https://arxiv.org/abs/2406.03459
LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection
In this paper, we present a light-weight detection transformer, LW-DETR, which outperforms YOLOs for real-time object detection. The architecture is a simple stack of a ViT encoder, a projector, and a shallow DETR decoder. Our approach leverages recent adv
arxiv.org
LW-DETR: 실시간 객체 검출을 위한 YOLO 대체 Transformer
Qiang Chen
(동등 기여, † 교신저자)
Xiangbo Su, Xinyu Zhang, Jian Wang, Jiahui Chen, Yunpeng Shen,
Chuchu Han, Ziliang Chen, Weixiang Xu, Fanrong Li, Shan Zhang,
Kun Yao, Errui Ding, Gang Zhang, Jingdong Wang
초록 (Abstract)
본 논문에서는 실시간 객체 검출(real-time object detection)을 위해 YOLO 계열을 능가하는 경량 검출 트랜스포머 LW-DETR를 제안한다. 제안하는 아키텍처는 ViT 인코더(ViT encoder), 프로젝터(projector), 그리고 얕은(shallow) DETR 디코더로 구성된 단순한 스택 구조를 가진다.
본 접근법은 최근의 다양한 고급 기법들을 효과적으로 활용한다. 구체적으로는 개선된 손실 함수와 사전학습(pretraining)과 같은 학습 효율 향상 기법(training-effective techniques)을 적용하고, ViT 인코더의 연산 복잡도를 줄이기 위해 윈도우 기반(window) 어텐션과 글로벌 어텐션을 교차(interleaved)로 사용하는 구조를 도입한다.
또한 ViT 인코더에서 다중 수준(multi-level)의 feature map을 집계하고, 인코더 내부의 중간(feature maps at intermediate layers) 및 최종 feature map을 함께 결합함으로써 보다 풍부한 표현력을 갖는 feature map을 형성한다. 더 나아가, window-major 방식의 feature map 구성을 제안하여 interleaved attention 연산의 효율을 향상시킨다.
실험 결과, 제안한 방법은 COCO 및 기타 벤치마크 데이터셋에서 YOLO 및 그 변형 모델을 포함한 기존 실시간 객체 검출기들을 전반적으로 능가하는 성능을 보임을 확인하였다. 코드와 사전 학습된 모델은 다음 링크에서 공개되어 있다.
https://github.com/Atten4Vis/LW-DETR
GitHub - Atten4Vis/LW-DETR: This repository is an official implementation of the paper "LW-DETR: A Transformer Replacement to YO
This repository is an official implementation of the paper "LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection". - Atten4Vis/LW-DETR
github.com
키워드 (Keywords)
객체 검출(Object Detection), 실시간 검출(Real-Time Detection), 트랜스포머(Transformer)

그림 1 설명 (Figure 1)
제안하는 방법은 기존의 최신 실시간 객체 검출기(SoTA)를 능가하는 성능을 보인다. x축은 추론 시간(inference time)을, y축은 COCO val2017 기준 mAP 점수를 나타낸다. 모든 모델은 Objects365 데이터셋으로 사전학습(pretraining)된 상태에서 학습되었다. YOLO, RTMDet 등의 기존 모델에 대해서는 NMS 후처리 시간이 포함되어 있으며, 이는 공식 구현 설정을 기반으로 COCO val2017에서 측정되었다. 또한, 잘 튜닝된 NMS 후처리 설정을 적용한 경우는 “*”로 표시하였다.
2. 관련 연구 (Related Work)
실시간 객체 검출 (Real-time object detection)
실시간 객체 검출은 다양한 실제 응용 분야에서 폭넓게 활용되고 있다 [31, 18, 25, 30, 49].
YOLO-NAS [1], YOLOv8 [29], RTMDet [46]와 같은 최신(state-of-the-art) 실시간 객체 검출기들은 초기 YOLO [50]에 비해 크게 발전하였으며, 그 배경에는 검출 프레임워크의 개선 [56, 20], 아키텍처 설계 [2, 33, 32, 65, 16, 59], 데이터 증강 기법 [69, 2, 20], 학습 기법 [20, 29, 1], 그리고 손실 함수 설계 [38, 68, 73] 등이 있다.
이러한 기존 실시간 검출기들은 대부분 합성곱(convolution) 기반 구조에 의존한다. 반면, 본 논문에서는 아직 충분히 탐구되지 않은 트랜스포머 기반(transformer-based) 실시간 객체 검출 해법을 연구 대상으로 삼는다.
객체 검출을 위한 ViT (ViT for object detection)
Vision Transformer(ViT) [17, 66]는 이미지 분류 분야에서 뛰어난 성능을 보였다. ViT를 객체 검출에 적용할 경우, 메모리 사용량과 연산 비용을 줄이기 위해 일반적으로 윈도우 어텐션(window attention) [17, 43]이나 계층적(hierarchical) 아키텍처 [62, 43, 70, 21]가 활용된다.
UViT [8]는 점진적 윈도우 어텐션(progressive window attention)을 사용하며, ViTDet [36]는 사전 학습된 plain ViT에 interleaved window 및 global attention [37]을 적용한다. 본 연구의 접근법은 ViTDet을 따라 interleaved window 및 global attention을 사용하되, 추가적으로 window-major 순서의 feature map 구성 방식을 도입하여 메모리 재배치(permutation)에 따른 비용을 줄인다.
DETR 및 그 변형들 (DETR and its variants)
Detection Transformer(DETR)는 anchor 생성 [51]이나 비최대 억제(non-maximum suppression, NMS) [24]와 같은 다수의 수작업(hand-crafted) 구성 요소를 제거한 end-to-end 객체 검출 방법이다. 이후 DETR을 개선하기 위한 다양한 후속 연구들이 제안되었으며, 여기에는 아키텍처 설계 [74, 47, 19, 67], object query 설계 [63, 41, 11], 학습 기법 [35, 67, 6, 27, 48, 7, 75], 그리고 손실 함수 개선 [42, 3] 등이 포함된다.
또한 연산 복잡도를 줄이기 위해 아키텍처 설계 [40, 34], 연산 최적화 [74], 가지치기(pruning) [53, 72], 지식 증류(distillation) [5, 9, 5, 64] 등 다양한 시도가 이루어졌다. 본 논문의 관심사는 이러한 기존 방법들이 충분히 탐구하지 않은 영역, 즉 실시간 객체 검출을 위한 단순한(simple) DETR 기반 베이스라인을 구축하는 데 있다.
동시 연구 (Concurrent work)
본 연구와 거의 동시에, RT-DETR [45] 역시 DETR 프레임워크를 실시간 객체 검출에 적용하였으며, 특히 CNN 백본을 인코더로 사용하는 구조에 초점을 맞추었다. 다만, 상대적으로 대형 모델 위주의 연구가 이루어졌고, 초소형(tiny) 모델에 대한 연구는 부족한 편이다. 이에 비해, 본 논문의 LW-DETR는 plain ViT 백본과 DETR 프레임워크가 실시간 객체 검출에 적용 가능한지를 탐구한다는 점에서 차별성을 가진다.

