https://arxiv.org/abs/2406.05835
Mamba YOLO: A Simple Baseline for Object Detection with State Space Model
Driven by the rapid development of deep learning technology, the YOLO series has set a new benchmark for real-time object detectors. Additionally, transformer-based structures have emerged as the most powerful solution in the field, greatly extending the m
arxiv.org
Mamba YOLO: 상태 공간 모델(State Space Model)을 활용한 객체 탐지를 위한 간단한 베이스라인
Zeyu Wang¹˒², Chen Li¹˒²,* Huiying Xu¹˒², Xinzhong Zhu¹˒²˒³,† Hongbo Li³
동등 기여. *교신저자.
초록(Abstract)
딥러닝 기술의 급속한 발전에 힘입어, YOLO 시리즈는 실시간 객체 탐지 분야에서 새로운 기준을 제시해 왔다. 또한 Transformer 기반 구조는 모델의 수용 영역(receptive field)을 크게 확장하고 유의미한 성능 향상을 달성하면서, 해당 분야에서 가장 강력한 해결책으로 부상하였다. 그러나 이러한 성능 향상은 self-attention 메커니즘의 이차적 복잡도(quadratic complexity)로 인해 모델의 계산 부담이 크게 증가한다는 비용을 동반한다.
이 문제를 해결하기 위해, 본 논문에서는 Mamba YOLO라 불리는 단순하면서도 효과적인 베이스라인 접근법을 제안한다. 본 연구의 주요 기여는 다음과 같다.
- ODMamba 백본(backbone) 에 선형 복잡도(linear complexity)를 갖는 상태 공간 모델(State Space Model, SSM)을 도입하여 self-attention의 이차적 복잡도 문제를 해결한다. 기존의 Transformer 기반 또는 SSM 기반 방법들과 달리, ODMamba는 사전 학습(pretraining) 없이도 간단하게 학습이 가능하다.
- 실시간 요구사항을 만족하기 위해 ODMamba의 거시적 구조(macro structure)를 설계하고, 최적의 stage 비율과 스케일 크기를 결정하였다.
- 채널 차원을 효과적으로 모델링하기 위해 다중 분기(multi-branch) 구조를 사용하는 RG Block을 설계하였다. 이는 시퀀스 모델링에서 SSM이 가질 수 있는 한계, 예를 들어 수용 영역 부족이나 이미지 위치 정보(localization)의 약함 문제를 보완한다. 해당 설계는 국소적인 이미지 의존성을 보다 정확하고 효과적으로 포착한다.
공개된 COCO 벤치마크 데이터셋에 대한 광범위한 실험 결과, Mamba YOLO는 기존 방법들과 비교하여 최첨단(State-of-the-Art) 성능을 달성함을 확인하였다. 특히, Mamba YOLO의 tiny 버전은 단일 RTX 4090 GPU 환경에서 추론 시간 1.5 ms로 동작하면서 mAP 기준 7.5%의 성능 향상을 달성하였다. PyTorch 코드는 다음 링크에서 확인할 수 있다.
https://github.com/HZAI-ZJNU/Mamba-YOLO
GitHub - HZAI-ZJNU/Mamba-YOLO: the official pytorch implementation of “Mamba-YOLO:SSMs-based for Object Detection”
the official pytorch implementation of “Mamba-YOLO:SSMs-based for Object Detection” - HZAI-ZJNU/Mamba-YOLO
github.com

그림 1: MS COCO 데이터셋에서의 실시간 객체 탐지기 비교. SSM 기반 객체 탐지 방법은 성능과 계산량 간의 균형 측면에서 가장 우수한 트레이드오프를 달성한다.
1. 서론(Introduction)
최근 몇 년간 딥러닝은 급속도로 발전해 왔으며, 특히 컴퓨터 비전 분야에서는 일련의 강력한 아키텍처들이 인상적인 성능을 달성해 왔다. 합성곱 신경망(Convolutional Neural Networks, CNNs) (Huang et al. 2017; Tan and Le 2020; Liu et al. 2022)부터 비전 트랜스포머(Vision Transformers, ViTs) (Liu et al. 2021; Shi 2023)에 이르기까지, 다양한 구조의 적용은 컴퓨터 비전 분야에서의 높은 잠재력을 입증하였다.
객체 탐지(object detection)라는 다운스트림 과제에서는 CNN 기반 방법(Ren et al. 2016; Liu et al. 2016)과 Transformer 구조(Carion et al. 2020; Zhang et al. 2022)가 주로 사용되고 있다. CNN과 그 변형들은 정확도를 유지하면서도 빠른 실행 속도를 제공하지만, 이미지 전반에 걸친 상관관계(correlation)를 충분히 포착하지 못한다는 한계를 가진다. 이러한 문제를 해결하기 위해, 연구자들은 self-attention의 강력한 전역(global) 모델링 능력을 활용하는 DETR 계열(Carion et al. 2020; Zhu et al. 2020)과 같은 ViT 기반 구조를 객체 탐지 분야에 도입하였다.
하드웨어의 발전과 함께, 이러한 구조가 요구하는 메모리 연산량 증가는 더 이상 큰 문제가 되지 않게 되었다. 그러나 최근에는 CNN을 어떻게 설계해야 모델을 더 빠르게 만들 수 있을지에 대해 재고하는 연구들(Liu et al. 2022; Zhang et al. 2023; Wang et al. 2023)이 등장하였으며, 점점 더 많은 실무자들이 Transformer 구조가 갖는 이차적 복잡도(quadratic complexity)에 대해 불만을 가지기 시작했다. 이에 따라 MobileViT(Mehta and Rastegari 2021), EdgeViT(Chen et al. 2022), EfficientFormer(Li et al. 2023)와 같이 하이브리드 구조를 사용하여 모델을 재구성하고 복잡도를 줄이려는 시도가 이루어지고 있다.
