https://arxiv.org/abs/2512.23273
YOLO-Master: MOE-Accelerated with Specialized Transformers for Enhanced Real-time Detection
Existing Real-Time Object Detection (RTOD) methods commonly adopt YOLO-like architectures for their favorable trade-off between accuracy and speed. However, these models rely on static dense computation that applies uniform processing to all inputs, misall
arxiv.org
YOLO-Master: 특화된 트랜스포머를 활용한 MoE 가속 기반 고성능 실시간 객체 탐지
Xu Lin¹, Jinlong Peng¹¹, Zhenye Gan¹, Jiawen Zhu², Jun Liu¹
¹Tencent Youtu Lab ²Singapore Management University
{gatilin, jeromepeng, wingzygan, juliusliu}@tencent.com
jwzhu.2022@phdcs.smu.edu.sg
공동 1저자(Equal contribution)
초록(Abstract)
기존의 실시간 객체 탐지(Real-Time Object Detection, RTOD) 방법들은 정확도와 속도 간의 유리한 절충을 위해 주로 YOLO 계열 아키텍처를 채택해왔다. 그러나 이러한 모델들은 모든 입력에 대해 동일한 처리를 적용하는 정적인 밀집 연산(static dense computation)에 의존하며, 이로 인해 표현 능력과 계산 자원이 비효율적으로 배분되는 문제가 있다. 즉, 단순한 장면에는 과도한 연산을 할당하는 반면, 복잡한 장면에는 충분한 연산을 제공하지 못한다. 이러한 불일치는 계산 중복을 초래할 뿐만 아니라 탐지 성능 저하로도 이어진다.
이러한 한계를 극복하기 위해, 우리는 RTOD를 위한 인스턴스 조건부 적응형 계산(instance-conditional adaptive computation)을 도입한 새로운 YOLO 계열 프레임워크 YOLO-Master를 제안한다. 이는 장면 복잡도에 따라 각 입력에 필요한 계산 자원을 동적으로 할당하는 효율적 희소 Mixture-of-Experts(Efficient Sparse Mixture-of-Experts, ES-MoE) 블록을 통해 구현된다.
YOLO-Master의 핵심에는 경량화된 동적 라우팅 네트워크(lightweight dynamic routing network)가 있으며, 이는 다양성 증진 목적 함수(diversity-enhancing objective)를 통해 학습 과정에서 각 전문가(expert)가 상호 보완적인 전문성을 갖도록 유도한다. 또한 이 라우팅 네트워크는 추론 단계에서 가장 관련성이 높은 전문가들만 선택적으로 활성화하도록 적응적으로 학습되며, 이를 통해 계산 오버헤드를 최소화하면서도 탐지 성능을 향상시킨다.
다섯 개의 대규모 벤치마크에 대한 포괄적인 실험을 통해 YOLO-Master의 우수성을 입증하였다. MS COCO 데이터셋에서 제안 모델은 1.62ms의 지연 시간(latency)으로 42.4% AP를 달성하였으며, 이는 YOLOv13-N 대비 mAP 기준 +0.8% 향상되고 추론 속도는 17.8% 더 빠른 결과이다. 특히 이러한 성능 향상은 객체가 밀집된 어려운 장면에서 더욱 두드러지며, 일반적인 입력에 대해서는 효율성을 유지하고 실시간 추론 속도 또한 안정적으로 보장한다.
코드: isLinXu/YOLO-Master
1. 서론(Introduction)
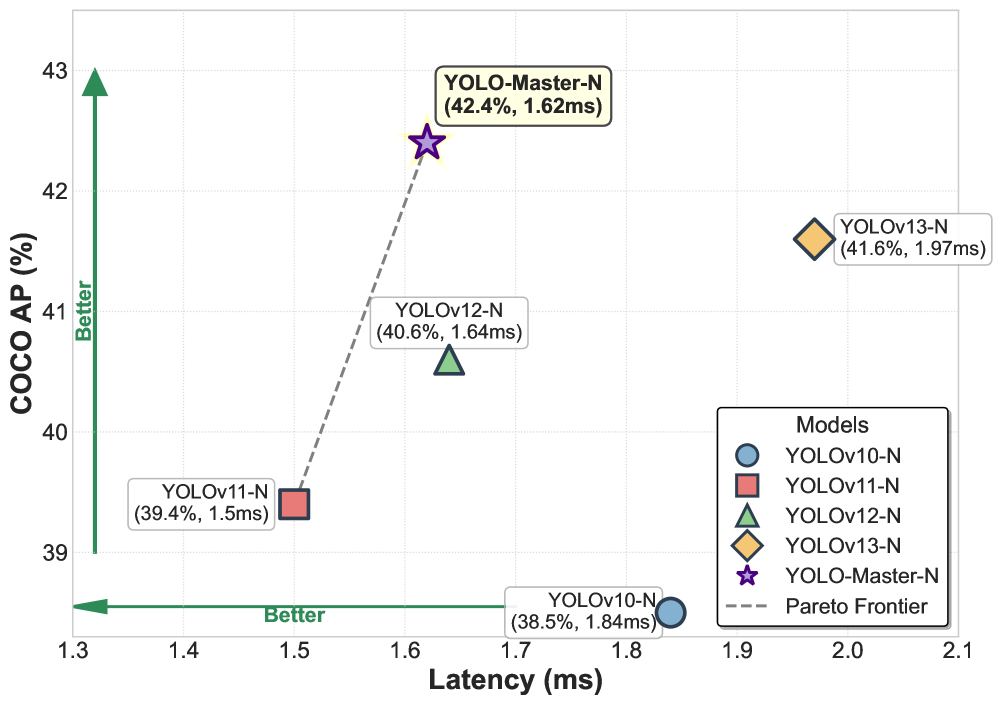
그림 1: MS COCO에서의 정확도–지연 시간(trade-off) 비교. YOLO-Master-N은 1.62ms의 지연 시간에서 42.4% AP를 달성하며, 파레토 프런티어 상에서 기존 기준 모델들을 능가한다.
