https://arxiv.org/abs/2511.09554
RF-DETR: Neural Architecture Search for Real-Time Detection Transformers
Open-vocabulary detectors achieve impressive performance on COCO, but often fail to generalize to real-world datasets with out-of-distribution classes not typically found in their pre-training. Rather than simply fine-tuning a heavy-weight vision-language
arxiv.org
RF-DETR: 실시간 탐지 트랜스포머를 위한 신경 아키텍처 탐색
Isaac Robinson¹, Peter Robicheaux¹, Matvei Popov¹, Deva Ramanan², Neehar Peri²
¹Roboflow, ²Carnegie Mellon University
초록 (Abstract)
오픈 보캐블러리(object vocabulary) 탐지기는 COCO와 같은 벤치마크에서 인상적인 성능을 보이지만, 사전 학습(pre-training) 과정에서 일반적으로 등장하지 않는 분포 외(out-of-distribution) 클래스가 포함된 실제 환경 데이터셋에 대해서는 일반화에 실패하는 경우가 많다. 새로운 도메인에 대해 단순히 대규모 비전-언어 모델(Vision-Language Model, VLM)을 파인튜닝하는 대신, 우리는 RF-DETR을 제안한다. RF-DETR은 가중치 공유(weight-sharing) 기반의 신경 아키텍처 탐색(Neural Architecture Search, NAS)을 통해, 주어진 타깃 데이터셋에 대해 정확도–지연시간(accuracy–latency) 파레토 곡선을 자동으로 탐색하는 경량화된 특화(specialist) 탐지 트랜스포머이다.
우리의 접근법은 사전 학습된 기본 네트워크(base network)를 타깃 데이터셋에 파인튜닝한 뒤, 추가적인 재학습 없이도 서로 다른 정확도–지연시간 트레이드오프를 갖는 수천 개의 네트워크 구성(configuration)을 평가할 수 있도록 한다. 또한, 다양한 타깃 도메인으로의 전이 성능을 향상시키기 위해 DETR 계열 모델에 적용 가능한 NAS의 “조절 가능한 요소(tunable knobs)”를 재검토한다.
실험 결과, RF-DETR은 COCO와 Roboflow100-VL 모두에서 기존의 실시간(state-of-the-art) 방법들을 유의미하게 능가한다. RF-DETR (nano)는 COCO에서 48.0 AP를 달성하여, 유사한 지연시간 조건에서 D-FINE (nano) 대비 5.3 AP 높은 성능을 보인다. 또한 RF-DETR (2x-large)는 Roboflow100-VL에서 GroundingDINO (tiny)보다 1.2 AP 높은 성능을 달성하면서도, 실행 속도는 20배 더 빠르다. 우리가 아는 한, RF-DETR (2x-large)는 COCO에서 60 AP를 초과한 최초의 실시간 객체 탐지기이다.
코드는 GitHub에 공개되어 있다.
1. 서론 (Introduction)
객체 탐지는 컴퓨터 비전 분야의 근본적인 문제로, 최근 수년간 지속적으로 성숙해 왔다 (felzenszwalb2009object; lin2014coco; ren2015faster). GroundingDINO (liu2023grounding)와 YOLO-World (Cheng2024YOLOWorld)와 같은 오픈 보캐블러리(open-vocabulary) 탐지기는 자동차, 트럭, 보행자와 같은 일반적인 카테고리에 대해 뛰어난 제로샷(zero-shot) 성능을 달성한다. 그러나 최신 비전-언어 모델(Vision-Language Model, VLM)은 여전히 사전 학습(pre-training) 과정에서 일반적으로 포함되지 않았던 분포 외(out-of-distribution) 클래스, 과제(task), 그리고 영상 획득 방식(imaging modality)에 대해서는 일반화에 어려움을 겪는다 (robicheaux2025roboflow100vl).
타깃 데이터셋에 대해 VLM을 파인튜닝하면 도메인 내부(in-domain) 성능은 크게 향상되지만, 대규모 텍스트 인코더로 인한 실행 시간 효율 저하와 오픈 보캐블러리 일반화 성능의 감소라는 대가를 치르게 된다. 반면, D-FINE (peng2024dfine)이나 RT-DETR (zhao2024rtdetr)과 같은 특화형(specialist), 즉 폐쇄 보캐블러리(closed-vocabulary) 객체 탐지기는 실시간 추론이 가능하지만, GroundingDINO와 같은 파인튜닝된 VLM에 비해서는 성능이 뒤처진다. 본 논문에서는 인터넷 규모의 사전 학습과 실시간 아키텍처를 결합함으로써, 최고 수준(state-of-the-art)의 성능과 빠른 추론 속도를 동시에 달성하는 방식으로 특화형 탐지기를 현대화한다.
특화형 탐지기는 COCO에 과도하게 최적화되어 있는가?
객체 탐지 분야의 지속적인 발전은 PASCAL VOC (pascalvoc)와 COCO (lin2014coco)와 같은 표준화된 벤치마크 덕분이라고 할 수 있다. 그러나 우리는 최근의 특화형 탐지기들이 맞춤형 모델 아키텍처, 학습률 스케줄러, 데이터 증강 스케줄러 등을 사용하면서, 실제 환경 성능을 희생하는 대신 COCO 데이터셋에 암묵적으로 과적합(overfitting)되어 있음을 확인하였다. 특히 YOLOv8 (yolov8)과 같은 최신 객체 탐지기는 COCO와 데이터 분포가 크게 다른 실제 환경 데이터셋(예: 이미지당 객체 수, 클래스 수, 데이터셋 규모)에 대해 일반화 성능이 매우 낮다.
이러한 한계를 해결하기 위해, 우리는 인터넷 규모 사전 학습을 활용하여 실제 환경 데이터 분포로의 일반화를 가능하게 하는 스케줄러 프리(scheduler-free) 접근법인 RF-DETR을 제안한다. 또한 다양한 하드웨어 플랫폼과 데이터셋 특성에 맞게 모델을 보다 효과적으로 특화시키기 위해, 엔드투엔드 객체 탐지 및 분할(end-to-end object detection and segmentation) 맥락에서 신경 아키텍처 탐색(Neural Architecture Search, NAS)을 다시 살펴본다.
DETR을 위한 신경 아키텍처 탐색(NAS)의 재고
신경 아키텍처 탐색(Neural Architecture Search, NAS)은 사전에 정의된 탐색 공간(search space) 내에서 다양한 아키텍처 변형을 탐색함으로써 정확도–지연시간(accuracy–latency) 트레이드오프를 발견하는 기법이다. NAS는 이미지 분류 분야(tan2019efficientnet; cai2019ofa)에서 이미 활발히 연구되었으며, 탐지기 백본(tan2020efficientdet)이나 FPN(ghiasi2019fpn)과 같은 모델의 하위 구성 요소(sub-component)를 대상으로도 적용되어 왔다. 기존 연구와 달리, 우리는 객체 탐지와 분할(object detection and segmentation)을 대상으로 한 엔드투엔드(end-to-end) 가중치 공유(weight-sharing) NAS를 탐구한다.
본 연구의 핵심 통찰은 OFA(cai2019ofa)에서 영감을 받은 것으로, 학습 과정에서 입력 이미지 해상도와 같은 모델 입력 요소뿐만 아니라 패치 크기(patch size)와 같은 아키텍처 구성 요소를 함께 변화시킬 수 있다는 점이다. 더 나아가, 가중치 공유 NAS를 활용하면 디코더 레이어 수나 쿼리 토큰(query token) 개수와 같은 추론 시 설정(inference configuration)을 수정함으로써, 추가적인 파인튜닝 없이도 강력한 기본(base) 모델을 특정 목적에 맞게 특화시킬 수 있다.
우리는 검증(validation) 세트 상에서 그리드 서치(grid search)를 통해 모든 모델 구성을 평가한다. 중요한 점은, 제안하는 접근법이 타깃 데이터셋에 대해 기본 모델이 완전히 학습된 이후에야 탐색 공간을 평가한다는 것이다. 그 결과, 탐색 공간 내에 존재하는 모든 서브넷(sub-net), 즉 개별 모델 구성들은 추가적인 파인튜닝 없이도 높은 성능을 달성할 수 있으며, 이는 새로운 하드웨어 환경에 맞게 모델을 최적화하는 데 필요한 계산 비용을 크게 줄여준다.
흥미롭게도, 학습 과정에서 명시적으로 등장하지 않았던 서브넷들 역시 높은 성능을 보이는 것을 확인하였으며, 이는 RF-DETR이 학습 시 보지 못한 아키텍처로도 일반화할 수 있음을 시사한다(cf. H). RF-DETR을 분할(segmentation) 문제로 확장하는 것 또한 비교적 간단하며, 경량의 인스턴스 분할 헤드(instance segmentation head)를 추가하는 것만으로 충분하다. 우리는 이 모델을 RF-DETR-Seg이라 부른다. 특히 이러한 확장은 실시간 인스턴스 분할(real-time instance segmentation)을 위한 파레토 최적 아키텍처를 발견하는 데에도 엔드투엔드 가중치 공유 NAS를 그대로 활용할 수 있게 해준다.
지연시간(latency) 평가의 표준화
우리는 COCO (lin2014coco)와 Roboflow100-VL(RF100-VL) (robicheaux2025roboflow100vl)에서 제안한 접근법을 평가하였으며, 실시간 객체 탐지기(real-time detector) 중에서 최고 수준(state-of-the-art)의 성능을 달성하였다. RF-DETR (nano)는 COCO에서 유사한 실행 시간(run-time) 조건 하에 D-FINE (nano)보다 5% AP 높은 성능을 보였으며, RF-DETR (2x-large)는 RF100-VL에서 GroundingDINO (tiny)를 훨씬 짧은 실행 시간으로 능가하였다. 또한 RF-DETR-Seg (nano)는 COCO에서 YOLOv11-Seg (x-large)보다 4배 빠른 속도로 실행되면서도 더 높은 성능을 기록하였다.
그러나 RF-DETR의 지연시간을 기존 연구들과 직접 비교하는 것은 여전히 쉽지 않은데, 이는 논문마다 보고되는 지연시간 평가 방식이 크게 다르기 때문이다. 특히, 새로운 모델이 등장할 때마다 공정한 비교를 위해 동일한 하드웨어에서 이전 연구의 모델 지연시간을 다시 측정(re-benchmark)하는 경우가 많다. 예를 들어, D-FINE에서 보고한 LW-DETR (chen2024lw)의 지연시간은 원래 보고된 수치보다 25% 더 빠르게 나타난다. 우리는 이러한 재현성 부족이 주로 추론 중 GPU 전력 스로틀링(power throttling) 현상에서 비롯된다는 점을 확인하였다. 또한 순전파(forward pass) 사이에 버퍼링(buffering)을 두는 방식이 전력 과소비(power over-draw)를 제한하고, 지연시간 평가를 표준화하는 데 효과적임을 발견하였다(cf. Table 1).
기여 (Contributions)
본 논문은 세 가지 주요 기여를 제시한다.
첫째, 우리는 스케줄러 프리(scheduler-free) NAS 기반 탐지 및 분할 모델 패밀리인 RF-DETR을 제안하며, RF100-VL (robicheaux2025roboflow100vl)과 COCO (lin2014coco)에서 지연시간이 40 ms 이하인 실시간 방법들 대비 최고 수준의 성능을 달성하였다(cf. Fig. 1). 우리가 아는 한, RF-DETR은 COCO에서 60 mAP를 초과한 최초의 실시간 객체 탐지기이다.
둘째, 엔드투엔드 객체 탐지에서 정확도–지연시간 트레이드오프를 개선하기 위해, 가중치 공유 NAS에서의 “조절 가능한 요소(tunable-knobs)”를 체계적으로 분석하였다(cf. Fig. 3). 특히 가중치 공유 NAS를 활용함으로써, 대규모 사전 학습을 효과적으로 활용하고 소규모 데이터셋으로도 우수한 전이 성능을 달성할 수 있음을 보였다(cf. Tab. 4).
마지막으로, 현재 사용되는 지연시간 벤치마킹 프로토콜을 재검토하고, 재현성을 향상시키기 위한 간단하면서도 표준화된 절차를 제안한다.