그러나 이러한 하이브리드 모델 역시 새로운 도전 과제를 동반하며, 특히 성능 저하가 명확히 나타난다는 점이 우려 사항으로 지적된다. 따라서 성능과 속도 간의 균형을 찾는 문제는 오랫동안 연구자들의 주요 관심사였다. 최근에는 Mamba(Gu and Dao 2023)와 같은 구조화된 자기 변조(Structured Self-Modulation, SSM) 기반 방법들이, 장거리 의존성(long-distance dependency)에 대한 강력한 모델링 능력과 선형 시간 복잡도(linear time complexity)라는 우수한 특성 덕분에 이러한 문제를 해결할 수 있는 새로운 아이디어를 제시하고 있다.

그림 2: Mamba YOLO 아키텍처의 개요도. Mamba YOLO는 선택적 SSM(selective SSM)을 적용한 ODSSBlock을 사용하여 백본(backbone)을 구성한다. 입력 이미지는 Simple Stem을 통해 여러 패치(patch)로 분할되며, 다운샘플링 연산에는 Vision Clue Merge가 사용된다. 백본 네트워크로부터 {C3, C4, C5}와 같은 다중 수준 특징(feature)이 추출된 후 PAFPN으로 융합된다. 이후 고수준 의미 특징(high-level semantic features)과 저수준 공간 특징(low-level spatial features)은 ODSSBlock을 통해 정제되고 결합되며, 최종적으로 {P3, P4, P5} 특징이 Decoupled Head로 전달되어 객체 탐지 결과를 출력한다.
본 논문에서는 Mamba YOLO라 불리는 객체 탐지기(detector) 모델을 제안한다. 우리는 그림 2에 제시된 바와 같이, 상태 공간 모델(State Space Model, SSM)을 객체 탐지 분야에 적용한 객체 탐지 구조화 모듈(Object Detection Structured ODSSBlock) 을 설계하였다.
이미지 분류를 위해 사용되는 Visual State Space Block(Liu et al. 2024)과 달리, 객체 탐지 과제는 일반적으로 더 높은 해상도와 픽셀 밀도를 가진 이미지를 다룬다. SSM은 본래 텍스트 시퀀스 모델링을 목적으로 설계되었기 때문에, 이미지가 지니는 채널 깊이(channel depth)를 충분히 활용하는 데에는 한계가 있다. 이러한 고해상도 이미지가 제공하는 풍부한 세부 정보와 다채널 정보를 효과적으로 활용하기 위해, 우리는 Residual Gated(RG) Block 아키텍처를 도입하였다.
이 구조에서는 Selective-Scan-2D(SS2D) 처리를 통해 출력을 정제하며, 고차원 점곱(high-dimensional dot product) 연산을 활용하여 채널 간 상관관계를 강화하고 보다 풍부한 특징 표현(feature representation)을 추출한다. MS COCO(Lin et al. 2015) 데이터셋에 대해 광범위한 실험을 수행한 결과, Mamba YOLO는 MS COCO 기반 일반 객체 탐지 과제에서 매우 경쟁력 있는 성능을 보임을 확인하였다. 본 논문의 주요 기여는 다음과 같이 요약할 수 있다.
- 본 논문에서 제안하는 SSM 기반 Mamba YOLO는 선형 메모리 복잡도를 갖는 단순하고 효율적인 구조를 가지며, 대규모 데이터셋에 대한 사전 학습(pre-training)을 필요로 하지 않는다. 이를 통해 객체 탐지 분야에서 YOLO의 새로운 베이스라인을 제시한다.
- SSM의 국소(local) 모델링 한계를 보완하기 위해 ODSSBlock을 제안한다. MLP 계층의 설계를 재고함으로써, 게이티드 집계(gated aggregation) 개념과 효과적인 합성곱, 잔차 연결(residual connectivity)을 결합한 RG Block을 도입하였으며, 이를 통해 국소 의존성을 효과적으로 포착하고 모델의 강건성을 향상시킨다.
- 서로 다른 크기와 스케일의 과제 배포를 지원하기 위해 Mamba YOLO (Tiny / Base / Large) 라는 다양한 스케일의 모델 세트를 설계하였다. 그림 1에 제시된 MS COCO 실험 결과에서 확인할 수 있듯이, Mamba YOLO는 기존의 최첨단(State-of-the-Art) 방법들과 비교하여 유의미한 성능 향상을 달성하였다.
관련 연구(Related Work)
실시간 객체 탐지기(Real-Time Object Detectors)
YOLO의 초기 성능 향상은 주로 백본(backbone)의 개선과 밀접하게 연관되어 있었으며, 그 결과 DarkNet의 광범위한 사용으로 이어졌다. YOLOv7(Wang, Bochkovskiy, and Liao 2023)은 기존 구조를 훼손하지 않으면서 모델의 표현력을 강화하기 위해 E-ELAN 구조를 제안하였다. YOLOv8(Jocher, Chaurasia, and Qiu 2023)은 이전 세대 YOLO들의 특징을 결합하고, 보다 풍부한 그래디언트 흐름을 제공하는 CSPDarknet53 기반의 2-Stage FPN(C2f) 구조를 채택하였다. 이 구조는 경량성을 유지하면서도 정확도를 고려하여 다양한 시나리오에 유연하게 적용될 수 있다.
최근에는 Gold YOLO(Wang et al. 2024)가 Gather-and-Distribute(GD) 라는 새로운 메커니즘을 도입하였다. 이는 self-attention 연산을 통해 구현되며, 기존의 Feature Pyramid Network(FPN)(Lin et al. 2017)와 Rep-PAN(Li et al. 2022)이 갖는 정보 융합 문제를 해결하는 것을 목표로 한다. 이러한 설계를 통해 Gold YOLO는 최첨단(State-of-the-Art, SOTA) 성능을 달성하는 데 성공하였다.
엔드투엔드 객체 탐지기(End-to-End Object Detectors)
DETR(Carion et al. 2020)는 Transformer를 객체 탐지에 최초로 도입한 모델로, 앵커(anchor) 생성이나 비최대 억제(Non-Maximum Suppression, NMS)와 같은 전통적인 수작업 기반 구성 요소를 우회하고, 객체 탐지를 하나의 단순한 집합 예측(ensemble prediction) 문제로 다루는 Transformer 인코더–디코더 아키텍처를 제안하였다.