실시간 객체 탐지(Real-time Object Detection)는 컴퓨터 비전 분야에서 핵심적인 과제로, 자율 주행, 영상 감시, 로봇 시스템 등 다양한 응용 분야에서 폭넓게 활용되고 있다 [31, 34, 28]. YOLO 계열은 단일 단계(one-stage) 탐지 프레임워크를 기반으로 탐지 정확도와 추론 속도 간의 효과적인 균형을 달성하며, 이 분야에서 지배적인 패러다임으로 자리 잡았다 [15, 16, 36, 18, 39].
최근 YOLO 계열 아키텍처의 발전은 주로 두 가지 방향에 집중되어 왔다. 첫째는 개선된 백본(backbone) 설계를 통해 특징 표현력을 향상시키는 것이며 [36], 둘째는 정교한 넥(neck) 아키텍처를 통해 다중 스케일 특징 융합(multi-scale feature fusion)을 최적화하는 것이다 [25]. 예를 들어, YOLOv5는 다중 스케일 특징 학습을 강화하기 위해 C2f 모듈을 도입하였고, YOLOv11은 전역 표현 능력을 향상시키기 위해 선택적 어텐션(selective attention) 메커니즘을 통합하였다.
그러나 이러한 개선에도 불구하고 근본적인 한계는 여전히 존재한다. 모든 기존 YOLO 아키텍처는 입력의 복잡도와 무관하게 동일한 네트워크 경로와 균일한 계산 자원을 적용하는 정적인 밀집 연산(static dense computation)에 기반하고 있다는 점이다. 이러한 ‘모든 경우에 동일하게 적용되는(one-size-fits-all)’ 패러다임은 심각한 비효율을 초래한다. 구체적으로, 객체가 드물고 크기가 큰 단순한 장면과, 작은 객체들이 밀집된 복잡한 장면이 동일한 계산 예산을 소모하게 되며, 그 결과 자원 낭비뿐만 아니라 특징 표현의 순도(feature purity) 저하로 이어진다 [27, 7].
더 나아가 YOLO 계열은 오랫동안 정확도와 속도 간의 균형을 맞추는 데 있어 근본적인 도전에 직면해 왔다. YOLOv1부터 최신 버전에 이르기까지, 각 세대는 아키텍처 혁신과 학습 전략을 통해 이 트레이드오프의 파레토 프런티어를 확장하려는 시도를 지속해왔다. 그러나 이러한 개선들은 본질적으로 정적이며 사전에 정의된 방식에 머물러 있다. 계산 예산과 네트워크 용량은 설계 단계에서 고정되어 있으며, 입력 특성에 따라 자원을 동적으로 할당할 수 있는 적응적 메커니즘이 결여되어 있다.
이러한 한계는 다양한 실제 환경을 다룰 때 특히 두드러진다. 예를 들어, 복잡한 도심 장면에 최적화된 탐지기는 단순한 고속도로 환경에서는 과도하게 파라미터화(over-parameterized)될 수 있으며, 반대로 효율성에 초점을 맞춘 모델은 난이도가 높은 장면을 처리하기에 충분한 표현 능력을 갖추지 못할 수 있다. 최근 대규모 언어 모델 연구에서는 서로 다른 입력이 모델 파라미터의 서로 다른 부분집합을 선택적으로 활성화하는 희소 활성화(sparse activation) 패턴이 효율성과 적응성을 동시에 크게 향상시킬 수 있음이 밝혀졌다 [35, 7]. 이러한 통찰은 실시간 객체 탐지 분야에서도 유사한 동적 계산 패러다임을 도입함으로써, 정확도–효율성 간의 지형 자체를 근본적으로 재구성할 수 있는지 탐구하도록 동기를 부여한다.
이러한 한계를 해결하기 위해, 우리는 YOLO 파이프라인에 Mixture of Experts(MoE) 프레임워크를 통합함으로써 실시간 객체 탐지에 조건부 계산(conditional computation)을 최초로 도입한 새로운 아키텍처 YOLO-Master를 제안한다. 본 접근법은 입력 내용에 따라 전문가 네트워크(expert network)의 부분집합을 동적으로 활성화함으로써, 모델 용량과 계산 비용 사이에 존재하던 기존의 정적인 트레이드오프를 근본적으로 타파한다.