그림 1: 정확도–지연시간 파레토 곡선(Accuracy-Latency Pareto Curve).
실시간 객체 탐지기를 대상으로 COCO 탐지 검증 세트(val-set, 좌상단 및 좌하단), COCO 분할 검증 세트(우상단), 그리고 RF100-VL 테스트 세트(우하단)에서의 정확도–지연시간 파레토 경계를 도시하였다. RF100-VL은 서로 다른 100개의 데이터셋으로 구성되어 있기 때문에, N, S, M, L, XL, 2XL 구성에 대해 목표 지연시간(target latency)을 설정하고, 해당 목표 대비 ±10% 범위 내의 지연시간을 갖는 RF-DETR 모델을 탐색한 뒤, 수렴(convergence)까지 파인튜닝한 후의 평균 성능을 보고한다. 중요한 점은, COCO에 대한 RF-DETR의 연속적인 파레토 곡선 상의 모든 지점이 단 한 번의 학습(run)으로부터 도출되었다는 것이다.
2. 관련 연구 (Related Works)
신경 아키텍처 탐색(Neural Architecture Search, NAS)은 서로 다른 정확도–지연시간(accuracy–latency) 트레이드오프를 갖는 모델 아키텍처들의 집합을 자동으로 찾아내는 기법이다 (zoph2016neural; zoph2018learning; real2019regularized; cai2018efficient). 초기 NAS 접근법들(zoph2016neural; real2019regularized)은 효율성에 대한 고려 없이 정확도 극대화에 주로 초점을 맞추었으며, 그 결과 NASNet이나 AmoebaNet과 같이 계산 비용이 매우 큰 아키텍처가 발견되는 경우가 많았다.
이러한 한계를 해결하기 위해, 최근의 하드웨어 인지(hardware-aware) NAS 방법들(cai2018proxylessnas; tan2019mnasnet; wu2019fbnet)은 하드웨어 피드백을 탐색 과정에 직접 포함시킨다. 그러나 이러한 방법들은 새로운 하드웨어 플랫폼마다 탐색과 학습 과정을 반복해야 한다는 단점이 있다. 이에 반해 OFA(cai2019ofa)는 가중치 공유(weight-sharing) NAS를 제안하여, 서로 다른 정확도–지연시간 특성을 갖는 수천 개의 서브넷(sub-net)을 동시에 최적화함으로써 학습(training)과 탐색(search)을 분리(decouple)한다.
기존의 최신 연구들은 객체 탐지에서 NAS를 평가할 때, 기존 탐지 프레임워크에 표준 백본(backbone)을 NAS 기반 백본으로 단순히 교체하는 방식에 그치는 경우가 많다. 본 연구는 이러한 선행 연구들과 달리, 엔드투엔드(end-to-end) 객체 탐지 정확도를 직접 최적화함으로써, 주어진 타깃 데이터셋에 대해 파레토 최적(Pareto-optimal)의 정확도–지연시간 트레이드오프를 찾는 것을 목표로 한다.
실시간 객체 탐지기는 안전이 중요한(safety-critical) 응용과 상호작용형(interactive) 응용 분야에서 매우 중요한 관심 대상이다. 전통적으로 Mask R-CNN (he2017mask)이나 Hybrid Task Cascade (chen2019hybrid)와 같은 2단계(two-stage) 탐지기는 높은 지연시간(latency)을 감수하는 대신 최고 수준(state-of-the-art)의 성능을 달성해 왔다. 반면, YOLO (redmon2016you)나 SSD (liu2016ssd)와 같은 1단계(single-stage) 탐지기는 정확도를 일부 희생하는 대신 최고 수준의 실행 속도(runtime)를 제공하였다.
그러나 최근의 탐지기들(zhao2024rtdetr)은 이러한 정확도–지연시간 트레이드오프를 다시 고찰하며, 두 축 모두에서 동시에 성능을 향상시키고 있다. 최신 YOLO 계열 모델들은 아키텍처, 데이터 증강, 학습 기법 측면에서 지속적인 혁신을 이루어(redmon2016you; wang2023yolov7; wang2024yolov9; yolov8; yolov11), 빠른 추론 속도를 유지하면서도 성능을 개선하고 있다. 그럼에도 불구하고 대부분의 YOLO 모델은 비최대 억제(Non-Maximum Suppression, NMS)에 의존하며, 이는 추가적인 지연시간을 유발한다는 한계를 가진다.
이에 반해, DETR (carion2020end)는 NMS나 앵커 박스(anchor box)와 같은 수작업(hand-crafted) 구성 요소를 제거한 구조를 제안하였다. 그러나 초기 DETR 변형들(zhu2020deformable; zhang2022dino; meng2021conditional; liu2022dab)은 높은 정확도를 달성하는 대신 실행 시간이 길어, 실시간 응용에서의 활용이 제한적이었다. 최근에는 RT-DETR (zhao2024rtdetr)과 LW-DETR (chen2024lw)과 같은 연구들이 고성능 DETR을 실시간 응용에 성공적으로 적용하였다.
비전-언어 모델(Vision-Language Model, VLM)은 웹으로부터 수집된 대규모의 약지도(weakly supervised) 이미지–텍스트 쌍을 사용해 학습된다. 이러한 인터넷 규모의 사전 학습은 오픈 보캐블러리 객체 탐지를 가능하게 하는 핵심 요인이다 (liu2023grounding; Cheng2024YOLOWorld). GLIP (li2021grounded)는 단일 텍스트 쿼리를 사용하는 구문 그라운딩(phrase grounding) 문제로 객체 탐지를 정식화하였으며, Detic (zhou2022detecting)은 ImageNet 수준의 지도 정보(russakovsky2015imagenet)를 활용해 롱테일(long-tail) 객체 탐지 성능을 향상시켰다. MQ-Det (xu2024multi)는 멀티모달 프롬프팅을 가능하게 하는 학습 가능한 모듈을 추가하여 GLIP를 확장하였다.
최근의 VLM들은 강력한 제로샷(zero-shot) 성능을 보여주며, 다양한 다운스트림 작업에서 “블랙박스(black-box)” 모델로 활용되는 경우가 많다 (ma2023long; pmlr-v205-peri23a; khurana2024shelf; sal2024eccv; takmaz2025cal). 그러나 robicheaux2025roboflow100vl에 따르면, 이러한 모델들은 사전 학습 과정에서 일반적으로 등장하지 않았던 카테고리에 대해 평가할 경우 성능이 크게 저하되며, 추가적인 파인튜닝이 필요하다. 또한 많은 비전-언어 모델은 추론 속도가 지나치게 느려 실시간 작업에 활용하기 어렵다.
이에 반해 RF-DETR은 실시간 객체 탐지기의 빠른 추론 속도와 VLM의 인터넷 규모 사전 학습에서 비롯된 사전 지식(prior)을 결합함으로써, RF100-VL에서 최고 수준(state-of-the-art)의 성능을 달성하고, COCO에서도 지연시간이 40 ms 이하인 모든 구간에서 우수한 성능을 보여준다.
3. RF-DETR: 파운데이션 모델을 활용한 가중치 공유 NAS
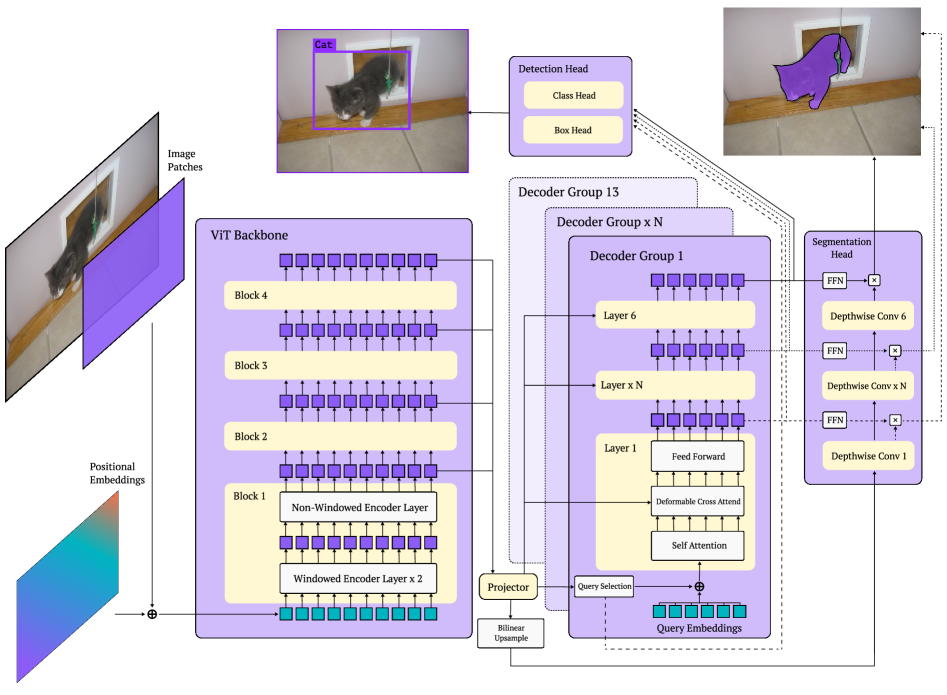
그림 2: RF-DETR 아키텍처.
RF-DETR은 사전 학습된 ViT 백본(backbone)을 사용하여 입력 이미지로부터 다중 스케일(multi-scale) 특징을 추출한다. 정확도와 지연시간의 균형을 맞추기 위해, 윈도우 기반(windowed) 어텐션 블록과 비윈도우(non-windowed) 어텐션 블록을 교차(interleave)하여 사용한다. 특히 변형 가능 크로스 어텐션(deformable cross-attention) 레이어와 분할(segmentation) 헤드는 모두 프로젝터(projector) 출력에 대해 이중선형 보간(bilinear interpolation)을 적용함으로써, 특징의 공간적 조직(spatial organization)을 일관되게 유지한다. 마지막으로, 추론(inference) 시 디코더 드롭아웃(decoder dropout)을 가능하게 하기 위해 모든 디코더 레이어에 탐지 및 분할 손실(detection and segmentation losses)을 적용한다.
본 절에서는 기본 모델(base model)의 아키텍처를 설명하고(cf. Fig. 2), 가중치 공유 NAS에서 사용되는 “조절 가능한 요소(tunable knobs)”를 제시한다(cf. Fig. 3). 또한 수작업으로 설계된 학습률(learning-rate) 및 데이터 증강(augmentation) 스케줄러의 한계를 짚고, 스케줄러 프리(scheduler-free) 접근법을 제안한다.
인터넷 규모 사전 지식(Internet-Scale Priors)의 통합
RF-DETR은 LW-DETR (chen2024lw)을 기반으로, 다양한 타깃 도메인에 대한 일반화 성능을 향상시키기 위해 아키텍처와 학습 절차를 단순화하여 현대화한다. 먼저, LW-DETR에서 사용하던 CAEv2 (zhang2022cae) 백본을 DINOv2 (oquab2023dinov2)로 교체한다. 실험 결과, DINOv2의 사전 학습 가중치로 백본을 초기화하는 것이 소규모 데이터셋에서 탐지 정확도를 크게 향상시키는 것으로 나타났다. CAEv2의 인코더는 패치 크기 16을 사용하는 10개 레이어로 구성된 반면, DINOv2의 인코더는 12개 레이어를 갖는다. 이로 인해 DINOv2 백본은 CAEv2보다 레이어 수가 많고 추론 속도도 느리지만, 이러한 지연시간 증가는 이후에 설명할 NAS를 통해 보완한다. 마지막으로, 멀티스케일 프로젝터(multi-scale projector)에서 배치 정규화(batch normalization) 대신 레이어 정규화(layer normalization)를 사용함으로써, 그래디언트 누적(gradient accumulation)을 통한 소비자급 GPU 환경에서도 효율적인 학습이 가능하도록 한다.
실시간 인스턴스 분할(Real-Time Instance Segmentation)
li2023maskdino에서 영감을 받아, 우리는 고품질의 분할 마스크를 공동으로 예측하기 위해 경량의 인스턴스 분할 헤드(instance segmentation head)를 추가한다. 이 분할 헤드는 인코더 출력에 이중선형 보간(bilinear interpolation)을 적용하고, 픽셀 임베딩 맵(pixel embedding map)을 생성하기 위한 경량 프로젝터를 학습한다. 구체적으로, 탐지 헤드와 분할 헤드가 동일한 저해상도 특징 맵(low-resolution feature map)을 업샘플링하여 사용하도록 함으로써, 공간적으로 의미 있는 정보를 충분히 포함하도록 한다. MaskDINO (li2023maskdino)와 달리, 우리는 지연시간을 최소화하기 위해 분할 헤드에서 멀티스케일 백본 특징을 사용하지 않는다. 마지막으로, 각 디코더 레이어 출력에서 FFN을 거친 모든 쿼리 토큰 임베딩과 픽셀 임베딩 맵 간의 내적(dot product)을 계산하여 분할 마스크를 생성한다. 흥미롭게도, 이러한 픽셀 임베딩은 YOLOACT(bolya2019yolact)에서 제안된 분할 프로토타입(segmentation prototype)으로 해석할 수 있다. LW-DETR에서 사전 학습이 DETR 계열 모델의 성능을 향상시킨다는 관찰에 기반하여, 우리는 SAM2 (ravi2024sam2)의 인스턴스 마스크로 의사 라벨링된 Objects365 (objects365) 데이터셋을 사용해 RF-DETR-Seg를 사전 학습한다.