Deformable DETR(Zhu et al. 2020)는 기준 위치(reference location) 주변에서 희소한 키포인트 집합을 샘플링하는 Deformable Attention이라는 Transformer Attention 변형을 도입함으로써, 고해상도 특징 맵을 처리하는 데 있어 DETR의 한계를 해결하고자 하였다.
DINO(Zhang et al. 2022)는 하이브리드 쿼리 선택 전략과 Deformable Attention을 통합하고, 학습 과정에서 노이즈를 주입(injected noise)하며 쿼리 최적화를 통해 성능을 향상시키는 학습 방식을 제시하였다.
RT-DETR(Zhao et al. 2023)는 효율적인 다중 스케일 특징 처리를 위해, 스케일 내부 상호작용(intra-scale interactions)과 스케일 간 융합(cross-scale fusion)을 분리(decouple)하는 하이브리드 인코더를 제안하였다.
그러나 DETR 계열의 우수한 성능은 대규모 데이터셋에 대한 사전 학습(pre-training)에 크게 의존하며, 학습 수렴의 어려움, 높은 계산 비용, 그리고 소형 객체(small-object) 탐지에서의 한계라는 문제를 여전히 안고 있다. 이러한 이유로, 정확도와 속도를 동시에 요구하는 소형 모델링 도메인에서는 현재까지도 YOLO 계열이 최첨단(State-of-the-Art, SOTA) 성능을 유지하고 있다.
비전 상태 공간 모델(Vision State Space Models)
상태 공간 모델(State Space Model, SSM)에 대한 기존 연구(Gu, Goel, and Ré 2022; Gu et al. 2021; Smith, Warrington, and Linderman 2023)를 바탕으로, Mamba(Gu and Dao 2023)는 입력 크기에 대해 선형 복잡도(linear complexity)를 보이며, 긴 시퀀스 모델링에서 Transformer가 가지는 계산 효율성 문제를 해결하였다.
일반화된 비전 백본(generalized visual backbone) 분야에서 Vision Mamba(Zhu et al. 2024)는 선택적 SSM(selective SSM)을 기반으로 한 순수 비전 백본 모델을 제안하여, Mamba를 비전 분야에 최초로 도입하였다. VMamba(Liu et al. 2024)는 Cross-Scan 모듈을 도입하여 2차원 이미지에 대한 선택적 스캐닝(Selective Scanning)을 가능하게 함으로써 시각적 처리 성능을 강화하였으며, 이미지 분류 과제에서 우수한 성능을 입증하였다.
LocalMamba(Huang et al. 2024)는 시공간(visuospatial) 모델을 위한 윈도우 스캐닝(window scanning) 전략에 초점을 맞추어, 국소적 의존성(local dependency)을 효과적으로 포착할 수 있도록 시각 정보를 최적화하였다. 또한 서로 다른 계층(layer)에 대해 최적의 선택을 탐색하기 위한 동적 스캐닝(dynamic scanning) 방법을 도입하였다.
VMamba가 비전 과제에서 달성한 뛰어난 성과에 영감을 받아, 본 논문에서는 Mamba YOLO를 최초로 제시한다. 이는 기존의 SSM 기반 비전 백본과 달리, ImageNet(Deng et al. 2009)이나 Object365(Shao et al. 2019)와 같은 대규모 데이터셋에 대한 사전 학습(pre-training)을 요구하지 않는 새로운 SSM 기반 모델이다. 본 모델은 전역 수용 영역(global receptive field)을 고려함과 동시에, 객체 탐지 과제에서의 잠재력을 입증하는 것을 목표로 한다.
방법(Method)
기초 이론(Preliminaries)

식 (1)에서 A ∈ ℝ^{N×N} 는 시간에 따라 은닉 상태가 어떻게 변화하는지를 제어하는 상태 전이 행렬(state transition matrix)을 의미하며, B ∈ ℝ^{N×1} 은 은닉 상태에 대한 입력 공간의 가중치 행렬을 나타낸다. 또한 C ∈ ℝ^{N×1} 은 은닉 중간 상태를 출력으로 사상하는 관측 행렬(observation matrix)이다.
Mamba는 고정된 이산화(discretization) 규칙을 사용하여 연속 시스템을 이산 시간 시퀀스 데이터에 적용한다. 구체적으로, 연속 파라미터 A와 B를 각각 이산 형태의 Ā 와 B̄ 로 변환함으로써, 해당 시스템을 딥러닝 아키텍처에 보다 효과적으로 통합한다. 이 과정에서 널리 사용되는 이산화 기법 중 하나가 Zero-Order Hold(ZOH) 이다. 이산화된 형태는 다음과 같이 정의된다.
Ā = exp(Δ · A) (3)
B̄ = (Δ · A)^{-1} · (exp(Δ · A) − I) · Δ · B (4)
식 (4)에서 Δ 는 모델의 시간 해상도를 조절하는 시간 스케일 파라미터를 의미하며, Δ · A 와 Δ · B 는 주어진 시간 구간에서 연속 파라미터에 대응하는 이산 시간 형태를 나타낸다. 여기서 I 는 단위 행렬(identity matrix)이다.
이러한 변환 이후, 모델은 선형 재귀 형태(linear recursive form)를 통해 계산되며, 이는 다음과 같이 정의된다.
h′(t) = Ā · h_{t−1} + B̄ · x_t (5)
y_t = C · h_t (6)
전체 시퀀스 변환은 합성곱(convolution) 형태로도 표현할 수 있으며, 이는 다음과 같이 정의된다.
K̄ = (C · B̄, C · A B̄, …, C · Ā^{L−1} · B̄) (7)
y = x ∗ K̄ (8)
여기서 K̄ ∈ ℝ^L 는 구조화된 합성곱 커널(structured convolutional kernel)을 의미하며, L 은 입력 시퀀스의 길이를 나타낸다.