MoE 기반 설계는 다음의 세 가지 핵심 메커니즘으로 구성된다.
(1) 동적 라우팅(dynamic routing): 학습 단계에서는 그래디언트 흐름을 보장하기 위해 soft Top-K 활성화를 사용하고, 추론 단계에서는 효율성을 위해 hard Top-K 희소화를 적용한다.
(2) 효율적인 전문가 그룹(Efficient expert groups): 서로 다른 수용 영역(receptive field)을 갖는 depthwise separable convolution(3×3, 5×5, 7×7 커널)을 활용하여 상이한 다중 스케일 패턴을 포착한다.
(3) 부하 균형(load balancing) 감독(supervision): 학습 중에는 전문가 사용을 균등하게 유지하면서, 배포(deployment) 단계에서는 실제적인 희소성(genuine sparsity)을 보장한다.
MS COCO 데이터셋에서의 평가 결과, YOLO-Master는 경쟁력 있는 추론 속도를 유지하면서도 YOLOv12 [36] 대비 1.8% mAP, YOLOv13 [18] 대비 0.8% mAP 향상을 달성하였다. 이는 적응적 용량 할당(adaptive capacity allocation)이 어려운 사례에 더 많은 자원을 배분하면서도 일반적인 입력에 대해서는 효율성을 유지함으로써, 실시간 객체 탐지를 위한 새로운 최신 성능(state-of-the-art)을 확립할 수 있음을 입증한다.
우리는 본 논문의 기여를 다음과 같이 요약한다.
• 실시간 객체 탐지를 위한 최초의 MoE 기반 조건부 계산 프레임워크를 제안하며, 입력 복잡도에 따라 모델 용량을 적응적으로 조절하는 동적 전문가 활성화를 통해 정적인 정확도–효율성 트레이드오프를 근본적으로 극복한다.
• 다중 스케일 전문가와 동적 라우팅 네트워크를 갖춘 Efficient Sparse MoE(ES-MoE) 블록을 설계하였다. 학습 시에는 그래디언트 전파를 위해 soft Top-K 전문가를, 추론 시에는 실제 희소성을 위해 hard Top-K 전문가를 사용함으로써 학습 안정성과 배포 효율성을 동시에 달성한다.
• 객체 탐지에 특화된 부하 균형 감독 메커니즘을 도입하여 전문가 붕괴(expert collapse)를 방지하면서도 균일한 활용을 유지하였으며, 이는 추론 희소성을 희생하지 않으면서 안정적인 MoE 학습을 가능하게 하는 핵심 요소임을 입증하였다.
• MS COCO, PASCAL VOC, VisDrone, KITTI, SKU-110K 등 다섯 개의 다양한 벤치마크에서 광범위한 실험을 수행하여 최신 성능을 달성하였다. 객체 밀도와 시각적 도메인이 서로 다른 환경 전반에서의 일관된 성능 향상은, 정적 아키텍처 대비 적응적 계산 방식의 높은 일반화 성능을 입증한다.

그림 2: YOLO-Master의 전체 프레임워크. 본 아키텍처는 특징 추출과 융합을 강화하기 위해 Backbone과 Neck에 ES-MoE 모듈을 통합한다. 입력 특징은 Softmax 게이팅을 갖는 동적 라우팅 네트워크를 통해 처리되며, 상위 K개의 전문가를 선택하여 가중 합산(weighted aggregation)을 수행한다. 또한 본 프레임워크는 P3, P4, P5 예측 계층 전반에 걸쳐 효율적인 다중 스케일 객체 탐지를 위해 표준(Standard), Soft Top-K(학습), Hard Top-K(추론) 라우팅 전략 간을 적응적으로 전환한다.
2. 관련 연구(Related Work)
2.1 실시간 객체 탐지기(Real-time Object Detectors)
YOLO 계열은 지속적인 아키텍처 개선을 거치며 실시간 객체 탐지를 위한 지배적인 패러다임으로 자리 잡아 왔다 [32, 30, 15, 17, 38, 16, 36, 18, 34]. 대표적인 개선 사례로는 다중 스케일 특징 피라미드(multi-scale feature pyramids) [30], 효율적인 레이어 집계(efficient layer aggregation) [15], NMS-free 학습 [38], 선택적 어텐션(selective attention) 메커니즘 [16], 그리고 적응적 시각 인지(adaptive visual perception) [18] 등이 있다. 이러한 방법들은 주로 백본(backbone) 아키텍처 최적화, 특징 융합(feature fusion) 전략, 그리고 학습 패러다임 개선에 초점을 맞추고 있다.
그러나 이들 방법은 모두 입력의 복잡도와 무관하게 동일한 네트워크 경로와 균일한 계산 자원을 사용하는 정적인 밀집 연산(static dense computation)에 의존한다. 이러한 근본적인 한계로 인해 입력 특성에 기반한 적응적 용량 할당(adaptive capacity allocation)이 불가능하다.