그림 3: NAS 탐색 공간(NAS Search Space).
가중치 공유 NAS에서 우리는 (a) 패치 크기, (b) 디코더 레이어 수, (c) 쿼리 수, (d) 이미지 해상도, (e) 어텐션 블록당 윈도우 개수를 변화시킨다. 수천 개의 네트워크 구성을 병렬로 학습하는 것뿐만 아니라, 이러한 “아키텍처 증강(architecture augmentation)”이 정규화 역할을 수행하여 일반화 성능을 향상시킨다는 점을 확인하였다.
엔드투엔드 신경 아키텍처 탐색(End-to-End Neural Architecture Search)
우리의 가중치 공유 NAS는 입력 이미지 해상도, 패치 크기, 윈도우 어텐션 블록, 디코더 레이어 수, 쿼리 토큰 수가 서로 다른 수천 개의 모델 구성을 평가한다. 각 학습 반복(iteration)마다 무작위로 하나의 모델 구성을 균등 샘플링하여 그래디언트 업데이트를 수행한다. 이 방식은 드롭아웃(dropout)을 활용한 앙상블 학습과 유사하게, 수천 개의 서브넷(sub-net)을 병렬로 효율적으로 학습할 수 있게 한다. 우리는 이러한 가중치 공유 NAS 접근법이 학습 과정에서 정규화(regularization) 역할도 수행하며, 사실상 “아키텍처 증강(architecture augmentation)”을 수행한다는 점을 확인하였다. 우리가 아는 한, RF-DETR은 객체 탐지와 분할에 적용된 최초의 엔드투엔드 가중치 공유 NAS이다. 아래에서는 각 구성 요소를 상세히 설명한다.
- 패치 크기(Patch Size).
더 작은 패치는 더 높은 정확도를 제공하지만 계산 비용이 증가한다. 우리는 학습 중 서로 다른 패치 크기 간을 보간(interpolate)할 수 있도록 FlexiVIT 스타일(beyer2023flexivit)의 변환을 채택하였다. - 디코더 레이어 수(Number of Decoder Layers).
최근의 DETR 계열 모델들(peng2024dfine; zhao2024rtdetr)과 유사하게, 학습 시 모든 디코더 레이어 출력에 회귀 손실(regression loss)을 적용한다. 따라서 추론 시에는 임의의 디코더 블록 하나 또는 전부를 제거할 수 있다. 흥미롭게도, 추론 단계에서 디코더 전체를 제거하면 RF-DETR은 사실상 단일 단계(single-stage) 탐지기로 변환된다. 또한 디코더를 단축(truncate)하면 분할(segmentation) 분기의 크기도 함께 줄어들어, 분할 지연시간을 보다 세밀하게 제어할 수 있다. - 쿼리 토큰 수(Number of Query Tokens).
쿼리 토큰은 바운딩 박스 회귀와 분할을 위한 공간적 사전 지식(spatial priors)를 학습한다. 테스트 시에는 인코더 출력에서 각 토큰에 대응하는 클래스 로짓의 시그모이드 최대값을 기준으로 정렬한 뒤 쿼리 토큰을 제거하여(부록 B 참조), 최대 탐지 개수를 조절하고 추론 지연시간을 감소시킨다. 파레토 최적의 쿼리 토큰 수는 타깃 데이터셋에서 이미지당 평균 객체 수와 같은 데이터셋 통계를 암묵적으로 반영한다. - 이미지 해상도(Image Resolution).
높은 해상도는 소형 객체 탐지 성능을 향상시키는 반면, 낮은 해상도는 실행 속도를 개선한다. 우리는 가장 큰 이미지 해상도를 가장 작은 패치 크기로 나눈 값에 해당하는
N
개의 위치 임베딩(positional embedding)을 미리 할당하고, 더 작은 해상도나 더 큰 패치 크기에 대해서는 이 임베딩을 보간하여 사용한다. - 윈도우 어텐션 블록당 윈도우 수(Number of Windows per Windowed Attention Block).
윈도우 어텐션은 자기 어텐션(self-attention)이 제한된 수의 인접 토큰만 처리하도록 한다. 블록당 윈도우 수를 늘리거나 줄임으로써 정확도, 전역 정보 혼합(global information mixing), 계산 효율성 사이의 균형을 조절할 수 있다.
추론 시에는 정확도–지연시간 파레토 곡선 상에서 원하는 동작 지점을 선택하기 위해 특정 모델 구성을 선택한다. 중요한 점은, 서로 다른 모델 구성들이 유사한 파라미터 수를 가질 수 있음에도 불구하고 지연시간은 크게 달라질 수 있다는 것이다. cai2019ofa와 유사하게, 우리는 COCO에서 NAS로 탐색된 모델을 추가로 파인튜닝해도 큰 이득이 없음을 확인하였다(부록 F). 반면, RF100-VL에서는 NAS로 탐색된 모델을 파인튜닝할 경우 소폭의 성능 향상이 관찰되었다. 이는 “아키텍처 증강”에 의한 정규화 효과가 소규모 데이터셋에서는 수렴(convergence)에 100 에폭 이상이 필요하기 때문에, 추가 파인튜닝이 도움이 된다고 해석할 수 있다. 한편, 기존의 가중치 공유 NAS 방법들(cai2019ofa)은 단계별(stage-wise) 학습과 각 단계마다 서로 다른 학습률 스케줄러를 사용한다. 그러나 이러한 스케줄러는 모델 수렴에 대해 엄격한 가정을 전제로 하며, 이는 다양한 데이터셋 환경에서는 항상 성립하지 않을 수 있다.
1️⃣ 기존 NAS vs RF-DETR NAS 한 줄 요약
❌ 기존 NAS (전통적)
- 아키텍처 하나당 훈련을 다시 해야 함
- 하드웨어 바뀌면 NAS 처음부터 다시
- 객체 탐지에서는 거의 백본만 NAS하고 head는 고정
✅ RF-DETR의 엔드투엔드 Weight-Sharing NAS
핵심 문장으로 요약하면 이거야:
"학습 중에 모든 가능한 모델 구조를 한 번에 같이 학습시켜 놓고,
추론 시에 필요한 구조만 꺼내 쓴다."
2️⃣ “엔드투엔드”라는 말의 진짜 의미
여기서 엔드투엔드는 두 가지 의미가 겹쳐 있어.
(1) 백본만 NAS ❌
- EfficientDet, 기존 NAS-DTR류
- NAS는 backbone만
- detection head, decoder는 고정
(2) RF-DETR 엔드투엔드 NAS ✅
NAS 대상이 모델 전체
| 입력 해상도 | ✅ |
| patch size | ✅ |
| window attention 구조 | ✅ |
| decoder layer 수 | ✅ |
| query token 수 | ✅ |
| detection / segmentation head | ✅ |
👉 아키텍처 + 입력 + 추론 구조까지 전부 NAS 공간에 포함
그래서 “end-to-end NAS”라고 부름.
3️⃣ 학습 단계에서 실제로 무슨 일이 일어나나?
🔁 매 iteration마다 이런 일이 발생
이걸 매 iteration 반복함.
🔥 중요한 포인트
- 서브넷마다 따로 파라미터 없음
- 모든 서브넷이 가중치를 공유
- 그래서 계산량은:
-
수천 개 모델을 동시에 앙상블 학습하는 느낌 (dropout과 매우 유사)
논문에서 말한 이 문장이 정확히 이 의미야:
“similar to ensemble learning with dropout”
4️⃣ 왜 이게 정규화(regularization)가 되나?
이게 핵심 인사이트야.
일반 학습
- 하나의 고정 구조
- 특정 해상도 / decoder 깊이에 과적합
RF-DETR 학습
- 매 iteration마다 구조가 바뀜
- 모델이 이렇게 강제됨:
-
"어떤 구조로 잘리더라도 잘 동작해야 한다"
👉 결과적으로
- 구조 변화에 강인한 표현 학습
- unseen architecture에도 성능 유지
논문에서 말한:
“architecture augmentation”
은 정확히
데이터 증강이 아니라 구조 증강이라는 뜻.
5️⃣ 추론 단계에서는 NAS가 어떻게 쓰이나?
여기서 많은 사람들이 헷갈림.
❌ 추론 중에 NAS를 돌리는 게 아님
✅ 추론 시에는 “선택”만 함
- 학습은 한 번
- 하드웨어·목표 latency에 맞게 설정만 선택
그래서:
파라미터 수는 비슷한데 latency는 크게 다를 수 있음
이라는 말이 나오는 거야.
6️⃣ 왜 fine-tuning이 거의 필요 없나?
이미 학습 중에:
- decoder 1개짜리
- decoder 6개짜리
- query 50, 100, 300
- 다양한 해상도
를 전부 경험했기 때문
그래서:
- COCO: fine-tuning 거의 의미 없음
- RF100-VL: 데이터 작아서 약간 도움 됨
7️⃣ 한 장으로 요약하면
8️⃣ 한 줄로 정리
RF-DETR의 엔드투엔드 NAS는
“NAS를 탐색 문제로 보지 않고,
학습 자체를 구조적으로 강인하게 만드는 정규화 기법으로 사용한 것”이다.
결론부터 말하면:
RF-DETR의 weight-sharing NAS는 LLM의 MoE와 개념적으로 매우 유사하고,
그 대가로 “수렴이 느리고 training 자체가 비싸다”는 문제가 실제로 존재한다.
다만 왜 그걸 선택했는지, 어디서 비용을 줄였는지를 보면 설계 의도가 또렷해져.
1️⃣ MoE랑 왜 본질적으로 같은 구조인가?
LLM MoE
- 토큰마다 다른 expert 서브네트워크 사용
- 전체 파라미터는 큼
- 한 step에서 일부 경로만 활성화
- 장점: 표현력
- 단점: 학습 안정성, 수렴 느림, 라우팅 노이즈
RF-DETR weight-sharing NAS
- iteration마다 다른 아키텍처 경로 활성화
- 전체는 “슈퍼 네트워크”
- 한 step에서 일부 구조만 활성화
- 장점: 아키텍처 일반화
- 단점: gradient noise 증가, 수렴 느림
👉 구조적으로 동일
- MoE = expert 선택
- RF-DETR = architecture 선택
그래서 네가 MoE 떠올린 게 정확함.
2️⃣ 그럼 진짜로 학습이 느리냐? → YES
논문 문장 자체가 힌트야:
“architecture augmentation regularization requires more than 100 epochs to converge on small datasets”
이 문장은 돌려 말한 게 아니라 직접적인 고백이야.
실제로 무슨 일이 벌어지냐면
- 같은 파라미터가
- decoder=1일 때도 쓰이고
- decoder=6일 때도 쓰이고
- query=50, 300 둘 다 커버해야 함
- 해상도도 매번 바뀜
👉 gradient가 항상 noisy
👉 특정 구조에 최적화되지 않음
👉 수렴이 느림
3️⃣ “epoch 문제가 아니라 training time 문제”라는 말이 정확한 이유
이 포인트가 진짜 핵심이야 👍
epoch 수가 의미 없는 이유
- epoch = 데이터 한 바퀴
- 하지만 구조 분포가 계속 바뀜
- 같은 데이터라도 다른 서브넷 경로
그래서:
epoch 수 ↑ ≠ 특정 아키텍처 수렴
실제로 중요한 건:
- effective update count per sub-net
- 즉, 한 서브넷이 “얼마나 자주 선택되었는가”
4️⃣ 그럼 왜 이걸 실용적으로 쓸 수 있나?
RF-DETR이 의도적으로 비용을 감수한 대신,
다음 4가지로 “폭발을 막음”
(1) NAS 탐색을 학습 중에 하지 않음
중요한 문장:
“our approach does not evaluate the search space until the base model has been fully-trained”
즉:
- 학습 중에는 성능 비교 안 함
- RL / EA / search loop 없음
👉 MoE + NAS 중에서 NAS 부분 비용 제거
(2) 재학습이 필요 없음
기존 NAS 비용:
RF-DETR:
👉 총 학습 비용은 크지만
👉 아키텍처당 비용은 0
이게 기업 관점에서 중요함.
(3) latency tuning이 “무료”
이게 MoE랑 가장 큰 차이.
- MoE: inference도 복잡
- RF-DETR: inference는 그냥 설정 선택
👉 edge / server / GPU 바뀌어도 재학습 없음
(4) dataset-specific specialization 제거
기존:
- COCO용 학습
- 다른 데이터셋 → 다시 튜닝
RF-DETR:
- 구조적으로 일반화된 표현
- 작은 데이터셋에서도 성능 유지
그래서 RF100-VL에서 의미가 있음.
5️⃣ 그럼 “이게 좋은 선택이냐?”에 대한 냉정한 답
연구 관점
✅ 매우 의미 있음
- DETR을 “아키텍처 고정 모델”에서
- “조절 가능한 시스템”으로 바꿈
실무 관점
⚠️ 모두에게 맞진 않음
이건 명확히 이런 팀용임:
- GPU 자원 있음
- 여러 하드웨어 타겟 있음
- 모델을 제품화해서 오래 쓸 계획
- edge/server 공통 backbone 필요
❌ 이런 경우엔 비추:
- single deployment
- 단일 latency target
- retrain 자주 못 함
6️⃣ 네 질문에 대한 정확한 한 줄 답
“MoE랑 비슷한데, 이러면 학습 엄청 오래 걸리는 거 아닌가?”
👉 맞다. 구조적으로 MoE와 같고,
수렴도 느리고 training 자체가 무겁다.
👉 대신 한 번 학습해두면
하드웨어·latency·task 변경이 거의 공짜가 된다.
1️⃣ 이걸 YOLO류에 적용하면 더 낫지 않나?
❓ 직관
YOLO도 single-stage고 빠른데
weight-sharing NAS + 구조 증강 붙이면 더 세지지 않나?
❌ 결론부터
YOLO에는 구조적으로 잘 안 맞는다.
(1) YOLO는 “구조 고정 + 데이터/트릭 최적화” 철학
YOLO의 성능 공식은 대략 이거야:
즉,
- 아키텍처가 안정적이어야
- 나머지 heuristic이 잘 작동함
(2) YOLO는 NAS에 필요한 “경로 독립성”이 없음
RF-DETR NAS가 가능한 이유:
- decoder layer = 독립적
- query token = 독립적
- resolution = 독립적
YOLO는?
- anchor-free라도
- head가 feature pyramid에 강하게 결합
- 특정 scale 전용 head 존재
- loss가 scale별로 엮임
👉 구조를 자르면 성능이 비선형적으로 붕괴
(3) YOLO에 NAS를 붙인 사례들이 실패한 이유
과거 시도들:
- YOLO-NAS
- NAS-YOLO
- EfficientDet-style YOLO
문제:
- NAS는 backbone까지만
- head는 고정
- latency 다양성 확보 실패
👉 RF-DETR처럼 “decoder drop” 같은 구조적 자유도 없음
🔑 요약
YOLO는 “잘 만든 고정 구조”가 강점이고
RF-DETR NAS는 “구조적 가변성”이 강점이다.
철학 자체가 다르다.
2️⃣ 왜 D-FINE은 이걸 안 썼나?
❓ D-FINE도 DETR인데?
✅ 이유는 아주 명확함
(1) D-FINE의 목표는 “빠른 수렴 + 단일 설정”
D-FINE의 핵심은:
- deformable attention 최적화
- 안정적 학습
- COCO에서 빠른 convergence
즉:
“NAS 없이도 충분히 빠르고 정확한 DETR”
(2) D-FINE은 이미 수렴이 빡센 모델
D-FINE 특징:
- fine-grained decoder supervision
- anchor-free지만 query 역할 강함
- 학습 안정성 확보가 최우선
👉 여기에 weight-sharing NAS 넣으면:
- gradient noise 폭증
- 수렴 더 느려짐
- 실용성 하락
(3) 논문 타깃이 다름
| D-FINE | COCO SOTA |
| RF-DETR | real-world + multi-hardware |
D-FINE은:
- COCO leaderboard
- single latency target
RF-DETR은:
- RF100-VL
- edge부터 server까지
👉 문제 정의가 다르다
3️⃣ decoder drop이 왜 성능을 유지하나?
이건 DETR 구조의 핵심 비밀이다.
(1) DETR decoder는 “refinement stack”이다
decoder 역할:
- 처음 query → 거친 박스
- 뒤 decoder → 미세 조정
즉:
(2) RF-DETR은 모든 decoder에 loss를 건다
중요:
“apply detection and segmentation losses at all decoder layers”
이게 의미하는 건:
- decoder_1도 완성형 예측을 학습
- 뒤 decoder 없어도 self-contained
👉 그래서 drop 가능
(3) single-stage처럼 변하는 이유
decoder를 전부 제거하면:
이건 구조적으로:
- YOLO-like
- anchor-free
- NMS-free
👉 DETR이 single-stage로 변환됨
4️⃣ query pruning이 왜 NMS보다 안정적인가?
이건 진짜 DETR 계열의 결정적 장점이다.
(1) NMS의 근본적 불안정성
NMS:
- heuristic
- IoU threshold 민감
- class별 분리
- 작은 노이즈에 결과 급변
특히:
- crowded scene
- small object
- long-tail
→ 불안정
(2) DETR query는 “1 object = 1 query” 가정
DETR의 핵심 제약:
- bipartite matching
- 중복 예측 자체가 학습에서 억제됨
즉:
중복이 나오면 학습 실패
(3) query pruning은 “capacity 조절”이다
query pruning은:
- 후처리 ❌
- 모델 용량 제한 ✅
👉 학습 시 이미 그 제약을 배움
(4) 왜 더 안정적이냐면
| 추론 후 heuristic | 모델 내부 제약 |
| threshold 민감 | threshold 없음 |
| class별 분리 | joint reasoning |
| non-differentiable | 학습 반영됨 |
5️⃣ 전체 구조 한 문장 요약
RF-DETR은
“DETR을 단일 모델이 아니라
하드웨어·latency·task에 따라 변형 가능한 시스템으로 재정의한 모델”이다.
1) VLM 시대의 detection 구조와 RF-DETR이 어떻게 이어지나
VLM 기반 탐지의 현실
- 장점: 오픈 보캐블러리, 제로샷, 롱테일에 강함
- 단점: 느림(텍스트 인코더/크로스모달), 도메인 밖(OOD)에서 흔들림, 제품화 어렵고 비용 큼
RF-DETR의 포지션: “VLM을 직접 쓰지 않고, VLM의 priors를 증류해서 쓰는 쪽”
논문에서 말하는 인터넷 규모 priors는 사실상 두 갈래야.
- 파운데이션 비전 백본(DINOv2 등)
- 텍스트 없이도 웹 규모에서 학습된 시각 표현
- 작은 데이터셋에서도 전이 좋음
- 실시간을 위해 VLM 전체가 아니라 비전 표현만 채택
- (논문 전체 맥락상) 오픈 보캐블러리로 바로 가기보다, 타깃 데이터셋에서 “스페셜리스트”로 변환
- RF100-VL처럼 데이터 분포가 제각각인 환경에서
- “텍스트 인코더 붙이고 프롬프트로 해결” 대신
- 빠른 DETR 계열로 재구성 + NAS로 하드웨어 맞춤
즉, VLM 시대의 구조 흐름을 이렇게 보면 깔끔해져.
큰 흐름
- 1세대: YOLO류 (빠르지만 NMS, 롱테일/오픈보캐 약함)
- 2세대: VLM 탐지(GroundingDINO/GLIP 등) (오픈보캐 강하지만 무겁고 느림)
- 3세대: “VLM priors를 가진 실시간 스페셜리스트” (RF-DETR 같은 방향)
- 비전 파운데이션의 표현을 흡수
- 탐지기는 실시간 구조로
- 제품화/하드웨어/지연시간 최적화는 NAS로
이게 RF-DETR이 “VLM 시대”에 놓이는 자리야.
오픈보캐를 끝까지 가져가진 않지만, VLM이 만든 웹 규모 사전지식을 실시간 탐지기로 가져오는 중간 다리 역할.
2) YOLO + DETR 하이브리드 가능하나?
가능해. 다만 “둘의 장점만 뽑아 붙이면 끝”은 아니고, 결합 지점이 2가지로 갈려.
A안: YOLO neck/head + DETR의 set prediction (NMS-free)
- YOLO의 강점: FPN/PAN 같은 멀티스케일 피처, 빠른 conv 연산
- DETR의 강점: bipartite matching 기반 set prediction, NMS 제거, 전역 reasoning
구조 예시:
- Backbone/Neck: YOLO 스타일 (C2f/PAN/FPN 등)
- Head: “DETR-style matching head”
- 쿼리 토큰을 쓰든, 멀티스케일 피처에서 동적으로 뽑든
- 목표: 실시간 + NMS-free + 중복 억제
이 방향이 RT-DETR류가 사실상 밟고 있는 길이고, “YOLO-like feature engineering + DETR-like set prediction”이라 보면 됨.
B안: DETR encoder + YOLO-like dense head (single-stage)
- DETR encoder(특히 ViT)가 가진 표현력을 쓰되
- decode를 가볍게 해서 YOLO처럼 dense prediction으로
- 단점: 중복 억제는 다시 NMS나 대체 기법 필요
현실적으로는 A안이 더 매끄러워.
왜냐면 “NMS-free”를 얻는 게 DETR의 핵심 이점이라서.
3) train이 어긋나면 수렴이 안 되는 거 아니냐?
이건 진짜 핵심 리스크고, 네 우려가 맞아.
weight-sharing NAS는 MoE처럼 학습 신호가 분산되고 gradient가 noisy해져서 “어긋나면” 수렴이 흔들릴 수 있음.
다만 RF-DETR이 수렴을 버티게 만드는 안전장치들이 있어.
(1) “모든 디코더 레이어에 loss” = 깊이 변화에 대한 안정장치
- 어떤 iteration에서는 decoder=2
- 어떤 iteration에서는 decoder=6
- 그래도 각 레이어가 직접 supervision을 받으니
- “뒤 레이어 없어서 학습 신호가 끊긴다”가 줄어듦
- decoder drop이 가능한 이유이자 수렴 안정 장치
(2) 검색을 학습 중에 하지 않음
- 학습은 “슈퍼넷을 강하게” 만드는 데 집중
- 탐색(그리드 서치)은 학습 끝난 뒤
- 학습 중에 아키텍처 성능 비교/선택을 하면 불안정성이 훨씬 커지는데 그걸 안 함
(3) 샘플링 분포가 중요 (여기서 어긋나면 진짜 망함)
논문은 “uniformly sample”이라 했는데,
실제로는 다음이 중요해:
- 극단 설정(아주 작은 res + 아주 큰 patch + decoder 0 등)이 너무 자주 나오면
- 학습이 그쪽으로 끌려가거나
- 전체 representation이 약해질 수 있음
- 반대로, 무거운 설정만 많이 나오면
- 경량 서브넷이 훈련을 덜 받아 성능이 깨짐
즉 샘플링 설계가 MoE의 라우팅 설계만큼 중요해.
(4) “아키텍처 증강”은 정규화지만, 정규화는 항상 수렴을 늦춘다
- 네가 말한 “epoch가 아니라 training time 자체” 문제는 여기서 발생
- 이건 트레이드오프야
- 수렴 빠른 단일 모델 vs
- 수렴 느리지만 수천 운영점을 공짜로 얻는 모델
그래서 결론은?
- 어긋나면 수렴 안 될 수 있다: 맞음
- RF-DETR은 그 리스크를 줄이려고
- deep supervision
- scheduler-free 주장(이건 장단이 있음)
- 학습-탐색 분리
- foundation backbone(DINOv2)로 초기 표현 강하게
를 배치한 것
짧게 답하면:
맞다. A안(YOLO neck/head + DETR set prediction)은 많이 시도됐지만,
“생각만큼 큰 효용”은 아직 못 얻었다. 그건 우연이 아니라 구조적 이유 때문이다.
아래에서 왜 그랬는지를 단계적으로 풀어볼게.
1️⃣ 왜 다들 A안을 시도했나 (기대치)
A안의 기대는 이거였음:
- YOLO의 장점
- 멀티스케일 FPN/PAN
- 빠른 conv 연산
- DETR의 장점
- bipartite matching
- NMS 제거
- 중복 억제의 학습 내재화
👉 “빠르고, 깔끔하고, 안정적일 것”이라는 기대
RT-DETR, LW-DETR, YOLOvX-DETR류 전부 이 방향임.
2️⃣ 그런데 왜 “체감 효용”이 작았나?
핵심 이유는 3가지가 동시에 작용했기 때문이야.
(1) NMS 제거의 이득이 생각보다 작다
이론 vs 현실
- 이론:
- NMS 제거 → latency 감소
- heuristic 제거 → 안정성 증가
- 현실:
- NMS는 GPU에서 이미 매우 싸다
- YOLO 추론 시간의 5~10% 수준
- 특히 batch=1에서는 더 미미
👉 NMS-free 자체로는 속도 이득이 제한적
그래서:
- “NMS-free인데 왜 안 빨라지지?”라는 체감 발생
(2) set prediction은 “공짜가 아니다”
DETR의 bipartite matching:
- 학습 시 Hungarian matching
- query 수 많을수록 비용 증가
- query 간 전역 상호작용 필요
즉:
- YOLO head의 local conv prediction보다
- 구조적으로 무거움
👉 NMS 없애서 얻는 이득보다
👉 set prediction에서 잃는 비용이 큼
(3) YOLO neck과 DETR head의 귀납 편향(inductive bias)이 충돌
YOLO neck의 철학
- “이 scale에는 이 크기 객체”
- locality, scale prior 강함
DETR head의 철학
- “모든 query가 전체 이미지 본다”
- global reasoning
👉 둘을 붙이면:
- neck은 local
- head는 global
- 학습이 깔끔하게 정렬되지 않음
그래서:
- 학습 안정성은 얻지만
- 성능 점프는 안 나옴
3️⃣ 실제로 얻은 건 “대폭 개선”이 아니라 “균형”
그래서 A안 계열의 실제 성과는:
| 정확도 | YOLO와 비슷하거나 약간 ↑ |
| 속도 | YOLO보다 약간 ↓ |
| 안정성 | NMS 이슈 감소 |
| 구조적 우아함 | ↑ |
| 체감 혁신 | ❌ |
RT-DETR, LW-DETR이:
- “나쁘지 않다”
- “정갈하다”
- “실무적으로 쓸 수 있다”
이지,
- “YOLO를 압도했다”는 아님.
4️⃣ RF-DETR은 왜 A안과 다른 결과를 냈나?
중요한 포인트.
RF-DETR은:
- YOLO neck을 가져오지 않음
- 처음부터 DETR에 맞게 설계된 구조
차이점 핵심:
(1) neck + head를 억지로 섞지 않음
- multi-scale은 projector에서 처리
- attention 구조와 일관됨
(2) NAS로 latency 문제를 구조적으로 해결
- decoder 수, query 수를 “설정”으로 줄임
- YOLO처럼 구조 고정 후 튜닝 아님
(3) VLM-scale backbone으로 표현력 확보
- DINOv2 backbone 덕분에
- local inductive bias에 덜 의존
👉 그래서:
- NMS 제거가 목적 ❌
- “전체 시스템을 가변화”가 목적
5️⃣ 그럼 A안은 완전히 실패한 방향인가?
아니야. 다만 **“목표를 잘못 잡았던 방향”**에 가까워.
A안이 잘 맞는 경우
- 중복 제거가 중요한 환경
- NMS가 불안정한 데이터
- DETR의 학습 안정성이 필요한 경우
A안이 못하는 것
- latency 대폭 개선
- 하드웨어별 free scaling
- 구조적 유연성
6️⃣ 더 가능성 있는 다음 단계는?
A안을 “약간 비틀어야” 함.
진짜 유망한 방향은 이거야:
(1) YOLO neck + query pruning 기반 capacity control
- NMS 제거가 아니라
- “query 수 = 최대 객체 수”로 제어
- 후처리 없음
(2) YOLO식 dense prior + DETR matching을 부분 적용
- 모든 head를 set prediction으로 바꾸지 말고
- crowded / ambiguous 영역만 query 기반
(3) RF-DETR 스타일로 decoder drop + NAS
- 하이브리드라도 구조 가변성 확보
7️⃣ 질문에 대한 정확한 답 한 문장
맞다. A안은 많이 시도됐지만
“NMS-free” 자체로는 생각만큼 큰 효용을 주지 못했다.
그 이유는 NMS 제거 이득보다, set prediction의 비용과 구조 충돌이 더 컸기 때문이다.
그리고 RF-DETR이 의미 있는 이유는:
A안을 단순 결합이 아니라,
DETR 중심의 구조 재설계 + 가변 시스템으로 풀었기 때문이야.
학습 스케줄러와 데이터 증강이 모델 성능에 편향을 유발함
최신(state-of-the-art) 객체 탐지기들은 표준 벤치마크에서 최대 성능을 달성하기 위해 세심한 하이퍼파라미터 튜닝을 요구하는 경우가 많다. 그러나 이러한 맞춤형(bespoke) 학습 절차는 특정 데이터셋 특성(예: 이미지 개수)에 모델을 암묵적으로 편향시키는 문제를 내포하고 있다. DINOv3 (simeoni2025dinov3)와 유사한 맥락에서, 우리는 코사인(cosine) 스케줄러가 사전에 알려진 고정된 최적화 구간(optimization horizon)을 가정한다는 점을 관찰하였으며, 이는 RF100-VL과 같이 서로 다른 특성을 지닌 다양한 타깃 데이터셋에 적용하기에는 비현실적이다.
데이터 증강(data augmentation) 역시 데이터셋 속성에 대한 사전 지식을 전제로 하면서 유사한 편향을 유발한다. 예를 들어, 기존 연구들은 효과적인 데이터셋 크기를 늘리기 위해 VerticalFlip, RandomFlip, RandomResize, RandomCrop, YOLOXHSVRandomAug, CachedMixUp과 같은 공격적인 데이터 증강 기법을 활용해 왔다. 그러나 VerticalFlip과 같은 일부 증강 기법은 안전이 중요한(safety-critical) 도메인에서 모델 예측에 부정적인 편향을 초래할 수 있다. 예를 들어, 자율주행 차량의 보행자 탐지기는 물웅덩이에 비친 반사(reflection)로 인한 오탐(false positive)을 방지하기 위해 VerticalFlip으로 학습되어서는 안 된다.
이러한 이유로, 우리는 데이터 증강을 수평 뒤집기(horizontal flip)와 랜덤 크롭(random crop)으로 제한한다. 마지막으로, LW-DETR은 이미지 단위(per-image) 랜덤 리사이즈 증강을 적용하는데, 이때 각 이미지는 배치 내에서 가장 큰 이미지 크기에 맞추어 패딩된다. 그 결과, 대부분의 이미지에 상당한 패딩이 포함되며, 이는 윈도우 아티팩트(window artifacts)를 유발하고 패딩 영역에 대한 불필요한 연산 낭비를 초래한다. 이에 반해, 우리는 배치 단위(batch-level)에서 이미지를 리사이즈함으로써 배치당 패딩 픽셀 수를 최소화하고, 모든 위치 인코딩 해상도(positional encoding resolution)가 학습 과정에서 균등하게 관찰되도록 한다.
4. 실험 (Experiments)
우리는 RF-DETR을 COCO와 RF100-VL에서 평가하여, 제안한 방법이 모든 실시간(real-time) 방법들 가운데 최고 수준(state-of-the-art)의 정확도를 달성함을 보인다. 또한, 기존 벤치마킹 프로토콜에 존재하는 불일치를 식별하고, 재현성을 향상시키기 위한 간단한 표준화 절차를 제시한다. LW-DETR (chen2024lw)을 따라, 모델을 파라미터 수가 아닌 유사한 지연시간(latency)을 기준으로 동일한 크기 버킷(size bucket)에 묶어 비교한다.
데이터셋과 평가 지표 (Datasets and Metrics)
우리는 기존 연구와의 공정한 비교를 위해 COCO에서 RF-DETR을 평가하고, 데이터 분포가 크게 상이한 실제 환경 데이터셋에 대한 일반화 성능을 평가하기 위해 RF100-VL에서도 실험을 수행한다. RF100-VL은 100개의 서로 다른 데이터셋으로 구성되어 있으므로, 이 벤치마크에서의 전체 성능은 임의의 타깃 도메인으로의 전이 가능성(transferability)을 나타내는 대리 지표(proxy)라고 본다. 평가는 pycocotools를 사용하여 평균 정밀도(mean average precision, mAP)를 포함한 표준 지표를 보고하며, AP50, AP75, APSmall, APMedium, APLarge에 대한 세부 분석도 함께 제공한다. 또한 효율성 평가는 NVIDIA T4 GPU에서 TensorRT 10.4와 CUDA 12.4를 사용하여 GFLOPs, 파라미터 수, 그리고 추론 지연시간을 측정함으로써 수행한다.
표 1: 지연시간 평가의 표준화 (Standardizing Latency Evaluation)
지연시간 측정값의 분산은 주로 전력 스로틀링(power throttling)과 GPU 과열로 인해 발생한다. 우리는 순전파(forward pass) 사이에 200ms의 버퍼링(buffering)을 두어 이러한 문제를 완화한다. 주목할 점은, 이 벤치마킹 방식이 지속 처리량(sustained throughput)을 측정하기 위한 것이 아니라, 재현 가능한 지연시간 측정을 보장하기 위한 목적이라는 것이다.
1️⃣ 일반적으로 우리가 쓰는 지연시간 측정 방식
현업이나 대부분 논문에서의 정상적인 latency benchmark는 보통 이 중 하나입니다.
(A) Throughput 기반
- warm-up 충분히
- batch=1 또는 batch>1
- 연속 inference
- 평균 / p95 / p99 latency
- 실제 서비스 조건에 가까움
👉 GPU 스로틀링, 발열, 커널 스케줄링까지 포함해서 재는 게 정상
(B) Real-time constraint 기반
- 일정 FPS 유지 가능한지
- sustained 30/60 FPS
- queue 밀림 없는지
👉 “얼마나 오래 안정적으로 버티느냐”가 핵심
2️⃣ RF-DETR 논문의 방식은 뭐가 다른가?
논문에서 한 방식은 이거죠:
forward pass 사이에 200ms sleep (buffering)
이건 사실상:
- GPU가 항상 idle → burst → idle
- power throttling 회피
- thermal steady state를 일부러 깨뜨림
즉,
❗ latency를 측정하는 게 아니라
“cold-ish single-shot kernel latency”를 재는 방식
입니다.
3️⃣ 왜 이 방식이 “비정상적으로” 느껴지냐면
✔️ 우리가 실제로 쓰는 상황과 완전히 다르기 때문
현실:
- 카메라 → 프레임 연속 유입
- GPU는 계속 바쁨
- thermal throttling은 시스템의 일부
논문 방식:
- 프레임 간 200ms 휴식
- 실시간 시스템에선 절대 일어나지 않음
- surveillance, drone, robotics 어디에도 없음
👉 실사용 latency를 재는 방식이 아님
4️⃣ 그럼 저자들이 틀린 거냐?
이건 좀 미묘합니다.
틀렸다기보다는, 목적이 다릅니다.
저자들의 목적은 이거예요:
“모델 간 상대적인 latency 비교를
GPU 상태 변수 없이 재현 가능하게 하자”
그래서:
- GPU 상태를 최대한 동일하게 만들고
- kernel-level latency만 비교
👉 benchmark purity를 택한 것
5️⃣ 문제는 이걸 “실시간”이라고 말한 점
여기서 논문의 가장 애매한 지점이 나옵니다.
- they say: real-time detector
- but they measure: de-throttled single inference latency
이건 엄밀히 말하면:
❌ real-time 시스템의 latency가 아님
✅ kernel execution latency
그래서 당신처럼 실무 경험 있는 사람이 보면:
“어? 이거 우리가 쓰는 방식이 아닌데?”
라고 느끼는 게 너무 정상입니다.
6️⃣ 특히 YOLO 비교에서 더 문제가 되는 이유
YOLO 계열은:
- NMS
- post-processing
- CPU/GPU sync
- memory copy
이런 게 연속 inference에서 더 불리해집니다.
그런데:
- RF-DETR 방식은 이런 overhead를 완화시키는 조건
- YOLO의 약점을 상대적으로 덜 드러내는 환경
👉 공정한 비교라고 보기 애매한 이유
7️⃣ 그래서 이걸 어떻게 받아들여야 하냐면
❌ 이렇게 받아들이면 안 됨
“RF-DETR이 실제 서비스에서 YOLO보다 항상 빠르다”
✅ 이렇게 받아들이는 게 맞음
“동일 GPU 상태에서,
모델 내부 연산 복잡도 관점에서는 RF-DETR이 효율적이다”
즉,
- architecture efficiency 비교용
- product latency claim은 아님
8️⃣ 개인적으로 이 논문의 가장 위험한 포인트
이 방식을 표준화된 latency benchmark처럼 제안한 점
이게 커뮤니티에 퍼지면:
- 실사용과 괴리된 숫자 경쟁
- “sleep 넣고 재면 다 빠름” 게임
👉 그건 바람직하지 않습니다.
9️⃣ 당신 감상 정리해주면, 이렇게 말할 수 있음
“논문이 말하는 latency는
**실시간 시스템의 latency라기보다는
GPU kernel-level execution time에 가깝다.
실사용 환경과는 괴리가 있다.”
이건 비판으로서 아주 정확하고 정당합니다.
10️⃣ 그래서 이 논문의 위치는 정확히 여기
- ✔️ 연구용 비교에는 의미 있음
- ✔️ 아키텍처 효율 논의에는 가치 있음
- ❌ 실서비스 latency 주장으로는 부적절
- ❌ 제품 선택 근거로 쓰기엔 위험
우리는 TensorRT 환경에서 YOLOv8과 YOLOv11의 mAP 결과를 재현하지 못했는데, 이는 해당 모델들이 평가 시에는 멀티 클래스 NMS를 사용하지만 추론 시에는 단일 클래스 NMS만 사용하기 때문인 것으로 보인다. 우리는 NMS 튜닝에 사용되는 표준 신뢰도 임계값(confidence threshold)인 0.01을 사용한다. 또한 YOLOv8과 YOLOv11은 FP32에서 FP16으로 양자화(quantization)할 경우 성능이 더 크게 저하되는데, 이는 모든 모델이 동일한 모델 아티팩트를 사용하여 지연시간과 정확도를 보고해야 함을 다시 한 번 확인시켜 준다. 특히, D-FINE을 단순히 FP16으로 양자화하면 성능이 0.5 AP까지 급격히 감소한다. 우리는 저자들의 내보내기(export) 코드를 수정하여 ONNX opset 17을 사용함으로써 이 문제를 해결하였다. 자세한 내용은 부록 A를 참조한다.

