어블레이션 실험의 일부를 제시한다. 우리는 가중 함수의 파라미터 a와 , 분포 bin의 개수 N, 그리고 KL 발산에서 로짓을 부드럽게(smoothing) 하기 위해 사용되는 온도 파라미터 T를 중심으로 분석을 수행하였다.

(2) 분포 bin의 개수 N.
분포 bin의 수를 증가시킬수록 성능이 점진적으로 향상되었으며, N=32에서 53.7% AP로 최고 성능을 달성하였다. 그러나 N=32를 초과하면 추가적인 성능 향상은 거의 관찰되지 않았다.
(3) 온도 파라미터 TT.
온도 TT는 증류 과정에서 로짓을 얼마나 부드럽게 만들지를 제어한다. T = 5에서 54.0% AP라는 최적 성능을 달성하였으며, 이는 분포를 적절히 완화하면서도 효과적인 지식 전달을 유지하는 균형점임을 보여준다.
5.4.3 증류 기법 비교 (Comparison of Distillation Methods)
표 5는 성능, 학습 시간, GPU 메모리 사용량 측면에서 서로 다른 증류 기법들을 비교한 결과를 보여준다. 기준 모델(baseline)은 53.0% AP를 달성하며, 4개의 NVIDIA RTX 4090 GPU 환경에서 에폭당 학습 시간은 29분, 메모리 사용량은 8552 MB이다. DETR에서의 일대일(one-to-one) 매칭은 본질적으로 불안정하기 때문에, Logit Mimicking이나 Feature Imitation과 같은 전통적인 증류 기법들은 성능 향상에 기여하지 못한다. 실제로 Logit Mimicking은 AP를 52.6%로 오히려 감소시키며, Feature Imitation 역시 52.9% AP에 그친다.
반면, 우리가 제안한 FDR 모듈을 통합하면 추가적인 학습 비용이 거의 증가하지 않으면서 AP가 53.8%로 향상된다. 여기에 기본적인 Localization Distillation(Zheng et al., 2022)을 적용하면 AP는 53.7%까지 증가한다. 최종적으로, GO-LSD 방법은 54.5% AP로 가장 높은 성능을 달성하며, 기준 모델 대비 학습 시간은 약 6%, 메모리 사용량은 약 2%만 증가한다. 특히 본 비교에서는 경량화(lightweight) 최적화를 전혀 적용하지 않고, 순수하게 증류 성능 자체에만 초점을 맞추었다는 점에서 GO-LSD의 효율성이 더욱 두드러진다.