YOLO 계열을 넘어, RT-DETR [43]과 같은 다른 실시간 탐지기들도 유사하게 정적인 계산 패턴을 갖는 트랜스포머 기반 아키텍처를 채택하고 있다. 이들 방법은 아키텍처 혁신을 통해 경쟁력 있는 정확도–효율성 트레이드오프를 달성하지만, 동적 자원 할당을 위한 메커니즘은 갖추고 있지 않다. 이에 비해 YOLO-Master는 Mixture of Experts 프레임워크를 통한 조건부 계산을 도입함으로써 이러한 공백을 메우며, 기존 아키텍처에 내재된 정적인 트레이드오프를 근본적으로 타파하는 적응적 전문가 활성화를 가능하게 한다.
2.2 Mixture of Experts
Mixture of Experts(MoE)는 게이팅 네트워크(gating network)가 입력을 특화된 전문가 서브네트워크(expert sub-network)로 라우팅하는 조건부 계산(conditional computation)을 통해 모델 용량을 확장하기 위해 처음 제안되었다 [14]. 이러한 희소 활성화(sparse activation) 전략은 계산 비용을 관리 가능한 수준으로 유지하면서도 언어 모델을 수조(trillion) 개 파라미터 규모로 확장하는 데에서 괄목할 만한 성공을 거두었다 [19, 7]. 최근 연구들은 MoE를 컴퓨터 비전 분야로 확장하여, 주로 Vision Transformer 기반의 이미지 분류 과제 [33, 4, 29] 및 멀티태스크 학습 [2]에 적용해 왔다.
그러나 객체 탐지와 같은 밀집 예측(dense prediction) 과제에 MoE를 적용하는 연구는 아직 거의 탐구되지 않았다. 분류 문제에서 라우팅은 전역 이미지 표현(global image representation)을 대상으로 동작하는 반면, 객체 탐지는 객체 밀도와 스케일 분포가 서로 다른 다중 스케일 공간 특징(multi-scale spatial features)을 처리해야 한다는 점에서 본질적으로 더 복잡하다. 초기 시도로 ViT 기반 탐지기에 MoE를 통합한 연구들이 존재하지만 [40], 이들 방법은 실시간 환경에 적합하지 않을 정도로 상당한 계산 오버헤드를 수반하는 경우가 많다.
이에 비해 YOLO-Master는 경량 CNN 기반 실시간 탐지기에 특화된 최초의 MoE 프레임워크를 제안함으로써 이러한 공백을 해소한다. 우리는 특징 피라미드 계층(feature pyramid hierarchies) 상에서 동작하는 동적 라우팅 메커니즘을 설계하여, 공간적 특성에 따라 전문가를 적응적으로 활성화할 수 있도록 한다. 또한 학습과 추론을 분리한 라우팅 전략(그래디언트 흐름을 위한 soft Top-K 학습, 실제 희소성을 위한 hard Top-K 추론)은 최적화 안정성과 배포 효율성을 동시에 보장하여, 실시간 객체 탐지 환경에서도 조건부 계산을 실질적으로 활용할 수 있도록 한다.
2.3 적응적 특징 처리(Adaptive Feature Processing)
어텐션 메커니즘은 정보성이 높은 영역에 집중함으로써 특징을 동적으로 재조정하기 위해 객체 탐지 분야에서 널리 사용되어 왔다 [13, 12, 41, 42, 10]. 이러한 기법들은 효과적이지만, 채널 어텐션(SE [13]), 공간 어텐션(CBAM [42]), 그리고 트랜스포머 기반 자기 어텐션(self-attention) [37, 1] 모두 입력과 무관한 정적 아키텍처 상에서 동작하며, 모든 입력에 동일한 계산을 적용한다는 한계를 지닌다. 최근 제안된 효율적인 어텐션 변형들 [26, 3]은 계산 복잡도를 줄이기는 했지만, 여전히 모든 공간 위치를 균일한 용량으로 처리하는 근본적으로 밀집(dense)된 계산 구조를 유지하고 있다.
이에 비해 본 연구의 MoE 기반 접근법은 본질적으로 다른 방향을 취한다. 어텐션 점수를 통해 특징의 중요도를 가중하는 대신, 조건부 전문가 활성화(conditional expert activation)를 통해 계산 자체를 적응적으로 수행한다. 이러한 패러다임 전환은 입력에 의존적인 용량 할당(input-dependent capacity allocation)을 가능하게 하여, 단순한 영역은 더 적은 전문가만을 활성화하고 복잡한 영역은 더 큰 모델 용량에 접근하도록 한다. 그 결과, 어텐션 기반 방법에 내재된 정적인 계산 제약을 근본적으로 타파한다.
3. 방법론(Methodology)
3.1 YOLO-Master 개요(Overview of YOLO-Master)
본 연구에서는 실시간 객체 탐지(Real-Time Object Detection, RTOD)를 위한 새로운 YOLO 계열 프레임워크인 YOLO-Master를 제안한다. YOLO-Master는 최근의 YOLO 아키텍처(예: YOLOv12 [36])를 기반으로 하며, 희소하고 인스턴스 조건부 적응 계산을 가능하게 하는 Efficient Sparse Mixture-of-Experts(ES-MoE) 모듈을 도입한다. 그림 2(좌상단)에 나타낸 바와 같이, YOLO-Master는 Backbone, Neck, Detection Head로 구성된 표준 YOLO 설계를 따른다. ES-MoE 모듈은 Backbone과 Neck 양쪽에 삽입되는데, Backbone에서는 객체 스케일과 장면 복잡도의 변화에 따라 특징 추출을 동적으로 강화하고, Neck에서는 다중 스케일 적응적 융합과 정보 정제를 가능하게 한다.