그림 2 설명 (Figure 2)
다중 수준 feature map 집계와 interleaved window 및 global attention을 사용하는 트랜스포머 인코더의 예시를 보여준다. 설명의 명확성을 위해 FFN과 LayerNorm 계층은 그림에서 생략되었다.
3. LW-DETR
3.1 아키텍처 (Architecture)
LW-DETR는 ViT 인코더(ViT encoder), 프로젝터(projector), 그리고 DETR 디코더(DETR decoder)로 구성된다.
인코더 (Encoder)
본 연구에서는 객체 검출용 인코더로 ViT를 채택한다. 일반적인 plain ViT [17]는 패치화(patchification) 계층과 다수의 트랜스포머 인코더 계층으로 구성된다. 초기 ViT의 트랜스포머 인코더 계층은 모든 토큰에 대해 글로벌 자기어텐션(global self-attention)과 FFN 계층을 포함한다. 그러나 글로벌 자기어텐션은 토큰(패치) 수에 대해 이차(quadratic) 시간 복잡도를 가지므로 계산 비용이 매우 크다.
이를 완화하기 위해, 우리는 일부 트랜스포머 인코더 계층에서 윈도우 자기어텐션(window self-attention)을 적용하여 계산 복잡도를 줄인다(자세한 내용은 3.4절 참조). 또한 인코더 내부의 중간 계층(feature maps at intermediate layers)과 최종 계층의 feature map, 그리고 다중 수준(multi-level) feature map을 집계(aggregation)하여, 보다 강력한 인코딩 feature map을 형성한다. 이러한 인코더 구조의 예시는 그림 2에 제시되어 있다.
디코더 (Decoder)
디코더는 여러 개의 트랜스포머 디코더 계층으로 구성된 스택 구조이다. 각 계층은 자기어텐션(self-attention), 교차어텐션(cross-attention), 그리고 FFN으로 이루어진다. 계산 효율성을 위해 deformable cross-attention [74]을 채택한다.
기존 DETR 및 그 변형 모델들은 일반적으로 6개의 디코더 계층을 사용한다. 반면, 본 구현에서는 3개의 트랜스포머 디코더 계층만을 사용한다. 이를 통해 디코더 추론 시간을 1.4 ms에서 0.7 ms로 감소시킬 수 있었으며, 이는 tiny 버전 기준으로 나머지 구성 요소가 차지하는 1.3 ms의 시간 비용과 비교했을 때 매우 유의미한 절감이다.
객체 쿼리(object query)는 혼합 쿼리 선택 방식(mixed-query selection scheme) [67]을 사용하여 콘텐츠 쿼리(content query)와 공간 쿼리(spatial query)의 합으로 구성한다. 콘텐츠 쿼리는 DETR과 유사하게 학습 가능한 임베딩이다. 공간 쿼리는 2단계(two-stage) 방식에 기반하여 생성되며, 구체적으로는 Projector의 마지막 계층에서 상위 K개의 feature를 선택한 뒤 bounding box를 예측하고, 해당 박스를 임베딩으로 변환하여 공간 쿼리로 사용한다.
프로젝터 (Projector)
프로젝터는 인코더와 디코더를 연결하는 역할을 한다. 인코더에서 집계된(encoded) feature map을 입력으로 받아 디코더에 전달한다. 본 논문에서는 YOLOv8 [29]에 구현된 C2f 블록(cross-stage partial DenseNet [26, 60]의 확장 형태)을 프로젝터로 사용한다.
LW-DETR의 large 및 xlarge 버전에서는, 프로젝터가 두 개의 스케일 (1/8, 1/32) feature map을 출력하도록 수정하고, 이에 맞추어 멀티스케일 디코더(multi-scale decoder) [74]를 사용한다. 이때 프로젝터는 두 개의 병렬(parallel) C2f 블록으로 구성된다. 하나는 deconvolution을 통해 업샘플링된 1/8 feature map을 처리하고, 다른 하나는 stride convolution을 통해 다운샘플링된 1/32 feature map을 처리한다. 단일 스케일 프로젝터와 멀티스케일 프로젝터의 전체 파이프라인은 그림 3에 제시되어 있다.
목적 함수 (Objective function)
분류 손실로는 IoU-aware classification loss, 즉 IA-BCE loss [3]를 사용한다.




그림 3 설명 (Figure 3)
(a) tiny, small, medium 모델을 위한 단일 스케일 프로젝터,
(b) large, xlarge 모델을 위한 멀티스케일 프로젝터 구조를 보여준다.
3.2 구체화 (Instantiation)
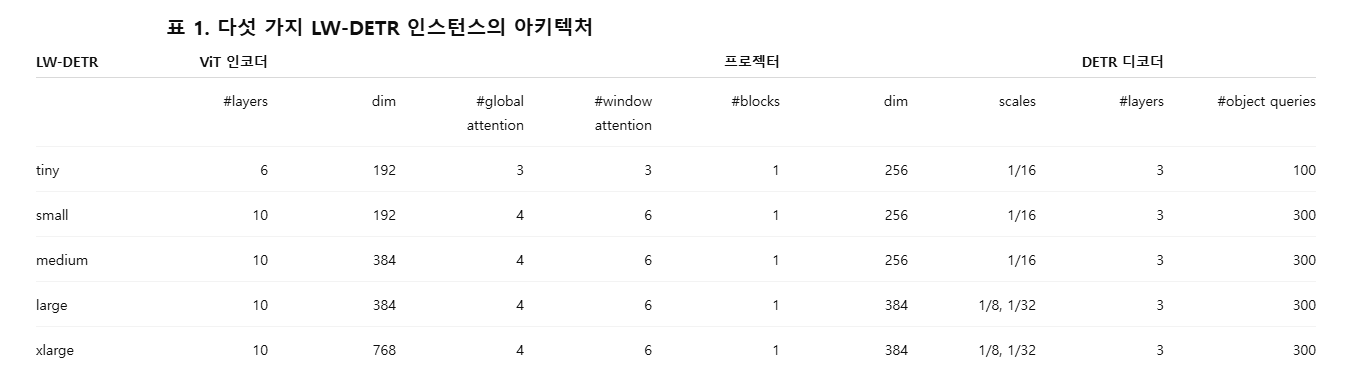
우리는 tiny, small, medium, large, xlarge의 다섯 가지 실시간 검출기 인스턴스를 구성한다. 각 설정의 세부 사항은 표 1에 정리되어 있다.
tiny 검출기는 6개의 계층으로 이루어진 트랜스포머 인코더를 사용한다. 각 계층은 다중 헤드 자기어텐션(multi-head self-attention) 모듈과 FFN(feed-forward network)으로 구성된다. 각 이미지 패치는 192차원의 표현 벡터로 선형 매핑된다. 프로젝터는 256 채널의 단일 스케일 feature map을 출력하며, 디코더에는 100개의 객체 쿼리(object queries)가 사용된다.
small 검출기는 10개의 인코더 계층과 300개의 객체 쿼리를 사용한다. 입력 패치 표현 차원과 프로젝터 출력 차원은 tiny와 동일하게 각각 192, 256이다. medium 검출기는 small과 유사하지만, 입력 패치 표현 차원이 384로 증가하며 이에 따라 인코더의 차원도 384로 설정된다.
large 검출기는 10계층 인코더를 사용하고, 두 개의 스케일 feature map을 활용한다(3.1절의 Projector 참조). 입력 패치 표현 차원과 프로젝터 출력 차원은 각각 384, 384이다. xlarge 검출기는 large와 유사하되, 입력 패치 표현 차원이 768이라는 점이 다르다.
3.3 효과적인 학습 (Effective Training)
추가적인 감독 신호 (More supervision)
DETR 학습을 가속화하기 위해 더 많은 감독 신호(supervision)를 도입하는 다양한 기법들이 제안되어 왔다 [6, 27, 75]. 본 연구에서는 추론 과정(inference)을 변경하지 않으면서도 구현이 간단한 Group DETR [6]를 채택한다. [6]을 따라, 학습 시에는 가중치를 공유하는 13개의 병렬 디코더를 사용한다. 각 디코더에 대해, 프로젝터의 출력 feature로부터 각 그룹에 대응하는 객체 쿼리(object query)를 생성한다. 추론 단계에서는 [6]과 동일하게 기본(primary) 디코더 하나만을 사용한다.
Objects365 사전학습 (Pretraining on Objects365)
사전학습 과정은 두 단계로 구성된다.
첫 번째 단계에서는, 사전학습된 모델을 기반으로 MIM(Masked Image Modeling) 기법인 CAEv2 [71]를 사용하여 Objects365 데이터셋에서 ViT를 사전학습한다. 이 과정만으로도 COCO 기준 0.7 mAP의 성능 향상을 얻을 수 있다.
두 번째 단계에서는 [67, 7]을 따라, Objects365 데이터셋에서 감독 학습(supervised learning) 방식으로 인코더를 재학습하고, 동시에 프로젝터와 디코더를 학습한다.
3.4 효율적인 추론 (Efficient Inference)
우리는 간단한 수정 [37, 36]을 통해 interleaved window attention과 global attention을 적용한다. 즉, 일부 글로벌 자기어텐션(global self-attention) 계층을 윈도우 자기어텐션(window self-attention) 계층으로 대체한다. 예를 들어, 6 계층으로 구성된 ViT의 경우, 첫 번째, 세 번째, 다섯 번째 계층을 윈도우 어텐션으로 구현한다. 윈도우 어텐션은 feature map을 겹치지 않는(non-overlapping) 윈도우로 분할한 뒤, 각 윈도우 내부에서만 자기어텐션을 수행하는 방식이다.
우리는 interleaved attention을 효율적으로 수행하기 위해 window-major feature map 구성 방식을 채택한다. 이 방식은 feature map을 윈도우 단위로 정렬한다. 기존 ViTDet 구현 [36]에서는 feature map을 행 우선(row-major) 방식으로 정렬하는데, 이 경우 윈도우 어텐션을 적용하기 위해서는 row-major에서 window-major로 변환하는 비용이 큰 permutation 연산이 필요하다. 반면, 본 구현에서는 이러한 연산을 제거함으로써 모델의 지연 시간(latency)을 줄인다.