그림 4: 다양한 검출 시나리오에서 FDR의 동작을 시각화한 예시. 초기 바운딩 박스와 정제된 바운딩 박스, 가중치가 적용되지 않은 분포와 적용된 분포를 함께 보여주며, 위치 추정 정확도가 어떻게 개선되는지를 강조한다.
5.5 시각화 분석 (Visualization Analysis)
그림 4는 다양한 검출 시나리오에서 FDR이 동작하는 과정을 시각적으로 보여준다. 이미지 위에는 두 개의 바운딩 박스를 중첩하여 표시한 필터링된 검출 결과를 제시한다. 빨간색 박스는 첫 번째 디코더 계층에서의 초기 예측을, 초록색 박스는 최종 디코더 계층에서 정제된 예측을 나타낸다. 최종 예측은 타깃 객체와 훨씬 더 정확하게 정렬됨을 확인할 수 있다.
이미지 아래 첫 번째 행은 네 개의 경계(좌, 상, 우, 하)에 대한 가중치가 적용되지 않은 확률 분포를 보여준다. 두 번째 행은 가중 함수 W(n)가 적용된 가중 분포를 나타낸다. 여기서 빨간 곡선은 초기 분포를, 초록 곡선은 최종적으로 정제된 분포를 의미한다. 가중 분포는 예측이 이미 정확한 구간에서는 미세한 조정을 강조하고, 더 큰 보정이 필요한 경우에는 빠른 변화가 가능하도록 설계되어 있다. 이를 통해 FDR이 초기 바운딩 박스의 오프셋을 점진적으로 정제하며, 위치 추정이 점점 더 정밀해지는 과정을 직관적으로 확인할 수 있다.
6. 결론 (Conclusion)
본 논문에서는 세밀한 분포 정제(Fine-grained Distribution Refinement, FDR)와 전역 최적 위치 자기 증류(Global Optimal Localization Self-Distillation, GO-LSD)를 통해 DETR 모델의 바운딩 박스 회귀 과제를 재정의한 강력한 실시간 객체 검출기 D-FINE을 제안하였다. COCO 데이터셋에서의 실험 결과는 D-FINE이 정확도와 효율성 측면에서 최첨단(state-of-the-art) 성능을 달성하며, 기존의 모든 실시간 객체 검출기를 능가함을 보여준다.
한계 및 향후 연구(Limitation and Future Work).
다만, 경량화된 D-FINE 모델과 다른 소형(compact) 모델 간의 성능 격차는 상대적으로 크지 않게 나타난다. 그 가능한 원인 중 하나는 얕은 디코더 계층이 최종 계층 수준의 정확한 예측을 충분히 제공하지 못해, 초기 계층으로의 위치 정보 증류 효과가 제한되기 때문일 수 있다. 이러한 문제를 해결하기 위해서는 추론 지연 시간을 증가시키지 않으면서도, 경량 모델의 위치 추정 능력을 강화하는 방법이 필요하다. 향후 연구에서는 학습 단계에서 더 정교한 디코더 계층을 추가하되, 테스트 단계에서는 이를 제거함으로써 경량 추론을 유지할 수 있는 고급 아키텍처 설계나 새로운 학습 패러다임을 탐구할 수 있을 것이다. 본 연구에서 제안한 D-FINE이 이 분야의 추가적인 발전을 촉진하는 계기가 되기를 기대한다.
부록 A (Appendix)
A.1 구현 세부 사항 (Implementation Details)
A.1.1 하이퍼파라미터 설정 (Hyperparameter Configurations)
표 6은 D-FINE 모델들의 하이퍼파라미터 설정을 요약한다. 모든 변형 모델은 ImageNet으로 사전학습된 HGNetV2 백본(Cui et al., 2021; Russakovsky et al., 2015)과 AdamW 옵티마이저를 사용한다. D-FINE-X는 임베딩 차원(embedding dimension)을 384, 피드포워드 차원(feedforward dimension)을 2048로 설정하며, 나머지 모델들은 각각 256과 1024를 사용한다. D-FINE-X와 D-FINE-L은 6개의 디코더 레이어를 사용하고, D-FINE-M과 D-FINE-S는 각각 4개와 3개의 디코더 레이어를 사용한다.

학습 스케줄은 D-FINE-X와 D-FINE-L의 경우 고급 데이터 증강(RandomPhotometricDistort, RandomZoomOut, RandomIoUCrop, RMultiScaleInput)을 적용한 72 에폭과 고급 증강을 적용하지 않은 2 에폭으로 구성된다. D-FINE-M과 D-FINE-S는 고급 증강을 적용한 120 에폭과 고급 증강 없이 4 에폭을 사용한다(표 3의 RT-DETRv2 학습 전략(Lv et al., 2024) 참조). 사전학습(pretraining) 에폭 수는 D-FINE-X와 D-FINE-L이 21 에폭, D-FINE-M과 D-FINE-S는 28~29 에폭 범위이다.
표 6. D-FINE 모델별 하이퍼파라미터 설정

A.1.2 데이터셋 설정 (Datasets Settings)
사전학습 단계에서는 기존 연구(Chen et al., 2022b; Zhang et al., 2022; Chen et al., 2024)를 따라 Objects365(Shao et al., 2019)의 학습(train) 세트와 검증(validate) 세트를 결합하되, 처음 5,000장의 이미지는 제외한다. 학습 효율을 높이기 위해, 해상도가 640×640을 초과하는 모든 이미지는 사전에 640×640으로 리사이즈한다. 이후 COCO2017(Lin et al., 2014b)의 표준 데이터 분할 정책을 사용하여, COCO train2017으로 학습하고 COCO val2017에서 평가를 수행한다.
A.2 D-FINE 예측 결과 시각화 (Visualization of D-FINE Predictions)
그림 5는 D-FINE-X 모델의 강건성을 보여주며, 다양한 도전적인 환경에서의 예측 결과를 시각적으로 제시한다. 이러한 환경에는 가림(occlusion), 저조도(low-light) 조건, 모션 블러(motion blur), 피사계 심도(depth of field) 효과, 회전(rotation), 그리고 다수의 객체가 밀집해 있는 고밀도 장면이 포함된다. 이러한 어려움에도 불구하고, 모델은 동물, 차량, 사람과 같은 객체들을 정확하게 식별하고 정밀하게 위치를 추정한다.
이 시각화 결과는 D-FINE이 복잡한 실제 환경에서도 강건한 검출 성능을 유지할 수 있음을 보여주며, 다양한 현실적 조건을 효과적으로 처리할 수 있는 모델의 능력을 강조한다.