지연시간 벤치마킹의 표준화 (Standardizing Latency Benchmarking)
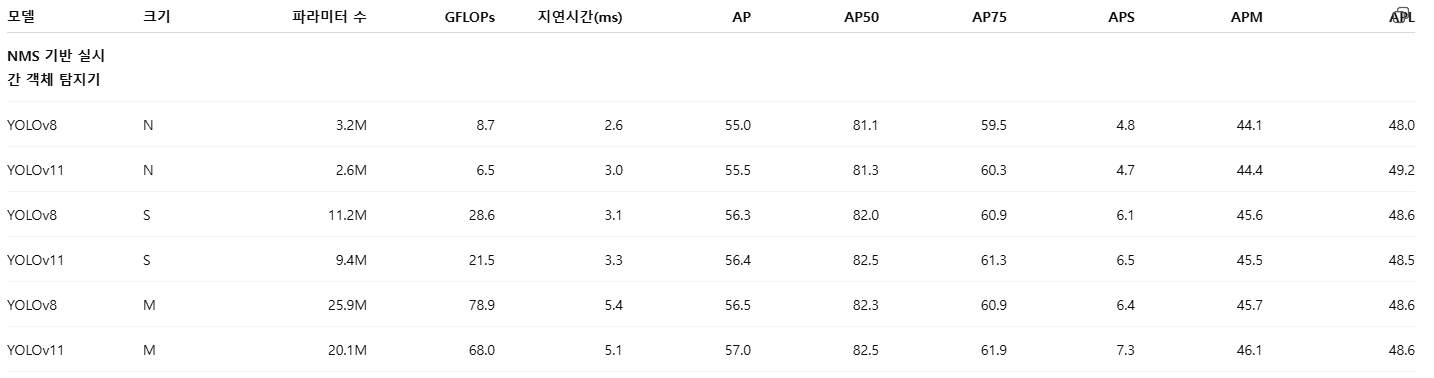
객체 탐지 분야가 충분히 성숙했음에도 불구하고, 기존 연구들 간의 지연시간(latency) 벤치마킹은 여전히 일관성이 부족하다. 예를 들어, YOLO 계열 모델들은 지연시간 계산 시 비최대 억제(Non-Maximum Suppression, NMS)를 제외하는 경우가 많아, 엔드투엔드(end-to-end) 탐지기와의 비교가 불공정해진다. 또한 YOLO 기반 분할(segmentation) 모델들은 실제로 바로 사용 가능한 객체 단위 마스크가 아니라, 프로토타입 예측을 생성하는 단계의 지연시간만을 측정하는 경우가 많아(yolov11), 실행 시간 측정에 편향이 발생한다.
더 나아가, D-FINE에서 보고한 LW-DETR의 지연시간은 chen2024lwdetr에서 보고된 수치보다 25% 더 빠르다. 우리는 이러한 차이가 GPU 과열 시 발생하는 전력 스로틀링(power throttling) 이벤트, 즉 측정 가능한 하드웨어 상태 변화에 기인함을 관찰하였다(cf. Table 1). 반면, 연속된 순전파(forward pass) 사이에 200ms의 대기 시간을 두는 것만으로도 전력 스로틀링을 상당 부분 완화할 수 있으며, 보다 안정적인 지연시간 측정이 가능해진다.
마지막으로, 기존 연구들은 종종 FP16으로 양자화된 모델을 사용해 지연시간을 보고하면서, 정확도는 FP32 모델로 평가하는 경우가 많다. 그러나 단순한(naive) 양자화는 성능을 크게 저하시킬 수 있으며, 일부 경우에는 AP가 거의 0에 가까울 정도로 붕괴되기도 한다. 공정한 비교를 위해, 우리는 동일한 모델 아티팩트를 사용하여 정확도와 지연시간을 함께 보고할 것을 권장한다. 또한, 재현 가능한 지연시간 측정을 위한 독립적인 벤치마킹 도구를 GitHub에 공개한다.
표 2: COCO 객체 탐지 평가 (COCO Detection Evaluation)
아래에서는 RF-DETR을 대표적인 실시간(real-time) 및 오픈 보캐블러리 객체 탐지기들과 비교한다. 실험 결과, RF-DETR (nano)는 D-FINE (nano)와 LW-DETR (tiny)를 5 AP 이상 상회한다. RF-DETR은 YOLOv8 및 YOLOv11을 전반적으로 크게 능가하며, RF-DETR의 nano 크기 모델은 YOLOv8 및 YOLOv11의 medium 크기 모델과 동등한 성능을 달성한다. TensorRT 실행을 지원하지 않는 모델은 별표(*)로 표시하고, 해당 경우 PyTorch 기반 지연시간을 보고한다. COCO에서의 RF-DETR L, XL, Max 변형에 대한 결과는 부록 E를 참조한다.