표 2. 효과적인 학습 및 효율적인 추론 기법의 영향
글로벌 어텐션만을 사용하는 초기 검출기부터 최종 LW-DETR-small 모델까지, 단계별로 적용한 기법들의 영향을 실험적으로 분석하였다. ‘†’는 ViTDet 구현을 사용했음을 의미한다. 마지막 행을 제외한 모든 결과는 45K iteration(12epoch에 해당)에서 측정되었으며, 마지막 행은 180K iteration으로 학습한 최종 모델의 결과이다.

1️⃣ 먼저 핵심 요약부터
이 문단의 요지는 딱 하나입니다.
“윈도우 어텐션과 글로벌 어텐션을 섞어 쓸 때,
feature map을 처음부터 ‘윈도우 기준(window-major)’으로 저장하면
비싼 메모리 재배열(permutation)을 안 해도 된다.”
성능(mAP) 얘기가 아니라, 순수하게 latency 줄이는 엔지니어링 트릭입니다.
2️⃣ 기본 전제: feature map은 결국 ‘1차원 배열’로 저장된다
우리가 흔히 말하는 4×4 feature map은 논리적 구조이고,
GPU 메모리 안에서는 결국 이렇게 쭉 늘어진 1차원 배열입니다.
4×4 feature map (논리적 모습)
f11 f12 f13 f14
f21 f22 f23 f24
f31 f32 f33 f34
f41 f42 f43 f443️⃣ Row-major (행 우선) 정렬이란?
👉 우리가 보통 쓰는 방식 (PyTorch 기본)
[f11, f12, f13, f14,
f21, f22, f23, f24,
f31, f32, f33, f34,
f41, f42, f43, f44]이게 row-major입니다.
- 한 행(row)을 끝까지 읽고
- 다음 행으로 내려감
✅ 장점
- 글로벌 어텐션에 바로 사용 가능
(어차피 모든 토큰을 한 번에 보니까)
❌ 문제
- 윈도우 어텐션에는 부적합
4️⃣ 윈도우 어텐션은 “2×2 블록 단위”로 묶어야 한다
윈도우 크기가 2×2라면, 우리가 원하는 토큰 묶음은 이거죠:
윈도우 1: f11 f12
f21 f22
윈도우 2: f13 f14
f23 f24
윈도우 3: f31 f32
f41 f42
윈도우 4: f33 f34
f43 f44즉, 윈도우 하나가 연속된 메모리에 있어야 attention 계산이 빠릅니다.
5️⃣ 그래서 나온 개념: window-major 정렬
window-major에서는 처음부터 이렇게 저장합니다
[f11, f12, f21, f22, ← window 1
f13, f14, f23, f24, ← window 2
f31, f32, f41, f42, ← window 3
f33, f34, f43, f44] ← window 4이게 논문에서 말하는 식 (4) 입니다.
6️⃣ 이게 왜 중요한가? (🔥 핵심)
ViTDet (기존 방식)
- feature map은 row-major
- 윈도우 어텐션 쓸 때마다:
- row-major → window-major
- permutation (메모리 재배열) 발생
- 이게 생각보다 매우 비쌈
- FLOPs에 잘 안 잡힘
- latency에 직격타
LW-DETR (이 논문)
- 처음부터 window-major로 저장
- 그러면:
- 🔹 윈도우 어텐션: 바로 사용
- 🔹 글로벌 어텐션: 그냥 전체를 한 번에 보면 됨
- ❗ 중간 permutation 연산이 아예 없음
→ 그래서 latency가 확 줄어듦
(표 2에서 3.9ms → 2.9ms)
7️⃣ “그럼 글로벌 어텐션은 문제 없나?”
여기서 중요한 직관 하나:
글로벌 어텐션은
**“모든 토큰을 다 보겠다”**는 거지
**“토큰 순서가 꼭 row-major여야 한다”**는 게 아님
즉,
- window-major든
- row-major든
전체 토큰 집합만 유지되면 결과는 동일합니다.
8️⃣ 한 줄로 다시 정리하면
- row-major → 인간 친화적, 윈도우 어텐션엔 불리
- window-major → GPU/윈도우 어텐션 친화적
- LW-DETR은
- attention 구조는 ViTDet과 유사
- 하지만 메모리 레이아웃을 바꿔서 실제 속도를 줄임
9️⃣ 왜 이게 “논문 포인트”가 되나?
이건 새로운 모델 구조가 아니라,
- ❌ “Transformer를 가볍게 만들었다”
- ❌ “Attention을 새로 설계했다”
가 아니라,
✅ “같은 연산을 더 싸게 돌리는 방법”
그래서 이 논문 전체 톤이
- 이론적 새로움 ❌
- 실시간 엔지니어링 최적화 ✅
인 이유이기도 합니다.
3.5 실증적 분석 (Empirical Study)
본 절에서는 효과적인 학습 기법(effective training)과 효율적인 추론 기법(efficient inference)이 DETR 성능을 어떻게 개선하는지를 실험적으로 분석한다. 예제로는 small 검출기를 사용한다. 본 분석은 다음과 같은 초기 검출기(initial detector)를 기준으로 수행된다. 해당 초기 모델에서는 인코더의 모든 계층이 글로벌 어텐션으로 구성되어 있으며, 인코더의 마지막 계층의 feature map만을 출력으로 사용한다. 실험 결과는 표 2에 제시되어 있다.
지연 시간(latency) 개선
ViTDet에서 채택한 interleaved window 및 global attention은, 연산 비용이 큰 글로벌 어텐션을 상대적으로 저렴한 윈도우 어텐션으로 대체함으로써 연산량을 23.0 GFlops에서 16.6 GFlops로 감소시킨다. 이는 글로벌 어텐션을 윈도우 어텐션으로 대체하는 전략의 이점을 입증한다.