본 논문에서 제시하는 설계에서는 병렬 학습(parallel training)을 위해 합성곱 형태를 사용하고, 효율적인 자기회귀 추론(autoregressive inference)을 위해 선형 재귀 표현을 활용한다.
전체 아키텍처(Overall Architecture)
Mamba YOLO의 아키텍처 개요는 그림 2에 제시되어 있다. 본 객체 탐지 모델은 ODMamba 백본(backbone) 과 넥(neck) 부분으로 구성된다. ODMamba는 Simple Stem과 Downsample Block으로 이루어져 있다. 넥(neck) 부분에서는 PAFPN(Jocher, Chaurasia, and Qiu 2023)의 설계를 따르되, 보다 풍부한 그래디언트 정보 흐름을 포착하기 위해 C2f 대신 ODSSBlock 모듈을 사용한다.
백본에서는 먼저 Stem 모듈을 통해 다운샘플링이 수행되며, 그 결과 해상도가 H/4, W/4인 2차원 특징 맵(feature map)이 생성된다. 이후 모든 모델은 ODSSBlock과 VisionClue Merge 모듈을 순차적으로 거치며 추가적인 다운샘플링을 수행한다. 넥 부분에서는 PAFPN 구조를 채택하고, C2f를 ODSSBlock으로 대체하였으며, 이때 Conv는 오직 다운샘플링 역할만을 담당한다.
Simple Stem
현대적인 ViT들은 일반적으로 이미지를 겹치지 않는 패치(non-overlapping patch)로 분할하는 방식을 초기 모듈로 사용한다. 이러한 분할 과정은 커널 크기 4, 스트라이드 4의 합성곱 연산을 통해 구현된다. 그러나 EfficientFormerV2(Li et al. 2023)와 같은 최근 연구에 따르면, 이러한 접근 방식은 ViT의 최적화 능력을 제한하여 전체 성능에 부정적인 영향을 미칠 수 있음이 보고되었다.
성능과 효율성 간의 균형을 맞추기 위해, 본 논문에서는 보다 간소화된 Stem 레이어를 제안한다. 기존의 겹치지 않는 패치 분할 방식 대신, 스트라이드 2와 커널 크기 3을 갖는 두 개의 합성곱 연산을 사용하여 입력을 처리한다.
Vision Clue Merge
CNN과 ViT 구조에서는 일반적으로 다운샘플링을 위해 합성곱 연산을 사용한다. 그러나 우리는 이러한 방식이 서로 다른 정보 흐름 단계에서 SS2D(Selective-Scan-2D) (Liu et al. 2024)의 선택적 연산을 방해한다는 점을 발견하였다. 이를 해결하기 위해 VMamba는 2차원 특징 맵을 분할하고, 1×1 합성곱을 사용하여 차원을 축소한다. 우리의 실험 결과에 따르면, SSM을 위해 더 많은 시각적 단서(visual clues)를 보존하는 것이 모델 학습에 유리하다.
기존의 차원을 절반으로 줄이는 방식과 달리, 본 논문에서는 다음과 같은 방식으로 해당 과정을 단순화하였다.
- 정규화(norm) 제거
- 특징 맵의 차원 분할
- 초과된 특징 맵을 채널 차원에 추가
4×압축된 포인트와이즈(pointwise) 합성곱을 사용한 다운샘플링 스트라이드 2를 갖는 3×3 합성곱을 사용하는 기존 방식과 달리, 본 방법은 이전 계층에서 SS2D에 의해 선택된 특징 맵을 그대로 보존한다.

그림 3: ODSSBlock 아키텍처의 구조도.

표 1: MS COCO val 데이터셋에서 Mamba YOLO와 다른 객체 탐지기들의 성능 비교. 공정한 비교를 위해, 모든 모델은 공식 사전 학습(pre-trained) 가중치를 사용하였으며, NVIDIA RTX 4090 GPU에서 반정밀도 부동소수점(FP16) 형식으로 지연 시간(latency)을 측정하였다. 이때 TensorRT 버전은 8.4.3, cuDNN 버전은 8.2.0을 사용하였다.
기호 ‘†’는 학습 완료 이후 추가적인 자기 증류(self-distillation)가 수행되었음을 의미하며, ‘*’는 ImageNet 또는 이와 유사한 대규모 객체 탐지 데이터셋을 이용한 지도 학습 기반 사전 학습이 사용되었음을 나타낸다. 제안하는 Mamba YOLO 모델에 해당하는 결과는 회색으로 강조 표시하였다. 최고 성능과 두 번째로 우수한 성능은 각각 굵은 글씨와 밑줄로 표시하였다.
ODSSBlock

SS2D
Scan Expansion, S6 Block, Scan Merge는 SS2D 알고리즘을 구성하는 세 가지 핵심 단계이며, 전체적인 처리 흐름은 그림 3에 제시되어 있다. Scan Expansion 연산은 입력 이미지를 일련의 하위 이미지(sub-image) 시퀀스로 확장하는 과정으로, 각 하위 이미지는 특정한 방향(direction)을 나타낸다. 대각선 관점에서 살펴보면, Scan Expansion 연산은 서로 대칭적인 네 가지 방향, 즉 위에서 아래(top-down), 아래에서 위(bottom-up), 왼쪽에서 오른쪽(left-to-right), 그리고 오른쪽에서 왼쪽(right-to-left) 방향을 따라 수행된다.
이와 같은 구성은 입력 이미지의 모든 영역을 포괄적으로 커버할 뿐만 아니라, 체계적인 방향 변환을 통해 후속 특징 추출 단계에 풍부한 다차원 정보 기반을 제공함으로써, 이미지 특징을 다차원적으로 포착하는 효율성과 포괄성을 동시에 향상시킨다.
SS2D의 Scan Merge 연산은 이렇게 얻어진 시퀀스들을 입력으로 받아 S6 Block(Gu and Dao 2023)에 전달한 뒤, 서로 다른 방향에서 생성된 시퀀스들을 병합하여 전역 특징(global features)으로 통합한다.