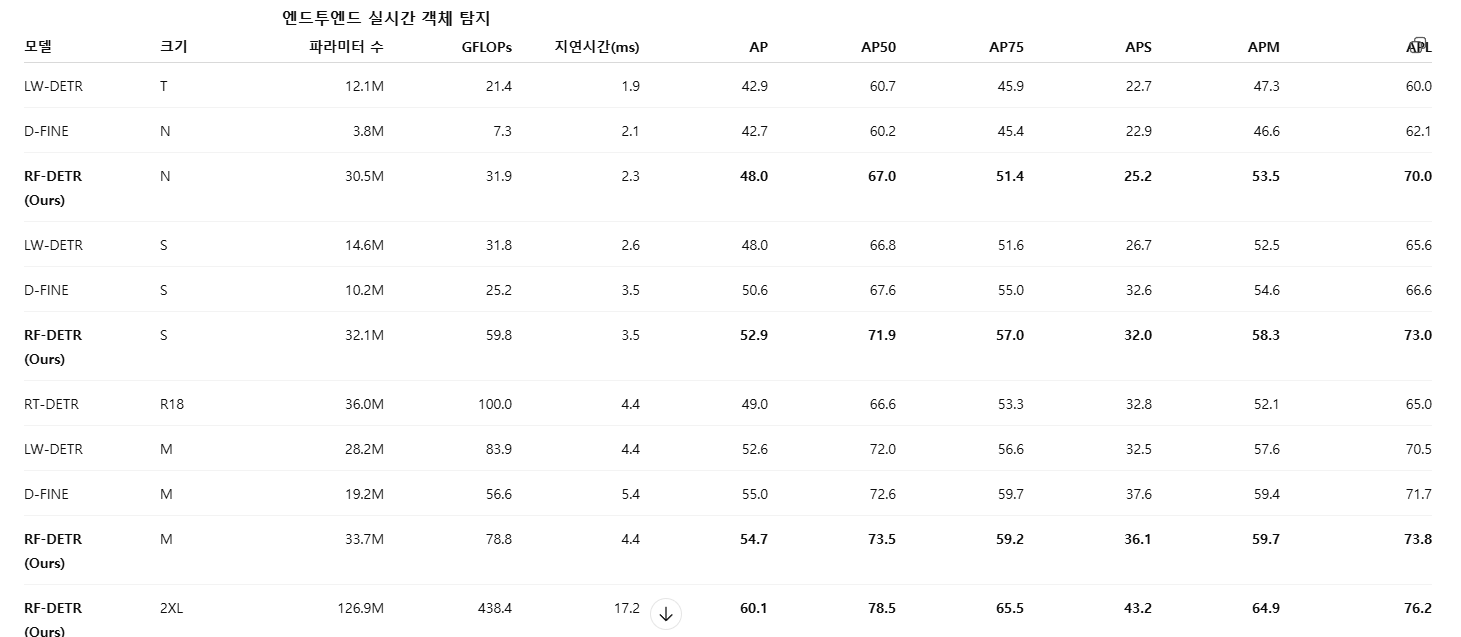
COCO에서의 RF-DETR 및 RF-DETR-Seg 평가
COCO (lin2014coco)는 객체 탐지와 인스턴스 분할을 위한 대표적인(플래그십) 벤치마크이다. 표 2에서는 RF-DETR을 주요 실시간(real-time) 및 오픈 보캐블러리 객체 탐지기들과 비교한다. 실험 결과, RF-DETR (nano)는 D-FINE (nano)와 LW-DETR (nano)를 모두 5 AP 이상 상회한다. 이러한 경향은 small 및 medium 크기 모델에서도 유사하게 관찰된다. 특히 RF-DETR은 YOLOv8과 YOLOv11을 유의미하게 능가하며, RF-DETR (nano)는 YOLOv8 및 YOLOv11의 medium 크기 모델과 성능 면에서 동등한 수준을 달성한다.
우리는 mmdetection에서 제공하는 GroundingDINO 구현을 사용하였으며, GroundingDINO가 COCO에 대해 파인튜닝된 모델 아티팩트를 공개하지 않기 때문에, 논문에서 보고된 AP 값을 그대로 포함하였다. 또한 공개된 오픈 보캐블러리 모델을 기준으로 mmGroundingDINO의 파라미터 수, GFLOPs, 그리고 지연시간을 벤치마킹하였다.
표 3에서는 RF-DETR-Seg을 실시간 인스턴스 분할 모델들과 비교한다. RF-DETR-Seg (nano)는 모든 크기 설정에서 YOLOv8과 YOLOv11을 능가한다. 더 나아가 RF-DETR-Seg (nano)는 FastInst보다 5.4% 높은 성능을 보이면서도, 실행 속도는 거의 10배에 달한다. 이와 유사하게, RF-DETR (x-large)는 GroundingDINO (tiny)를 능가하며, RF-DETR-Seg (large)는 MaskDINO (R50)를 훨씬 짧은 실행 시간으로 상회한다.
한 줄 요약
YOLOv8과 YOLOv11만 비교한 이유는
“최신·공식·재현 가능한 YOLO 계열의 대표”만 남기고
논쟁 소지가 큰 변형들을 의도적으로 배제했기 때문이다.
아래에서 이유를 단계적으로 풀어볼게.
1️⃣ “YOLO”라는 이름의 문제
YOLO 계열은 지금 사실상 이렇게 갈라져 있어:
(A) 공식 Ultralytics 라인
- YOLOv8
- YOLOv11
→ 가중치, 코드, TensorRT export, 벤치마크 재현 가능
(B) 논문·파생·커스텀 라인
- YOLOv7
- YOLOv9
- YOLOX
- YOLO-NAS
- YOLOv6 등
→ 훈련 설정, 증강, head, NMS 설정이 제각각
RF-DETR 논문의 핵심 주장 중 하나가 뭐였지?
“벤치마킹이 일관되지 않다”
그래서 저자 입장에서는:
- 비교군 자체가 재현 불가능하면 주장 신뢰도가 무너짐
2️⃣ YOLOv7, v9를 안 넣은 “현실적인 이유”
(1) YOLOv7
- 공식 repo 유지 거의 중단
- TensorRT export 표준화 ❌
- 학습/추론 설정이 paper와 코드가 다름
- pruning/FP16 시 성능 변동 큼
👉 “공정 비교”를 표방한 논문에 넣기엔 리스크 큼
(2) YOLOv9
- 구조적으로 매우 공격적
- re-parameterization + GELAN
- 성능은 좋지만:
- 학습 트릭 의존도 높음
- inference path가 paper마다 다름
👉 RF-DETR이 공격하는 포인트가:
“트릭과 스케줄러에 의존하지 않는 구조”
YOLOv9를 넣으면:
- “왜 이건 augmentation 안 뺐냐”
- “왜 scheduler 다르냐”
- 논점이 흐려짐
3️⃣ 왜 하필 YOLOv8 + YOLOv11이었나
이유 1: 산업 표준에 가장 가까움
- 실제 배포에서 가장 많이 쓰임
- TensorRT, ONNX, FP16, INT8 경로 정리됨
- edge/서버에서 모두 사용됨
이유 2: 비교가 깔끔함
- 동일 프레임워크
- 동일 export 파이프라인
- 동일 NMS 설정(논문에서도 NMS 문제 지적)
이유 3: “YOLO 최신 상태”를 대표
- v8 = 안정화된 베이스라인
- v11 = 최신 아키텍처 + segmentation 포함
👉 이 둘만으로도:
“최신 YOLO를 이겼다”는 메시지는 충분
4️⃣ 사실 더 중요한 이유 (논문의 숨은 의도)
RF-DETR 논문은 단순 SOTA bragging이 목적이 아님.
이 논문의 주 공격 대상은:
- ❌ YOLO 자체
- ❌ 특정 버전
진짜 공격 대상은:
“데이터셋/하드웨어마다 모델을 다시 튜닝해야 하는 관행”
그래서 저자들은:
- YOLO의 최신 공식 구현만 최소한으로 넣고
- 논문의 메시지를 아키텍처 설계 철학으로 가져가고 싶었던 것
5️⃣ 만약 YOLOv7/9를 넣었으면 벌어졌을 일
현실적으로 이런 리뷰가 달렸을 가능성이 큼:
- “YOLOv7은 이 세팅이면 더 잘 나옵니다”
- “YOLOv9은 augmentation 줄이면 성능 떨어집니다”
- “왜 official config 안 썼나요?”
👉 논문이 벤치마크 논쟁으로 빨려 들어감
👉 RF-DETR의 핵심 기여(NAS, scheduler-free, latency 표준화)가 묻힘
6️⃣ 그래서 이 선택은 합리적인가?
연구 논문 관점
✅ 매우 합리적
- 재현성
- 비교 명확성
- 리뷰 리스크 최소화
실무/도메인 관점
⚠️ “YOLO 전체를 대표한다고 보긴 어렵다”는 한계는 있음
- 특히 드론/항공/초소형 객체 쪽에서는
- YOLOv7/9가 더 강할 수 있음 (네가 지적한 바로 그 포인트)
7️⃣ 네 질문의 진짜 의미 (이게 핵심)
네가 사실 묻고 싶은 건 이거잖아:
“YOLOv7/9 같은 도메인 최적화된 YOLO까지 포함하면
RF-DETR의 우위가 유지될까?”
👉 정직한 답:
- COCO: 여전히 RF-DETR 강함
- UAV/드론/소형 객체: YOLO 계열이 이길 가능성 큼
그래서 앞에서 우리가 이야기한:
“RF-DETR은 모든 데이터용이 아니다”
로 다시 연결되는 거야.
8️⃣ 한 문장 결론
YOLOv8·v11만 비교한 것은
RF-DETR의 성능을 가장 공정하고 재현 가능하게 보여주기 위한
의도적인 최소 비교 전략이다.
표 3: COCO 인스턴스 분할 평가 (COCO Instance Segmentation Evaluation)
우리는 COCO에서 RF-DETR을 대표적인 실시간(real-time) 인스턴스 분할 방법들과 비교한다. 주목할 점은 RF-DETR (nano)가 보고된 모든 YOLOv8 및 YOLOv11 모델 크기를 능가한다는 것이다. 또한 RF-DETR (nano)는 FastInst보다 4.4% 높은 성능을 보이면서도, 실행 속도는 거의 10배에 달한다. RF-DETR (medium)은 MaskDINO에 근접한 성능을 훨씬 짧은 실행 시간으로 달성한다. TensorRT 실행을 지원하지 않는 모델은 별표(*)로 표시하고, 해당 경우 PyTorch 기반 지연시간을 보고한다. 아울러, 본 연구에서 보고한 YOLO 계열 모델의 지연시간에는 프로토타입(protos)을 실제 마스크로 변환하는 과정도 포함되어 있는데, 이는 기존 벤치마크에서는 보통 제외되지만 실제 사용 환경에서는 의미 있는 지연시간을 차지한다. COCO에서의 RF-DETR-Seg L, XL, Max 변형 결과는 부록 E를 참조한다.


RF100-VL에서의 RF-DETR 평가
RF100-VL은 서로 다른 100개의 데이터셋으로 구성된 매우 도전적인 객체 탐지 벤치마크이다. 표 4에서는 100개 데이터셋 전체에 대해 평균 낸 지연시간, FLOPs, 정확도를 보고한다. 실험 결과, RF-DETR (2x-large)는 GroundingDINO와 LLMDet을 훨씬 짧은 실행 시간으로 능가한다. 흥미롭게도, RT-DETR은 mAP50 기준에서 D-FINE(D-FINE은 RT-DETR을 기반으로 함)보다 높은 성능을 보이는데, 이는 D-FINE의 하이퍼파라미터가 COCO에 과도하게 최적화되었을 가능성을 시사한다. 또한 RF-DETR은 더 큰 백본 크기로 스케일링할수록 성능이 향상되는 이점을 보인다(부록 E 참조). 반면, YOLOv8과 YOLOv11은 RF100-VL에서 일관되게 DETR 기반 탐지기보다 낮은 성능을 보이며, 이들 모델 패밀리를 더 큰 크기로 확장하더라도 RF100-VL 성능은 개선되지 않는다.
표 4: RF100-VL 평가 (RF100-VL Evaluation)
우리는 RF100-VL에서 RF-DETR을 실시간(real-time) 및 오픈 보캐블러리 객체 탐지기들과 비교한다. 흥미롭게도 RF-DETR (2x-large)는 GroundingDINO (tiny)와 LLMDet (tiny)를 훨씬 짧은 실행 시간으로 능가한다. 표에는 100개 데이터셋 전체에 대해 평균 낸 지연시간(latency)과 FLOPs를 보고한다. 또한 YOLOv8과 YOLOv11의 지연시간 측정값은, 기본으로 튜닝된 NMS 임계값 0.01이 RF100-VL의 모든 데이터셋에 최적으로 작동하지 않을 수 있기 때문에 다소 비최적일 가능성이 있음을 언급한다. TensorRT 실행을 지원하지 않는 모델은 별표(*)로 표시하고, 해당 경우 PyTorch 기반 지연시간을 보고한다. RF100-VL에서의 RF-DETR L, XL, Max 변형 결과는 부록 E를 참조한다.



신경 아키텍처 탐색(NAS)의 영향 (Impact of Neural Architecture Search)
표 3에서는 가중치 공유 NAS의 영향을 분석(ablation)한다. LW-DETR과 비교했을 때, 더 완만한 하이퍼파라미터 설정(예: 더 큰 배치 크기, 더 낮은 학습률, 배치 정규화(batch normalization)를 레이어 정규화(layer normalization)로 대체)을 적용하면 성능이 1.0% 감소하는 것을 확인하였다. 특히 배치 정규화를 레이어 정규화로 교체하면 성능이 저하되지만, 이는 소비자급 하드웨어에서 학습을 가능하게 하기 위해 필요한 선택이다. 반면, LW-DETR의 CAEv2 백본을 DINOv2로 교체하면 성능이 2% 향상된다. 특히 낮은 학습률은 DINOv2의 사전 학습된 지식을 보존하는 데 도움이 되며, Objects-365 데이터셋에서의 추가적인 사전 학습 에폭은 느린 최적화를 보완한다. 최종적으로, 가중치 공유 NAS를 적용한 우리의 모델은 지연시간 증가 없이 LW-DETR 대비 2%의 성능 향상을 달성한다.
표 5: 신경 아키텍처 탐색(NAS)에 대한 소거 실험(Ablation)
아래에서는 각 “조절 가능한 요소(tunable knob)”가 정확도와 지연시간에 미치는 영향을 분석한다. LW-DETR 대비 더 완만한 하이퍼파라미터 설정(예: 더 작은 배치 크기, 더 낮은 학습률, 배치 정규화(batch normalization)를 레이어 정규화(layer normalization)로 대체)을 사용하면 성능이 약 1% 감소한다. 그러나 LW-DETR의 CAEv2 백본을 DINOv2로 교체함으로써 이 성능 손실을 회복할 수 있다. 중요한 점은, 낮은 학습률과 레이어 정규화가 DINOv2의 파운데이션 지식(foundational knowledge)을 더 잘 보존하도록 도와주며, 더 큰 배치 크기로 학습할 수 있게 해 가중치 공유 NAS의 효과를 극대화한다는 것이다. 직관에 반하게도, NAS 탐색 공간에 패치 크기 14가 포함되어 있지 않음에도 불구하고, 학습 과정에 가중치 공유 NAS를 도입하면 기본 구성(base configuration)의 성능이 오히려 향상된다.