그러나 실제 지연 시간(latency)은 감소하지 않았으며, 오히려 0.2 ms 증가하였다. 이는 row-major feature map 구성 방식에서 윈도우 어텐션을 수행하기 위해 추가적인 비용이 큰 permutation 연산이 필요하기 때문이다. 반면, window-major feature map 구성 방식을 적용하면 이러한 부작용이 완화되며, 지연 시간이 3.7 ms에서 2.9 ms로 감소하여 총 0.8 ms의 큰 개선 효과를 얻을 수 있다.
성능(mAP) 개선
다중 수준 feature 집계(multi-level feature aggregation)는 0.7 mAP의 성능 향상을 가져온다. 또한 IoU-aware 분류 손실과 추가적인 supervision을 적용함으로써 mAP는 각각 34.7 → 35.4, 34.7 → 38.4로 향상된다.
박스 회귀 대상에 대한 bounding box 재파라미터화(reparameterization) [40](자세한 내용은 보충 자료 참조)는 소폭의 성능 개선을 제공한다. 가장 큰 성능 향상은 Objects365 데이터셋을 이용한 사전학습에서 나타나며, 총 8.7 mAP의 개선을 달성한다. 이는 트랜스포머가 대규모 데이터로부터 실질적인 이점을 얻을 수 있음을 시사한다. 더 긴 학습 스케줄을 적용하면 추가적인 성능 향상이 가능하며, 이를 통해 최종 LW-DETR-small 모델이 완성된다.
4. 실험 (Experiments)
4.1 설정 (Settings)
데이터셋 (Datasets)
사전학습(pretraining)에 사용한 데이터셋은 Objects365 [54]이다. [67, 7]을 따라, 탐지 사전학습을 위해 train 세트의 이미지와 validate 세트 중 처음 5k 이미지를 제외한 나머지 이미지를 결합하여 사용한다. 평가는 표준 COCO2017 [39] 데이터 분할 정책을 따르며, COCO val2017에서 수행한다.
데이터 증강 (Data augmentations)
DETR 및 그 변형들에서 사용된 데이터 증강 기법을 채택한다 [4, 74]. 학습 시에는 실시간 객체 검출 알고리즘들 [1, 29, 46]을 따라 이미지를 무작위로 정사각형 크기로 리사이즈한다. 성능 평가 및 추론 시간 측정 시에는 동일한 실시간 검출 알고리즘들 [1, 29, 46]에서 사용하는 평가 방식에 따라 이미지를 640 × 640 크기로 리사이즈한다. 또한 이미지 크기가 윈도우 크기로 나누어 떨어지도록 하기 위해 10 × 10의 윈도우 크기를 사용한다.
구현 세부 사항 (Implementation details)
Objects365 [54]에서 30 epoch 동안 검출 모델을 사전학습한 뒤, COCO [39]에서 총 180K iteration 동안 파인튜닝한다. 학습 안정화를 위해 EMA(exponential moving average) 기법 [55]을 적용하며, decay 값은 0.9997 이다. 옵티마이저로는 AdamW [44]를 사용한다.
사전학습 단계에서는 프로젝터와 DETR 디코더의 초기 학습률을 4 × e⁻⁴, ViT 백본의 초기 학습률을 6 × e⁻⁴ 로 설정하고, 배치 크기는 128 로 설정한다. 파인튜닝 단계에서는 프로젝터와 DETR 디코더의 초기 학습률을 1 × e⁻⁴, ViT 백본의 초기 학습률을 1.5 × e⁻⁴ 로 설정한다. 배치 크기는 tiny, small, medium 모델에서 32, large 및 xlarge 모델에서는 16 으로 설정한다.
총 180K training iteration은 tiny, small, medium 모델의 경우 50 epoch, large 및 xlarge 모델의 경우 25 epoch 에 해당한다. weight decay, ViT 인코더에서의 layer-wise decay, 그리고 파인튜닝 과정에서의 component-wise decay [7]와 같은 추가적인 세부 사항은 보충 자료(Supplementary Material)에 제시되어 있다.
추론 시간 측정 (Inference latency measurement)
추론 지연 시간(latency)은 COCO val2017에서 batch size 1, fp16 precision, T4 GPU 환경에서 end-to-end 방식으로 측정한다. 실험 환경은 TensorRT-8.6.1, CUDA-11.6, CuDNN-8.7.0으로 구성된다. 효율적인 NMS 구현을 위해 TensorRT의 efficientNMSPlugin을 사용한다. 모든 실시간 검출기의 성능과 end-to-end latency는 공식 구현(official implementation)을 사용하여 측정한다.
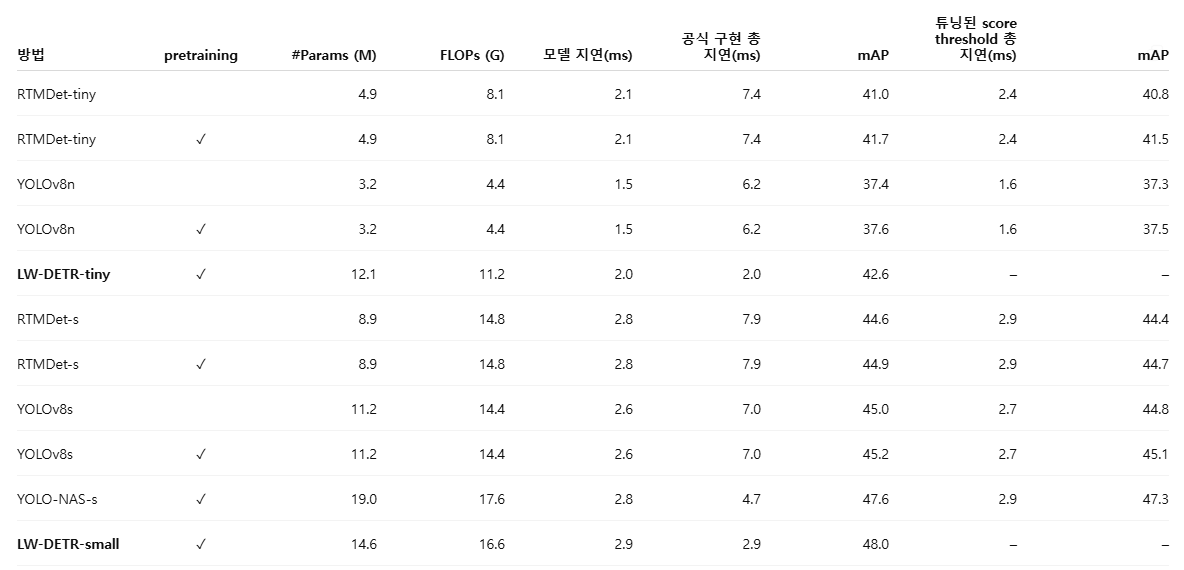
표 3. 최신 실시간 객체 검출기와의 비교
RTMDet [46], YOLOv8 [29], YOLO-NAS [1]를 포함한 최신 실시간 객체 검출기들과의 비교 결과를 제시한다. 전체 지연 시간(total latency)은 COCO val2017에서 end-to-end 방식으로 측정되며, 모델 추론 시간과 비-DETR 계열 모델에 필요한 후처리 단계인 NMS 시간을 모두 포함한다. NMS에 대해서는 두 가지 설정을 사용해 전체 지연 시간을 측정한다: 공식 구현 설정과 튜닝된 score threshold 설정.
LW-DETR은 NMS가 필요 없기 때문에, 전체 지연 시간은 모델 추론 시간과 동일하다. 표에서 ‘pretraining’은 Objects365로 사전학습한 결과임을 의미한다.