RG Block
기존의 MLP는 여전히 가장 널리 사용되는 구조이며, VMamba 아키텍처에서의 MLP 또한 Transformer 설계를 따르며 입력 시퀀스에 비선형 변환을 적용하여 모델의 표현력을 향상시킨다. 최근 연구에 따르면 Gated MLP(Dauphin et al. 2017; Rajagopal and Nirmala 2021)는 자연어 처리 분야에서 우수한 성능을 보였으며, 본 논문에서는 이러한 게이팅(gating) 메커니즘이 비전 분야에서도 동일한 잠재력을 지닌다고 판단하였다.


만약 gelu말고 silu나 relu쪽으로 간다면 얼마나 영향이갈까?

2️⃣ RG Block에서 activation의 역할이 중요해지는 이유
RG Block은 일반 MLP가 아님.
핵심 구조를 다시 보면:
즉,
- activation 출력이
- 곱셈 게이트(gating) 로 바로 사용됨
👉 이 말은:
activation의 출력 분포(shape) 가
곧 정보 통과량(control signal) 이 된다는 뜻
3️⃣ GELU vs SiLU vs ReLU를 기능적으로 비교하면
🔹 (1) GELU
특징:
- 부드러운 비선형
- 음수 영역에서도 완전 차단이 아님
- 출력 분포가 연속적
RG Block 관점에서:
- 게이트가 연속적으로 열리고 닫힘
- global ⊙ local 곱셈이 안정적
- SSM에서 누적되는 state가 폭주하지 않음
➡️ 가장 안전한 선택
🔹 (2) SiLU (Swish)
정의:
특징:
- GELU와 매우 유사한 곡선
- 음수도 일부 통과
- gradient 흐름도 부드러움
실제로:
- 많은 ViT / CNN hybrid에서
- GELU ↔ SiLU 거의 interchangeable
RG Block에서의 영향:
- 게이팅의 연속성 유지
- 곱셈 구조와 충돌 없음
📌 실험적으로는
- mAP 기준 0.1~0.3%p 수준 차이
- latency 차이는 거의 없음
➡️ 현실적인 대체재
🔹 (3) ReLU — 문제의 핵심
ReLU:
RG Block에서 치명적인 이유 👇
❌ (a) 게이팅이 이산적이 됨
- 음수 → 0 (완전 차단)
- 양수 → 선형 통과
➡️ 곱셈 게이트가
- hard gate 처럼 동작
- fine-grained control 불가
❌ (b) local feature 소실
- Y(R_local)이 0이면
- global 정보도 함께 사라짐
➡️ RG Block의 설계 의도 붕괴
❌ (c) SSM 누적 특성과 충돌
- ReLU는 분포를 한쪽으로 치우치게 함
- SS2D의 state update가 불안정
📉 실제로 기대되는 현상:
- small object AP ↓
- AP75 ↓
- 학습 초반 loss oscillation ↑
4️⃣ 왜 논문들이 거의 항상 GELU를 쓰는가
이건 “유행” 문제가 아니라 구조 문제야.
- SSM / Transformer / gated MLP
- 공통점: multiplicative interaction
이 구조에서는:
- ReLU ❌
- GELU / SiLU ⭕
- 심지어 ELU, Mish도 종종 사용됨
5️⃣ 실전 조언 (네 상황 기준)
네가 이미 말한 조건을 기준으로 하면:
🔧 만약 바꾼다면
- GELU → SiLU ✅
- TRT 영향 없음
- 학습 안정성 거의 동일
- GELU → ReLU ❌
- 성능 손실 큼
- RG Block 의미 퇴색
🔬 ablation 관점에서
논문에서 만약 reviewer가:
“GELU 아니어도 되냐?”
라고 물으면:
- SiLU 실험 하나 넣는 건 합리적
- ReLU는 굳이 안 해도 됨 (이론적으로 불리)
🔚 최종 한 줄 정리
RG Block처럼 곱셈 게이팅이 있는 구조에서는
GELU ↔ SiLU는 거의 동등하지만,
ReLU는 구조적으로 맞지 않아 성능 저하가 크다.
실험(Experiments)
본 절에서는 객체 탐지 과제를 대상으로 Mamba YOLO에 대한 포괄적인 실험을 수행한다. 제안한 Mamba YOLO의 우수성을 검증하기 위해 MS COCO 데이터셋을 사용하여 최신(State-of-the-Art) 방법들과의 성능 비교를 진행하였다. 모든 모델은 NVIDIA H800 GPU 8대 환경에서 학습되었다.

그림 4: GPU 메모리 효율성과 mAP 관점에서의 DINO-R50과 Mamba YOLO-L 비교. 입력 이미지 해상도가 증가함에 따라, DINO는 높은 mAP를 유지하기 위해 더 높은 해상도를 요구하며, GPU 메모리 사용량과 FLOPs 모두에서 이차적(quadratic) 증가 추세를 보인다. 반면, Mamba YOLO는 GPU 메모리 요구량이 선형적으로 증가하는 특성을 유지하면서, 640×640의 비교적 작은 해상도에서도 더 적은 FLOPs와 더 빠른 추론 속도로 최고 성능을 달성한다.

그림 5: COCO 데이터셋에서 각 객체 탐지기의 추론 결과 비교. 보다 명확한 시각화를 위해 세부 객체 영역을 확대하여 제시하였다.
최신 기법(State-of-the-Arts)과의 비교
표 1은 MS COCO val 데이터셋에서의 실험 결과를 제시하며, 제안한 방법이 FLOPs, 파라미터 수, 정확도, 그리고 측정된 GPU 지연 시간(latency) 측면에서 전반적으로 가장 우수한 트레이드오프를 달성했음을 보여준다. 구체적으로, PPYOLOE-S(Long et al. 2020) 및 YOLO-MS-XS(Chen et al. 2023)와 같은 고성능 초경량 모델들과 비교했을 때, Mamba YOLO-T는 AP가 각각 1.1% / 1.5% 향상되었으며, GPU 추론 지연 시간은 0.9ms / 0.2ms 감소하였다. 유사한 정확도를 보이는 기준 모델 YOLOv8-S와 비교하면, Mamba YOLO-T는 파라미터 수를 48%, FLOPs를 53% 줄이면서 GPU 추론 지연 시간 또한 0.4ms 감소시켰다.