백본 아키텍처와 사전 학습의 영향 (Impact of Backbone Architecture and Pre-Training)
우리는 RF-DETR에서 서로 다른 백본 아키텍처가 성능에 미치는 영향을 분석한다. 그 결과, DINOv2가 가장 우수한 성능을 보였으며, CAEv2 대비 약 2% 높은 성능을 달성하였다. 흥미롭게도, SigLIPv2보다 파라미터 수가 적음에도 불구하고 SAM2의 Hiera-S 백본은 상당히 느린 것으로 나타났다. 이는 Hiera-S가 유사한 성능의 ViT 대비 의미 있게 더 빠르다고 주장한 내용과는 상반되는 결과이다. 그러나 Hiera는 TensorRT와 같이 컴파일러 수준에서 고도로 최적화된 Flash Attention과 같은 커널 환경에서의 지연시간(latency)을 충분히 탐구하지 않았다. 또한, 기존의 파운데이션 모델 패밀리들은 ViT-S나 ViT-T와 같은 경량 ViT 변형을 일반적으로 공개하지 않기 때문에, 이러한 모델들을 실시간 응용(real-time application)에 재활용하기가 어렵다는 한계가 있다.
표 6: 백본에 대한 소거 실험 (Ablation on Backbone)
아래에서는 RF-DETR에서 서로 다른 백본 아키텍처를 사용했을 때의 영향을 분석한다. 실험 결과, DINOv2가 가장 높은 성능을 보였으며, CAEv2 대비 2.4% 성능 향상을 달성하였다. 모든 모델은 Objects365 데이터셋으로 60 에폭 사전 학습되었으며, ‘완만한 하이퍼파라미터(Gentler Hyperparameters)’ 설정을 사용하였다. 한편, SAM2와 SigLIPv2는 FP16 환경에서 평가할 경우 성능이 크게 저하되는 문제가 있다. 따라서 이 두 모델에 대해서는, FP16에 최적화되었을 경우 달성 가능한 성능의 상한(upper bound)으로서 FP16 TensorRT 지연시간과 FP32 ONNX 정확도를 함께 보고한다.

* FP16 최적화가 충분히 이루어지지 않은 모델
표준 정확도 벤치마킹 관행에 대한 재고 (Rethinking Standard Accuracy Benchmarking Practices)
기존 연구를 따르며, 우리는 모든 COCO 결과를 검증 세트(validation set)에서 보고한다. 그러나 모델 선택과 평가를 모두 검증 세트에만 의존할 경우 과적합(overfitting)의 위험이 있다. 예를 들어, RT-DETR을 기반으로 한 D-FINE은 COCO 검증 세트에서 광범위한 하이퍼파라미터 탐색을 수행한 뒤 가장 성능이 좋은 모델을 보고한다. 하지만 이 설정을 RF100-VL에서 평가해 보면, 테스트 세트 기준에서는 D-FINE이 RT-DETR보다 성능이 낮게 나타난다. 반면, 우리의 방법은 RF100-VL과 COCO 모두에서 실시간 탐지기 중 최고 수준의 성능을 달성하여, 가중치 공유 NAS의 강건성을 입증한다. COCO 평가에 더해, 향후 탐지 모델들은 RF100-VL과 같이 검증 세트와 테스트 세트가 공개된 데이터셋에서도 평가를 수행할 것을 권장한다.
한계점 (Limitations)
추론 과정에서 전력 스로틀링과 GPU 과열을 제어했음에도 불구하고, TensorRT 컴파일 과정의 비결정성(non-deterministic behavior)으로 인해 지연시간 측정에는 최대 0.1ms 수준의 분산이 여전히 존재한다. 구체적으로, TensorRT는 컴파일 과정에서 전력 스로틀링을 유발할 수 있으며, 이는 생성되는 엔진(engine)에 영향을 주어 지연시간의 무작위 변동을 초래한다. 특정 TensorRT 엔진에 대한 측정값은 일반적으로 일관되지만, 동일한 ONNX 아티팩트를 다시 컴파일할 경우 서로 다른 지연시간 결과가 나올 수 있다. 이러한 이유로, 우리는 지연시간을 소수점 이하 한 자리까지만 보고한다.
5. 결론 (Conclusion)
본 논문에서는 타깃 데이터셋과 하드웨어 플랫폼에 맞추어 전문가(specialist)형 엔드투엔드 객체 탐지기를 파인튜닝하기 위한, 최신 NAS 기반 방법인 RF-DETR을 제안하였다. 제안한 접근법은 COCO와 RF100-VL에서 기존의 실시간(state-of-the-art) 방법들을 능가하며, 특히 COCO에서 D-FINE (nano) 대비 5% AP 향상을 달성하였다.
또한, 현재 널리 사용되는 아키텍처, 학습률 스케줄러, 데이터 증강 스케줄러들이 COCO 성능 극대화에 과도하게 맞추어 설계되어 있음을 지적하며, 이러한 암묵적 과적합을 방지하기 위해 커뮤니티가 보다 다양하고 대규모의 데이터셋에서 모델을 벤치마킹해야 함을 제안한다.
마지막으로, 전력 스로틀링으로 인해 지연시간(latency) 벤치마킹에 큰 분산이 발생한다는 점을 강조하고, 재현성을 향상시키기 위한 표준화된 평가 프로토콜을 제안한다.
부록 A. 구현 세부 사항 (Implementation Details)
학습 하이퍼파라미터 (Training Hyperparameters)
RF-DETR은 신경 아키텍처 탐색(NAS)을 위해 LW-DETR (chen2024lw)을 확장한 모델이다. 아래에서는 학습 절차에서의 주요 차이점을 정리한다. 먼저, 탐지 헤드와 분할 헤드를 동일한 데이터로 사전 학습할 수 있도록, Objects365 (objects365)에 대해 SAM2 (ravi2024sam2)를 사용해 의사 라벨(pseudo-label)을 생성하였다. 학습률은 1e-4를 사용하며(LW-DETR은 4e-4 사용), 배치 크기는 128로 설정하였다(LW-DETR과 동일).
DINOv3 (simeoni2025dinov3)와 유사하게, EMA가 제대로 동작하기 위해 EMA 스케줄러를 사용한다. 다만 DINOv3와 달리, 학습률 워밍업(learning-rate warm-up)은 적용하지 않는다. 모든 그래디언트 중 0.1을 초과하는 값은 클리핑하며, DINOv2 백본의 정보(특히 초기 레이어)를 보존하기 위해 레이어별 곱셈 감쇠(per-layer multiplicative decay) 0.8을 적용한다.
윈도우 어텐션 블록은 레이어 {0, 1, 3, 4, 6, 7, 9, 10} 사이에 배치하며, LW-DETR은 {0, 1, 3, 6, 7, 9}에 배치한다. 두 방법 모두 윈도우 수는 동일하지만, 연속된 윈도우 블록은 추가적인 리쉐이프 연산이 필요 없기 때문에 우리의 구현이 약간 더 효율적이다. 또한, 기본 스케일을 기준으로 증강이 대칭이 되도록, LW-DETR(0.7~1.4 스케일)보다 더 넓은 멀티스케일 해상도 범위(0.5~1.5 스케일)로 학습한다. 특히, 우리는 해상도를 NAS 탐색 공간의 “조절 가능한 요소(tunable knob)”로 추가한 반면, LW-DETR은 이를 데이터 증강의 한 형태로만 사용한다. 모델 학습 및 추론 코드는 GitHub에 공개되어 있다.
지연시간 평가 (Latency Evaluation)
모델 간 공정한 비교를 위해, 동일한 모델 아티팩트를 사용하여 탐지 정확도와 지연시간을 함께 측정한다. 또한 추론 과정을 더욱 표준화하기 위해 TensorRT에서 CUDA 그래프(CUDA graphs)를 사용한다. CUDA 그래프는 실행 중 CPU가 커널을 순차적으로 실행하는 대신, 모든 커널을 미리 큐잉(pre-queue)하여 일부 네트워크에서 속도 향상을 제공한다. 우리는 RT-DETR, LW-DETR, RF-DETR이 이러한 최적화의 이점을 얻는 것을 확인하였다. 더 나아가, CUDA 그래프를 사용하면 LW-DETR의 속도가 향상되지만 D-FINE에는 큰 이점이 없기 때문에, 결과적으로 LW-DETR은 D-FINE과 동일한 지연시간–정확도 곡선 상에 위치하게 된다. 우리는 독립적인 지연시간 벤치마킹 도구를 GitHub에 공개한다.
COCO에서의 파레토 최적 모델 구성 (Pareto-Optimal Model Configurations on COCO)
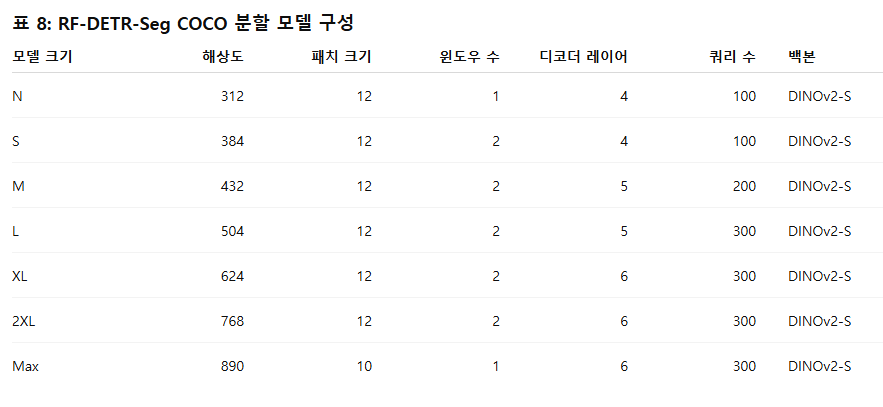
표 7과 표 8에는 COCO에서의 파레토 최적 RF-DETR 및 RF-DETR-Seg 구성들을 제시한다. RF-DETR의 파레토 최적 아키텍처에 대한 주요 경향은 부록 H에서 추가로 논의한다.

부록 B. 쿼리 토큰과 디코더 레이어에 대한 소거 실험
(Ablation on Query Tokens and Decoder Layers)

그림 4: 디코더 레이어 수와 쿼리 토큰 수의 영향.
RF-DETR (nano)에서 추론 시 쿼리 제거(query dropping)를 통해 정확도와 지연시간 간의 트레이드오프를 평가한다. 흥미롭게도, 신뢰도가 가장 낮은 100개의 쿼리를 제거해도 성능은 크게 감소하지 않으면서, 모든 디코더 레이어 설정에서 지연시간은 소폭 개선됨을 확인하였다.
우리는 실시간 DETR 기반 객체 탐지기의 표준 관행을 따라 RF-DETR (nano)를 300개의 객체 쿼리로 학습한다. 그러나 많은 데이터셋에서는 이미지당 객체 수가 300개보다 훨씬 적다. 따라서 300개 쿼리를 모두 처리하는 것은 계산적으로 낭비가 될 수 있다. LW-DETR (tiny)는 더 적은 수의 쿼리로 학습할 경우 지연시간–정확도 트레이드오프가 개선될 수 있음을 보여준다.
우리는 최적의 쿼리 수를 사전에(apriori) 결정하는 대신, 재학습 없이 테스트 시점에서 쿼리를 제거할 수 있음을 발견하였다. 구체적으로, 인코더 출력에서 각 토큰의 신뢰도를 기준으로 정렬한 뒤 신뢰도가 가장 낮은 쿼리들을 버리는 방식이다. 그림 4에서 보이듯, 이 방법은 의미 있는 지연시간–정확도 트레이드오프를 제공한다.
또한 기존 연구(zhao2024rtdetr)는 학습 시 각 디코더 레이어가 독립적으로 감독(supervision)되기 때문에, 테스트 시점에서 디코더 레이어를 제거(prune)할 수 있음을 보였다. 우리는 나아가 모든 디코더 레이어를 제거하고, 2단계 DETR 파이프라인에서 생성된 초기 쿼리 제안(initial query proposals)에만 의존하는 것도 가능함을 확인하였다. 이 경우 인코더 상태에 대한 크로스 어텐션이나 쿼리 간 셀프 어텐션이 존재하지 않게 되어, 실행 시간이 크게 감소한다.
이렇게 얻어진 모델은 NMS가 없는 단일 단계(single-stage) YOLO 스타일 아키텍처와 유사한 형태를 띤다. 그림 4에서 보이듯, 마지막 디코더 레이어를 제거하면 지연시간은 약 10% 감소하는 반면, 성능 저하는 약 2 mAP에 그친다.
부록 C. FLOPs 벤치마킹 (Benchmarking FLOPs)
우리는 PyTorch의 FlopCounterMode를 사용하여 RF-DETR, GroundingDINO, YOLO-E의 FLOPs를 벤치마킹하였다. 그 결과, FlopCounterMode가 YOLOv11, D-FINE, LW-DETR에 대해 커스텀 벤치마킹 도구로 얻은 FLOPs 수치를 매우 근접하게 재현함을 확인하였다. 실제로는 CalFLOPs (calflops)보다도 더 신뢰할 수 있는 결과를 제공하는 것으로 나타났다.
특히 주목할 점은, LW-DETR의 FLOPs 수치가 기존에 보고된 값의 약 두 배에 해당한다는 것이다(cf. 표 9). 우리는 이러한 불일치가 LW-DETR이 FLOPs가 아니라 MACs(Multiply–Accumulate Operations)를 보고했기 때문일 가능성이 크다고 판단한다. 한편, YOLOv11, YOLOv8, D-FINE, RT-DETR에 대해서는 각 논문에서 공식적으로 보고된 FLOPs 수치를 그대로 사용한다.
표 9: FLOPs 벤치마킹 비교 (FLOPs Benchmarking Comparison)
아래 표에서는 커스텀 벤치마킹 도구, CalFLOPs, 그리고 PyTorch의 FlopCounterMode로 측정한 FLOPs를 비교한다. 특히 FlopCounterMode가 커스텀 벤치마킹 코드로 보고된 결과와 거의 일치함을 확인할 수 있으며, 이는 기존의 범용 벤치마킹 도구들보다 더 신뢰도가 높다는 점을 시사한다.