그림 5: Objects365 사전학습 없이 학습된 D-FINE-X 모델의 예측 결과 시각화. 가림, 저조도, 모션 블러, 피사계 심도 효과, 회전, 고밀도 장면 등 어려운 조건에서의 성능을 보여준다(신뢰도 임계값 = 0.5).
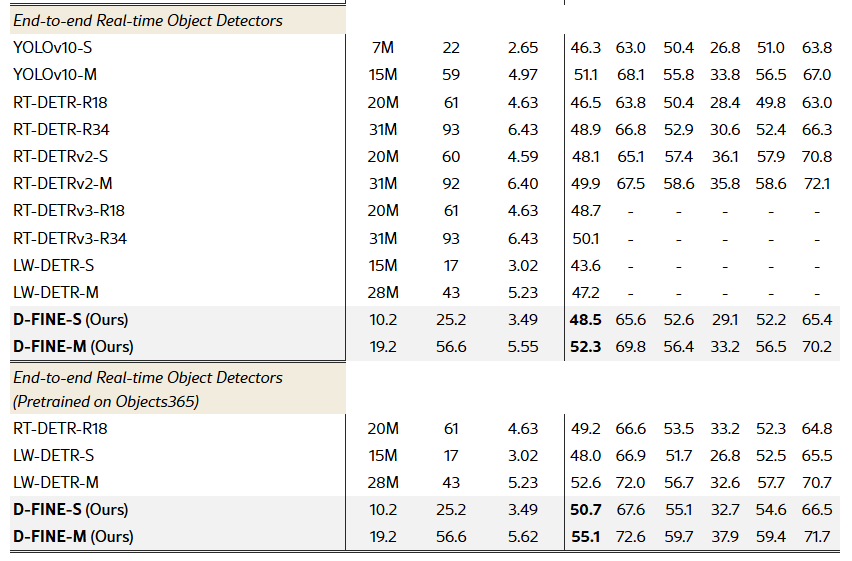
A.3 경량 검출기와의 비교 (Comparison with Lighter Detectors)
표 7은 COCO val2017 데이터셋에서 S 및 M 크기 모델 기준으로, D-FINE 계열과 다양한 경량(real-time) 객체 검출기들을 종합적으로 비교한 결과를 제시한다. D-FINE-S는 48.5% AP를 달성하여 Gold-YOLO-S(46.4%)와 RT-DETRv2-S(48.1%)를 능가하며, 10.2M 파라미터, 25.2 GFLOPs, 3.49 ms의 낮은 지연 시간을 유지한다. Objects365로 사전학습을 적용할 경우, D-FINE-S의 성능은 50.7% AP로 향상되어 +2.2%의 추가 이득을 얻는다.
유사하게, D-FINE-M은 19.2M 파라미터, 56.6 GFLOPs, 5.62 ms 조건에서 52.3% AP를 달성하여 YOLOv10-M(51.1%)과 RT-DETRv2-M(49.9%)를 앞선다. Objects365 사전학습을 적용하면 D-FINE-M 역시 +2.8% AP의 성능 향상을 보인다. 이러한 결과는 D-FINE 모델들이 정확도와 효율성 사이에서 뛰어난 균형을 달성하며, 실시간 성능을 유지하면서도 기존의 최첨단 경량 검출기들을 지속적으로 능가함을 보여준다.
표 7. COCO val2017에서 S 및 M 크기 실시간 객체 검출기의 성능 비교