Mamba YOLO-B는 파라미터 수와 FLOPs가 유사한 Gold-YOLO-M과 비교하여 AP가 3.7% 더 높다. 또한 유사한 정확도를 보이는 PPYOLOE-M과 비교했을 때, 파라미터 수를 18%, FLOPs를 9% 줄이면서 GPU 추론 지연 시간을 1.8ms 감소시켰다. 대형 모델 구간에서도 Mamba YOLO-L은 모든 최신 객체 탐지기들과 비교하여 더 우수하거나 최소한 동등한 성능을 달성한다. 최고 성능을 보이는 Gold-YOLO-L(Wang et al. 2024)과 비교하면, Mamba YOLO-L은 AP를 0.3% 향상시키면서 파라미터 수를 0.9% 줄였다. 표에서 확인할 수 있듯이, 스크래치 학습(scratch training) 방식을 사용하는 Mamba YOLO-T는 다른 모든 학습 방식의 모델들보다 우수한 성능을 보인다.
더 나아가, 그림 4에서는 Mamba YOLO-L과 DINO-R50을 FPS와 GPU 메모리 사용량 측면에서 비교한다. 그 결과, 입력 해상도가 증가함에도 불구하고 Mamba YOLO-L은 선형적인 메모리 사용량 및 FLOPs 증가 특성을 유지하면서 더 높은 정확도와 빠른 속도를 달성함을 확인할 수 있다. 이러한 비교 결과는, 다양한 스케일의 Mamba YOLO 전반에 걸쳐 제안한 모델들이 기존 최신 기법들 대비 뚜렷한 이점을 지니고 있음을 보여준다.
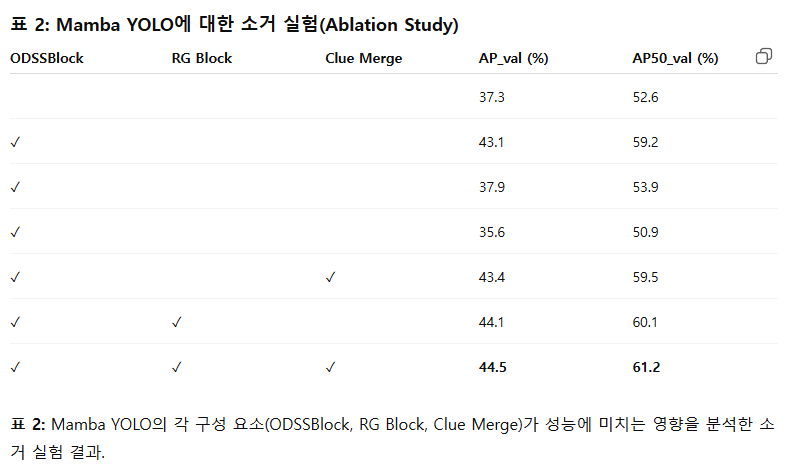
Mamba YOLO에 대한 소거 실험(Ablation Study)
본 절에서는 ODSSBlock 내 각 모듈을 독립적으로 분석한다. 또한 Clue Merge를 사용하지 않는 경우에는 기존의 합성곱 기반 다운샘플링을 적용하여, Vision Clue Merge가 정확도에 미치는 영향을 평가한다. 소거 실험은 MS COCO 데이터셋에서 수행되었으며, 테스트 모델로는 Mamba YOLO-T를 사용하였다.
표 2의 실험 결과는 Clue Merge가 SSM을 위해 더 많은 시각적 단서(visual cues)를 보존함을 보여주며, 동시에 ODSSBlock 구조가 실제로 최적의 설계임을 뒷받침하는 근거를 제공한다.
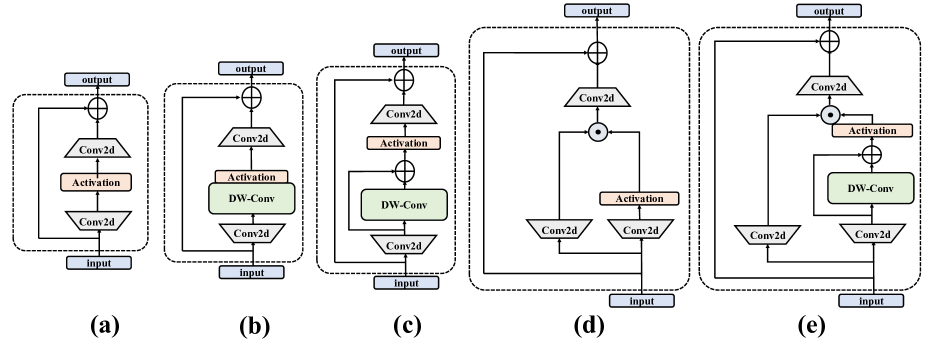
그림 6: 소거 실험에서 탐색된 다양한 RG Block 통합 설계.
RG Block 구조에 대한 소거 실험(Ablation Study)
RG Block은 픽셀 단위(pixel-by-pixel)로 전역 의존성(global dependency)과 전역 특징(global feature)을 활용하여, 픽셀 간 국소 의존성(local dependency)을 효과적으로 포착하는 것을 목표로 한다. RG Block은 채널 차원을 모델링하기 위해 다중 분기(multi-branch) 구조를 사용하며, 이를 통해 시퀀스 모델링에서 SSM이 갖는 한계, 즉 수용 영역 부족(insufficient receptive field) 과 약한 이미지 위치 정보(image localization) 문제를 보완한다.
RG Block의 설계 세부 사항을 검증하기 위해, 본 연구에서는 다음과 같은 세 가지 변형 구조를 함께 고려하였다.