좋은 질문이야. 여기서 헷갈리는 포인트를 정확히 짚었고, 결론부터 말하면:
네, 맞다.
이 차이는 “1 batch에서 실제 수행되는 연산 정의 자체가 다르기 때문에” 발생한다.
특히 MACs와 FLOPs를 어떻게 정의·계산하느냐의 차이에서 온다.
아래에서 개념 → 왜 LW-DETR에서 특히 크게 벌어졌는지 → 왜 FlopCounterMode가 더 믿을 만한지 순서로 정리할게.
1️⃣ MACs vs FLOPs: 정의부터 정확히
(1) MACs (Multiply–Accumulate Operations)
보통 논문에서 말하는 MAC은:
그런데 문제는:
- 어떤 논문은
👉 1 MAC = 1 연산으로 카운트 - 어떤 논문은
👉 1 MAC = 2 FLOPs로 환산
👉 정의가 통일되어 있지 않다
(2) FLOPs (Floating Point Operations)
FLOPs는 보통:
- 곱셈 1회 = 1 FLOP
- 덧셈 1회 = 1 FLOP
- 활성화, 정규화, attention softmax 등도 포함 가능
즉:
👉 정의가 더 포괄적이고 구현 친화적
2️⃣ 왜 LW-DETR에서 차이가 특히 크게 났나?
논문에서 말한 핵심 문장 다시 보면:
“LW-DETR’s FLOPs count is roughly twice that of the originally reported result.”
이건 우연이 아님.
🔥 LW-DETR에서 차이가 커진 이유 3가지
(1) LW-DETR은 MACs 기준 보고
- paper에서는:
- Conv / Linear 중심
- attention 내부 연산 일부 제외
- MACs 기준으로 보고
👉 그래서 숫자가 작게 나옴
(2) FlopCounterMode는 실제 forward 기준
PyTorch FlopCounterMode는:
- 실제 forward()를 트레이스
- 실행된 연산을 기준으로 FLOPs 계산
- 포함하는 것:
- QKV projection
- attention score matmul
- softmax
- value aggregation
- FFN
- layer norm
- reshape / transpose에 따른 연산
👉 DETR 계열에 불리한 방식 (하지만 현실적)
(3) DETR는 “Conv 위주 모델”이 아님
YOLO:
- Conv 중심
- MACs ≈ FLOPs × (상수)
DETR / LW-DETR:
- Attention 중심
- MACs 기준으로 계산하면:
- softmax, scaling, normalization 누락
- cross-attention 비용 과소평가
👉 그래서:
3️⃣ “1 batch라서 그런가?”에 대한 정확한 답
질문 다시 보면:
“1batch에 대해서 MAC이랑 Flopcounter랑 연산방식이 달라서 나오는 부분인가?”
정확한 답은 이거야 👇
✅ 부분적으로 YES, 핵심은 “batch”가 아니라 “연산 정의”
- batch size = 1이든 N이든
- 차이의 본질은:
- 무엇을 연산으로 인정하느냐
- attention 내부 연산을 포함하느냐
즉:
❌ batch 때문은 아님
✅ 연산 카운트 기준 차이 + attention 연산 포함 여부 때문
4️⃣ 왜 FlopCounterMode가 더 “정직한가”
논문에서 이렇게 말하는 이유가 있음:
“FlopCounterMode closely matches custom benchmarking code”
이유는:
- 커스텀 코드들도 보통:
- 실제 forward 연산 기준
- attention 내부 연산 포함
- CalFLOPs 같은 툴은:
- Conv 위주 heuristic
- Transformer에 부정확
👉 그래서 FlopCounterMode가 실제 latency와 상관관계가 더 높음
5️⃣ 그래서 이 논문의 주장, 타당한가?
✔ 기술적으로 매우 타당
- LW-DETR이 거짓말했다 ❌
- 서로 다른 기준을 쓴 것뿐
- 하지만:
- DETR 계열에서 MACs 보고는 과소평가를 유발
- 실시간 비교엔 부적합
그래서 RF-DETR이 말하는 핵심 메시지는 이거야:
“이제는 FLOPs도, latency도
실제 실행 기준으로 통일하자.”
6️⃣ 한 문장으로 정리
LW-DETR의 FLOPs가 두 배로 튀는 이유는
batch 때문이 아니라,
MACs 기반 보고와 실제 forward 기준 FLOPs 계산의 정의 차이 때문이다.
특히 attention 연산을 얼마나 포함하느냐가 결정적이다.
부록 D. 오픈 보캐블러리 탐지기에서 클래스 이름의 영향
(Impact of Class-Names on Open-Vocabulary Detectors)
표 10에서는 RF100-VL에서 GroundingDINO와 같은 오픈 보캐블러리 탐지기를 클래스 이름과 함께 파인튜닝했을 때의 영향을 평가한다. 직관적으로 보면, GroundingDINO의 비전–언어 사전 학습은 클래스 인덱스(예: 0, 1, 2) 대신 클래스 이름(예: car, truck, bus)을 프롬프트로 사용할 때 더 유용할 것으로 기대된다. 파인튜닝 단계에서 클래스 이름을 사용하면, 비전–언어 모델(VLM)은 비(非) VLM 탐지기에서는 이용할 수 없는 추가적인 의미 정보를 데이터에 대해 얻게 되며, 이는 다운스트림 성능 향상으로 이어질 가능성이 있다.
그러나 실험 결과, RF100-VL에서 GroundingDINO를 파인튜닝했을 때 두 경우의 성능은 거의 동일하게 나타났다. 이는 엔드투엔드 방식으로 모델을 단순히 파인튜닝하는 것이 오픈 보캐블러리 사전 학습의 이점을 상당 부분 상쇄시킨다는 점을 시사한다. 향후 연구에서는 파운데이션 사전 학습의 효과를 보존하면서 VLM을 효과적으로 파인튜닝하는 방법을 탐구할 필요가 있다.
표 10: 클래스 이름 사용의 영향 평가 (Evaluating the Impact of Class Names)
아래 표에서는 GroundingDINO와 같은 VLM을 파인튜닝할 때 클래스 이름을 사용하는 것의 효과를 평가한다. 실험 결과, 클래스 이름을 사용하는 것이 클래스 인덱스를 프롬프트로 사용하는 것에 비해 유의미한 이점을 제공하지 못함을 확인하였다. 이는 파인튜닝 과정에서 인터넷 규모 사전 학습의 영향이 약화되었음을 시사한다.

부록 E. 대형 모델 변형에 대한 벤치마킹
(Benchmarking Larger Model Variants)
LW-DETR (chen2024lw)나 D-FINE (peng2024dfine)과 같은 탐지기들은 모델 패밀리를 확장하기 위해 대형 변형을 수작업으로 설계한다. 반면, RF-DETR과 같은 NAS 기반 아키텍처는 그리드 기반 탐색을 통해 스케일링 전략을 자동으로 발견한다. 우리는 서로 다른 스케일링 전략에서 파생된 두 가지 RF-DETR 모델 패밀리를 분석한다. 하나는 DINOv2-S 백본을 기반으로 한 패밀리이고, 다른 하나는 DINOv2-B 백본을 기반으로 한 패밀리이다. 각 패밀리의 스케일링 성능을 평가하기 위해, NAS로 생성된 파레토 곡선을 D-FINE의 파레토 곡선과 비교한다. 구체적으로, 각 D-FINE 크기에서 유사한 지연시간(latency)을 유지하면서 최대 성능을 달성하는 RF-DETR 변형을 선택한다. 예를 들어 D-FINE (small)과 비교할 때는, D-FINE (small)의 지연시간을 초과하지 않으면서 가장 높은 정확도를 제공하는 RF-DETR 모델을 선택한다.
표 11에서 보이듯, DINOv2-S 백본 패밀리는 초기에는 mAP@50:95 기준으로 D-FINE을 능가하지만, 모델 크기가 커질수록 이러한 이점을 유지하지 못한다. 이는 해당 패밀리의 스케일링 전략이 D-FINE의 수작업 설계만큼 효과적이지 않음을 시사한다. 반면, DINOv2-B 백본 패밀리는 정반대의 경향을 보이는데, 지연시간이 증가할수록 D-FINE과 RF-DETR 간의 성능 격차가 점차 줄어든다. 이는 더 높은 지연시간 영역에서는 DINOv2-B 기반 RF-DETR 모델들이 D-FINE을 능가할 가능성이 있음을 의미하며, 실제로 RF-DETR (2x-large)는 mAP@50:95에서 D-FINE을 상회한다.
중요한 점은, D-FINE 모델 패밀리를 확장하려면 상당한 추가 엔지니어링 노력이 필요한 반면, RF-DETR 모델 패밀리는 동일한 NAS 탐색 공간에서 재학습 없이 더 높은 지연시간 변형을 간단히 샘플링함으로써 확장이 가능하다는 것이다. 우리는 대형 변형들에 대한 COCO 및 RF100-VL 결과를 표 12, 13, 14에 제시한다. 또한, 지연시간 100ms 미만에서의 최대 성능을 보여주기 위해 각 데이터셋에 대해 RF-DETR Max 변형도 포함하였는데, 이는 다른 모델 패밀리들이 도달하지 못한 스케일이다.
표 11: 유사한 지연시간에서 RF-DETR과 D-FINE의 mAP@50:95 격차
(mAP@50:95 Gap of RF-DETR vs D-FINE at Similar Latencies)
서로 다른 RF-DETR 모델 패밀리가 D-FINE에 비해 어떻게 스케일링되는지를 비교한다. D-FINE (nano)는 Objects-365로 사전 학습되지 않았기 때문에 유사한 스케일링 경향을 따르지 않을 것으로 예상되어 비교에서 제외하였다. 각 RF-DETR 백본에 대해, 대응되는 D-FINE 변형의 지연시간까지 허용하는 범위 내에서 가장 높은 정확도를 보이는 파레토 최적 NAS 모델을 선택하였다. 특히, RF-DETR (DINOv2-B)는 RF-DETR (DINOv2-S)와 D-FINE보다 더 우수한 확장성을 보인다. 참고로, COCO에 대한 모든 RF-DETR 모델은 파인튜닝되지 않은 상태이다.

표 12: 대형 모델 변형에 대한 COCO 탐지 평가
(COCO Detection Evaluation for Larger Model Variants)
아래에서는 COCO에서 RF-DETR의 L, XL, 2XL 크기 모델 성능을 제시한다. 주목할 점은 D-FINE (x-large)가 mAP@50:95 기준으로 RF-DETR (x-large)를 상회한다는 것이다. 그러나 RF-DETR (2x-large)는 D-FINE을 0.8 AP 차이로 능가하며, COCO에서 60 AP를 돌파한 최초의 실시간 탐지기이다.

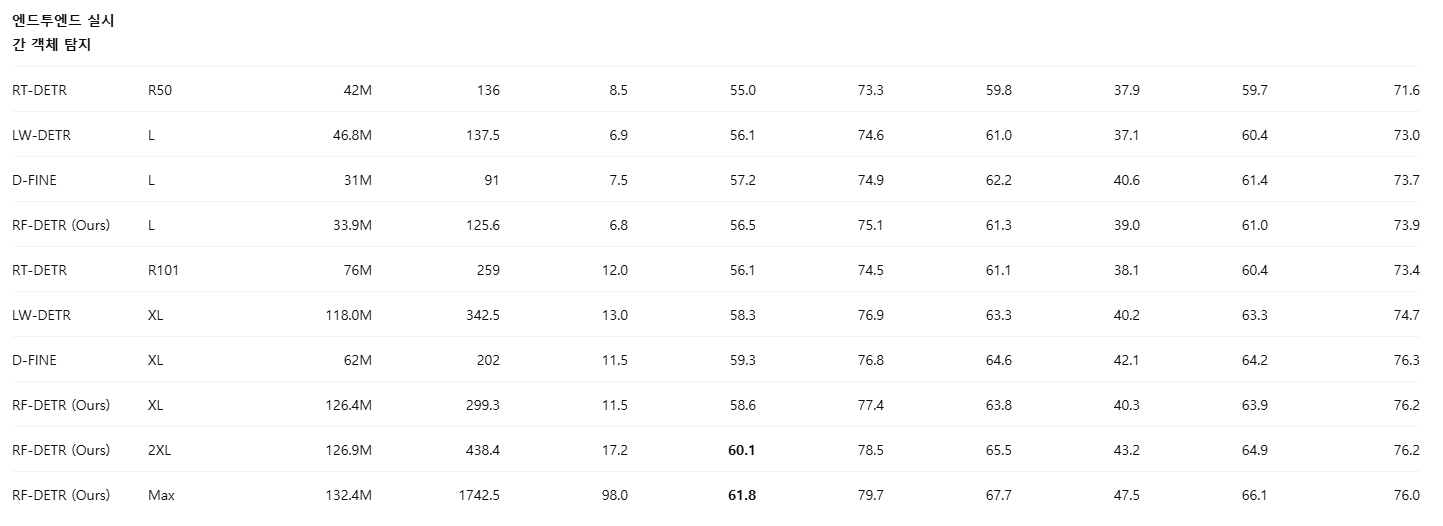
표 13: 대형 모델 변형에 대한 COCO 분할 평가
(COCO Segmentation Evaluation for Larger Model Variants)
아래에서는 COCO 인스턴스 분할 벤치마크에서 RF-DETR의 L, XL, 2XL 크기 성능을 제시한다. RF-DETR은 스케일을 키울수록 유의미한 성능 향상을 보인다. 반면, YOLOv8과 YOLOv11은 스케일 확대로 인한 성능 개선이 제한적이다.

표 14: 대형 모델 변형에 대한 RF100-VL 탐지 평가
(RF100-VL Detection Evaluation for Larger Model Variants)
아래에서는 RF100-VL에서 RF-DETR의 L, XL, 2XL 크기 성능을 제시한다. 특히 RF-DETR (x-large)는 D-FINE 대비 0.5 AP 높은 성능을 보이며, RF-DETR (x-large)를 파인튜닝하면 추가로 0.4 AP의 성능 향상이 관찰된다.

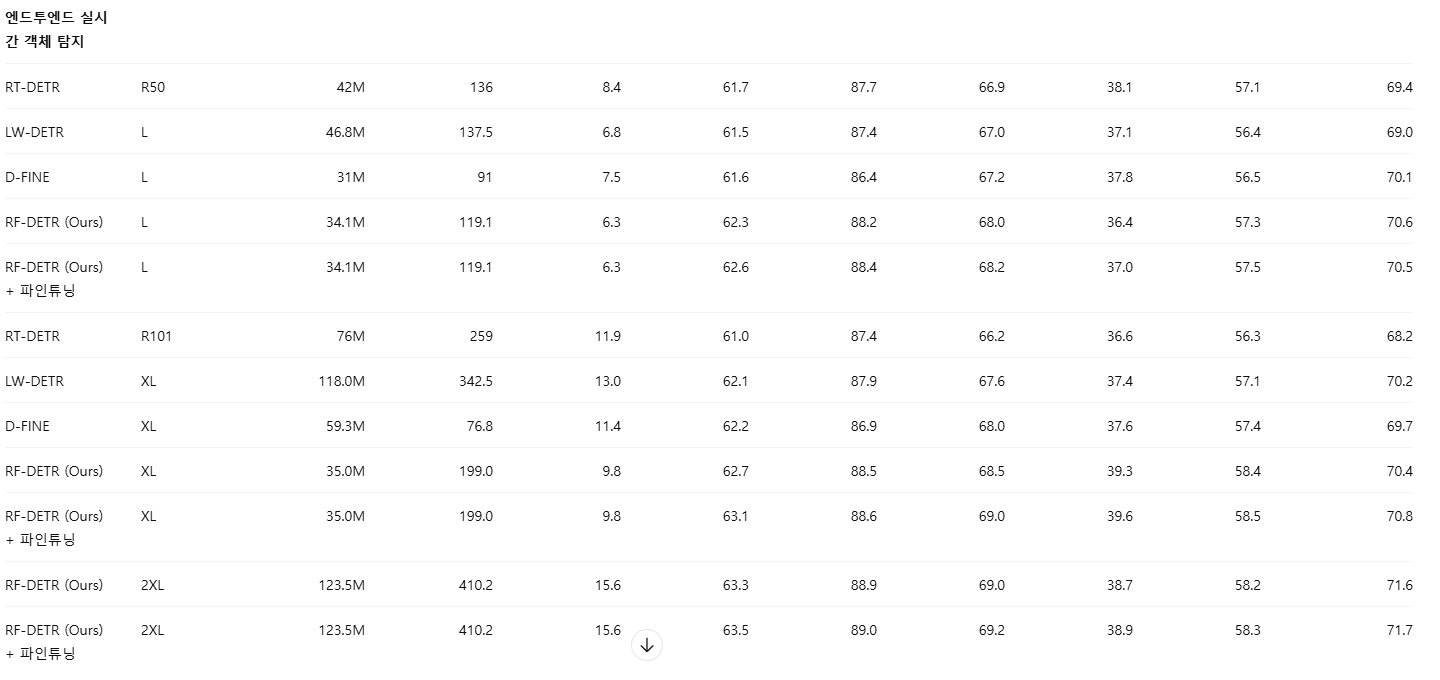
Appendix F: COCO에서 NAS 이후 파인튜닝의 영향
(Impact on NAS Fine-Tuning on COCO)
우리는 NAS 이후의 파인튜닝이 COCO에서는 제한적인 이득만 제공한다는 것을 확인하였다. 이는 NAS의 “아키텍처 증강(architecture augmentation)”이 강력한 정규화 역할을 수행하며, 이 정규화 없이 추가 학습을 진행하면 오히려 성능이 저하될 수 있기 때문이라고 본다. 구체적으로, 강한 정규화 하에서 사전학습된 모델에 대해 파인튜닝 단계에서 해당 정규화를 제거하면 과적합(overfitting)이 발생하기 쉽다. 표 15와 표 16에서 보이듯이, 이러한 경향은 객체 탐지와 인스턴스 분할 모두에서 일관되게 관찰된다.
흥미롭게도, RF100-VL에서 학습된 모델들은 파인튜닝의 이점을 더 크게 얻는데, 이는 해당 데이터셋에서 수렴에 100 에폭 이상이 필요하기 때문으로 보인다. 이러한 경우에는 학습 중 NAS 구성(configuration)의 총 개수를 줄이거나, 혹은 가중치 공유 NAS를 유지한 채 100 에폭 이상 학습하는 것이 성능 향상에 도움이 될 수 있다고 판단한다.
표 15: COCO 탐지 파인튜닝 평가
(COCO Detection Fine-Tuning Evaluation)
NAS 이후 파인튜닝은 COCO 탐지에서, 특히 대형 모델 크기일수록 성능 향상이 제한적임을 확인하였다.