4.2 결과 (Results)
표 3에는 다섯 가지 LW-DETR 모델의 성능 결과를 제시한다. LW-DETR-tiny는 T4 GPU 기준으로 500 FPS에서 42.6 mAP를 달성한다. LW-DETR-small과 LW-DETR-medium은 각각 340 FPS 이상에서 48.0 mAP, 178 FPS 이상에서 52.5 mAP를 기록한다. large와 xlarge 모델은 각각 113 FPS에서 56.1 mAP, 52 FPS에서 58.3 mAP를 달성한다.
최신 실시간 객체 검출기와의 비교
표 3에서는 YOLO-NAS [1], YOLOv8 [29], RTMDet [46]를 포함한 대표적인 최신 실시간 객체 검출기들과 LW-DETR 모델을 비교한다. 사전학습(pretraining) 유무와 관계없이, LW-DETR은 기존의 최신 실시간 검출기들을 일관되게 능가함을 확인할 수 있다. 특히 tiny부터 xlarge까지 모든 스케일에서, 지연 시간(latency)과 검출 성능(mAP) 측면 모두에서 YOLOv8과 RTMDet 대비 명확한 우위를 보인다.
신경망 아키텍처 탐색(NAS)을 통해 설계된 기존 최고 수준의 방법 중 하나인 YOLO-NAS와 비교하면, LW-DETR은 small과 medium 스케일에서 각각 0.4 mAP, 0.9 mAP 더 높은 성능을 보이며, 속도 또한 각각 1.6배, 약 1.4배(∼1.4×) 빠르다. 모델 크기가 커질수록 이러한 개선 효과는 더욱 두드러지며, large 스케일에서는 동일한 속도 조건에서 3.8 mAP의 성능 향상을 달성한다.
또한 NMS 과정에서 분류 점수 임계값(score threshold)을 정교하게 튜닝하여 다른 방법들의 성능을 추가로 개선하고, 그 결과를 표의 오른쪽 두 열에 보고한다. 이 경우 성능은 크게 향상되지만, 여전히 LW-DETR에는 미치지 못한다. 저자들은 NAS, 데이터 증강, 의사 라벨(pseudo-labeled) 데이터, 지식 증류(knowledge distillation) 등 기존 실시간 검출기들이 활용한 다양한 기법들 [46, 29, 1]을 LW-DETR에도 적용할 경우, 추가적인 성능 향상이 가능할 것으로 기대한다.
동시 연구(concurrent works)와의 비교
실시간 객체 검출 분야의 동시 연구인 YOLO-MS [12], Gold-YOLO [58], RT-DETR [45], YOLOv10 [57]과 LW-DETR을 비교한다. YOLO-MS는 다중 스케일 feature 표현을 강화하여 성능을 개선하며, Gold-YOLO는 다중 스케일 feature 융합을 강화하고 MAE 방식의 사전학습 [22]을 적용하여 YOLO의 성능을 향상시킨다. YOLOv10은 효율성과 정확도를 목표로 한 여러 모듈을 설계하였다. RT-DETR [45]는 LW-DETR과 밀접하게 연관된 방법으로, 동일하게 DETR 프레임워크를 기반으로 하지만, 백본, 프로젝터, 디코더, 학습 방식에서 본 논문과 여러 차이를 가진다.
비교 결과는 표 4와 그림 4에 제시되어 있다. LW-DETR은 검출 성능과 지연 시간 사이에서 일관되게 더 나은 균형을 달성한다. YOLO-MS와 Gold-YOLO는 모든 모델 스케일에서 LW-DETR 대비 명확히 열세를 보인다. LW-DETR-large는 RT-DETR-R50 대비 0.8 mAP 더 높은 성능을 보이면서도 더 빠른 속도(8.8 ms vs. 9.9 ms)를 달성한다. 다른 스케일에서도 LW-DETR은 RT-DETR보다 전반적으로 더 우수한 결과를 보인다. 최신 방법인 YOLOv10-X [57]와 비교해도, LW-DETR-large는 더 높은 성능(56.1 mAP vs. 54.4 mAP)과 더 낮은 지연 시간(8.8 ms vs. 10.70 ms)을 동시에 달성한다.
표 4. 동시 연구들과의 비교 (COCO 기준)
YOLO-MS [12], Gold-YOLO [58], YOLOv10 [57], RT-DETR [45]와의 비교 결과를 제시한다. YOLO-MS와 Gold-YOLO에 대해서는 NMS에 대해 공식 구현 설정과 튜닝된 score threshold 설정의 두 가지 경우로 전체 지연 시간을 측정하였다. YOLOv10의 결과는 공식 논문 [57]의 수치를 보고한다. RT-DETR은 DETR 기반 방법으로 NMS가 필요 없으므로, 전체 지연 시간은 모델 지연 시간과 동일하다. RT-DETR의 경우, 논문 [45]에 보고된 추론 시간과 본 실험 환경에서 측정된 시간 중 더 빠른 값을 사용하였다. 전반적으로 LW-DETR이 가장 우수한 결과를 보인다. ‘pretraining’은 Objects365로 사전학습한 결과임을 의미한다.