- Convolutional MLP: 기존 MLP에 DW-Conv를 추가한 구조
- Res-Convolutional MLP: 기존 MLP에 잔차 연결(residual concatenation) 형태로 DW-Conv를 추가한 구조
- Gated MLP: 게이팅(gating) 메커니즘을 기반으로 설계된 MLP 변형
그림 6은 이러한 변형 구조들을 시각적으로 보여주며, 표 3은 MS COCO 데이터셋에서 Mamba YOLO-T를 테스트 모델로 사용하여, 기존 MLP, RG Block, 그리고 각 변형 구조들의 성능을 비교한 결과를 제시한다. 이를 통해 MLP 구조에 대한 본 분석의 타당성을 검증한다.
실험 결과, 단순히 합성곱을 도입하는 것만으로는 성능 향상이 효과적으로 이루어지지 않음을 확인하였다. 반면, 그림 6에 제시된 Gated MLP 변형에서는 출력이 두 개의 선형 투영(linear projection)의 원소별 곱(element-wise multiplication)으로 구성되며, 이 중 하나는 잔차 연결된 DWConv와 게이팅 활성화 함수를 포함한다. 이러한 설계는 계층적 구조 전반에 걸쳐 중요한 특징을 효과적으로 전달할 수 있는 능력을 모델에 부여하며, 결과적으로 정확도와 강건성을 유의미하게 향상시킨다.
이 실험은 복잡한 이미지 과제를 다룰 때 합성곱 도입에 따른 성능 향상이, 잔차 연결 맥락에서 적용된 게이티드 집계(gated aggregation) 메커니즘과 밀접하게 연관되어 있음을 보여준다.

Mamba YOLO 변형에서 값 설정 유형에 대한 소거 실험(Ablation Study)
본 절에서는 백본(backbone)에서 ODSSBlock 반복 횟수에 대한 네 가지 서로 다른 설정을 탐구한다.
설정 [9,3,3,3]은 추가적인 계산 오버헤드를 유발하지만, 이에 상응하는 정확도 향상은 나타나지 않는다.
반면 [3,9,3,3], , 설정은 ODSSBlock의 과도한 중복으로 인해 사실상 중복(redundancy) 이 발생한다.
실험 결과, [3,6,6,3] 이 Mamba YOLO에서 보다 합리적인 설정임을 확인하였다.
Neck 부분에서는 ODSSBlock을 제거하면 모델을 더 경량화할 수 있지만, 이는 불가피하게 정확도 저하로 이어진다. 반대로 Neck에 ODSSBlock을 포함할 경우, 풍부한 그래디언트 흐름과 효과적인 특징 융합을 제공할 수 있다.
출력 Feature Map을 {P2,P3,P4,P5}로 설정하면 정확도가 크게 향상되지만, 그만큼 GFLOPs 또한 크게 증가한다. 최종적으로 Mamba YOLO는
- Blocks = [3,6,6,3]
- Feature Map = {P3,P4,P5}
- Neck 부분에 ODSSBlock 사용
이라는 구성을 채택하였다. 이 설정은 정확도와 복잡도 간의 균형을 가장 잘 달성하며, 인스턴스 분할(instance segmentation) 과제를 효율적으로 수행하는 데에도 적합하다. 실험 결과는 표 4에 제시되어 있다.

시각화(Visualization)
제안한 탐지 프레임워크의 장점을 추가로 검증하기 위해 MS COCO에서 무작위로 두 개의 샘플을 선택하였다. 그림 5는 Mamba YOLO와 주요 객체 탐지기들의 시각화 결과를 보여준다. 그 결과, Mamba YOLO는 다양한 어려운 조건에서도 정확한 탐지를 수행할 수 있으며, 복잡한 배경에서 높은 중첩(overlap) 과 심한 가림(occlusion) 이 존재하는 객체들을 탐지하는 데에서도 강력한 성능을 보임을 확인할 수 있다.
결론(Conclusion)
본 논문에서는 SSM을 기반으로 하고 YOLO를 확장한 객체 탐지기를 제안하였다. 제안한 모델은 대규모 데이터셋에 대한 사전 학습(pre-training)을 필요로 하지 않기 때문에 학습 과정이 매우 단순하다. 우리는 기존 MLP의 한계를 재분석하고, 계층적 구조 전반에 걸쳐 중요한 특징을 효과적으로 전달할 수 있도록 게이팅 메커니즘과 깊은 합성곱 기반 잔차 연결을 갖는 RG Block을 제안하였다. 본 연구의 목표는 YOLO의 새로운 베이스라인을 제시하고, Mamba YOLO가 매우 경쟁력 있는 성능을 지닌다는 점을 입증하는 것이다. 본 연구는 실시간 객체 탐지 과제에서 Mamba 아키텍처를 최초로 탐구한 사례이며, 관련 분야 연구자들에게 새로운 아이디어를 제공하길 기대한다.
감사의 글(Acknowledgement)
본 연구는 다음 연구비의 지원을 받아 수행되었다.
중국 국가자연과학재단(62376252); 저장성 자연과학재단 중점 프로젝트(LZ22F030003); 저장성 Leading Geese Plan(2024C02G1123882).
Mamba YOLO 변형에서 값 설정 유형에 대한 소거 실험(Ablation Study)을 잘 이해 못하겠는데, ODSSBlock 반복 횟수가 정확히 말그대로 해당 P안에서 반복수인가?
결론부터 정확히 말하면
네, 맞다.
Blocks = [a, b, c, d] 는
백본(backbone) 각 stage(P-stage)에서 ODSSBlock이 반복되는 횟수를 의미한다.
하지만 ❗
“P2/P3/P4/P5와 1:1 대응”은 아니다
이게 헷갈리는 핵심 포인트야.
1️⃣ Blocks = [3, 6, 6, 3] 이 의미하는 것
Mamba YOLO backbone은 전형적인 YOLO 계열처럼 4-stage 구조야.
구조를 단순화하면:
Stem
↓
Stage 1 → ODSSBlock × a
↓
Stage 2 → ODSSBlock × b
↓
Stage 3 → ODSSBlock × c
↓
Stage 4 → ODSSBlock × d그래서
Blocks = [a, b, c, d]는:
- Stage별 ODSSBlock 반복 횟수
- 해상도는 stage가 내려갈수록 줄어듦
예:
[3, 6, 6, 3]는
- Stage 1: ODSSBlock ×3
- Stage 2: ODSSBlock ×6
- Stage 3: ODSSBlock ×6
- Stage 4: ODSSBlock ×3
2️⃣ 그럼 이게 P3 / P4 / P5랑 뭐가 다른가?