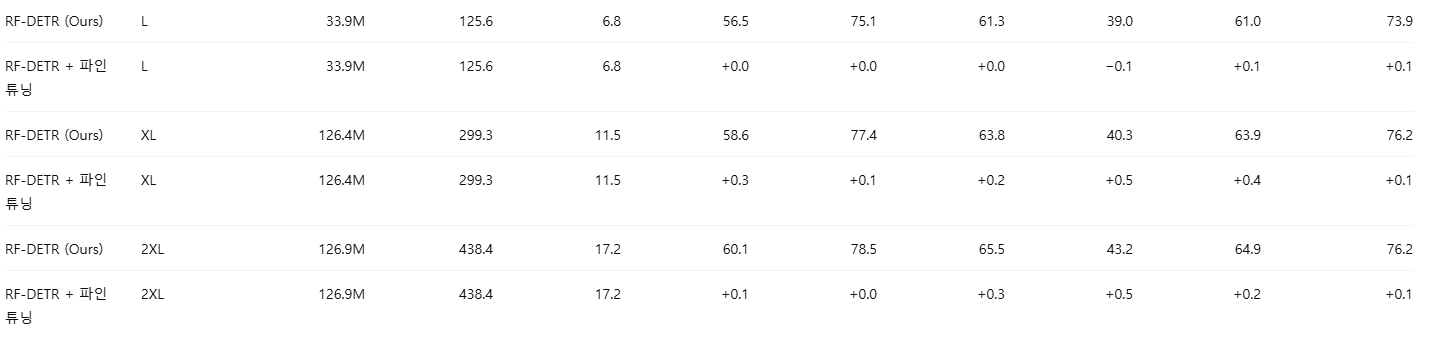
표 16: COCO 분할 파인튜닝 평가
(COCO Segmentation Fine-Tuning Evaluation)
NAS 이후 파인튜닝은 COCO 인스턴스 분할에서도, 특히 대형 모델에서 성능 개선이 거의 나타나지 않았다.
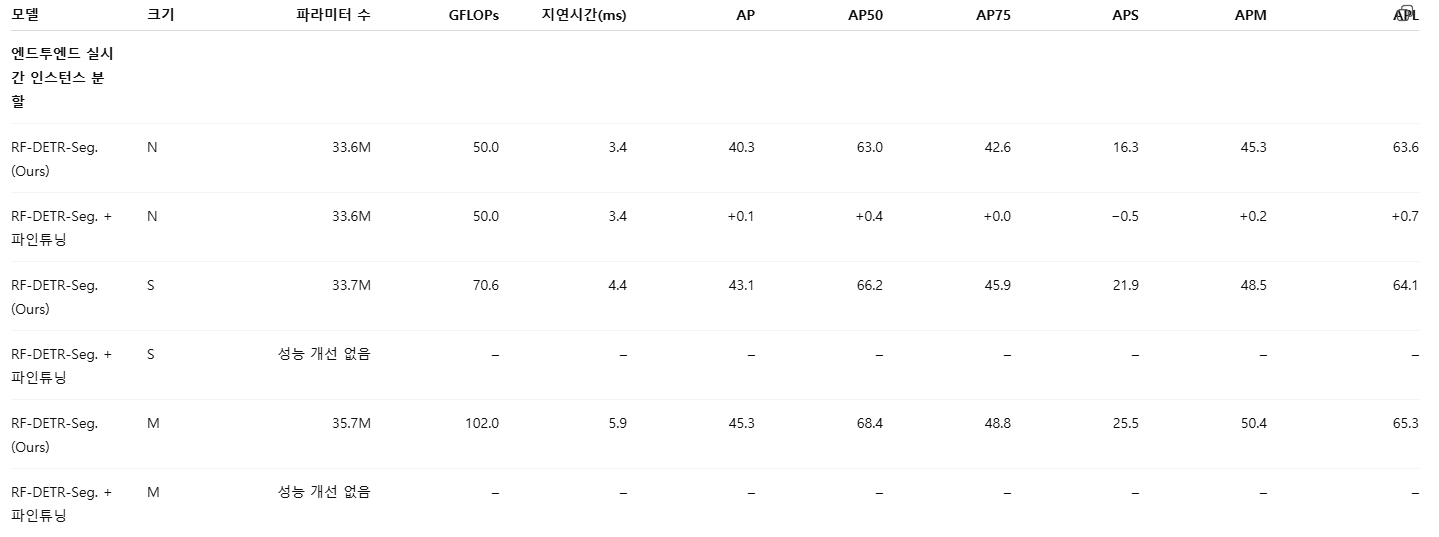

부록 G. RF100-VL에서 고정 아키텍처의 영향
(Impact of Fixed Architecture on RF100-VL)
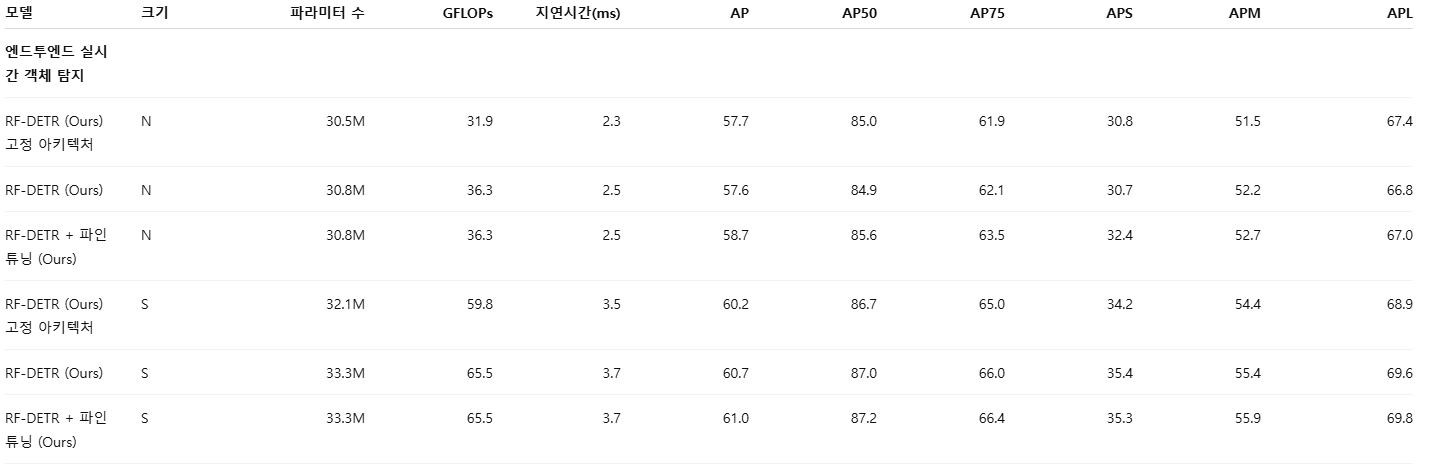
표 17에서는 COCO에 최적화된 NAS 아키텍처를 RF100-VL로 전이했을 때의 영향을 평가한다. 그 결과, 추가적인 데이터셋별 NAS 없이도 이러한 고정 아키텍처 모델들이 매우 우수한 성능을 보임을 확인하였다. 특히 고정 아키텍처를 사용하는 RF-DETR (large) 모델은 COCO 기준에서 기존의 모든 실시간 모델들 가운데 최고 성능을 달성한다. 다만, 데이터셋별 NAS를 적용하면 추가적인 성능 향상이 크게 발생한다. 주목할 점은, N, S, M 스케일 모델에서 LW-DETR → 고정 아키텍처로의 개선 폭이 고정 아키텍처 → 타깃 데이터셋에 최적화된 NAS 모델로의 개선 폭과 유사하다는 것이다.

그림 5: RF100-VL에서 고정 아키텍처의 소거 실험(Ablation)
COCO에 최적화된 RF-DETR 아키텍처를 RF100-VL로 전이하여 데이터셋별 NAS의 이점을 평가한다. 고정 아키텍처는 RF100-VL에 맞게 튜닝되지 않았음에도 불구하고 LW-DETR을 능가한다. RF100-VL에서 NAS를 직접 수행하면 고정 아키텍처 대비 성능이 추가로 향상된다. 또한 추가 파인튜닝은 모든 모델 크기에서 일관된 성능 개선을 제공하며, 특히 소형 모델에서 향상이 두드러진다. 이는 COCO 객체 탐지에서의 관찰 결과와 일치한다.
표 17: RF100-VL 고정 아키텍처 평가
(RF100-VL Fixed Architecture Evaluation)
COCO에 최적화된 아키텍처를 RF100-VL로 전이했을 때의 성능을 평가한다. 고정 아키텍처 모델은 데이터셋별 NAS 없이도 강력한 성능을 보이며, 특히 RF-DETR (large)는 기존 실시간 모델들 가운데 최고 성능을 달성한다. 그러나 데이터셋별 NAS는 추가적인 큰 성능 향상을 제공한다.


부록 H. 주목할 만한 발견된 아키텍처에 대한 논의
(Discussion on Notable Discovered Architectures)
파레토 최적 모델 패밀리를 정의할 때 모든 “튜닝 가능한(tunable)” 노브가 실제로 사용되었으며, 이는 우리가 설정한 탐색 공간(search space)의 선택이 타당했음을 보여준다. 이는 탐색 공간을 추가로 확장할 경우, 다운스트림 성능이 더 향상될 가능성도 있음을 시사한다.
파레토 최적 모델들은 대체로 동일한 패치 크기(patch size)를 사용하는 경향이 있으며, 예외는 지연시간 100ms 미만에서 최고 정확도를 목표로 선택된 Max 변형들이다. 예를 들어, DINOv2-S 백본을 사용하는 RF-DETR의 최적 패치 크기는 16으로 수렴하는 반면, DINOv2-B 백본은 20으로 수렴한다. DINOv2-S 백본을 사용하는 RF-DETR-Seg의 최적 패치 크기는 12이다. 모든 파레토 최적 모델 패밀리는 인코더와 디코더의 연산량을 동시에 스케일링한다. 패치 크기, 윈도우 수, 해상도는 인코더에 영향을 미치며, 디코더 레이어 수와 쿼리 수는 디코더에 영향을 준다. RF-DETR-Seg의 경우, 해상도 스케일링은 분할 헤드(segmentation head)에도 영향을 준다.
우리는 인코더에서 윈도우 수 2개가 일반적으로 최적이며, 동일 패밀리 내에서 지연시간이 증가함에 따라 해상도가 함께 증가하는 경향을 발견하였다. 디코더 측면에서 보면, COCO 기준 객체 탐지 모델은 쿼리 수를 고정한 채 디코더 레이어 수만 증가시키는 반면, 분할 모델은 쿼리 수와 디코더 레이어 수를 동시에 스케일링한다. 이는 분할 헤드의 깊이가 디코더 레이어 수에 종속되어 있으며, 의미 있는 마스크를 생성하기 위해 필요한 최소 레이어 수가 존재하기 때문일 수 있다. 따라서 가장 낮은 지연시간 모델조차도 그 최소 레이어 수를 유지한다. 추가된 디코더 레이어로 인한 지연시간 증가를 보상하기 위해, 분할 모델은 작은 모델 크기에서 쿼리 수를 줄여 디코더의 폭(width)을 감소시키는 방식으로 지연시간을 낮춘다. 결과적으로, COCO에서 객체 탐지 모델은 넓고 얕은(wide & shallow) 디코더를 선호하는 반면, 분할 모델은 얇고 깊은(thin & deep) 디코더를 선호한다.
우리는 RF-DETR의 성능이 해상도나 패치 크기 자체보다는, 공간 위치의 개수(예: 해상도 ÷ 패치 크기)에 더 크게 의존함을 발견하였다. 패치 크기를 고정한 채 해상도를 스케일링하는 것과, 해상도를 고정한 채 패치 크기를 스케일링하는 것은 유사한 결과를 보이는데, 이는 비전 트랜스포머가 패치화(patchify) 및 투영 이후에는 절대적인 입력 해상도에 비의존적이기 때문이다. 이를 검증하기 위해, 우리는 해상도를 640으로 고정하고 패치 크기를 조절하여 공간 위치 수를 유지하는 대체 모델 패밀리를 구성하였다. 구체적으로, RF-DETR (nano)는 패치 크기 27, RF-DETR (small)은 21, RF-DETR (medium)은 18을 사용했으며, 파레토 최적 패밀리와 거의 동일한 성능을 달성하였다. 특히 27과 18의 패치 크기는 학습 중 한 번도 보지 못한 값이었음에도 불구하고, 이는 RF-DETR이 새로운 패치 크기에 대해서도 강한 일반화 능력을 갖고 있음을 보여준다.
그러나 이러한 경향은 RF-DETR-Seg에는 그대로 적용되지 않는다. 분할 헤드의 특성 맵은 항상 입력 이미지 해상도의 1/4 스케일로 업샘플링되기 때문이다. 따라서 해상도를 스케일링하면 공간 위치 수뿐만 아니라 분할 헤드의 해상도 자체도 함께 변화한다. 예를 들어, RF-DETR-Seg (nano)는 해상도 312, 패치 크기 12를 사용하여 분할 헤드 해상도 78, 공간 위치 26을 갖는다. RF-DETR-Seg (small)은 해상도 384, 패치 크기 12로 분할 헤드 해상도 96, 공간 위치 32를 갖고, RF-DETR-Seg (medium)은 해상도 432, 패치 크기 12로 분할 헤드 해상도 108, 공간 위치 36을 갖는다. 반면, 패치 크기만 스케일링하는 경우(예: 해상도 576에서 패치 크기 16)에는 공간 위치 수를 고정한 채 분할 헤드 해상도만 144로 증가시킬 수 있다. 이는 RF-DETR 객체 탐지에서 관찰된 것보다 패치 크기와 해상도 간의 상호작용이 더 미묘함을 의미한다. RF-DETR (medium)은 576/16 = 36개의 공간 위치를 사용하고, RF-DETR-Seg (medium)은 432/12 = 36개의 공간 위치를 사용하지만, 분할 헤드 해상도가 더 낮다. 이는 마스크 해상도가 추가로 묶여(tied) 있기 때문에, 동일한 공간 위치 수를 유지하더라도 파레토 최적 해상도가 달라질 수 있음을 보여준다.
데이터셋의 특성 또한 최적 아키텍처에 영향을 미친다. RF100-VL에서 NAS를 수행한 결과, 낮은 지연시간 모델일수록 COCO 대비 더 적은 쿼리 수를 사용하는 경향이 있음을 발견하였다. COCO 모델은 동일한 지연시간 구간에서 항상 300개의 쿼리를 사용하는 반면, RF100-VL 데이터셋은 이미지당 객체 수가 더 적은 경우가 많아, 모든 객체를 찾기 위해 필요한 쿼리 수 자체가 더 적기 때문이다. 각 쿼리는 기본적으로 하나의 객체를 담당한다.
대부분의 파레토 최적 RF-DETR 모델은 윈도우 수 2개에서 최고 성능을 보이는 반면, LW-DETR은 4개 윈도우에서 최고 성능을 보인다. 우리는 이 차이를 클래스 토큰을 처리하는 방식의 차이에서 비롯된 것으로 해석한다. LW-DETR의 CAEv2 백본은 클래스 토큰을 사용하지 않는 반면, RF-DETR의 DINOv2 백본은 클래스 토큰을 사전 학습의 핵심 요소로 활용한다. 윈도우 어텐션에서 클래스 토큰을 호환시키기 위해, 우리는 각 윈도우마다 클래스 토큰을 복제한다. 전역 어텐션에서는 윈도우별 클래스 토큰들이 서로 어텐션을 수행하고, 다른 모든 토큰들은 모든 클래스 토큰에 어텐션을 수행한다. 실제로 RF-DETR (nano), (small), (medium)은 모두 2개 윈도우를 사용하는데, 윈도우 수를 늘릴수록 클래스 토큰 복제로 인한 실행 시간 비효율이 커지기 때문이다. 그 결과, LW-DETR과 달리 RF-DETR은 4개 윈도우로 스케일링해도 이득을 보지 못한다.
DINOv2-B 기반 모델을 생성할 때, 우리는 ViT-S에서 ViT-B로의 스케일링 전략을 그대로 따라 모든 레이어의 폭(width)을 두 배로 증가시켰다. 이러한 단순한 스케일링만으로도, 우리가 정의한 NAS 변동 축을 탐색하도록 허용하면 충분히 강력하고 차별화된 성능을 얻을 수 있음을 확인하였다. 주목할 점은, LW-DETR의 대형 변형들과 달리, 우리는 백본에서 더 높은 해상도의 특성 맵을 사용하지 않았다는 것이다.
부록 I. 모델 예측 시각화
(Visualizing Model Predictions)
그림 6에서는 RF-DETR (nano)의 모델 예측 결과를 시각화하고, 유사한 탐지 및 분할 베이스라인들과 비교한다. 실험 결과, RF-DETR (nano)는 오탐(false positive)이 더 적은 예측을 수행하는 것으로 나타났다(예: 표지판(sign post)을 사람으로 잘못 인식하는 경우 감소). 마찬가지로 RF-DETR-Seg (nano)는 객체 경계를 보다 정확하게 분할하는 마스크를 예측한다.

그림 6: 모델 예측 시각화
왼쪽에서는 RF-DETR (nano)와 LW-DETR (tiny)의 객체 탐지 결과를 비교한다. 오른쪽에서는 RF-DETR-Seg (nano)와 YOLOv11 (nano)의 인스턴스 분할 마스크를 비교한다.