그림 4 설명 (Figure 4)
본 접근법은 동시 연구 방법들을 능가하는 성능을 보인다. x축은 추론 시간(ms), y축은 COCO val2017 기준 mAP를 나타낸다. LW-DETR, RT-DETR [45], YOLO-MS [12], Gold-YOLO [58]는 Objects365 사전학습을 적용하였으며, YOLOv10 [57]은 사전학습을 사용하지 않았다. YOLO-MS와 Gold-YOLO에 대해서는 NMS 후처리 시간이 포함되어 있으며, 이는 공식 구현 설정과 잘 튜닝된 NMS 설정(“*”로 표시)을 기준으로 COCO val2017에서 측정되었다.
4.3 논의 (Discussions)
NMS 후처리 (NMS post-processing)
DETR 방식은 NMS(non-maximum suppression) 후처리가 필요 없는 end-to-end 알고리즘이다. 반면, YOLO-NAS [1], YOLOv8 [29], RTMDet [46]와 같은 기존 실시간 객체 검출기들은 NMS 후처리 [24]가 필요하다. 이 NMS 과정은 추가적인 시간을 소요한다. 본 논문에서는 실제 응용 환경에서 고려되는 end-to-end 추론 비용을 측정하기 위해, 이러한 추가 시간을 모두 포함하였다. 공식 구현에서 사용되는 NMS 설정을 적용한 결과는 그림 1과 표 3에 제시되어 있다.
우리는 NMS를 사용하는 방법들에 대해, NMS 후처리 단계에서의 분류 점수 임계값(classification score threshold)을 조정함으로써 추가적인 개선을 시도하였다. YOLO-NAS, YOLOv8, RTMDet에서 기본적으로 사용되는 점수 임계값 0.001 은 높은 mAP를 제공하지만, 매우 많은 수의 박스를 생성하여 지연 시간이 크게 증가하는 문제를 야기한다. 특히 모델이 작은 경우, end-to-end 지연 시간은 NMS 지연 시간에 의해 지배되는 현상이 나타난다.
이에 점수 임계값을 조정하여 mAP와 지연 시간 간의 균형을 맞추었다. 그 결과, mAP는 약 −0.1 mAP에서 −0.5 mAP 정도로 소폭 감소하는 반면, 실행 시간은 크게 감소하였다. 구체적으로, RTMDet와 YOLOv8에서는 4∼5 ms, YOLO-NAS에서는 1∼2 ms 수준의 지연 시간 감소가 관찰되었다. 이는 점수 임계값 조정으로 인해 NMS 단계에 입력되는 예측 박스의 수가 감소했기 때문이다. 서로 다른 점수 임계값에 따른 상세한 결과와 COCO val2017 전반에 걸친 잔여 박스 수 분포는 보충 자료(Supplementary Material)에 제시되어 있다.
그림 1은 잘 튜닝된 NMS 절차를 적용한 다른 방법들과의 비교 결과를 보여준다. NMS를 사용하는 방법들의 성능은 개선되었지만, 제안하는 방법은 여전히 다른 방법들을 능가한다. 두 번째로 우수한 방법인 YOLO-NAS는 신경망 아키텍처 탐색(NAS)을 기반으로 한 알고리즘으로, 제안한 베이스라인과 매우 근접한 성능을 보인다. 저자들은 YOLO-NAS에서 사용된 것과 같은 복잡한 네트워크 아키텍처 탐색 기법이 DETR 접근법에도 잠재적으로 이점을 제공할 수 있으며, 이를 통해 추가적인 성능 향상이 가능할 것으로 기대한다.
표 5. LW-DETR에서의 사전학습(pretraining) 효과
Objects365에서의 사전학습은 LW-DETR의 성능을 크게 향상시킨다. 이러한 관찰 결과는 대규모 모델을 사용하는 기존 방법들 [67, 7, 75]에서 보고된 결과와도 일관된다.

표 6. 비 end-to-end 검출기에서 사전학습과 학습 epoch 수의 영향
사전학습 유무와 학습 epoch 수 증가에 따른 비 end-to-end 검출기들의 성능 변화를 비교한다.

사전학습 (Pretraining)
우리는 사전학습의 효과를 실증적으로 분석하였다. 표 5에 제시된 결과에 따르면, 사전학습은 제안한 방법의 성능을 크게 향상시키며, 평균적으로 5.5 mAP의 개선을 가져온다. tiny 모델은 6.1 mAP, xlarge 모델은 5.3 mAP의 성능 향상을 보인다. 이는 대규모 데이터셋에서의 사전학습이 DETR 기반 모델에 매우 유익함을 시사한다.
또한 본 논문에서 사용한 학습 절차가 합성곱 인코더를 사용하는 DETR 접근법에도 적용 가능함을 보인다. 이를 위해 트랜스포머 인코더를 ResNet-18과 ResNet-50으로 대체하였다. 표 5에서 확인할 수 있듯이, 이러한 LW-DETR 변형들은 지연 시간과 mAP 측면에서 트랜스포머 인코더를 사용하는 LW-DETR과 유사한 성능을 보이며, 사전학습 역시 트랜스포머 기반 LW-DETR과 유사하거나 다소 낮은 수준의 이점을 제공한다.
한편, 비 end-to-end 검출기에서의 사전학습 효과도 함께 분석하였다. 표 3, 표 4, 표 6의 결과에 따르면, Objects365에서의 사전학습은 비 end-to-end 검출기 [46, 29, 12, 58]에서는 제한적인 성능 향상만을 제공하는 것으로 보인다. 이는 사전학습이 DETR 기반 검출기에서 큰 성능 향상을 가져오는 현상과는 대조적이다. 비 end-to-end 검출기들은 YOLOv8의 경우 300 epoch, 심지어 500 epoch까지 학습하므로, 이러한 제한적인 성능 향상이 학습 epoch 수와 관련이 있는지를 추가로 살펴보았다.
이에 사전학습 가중치로부터 얻는 성능 향상을 학습 epoch 수와 함께 비교하였다. 표 6에서 볼 수 있듯이, 학습 epoch이 증가할수록 사전학습으로 인한 성능 향상은 점차 감소하며, 이는 앞선 가설을 부분적으로 뒷받침한다. 다만 이러한 분석은 아직 초기적인 단계(preliminary step)에 해당하며, 사전학습 효과의 차이가 발생하는 근본적인 원인을 규명하기 위해서는 추가적인 연구가 필요하다고 판단한다.
4.4 추가 데이터셋에 대한 실험 (Experiments on more datasets)
LW-DETR의 일반화 성능(generalizability)을 추가적인 객체 검출 데이터셋에서 평가한다. 우리는 두 가지 평가 방식을 고려한다. 하나는 도메인 간 평가(cross-domain evaluation)이고, 다른 하나는 다중 도메인 파인튜닝(multi-domain finetuning)이다.
도메인 간 평가에서는 COCO에서 학습된 실시간 검출기를 Unidentified Video Objects (UVO) [61] 데이터셋에서 직접 평가한다. 다중 도메인 파인튜닝의 경우, 사전학습된 실시간 검출기를 Roboflow 100 (RF100) [13] 다중 도메인 검출 데이터셋에서 파인튜닝한다. 모든 모델에 대해 각 데이터셋별로 학습률과 같은 하이퍼파라미터에 대해 거친 탐색(coarse search)을 수행하였다. 보다 자세한 설정은 보충 자료(Supplementary Material)를 참고한다.
표 7. UVO에서의 도메인 간 평가 (Cross-domain evaluation)
UVO는 클래스 비의존(class-agnostic) 데이터셋이므로, 클래스 비의존 방식으로 성능을 평가한다. LW-DETR은 다른 검출기들보다 더 높은 AP와 AR을 달성한다.
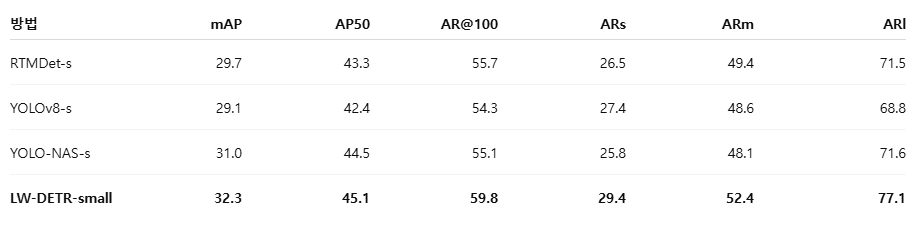
표 8. RF100에서의 다중 도메인 파인튜닝 (Multi-domain finetuning)
YOLOv5, YOLOv7, RTMDet, YOLOv8, YOLO-NAS를 포함한 기존 실시간 검출기들과 LW-DETR을 RF100의 모든 데이터 도메인에서 비교한다. 회색으로 표시된 항목은 RF100 논문 [13]에서 보고된 결과이다. 데이터 도메인은 항공(aerial), 비디오게임(videogames), 현미경(microscopic), 수중(underwater), 문서(documents), 전자기(electromagnetic), 실세계(real world)로 구성된다. 평가 지표로는 AP50을 사용한다. ‘–’는 YOLO-NAS [1]에서 세부 결과를 보고하지 않았음을 의미한다.