ES-MoE 모듈의 정보 흐름은 그림 2(좌하단)에 도시되어 있다. 구체적으로 ES-MoE는 다음의 세 가지 핵심 구성 요소로 이루어진다.
(i) 인스턴스 의존적 라우팅 신호를 생성하는 동적 라우팅 네트워크(Dynamic Routing Network),
(ii) 가장 관련성이 높은 전문가를 선택하는 Softmax 게이팅 메커니즘(Softmax Gating Mechanism),
(iii) 활성화된 전문가들의 출력을 하나의 정제된 표현으로 결합하는 가중 집계(Weighted Aggregation) 유닛이다. 핵심이 되는 동적 라우팅 네트워크는 단계적(phased) 라우팅 전략을 사용하며, 학습 단계에서는 전문가 특화를 유도하기 위해 soft 라우팅을 적용하고, 추론 단계에서는 그림 2(우측)에 나타난 것처럼 가장 관련성이 높은 전문가만을 선택하는 hard Top-K 활성화를 사용한다. 다음에서는 각 구성 요소를 상세히 설명한다.

이러한 설계를 통해 입력 특징의 국소적 특성과 복잡도에 따라 계산 자원을 동적으로 할당할 수 있다.
ES-MoE의 핵심적인 혁신은 그림 2(우측 패널)에 제시된 단계적 라우팅 전략에 있다. 학습 단계에서는 Soft Top-K 라우팅 메커니즘을 사용하여 모든 전문가에 대해 부드럽고 미분 가능한 가중치를 할당함으로써 그래디언트의 연속성을 보장하는 동시에, 상위 전문가들을 강조한다. 반면 추론 단계에서는 인 Hard Top-K 전략으로 전환하여 KK개의 전문가만을 활성화함으로써, 실질적인 계산 희소성과 가속을 달성한다 [7]. 이 적응적 메커니즘은 기존의 밀집 모델에 내재된 계산 중복 문제를 효과적으로 해소하며, 서로 다른 배포 단계 전반에서 효율적인 전문가 선택을 가능하게 한다. 본 라우팅 전략의 상세한 설계와 분석은 3.4절에서 제시한다.
3.2 동적 라우팅 네트워크(Dynamic Routing Network)
전문가 네트워크는 입력 특징 X에 대해 서로 다른 비선형 변환을 수행하도록 설계된 E개의 독립적인 특징 변환 모듈 Expert_i로 구성된다. 본 설계의 핵심 목표는 높은 계산 효율성과 다양한 수용 영역(receptive field)을 동시에 달성하여, 입력에 따라 가장 적합한 특징 처리 경로를 모델이 적응적으로 선택할 수 있도록 하는 것이다.



3.3 게이팅 네트워크 설계(Gating Network Design)
게이팅 네트워크 G는 ES-MoE 모듈에서 핵심적인 역할을 수행하며, E개의 전문가를 활성화하기 위한 원시 로짓(raw logits)
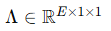
을 생성한다. 본 네트워크의 설계는 라우팅 결정 과정 자체가 계산 병목이 되지 않도록 경량화 원칙을 엄격히 준수한다 [33].
정보 집계(Information aggregation).
먼저, 전역 정보 집계를 위해 라우팅 가중치는 국소적 특징이 아닌 전역 문맥 정보로부터 도출되어야 하며, 이를 통해 전체 입력 특징 맵

에 대해 일관된 가이드를 제공할 수 있다. 이를 위해 우리는 전역 평균 풀링(Global Average Pooling, GAP)을 사용하여 입력 특징 맵을 간결한 전역 디스크립터

로 압축한다 [13, 23].



3.4 단계적 라우팅 전략(Phased Routing Strategy)
라우팅 패러다임 설계는 ES-MoE 프레임워크의 근본적인 목표를 추구한다. 즉, 학습 단계에서는 모든 전문가가 충분히 학습되도록 보장하면서도, 추론 단계에서는 엄격한 희소 활성화를 강제하여 계산 가속을 달성하는 것이다. 이러한 이중 목표는 단계적 동적 라우팅 메커니즘을 통해 구현된다 [7, 45].








4. 실험(Experiment)
4.1 실험 설정(Experimental Setup)
데이터셋(Datasets).
본 연구에서는 서로 다른 특성을 지닌 다섯 개의 벤치마크에서 성능을 평가한다.
MS COCO 2017 [24] (학습 이미지 118k장, 80개 카테고리), PASCAL VOC 2007+2012 [6] (16.5k 이미지, 20개 카테고리), VisDrone-2019 [5] (6.5k 이미지, 10개 카테고리), KITTI [8] (7.5k 이미지, 3개 카테고리), SKU-110K [9] (8.2k 이미지, 1개 카테고리).
구현(Implementation).