중요한 구분이야 👇
🔹 Backbone stage
- feature를 생성
- downsampling + representation learning
- 여기서 Blocks가 적용됨
🔹 P3 / P4 / P5
- backbone에서 나온 feature를
- neck에서 재가공(FPN/PAFPN)
- detection head로 전달
즉:
❌ Blocks는 P-level 반복 수가 아님
✅ Blocks는 backbone stage 내부 깊이
3️⃣ 왜 [9,3,3,3] 같은 설정이 안 좋은가?
논문 설명을 해석하면:
[9,3,3,3]
- 초반 stage에만 너무 깊음
- 고해상도 feature에서 SSM 과다 사용
- 계산량 ↑
- global context는 아직 부족
➡️ 비효율
[3,9,3,3], [3,3,9,3], [3,3,3,9]
- 특정 stage만 과도하게 깊음
- ODSSBlock 중복 효과
- 표현력 증가 대비 정보 다양성 ↓
➡️ redundancy
[3,6,6,3]
- 중간 stage(P4/P5로 이어지는 영역)에
- 충분한 depth 확보
- global + local 균형
➡️ SSM에 가장 잘 맞는 분배
4️⃣ Neck에서 ODSSBlock 유무는 별개의 축
표를 보면:
[3,6,6,3] + w/o SSM Neck이 있음.
이건:
- backbone 구조는 동일
- neck에서
- ODSSBlock 사용 ❌
- Conv only
결과:
- FLOPs ↓
- AP도 ↓
👉 SSM은 neck에서도 의미 있음이라는 걸 보여주는 ablation
5️⃣ Feature Map {P2, P3, P4, P5}는 또 다른 축
이건 완전히 다른 차원의 선택이야.
- P2까지 쓰면:
- 작은 물체 ↑
- FLOPs 폭증
- P3~P5:
- YOLO의 전통적인 trade-off
그래서:
Blocks = [3,6,6,3]
Feature Map = {P3, P4, P5}
Neck SSM = ✓이 최종 선택.
6️⃣ 한 장으로 정리하면 (개념도)
Input
↓
Stem
↓
Stage1 (ODSS ×3) ← Blocks[0]
↓
Stage2 (ODSS ×6) ← Blocks[1]
↓
Stage3 (ODSS ×6) ← Blocks[2]
↓
Stage4 (ODSS ×3) ← Blocks[3]
↓
{C3, C4, C5}
↓
Neck (PAFPN + ODSS)
↓
{P3, P4, P5}
↓
Head🔚 핵심 요약
- ✅ Blocks = backbone stage별 ODSSBlock 반복 횟수
- ❌ P3/P4/P5에서 반복되는 게 아님
- [3,6,6,3]은
- SSM 특성상 가장 균형 잡힌 깊이 배분
- 이 ablation은
- “SSM은 어디에, 얼마나 써야 좋은가”를 보여주는 실험
종합 평점: 3 / 5
SSM(Mamba)을 실시간 객체 탐지에 본격적으로 적용한 의미 있는 첫 시도라는 점에서는 분명 가치가 있으나, 전반적으로는 아이디어 검증과 엔지니어링 정합성에 초점이 맞춰진 논문으로, 근본적인 구조적 돌파구까지 도달했다고 보기는 어렵습니다.
긍정적인 점 (플러스 요인)
- SSM을 YOLO 계열에 현실적으로 접목
- Transformer의 quadratic complexity 문제를 피하면서도, 전역 문맥을 다루려는 방향성은 타당함
- 특히 SS2D의 선형 메모리 증가 특성은 고해상도 입력에서 분명한 장점
- ODSSBlock + RG Block의 설계 논리는 일관됨
- SSM의 약점(채널 활용, localization)을 RG Block으로 보완하려는 접근은 설득력 있음
- 단순 MLP 대비 gated + depthwise conv가 효과적이라는 ablation도 납득 가능
- 사전학습 없이도 경쟁력 있는 성능
- ImageNet/Object365 pre-training 없이 이 정도 AP를 달성한 점은 분명 강점
- 특히 Tiny/Base 구간에서는 실용적인 메시지가 있음
아쉬운 점 (감점 요인)
- 구조적 새로움은 제한적
- 핵심 구성 요소(SSM, gated MLP, residual, depthwise conv)는 모두 기존 아이디어의 조합
- “Mamba를 YOLO에 잘 얹었다” 이상으로, 새로운 패러다임을 열었다고 보긴 어려움
- SSM이 ‘왜 detection에 본질적으로 좋은가’에 대한 근본적 설득은 부족
- long-range dependency가 실제 detection에서 어떤 failure case를 얼마나 해결했는지에 대한 분석이 약함
- qualitative 결과는 있으나, case-driven insight까지는 못 감
- 엔지니어링 튜닝 논문의 성격이 강함
- Blocks 분배, Neck에서의 SSM 사용 여부, Feature Map 선택 등
- 결과적으로 “잘 튜닝된 설정”은 얻었지만, 일반화 가능한 원칙으로 정리되지는 않음
종합적으로 보면
이 논문은
“SSM 기반 구조가 실시간 객체 탐지에서도 충분히 경쟁력이 있다”
는 것을 처음으로 깔끔하게 증명한 논문이지,
“객체 탐지의 구조를 다시 정의한 논문” 은 아닙니다.
그래서:
- 리뷰어 입장: Accept 가능
- 독자 입장: 아이디어 참고용으로는 좋음
- 후속 연구 관점: 여기서 진짜 중요한 건 ‘다음 단계’
한 줄 평가
흥미로운 방향성과 성실한 실험을 갖춘 첫 시도이지만,
결정적인 구조적 통찰까지는 아직 도달하지 못한 논문.