도메인 간 평가 (Cross-domain evaluation)
모델의 일반화 성능을 평가하는 한 가지 방법은, 서로 다른 도메인의 데이터셋에서 직접 성능을 측정하는 것이다. 우리는 클래스 비의존 객체 검출 벤치마크인 UVO [61]를 사용한다. UVO에서는 전체 객체 인스턴스의 57% 가 COCO의 80 개 클래스 중 어느 것에도 속하지 않는다. UVO는 YouTube 영상 기반 데이터셋으로, egocentric 시점이나 강한 모션 블러를 포함하는 등 COCO와는 시각적 특성이 크게 다르다. COCO에서 학습된 모델들(표 3 참조)을 UVO validation split에서 평가하였다.
표 7의 결과에서 볼 수 있듯이, LW-DETR은 경쟁하는 최신 실시간 검출기들보다 우수한 성능을 보인다. 구체적으로, LW-DETR-small은 RTMDet-s, YOLOv8-s, YOLO-NAS-s 중 최고 성능 대비 1.3 mAP, 4.1 AR 더 높은 결과를 달성한다. 또한 recall 측면에서도 소형, 중형, 대형 객체 전반에 걸쳐 더 많은 객체를 검출하는 향상된 능력을 보인다. 이러한 결과는 LW-DETR의 우수성이 COCO에 특화된 튜닝 때문이 아니라, 보다 일반화 가능한 표현을 학습했기 때문임을 시사한다.
다중 도메인 파인튜닝 (Multi-domain finetuning)
또 다른 방법은 서로 다른 도메인의 소규모 데이터셋에서 사전학습된 검출기를 파인튜닝하는 것이다. RF100은 100개의 소규모 데이터셋, 7개의 이미지 도메인, 224k장의 이미지, 829개의 클래스 레이블로 구성되어 있다. 이는 실제 환경 데이터에 대한 모델의 일반화 성능을 평가하는 데 유용하다. 우리는 RF100의 각 소규모 데이터셋에서 실시간 검출기들을 파인튜닝하였다.
표 8의 결과에서, LW-DETR-small은 다양한 도메인 전반에 걸쳐 기존 최신 실시간 검출기들보다 우수한 성능을 보인다. 특히 문서(documents)와 전자기(electromagnetic) 도메인에서는 YOLOv5, YOLOv7, RTMDet, YOLOv8 중 최고 성능 대비 각각 5.7 AP, 5.6 AP 더 높은 성능을 달성한다. LW-DETR-medium은 전체적으로 추가적인 성능 향상을 제공한다. 이러한 결과는 LW-DETR의 범용성과 유연성을 강조하며, 다양한 폐쇄 도메인(closed-domain) 작업에서 강력한 베이스라인으로 자리매김할 수 있음을 보여준다.
5. 한계 및 향후 연구 (Limitation and Future Works)
현재로서는 LW-DETR의 효과를 실시간 객체 검출(real-time detection)에 대해서만 입증하였다. 이는 첫 번째 단계에 해당한다. 오픈 월드 객체 검출(open-world detection)로의 확장이나, 다중 인원 포즈 추정(multi-person pose estimation), 다중 시점 3D 객체 검출(multi-view 3D object detection)과 같은 보다 다양한 비전 과제에 LW-DETR을 적용하는 것은 추가적인 연구가 필요하다. 이러한 방향들은 향후 연구 과제로 남긴다.
6. 결론 (Conclusion)
본 논문은 검출 트랜스포머(detection transformer)가 기존의 실시간 객체 검출기들과 비교하여 경쟁력 있는 성능은 물론, 경우에 따라서는 더 우수한 성능을 달성할 수 있음을 보여준다. 제안한 방법은 구조적으로 단순하면서도 효율적이다. 이러한 성과는 다중 수준 feature 집계와 함께, 학습 효율을 높이는 기법(training-effective techniques)과 추론 효율을 개선하는 기법(inference-efficient techniques)에서 비롯된다. 본 연구에서 얻은 경험이, 향후 트랜스포머 기반 실시간 비전 모델을 설계하는 데 유용한 통찰을 제공할 수 있기를 기대한다.
보충 자료 (Supplementary Material)
A. 실험 세부 사항 (Experimental Details)
본 절에서는 Objects365 [54]에서의 사전학습(pretraining), COCO [39]에서의 파인튜닝(finetuning), Roboflow 100 (RF100) [13]에서의 파인튜닝에 사용된 하이퍼파라미터 설정, 합성곱 인코더(convolutional encoder)의 아키텍처, 그리고 박스 회귀(box regression) 모델링 방식에 대한 세부 내용을 다룬다. 표에서는 표현의 간결함을 위해 LW-DETR의 tiny / small / medium / large / xlarge 버전을 각각 T / S / M / L / X로 표기한다.
A.1 실험 설정 (Experimental settings)
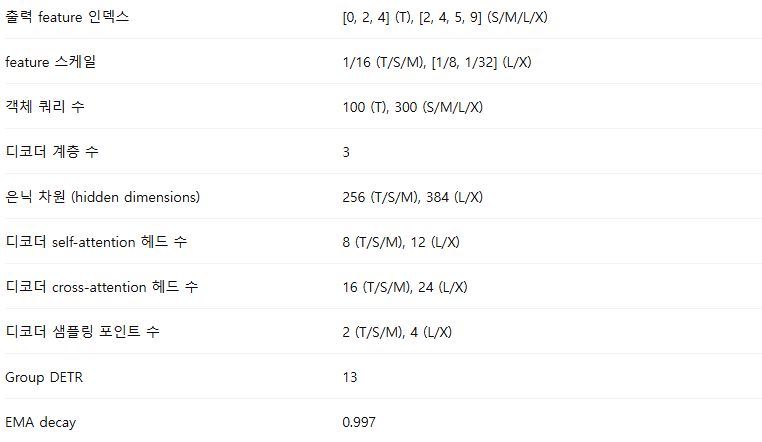
사전학습 설정 (Pretraining settings)
기본적인 사전학습 설정은 표 9에 제시되어 있다. 학습률 감소 스케줄(learning rate drop schedule)은 사용하지 않으며, 초기 학습률을 전체 학습 과정 동안 그대로 유지한다. ViT 인코더에서 윈도우 어텐션(window attention)을 적용할 때에는, 구현의 단순화를 위해 이미지 해상도와 무관하게 윈도우 개수를 16으로 고정한다. 또한 기존 MIM(Masked Image Modeling) 방법들 [22, 10, 71]을 따라 계층별 학습률 감소(layer-wise learning rate decay) [14] 기법을 사용한다.