MoE 모듈을 통합한 YOLOv12-Nano [36] (너비 스케일링 계수 0.5)를 기준선 모델로 사용한다. 모든 모델은 입력 해상도 640×640에서 600 에폭 동안 학습되며, 코사인 학습률 스케줄링을 적용한 SGD 옵티마이저를 사용한다. 전체 배치 크기는 256이다. 데이터 증강으로는 Mosaic(p=1.0), Copy-Paste(p=0.1), MixUp(Nano 변형에서는 비활성화)을 사용하며, 이 외에도 랜덤 어파인 변환(random affine), HSV 색상 지터링과 같은 표준 증강 기법을 적용한다. 모든 학습과 테스트는 4대의 고성능 연산 장비에서 수행된다.
평가 지표(Metrics).
모든 벤치마크에 대해 mAP50:95와 mAP50을 보고한다. 효율성 지표로는 활성화된 전문가 수가 K일 때의 파라미터 수(Params, M), 지연 시간(latency, ms), 그리고 FPS를 사용하며, 이는 YOLOv12 기준선과 동일한 표준 하드웨어 설정(FP16, 배치 크기=1)을 따르는 전용 추론 가속기에서 측정된다. 이를 통해 실시간 배포 가능성에 초점을 맞춘다.
4.2 주요 결과(Main Results)
표 1은 YOLO-Master-N이 실시간 추론 속도를 유지하면서도 다섯 개의 모든 벤치마크에서 최신(state-of-the-art) 성능을 달성함을 보여준다. YOLO-Master-N은 mAP 기준으로 YOLOv13-N 대비 COCO에서 +0.8%, VOC에서 +1.4%, VisDrone에서 +2.1%, KITTI에서 +1.5%, SKU-110K에서 +0.7%의 성능 향상을 기록하였다. 특히 VisDrone(+2.1%)와 KITTI(+1.5%)에서 가장 큰 성능 개선이 관찰되었으며, 이는 소형 객체 탐지와 정밀한 위치 추정에 대한 본 설계의 타당성을 입증한다.
정확도가 향상되었음에도 불구하고, YOLO-Master-N은 YOLOv13-N 대비 18% 더 빠르며, 가장 빠른 YOLOv11-N 대비로는 단 8%만 느린 수준으로, 효율성과 정확도 간의 최적의 균형을 보여준다. 이미지당 평균 147개의 객체가 존재하는 고밀도 환경인 SKU-110K 데이터셋에서 본 방법은 58.2% mAP를 달성하여, 혼잡한 장면에서도 효과적으로 동작함을 입증하였다.
이러한 결과들은 선택적 특징 처리를 수행하는 MoE 기반 아키텍처가 다양한 객체 탐지 시나리오 전반에서 더 높은 정확도와 실용적인 추론 속도를 동시에 달성할 수 있음을 검증한다.
4.3 소거 실험(Ablation Studies)
4.3.1 ES-MoE 모듈의 효과성(Effectiveness of ES-MoE Module)
표 5에서는 ES-MoE 모듈의 최적 배치 전략을 분석한다. Backbone에만 ES-MoE를 통합한 경우가 62.1% mAP와 2.66M 파라미터로 가장 우수한 성능을 보였으며, 이는 기준선(60.8%) 대비 +1.3% 향상이다. 이는 초기 단계의 특징 추출에서 전문가 특화가 매우 중요함을 검증한다. 즉, 백본의 ES-MoE는 스케일 적응적(scale-adaptive)이면서 의미적으로 다양한(semantic-diverse) 표현을 효과적으로 학습하여, 이후 탐지 성능에 긍정적인 영향을 준다.
반면 Neck에만 ES-MoE를 통합한 경우는 58.2% mAP로 성능이 저하되었다(-2.6%). 이는 백본으로부터 충분히 다양한 입력 특징을 제공받지 못한 상태에서는 라우팅 메커니즘이 효과적으로 전문가 특화를 학습할 수 없기 때문이다. 기본 백본은 비교적 균질한(homogeneous) 특징을 생성하므로, 넥에서 상호 보완적인 전문가 패턴을 발견하는 데 한계가 있다.
흥미롭게도 Backbone과 Neck 모두에 ES-MoE를 적용한 전체 통합(full integration)의 경우, 성능이 54.9% mAP로 크게 저하되었다(기준선 대비 -5.9%). 이는 연쇄적으로 배치된 라우팅 메커니즘 간의 그래디언트 간섭(gradient interference) 때문으로 해석된다. 즉, 백본과 넥의 ES-MoE 모듈이 역전파 과정에서 서로 충돌하는 라우팅 그래디언트를 생성하여 학습을 불안정하게 만들고, 결과적으로 전문가 특화를 방해한다.
이 결과는 중요한 설계 원칙을 시사한다. ES-MoE 모듈을 많이 넣는다고 해서 반드시 성능이 향상되는 것은 아니며, 부정적인 상호작용을 피하기 위해 신중한 배치가 필수적이다. 이러한 분석을 바탕으로, 본 연구에서는 정확도와 학습 안정성의 균형을 고려하여 Backbone 단독 ES-MoE 구성을 기본 설정으로 채택한다.





4.3.2 전문가 수(Number of Experts)
표 6은 전문가 수가 성능–효율성 트레이드오프에 미치는 영향을 분석한다. 전문가 4개 설정은 2.76M 파라미터로 62.3% mAP와 82.2% mAP50을 달성하며 최적의 균형을 보인다. 전문가를 2개만 사용할 경우 mAP가 -1.3% 감소(61.0%)하여, 서로 다른 스케일과 의미 범주에 걸친 다양한 객체 패턴을 모델링하기에 용량이 부족함을 시사한다. 반대로 8개 전문가로 확장하면 파라미터가 33% 증가(3.68M)함에도 성능 향상은 없고(62.0% mAP, -0.3%), 중복된 전문가로 인한 과도한 파라미터화로 수익 체감이 발생함을 보여준다. 이는 객체 탐지에서 다중 스케일 변화를 포착하는 데 적당한 수준의 전문가 다양성이면 충분함을 검증하며, 본 연구에서는 전문가 4개를 기본 설정으로 채택한다.
4.3.3 Top-K 선택 전략(Top-K Selection Strategy)
전문가 4개를 기준으로, 표 7에서는 Top-K 라우팅의 영향을 분석한다. Top-2 라우팅은 50% 희소도에서 61.8% mAP로 최적의 성능을 달성한다. Top-1 라우팅은 -0.5% mAP 하락(61.3%)을 보이며, 표현 용량이 부족함을 나타낸다. 3개 또는 4개 전문가 활성화는 각각 성능 개선이 없다. K=2에서의 최적점은 본 설계를 뒷받침한다. 즉, 두 개의 상호 보완적인 전문가가 충분한 특징 다양성을 제공하면서도 계산 효율을 유지한다. 이러한 결과는 비전 과제에서 K=2를 초과하면 수익 체감이 발생한다는 최근 MoE 연구 [7, 33]와도 일치한다.

그림 3: 다양한 설정에 대한 손실 소거 실험.
(a) DFL 손실 비교, (b) MoE 손실 비교, (c) 검증 mAP, (d) 전체 손실, (e) MoE 손실의 변화, (f) mAP 수렴.


그림 4: 네 가지 도전적인 시나리오에서의 정성적 비교. 모든 테스트 이미지는 MS COCO [24] 및 PASCAL VOC 2007+2012 [6] 테스트 세트에서 가져왔다.
4.3.4 손실 함수 구성(Loss Function Configuration)
표 8과 그림 3은 다섯 가지 손실 구성에 대한 분석 결과를 제시한다. 흥미롭게도 DFL 손실을 완전히 제거하고 MoE 손실만을 사용한 구성(MoE-only, 가중치=1.5)이 62.2% mAP로 가장 우수한 성능을 보였으며, 이는 기준선 대비 +0.3% 향상이다. 학습 동역학(그림 3)을 통해 그 원인을 설명할 수 있다. 구성 4(DFL + 강한 MoE, λ=1.5)는 심각한 진동 현상을 보이는 반면, 구성 5(MoE-only)는 매끄럽게 수렴한다.
우리는 이러한 현상이 DFL 손실과 MoE 손실 간의 그래디언트 충돌에서 비롯된다고 가설을 세운다. 구체적으로, DFL은 균일한 분포 기반의 정제를 강제하는 반면, MoE 손실은 인스턴스 적응형 전문가 특화를 유도한다. 두 손실이 모두 큰 가중치를 가질 경우, 그래디언트의 주도권을 놓고 경쟁하게 되어 학습 불안정성이 발생한다(구성 4: 61.4% mAP, 최저 성능). DFL을 제거하면 이러한 충돌이 해소되어, MoE 손실이 박스 회귀와 전문가 특화를 동시에 효과적으로 유도할 수 있다. 이는 Mixture-of-Experts 아키텍처에서 MoE 손실이 DFL의 역할을 실질적으로 대체(subsume)할 수 있음을 시사한다. 이에 따라 본 연구에서는 구성 5(MoE-only, λ=1.5)를 기본 설정으로 채택한다.
4.3.5 다운스트림 과제로의 일반화(Generalization to Downstream Tasks)
YOLO-Master의 범용성을 추가로 평가하기 위해, 소거 실험에서 도출한 최적 구성을 이미지 분류와 인스턴스 분할 과제로 확장하였다.
분류(Classification).
표 3에 나타난 바와 같이, YOLO-Master-cls-N은 ImageNet에서 76.6% Top-1 정확도를 달성하여 YOLOv11 대비 +6.6%, YOLOv12 대비 +4.9%의 큰 성능 향상을 보였다. 이는 본 백본이 강건한 특징 표현 능력을 갖추고 있음을 보여준다.
분할(Segmentation).
표 4에서 YOLO-Master-seg-N은 35.6% mAP_mask를 기록하여 YOLOv12-seg-N 대비 +2.8% 향상되었으며, 이는 위치 추정과 마스크 예측 모두에서 동시적인 성능 개선을 달성했음을 의미한다.
탐지 요약(Detection Summary).