COCO 실험 설정 (COCO experimental settings)
대부분의 설정은 사전학습 단계에서 사용한 설정을 따른다. 변경된 설정 사항은 표 10에 정리되어 있다. COCO에서 LW-DETR을 파인튜닝할 때에는 컴포넌트별 학습률 감소(component-wise learning rate decay) [7]를 사용하며, 이를 통해 ViT 인코더, 프로젝터(Projector), DETR 디코더에 서로 다른 학습률 스케일을 적용한다.
예를 들어, 컴포넌트별 학습률 감소 값이 0.7인 경우, 학습률 스케일은 다음과 같이 설정된다.

Roboflow 100 실험 설정 (Roboflow 100 experimental settings)
Roboflow 100 (RF100) [13]은 100개의 소규모 데이터셋으로 구성되어 있다. 우리는 Objects365 [54]에서 사전학습된 모델을 기반으로, 이 데이터셋들에서 LW-DETR을 파인튜닝한다. 학습 이미지 수가 충분하지 않기 때문에, 배치 크기를 16으로 설정하고, [13]을 따라 모든 소규모 데이터셋에서 100 epoch 동안 파인튜닝하여 충분한 학습 반복 횟수를 확보한다.
학습률, 인코더 계층별 학습률 감소, 그리고 컴포넌트별 학습률 감소(표 11 참조)는 ‘microscopic’ 도메인에서 거친 탐색(coarse search)을 통해 튜닝한 뒤, 해당 하이퍼파라미터를 다른 데이터셋에도 동일하게 적용한다. 그 외의 하이퍼파라미터는 COCO 파인튜닝 실험과 동일하게 유지한다. 또한 공정한 비교를 위해, RTMDet [46]와 YOLOv8 [29]에 대해서도 동일한 절차를 적용한다.
A.2 합성곱 인코더 설정 (Settings for convolutional encoders)
본 연구에서는 LW-DETR에 합성곱 인코더(convolutional encoder)로 ResNet-18과 ResNet-50도 함께 탐구한다. 인코더의 가중치는 RT-DETR 저장소에서 제공하는 ImageNet [15] 사전학습 가중치를 사용한다.
(참고: https://github.com/lyuwenyu/RT-DETR/issues/42#issue-1860463373)
기존처럼 [1/8, 1/16, 1/32] 스케일의 다중 수준 feature map을 직접 출력하는 대신, 1/16 스케일의 단일 feature map만 출력하도록 간단한 수정을 가한다. 구체적으로,
- 1/32 스케일의 feature map은 업샘플링하여 1/16으로 변환하고,
- 1/8 스케일의 feature map은 다운샘플링하여 1/16으로 변환한 뒤,
- 모든 feature map을 연결(concatenate)한다.
이후, 최종적으로 결합된 feature map의 채널 차원이 지나치게 커지는 것을 방지하기 위해, 추가적인 합성곱 계층을 삽입하여 feature 차원을 줄인다.
A.3 박스 회귀 타깃 재파라미터화 (Box regression target reparameterization)
박스 회귀 타깃 재파라미터화는 입력 proposal을 예측된 박스로 변환하는 박스 변환(box transformation) 파라미터를 예측하는 기법으로, 2단계 및 1단계 검출기에서 널리 사용되어 왔다 [51, 38, 2, 28]. 본 연구에서는 Plain DETR [40]을 따라, 이 기법을 LW-DETR에 적용한다.

표 12. 비 end-to-end 검출기에서의 score threshold 튜닝
비 end-to-end 검출기에서 score threshold가 NMS 수행 시간과 검출 성능에 어떤 영향을 미치는지를 보여준다. YOLO-NAS, YOLOv8, RTMDet, YOLO-MS, Gold-YOLO에 대해, 서로 다른 세 가지 score threshold 설정에서의 검출 성능(mAP)과 전체 지연 시간(total latency)을 제시한다.
첫 번째 score threshold는 각 모델의 공식 구현에서 사용하는 기본값이다. 표에서 굵게 표시된 score threshold는 mAP와 NMS 지연 시간 간의 균형이 가장 좋은 설정을 의미한다.

B. NMS에 대한 분석 (Analysis on NMS)
Score threshold 튜닝
비 end-to-end 검출기에서 score threshold는 NMS 단계로 전달되는 예측 박스의 개수를 결정하며, 이는 NMS 지연 시간에 큰 영향을 미친다. 표 12는 YOLO-NAS, YOLOv8, RTMDet, YOLO-MS, Gold-YOLO를 대상으로 이러한 영향을 실증적으로 보여준다.
score threshold를 크게 설정하면 NMS의 연산 부담을 크게 줄일 수 있지만, 그 대가로 검출 성능은 저하된다. 본 연구에서는 비 end-to-end 검출기들에 대해 score threshold를 정교하게 튜닝함으로써, 검출 성능과 전체 지연 시간 간의 균형을 달성한다. 그 결과, 검출 성능은 소폭 감소하는 대신, NMS로 인한 오버헤드는 0.1∼0.5 ms 수준까지 크게 감소한다.
NMS를 위한 박스 개수 분포 (Distribution of the number of boxes for NMS)
지연 시간은 COCO val2017의 5000장 이미지 평균을 기준으로 측정된다. 그림 5는 YOLO-NAS에서 서로 다른 score threshold 설정 하에서, NMS 이후 남는 박스 개수의 분포를 COCO val2017 전체에 대해 보여준다.
기본 score threshold 설정에서는 남는 박스의 개수가 매우 많아, NMS로 인한 큰 연산 오버헤드가 발생한다. 반면, score threshold를 조정하면 NMS 단계에 남는 박스 수가 효과적으로 감소하며, 그 결과 비 end-to-end 검출기의 전체 지연 시간이 최적화된다.

그림 5 설명 (Figure 5)
NMS에 입력되는 박스 개수의 분포를 시각화한 결과이다.
x축은 NMS에 전달되는 박스 개수, y축은 해당 구간에 속하는 COCO val2017 이미지 수를 의미한다.
(a)는 기본 score threshold 설정,
(b)는 검출 성능과 지연 시간의 균형을 맞춘 score threshold 설정,
(c)는 더 높은 score threshold를 적용한 경우를 나타낸다.