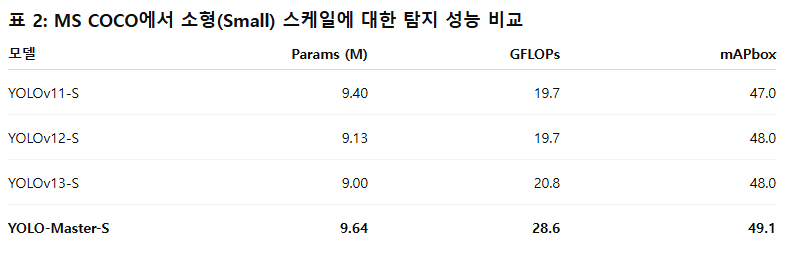
이러한 결과를 보완하듯, 탐지 변형(Table 2)은 49.1% mAP_box를 달성하여 소형(small-scale) 모델 기준으로 새로운 최신 성능(state-of-the-art)을 수립하였다. 과제 전반에 걸친 이러한 일관된 성능 향상은 YOLO-Master가 다양한 시각 인식 패러다임에서 성능을 효과적으로 끌어올릴 수 있는 강력하고 범용적인 아키텍처임을 입증한다.
4.4 정성적 분석(Qualitative Analysis)
그림 4는 네 가지 대표적인 도전적 시나리오에 대한 정성적 비교 결과를 제시한다. YOLO-Master-N은 모든 경우에서 기준선 방법들 대비 일관된 성능 향상을 보여준다.
소형 객체 탐지(Small Object Detection, 1행).
잔디 위에 작은 동물이 있는 야외 장면에서, 초기 버전(v10–v11)은 먼 거리의 객체를 탐지하지 못한다. YOLOv12-N은 낮은 신뢰도(0.47)로 탐지를 시작하고, YOLOv13-N은 이를 0.53까지 개선한다. 반면 YOLO-Master-N은 정확한 위치 추정과 함께 0.65–0.82의 높은 신뢰도로 객체를 탐지하여, 복잡한 배경에서 소형 객체에 대한 스케일 적응형 전문가 라우팅의 효과를 입증한다.
카테고리 판별(Category Disambiguation, 2행).
바위 근처에 새가 있는 해안 장면은 배경 위장(camouflage)이 심한 도전적 상황이다. YOLOv10-N부터 v12-N까지는 가려진 사람을 탐지하지 못하며, YOLOv13-N은 간신히 탐지에 성공한다. 이에 비해 YOLO-Master-N은 정확한 위치 추정(청록색 박스)과 함께 확실한 탐지를 수행하여, 전문가 특화가 복잡한 배경 속에서 가려진 객체를 더 잘 구분할 수 있음을 보여준다.
복잡한 장면(Complex Scene, 3행).
동물들이 겹쳐 있고 사람과의 상호작용이 포함된 양 털깎기 장면에서, YOLO-Master-N은 깨끗한 탐지 결과와 정확한 위치 추정을 달성한다(평균 신뢰도 0.85, v13의 0.77 대비). 이는 복잡한 장면을 효과적으로 처리할 수 있음을 입증한다.
고밀도 장면(Dense Scene, 4행).
병, 컵, 식기 등 많은 객체가 서로 겹쳐 있고 사람이 포함된 식사 장면에서는, 기존 버전들이 다수의 소형 객체를 놓친다. YOLO-Master-N은 0.87–0.97의 높은 신뢰도로 포괄적인 탐지를 수행하여, 밀집되고 혼잡한 환경에서의 우수한 처리 능력을 보여준다.
모든 시나리오 전반에서 YOLO-Master-N은 더 높은 평균 신뢰도와 더 완전한 탐지 커버리지를 달성하며, 다양한 실제 환경의 도전 과제에 대응하는 데 있어 ES-MoE의 적응적 전문가 특화가 효과적임을 입증한다.
5. 결론(Conclusion)
본 논문에서는 YOLO 아키텍처에 Efficient Sparse Mixture-of-Experts(ES-MoE)를 도입한 새로운 실시간 객체 탐지 프레임워크 YOLO-Master를 제안하였다. 제안한 접근법은 경량화된 동적 라우팅 네트워크를 통해 모델 용량과 계산 효율성 간의 근본적인 트레이드오프를 효과적으로 해결한다. 학습 단계에서는 그래디언트 흐름을 유지하기 위해 soft Top-K 라우팅을 사용하고, 추론 단계에서는 hard Top-K 라우팅으로 전환하여 실질적인 계산 희소성을 달성한다.
다섯 개의 대규모 벤치마크에 대한 포괄적인 실험을 통해, YOLO-Master가 뛰어난 효율성과 함께 최신(state-of-the-art) 성능을 달성함을 입증하였다. 이는 희소 MoE 아키텍처가 밀집 예측(dense prediction) 과제에도 성공적으로 적용될 수 있음을 보여주며, 동적 전문가 선택이 정확도와 효율성을 동시에 향상시킨다는 점을 실증한다. 향후 본 접근법은 객체 탐지를 넘어 다른 시각 인식 과제들로 확장될 수 있으며, 조건부 계산을 활용한 적응적 신경망 아키텍처를 통해 자원 제약 환경에서도 효율적인 실시간 비전 시스템을 구현하는 데 중요한 기반을 제공할 것이다.